Concreteness Effects of Constituents in Naming Mandarin Compounds
Jiaqi Wang, Niels O. Schiller, Claartje Levelt

TL;DR
This study explores how concrete and abstract word parts affect the speed of naming Mandarin compound words.
Contribution
The study provides new evidence for decompositional processing in Mandarin compound word production.
Findings
Concrete compounds with two concrete constituents were named faster than those with two abstract constituents.
Results support the decompositional model of Mandarin compound word processing.
Constituent concreteness significantly influences naming latency in Mandarin.
Abstract
The present study aims to use the concreteness effect to provide a detailed investigation of how Mandarin compounds are represented in the mental lexicon, that is, whether abstract and concrete morpheme constituents can influence the retrieval of Mandarin compounds during production. Our study investigated the question of the representation of Mandarin compound words through a picture naming task where forty-one participants were recruited. The behavioral outcomes indicated that there was a constituent concrete effect in Mandarin compounds due to the naming latencies for concrete compounds with two concrete constituents (cc condition) were much faster than concrete compounds with two abstract constituents (aa condition), which provided support for the decompositional model where constituents play important roles in the production of Mandarin compounds.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
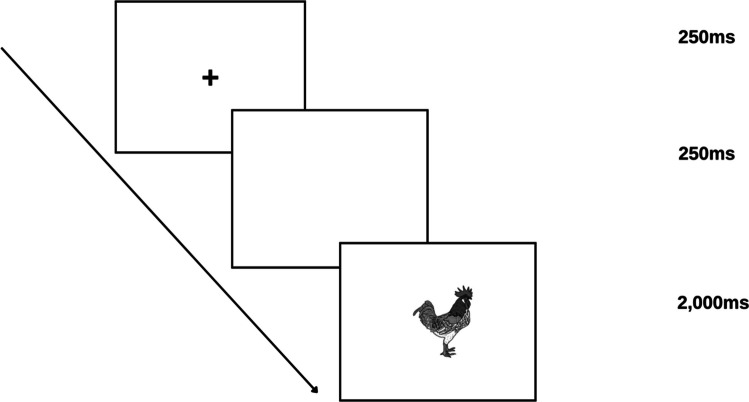 Figure 1
Figure 1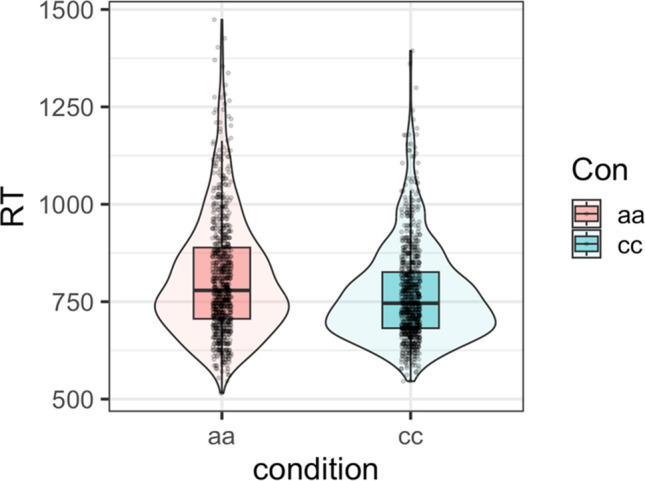 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNeurobiology of Language and Bilingualism · Categorization, perception, and language · Reading and Literacy Development
Introduction
Research on the processing of morphologically complex words is well-established in the domain of language comprehension, where theoretical accounts are broadly divided into decompositional models (Koester et al., 2004, 2009; Longtin & Meunier, 2005; Rastle & Davis, 2008), full-listing models (e.g., Butterworth, 1983; Norris & McQueen, 2008), and hybrid models (Caramazza et al., 1988; Frauenfelder & Schreuder, 1991). Studies employing the morphological violation paradigm - for instance, presenting incorrect German past participles (e.g., *getanz-en instead of getanz-t) - have demonstrated distinct EEG responses to regular versus irregular verbs. This neurological dissociation supports hybrid models that posit different processing routes for regular and irregular morphology (Penke et al., 1997). Evidence for decomposition comes from studies on compound word processing where research on the time course of semantic integration in auditory compound comprehension has shown that constituents are integrated incrementally, aligning with a decompositional account (Koester et al., 2009).
A substantial body of work has focused on inflectional and derivational processes (Bozic & Marslen-Wilson, 2010; Marslen-Wilson et al., 1994; Penke et al., 1997; Rodriguez-Fornells et al., 2001; Smolka et al., 2015), with less attention given to the processing of compound words. This focus, however, diverges for Mandarin Chinese, where the study of compound representation has been a central concern from multiple theoretical and empirical perspectives, reflecting the dominant role of compounding in Mandarin morphology. A primary line of inquiry concerns the role of semantic transparency (Han et al., 2014; Liu & Peng, 1997; Peng et al., 1999; Su, 1998; Tsai, 1994). Researchers have also examined the influence of distributional properties, such as word frequency (Chen & Chen, 2006; Janssen et al., 2008; Peng et al., 1999; Taft, 1994; Yan et al., 2006; Zhang & Peng, 1992; Zhou & Marslen-Wilson, 1994) and transition probability between constituents (Myers & Gong, 2002; Taft, 1994). Additionally, studies have explored how compound-internal features - including morphological structure (Chung et al., 2010; Ji & Gagné, 2007; Liu, 2017) and headedness (Ceccagno & Basciano, 2007; Libben et al., 2003; Starosta et al., 1997) - affect processing.
In language production, however, two prominent models address the lexical representation of compound words during production processes: full-listing models (Butterworth, 1983; Caramazza, 1997; Dell, 1986) and decompositional models (Levelt et al., 1999), with hybrid models somewhat scarcer. According to the language production model proposed by Levelt et al. (1999), producing a word involves conceptual preparation, lexical access, phonological encoding, and articulation. Conceptual representations become activated when we engage in speech production, which then spreads to lexical representations linked to that concept. Before words can be articulated, phonological information is retrieved, involving word form encoding. According to full-listing models, compound words are stored holistically in the mental lexicon. In contrast, decompositional models suggest that compounds are represented and processed through their constituents. Both models are supported by empirical studies. For instance, to investigate the representation of compound words, Janssen et al. (2008) found that overall word frequency, rather than constituent frequency, influenced naming latencies in Mandarin compound words, supporting the full-listing hypothesis in language production. This was further supported by Bi et al. (2007), who showed that compound word frequency, not constituent morpheme frequency, affected the production performance of Chinese patients with aphasia. Additionally, Chen and Chen (2006) found that in Mandarin, naming latencies were not sensitive to constituent frequency, which aligned with the idea of a single lexical level between semantics and phonology.
In contrast, other studies support the decompositional model of compound word production. For instance, Roelofs (1996) and Bien et al. (2005) demonstrated that morpheme frequency and the morphological structure of compounds played a significant role in speech production planning, indicating that compound words are decomposed into their morphemes during production. Further evidence for the decompositional model comes from studies employing the long-lag priming paradigm (Kaczer et al., 2015; Koester & Schiller, 2008, 2011; Lensink et al., 2014; Verdonschot et al., 2012; Wang et al., 2024). This paradigm which was first demonstrated by Zwitserlood (2000, 2002), capitalizes on a key discovery: morphological priming effects persist across many intervening items, while semantic and phonological priming effects dissipate rapidly. In the critical priming trials, primes are selected to share either the first or second constituent morpheme with their corresponding targets (e.g., prime: sunshine; target: sunflower). According to a decompositional account of lexical representation, such morphological overlap should facilitate the processing of the target compound, because the shared constituent is pre-activated during prime processing. Therefore, the observation of a significant priming facilitation effect (e.g., faster reaction times) for morphologically related prime-target pairs, relative to unrelated control pairs, constitutes direct evidence in favor of morphological decomposition during compound word processing.
The research summarized above explores the representation of compound words in the mental lexicon of various languages in the process of production and comprehension. However, there are no consistent findings regarding this question. Examining the concreteness and abstractness of constituents to further explore their roles in compound production could offer valuable insights.
The concept of abstractness refers to ideas that are neither purely physically nor spatially constrained, making them generally more variable in their content across individuals and more challenging to associate with a single image than concrete concepts (Del Maschio et al., 2021). Compared to abstract words, concrete words are easier to comprehend, faster to read aloud and to evaluate for meaningfulness, and easier to remember (Belmore et al., 1982; Gerhand & Barry, 2000; Lee & Federmeier, 2008; Paivio, 1991; Schwanenflugel, 1991; Schwanenflugel et al., 1988). For instance, a concrete word like “table” is processed more quickly and accurately than an abstract word like “honesty” at the behavioral level. This preferential processing of concrete over abstract words is known as the concreteness effect (Holcomb et al., 1999; Kounios & Holcomb, 1994; West & Holcomb, 2000). Extending from single word to compounds processing, the concrete/abstract constituents could influence the retrieval of the compound words. For instance, consider the concrete compound words “church bell” and “apple core.” In “church bell,” both two constituents “church” and “bell” are concrete, whereas in “apple core,” the constituent “core” is relatively abstract. Therefore, the present study aimed to use the concreteness effect of constituents to investigate their influence on the retrieval of compound in Mandarin production.
There are studies examining concreteness effect in language production. For instance, research conducted by Hanley et al. (2013) used different paradigms to investigate the concreteness effect during language production. He designed two experiments to examine the impact of concreteness on word retrieval within sentence contexts. In Experiment 1, participants were asked to generate words from dictionary definitions. Results showed that abstract words were more challenging to retrieve, leading to more omissions and alternate responses than concrete words. Participants also experienced more tip-of-the-tongue (TOT) states when retrieving abstract words, indicating more phonological retrieval difficulties. In Experiment 2, participants generated words to complete sentences describing specific events. The number of abstract words recalled was significantly higher than that of concrete words in this task. The above literature showed that concreteness effects existed during language production and could serve as a robust method to investigate the research question in the present study.
Additionally, the neural mechanisms underlying the differences between concreteness and abstractness have been explored through the performance of patients with neural system damage, who often perform better on concrete than abstract words. For instance, in a study by Catricalà et al. (2014), patients with Alzheimer’s disease (AD) and the semantic variant of primary progressive aphasia (sv-PPA) completed tasks with controlled abstract and concrete stimuli. Results indicated that sv-PPA patients performed better with abstract than concrete concepts, showing category-specific effects: emotion concepts were preserved in AD, whereas social relations were selectively impaired in sv-PPA. Occasionally, AD patients displayed a living vs. non-living dissociation. These findings suggested that semantic memory disorders led to distinct patterns in abstract and concrete domains, highlighting differences in the brain regions affected by each condition.
Though much research has demonstrated that concrete expressions were processed more efficiently than abstract expressions across various languages and cognitive tasks, most of these studies have been conducted in language comprehension. Work has rarely been done in language production. One primary reason could be that it is hard in production tasks, for instance, picture naming, to present and name pictures of abstract concepts. Previous studies, for instance, Hanley et al. (2013) addressed this limitation using indirect methods, embedding concrete and abstract words within sentence contexts. The present study, however, aims to investigate the concreteness effect of constituents in Mandarin compound words during the production process by using two sets of concrete compounds as targets in a picture-naming task. At the same time, the concreteness of their constituents was manipulated to explore whether constituent concreteness affects Mandarin compound production while controlling for the overall concreteness of the compounds. Two conditions were created: the “aa” condition, where both constituents of the concrete compound were abstract, and the “cc” condition, where both constituents were concrete. It was predicted in the present study that naming latencies would be shorter for the “cc” condition compared to the “aa” condition due to the concreteness effect of the constituents at the behavioral level.
Methodology
Participants
Forty native right-handed Mandarin speakers, including six males, were recruited from Leiden University. The mean age was 24.05, with an SD of ± 2.31. All participants were from Mandarin-speaking provinces in China and spoke Mandarin as their mother tongue. Participants who had been living in the Netherlands for less than two years were included, while those who had been residing in the Netherlands for longer than two years were excluded from recruitment due to potentially higher proficiency in English and Dutch. All participants had normal or corrected-to-normal vision and received monetary compensation for their participation.
This study was approved by the Faculties of Humanities and Archaeology ethics committee at Leiden University (acceptance number: 2022/09). At the time of testing, none of the participants reported color blindness, learning disorders, hearing or visual impairments, or psychological or neurological conditions. Participants read an information sheet and provided informed consent by signing a consent form before the study began.
Materials
In this study, we examined two conditions: the abstract (“aa”) condition, where the compound words were concrete, but their two constituents were abstract, and the concrete (“cc”) condition, where both the compound words and their constituents were concrete. Hence, only concreteness of the constituents varied between conditions. For example, in the “cc” condition, 河马 (/he2ma3/ “hippo”) is a concrete compound word with two concrete constituents: 河 (/he2/ “river”) and 马 (/ma3/ “horse”); in the “aa” condition, 乐队 (/yue4dui4/ “band”) is a concrete compound word with two abstract constituents: 乐 (/yue4/ “music”) and 队 (/dui4/ “team”). It is important to note that all target stimuli in both conditions were concrete disyllabic noun compounds. Forty-two Mandarin disyllabic compound nouns were selected as stimuli, with twenty-one words assigned to each condition.
We first calculated the concreteness and word frequencies of our stimuli by using two corpora to assess the concreteness and word frequency of the entire compound words in order to ensure no significant differences in concreteness and word frequency between two conditions.
For this, we utilized the MELD-SCH corpus, which provides concreteness and abstractness ratings for 9,877 two-character Mandarin Chinese words (Xu & Li, 2020), and SUBTLEX-CH corpus (Cai & Brysbaert, 2010), which provides word frequencies. We controlled for the concreteness of the compounds (t (40) < 1) based on MELD-SCH, as well as the compound frequency (t (40) < 1) using the SUBTLEX-CH corpus (see Table 1).Table 1. The concreteness and word frequency calculation of compound words in our stimuli listCorpusConditionMeanFrequency (SD)Concreteness (SD)MELD-SCH & SUBTLEX-CHaa2.58 (0.48)1.49 (0.18)cc2.36 (0.46)1.44 (0.14)p-value0.140.30
To control for the concreteness and word frequency of constituents, we conducted a cross-corpus comparison based on two corpora. One was the Hong Kong Chinese Character Psycholinguistic Norms corpus (Su et al., 2023), which provides ratings for 4,376 individual Chinese characters on various factors, including word frequency, age of acquisition, familiarity, imageability, and concreteness. This corpus allowed for frequency and concreteness analysis for constituents.
The other corpus we used to calculate concreteness and frequency of constituents was from Liu et al. (2007), which provides word naming and psycholinguistic norms in Chinese, including information on familiarity, imageability, frequency (times/million), age of acquisition, and concreteness. By utilizing above corpora, we ensured a thorough control of the concreteness and word frequency of the constituents in our study.
We then ensured that each constituent’s concreteness was carefully controlled, confirming that the mean concreteness levels of constituents and the concreteness levels of each constituent differed significantly between the conditions. Furthermore, we controlled for each constituent’s frequency to ensure no significant differences across conditions (see Table 2). In addition, we controlled for other sub-lexical variables of the constituents, including stroke count (t (40) < 1) and imageability (t (40) < 1), ensuring that these factors did not significantly differ across the two conditions in the present study. Furthermore, the concreteness of the selected compounds and their constituents were rated by a group of 20 participants online, and their ratings (t (40) < 1) confirmed the validity of these chosen stimuli. See Appendix 1 for detailed stimuli list.Table 2. The concreteness and word frequency calculation of constituents in our stimuli listCorpus Condition1st Constituent2nd ConstituentMean for two constituents Frequency(SD)Concreteness (SD) Frequency (SD) Concreteness(SD)Frequency (SD) Concreteness (SD)Su et al. (2023)aa2.54 (0.62)4.10 (0.79)2.25 (0.92)4.30 (0.76)2.39 (0.79)4.20 (0.77)cc2.47 (0.54)6.44 (0.37)1.97 (0.67)6.06 (0.40)2.22 (0.65)6.24 (0.43)p0.71 < 0.0010.26 < 0.0010.29 < 0.001Liu et al. (2007)aa156.44(424.83)4.65 (0.62)75.72(123.56)5.12(1.03)116.08(311.05)4.88 (0.87)cc187.21(189.20)6.62 (0.46)57.79(114.42)6.57(0.34)122.5(167.58)6.60 (0.40)p0.78 < 0.0010.65 < 0.0010.91 < 0.001
We employed 42 colored pictures, with 21 pictures assigned to each condition in the present study. Thirty-four of these pictures were selected from the Multipic corpus (Duñabeitia et al., 2018), while eight were created by an illustrator in a similar style. The name agreement (t (40) < 1) and picture complexity (t (40) < 1) of these selected pictures were evaluated by another 20 participants online, following the method outlined by Snodgrass and Vanderwart (1980). In addition, we included ten filler pictures, which were used as warm-up trials at the beginning of each block, and as filler pictures during the experiment, with their frequencies and concreteness spanning a wide range. Participants were presented with 52 pictures in total, including 42 experimental pictures and 10 filler pictures.
Design
The experiment in the present study employed a one-factorial within-subject design, with Concreteness as the fixed factor and Subject and Item as random factors. Participants engaged in a picture-naming task, where a pseudorandomized design was applied. Two versions of the pseudorandomized stimuli list were created during the experiment, with the first half of participants using the first version and the other half using the second version. Pictures from the same categories or those with the same phonological onset were not shown consecutively in the pseudorandomized design to avoid priming effects.
Procedure
The experiment was presented using E-prime 3.0 (Psychology Software Tools) and was conducted in a soundproof booth. Participants were seated in front of a computer in a dimly lit room. They used a microphone that was connected to a Chronos response device containing a voice key. The experiment consisted of three phases.
First, participants were given 10-15 min to familiarize themselves with target pictures and their names by studying a booklet at their own pace. Subsequently, the experimenter assessed whether participants correctly remembered the picture names by conducting a practice session through another booklet without their picture names. In this session, participants were asked to name all the target pictures as soon as possible, and the experimenter would correct them if they misnamed any pictures.
In the experiment session, each trial began with a fixation cross displayed for 250 ms, followed by a blank screen for another 250 ms. Then, the target picture appeared in the center of the screen for 2,000 ms. Therefore, each trial lasted 2,500 ms, which was applied to all target and filler pictures. See Fig. 1 for a detailed demonstration of the experiment trial in the present study.Fig. 1A trial sequence for the picture-naming task
Data analysis and results
Data exclusion
For the analysis of reaction times (RTs), two types of trials were excluded: (1) error trials, in which an incorrect name was produced (1.49% of trials) by participants, and (2) outlier trials, defined as those with RTs exceeding 2.5 standard deviations above or below the participant’s mean RT for conditions (3.10% of remaining trials).
Data analysis
Behavioral data were analyzed using RStudio Version 4.2.2. We first calculated descriptive statistics for naming latencies for each condition (see Table 3 and Fig. 2). Then, we employed a generalized linear mixed effect model (GLMM) (Lo & Andrews, 2015) using the glmer () function from the lme4 package with inverse Gaussian errors to model positively skewed RT data.Table 3. Mean naming latencies (only correct trials were included) for each condition (n = 40)ConditionNaming latencies (ms)MeanSDaa811.90152.22cc770.63123.91Fig. 2Mean naming latencies for each condition (n = 40)
To avoid over-parameterization and achieve a balance between Type-I error and statistical power, we employed a backward elimination strategy for the random effects structures of the model (Bates et al., 2015; Matuschek et al., 2017). Model comparisons and likelihood ratio tests were conducted at each step using the anova() function, evaluating Akaike’s Information Criterion (AIC) (Akaike, 1974), Bayesian Information Criterion (BIC) (Neath & Cavanaugh, 2012), and log-likelihood to determine whether the addition of a new factor significantly improved the model.
In this analysis, Concreteness was included as a fixed effect, while Subject and Item were introduced as random effects. For naming latencies, the model of the best fit was RT ~ Concreteness + (1 + Concreteness | Subject) + (1 | Item). The results showed that the naming latencies of the “aa” and “cc” conditions significantly differed with β = -41.85 (95% CI [-57, -26.7]), SE = 7.73, t = -5.42, and p < 0.001. The by-subject random slope of concreteness in this model accounts for individual differences in the effect itself, showing that the effect of concreteness is not identical for all participants in the present study.
Discussion and conclusion
The ongoing debate regarding the representation of compound words in our mental lexicon has led to numerous studies exploring this issue. The present study aimed to address this question by examining the concreteness effect of word constituents in compounds. Two conditions were established: “cc” condition representing concrete compound words with two concrete constituents and “aa” condition representing concrete compound words with two abstract constituents. The behavioral results in the present study showed significantly faster reaction times for the “cc” condition than the “aa” condition, suggesting concreteness effects of the constituents in Mandarin compound production.
The results reported in the present study have implications for the two models of lexical representation in production as discussed in Introduction. According to the full-listing model of lexical representations, compounds are stored in their full-listing format at the lexical level. In other words, the whole word is retrieved when naming the pictures instead of the individual constituents, which predicts no constituent effects. Contrastingly, the decompositional model predicts constituent effects due to the fact that each constituent is retrieved during compound production, which allows the possibilities of concrete constituent being retrieved faster than abstract constituents. Therefore, the concreteness effects of constituents found in the present study provide evidence for the decompositional hypothesis in the process of Mandarin compounds production.
Besides, the representation of multi-word units, including compounds, is a central topic in language processing research. While much of the evidence on this issue originates from studies of comprehension, the present investigation seeks to resolve this long-standing theoretical debate between decompositional (e.g., Levelt et al., 1999) and holistic (e.g., Caramazza, 1997) models of compound representation by shifting the empirical focus to language production, offering a critical, complementary testing ground for these competing theoretical claims. Testing the divergent hypotheses of compounds processing within the production domain is therefore theoretically imperative. A production task (e.g., picture naming task), by directly probing the stages of lexical access and phonological encoding, can reveal the underlying representational format - decomposed or holistic - free from potential parsing strategies that may dominate comprehension, which provides the primary rationale for investigating compound representation using a language production paradigm in the present study. Therefore, the resulting knowledge makes contributions to the existing literature in aspects of providing a direct test of model-specific production mechanisms.
Next, a critical, unresolved question is whether morphological decomposition is a central property of the lexicon or a task-specific strategy. If the production data align with patterns previously observed in comprehension (e.g., constituent frequency effects), this would support a domain-general linguistic principle that compounds are represented as morphologically structured units regardless of the processing direction (input vs. output). This would unify theories across comprehension and production. However, if the production data reveal a distinct pattern - for instance, showing whole-word dominance where comprehension studies normally show decomposition - it would instead argue for task-dependent or modality-specific representations. This outcome would necessitate more complex models where representational format is flexible or determined by processing constraints. Therefore, the discovery of a concreteness effect for morphological constituents in production in the present study, consistent with previous comprehension studies, supports domain-general morphological representation. By adjudicating between competing production models, testing the modality-generality of morphological effects, this study moves the field beyond descriptive debates toward a more integrated and mechanistic understanding of how complex words (especially compound words) are represented in our mental lexicon and planned for production.
The constituent-level concreteness effects we observed align with previous theoretical explanations including lexico-semantic weights hypothesis. This hypothesis claims that abstract words possess weaker semantic-lexical associations compared to concrete words as stated in previous studies (Hanley et al., 2004, 2013). For instance, Hanley et al. (2004) used Foygel and Dell’s (2000) speech production model to simulate imageability differences by varying lexico-semantic connection strengths. They posited that high-imageability words have stronger lexico-semantic association, while low-imageability words have weaker ones. In this model, lower association results in weaker activation of lexical units, causing more alternates and omissions for low-imageability words. Besides, in a definition task by Hanley et al. (2013), participants rated the most common alternatives to abstract target words as more compatible with definitions than those for concrete words, supporting this lexico-semantic weights hypothesis. In the present study, the facilitation of concrete constituents potentially show support for the above claim that it is easier for concrete concepts which have more distinctive semantic features and higher imageability to reach the activation threshold.
On the other hand, the concreteness effects have also been explained by alternative theoretical frameworks. For instance, Newton and Barry (1997) argued that abstract words are more difficult to retrieve in production because they face stronger competition from semantically related words. They proposed that retrieval issues for abstract words arise after activating the target word’s semantic representation. Since abstract words typically share many semantic features with other words, phonological representations of competing words are more likely to reach the activation threshold, increasing semantic errors. Although concrete words also activate competing items, their distinctive semantic features make them more likely to reach the activation threshold over competitors in tasks like word definition, reducing the likelihood of errors. Besides, Hoffman et al. (2011) found that abstract words are more ambiguous and have more senses than concrete words, as demonstrated through latent semantic analysis. The imageability effect observed in their study suggested that abstract words may be more difficult to process because they depend more on context for meaning, which is often lacking in experimental settings (Schwanenflugel et al., 1988).
Since the present results suggest that the explanatory frameworks offered for the single-word concreteness effect might provide a useful starting point or analytical lens for investigating the novel constituent-level effect we observed, these frameworks offer testable hypotheses for future research specifically designed to explore the mechanisms behind constituent concreteness in compounds production.
Additionally, since concreteness is a semantic feature, which is corresponding to the phase of conceptualization in the Levelt’s production model (1999), the present findings offer insights into models of lemma representation of compound words (Levelt et al., 1999; Marelli et al., 2012; Sprenger et al., 2006). According to Levelt et al.’s model (1999), compounds are initially represented as a single lemma, which is later decomposed at the lexeme level for phonological encoding. However, the concreteness effects observed in this study suggest that distinct lemma entries may exist for individual constituents during the production of Mandarin compound words. The fact that the concreteness of the constituents influences the production of compounds in the present study supports the hybrid lemma account proposed by Marelli et al. (2012) and Sprenger et al. (2006). The concreteness effects observed at the lemma level in the present study went against previous studies in Indo-European languages supporting a two-staged model (Mondini et al., 2004) with only a single lemma for word production. This difference could stem from cross-linguistic distinctions. First, Chinese writing is classified as a logographic system, where Chinese speakers may exhibit heightened lexical awareness attributed to the presence of Chinese characters and radicals, serving as visual cues. In addition, unlike alphabetic languages, Chinese characters do not directly correspond to phonemes but map onto meaningful morphemes in spoken language. This aspect implies that the regular or quasi-regular grapheme-phoneme conversions commonly found in alphabetic languages are not feasible in Mandarin Chinese (Plaut, 1996; Tan & Perfetti, 1998). Future studies should examine these points further.
It is also essential to acknowledge the limitations of this study. One such limitation is that it did not control for semantic transparency, a factor that has been more extensively investigated in the literature on comprehension, as noted earlier (Han et al., 2014; Liu & Peng, 1997; Peng et al., 1999; Su, 1998; Tsai, 1994). In language production, however, the distinction between opacity and transparency seems to have less impact in Indo-European languages based on previous literature (e.g., Koester & Schiller, 2008; but also see Zwitserlood, 2014). For instance, both opaque and transparent primes exhibit priming effects in compound production, as observed in the works of Koester and Schiller (2008). Nevertheless, there is a possibility that the obtained results may differ when applying to transparent or opaque words, suggesting that future research endeavors could also consider investigating opaque compound words in their research design.
Besides, we did not control for the Age of Acquisition (AoA) of compounds in the present study, but we conducted a post-hoc analysis to examine AoA as a potential confounding factor based on a corpus of Age of Acquisition ratings for 19,716 simplified Chinese words (Xu et al., 2021).1 The results revealed a significant influence of AoA for compounds themselves (p = 0.04) and for the mean AoA of both constituents (p = 0.0003). These findings indicate that AoA is likely to be a confounding variable in the observed concreteness effect, highlighting the need for future research to explicitly control for and investigate the nuanced role of AoA in this effect.
Furthermore, although we selected noun compounds as stimuli, we did not control for the word category (e.g., noun, verb, etc.) of their constituents. Hanley et al. (2013) highlighted the effects of word category on lexical retrieval in their two experiments. Therefore, future research should investigate this aspect further to provide more detailed evidence addressing the role of word class in compound words representation.
In conclusion, the present study’s results demonstrated that the concreteness of constituents probably plays a role in Mandarin compounds production and further supported the decompositional account instead of the full-listing account in Mandarin compounds production. The present study also highlights the importance of concreteness in language production along with some confounding factors, suggesting that future research could explore how concreteness influences language production more broadly.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Butterworth, B. (1983). Lexical Representation. In B. Butterworth (Ed.), Language production: Vol. II. Development, writing and other language processes (pp. 257–294). Academic Press.
- 2Frauenfelder, U. H., & Schreuder, R. (1991). Constraining psycholinguistic models of morphological processing and representation: The role of productivity. In Yearbook of Morphology 1991 (pp. 165–183). Springer.
- 3Starosta, S., Kuiper, K., Ng, S. S., & Wu, Z.-Q. (1997). On Chinese compounding and Chinese VR compounds. In New approaches to Chinese word formation: Morphology, phonology and the lexicon in modern and ancient Chinese (Vol. 105, pp. 347–376). Berlin, New York: Mouton de Gruyter.
- 4Su, Y.-C. (1998). The representation of compounds and phrases in the mental lexicon: Evidence from Chinese. University of Maryland Working Papers in Linguistics, 6,179–199.
- 5Taft, M. (1994). The influence of character frequency on word recognition responses in Chinese. In H.-W. Chang, J.-T. Huang, C.-W. Hue, & O. J. L. Tzeng (Eds.), Advances in the study of Chinese language processing (Vol. 1, pp. 59–73). National Taiwan University.
- 6Tsai, C.-H. (1994). Effects of semantic transparency on the recognition of Chinese two-character words: Evidence for a dual-process model [Master’s thesis, National Chung Cheng University, Chia-Yi, Taiwan].
- 7Zhang, B. & Peng, D. (1992). Decomposed storage in the Chinese lexicon. In Advances in psychology (Vol. 90, pp. 131–149).
- 8Zwitserlood, P. (2014). The role of semantic transparency in the processing and representation of Dutch compounds. In Morphological Structure, Lexical Representation and Lexical Access (RLE Linguistics C: Applied Linguistics) (pp. 341–368). Routledge. 10.4324/9781315857213