Adaptive and lightweight surrogate gradients: enhancing training efficiency of spiking neural networks
Kungjui Hou, Kunlun Wu, Yongcheng Zhou

TL;DR
This paper introduces a new method called AdaLi to improve the training of energy-efficient spiking neural networks by addressing common issues like gradient mismatch and instability.
Contribution
AdaLi introduces adaptive and lightweight surrogate gradients to enhance training efficiency and stability in spiking neural networks.
Findings
AdaLi outperforms baseline methods in training efficiency and accuracy on static and neuromorphic datasets.
The method effectively mitigates gradient vanishing and explosion through stable surrogate gradients.
AdaLi provides hyperparameters that can be manually or automatically adjusted to address gradient mismatch.
Abstract
Spiking Neural Networks (SNNs) have emerged as a promising paradigm in artificial intelligence due to their energy efficiency. However, training SNNs remains a formidable challenge because the nondifferentiable nature of spike activation functions prevents the direct application of conventional backpropagation. Existing surrogate gradient methods often suffer from critical limitations, including gradient mismatch, gradient explosion or vanishing, and high computational overhead. In this paper, we propose an Adaptive and Lightweight (AdaLi) backpropagation method to address these issues. AdaLi reduces the computational complexity of the training process by introducing lightweight surrogate gradients and dynamically adjusting gradient update boundaries. Furthermore, it employs an adaptive mechanism to adjust the surrogate gradients based on training epochs, thereby enhancing network…
Click any figure to enlarge with its caption.
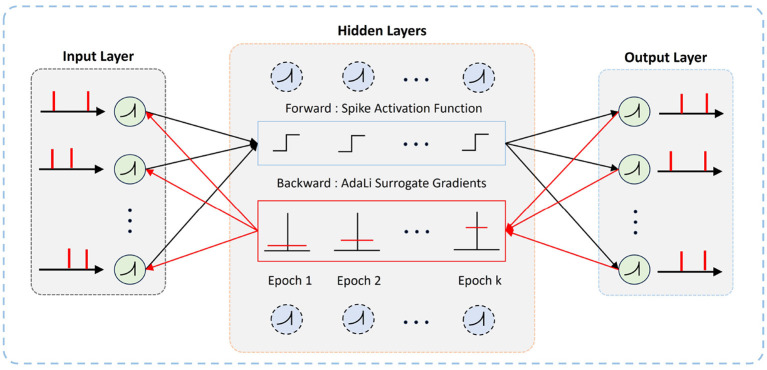 Figure 1
Figure 1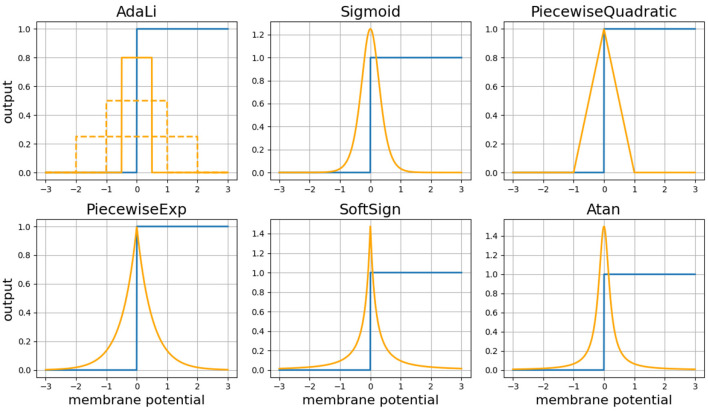 Figure 2
Figure 2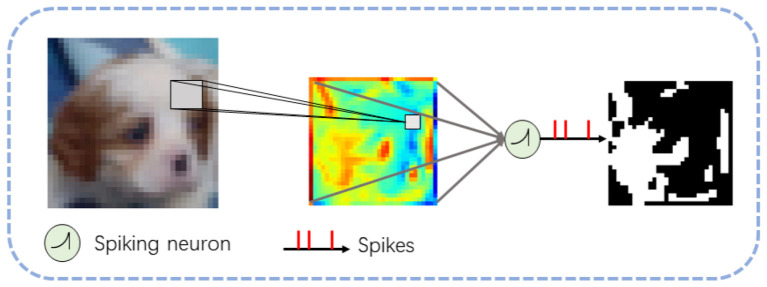 Figure 3
Figure 3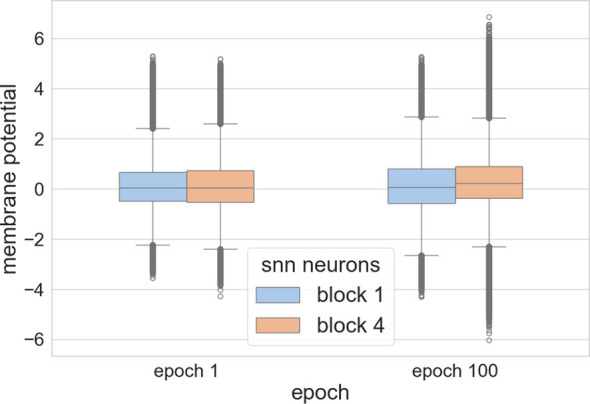 Figure 4
Figure 4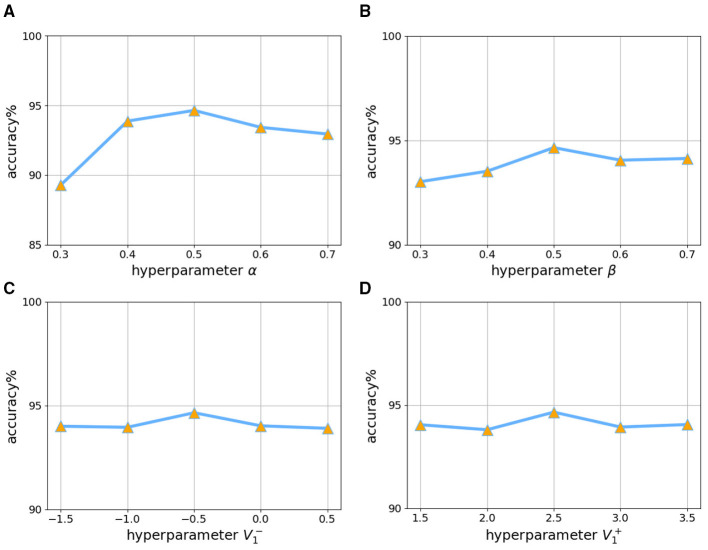 Figure 5
Figure 5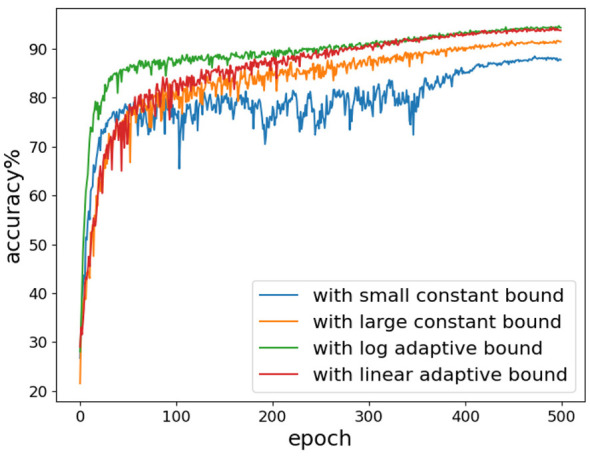 Figure 6
Figure 6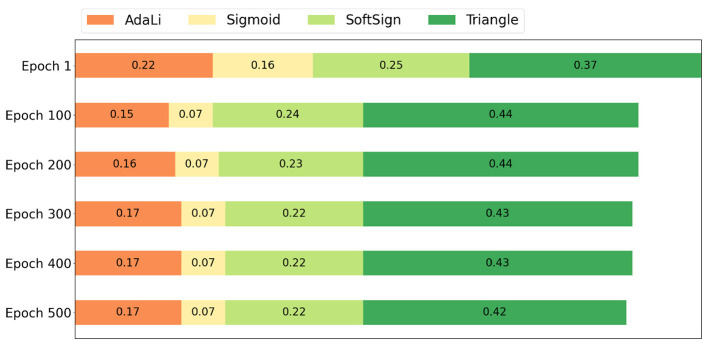 Figure 7
Figure 7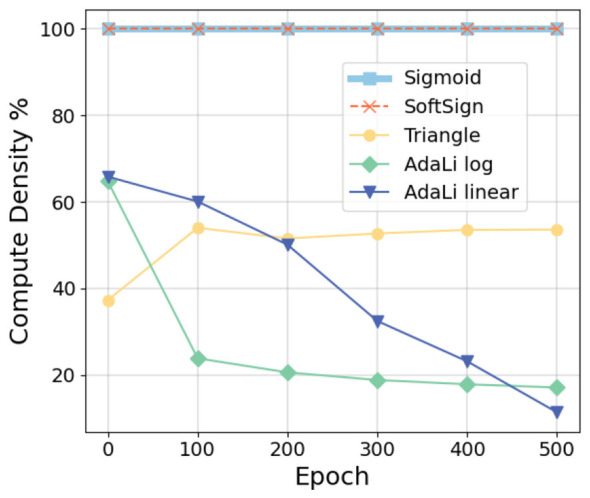 Figure 8
Figure 8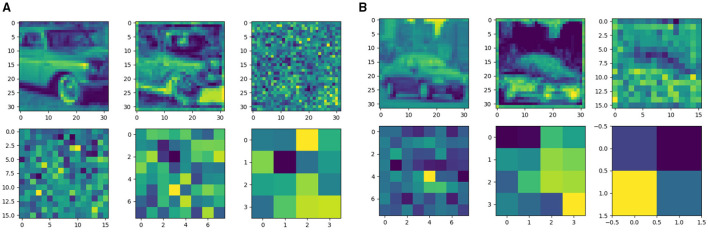 Figure 9
Figure 9|
|
|
|
|
|---|---|---|---|
| Latency | High | Low | Low |
| Compute density | High | Medium | Low |
| Performance w/low latency | Low | Medium | High |
| Neuromorphic data | Non-applicable | Applicable | Applicable |
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
| CIFAR-10 | SATP ( | ANN-to-SNN conversion | VGG16 | RMP-IF | 128 | 91.92% |
| Event-driven BP ( | Direct training | ResNet14 | LIF | \ | 92.45% | |
| TSSL-BP ( | Direct training | CIFARNet | LIF | 5 | 91.41% | |
| FT-SNN ( | Direct training | \ | LIF | \ | 93.69% | |
| MPD-ATP ( | Direct training | \ | LIF | 8 | 94.27% | |
| STD-ED ( | Direct training | \ | LIF | \ | 94.33% | |
| HP-SNN ( | Hybrid training | \ | LIF | 4.5 (average) | 91.08% | |
| PLIF ( | Direct training | PLIFNet | PLIF | 8 | 93.50% | |
| Dspike ( | Direct training | ResNet18 | LIF | 6 | 94.25% | |
| DSR ( | Direct training | ResNet18 | LIF | 20 | 95.40% | |
| BKDSNN (Xu Z. et al., | Direct training | ResNet18 | IF | 4 | 93.41% | |
| TET ( | Direct training | ResNet18 | LIF | 2 | 94.16% | |
| 4 | 94.44% | |||||
| STBP-tdBN ( | Direct training | ResNet18 | Iterative LIF | 6 | 93.16% | |
| 4 | 92.92% | |||||
| 2 | 92.34% | |||||
| IM-Loss ( | Direct training | ResNet18 | LIF | 2 | 93.85% | |
| VGG16 | 5 | 93.85% | ||||
| CIFARNet | 4 | 92.20% | ||||
| RecDis-SNN ( | Direct training | ResNet18 | LIF | 2 | 93.64% | |
| 4 | 95.53% | |||||
| Real Spike ( | Direct training | ResNet18 | LIF | 2 | 95.31% | |
| 4 | 95.51% | |||||
| ResNet20 | 4 | 91.89% | ||||
| Direct training | ResNet18 | LIF | 1 | |||
| 2 | ||||||
| 4 | ||||||
| VGG16 | LIF | 4 | ||||
| CIFAR-100 | Event-driven BP ( | Direct training | VGG11 | LIF | \ | 63.97% |
| FT-SNN ( | Direct training | \ | LIF | \ | 72.24% | |
| MPD-ATP ( | Direct training | \ | LIF | 8 | 74.41% | |
| STD-ED ( | Direct training | \ | LIF | \ | 73.01% | |
| LTL ( | Tandem learning | ResNet20 | LIF | 31 | 76.08% | |
| RecDis-SNN ( | Direct training | ResNet18 | LIF | 4 | 74.01% | |
| IM-Loss ( | Direct training | VGG16 | LIF | 5 | 70.18% | |
| Real Spike ( | Direct training | ResNet20 | LIF | 5 | 66.60% | |
| VGG16 | 5 | 70.62% | ||||
| Dspike ( | Direct training | ResNet20 | LIF | 2 | 71.68% | |
| 4 | 73.35% | |||||
| TET ( | Direct training | ResNet18 | LIF | 2 | 72.87% | |
| 4 | 74.47% | |||||
| InfLoR-SNN ( | Direct training | ResNet20 | LIF | 5 | 71.19% | |
| VGG16 | LIF | 5 | 71.56% | |||
| 10 | 73.17% | |||||
| MPBN ( | Direct training | VGG16 | LIF | 4 | 74.74% | |
| ResNet20 | LIF | 2 | 70.79% | |||
| 4 | 72.30% | |||||
| Direct training | VGG16 | LIF | 4 | |||
| ResNet18 | LIF | 2 | ||||
| 4 |
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
| DVS-CIFAR-10 | SATP ( | ANN-to-SNN conversion | VGG16 | RMP-IF | 230 | 67.09% |
| MPD-ATP ( | Direct training | \ | LIF | 20 | 74.93% | |
| HP-SNN ( | Hybrid training | \ | LIF | 50 | 67.81% | |
| Rollout ( | Streaming | DenseNet | IF | 10 | 66.80% | |
| ANN-to-SNN conversion | DenseNet | 10 | 65.61% | |||
| STBP-tdBN ( | Direct training | ResNet18 | Iterative LIF | 10 | 67.80% | |
| RSNN (Xu Q. et al., | Direct training | RSNN | LIF | \ | 67.10% | |
| AdaLi (ours) | Direct training | VGG11 | IF | 16 | ||
| VGG16 | 16 | |||||
| DVSGesture | STBP ( | Direct training | CNN-based | LIF | 25 | 93.40% |
| MPD-ATP ( | Direct training | \ | LIF | 20 | 97.35% | |
| HP-SNN ( | Hybrid training | \ | LIF | 400 | 97.01% | |
| MISNN ( | Motion information | CNN-based | LIF | \ | 92.7% | |
| SATP ( | ANN-to-SNN conversion | SCRNN | LIF | 389 | 82.59% | |
| RSNN (Xu Q. et al., | Direct training | RSNN | LIF | \ | 95.10% | |
| AdaLi (ours) | Direct training | DVSGestureNet | IF | 16 | ||
| VGG11 | IF | 16 |
|
|
|
|---|---|
| Sigmoid, α = 1 | 69.55%±0.11% |
| SoftSign, α = 2 | 83.69%±0.06% |
| Triangle, α = 1 | 87.07%±0.05% |
| AdaLi, α = 0.5, β = 0.5 | 95.03%±0.07% |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Memory and Neural Computing · Neural Networks and Reservoir Computing · Neural dynamics and brain function
Introduction
1
The rapid advancement of artificial neural networks (ANNs) has revolutionized various domains of machine intelligence (Wang et al., 2023; Liu et al., 2023; He et al., 2016; Ronneberger et al., 2015; Bewley et al., 2016). However, ANNs rely on dense-valued tensors for computation, a mechanism fundamentally distinct from the brain's sparse, event-driven processing of information (Guo et al., 2024; Shen et al., 2024).
This discrepancy underscores the challenge of replicating the brain's efficiency and adaptability in artificial systems. Spiking neural networks (SNNs) have emerged as a promising alternative, offering higher biological fidelity by mimicking the use of sparse, binary spike events for communication and computation (Mainen and Sejnowski, 1995; Zhang et al., 2022b, 2023). By leveraging sparsity and asynchrony (Zhang et al., 2024; Histed et al., 2009), SNNs enable energy-efficient, event-driven processing that aligns more closely with the natural mechanisms (Yamazaki et al., 2022; Zhang et al., 2022a; Zhou et al., 2024). Moreover, SNNs excel at encoding information through spatio-temporal dynamics (Baronig et al., 2025), making them particularly suited for tasks involving time-series data or neuromorphic hardware (Painkras et al., 2013; Zhang et al., 2023; Luo et al., 2023; Merolla et al., 2014; Davies et al., 2018; Pei et al., 2019; Ye et al., 2023; Liu et al., 2024; Zhang and Zhang, 2025).
Despite their potential, training SNNs remains a significant challenge due to the non-differentiable nature of the spiking activation function (Guo et al., 2023b; Eshraghian et al., 2023; Rançon et al., 2022). This non-differentiability prevents the direct application of backpropagation, a cornerstone of ANN training, limiting the optimization methods available for SNNs. While surrogate gradient methods have been proposed to address this issue (Deng et al., 2022; Neftci et al., 2019; Meng et al., 2022; Guo et al., 2022a; Wu et al., 2018; Meng et al., 2023), they often introduce gradient mismatch problems (Zenke and Vogels, 2021), leading to performance degradation during training (Guo et al., 2022b). Additionally, the spike activation function's infinite derivative at the threshold and zero derivative elsewhere exacerbate issues of gradient vanishing and explosion, further destabilizing the training process (Liang et al., 2023; Yao et al., 2023; Lian et al., 2024).
To this end, this paper proposes an Adaptive and Lightweight (AdaLi) backpropagation method to optimize SNN training. AdaLi introduces a lightweight surrogate gradient that reduces computational complexity while maintaining stability, addressing the gradient vanishing and explosion issues inherent in traditional surrogate gradients. Furthermore, AdaLi incorporates an adaptive mechanism that dynamically adjusts gradient update boundaries based on training epochs, enhancing training stability and efficiency. This adaptive function also provides hyperparameters to mitigate gradient mismatch, which can be manually fine-tuned or automatically determined based on the distribution of spiking neuron membrane potentials. By these design, AdaLi optimizes the network training process, achieving satisfactory results across various networks and datasets. A comparison of the properties between the AdaLi method and other methods is illustrated in Table 1.
The main contributions of this work can be summarized as follows:
We designed a lightweight surrogate gradient that reduces computational complexity during backpropagation, making it particularly effective for training large-scale networks. This design inherently resolves the gradient vanishing and explosion issues prevalent in traditional surrogate gradients.We proposed an adaptive function that autonomously controls the range of gradient updates, maximizing training stability while reducing the computational overhead. This function also provides hyperparameters to mitigate gradient mismatch, which can be flexibly adjusted or automatically set based on neuron membrane potential distributions.We evaluated AdaLi on both static and neuromorphic datasets, demonstrating its superior performance across various network architectures and tasks. Experimental results confirmed that AdaLi achieves high efficiency and accuracy, outperforming other SOTA methods.
Related work
2
In this section, we provide a brief overview of the network learning methods employed for SNNs, with a particular focus on direct training approaches.
Network learning of SNNs
2.1
The training of SNNs typically involves three primary methodologies: ANN-to-SNN conversion, unsupervised learning paradigms [e.g., Spike-Timing-Dependent Plasticity (STDP) (Caporale and Dan, 2008; Dan and Poo, 2004; Rahman and Yusoff, 2025)], and direct training using surrogate gradients. ANN-to-SNN conversion approximates the firing dynamics of an SNN by utilizing the activation patterns of an ANN with the similar architecture and weights configuration (Rueckauer et al., 2017). This method directly derives SNN parameters from a pre-trained ANN, ideally ensuring comparable performance to its ANN counterpart, with minimal performance degradation. However, this approach often incurs increased latency to replicate the high-resolution activation values of the ANN, thereby compromising the energy efficiency that is a core advantage of SNNs.
STDP, a prominent unsupervised learning method for SNNs, modulates synaptic efficacy based on the precise timing of pre- and post-synaptic spikes (Brzosko et al., 2019; Saponati and Vinck, 2023; Debanne and Inglebert, 2023). While STDP has significant potential in shaping network connectivity and information processing, its inability to capture global information poses challenges for convergence in large-scale models, particularly with complex datasets (Masquelier and Thorpe, 2007; Tavanaei and Maida, 2016; Diehl and Cook, 2015).
In contrast to aforementioned methods, direct training approaches based on surrogate gradients offer notable advantages, particularly in reducing inference latency, which improves computational efficiency while preserving the energy efficiency inherent to SNNs (Wu et al., 2019; Su et al., 2023; Zhou et al., 2024). Moreover, surrogate gradient-based training methods address the challenges associated with unsupervised learning, especially for large-scale datasets. By incorporating established gradient-based optimization algorithms, these techniques have demonstrated robust performance across a wide range of datasets.
Surrogate gradients based direct training
2.2
Direct training methods can be broadly categorized into time-based and activation-based approaches, depending on whether the gradient reflects spike timing (time-based) (Cai et al., 2023) or spike magnitude (activation-based) (Guo et al., 2023b; Zhu et al., 2022).
Time-based methods adjust spike timing by directing whether to advance or delay spike emission. Works such as (Bohte et al. 2002) and (Hong et al. 2019) distribute errors across each firing time rather than through individual neurons, using the negative reciprocal of the time derivative of the membrane potential to estimate spike timing derivatives. Despite reducing computational complexity, training deep time-based SNN models on large-scale datasets remains challenging (Mostafa, 2018; Xiao et al., 2022).
Activation-based methods (Fang et al., 2021a; Rathi and Roy, 2020) use differentiable surrogate functions to approximate the non-differentiable spike activity function for gradient calculation during backpropagation. (Zenke and Ganguli 2018) introduced SuperSpike, a supervised learning method for training multilayer SNNs using non-zero surrogate gradients to address gradient-related issues. (Cheng et al. 2020) encoded visual features into spike sequences and trained SNN models with backpropagation, incorporating lateral interactions. However, fixed surrogate gradient forms in these methods make it difficult to address the issue of gradient mismatch. (Li et al. 2021) proposed differentiable spike functions based on hyperbolic tangent functions, incorporating finite difference gradients and adjusting a temperature factor to modify the function's shape. (Guo et al. 2022a) introduced evolutionary surrogate gradients, using smaller coefficients during early training stages to improve convergence and accuracy. Despite their dynamic adjustments, these methods' complexity and numerous parameters increase computational demands, making them less suitable for large-scale networks and prone to gradient vanishing and explosion issues.
In contrast, the surrogate gradients in our proposed AdaLi method are computationally efficient and mitigate gradient vanishing and explosion issues. AdaLi adjusts parameters based on the distribution of neuron membrane potentials, improving gradient mismatch problems. Combined with an adaptive function, AdaLi reduces the gradient computation overhead during training while enhancing SNN training stability.
Proposed method
3
Framework overview
3.1
Figure 1 illustrates the comprehensive diagram of our proposed AdaLi method. In the forward propagation phase, spiking neurons utilize the Heaviside function to determine spike emission. During backpropagation, parameters are no longer updated by calculating the gradient of the Heaviside function. Instead, AdaLi introduces surrogate gradients that adapt over the course of training epochs, thereby enhancing network performance while concurrently reducing computational demands. As shown in Figure 2, a comparison in shape between our proposed AdaLi and other commonly surrogate gradients-based methods.
The overall framework of our proposed AdaLi method. The method automatically evolves in each epoch in backpropagation to reduce the range of parameters update.
The illustration delineates six distinct activation functions along with their corresponding surrogate gradient curves. The blue curve corresponds to the forward propagation process, whereas the orange curve depicts the surrogate gradient utilized during backpropagation. The dashed lines in the AdaLi activation function subplot represent the surrogate gradients across different epochs, which gradually narrow inward with training progression and shrink the effective gradient update range. This contraction trend is positively correlated with the training effect, balancing the stability of early training and the computational efficiency of later training stages.
Additionally, the representation of information in SNNs differs from that of ANNs. SNNs leverage spike sequence transmissions, primarily employing two encoding strategies: temporal coding and rate coding. Temporal coding emphasizes precise spike timing, whereas rate coding focuses on spike frequency as the conduit of information. Temporal coding is typically recognized for its energy-efficient deployment on neuromorphic hardware due to the emission of sparse spikes. However, temporal coding may necessitate configurations less conducive to chip compatibility or exhibit optimal performance only with simplistic datasets, as noted in (Meng et al. 2022). In this paper, we employ rate coding as our methodology for SNN training due to its robustness.
Considering that the pixel values of static datasets are continuous, while SNNs typically receive discrete spike signals as input and output discrete spike signals, we designate the first convolutional layer and spiking neurons of the network as encoding units for the input, as shown in Figure 3. After the convolutional layer processes the input image to generate feature maps, the first spiking neuron receives these feature maps as input, encodes them into discrete spike signals, and transmits them to the next layer.
Representation of images in SNNs, the first layer of the network encodes the image from continuous values to discrete spike signals.
Assuming a two-dimensional input data X, the operation of encoding input data into spikes can be given as:
where Conv denotes the convolution operation, S denotes the spiking neurons' firing operation, and the firing process of spiking neurons will be elaborated later in Section 3.2. Let the convolution kernel (filter) be W, the convolution operation is expressed as:
where Y(i, j) is the element of the output feature map with i and j being the row and column indices. m and n denote the row and column indices of the input feature map. More specifically, the encoding operation can be represented as:
where Vth denotes the firing threshold of spiking neurons, and H is the Heaviside function defined as:
Forward pass
3.2
Inspired by the communication mechanisms in biological neurons, spiking neurons emulate these intricate interactions using binary signals. This paper leverages the widely adopted integrate-and-fire (IF) and leaky-integrate-and-fire (LIF) models (Burkitt, 2006) to streamline the simulation of spike generation and subsequent binary signal communication among neurons. Upon receiving a spike signal, it is integrated into the neuron's membrane potential, akin to electrical charge accumulation. This accumulation process, which captures the dynamic behavior of the membrane potential, can be expressed mathematically as follows:
where τ is the membrane time constant, Vrest is the resting potential, and I is the input current linked to the received spikes. When the membrane potential V exceeds the predefined threshold Vth at time tf, the neuron initiates a spike and resets its membrane potential to Vrest. The output spike train can be formulated using the Dirac delta function .
The aforementioned scenario depicts the continuous process of neuron dynamics. As computers can only approximate continuity through discrete representations, it is essential to understand the discrete representation of neuron dynamics. The model is represented in discrete form as:
where the variables U[n], s[n], and V[n] indicate the accumulated membrane potential upon receiving input, the output spikes, and the membrane potential after spike emission, respectively. If a spike is emitted, V[n] represents the membrane potential post-emit, whereas if no spike is emitted, V[n] equals U[n]. H(x) represents the Heaviside step function, signifying the process of spike generation. The function f(·, ·) denotes the membrane potential update function, taking the previous membrane potential and current input currents as inputs, and is defined as:
In the LIF model, Δt < τ represents the discrete step, typically set to be significantly smaller than τ in practice. By combining Equations 7a, c, we derive a more condensed update rule for the membrane potential:
Equation 10 is employed to establish the forward pass of SNNs. Assuming the SNN comprises L layers and follows a feedforward structure, the dynamic process of neurons in the IF model can be represented by integrating Equations 8, 10 as:
where the index i = 1, 2, ⋯ , L iterates through the layers, with s^i^ representing the output spike of the i^th^ layer, generated by Equation 7b. W^i^ denotes the weight parameters from the (i−1)^th^ layer to the i^th^ layer. is the input currents for the i^th^ layer. The spike thresholds are uniform across all layers. Similarly, by combining Equations 9, 10, the dynamic of neurons in the LIF model can be represented as:
Proposed AdaLi method
3.3
The spike activation function in Equation 7b can be considered a variant of the sign function. Its derivative is zero when the membrane potential is not equal to the threshold potential, and infinite when the membrane potential equals the threshold potential. Due to this non-differentiable characteristic, the backpropagation algorithm cannot be directly applied to SNNs. For a more detailed demonstration, we provide the expression for calculating parameter gradients:
where is the loss function, Wl is the weight matrix of layer l., and represents the output of neuron in layer l at time t. The gradient of the spike activation function at time step t in the lth layer is denoted by . The weight update rules are as follows:
where η denotes the update rate and ΔW denotes the weight update amount. In Equation 7b, the neuron's firing process is described by a Heaviside step function, making its derivative the Dirac delta function:
where U represents the membrane potential of a spiking neuron subtracted by the threshold before the neuron fires a spike.
Directly employing the Dirac delta function for gradient descent introduces substantial instability into the network's training regimen. The predominant zero-value scenario results in zero changes to the weight adjustments, ΔW, rendering network parameter updates ineffectual. Conversely, in scenarios where the derivative encounters infinite values, ΔW escalates to infinity, leading to exceedingly erratic and unpredictable updates of the network parameters.
It is widely acknowledged that gradients indicate the direction and rate of change of a function at a given point. However, due to the discontinuity of the spike activation function at the threshold, gradients are zero everywhere except at the threshold. In fact, the points with gradient equal to zero also have a trend of numerical change at the macro level. Therefore, the gradient of the spike activation function is unable to provide suitable direction or the rate of change. This paper proposes that this is why traditional gradient descent algorithms are challenging to apply to SNNs. To successfully apply gradient descent algorithms to SNNs, the key is not merely handling the gradient at the threshold potential, but reconstructing the direction and rate of change of the spike activation function for most membrane potential values.
The discontinuity point of the spike activation function is at the threshold potential. Determining the rough direction of change of the spike activation function at a given point is straightforward. When the membrane potential is less than the threshold, an increase in membrane potential may cause the spike activation function value to increase from 0 to 1. Conversely, when the membrane potential is greater than the threshold potential, a decrease in membrane potential may cause the spike activation function value to decrease from 1 to 0. Once the direction of change is determined, further research on the rate of change of the spike activation function at a given point is conducted. An intuitive approach is to determine the rate of change of the spike activation function at a given point based on the range of membrane potential that needs gradient updates. If there is no restriction on the range of membrane potential that needs gradient updates, outliers in the membrane potential may lead to unstable training when updating their gradients.
Suppose V^−^ and V^+^ are the boundaries for the gradient update of membrane potential, generally, and , we can obtain the basic form of the surrogate gradient:
where and are the reconstructed rate and direction of change of the spike activation function on the left and right sides of the threshold, respectively. U represents the membrane potential of the spiking neuron, while α and β are appropriate constant gradient intensity factors obtained experimentally to mitigate the gradient mismatch issue effectively. The selection of α and β is discussed in Section 4.2.
Compared to the traditional methods of using the sigmoid function as a surrogate for the spike activation function, our approach simplifies the calculation of membrane potential gradients during backpropagation, making it a lightweight backpropagation method. As the form of surrogate gradients is always constant, stable values prevent gradient vanishing and exploding issues.
The training process encounters significant challenges due to the overly narrow update range, leading to a dearth of gradient updates during backpropagation, and conversely, an excessively expansive update range that accommodates outliers, triggering instability and amplifying the computational burden. To address these issues, we craft adaptive functions designed to gradually constrict the gradient update range at distinct rates as training epochs progress. This novel approach mitigates the computational intensity associated with backpropagation. For a logarithmic reduction rate for the gradient update range, we define the adaptive function as follows:
Thus, to decrease the update range of gradients with a linear rate of change, the expression for the adaptive function is:
where Vk has two forms, and , representing the boundaries of membrane potential requiring gradient updates on the left and right sides of the threshold in the k-th training round. N and k denote the total epochs and the current epoch, respectively. The values of and are the initial boundaries of membrane potential that needs gradient updates. We choose a relatively large value at the start of training to stabilize the training process. and are the boundaries of membrane potential requiring gradient updates at the end of training. Their calculation formulas are as follows:
where p is a constant between 0 and 1. This formula implies that the final update boundary is set to a fixed proportion p of the distance from the threshold Vth to the initial boundary . The selection of hyperparameters is discussed in Section 4.2. For clearer illustration, we present the pseudocode of one iteration of SNN training with our AdaLi method in Algorithm 1.
Algorithm 1One iteration of SNN training with the proposed AdaLi method.
During the initial training phase, a substantial gradient update scope, encompassing upwards of 50% of the membrane potential gradient values, is established to secure the training process's stability. As training progresses and stability becomes assured, the gradient update extent is reduced, diminishing the computational overhead associated with the backpropagation gradients. Upon training completion, the gradient update bandwidth is minimized, optimizing performance efficiency.
Experimental results
4
In this section, we demonstrate the effectiveness of our proposed AdaLi method through a comprehensive set of experimental results. We conducted experiments using established neural network architectures, including ResNet18 (He et al., 2016), VGG models (VGG11 and VGG16) (Simonyan and Zisserman, 2014), and evaluated them on widely-used static image benchmark datasets, such as CIFAR-10 and CIFAR-100 (Krizhevsky and Hinton, 2009). Further, to showcase the adaptability of AdaLi to spatiotemporal visual data, we extended our evaluation to neuromorphic datasets, specifically CIFAR-10-DVS (Li et al., 2017) and DVS128Gesture (Amir et al., 2017).
Comparisons with other methods
4.1
We compared our AdaLi with other SOTA methods on both static and neuromorphic datasets, as shown in Tables 2, 3. On the CIFAR-10 dataset, our method achieved a top-1 accuracy of 95.33% using ResNet18 with 4 time steps, surpassing the performance of (Deng et al. 2022) by 0.89% under the same conditions. Notably, even with a single time step, AdaLi achieved a top-1 accuracy of 94.65% using ResNet18, outperforming the results obtained with 6 time steps in (Zheng et al. 2021). For CIFAR-100, AdaLi reached a top-1 accuracy of 76.22% using ResNet20 with 4 time steps, which is 3.92% higher than the performance reported in (Guo et al. 2023c) with the same network architecture and time steps. Additionally, our method outperformed results achieved with 10 time steps in (Guo et al. 2023a) using just 4 time steps with the VGG16 network architecture. These experimental results demonstrated that the AdaLi method delivers low latency and high performance on static datasets.
For neuromorphic datasets, AdaLi achieved a top classification accuracy of 68.4% on DVS-CIFAR-10 using ResNet18 with 10 time steps, outperforming (Zheng et al., 2021) by 0.6% at the same time steps. On the DVSGesture dataset, AdaLi attained an accuracy of 96.87% with 16 time steps on DVSGestureNet, demonstrating superior performance with lower latency compared to (Zhang et al. 2024) and (He et al. 2020).
Hyperparameters selection
4.2
Determining the optimal threshold Vth for membrane potential gradients that require updates is critical aspect for ensuring training stability and efficiency. Incorrect gradient boundaries, whether too high or too low, can lead to unstable training dynamics. Furthermore, excessively broad gradient boundaries increase the computational burden during backpropagation, counteracting the energy-efficient potential of SNNs.
In our experiments with a ResNet18 architecture trained on the CIFAR-10 dataset without an adaptive mechanism, we mapped the membrane potential distributions across various layers at different training epochs. As shown in Figure 4, outliers in the neuronal membrane potential data was observed. We initially set the boundary value to approximately 1.5 times the threshold Vth, allowing for the calculation of gradients in over half of the neuronal membrane potentials, thereby promoting parameter updates for a large fraction of the network. We set p = 0.2 in Equation 19. According to statistics, only about 20% of the parameter gradients are computed and updated.
The membrane potential distributions of spiking neurons in the first and fourth blocks of ResNet18 at epoch 1 and 100 during training on CIFAR-10 without adaptive function.
This adaptive function approach balances the training regimen effectively. It maintains stability during the early stages of training and gradually reduces computational intensity as the training progresses. Additionally, under the same experimental conditions but with the adaptive function set to a logarithmic rate of change, we investigated how different membrane potential boundaries requiring gradient updates and gradient intensity impact factors affected network performance on the CIFAR-10 dataset.
The results, as shown in Figure 5, indicate that network performance is highly sensitive to changes in the gradient intensity impact factor. An optimal value for this factor was identified around 0.5; deviations from this median, either higher or lower, significantly degraded network performance. Conversely, network performance shows comparatively less sensitivity to variations in the membrane potential boundary for gradient updates, remaining relatively stable within a certain range. Our findings suggest that setting the boundary value to approximately 1.5 times the threshold value is judicious.
The impact of hyperparameter selection on the performance of training ResNet18 on the CIFAR-10 dataset when the threshold value is equal to 1. (a) β = 0.5, V1-=-0.5, V1+=2.5. (b) α = 0.5, V1-=-0.5, V1+=2.5. (c) α = 0.5, β = 0.5, V1-=-0.5. (d) α = 0.5, β = 0.5, V1+=2.5.
Although these experiments for hyperparameter selection were conducted using the CIFAR-10 dataset, subsequent experiments across different datasets and networks, using the optimal hyperparameters identified here, achieved good performance. This demonstrates the generalization ability of these hyperparameters.
Impact of boundary size
4.3
We investigate the impact of different boundary sizes on training outputs. We conducted experiments by training ResNet18 on the CIFAR-10 dataset, setting the time step of spiking neurons to 1. As illustrated in Figure 6, directly setting a small constant boundary without using an adaptive function to adjust the boundary size adaptively results in unstable network training. Significant fluctuation occurs during the mid-term training phase, although it decreases in the later stages.
The results of training ResNet18 on the CIFAR-10 dataset using the AdaLi method and only lightweight surrogate gradients. The large constant bound refers to 1.5 times the threshold, which corresponds to the initial value of the adaptive boundary at the beginning of training. The small constant bound refers to the boundary value when p = 0.2, which corresponds to the final value of the adaptive boundary at the end of training.
This observation implies that a larger update boundary is necessary during the early to mid-term phases of training. Conversely, reducing the gradient update boundary in the later stages can help lower computational costs. This behavior aligns with our proposed adaptive function. The orange curve in Figure 6 represents a scenario with a large update boundary. An excessively large update boundary might lead to gradient calculations for membrane potential outliers, resulting in lower accuracy compared to the method employing an adaptive function.
Both adaptive functions, which adjust the boundary size at different rates, eventually achieve high classification accuracy. This demonstrates the efficacy of adaptively adjusting the boundary size throughout the training process.
Firing rate
4.4
One major advantage of SNNs is the sparse firing property of spiking neurons. Sparse firing enhances the efficiency of information representation, as only activated neurons fire spikes. This selective firing reduces energy consumption compared to continuously active neurons. The event-driven nature of SNNs allows them to adapt well to neuromorphic hardware, which also relies on event-driven processing. This means that processing is triggered only when there are changes in inputs or specific conditions are met, thereby improving system efficiency and reducing processing complexity.
Maintaining the sparse firing property of spiking neurons offers numerous benefits. We recorded the spiking activity of all neurons in the SNN during inference, after training on the CIFAR-10 dataset for 500 epochs using the ResNet18 model and various surrogate gradients. The adaptive function in the AdaLi method is a logarithmic adaptive function, while the parameters for other traditional surrogate gradients remain consistent with those in Table 4. As shown in Figure 7, compared to the SoftSign (Zenke and Ganguli, 2018) and Triangle (Bellec et al., 2018) surrogate gradients, the AdaLi method significantly reduces the spiking rate while maintaining high performance. This balance ensures that sufficient information is transmitted for the network to make accurate predictions, while reducing the spike rate to decrease the computational load during inference.
Comparison of the firing rates of different surrogate gradients in SNNs trained on the CIFAR-10 dataset using the ResNet18 model for 500 epochs.
Although the Sigmoid (Wu et al., 2018) surrogate gradient shows a much lower spiking rate in Figure 7, Table 4 indicates that using the derivative of the Sigmoid function as the surrogate gradient results in suboptimal training performance. Despite its low spike rate, network performance is negatively affected. Meanwhile, the other two traditional surrogate gradients maintain a relatively higher spiking rate compared to AdaLi. This further demonstrates the superiority of the AdaLi method in achieving high performance with low power consumption.
Computational overheads
4.5
We also investigate the impact of AdaLi on computational cost during the training of SNNs. The initial conditions in the experiment are set as detailed in Section 4.3. We record the membrane potential distribution of all spiking neurons in the ResNet18 model and the membrane potential boundary values requiring gradient updates at different training epochs using various surrogate gradients. By calculating the proportion of neurons needing gradient updates, we determine the computational density for each training epoch.
Initially, with the boundary set to 1.5 times the threshold value, about 65% of spiking neurons require gradient updates at the beginning of training. As training progresses, AdaLi reduces the boundary for membrane potential updates, which in turn decreases computational density. Ultimately, only about 20% of spiking neurons need to update gradients. From Figure 6, we observe that even though the log adaptive function has discarded nearly half of the gradient calculations by the 100th epoch, training with this method still outperforms the linear adaptive function. This indicates that the calculation of gradients for most spiking neurons can be omitted without affecting performance.
Figure 8 compares the computational density of different surrogate gradient methods of SNNs trained on the CIFAR-10 dataset using the ResNet18 model for 500 epochs. A computational density of 100% means that the gradient of the membrane potential of each spiking neuron needs to be calculated. Our AdaLi method, including the log and linear adaptive functions, shows a continuous reduction in computational density as training progresses, ultimately dropping below 20%. Especially after 100 epochs, AdaLi reduces computational density by approximately 80% compared to the Sigmoid and SoftSign methods, and by about 30% compared to the Triangle method, without compromising network performance. AdaLi's adaptive gradient update mechanism brings a notable boost in actual training efficiency, outperforming other traditional surrogate gradient methods by a large margin in training speed while maintaining high model accuracy.
Comparison of the compute density of different surrogate gradients in SNNs trained on the CIFAR-10 dataset using the ResNet18 model for 500 epochs. A computational density of 100% means that the gradient of the membrane potential of each spiking neuron needs to be calculated.
Feature visualization
4.6
Figure 9 illustrate the feature representations of ResNet18 and VGG16, respectively. The first two sub-figures depict the network's encoding of input information before and after training. The subsequent four sub-figures show the feature maps after the last convolutional layer of each block extracts the input information. It can be observed that, similar to conventional ANNs, the features in SNN models become more abstract as the network depth increases. Furthermore, different network architectures exhibit varying levels of granularity in feature extraction.
Feature representation of spiking ResNet18 (a) and VGG16 (b). The first two subfigures show the feature before and after the coding layer. The last four subfigures show the feature representation after each block.
Generally, before entering the classification layer, it is desirable to reduce the spatial dimensions of the feature map while increasing its depth (i.e., the number of channels). Smaller spatial dimensions enable each position in the feature map to capture more localized information, while greater depth allows the capture of richer and more abstract features. Increasing the depth helps the model learn more complex image features, thereby enhancing classification performance.
Notably, after passing through all blocks, our ResNet18 model retains relatively large spatial dimensions in its feature maps, whereas the VGG16 model reduces the spatial dimensions more significantly. Consequently, a pooling layer is employed in ResNet18 before the classification layer to reduce the spatial dimensions and improve classification results.
Conclusion
5
This work addresses the challenges of gradient mismatch, gradient vanishing/explosion, and high computational complexity in SNN training. We propose a lightweight gradient to alleviate the computational burden associated with surrogate gradients during backpropagation. The stable nature of these lightweight gradient values helps to mitigate issues related to gradient vanishing and explosion. Additionally, the gradient intensity factor and update boundary in the AdaLi method collaboratively address the gradient mismatch problem. The application of the adaptive function in our approach effectively reduces computational load during backpropagation while maintaining training stability. We also provide optimal initial and final values for the update boundary and verifies the effectiveness of the adaptive function. Leveraging these advancements, AdaLi achieves stable, high-performance training with reduced computational costs.
One limitation of this work is the manual selection of the gradient update range, which can introduce some subjectivity into the process. Additionally, the determination of optimal hyperparameters is based on empirical experimentation rather than theoretical foundations. Future work can aim for a deeper investigation into the relationship between the update range and the threshold, with the goal of developing a more systematic and theoretically grounded method for parameter selection. Another promising direction is exploring the underlying causes of the sensitivity of experimental results to the gradient intensity factor, which could provide a clearer understanding of its impact on model performance. Furthermore, investigating the use of more suitable adaptive functions for dynamically updating the gradient range could enhance model robustness and reduce sensitivity to hyperparameter selection. By addressing these limitations, future research can refine the proposed methods and improve their generalizability and performance across various tasks and datasets.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Amir A. Taba B. Berg D. Melano T. Mc Kinstry J. Di Nolfo C. . (2017). “A low power, fully event-based gesture recognition system,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (Honolulu, HI: IEEE), 7243–7252.
- 2Baronig M. Ferrand R. Sabathiel S. Legenstein R. (2025). Advancing spatio-temporal processing through adaptation in spiking neural networks. Nat. Commun. 16:5776. doi: 10.1038/s 41467-025-60878-z 40593685 PMC 12218304 · doi ↗ · pubmed ↗
- 3Bellec G. Salaj D. Subramoney A. Legenstein R. Maass W. (2018). “Long short-term memory and learning-to-learn in networks of spiking neurons,” in Advances in Neural Information Processing Systems (Red Hook, NY: Curran Associates, Inc.), 31.
- 4Bewley A. Ge Z. Ott L. Ramos F. Upcroft B. (2016). “Simple online and realtime tracking,” in 2016 IEEE inter NATIONAL conference on Image Processing (ICIP) (Phoenix, AZ: IEEE), 3464–3468.
- 5Bohte S. M. Kok J. N. La Poutre H. (2002). Error-backpropagation in temporally encoded networks of spiking neurons. Neurocomputing 48, 17–37. doi: 10.1016/S 0925-2312(01)00658-0 · doi ↗
- 6Brzosko Z. Mierau S. B. Paulsen O. (2019). Neuromodulation of spike-timing-dependent plasticity: Past, present, and future. Neuron 103, 563–581. doi: 10.1016/j.neuron.2019.05.04131437453 · doi ↗ · pubmed ↗
- 7Burkitt A. N. (2006). A review of the integrate-and-fire neuron model: I. homogeneous synaptic input. Biol. Cybernet. 95, 1–19. doi: 10.1007/s 00422-006-0068-616622699 · doi ↗ · pubmed ↗
- 8Cai Z. Kalatehbali H. R. Walters B. Rahimi Azghadi M. Amirsoleimani A. Genov R. (2023). Spike timing dependent gradient for direct training of fast and efficient binarized spiking neural networks. IEEE J. Emerg. Select. Topics Circuits Syst. 13, 1083–1093. doi: 10.1109/JETCAS.2023.3328926 · doi ↗