Conceptual proposal for LLM-generated FDG PET/CT follow-up reports in melanoma: a pilot study on model stability and blinded expert evaluation
Wolfram A. Bosbach, Marie S. Heide, Nasir Gözlügöl, Dana Fatemeh, Foroud Aghapour Zangeneh, David Ventura, Philipp Schindler, Wolfgang Roll, Franziska Strunz, Federico Caobelli, Kuangyu Shi, Ali Afshar-Oromieh, Axel Rominger, Robert Seifert

TL;DR
This pilot study explores whether large language models can generate high-quality follow-up reports for melanoma PET/CT scans, showing results comparable to human experts.
Contribution
The study introduces a novel approach to evaluating LLM-generated medical reports using blinded expert assessments and test–retest stability analysis.
Findings
LLM-generated reports showed high intra-case coherence and comparable quality to human-authored reports.
External human readers rated LLM reports higher than internal readers and preferred LLM impressions.
LLM performance improved with case complexity, unlike human performance which declined.
Abstract
Oncological patients regularly undergo PET/CT re-staging, which requires a report that outlines their current disease status and highlights relevant changes compared to the previous PET/CT. Large language models (LLMs) may be helpful with documentation in the future. This study is a pilot on LLM performance, focusing on test–retest stability and reproducibility. Three textbook melanoma follow-up cases of increasing complexity (involving one to eight organs) were selected. From standardized text-only prompts (no imaging data), follow-up reports were written by GPT-4o, Claude Sonnet 4 (each producing three independent revisions), and three nuclear medicine residents. This yielded nine reports per case (27 in total). Six blinded nuclear medicine experts (three internal, three external) performed test–retest evaluations of report quality and authorship identification. The cosine…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
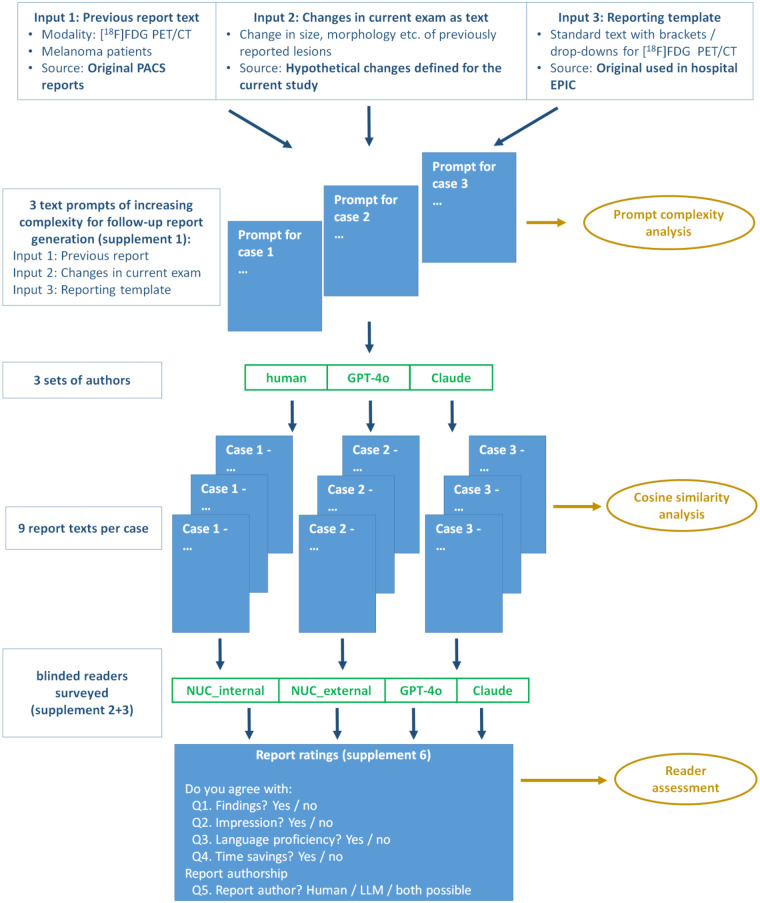 Figure 1
Figure 1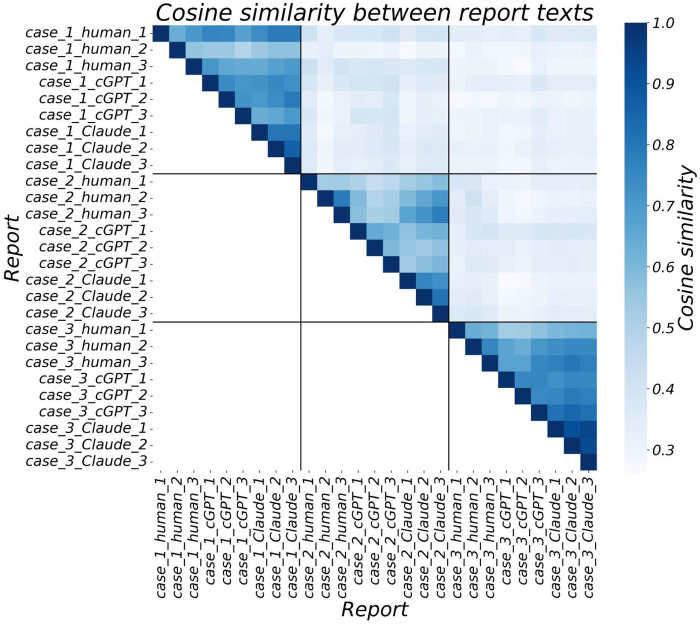 Figure 2
Figure 2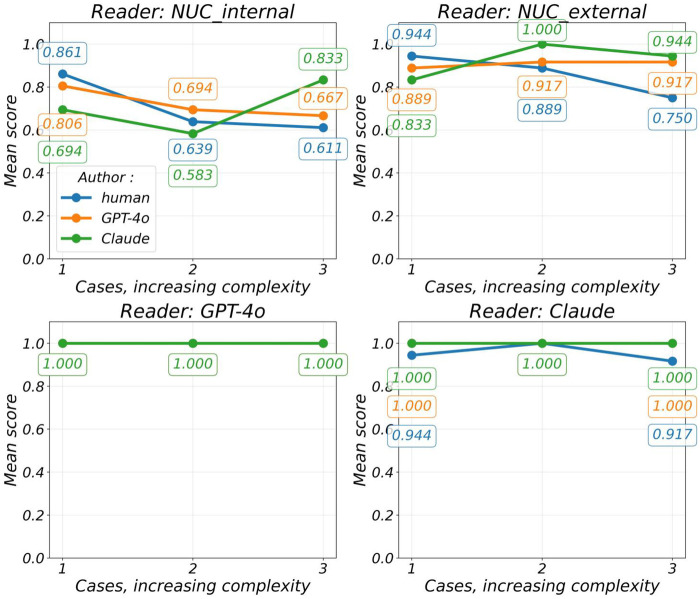 Figure 3
Figure 3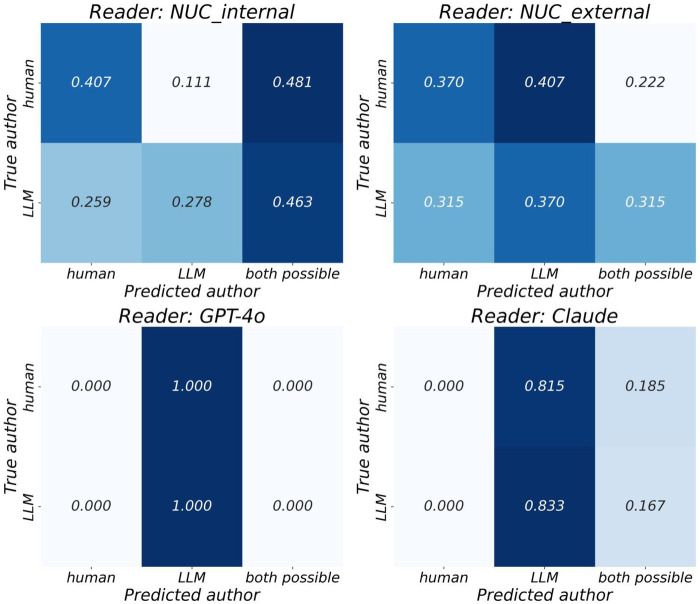 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAuthorship Attribution and Profiling · Artificial Intelligence in Healthcare and Education · Radiomics and Machine Learning in Medical Imaging