Urgent samples in clinical laboratories: stochastic batching to minimize patient turnaround time
Antonin Novak, Andrzej Gnatowski, Premysl Sucha

TL;DR
This paper improves hospital lab efficiency by optimizing sample batching to reduce turnaround time for urgent patient tests.
Contribution
A novel stochastic mixed-integer quadratic programming model integrated with discrete-event simulation for urgent sample batching.
Findings
Incorporating transport time distributions reduces median TAT for vital samples by 4.9 minutes.
The 0.95 quantile of TAT for vital samples is reduced by 9.7 minutes.
The results are nearly optimal when compared to a perfect-knowledge offline algorithm.
Abstract
This paper addresses the problem of batching laboratory samples in hospital laboratories where samples of different priorities are received continuously with uncertain transportation times. The focus is on optimizing the control strategy for loading a centrifuge to minimize patient turnaround time (TAT). While focusing on samples of patients in life-threatening situations (i.e., vital samples), we propose several online and offline methods, including a stochastic mixed-integer quadratic programming model integrated within a discrete-event system simulation. This paper aims to enhance patient care by providing timely laboratory results through improved batching strategies. The case study, which uses real data from a university hospital, demonstrates that incorporating distributional knowledge of transport times into our decision policy can reduce the median patient TAT of vital samples…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
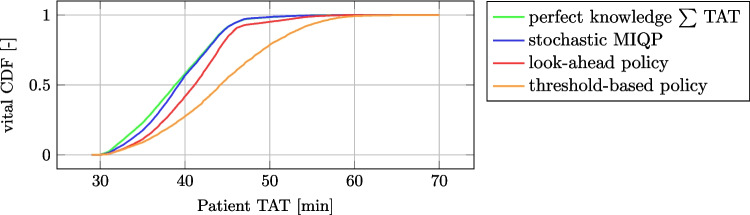 Figure 10
Figure 10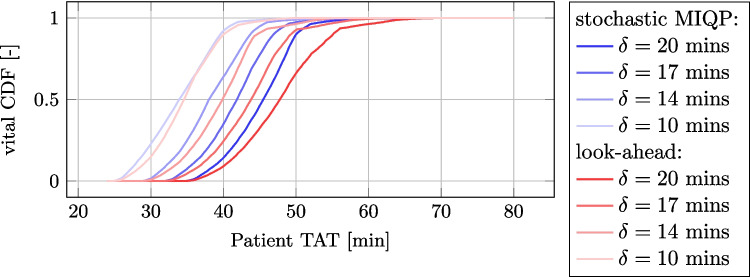 Figure 11
Figure 11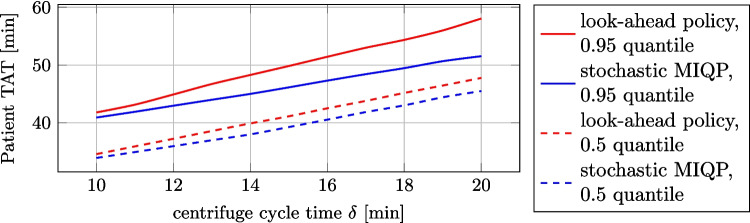 Figure 12
Figure 12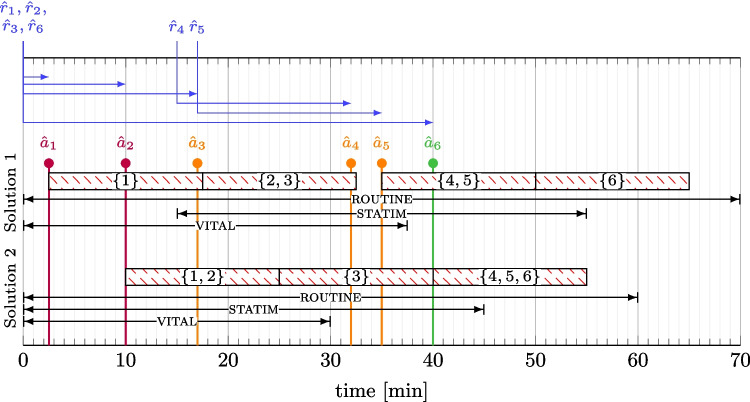 Figure 13
Figure 13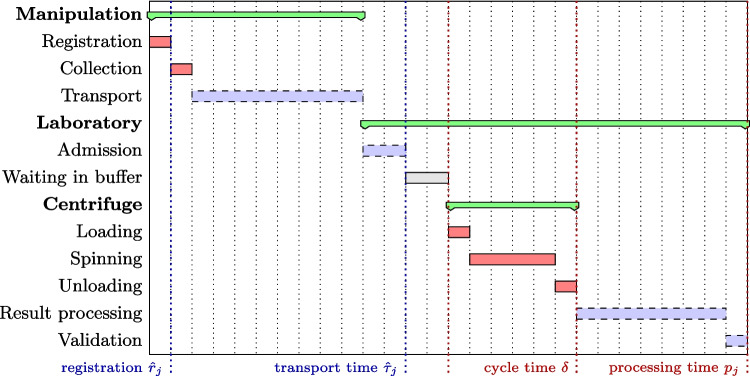 Figure 1
Figure 1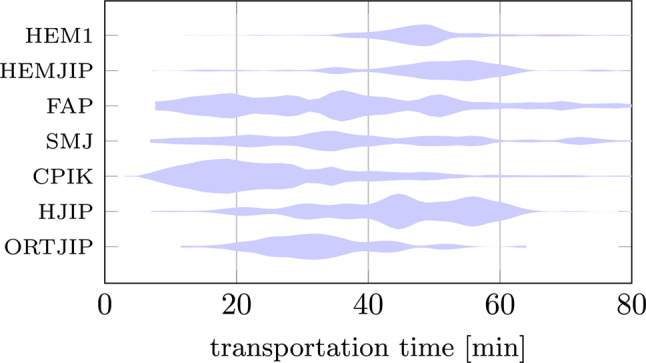 Figure 2
Figure 2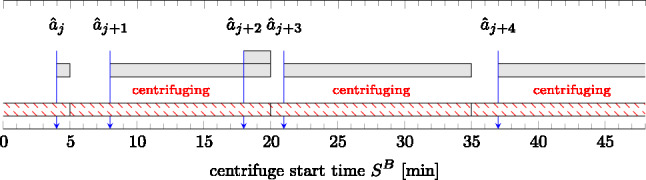 Figure 3
Figure 3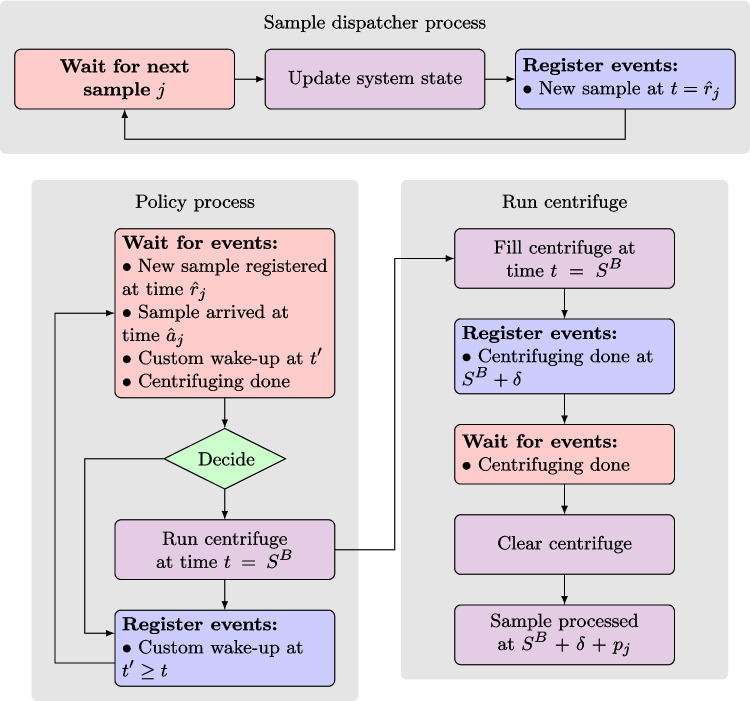 Figure 4
Figure 4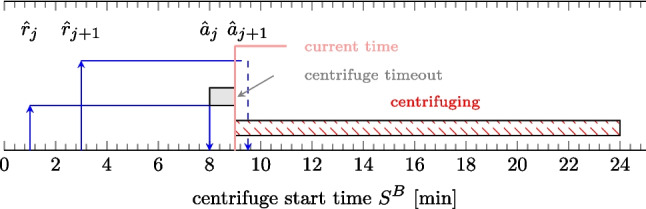 Figure 5
Figure 5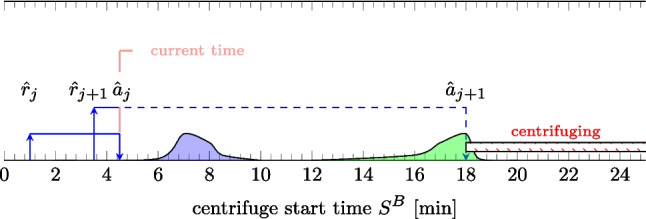 Figure 6
Figure 6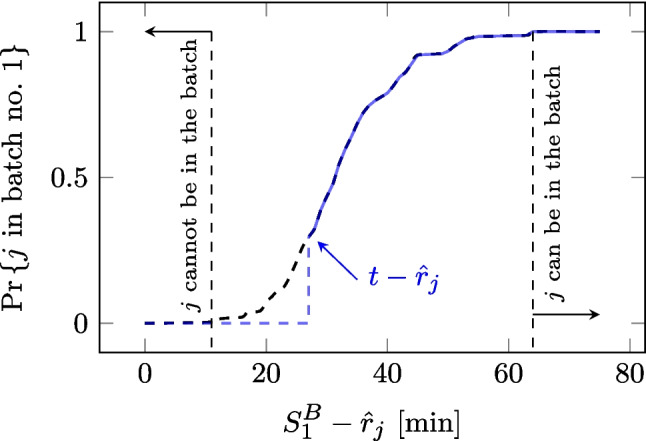 Figure 7
Figure 7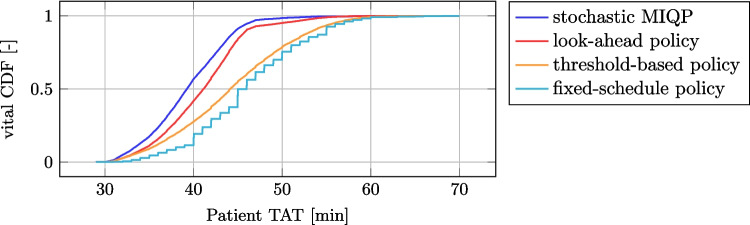 Figure 8
Figure 8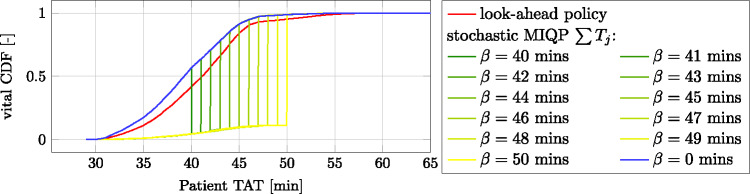 Figure 9
Figure 9 Figure 14
Figure 14 Figure 15
Figure 15- —Czech Technical University in Prague
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHealthcare Operations and Scheduling Optimization · Advanced Queuing Theory Analysis · Simulation Techniques and Applications
Highlights
- We study the problem of batching clinical samples with uncertain transport time for the centrifuge of a laboratory automation system.
- We integrate the flow of vital samples inside the classical laboratory automation systems, supporting only standard and low-priority samples.
- We develop optimization techniques that focus on the patient turnaround time (TAT) rather than laboratory TAT, increasing the impact of the decision on the patient.
- We propose an online stochastic mathematical model that utilizes information about transiting samples to optimize the batching and start times of the centrifuge.
- We validate our approaches using discrete-event simulation on a case study that utilizes real data obtained from a university hospital.
- The results show that our online centrifuging policy improves the 0.95 quantile of patient TAT for vital samples compared to the existing solution by 9.7 minutes, utilizing distributional knowledge of uncertain transport times.
Introduction
Medical laboratories play an irreplaceable role in modern health care. Many diseases are diagnosed or confirmed by laboratory tests [1]. Moreover, early diagnosis is critical to prevent significant harm and even the death of a patient suffering from a disease such as an acute ischemic stroke or heart attack. Therefore, modern medical laboratories must be able to analyze samples quickly and provide results as soon as possible. An example of such a situation is when a patient with suspected myocardial infarction is brought into the hospital by an ambulance. The literature addressing such situations defines the door-to-balloon time [2] as the interval from the patient’s arrival at the emergency department to the inflation of a balloon within the occluded coronary artery. This time should not exceed 90 minutes; otherwise, the risk of short-term mortality and major adverse cardiac events significantly increases. Myocardial infarction is diagnosed using the electrocardiogram. However, a troponin test is used to confirm or rule out myocardial damage if the electrocardiogram is inconclusive. In such a case, a blood sample is taken and immediately transported to the laboratory in vital mode, i.e., as a sample with the highest priority. In a situation where the team of specialists is waiting for confirmation or refutation of the diagnosis, every minute counts. For example, the authors in [3] reported that for patients with cardiogenic shock and out-of-hospital cardiac arrest, every 10-minute treatment delay resulted in 3.31 additional deaths among 100 percutaneous coronary intervention-treated patients.
The key performance indicator measuring how fast a laboratory can analyze a sample is called turn-around time (TAT). Laboratories typically use laboratory TAT, which is defined as the time between the moment when a sample is received by the laboratory and the time when the results are reported. Nevertheless, for patients or their physicians, this performance indicator is not relevant, as they are interested in draw-to-report TAT [4], denoted in this paper as patient TAT, which is defined as the time from collection of the sample from a patient to the reporting of the results.
The main reason why laboratories currently do not focus on patient TAT is that they cannot influence how samples are handled at individual wards and how quickly they are transported to the laboratory. In other words, the collection and transport of samples to the laboratory are often not automated, while laboratories aim at total laboratory automation (TLA) [5], which minimizes human interaction with samples and thus indirectly makes the processing of samples much more predictable. The laboratories are often equipped with fully automated systems, such as the Beckman Coulter DxA 5000, that can sort, centrifuge, and deliver samples to appropriate analyzers, perform prescribed tests, and report the results. However, handling of samples is mostly not automated; even though information about sample collection is typically available in the laboratory information system, it is not yet exploited by laboratory automation systems to control patient TAT.
The research question we study in this paper is whether laboratory automation systems may benefit from information about samples that are on the way to the laboratory to minimize patient TAT. We focus on urgent samples that are usually associated with patients in life-threatening situations, e.g., acute myocardial infarction. Specifically, we study the processing of samples by centrifuge, which is carried out in batches, such as up to 56 samples in the case of the DxA 5000. If the centrifuge is started, it cannot be interrupted even if a priority sample has arrived or is about to arrive at the laboratory. A straightforward idea is to postpone the start of the centrifuge to process the incoming priority sample immediately. Nevertheless, the solution is not that easy in general. First, we cannot focus on a single sample, and more importantly, the transport time of samples to the laboratory is uncertain. Even if one knows that the sample was taken and is on the way, a decision requires consideration of many aspects, such as when the sample was taken, where it was taken, how it was transported (manually or by tube mail transport), and how likely different transport times are.
In this paper, we study an online sample batching problem, i.e., how to group clinical samples for centrifugation and when the centrifuge should be started. In this research, we assume that there is a single centrifuge. We are inspired by the laboratory automation system DxA 5000, which typically features a single centrifuge, ideal for small and medium-sized hospitals. Another reason is the space limitations in laboratories, which typically do not allow the installation of multiple configuration modules, which would result in a higher system cost. To minimize patient TAT, we exploit online information given when a sample is collected from a patient. The transport time of a sample is modeled as a random variable characterized by a probability density function. The problem is formulated as a stochastic optimization problem minimizing patient TAT for the samples with the highest priority, denoted as vital; this category is reserved for patients in immediate danger of death. Lower priorities are statim, which is used for less urgent situations than vital situations, e.g., suspicion of a disease, and routine, for ordinary samples, where the result can typically be delivered the next day. The benefit of our approach is demonstrated using real data from University Hospital Královské Vinohrady, Czech Republic. We show that a simple rule-based solution deteriorates patient TAT for high-priority samples, whereas our solution provides significantly better solutions and delivers more predictable (consistent) patient TAT.
Contributions and outline
In this paper, we aim to increase the efficiency and reliability of TLA systems with mathematical optimization tools to improve the dispatching of the centrifuge. Specifically, the main contributions are as follows:
- We propose a new way vital samples can be processed in the classic laboratory automation systems supporting only statim and routine sample priorities;
- We develop optimization techniques that focus on the patient TAT rather than laboratory TAT, increasing the impact of the decision directly for the patient;
- We propose an online stochastic mathematical model that uses information about transiting samples to optimally control batching and the start times of the centrifuge;
- We validate our approaches using discrete event simulation on a case study that uses real data obtained from a university hospital;
- The experiments show that our online dispatching policy improves the 0.95 quantile of patient TAT compared to the existing solution by 9.7 minutes by using distributional knowledge of the uncertain transport times combined with the stochastic mathematical optimization model;
- The proposed perfect-knowledge offline algorithm demonstrates that the performance of the online dispatching policy is essentially optimal;
- We provide a complexity characterization of the problem in the offline setting. The paper is structured as follows. In Section 2, we survey related works concerning the problem considered and the optimization techniques used. The formal problem statement is given in Section 3. Our dispatching policies are proposed in Section 4 and are benchmarked using our discrete event simulation system (Section 4.1) in Section 5.
In the text below, we use the following notation. The uncertain parameters that are treated as random variables are denoted with the tilde symbol \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{x}$$\end{document} , where their realizations are denoted with the hat symbol \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{x}$$\end{document} . The other parameters that are assumed to be deterministic are denoted in plain x. See Table 1 for a detailed description of the parameters used.
Related work
The review of the related literature is split into two sections to reflect two perspectives: (i) the application point of view, reflecting the work on the modeling and optimization of laboratory automation, including its impact on the TAT, and (ii) related combinatorial problems from the area of batching, simulation and optimization paradigms, scheduling with uncertain release and transport times and online (dynamic) scheduling problems.
Optimization of laboratories
In the area of the optimization of automated laboratory systems, it is essential to define key performance indicators, which may differ substantially among the various stakeholders. For example, commercial laboratories that focus on routine tests primarily minimize operating costs (e.g., material consumption, method duplication), whereas a hospital laboratory typically minimizes the TAT of priority (vital and statim) samples because the lives of the patients depend on these. However, as mentioned in Section 1, laboratories currently keep track only of the laboratory TAT, whereas it was shown that the preanalytical phase is the most error-prone [6]; thus, it should not be excluded from the TAT calculation. In our work, we follow this line of reasoning; thus, we focus on minimizing the patient TAT instead of the laboratory TAT. A crucial consideration that is equally important is which function of patient TAT to minimize. For a set of processed samples, we observe an empirical distribution of patient TATs—the time to complete the results is not deterministic, as it depends on the transportation time, waiting time in the buffer, congestion at analyzers, etc. Again, different parties may opt to optimize the expected patient TAT, the worst-case TAT, or generally an arbitrary quantile of the TAT distribution. In [7], the impact of the TAT on patient length of stay was analyzed. It was shown that the mean TAT does not well correspond to the length of stay but rather is affected by the so-called TAT outlier percentage, which reflects the number of samples that were completed well beyond the nominal level. This finding suggests that reducing patient TAT at high quantile levels contributes to shorter patient length of stay.
A problem similar to our setting was addressed by Yang et al. [8], where the authors identified limitations and bottlenecks of laboratories in a medical center in Taiwan. The analysis revealed high waiting times for the three identical DxC analyzers, which were caused by an uneven distribution of samples among the analyzers. They optimized the controls for the batch waiting time of the centrifuge (i.e., how long the centrifuge waits for a whole batch) and the distribution of samples among the DxC analyzers. The typical classes of samples are distributed among DxC analyzers on the basis of their average processing time with respect to two defined value thresholds. Mixed-integer programming (MIP) is utilized to find optimal values for thresholds and the waiting time of the centrifuge to maximize the number of samples with TATs less than 60 minutes, yielding a 54% improvement in the average sample TAT. This work disregards the priorities of samples and transportation times; nevertheless, the main distinction between their work and ours is that they do not consider the centrifuge dispatching algorithm in an online setting. Instead, they derive optimal timeout thresholds from historical data and then set them statically. On the other hand, we treat the centrifuge control in an online setting and adjust the decision optimally with respect to the available information about transiting samples.Fig. 1. Timing diagram of the laboratory process for a patient sample. The red rectangles correspond to activities whose duration is essentially deterministic, whereas the blue rectangles correspond to activities whose duration is uncertain. The light gray depicts the idle time of a sample
Similarly, Sojma [9] utilizes a discrete event system (DES) to describe the workflow of the DxA 5000 system, encompassing the complete sample life cycle from input to centrifuging, sample transport on the conveyor belt, and method testing at various analyzers. The optimization aimed to redistribute the allocation of methods among the laboratory analyzers, balancing their utilization and increasing the system throughput. For this purpose, a simplified surrogate MIP formulation of the system was proposed, with the DES being used to validate the newly proposed method assignment. The simulation confirmed that the new assignment improved the throughput of biochemical analyzers by 11.7%.
Laboratory processes share certain characteristics with the production domain. Thus, similar optimization approaches, objective functions, and modeling paradigms can be used. For example, [10] represents a laboratory workflow as a production process with the optimization of so-called weighted flow time minimization. They consider each analyzer as a machine and the patient’s sample as a job to be processed on a machine. They designed an online policy that batches the samples of different priorities to be processed by a set of laboratory analyzers to minimize the maximum weighted flow time. The online policy essentially achieves optimal performance among all online policies for the case in which the batch has infinite capacity. Under the bounded capacity model, their policy has optimal performance for weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Omega _j\in \left[ 1,2\right]$$\end{document} . Work [10] is particularly relevant to our problem. However, the main difference is that in our work, we focus on the preanalytic stage of the process (i.e., centrifuge rather than biochemical analyzers). In addition, the model presented in their work disregards the transport times of samples, and the processing time of samples is always one.
With respect to algorithmic tools, MIP is a successful technique for optimizing health care processes. For example, Farhadi et al. [11] used MIP for scheduling patient appointments with technicians in hemodialysis centers. In cases where some parameters of the problem are uncertain, theoretical frameworks, such as stochastic programming or distributional robust optimization, must be deployed for uncertainty mitigation [12]. For example, to address demand uncertainty, [13] employed a two-stage stochastic programming framework to reformulate a stochastic formulation of operating room allocation. Alternatively, predictive models [14, 15] can be used to estimate the parameter distribution and employ those in a data-driven mathematical programming model. However, some health care management processes are too complex to be modeled by an MIP model. In these cases, the processes can often be modeled by a DES [16] to provide high-fidelity simulation. However, the direct optimization of the parameters within such a system often becomes intractable; thus, the approaches often resort to using DES simulation as a fitness function oracle in a black-box optimization or using DES as a tool to verify the optimization results from a surrogate optimization problem that can be solved. For example, Osorio et al. [16] employed the iterative optimization-based simulation scheme to solve the production planning problem in the blood supply chain, where they iteratively used DES to compute values that act as the inputs to the MIP for the following iterations.Table 1. Overview of the used parameters and symbolsparameterdescriptionvalue \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{r}_j$$\end{document} sample registration timeuncertain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{r}_j$$\end{document} realization of registration timedeterministic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\tau }_j$$\end{document} sample transportation timeuncertain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\tau }_j$$\end{document} realization of transportation timedeterministic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{a}_j$$\end{document} sample arrival timeuncertain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{a}_j$$\end{document} realization of arrival timedeterministic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _j$$\end{document} sample prioritydeterministic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_j$$\end{document} hospital ward of sample registrationdeterministic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_j$$\end{document} sample processing timedeterministic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_j$$\end{document} sample completion timedeterministic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S^B$$\end{document} batch start timedeterministic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta$$\end{document} centrifuge cycle timedeterministic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_t$$\end{document} set of vitals available at time tdeterministic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{V}_t$$\end{document} set of vitals in transit at time tdeterministic
Batching and allocation problems in stochastic and online environments
Timing the centrifuge runs resembles a parallel batching (p-batching) problem [17]. In a typical setting, the jobs have processing times, release times, and due dates, and the goal is to group available jobs into a batch with a limited capacity, whose processing time is given as the maximum of the processing times of jobs within the batch. The goal is often to minimize a function of the completion times of the jobs. In that respect, perhaps the most similar problem to ours is the setting where we consider a single machine (centrifuge), jobs with constant processing times (constant spinning duration of the centrifuge), release times, and due dates. This problem under an offline, deterministic setting was studied by Baptiste [18], who reported that the problem is solvable in polynomial time for various natural objective functions. Later, his result was improved by [19], who proposed a much faster and thus more practical algorithm for the feasibility variant of the problem. To support comparison with the perfect knowledge offline algorithm, we build on their work. However, the main differences in optimizing the laboratory centrifuge from the problems described above are the presence of uncertain parameters, such as release and transport times.
A recent survey on offline p-batch problems was conducted by Fowler and Mönch [17]. As one of their conclusions, they argue for the increased need to study batching problems in a stochastic setting. Indeed, as noted by [20] “there are only a very few papers that deal with the p-batch scheduling problem involving uncertain data”. Therefore, [20] consider a p-batching problem with incompatible jobs (i.e., some families of jobs cannot be processed in the same batch) and uncertain ready times with the total weighted tardiness criterion. They introduce sampling-based heuristics that assume a distribution of delays in the release times to create a robust baseline schedule. However, owing to the unforeseen realizations of the release times, the schedule must be repaired through an online policy as the realizations unfold.
In fact, our problem also resembles a variant of a stochastic p-batching problem with uncertain release times. Nevertheless, the difference is that the decision-maker learns about sample j at the time it is registered in the system \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{r}_j$$\end{document} , but it becomes available for centrifuging when it arrives at the laboratory after an uncertain duration \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\tau }_j$$\end{document} ; thus, the release time is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{r}_j = \hat{r}_j+\tilde{\tau }_j$$\end{document} . Moreover, the registration times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{r}_j$$\end{document} are revealed gradually, without a particular assumption regarding their distribution. Therefore, our work is also related to the stream of works considering the online setting of the batching problem [21], where the set of jobs is not known in advance but is released over time [10, 22]. The goal is to design a policy that makes online (here-and-now) decisions about which jobs should be batched together and when to start the batch. This problem frequently arises in semiconductor manufacturing, wafer fabrication [23], and e-commerce order fulfillment [24]. Koo and Moon [23] classify the dispatching policies into two main categories: (i) threshold-based policies that are applied in situations where no information except the observable state of the system is available and (ii) look-ahead policies that use information on the near-future system state. In this paper, we describe various centrifuge policies with increasing amounts of utilized information, exactly matching the above classification of the dispatching rules. Additionally, the problem of dispatching the centrifuge can be considered through the lens of the control theory of discrete systems, which has been recently addressed by the reinforcement learning paradigm [21]. In this context, the task is to derive a controller represented by a neural network model through extensive simulation of the system and the environment. The model observes samples from the observation space (e.g., sensor values) and performs certain actions with its actuators (e.g., required motor torque). However, in our setting, the observation space is not fixed in size, as there might be an arbitrary number of transiting samples at a given time. Reinforcement learning models and algorithms typically disregard this aspect. Furthermore, even though it was empirically observed that such reinforcement learning controllers might achieve good performance in the expected sense, how to verify the trained policies they represent [25] to obtain guarantees for the worst-case scenario remains an open problem.
Some aspects of the problem, such as uncertain arrival time, also appear in queuing theory [26, 27], where one of the targets is to directly minimize response tail time or the q-th quantile of response time, i.e., the time between the completion and the release of the job. The problem of sharing system resources (i.e., centrifuges) among activities with different criticalities (i.e., samples with different priorities) has been studied in mixed-criticality systems [28].
Problem statement
We assume a set of n samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {S}=\{1, 2, \ldots , j, \ldots , n\}$$\end{document} to be released over the horizon of 24 hours. Each sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j\in \mathcal {S}$$\end{document} is characterized by its registration time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{r}_j$$\end{document} , transportation time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\tau }_j$$\end{document} , and sample priority \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _j \in \{\textsc {routine},\ \textsc {statim},\ \textsc {vital}\}$$\end{document} with routine being the least and vital being the most important priority. Furthermore, the hospital ward where the sample is taken is denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_j\in \{\textsc {ward}_1, \textsc {ward}_2, \ldots , \textsc {ward}_W\}$$\end{document} , where W represents the total number of wards in a hospital. Finally, sample j is associated with processing time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_j$$\end{document} , which represents the time the laboratory system needs to provide the result from the centrifuged sample. The number of n samples, their registration times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{r}_j$$\end{document} , and their transport times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\tau }_j$$\end{document} are random variables; thus, the realizations are not known beforehand. When the sample is registered in the system, we observe the realization of its registration (release) time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{r}_j$$\end{document} . Furthermore, we assume that by registering sample j into the system, we also learn the realization of sample priority \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _j$$\end{document} , the hospital ward \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_j$$\end{document} , and its processing time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_j$$\end{document} . The realization of transportation time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\tau }_j$$\end{document} is not revealed until sample j arrives at the laboratory. To simplify the notation, we also introduce the sample arrival time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{a}_j = \hat{r}_j + \hat{\tau }_j$$\end{document} .
Every sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j\in \mathcal {S}$$\end{document} needs to be centrifuged before it is processed by laboratory analyzers. The processing time of a sample depends on the methods that should be performed on the sample. We assume that when the sample is registered, we learn the list of methods that can be used to estimate its processing time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_j$$\end{document} in the analytical part of the system. The capacity of the centrifuge is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N=56$$\end{document} , and its cycle time, including spinning time, sample loading, and sample unloading, is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta =15\cdot 60$$\end{document} seconds. When the centrifuge is started, its run cannot be interrupted, and it must complete its cycle. Therefore, when sample j is included in the current batch and the centrifuge starts its cycle at time t, the sample is processed at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_j=t + \delta + p_j$$\end{document} . We call patient turn-around time (patient TAT) the time between sample completion and registration (sample collection); i.e., the turn-around time of sample j is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {TAT}_j = C_j - \hat{r}_j$$\end{document} . Thus, the patient TAT is the sum of the manipulation time plus the laboratory TAT. Note also that the notion of patient TAT directly corresponds to the term flow time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_j$$\end{document} typically used in production scheduling. The main symbols and notations used are summarized in Table 1. An example of a sample life cycle is illustrated in Fig. 1. The red rectangles correspond to activities that have essentially deterministic durations. The blue rectangles represent activities with uncertain duration, i.e., transportation and processing time. Here, we model the sample transportation time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\tau }_j$$\end{document} using a probability distribution, which is assumed to be a function of sample priority \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _j$$\end{document} and its hospital ward \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_j$$\end{document} . For example, see the transport time distribution for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _j=\textsc {statim}$$\end{document} for seven different wards at University Hospital Královské Vinohrady depicted in Fig. 2. For simplicity, we further assume that the duration of registration and sample collection is included within \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\tau }_j$$\end{document} . The processing time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_j$$\end{document} of the sample is influenced primarily by the list of methods to be performed and the utilization of the analyzers, as well as their potential outages. In this paper, we do not focus on modeling the processing component of the system. Instead, we use a coarse approximation that estimates \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_j$$\end{document} as the processing time of the longest method to be performed on sample j (i.e., the requested methods of the sample are evaluated in parallel). The light gray rectangle in Fig. 1 depicts the idle time of the sample and is subject to optimization. In this paper, we aim to reduce the sample idle time by suitable batching decisions and centrifuge timing so that it decreases the patient TAT.Fig. 2. Transport time probability densities estimated by kernel density estimation of statim samples for different hospital wards
The main key performance indicator of the laboratory is the expected TAT of vital samples to ensure timely delivery of the results. However, the laboratories also keep track of the 0.95 TAT quantile of vital samples to prevent too many samples from being delayed in processing. The value 0.95 is typically chosen to discard outliers from the statistical indication that occasionally occur in the analytical part of the process (e.g., reruns of inconclusive test results). Next, in order of importance, the expected and 0.95 quantile of the statim sample is considered. To model the problem, we use the following assumptions. We assume that the sample transportation time is a function of the priority and the hospital ward, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\tau }_j \sim f(\lambda _j, w_j)$$\end{document} .
However, in principle, our approach works with any model that estimates the probability density function of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\tau }_j$$\end{document} [15] or provides a single-point estimate with confidence intervals. Without loss of generality, we assume that the samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {S}$$\end{document} are about to be released (registered) over the 24-hour time horizon. Finally, we assume that when the centrifuge starts loading, the set of samples to be loaded is fixed and cannot change. Therefore, it can be seen as a process where all samples in the batch are loaded/unloaded at the same time, taking a constant time.
One of the simplest solutions to the above problem would be to start the centrifuge every \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta$$\end{document} seconds, thus achieving its highest utilization. However, such a strategy, which we refer to as the fixed-schedule policy, can be inefficient from the perspective of the patient TAT. Indeed, consider the example in Fig. 3, where blue arrows correspond to time instances where a sample enters the laboratory, and the hatched red parts correspond to the intervals where the centrifuge is occupied. If the timing of the centrifuge is not optimized, the sample may need to wait in the buffer to be processed in the next centrifuge run, as shown by the gray rectangles. In this paper, we aim to design control strategies that mitigate the long waiting times of the samples with the goal of minimizing the patient TAT of samples with respect to the key performance indicators mentioned above.Table 2. Overview of the analyzed and proposed methods methodenvironment informationavailable samplesregistered samplestransport distributionfixed-schedule policy, Section 3✗✗✗threshold-based policy, Section 4.2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} ✗✗look-ahead policy, Section 4.3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} ✗stochastic MIQP policy, Section 4.4 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} offline perfect-knowledge, Section 4.5N/AN/AN/A
Fig. 3A fixed-schedule centrifuge policy that is not triggered by sample arrival may miss an arriving sample. The idle times of the samples are depicted in gray
Batching algorithms
In this section, we present three batching methods that address the problem of optimal centrifuge timing and sample batching. Their high-level strategies and capabilities differ mainly in the amount of information utilized by the algorithm, ranging from observing only the samples waiting inside the laboratory to assuming the distribution of the transport times of the samples. Table 2 summarizes the algorithms proposed in this work. Additionally, the distinction between the methods that are agnostic to transporting samples and those that utilize transport time distribution can be seen as the difference between optimizing laboratory TAT versus patient TAT.
Section 4.1 describes the discrete event system simulation, which represents a unified interaction of the batching policies with the process outlined in Fig. 1. The following subsections address the batching methods. Arguably, the simplest imaginable batching method is the fixed-schedule policy demonstrated in Fig. 3, which runs the centrifuge every \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta$$\end{document} seconds. An improved solution is presented in Section 4.2, where we describe an algorithm that is often used in laboratories and is considered the baseline in this paper. According to the batching policy classification, e.g., by [8, 23], when no information except the current system state is available, the policy is referred to as a threshold-based policy. In Section 4.3, we introduce our algorithm, which addresses some of the disadvantages of the baseline solution. The algorithms that make use of the near-future state of the system are referred to as look-ahead policies. Finally, in Section 4.4, we propose a stochastic mathematical optimization model that uses the transport time distribution to minimize the patient TAT of vital samples. To derive the best theoretical performance achievable, in Section 4.5, we develop an offline perfect-knowledge algorithm that has access to all future realizations of registration and transport times.
Discrete event system simulation
To verify the functionality and evaluate the efficiency of the proposed methods, we designed a discrete event simulation [16]. It provides an environment resembling the process outlined in Fig. 1, i.e., the registration of new samples into the system, their transport, the behavior of the centrifuge with its control algorithm, and the calculation of the patient TAT. Therefore, all the proposed and investigated control algorithms for the centrifuge follow an identical protocol for interaction with the environment and for evaluation.
A discrete event system (DES) is a model in which the state evolution is determined by the occurrence of a finite number of events over time. The time is discrete, and between events, the system state cannot change. To simulate processing samples in a clinical laboratory, we designed a DES, as summarized in the diagram in Fig. 4. It consists of two processes–the sample dispatcher process and the policy process. The policy process controls the centrifuge and is invoked either when (i) a new sample is registered, (ii) a sample arrives, (iii) a centrifuging cycle is completed, or (iv) at a custom time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t^\prime$$\end{document} , if requested by the policy process.Fig. 4. Discrete event simulation modeling the sample transit and centrifuging in a clinical laboratory
Threshold-based policy
The baseline algorithm that is often deployed in laboratories [8] can be classified as a priority threshold-based batching algorithm. The threshold-based policy consists of a set of rules that decide whether to postpone or dispatch the centrifuge on the basis of the information about the samples that are already available in the laboratory. The advantage of rule-based methods is their explainability and predictable behavior, but as will be demonstrated later, they may lead to suboptimal performance.
The algorithm proceeds as follows. The samples delivered to the laboratory are monitored from the perspective of their priority and arrival time. The centrifuge is loaded with the samples and started afterward if the available samples fully meet the centrifuge capacity or if the designed timeout has expired after the last sample has arrived. For this, two different timeouts are considered—a long one for statim/routine samples and a short one for vital samples. The short timeout applies whenever a vital becomes available. The samples to be batched are chosen by the priority-first rule (i.e., all available vitals are loaded first, then statims, and finally routines), with ties broken by the sample arrival time (i.e., first in, first out). We assume that the timeout is set to 2 minutes for vitals and 4 minutes for statim/routine samples [8].Fig. 5. Example demonstrating the unsuitable timing of the centrifuge. The centrifuge is started too early
The main source of inefficiency of this strategy is the following. The scenario in Fig. 5 represents the situation in which sample j is available at time 8 while sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j+1$$\end{document} is registered in the system but has not yet arrived. If the centrifuge is activated after the timeout (e.g., 1 minutes) past the arrival of sample j, then sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j+1$$\end{document} arrives just a few moments later and cannot be included in the current batch, and its TAT is prolonged by at least one spinning cycle. Thus, even if the timeouts are designed to mitigate these situations, they cannot be completely avoided. This shortcoming motivates us to design an algorithm that account for the samples in transport and is able to postpone the run of the centrifuge until the vital sample arrives. This strategy is described in the following section.
Look-ahead policy
To address the main disadvantage of the baseline solution (threshold-based policy), which is agnostic to the samples that are currently in transit, we propose a look-ahead batching algorithm. Thus, in contrast to the algorithm described in Section 4.2, it attempts to prevent the situations illustrated in the example in Fig. 5, where a vital sample is postponed because of an overly early centrifuge run. This is achieved by utilizing information about samples registered in the system prior to their arrival at the laboratory. All samples currently in transit are considered, but the selection can be further refined by mitigating samples that were registered in the past d minutes, for example. The reason for this refinement is to steer the look-ahead policy toward samples that are likely to arrive soon, rather than blocking the centrifuge with samples that were registered just now and thus will not arrive anytime soon.
The rules governing the dispatch of the centrifuge and sample batching resemble natural requirements, prioritizing vital samples through the system. Essentially, dispatch is guided by the following rules: (a) if a vital sample is available and no other vital sample is currently under consideration, then run the centrifuge, and (b) if no samples are included in the centrifuge within the timeout and no vital sample is under consideration, then run the centrifuge, or (c) run the centrifuge if no samples are included in the centrifuge within the defined timeout and a vital sample is available. The timeout is a parameter of the policy subject to modification. In our experiments, we kept the same values as in the currently deployed threshold-based policy. The above rules aim to anticipate the registration of unforeseen vital samples to mitigate excessively early runs when centrifugation commences just before a vital sample arrives.
The look-ahead strategy is driven by both incoming and registered vital samples, with the goal of mitigating problems with the centrifuge starting too early and resulting in fewer vital sample misses. However, even considering samples currently in transit without assuming their distribution of transportation times does not guarantee efficient control of the centrifuge. The main difficulty with the system based on priority rules and hard-coded logic is that it is not flexible enough. Given a fixed set of decision rules, one can often devise an adversarial scenario that these rules would not handle well. The emergence of these corner cases is also amplified by the presence of many samples in the system with different distributions of transport times and processing time requirements, which leads to conflicting goals.Fig. 6. Example demonstrating the unsuitable timing of a centrifuge with uncertain transport times. The centrifuge is started too late
To see this, consider the following simple scenario in Fig. 6. Sample j is available at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t=4.5$$\end{document} , while sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j+1$$\end{document} is in transit, similar to the scenario in Fig. 5. However, waiting for the arrival of sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j+1$$\end{document} could be a suboptimal decision in this case since the efficiency of the decision to wait for the transiting sample depends on the distribution of its transport times, as shown in green in Fig. 6. In that case, it is more beneficial to run the centrifuge immediately and not wait for the arrival of sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j+1$$\end{document} . Sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j+1$$\end{document} is unlikely to arrive before the centrifuge finishes; thus, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j+1$$\end{document} can be comfortably included in the next run, and the TAT of sample j is unaffected. However, if the transport distribution is like the one depicted in light blue, then it is better to postpone the centrifuge until \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j+1$$\end{document} arrives.
The examples in Figs. 5 and 6 highlight some of the difficulties encountered when designing rule-based solutions that utilize the information about samples in transit but do not account for the probability distributions of the transport times. Enhancing the set of decision rules with information about the distribution of transport times leads to an optimization problem rather than a fixed decision tree that triggers the centrifuge to run at a specific time on the basis of some designed conditions. Therefore, a more flexible and informed solution is needed to solve this problem efficiently.
In the following sections, we propose to improve the timing of the centrifuge with a mathematical model that minimizes the total flow time of the available samples under a soft-deadline constraint with respect to the artificially chosen due date. To include the uncertainty in the transport times, we also minimize the expected flow time of samples in transit. Combining these two terms inside the objective function, the model provides centrifuge timings requested by the available samples while also accounting for the arriving samples according to the estimated transport time distributions.
The uncertainty in our optimization problem is imposed via uncertain registration times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{r}_j$$\end{document} , transport times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\tau }_j$$\end{document} , priorities, and the total number of samples. In the considered setting at work, we do not assume any particular distribution over registration times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{r}_j$$\end{document} ; therefore, we treat them as unpredictable random events. Thus, the only uncertain parameters reflected in our model are the collection of transport times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{\hat{\tau }_j\}_{j}$$\end{document} of samples currently in transport.
General strategies for solving optimization problems with uncertain parameters can be classified into two main groups. The first group of methods aims to replace the uncertain parameter with its estimate, hence reducing it back to a deterministic problem. The most typical choice might be to use expected values, some quantile of the empirical distribution, or essentially any other single-point estimate. This intuitive approach works well if the underlying distribution of the uncertain parameter can be expressed with a single number sufficiently well, e.g., for a normal distribution with low variance.
The second group of methods models the uncertainty of the parameters as a part of the optimization model—typically expressed via an uncertainty set or by a cumulative distribution function (CDF). These methods are especially useful in cases in which the distribution cannot be effectively expressed via single-point estimates, e.g., complex distributions with high variance or even multimodal distributions. If the transport time distribution took a bimodal form with two peaks, as shown, e.g., in Fig. 6 in blue and green, then no single-point estimate would effectively capture the nature of such a distribution. On the other hand, if the distribution of the parameter is narrow enough, then this stochastic modeling essentially converges to a single-point method and thus may be viewed as a more general method.
In the considered problem with sample transportation, it is reasonable to assume that the resulting distribution could be complex, e.g., because it reflects time-of-day factors or even because of the possibility of different modes of transportation (courier or tube mail). Therefore, in the following section, we propose a stochastic batching mathematical model that models the transport time uncertainty via a CDF as a part of the optimization model.
Stochastic batching mathematical model
In Section 4.3, we have demonstrated how the unsuitable timing of the centrifuge can negatively impact the values of patient TAT. To mitigate timings that are too early and too late, we propose a stochastic batching mathematical model that exploits information about the registration of new samples in the system and the estimated transport time distribution. The mathematical model is included in the DES simulation and is used to determine the timing of the next centrifuge run and the content of the batch.
The core principle of the model is to prioritize vital samples exclusively, i.e., minimize the overall patient TAT of vital samples. Consequently, the centrifuge’s operational schedule is determined by the processing requirements of these vital samples. Nevertheless, the capacity of the centrifuge is shared with statim and routine samples, which are loaded in a priority-based first-in, first-out order. As demonstrated in Section 5, this approach enables real-time operation of the model without adversely affecting the TAT of non-vital samples.
We express the criterion as the minimization of the sum of the expected flow times, i.e., the expected completion times of samples minus their release times [12], with a soft deadline constraint. The reason we do not directly optimize, e.g., for the 0.95 quantile of the TAT distribution, is that it is not a criterion but rather a statistical indicator to keep track of, as it indicates whether an excessive number of samples are late in the presence of outliers introduced by random errors in the process. Since we cannot affect the sources of these errors, the model optimizes the expected patient TAT.
The batching model performs relatively short-term decision-making because of the typical transport times of vital samples and centrifuge capacity. Specifically, we consider only which vital samples currently available or transported should be included in the next centrifuge run and what can be postponed until the following run. The model distinguishes two sets of samples. First, a set of vital samples that arrived at the laboratory and thus are available at time t is denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_t$$\end{document} . Next, it keeps track of the samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{V_t}$$\end{document} that are registered in the system at time t but have not yet arrived in the laboratory. For the available samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j\in V_t$$\end{document} , we possess the full information; thus, we can express the time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_j$$\end{document} when sample j is completed as a function of the centrifugation start time. As suggested above, one of the main functions of the model is to determine the content of the batches for the next two consecutive runs of the centrifuge. This is based on the assumption of typical transportation times for vital samples in our data, the centrifuge’s capacity, and its cycle time. With those, every transiting vital sample can be processed within two upcoming spinning cycles. Thus, the model uses optimization variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S^B_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S^B_2$$\end{document} to determine the start times of the next batch or the second next batch, respectively. Thus, we can compute \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_j$$\end{document} depending on whether the sample is assigned to the current or the next batch using binary variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{j,1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{j,2}$$\end{document} . An available vital sample might be postponed to the next batch (i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{j,2}=1$$\end{document} ) because of the limited capacity N of the centrifuge, although in practice, this would unlikely be a binding constraint.
On the other hand, we cannot compute the completion time of samples that are in transit because of the uncertainty of the transport time. Therefore, for samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j\in \overline{V_t}$$\end{document} , we compute the probability that sample j will arrive before the scheduled start of the k-th centrifuge batch, denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Pr \left\{ j \text { in } \text {batch no. }k\right\}$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k\in \{1,2\}$$\end{document} , as the considered horizon assumes two upcoming batches. This probability is computed from the cumulative distribution function of the transport time of sample j, which is estimated from historical data as a function of the sample priority \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _j$$\end{document} and the ward \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$w_j$$\end{document} . The use of an empirical distribution may capture potentially complex transport time distributions, enabling efficient centrifuge scheduling by identifying low-probability arrival windows. Modeling transport time uncertainty via its full CDF may be a more effective choice, for example, when a bimodal distribution for which a single-point estimate, such as the expected value, could produce an outcome that even has a zero probability of occurrence.
A natural question arises regarding whether the distribution modeled via its CDF is stationary; that is, whether it depends on the particular hour of the day. The model we propose below does not make any assumptions about this. Therefore, the distribution can even be nonstationary and can be incorporated by simply using a different CDF for each hour of the day if enough data are available. In this work, we assume that the distribution does not change over the course of a day; however, the model may benefit from utilizing more of the structure hidden within the transport time distribution.
The example in Fig. 7 shows how the probability of sample j being included in the next centrifuge run depends on the centrifuge start time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S^B_1$$\end{document} . If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S^B_1$$\end{document} is too small, then sample j will surely miss the run because of its minimum transport time. When it is large enough, then sample j will surely be available in the laboratory to be centrifuged. As simulation time t progresses, the relationship between the centrifuge start time and the probability of sample arrival is readjusted such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S^B_1\ge t$$\end{document} always holds, as shown in blue in Fig. 7.Fig. 7. Probability that sample j from ortjip department registered at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{r}_j$$\end{document} can be included in the upcoming batch as a function of batch start time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S^B_1$$\end{document}
Although we compute the probability that a sample arrives before the start of the centrifuge for each vital sample currently in transport, this does not necessarily mean that the model decides to include all these samples in the earliest possible batch. Similarly, as in the case of available samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_t$$\end{document} , the model can postpone transiting vital sample j to the next batch. Thus, for vital samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j\in \overline{V}_t$$\end{document} that are currently in transport, we introduce a binary variable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{y}_{j,2}$$\end{document} with meaning \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{y}_{j,2}=1$$\end{document} when transiting sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j\in \overline{V}_t$$\end{document} is considered for the second batch. Allowing this degree of freedom is beneficial, for example, in cases where the minimum transport time of the transiting sample is greater than the centrifuge cycle time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta$$\end{document} .
To model this decision, we introduce a new set of variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{Pr }\left\{ j \text { in } \text {batch no. }k\right\}$$\end{document} , which models the probability that sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j\in \overline{V_t}$$\end{document} will be included in the batch \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k\in \{1,2\}$$\end{document} . The difference from the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Pr \left\{ j \text { in } \text {batch no. }k\right\}$$\end{document} variables is that it reflects the value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{y}_{j,2}$$\end{document} ; thus, if sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j\in \overline{V_t}$$\end{document} is set to be postponed to the second centrifuge run (i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{y}_{j,2}=1$$\end{document} ), then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{Pr }\left\{ j \text { in } \text {batch no. }1\right\} =0$$\end{document} . These variables are used to express a part of the criterion that computes the expected flow time of samples in transport. The full model is given by Eqs. 4.1–4.24. The objective (4.1) minimizes the sum of the flow times for the available samples plus the expected flow time of the samples in transit. The last term of the objective penalizes the use of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\xi _j$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{\xi }_j$$\end{document} variables for violation of the soft deadline constraint. Constraints (4.2) and (4.3) model the minimum possible start times of the next two following runs of the centrifuge. The constraint (4.2) asserts that the next start time must be greater than or equal to the last centrifuge start time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S^B_0$$\end{document} plus its cycle time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta$$\end{document} . The constraint (4.3) defines the ordering of the first and the second considered batches. The expected utilization of centrifuge capacity is constrained by Eq. 4.4. The constraint (4.5) enforces that each available sample is included in either the first or the second centrifuge run, while constraints (4.6) and (4.7) are indicator constraints used to compute the completion time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_j$$\end{document} of sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j\in V_t$$\end{document} based on the start time of the assigned batch and the processing time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_j$$\end{document} of the sample in the analytic part of the system.
The constraint (4.8) models the probability of an early sample arriving as a piecewise linear approximation of the sample transportation time cumulative distribution function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {CDF}_{j}(x) \in [0,1]$$\end{document} , exactly as demonstrated in Fig. 7. The assumption that a vital sample currently in transit will surely arrive for the second batch at the latest is expressed by Eq. 4.9. The indicator constraints (4.10)–(4.13) interconnect the semantic of the probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Pr \left\{ j \text { in } \text {batch no. }k\right\}$$\end{document} that sample j can be included and the actual planned decision \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{y}_{j,2}$$\end{document} that sample j is included in the corresponding batch. Finally, the constraints (4.14)–(4.15) impose a soft deadline in that the (expected) completion times of both available and transiting vital samples must be before the requested due date of D seconds from registration via \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\xi _j, \overline{\xi }_j$$\end{document} , slack variables.
We include this constraint since, in preliminary experiments, we observed that the model occasionally yields solutions that sacrifice the worst-case performance (i.e., maximum patient TAT) in favor of optimizing the lower quantiles. However, including this constraint is solely the user’s choice and may be omitted if a small percentage of high TAT values does not represent an issue.
The model resembles a nonconvex mixed-integer quadratic program (MIQP) but can be solved up to global optimality by modern solvers, such as Gurobi. The full model is given as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\min \sum _{j\in V_t} \left( C_j - \hat{r}_j\right) +\sum _{k\in \{1,2\}}\nonumber \\&\sum _{j\in \overline{V_t}}\overline{Pr }\left\{ j \text { in } \text {batch no. }k\right\} \cdot \left( S^B_k+\delta + p_j-\hat{r}_j\right) +\nonumber \\&+M\cdot \left( \sum _{j\in V_t} \xi _j + \sum _{j\in \overline{V}_t} \overline{\xi }_j \right) \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&{\text{subject to }}\\&S^B_1 \ge \max \{t, S^B_0 + \delta \} \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&S^B_2 \ge S^B_1 + \delta \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\sum _{j\in V}y_{j,1}+\sum _{j\in \overline{V_t}}\overline{Pr }\left\{ j \text { in } \text {batch no. }1\right\} \le N\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&y_{j,1}+y_{j,2} = 1\quad \forall j \in V_t\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&y_{j,1} \implies C_j = S^B_1 + \delta + p_j\quad \forall j \in V_t\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&y_{j,2} \implies C_j = S^B_2 + \delta + p_j\quad \forall j\in V_t\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&Pr \left\{ j \text { in } \text {batch no. }1\right\} = \text {CDF}_{j}(S^B_1-r_j) \quad \forall j\in \overline{V_t}\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&Pr \left\{ j \text { in } \text {batch no. }1\right\} =\nonumber \\&=1-Pr \left\{ j \text { in } \text {batch no. }2\right\} \quad \forall j\in \overline{V_t} \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\overline{y}_{j,2} = 1 \implies \overline{Pr }\left\{ j \text { in } \text {batch no. }1\right\} = 0\quad \forall j \in \overline{V_t}\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\overline{y}_{j,2} = 1 \implies \overline{Pr }\left\{ j \text { in } \text {batch no. }2\right\} = 1\quad \forall j \in \overline{V_t}\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\overline{y}_{j,2} = 0 \implies \overline{Pr }\left\{ j \text { in } \text {batch no. }1\right\} = \nonumber \\&=Pr \left\{ j \text { in } \text {batch no. }1\right\} \quad \forall j \in \overline{V_t}\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\overline{y}_{j,2} = 0 \implies \overline{Pr }\left\{ j \text { in } \text {batch no. }2\right\} = \nonumber \\&=Pr \left\{ j \text { in } \text {batch no. }2\right\} \quad \forall j \in \overline{V_t}\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&C_j - \hat{r}_j \le D + \xi _j \quad \forall j \in V_t \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\sum _{k\in \{1,2\}}\sum _{j\in \overline{V_t}}\overline{Pr }\left\{ j \text { in } \text {batch no. }k\right\} \cdot \nonumber \\&\cdot (S^B_k+\delta + p_j-\hat{r}_j) \le D + \overline{\xi }_j \quad \forall j \in \overline{V}_t\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \multicolumn{2}{l}{\text{ where }}\\&S^B_0 = \text {the last centrifuge start time}\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&y_{j,1},y_{j,2}\in \{0,1\}\quad \forall j\in V_t\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\overline{y}_{j,2}\in \{0,1\}\quad \forall j \in \overline{V_t}\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&S^B_1,S^B_2\ge 0\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&C_j\ge 0 \quad \forall j\in V_t\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&Pr \left\{ j \text { in } \text {batch no. }k\right\} \in [0,1] \quad \forall j \in \overline{V_t}, k \in \{1,2\}\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\overline{Pr }\left\{ j \text { in } \text {batch no. }k\right\} \in [0,1] \quad \forall j \in \overline{V_t}, k \in \{1,2\}\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\xi _j \ge 0 \quad \forall j\in V_t\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned}&\overline{\xi }_j \ge 0 \quad \forall j\in \overline{V}_t \end{aligned}$$\end{document}The model (4.1)–(4.24) is employed inside the online setting in the following way. As asserted above, the stochastic MIQP model is driven only by vital samples. Although the policy is agnostic to the registration and arrival of statim and routine samples, it still shares the available capacity of the centrifuge with other available samples. At time instances t of the DES simulation when a vital sample is present in the system (i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_t\ne \emptyset$$\end{document} ), the model (4.1)–(4.24) is constructed and solved. Suppose that the (optimal) value of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S^B_1$$\end{document} variable is greater than t. In that case, the model registers a custom wake-up event (see Fig. 4, Policy process) for a future time instant equal to the computed value of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S^B_1$$\end{document} variable. If the value of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S^B_1$$\end{document} variable equals t, then the centrifuge is dispatched with the vital samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j\in V_t$$\end{document} , for which \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{j,1}=1$$\end{document} . If this amount is less than the centrifuge capacity N, then the rest of the capacity is filled with available samples in order of their priority, with ties broken by the sample arrival time. When no vital sample is available or registered in the system, the model (4.1)–(4.24) is not constructed. Instead, the centrifuge is operated following the look-ahead policy described in Section 4.3.
Here, we would like to make a few remarks about the model (4.1)–(4.24). First, note that the objective function (4.1) is the sum of (expected) flow times plus the soft constraint violation penalty. This choice seems to be natural, as the flow time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_j = C_j - \hat{r}_j$$\end{document} is precisely the patient TAT of a sample j. However, we also experimented with different objective functions, such as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum T_j$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_j=\max \{0, C_j - d_j\}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_j$$\end{document} is a virtual due date set as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_j=\hat{r}_j + \beta$$\end{document} for some \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta> 0$$\end{document} . The idea is to allow each sample to accommodate some defined lateness \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} (e.g., 45 minutes) before incurring a penalty. With that, the model becomes more flexible in postponing the centrifuge run to accommodate more transiting samples. However, with our data, the total tardiness or other related objectives, such as minimizing the number of tardy jobs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum U_j$$\end{document} or minimizing squared flow times, did not present better performance than the total flow time minimization, as will be shown in Section 5.3.
Finally, we highlight the limitations of the above model, which utilizes a full CDF transport time distribution. Specifically, one may wonder whether modeling a full CDF of the transport time distribution yields a significant improvement over simpler (e.g., look-ahead) methods, which may be equipped with just single-point estimates of transport times. The first such setting is where the transport time distribution is narrow or, at the very least, close to a deterministic distribution that can be efficiently captured by a single parameter. This situation is discussed at the end of Section 4.3. Other scenarios where the knowledge of the full CDF does not present a significant advantage include cases where either too few or too many vital samples are released during the day. In the first scenario, the method effectively converges toward a look-ahead policy, whereas in the second scenario, the vital priority essentially becomes statim, as there are not enough lower-priority samples to take advantage of. Additionally, if vital samples tend to have a long transport time relative to the centrifuge cycle time, then the relative improvement in patient TAT tends to diminish. We study this case in Section 5.5, where we investigate the relative improvement over the look-ahead method for scenarios with different cycle times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta$$\end{document} .
Offline perfect-knowledge algorithm
To construct a point of reference for the proposed online algorithms, we also consider a deterministic, offline variant of the problem, with full information about uncertain parameters available to the decision-maker. That is, for the offline algorithm, the release times of the samples and the actual values of the transportation times are known in advance. In this sense, the results of such a perfect knowledge algorithm represent the theoretical boundary that can be attained by any method provided that the offline algorithm is exact. First, we describe a general schema of the proposed offline algorithm and discuss the design choices. Then, we provide details of two algorithms for different criteria functions that can be incorporated into the introduced optimization schema.
Baptiste et al. [18] reported that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1\ |\ p\text {-batch},\ b<n,\ r_j,\ p_j=p\ |\ f$$\end{document} is polynomial for at least \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f \in \{ \sum w_j U_j,\ \sum w_j C_j,\ \sum T_j,\ \max _j T_j\}$$\end{document} and some other objective functions following specific properties. While these results could also be applied to solve some variants of our problem in an offline perfect-knowledge setting, their algorithm has time complexity in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(n^8)$$\end{document} . However, a typical laboratory processes hundreds to thousands of samples daily, which renders any high-order polynomial algorithm intractable in practice. For smaller instances, e.g., when only vital samples are considered, polynomial algorithms can indeed be used, but such small instances can also be easily solved by modern MIP solvers.
While minimizing functions such as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum w_j U_j,\ \sum w_j C_j,\ \sum T_j$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max _j T_j$$\end{document} for instances beyond the reach of MIP solvers may be relatively difficult because of the high polynomial order of the algorithm of [18], the feasibility problem \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1\ |\ p\text {-batch},\ b < n,\ r_j,\ p_j = p,\ \text {deadlines } d^\prime _j\ |-$$\end{document} with deadlines \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^\prime _j$$\end{document} is solvable in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(n^2)$$\end{document} time when the algorithm proposed in [19] is used. There, an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(n^2 \log n)$$\end{document} -time algorithm was proposed for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1\ |\ p\text {-batch},\ b < n,\ r_j,\ p_j = p\ |\ L_{\text {max}}$$\end{document} , i.e. minimizing the maximum lateness \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max _j L_j = \max _j C_j - d_j$$\end{document} for the case when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_j$$\end{document} are soft bounds (i.e., due dates). A similar approach can be used to minimize the maximal patient TAT while respecting the priority of samples, as will be shown later.
We designed an offline perfect-knowledge algorithm to address the challenges described above, taking advantage of the properties of the problem; that is, the hierarchical properties of sample priorities—a vital sample is more important than any statim sample, and the same relation holds for statim and routine samples. Therefore, we can use a hierarchical approach, where we first derive completion times for vital samples alone without considering other sample priorities. Then, the algorithm schedules statim samples and, finally, the routine ones so that the completion times of vitals and statims derived by the previous stages are not violated. We refer to the problem of scheduling samples of a certain priority as a stage. Each stage may use a different objective function and is solved by its own algorithm, which we refer to as a subroutine.
Details are described in Appendix A. The pseudocode of the hierarchical optimization method is shown in Algorithm 1. The algorithm starts with the subroutine SubroutineVital. Each subroutine accepts three parameters: a set of samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}$$\end{document} scheduled in the previous stage, whose completion times are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C^P$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C^P_i$$\end{document} is the completion time of sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i \in \mathcal {P}$$\end{document} , and a set of samples to be scheduled during the current stage \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}, \ \mathcal {P} \subseteq \mathcal {J} \subseteq \mathcal {S}$$\end{document} . The subroutine provides one or more (optimal) schedules for the samples contained in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} , each characterized by completion times. Here, in line 2, the set of schedules returned by the subroutine is denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {C}$$\end{document} . At the beginning, the set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} consists exclusively of vital samples. In the first stage, there are no previously scheduled samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}$$\end{document} ; thus, their completion times are not available. Then, statim samples are scheduled by SubroutineStatim, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} consisting of both vital and statim samples. Since it is the second stage, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}$$\end{document} contains all the vital samples, and each schedule from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {C}$$\end{document} must be considered separately (lines 4–5). Therefore, the subroutine is executed for each schedule obtained from the vital stage, and the results are combined into a single set of new schedules \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {C}'$$\end{document} . Next, all the schedules with the optimal value of the objective function from the statim stage are preserved and passed into \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {C}$$\end{document} . The same steps are followed for the routine samples. Finally, the start times of the batches \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S^B$$\end{document} are calculated on the basis of one of the optimal schedules from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {C}$$\end{document} . If the subroutines at each stage are exact and return all optimal schedules, the hierarchical algorithm is also exact. We introduced two subroutines, built upon exact algorithms: the total TAT minimization subroutine (based on an MIP formulation) and the maximum TAT minimization subroutine (based on a polynomial-time algorithm). Both are described in detail in Appendix A.
Algorithm 1Offline perfect-knowledge algorithm.
Experiments
All the algorithms in the experiments were implemented in Julia 1.11.5. The discrete event system (DES) simulation uses the ConcurrentSim library, a Julia implementation of DES inspired by the well-known Python DES framework Simpy. For the solutions of the MIP and MIQP models, we use the Gurobi solver version 11. The benchmarks were conducted on commodity hardware, i.e., an AMD Ryzen 9 5950X 16-core processor with 64 GB of RAM. The source codes are available on GitHub https://github.com/CTU-IIG/centrifuge-batching.
In Section 5.1, we describe which data were used for this case study and what data cleansing steps were applied. We subsequently compare the distributions of patient TATs obtained with the methods discussed in this paper, utilizing different environmental information, as denoted in Table 2. The aim of this experiment is to show the benefit of the proposed solution with respect to the baseline solution that is often used in laboratories. Different objective functions and their effects on the solution are analyzed in Section 5.3. Next, we use the perfect-knowledge offline method introduced in Section 4.5 to establish the best possible results attainable with the current laboratory hardware. Furthermore, we use our DES simulation and batching algorithms to explore the space of centrifuge parameters to assess under which configurations the proposed solutions achieve the best performance over the look-ahead policy. These considerations are reflected in the managerial insights in Section 5.6, which discusses the impact on the quality of the provided health care and the economic implications depending on the system configuration and the dispatching algorithm used.
Data description
Our data for the purposes of this study come from University Hospital Královské Vinohrady, Czech Republic. We obtained anonymized patient records for October 2018 from the Laboratory Information System (LIS), which were derived from the laboratory workflow analysis we performed for this hospital.
This work focuses on improving laboratory systems with a high level of automation, such as an automated centrifuge, sample distribution system, and analytical section, e.g., DxA 5000. Nevertheless, we do not concentrate on any specific laboratory system in the experimental analysis since the described approach is general and can be applied to other automated systems as well. On the other hand, since the data we use in our experiments are associated with the laboratory analyzers Cobas c702, c501, and e602, the processing time of each laboratory method, e.g., glucose, albumin, and troponin-I, assigned to each sample is set according to the parameters of those analyzers. Therefore, the processing time is deterministic and takes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_j\in \{9, 10, 18, 27\}$$\end{document} minutes depending on the prescribed method. If the sample contains more methods to be performed, we estimate the processing time of the sample as the longest method it contains (methods are typically evaluated in parallel inside the laboratory analyzer). In total, 8799 routine, 6635 statim, and 142 vital samples were initially considered.
We excluded samples whose transportation time exceeded 200 minutes or whose duration between sample admission and result validation exceeded 24 hours. The procedure left 4936 routine, 4787 statim, and 137 vital samples. Furthermore, for the vital samples, the transport time threshold was set to 22 minutes. Any transport time above this threshold was redrawn from U(5, 22) to keep the overall number of vital samples intact while providing a more balanced input for the data generation procedure described below. These thresholds were selected on the basis of laboratory guidance to eliminate erroneous data, special samples processed only on specific days, and other outliers. Next, to ensure sufficient data for estimating transport time distributions in subsequent steps and to exclude insignificant, dummy, or outlier wards, we included only samples from the 30 hospital wards with the highest volume of nonvital samples while retaining all vital samples.
To enrich the dataset, we created alternative realizations of the uncertain parameters observed in the real data, resembling different variants of the observed days. That is, we generate new data by drawing realizations of transport times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\tau }_j$$\end{document} from the estimated transport distribution of samples from the hospital ward w associated with sample j. If the number of samples from ward w was insufficient for reliable estimation (fewer than 3 samples), we constructed a distribution using the combined sample set from such wards. This occurred only for vital samples, since otherwise, we kept only data from the top 30 wards. In the case of routine and statim samples, the transport times are sampled from kernel density estimates derived from real data. For the vital samples, owing to the small amount of data when conditioning on the hospital ward, the transport time distribution for hospital ward w was estimated using a uniform distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\tau }_j\sim U(lb_w, ub_w)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$lb_w$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ub_w$$\end{document} are the lowest and the highest observed transport time realizations, respectively, for ward w in real data. This choice leads to a distribution with the maximum discrete entropy, thus imposing the least amount of bias and a priori knowledge on the system. For the experiments below, we use the enriched dataset, which is worth 100 months of data.
Patient TAT minimization
In this section, we compare the efficiency of the studied and proposed methods for centrifuge batching (summarized in Table 2). Specifically, we compare the fixed-schedule policy, which serves as a deterministic and predictable baseline, with the threshold-based policy, which represents the solution often deployed in hospital laboratories [8]. Next, we analyze the performance of the online methods proposed in this paper, which are the look-ahead policy from Section 4.3 and the stochastic MIQP model introduced in Section 4.4. All methods are executed in the online setting and interact with the environment using the DES simulation described in Section 4.1.Fig. 8. Distribution of patient TAT for vital samplesTable 3Numerical results of patient TAT and laboratory TAT achievable by different policiesPriorityAlgorithmPatient TAT [min]Laboratory TAT [min]0.95 quantile0.5 quantile0.95 quantile0.5 quantilevitalstochastic MIQP46.239.233.025.0look-ahead49.941.136.525.0threshold-based55.944.139.230.5fixed-schedule57.046.039.532.8statimstochastic MIQP113.471.743.233.0look-ahead113.271.542.433.0threshold-based113.271.442.033.0fixed-schedule115.070.043.033.7routinestochastic MIQP129.387.649.635.5look-ahead129.187.448.435.4threshold-based129.087.248.035.4fixed-schedule130.087.048.035.4
In the first experiment, we compare the patient TAT distributions for all the methods. The results are shown in Fig. 8. Generally, the more information an algorithm uses, the better the results that can be obtained for vital samples. An important finding is that the stochastic MIQP and look-ahead policies are driven only by vital samples (i.e., their decision to trigger the centrifuge is not influenced by the arrival or registration of a nonvital sample) and do not incur significant performance degradation for those priorities, as shown in Table 3. The detailed results in the table reveal that stochastic MIQP achieves 3.7 minutes of improvement over the rule-based look-ahead policy in terms of the 0.95 quantile for vital samples, with the price of only 0.2 minutes degradation for statim samples. With respect to the median performance, the patient TAT of vital samples is improved by 4.9 minutes when stochastic MIQP is used instead of the threshold-based policy. In both cases, the improvement for vital samples was carried out only at minor degradation for statim samples and at no cost for routine samples. Finally, as expected, the fixed-schedule policy yields the best results in terms of the median patient TAT for statim and routine samples.
Compared with the threshold-based policy (which is often used in laboratories), the improvements for vitals are even more pronounced—9.7 minutes for vital samples at the 0.95 quantile level and 4.9 minutes at the median patient TAT. Although the benefit of using stochastic decision-making by the optimization MIQP model in terms of absolute numbers may not seem very large over the reactive look-ahead policy, which does not use distributional information, it needs to be considered that the centrifuge timing is the only degree of freedom in the considered problem, as depicted in Fig. 1. Thus, the results should be interpreted in terms of relative patient TAT reduction with respect to a cycle time of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta =15\cdot 60$$\end{document} seconds. In this view, the stochastic MIQP policy virtually “shortens” the cycle time of the centrifuge by 65% compared with the currently deployed threshold-based policy or 25% compared with the look-ahead policy.
We also evaluated the achieved laboratory TAT to assess how it differs from the patient TAT. When we compute the patient-laboratory TAT difference for vital samples for different algorithms at the 0.95 quantile level, it can be seen that this gap is not constant and is strictly increasing with decreasing amounts of information exposed to the algorithm. Furthermore, when focusing on the median laboratory TAT for vital samples, the stochastic MIQP and look-ahead policies achieve the same laboratory TAT but different patient TAT values. Therefore, these observations suggest that patient and laboratory TATs, although correlated, are generally different quantities, and the transport time of samples should not be overlooked.
Finally, we discuss the computational time consumed by the solution of the MIQP model. We impose a time limit of 10 seconds for solving the model as a safeguard to ensure its real-time performance. However, the Gurobi solver in version 11 presents substantial improvements in the solution of nonconvex MIQPs, and on the considered dataset, it typically achieves run times below 1 second. Therefore, its efficiency for the number of samples considered in this case study is sufficient. If the number of samples increases over time, the model’s performance could be further improved by providing a warm-started solution, since finding a feasible solution to the problem is easy. However, we have not explored this option further, as performance is not an issue.
Different objective functions
In this experiment, we are interested in how different objective functions applied inside the stochastic MIQP model introduced in Section 4.4 influence the patient TAT distribution. Specifically, we investigate the use of the tardiness function and the related objectives, such as the total squared tardiness and the number of tardy jobs, and their impact on the patient TAT of the vital samples.
To introduce the concept of tardy samples, we need to define so-called virtual due dates. The virtual due date for a sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j\in \mathcal {S}^{\textsc {vital}}$$\end{document} is the maximum patient TAT that we allow sample j to reach without incurring any loss. Thus, it is given as the time from its registration in the system \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{r}_j$$\end{document} plus a given slack time of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} minutes that the user is willing to accept as a completion time. Having virtual due dates defined, one can work with objective functions, such as the total tardiness \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _j T_j = \sum _j \max \{0, C_j - \hat{r}_j-\beta \}$$\end{document} , squared tardiness \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _j T_j^2$$\end{document} , or the number of tardy jobs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _j U_j = \sum _j \Bbb{1}(C_j - \hat{r}_j-\beta )$$\end{document} .Fig. 9. The performance for vital samples of the model with the total tardiness objective
The motivation behind the total tardiness objective is to increase the decision space of the algorithm by allowing it to postpone the centrifuge run to anticipate the registration and transport of new samples. The results are shown in Fig. 9 for values of virtual due date \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta \in \{0, 40, 41, \ldots , 50\}$$\end{document} minutes. Furthermore, note that the total tardiness objective with a value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta =0$$\end{document} minutes resembles total flow time minimization since \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{r}_j \le C_j$$\end{document} . A closer inspection of the results suggests that the distribution of patient TAT becomes narrower since the model exploits the tardiness function and runs the centrifuge so that most samples are completed exactly \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} minutes after their registration. The narrower distribution of TATs is generally better, as laboratories and their clients (i.e., medical doctors) prefer a more predictable TAT. Therefore, it would be meaningful to optimize, e.g., the difference between the 0.75 and 0.25 quantiles of the patient TAT distribution, to improve patient TAT consistency. However, we do not further explore this possibility in this paper.
Similar outcomes were observed for the sum of the squared tardiness function. The pronounced effect on the distribution of patient TATs seems to reflect the (expected) number of tardy jobs criterion. In this case, the solution is more sensitive to the actual value of the virtual due date \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} ; however, it is still superior to the total flow time minimization. From the observations above, it appears that the stochastic MIQP model achieves similar results as long as the objective function is strictly nondecreasing (i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f(C_1, \ldots , C_n)$$\end{document} is unbounded as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_j \xrightarrow {} +\infty$$\end{document} ) in the completion times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_j$$\end{document} of the samples.
Perfect-knowledge offline setting
In this experiment, we compute some upper bounds on the performance that any online policy can achieve. To assess this, we use the perfect-knowledge offline algorithm proposed in Section 4.5. This algorithm has access to all realizations of registration \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{r}_j$$\end{document} and transportation times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\tau }_j$$\end{document} in advance and thus makes globally optimal decisions concerning patient TAT minimization for vital samples and—with some assumptions discussed further—samples of other priorities. To make the computations tractable, we give the perfect-knowledge algorithm information about the samples to be released over a one-day horizon. Therefore, the achievable patient TATs are optimized for every day separately. However, in the real data, we observed a gap of several hours between the last sample of a day and the first sample of the following day. Considering the centrifuge cycle time of 15 minutes, this gap effectively voids the dependencies between the days and makes the laboratory process memoryless on the scale of the 24-hour horizon. Thus, we conclude that solving each day separately is, in practice, essentially identical to the solution that considers the whole horizon worth months of data.
We use 100 months’ worth of data to estimate this upper bound on the performance of any online policy on the vital samples. The perfect-knowledge offline algorithm, which minimizes the daily sum of TATs, has access to all the realizations in advance and thus possesses complete information. The fixed-schedule, threshold-based, look-ahead, and stochastic MIQP policies are executed in the online setting without access to all realizations in advance, which is the same as in the previous sections. The distribution of patient TATs of vital samples resulting from this experiment is shown in Fig. 10. The most important outcome is that with perfect knowledge of all samples, slightly better patient TAT results are attainable for low quantiles. Nevertheless, for the high quantiles, the results of the offline algorithm with perfect knowledge almost match the performance of our online stochastic MIQP policy, which does not have access to future realizations of registration and transportation times. This perhaps surprising result also suggests that, for example, even an optimal predictor of transportation times would not significantly improve the performance of the online stochastic MIQP policy.Fig. 10. Patient TAT for vital samples obtained by the offline perfect-knowledge algorithm compared to online policies without perfect knowledge of all parameters
Computing an upper bound on the performance of the algorithms for other sample priorities, i.e., statim and routine, is more challenging for two reasons: (i) the problem resembles a hierarchical optimization problem; i.e., the solution adopted for vital samples affects the solution space of statim samples and so on for routine, and (ii) a large number of statim and routine samples rules out the use of objective functions other than the minimization of the maximum TAT, as discussed in Section 4.5. As these aspects make the evaluation of the algorithms more complex, we provide more insights into the results and present them in two tables—Table 4 for statim and Table 5 for routine samples. To increase the statistical significance of the results produced by the hierarchical optimization procedure, we used 100 months’ worth of data in this experiment.
In Tables 4 and 5 below, each column in All offline and All online sections represents a sequence of algorithms that were used in the corresponding stages. The algorithms we consider are offline with perfect knowledge (denoted as All offline) or online policies (threshold-based or stochastic MIQP), denoted as All online. We compute statistics for the samples in a hierarchical manner. That is, first, we compute statistics ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max$$\end{document} , 0.95 quantile, and mean) over the samples in each day individually and then compute \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max$$\end{document} and mean statistics over the aggregated days, as given in the Aggregation column. In this way, we report six numbers for each sequence of algorithms used in different stages (sample priorities) in the optimization. The best results in each row are highlighted in bold.
The results in Table 4 show that the best achievable performance in terms of the maximum patient TAT for the statim samples is 244 minutes, which is only 7.2 minutes shorter than that of the stochastic MIQP, which has incomplete knowledge. However, owing to the objective function focusing on the worst-case patient TAT, the performance of the perfect knowledge offline algorithms is less dominant in the 0.95 quantile measure. The outcomes confirm that the threshold-based policy is competitive for the statim samples, especially when it is optimized for the expected case.
With respect to the performance for routine samples in terms of the maximum TAT, the difference between the best offline perfect-knowledge algorithm and stochastic MIQP is only 4.4 minutes. Furthermore, the impact of using different online methods (threshold-based and stochastic MIQP) for routine samples alone is marginal. This is because the starting times of the majority of batches are predetermined before routine samples because of the large number of statim samples optimized in the previous stage, which leaves little room for optimizing routine samples.
In any case, looking at the minimum along each row of Tables 5 and 4, the numbers provide some guidance on what can be achieved with different sequences of full-knowledge offline algorithms and online policies combined with different aggregations of results. From this, we estimate that our best online policy, the stochastic MIQP, delays routine samples by up to 7.2 minutes compared with the theoretical optimum. Interestingly, the mean TATs are similar for all the considered strategies and for both the statim and routine samples. This suggests that optimization for different robust objectives, such as the daily maximum or 95th percentile, can be performed without a detrimental impact on the average case.Table 4. Patient TATs in minutes of statim samples achieved by different sequences of algorithmsAggregationStageAll offline [min]All online [min] DailyTotalvital \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max$$\end{document} TAT \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum$$\end{document} TATthreshold-basedstochastic MIQPstatim \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max$$\end{document} TAT \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max$$\end{document} TATthreshold-basedstochastic MIQPmaxmax244.0****244.0247.3251.2mean166.1****166.1171.9172.2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$95^{\text {th}}$$\end{document} max170.9****170.9173.3173.3mean112.0112.1112.2112.4meanmax83.583.583.683.6mean73.973.973.573.7Legend: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum$$\end{document} TAT: Section 8.1, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max$$\end{document} TAT: Section 8.2, threshold-based: Section 4.2, stochastic MIQP: Section 4.4Table 5Patient TATs in minutes of routine samples achieved by different sequences of algorithmsAggregationStageAll offline [min]All online [min] DailyTotalvital \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max$$\end{document} TATthreshold-basedstochastic MIQPstatim \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max$$\end{document} TATthreshold-basedstochastic MIQProutine \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max$$\end{document} TATthreshold-basedstochastic MIQPmaxmax259.4265.8263.8mean161.9167.1167.3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$95^{\text {th}}$$\end{document} max192.2196.2196.2mean123.7****123.7123.9meanmax133.8144.6144.6mean89.389.489.7Legend: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max$$\end{document} TAT: Section 8.2, threshold-based: Section 4.2, stochastic MIQP: Section 4.4
Influence of system parameters
The cycle time of the centrifuge is among the system parameters that significantly influence the patient TAT. The cycle time of the centrifuge (including the loading and unloading of samples) depends on the manufacturer, its setup, and its capacity. When comparing the quality of different batching policies, it should be noted that the perceived efficiency of a policy depends on the values of the system parameters, such as the cycle time, that are applied. Intuitively, if the cycle time is very long, e.g., two hours, then the performance of any online policy would essentially converge to the fixed-schedule policy that runs the centrifuge every two hours, since there would be a high probability of having some sample that missed the centrifuge start. Additionally, if the centrifuge is very fast, e.g., 1 minute, then the potential advantage of any nontrivial method is upper-bounded by 1 minute since the samples can enter the centrifuge any minute, assuming that it has sufficient capacity. In contrast, the efficiency of a batching policy becomes apparent when the cycle time falls into a range that is not too short and not too long.Fig. 11. Patient TAT distribution of vital samples for different centrifuge cycle times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta$$\end{document}
To evaluate the efficiency of different alternative system configurations, we created separate simulations with centrifuge cycle times of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta \in \{10,14,17,20\}$$\end{document} minutes. A comparison between the look-ahead policy and the stochastic MIQP model is shown in Fig. 11. The two methods perform similarly well in terms of the best cases and lower quantiles of the patient TAT. However, with increasing cycle time, stochastic MIQP gains greater advantages in terms of higher quantiles as the precise timings of the centrifuge become more critical to avoid penalties for sample miss. This is apparent in the graph in Fig. 12, which depicts the values of the 0.95 and 0.5 quantiles of the patient TAT depending on the value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta \in \{10, 11, \ldots , 20\}$$\end{document} . With respect to the 0.95 quantile, the results suggest that with increasing cycle time, stochastic MIQP gains more advantages, whereas for shorter cycle times below 10 minutes, the advantage of stochastic MIQP essentially diminishes. The difference in the median performance is largely preserved across different cycle times.Fig. 12. The 0.95 and 0.5 quantiles of patient TAT for different centrifuge cycle times
Summary
One of the main outcomes of this study is the assessment of how different information contexts can improve the patient TAT of vital samples. In that regard, these results are best seen in Fig. 10 and in Table 3. The difference between the curves corresponding to the threshold-based and look-ahead policies quantifies the benefits of using the information regarding sample registration in the system. It can be seen that implementing a system that considers such information improves the 0.95 quantile of patient TAT by as much as 6.7 minutes (see Table 3). An additional 3.7-minute improvement can be achieved by utilizing the distributional information of transportation times and optimization-based decision-making, which avoids various rule-based logic and timeout policies in favor of an optimization model that continually reevaluates its decision on the basis of newly revealed information to determine the optimal centrifuge start time. These improvements are obtained at virtually no cost in terms of degradation of the patient TAT of statim samples (0.2 minutes, both for the 0.95 and 0.5 quantiles). The perfect-knowledge MIQP curve shows an upper bound on the performance of any online policy with respect to vital samples. Knowing the exact transportation times and registration times in advance cannot be used to eliminate the upper tail of patient TAT cases, but such information might be used to slightly improve patient TAT in the bottom 50% of vital samples.
Managerial insights
Our research contributes to the management of laboratories and hospitals aiming at total laboratory automation (TLA), where the ultimate goal is to process samples without any assistance from a human operator except for clinical validation of the results. Current automation systems typically distinguish between two sample priorities, i.e., statim and routine. However, if the hospital defines vital priorities, such samples are processed manually. In practice, this means that a laboratory employee takes the sample and manually performs all the operations with the sample (e.g., using manual input for individual analyzers). If multiple vital samples arrive at the laboratory simultaneously, the laboratory should have sufficient staff to process them. Therefore, the manual processing of vital samples increases the demands on human resources. On the other hand, the manual processing of vital samples contradicts the TLA. Therefore, our research addresses the processing of vital samples and examines how they should be handled by laboratory automation–specifically, by a centrifuge. From a laboratory management point of view, this is an important step in eliminating manual and routine work (which is often a source of mistakes, such as incorrect blood in tube errors [29]). With TLA, which also covers vital samples, highly skilled laboratory employees can be reassigned to more qualified positions, supporting the more efficient use of human resources.
This paper also concerns sample flow quality control. Hospitals often see laboratory TAT as the main key performance indicator for laboratory samples. The reason for this is that responsibility for the flow of samples–from the moment the sample is drawn until the result is reported–is distributed among multiple stakeholders. No single party has overall responsibility for or control over the entire process. Individual hospital wards are responsible for collecting the samples and passing them to the transport. A technical department is responsible for transporting the samples, often via tube mail. Finally, the laboratory receives the samples, analyzes them, and reports the results back to the doctor. However, hospitals typically do not have a body that monitors and manages the entire process. This aspect may result in a significant variation in the time it takes to deliver laboratory results, which may be perceived negatively by doctors. This opinion is supported by data from University Hospital Královské Vinohrady, Czech Republic presented in Fig. 2, which shows how transport times from different wards can be diverse; thus, one department may consider a certain laboratory TAT to be sufficient, while another may not. Given that laboratory TATs may not provide all relevant information about the quality of care, we want to draw the attention of hospital authorities to patient TATs. Hospitals should periodically monitor patient TAT and analyze how individual departments contribute to this time (see the timing diagram in Fig. 1). Moreover, hospitals should have a single entity responsible for managing the quality of the process and ensuring that the entire workflow is centrally monitored. Managers should also look for ways to automate the process and eliminate the need for human interaction with samples, which often causes delays and introduces unpredictability. Of course, transport time may vary across different departments due to their distance from the laboratory. Therefore, our paper shows how information related to the transport of samples can be incorporated into laboratory automation systems to improve patient TAT, and it can serve as further motivation for automated sample processing. This should be in the economic interest of hospitals, as reducing patient TAT at high quantile levels contributes to shorter patient length of stay [7] and thus has an eminent impact on the quality of care provided by the hospital and healthcare costs.
Conclusion and future research
This paper addresses an important topic concerning the speed of delivery of laboratory test results. We highlight the current limitations of laboratories that evaluate laboratory TAT, not patient TAT. Therefore, we propose a new batching strategy for centrifuging samples that incorporates knowledge of transport times from individual wards. Experimental results on real data show that the proper batching of samples obtained by our strategy can significantly reduce the patient TAT of vital samples, i.e., samples of patients in immediate danger of death, while not degrading the patient TAT of less urgent samples.
Regarding the method proposed in this paper, several natural extensions of our work are possible. First, we do not address the analytic part of the system. If the load of analyzers is high, then a sample may need to wait before it is processed, and this waiting time depends on the composition of the sample methods to be evaluated within a certain short-term time window. Therefore, it would be interesting to model the analytic part of the system, consider it in the patient TAT calculation, and utilize it by the batching strategy in a way that leads to balanced use of the analyzers. Moreover, since handling vital samples is time-critical and the historical data may be insufficient to construct a complex model of the transport time distribution, a distributionally robust approach [12] could be employed. Such methods are already applied in the medical field, for example, for surgical block allocation [30]. Next, the stochastic MIQP model could be extended to handle samples with different priorities, leading to optimized batching of non-vital samples as well. Finally, it would be interesting to extend the method to consider more than a single centrifuge.
Further research should also address the use of priorities in total laboratory automation. As described in the previous section, vital samples are often handled manually, contrary to the concept of total laboratory automation. Nevertheless, this is not the only issue that current laboratories face regarding sample priorities. Statim priorities, which should be used for patients with slightly less urgent needs than those requiring a vital indication, are often overused for samples that need to be processed, e.g., before a ward round. Then, the laboratory may first process samples from inpatients who are waiting for the ward round, and the sample of a patient taken to the hospital by ambulance and suffering from acute myocardial infarction (whose sample was also labeled statim) may be processed subsequently. In such a situation, care for the patient with acute myocardial infarction is delayed since the laboratory is not able to distinguish which statim sample is most urgent. To the best of our knowledge, no existing work addresses total laboratory automation and the design of sample priorities.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Sojma D (2022) Simulation and optimization of laboratory processes. Master’s thesis, Czech Technical University in Prague. https://dspace.cvut.cz/handle/10467/101702