Inference for microbe–metabolite association networks using a latent graph model
Jing Ma

TL;DR
This paper introduces a new method to better detect relationships between microbes and metabolites in biological networks.
Contribution
A novel inference procedure using a bipartite stochastic block model to enhance power and control false discovery rates in microbe-metabolite networks.
Findings
The proposed method improves detection of significant associations in microbe-metabolite networks.
The approach clusters microbes and metabolites into modules for better interpretation.
The method was validated through simulations and applied to bacterial vaginosis data.
Abstract
Correlation networks are commonly used to infer associations between microbes and metabolites. The resulting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}-values are then corrected for multiple comparisons using existing methods such as the Benjamini & Hochberg (BH) procedure to control the false discovery rate (FDR). However, most existing methods for FDR control assume the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}-values are weakly dependent. Consequently, they can have low power in…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
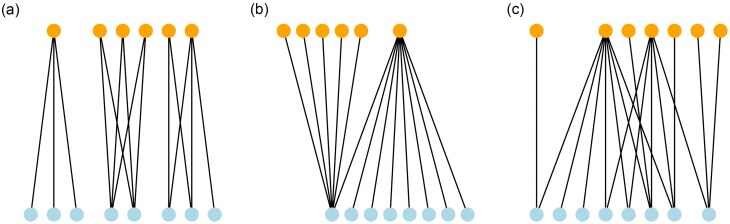 Figure 1
Figure 1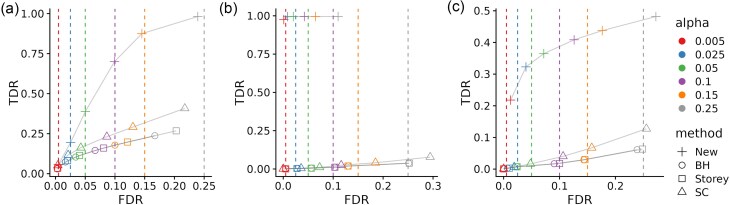 Figure 2
Figure 2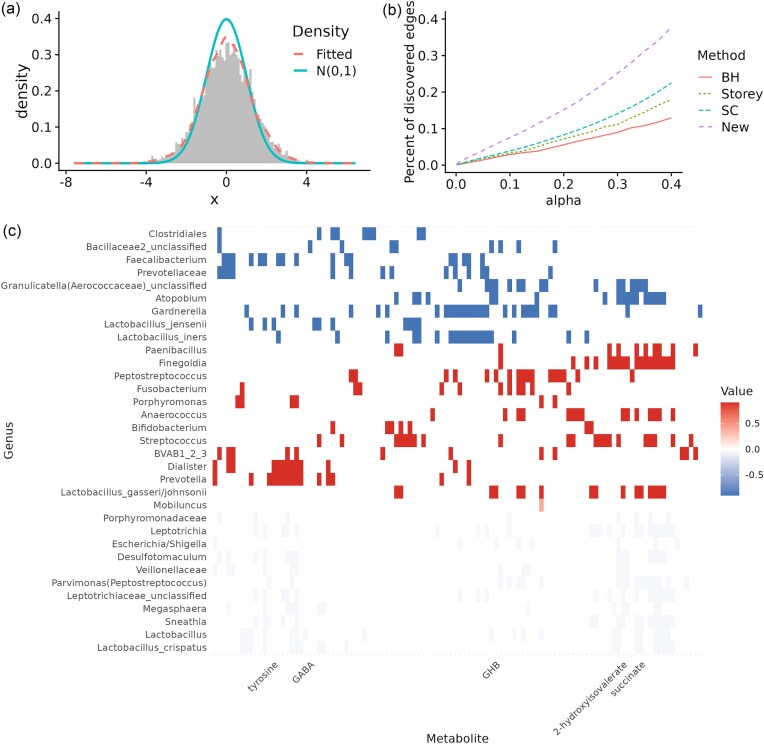 Figure 3
Figure 3- —NIH10.13039/100000002
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGut microbiota and health · Reproductive tract infections research · Bioinformatics and Genomic Networks
Introduction
1
The gut microbiome plays an important role in human health and diseases (Hou et al., 2022). One potential pathway by which the gut microbiome impacts host health is through microbial-derived metabolites: these molecules can modulate the immune system (Dinglasan et al., 2025; Williams and Cao, 2024). Yet, despite extensive experimental and computational work, a large number of microbe–metabolite relationships remain unknown, leaving a significant knowledge gap (Liu et al., 2022).
Our motivating example concerns a study of bacterial vaginosis (BV) using paired microbiome and metabolome profiling (McMillan et al., 2015). The vaginal microbiota is an intricate ecosystem in which microbes trade nutrients, defense molecules, and signaling compounds with both the host epithelium and one another. Disruption of this ecosystem manifests clinically as BV, a condition affecting up to 30% of women worldwide (Koumans et al., 2007) and linked to adverse outcomes such as pre-term birth and increased risk to sexually transmitted infections (Guerra et al., 2006; Atashili et al., 2008). A growing body of evidence suggests that BV is not driven by a single pathogen but reflect a community-wide metabolic shift (Srinivasan et al., 2015; Łaniewski and Herbst-Kralovetz, 2021). Improved diagnosis and treatment of BV requires a detailed understanding of these metabolic activities.
The data set contains 49 taxa and 128 metabolites collected from 124 individuals. For the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} -th taxon and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} j\end{document} -th metabolite, a correlation statistic and its \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p\end{document} -value can be derived. The task is to perform simultaneous inference for the null hypothesis of no association between all taxa and metabolites, for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i=1,\ldots ,49\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} j=1,\ldots ,128\end{document} .
The goal of large-scale hypothesis testing is to identify as many interesting ones as possible while keeping the error rate low. The false discovery rate (FDR), defined as the average proportion of errors among the discoveries, is a commonly used metric to assess the significance of testing multiple hypotheses simultaneously. In practice, the Benjamini & Hochberg (BH) procedure based on ranking \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p\end{document} -values (Benjamini and Hochberg, 1995) is often used to control FDR. While easy to implement, this vector-based approach suffers from two main limitations. First, it provides a list of significant associations that can be hard to interpret biologically. Second, BH and related methods such as Storey’s \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q\end{document} -value (Storey et al., 2004) assume weakly dependent \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p\end{document} -values; this assumption is often violated when analyzing high-dimensional microbiome and metabolomic data, especially when microbes and metabolites form densely connected modules.
For vector-based testing problems, many authors have improved power by estimating the null/alternative mixture distributions (Efron, 2004; Sun and Cai, 2007) and modeling the dependence explicitly (Sun and Cai, 2009; Li et al., 2024; Wang and Wang, 2024). Those advances, however, do not translate directly to matrix-valued data such as correlation or cross-correlation matrices: here the tests exhibit structured dependence that is not exploited by existing tools. In large-scale testing of (partial) correlations, Liu (2013), Cai and Liu (2016), Xia et al. (2015) and Cai et al. (2019) established valid FDR control for test statistics obtained from high-dimensional data under mild regularity conditions, but they do not take into account the structural information in the data.
Rebafka et al. (2022) recently bridged this gap with the noisy stochastic block model (noisySBM), which treats the constellation of null and non-null hypotheses itself as an SBM and models the observed statistics as a perturbed version of that latent graph. Applied naively to bipartite data, however, the standard noisySBM (i) is computationally heavy and (ii) tends to merge features of different types into the same community (Larremore et al., 2014), degrading FDR control.
We introduce a bipartite noisySBM that models the hidden microbe–metabolite interaction network as a bipartite SBM and embeds it in the observed statistics through a two-component mixture of the null and alternative densities. The proposed framework offers three key advances. First, separate block memberships are learned for microbes and metabolites, respecting their asymmetry and avoiding the mixing issue of the standard SBM. These inferred modules are useful for biological interpretation. Second, within each block the method pools information to compute structured \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \ell\end{document} -values which are the posterior of a null hypothesis being true given observed data and the latent graph. Thresholding these quantities controls the (marginal) FDR at the nominal level while markedly boosting the true discovery rate. Lastly, we develop a variational expectation-maximization algorithm to estimate the model parameters. This algorithm solves two smaller, type-specific sub-problems, delivering order-of-magnitude speed-ups over the original noisySBM without sacrificing accuracy. Through extensive simulations we show that the bipartite noisySBM achieves superior FDR control and power compared to existing methods. We then apply the method to paired microbiome and metabolomic data from McMillan et al. (2015). The analysis uncovers three distinct groups of taxa–metabolite associations between healthy and BV individuals. Metabolites previously linked to BV, including 2-hydroxyisovalerate (2HV), succinate, and GHB, also displayed altered associations with multiple taxa. These findings illustrate how the proposed method can detect shifts in microbial–metabolite network structure and highlight taxa–metabolite relationships that may warrant further study.
The rest of the paper is organized as follow. Section 2 introduces the bipartite noisySBM and the multiple testing procedure. Section 3 describes the algorithm and model selection strategy. Section 4 benchmarks the proposed method on simulated data and Section 5 applies it to BV multi-omics data. We close with a discussion in Section 6.
Bipartite graph inference
2
Noisy bipartite stochastic block model
2.1
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n_1\ge 2\end{document} be the number of microbes and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n_2\ge 2\end{document} the number of metabolites. We observe \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\bf X}=(x_{ij})\in {\mathbb {R}}^{n_1\times n_2}\end{document} , for which each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} x_{ij}\end{document} corresponds to an association score between the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} -th microbe and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} j\end{document} -th metabolite. We record the trueness/falseness of the null hypothesis of no association between each pair of features in a bipartite adjacency matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\bf A}\in \lbrace 0,1\rbrace ^{n_1\times n_2}\end{document} , such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} A_{ij} = 0\end{document} if and only if the corresponding null hypothesis is true. In other words, we consider simultaneously testing
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} H_{0,ij}: A_{ij} = 0\quad \mbox{versus.} \quad H_{1,ij}: A_{ij} = 1, \end{eqnarray*}\end{document}for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 1\le i \le n_1\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 1\le j \le n_2\end{document} .
We model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\bf A}\end{document} with a bipartite stochastic block model characterized by two independent membership vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\bf Z}1=(Z{i,1}){1\le i\le n_1}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\bf Z}2=(Z{j,2}){1\le j\le n_2}\end{document} where
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} Z_{i,1}\sim \mathrm{Multinomial}\bigl (1,\boldsymbol{\alpha }_1\bigr ),\qquad Z_{j,2}\sim \mathrm{Multinomial}\bigl (1,\boldsymbol{\alpha }_2\bigr ). \end{eqnarray*}\end{document}The mixing proportions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\alpha }_1=(\alpha {q,1}){1\le q\le B_1}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\alpha }_2=(\alpha {l,2}){1\le q\le B_2}\end{document} satisfy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \sum _{q=1}^{{B_1}}\alpha _{q,1} = 1\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \sum _{q=1}^{{{B_2}}}\alpha _{q,2} = 1\end{document} . Conditional on the membership vectors, the edges are independent Bernoulli variables with
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} A_{ij}\,\,|\,\,{\bf Z}_1,{\bf Z}_2\,\,\sim \,\,\mathrm{Bernoulli}\bigl (\pi _{Z_{i,1},\, Z_{j,2}}\bigr ), \, \boldsymbol{\Pi }=(\pi _{ql})\in (0,1)^{B_1\times B_2}. \end{eqnarray*}\end{document}For each pair \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (i,j)\end{document} the test statistic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} x_{ij}\end{document} is modeled as a two-component mixture:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} x_{ij}\, \bigl |\, {\bf A},{\bf Z}_1,{\bf Z}_2 \sim \left\lbrace \begin{array}{@{}l@{\quad }l@{}}g_0(\, \cdot \, ;\nu _0), & A_{ij}=0,\\ g(\, \cdot \, ;\nu _{Z_{i,1},\, Z_{j,2}}), & A_{ij}=1, \end{array}\right. \end{eqnarray*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} g_0(\cdot ; \nu _0)\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} g(\cdot ; \nu )\end{document} are pre-specified null and alternative densities with parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \nu _0\subset {\cal V}_0\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \nu \subset {\cal V}\end{document} . Both families are parametric with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\cal V}_0 \subset \mathbb {R}^{d_0}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\cal V}\subset \mathbb {R}^{d_1}\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} d_0\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} d_1\end{document} are the respective dimensions of the parameter spaces. The density functions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} g_0\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} g\end{document} are usually Gaussian but can take other forms. The complete parameter set is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\theta }=(\boldsymbol{\alpha }_1,\boldsymbol{\alpha }_2,\boldsymbol{\Pi },\nu _0,\nu )\end{document} .
The formulation reduces to the noisySBM when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} B_1!=!B_2\end{document} and rows/columns share a single clustering, but the bipartite version avoids the tendency of a standard SBM to merge different vertex types into the same community and greatly improves both speed and accuracy for bipartite data (Larremore et al., 2014). In general, the number of row clusters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {B_1}\end{document} and the number of column clusters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {{B_2}}\end{document} do not have to be the same (Yen and Larremore, 2020).
Identifiability
2.2
Before we discuss the testing procedure and model estimation, we address the model’s identifiability issue. To this end, we introduce the following assumptions.
Assumption 1:The parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \lbrace \nu _0\subset {\cal V}_0 \subset {\cal V}, \nu _{ql}\subset {\cal V}: 1\le q \le B_1, 1\le l \le B_2\rbrace\end{document} are distinct.
Assumption 2:The parameters of any finite mixture of distributions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \lbrace g(\cdot ; \nu ): \nu \subset {\cal V}\rbrace\end{document} are identifiable, up to label swapping.
Assumption 2 is satisfied for the class of Gaussian densities that often arises in hypothesis testing.
Theorem 1:Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n_1,n_2\ge 2\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} B_1,B_2\ge 2\end{document} . Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} g_0(\cdot ;\nu )\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} g(\cdot ;\nu )\end{document} be from the same family of distributions. Under Assumptions 1-2, all parameters of the bipartite noisy stochastic block model are identifiable, up to label swapping.
The proof of Theorem 1 can be adapted from the proofs in Allman et al. (2011) and Rebafka et al. (2022), and is thus omitted. The key modification required is to replace the triangle \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (X_{ij},X_{jk},X_{ki})\end{document} with the smallest fully connected subgraph \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (X_{i_1 j_1},X_{i_1 j_2},X_{i_2 j_1}, X_{i_2 j_2})\end{document} . Just as the triangle is “minimal” for the unipartite SBM, the 2 by 2 square is minimal for the bipartite case: four edges are enough to identify \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \nu _0, \nu _{ql}\end{document} and the mixing proportions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\alpha }_1, \boldsymbol{\alpha }_2\end{document} . When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} g(\cdot ,\nu _0)\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} g(\cdot ,\nu )\end{document} are Gaussian densities, the model is identifiable provided the parameter pairs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (\mu _{ql},\sigma _{ql}^2)\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (0,\sigma _0^2)\end{document} are all distinct. More generally, identifiability still holds if a single alternative density is shared across blocks ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mu {ql}=\mu ,,,\sigma ^2{ql}=\sigma ^2\end{document} ).
Graph-based multiple-testing
2.3
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \varphi ({\bf X})\in \lbrace 0,1\rbrace ^{{\bf A}}\end{document} be a decision rule that rejects \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} H_{0,ij}\end{document} when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \varphi _{ij}({\bf X})=1\end{document} . Under parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\theta }\end{document} we evaluate the false discovery rate (FDR), true discovery rate (TDR), and marginal FDR (mFDR) defined by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \mathrm{FDR}_{\boldsymbol{\theta }}(\varphi ) &=& \mathbb {E}_{\boldsymbol{\theta }}\!\left[ \frac{\sum _{(i,j)}(1-A_{ij})\varphi _{ij}({\bf X})}{\bigl \lbrace \sum _{(i,j)}\varphi _{ij}({\bf X})\bigr \rbrace \vee 1} \right], \\ \mathrm{TDR}_{\boldsymbol{\theta }}(\varphi ) &=& \frac{\mathbb {E}_{\boldsymbol{\theta }}\bigl [\sum _{(i,j)}A_{ij}\varphi _{ij}({\bf X})\bigr ]}{\mathbb {E}_{\boldsymbol{\theta }}\bigl [\sum _{(i,j)}A_{ij}\bigr ]}, \end{eqnarray*}\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \mathrm{mFDR}_{\boldsymbol{\theta }}(\varphi ) = \frac{\mathbb {E}_{\boldsymbol{\theta }}\bigl [\sum _{(i,j)}(1-A_{ij})\varphi _{ij}({\bf X})\bigr ]}{\mathbb {E}_{\boldsymbol{\theta }}\bigl [\sum _{(i,j)}\varphi _{ij}({\bf X})\bigr ]}. \end{eqnarray*}\end{document}The mFDR is easier to estimate because it involves the ratio of expectations as opposed to the expectation of a ratio; for large numbers of tests it is asymptotically equivalent to the FDR (Genovese and Wasserman, 2002).
Given a target level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \alpha\end{document} , we seek a rule that maximizes TDR subject to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathrm{mFDR}_{\boldsymbol{\theta }}\le \alpha\end{document} . Define the structured \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \ell\end{document} -value
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \ell (x_{ij};{\bf Z}_1,{\bf Z}_2,\boldsymbol{\theta })=P\bigl (A_{ij}=0\mid {\bf X},{\bf Z}_1,{\bf Z}_2;\boldsymbol{\theta }\bigr ) = \ell \bigl (x_{ij},Z_{i,1},Z_{j,2};\boldsymbol{\theta }\bigr ), \end{eqnarray*}\end{document}where, for block \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (q,\ell )\end{document} ,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \ell (x_{ij},q,\ell ;\boldsymbol{\theta })= \frac{(1-\pi _{ql})\, g_0(x_{ij};\nu _0)}{\pi _{ql}\, g(x_{ij};\nu _{ql}) + (1-\pi _{ql})\, g_0(x_{ij};\nu _0)}. \end{eqnarray*}\end{document}Unlike a classical BH \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p\end{document} -value, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \ell\end{document} -value pools information across all observations via the shared parameters and cluster memberships, leading to substantial power gains.
In practice \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ({\bf Z}_1,{\bf Z}_2,\boldsymbol{\theta })\end{document} are unknown. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (\widehat{{\bf Z}}_1,\widehat{{\bf Z}}2,\widehat{\boldsymbol{\theta }})\end{document} denote their estimates obtained using the algorithm discussed in Section 3. The hypothesis \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} H{0,ij}\end{document} is rejected whenever
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \ell \bigl (x_{ij};\widehat{{\bf Z}}_1,\widehat{{\bf Z}}_2,\widehat{\boldsymbol{\theta }}\bigr )\le \tau , \end{eqnarray*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \tau =\tau (\alpha )\end{document} is the largest threshold for which the plug-in estimate of mFDR does not exceed \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \alpha\end{document} .
Parameter estimation
3
Estimating the model parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\theta }=!(\boldsymbol{\alpha }_1,\boldsymbol{\alpha }_2,\boldsymbol{\Pi },\nu 0,\nu )\end{document} from the observed data matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\bf X}=(x{ij})\end{document} is challenging, because the likelihood must be integrated over the unobserved adjacency matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\bf A}\end{document} and the block-membership vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ({\bf Z}_1,{\bf Z}_2)\end{document} . In addition, the conditional distribution of the latent variables ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\bf A},{\bf Z}_1,{\bf Z}_2\end{document} ) given observed data does not have a closed-form expression. We therefore maximize a variational lower bound on the marginal likelihood via a variational expectation–maximization (VEM) algorithm.
Variational EM algorithm
3.1
For any distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Q\end{document} on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} ({\bf A},{\bf Z}_1,{\bf Z}_2)\end{document} , the observed data log-likelihood can be decomposed as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \log L({\bf X};\boldsymbol{\theta })&=& \mbox{E}_Q\bigl [\log L({\bf X},{\bf A},{\bf Z}_1,{\bf Z}_2;\boldsymbol{\theta })\bigr ] \,\,+\,\,H(Q) \\ &&+\mathrm{KL}\bigl (Q\, \Vert \, P_{{\bf A},{\bf Z}_1,{\bf Z}_2\mid {\bf X};\boldsymbol{\theta }}\bigr ), \end{eqnarray*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} H(Q)\end{document} is the entropy and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathrm{KL}(\cdot \Vert \cdot )\end{document} denotes Kullback–Leibler divergence. Because the KL term is non-negative, the first two terms form an evidence lower bound (ELBO) on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \log L({\bf X};\boldsymbol{\theta })\end{document} .
The exact posterior \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} P_{{\bf A},{\bf Z}_1,{\bf Z}_2\mid {\bf X};\boldsymbol{\theta }}\end{document} is intractable due to the complex structure of our model, so we restrict \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Q\end{document} to the factorized family
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} Q_{\boldsymbol{\beta }_1,\boldsymbol{\beta }_2}({\bf A},{\bf Z}_1,{\bf Z}_2)\,\,=\,\, P({\bf A}\mid {\bf Z}_1,{\bf Z}_2,{\bf X};\boldsymbol{\theta }) \prod _{i=1}^{n_1}\!\beta _{i,Z_{i,1},1} \prod _{j=1}^{n_2}\!\beta _{j,Z_{j,2},2}, \end{eqnarray*}\end{document}with variational parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\beta }_r=(\beta _{i,q,r})\in [0,1]^{n_r\times B_r}\end{document} satisfying \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \sum _{q=1}^{B_r}\beta _{i,q,r}=1\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} r=1,2\end{document} .
E-step (update of \documentclass[12pt]{minimal}
\usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document})
Keeping \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\theta }\end{document} fixed at its current estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\theta }^{(t)}\end{document} , we choose \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (\boldsymbol{\beta }_1^{(t+1)},\boldsymbol{\beta }_2^{(t+1)})\end{document} to maximize the ELBO. This is equivalent to minimizing the KL divergence in (1) and yields the fixed-point updates (see Web Appendix A)
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} &&\beta _{i,q,1}\,\,\propto \,\, \alpha _{q,1}\, \exp \Bigl \lbrace \! \sum _{j=1}^{n_2}\sum _{\ell =1}^{B_2} \beta _{j,\ell ,2}\, d_{ij}^{ql} \Bigr \rbrace , \\ && \beta _{j,\ell ,2}\,\,\propto \,\, \alpha _{\ell ,2}\, \exp \Bigl \lbrace \! \sum _{i=1}^{n_1}\sum _{q=1}^{B_1} \beta _{i,q,1}\, d_{ij}^{ql} \Bigr \rbrace , \end{eqnarray*}\end{document}where
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} d_{ij}^{ql}\,\,=\,\, \rho _{ij}^{ql}\, \log \!\frac{\pi _{ql}\, g_{\nu _{ql}}(x_{ij})}{\rho _{ij}^{ql}} +(1-\rho _{ij}^{ql})\, \log \!\frac{(1-\pi _{ql})\, g_{\nu _0}(x_{ij})}{1-\rho _{ij}^{ql}} \end{eqnarray*}\end{document}and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \rho {ij}^{ql}=P(A{ij}=1\mid Z_{i,1}=q,Z_{j,2}=\ell ,{\bf X};\boldsymbol{\theta }^{(t)})\end{document} . In practice, 3–5 inner iterations suffice for convergence of the fixed-point updates.
M-step (update of \documentclass[12pt]{minimal}
\usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document})
Assume for the moment the null and alternative densities are Gaussian. With \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (\boldsymbol{\beta }_1,\boldsymbol{\beta }_2)\end{document} fixed, maximizing the ELBO gives closed-form updates of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\theta }\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \hat{\alpha }_{q,1}&=& \frac{1}{n_1}\sum _{i=1}^{n_1}\beta _{i,q,1},\qquad \hat{\alpha }_{\ell ,2}= \frac{1}{n_2}\sum _{j=1}^{n_2}\beta _{j,\ell ,2}, \\ && \hat{\pi }_{ql}= \frac{\sum _{i,j}\beta _{i,q,1}\beta _{j,\ell ,2}\, \rho _{ij}^{ql}}{\sum _{i,j}\beta _{i,q,1}\beta _{j,\ell ,2}}, \end{eqnarray*}\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \hat{\nu }_0:\,\, \sigma _0^{2}= \frac{\sum _{i,j}\!x_{ij}^{2} \sum _{q,\ell }\beta _{i,q,1}\beta _{j,\ell ,2}(1-\rho _{ij}^{ql})}{\sum _{i,j}\sum _{q,\ell } \beta _{i,q,1}\beta _{j,\ell ,2}(1-\rho _{ij}^{ql})}, \end{eqnarray*}\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \hat{\nu }_{ql}:\,\, \mu _{ql}&=& \frac{\sum _{i,j}\beta _{i,q,1}\beta _{j,\ell ,2}\rho _{ij}^{ql}x_{ij}}{\sum _{i,j}\beta _{i,q,1}\beta _{j,\ell ,2}\rho _{ij}^{ql}},\quad \sigma _{ql}^{2} \\ &=& \frac{\sum _{i,j}\beta _{i,q,1}\beta _{j,\ell ,2}\rho _{ij}^{ql}(x_{ij}-\mu _{ql})^{2}}{\sum _{i,j}\beta _{i,q,1}\beta _{j,\ell ,2}\rho _{ij}^{ql}}. \end{eqnarray*}\end{document}Updates for other tractable null and alternative densities, e.g., Gamma, can be derived similarly.
The E- and M-steps are alternated until the algorithm converges. Finally, the estimated memberships \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \widehat{{\bf Z}}_r=\arg \max _q\beta _{i,q,r} \ (r=1,2)\end{document} provide an interpretable biclustering of microbes and metabolites.
Initialization
3.1.1
We initialize parameters in the algorithm in the following order: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\beta }_r, \boldsymbol{\rho }, \boldsymbol{\Pi }, \nu _0,\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \nu\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\rho }\end{document} again before initiating the M-step of the algorithm. To initialize \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\beta }_r\end{document} , we use k-means clustering on the rows and columns. We threshold the observed statistics at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p\end{document} -value 0.5 to obtain a rough estimate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\rho }=(\rho _{ij}^{ql})\end{document} so that we can initialize \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Pi }\end{document} . The parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \nu _0\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \nu\end{document} are derived conditional on the initial cluster memberships. Finally, we improve the initialization of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\rho }\end{document} conditional on the initial cluster memberships, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Pi }, \nu _0\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \nu\end{document} .
Selecting the number of clusters
3.2
The VEM algorithm requires knowing the row and column block counts \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (B_1,B_2)\end{document} . We choose them by maximizing the integrated classification likelihood (ICL):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \operatorname{ICL}(B_1,B_2)= \mbox{E}_{\widehat{Q}}\bigl [\log L({\bf X},{\bf A},{\bf Z}_1,{\bf Z}_2;\hat{\boldsymbol{\theta }})\bigr ] -\operatorname{pen}_{\mathrm{BIC}}(B_1,B_2), \end{eqnarray*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \widehat{Q}\end{document} is the fitted variational distribution for the given pair \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (B_1,B_2)\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{\boldsymbol{\theta }}\end{document} the associated parameter estimate, and
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} &&\operatorname{pen}_{\mathrm{BIC}}(B_1,B_2)= (B_1-1)\log n_1+(B_2-1)\log n_2 \\ &&+\bigl [d_0+(1+d_1)B_1B_2\bigr ]\log (n_1n_2) \end{eqnarray*}\end{document}is the usual BIC penalty with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} d_0\end{document} (null) and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} d_1\end{document} (alternative) density parameters. The first two terms in the BIC penalty penalizes the number of parameters in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\alpha }_r\end{document} , while the last term penalizes the number of parameters in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol{\Pi }, \nu _0\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \nu\end{document} . By Equation (1), the ICL criterion can also be written in terms of the observed data likelihood, the entropy of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \widehat{Q}\end{document} , and the BIC penalty. The entropy term favors compact, well-separated clusters and therefore guards against over-fitting.
Numerical experiments
4
We compared the proposed new procedure with the BH procedure, Storey’s \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q\end{document} -value procedure, and the Sun and Cai procedure (Sun and Cai, 2007, SC). We implemented the new procedure with known null density and used the ICL criterion to perform model selection. For fair comparison, we also implemented the SC procedure with known null density.
We simulated data in the following scenarios. In all scenarios, undirected bipartite graphs of dimension \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n_1=150\end{document} by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n_2=200\end{document} were generated and the standard normal distribution was chosen as the null.
Data were sampled with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} B_1 = B_2 = 3\end{document} latent biclusters and equal group probabilities \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \alpha _{q,1}=\alpha _{q,2} = 1/3\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q=1,2,3\end{document} . The connectivity parameters were set such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \pi _{ql} = 0.1 \cdot {\bf 1}(q\ne l) + 0.8 \cdot {\bf 1}(q=l)\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q,l = 1,2,3\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\bf 1}(\cdot )\end{document} is the indicator function. Under the alternative we drew observations from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} N(\mu _{ql},1)\end{document} . The three densest blocks are given a moderate signal, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mu _{11}=\mu _{22}=\mu _{33}=1\end{document} , whereas all other blocks are given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mu _{ql}=3\end{document} , ensuring that the sparser clusters have a larger effect size.
Besides the above modular bipartite graph, we also considered fixed graphs with other topological properties. Given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} A\end{document} , data were sampled independently from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} N(0,1)\end{document} is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} A_{ij}=0\end{document} and from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} N(2,1)\end{document} if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} A_{ij} = 1\end{document} .
The latent graph \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} A\end{document} is a fully nested bipartite graph (Figure 1 B) (Pavlopoulos et al., 2018). In other words, there is a single ‘generalist’ in each vertex type that is connected with all the nodes in the other vertex type.The latent graph \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} A\end{document} is generated according to a bipartite preferential attachment model (Figure 1 C) (Guillaume and Latapy, 2006). At each step, a new type I vertex is added and its degree \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} d\end{document} is sampled uniformly at random from the set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \lbrace 2,3,4,5,6\rbrace\end{document} . Then, for each of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} d\end{document} edges of the new vertex, either a new type II vertex is added (with probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 1-\lambda\end{document} ) or one is picked among the preexisting ones using preferential attachment (with probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \lambda\end{document} ). We set the parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \lambda =0.8\end{document} , which is the average ratio of preexisting type II vertices to which a new type I vertex is connected.
Illustrations of the latent bipartite network in the three scenarios: (a) three biclusters, (b) nested, and (c) preferential attachment. Color of the vertices indicates types of vertices in the graph.
Figure 1 presents illustrations of the latent bipartite network in each scenario.
We simulated 100 data sets for each scenario and applied every testing procedure at nominal FDR level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \alpha \in \lbrace 0.005,0.025, 0.05, 0.1, 0.15, 0.25\rbrace\end{document} . Figure 2 provides the ROC curves of the empirical FDR vs TDR as functions of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \alpha\end{document} .
Plot of the empirical \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} as functions of the nominal level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} for the new procedure, BH, Storey’s \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}-value, and the SC procedure. Dashed lines indicate the nominal level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}.
Across all scenarios, the BH and Storey’s \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q\end{document} -value procedures behave almost identically: they keep FDR near the nominal levels but achieve only modest TDR, with Storey’s method being slightly less conservative. The SC procedure controls the FDR at nominal levels in scenarios (a) and (c) but inflates FDR in scenario (b); its power is only marginally better than the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q\end{document} -value approach.
By contrast, the new procedure consistently outperforms existing methods across all scenarios. In scenario (a), its FDR stays close to the nominal level while its TDR is much higher. In 90% of the simulations the ICL criterion correctly selects three biclusters, and this accurate recovery of the latent structure markedly boosts the new method’s power. In scenario (b), although the data do not follow the assumed model, the ICL criterion chooses two biclusters in 83% of the simulations—one “generalist” cluster in each vertex set and a complementary “specialist” cluster. Estimated connection probabilities reflect the nested structure ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \approx 0.99\end{document} for generalist–specialist edges, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \approx 0\end{document} for specialist–specialist edges), enabling FDR below nominal levels and high TDR—something competing methods miss without explicit modeling. In scenario (c), the new method shows a slight FDR inflation, yet its ROC curve still dominates those of all other procedures, indicating robustness to model misspecification. In most simulations, the ICL criterion discovers three clusters in type-I vertices (high-, medium-, and low-degree nodes) and one in type-II vertices, yielding a meaningful partition and sustained power despite imperfect model fit.
In Web Appendix B.1, we demonstrate the new procedure is computationally more efficient and achieves improved FDR control than the original SBM. In Web Appendix B.2 & B.3, we provide additional simulation studies illustrating the performance of the new procedure when the number of clusters is specified differently from the truth or when the signal-to-noise ratio (SNR) is lower. The SNR in our model is determined jointly by the block structure and the contrast between the null and alternative distributions. If SNR is extremely low, parameter estimation may be inaccurate and the advantage of the new procedure over existing methods is likely to be small (Web Figure 3 and Web Table 1). Overall, by learning an appropriate biclustering, the new procedure maintains or improves FDR control and delivers substantially higher power, while existing methods remain conservative but underpowered.
Application to bacterial vaginosis
5
We analyzed paired microbiome–metabolome data from 131 Rwandan women reported in (McMillan et al., 2015). This study performed 16S rRNA sequencing to obtain taxonomic counts. After pre-processing (Web Appendix C.1), 49 taxa and 128 vaginal metabolites were retained. Among the 131 participants, 79 were classified as “normal”, 23 as BV, 22 as “intermediate” and 7 had no clinical diagnosis. Following McMillan et al. (2015), we pooled the BV and intermediate groups into a single disease cohort ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n=45\end{document} ) and compared it with the normal cohort ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n=79\end{document} ) to identify metabolic alterations associated with BV.
The proposed inference procedure requires a matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\bf X}=(x_{ij})\end{document} of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} z\end{document} -scores, each summarizing the association between the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} -th microbe and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} j\end{document} -th metabolite. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\bf Y}1\in \mathbb {R}^{m\times n_1}\end{document} denote the microbiome data block and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\bf Y}2\in \mathbb {R}^{m\times n_2}\end{document} the metabolome block with matched rows. The empirical Pearson correlation between the two blocks is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\widehat{\rho }}{ij}=m^{-1}\sum {k=1}^{m}{\widetilde{Y}}{1,k,i}{\widetilde{Y}}{2,k,j},\end{document} with an asymptotic variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} s_{ij}=m^{-1}\sum {k=1}^{m} \bigl (2{\widetilde{Y}}{1,k,i}{\widetilde{Y}}{2,k,j}-{\widehat{\rho }}{ij}{\widetilde{Y}}{1,k,i} -{\widehat{\rho }}{ij}{\widetilde{Y}}{2,k,j}\bigr )^{2}\end{document} (Cai and Liu, 2016), where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\widetilde{{\bf Y}}}k\ (k=1,2)\end{document} denotes the standardized matrix after centering and scaling each column of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\bf Y}k\end{document} to have mean zero and variance 1. To detect changes in microbe–-metabolite correlation between two clinical subgroups ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} d=1,2\end{document} ) with sample sizes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} m_d\end{document} , let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\widehat{\rho }}^{(d)}{ij}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} s^{(d)}{ij}\end{document} be the within-group estimates defined above. The null hypothesis \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} H{0,ij}:\rho ^{(1)}{ij}=\rho ^{(2)}{ij}\end{document} is tested by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} x_{ij}={2\bigl ({\widehat{\rho }}^{(1)}{ij}-{\widehat{\rho }}^{(2)}{ij}\bigr )}/ {\sqrt{s^{(1)}{ij}/m_1+s^{(2)}{ij}/m_2}} .\end{document}
Dataset-specific diagnostics confirmed that the proposed inference procedure is appropriate for this dataset (Web Appendix C.3). Because the data were relatively noisy, we complemented the ICL criterion with cluster stability estimation (Web Appendix C.4 and Web Table 3) to avoid overfitting and identify the most reproducible block structure. The highest stability was achieved for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Q_1 = 4\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Q_2=1\end{document} , although its ICL value was slightly lower than the maximum value. We therefore applied the proposed testing procedure with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Q_1 = 4\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Q_2=1\end{document} , assuming the null density follows a standard normal distribution.
Figure 3 A shows the distribution of the observed \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} z\end{document} -scores. Although the test statistics appear to be normally distributed, they deviate noticeably from the standard normal curve; the marginal density recovered by our method offers a better fit than the standard normal. Panel B demonstrates that, across every significance threshold, the new procedure yields more discoveries than competing methods, confirming its superior power. Not all discoveries identified by existing methods were declared significant by the new procedure (Web Figure 11). This is because, unlike existing approaches that evaluate each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} z\end{document} -score independently, the proposed procedure pools information within blocks to make more informed decisions. By accounting for the global structure of the graph, the new procedure interprets some extreme test statistics as noise rather than true signals, and consequently finds no evidence of a difference between BV and healthy individuals for those associations.
(A) Histogram of observed z-scores compared to the standard normal distribution and to the estimated marginal distribution by the proposed approach. (B) Percent of rejected edges as a function of the significance level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} for the different procedures. (C) Heatmap of the inferred network at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} with colors indicating the estimated mean values in each block. Labels of selected metabolites of interest to BV are shown.
Panel C displays the heatmap of the network inferred by our method at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \alpha =0.1\end{document} . Rows are ordered by the clusters identified by the algorithm, while columns are ordered by hierarchical clustering with the correlation distance. Taxa or metabolites with no detected associations to any other variables were removed. Each block is colored by its alternative mean values, indicating up-regulation (negative mean) or down-regulation (positive mean) in BV. The heatmap reveals a clear partition of taxa with distinct association patterns. Some taxa (e.g., Lactobacillus gasseri/johnsonii, Bifidobacterium, Prevotella) show stronger associations with metabolites in healthy individuals, whereas others (e.g., L. iners, L. jensenii, Gardnerella, Atopobium) exhibit stronger associations in BV. Although Lactobacillus and L. crispatus show differential associations with metabolites, the magnitude of these associations is small. Several taxa, including Gardnerella, L. iners, L. jensenii, L. gasseri/johnsonii, and Finegoldia, are connected to a large number of metabolites, suggesting that they may play central roles in microbial metabolic interactions during BV onset. A few key metabolites (e.g., 2-hydroxyisovalerate (2HV), succinate, GHB, GABA, and tyrosine), previously identified as biomarkers for BV (McMillan et al., 2015; Srinivasan et al., 2015), were also highlighted in Figure 3 C. While McMillan et al. (2015) experimentally validated the production of GHB by Gardnerella, our differential network analysis suggests that the association between these two variables does not differ substantially between BV and healthy individuals. In contrast, GHB shows altered associations with L. gasseri/johnsonii, Atopobium, Peptostreptococcus and Escherichia/Shigella. Similarly, 2HV displays altered associations with several taxa, including L. gasseri/johnsonii, Atopobium, Sneathia, and Leptotrichia. Although succinate was not significant in the univariate analysis of McMillan et al. (2015), our multivariate approach highlights its importance through “guilt by association”, consistent with previous reports implicating succinate in BV (Srinivasan et al., 2015). Together, these results indicate shifts in microbial metabolic interactions between BV and healthy states, and identify taxa–metabolite relationships that may warrant further investigation.
Discussion
6
Joint analysis of microbiome and metabolomic data can illuminate the metabolic circuitry that underlies host–microbe interactions and, ultimately, guide the design of microbiome-based therapeutics. This paper introduced a bipartite noisy stochastic block model that models the observed \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} z\end{document} -score matrix with a latent microbe–-metabolite interaction graph. By exploiting the latent block structure, the method (i) achieves reliable FDR control, (ii) delivers substantially higher power than existing procedures, and (iii) provides a biologically interpretable biclustering of taxa and metabolites. Simulations confirmed the gains in speed and accuracy over the original (noisy) SBM and over conventional FDR tools. The BV case study further demonstrated how the proposed testing procedure complements differential abundance analyses done in McMillan et al. (2015).
In our model, we can view the indicator matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} A\end{document} as an unobserved parameter drawn from a structured prior—in our case, a bipartite SBM. Estimating the hyper-parameters via marginal maximum likelihood, and replacing them in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \ell\end{document} -value formula, is analogous to the empirical Bayes framework originally introduced in Efron et al. (2001). The key difference is that we encode dependence through the latent graph, so the procedure can borrow strength without assuming weak \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p\end{document} -value correlations. Graphical models and network structures have been widely used to model dependence, including in the Bayesian literature. For instance, Peterson et al. (2015) use a Markov random field prior to encourage similarity among precision matrices across related groups, while Choi et al. (2025) introduce a hub random network prior to capture biologically realistic hub structures in directed graphs. These approaches and ours can be viewed as complementary perspectives on leveraging graphical dependence for high-dimensional inference.
Our method assumes each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} x_{ij}\end{document} has a tractable null and alternative density. In our simulations, the test statistics were drawn from Gaussian distributions. The Gaussian assumption is common in the Empirical Bayes and local false discovery rate literature (Efron et al., 2001; Efron, 2004; Sun and Cai, 2007; 2009; Efron, 2007). It is reasonable because many test statistics used in such procedures are, or can be transformed into, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} z\end{document} -values. These include statistics from student’s \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} t\end{document} -test, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} F\end{document} -test, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \chi ^2\end{document} test, likelihood ratio test, Wald test and Score test. While it is possible to work directly with statistics that have heavier tails, transforming them to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} z\end{document} -values simplifies the core analytical steps and provides robustness against nuisance parameters. If the test statistics instead follow a different parametric family that does not admit an easy transformation to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} z\end{document} -values—for example, the exponential distribution—our framework can be adapted to estimate densities within that family (Web Appendix B.5). However, when the distributional family of the test statistics is completely unknown, we do not recommend using model-based FDR control methods, because these methods will fail to maintain valid FDR control.
The VEM algorithm can be viewed as an EM algorithm in which the E-step is approximated using variational inference techniques such as coordinate ascent variational inference (CAVI) (Blei et al., 2017). Although variational approximations are known to underestimate posterior variance (Blei et al., 2017), FDR in our framework depends primarily on posterior means rather than higher-order uncertainty. Consistent with this, our simulation studies show that the empirical FDR remains close to the nominal level across a wide range of scenarios, indicating that the variational approximation does not materially compromise inferential validity. The VEM algorithm scales linearly in the number of edges and converges rapidly. Under scenario (a) in Section 4, it took about 15 seconds for the algorithm to converge on a 24-in iMac with Apple M3 chip and 16 GB memory for a single pair of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (B_1,B_2)\end{document} . Yet the search over \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (B_1,B_2)\end{document} via the ICL criterion can still be time-consuming. A promising alternative is the greedy ICL maximization of (Kilian et al., 2024), which iteratively reassigns vertices and naturally prunes empty blocks.
Zero inflation is pervasive in microbiome data and poses challenges for reliable statistical inference. In addition, microbiome abundances are subject to total sum constraints. In the BV case study, we addressed these concerns using the mclr transformation, which preserves the original zero measurements and is overall rank-preserving. However, mclr-transformed components are still constrained to sum to zero. Our simulations applying the new procedure to simulated multi-omic profiles rather than test statistics demonstrate that both zero inflation and compositionality can affect FDR control, with the latter exerting a stronger influence (Web Appendix B.6; Web Figures 8 & 9). This observation underscores a more fundamental challenge that is not specific to the chosen test statistics: testing correlations at the absolute abundance level is challenging when only relative abundances are observed. To our knowledge, no established alternative currently provides a principled way to test correlations while simultaneously accounting for compositionality. Developing such correlation statistics remains an important but open methodological problem, which is beyond the scope of the present work. Practically speaking, if clr or mclr are employed to deal with the total sum constraint, care must be taken to interpret the results accordingly.
Supplementary Material
ujag042_Supplemental_FilesWeb Appendices, Tables, Figures from additional simulation and case studies, and data and code for reproducing the results referenced in Sections 3–6 are available with this article at the Biometrics website on Oxford Academic.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Allman E. S., Matias C., Rhodes J. A. (2011). Parameter identifiability in a class of random graph mixture models. Journal of Statistical Planning and Inference, 141, 1719–1736.
- 2Atashili J., Poole C., Ndumbe P. M., Adimora A. A., Smith J. S. (2008). Bacterial vaginosis and HIV acquisition: a meta-analysis of published studies. AIDS (London, England), 22, 1493.18614873 10.1097/QAD.0b 013e 3283021 a 37PMC 2788489 · doi ↗ · pubmed ↗
- 3Benjamini Y., Hochberg Y. (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 57, 289–300.
- 4Blei D. M., Kucukelbir A., Mc Auliffe J. D. (2017). Variational inference: A review for statisticians. Journal of the American Statistical Association, 112, 859–877.
- 5Cai T. T., Li H., Ma J., Xia Y. (2019). Differential markov random field analysis with applications to detecting differential microbial community structures. Biometrika, 106, 401–416.31097834 10.1093/biomet/asz 012PMC 6508037 · doi ↗ · pubmed ↗
- 6Cai T. T., Liu W. (2016). Large-scale multiple testing of correlations. Journal of the American Statistical Association, 111, 229–240.27284211 10.1080/01621459.2014.999157 PMC 4894362 · doi ↗ · pubmed ↗
- 7Choi J., Chapkin R. S., Ni Y. (2025). Bayesian differential causal directed acyclic graphs for observational zero-inflated counts with an application to two-sample single-cell data. The Annals of Applied Statistics, 19, 1908.40893137 10.1214/25-aoas 2042 PMC 12395422 · doi ↗ · pubmed ↗
- 8Dinglasan J. L. N., Otani H., Doering D. T., Udwary D., Mouncey N. J. (2025). Microbial secondary metabolites: advancements to accelerate discovery towards application. Nature Reviews Microbiology, 23, 338–354.39824928 10.1038/s 41579-024-01141-y · doi ↗ · pubmed ↗