Generalist Foundation Models Are Not Clinical Enough for Hospital Operations
Lavender Y. Jiang, Angelica Chen, Xu Han, Xujin Chris Liu, Radhika Dua, Kevin Eaton, Frederick Wolff, Robert Steele, Jeff Zhang, Anton Alyakin, Qingkai Pan, Yanbing Chen, Karl L. Sangwon, Daniel A. Alber, Jaden Stryker, Jin Vivian Lee, Yindalon Aphinyanaphongs, Kyunghyun Cho

TL;DR
This paper shows that healthcare AI models need to be trained on real hospital data to perform well in tasks like predicting patient readmissions or insurance denials.
Contribution
The paper introduces Lang1, a new family of language models trained on a blend of clinical and internet data, showing superior performance in hospital operations tasks.
Findings
Lang1-1B outperforms larger generalist and zero-shot models in four of five hospital operations tasks after fine-tuning.
Multi-task fine-tuning improves Lang1's ability to transfer to unseen tasks and external health systems.
The study emphasizes the importance of in-domain pretraining and supervised fine-tuning for effective healthcare AI.
Abstract
Operational decisions governing patient flow, cost, and quality of care demand specialized predictive models, yet most clinical NLP efforts focus on medical knowledge benchmarks. We introduce Lang1, a family of language models (100M-7B parameters) pretrained on 80 billion clinical tokens from NYU Langone Health electronic health records blended with 627 billion internet tokens. We evaluate Lang1 on the REalistic Medical Evaluation (ReMedE), an evaluation suite derived from 668,331 Electronic Health Records (EHR) notes spanning five tasks: readmission, mortality prediction, length of stay, comorbidity coding, and insurance denial. In zero-shot settings, both general-purpose and biomedical models underperform on four of five tasks. After finetuning, Lang1-1B outperforms finetuned generalist models up to 70 × larger and zero-shot models up to 671× larger. Joint multi-task finetuning yields…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
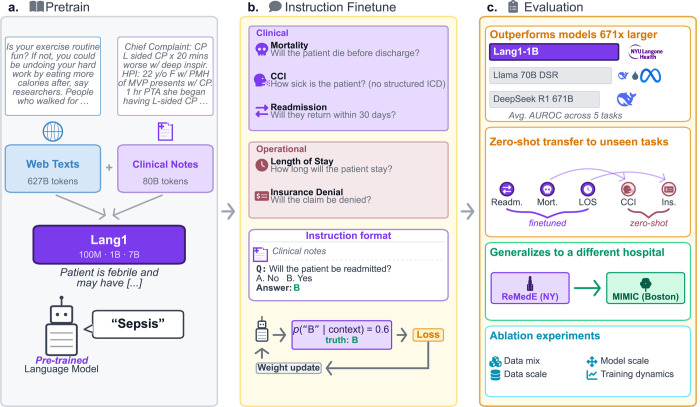 Figure 1
Figure 1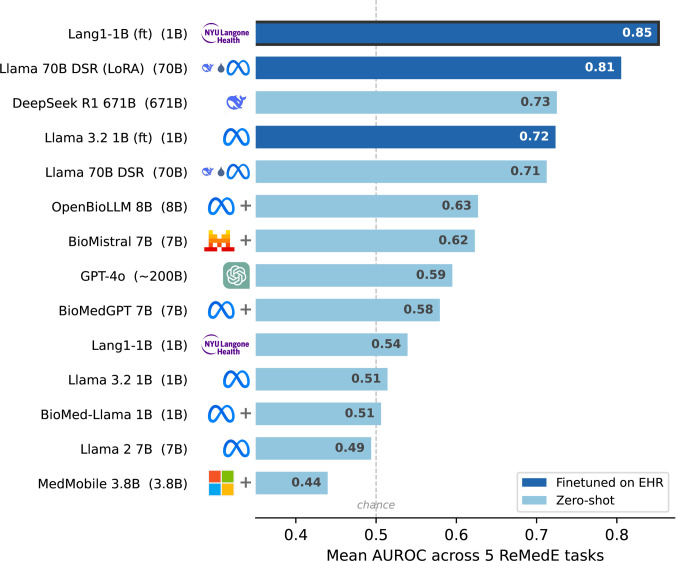 Figure 2
Figure 2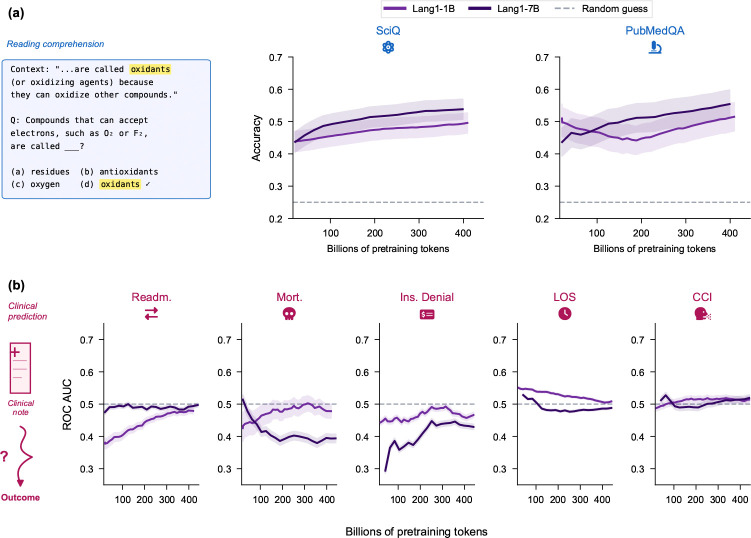 Figure 3
Figure 3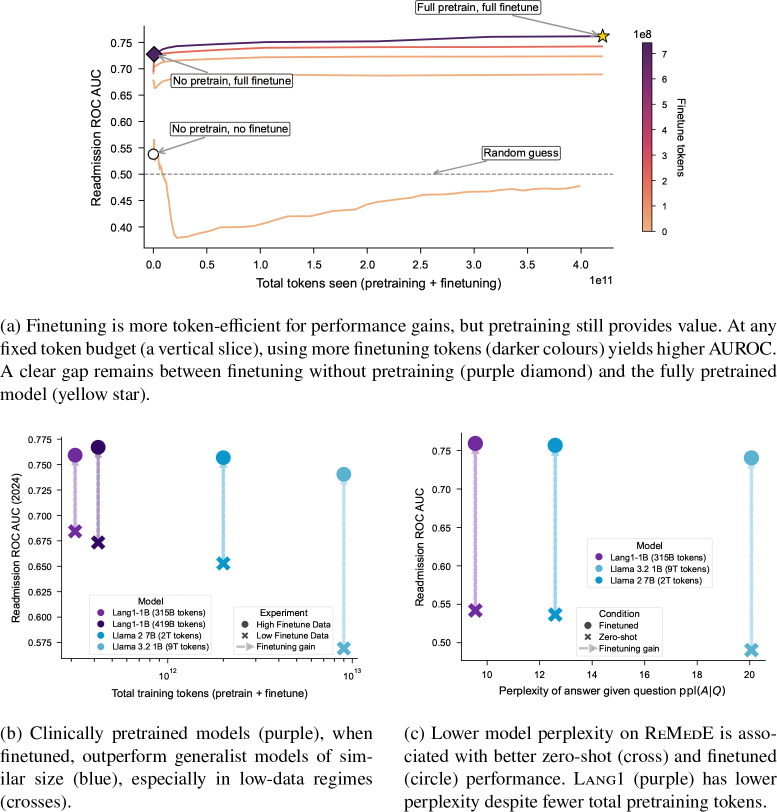 Figure 4
Figure 4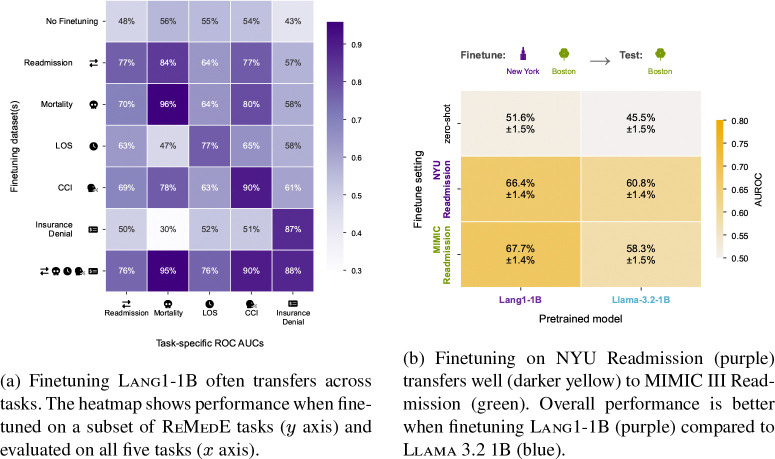 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Healthcare · Artificial Intelligence in Healthcare and Education · Topic Modeling