PVRI‐GoDeep—A Global Meta‐Registry at the Crossroads of Heart and Lung
Meike T. Fuenderich, Athiththan Yogeswaran, Patrick Janetzko, Khodr Tello, Werner Seeger, Raphael W. Majeed, Jochen Wilhelm, Mauro Acquaro, Mauro Acquaro, Imad Al Ghouleh, James Anderson, Jeffrey S. Annis, Anastasia Anthi, Alexandra Arvanitaki, Aparna Balasubramanian

TL;DR
PVRI GoDeep is a global registry combining data from multiple pulmonary hypertension centers to improve understanding and treatment of the disease.
Contribution
PVRI GoDeep introduces a harmonized global meta-registry for pulmonary hypertension with over 45,000 patients.
Findings
PVRI GoDeep integrates anonymized patient data from global PH registries into a harmonized dataset.
The registry enables robust phenotyping and international comparisons across diverse PH subgroups.
It supports research on rare subtypes, treatment responses, and newly recognized entities like mild PH.
Abstract
Pulmonary hypertension (PH) is a complex disease characterized by increased pressure in the pulmonary arteries. It encompasses a heterogeneous group of entities that increase right heart afterload and often lead to right heart failure and premature death. Advancing diagnosis, risk stratification, and treatment across the diverse PH spectrum requires large, high‐quality, longitudinal datasets that exceed the scope of individual national or regional registries. To address this need, PVRI GoDeep was founded under the umbrella of the Pulmonary Vascular Research Institute (PVRI). This global meta registry harmonizes and integrates anonymized patient‐level data from existing PH registries at expert centers worldwide. PVRI GoDeep enables the reuse of locally collected real‐world data by mapping heterogeneous datasets to a predefined data dictionary, thorough quality checks, and regular…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
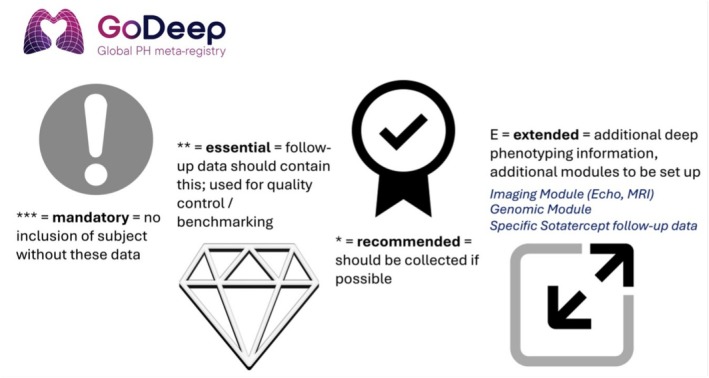 FIGURE 1
FIGURE 1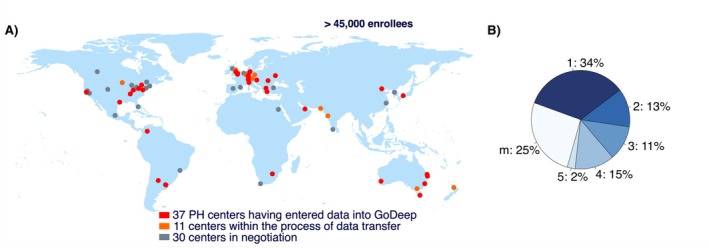 FIGURE 2
FIGURE 2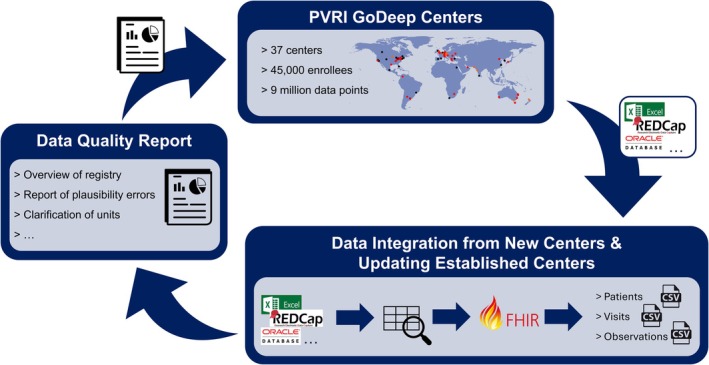 FIGURE 3
FIGURE 3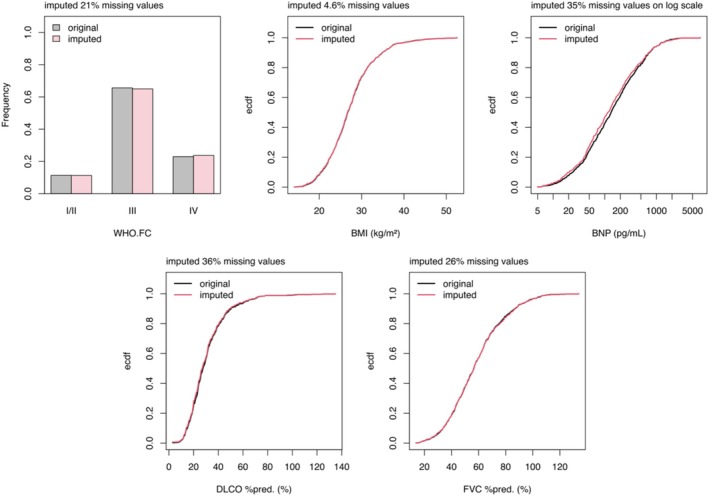 FIGURE 4
FIGURE 4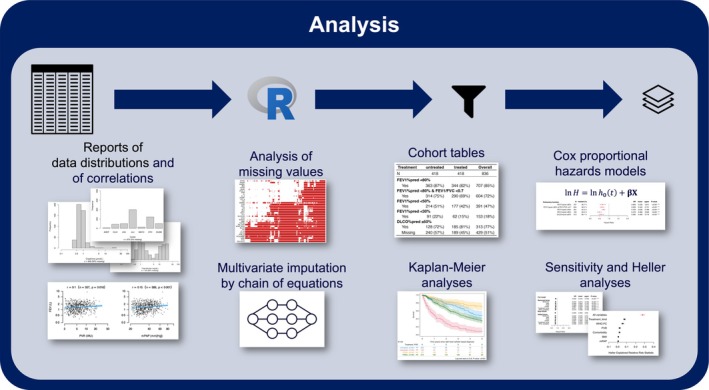 FIGURE 5
FIGURE 5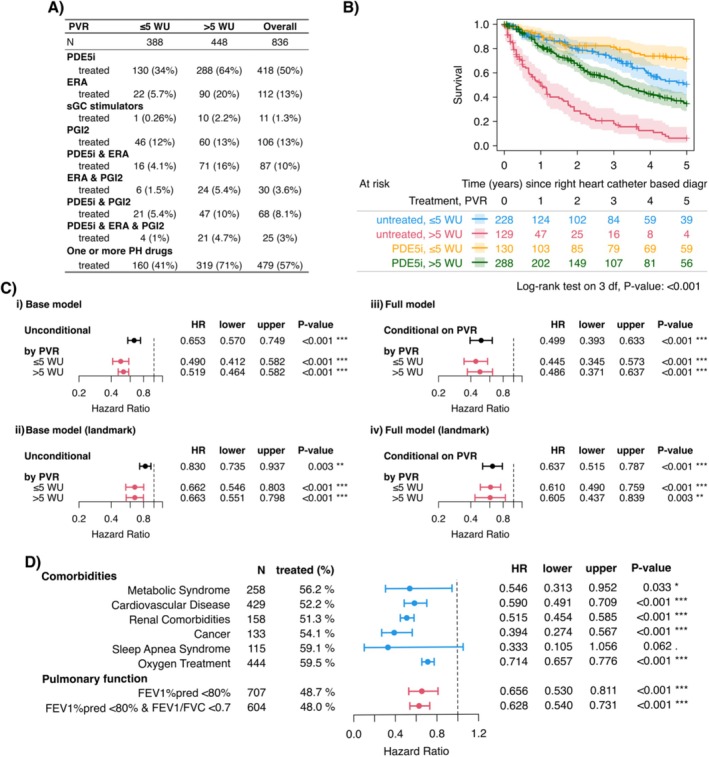 FIGURE 6
FIGURE 6| Pulmonary hypertension classification |
|---|
| GROUP 1 Pulmonary arterial hypertension (PAH)* |
| 1.1 Idiopathic |
| 1.1.1 Non‐responders at vasoreactivity testing |
| 1.1.2 Acute responders at vasoreactivity testing |
| 1.2 Heritable |
| 1.3 Associated with drugs and toxins |
| 1.4 Associated with: |
| 1.4.1 Connective tissue disease |
| 1.4.2 HIV infection |
| 1.4.3 Portal hypertension |
| 1.4.4 Congenital heart disease |
| 1.4.5 Schistosomiasis |
| 1.5 PAH with features of venous/capillary (PVOD/PCH) involvement |
| 1.6 Persistent PH of the newborn |
| GROUP 2 PH associated with left heart disease*** |
| 2.1 Heart failure: |
| 2.1.1 with preserved ejection fraction |
| 2.1.2 with reduced or mildly reduced ejection fraction |
| 2.2 Valvular heart disease |
| 2.3 Congenital/acquired cardiovascular conditions leading to post‐capillary PH |
| GROUP 3 PH associated with lung diseases and/or hypoxia*** |
| 3.1 Obstructive lung disease or emphysema |
| 3.2 Restrictive lung disease |
| 3.3 Lung disease with mixed restrictive/obstructive pattern |
| 3.4 Hypoventilation syndromes |
| 3.5 Hypoxia without lung disease (e.g., high altitude) |
| 3.6 Developmental lung disorders |
| GROUP 4 PH associated with pulmonary artery obstructions** |
| 4.1 Chronic thrombo‐embolic PH |
| 4.2 Other pulmonary artery obstructions |
| GROUP 5 PH with unclear and/or multifactorial mechanisms (to be expanded by specific pediatric conditions)* |
| 5.1 Hematological disorders |
| 5.2 Systemic disorders |
| 5.3 Metabolic disorders |
| 5.4 Chronic renal failure with or without hemodialysis |
| 5.5 Pulmonary tumor thrombotic microangiopathy |
| 5.6 Fibrosing mediastinitis |
| Category | Example |
|---|---|
| “Classical” PAH (group 1) focus | Risk Scores ( |
| Specific PAH subgroups | “Mild PAH” ( |
| PoPH ( | |
| Non‐PAH PH | COPD‐PH ( |
| PH‐ILD ( | |
| The global PH view | Impact of Sex and Race (Yogeswaran, Annis, et al. |
| The systemic arterial hypertension paradox in PH (under review) | |
|
Obesity as survival confounder in PH (under review) Pulmonary Artery Compliance and Prognosis Across the Spectrum of Pulmonary Vascular Diseases (under review) | |
| Enhancement of (global) trial design and in silico studies |
- —Pulmonary Vascular Research Institute (PVRI).
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPulmonary Hypertension Research and Treatments · Chronic Obstructive Pulmonary Disease (COPD) Research · Cardiac Valve Diseases and Treatments
Introduction
1
Pulmonary Hypertension (PH) is a complex disorder defined by elevated pressure in the pulmonary arteries, a condition that can lead to right heart failure and premature death. It represents a heterogeneous spectrum of diseases with multiple underlying causes and is categorized into five clinical groups, including pulmonary arterial hypertension (PAH), PH due to left heart disease, and PH associated with lung disorders, among others (Humbert et al. 2022). All of these groups are further sub‐divided into specific categories, as shown in Table 1.
Globally, PH is recognized as a major health concern affecting people across all age ranges (Humbert et al. 2022). Current estimates suggest that around 1% of the world's population is affected, with prevalence rising significantly in individuals over 65 years, largely due to the increased incidence of cardiac and pulmonary conditions initiating PH in this age group (Hoeper et al. 2016). Left heart disease and chronic lung conditions represent the most frequent causes of PH worldwide (Vahanian et al. 2022). Irrespective of etiology, the development of PH is consistently associated with worsening symptoms, progressive functional decline, increased challenge to the right heart, and an increased risk of mortality (Hoeper et al. 2016).
Research into PH and the right ventricular response to increased afterload is critical to improving early detection, understanding disease mechanisms, optimizing treatment strategies, and ultimately enhancing patient outcomes. However, the heterogeneity of PH and the rarity of some of the PH (sub)‐groups create challenges in accumulating large‐scale, high‐quality data (Galie et al. 2016). National and regional PH registries have become important resources to address this gap, enabling the systematic collection and analysis of real‐world clinical, demographic, and treatment data. These single registries have advanced understanding of regional disease patterns, treatment choice and responses, and outcomes, and have provided important information extrapolated to a global view of PH (Farber et al. 2015; Gall et al. 2017; Swift et al. 2012).
Yet, despite their undisputed value, individual registries are inherently constrained by geographic, demographic, and practice‐specific limitations. To overcome these challenges, the development of a global PH registry that harmonizes and integrates existing national and regional databases offers a transformative opportunity to generate deeper and more generalizable insights. By combining diverse patient populations and healthcare systems and markedly scaling up the number of enrollees, such a registry can enhance the statistical power of research, reveal international variations in care and outcomes, provide evidence for the impact of different altitudes, air pollution conditions, drug accessibility and ethnicities, identify and more deeply characterize rare subtypes, and contribute to the development of universally applicable clinical guidelines.
An international, overarching registry also allows for the integration of heart function metrics and lung‐specific variables to bridge the understanding of cardio‐pulmonary physiology and pathophysiology. This integrative approach enables the exploration of mechanistic links between pulmonary vascular changes and cardiac remodeling. In doing so, it supports the study of disease trajectories, the evaluation of known and the identification of novel cardiopulmonary biomarkers, and the advancement of in‐depth response to therapy profiling, considering both the impact on the lung vascular and the cardiac systems. This approach supports treatment strategies informed by underlying pathophysiology and strengthens efforts to connect genetic markers with clinical disease expression.
To follow this view and to harness large‐scale data, PVRI GoDeep was established as a global PH meta‐registry, integrating information from existing local PH registries throughout the world (Majeed et al. 2022). Unlike other international efforts such as PRECISION ALS (McFarlane et al. 2023) or COMPERA (Comparative, Prospective Registry of Newly Initiated Therapies for Pulmonary Hypertension) (Pittrow et al. 2009), which require centers to manually re‐enter their data into a centralized system, thereby duplicating efforts, GoDeep offers a more streamlined solution. Participating centers can retain their current systems while contributing to a unified dataset without manual and duplicate data entry. Our data management team handles the technical work of identifying, mapping, and standardizing the data, minimizing the work on participating sites. Although real‐world data are rarely perfect, it is ensured through close collaboration with each center and a robust quality assurance process that the data integrated into GoDeep meet the highest standards of accuracy and consistency.
This paper outlines the registry's structure, details its robust data framework with a focus on data quality assurance, and highlights the analytical approaches and key outputs, including phenotyping, predictive modeling, and novel research findings.
Overview
2
PVRI GoDeep is a global meta‐registry established in 2020 under the umbrella of the Pulmonary Vascular Research Institute (PVRI) and the Justus Liebig University in Giessen, Germany (NCT05329714). Its central data repository structure has been approved by the Ethics Committee of the University of Giessen/University Hospital (AZ 30/19). It is coordinated as a scientific initiative by the Institute for Lung Health (ILH) in Giessen, a member of the German Center for Lung Research (DZL). GoDeep was created to address the growing need for large‐scale, harmonized, real‐world data on PH and right ventricular adaptation versus failure across diverse geographic regions and healthcare contexts. It integrates anonymized, patient‐level data from existing PH registries at expert centers worldwide. Participating centers contribute their data following institutional ethical approval and the signing of a participation agreement.
Recognizing that individual registries vary in clinical focus and data collection practices, GoDeep initiated a series of consensus meetings, described in more detail in Majeed et al. (2022), to define a dataset with variables categorized as mandatory, essential, recommended, or extended, based on clinical relevance and availability (Figure 1). Mandatory variables are required for patient inclusion in the registry. Without those variables, such as the date of diagnosis, baseline right heart catheterization (RHC) data, and survival status, a patient record cannot be integrated into the dataset. Essential variables are expected to be available at baseline and during follow‐up and play a key role in quality control, longitudinal tracking, and benchmarking. Recommended variables should be collected when possible; although not strictly required, they enhance the depth and analytical value of the data. Extended variables comprise additional deep phenotyping elements, such as CPET (cardiopulmonary exercise testing), imaging, or other specialized data modules, and are collected in selected research contexts to broaden the registry's capabilities over time. This list evolves continuously to incorporate emerging clinical developments, for example new therapies such as sotatercept, and genomic data. All variables are catalogued in a comprehensive data dictionary, which includes both short and long descriptive labels, standardized codes (e.g., LOINC [Logical Observation Identifiers Names and Codes]; (McDonald et al. 2003) and SNOMED CT [Systematized Nomenclature of Medicine—Clinical Terms]; (El‐Sappagh et al. 2018)), agreed‐upon units of measurement, and ranges of physiologically viable values.
GoDeep Categories of Variable Importance. At the initiation of GoDeep data acquisition, consortium members defined four categories of variable importance: Mandatory variables (e.g., age at diagnosis, sex, right heart catheterization), Essential variables (e.g., WHO functional class, BNP, 6‐min walk distance), Recommended variables, and Extended variables (e.g., imaging, echocardiography, MRI). A complete and up‐to‐date list of all variables is available on the GoDeep webpage: https://ilh‐giessen.de/en/pvri‐godeep/.
As described in Majeed et al. (2022), GoDeep operates under a governed, tiered‐access model in which centers provide data in exchange for full access to the meta‐registry and representation on the steering board, which oversees the scientific use of the data. Public access includes detailed metadata and aggregated summaries. Registered users may perform real‐time feasibility queries on selected data, primarily for consortium members but also for external academic or industry partners, upon case‐by‐case approval by the steering board, with contributing centers retaining autonomy over the inclusion of their data. All subsequent analyses are conducted by a member of the steering board committee, and the underlying data are not made available to third parties.
As of January 2026, GoDeep has aggregated data from over 37 centers and encompasses > 45,000 enrolled individuals, with > 39,000 patients with hemodynamically proven PH based on the current definition of mean pulmonary artery pressure > 20 mmHg. A further group includes patients in whom PH was suspected based on clinical and non‐invasive diagnostic criteria, but the RHC undertaken due to this clinical reasoning showed a mPAP ≤ 20 mmHg. An additional 11 centers have signed participation agreements and are actively in preparation for integrating their data, further expanding this diverse resource. The patient cohort spans all continents, with roughly 48% from the United States, 44% from Europe, and 8% from the rest of the world; the latter percentage currently growing with the inclusion of several newly recruited centers (Figure 2).
Centers Contributing to GoDeep. (A) World map shows the contributing centers. (B) The pie chart shows the distribution of pulmonary hypertension groups (1–5), as well as patients assigned to multiple groups or not assigned to any specific group (m).
Patients in the registry were diagnosed with PH between 1980 and 2025, covering the full spectrum of clinical classifications. Within this population, 34% are classified as Group 1, 12% as Group 2, 11% as Group 3, 13% as Group 4, and 3% as Group 5. Additionally, 27% have been assigned to more than one group or remained unclassified (Figure 2). As the PVRI GoDeep meta‐registry exclusively includes patients treated at specialized PH expert centers, the distribution of PH groups does not reflect the global epidemiology of PH. In particular, PAH is over‐represented, consistent with the historical focus of expert centers on PAH and similar observations in other large PH registries. Furthermore, while PAH has traditionally been considered a disease of younger women, contemporary registry data demonstrate a shift toward older and more comorbid patients with a less pronounced female predominance. Accordingly, the age and sex distribution observed in GoDeep are in line with recent real‐world P(A)H cohorts (Gall et al. 2017; Hoeper et al. 2022; Hurdman et al. 2012).
The median follow‐up duration stands at 2.26 years [0.42, 5.5] post‐diagnosis. Overall, 34% of the cohort have deceased. The median age at diagnosis is 63 years [50, 72], and 58% of patients are female. Race data are available for 69% of patients, among whom 81% are White, 12% Black, 5% Asian, and the race of 2% was classified as “other or mixed”, according to internationally accepted definitions (McKenney and Bennett 1994). As to WHO functional class at the time of diagnosis, 3% were classified as Class I, 21% as Class II, 64% as Class III, and 12% as Class IV, reflecting the broad range of disease severity represented in the registry.
Data Entry Cycle
3
Anonymization procedures follow local regulatory requirements but always involve the removal of identifiable information such as names, addresses, social security numbers, passport or ID numbers, phone numbers, and similar personal data. In addition, dates are modified to further protect patient privacy: This includes anonymizing birth and diagnosis dates, either by generalizing them to the decade or by shifting them within a predefined narrow time window. As the date of diagnosis, the first right heart catheterization fulfilling the hemodynamic definition of PH (Kovacs et al. 2024) is used. All other dates are expressed relative to the diagnosis date, typically in months before or after diagnosis. Anonymization is performed locally before transferring the data to GoDeep, with an anonymization script provided by GoDeep central if needed (e.g., K‐anonymization). All further transfers, processing and analyses is done on this anonymized data set. After transfer to GoDeep, each submitted dataset is first assessed for structural compatibility and completeness, with a particular focus on the availability of mandatory variables and dates. Once the mandatory variables have been identified and their completeness confirmed, our data management team uses the data dictionary to map all other variables to the corresponding standardized codes. This harmonization is essential, as centers often use different abbreviations, descriptive labels, and, in non‐English‐speaking countries, their native languages. After the mapping is complete, the data are converted into three standardized CSV files: patients, encounters, and observations using FHIR (Fast Healthcare Interoperability Resources) format. The patients file contains key demographic information: a GoDeep patient ID (assigned by us), the original center‐specific ID created after anonymization, gender, and dates of birth and death (if applicable), both expressed relative to the anonymized diagnosis date, as well as vital status. The encounters file lists all dates on which data points were collected upon visits, with an encounter ID for each generated by us. The observations file contains individual data points, each linked to the GoDeep patient ID and corresponding encounter ID, along with the standardized codes, start dates, data type (e.g., numeric), value, and unit, each specific to the respective observation. The end dates are collected when applicable/available (Figure 3).
Data entry cycle.
It is important to note that patients can be mapped to different PH classifications based on the classification the center is using. Furthermore, because detailed right heart catheterization data are available, post hoc reclassification is possible. This approach has been demonstrated in a recent publication on the treatment of patients with mild PH (Yogeswaran, Funderich, et al. 2025), who met the diagnostic criteria according to the 2022 ESC/ERS guidelines but would not have been classified as having PH under the 2015 guidelines (Galie et al. 2015; Humbert et al. 2022).
The dataset is then enriched with derived and aggregated variables. These include survival time (in months) from diagnosis, the number of distinct PH diagnoses, assignment to PH diagnosis (groups, subgroups, overlapping groups), the number of recorded visits, PAH specific medication (broken down by drug classes), oxygen therapy, and geographic details such as the city, country, and continent of the PH expert center for each patient. Additionally, comorbidities are mapped to standardized disease groups, and relevant classifications are derived from numeric variables, for example, ascribing to underweight, normal weight, overweight, and obesity based on body mass index (BMI) according to WHO/CDC standards (CDC.gov 2024; de Onis et al. 2007). The original, more granular data remain preserved and can be accessed for analysis if needed.
Data quality checks are carried out as part of the quality assurance process (detailed in the next section). The results are compiled into a data quality report to be provided to the individual centers, along with the number of enrolees, the units identified for each variable, and an overview of data availability. The data availability is presented in two ways: (i) a table by data domain (e.g., laboratory, RHC, echocardiography), showing the number of enrolees with data for each variable, the corresponding percentage of the total cohort, and the average number of records per patient; and (ii) a bar plot grouped by classification (mandatory, essential, recommended and extended) to visualize overall coverage. This report is sent to the respective center along with any outstanding queries. The medical and data management team at each center reviews the report and provides feedback concerning missingness, discrepancies, and any further issues. If necessary, they resubmit a corrected version of their data. Should further clarification be required, a video meeting is arranged between their team and GoDeep central.
As soon as all queries have been resolved, the data is included into the central meta‐registry and used for analyses. The center then enters a regular update cycle, typically every 3–4 months. During each cycle, the center provides an updated data export file, which is again reviewed as described above, with putative adjustments concerning interim changes (e.g., changes in the local data storage systems or export configurations). Each new export then fully replaces the previous one in the meta‐registry, thus allowing capturing of long‐term data. Otherwise, already reported data could not be merged with previous patient specific records due to the anonymization process. A new data quality report, including any additional queries, is then again sent to the center for clarification and feedback.
Data Quality Assurance
4
While this update cycle is continuously ongoing for both new and existing centers, a snapshot of the current state of the registry for extraction of a fixed dataset for analytical purposes can be made at any time. Prior to capturing this snapshot, rigorous data quality checks are again carried out. Any errors identified during these checks are compiled in an additional data quality report and shared with the centers for review and correction. As long as there is no feedback for correction, data identified as putatively incorrect are excluded from the analytical procedure. The quality assurance processes generally focus on five key dimensions: timeliness, validity, consistency, completeness, and accuracy.
Completeness
4.1
A data completeness check is essential to ensure that all required information is present and preserved throughout the ETL (extract, transform, load) process. During data transformation, even minor formatting inconsistencies, such as incorrect decimal separators, spelling mistakes, and inconsistent use of labels and date formats, can lead to considerable amounts of data being unusable because they cannot be transferred. The feedback report summarizes the availability of each variable across all patients to be compared to the original dataset submitted by the center. It is important to note that variables flagged as putatively incorrect during validation are excluded from the availability summaries and reported separately. As such, data availability reflects only the usable portion of the data and not the full submission.
Timeliness
4.2
A reasonable refresh cycle is essential to capture ongoing clinical developments, support longitudinal analyses, and enhance the overall utility of the registry for research purposes. To this end, and to ensure continued relevance, regular data updates are scheduled every 3 months.
Validity
4.3
As part of the data validation process, several checks are performed to ensure plausibility as well as internal and external consistency. An important tool in this process is the use of boxplots to visually assess the distribution of each variable within the reporting history of an individual center, as well as across centers, allowing for the quick identification of “outlying submissions”, which might indicate incorrectly used units for the respective variable or systemic deviance of data assessment procedures as compared to all other centers.
Consistency
4.4
Ensuring consistency with the original records remains the responsibility of the contributing centers. However, when multiple entries exist for values that should remain constant, such as birth date, diagnosis date, diagnosis‐defining right heart catheter‐derived variables, WHO functional class at study entry, or date of death, these discrepancies are identified and reported back to the respective centers for clarification or correction. Until such issues are resolved, the affected patients are flagged and excluded from any further analyses.
A particular challenge arises when patients transfer between hospitals. To avoid potential duplicate entries, cross‐center checks are conducted using key variables such as detailed diagnosis‐defining right heart catheterization data, age at diagnosis, birth decade, and diagnosis decade. Applying these GoDeep‐based “identifiers,” less than 1 per mille of data indicated putatively across‐center duplicates, which could be clarified by feedback from the respective centers in each case. This procedure ensures that each patient is represented only once in the GoDeep dataset.
Accuracy
4.5
As part of the accuracy dimension within the quality assurance process, both plausibility and coherence checks are conducted. During the plausibility check, values that are incompatible with life are identified and excluded, using thresholds adapted to the expected range for patients with PH. These thresholds are defined by clinical experts and maintained within our data dictionary, with updates as needed. Values outside the range of physiological or pathophysiological viability are flagged and not entered into any review process until clarification by feedback from the respective PH referral center.
Coherence checks involve assessing the internal consistency of physiologically and/or methodologically related variables, such as the interdependence between systolic, diastolic, and mean pulmonary arterial pressure (mPAP), pulmonary arterial wedge pressure (PAWP), cardiac output (CO), and pulmonary vascular resistance (PVR), or the interdependence of oxygenation, oxygen content, cardiac output, and central venous oxygen saturation. If a set of values is found to be insufficiently coherent, it is flagged and reviewed by our medical advisory team. Unless the clinicians indicate that one or more values in the set are incorrect, all values are retained and used in the analysis.
Preparing Data for Analysis
5
Once all necessary modifications have been completed, the data extraction and preprocessing steps begin, initiating the process by which clinical research questions are translated into structured specifications. The research process begins with a clinical question formulated by medical experts. Based on this research idea, they define the subset of patients relevant to the analysis, the baseline and follow‐up periods (if applicable), and the specific variables required. These specifications are then translated into a structured project configuration file, which outlines the cohort definition and variable selection in a standardized yet human‐readable format. A custom R script then parses the project configuration file and combines it with internal logic to extract the relevant patient‐level data. The result is a tabular text file (comma separated values, CSV) following the structure “cases in rows, variables in columns”, in which each row contains data for a single patient.
The extracted values of time‐varying variables such as laboratory values, RHC, measurements, or echocardiographic data, are those closest to the desired time‐point (as given in months after diagnosis) that exist within a predefined (time) window around the given time point. If there is no recorded value for the patient within this time window, the value is “missing”. If several desired time‐points are given, e.g., to analyse changes over time, this process is repeated for each given time‐point, resulting in several columns in the CSV file. For each of these columns, two additional columns are added, indicating the time spans from the measurement to the given reference time point and to the time of diagnosis, respectively.
Creating a structured project configuration file that thoroughly documents the selection decision ensures traceability and allows the dataset to be consistently reproduced at a later time. Additionally, by focusing only on the data relevant to the respective analysis, the amount of data is reduced, thereby considerably enhancing clarity and providing a better overview of the dataset for the analyst.
Automatic Data Completion
5.1
The data in the CSV file is then automatically completed in two ways: (a) columns for additional derived variables are added, and (b) missing values are completed by calculation from given values of other variables. For instance, data from pulmonary function tests will always be given as absolute values and as percent predicted values. The calculations from absolute values to %predicted values in pulmonary function tests are used as shown in Stanojevic et al. (2017) and Bowerman et al. (2023). Missing BNP values were calculated from available N‐terminal pro‐B.type natriuretic peptide (NT‐proBNP) measurements using the relationship lnBNP=ln(NT‐proBNP)‐0.791.348; conversely, missing NT‐proBNP values were obtained by algebraic rearrangement of this equation (Rorth et al. 2020). If one of these variables is not part of the CSV file, it will be added. Missing values in a variable may be calculated from given values of other variables. The calculations are iteratively repeated, including already calculated values, until no more missing values can be calculated. For example, consider a patient for whom body surface area (BSA), cardiac index (CI), mPAP, and PAWP are given, but CO and PVR are missing. In a first step, CO is calculated as CO = CI*BSA, and in the next iteration, PVR is calculated as PVR = (mPAP‐PAWP)/CO, using the previously calculated CO value. Each computed value is checked for falling outside the range of viability.
Data Enrichment by Imputation
5.2
A common characteristic of registry and real‐world data is that values are missing, which cannot be obtained by feedback from the original referral center or derived (re‐calculated) from existing variables, as discussed above. In this case, statistical evaluations will either be performed on the basis of the given “missingness” with the available data set (checking that missingness is distributed at random, thereby avoiding a bias; see discussion below), or missing values are imputed using multiple imputation by chained equations (MICE) with predictive mean matching (pmm) (Van Buuren and Groothuis‐Oudshoorn 2011). Predictive mean matching imputes missing values by finding observed cases with predicted values closest to the missing case's predicted value, then randomly selecting one observed value as the replacement. Typically, all available variables known to be predictive are included in the imputation model, with the specific variables imputed chosen according to the research question. This method generates realistic imputations within the observed data range, works for both continuous and discrete variables, and is relatively robust to model misspecification (Van Buuren and Van Buuren 2012). MICE in general avoids the high data loss of listwise deletion and the distortions and artificial homogeneity of mean imputation.
Since the cumulative baseline hazard is unknown, the Nelson–Aalen estimator is applied to approximate it during the imputation process. Following imputation, a thorough sanity check is conducted to assess the quality and reliability of the imputed values. This involves comparing the empirical cumulative distribution functions of the original observed data against the combined dataset that includes both observed and imputed values. These figures (an example given in Figure 4 (Yogeswaran, Hassoun, et al. 2025)) help verify that the imputed data maintain a realistic distribution consistent with the original data, ensuring the imputation process does not introduce bias or distortions. Imputation is based on the assumption that data are missing completely at random or minimum, missing at random. To examine the plausibility of this assumption, the correlation between missingness, defined as the total number of missing values across all variables for each patient, and the survival outcome is assessed, using the parameter of interest (e.g., phosphodiesterase‐5 inhibitors and survival in the example figure). This missingness indicator is included in the model of interest as a predictor of survival and tested for significance by a likelihood ratio test. To capture potential nonlinear relationships between missing data and the log hazard, the missingness variable is modeled using natural splines with one, two, and three degrees of freedom, allowing for linear, quadratic, and cubic effects. The plausibility of imputed values is assessed by diagnostic plots, for instance comparing the empirical distributions of data with and without imputed values.
Examples of a comparison of the empirical cumulative distributions before and after imputation from Yogeswaran, Hassoun, et al. (2025). The diagrams present the empirical cumulative distributions of the variables subjected to imputation. The black line represents the distribution of the observed data, while the red lines depict the distributions after incorporating the imputed values.
Application Examples
6
Harmonized GoDeep data was successfully used in several projects addressing a variety of questions that require data from large cohorts of PH patients (Table 2). These analyses apply a wide range of statistical methods suited to the structure and complexity of the data and the respective research questions. Our approach combines Cox survival models with more flexible modeling tools and a set of sensitivity checks to ensure the reliability of results (Figure 5).
Schematic of standard analysis pipeline.
One key application has been the validation of risk stratification models, such as REVEAL 2.0, across all major PH groups (Yogeswaran et al. 2024). This study has shown that tools originally developed for Group 1 PAH retain prognostic value in other PH subgroups, helping to improve patient risk assessment and clinical decision‐making across broader populations. The analysis employed Cox proportional hazard models and discrimination metrics, such as c‐statistics and akaike information criteria values, to evaluate the predictive performance of various risk scores for mortality outcomes. The primary cohort included over 8500 patients with detailed hemodynamic data.
GoDeep has also supported analyses of the use and impact of therapies beyond their approved indications for pulmonary hypertension. For instance, phosphodiesterase‐5 inhibitors (PDE5i), while primarily recommended for patients with pulmonary arterial hypertension (PAH; group 1), are broadly used off‐label in other PH groups. One such group includes patients with PH due to chronic obstructive pulmonary disease (COPD‐PH). To examine whether PDE5i therapy is associated with improved survival in this population, data from the registry were extracted and analysed (Tello et al. 2025). Although COPD‐PH patients are typically excluded from randomized trials investigating PAH‐specific drugs, our findings suggest a potential survival benefit in those receiving PDE5i treatment, as shown in summary Figure 6. In another study, GoDeep data were used to investigate the use and outcomes of targeted therapies in portopulmonary hypertension, offering new insights into treatment patterns in this rare PH subtype (Jose et al. 2025).
PDE‐5 Inhibitor Therapy in COPD‐PH: Survival Outcomes. Modified from Tello et al. (2025). (A) Use of PH‐targeted therapy among COPD‐PH patients in the GoDeep meta‐registry, stratified by hemodynamic severity. The table reports the number and percentage of patients receiving each type of PH‐targeted therapy within different severity groups. The final row summarizes all patients who received at least one PH medication. (B) Overall survival of COPD‐PH patients, stratified by PDE5i treatment status and hemodynamic severity. Kaplan–Meier curves with 95% confidence intervals are presented for patients treated with PDE5i versus those not receiving any PH‐targeted therapy, further divided into groups with PVR ≤ 5 WU and PVR > 5 WU. (C) Hazard ratios for patients receiving PDE5i treatment compared with those without PDE5i treatment, derived from Cox proportional hazards models. Diagrams display the estimates with 95% confidence intervals. p‐values are based on Wald z‐tests. (i) Results from the base model. The unconditional estimate represents the HR of PDE5i, adjusted only for age. Estimates for the separate PVR groups are obtained from the base model including the interaction term between dichotomized PVR and PDE5i treatment. This model uses non‐imputed data only. (ii) Results from the base model, as in (i), but after applying the landmark approach to reduce immortal time bias. (iii) Results from the full model. The estimate conditional on PVR is adjusted for a linear relationship between PVR and the log hazard, as specified in the full model. Estimates for the separate PVR groups are obtained in the same way as in (i). This model uses imputed data for variables with missing covariates. (iv) Results from the full model, as in (iii), but after applying the landmark approach. (D) Association of PDE5i treatment with comorbidities and pulmonary function impairment. Results are based on the base model applied to subgroups defined by comorbidities and pulmonary function. Hazard ratios compare patients receiving PDE5i with those not treated, derived from Cox proportional hazards models. Diagrams display estimates with 95% confidence intervals, and p‐values are based on Wald z‐tests. COPD, chronic obstructive pulmonary disease; ERA, endothelin receptor antagonists; FEV1% pred, forced expiratory volume percent predicted; FVC, forced vital capacity; HR, hazard ratio; lower and upper, lower and upper limits of the 95% confidence interval of the HR; PDE5i, phosphodiesterase‐5 inhibitors; PGI2, prostaglandin I2 and its analogues (inhalative or parenteral); PH, pulmonary hypertension; PVR, pulmonary vascular resistance; sGC, soluble guanylate cyclase; WU, wood units.
A notable example of GoDeep's added value is the analysis of patients with so‐called “mild” pulmonary hypertension, as presented in Yogeswaran, Funderich, et al. (2025). In 2018, the clinical definition of PH was revised by the 6th World Symposium on Pulmonary Hypertension, lowering the diagnostic threshold for mPAP from ≥ 25 mmHg to > 20 mmHg. As a result, patients with mPAP between 20 and 25 mmHg, previously not classified as having PH, were newly recognized as part of the disease spectrum. These patients were, however, excluded in all pivotal trials underlying market access of PAH‐specific drugs, and they remain a small minority in most cohorts, making robust analysis at the level of individual centers difficult. By pooling data across multiple international sites within GoDeep, this limitation is overcome, enabling a comprehensive analysis of this understudied subgroup and providing first evidence for the efficacy of PAH‐specific medication also in the sub‐cohort with “mild PH”.
In the most recent publication, Hemodynamics and PDE5i Treatment Associated with Survival in Pulmonary Hypertension in Interstitial Lung Disease (Yogeswaran, Hassoun, et al. 2025), a significant association was observed between PDE5i use and survival in PH patients with PVR > 5 wood units (WU), but not for patients with PVR below 5 WU. Another example examined sex‐based differences in survival among more than 21,000 patients with pulmonary hypertension across different disease conditions (Yogeswaran, Annis, et al. 2025). Male patients consistently showed higher mortality than females for patients with different ages, disease severities, comorbidities, and treatments.
In all these application examples, it was important to rigorously evaluate the proportional hazards assumption. To this end, diagnostic plots of Schoenfeld residuals are routinely generated, while deviance residuals are examined to uncover influential data points that could destabilize the model. Beyond assumption testing, model performance is explored using Heller's Explained Relative Risk, which highlights the proportion of total explained risk attributable to individual covariates. This not only quantifies predictive accuracy but also provides a clear view of how strongly each variable impacts survival outcomes. Robustness is assessed by systematically modifying Cox proportional hazards models, sequentially adding or removing individual covariates and groups of covariates. Such iterative refinement allows a deeper understanding of the stability of effect estimates and the sensitivity of findings to specific modeling choices, thereby strengthening transparency and interpretability. In selected cases, analyses contrast a streamlined base model, containing only the core covariates necessary for adjustment (e.g., age at diagnosis, diagnosis decade, center of origin, sex and treatment information for PDE5i), with an expanded full model that incorporates additional variables (e.g., WHO functional class, body mass index, PVR, mPAP, Brain natriuretic peptide, forced vital capacity percent predicted and diffusing capacity of the lung for carbon monoxide percent predicted), as applied e.g., in Yogeswaran, Hassoun, et al. (2025). Comparing these two models highlights the added value of additional covariates, revealing not only their statistical contribution but also their potential clinical significance.
For survival analyses investigating treatment effects, landmark analysis is applied to reduce immortal time bias, the distortion that occurs when patients must survive a predefined period before becoming eligible for treatment, particularly when therapy is not initiated immediately after diagnosis. In Tello et al. (2025), for instance, the landmark was set at 3 months following the initial RHC. Only patients who survived at least this 3‐month period and were either untreated with PDE5i or initiated therapy within that timeframe are included in the analysis. Survival times are then recalculated by subtracting the 3‐month landmark. An alternative approach to minimize immortal time bias is the target trial emulation framework, which seeks to replicate a randomized controlled trial (RCT) by explicitly defining eligibility criteria, baseline, treatment strategies, and follow‐up in order to estimate causal effects, with the aim of replicating a hypothetical trial using existing data (Hernan et al. 2022).
To assess the robustness of our estimated treatment effect to potential unmeasured confounding, a dual‐parameter sensitivity analysis is carried out using the survSensitivity method based on the R package survSens (Huang et al. 2020; Huang 2023). This approach evaluates how the estimated log hazard ratio for the treatment varies with hypothetical levels of unmeasured confounding, represented by sensitivity parameters on both the log hazard ratio scale and the probit scale (ζ_Z_). Contour plots illustrate the range of sensitivity parameters for which the intervention effect (e.g., treatment of PAH‐specific drugs) remains statistically significant, providing a rigorous evaluation of the stability of the findings under varying assumptions about unmeasured confounding.
These use cases highlight the potential of GoDeep to support analyses across a broad range of patient populations, using harmonized real‐world data from multiple international centers. By reflecting real‐world clinical practice, GoDeep helps address research questions that may be difficult to study through prospective trials, offering additional insights that can generate interesting research hypotheses and inform care in PH and right heart adaptation.
Challenges and Perspective
7
Working with data from diverse sources presents inherent challenges. International collaborations must comply with country‐specific privacy laws, ethics approvals, and data‐sharing agreements, which can complicate or delay data integration. In addition, differences in clinical practice, documentation standards, and data completeness across sites mean that careful harmonization is required. Terminologies and formats must be aligned and missing or inconsistent values must be carefully handled to preserve analytical validity. These steps, spanning data cleaning, transformation, and validation, are time‐intensive but crucial to ensuring the resulting dataset is both robust and suitable for high‐quality research.
Furthermore, integrating data from international registries requires close coordination between the data management team, medical experts, and participating centers. In cases of medical ambiguity, consultation with clinicians is essential to ensure correct interpretation. Different measurement units must be standardized to ensure strict consistency. A detailed account of these challenges and the solutions implemented is provided in Fuenderich et al. (2024).
Additional challenges arise from the current classification of PH patients into groups 1–5 (Humbert et al. 2022). For example, patients with HFpEF may be misclassified as Group 1, as recent studies suggest (Reddy et al. 2024). Such misclassifications can be addressed using detailed clinical data, RHC measurements and imaging data (ECHO, cardiac MRI), which are available in GoDeep and could inform further refinement of patient categorization. Moreover, GoDeep is exploring the inclusion of RHC exercise data, which would allow assessment of PVR increase, CO increase, and PAWP increase upon exercising, further enhancing phenotyping accuracy. Also, despite the large sample size, certain rare PH subtypes may still have limited numbers, limiting generalizability and the confidence in conclusions and statistical analyses, as we see in Group 5.
With the ongoing expansion of GoDeep, the integration of new therapies, biomarkers, or updated clinical guidelines may necessitate revisions to variable definitions, potentially leading to discrepancies with previously collected data.
Despite these challenges, the GoDeep framework offers substantial advantages. By enabling the re‐use of existing infrastructure and minimizing redundant data entry, it lowers the barrier for participation and enhances scalability. Its modular design supports deep phenotyping and future extensions, such as linkage with genomic and omics data or imaging and emulating target trials. Most importantly, GoDeep creates a research‐ready environment for longitudinal, patient‐level analysis on an international scale, offering new perspectives for precision medicine, outcome benchmarking, and real‐world evidence generation in pulmonary hypertension and right heart adaptation. The principles and infrastructure behind GoDeep are disease‐agnostic, making this framework readily transferable to other medical domains that rely on high‐quality, longitudinal real‐world data.
Funding
This work is funded by the Pulmonary Vascular Research Institute (PVRI).
Conflicts of Interest
MFünderich has nothing to disclose. AYogeswaran reports non‐financial support from the University of Giessen during the conduct of the study, research grants from the German Research Foundation, support for attending a meeting from OrphaCare and AOP, and personal fees from MSD and Ferrer outside the submitted work. PJanetzko has nothing to disclose. KTello has received personal fees from Bayer, AstraZeneca, Gossamer. WSeeger has received consultancy fees from United Therapeutics, Tiakis Biotech AG, Liquidia, Pieris Pharmaceuticals, Abivax, Pfitzer, Medspray BV. RWMajeed and JWilhelm have nothing to disclose.
Supporting information
Table S1: Example of equations used for variable conversion and consistency checks. The equations in the table are used for variable conversions and consistency checks, and any necessary rearrangements of these equations are applied. The Du Bois formula is used to calculate body surface area. The BNP to NT‐proBNP conversion is based on data from Rorth et al. (2020), with a total least squares regression model fitted to determine the intercept and slope.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bowerman, C. , N. R. Bhakta , D. Brazzale , et al. 2023. “A Race‐Neutral Approach to the Interpretation of Lung Function Measurements.” American Journal of Respiratory and Critical Care Medicine 207, no. 6: 768–774. 10.1164/rccm.202205-0963 OC.36383197 · doi ↗ · pubmed ↗
- 2CDC.gov . 2024. “Adult BMI Categories.” https://www.cdc.gov/bmi/adult‐calculator/bmi‐categories.html.
- 3de Onis, M. , A. W. Onyango , E. Borghi , A. Siyam , C. Nishida , and J. Siekmann . 2007. “Development of a WHO Growth Reference for School‐Aged Children and Adolescents.” Bulletin of the World Health Organization 85, no. 9: 660–667. 10.2471/blt.07.043497.18026621 PMC 2636412 · doi ↗ · pubmed ↗
- 4El‐Sappagh, S. , F. Franda , F. Ali , and K. S. Kwak . 2018. “SNOMED CT Standard Ontology Based on the Ontology for General Medical Science.” BMC Medical Informatics and Decision Making 18, no. 1: 76. 10.1186/s 12911-018-0651-5.30170591 PMC 6119323 · doi ↗ · pubmed ↗
- 5Farber, H. W. , D. P. Miller , A. D. Poms , et al. 2015. “Five‐Year Outcomes of Patients Enrolled in the REVEAL Registry.” Chest 148, no. 4: 1043–1054. 10.1378/chest.15-0300.26066077 · doi ↗ · pubmed ↗
- 6Fuenderich, M. T. , P. Krieb , W. Seeger , and R. W. Majeed . 2024. “Data Integration for a Global Deep‐Phenotyping Registry for Pulmonary Hypertension—Lessons Learned.” Studies in Health Technology and Informatics 316: 334–338. 10.3233/SHTI 240412.39176741 · doi ↗ · pubmed ↗
- 7Galie, N. , M. Humbert , J. L. Vachiery , et al. 2015. “2015 ESC/ERS Guidelines for the Diagnosis and Treatment of Pulmonary Hypertension: The Joint Task Force for the Diagnosis and Treatment of Pulmonary Hypertension of the European Society of Cardiology (ESC) and the European Respiratory Society (ERS): Endorsed by: Association for European Paediatric and Congenital Cardiology (AEPC), International Society for Heart and Lung Transplantation (ISHLT).” European Respiratory Journal 46, no. 4: 90 · doi ↗ · pubmed ↗
- 8Galie, N. , M. Humbert , J. L. Vachiery , et al. 2016. “2015 ESC/ERS Guidelines for the Diagnosis and Treatment of Pulmonary Hypertension.” Revista Española de Cardiología 69, no. 2: 177. 10.1016/j.rec.2016.01.002.26837729 · doi ↗ · pubmed ↗