Performance of predictive AI-based clinical decision support systems across clinical domains: A systematic review and meta-analysis
William J. Waldock, Ahmad Guni, Ara Darzi, Hutan Ashrafian

TL;DR
This study reviews how well AI tools help doctors make decisions across many medical fields, finding moderate accuracy but highlighting the need for better real-world testing.
Contribution
The study introduces the ROADMAP framework to bridge the gap between AI performance and real-world clinical integration.
Findings
AI-based CDSS showed moderate discriminatory ability (AUC: 0.652) and high specificity (0.819) across 17 medical specialties.
Most studies (76%) were retrospective, and only 24% involved prospective deployment, highlighting a gap in real-world validation.
The ROADMAP framework is proposed to guide the development and evaluation of AI tools for clinical integration.
Abstract
Despite advances in deep learning and transformer architectures, prior reviews have focused narrowly on traditional clinical decision support systems (CDSS) or single medical domains, leaving significant gaps in understanding contemporary AI-driven predictive tools. This systematic review and meta-analysis evaluated the predictive performance of artificial intelligence-based CDSS (AI-CDSS) across multiple medical specialties. Following PRISMA guidelines, PubMed and Cochrane Library were searched through December 2024 for studies evaluating predictive AI-CDSS using real-world clinical data. Two reviewers independently screened 3,296 records (κ = 0.833), with study quality assessed via QUADAS-2 and performance measures pooled using random-effects meta-analysis. Fifty studies spanning 17 medical specialties were included. Meta-analysis demonstrated moderate discriminatory ability (pooled…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
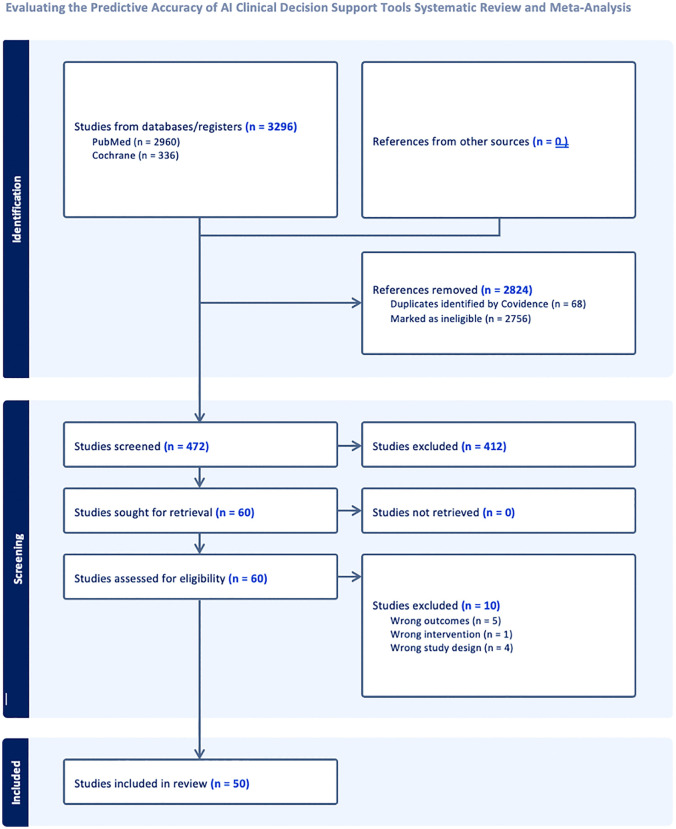 Fig 1
Fig 1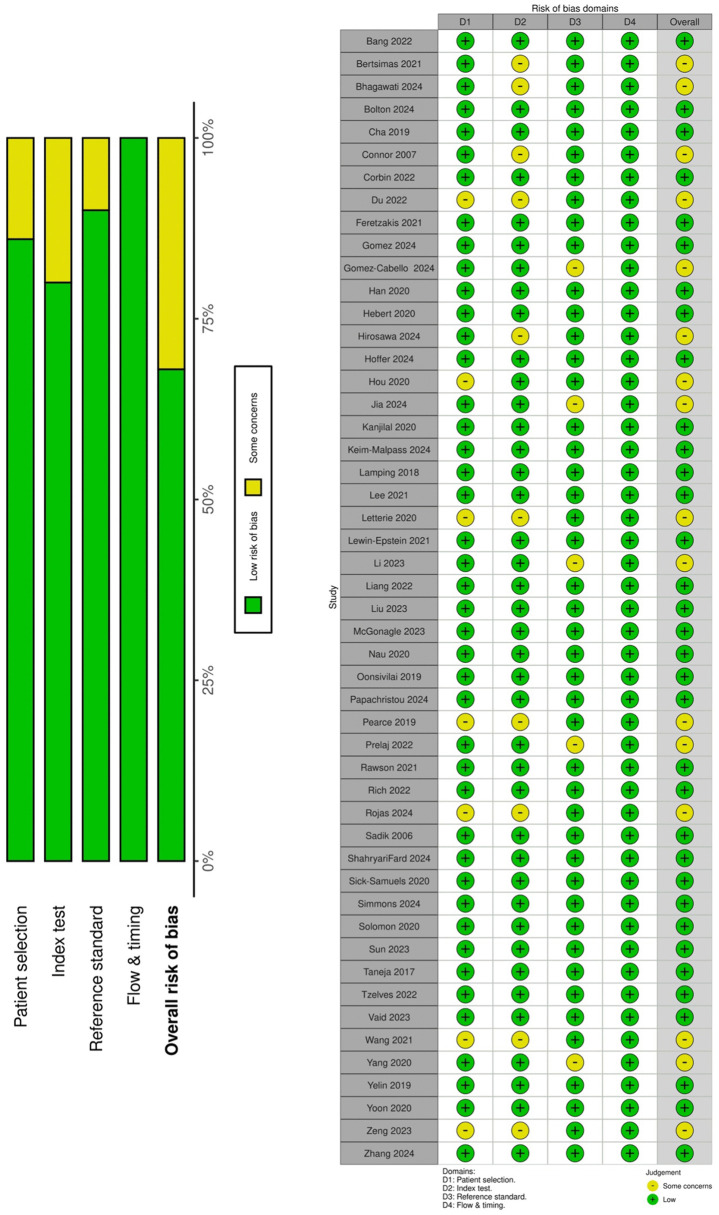 Fig 2
Fig 2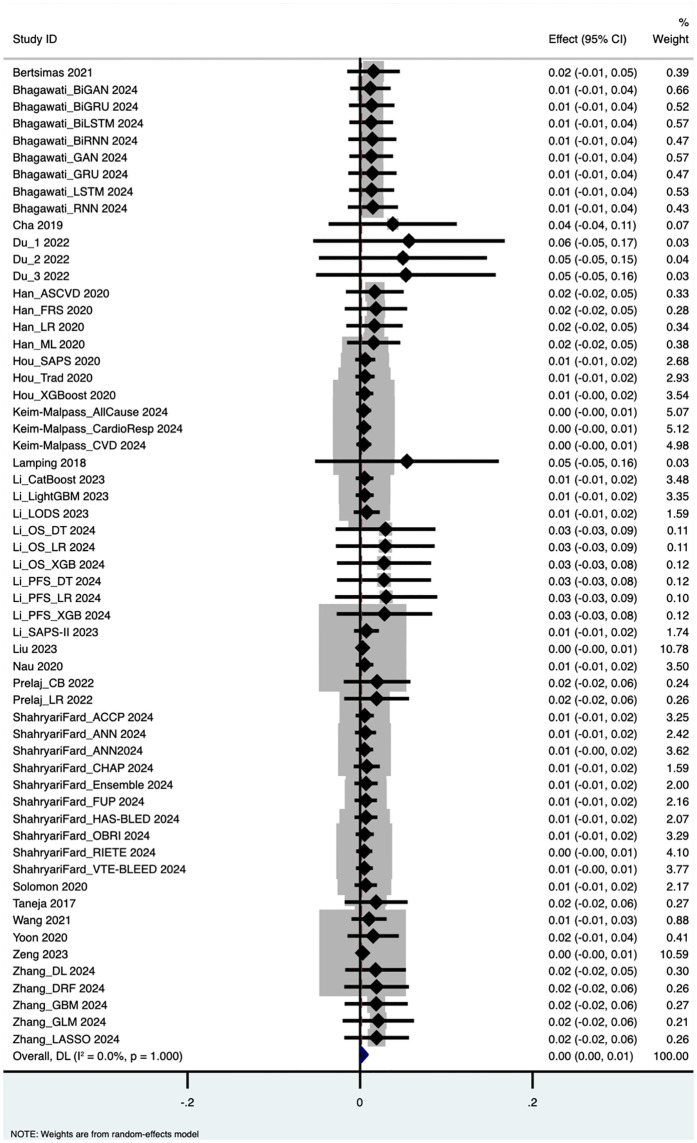 Fig 3
Fig 3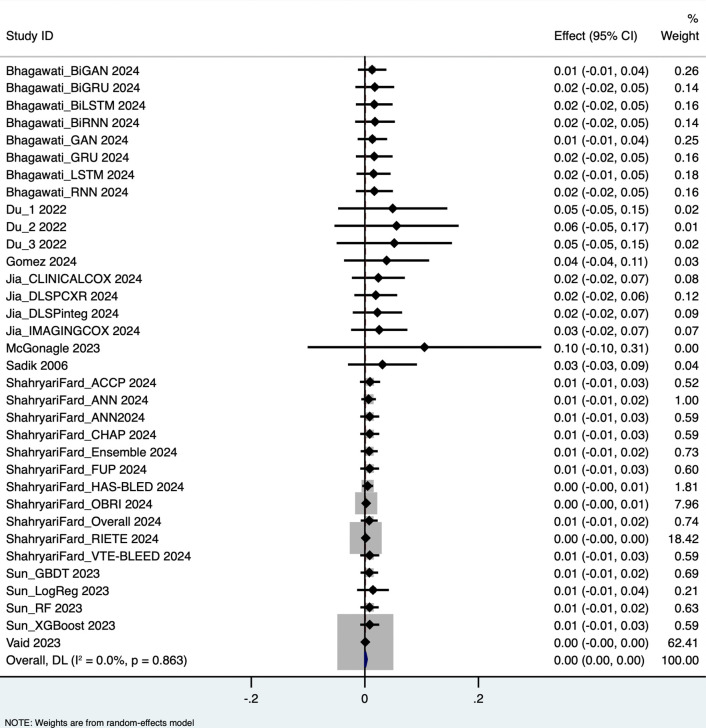 Fig 4
Fig 4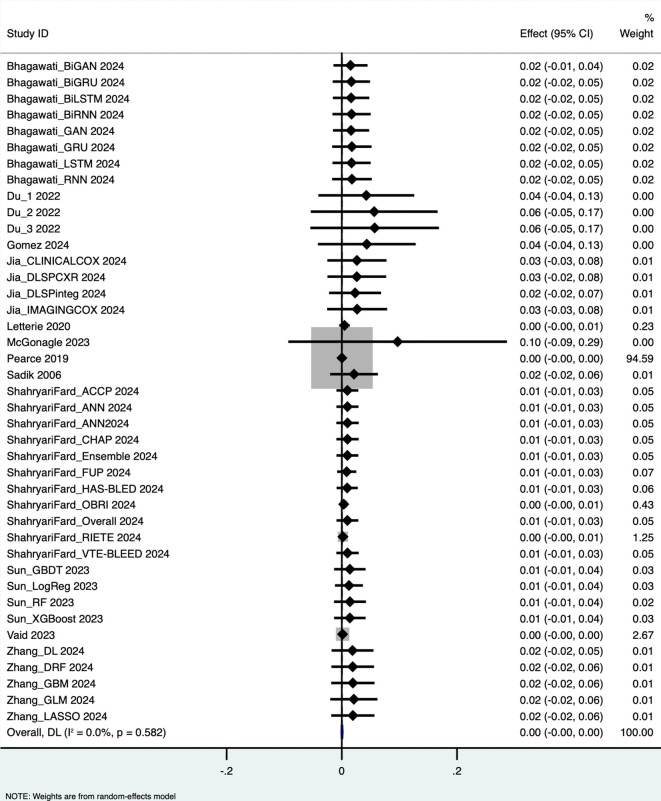 Fig 5
Fig 5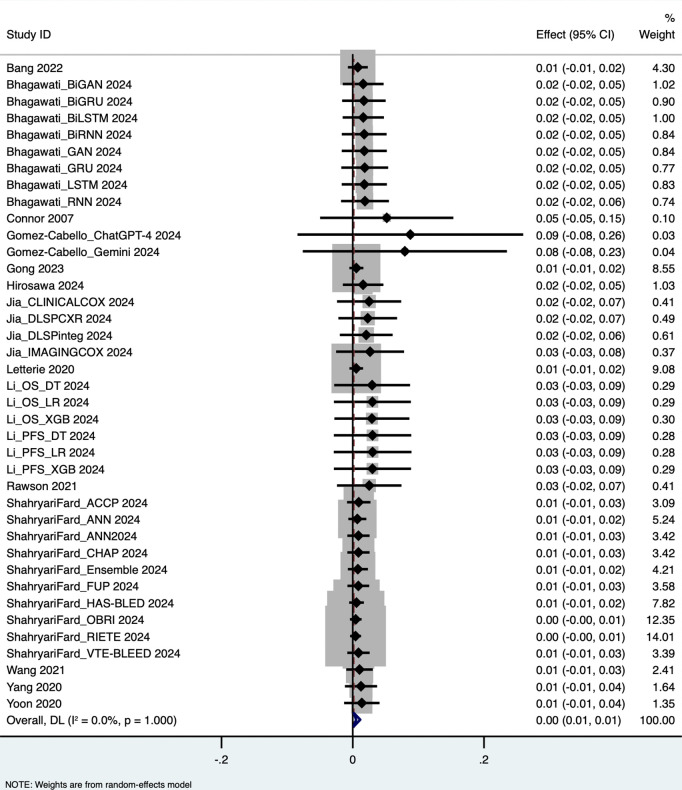 Fig 6
Fig 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Machine Learning in Healthcare · Electronic Health Records Systems
Background
Artificial Intelligence (AI), encompassing a wide spectrum of computational approaches, has transformed clinical decision-making in healthcare by enhancing predictive capabilities and enabling precise, data-driven interventions [1]. The landscape of clinical decision support has evolved rapidly with recent advances in AI methodologies, particularly deep learning architectures, convolutional neural networks, and transformer-based models. These modern AI techniques have demonstrated unprecedented capacity to identify complex patterns in clinical data, generating predictions that inform diagnostic, prognostic, and therapeutic decisions.
Despite the proliferation of AI-CDSS development and the growing body of literature reporting technically promising but with limited evidence of real‑world impact, several critical knowledge gaps persist. First, previous systematic reviews have primarily focused on traditional CDSS or have been limited to single clinical domains such as cardiology, oncology, or radiology [2–4], lacking comprehensive synthesis across the diverse landscape of AI-driven predictive tools. Second, the rapid evolution of AI methodologies, particularly the emergence of deep learning and transformer-based architectures in recent years [5], necessitates contemporary evaluation that reflects current technological capabilities. Third, significant heterogeneity exists in how AI-CDSS performance is evaluated and reported, with inconsistent use of metrics and validation approaches across studies [6]. This variability complicates efforts to assess the true clinical utility of these tools and compare performance across different systems and clinical contexts.
Furthermore, concerns regarding explainability, clinical integration, and liability have been identified as barriers to frontline clinical adoption [7]. While AI models may achieve high technical performance in controlled settings, questions remain about their real-world effectiveness, including how well they integrate into clinical workflows, whether clinicians trust and adopt their recommendations, and whether they ultimately improve patient outcomes. The gap between technical validation and clinical implementation represents a critical consideration for the field.
The need for rigorous, comprehensive evaluation of AI-CDSS spans multiple clinical domains. While specific applications, such as antimicrobial stewardship, where prescription surveillance has been implemented in Australia [8], Japan [9], and Africa [10], demonstrate the potential impact of decision support tools, the broader landscape of predictive AI-CDSS warrants systematic examination. A previous systematic review examining traditional Clinical Decision Support Systems and their role in antibiotic stewardship [11] found that CDSS interventions significantly improved outcomes relevant to antibiotic prescribing, with both active and passive systems contributing to more appropriate antibiotic use and improved patient outcomes. However, this work focused specifically on antibiotic stewardship and did not comprehensively evaluate modern AI-driven predictive models across diverse clinical domains. Unlike domain-specific reviews of AI-CDSS in nursing, psychiatry, obstetrics, and oncology, our review delivers the first multi-domain synthesis of predictive AI-CDSS performance across more than 15 specialties using standardised metrics, explicitly excluding rule-based systems and non-predictive tools examined in prior work. We uniquely quantify the critical implementation gap, demonstrating that while AI-CDSS show strong technical performance, evidence for clinical integration remains severely limited.
Objective
This study aims to systematically evaluate the predictive performance of AI-based clinical decision support systems (AI-CDSS) across a broad range of medical domains. By synthesizing evidence on diagnostic accuracy, prognostic capability, and, where reported, clinical implementation metrics, we seek to:
Quantify the pooled diagnostic performance of predictive AI-CDSS using standardized metrics (sensitivity, specificity, accuracy, and AUROC)Assess the methodological quality and risk of bias in AI-CDSS evaluation studiesIdentify sources of heterogeneity in reported performance across clinical domains, patient populations, and AI methodologiesInform the potential and limitations of predictive AI-CDSS for integration into routine clinical practice across diverse healthcare settings
This multi-domain synthesis provides a foundation for understanding the current state of predictive AI-CDSS development and validation, highlighting both the promise of these technologies and the critical needs for standardized evaluation methodologies and real-world clinical assessment.
Results
Study selection and screening process
This systematic review adheres to the PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) [12] guidelines to ensure transparency and methodological rigor. The study selection process is summarized in the PRISMA flow diagram (Fig 1), with Supplementary PRISMA Checklist (S1 File). A total of 3,296 studies were identified through database searches (PubMed: 2,960; Cochrane: 336). After removing 2,824 studies due to duplication or clear ineligibility, 472 abstracts were screened in detail. Of these, 60 studies were retrieved for full-text assessment, and 50 met the inclusion criteria and were included in the final analysis (Tables 1,2).
Table 1: Study characteristics.
Table 2: Study results.
PRISMA diagram.
Ten studies were excluded at the full-text stage for the following reasons: inappropriate or irrelevant outcome measures (n = 5), absence of a true AI intervention (n = 1), or ineligible study design such as simulation studies or narrative reviews (n = 4). No studies were classified as ongoing or awaiting assessment.
Reviewer agreement and inter-rater reliability
The screening process demonstrated high inter-reviewer agreement, confirming the robustness and reliability of study selection: title screening: 3,146 of 3,296 records agreed upon (κ = 0.911, Cohen’s kappa statistic); abstract screening: 429 of 472 records agreed upon (κ = 0.818); full-text screening: 55 of 60 records agreed upon (κ = 0.833). These kappa statistics indicate excellent agreement beyond chance, reflecting consistent application of inclusion criteria.
Characteristics of included studies
Specialty distribution.
The 50 included studies encompassed a diverse range of medical specialties, reflecting the broad applicability of predictive AI-based CDSS across clinical domains. The distribution was as follows: Infectious Diseases (n = 14), Cardiology (n = 8), Emergency Medicine (n = 5), Oncology (n = 4), Gastroenterology (n = 2), Obstetrics and Gynaecology (n = 2), Orthopaedics (n = 2), Otolaryngology (n = 2), Paediatrics (n = 2), Renal (n = 2), and one study each in Dermatology, Endocrinology, Haematology, Plastic Surgery, Respiratory, Urology, and Vascular specialties.
This distribution indicates that research on predictive AI-CDSS spans multiple clinical fields, with concentration in areas characterized by high data availability, complex decision-making requirements, and urgent clinical needs.
Geographic distribution
Studies were conducted across multiple countries, demonstrating global interest in AI-CDSS development and validation: USA (n = 16), China (n = 10), South Korea (n = 3), Israel (n = 3), Canada (n = 2), Australia (n = 2), Sweden (n = 2), Greece (n = 2), United Kingdom (n = 2), and one study each from Colombia, Germany, Hong Kong, Ireland, Italy, Japan, Thailand, and Turkey.
AI tool characteristics (Table 3)
The AI models evaluated ranged from traditional machine learning algorithms (logistic regression, random forests, gradient boosting machines, support vector machines) to complex deep learning approaches (neural networks, convolutional neural networks for imaging, recurrent neural networks). Approximately one-third of studies involved imaging data (e.g., radiology or pathology images interpreted by AI), another third focused on electronic health record (EHR) tabular data or vital signs, and the remainder used other data types including genomic data, clinical text, and multimodal inputs.
Table 3: Summary of Studies Using AI Models and Explainability Tools.
Clinical implementation and deployment context
Of the 50 included studies, the majority (76%) evaluated AI-CDSS using retrospective clinical datasets, while 12 studies (24%) involved prospective clinical deployment or real-time implementation in healthcare settings.
Among studies reporting clinical implementation details (n = 18), the following metrics were documented: workflow integration: 11 studies described integration approaches, including EHR embedding (n = 7), standalone dashboard systems (n = 3), and mobile applications (n = 1); clinician adoption/usage rates: Reported in 6 studies, ranging from 45% to 89% of eligible cases; alert response metrics: 4 studies documented alert override rates (range: 12%–38%); time-to-decision: 3 studies reported decision time improvements (reductions of 2.3–15.7 minutes); clinical outcome measures: 8 studies assessed impacts on patient outcomes, including mortality (n = 4), length of stay (n = 3), and diagnostic accuracy in practice (n = 5)
However, the majority of studies (n = 32, 64%) focused exclusively on technical performance metrics without reporting clinical workflow integration or adoption data, representing a significant gap between ML model development and clinical utility assessment.
Meta-analysis overview
The meta-analysis incorporated 58 outcome measurements from the 50 included studies (some studies contributed multiple outcomes) assessing the diagnostic performance of predictive AI-based clinical decision support tools. A random-effects inverse variance model using DerSimonian-Laird estimates for between-study variance (τ²) was employed.
Diagnostic performance measures
The pooled analysis yielded the following performance metrics: Area Under the Curve (AUC): 0.652 (95% CI: 0.562–0.743), based on 58 outcome measurements; z = 14.162, p < 0.001; Specificity: 0.819 (95% CI: 0.793–0.844), based on 34 studies; Sensitivity: 0.660 (95% CI: 0.535–0.785), based on 40 studies; Accuracy: 0.765 (95% CI: 0.734–0.796), based on 39 studies. These results are visualized in forest plots (Figs 3–6).
QUADAS-2 risk of bias assessment.
Area under the curve.
Specificity.
Sensitivity.
Accuracy.
Heterogeneity and variability across studies
Substantial heterogeneity was observed across all performance metrics, confirming extreme variability unlikely to be due to chance alone: AUC Heterogeneity: Cochran’s Q = 1.2 × 10⁵; H = 46.414; I² = 100%; τ² = 0.1227; Specificity Heterogeneity: Q = 7,107.85; H = 14.676; I² = 99.5%; τ² = 0.0054; Sensitivity Heterogeneity: Q = 2.7 × 10⁵; H = 83.015; I² = 100%; τ² = 0.1624; Accuracy Heterogeneity: Q = 3,354.90; H = 9.396; I² = 98.9%; τ² = 0.0092.
Explainability and model transparency
Among the 50 studies reviewed, 13 (26%) incorporated explainability tools to enhance model transparency. Specifically, 12 studies used SHAP (Shapley Additive Explanations), and 1 study used both SHAP and LIME (Local Interpretable Model-Agnostic Explanations). These methods were applied post hoc and did not influence the underlying predictive performance. Our analysis found no consistent differences in AUROC or accuracy between models with or without reported use of explainability tools, as these techniques are model-agnostic and do not modify algorithm outputs. Explainability tools improved model transparency and aided in identifying potential sources of bias but were insufficient for bias mitigation on their own. It should be noted that transparency is not the same as safety since SHAP and LIME alone do not mitigate bias, nor guarantee generalisability.
Risk of Bias Assessment (QUADAS-2)
The QUADAS-2 tool (Quality Assessment of Diagnostic Accuracy Studies) [13] was employed to evaluate the methodological quality and risk of bias across included studies. Fig 2 presents a summary of QUADAS-2 risk of bias assessments for all studies. Methodological quality was heterogeneous, with most studies demonstrating at least one domain rated as high or unclear risk of bias.
Regarding patient selection, approximately 85% of studies were rated as low risk, employing consecutive patient recruitment or random sampling from existing databases to ensure representative samples. The remaining 15% exhibited unclear or high risk attributable to case-control designs or convenience sampling methodologies. For the index test domain, most studies provided comprehensive descriptions of their AI algorithms and implementation protocols. However, approximately 20% demonstrated unclear risk due to insufficient documentation of model training procedures, validation protocols, or threshold selection criteria. Concerning reference standards, the majority of studies utilized appropriate gold standards, including laboratory-confirmed diagnoses, expert consensus determinations, or validated clinical outcomes. Approximately 15% showed unclear or high risk resulting from suboptimal reference standards or inadequate blinding procedures. In the flow and timing domain, approximately 70% of studies achieved low risk ratings, with complete or near-complete patient accounting and consistent application of reference standards. The remaining 30% exhibited concerns including substantial attrition, exclusion of indeterminate results, or differential assessment timing, factors potentially introducing bias if inadequately addressed. Overall applicability was satisfactory regarding patient populations and index tests in relation to the review objectives. Given this review’s intentionally broad, multi-domain scope, most studies were deemed applicable to the research question.
The AI-specific bias evaluation revealed several critical limitations. External validation was conducted in only 32% of studies (16/50). Explainability methods, such as SHAP or LIME, were implemented in 28% of studies (14/50). Algorithmic bias was explicitly assessed in merely 4% of studies (2/50; Bolton 2024, Du 2022). Prospective validation was performed in 8% of studies (4/50).
An important distinction exists between domain-specific and global bias assessment. Re-analysis revealed that only 15 studies (30%) demonstrated low risk of bias across all four QUADAS-2 domains (patient selection, index test, reference standard, and flow/timing). While approximately 85% achieved low risk in patient selection alone, this metric does not reflect overall methodological quality. High-risk AI-specific concerns were prevalent: approximately 70% of studies (35/50) lacked external validation, 30% (15/50) demonstrated flow and timing concerns, and 20% (10/50) provided insufficient detail regarding model training or threshold determination.
A substantial gap exists between technical validation and real-world implementation evidence. Technical validation alone characterised 92% of studies (46/50), while only 8% (4/50) reported implementation outcomes. Critical metrics remained largely unreported: no studies documented adoption rates, one study reported alert override rates, no studies measured time-to-decision, and only two studies assessed patient outcomes beyond diagnostic accuracy.
Interpretation and implications
The pooled analysis demonstrates technically promising performance but limited evidence of real‑world impact, particularly regarding specificity (0.819) and accuracy (0.765). However, sensitivity (0.660) and discriminatory ability as measured by AUC (0.652) were more moderate. The substantial heterogeneity across all metrics (I² > 98.9% for all measures) underscores considerable variability in study populations, clinical tasks, AI methodologies, and evaluation approaches. The limited reporting of clinical implementation metrics in the majority of studies highlights a critical gap between technical performance validation and real-world clinical utility assessment. While ML performance metrics provide essential information about model accuracy, they do not fully capture whether AI-CDSS tools integrate effectively into clinical workflows, achieve clinician adoption, or improve patient outcomes in practice. These findings emphasize the need for standardized evaluation methodologies, more comprehensive reporting of both technical and clinical metrics, and further validation in diverse clinical environments to enhance the generalizability and practical utility of predictive AI-CDSS tools.
Discussion
Principal findings
This systematic review and meta-analysis of 50 studies across 17 medical specialties revealed moderate-to-good predictive performance of AI-based clinical decision support systems, with notable variability across performance metrics and substantial methodological heterogeneity. Specificity was notably high at 81.9% (95% CI: 0.793–0.844), indicating strong potential for accurately identifying true negatives and reducing unnecessary interventions. Accuracy was robust at 76.5% (95% CI: 0.734–0.796), highlighting overall reliability in practical applications. However, sensitivity was more moderate at 66% (95% CI: 0.535–0.785), suggesting limitations in identifying true positives and raising concerns about missed diagnoses. The pooled AUC of 0.652 (95% CI: 0.562–0.743) demonstrated moderate discriminatory ability across diverse clinical contexts. Our analysis prioritised clinically meaningful discrimination metrics: primary outcomes included sensitivity, specificity, and AUROC (reported for all studies), with secondary outcomes of PPV and NPV where available. Critically, the absence of calibration assessments and prediction-decision curves in most studies represents a significant evaluation gap. While discrimination metrics reveal whether models distinguish between outcome classes, they fail to assess whether predicted probabilities align with actual outcome frequencies (essential for clinical decision-making, particularly for rare but high-consequence events where miscalibration can have catastrophic implications). We strongly advocate that future AI-CDSS evaluations adopt calibration curves and prediction-decision analyses as mandatory reporting elements, alongside explicit acknowledgment that accuracy alone may be misleading in imbalanced datasets. These tools are indispensable for evaluating whether AI systems provide actionable, reliable probability estimates that support clinical judgment, especially in scenarios where false negatives carry severe consequences.
The substantial heterogeneity observed across all performance metrics reflects the diversity of clinical tasks, patient populations, AI methodologies, and evaluation approaches encompassed in this review. This variability underscores that AI-CDSS performance is highly context-dependent and cannot be easily generalized across clinical domains without careful consideration of task-specific characteristics and implementation settings. Our meta-analysis employed the DerSimonian-Laird random-effects model, which may underestimate between-study variance under conditions of extreme heterogeneity. While alternative estimators such as restricted maximum likelihood (REML) or Paule-Mandel, potentially with Hartung-Knapp adjustments, might provide more conservative confidence intervals, we maintained the DL approach for consistency with established systematic review methodology. The substantial heterogeneity observed (I² > 90%) reflects genuine diversity in clinical domains, AI methodologies, and patient populations rather than methodological limitations, reinforcing the need for domain-specific validation of AI-CDSS.
Gap between technical performance and clinical implementation
A critical finding is the marked gap between technical validation and real-world clinical implementation. While 76% of studies evaluated AI-CDSS using retrospective datasets, only 24% involved prospective deployment. Furthermore, 64% reported exclusively on technical metrics (sensitivity, specificity, accuracy, AUROC) without documenting workflow integration, clinician adoption, or patient outcomes. Among 18 studies (36%) reporting implementation details, approaches varied considerably, including EHR embedding, standalone dashboards, and mobile applications. However, inconsistent reporting limits assessment of clinical utility beyond technical performance. This gap highlights a fundamental challenge: demonstrating high predictive accuracy in controlled settings does not guarantee successful clinical integration or improved outcomes. Transition from development to deployment requires attention to human factors, workflow compatibility, and organizational readiness, dimensions that remain understudied.
A key methodological issue is inconsistency in performance metric reporting [14,15]. Terms like AUC and AUROC were used interchangeably, often without clear definitions [16]. Some studies differentiated AUROC from AUC-PR, offering better understanding of model performance in imbalanced datasets [17,18]. Others used “AUC” ambiguously, complicating cross-study comparisons [19]. While sensitivity and specificity were generally reported consistently, they were calculated at varying probability thresholds, making direct comparisons problematic [20,21]. Threshold choice has substantial clinical implications; optimizing for high sensitivity versus specificity represents different priorities depending on context [22,23]. Predictive values (PPV and NPV), crucial for clinical decision-making, were seldom reported despite their direct clinical relevance [24,25]. This lack of standardization undermines evidence synthesis and limits generalizability [26,27]. The field would benefit from consensus guidelines on performance metric reporting, similar to TRIPOD-AI or CONSORT-AI initiatives [28,29].
Explainability and trust in AI-CDSS
Explainability emerged as critical for clinician trust and adoption, yet remains inadequately addressed [30,31]. Complex models, particularly deep neural networks and ensemble methods, often function as “black boxes” [32,33]. This opacity leads to clinician hesitation, especially when AI outputs conflict with clinical judgment [34,35]. Lack of explainability raises legal and ethical concerns, as clinicians must justify decisions to patients, colleagues, and in medico-legal contexts [36,37]. The question of accountability remains unresolved in most healthcare systems [38,39]. Explainability techniques such as LIME and SHAP were employed in 26% of studies [40,41]. These methods identify which features most influenced model outputs [42,43]. However, explainability tools were applied retrospectively and did not consistently improve performance or adoption [44,45]. There is an important distinction between model interpretability and prediction explainability; both are needed for full integration, yet most studies addressed only the latter [46,47]. The tension between model complexity and interpretability remains fundamental [48,49]. Simpler models offer inherent interpretability but may sacrifice accuracy compared to deep learning [50,51]. Future research must balance predictive performance with explainability, potentially through hybrid models or interpretable-by-design architectures [52,53].
Bias, fairness, and ethical concerns in AI-CDSS
AI models inherit biases from training data, potentially perpetuating healthcare disparities [54,55]. Development must prioritize diverse, representative datasets ensuring adequate representation across race, ethnicity, sex, age, socioeconomic status, and geography [56,57]. However, diverse data alone is insufficient; developers must assess performance across demographic subgroups, implement fairness-aware algorithms, and monitor deployed models for bias [58,59]. Regulatory frameworks emphasize these requirements, though standardized approaches remain underdeveloped [60,61].
Ethical implications extend beyond technical fairness to consent, transparency, and patient autonomy [62,63]. Patients should be informed when AI contributes to their care and have mechanisms to understand or contest AI-influenced decisions [64,65]. Current practice rarely includes such transparency measures [66,67].
This review represents one of the first comprehensive multi-domain assessments of predictive AI-CDSS, addressing a critical literature gap [68,69]. Previous reviews focused on rule-based CDSS or single clinical domains [70,71]. By synthesizing evidence across 17 specialties, this review reveals patterns transcending individual contexts [72,73].
ROADMAP framework for AI-driven clinical decision support systems in antimicrobial resistance management
We propose the ROADMAP framework to synthesise evidence-based principles for developing, implementing, and evaluating AI-driven CDSS addressing antimicrobial resistance challenges [74,75].
Representative development principles
Development requires representative training datasets reflecting target population diversity [76–81].
Outcomes and patient-centred evaluation
Evaluation must expand beyond technical performance to patient-centered outcomes including quality of life, satisfaction, treatment burden, and health equity impacts [82,83].
Assessment requirements for clinical deployment
AI-CDSS applications demonstrate potential through pathogen resistance profiling [84], contact tracing [85], and predicting Gram-negative bacterial resistance [86]. Digital health tools reveal disparities between high and low-income countries [87], while intrinsic resistance mechanisms contribute significantly to mortality [88]. Infection risk modeling incorporates vital signs and laboratory results [89], with applications in sepsis prediction [90], diagnostics and drug discovery [91], battlefield medicine [92], and sociotechnical frameworks [93]. Adaptive learning systems provide implementation frameworks [94], while AI enhances biosafety protocols and outbreak management [95]. Prediction models for decompensated cirrhosis [96], nosocomial infections [97], and resistant Enterobacterales [98] demonstrate utility. Genomic surveillance informs vaccine development [99], though antibiotic therapy thresholds vary considerably [100]. Context-specific evaluation is essential given performance heterogeneity [101,102]. The COMBACTE-Magnet EPI-Net COACH project assembled evidence for surveillance systems [103], while European surveillance programs publish annual reports [104]. Machine learning for IV-to-oral antibiotic switches faces workflow integration and trust challenges [105]. Case-based reasoning systems demonstrate enhanced prescribing appropriateness [106], while microbiome analysis separates biological signals for AMR surveillance [107].
Data harmonization and global surveillance
Critical gaps include limited understanding of environmental AMR levels, unclear high-risk transmission definitions, and insufficient knowledge of concentrations driving resistance [108]. These gaps are compounded by training biases, inequitable access, and standardization needs [109,110]. Global sewage analysis accommodates regional AMR diversity [111], while clinical microbiologists’ collaboration requires international consensus [112]. The TSARA trial generates actionable data on resistance and prescriptions for low-resource settings [113].
Monitoring challenges in AMR surveillance
Ongoing monitoring addresses performance degradation, bias emergence, and evolving clinical utility [114,115]. Successful implementation encompasses workflow integration, training programs, and organizational readiness [116,117].
Allocation of resources and economic sustainability
Rigorous health economic evaluations (cost-effectiveness analyses, budget impact assessments, value-based implementation modelling) inform resource allocation and guide sustainable integration within resource-constrained systems, fundamental to long-term viability [118,119].
Priorities for targeted research
Critical gaps include standardized reporting frameworks, prospective validation studies in diverse settings, and implementation science frameworks elucidating determinants of AI-CDSS adoption [120,121].
Limitations
Several limitations warrant acknowledgment. First, our focus on predictive AI-CDSS excludes knowledge graphs, natural language generation, and conversational agents [122,123]. Second, the predominance of retrospective evaluations (76%) versus prospective deployments introduces potential performance bias [124,125]. Retrospective performance often represents an upper bound for prospective deployment [126]. Third, limited reporting of implementation metrics prevented comprehensive assessment of real-world utility [127,128]. Fourth, QUADAS-2, while providing valuable quality assessment, was not designed for AI-driven diagnostic tools and may not capture AI-specific biases such as overfitting, poor generalizability, or data leakage [13,129]. The upcoming QUADAS-AI tool [130] will standardize assessment in systematic reviews [131]. Finally, our search was limited to PubMed and Cochrane Library [132]. Although these provide extensive coverage, relevant studies in computer science venues or preprint servers may have been missed [133].
Materials and methods
This systematic review adheres to the PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) [12] guidelines to ensure transparency and methodological rigor.
Rationale and scope
The landscape of clinical decision support has been transformed by recent advances in artificial intelligence, particularly deep learning and transformer-based architectures. While earlier systematic reviews examined traditional clinical decision support systems, the rapid evolution of AI methodologies, including convolutional neural networks, recurrent neural networks, and attention mechanisms, has created a knowledge gap requiring contemporary synthesis. Previous reviews have not comprehensively evaluated AI-based CDSS performance across multiple clinical domains using modern predictive modelling approaches, nor have they systematically assessed the standardization of performance metrics in this rapidly evolving field.
This review focuses specifically on predictive AI-based clinical decision support systems; tools that use machine learning or deep learning to generate individualized predictions or risk assessments to inform clinical decisions. This represents the largest and fastest-growing segment of AI-CDSS applications and merits focused analysis given its clinical prevalence. This operational definition intentionally excludes other AI-CDSS types such as knowledge graphs, natural language generation systems, and conversational agents, which would require different methodological approaches and are noted as a limitation of this review.
Definition and identification of CDSS studies
To ensure consistency and reproducibility in study selection, we established explicit operational definitions. A Clinical Decision Support System (CDSS) was defined as a health information technology system designed to assist clinicians in making decisions by providing individualized, actionable recommendations or predictions based on clinical data inputs.
An AI-based predictive CDSS was defined as a digital clinical decision support tool that utilizes artificial intelligence techniques, including machine learning (ML), deep learning (DL), or natural language processing (NLP), to derive predictions or risk assessments from clinical data. This focus on predictive modeling reflects the dominant paradigm in current AI-CDSS research and clinical implementation.
Tools were excluded if they met any of the following criteria: (1) use of rule-based logic without learning algorithms (e.g., IF-THEN statements); (2) being non-digital (e.g., paper-based algorithms); (3) functioning solely as descriptive analytics tools without providing individualized outputs for clinical decision-making; or (4) representing non-predictive AI-CDSS types such as knowledge retrieval systems, natural language generation tools, or conversational agents.
Search strategy
A systematic literature search was conducted across major biomedical databases, covering studies published up to December 6, 2024. We searched PubMed and the Cochrane Library, which were selected based on their comprehensive coverage of peer-reviewed medical literature and their established role as primary sources for clinical evidence synthesis. PubMed provides extensive indexing of biomedical journals with robust MeSH term capabilities, while Cochrane captures high-quality systematic reviews and controlled trials. For our research question focused on clinical decision support systems in healthcare settings, these databases offer comprehensive coverage of the target literature. While EMBASE provides additional European coverage, preliminary scoping indicated substantial overlap with PubMed for our inclusion criteria. IEEE Xplore, while valuable for computer science perspectives, primarily indexes technical implementations rather than clinical evaluations, which formed the core of our inclusion criteria.
The search strategy employed combinations of terms including “Clinical Decision Support System,” “CDSS,” “Artificial Intelligence,” “Machine Learning,” “Deep Learning,” “Predictive model,” and associated Medical Subject Headings (MeSH) terms. Results were supplemented with grey literature and clinical trial registries to minimize publication bias.
Eligibility criteria
Studies were included if they met all of the following criteria:
- Tool Characteristics: The study evaluated an AI-based Clinical Decision Support System (CDSS) that used machine learning, deep learning, or related AI methods to generate individualized clinical predictions or recommendations.- Evaluation Focus: The study assessed predictive performance using standard metrics (accuracy, sensitivity, specificity, or AUROC).- Clinical Context: The CDSS was evaluated using real-world clinical datasets or implemented in actual healthcare settings. This included both systems deployed in clinical practice and systems rigorously validated using authentic clinical data.- Study Design: The study used a quantitative observational or experimental design, such as retrospective cohort studies, prospective trials, or randomized controlled trials.- Language and Publication Date: Studies published in English on or before December 6, 2024.
Exclusion criteria
Studies were excluded if they:
- Did not use AI methodologies (e.g., relied solely on rule-based or expert systems)- Failed to report predictive performance using standard metrics- Were published in non-peer-reviewed formats (e.g., editorials, conference abstracts, case reports)- Described AI tools that did not directly support clinical decision-making (e.g., image segmentation algorithms without interpretive or predictive outputs)- Involved non-predictive AI-CDSS types (knowledge graphs, conversational agents, NLP generation systems)
Study selection
Two reviewers (WW and AG) independently screened all retrieved records in two stages. First, they reviewed titles and abstracts to identify potentially eligible studies. Second, they conducted full-text reviews to confirm eligibility.
Discrepancies were resolved through discussion. When consensus could not be reached, a third senior reviewer (HA) made the final decision. A detailed screening log documented all decisions and rationales. Inter-rater reliability was assessed using Cohen’s kappa statistic at each stage.
Data extraction
Data extraction was performed independently by the same two reviewers (WW and AG) using a standardized extraction template. Extracted information included: publication details: Authors, year, journal, geographic location; clinical domain and setting: Specialty, care setting (inpatient/outpatient/emergency), patient population; study characteristics: Sample size, study design, data sources; AI-CDSS characteristics: Algorithm type (e.g., random forest, neural network), input features, targeted clinical task, training dataset details; performance metrics: Sensitivity, specificity, accuracy, AUROC, PPV, NPV; clinical implementation metrics: Where reported, we extracted data on clinical workflow integration, clinician adoption rates, time-to-decision, alert override rates, and clinical outcome measures (e.g., changes in mortality, length of stay, diagnostic accuracy in practice). Any disagreements encountered during data extraction were resolved through discussion or, when necessary, through consultation with the third reviewer (HA).
Risk of bias assessment
The QUADAS-2 tool (Quality Assessment of Diagnostic Accuracy Studies) [13] was applied to assess the methodological quality and risk of bias in the included studies. QUADAS-2 evaluates risk of bias in four domains: patient selection, index test, reference standard, and flow of patients/timing of assessments. Two reviewers independently applied QUADAS-2 to each study, with disagreements resolved by consensus.
Signalling questions were answered per QUADAS-2 guidance, and each domain was rated as “low,” “high,” or “unclear” risk of bias. We also evaluated concerns regarding applicability in each domain. It is important to note that QUADAS-2 was not originally designed to assess AI-driven diagnostic tools, which often have unique sources of bias such as overfitting to training data, poor generalizability across populations, and data leakage. As such, this quality assessment may not fully capture AI-specific bias issues. The overall QUADAS-2 ratings for each study are presented in Fig 1a and 1b.
Outcome measures and standardization
For consistency, we standardized the definitions of key metrics across studies: Sensitivity (recall): The proportion of true positive cases correctly identified by the AI tool; Specificity: The proportion of true negative cases correctly identified; PPV (precision): The probability that a positive prediction by the AI is a true positive; NPV: The probability that a negative prediction is a true negative; Accuracy: The overall proportion of correct classifications (true positives plus true negatives over all cases); AUC (AUROC): The Area Under the Receiver Operating Characteristic curve, which plots sensitivity versus (1–specificity).
Data synthesis and analysis
We summarized key findings of included studies qualitatively and, where appropriate, quantitatively via meta-analysis. For studies sufficiently homogeneous in terms of reported metrics, we pooled performance measures using random-effects meta-analysis models (DerSimonian-Laird method). We chose a random-effects model a priori given the anticipated heterogeneity in study populations, clinical tasks, and AI models.
Pooled estimates with 95% confidence intervals (CI) were computed for the primary metrics of interest (sensitivity, specificity, accuracy, and AUROC). Each study’s contribution was weighted by the inverse of its variance (incorporating sample size and outcome prevalence), so that larger studies (with more precise estimates) had greater influence on the pooled result.
We assessed statistical heterogeneity using Cochran’s Q and the I² statistic, with I² > 75% indicating substantial heterogeneity. The I² statistic is used to quantify the dispersion of effect sizes in a meta-analysis, representing the percentage of total variation across studies that is due to heterogeneity rather than chance; values of 25%, 50%, and 75% are commonly interpreted as low, moderate, and high heterogeneity, respectively. We also report τ² as the between-study variance. All meta-analyses were conducted using Stata Statistical Software Release 15 (StataCorp), and results are displayed in forest plots (Fig 3–6).
We evaluated publication bias qualitatively (e.g., noting if only positive studies were published in certain domains) and with funnel plots for the main outcome (AUC) when ≥10 studies were available.
Where reported in source studies, we qualitatively synthesized clinical implementation metrics including workflow integration approaches, clinician adoption patterns, alert response rates, and impacts on clinical outcomes.
No formal patient or public involvement was applicable in this evidence synthesis, as it relied on previously published studies.
Conclusion
This review identifies that predictive AI-CDSS achieve moderate diagnostic performance across diverse specialties, with particular strength in specificity [134,135]. However, substantial performance heterogeneity, predominance of retrospective studies, and limited reporting of implementation metrics highlight a critical gap between technical validation and real-world utility assessment [136,137]. To realize AI-CDSS potential in enhancing clinical decision-making and patient care, the field must transition from focusing on technical metrics toward comprehensive evaluation encompassing workflow integration, clinician adoption, patient outcomes, and health equity impacts [138,139]. This requires collaboration across AI developers, clinicians, patients, health system administrators, regulators, and policymakers to establish standardized frameworks, address ethical concerns, and develop implementation strategies facilitating successful translation from development to deployment [140,141]. As AI methodologies evolve rapidly with deep learning, transformer architectures, and foundation models, maintaining rigorous, transparent, and clinically meaningful evaluation standards will be essential [142,143]. The QUADAS-AI tool [130] represents an important step toward standardizing quality assessment [144], and its adoption should be prioritized. By addressing identified gaps, particularly the need for prospective validation, standardized reporting, and implementation-focused research, the field can move toward evidence-based integration of AI-CDSS that demonstrably improves clinical care while maintaining safety, fairness, and patient trust [145,146].
Supporting information
S1 FilePRISMA Checklist (From: Page MJ, McKenzie JE, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, et al. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews.BMJ 2021;372:n71. https://doi.org/10.1136/bmj.n71. This work is licensed under CC BY 4.0. To view a copy of this license, visit https://creativecommons.org/licenses/by/4.0/).(PDF)
S1 TextFinal Search Strategy.(PDF)
S1 TableSystematic Review Study Characteristics.(PDF)
S2 TableIncluded Studies Data.(PDF)
S3 TableSummary of Studies Using AI Models and Explainability Tools.(PDF)
S4 TableAll Studies Identified in Literature Search (excel spreadsheet).(CSV)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Magrabi F, Ammenwerth E, Mc Nair JB, De Keizer NF, Hyppönen H, Nykänen P, et al. Artificial Intelligence in Clinical Decision Support: Challenges for Evaluating AI and Practical Implications. Yearb Med Inform. 2019;28(1):128–34. doi: 10.1055/s-0039-1677903 31022752 PMC 6697499 · doi ↗ · pubmed ↗
- 2Moazemi S, Vahdati S, Li J, Kalkhoff S, Castano LJV, Dewitz B, et al. Artificial intelligence for clinical decision support for monitoring patients in cardiovascular IC Us: A systematic review. Front Med (Lausanne). 2023;10:1109411. doi: 10.3389/fmed.2023.1109411 37064042 PMC 10102653 · doi ↗ · pubmed ↗
- 3Oehring R, Ramasetti N, Ng S, Roller R, Thomas P, Winter A, et al. Use and accuracy of decision support systems using artificial intelligence for tumor diseases: a systematic review and meta-analysis. Front Oncol. 2023;13:1224347. doi: 10.3389/fonc.2023.1224347 37860189 PMC 10584147 · doi ↗ · pubmed ↗
- 4Beşler MS, KoçU. Systematic review of artificial intelligence competitions in radiology: a focus on design, evaluation, and trends. Diagn Interv Radiol. 2026;32(2):164–70. doi: 10.4274/dir.2025.243152 40192339 PMC 12954092 · doi ↗ · pubmed ↗
- 5Moor M, Banerjee O, Abad ZSH, Krumholz HM, Leskovec J, Topol EJ, et al. Foundation models for generalist medical artificial intelligence. Nature. 2023;616(7956):259–65. doi: 10.1038/s 41586-023-05881-4 37045921 · doi ↗ · pubmed ↗
- 6Hama T, Alsaleh MM, Allery F, Choi JW, Tomlinson C, Wu H, et al. Enhancing Patient Outcome Prediction Through Deep Learning With Sequential Diagnosis Codes From Structured Electronic Health Record Data: Systematic Review. J Med Internet Res. 2025;27:e 57358. doi: 10.2196/57358 40100249 PMC 11962322 · doi ↗ · pubmed ↗
- 7Jones C, Thornton J, Wyatt JC. Artificial intelligence and clinical decision support: clinicians’ perspectives on trust, trustworthiness, and liability. Med Law Rev. 2023;31(4):501–20. doi: 10.1093/medlaw/fwad 013 37218368 PMC 10681355 · doi ↗ · pubmed ↗
- 8Maher D, Sluggett JK, Soriano J, Hull D-A, Hillock NT. Surveillance of Antimicrobial Use in Long-Term Care Facilities: An Antimicrobial Mapping Survey. J Am Med Dir Assoc. 2024;25(9):105144. doi: 10.1016/j.jamda.2024.105144 38991651 · doi ↗ · pubmed ↗