Correlations without causation do not support claims of human–LLM reasoning alignment
Ivan I. Vankov, Federico Adolfi, Rachel F. Heaton, Guillermo Puebla, Jeffrey S. Bowers

Abstract
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
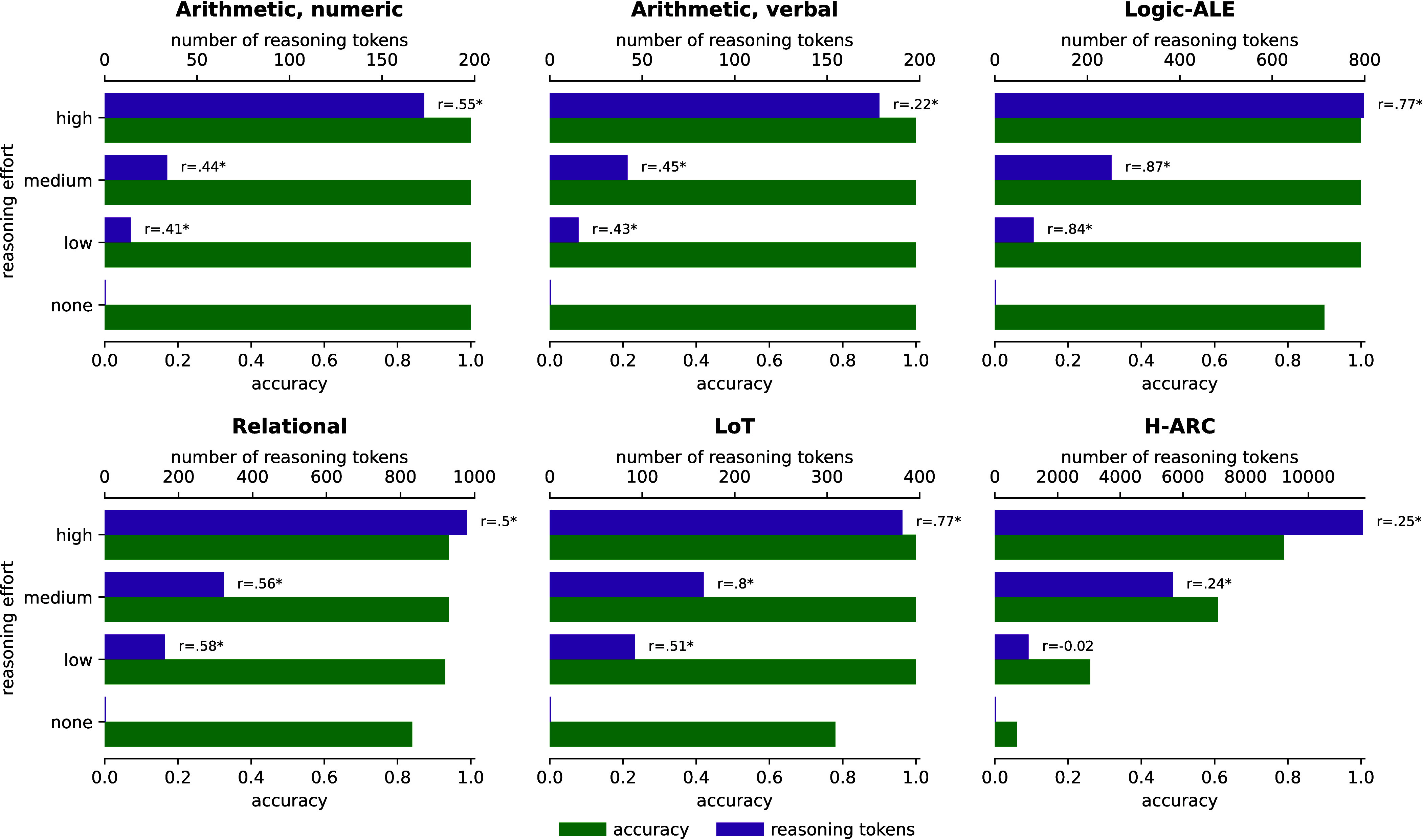 Figure 1
Figure 1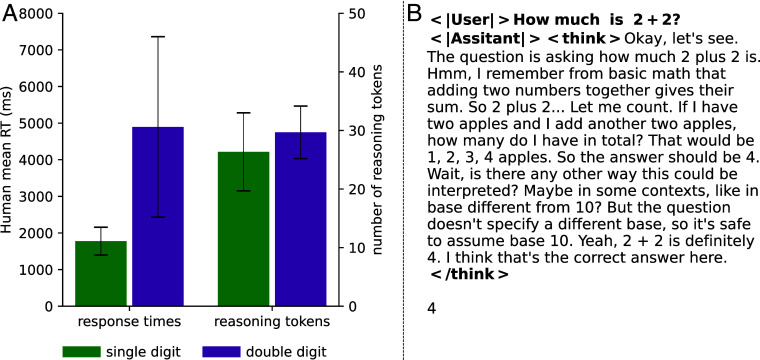 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsChild and Animal Learning Development · Biomedical Text Mining and Ontologies · Genomics and Rare Diseases
de Varda et al. (1) ask whether large language reasoning models (LRMs) can serve as models of human reasoning. To address this question, they compared LRM and human performance across seven tasks that varied in difficulty and found that the number of “reasoning” tokens generated by LRMs predicted human reaction times. The authors concluded that “LRMs exhibit strong alignment with human reasoning behavior, not only in terms of which problems are solved correctly but also in the processing cost associated with solving them.” They also took these findings to challenge the view that symbolic architectures are required to support human-like thinking.
Central to their argument is the assumption that the correlations were causal, with successful predictions reflecting similar reasoning processes. We tested this assumption by manipulating the length of the reasoning trace generated by the LRM gpt-oss-120b on six tasks used by de Varda et al. These manipulations had minimal effect on accuracy in 5 of 6 tasks (Fig. 1). Furthermore, the LRM generated a similar number of tokens when adding single- and double-digit numbers (Fig. 2A). If the observed correlations reflected LRM-Human alignment, then increasing/decreasing the number of tokens output by the LRM should have improved/impaired its performance, and the LRM should have generated many more tokens when adding 2-digit numbers. An inspection of a sample LRM reasoning trace illustrates the problem (Fig. 2B).
Our results align with studies showing that reasoning-trace length is often unrelated to model performance (2, 3). Why do de Varda et al. observe correlations between token length and RTs? LRMs have been trained on datasets where more difficult problems are paired with longer demonstrations. Accordingly, they may simply be reproducing training-induced output patterns rather than allocating additional computation in response to difficulty.
With regard to de Varda et al.’s claim regarding symbolic architectures, it is important to note that there is a debate as to whether LRMs implement symbolic processes (4, 5). So even if the authors’ premise was correct and LRM-human reasoning was aligned, it would not speak to the role of symbols in thinking.
The field of NeuroAI contains many cases in which correlations are interpreted causally (6). For example, the LLM Centaur was claimed to provide “…tremendous potential for guiding the development of cognitive theories” (7). However, the model failed spectacularly when alignment was assessed through manipulations, such as perfectly repeating 256 digits in a digit-span task (8). Similarly, Brain-Score is designed to “score any ANN on how similar it is to the brain mechanisms for “core object recognition” (9). However, following an image manipulation, it was found that predictions were largely driven by the backgrounds rather than the objects themselves (10). These and many other examples highlight the importance of manipulating variables to test causal hypotheses rather than relying on correlations to draw conclusions regarding alignment.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1A. G. de Varda, F. P. D’Elia, H. Kean, A. Lampinen, E. Fedorenko, The cost of thinking is similar between large reasoning models and humans. Proc. Natl. Acad. Sci. U.S.A. 122, e 2520077122 (2025).41259137 10.1073/pnas.2520077122 PMC 12663947 · doi ↗ · pubmed ↗
- 2J. Su, J. Healey, P. Nakov, C. Cardie, Between underthinking and overthinking: An empirical study of reasoning length and correctness in LL Ms. ar Xiv [Preprint] (2025). https://arxiv.org/abs/2505.00127 (Accessed 12 December 2025).
- 3K. Valmeekam, K. Stechly, V. Palod, A. Gundawar, S. Kambhampati, Beyond semantics: The unreasonable effectiveness of reasonless intermediate tokens. ar Xiv [Preprint] (2025). https://arxiv.org/abs/2505.13775 (Accessed 12 December 2025).
- 4Y. Yang, , “Emergent Symbolic Mechanisms Support Abstract Reasoning in Large Language Models” in Proceedings of the 42nd International Conference on Machine Learning, A. Singh , Eds. (ICML, Vancouver, Canada, 2025).
- 5J. Feng, J. Steinhardt, “How do language models bind entities in context?” in Proceedings of the Twelfth International Conference on Learning Representations, B. Kim , Eds. (ICLR, Vienna, Austria, 2024).
- 6O. Guest, A. E. Martin, On logical inference over brains, behaviour, and artificial neural networks. Comput. Brain Behav. 6, 213–227 (2023).
- 7M. Binz , A foundation model to predict and capture human cognition. Nature 644, 1002–1009 (2025).40604288 10.1038/s 41586-025-09215-4PMC 12390832 · doi ↗ · pubmed ↗
- 8J. S. Bowers, G. Puebla, S. Thorat, K. Tsetsos, C. J. H. Ludwig, On the misuse of LL Ms as models of mind: A case study of Centaur. Psy Arxiv [Preprint] (2025). 10.31234/osf.io/v 9w 37_v 2 (Accessed 12 December 2025). · doi ↗