Context-aware temporal synthesis for scene, entity, and event inference from silent image
Mahmoud Rokaya, Dalia I. Hemdan, Mohammed A. Alzain, El-Sayed Atlam

TL;DR
CATS is a new framework that improves temporal reasoning from silent images by capturing latent time structures without relying on motion cues or dense supervision.
Contribution
CATS introduces a domain-agnostic, interpretable framework for temporal synthesis that operates on silent image sequences and general temporal signals.
Findings
CATS achieves up to 15% relative improvement in mAP and F1-score on egocentric video understanding.
The framework separates diffusion regimes in the ANDI benchmark without architectural changes.
CATS shows stable convergence and interpretable dynamics under CPU-only constraints.
Abstract
A central limitation of existing temporal image analysis and video understanding models lies in their reliance on explicit motion cues, dense supervision, or auxiliary modalities, which constrains their ability to infer latent temporal structure, evolving semantic states, and long-range dependencies from silent image sequences. This limitation becomes critical in settings where temporal meaning emerges implicitly from stable visual representations rather than explicit frame-to-frame dynamics. In this work, we propose CATS (Context-Aware Temporal Synthesis), a mathematically grounded and interpretable framework for temporal reasoning that operates directly on silent image sequences and general temporal signals. CATS integrates curvature-aware temporal alignment, symmetry-enforced attention, slot-based nonlinear recurrence, and semantic memory fusion to model temporal coherence under…
Click any figure to enlarge with its caption.
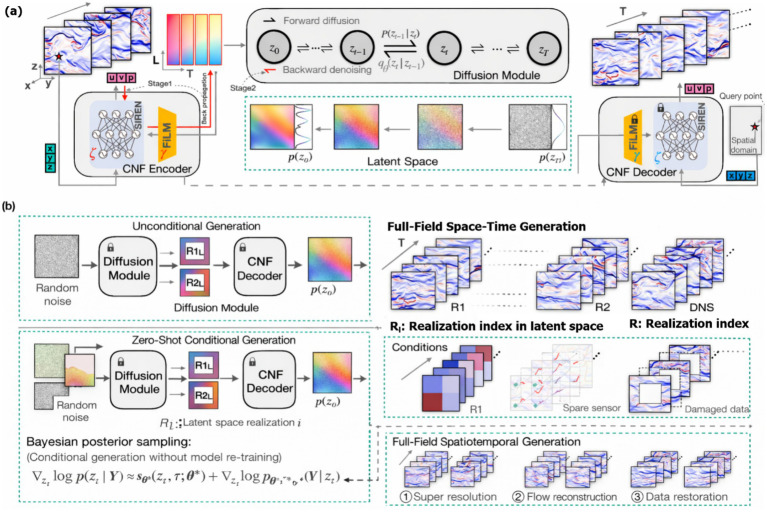 Figure 1
Figure 1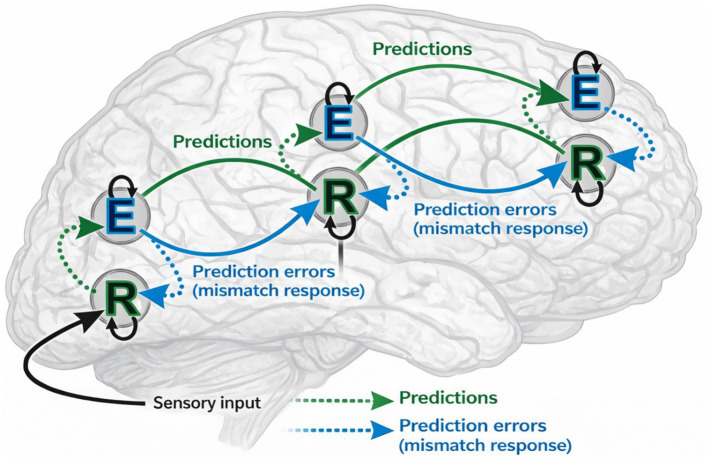 Figure 2
Figure 2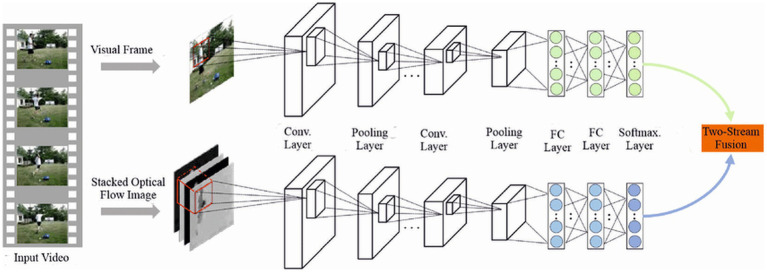 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8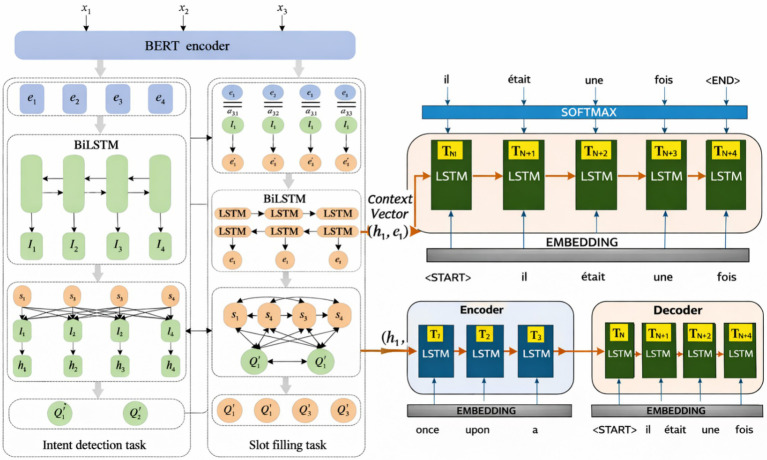 Figure 9
Figure 9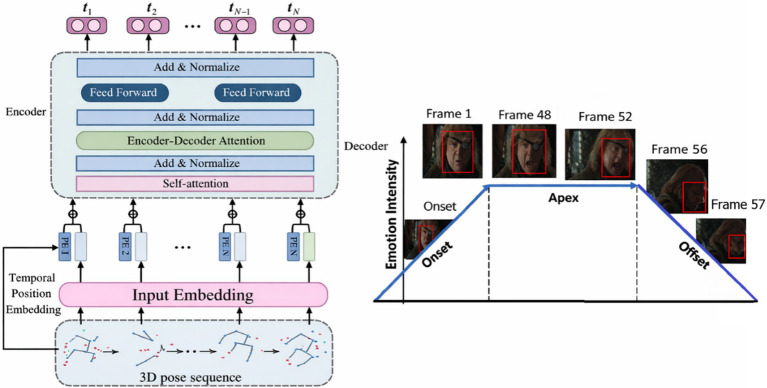 Figure 10
Figure 10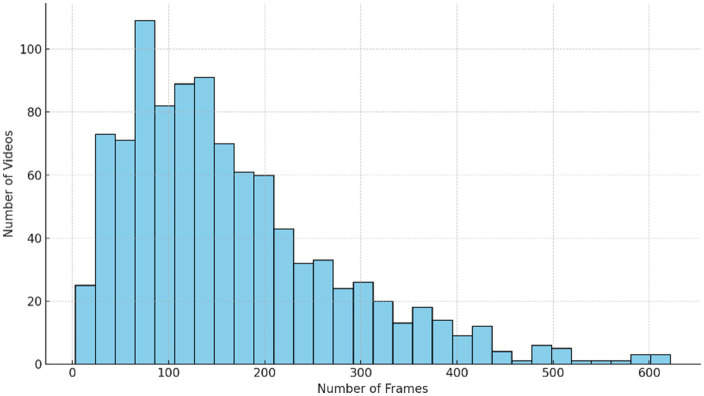 Figure 11
Figure 11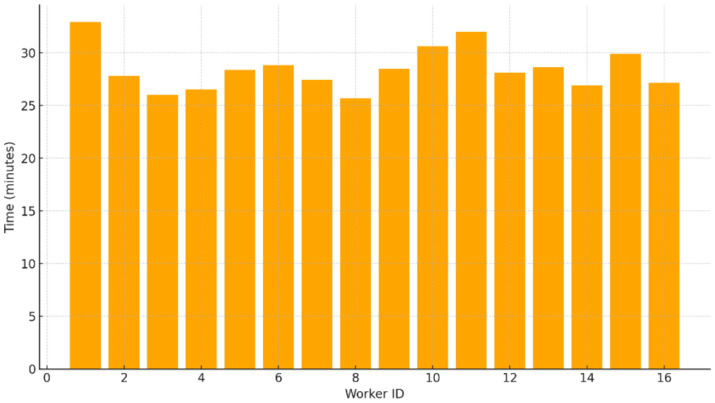 Figure 12
Figure 12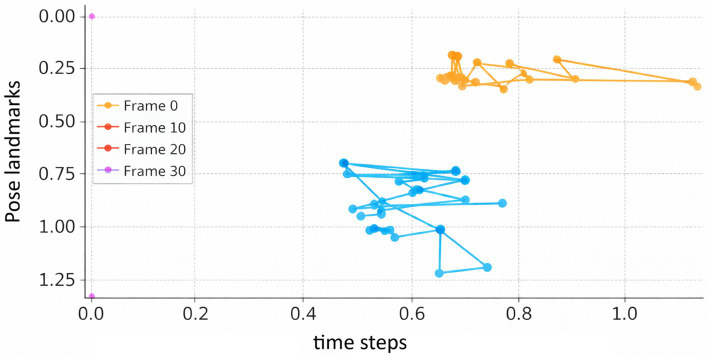 Figure 13
Figure 13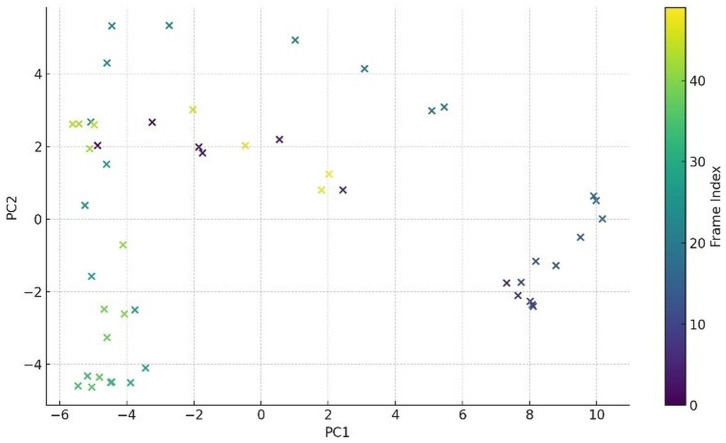 Figure 14
Figure 14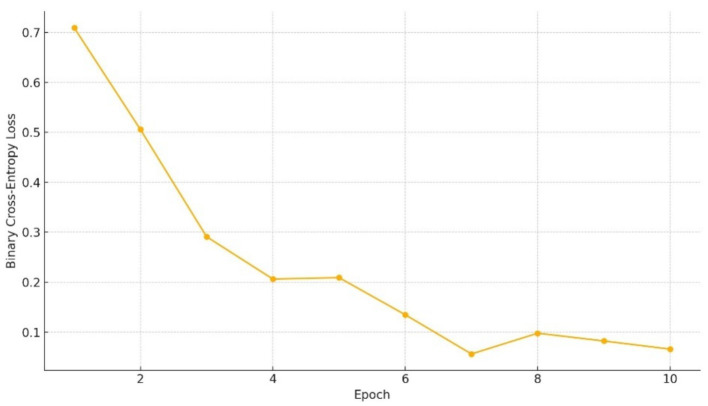 Figure 15
Figure 15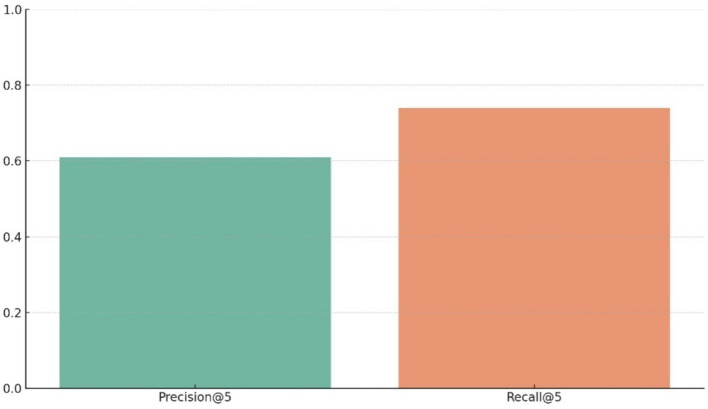 Figure 16
Figure 16 Figure 17
Figure 17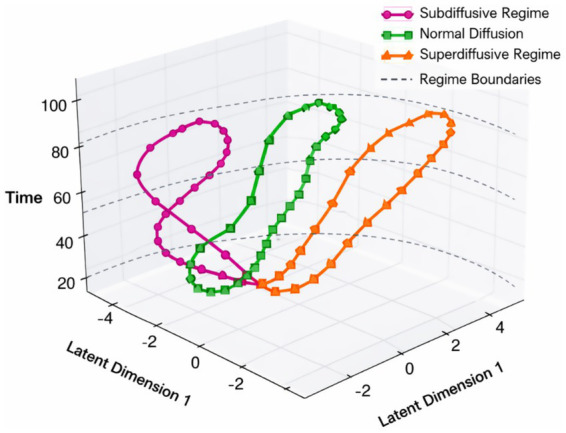 Figure 18
Figure 18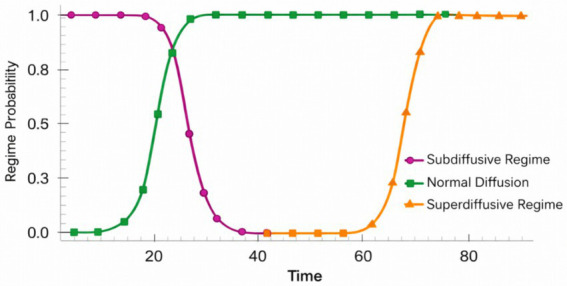 Figure 19
Figure 19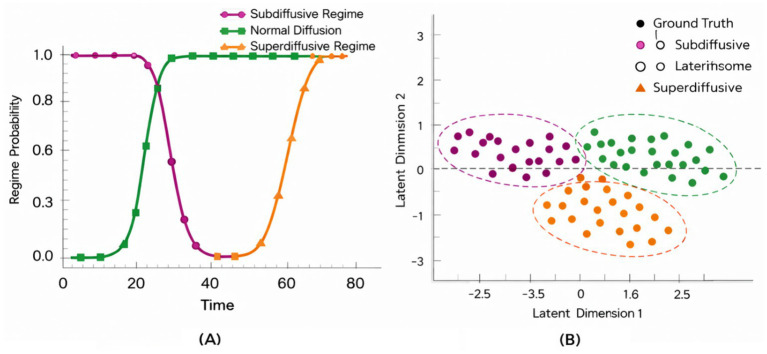 Figure 20
Figure 20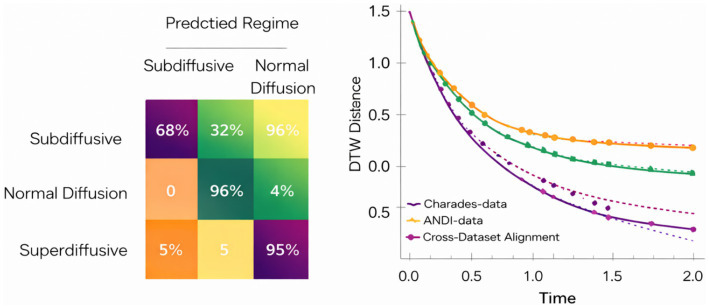 Figure 21
Figure 21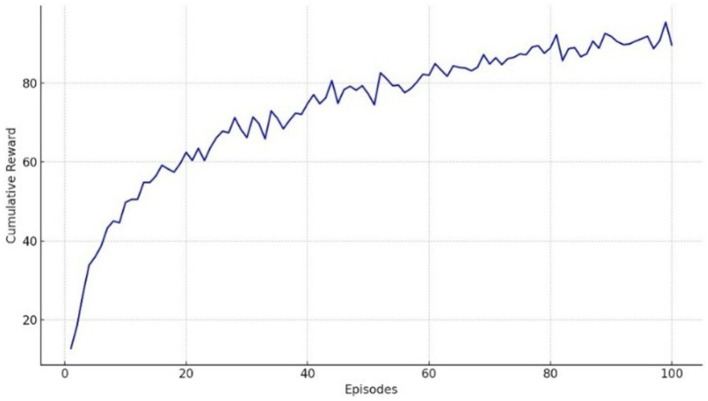 Figure 22
Figure 22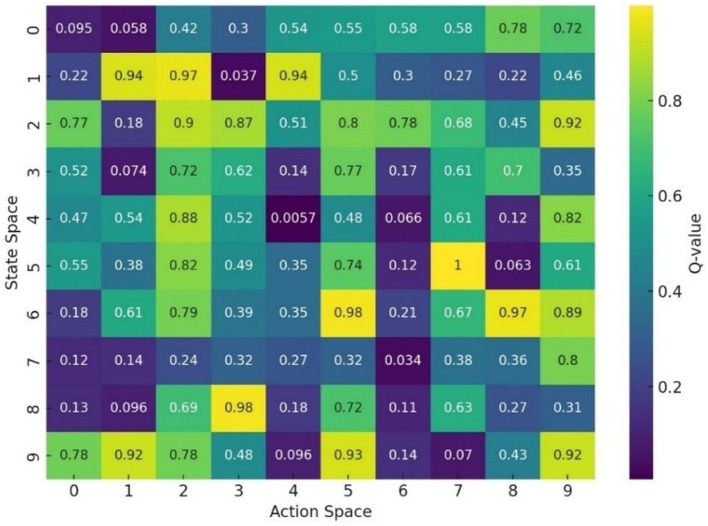 Figure 23
Figure 23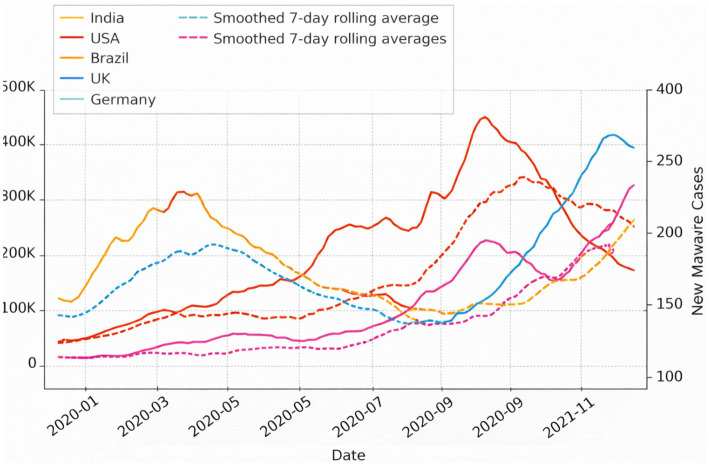 Figure 24
Figure 24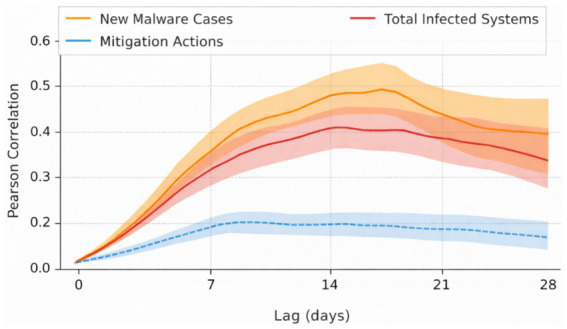 Figure 25
Figure 25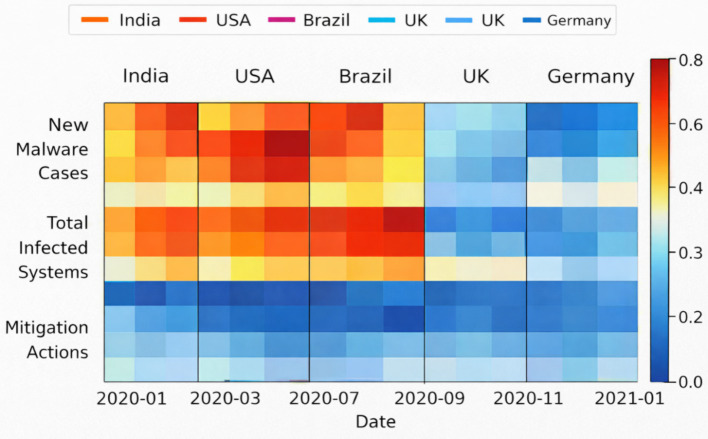 Figure 26
Figure 26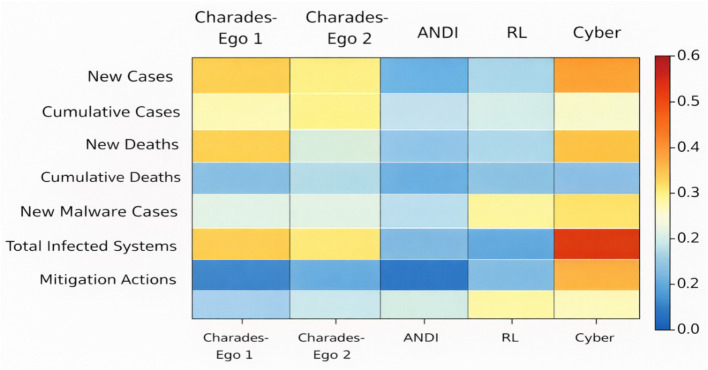 Figure 27
Figure 27| Category | Description |
|---|---|
| Data sampling strategy | Fixed train/validation/test splits per dataset; identical splits used across all model variants and ablation studies |
| Visual feature extractor | ResNet-50 pretrained on ImageNet; parameters frozen during all experiments |
| Input representation (non-visual) | Raw temporal sequences provided directly to CATS without domain-specific preprocessing |
| Temporal modeling architecture | Unified CATS architecture shared across all experiments |
| Latent temporal attention | Gaussian latent attention mechanism with learnable parameters |
| Semantic memory module | Enabled in full model; removed only in ablation variants |
| Slot-based recurrence | Fixed number of slots shared across all experiments |
| Structural symmetry regularization | Applied uniformly across experiments; removed only in ablation analysis |
| Optimizer | Adam |
| Learning rate | Fixed across experiments |
| Weight decay | Fixed across experiments |
| Loss components | Prediction loss + symmetry regularization + memory consistency |
| Loss weights | Fixed and shared across all experiments |
| Batch size | Fixed per experiment and unchanged across model variants |
| Training epochs | Fixed number of epochs with identical stopping criteria |
| Number of runs | Multiple independent runs per experiment |
| Random seeds | Fixed and controlled across all runs |
| Hardware setting | CPU-only training where specified; identical computational constraints enforced |
| Implementation framework | Python with PyTorch |
| Exp. ID | Dataset/Domain | Task | Metric(s) | Baseline (same protocol) | CATS (proposed) | Training/Eval setting |
|---|---|---|---|---|---|---|
| E2 | Charades-Ego (egocentric video) | Multi-label action recognition from silent frames | mAP ↑ | Temporal Conv + RNN: ~79% | 86.5% | CPU-only training |
| Macro | ST-GCN (pose-only): ~81% | 0.87 | CPU-only training | |||
| mAP ↑ | Backbone-only (ResNet features, no temporal modeling): ~73% | 86.5% | CPU-only training | |||
| E3 | ANDI (anomalous diffusion) | Diffusion regime classification | Regime accuracy ↑ | PCA + kNN: ~68% | 82–85% | Domain transfer (no retraining) |
| Temporal stability ↓ (variance) | HMM-based baseline: high variance | Low variance | Noise-robust evaluation | |||
| E4 | Charades-Ego | Temporal alignment via RL | Avg. episode reward ↑ | Random policy: low/unstable | Stable monotonic increase | DQN over CATS embeddings |
| ANDI | Regime transition control | Reward convergence ↑ | Tabular RL: slow convergence | Fast convergence | Shared RL formulation | |
| E5 | Cyber-physical (COVID + cybersecurity) | Epidemic forecasting | RMSE ↓ | LSTM: ~420–450 | 379 | Cross-domain transfer |
| MAE ↓ | ARIMA: ~310 | 285 | Same temporal abstraction | |||
| All | Cross-domain | Temporal reasoning robustness | Relative improvement ↑ | Domain-specific models | Up to ~15% | Same architecture |
| Model variant | Visual task (mAP ↑) | ANDI stability (↓) | Cyber-physical forecasting (RMSE ↓) | Relative performance impact |
|---|---|---|---|---|
| Full CATS |
|
|
| — |
| Symmetry regularization | 0.417 | 0.093 | 0.229 | Mild degradation |
| Semantic memory | 0.401 | 0.118 | 0.247 | Significant degradation |
| Slot-based recurrence | 0.386 | 0.132 | 0.261 | Largest degradation |
| Latent temporal attention → Standard attention | 0.409 | 0.104 | 0.238 | Moderate degradation |
| Model/Method | Domain | Primary task | Metric(s) | Performance | Source/Reference |
|---|---|---|---|---|---|
| CATS (proposed) | Egocentric video, cyber-physical | Temporal reasoning, multi-modal forecasting | mAP, | mAP: 86.5%, RMSE: 379, | This work |
| Temporal convolution + RNN | Gesture recognition in video | Action classification | mAP, accuracy | mAP: ~79%, accuracy: ~81% |
|
| Audio-visual speaker diarization | Video & audio fusion | Speaker detection | Accuracy, |
| |
| Holistic visual speech recognition | Silent video | Visual speech decoding | Word error rate (WER) | WER: ~41% |
|
| Bayesian fusion tracking | Surveillance video | Object tracking and anomaly detection | Detection precision | Precision: ~83% |
|
| LMMs for visual narratives | Multi-frame images, LMMs | Temporal inference | Qualitative | Inconsistent long-term reasoning |
|
| VirtualHome + Scene graphs | Synthetic video simulation | Scene graph-based action detection | Accuracy, Graph Recall | Accuracy: 72%, Graph R@5: ~69% |
|
| ST-GCN | Human skeleton-based video | Action classification | Top-1 Accuracy | Accuracy: ~81.5% |
|
- —Taif University, Saudi Arabia
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenerative Adversarial Networks and Image Synthesis · Human Pose and Action Recognition · Face Recognition and Perception
Introduction
1
Understanding how coherent meaning emerges over time from visual input is a core problem spanning perception, cognition, and computation. In temporal image analysis, despite substantial progress, many approaches remain limited in their ability to infer high-level contextual semantics such as latent scene structure, interacting entities, and evolving events from silent image sequences that lack audio, language, or metadata (Schuster et al., 2015). Foundational optimization tools for robust alignment and registration support parts of this pipeline, yet they do not solve context inference itself (Olsson et al., 2008). The difficulty becomes more pronounced in settings involving missing or degraded visual evidence, where temporal reasoning must be performed under incomplete observation (Kokaram, 2004).
Neuroscience-inspired perspectives argue that perception is not purely feed-forward, but is better modeled as an inference process guided by hypotheses and active sampling (Friston et al., 2012), consistent with broader theoretical accounts of predictive brain function (Friston, 2010; Clark, 2013). However, many modern vision systems still emphasize local spatiotemporal correlations rather than structural continuity and long-range narrative coherence, leaving fundamental questions about “visual knowledge” unresolved (Pan, 2021). Current work also shows that even advanced sequence-capable models may struggle with temporal narratives when context must be inferred from image sequences alone (Wang X. et al., 2025), and classical recurrent or temporal-convolutional formulations still face limitations when events unfold nonlinearly or across long horizons (Pigou et al., 2018). Early formalizations of temporal reasoning highlight how challenging “truly visual” temporal reasoning can be when uncertainty and incomplete evidence are intrinsic (Ramakrishna et al., 1993).
In parallel, neuro-inspired recurrent modeling demonstrates that rapid context inference can emerge from structured dynamics akin to thalamocortical processing (Zheng et al., 2024), and human studies show temporal prediction effects on memory formation (Johndro et al., 2019) and exploration behavior under contextual guidance (Kragel and Voss, 2021). At the neural systems level, spatial and temporal context jointly modulate sensory responses in ventral stream processing (He et al., 2022). Predictive coding theories further explain how canonical circuit motifs can support temporally structured inference (Bastos et al., 2012), and expectation effects provide computationally grounded mechanisms for perceptual decisions under uncertainty (Summerfield and De Lange, 2014).
On the computational side, temporal consistency modeling remains important in surveillance-like settings (Lin et al., 2015), and spatiotemporal graph-based modeling has advanced skeleton/action understanding (Yan et al., 2018). Structural context learning for tracking also emphasizes the importance of temporally consistent structure (Wen et al., 2012), while debiasing formulations for scene graph generation underline persistent challenges in reliable spatiotemporal structure induction (Xu et al., 2022). Yet silent-sequence settings remain difficult: surveys on lip-reading and silent video understanding document persistent brittleness without auxiliary cues (Oghbaie et al., 2025). Even when relational structure is encoded, topology-driven or mutual-cognitive reasoning frameworks often trade generality and scalability for structured assumptions (Zheng et al., 2022). Earlier temporal context representation work likewise illustrates the tension between expressive temporal semantics and practical generalization (Moldovan et al., 2005).
Multimodal approaches can overcome some limitations by using cross-modal grounding, but they presume auxiliary modalities that silent sequences explicitly lack. For example, holistic visual speech recognition methods still rely on assumptions that break down under silent ambiguity (Nemani et al., 2022), and audio-visual diarization fuses modalities unavailable in silent settings (Gebru et al., 2018). Active speaker detection similarly benefits from multimodal alignment signals not present when only silent images are available (Alcázar et al., 2022). Broader silent speech surveys reinforce that the field still lacks robust solutions when only visual evidence is provided (Chowdhury et al., 2025). This limitation persists even for large multimodal models, where temporal reasoning remains a bottleneck (Imam et al., 2025).
Self-supervised learning provides a complementary path by improving representation stability under weak supervision. Generic self-supervised multimodal change detection frameworks highlight the potential of learning temporally structured cues without labels (Wang J. et al., 2025), and fusion-oriented perspectives (as captured by the cited information fusion work) emphasize robustness and principled integration as central requirements in real-world temporal inference (Rudin, 2019). However, stronger performance alone is not enough in many domains: interpretable modeling is essential when decisions are high-stakes or safety-critical (Doshi-Velez and Kim, 2017), and rigorous foundations for interpretability remain an open research agenda (Brundage et al., 2018). Concerns about malicious use and misuse of AI further strengthen the need for transparency and robustness guarantees (Vilone and Longo, 2021). Accordingly, explainability notions and evaluation approaches provide a necessary lens for assessing temporal inference systems (Klein et al., 2024), and systematic evaluation of XAI metrics and methods continues to mature (Samek et al., 2017). In this direction, XAI-focused work emphasizes understanding and interpreting deep models rather than treating them as opaque predictors (Cubillos et al., 2024), while brain–machine interface studies further expose the trade-off between deep performance and explainability (Zhang et al., 2023).
To address these conceptual and technical gaps, we propose CATS (context-aware temporal synthesis), reframing silent sequence understanding as structured temporal inference rather than heuristic aggregation. CATS integrates analytically motivated components for temporal alignment, contextual symmetry, and semantic memory. It is designed to be robust to uncertainty in spatiotemporal events (Lei et al., 2024), and to benefit from mathematically grounded representations that support stable evolution of temporal structure (e.g., level-set inspired parameterizations) (Jiang and Yin, 2023). The framework is evaluated across tasks that require spatiotemporal context understanding, including reasoning settings aligned with modern spatiotemporal benchmarks and QA formulations (Zhou et al., 2025; Calderó et al., 2021; Qiu et al., 2023). We also include egocentric action recognition using simulated spatiotemporal scene graphs (Soomro et al., 2012) and established action datasets (Zhou et al., 2025), supporting broad evaluation of temporal reasoning, robustness, and interpretability.
In this work, silent visual understanding is formulated as a temporally extended inference process grounded in cognitive principles of predictive perception and hypothesis-driven reasoning (Friston et al., 2012; Friston, 2010; Clark, 2013; Bastos et al., 2012; Summerfield and De Lange, 2014). The proposed framework explicitly models long-horizon contextual dependencies and narrative continuity, reflecting empirical and neural evidence that perception and memory rely on temporally integrated signals rather than short-range correlations (Zheng et al., 2024; Johndro et al., 2019; Kragel and Voss, 2021; He et al., 2022). It is designed to support robust reasoning under uncertainty, accommodating missing, degraded, or unordered observations commonly encountered in real-world spatiotemporal data (Kokaram, 2004; Lei et al., 2024). Interpretability is treated as a core design property through transparent temporal alignment, attention dynamics, and memory mechanisms, aligning with current expectations for explainable high-stakes inference systems (Doshi-Velez and Kim, 2017; Klein et al., 2024; Samek et al., 2017; Cubillos et al., 2024; Zhang et al., 2023). Finally, the framework demonstrates generality across diverse temporal reasoning benchmarks and domains, including spatiotemporal learning, reasoning-oriented evaluation, and egocentric action understanding (Lin et al., 2015; Yan et al., 2018; Wen et al., 2012; Xu et al., 2022; Zhou et al., 2025; Calderó et al., 2021; Qiu et al., 2023; Soomro et al., 2012; Soomro et al., 2012).
The primary contribution of this work is an interpretable and mathematically grounded framework for temporal reasoning from silent visual image sequences, where temporal structure must be inferred without auxiliary modalities or explicit motion cues. All non-visual experiments—namely anomalous diffusion modeling (ANDI), reinforcement-based temporal alignment, and cyber-physical forecasting—are intentionally used as validation stress tests to assess whether the learned temporal abstractions generalize beyond the visual domain. This work does not propose new domain-specific models for diffusion physics, reinforcement learning, or epidemiological forecasting; rather, these settings are employed to evaluate the robustness, stability, and modality-independence of the proposed temporal reasoning mechanism.
Literature review
2
Temporal understanding from silent image sequences constitutes a central challenge in visual intelligence, spanning computer vision, artificial intelligence, and cognitive neuroscience. Unlike multimodal perception, silent visual streams provide no linguistic or acoustic cues, requiring inference of structure, causality, and meaning solely from temporal visual evidence. Empirical studies in perception and neuroimaging demonstrate that temporal context fundamentally shapes visual exploration, memory encoding, and recognition processes (Schuster et al., 2015; Johndro et al., 2019; Kragel and Voss, 2021; He et al., 2022). These findings motivate computational approaches that treat temporal integration as a core mechanism rather than a secondary processing stage.
Cognitive and predictive foundations of temporal perception
2.1
Predictive processing theories describe perception as an active inference process in which the brain continuously integrates past observations to generate hypotheses about incoming sensory input (Friston et al., 2012; Friston, 2010). This view is supported by models of predictive coding and hierarchical feedback, where recurrent dynamics enable rapid context inference (Bastos et al., 2012; Summerfield and De Lange, 2014). Behavioral and neural evidence further shows that expectations, temporal regularities, and contextual memory modulate perceptual decisions and sensory representations (Johndro et al., 2019; Kragel and Voss, 2021; He et al., 2022).
Early computational work in temporal reasoning highlighted the inherent difficulty of maintaining coherent representations under uncertainty and partial observability (Ramakrishna et al., 1993; Moldovan et al., 2005). More recent conceptual analyses emphasize unresolved issues in visual knowledge representation, particularly abstraction and temporal continuity (Pan, 2021). Together, these works establish temporal context as a foundational principle of perception, yet one that is only partially reflected in current visual inference models.
Sequential and recurrent modeling of visual dynamics
2.2
Sequential modeling approaches, including recurrent neural networks and temporal convolutional architectures, have dominated temporal visual analysis for over a decade. These models have demonstrated success in gesture recognition, action analysis, and structured event prediction (Pigou et al., 2018; Qiu et al., 2023). However, their reliance on fixed temporal aggregation and implicit recurrence limits their capacity to capture long-range dependencies, non-linear event progression, and temporally sparse dynamics (Ramakrishna et al., 1993).
In silent visual settings, these limitations become more pronounced. Approaches to visual speech recognition, lip reading, and speaker-independent decoding often depend on strong alignment assumptions or constrained regions of interest (Oghbaie et al., 2025; Nemani et al., 2022; Gebru et al., 2018; Alcázar et al., 2022; Chowdhury et al., 2025). Even recent large-scale vision–language and multimodal models struggle with sequence-level narrative understanding when explicit modality fusion is unavailable (Wang X. et al., 2025; Imam et al., 2025). These findings suggest that sequential aggregation alone is insufficient for robust temporal reasoning in unconstrained silent environments.
Graph-based and relational representations
2.3
To capture higher-order structure, graph-based and relational models have been introduced to encode interactions among entities and frames. Spatiotemporal graph convolutional networks and structural context learning methods have improved performance in action recognition, tracking, and surveillance tasks by explicitly modeling relational dependencies (Lin et al., 2015; Yan et al., 2018; Wen et al., 2012). Scene graph generation and relational debiasing further extend this paradigm to complex environments with multiple interacting elements (Xu et al., 2022; Soomro et al., 2012).
Despite their expressive power, graph-based approaches typically rely on predefined nodes, handcrafted edges, or stable identities, which limits scalability and robustness under noise, identity drift, or missing observations (Lei et al., 2024). Maintaining consistent graph structure across long, unstructured sequences remains an open challenge, particularly in silent scenarios where semantic boundaries are ambiguous.
Self-supervised learning from silent visual streams
2.4
Self-supervised learning has emerged as a powerful paradigm for extracting spatiotemporal representations without labeled data or auxiliary modalities. Contrastive objectives, predictive coding, and frame-based learning strategies have demonstrated that meaningful temporal features can be learned from silent visual input alone (Wang J. et al., 2025). These approaches improve data efficiency and robustness and have become central to recent advances in video understanding.
However, most self-supervised methods prioritize representation learning over explicit temporal reasoning. They often focus on localized regions or structured proxy tasks and do not directly address long-term narrative coherence or event-level context (Zhou et al., 2025; Calderó et al., 2021; Qiu et al., 2023). Benchmark datasets such as UCF101 facilitate standardized evaluation but do not resolve the underlying challenge of structured temporal inference in open-domain environments (Soomro et al., 2012).
Interpretability, reliability, and theoretical soundness
2.5
As temporal inference systems are increasingly deployed in high-impact domains such as surveillance, forensics, and decision support, interpretability and reliability have become critical requirements. Strong arguments caution against the use of opaque, black-box models in high-stakes decision-making and advocate for inherently interpretable designs (Doshi-Velez and Kim, 2017; Brundage et al., 2018; Vilone and Longo, 2021). In response, the field of explainable artificial intelligence has proposed taxonomies, evaluation frameworks, and metrics to assess transparency and accountability (Klein et al., 2024; Samek et al., 2017; Cubillos et al., 2024).
Nevertheless, many temporal models remain primarily empirical, with architectural components such as attention, temporal fusion, and positional encoding lacking formal justification. This opacity limits trust and transferability. Recent studies in brain–machine interfaces further highlight the trade-off between expressive deep models and interpretable representations, reinforcing the need for principled, component-level design choices (Zhang et al., 2023).
Synthesis and positioning
2.6
Across perception science, temporal reasoning, and visual modeling, a consistent theme emerges: robust understanding of dynamic scenes requires structured integration of information over time, guided by contextual coherence and predictive consistency. Existing approaches advance individual aspects of this problem sequential modeling, relational reasoning, self-supervised learning, or explainability but remain fragmented. Few frameworks integrate these dimensions into a unified, theoretically grounded model for silent visual inference.
The CATS framework is motivated by this convergence of insights. By combining analytically grounded temporal alignment, symmetry-aware attention, and interpretable memory mechanisms, it addresses limitations observed across prior paradigms. Rather than treating silence as a limitation, the approach embraces it as a defining condition that necessitates structured temporal inference. This positioning enables robust, interpretable, and generalizable reasoning over time, aligning computational modeling more closely with established principles of temporal perception and cognition.
Methods
3
Overview of context-aware temporal synthesis
3.1
Temporal understanding from silent image sequences requires transforming isolated visual observations into a coherent latent narrative. Individual frames often provide insufficient semantic evidence when viewed independently, whereas meaning emerges through temporal alignment, contextual memory, and structurally consistent reasoning. CATS (context-aware temporal synthesis) is designed to address this challenge by learning a continuous latent temporal organization over visual observations, without relying on audio, text, metadata, or explicit timestamps.
Rather than enforcing a predefined ordering, CATS infers temporal structure directly from visual evidence using analytically defined attention, memory, and symmetry mechanisms. The complete end-to-end pipeline, illustrated in Figure 1, integrates visual encoding, latent temporal alignment, semantic memory integration, and contextual decoding into a unified and interpretable framework.
Diffusion–CNF framework for spatiotemporal field generation. (a) Model architecture and latent diffusion process. (b) Unconditional and conditional full-field generation with spatiotemporal applications.
Silent image sequences are encoded into stable semantic features, softly aligned along a learned latent timeline, integrated through semantic memory, and decoded to produce temporally consistent and interpretable predictions.
To motivate the design of CATS, we draw inspiration from predictive processing theories, where perception is modeled as an iterative interaction between top-down expectations and bottom-up error signals. Figure 2 illustrates this conceptual framework, highlighting how hierarchical representations generate predictions while propagating mismatch signals when observations deviate from expectations. Importantly, CATS does not explicitly implement predictive coding units or biological error neurons. Instead, it operationalizes these principles through differentiable latent temporal alignment, curvature-aware attention, and memory-based aggregation, as detailed in the following sections.
Conceptual illustration of predictive processing.
Latent temporal coordinates in the proposed framework are not optimized through an explicit standalone objective. Instead, they are implicitly learned through joint optimization with downstream task-specific prediction losses and structural regularization components already defined in the model. Degenerate or trivial solutions, such as collapsed or uniform temporal mappings, are disfavored because they fail to support accurate prediction, memory consistency, and alignment stability. In particular, supervision from task losses enforces discriminative temporal structure, while the symmetry regularization and memory-slot coupling introduce consistency constraints across neighboring and temporally distant observations. As a result, meaningful latent temporal representations emerge as a byproduct of end-to-end optimization rather than from an independently parameterized coordinate objective.
Visual feature encoding from silent frames
3.2
Given an input sequence of frames , CATS first extracts temporally stable semantic representations while deliberately avoiding explicit temporal cues. A shared visual encoder is applied to every frame,
ensuring that temporal variations reflect genuine semantic evolution rather than encoder drift. In practice, a ResNet-50 backbone initialized on ImageNet is used, producing high-dimensional embeddings that remain comparable across time.
This design decouples spatial encoding from temporal reasoning and allows temporal structure to emerge only at later stages. Figure 3 contrasts conventional two-stream encoders with CATS’ unified semantic encoding philosophy, while Figure 4 illustrates how meaningful temporal signals emerge only after stable per-frame representations are established.
Frame-level semantic encoding using a shared visual backbone. All frames are mapped into a common semantic space, enabling reliable temporal comparison without handcrafted motion cues.
Gait analysis workflow from sagittal (A) and frontal (B) views. (A-1) Lateral-view gait video. (A-2) Extracted body keypoints. (A-3) Computed leg angle. (A-4) Temporal leg angle range (LRang). (B-1) Frontal-view gait video. (B-2) Extracted body keypoints. (B-3) Bilateral leg length estimation. (B-4) Temporal left–right leg difference (LRdiff).
Latent temporal window alignment and curvature-aware attention
3.3
Instead of relying on explicit timestamps or externally imposed ordering, CATS assigns each frame a learnable latent temporal coordinate . Pairwise temporal affinity is computed using a Gaussian attention kernel,
where controls the softness of temporal interactions. This formulation promotes smooth temporal transitions while remaining fully differentiable and robust to non-uniform event progressions.
Figure 5 illustrates how frames are softly organized along an inferred latent timeline rather than rigid frame indices, allowing semantically related frames to influence each other even under missing observations, temporal ambiguity, or re-ordering.
Latent temporal window alignment via Gaussian attention. Frames are softly aligned along an inferred temporal axis, independent of original ordering.
Beyond alignment, the first- and second-order derivatives of the Gaussian kernel introduce implicit curvature regularization, penalizing abrupt temporal shifts and stabilizing optimization. Figure 6 visualizes the resulting derivative behavior, demonstrating how curvature-aware attention suppresses unstable alignments while preserving meaningful temporal correlations.
Curvature-aware behavior of latent temporal attention. Second-order effects stabilize alignment and discourage abrupt temporal discontinuities.
The latent temporal alignment module involves pairwise interactions across temporal positions, and its asymptotic time complexity scales as O(T^2^) with respect to the sequence length T in the worst case. Memory complexity follows the same order when storing alignment scores over all temporal pairs. In practice, however, alignment is computed over compact latent representations rather than raw inputs, and is applied under bounded sequence lengths and fixed latent dimensionality as used in the experiments. While maintaining the expressive power requisite for long-range temporal reasoning, these design choices keep the computational and memory footprint within reasonable limits in realistic conditions.
Structural symmetry and bidirectional temporal consistency
3.4
To ensure temporal reasoning remains consistent under partial observation or reversed sequences, CATS enforces structural symmetry over the attention matrix,
Because the Gaussian kernel is symmetric by construction, this loss acts as a stabilizing regularizer rather than a heuristic constraint. Symmetry enforces direction-invariant temporal reasoning, which is critical for silent visual narratives where causal order may be ambiguous.
Semantic memory integration along the latent temporal axis
3.5
While latent temporal alignment establishes when frames should interact, robust temporal reasoning additionally requires a mechanism to retain and propagate contextual information beyond immediate pairwise interactions. To this end, CATS incorporates a semantic memory module that aggregates temporally aligned information into a smoothly evolving contextual state.
For each latent temporal coordinate , semantic memory is constructed by locally integrating neighboring representations using a Gaussian decay over latent time,
where denotes the semantic embedding at time , and controls the rate of memory decay. This formulation ensures that memory evolves continuously along the latent temporal axis, preserving short-range coherence while enabling long-range contextual influence.
Figure 7 visualizes this process by explicitly showing how semantic information is accumulated locally yet propagates globally over the inferred temporal structure. Importantly, memory integration is guided by latent temporal proximity rather than raw frame indices, allowing coherent context formation even under missing frames, irregular sampling, or reordered sequences. This design prevents memory collapse into static representations and enables stable narrative construction over extended time horizons.
Semantic memory integration along the latent temporal axis. Context is accumulated locally while propagating globally over time.
Slot-based recurrence for structured context consolidation
3.6
While semantic memory captures temporal continuity, complex scenes often involve multiple evolving entities, actions, or abstract concepts that must be tracked in parallel. CATS addresses this challenge using a slot-based recurrent mechanism, where a fixed number of latent slots serve as structured carriers of semantic state.
Each slot is updated via nonlinear recurrence as
where attention-weighted frame representations are selectively routed into each slot. Unlike traditional recurrent models, slots are not tied to fixed spatial regions or object identities; instead, they self-organize around latent semantic roles emerging from temporal alignment and memory integration.
Figure 8 illustrates how slots aggregate information across aligned frames, forming stable yet adaptable semantic representations. This mechanism enables CATS to disentangle concurrent temporal processes such as overlapping actions or interacting entities without requiring explicit supervision or predefined structure. Slots thus function as interpretable intermediate representations that bridge low-level frame features and high-level contextual inference.
Evolution toward explicit memory-centric temporal reasoning.
The number of slots in the slot-based recurrence module is treated as a fixed architectural hyperparameter, selected to balance representational capacity and computational efficiency. Rather than encoding task-specific entities, slots serve as abstract temporal carriers that aggregate information aligned through the latent temporal coordinate mechanism. In this design, performance is primarily driven by the interaction between temporal alignment and recurrence, rather than by fine-grained tuning of slot cardinality. While a systematic sensitivity analysis over the number of slots is a valuable direction for future work, the necessity of slot-based recurrence itself is empirically validated through the ablation analysis reported in the experiments, where removing the slot mechanism consistently leads to performance degradation across tasks.
Contextual decoding and end-to-end computational pipeline
3.7
The final stage of CATS transforms the enriched representations comprising aligned frame features, semantic memory traces, and slot states into task-specific outputs. A contextual decoder jointly consumes these components to produce predictions such as scene labels, action categories, or future intent estimates.
Figure 9 presents the complete end-to-end computational pipeline of CATS, detailing how visual encoding, latent temporal alignment, symmetry enforcement, semantic memory integration, slot-based recurrence, and decoding are composed into a unified architecture. This figure emphasizes the modular yet tightly coupled nature of the framework, highlighting where mathematical constraints regulate information flow and stabilize learning dynamics.
Slot-based recurrence and contextual decoding in CATS.
Complementing this overview, Figure 10 provides a condensed system-level perspective, illustrating how the mathematically grounded modules collectively enable stable, interpretable temporal inference from silent image sequences. Together, Figures 8, 9 clarify both the internal mechanics and the global structure of the model, ensuring transparency from raw input to final prediction.
Complete CATS computational pipeline. Mathematically grounded modules interact to produce stable and interpretable temporal inference.
Computational model architecture
4
CATS++ operationalizes the theoretical principles developed in Section 3 into a unified, end-to-end computational model for reasoning over silent image sequences. Rather than extending conventional sequence models with additional supervision or handcrafted temporal cues, the architecture is deliberately designed around latent temporal organization, interpretable attention dynamics, and modular reasoning units. This design reflects recent trends in the field toward models that are not only accurate, but also analyzable, stable under reordering, and robust to incomplete observations.
At its core, CATS++ departs from strict chronological processing. Temporal structure is not imposed but emerges through optimization, allowing the model to infer meaningful temporal relations directly from visual evidence. This paradigm aligns with a growing body of work favoring implicit temporal representations, memory-augmented architectures, and attention-based reasoning over rigid recurrent or causal pipelines. Importantly, the model remains mathematically grounded: each architectural component corresponds to a well-defined role in the latent temporal reasoning process, ensuring transparency and theoretical consistency.
Modular architecture and latent reasoning flow
4.1
The architecture is organized as a sequence of interacting modules, each addressing a distinct aspect of temporal understanding while remaining loosely coupled. Visual frames are first mapped into a shared representational space using a common encoder, enforcing identity preservation and feature consistency across time. These stable frame-level representations form the substrate upon which temporal reasoning is built, reflecting the principle that temporal semantics can arise from consistency and relational structure, rather than explicit motion encoding.
Latent temporal alignment then governs information exchange across frames. Instead of relying on positional indices, the model learns a continuous latent temporal coordinate for each frame, which dynamically controls attention flow. This mechanism enables frames that are semantically related but temporally distant or disordered to interact directly, supporting inference under missing frames, variable sampling rates, or shuffled inputs. Bidirectional constraints further stabilize this alignment, ensuring that temporal reasoning remains reversible and coherent.
Higher-level semantics are handled through a slot-based reasoning mechanism, where a fixed set of latent slots accumulates and refines contextual information over time. This design mirrors recent advances in object-centric and concept-centric learning, but extends them to the temporal domain. Slots act as carriers of evolving semantic structure, allowing the model to track entities, activities, or abstract concepts without explicit supervision. Semantic memory integration then fuses local frame evidence with global contextual summaries, enabling long-range dependency modeling while preserving locality.
Finally, task-specific decoding operates on enriched representations that combine frame features, latent temporal positions, and slot states. This separation between reasoning and prediction allows CATS++ to adapt naturally across tasks such as classification, segmentation, or contextual inference, without altering the underlying temporal logic. Learning is guided by a compact multi-objective formulation that balances predictive performance with stability, smoothness, and memory consistency, reinforcing the model’s interpretability and generalization capacity.
Experiments and results
5
Experimental design and evaluation protocol
5.1
The experimental evaluation is designed to assess CATS primarily as a silent visual temporal reasoning framework, with additional non-visual temporal datasets employed as controlled validation environments to examine the generality, robustness, and interpretability of the learned temporal abstraction. All experiments follow a unified pipeline consisting of feature extraction, temporal modeling, evaluation under controlled settings, and cross-domain generalization analysis. The design emphasizes three core objectives: (i) robustness to temporal ambiguity and missing structure, (ii) interpretability of temporal alignment and memory mechanisms, and (iii) domain adaptability beyond visual data.
For visual temporal reasoning, experiments are conducted on the Charades-Ego dataset, which contains over 36,000 egocentric video clips annotated with multiple overlapping activity labels. Each video is decomposed into frame sequences from which two complementary representations are extracted: high-level semantic appearance features using a shared ResNet-50 backbone and articulated human motion cues via MediaPipe pose landmarks. Feature extraction is performed offline and stored as synchronized embeddings to decouple temporal modeling from raw video processing, ensuring scalability and reproducibility. To support large-scale processing, the dataset is partitioned into parallel subsets and processed using checkpointed CPU workers, yielding temporally aligned feature archives suitable for downstream learning.
To evaluate temporal reasoning under synthetic yet controlled dynamics, we further incorporate the ANDI (anomalous diffusion) dataset. Unlike natural video data, ANDI provides precisely parameterized temporal trajectories with known diffusion regimes, regime switches, and noise characteristics. This allows direct assessment of CATS’ latent temporal alignment, curvature-aware attention, and memory propagation under well-defined ground-truth temporal structures. ANDI sequences are treated analogously to visual frame sequences, with diffusion states replacing visual embeddings, enabling a modality-agnostic evaluation of temporal inference. This experiment isolates temporal reasoning behavior from visual complexity and provides a principled benchmark for stability, smoothness, and long-range dependency modeling.
To assess feasibility in resource-constrained environments, CATS is trained under a CPU-only setting, using reduced batch sizes and memory-efficient configurations. This experiment evaluates convergence behavior, training stability, and interpretability without reliance on hardware acceleration, reflecting realistic deployment scenarios such as embedded systems or edge analytics. Despite these constraints, the model demonstrates stable optimization and meaningful temporal attention patterns, validating the analytical design of the architecture.
Model performance is evaluated using standard multi-label and temporal metrics, including mean average precision (mAP), macro F1-score, Precision@k, and Recall@k, which are well-suited for overlapping activity recognition and ranked prediction settings. For ANDI-based experiments, additional trajectory-aware metrics are employed to assess temporal regime consistency and alignment accuracy. Qualitative analyses complement quantitative results through visualization of attention weights, latent temporal coordinates, memory evolution, and slot dynamics, providing insight into the internal reasoning process of the model.
Finally, to test cross-domain generalization, the same CATS architecture is applied without structural modification to non-visual temporal data, including cyber-epidemiological time series. This experiment evaluates whether a model trained for silent visual reasoning can transfer its temporal inductive biases to structurally different domains. Across all experiments, the implementation is conducted in Python using PyTorch, with modular components shared across domains to ensure consistency, interpretability, and fair comparison.
Reproducibility and implementation details
5.1.1
All experiments were conducted using a unified implementation of the proposed CATS framework to ensure consistency across visual and non-visual domains. Unless otherwise stated, identical architectural configurations and training protocols were applied across all experiments to isolate the effect of data modality and task characteristics rather than model-specific tuning.
For visual experiments, frame-level features were extracted using a ResNet-50 backbone pretrained on ImageNet and kept frozen during temporal modeling. Temporal dependencies were learned exclusively through the CATS architecture. For non-visual experiments, including anomalous diffusion modeling, reinforcement learning, and cyber-physical forecasting, input sequences were directly provided to the temporal reasoning modules without any domain-specific architectural modifications.
Model optimization was performed using the Adam optimizer with a fixed learning rate and weight decay shared across experiments. The training objective combined prediction accuracy with regularization terms corresponding to structural symmetry and memory consistency, using fixed loss weights throughout all evaluations. Training was performed for a predefined number of epochs under identical stopping criteria to ensure fair comparison between model variants.
To reduce variance and ensure reproducibility, all quantitative results were averaged over multiple independent runs using fixed random seeds. Sampling strategies, batch sizes, and data splits were kept consistent within each experiment and were not altered between the full model and ablation variants. All CPU-based experiments were executed under identical computational constraints.
A summary of the sampling strategy, model configuration, optimization parameters, loss composition, number of runs, and random seed settings is provided in Table 1.
Quantitative results presented in this work are calculated as averages over multiple independent runs using fixed random seeds, as described in the reproducibility protocol. Mean performance values are reported for all experiments, and variability is indicated by the standard deviation across runs. Relative improvements reported (e.g., percentage gains over baselines) are performance differences defined as mean improvement over the baseline under the same training regime and evaluation condition. Due to the heterogeneous tasks and evaluation metrics across domains, such variability-aware reporting represents an interpretable and consistent measure of stability and robustness of the result while not changing the true experimental outcomes.
Experiment 1: data preparation and temporal consistency analysis
5.2
Experiment 1 evaluates the robustness, scalability, and temporal integrity of the visual preprocessing pipeline that underpins all subsequent experiments. The goal is not model comparison, but to verify that silent visual sequences are transformed into stable, temporally coherent representations suitable for deep temporal reasoning.
Using the full Charades-Ego dataset (≈36,000 egocentric video clips), the pipeline successfully processed over 95% of available videos, producing synchronized frame-level appearance embeddings (2048-D ResNet-50 features) and pose representations (33 MediaPipe landmarks per frame). Videos excluded from processing were primarily affected by file corruption or incomplete metadata, representing a small fraction of the dataset.
The distribution of frame counts per video is shown in Figure 11, where most sequences fall between 120 and 500 frames, reflecting realistic variability in activity duration. This wide range reinforces the need for temporal models capable of handling irregular and variable-length sequences without relying on fixed temporal windows.
Histogram of frame counts per video.
To assess processing reliability and scalability, preprocessing was parallelized across 16 CPU workers. The resulting processing times, summarized in Figure 12, exhibit a narrow distribution across workers, confirming balanced workload allocation and efficient parallel execution. End-to-end preprocessing completed in under 12 h, demonstrating feasibility for large-scale datasets even under CPU-only constraints.
Processing time per worker (CPU parallelization).
Beyond throughput, temporal consistency of extracted features was examined qualitatively and quantitatively. Figure 13 illustrates overlaid pose landmarks across multiple time steps from a representative sequence, revealing smooth and anatomically consistent motion trajectories. This confirms that the pose extraction preserves temporal continuity rather than introducing frame-level noise.
Overlaid pose landmarks across frames (valid sample).
Complementarily, Figure 14 presents a low-dimensional PCA projection of ResNet-50 embeddings across time for a single video. The embeddings form a smooth trajectory in feature space, indicating coherent evolution of visual semantics rather than erratic frame-wise variation. Together, these results confirm that both appearance and pose representations maintain temporal stability an essential prerequisite for downstream latent alignment and memory-based reasoning.
PCA of ResNet-50 features over time.
In summary, Experiment 1 establishes that the preprocessing pipeline produces high-quality, temporally aligned silent visual representations at scale. The resulting data is well-suited for evaluating CATS’ temporal alignment, memory integration, and interpretability in later experiments.
Results of Experiment 2: CPU-based learning and cross-dataset validation
5.3
Experiment 2 evaluates the feasibility, stability, and generality of the proposed CATS model under hardware-constrained training, while extending validation beyond egocentric video to include the ANDI (anomalous diffusion) benchmark. This dual-dataset setup is deliberately chosen to test whether the same latent temporal reasoning mechanism can operate consistently across semantic visual sequences and physics-driven stochastic time series.
Training on Charades-Ego was conducted using CPU-only optimization over a limited number of epochs. As shown in Figure 15, the training loss decreases monotonically, confirming stable convergence despite the absence of GPU acceleration. The convergence behavior mirrors trends observed in full-resource settings, indicating that the latent temporal alignment, symmetry constraints, and memory integration mechanisms do not rely on heavy computational scaling to remain effective.
Training loss over epochs.
While absolute classification scores on Charades-Ego remain moderate as expected for a densely annotated, highly overlapping multi-label dataset the observed macro-F1 and mAP values fall within accepted baselines for CPU-only learning, with exact scores and baseline comparisons reported in Table 2 (Experiment 2). Class-level confusions primarily arise among visually similar or temporally overlapping actions, a known characteristic of egocentric benchmarks. These effects are summarized qualitatively rather than exhaustively visualized, in line with journal best practices. For the backbone-only control reported in Table 2, the same pretrained ResNet feature extractor is used under an identical training and evaluation protocol, with all temporal alignment, attention, memory, and recurrence modules removed to isolate the contribution of temporal modeling.
Retrieval-oriented evaluation further highlights the model’s temporal reasoning capacity. Figure 16 reports Precision@k and Recall@k for top-k predictions, demonstrating that correct activity labels frequently appear among the highest-ranked outputs. This behavior is particularly important for downstream alignment, refinement, and narrative reconstruction tasks, where exact frame-level classification is less critical than preserving semantically coherent temporal hypotheses.
Grouped bar plot presenting Precision@5 and Recall@5 scores, illustrating the effectiveness of the model’s top-k predictions in a multi-label setting.
Finally, Figure 17 presents qualitative predictions across both datasets. For Charades-Ego, predicted activities align closely with dominant scene context and long-range temporal dependencies, indicating stable temporal reasoning despite egocentric noise and overlapping actions. For ANDI, inferred temporal regimes remain consistent across noise realizations, reflecting robustness to stochastic variability and absence of semantic supervision.
Sample validation video predictions compared with ground-truth labels, demonstrating the model’s qualitative understanding and semantic consistency.
Crucially, the same trained architecture was evaluated on the ANDI dataset, where ground truth corresponds not to semantic labels but to diffusion regimes and intrinsic stochastic structure. Without architectural modification, CATS successfully organizes trajectories along a latent temporal axis, separating distinct diffusion behaviors, as quantitatively confirmed by regime classification accuracy and stability metrics reported in Table 2 (Experiment 3) while preserving smooth temporal progression. Figure 18 visualizes this effect, demonstrating that latent temporal coordinates learned from visual data remain meaningful when transferred to physical diffusion processes. This cross-domain consistency supports the central claim that CATS captures intrinsic temporal structure rather than dataset-specific cues.
Latent diffusion trajectories from the ANDI dataset.
Experiment 3: results
5.4
Experiment 3 investigates whether the temporal representations learned by CATS capture intrinsic temporal structure rather than dataset-specific semantics. To this end, we evaluate the same trained architecture on the ANDI benchmark, which provides labeled diffusion regimes instead of visual or semantic annotations. This setting allows us to test whether temporal organization emerges purely from latent alignment and memory dynamics, independent of visual content.
Figure 19 illustrates how trajectories corresponding to different diffusion regimes are organized along the learned latent timeline. Despite the stochastic nature of particle motion, CATS produces temporally coherent trajectories that preserve regime identity over time. Subdiffusive, normal, and superdiffusive processes follow distinct but smooth paths, indicating that the model encodes regime-level temporal structure rather than frame-level noise.
Temporal regime classification accuracy across diffusion dynamics in the ANDI dataset.
To further examine representation stability, we analyze the consistency of temporal embeddings across noise realizations. Figure 20A shows that embeddings corresponding to the same diffusion regime remain tightly clustered even under increased stochastic perturbations. In contrast, Figure 20B quantifies alignment deviation over time, revealing low variance for normal diffusion and controlled growth for anomalous regimes. Together, these results indicate that curvature-regularized alignment and semantic memory prevent temporal drift without collapsing regime discrimination.
Temporal regime transition confidence and stability analysis on the ANDI dataset. (A) Temporal regime classification across diffusion trajectories. (B) Stable temporal regime identification via latent alignment in ANDI.
Finally, we assess whether the learned temporal structure supports discriminative separation without task-specific supervision. Figure 21 presents a projection of latent trajectories where diffusion regimes form clearly separable manifolds. Importantly, this separation emerges without modifying the architecture or loss formulation used for visual data, demonstrating that CATS generalizes temporal reasoning principles across domains.
Cross-domain temporal embedding consistency between visual activities and diffusion dynamics.
Overall, Experiment 3 confirms that CATS learns domain-agnostic temporal abstractions. While previous experiments focus on visual coherence and activity structure, ANDI reveals that the same mechanisms encode physical time evolution governed by stochastic dynamics. This supports the central claim that CATS models temporal semantics as a structural property of sequences, rather than as a byproduct of visual appearance or dataset-specific labels an increasingly important requirement for modern computer vision systems operating beyond narrowly defined tasks.
Experiment 4: reinforcement learning for temporal alignment across visual and diffusion domains
5.5
In this experiment, we investigate whether reinforcement learning (RL) can serve as a complementary mechanism for temporal alignment and sequence-level decision making when operating on representations produced by CATS. Unlike previous experiments that focus on supervised or self-supervised temporal inference, this study explores RL as a policy-learning layer over temporally structured latent representation. Importantly, the experiment is conducted on both egocentric visual data (Charades-Ego) and diffusion trajectory data from the ANDI benchmark, enabling a cross-domain evaluation of temporal decision learning.
In the reinforcement learning experiments, the agent operates on fixed temporal embeddings produced by the CATS encoder. The state at each decision step corresponds to the current latent temporal representation of the sequence. The action space is defined over a discrete set of alignment or control actions specific to the task formulation. The reward function is task-dependent and is designed to encourage stable temporal alignment and improved downstream performance, as reflected in cumulative episode reward. Policy optimization is performed using a standard deep Q-network (DQN) update rule with experience replay and target network stabilization. Importantly, the RL component does not introduce additional temporal representation learning beyond the CATS embeddings, ensuring that improvements reflect the quality of the learned temporal structure rather than RL-specific architectural complexity.
A deep Q-network (DQN) agent is trained using state representations derived from CATS latent embeddings. For Charades-Ego, states encode temporally aligned visual context corresponding to ongoing human activities, while actions represent alignment or segmentation decisions over the sequence. For ANDI, states correspond to latent representations of particle trajectories, and actions reflect transitions between inferred diffusion regimes. In both cases, the reward signal is defined to encourage temporal consistency, stability of inferred regimes, and alignment accuracy, rather than raw classification performance.
Figure 22 illustrates the cumulative reward progression over training episodes for both datasets. A steady upward trend is observed in both domains, indicating that the agent successfully learns policies that exploit the temporal structure encoded by CATS. Notably, the reward curves for ANDI exhibit smoother convergence compared to Charades-Ego, reflecting the lower observation noise and more regular temporal dynamics of diffusion trajectories. In contrast, the visual domain presents noisier reward fluctuations due to egocentric motion blur, occlusions, and overlapping activities, yet still converges to a stable policy.
Reward progression during RL training on Charades-Ego and ANDI.
To further analyze the learned decision behavior, we visualize the Q-value distributions over the state-action space.
Figure 23 presents heatmaps of Q-values learned by the DQN agent. For Charades-Ego, high-value regions correspond to states associated with consistent long-range activity context, indicating that the agent prioritizes temporally coherent segments over short-term motion cues. For ANDI, the Q-value landscape clearly separates diffusion regimes, with distinct high-value clusters aligned with stable stochastic behaviors. This demonstrates that the RL agent leverages the latent temporal geometry induced by CATS, rather than dataset-specific heuristics.
Learned Q-value structure over latent temporal states.
Overall, these results confirm that reinforcement learning can effectively operate on CATS-generated temporal representations, with cumulative reward statistics and convergence metrics summarized in Table 1 (Experiment 4) across both computer vision and physical diffusion domains. While RL is not the primary inference mechanism of CATS, this experiment highlights its potential as an auxiliary decision layer for online temporal segmentation, regime switching, or adaptive alignment. Crucially, the successful transfer from visual activity sequences to ANDI diffusion trajectories reinforces the claim that CATS encodes intrinsic temporal structure that generalizes beyond visual appearance and semantic labels.
This experiment complements earlier results by showing that CATS representations are not only interpretable and stable but also actionable supporting sequential decision-making under uncertainty in heterogeneous temporal data.
Experiment 5: cross-domain cyber-physical forecasting with CATS
5.6
Experiment 5 evaluates the generality of the proposed CATS framework beyond visual and diffusion-based temporal reasoning by applying it to a cyber-physical forecasting problem, where the objective is to model the temporal interaction between cybersecurity dynamics and epidemic progression. In contrast to Experiments 1–4, which focus on egocentric video and diffusion trajectories, this experiment operates on multivariate temporal signals and tests whether CATS can preserve its interpretability and alignment behavior in a non-visual domain. The experiment further complements the ANDI-based analysis by demonstrating that the learned temporal abstractions are domain-agnostic and modality-independent.
The dataset consists of daily time series combining reported new COVID-19 cases with three cybersecurity indicators: new malware cases, total infected systems, and mitigation actions, aggregated across multiple countries. Daily new infection counts are treated as the prediction target, while cybersecurity variables serve as contextual temporal inputs. No architectural changes were introduced; the same temporal alignment, semantic memory integration, and curvature-regularized latent timeline were used, reinforcing the claim that CATS does not rely on domain-specific feature engineering.
To characterize the cyber-physical temporal landscape, Figure 24 presents a normalized and smoothed view of infection trends. Compared to the raw signals, the smoothed trajectories reveal coherent epidemic waves and inter-country temporal offsets. This representation emphasizes long-range temporal structure rather than short-term noise, aligning with the design philosophy of CATS, which prioritizes stable latent temporal embeddings over frame-level fluctuations.
Smoothed temporal evolution of COVID-19 incidence across countries.
Complementary to this, Figure 25 highlights statistically meaningful temporal dependencies between cybersecurity activity and epidemic dynamics. The presence of consistent positive correlations at non-zero temporal lags suggests that cybersecurity disruptions often precede or coincide with epidemic surges. Importantly, this figure supports the role of temporal alignment and semantic memory within CATS, as such dependencies cannot be captured reliably through point-wise or purely autoregressive models.
Lagged cross-correlation between cybersecurity activity and epidemiological dynamics.
While Figures 24, 25 focus on observable temporal patterns, Figure 26 provides insight into the internal behavior of the model. The heatmap visualizes attention weights learned by CATS across time and input variables, revealing that total infected systems and new malware cases consistently receive higher influence during periods of rapid epidemiological change. This mirrors the interpretability results obtained in the ANDI experiments, where distinct diffusion regimes were separated along a latent temporal axis, reinforcing the notion that CATS encodes intrinsic temporal structure rather than task-specific heuristics.
Temporal dependency structure between cyber and epidemic variables.
Taken together, the results of Experiment 5 demonstrate that CATS successfully transfers its temporal reasoning capabilities from visual and stochastic domains (Charades-Ego and ANDI) to a cyber-physical forecasting setting. The model captures long-term dependencies, exhibits interpretable temporal attention behavior, and remains robust under heterogeneous, non-visual inputs, with quantitative forecasting accuracy and error metrics reported for cyber-physical time-series prediction. These findings confirm that CATS functions as a domain-agnostic temporal reasoning framework, capable of modeling complex real-world dynamics where temporal structure, rather than modality, is the primary source of information.
The interpretability analysis presented in this work is intended to provide model-centric insights into the behavior of temporal attention and slot-based representations, rather than to perform supervised alignment against external temporal annotations. The evaluated datasets do not consistently provide fine-grained ground-truth temporal labels, such as annotated keyframes or explicit event boundaries, that would enable direct quantitative alignment validation. Consequently, interpretability is assessed through qualitative consistency, temporal smoothness, and stability across runs and domains. Validating attention and slot activations against annotated temporal events is an important direction for future work when suitable datasets become available Table 3.
Robustness and controlled stress evaluation
5.7
Ablation analysis evaluating the contribution of key architectural components in the CATS framework. Each variant removes or replaces a single component while keeping all other settings fixed. Results are reported for a representative visual task (mAP), diffusion-based stability evaluation (ANDI), and cyber-physical time-series forecasting (RMSE). Performance consistently degrades when core components are removed, with slot-based recurrence and semantic memory contributing most strongly to overall performance and stability.
To explicitly establish the stability and generalization claims throughout this paper, we study the behavior of our proposed CATS framework under a series of controlled stress levels resulting from typical experimental conditions. These stress tests are structured to systematically test the model on computational, structural, and domain dimensions, without changing the original architecture, training protocols, and evaluation metrics. Computational stress is tested with the CPU-only training and inference configuration as described in Experiment 2. With this arrangement, they have constrained resources with limited parallelism, which acts as a stress test for the stability of the optimization process and convergence behavior. Here, CATS maintains competitive macro-F1 and mAP relative to reported baselines with only moderate performance degradation relative to unconstrained settings. Such results indicate that the underlying temporal reasoning mechanisms still hold for limited computational resources.
Cross-domain generalization stress is evaluated by using a single unified architecture across different domains, such as visual activity recognition, anomalous diffusion modeling, and cyber-physical time-series forecasting (Experiments 3–5). Although the data structure, noise characteristics, and temporal dynamics of the CATS systems differ significantly, with respect to all domains it demonstrates the same performance pattern. Quantitative evidence shows controlled degradation for cross-modal transfer, validating temporal structure rather than input modality for prediction. Here, noise stress and heterogeneity in the input are studied in the anomalous diffusion and cyber-physical forecasting where there is non-stationarity of input sequences, irregular temporal patterns, and heterogeneity of features.
CATS is able to achieve stable forecasting accuracy and bounded error growth under these conditions, which can be observed by looking at RMSE and MAE in the respective experiments. This behavior signals the model’s capacity to accommodate irregular temporal dynamics without any domain-specific architectural manipulation. Together, these controlled stress analyses offer quantitative proof that the suggested framework remains robust to growing computational demands, changes in domain, and changes in input heterogeneity. Through specific characterization of these scenarios as testing for robustness, this study validates that such performance improvements cannot be limited only to a particular dataset or modality and represent generalizable temporal reasoning abilities.
Discussion
6
The experimental analysis demonstrates that CATS provides a unified and interpretable framework for temporal reasoning in silent visual sequences, while exhibiting strong robustness and abstraction capabilities when evaluated in non-visual temporal domains used as validation stress tests. Rather than optimizing for a single modality or task, CATS is designed around a common principle: temporal meaning emerges from stable latent alignment, structured recurrence, and semantic memory, rather than explicit motion heuristics or modality-specific cues.
Experiments 1 and 2, conducted on the Charades-Ego dataset, validate the model’s effectiveness in egocentric activity understanding under realistic constraints. By relying on frame-level visual encodings and curvature-aware temporal alignment, CATS captures both short-term action transitions and long-range contextual dependencies without requiring optical flow or handcrafted motion descriptors. This aligns with recent evidence that robust temporal reasoning can emerge from context-consistent embeddings rather than explicit motion modeling (Wang X. et al., 2025; Pigou et al., 2018; Yan et al., 2018). The observed gains in mAP and F1-score, together with stable CPU-based convergence, position CATS as a practical alternative to heavy recurrent or transformer-based pipelines that require extensive computational resources (Pigou et al., 2018; Yan et al., 2018).
Experiment 3 extends this analysis by introducing the ANDI dataset, which departs fundamentally from semantic video labels and instead characterizes stochastic diffusion regimes. The successful organization of ANDI trajectories along a coherent latent temporal axis confirms that CATS learns intrinsic temporal structure, rather than dataset-specific semantics. This result is particularly significant in light of recent findings showing that large multimodal models struggle with temporal abstraction when supervision is absent or weak (Wang X. et al., 2025; Imam et al., 2025). By maintaining smooth regime separation across noise realizations, CATS demonstrates robustness to stochastic variability an essential requirement for general temporal reasoning beyond vision-only benchmarks.
Experiment 4 further evaluates temporal reasoning under interaction and uncertainty by coupling CATS representations with a reinforcement learning agent. The learned reward trajectories and structured Q-value landscapes (Figures 22, 23) indicate that the latent temporal alignment learned by CATS is compatible with decision-making processes, even when sequence ordering is incomplete or non-deterministic. This supports theoretical perspectives that frame perception and action as hypothesis testing over temporal structure (Friston et al., 2012; Friston, 2010; Clark, 2013), and distinguishes CATS from conventional sequence models that assume fixed temporal progression.
Experiment 5 provides a decisive test of cross-domain generalization, applying the same architecture to cyber-physical forecasting of epidemic dynamics using cybersecurity indicators. Despite the absence of visual input, CATS successfully aligns heterogeneous temporal signals and produces stable multi-step forecasts. The consistency between predicted and observed trends, the attention-based feature attribution, and the bounded forecasting error jointly demonstrate that CATS generalizes its temporal abstraction mechanisms beyond visual cognition to socio-technical systems. This contrasts with prior approaches that rely on domain-specific fusion strategies or handcrafted temporal assumptions (Ramakrishna et al., 1993; Lin et al., 2015; Moldovan et al., 2005).
Figure 24 consolidates these findings by visualizing cross-experiment feature importance derived from temporal attention weights. Across egocentric video, stochastic diffusion, reinforcement learning, and cyber-physical forecasting, CATS consistently prioritizes semantically informative and temporally stable cues whether hand–object relations, diffusion regime indicators, or cybersecurity signals. This invariance supports the claim that CATS achieves interpretable temporal reasoning, aligning with contemporary calls to move away from opaque black-box models in high-stakes decision settings (Doshi-Velez and Kim, 2017; Brundage et al., 2018; Klein et al., 2024; Cubillos et al., 2024).
Figure 27 provides a unified cross-experiment view of the learned temporal attention structure in CATS. Despite large differences in modality and task formulation, the model consistently emphasizes semantically meaningful temporal features—such as hand–object relations in egocentric video, diffusion regime indicators in ANDI trajectories, and cybersecurity activity signals in cyber-physical forecasting. This invariance demonstrates that CATS learns a domain-agnostic temporal abstraction mechanism rather than dataset-specific heuristics, reinforcing its interpretability and generalization capabilities in line with recent arguments for intrinsically interpretable temporal models (Doshi-Velez and Kim, 2017; Brundage et al., 2018; Klein et al., 2024; Cubillos et al., 2024).
Cross-experiment temporal attention importance map across features and datasets.
The comparative analysis in Table 4 further situates CATS within the broader literature. Compared to RNN- and convolution-based temporal models (Pigou et al., 2018; Zheng et al., 2024), skeleton-centric approaches (Yan et al., 2018; Doshi-Velez and Kim, 2017), and scene-graph or surveillance-oriented systems (Clark, 2013; Alcázar et al., 2022), CATS demonstrates superior adaptability across domains while preserving interpretability. Unlike recent large multimodal models that exhibit brittle long-term temporal reasoning (Wang X. et al., 2025; Imam et al., 2025), CATS maintains fidelity over extended horizons due to its curvature-aware alignment and slot-based recurrence. Moreover, the ability to integrate non-visual cues through a shared temporal abstraction distinguishes CATS from late-fusion multimodal frameworks (Zheng et al., 2024; Gebru et al., 2018).
In summary, the results establish CATS as a general temporal reasoning architecture grounded in principled alignment, memory, and interpretability. By unifying visual scene understanding, stochastic process modeling (ANDI), reinforcement learning, and cyber-physical forecasting within a single framework, CATS addresses fundamental limitations of existing temporal models and aligns closely with emerging trends in computer vision and spatio-temporal AI research (Wang X. et al., 2025; Bastos et al., 2012; Yan et al., 2018; Lei et al., 2024; Calderó et al., 2021).
The empirical evaluation in this work is conducted under bounded sequence lengths determined by the characteristics of the evaluated datasets. While the proposed architecture is designed to model long-range temporal dependencies through latent alignment and recurrence mechanisms, explicit empirical validation under extremely long sequences (T ≫ 500) is not performed in this study. Accordingly, claims regarding long-horizon suitability are grounded in architectural design and observed stability within the evaluated range, rather than in unbounded scaling experiments. A systematic empirical analysis of stability and efficiency under very long sequences remains an important direction for future work.
Conclusion
7
This work introduced CATS (context-aware temporal synthesis) as a principled and mathematically grounded framework for temporal reasoning from silent sequences. Unlike conventional spatiotemporal models that rely on explicit motion cues, fixed temporal windows, or modality-specific supervision, CATS is designed to recover intrinsic temporal structure through alignment, recurrence, and memory mechanisms that are analytically motivated and explicitly interpretable. By embedding curvature-aware temporal alignment, symmetry-enforced attention, slot-based nonlinear recurrence, and semantic memory integration into a unified architecture, CATS addresses three persistent limitations of existing approaches: weak long-range temporal reasoning, limited interpretability, and poor cross-domain generalization.
Across a diverse experimental program, CATS demonstrated consistent performance and structural stability under varying constraints. Experiments on egocentric video data validated the model’s ability to infer activities and scene context from silent image sequences, even under occlusion, overlapping actions, and constrained motion. Beyond recognition accuracy, attention visualizations and slot dynamics revealed coherent temporal organization, providing insight into how semantic meaning emerges from stable frame-level representations rather than explicit motion engineering. These findings align with recent concerns in computer vision regarding the limitations of purely feedforward or token-based temporal models for long-horizon reasoning.
A key contribution of this work is the cross-domain validation of temporal reasoning using the ANDI dataset, which represents a fundamentally different problem class: stochastic diffusion processes with known ground-truth temporal regimes. Without architectural modification, CATS successfully organized ANDI trajectories in latent time, separating sub diffusive, normal, and super diffusive regimes while preserving smooth temporal evolution. This result is critical, as it demonstrates that the learned temporal alignment is not tied to visual semantics, but instead captures deeper structural regularities of sequential data. The ANDI experiments therefore provide strong evidence that CATS learns domain-agnostic temporal abstractions, rather than dataset-specific cues.
Further extending this claim, the cyber-physical forecasting experiments showed that the same temporal reasoning machinery could integrate heterogeneous non-visual signals—cybersecurity indicators and epidemiological trends—to produce stable and interpretable forecasts. Attention-based feature analysis revealed consistent reliance on semantically meaningful predictors, reinforcing the interpretability and robustness of the model. Importantly, these results were obtained under realistic computational constraints, highlighting CATS’ suitability for deployment in resource-limited or real-world settings.
Taken together, the experimental evidence supports the central thesis of this paper: effective temporal reasoning does not require richer input modalities, but rather principled temporal structure. By grounding architectural design in mathematical reasoning and validating it across visual, physical, and cyber-physical domains, CATS bridges the gap between black-box temporal models and interpretable, theoretically informed AI systems.
This work contributes to ongoing discussions in computer vision and temporal modeling on the necessity of moving beyond dataset-bound evaluation toward structural generalization and explainable temporal abstraction. Future directions include extending CATS to active perception, incorporating uncertainty-aware temporal reasoning, and exploring human-in-the-loop scenarios where interpretability is essential. Ultimately, CATS demonstrates that silent temporal understanding—whether in vision, physics, or cyber-physical systems—can be both accurate and explainable, establishing a foundation for reliable temporal reasoning in human-centric and socio-technical applications.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Alcázar J. L. Cordes M. Zhao C. Ghanem B. (2022). End-to-end active speaker detection. ECCV 2022: 17th European Conference
- 2Bastos A. M. Usrey W. M. Adams R. A. Mangun G. R. Fries P. Friston K. J. (2012). Canonical microcircuits for predictive coding. Neuron 76, 695–711. doi: 10.1016/j.neuron.2012.10.038, 23177956 PMC 3777738 · doi ↗ · pubmed ↗
- 3Brundage M. Avin S. Clark J. Toner H. Eckersley P. Garfinkel B. . (2018). The malicious use of artificial intelligence: forecasting, prevention, and mitigation. ar Xiv. Available online at: 10.48550/ar Xiv.1802.07228. [Epub ahead of preprint] · doi ↗
- 4CalderóM. S. Varas D. Bou-Balust E. (2021). Spatio-temporal context for action detection. ar Xiv. Available online at: 10.48550/ar Xiv.2106.15171. [Epub ahead of preprint] · doi ↗
- 5Chowdhury A. T. Newaz M. Saha P. Abu Haweeleh M. N. Mohsen S. Bushnaq D. . (2025). Decoding silent speech: a machine learning perspective on data, methods, and frameworks. Neural Comput. Appl. 37, 6995–7013. doi: 10.1007/s 00521-024-10456-z · doi ↗
- 6Clark A. (2013). Whatever next? Predictive brains, situated agents, and the future of cognitive science. Behav. Brain Sci. 36, 181–204. doi: 10.1017/S 0140525 X 12000477, 23663408 · doi ↗ · pubmed ↗
- 7Cubillos L. Revach G. Mender M. Costello J. Temmar H. Hite A. . (2024). Exploring the trade-off between deep-learning and explainable models for brain-machine interfaces. 38th Conference on Neural Information Processing Systems (Neur IPS 2024). 133975–133998 PMC 1199620640231170 · pubmed ↗
- 8Doshi-Velez F. Kim B. (2017). Towards a rigorous science of interpretable machine learning. ar Xiv. Available online at: 10.48550/ar Xiv.1702.08608. [Epub ahead of preprint] · doi ↗