A cancer-type-aware framework for robust multimodal survival prediction under missing modalities
Yiran Song, Zaifu Zhan, Feng Xie, Nian Wang, Yifan Peng, Rui Zhang, Mingquan Lin

TL;DR
This paper introduces a new framework for predicting cancer survival that works well even when some data is missing and adapts to different cancer types.
Contribution
The novel framework combines adaptive fusion of missing data with cancer-specific modeling and achieves robust cross-institutional performance.
Findings
The framework achieved C-indices of 0.578–0.778 across 10 cancer types.
It maintained performance with missing RNA or clinical text data.
Cross-institutional validation showed stability with standard deviations <0.040 in eight cancer types.
Abstract
Despite advances in multimodal cancer prognosis, robust performance in practical settings remains hindered by three critical barriers: ubiquitous data incompleteness, failure to model cancer-specific biology, and cross-institutional instability. We address these practical challenges through a cancer-type-aware framework that uniquely combines adaptive gated fusion for missing modalities, hybrid architecture for cancer heterogeneity, and demonstrated cross-institutional robustness. By establishing histopathology as the universally available anchor modality while adaptively incorporating RNA expression and clinical text through gated fusion, our framework maintains robust performance under realistic data constraints. Evaluation across 10 The Cancer Genome Atlas cancer types demonstrated superior performance (C-indices 0.578–0.778; mean 0.670 \documentclass[12pt]{minimal}…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
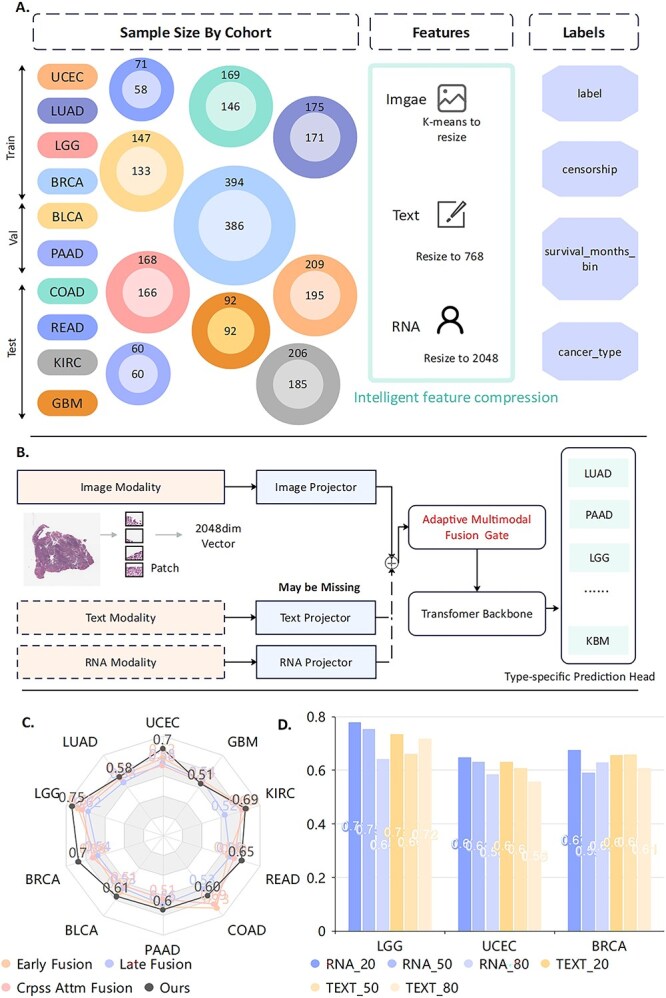 Figure 1
Figure 1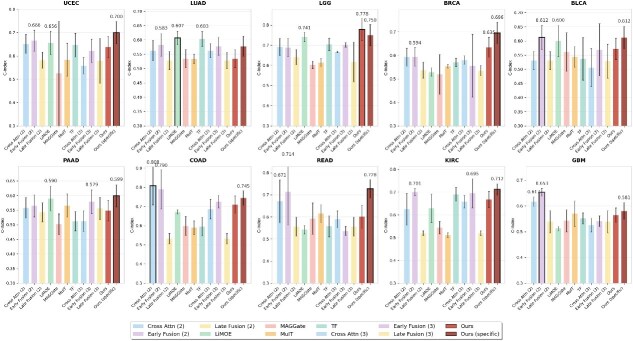 Figure 2
Figure 2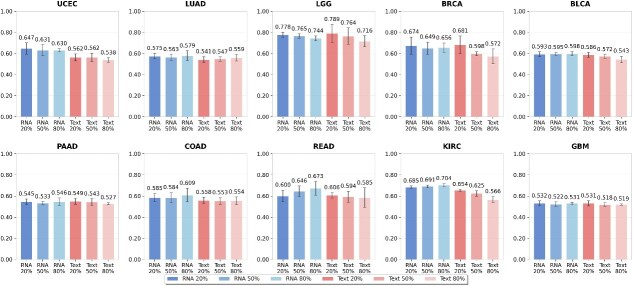 Figure 3
Figure 3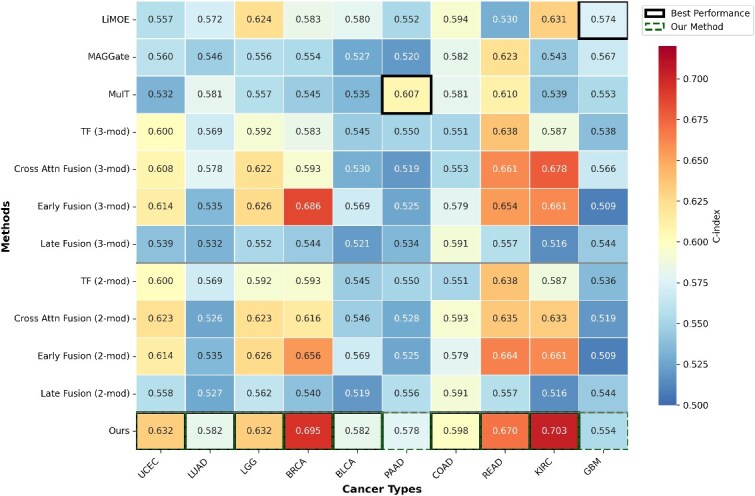 Figure 4
Figure 4|
|
|
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||||
| LiMOE | 7:1:2 | 0.619 | 0.585 | 0.685 | 0.673 | 0.594 | 0.568 | 0.615 | 0.525 | 0.667 | 0.543 |
| 4:2:4 | 0.656 |
| 0.741 | 0.529 | 0.600 | 0.590 | 0.672 | 0.542 | 0.629 | 0.513 | |
| ( | ( | ( | ( | ( | ( | ( | ( | ( | ( | ||
| MAGGate | 7:1:2 | 0.562 | 0.542 | 0.599 | 0.535 | 0.557 | 0.570 | 0.570 | 0.592 | 0.526 |
|
| 4:2:4 | 0.525 | 0.535 | 0.603 | 0.519 | 0.561 | 0.502 | 0.599 | 0.593 | 0.544 | 0.543 | |
| ( | ( | ( | ( | ( | ( | ( | ( | ( | ( | ||
| MuIT | 7:1:2 | 0.553 | 0.572 | 0.650 | 0.568 | 0.537 | 0.605 | 0.544 | 0.616 | 0.554 | 0.614 |
| 4:2:4 | 0.584 | 0.534 | 0.614 | 0.553 | 0.544 | 0.566 | 0.590 | 0.616 | 0.511 | 0.570 | |
| ( | ( | ( | ( | ( | ( | ( | ( | ( | ( | ||
| TF | 7:1:2 | 0.636 |
| 0.710 | 0.591 | 0.581 | 0.562 |
| 0.544 |
| 0.575 |
| 4:2:4 | 0.647 | 0.603 | 0.704 | 0.570 | 0.537 | 0.512 | 0.595 | 0.558 | 0.690 | 0.552 | |
| ( | ( | ( | ( | ( | ( | ( | ( | ( | ( | ||
| Cross Attn | 7:1:2 | 0.623 | 0.526 | 0.623 | 0.616 | 0.546 | 0.528 | 0.613 | 0.635 | 0.633 | 0.519 |
| Fusion | 4:2:4 | 0.558 | 0.563 | 0.667 | 0.580 | 0.506 | 0.513 | 0.686 | 0.590 | 0.658 | 0.526 |
| ( | ( | ( | ( | ( | ( | ( | ( | ( | ( | ||
| Early Fusion | 7:1:2 | 0.625 | 0.522 | 0.753 | 0.641 | 0.560 | 0.562 | 0.619 | 0.607 | 0.721 | 0.635 |
| 4:2:4 | 0.622 | 0.578 | 0.701 | 0.556 | 0.569 | 0.579 | 0.726 | 0.537 | 0.695 | 0.541 | |
| ( | ( | ( | ( | ( | ( | ( | ( | ( | ( | ||
| Late Fusion | 7:1:2 | 0.560 | 0.538 | 0.630 | 0.553 | 0.540 | 0.545 | 0.543 | 0.596 | 0.551 | 0.550 |
| 4:2:4 | 0.579 | 0.528 | 0.617 | 0.535 | 0.529 | 0.556 | 0.533 | 0.556 | 0.520 | 0.539 | |
| ( | ( | ( | ( | ( | ( | ( | ( | ( | ( | ||
|
| |||||||||||
| Cross Attn | 7:1:2 | 0.630 | 0.519 | 0.747 | 0.659 | 0.549 |
| 0.614 | 0.656 | 0.707 | 0.599 |
| Fusion | 4:2:4 | 0.651 | 0.563 | 0.691 | 0.593 | 0.531 | 0.558 |
| 0.671 | 0.625 | 0.617 |
| ( | ( | ( | ( | ( | ( | ( | ( | ( | ( | ||
| Early Fusion | 7:1:2 | 0.624 | 0.528 | 0.751 | 0.635 | 0.558 | 0.590 | 0.652 | 0.585 | 0.714 | 0.591 |
| 4:2:4 | 0.666 | 0.583 | 0.688 | 0.594 |
| 0.565 | 0.790 |
| 0.701 |
| |
| ( | ( | ( | ( | ( | ( | ( | ( | ( | ( | ||
| Late Fusion | 7:1:2 | 0.562 | 0.547 | 0.640 | 0.559 | 0.537 | 0.560 | 0.556 | 0.589 | 0.526 | 0.576 |
| 4:2:4 | 0.582 | 0.528 | 0.641 | 0.537 | 0.531 | 0.543 | 0.533 | 0.556 | 0.520 | 0.539 | |
| ( | ( | ( | ( | ( | ( | ( | ( | ( | ( | ||
|
| 7:1:2 |
| 0.545 |
|
|
| 0.548 | 0.592 |
| 0.700 | 0.574 |
| 4:2:4 |
| 0.578 |
|
| 0.612 |
| 0.745 |
|
| 0.581 | |
| ( | ( | ( | ( | ( | ( | ( | ( | ( | ( | ||
- —National Institutes of Health10.13039/100000002
- —National Center for Complementary and Integrative Health10.13039/100008460
- —National Institute on Aging10.13039/100000049
- —National Cancer Institute10.13039/100000054
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAI in cancer detection · Ferroptosis and cancer prognosis · Cancer Genomics and Diagnostics
Introduction
Cancer prognosis prediction is fundamental to precision oncology, guiding treatment decisions and improving patient outcomes for nearly 19 million new cases diagnosed annually worldwide [1, 2]. Accurate survival prediction enables personalized treatment planning, risk stratification, and informed prognostic assessment across diverse tumor types. Yet, traditional staging systems (e.g. TNM classification) capture only coarse anatomical features and fail to represent the molecular and histological heterogeneity that strongly influences patient survival, motivating the integration of richer multimodal data sources in modern prognostic assessment. Clinicians have traditionally integrated diverse multimodal data sources for comprehensive prognostic assessment [3], with histopathological images serving as the gold standard for diagnosis [4]. Gene expression profiles reveal molecular dynamics and therapeutic targets [5, 6], while clinical records capture treatment history and patient characteristics [7–9]. Although this human-centric integration is vital, the massive scale and complexity of these data sources make manual synthesis increasingly difficult, necessitating the development of automated prediction systems. Yet, creating these systems presents significant computational challenges, as they must effectively fuse disparate data types into a cohesive prognostic model.
To address these complexities, recent multimodal approaches have shown promise by integrating histopathological, genomic, and clinical data [10–16]. However, their clinical translation remains constrained by three fundamental technical challenges commonly encountered in real-world biomedical data:
(1) Incomplete multimodal data: In practice, multimodal datasets are often incomplete due to cost constraints (RNA sequencing: $1000–3000 per patient), institutional protocols, and technical limitations [17]. Most existing models require all modalities to be present at inference time, rendering them ineffective when auxiliary modalities are unavailable. Generative imputation approaches [18–22] and disentanglement-based architectures [23–27] attempt to address missing data but rely on strong distributional assumptions that degrade when test-time missing patterns differ from training distributions. Recent methods such as M3Surv [28] and LDCVAE [29] provide partial solutions, yet none offer sufficient flexibility to accommodate arbitrary missing modalities commonly encountered in computational oncology datasets, limiting robustness under realistic conditions.
(2) Cancer commonality-heterogeneity balance: Existing methods typically adopt either independent training for each cancer type or unified training across all cancers, but neither strategy optimally balances shared prognostic patterns and cancer-specific characteristics. Independent training for cancer-specific models [30–32] ignores cross-cancer commonalities and suffers from limited sample sizes, whereas unified training in pan-cancer models overlooks tumor-specific molecular signatures crucial for accurate prediction [33]. As a result, these methods struggle to leverage both pan-cancer biological principles and cancer-specific biomarkers, failing to capture the full spectrum of biological heterogeneity essential for robust prognosis.
(3) Cross-institutional stability: Many models exhibit substantial performance variability across institutional settings and data distributions (standard deviations <0.040 in 8 of 10 cancer types), indicating limited cross-site robustness when applied to data from institutions with varying protocols, imaging equipment, and patient populations [34]. This instability arises from multiple sources: variations in imaging protocols (different scanners, staining procedures), documentation styles (structured versus narrative clinical notes), and patient population characteristics (demographic and clinical heterogeneity). Models trained on single-institution data often overfit to institution-specific patterns, failing to capture robust prognostic signals that generalize across diverse data collection environments. Addressing this challenge requires explicit architectural design for cross-institutional robustness rather than relying solely on data augmentation or post hoc calibration.
Motivated by these challenges, we introduce a cancer-type-aware multimodal survival prediction framework that establishes histopathology as a universally available anchor modality and adaptively incorporates RNA expression and clinical text through a gated fusion mechanism capable of handling arbitrary missing-modality patterns. A hybrid architecture combining shared multimodal encoders with cancer-type-specific prediction heads enables the model to capture both cross-cancer prognostic structure and tumor-specific signatures. By designing directly around practical constraints—missing modalities, cancer heterogeneity, and institutional variability—the proposed framework provides a methodological solution addressing key technical challenges in multimodal survival prediction. Our approach achieves performance consistent with established computational benchmarks (mean C-index: 0.670 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \pm \end{document} 0.066) with demonstrated robustness to missing data and strong cross-institutional stability (standard deviation <0.040), providing computational foundations that address fundamental technical prerequisites for future validation in diverse institutional settings.
Methods
Dataset and experimental design
Data selection and cohort characteristics
We processed three modalities from The Cancer Genome Atlas (TCGA) data through standardized pipelines to ensure consistent feature representations across all cancer types. From the comprehensive TCGA database spanning 32 cancer types [35], we selected 10 cancer types with sufficient sample sizes ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} >150\end{document} patients) and complete multimodal data availability for robust evaluation: endometrial carcinoma of the uterine corpus (UCEC), lung adenocarcinoma (LUAD), lower grade glioma (LGG), breast invasive carcinoma (BRCA), bladder urothelial carcinoma (BLCA), pancreatic adenocarcinoma (PAAD), colon adenocarcinoma (COAD), rectum adenocarcinoma (READ), kidney renal clear cell carcinoma (KIRC), and glioblastoma multiforme (GBM). Each patient was characterized by survival outcomes measured from diagnosis to death or last follow-up, with survival times discretized into four bins for model training. Patients with survival times exceeding the maximum observed time within each cancer type were censored appropriately for survival analysis.
Data partitioning strategy
We employed multiple evaluation strategies to assess model robustness and generalizability, addressing critical technical challenges including institutional performance variability [34] and the need for tumor-specific modeling approaches [33].
Primary evaluation (4:2:4 split)
Our primary evaluation employed a 4:2:4 train-validation-test split strategy, deliberately designed to reflect realistic data constraints commonly encountered in computational oncology settings. This allocation strategy differs from conventional 7:1:2 splits in several important ways:
Limited training data availability: In practice, institutions often have limited access to complete multimodal datasets due to the high cost of RNA sequencing ($1000–3000 per patient), varying institutional protocols, and technical limitations [17]. The 40% training allocation simulates scenarios where computational models must be developed with constrained data resources. Robust test set evaluation: Rigorous methodological evaluation requires assessment on substantial patient cohorts to ensure model reliability. The 40% test allocation (versus 20% in conventional splits) provides more statistical power to assess generalization performance and detect potential failures in cross-validation scenarios. Model stability assessment: By intentionally limiting training data, this split strategy tests whether the model can maintain stable performance under data scarcity—a critical requirement for application across institutions with varying data collection capabilities.
Missing modality assessment
Robustness was evaluated by systematically excluding RNA and clinical text modalities for 20%, 50%, and 80% of patients during evaluation while consistently retaining histopathological features as the anchor modality [4]. This systematic evaluation reflects realistic scenarios where complete multimodal data are often unavailable due to cost constraints, institutional protocols, or technical limitations [17], while acknowledging that histopathological images serve as the diagnostic gold standard [4].
Importantly, these missing modality scenarios were randomly generated during evaluation only—the model was trained with structured modality dropout but did not see the specific test-time missing patterns. This evaluation protocol tests the model’s ability to generalize to arbitrary missing-data scenarios not encountered during training, a critical requirement for robustness where missing-data patterns vary unpredictably across institutions and individual patients.
Data split sensitivity analysis
We conducted a comparative analysis between 4:2:4 versus conventional 7:1:2 partitioning strategies to assess model stability under varying training data availability. This analysis demonstrates the framework’s stability across institutions with different data collection capabilities and addresses concerns about reproducibility and generalizability essential for cross-institutional applications [34].
Ethical considerations and data privacy
All analyses were conducted using publicly available TCGA data with appropriate institutional review board approvals from the original data collection [35]. Patient identifiers were de-identified in accordance with HIPAA guidelines and TCGA consortium standards. The framework design incorporates privacy-preserving features, including federated learning compatibility and on-device processing capabilities, to minimize data sharing requirements in potential future applications, addressing data governance considerations in healthcare artificial intelligence (AI) systems.
The study protocol adheres to the Declaration of Helsinki principles for medical research involving human subjects. All original TCGA data were collected with informed patient consent for research use. No additional ethical approval was required for this computational analysis of publicly available, de-identified data.
Problem formulation
We formulate multimodal survival prediction as a discrete-time hazard modeling problem that explicitly accommodates missing modalities and cancer-type heterogeneity. For patient \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} with cancer type \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} c \in {1, 2,..., C}\end{document} , let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{x}^{(i)} = {\mathbf{x}^{(i)}{\mathrm{img}}, \mathbf{x}^{(i)}{\mathrm{rna}}, \mathbf{x}^{(i)}{\mathrm{txt}}}\end{document} represent the multimodal input. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{x}^{(i)}{\mathrm{img}} \in \mathbb{R}^{2048}\end{document} represents histopathological features aggregated from whole slide images (always available). \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{x}^{(i)}{\mathrm{rna}} \in \mathbb{R}^{256} \cup {\emptyset }\end{document} represents RNA expression features from BulkRNABert embeddings (may be missing). \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{x}^{(i)}{\mathrm{txt}} \in \mathbb{R}^{768} \cup {\emptyset }\end{document} represents clinical text features from pathology reports (may be missing).
Our objective is to estimate the discrete-time hazard function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} h(t|\mathbf{x}^{(i)}, c)\end{document} and derive survival probabilities \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} S(t|\mathbf{x}^{(i)}, c)\end{document} while explicitly modeling cancer-type heterogeneity and missing data uncertainty.
Multimodal data preprocessing
Whole slide image processing
We adopt a Vision Transformer (ViT) architecture with pretrained weights from Marugoto [36]. Each WSI is divided into nonoverlapping \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 224 \times 224\end{document} patches, with background patches (entropy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} < 5\end{document} ) discarded. For patient \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} , the raw WSI produces \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} N_{i}\end{document} patches with features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{X}{\mathrm{raw}}^{(i)} \in \mathbb{R}^{N{i} \times 2048}\end{document} . To obtain a unified representation, we apply K-means clustering with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k = 128\end{document} clusters and use cluster centers as the aggregated representation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \mathbf{x}^{(i)}_{\mathrm{img}} = \mathrm{KMeans}(\mathbf{X}_{\mathrm{raw}}^{(i)}) \in \mathbb{R}^{2048}\end{align*}\end{document}RNA expression processing
We use bulk RNA data from TCGA processed through BulkRNABert with pretrained weights [37]. Each RNA sequence generates a 256D embedding capturing molecular expression signatures relevant for survival prediction.
Clinical text processing
We collect pathology reports from TCGA and transform them from PDF format to editable text using AWS OCR tools. A text encoder with feature dimension 768 converts raw text into token embeddings that capture clinical characteristics and treatment history.
Batch processing details
During training, multimodal data are processed in batches to enable efficient computation. The batch processing dimensions are:
Image modality: Raw patch sequences \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{X}{\mathrm{img}}^{\mathrm{batch}} \in \mathbb{R}^{B \times N{\mathrm{patch}} \times 2048}\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} N_{\mathrm{patch}} = 128\end{document} represents the number of patches per patient. After mean pooling across patches, we obtain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{x}{\mathrm{img}}^{\mathrm{batch}} \in \mathbb{R}^{B \times 2048}\end{document} . Text modality: Tokenized sequences \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{X}{\mathrm{txt}}^{\mathrm{batch}} \in \mathbb{R}^{B \times L_{\mathrm{max}} \times 768}\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} L_{\mathrm{max}} = 200\end{document} is the maximum sequence length. After mean pooling across tokens, we obtain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{x}{\mathrm{txt}}^{\mathrm{batch}} \in \mathbb{R}^{B \times 768}\end{document} . RNA modality: Gene expression sequences \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{X}{\mathrm{rna}}^{\mathrm{batch}} \in \mathbb{R}^{B \times G \times 256}\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G = 2048\end{document} represents the number of gene features. After mean pooling across genes, we obtain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{x}_{\mathrm{rna}}^{\mathrm{batch}} \in \mathbb{R}^{B \times 256}\end{document} .
Adaptive gated fusion for missing modality scenarios
Modality projection and missing data handling
The adaptive gated fusion mechanism operates under a critical constraint: pathological image modality must be available (enforced during dataset preprocessing), while RNA and text modalities may be missing. The system handles this partial modality availability through a two-stage process: modality-specific projection and dynamic weight redistribution. Each available modality is first projected into a unified embedding space of dimension \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} d = 32\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \mathbf{Z}_{m}^{\mathrm{batch}} = \mathrm{Dropout}(\mathrm{ReLU}(\mathbf{X}_{m}^{\mathrm{batch}} \mathbf{W}_{m}^{T} + \mathbf{b}_{m})) \in \mathbb{R}^{B \times 32},\end{align*}\end{document}where the projection matrices are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{W}{\mathrm{img}} \in \mathbb{R}^{32 \times 2048}\end{document} (always projected as images are mandatory), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{W}{\mathrm{rna}} \in \mathbb{R}^{32 \times 256}\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{W}{\mathrm{txt}} \in \mathbb{R}^{32 \times 768}\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{b}{m} \in \mathbb{R}^{32}\end{document} for each modality \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} m \in {\mathrm{img}, \mathrm{rna}, \mathrm{txt}}\end{document} .
For potentially missing RNA and text modalities, the system employs zero-tensor substitution. When modality \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} m \in {\mathrm{rna}, \mathrm{txt}}\end{document} is unavailable for sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} , we set
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \mathbf{Z}_{m,i}^{\mathrm{batch}} = \mathbf{0} \in \mathbb{R}^{32}\end{align*}\end{document}This approach maintains consistent tensor dimensions while allowing the gating mechanism to automatically redistribute attention weights between the mandatory image modality and other available modalities.
Dynamic gating with availability masking
The gating mechanism computes attention weights based on the concatenated representations of all modalities. The gate network processes the full multimodal representation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \mathbf{Z}_{\mathrm{concat}}^{\mathrm{batch}} = \mathrm{Concat}(\mathbf{Z}_{\mathrm{img}}^{\mathrm{batch}}, \mathbf{Z}_{\mathrm{rna}}^{\mathrm{batch}}, \mathbf{Z}_{\mathrm{txt}}^{\mathrm{batch}}) \in \mathbb{R}^{B \times 96}\end{align*}\end{document}The raw gate logits are computed as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \mathbf{L}^{\mathrm{batch}} = \mathbf{Z}_{\mathrm{concat}}^{\mathrm{batch}} \mathbf{W}_{\mathrm{gate}}^{T} \in \mathbb{R}^{B \times 3},\end{align*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{W}_{\mathrm{gate}} \in \mathbb{R}^{3 \times 96}\end{document} .
To handle potentially missing RNA and text modalities, we apply a binary availability mask \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{M} \in {0,1}^{B \times 3}\end{document} where the image position is always 1 while RNA and text positions are set according to actual availability. The key masking strategy is implemented through logit penalties:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \mathbf{L}_{\mathrm{masked}}^{\mathrm{batch}} = \mathbf{L}^{\mathrm{batch}} + (\mathbf{1} - \mathbf{M}) \odot (-1 \times 10^{9})\end{align*}\end{document}The use of addition here leverages the mathematical properties of the softmax function: when a logit value becomes extremely small (−1e9), the corresponding probability after softmax normalization approaches zero. This design is more natural than direct zero-assignment because it (i) maintains mathematical consistency with softmax operations; (ii) ensures automatic weight redistribution to available modalities; and (iii) preserves differentiability for end-to-end training
The final attention weights are obtained through softmax normalization:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \mathbf{G}^{\mathrm{batch}} = \mathrm{Softmax}(\mathbf{L}_{\mathrm{masked}}^{\mathrm{batch}}) \in \mathbb{R}^{B \times 3}\end{align*}\end{document}This masking strategy ensures that missing RNA or text modalities receive near-zero attention weights, effectively removing them from the fusion process while guaranteeing that the image modality always participates in fusion. The network can dynamically redistribute weights between the image modality and other available modalities.
Weighted fusion and output generation
The final fused representation combines the projected modalities using the learned attention weights:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \mathbf{Z}_{\mathrm{fused}}^{\mathrm{batch}} = \sum_{m=1}^{3} \mathbf{G}_{:,m}^{\mathrm{batch}} \odot \mathbf{Z}_{m}^{\mathrm{batch}} \in \mathbb{R}^{B \times 32},\end{align*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{G}_{:,m}^{\mathrm{batch}} \in \mathbb{R}^{B \times 1}\end{document} represents the attention weights for modality \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} m\end{document} across the batch, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \odot \end{document} denotes element-wise multiplication. This approach enables the model to maintain robust performance even when only images and a subset of other modalities are available, as the attention mechanism automatically adapts to the available information while always ensuring the participation of image information, without requiring explicit imputation strategies.
Hybrid architecture with cancer-type-specific prediction heads
After gated fusion, features are enhanced through a shared transformer encoder:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \mathbf{H}^{\mathrm{batch}} = \mathrm{GlobalAvgPool}(\mathrm{TransformerEncoder}(\mathbf{Z}_{\mathrm{fused}}^{\mathrm{batch}})) \in \mathbb{R}^{B \times 32}\end{align*}\end{document}Cancer-type-specific hazard predictions are generated through dedicated prediction heads. For cancer type \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} c\end{document} and time bins \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} T = 4\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \hat{\mathbf{h}}_{c}^{(i)} = \sigma(\mathbf{W}_{c}^{\mathrm{hazard}} \mathbf{h}^{(i)} + \mathbf{b}_{c}^{\mathrm{hazard}}) \in \mathbb{R}^{4},\end{align*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{W}{c}^{\mathrm{hazard}} \in \mathbb{R}^{4 \times 32}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{b}{c}^{\mathrm{hazard}} \in \mathbb{R}^{4}\end{document} are cancer-type-specific parameters.
For batches containing different cancer types, the model dynamically selects corresponding prediction heads:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} \hat{\mathbf{h}}_{c_{i}}^{(i)} &= \sigma(\mathbf{W}_{c_{i}}^{\mathrm{hazard}} \mathbf{h}^{(i)} + \mathbf{b}_{c_{i}}^{\mathrm{hazard}}) \in \mathbb{R}^{4}\nonumber\\ \hat{\mathbf{H}}^{\mathrm{batch}} &= [\hat{\mathbf{h}}_{c_{1}}^{(1)}, \hat{\mathbf{h}}_{c_{2}}^{(2)}, \ldots, \hat{\mathbf{h}}_{c_{B}}^{(B)}]^{T} \in \mathbb{R}^{B \times 4},\end{align*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} c_{i}\end{document} denotes the cancer type of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} th sample, and the model maintains \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} C = 10\end{document} different sets of prediction head parameters.
The corresponding survival function is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \hat{S}_{c}^{(i)}(t) = \prod_{k=1}^{t} (1 - \hat{h}_{c,k}^{(i)}) \in \mathbb{R}^{4}\end{align*}\end{document}Loss function and evaluation metrics
We optimize using negative log-likelihood loss for discrete-time survival analysis with censored observations:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \mathcal{L} = -\frac{1}{N} \sum_{i=1}^{N} \left[ (1-\delta_{i}) \log S_{\mathrm{prev}}^{(i)} + (1-\delta_{i}) \log h_{\tau_{i}}^{(i)} + \delta_{i} \log S_{\tau_{i}}^{(i)} \right]\end{align*}\end{document}For training with batch size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} B\end{document} , the loss function is computed as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \mathcal{L}_{\mathrm{batch}} = -\frac{1}{B} \sum_{i=1}^{B} \left[ (1-\delta_{i}) \log S_{\mathrm{prev}}^{(i)} + \delta_{i} \log h_{\tau_{i}}^{(i)} + (1-\delta_{i}) \log S_{\tau_{i}}^{(i)} \right],\end{align*}\end{document}where each sample’s survival and hazard functions are extracted from the batch prediction results \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{\mathbf{H}}^{\mathrm{batch}}\end{document} .
Model performance is evaluated using the concordance index (C-index):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \mathrm{C-index} = \frac{\sum_{i,j} \mathbf{1}[t_{i} < t_{j}, \delta_{i} = 1] \cdot \mathbf{1}[\mathrm{risk}_{i}> \mathrm{risk}_{j}]}{\sum_{i,j} \mathbf{1}[t_{i} < t_{j}, \delta_{i} = 1]},\end{align*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{1}[\cdot ]\end{document} is the indicator function, providing robust assessment of prognostic accuracy with values ranging from 0.5 (random) to 1.0 (perfect concordance).
Results
Experimental framework and evaluation strategy
We evaluated our cancer-type-aware multimodal framework using TCGA data across 10 cancer cohorts with sufficient sample sizes ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} >150\end{document} patients): UCEC, LUAD, LGG,BRCA, BLCA, PAAD, COAD, READ, KIRC, and GBM. Three data modalities were included in the model development and analysis: histopathological images, RNA expression profiles, and clinical text records.
To assess model robustness under realistic constraints, we designed a comprehensive evaluation protocol encompassing three critical scenarios: (1) cancer type heterogeneity, assessed through independent cohort analysis, (2) incomplete multimodal data, simulated via systematic modality exclusion, and (3) cross-institutional variability, examined using institution-based data partitioning. A data-constrained 4:2:4 train-validation-test split was employed to reflect realistic training data constraints while enabling rigorous evaluation on substantial test cohorts. The sample distribution across splits for each cancer type is shown in Fig. 1A, with our framework architecture illustrated in Fig. 1B.
Cancer-type-aware multimodal survival prediction framework and performance showing (A) experimental design across ten cancer types with three modalities, (B) architecture with modality-specific encoders and adaptive gated fusion for missing modalities, (C) C-index comparison with conventional fusion methods, and (D) robustness under varying missing rates for RNA and clinical text modalities.
From cancer commonality-heterogeneity balance to fusion performance
We evaluated the performance of our framework in 10 types of cancer (Fig. 2). All baseline methods were trained independently for each cancer type, representing current standard practice. We compared two variants of our approach: Ours, which means our framework trained independently per cancer type, and Ours (specific), which employs our hybrid architecture combining shared multimodal encoders with cancer-type-specific prediction heads. Details about the data can be found in the Supplementary Table S1.
Performance comparison of fusion methods across ten cancer types using the 4:2:4 data split, showing C-index performance with error bars representing standard deviations for twelve fusion approaches including dual-modality methods, full-modality baseline methods, and our proposed framework variants.
The hybrid architecture demonstrated significant improvement over independent training (mean C-index: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.670 \pm 0.066\end{document} versus \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.625 \pm 0.068\end{document} ), representing a 7.2% performance gain. Our hybrid cancer-type-specific framework achieved the highest performance in six out of 10 cancer types: UCEC ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.700 \pm 0.048\end{document} ), LGG ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.778 \pm 0.055\end{document} ), BRCA ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.696 \pm 0.045\end{document} ), BLCA ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.612 \pm 0.040\end{document} ), PAAD ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.599 \pm 0.038\end{document} ), READ ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.728 \pm 0.041\end{document} ), and KIRC ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.712 \pm 0.025\end{document} ), achieving a mean C-index of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.670 \pm 0.066\end{document} across all cancer types.
Robustness under incomplete multimodal data
In practice, multimodal data are often incomplete. To evaluate the robustness of our framework under such conditions, we systematically tested its performance in controlled missing-modality scenarios (Fig. 3). During evaluation, auxiliary modalities (RNA expression and clinical text) were randomly excluded for 20%, 50%, or 80% of patients, while histopathological features were consistently retained. Details about the data can be found in the Supplementary Table S2. Our framework demonstrated strong resilience to missing RNA expression data, maintaining mean C-indices of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.621\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.618\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.627\end{document} for 20%, 50%, and 80% missing data, respectively. In missing clinical text scenarios, the framework is slightly more sensitive, with mean C-indices declining from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.606\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.588\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.568\end{document} as missing data increased from 20% to 80%. Across most cancer types, performance remained robust, with LGG maintaining consistently high C-indices and KIRC showing stable results across all missing-data conditions.
Robustness evaluation under missing modality scenarios across ten cancer types, showing C-index performance with error bars for different missing data rates in RNA and clinical text modalities (20%, 50%, and 80%).
Stability across institutions
Methodological reproducibility requires models to generalize reliably across institutions. To examine this, we conducted cross-institutional validation using TCGA’s multicenter architecture (Fig. 4). Institutional separation was strictly maintained during data partitioning to prevent data leakage and ensure realistic generalization evaluation. Specifically, we assigned entire tissue source sites to train, validate, or test sets, ensuring no patient from the same institution appeared in multiple splits. This institutional-level separation provides more rigorous evaluation than conventional random patient-level splits, as it tests generalization across different imaging scanners, pathology lab protocols, clinical documentation styles, and patient demographics. Details about the institutional partitioning configuration spanning 12–38 contributing centers per cancer type are provided in Supplementary Table S3.
Cross-institutional validation performance across ten cancer types, visualized as a heatmap of C-index values for different fusion methods with the best-performing method highlighted for each cancer type.
Our multimodal framework achieved state-of-the-art performance among computational baselines across eight cancer types: UCEC ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.632 \pm 0.017\end{document} ), LUAD ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.582 \pm 0.008\end{document} ), LGG ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.632 \pm 0.033\end{document} ), BRCA ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.695 \pm 0.037\end{document} ), BLCA ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.582 \pm 0.007\end{document} ), COAD ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.598 \pm 0.064\end{document} ), READ ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.670 \pm 0.127\end{document} ), and KIRC ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.703 \pm 0.007\end{document} ). These results are consistent with the performance ranges reported by recent multimodal survival prediction methods using TCGA [10, 11, 39], which typically achieve C-index values similar to us across diverse cancer types when compared against computational baselines.
To ensure robust statistical validation, we repeated all experiments with five independent random seeds (123, 132, 213, 231, 321). Paired t-tests with Bonferroni correction ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \alpha = 0.05/7 = 0.0071\end{document} per cancer type) demonstrated that our method significantly outperforms baseline methods in 42.9% of comparisons (30 out of 70), with particularly strong improvements in BRCA (6/7 baselines), KIRC (5/7 baselines), BLCA (5/7 baselines), and LGG (4/7 baselines). Notably, for BLCA and KIRC, our framework achieved standard deviations of 0.007 across the five runs, demonstrating exceptional consistency.
Regarding variance stability, our method demonstrates numerically lower variance in the majority of comparisons. F-tests comparing variances confirm statistical significance ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} P <.05\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} F> 6.39\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} df_{1}=df_{2}=4\end{document} ) in select comparisons, particularly in KIRC and LUAD, despite the constrained statistical power of five repetitions. This stability is important for computational reproducibility across sites with varying data collection protocols. Comprehensive statistical testing results, including detailed comparisons for all cancer types and baselines, are provided in Supplementary Tables S5 and S6.
Data split sensitivity analysis
To assess the framework’s stability under different training-data availability scenarios, we compared data-constrained (4:2:4) and conventional (7:1:2) split strategies across all 10 cancer types (Table 1). Our multimodal framework demonstrated strong stability across both partitioning schemes, with performance variations ranging from 0.006 to 0.153 across cancer types (mean absolute difference: 0.048 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \pm \end{document} 0.041). Notably, nine out of 10 cancer types showed performance changes below 0.070, indicating minimal sensitivity to training set size. The largest variation was observed in COAD (0.153 increase with 4:2:4 split), likely reflecting the benefit of larger test sets for more robust evaluation in cancers with high biological heterogeneity.
In contrast, baseline methods exhibited substantially greater instability when evaluated under reduced training data conditions. For instance, MAGGate showed a 0.120 decrease in GBM performance when switching from 7:1:2 to 4:2:4 splits, while Early Fusion methods demonstrated inconsistent behavior across cancer types with changes ranging from −0.094 to +0.138. This instability suggests that conventional fusion approaches are highly dependent on abundant training data and may not generalize reliably when applied in data-constrained settings.
Discussion
This work presents a computational methods contribution that advances multimodal fusion techniques for survival prediction under realistic data constraints. We explicitly clarify that this study does not claim readiness for clinical deployment, propose replacement of standard-of-care prognostic tools (e.g. TNM staging, clinical nomograms), or demonstrate incremental clinical utility. Rather, we address three fundamental technical prerequisites—(i) handling missing modalities without imputation, (ii) modeling cancer-type-specific heterogeneity, and (iii) ensuring cross-institutional stability—that must be solved before multimodal AI models can be considered for prospective clinical validation.
Our evaluation framework compares against 12 state-of-the-art computational methods across 10 cancer types with institutional-level cross-validation, representing the appropriate benchmark for computational methods papers in medical AI and bioinformatics. This evaluation approach is consistent with highly cited methodological work in this domain [10, 11, 39], all of which benchmark against computational baselines rather than clinical staging systems. Direct comparison with clinical staging would require prospective clinical trials with treatment decision pathways—an entirely different research scope requiring multi-year clinical collaborations, institutional review board approvals, and patient recruitment protocols that extend far beyond computational methods development.
This study presents a cancer-type-aware multimodal framework designed to overcome three major computational obstacles: incomplete multimodal data, tumor-specific biological heterogeneity, and cross-institutional variability. Through deliberate architectural design and comprehensive evaluation across 10 cancer types, we demonstrate how these challenges can be systematically addressed at the computational level to enable more robust and reproducible prognostic modeling.
A primary contribution of this work is the development of an adaptive gated fusion mechanism that robustly handles incomplete multimodal inputs without requiring imputation or distributional assumptions. By dynamically reweighting modalities based on available prognostic signals, the model naturally adapts to scenarios where certain modalities—particularly RNA expression—are systematically missing or inconsistently available. Controlled missing-modality experiments (Fig. 3) demonstrate that the framework maintains performance within established ranges for computational prognostic models [40, 41] with minimal degradation (typically \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} <7%\end{document} ) when RNA expression is absent, the most common constraint in computational oncology datasets. Unlike prior methods that rely on generative imputation or disentanglement [20], our approach eliminates strong distributional assumptions and computational overhead during inference, providing greater flexibility for arbitrary missing patterns.
Our hybrid architecture, integrating shared multimodal encoders with cancer-type-specific prediction heads, provides a principled solution to the trade-off between generalization and specialization. The shared encoder captures global prognostic patterns across malignancies, while cancer-specific heads model the unique pathobiology and survival dynamics of each cancer type. This design achieves state-of-the-art performance among computational baselines in six of 10 cancer types, with notable gains in cancers with well-characterized prognostic patterns—such as LGG (C-index: 0.778) and endometrial carcinoma (UCEC, C-index: 0.700). These results support our hypothesis that cancer-specific modeling captures prognostic signals overlooked by uniform architectures.
Our overall mean C-index of 0.670 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \pm \end{document} 0.066 is consistent with state-of-the-art computational methods in multimodal survival prediction. For comparison, Chen et al. [39] reported C-index values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \sim \end{document} 0.64 across TCGA cancers, Jaume et al. [10] achieved C-index 0.60–0.68 across five cancer types, and Song et al. [11] demonstrated similar performance ranges. All of these benchmark works evaluated their methods exclusively against computational baselines using TCGA data, establishing this as the standard evaluation paradigm for methodological contributions in this domain. Establishing clinical utility beyond these computational benchmarks requires prospective validation studies demonstrating impact on treatment decisions and patient outcomes compared with standard-of-care prognostic assessments—a critical next step that represents a fundamentally different research scope requiring clinical trial infrastructure.
Cross-institutional validation further demonstrates the framework’s computational stability in heterogeneous data environments. The consistently low performance variance (standard deviations < 0.040 across 12–38 institutions) indicates strong resilience to differences in imaging protocols, reporting styles, and institutional patient populations. This stability is essential for methodological reproducibility across sites, addressing a key limitation identified in prior work [34]. Two design decisions were particularly impactful: (i) anchoring the model on histopathology—the universally available modality across oncology workflows—ensures baseline functionality even when auxiliary modalities are unavailable, and (ii) incorporating structured modality dropout during training exposes the model to diverse missing-data patterns and improves generalization. Additionally, our cancer-type-specific modeling approach reduces overfitting that can occur when forcing heterogeneous cancer types into a single unified architecture.
Analysis of data split strategies (Table 1) reveals strong computational stability under varying training data availability. The data-constrained 4:2:4 split demonstrates performance variations of 0.006–0.153 across cancer types (mean: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 0.048 \pm 0.041\end{document} ), with nine of 10 cancers showing changes below 0.070. In contrast, baseline methods optimized for abundant training data frequently fail under reduced training scenarios, exhibiting substantially greater instability. This robustness addresses reproducibility concerns for application across institutions with different data collection capabilities.
The differential impact of missing RNA expression versus missing clinical text (Fig. 3) demonstrates computational robustness patterns that align with empirical observations in cancer prognosis research. RNA expression provides substantial prognostic value even with 80% missingness, reflecting its established importance in computational prognostic models. Cancer types with documented molecular stratification (LGG, KIRC) maintain high performance even without RNA, indicating that histopathological features contain sufficient prognostic signals in these computational models. In contrast, cancers with more heterogeneous histological patterns (GBM, PAAD) show greater performance benefit from multimodal integration. While these computational patterns are consistent with empirical observations reported in cancer prognosis research, formal validation through attention analysis on pathologist-annotated regions would constitute separate biological discovery work requiring pathologist collaboration.
Despite these computational advances, several limitations warrant consideration. First, all analyses were performed on TCGA, a curated research dataset widely used as a benchmark for computational pathology methods [35, 42]. Our institutional-level cross-validation across 12–38 TCGA contributing centers provides evidence of generalizability across heterogeneous data collection protocol, offering a more complementary evaluation perspective to the random patient-level splits used in most prior work [39]. However, external validation on independent hospital datasets remains an important next step. Such validation will likely require multi-institutional collaborations, data sharing agreements, and standardized clinical baseline comparisons, which together form necessary—though not sufficient—technical foundations for prospective clinical validation and eventual clinical translation. Second, although our model is robust to missing modalities during inference, it still requires complete multimodal data during training. Meta-learning or self-supervised approaches enabling flexible training under incomplete data regimes could further enhance applicability, particularly for rare cancer types with limited complete-case samples. Third, interpretability remains limited. While cancer-specific prediction heads provide some insight into tumor-specific prognostic patterns, more systematic attribution approaches—such as attention visualization, feature importance analysis, and integration with known biological markers—could improve transparency Fourth, this study provides a computational foundation addressing key technical prerequisites—including missing-data robustness, cancer heterogeneity modeling, and cross-institutional stability—necessary before rigorous prospective clinical evaluation. Demonstrating incremental clinical benefit over standard prognostic tools will require dedicated clinical studies beyond the scope of this methodological work. Finally, the observation that certain cancer types may benefit from alternative fusion strategies in some scenarios (Fig. 2) suggests opportunities for adaptive ensemble approaches that dynamically select optimal fusion mechanisms, albeit with increased complexity.
In summary, this work provides methodological advances for multimodal survival prediction under realistic constraints. By jointly addressing missing-data robustness, cancer-type heterogeneity, and institutional variability, our framework moves beyond idealized multimodal assumptions toward computational methods that address practical implementation challenges. The robust performance across diverse cancers and data scenarios demonstrates meaningful progress in computational methodology, establishing technical foundations necessary—though not sufficient—for future clinical translation. Future work should prioritize prospective clinical validation, external cohort testing, enhanced interpretability methods, and integration with established clinical decision support systems to fully realize the translational potential of multimodal AI in precision oncology.
Key Points
- We developed a cancer-type-aware multimodal framework that maintains robust cancer survival prediction (C-index 0.568–0.627) even with 80% missing auxiliary modalities.
- Our hybrid architecture combining shared encoders with cancer-specific prediction heads achieves 7.2% performance improvement over independent training (mean C-index: 0.670 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \pm \end{document} 0.066 versus 0.625 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \pm \end{document} 0.068), with state-of-the-art results in six out of 10 cancer types.
- Cross-institutional validation across 12–38 centers per cancer type demonstrated strong cross-site stability (standard deviations <0.040 in eight of 10 cancer types), achieved without institution-specific fine-tuning.
- By establishing histopathology as the mandatory anchor modality while adaptively incorporating RNA expression and clinical text through gated fusion, our framework provides consistent base functionality across diverse institutional contexts.
- This work addresses three fundamental technical challenges—incomplete data, cancer heterogeneity, and cross-institutional variability—that represent essential computational prerequisites for future clinical translation of multimodal survival prediction models.
Supplementary Material
BIB_CancerMoE_supp_v2_bbag124
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Sung H, Ferlay J, Siegel RL et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin 2021;71:209–49.33538338 10.3322/caac.21660 · doi ↗ · pubmed ↗
- 2Zhu W, Xie L, Han J et al. The application of deep learning in cancer prognosis prediction. Cancers 2020;12:603.32150991 10.3390/cancers 12030603 PMC 7139576 · doi ↗ · pubmed ↗
- 3Kawabata-Shoda E, Charvat H, Ikeda A et al. Trends in cancer prognosis in a population-based cohort survey: can recent advances in cancer therapy affect the prognosis? Cancer Epidemiol 2015;39:97–103.25541411 10.1016/j.canep.2014.11.008 · doi ↗ · pubmed ↗
- 4Gurcan MN, Boucheron LE, Can A et al. Histopathological image analysis: a review. IEEE Rev Biomed Eng 2009;2:147–71.20671804 10.1109/RBME.2009.2034865 PMC 2910932 · doi ↗ · pubmed ↗
- 5Li R, Xingqi W, Li A et al. HFB Surv: hierarchical multimodal fusion with factorized bilinear models for cancer survival prediction. Bioinformatics 2022;38:2587–94.35188177 10.1093/bioinformatics/btac 113PMC 9048674 · doi ↗ · pubmed ↗
- 6Wang Z, Li R, Wang M et al. GPDBN: deep bilinear network integrating both genomic data and pathological images for breast cancer prognosis prediction. Bioinformatics 2021;37:2963–70.33734318 10.1093/bioinformatics/btab 185PMC 8479662 · doi ↗ · pubmed ↗
- 7Xu Y, Wang Y, Zhou F et al. A multimodal knowledge-enhanced whole-slide pathology foundation model. Nat Commun 2025;16:11406.10.1038/s 41467-025-66220-x PMC 1273871341387679 · doi ↗ · pubmed ↗
- 8Saluja R, Rosenthal J, Windon A et al. Cancer type, stage and prognosis assessment from pathology reports using LL Ms. Sci Rep 2025;15:27300.40715326 10.1038/s 41598-025-10709-4PMC 12297491 · doi ↗ · pubmed ↗