Targetless LiDAR–camera extrinsic calibration via semantic distribution alignment
Xi Chen, Bingyu Sun

TL;DR
This paper introduces a new method for calibrating LiDAR and camera sensors without targets, using semantic alignment to improve stability and accuracy in robotic systems.
Contribution
The novel approach uses semantic distribution alignment with an anchor-fixed pixel measure and direction-aware weighting for robust targetless LiDAR-camera calibration.
Findings
The method reliably converges even with large initial perturbations.
It provides stable extrinsic estimates on the KITTI Odometry dataset.
The approach improves robustness in challenging outdoor scenes.
Abstract
LiDAR–camera fusion systems are widely used in robotic localization and perception, where accurate extrinsic calibration is crucial for multi-sensor fusion. During long-term operation, extrinsic parameters can drift due to vibration and other disturbances, while target-based recalibration is inconvenient in the field and targetless approaches often suffer from highly non-convex objectives and limited robustness in challenging outdoor scenes. We propose a targetless LiDAR–camera extrinsic calibration method by minimizing a semantic distribution consistency risk on SE(3). We align semantic probability distributions from the two sensing modalities in the image domain and freeze the pixel sampling measure at an anchor pose, so that pixel weighting no longer depends on the current extrinsic estimate and the objective landscape remains stable during optimization. On top of this anchor-fixed…
Click any figure to enlarge with its caption.
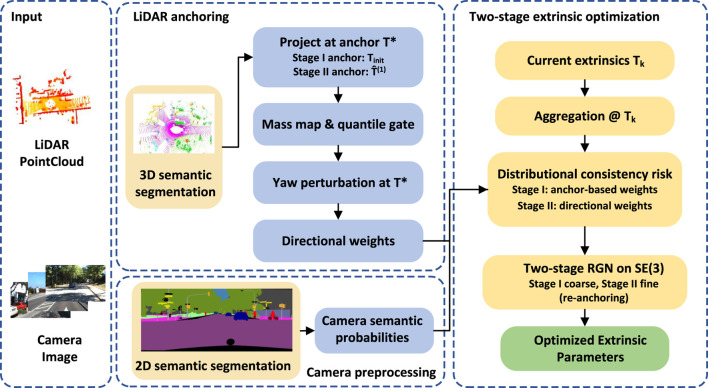 FIGURE 1
FIGURE 1 FIGURE 2
FIGURE 2| Method | Rot. Mean | Rot. Median | Rot. Max | Trans. Mean |
|---|---|---|---|---|
| Ours | 0.188 | 0.198 | 0.500 | 0.26 |
| CalibAnything | 0.299 | 0.259 | 0.697 | 12.08 |
| DirectVLCalib | 5.023 | 5.169 | 10.750 | 8.91 |
| Tsaregorodtsev et al. | 1.595 | 0.936 | 4.688 | 15.85 |
| Pandey et al. (MI) | 30.822 | 25.852 | 83.950 | 35.74 |
| Sequence | Rot. Mean | Rot. Median | Rot. Max | Trans. Mean |
|---|---|---|---|---|
| 01 | 0.175 | 0.166 | 0.524 | 0.15 |
| 07 | 0.247 | 0.262 | 0.348 | 0.23 |
| Init. Range | Rot. Mean | Rot. Median | Rot. Max | Trans. Mean |
|---|---|---|---|---|
| Moderate | 0.295 | 0.215 | 0.991 | 1.60 |
| Large | 0.560 | 0.615 | 0.928 | 2.68 |
| Setting | Rot. Mean | Rot. Median | Rot. Max | Trans. Mean |
|---|---|---|---|---|
| InternImage | 0.951 | 1.105 | 2.752 | 2.24 |
| Optimizer | Rot. Mean | Trans. Mean | Outer iters. Mean |
|---|---|---|---|
| RGN/LM (ours) | 0.188 | 0.26 | 5 |
| RGD + Armijo | 0.362 | 1.29 | 6.8 |
| Scene category | Rot. Mean | Rot. Median | Trans. Mean |
|---|---|---|---|
| A1 road-dominant | 0.333 | 0.102 | 0.40 |
| A2 vehicle-dense | 0.185 | 0.110 | 0.24 |
| A3 balanced | 0.191 | 0.196 | 0.22 |
| Configuration | Rot. Mean | Rot. Median | Trans. Mean |
|---|---|---|---|
| M1 vehicle-tuned (strict) | 0.185 | 0.110 | 0.24 |
| M2 Mass-loose (relaxed) | 0.188 | 0.199 | 0.35 |
| M3 Mass-strict (tightened) | 0.275 | 0.201 | 0.45 |
| Ablation | Rot. Mean | Rot. Median | Rot. Max | Trans. Mean |
|---|---|---|---|---|
| Baseline (full) | 0.188 | 0.198 | 0.500 | 0.26 |
| Anchor-fixed measure | 0.252 | 0.209 | 0.670 | 0.41 |
| Continuous field | 0.471 | 0.301 | 1.100 | 0.83 |
| Multi-scale | 0.219 | 0.203 | 0.587 | 0.33 |
| Kernel bandwidth | 0.198 | 0.199 | 0.548 | 0.27 |
| Kernel bandwidth | 0.203 | 0.200 | 0.556 | 0.37 |
| Directional observability weighting off | 0.231 | 0.208 | 0.598 | 0.28 |
| JS risk | 0.316 | 0.234 | 0.742 | 0.35 |
| Histogram matching removed | 0.261 | 0.211 | 0.603 | 0.33 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Advanced Vision and Imaging · Optical measurement and interference techniques
Introduction
1
Perception and localization in mobile robots and autonomous vehicles increasingly rely on multi-sensor fusion. LiDAR offers accurate three-dimensional range measurements, while cameras provide rich appearance information and strong semantic cues. However, effective multi-sensor fusion depends strongly on accurate extrinsic parameters. In most practical workflows, these parameters are calibrated manually or semi-automatically in an offline procedure before the robot or vehicle is built or first deployed. However, during long-term robot operation, factors such as mechanical vibration, load variations, and external disturbances can gradually shift the pre-calibrated extrinsic parameters. Even modest drift can weaken cross-modal alignment and, as a result, degrade perception and localization performance. These considerations underscore the value of developing a targetless calibration method that remains accurate and dependable in real operating environments.
Although a number of extrinsic calibration methods have been proposed, most still fall short when it comes to performing targetless recalibration in the kinds of conditions robots actually operate in. Broadly speaking, existing LiDAR–camera calibration techniques split into target-based procedures and targetless approaches. Target-based methods use dedicated patterns and controlled environments to achieve high accuracy and good repeatability (Zhang and Pless, 2004; Geiger et al., 2012; An et al., 2020; Cai et al., 2020), but they are cumbersome to deploy during routine operation. Targetless methods exploit natural scene structure, motion, or semantic cues instead of artificial targets (Moghadam et al., 2013; Pandey et al., 2012; Taylor et al., 2013; Koide et al., 2023; Ma et al., 2021; Strobl and Hirzinger, 2006; Ishikawa et al., 2018). However, many of these formulations still suffer from non-convex and sometimes effectively iteration-dependent objectives (e.g., when associations, sampling sets, or pixel-wise weights are updated with the current pose), sensitivity to initialization and motion excitation, and degraded performance in low-excitation scenarios (see Section 2 for a detailed review).
More recently, semantic-consistency-based targetless calibration methods (e.g., aligning semantic edges or object masks) have attempted to leverage high-level semantic information to mitigate low-level geometric mismatches (Liao et al., 2023; Luo et al., 2024). However, directly aligning discrete labels or masks introduces strong non-convexity and makes the methods sensitive to segmentation noise and dynamic occlusions. Furthermore, updating pixel weights together with extrinsics may produce a “moving yardstick” effect that reduces numerical stability.
To address these issues, we cast LiDAR–camera extrinsic calibration as minimizing a distributional inconsistency risk over rigid-body transformations on the manifold. Instead of aligning sparse correspondences or discrete labels, we align continuous, pixel-wise semantic probability fields in the image domain: the camera provides per-pixel semantic probabilities, while semantically labeled LiDAR points are projected into the image and softly aggregated into a dense LiDAR-induced semantic probability field. The extrinsic parameters are then estimated by minimizing a robust distributional divergence between the two fields, augmented with a global semantic-class histogram consistency term.
To improve stability and identifiability during optimization, we introduce three design strategies: (1) anchor-fixed sampling, where the pixel sampling/weighting is computed once at an anchor estimate and kept fixed within each optimization stage to avoid the “moving yardstick” effect; (2) direction-aware (yaw-sensitive) weighting, which emphasizes pixels whose LiDAR-induced semantics change most under small yaw perturbations to improve conditioning for rotation estimation in road-dominant scenes; and (3) a robust objective based on a log-saturated Jensen–Shannon divergence together with global histogram balancing and a multi-scale organization to mitigate outliers, noise, and class imbalance. Formal definitions of all symbols and operators are provided in Section 3.1–3.4. The complete mathematical formulation is provided in Equations 1–26.
In summary, the proposed method aims to maintain stable extrinsic estimates during long-term operation and improves robustness compared with existing targetless calibration objectives. Our main contributions are as follows:
- We propose a targetless LiDAR–camera extrinsic calibration framework that aligns dense semantic probability fields in the image domain and optimizes the extrinsic parameters directly on .
- We introduce an anchor-fixed sampling strategy that decouples pixel sampling/weighting from the evolving pose estimate, improving numerical stability by avoiding measure/metric drift during iterative optimization.
- We design a direction-aware yaw observability weighting that emphasizes pixels most informative for yaw estimation, improving identifiability in road-dominant or low-structure scenes.
- We develop a robust objective based on a log-saturated Jensen–Shannon divergence with global semantic histogram balancing and a multi-scale formulation, and solve it using a Riemannian Gauss–Newton optimizer. We validate the method on public driving datasets under controlled initialization biases.
The remainder of this paper is organized as follows. Section 2 reviews target-based, targetless, and semantic-driven calibration methods. Section 3 describes the proposed approach in detail. Section 4 presents the experimental setup, baseline comparisons, factor analysis, and ablation studies. Section 6 concludes the paper and discusses possible future directions.
Related work
2
LiDAR–camera extrinsic calibration methods can be broadly grouped into target-based approaches and targetless approaches. Within the targetless category, semantic-driven methods have recently emerged as an important subclass. Although target-based and targetless methods have established relatively mature offline calibration procedures, they often face challenges related to adaptability and robustness in continuous or long-term operation. In recent years, semantic-consistency-based approaches have attempted to alleviate low-level geometric mismatches by leveraging high-level semantic information. Several survey papers have systematically summarized these developments and highlighted remaining open challenges (Li et al., 2023; An et al., 2024).
Target-based methods
2.1
Target-based methods rely on predefined geometric patterns to establish accurate 3D–2D correspondences and solve for extrinsic parameters using reprojection or geometric constraints. Early work largely focused on calibrating a camera with a 2D laser range finder (2D LiDAR). Zhang and Pless used a planar checkerboard target and point-on-plane constraints (Zhang and Pless, 2004), whereas Chen et al. employed a cubic calibration target covered with chessboard patterns and derived point-to-line constraints for 2D LiDAR–camera calibration (Chen et al., 2012). These formulations led to a large body of follow-up work on target design, geometric modeling, and nonlinear refinement.
To reduce manual effort, Geiger et al. later proposed a single-shot method that jointly calibrates cameras and range sensors (Geiger et al., 2012). More recent studies have designed fiducial patterns specifically adapted to modern solid-state LiDARs (Xie et al., 2022). Recent work further improves plane-based target calibration by modeling the uncertainty of checkerboard planes and constructing analytic plane covariances, which enables principled weighting in the optimization (Koo et al., 2020).
While target-based approaches can deliver high accuracy and good repeatability in controlled conditions, they fundamentally rely on dedicated calibration objects and carefully arranged scenes. In practice, this means that calibration often has to be performed in a separate, instrumented environment, limiting the usefulness of these methods for continuous deployment and long-term operation, where systems are expected to maintain calibration without access to such controlled setups (Li et al., 2023; An et al., 2024).
Targetless methods
2.2
Compared with target-based approaches, targetless calibration does not rely on artificial calibration objects and is therefore better suited for recalibration in real operating environments. Existing targetless methods can be broadly grouped into two categories: geometric or information-theoretic alignment, and motion-based approaches.
Geometric and information-theoretic methods
2.2.1
Geometric alignment methods construct cross-modal correspondences by leveraging naturally occurring environmental structures—such as planes, edges, and corners—and solve for the extrinsics by minimizing geometric consistency error. Representative methods use Gaussian mixture models and coarse-to-fine optimization procedures, achieving good performance in structured scenes; however, they remain sensitive to feature detection quality and initialization (Castorena et al., 2016; Kang and Doh, 2020; Yin et al., 2023). Information-theoretic approaches maximize the statistical dependence between sensor modalities without performing explicit feature matching. Pandey et al. introduced a mutual-information-based method (Pandey et al., 2012). Although broadly applicable, such methods often produce non-convex cost landscapes with multiple local optima, making them highly sensitive to initialization and sometimes requiring global search strategies. More recently, Koide et al. developed a general single-shot toolbox for targetless calibration based on MI and NMI (Koide et al., 2023).
Motion-based methods
2.2.2
Motion-based methods infer extrinsic parameters by analyzing relative sensor motions across multiple time steps, typically cast as a hand–eye calibration problem (Strobl and Hirzinger, 2006). While hand–eye calibration itself does not require overlapping sensor fields of view, some LiDAR–camera pipelines use it only for initialization and then perform a correspondence-based refinement that does require overlap (e.g., Ishikawa et al., 2018).
However, these methods strongly depend on motion estimation quality and require sufficient excitation, and they are particularly sensitive to sensor synchronization errors and low-excitation conditions such as near-straight-line trajectories.
Semantic-driven targetless methods
2.3
Semantic-driven calibration approaches form a subclass of targetless methods and make use of high-level semantic cues such as categories, instances, or semantic edges to improve robustness in targetless and online scenarios. Tsaregorodtsev et al. incorporated semantic segmentation of images and point clouds to define registration objectives tailored for infrastructure–vehicle configurations (Tsaregorodtsev et al., 2022). SE-Calib introduced a semantic-edge consistency objective for online boresight calibration under urban environments (Liao et al., 2023). Calib-Anything used the Segment Anything Model (SAM) to generate zero-shot semantic masks and optimized cross-modal consistency across semantic object regions (Luo et al., 2024). Other semantic-based methods include semantic mutual information estimation (SemCal) Jiang et al. (2021), consistency-based single-shot inference (RobustCalib) (Xu et al., 2023), and semantic alignment for online calibration in autonomous driving (Zhu et al., 2020). However, semantic-driven approaches often directly align discrete labels or masks, resulting in strongly non-convex optimization landscapes and high sensitivity to segmentation noise and dynamic occlusions, as also emphasized in recent surveys (Li et al., 2023; An et al., 2024). From a numerical perspective, jointly recomputing pixel or mask weights and updating the extrinsic parameters effectively changes the underlying measurement reference during optimization, which can lead to a “moving yardstick” effect and reduce stability in practice.
In summary, existing target-based and targetless approaches, including recent semantic-driven variants, have advanced LiDAR–camera calibration but still struggle to maintain stable optimization and to prevent extrinsic drift in changing environments. We propose a unified semantic-consistency framework that combines an anchor-fixed sampling measure, direction-aware yaw weighting, and a robust objective on semantic probability fields, aiming for more reliable calibration in realistic conditions and better support for long-term deployment.
Proposed methods
3
We formulate LiDAR–camera extrinsic calibration as a distributional consistency risk minimization problem on the special Euclidean group . Concretely, we represent the camera output as a semantic probability field in the image domain and construct a LiDAR-induced field by projecting semantically labeled LiDAR points into the image via an aggregation operator. To avoid metric drift during optimization, we freeze the pixel sampling measure at an anchor pose and build yaw-sensitive pixel weights at each scale by combining this fixed measure with a direction-aware observability weighting. On top of these fields, we define a log-saturated distributional consistency objective based on multi-scale Jensen–Shannon (JS) divergence, complemented by global semantic histogram balancing to mitigate class imbalance. The resulting objective is minimized on using a Riemannian Gauss–Newton method with Levenberg–Marquardt damping, embedded in a two-stage scheme: a coarse stage without yaw weighting to pull the estimate into a good basin, followed by a fine stage that reintroduces directional weighting to refine the yaw and translation. A schematic overview of the full pipeline is shown in Figure 1.
Schematic pipeline of the proposed LiDAR–camera extrinsic calibration method via semantic distribution alignment on SE(3) .
Problem setup and notation
3.1
Let the image domain be and let the number of semantic classes be with class index . The camera-side semantic probability field is written as
where denotes the -dimensional probability simplex over classes.
The LiDAR sensor provides a set of semantically labeled points in its own coordinate frame, The extrinsic parameters are denoted by , where and . The pinhole projection operator is . In the implementation, we undistort the images in advance so that depends only on the intrinsic matrix . After transforming LiDAR points into the camera frame as , points with depth (we use a more conservative threshold in practice) or whose projections fall outside the image bounds are discarded.
To construct a smooth semantic field from sparse LiDAR points, we use a truncated Gaussian kernel
With this kernel, each pixel aggregates only a finite and spatially local set of projected points, which limits the influence of far-away measurements and stabilizes the constructed semantic field. In practice, the resulting objective is sufficiently smooth for second-order methods such as Gauss–Newton to behave robustly in our experiments.
Semantic field and aggregation operator
AT
3.2
Given a candidate extrinsic , we first transform LiDAR points from the LiDAR frame to the camera frame, , and then project them onto the image plane using . Only points with positive depth and projections within are kept for aggregation.
At pixel , the unnormalized semantic mass of class is defined as
After normalization, we obtain the LiDAR-induced semantic probability field in the image domain,
Equations 3, 4 define an aggregation operator that maps the semantic point set to the semantic field ,
To avoid numerical underflow, we truncate entries of and that are smaller than and renormalize them, so that the resulting vectors still lie in the simplex .
To improve robustness to scale changes and noise, we construct semantic fields at two resolutions: the original resolution and a half resolution . After obtaining and at the original resolution, we apply Gaussian smoothing and downsampling to : , and then apply the same clamping and renormalization at each scale so that for .
Anchor-fixed measure and directional observability weighting
3.3
If pixel weights depend directly on the current pose , then the “ruler” of the objective changes whenever changes during optimization. This can distort the loss landscape and weaken yaw observability. To avoid this, we freeze the sampling measure at an anchor pose and then place a yaw-sensitivity weighting on top of it.
At the beginning of a local optimization stage, we set the anchor as where comes from the previous estimate or from an external initialization. Within this stage, remains fixed. From the definition in (3) at the anchor pose, we obtain the unnormalized semantic mass .
To steer the sampling measure toward structurally informative regions, we introduce a non-road mass weight and split the class index set as follows: The anchor-space semantic mass of non-road and background classes are then
The total semantic mass map at the anchor is
Here emphasizes non-road regions such as buildings and vehicles, while downweights potentially noisy non-road evidence. In our default configuration, we adopt a slightly conservative setting , which empirically yields more stable calibration in sparse scenes.
Let and denote the 30th and 90th pixel-wise quantiles of . We set and construct a piecewise linear gating function
This gives a normalized anchor measure
If the denominator is zero, we regard the frame as degenerate and discard it. At multiple scales, we apply the same smoothing and downsampling procedure as in Sec. 3.2 to , which yields scale-specific measures .
To ensure that non-road classes have sufficient coverage under this measure, we compute a coverage ratio
We require ; otherwise the frame is considered to have insufficient semantic coverage and is discarded. In our default configuration, we set , so that at least 10% of the high-mass pixels must carry non-road evidence for a frame to be used in calibration.
On top of this measure, we evaluate yaw-perturbation sensitivity at the anchor. Yaw is singled out because in our road-dominant setting it is typically the most weakly conditioned rotational direction (heading), whereas roll/pitch are usually bounded and already constrained by strong vertical/ground structure. The same sensitivity-based reweighting can be applied to roll or pitch by replacing with the corresponding generators; we focus on yaw for simplicity and because it provides the dominant empirical gain. Let denote the unit generator of rotation around the -axis, with scalar yaw coordinate . Perturbations are applied in a left-multiplicative form, At scale , the pixel-wise sensitivity is defined as
and we compute the weighted mean using ,
In our implementation, we use fixed parameters and . The final pixel weights at scale are
At full resolution, we write .
Intuitively, approximates the first-order sensitivity at pixel , and its magnitude is monotonically related to a Fisher-information-like term along yaw. Reweighting based on therefore acts as a numerical pre-conditioning that strengthens the yaw component of the local (Gauss–Newton) Hessian, increasing the curvature with respect to and facilitating yaw correction in practice. Since rotational and translational increments are coupled by the projection model in the same normal equations, improving the yaw curvature also tends to improve the conditioning of the full 6-DOF update, mitigating yaw–translation ambiguity.
Distributional consistency risk
3.4
We use a log-saturated robust function
and measure consistency between semantic distributions using the Jensen–Shannon (JS) divergence
where the Kullback–Leibler divergence uses the natural logarithm. For discrete distributions we have , so remains smooth and bounded over the full range.
At scale , the pixel-wise distributional consistency term is
To reduce the effect of class imbalance, we add a global histogram term at full resolution. Using the weights , we define
and construct
The final unified calibration objective is
Because each is a probability measure and with monotone and bounded, these three terms naturally stay on a similar scale. In practice, we do not introduce extra manual weights between them.
Yaw observability analysis
3.5
In this subsection, denotes the directional derivative associated with a left perturbation . We assume that the truncated Gaussian kernel and any depth-based weights satisfy basic boundedness conditions, and that there exist constants such that, after truncation and normalization,
where is the true extrinsic. We let be the pixel sampling measure induced by .
If there exists a constant such that
then we say that is observable in the yaw direction. Intuitively, (21) requires that a small yaw perturbation induces a non-negligible change in the LiDAR-induced semantic distribution under the sampling measure .
Under the regularity assumptions in (20), the JS divergence is strongly convex in both arguments on the interior of the simplex, and its Hessian admits a uniform lower bound that depends only on and . Combining this strong convexity with (21) and the fact that defines a probability measure, one can show that there exists a constant such that, in a neighborhood of ,
A full derivation is beyond the scope of this paper; the role of (22) here is to provide an analytical motivation for the yaw-weighting scheme.
For simplicity, we state the result in terms of the full-resolution term; the additional multi-scale and histogram terms are non-negative and share the same sampling measure, so they can only increase the curvature of along the yaw direction. In other words, the yaw observability condition implies a strictly positive local lower bound on the second derivative of along the yaw direction, which helps parameter identification and supports stable convergence of second-order optimization methods.
Riemannian Gauss–Newton on
SE(3) and two-stage optimization
3.6
To minimize , we rewrite it as a multi-scale weighted nonlinear least-squares problem and solve it on using a Riemannian Gauss–Newton (RGN) method with Levenberg–Marquardt damping.
At each scale and pixel , we first compute
and use as the working residual for that pixel. The global histogram term is treated in the same way: Given , we adopt an IRLS scheme and define
With these weights, the robust objective is locally equivalent to a weighted norm of the residual vector in the sense that the two formulations share the same first-order derivative with respect to at the current iterate. This yields a standard weighted nonlinear least-squares problem amenable to a Gauss–Newton/Levenberg–Marquardt update.
Let be a basis of the Lie algebra , and let denote parameter increments in the Lie algebra. We use a left-multiplicative update on ,
At each iteration, we stack all residuals from all scales and the histogram term into a single vector , approximate the Jacobian along each basis direction in using central finite differences, and solve damped normal equations to obtain . We employ standard stopping criteria (step size, relative objective change, and maximum iterations).
Given an anchor and the associated multi-scale weights , the procedure above provides one local optimization of . To increase robustness to larger initialization errors, we build a two-stage optimization strategy with re-anchoring on top of this process.
Event-driven re-anchoring
3.6.1
Rather than updating the anchor pose at a fixed frequency, we adopt an event-driven re-anchoring rule to keep the anchor piecewise constant during optimization. We compute , and re-freeze the anchor when . This avoids a continuously moving reference while still preventing drift when the update becomes sufficiently large.
Stage 1 (coarse alignment)
3.6.2
Given the initial extrinsic , we first set and construct the semantic mass map and multi-scale measures as in Section 3.3. To reduce the risk of incorrect yaw weighting under large misalignment, we ignore yaw sensitivity in this coarse stage and set
When is far from , the finite-difference yaw perturbations can project points into largely mismatched regions, so the resulting may not reflect the true yaw sensitivity and can even emphasize misleading pixels. The coarse stage therefore uses only the structurally informed but direction-independent measures to define a fixed sampling “ruler”. We replace with in the pixel-wise term (16) and in the IRLS weights, obtaining a direction-independent coarse objective, denoted by . With this fixed measure, we run several RGN/LM iterations on to move from a larger initialization error into a local neighborhood of the true extrinsic .
Stage 2 (fine alignment)
3.6.3
After the coarse stage, we take the intermediate estimate as a new anchor and set . We then recompute , the multi-scale measures , and yaw sensitivities , and from these build the full direction-aware pixel weights . Under this new fixed measure, we return to the original objective in (19) and run RGN/LM until convergence to obtain the final estimate . The directional weights explicitly increase curvature along the yaw direction, which improves both the ability to correct yaw and the stability of fine optimization.
It is worth emphasizing that the two-stage strategy only introduces re-anchoring and a layered objective at the implementation level. Within each stage, the anchor and the corresponding weights or remain fixed, so the optimization problems reduce to minimizing or under a fixed sampling measure.
After Stage 1, the intermediate estimate is typically within a small neighborhood of (see Section 4 for quantitative evidence). Since both and its yaw derivative vary continuously with , the pixel weights constructed at satisfy the yaw observability condition (21) with a possibly modified constant. Consequently, the curvature lower bound in (22) applies to the fine stage, while the coarse stage empirically enlarges the range of initial errors from which the method can still converge to a high-accuracy solution.
As with other Gauss–Newton–type calibration schemes, the proposed solver is inherently local: it leverages the curvature of only in the neighborhood of the current estimate and therefore assumes that the available initialization is not arbitrarily far from the ground truth.
Optional coarse hypothesis initialization
3.6.4
When substantially larger misalignments are expected, we optionally prepend a lightweight coarse initialization step that selects a safer starting pose by evaluating a bounded set of pose hypotheses at the coarsest pyramid level. In our implementation, the hypothesis set primarily discretizes yaw within a limited range, and may additionally include a small number of translation hypotheses when translation uncertainty is non-negligible. Each hypothesis is scored using the same semantic objective (or its coarse, direction-independent variant ), and hypotheses are evaluated independently by resetting any per-evaluation cached states before scoring so that the scores are order-independent. To avoid degenerate low-cost solutions caused by support collapse, we discard hypotheses that fail basic validity checks, such as insufficient valid frames or insufficient effective support (e.g., too few active pixels or too small accumulated weights) relative to the seed. Among the remaining hypotheses, we select a candidate primarily by objective value while discouraging solutions that reduce the cost mainly by shrinking the effective support; in addition, we retain the minimum raw-cost candidate as a conservative fallback and prefer it whenever it offers a clear cost advantage without violating the support constraints. The selected hypothesis can be optionally refined by a small local rotation micro-search and is then passed to the two-stage RGN/LM procedure as . This initialization is an optional engineering component, does not modify the underlying objective or the two-stage optimization within each stage.
Experimental results
4
Setup and evaluation protocol
4.1
Dataset and evaluation task
4.1.1
Our main benchmark and the baseline comparisons in Section 4.2 are conducted on sequence 00 under the official LiDAR–camera geometric configuration. To assess cross-sequence generalization beyond a single driving sequence, we additionally evaluate our method on sequences 01 and 07 under the same protocol (Section 4.3), and evaluate robustness under network-predicted 2D/3D semantics on sequence 07 (Section 4.5).
The ground-truth extrinsics (GT) are used solely for computing evaluation metrics and for constructing a fixed semantic reference in the image domain, as described later. Importantly, GT is never introduced into the optimization process, ensuring that the optimizer always operates under unknown extrinsics and never has direct access to ground-truth information.
Clip selection
4.1.2
We construct twelve fixed 50-frame clips from sequence 00, starting at frames {0, 200, 400, 600, 1,000, 2000, 2,400, 2,600, 3,000, 3,200, 3,600, 3,800}. Each clip contains 50 synchronized camera–LiDAR frames, and the same set of clips is used across all methods to ensure a fair and directly comparable evaluation. For cross-sequence generalization, we additionally sample six fixed 50-frame clips for each of sequence 01 and sequence 07, starting at frames {0, 200, 400, 600, 800, 1,000}. Unless otherwise stated, we use the same initialization bias and identical hyperparameters across all sequences.
For each clip, we run a fixed-window batch optimization: the calibrator iterates over the same set of 50 paired frames throughout optimization, without sliding the window forward in time or propagating extrinsics across windows. Consequently, accumulated calibration drift caused by online/recursive updates is not applicable under our evaluation protocol. For the scene-type analysis in Section 4.7, we additionally include several more clips to better cover different semantic compositions. Although we use fixed clips for a reproducible benchmark, we further derive a simple automatic “calibration-friendly” triggering heuristic from the scene-composition analysis in Section 4.7.
Initialization and perturbation settings
4.1.3
For the main cross-method benchmark (Table 1), we use a shared deterministic initialization for all methods and all clips: we perturb the ground-truth (GT) extrinsics by a yaw rotation of and a translation of (expressed in the LiDAR coordinate frame). This choice ensures that every compared method starts from an identical initial estimate, avoiding confounding effects due to different random draws.
TABLE 1: Overall rotation and translation performance on KITTI 00 under the shared 5°/50 mm initialization. Rotation errors are in degrees; translation mean errors are in centimeters.
To assess sensitivity to initialization and the practical convergence basin of our solver, we additionally run Monte-Carlo trials with random perturbations. In these trials, we perturb only the yaw angle (roll/pitch are kept at zero) and independently sample translations along each LiDAR axis as in Equation 27:
We report results for two ranges: (i) Moderate: and ; (ii) Large: and . Unless otherwise stated, random-initialization experiments use the same 50-frame clips and metrics as the main benchmark.
Semantic sources
4.1.4
To provide a clean and consistent reference for semantic alignment while avoiding the influence of recognition errors, we use the official 3D semantic annotations provided by the SemanticKITTI labels Behley et al. (2019) as a noise-free source. Each LiDAR point is associated with a semantic class label from the 3D ground truth. During preprocessing, we project these 3D labeled points into the image plane once via the ground-truth extrinsic transformation, producing a fixed image-space probability field that serves as a stable semantic reference. This projection step is performed only once in the offline phase and does not participate in any optimization. During calibration, the online LiDAR-side distribution is generated from the same 3D labeled points via soft projection under the candidate extrinsic . Since is fixed and never updated by the optimizer, and the ground-truth transformation is used only once offline to construct the reference field, this setting constitutes an oracle-style (upper-bound) benchmark. Ground-truth extrinsics are used only for reference construction and evaluation, and are never accessed during the optimization iterations. This deterministic setup isolates calibration behavior from segmentation uncertainty.
Evaluation metrics
4.1.5
Rotation error is defined as the norm of the axis–angle representation and is reported in degrees. Translation error is computed as measured in centimeters. In all experiments, rotation is treated as the primary metric for calibration quality: we therefore report mean and median rotation errors, and for the main cross-method comparison (Table 1) and the ablation study (Table 8) we additionally include the maximum rotation error to characterize tail behavior. Translation mainly serves as a sanity check of scale consistency, so we focus on its mean (and, where space allows, median) and omit further statistics to keep the tables compact. Whenever results are pooled across multiple clips, we explicitly state the aggregation scheme.
Efficiency and limitations
4.1.6
Our method targets on-demand/offline calibration with fixed-window batch optimization, using precomputed semantic probability/label maps loaded from disk. Under the paper setting ( , , ), the runtime of our current implementation is minutes-level per window and is dominated by the RGN/LM (semantic I/O ). The current prototype is not optimized for real-time deployment; improving efficiency is left for future work.
Overall comparison across methods
4.2
All methods are evaluated on the same 50-frame clips from KITTI sequence 00 with a shared initialization of and , following the protocol described in Section 4.1. Robustness to randomized initializations is evaluated separately in Section 4.4.
In addition to our method, we compare against CalibAnything (Luo et al., 2024), DirectVLCalib (Koide et al., 2023), Tsaregorodtsev et al. (2022), and the mutual-information-based method of Pandey et al. (2012), using the publicly available open-source implementations with recommended parameter settings.
Several recent targetless calibration methods also exploit semantic cues, e.g., SemCal (Jiang et al., 2021), SE-Calib (Liao et al., 2023), and SGCalib (Lin et al., 2024). We do not include them in the quantitative comparison in Table 1 because their task settings and evaluation protocols are not directly aligned with our clip-based drift-refinement benchmark, and we could not find publicly available implementations that can be executed under our protocol at the time of revision.
Under this common setting, our method achieves the smallest rotation median and mean among the compared approaches. The reported rotation errors remain at the sub-degree level, whereas the baselines exhibit clearly larger medians and means, especially for Tsaregorodtsev et al., DirectVLCalib and the MI-based method of Pandey et al.
For translation, the mean error of our method is 0.26 cm, while the corresponding values for CalibAnything, DirectVLCalib, Tsaregorodtsev et al., and Pandey et al. (MI) are 12.08 cm, 8.91 cm, 15.85 cm, and 35.74 cm, respectively. These results indicate that, for the chosen dataset and initialization, the proposed semantic distribution alignment with an anchor-fixed sampling measure yields more stable extrinsic estimates in both rotation and translation. The baseline results are based on the authors’ open-source implementations without manual per-clip tuning; although different tuning choices or datasets could change the absolute numbers, the relative performance trends in Table 1 were consistent across all evaluated clips. In addition, this comparison is not fully apples-to-apples: our method currently relies on oracle semantic labels as described in Section 4.1 whereas the baselines operate on their default visual, geometric, or semantic cues, so the numbers in Table 1 should be interpreted as indicative rather than as a definitive ranking. We therefore additionally report a realistic evaluation using network-predicted 2D/3D semantics in Section 4.5.
Cross-sequence generalization
4.3
To assess the generalizability of our proposed calibration objective beyond the initially evaluated KITTI odometry sequence 00, we conduct further validation on two additional sequences—KITTI odometry sequences 01 and 07. We follow the same protocol as in Section 4.1: 50-frame clips, the same shared initialization bias , and identical hyperparameters across sequences. Table 2 reports the results.
TABLE 2: Cross-sequence generalization of our method on additional KITTI odometry sequences under the shared 5°/50 mm initialization. Rotation errors are in degrees; translation mean errors are in centimeters.
Quantitative results indicate that the calibration objective achieves good generalization performance across these sequences. The rotation errors consistently remain at sub-degree magnitudes, with a maximum rotation error of observed for sequence 01, while translation errors exhibit stability at the millimeter-to-centimeter scale, showing mean translation errors of 0.15 cm for sequence 01 and 0.23 cm for sequence 07, respectively.
Robustness to random initializations
4.4
The deterministic perturbation is useful for a controlled cross-method comparison, but it does not characterize how sensitive a solver is to the specific initialization. We therefore additionally evaluate our method under randomized initial perturbations sampled as described in Section 4.1. We run 5 random seeds for each 50-frame clip from KITTI sequence 00 and aggregate the final residual errors after convergence.
In this experiment, we enable the optional coarse hypothesis initialization described in Section 3.6 to obtain a safer starting pose when needed, and then apply the proposed two-stage RGN/LM refinement unchanged. This initializer is executed at the coarsest level and serves only to propose ; it does not modify the objective or the within-stage optimization.
Across all trials, our method converges reliably under both perturbation ranges, achieving sub-degree rotation errors and translation mean errors of 1.60 cm (Moderate) and 2.68 cm (Large). While the proposed solver remains a local optimizer (Section 3.6) and extreme meter-level misalignments may require a coarse global initializer, the above results demonstrate robustness in a practically relevant regime where a rough extrinsic is available. The robustness results are summarized in Table 3.
TABLE 3: Robustness of our method to random initialization perturbations on KITTI sequence 00. Moderate: yaw ∈[−10°,10°] , tx,y,z∈[−5,5] cm; Large: yaw ∈[−20°,20°] , tx,y,z∈[−10,10] cm. Rotation errors are in degrees; translation errors in centimeters.
Robustness under network-predicted semantic noise
4.5
To evaluate the effect of segmentation noise in a realistic non-oracle scenario, we conduct experiments where both camera and LiDAR semantic fields are derived entirely from neural network predictions. For the camera modality, we employ the InternImage-based 2D semantic segmentation model Wang et al. (2023) with Mask2Former pretrained weights (evaluated via projection of ground-truth LiDAR point clouds, mIoU = 65.85) on each RGB frame to generate per-pixel semantic probability fields , which represent softmax probabilities. These semantic predictions are computed offline and remain fixed throughout the optimization process. For the LiDAR modality, we obtain per-point semantic predictions using MinkowskiNet (Choy et al., 2019) implemented in OpenPCSeg (official pretrained weights, mIoU = 70.04), and form the projected field using the same projection operator as in the oracle setting.
All other settings follow Section 4.1. Experimental results obtained from KITTI sequence 07 are summarized in Table 4. As anticipated, replacing oracle annotations with semantic predictions from neural networks introduces additional errors into the calibration results. Despite this increased semantic noise, the optimization framework demonstrates robust and stable convergence under these more practical conditions.
TABLE 4: Calibration results under network-predicted 2D/3D semantics on KITTI sequence 07 ( P from InternImage; QT from MinkowskiNet/OpenPCSeg). Rotation errors are in degrees; translation mean errors are in centimeters.
Optimizer comparison and convergence behavior
4.6
The calibration objective is optimized over and is generally non-convex. In addition to the objective design, the practical outcome can be affected by the numerical optimizer. To isolate the optimizer effect, we keep the objective, initialization , and stopping criteria fixed, and only change the solver.
Our default solver is a Riemannian Gauss–Newton method with Levenberg–Marquardt damping (RGN/LM) (Section 3.6). As a first-order baseline, we implement Riemannian gradient descent (RGD) with Armijo backtracking line search. Table 5 summarizes the final calibration errors and iteration statistics aggregated over representative clips from KITTI sequence 00. Under the same experimental setting, RGN/LM reaches substantially lower final rotation and translation errors than RGD.
TABLE 5: Optimizer comparison aggregated over KITTI sequence 00 clips under the shared 5°/50 mm initialization. We report mean across clips. Rotation errors are in degrees; translation errors are in centimeters.
The reported iteration count is provided only as a coarse convergence statistic and should not be interpreted as computational cost. In particular, Armijo backtracking may evaluate the objective multiple times within a single RGD iteration, whereas LM damping changes the effective step acceptance and progress per iteration. Accordingly, we interpret the comparison primarily through the final accuracy, and use the iteration numbers only as auxiliary information.
Effect of semantic class-distribution shifts
4.7
To examine how differences in scene composition affect calibration performance, we characterize each 50-frame clip by the pixel-level proportions of road and vehicle labels in (road versus non-road/vehicle), and group clips from KITTI sequence 00 according to these statistics.
For this analysis, we use an extended set of 18 non-overlapping 50-frame clips from sequence 00, starting at frames 0, 200, 400, 600, 800, 1,000, 1,200, 1,400, 2000, 2,200, 2,400, 2,600, 2,800, 3,000, 3,200, 3,400, 3,600, and 3,800. Based on their measured road/vehicle pixel proportions, these clips are partitioned into three semantic categories:
- A1 Road-dominant: clips in which the roadway accounts for the largest share of pixels and vehicles are comparatively rare. This group contains 00_s0000, 00_s0400, 00_s1200, 00_s1400, 00_s3000, and 00_s3400.
- A2 Vehicle-dense: clips with the strongest vehicle and non-road coverage. This group contains 00_s0600, 00_s1000, 00_s2200, 00_s2800, 00_s3200, and 00_s3600.
- A3 Balanced: the remaining clips. This group contains 00_s0200, 00_s0800, 00_s2000, 00_s2400, 00_s2600, and 00_s3800.
All experiments in this subsection use the shared deterministic initialization bias (5°/50 mm). For each clip, we run the calibration once under this fixed perturbation and aggregate the resulting residuals over all clips within each cluster.
As summarized in Table 6, A2 and A3 achieve similarly low mean rotation residuals (around ), indicating that the proposed method remains stable in both balanced and vehicle-rich scenes. In the vehicle-dense A2 group, the median rotation error further drops to about , which is consistent with the additional geometric support provided by vehicles and other non-road structures.
The behavior of A1 is noticeably different. Although the median rotation error remains small (around ), the mean increases to and the average translation residual also becomes larger. This indicates that occasional larger errors occur more frequently in road-dominant scenes, where vertical structures are scarce and yaw is more easily coupled with lateral translation.
Overall, these results suggest that the scene’s semantic composition has a clear impact on calibration quality. Scenes with richer structure (A2, A3) tend to produce more stable estimates, whereas road-dominant segments (A1) naturally exhibit weaker observability. A practical implication is that LiDAR–camera recalibration does not need to run continuously: it is more effective to trigger recalibration only on clips that contain sufficient semantic and structural richness (similar to A2 or A3), while largely ignoring frames dominated by road surface, thereby reducing computational load without degrading calibration quality. We operationalize this intuition with the following lightweight triggering heuristic.
Motivated by the above finding that road-dominant segments exhibit weaker observability, we propose a simple online triggering rule for practical deployment. Given per-frame semantic probability maps , we maintain sliding-window estimates of the road and vehicle pixel proportions over the most recent frames using the same definitions as in this subsection. We trigger recalibration when the window is not road-dominant and contains sufficient non-road structure, as summarized in Equation 28:
where denotes the number of valid projected LiDAR points within the image. The thresholds can be set automatically from running statistics (e.g., percentile-based filtering) to suppress road-dominant windows. Note that this heuristic is proposed for online triggering and is not used to select the fixed evaluation clips in this subsection.
Effect of semantic mass prior and gating
4.8
We next examine how the semantic mass prior and its gating mechanism influence yaw observability and the stability of translation estimates. On top of the default configuration, we consider three variants of the semantic weighting:
- M1 Vehicle-tuned (strict): a prior originally tuned for vehicle-dense scenes, using a higher non-road gain and a relatively selective retention of pixels.
- M2 Mass-loose (relaxed): a relaxed prior with a lower non-road gain and a less selective retention, admitting more low-mass (low-support) pixels into the loss.
- M3 Mass-strict (tightened): an over-pruned prior that keeps only a small subset of relatively “clean” non-road pixels.
All three settings are evaluated on the same clip set and with the same fixed initial perturbation, and the residuals are aggregated over all clips.
As shown in Table 7, the vehicle-tuned setting M1 achieves the lowest median rotation error and the smallest mean translation error (0.24 cm). In this regime, discarding obviously noisy pixels while still preserving sufficient non-road coverage improves the effective signal-to-noise ratio and leads to stable rotation and translation estimates.
When the prior is relaxed (M2), the rotation statistics remain close to those of M1, but the translation mean increases to 0.35 cm. Admitting more low-mass (low-support) pixels does not immediately harm rotation accuracy, but it can reduce translation stability, as reflected by the higher mean translation error.
If the prior is tightened too aggressively (M3), both rotation and translation degrade: the mean rotation error rises to , and the mean translation error increases to 0.45 cm. In this case, the pixel set is pruned so strongly that the objective loses curvature in the rotation direction.
Taken together, these variants and the scene-type analysis in Section 4.7 suggest a simple guideline: use a moderately conservative prior by default, tighten it only in clearly vehicle-dense scenes, and keep it less aggressive in road-dominant segments.
Ablation analysis
4.9
Table 8 summarizes the effect of several key components, with rotation errors reported in degrees and translation errors in centimeters.
Replacing the bounded JS risk with a plain loss yields the worst overall performance. The mean rotation error increases from 0.188 to , the translation mean rises from 0.26 to 0.35 cm, and the maximum rotation error grows from to . In this configuration, a few large residuals in outlier/mismatch regions dominate the objective, showing that the JS-based formulation is critical for keeping tail errors in check.
Disabling the directional observability weighting weakens the contribution of yaw-sensitive pixels and effectively shrinks the update step along the yaw axis. The mean rotation error increases by about 23% (0.188 0.231), and the translation mean also deteriorates (0.26 0.28 cm). Emphasizing yaw-sensitive pixels is important for both convergence stability.
Removing the global histogram term produces errors between the two extremes above, but still increases the maximum rotation error to and raises the translation mean to 0.33 cm. Without this global class-distribution constraint, road pixels tend to dominate the measure in some clips, making the method more vulnerable to long-tail failures in regions where semantic evidence is weak.
From a system perspective, these ablations suggest a clear division of labor: the JS loss handles outliers, the observability weighting stabilizes yaw, and the histogram matching corrects for semantic bias in road-heavy scenes. The full configuration in Table 8 combines these effects and explains the compact error distributions observed in the main results.
Beyond the core JS risk and yaw-weighting, Table 8 also validates several implementation choices. (i) Anchor-fixed dynamic measure recomputes the sampling/weighting measure at every iteration, which reintroduces a moving reference and degrades accuracy, supporting our anchor-fixed design. (ii) Continuous field discrete label replaces the probabilistic semantic field with hard labels, reducing smoothness of the objective and harming convergence. (iii) Multi-scale single-scale removes the coarse-to-fine support and leads to a consistent performance drop, indicating the benefit of multi-scale alignment. (iv) A light kernel bandwidth sweep shows the method is reasonably stable around the default ; overly small/large tends to under/over-smooth the field and slightly worsens the solution.
This confirms that emphasizing yaw-sensitive pixels is important for stable optimization and yaw identifiability. A 1D objective slice along yaw is provided in Supplementary Figure S1 to visualize the local optimization behavior of our objective.
Qualitative comparison
4.10
Figure 2 presents a qualitative comparison illustrating the calibration effect under a representative initial drift, showing how the proposed method corrects the misalignment between the two modalities. Before calibration, noticeable misalignments and parallax can be observed between the LiDAR projection and scene structures such as building facades, guardrails and vehicle contours, revealing the underlying extrinsic errors between the sensor coordinate frames. After optimization, the projected point cloud aligns closely with these structures at the pixel level: road edges exhibit continuous and well-fitted point distributions, vertical edges of building facades remain consistent across the two modalities, and vehicle outlines match the point cloud boundaries with high fidelity.
Qualitative comparison before (left) and after (right) calibration. After optimization, the projected LiDAR points align closely with image structures such as road edges, vehicle contours and building facades.
These qualitative observations are consistent with the quantitative statistics and the semantic-cluster analyses in Section 4, and visually corroborate the sub-degree rotation and millimeter-level translation residuals reported in our results.
Discussion
5
This work introduces a semantic distribution alignment method that directly targets the metric drift often observed in LiDAR–camera calibration. The anchor-fixed sampling measure keeps the optimization metric stable, while the direction-aware weighting is designed to improve yaw identifiability in scenes with limited geometric cues; this design is reflected in the reduced rotation errors observed in our ablations. The log-saturated JS divergence, together with semantic histogram balancing and multi-scale processing, further improves robustness to outliers and cross-modal mismatches and to sparse semantic support. Experiments on the KITTI odometry show that the method achieves higher accuracy and stronger robustness than the representative geometric, semantic-mask, and direct-alignment baselines reproduced in our experiments. Ablation studies confirm that the observability weighting, the JS-based risk, and the global histogram term each contribute independently and complementarily, while the anchor-fixed measure stabilizes the metric by construction.
The method still faces challenges in cases with extremely sparse semantics or large cross-modal discrepancies. Translation observability may also degrade during long periods of weak excitation, such as extended straight-line motion, and incorporating additional geometric or semantic cues may help address these limitations. In this work, we primarily benchmark on KITTI odometry sequence 00 and additionally evaluate on sequences 01 and 07 (Section 4.3) with clean SemanticKITTI labels in order to isolate calibration behavior from segmentation uncertainty. We further report a realistic evaluation under network-predicted 2D/3D semantics in Section 4.5. Extending the evaluation to the full KITTI odometry set and to additional datasets remains an interesting direction for future work and would further clarify robustness under realistic perception pipelines.
Conclusion
6
This work introduced a LiDAR–camera extrinsic calibration framework based on semantic distribution alignment. By combining an anchor-fixed sampling measure with direction-aware weighting and a robust JS-based semantic objective, the method achieves stable optimization and low residual errors under both the shared deterministic initialization used for cross-method comparison and randomized initial perturbations up to yaw and cm per-axis translation. In addition to the main benchmark on KITTI sequence 00, cross-sequence experiments on KITTI sequences 01 and 07 further suggest that the proposed objective generalizes beyond a single sequence. Beyond this setting, future work will extend the framework to multi-frame optimization with temporal consistency, incorporate explicit occlusion handling, and evaluate the approach on additional datasets.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1An P. Ma T. Yu K. Fang B. Zhang J. Fu W. (2020). Geometric calibration for lidar-camera system fusing 3d-2d and 3d-3d point correspondences. Opt. Express 28, 2122–2141. 10.1364/oe.381176 32121909 · doi ↗ · pubmed ↗
- 2An P. Ding J. Quan S. Yang J. Yang Y. Liu Q. (2024). Survey of extrinsic calibration on lidar-camera system for intelligent vehicle: challenges, approaches, and trends. IEEE Trans. Intelligent Transp. Syst. 25, 15342–15366. 10.1109/tits.2024.3419758 · doi ↗
- 3Behley J. Garbade M. Milioto A. Quenzel J. Behnke S. Stachniss C. (2019). “Semantickitti: a dataset for semantic scene understanding of lidar sequences,” in Proceedings of the IEEE/CVF international conference on computer vision (IEEE), 9297–9307. 10.1109/iccv.2019.00939 · doi ↗
- 4Cai H. Pang W. Chen X. Wang Y. Liang H. (2020). A novel calibration board and experiments for 3d lidar and camera calibration. Sensors 20, 1130. 10.3390/s 20041130 32092995 PMC 7070607 · doi ↗ · pubmed ↗
- 5Castorena J. Kamilov U. S. Boufounos P. T. (2016). Autocalibration of lidar and optical cameras via edge alignment. IEEE, TR 2016-009, 2862–2866. 10.1109/icassp.2016.7472200 · doi ↗
- 6Chen Z. Zhuo L. Sun K. Zhang C. (2012). Extrinsic calibration of a camera and a laser range finder using point to line constraint. Procedia Eng. 29, 4348–4352. 10.1016/j.proeng.2012.01.669 · doi ↗
- 7Choy C. Gwak J. Savarese S. (2019). 4d spatio-temporal convnets: minkowski convolutional neural networks. Los Alamitos, CA: IEEE Computer Society.
- 8Geiger A. Moosmann F. Car O. Schuster B. (2012). “Automatic camera and range sensor calibration using a single shot,” in 2012 IEEE international conference on robotics and automation (ICRA) (IEEE), 3936–3943. 10.1109/icra.2012.6224570 · doi ↗