Finding low-complexity DNA sequences with longdust
Heng Li, Brian Li

TL;DR
Longdust is a new algorithm that efficiently identifies low-complexity DNA sequences, such as satellite and tandem repeats, using a statistical model of k-mer counts.
Contribution
Longdust introduces a novel, efficient method for identifying long low-complexity DNA sequences with a statistically defined complexity threshold.
Findings
Longdust efficiently identifies long low-complexity sequences like centromeric satellites.
The algorithm uses a statistical model of k-mer count distribution to define string complexity.
Longdust performs well on real data and aligns consistently with existing methods.
Abstract
Low-complexity (LC) DNA sequences are compositionally repetitive sequences that are often associated with spurious homologous matches and variant calling artifacts. While algorithms for identifying LC sequences exist, they either lack concise mathematical definition of complexity or are inefficient with long or variable context windows. Longdust is a new algorithm that efficiently identifies long LC sequences including centromeric satellite and tandem repeats with moderately long motifs. It defines string complexity by statistically modeling the k-mer count distribution with the parameters: the k-mer length, the context window size and a threshold on complexity. Longdust exhibits high performance on real data and high consistency with existing methods. https://github.com/lh3/longdust
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
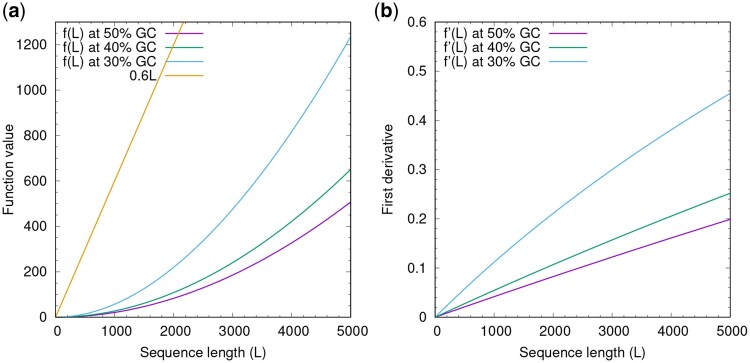 Figure 1
Figure 1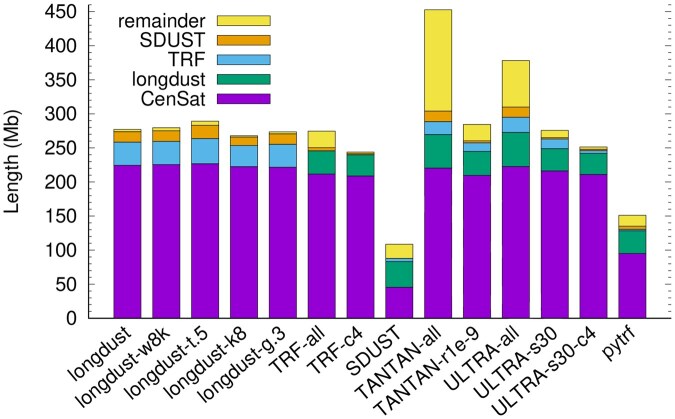 Figure 2
Figure 2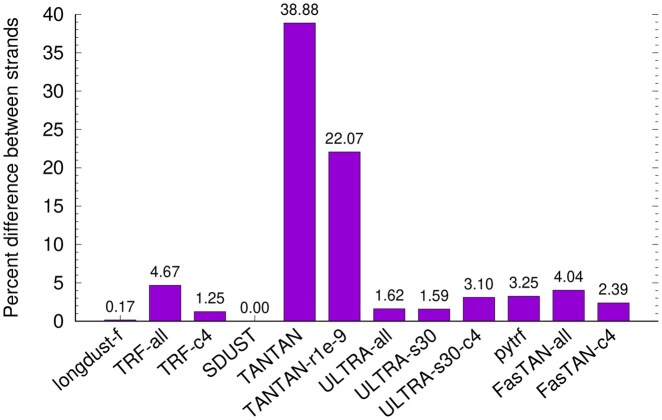 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFractal and DNA sequence analysis · DNA and Biological Computing · Genome Rearrangement Algorithms