Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion
Yunhao Chen, Qian Yin, Li Zhao, Jianlong Wang, Sida Zhou, Jianing Tang

TL;DR
A new framework improves depth estimation in distant regions by combining CNNs and transformers with a novel fusion module.
Contribution
A novel monocular depth estimation framework with a heterogeneous encoder and Cross-dimensional Semantic Fusion module.
Findings
The framework achieves 0.050 Abs-Rel and 2.107 RMSE on the KITTI dataset.
It demonstrates strong generalization with 0.142 Abs-Rel on the SUN RGB-D dataset.
The CSF module enhances feature aggregation for distant objects with low pixel occupancy.
Abstract
Monocular depth estimation enables 3D scene reconstruction from a single 2D image, offering a cost-effective solution widely applied in autonomous driving and UAVs. However, existing deep neural networks often fail to balance local texture details with global contextual information, leading to significant inaccuracies in distant-region depth prediction. To address this challenge, we introduce a novel monocular depth estimation framework featuring a heterogeneous encoder and a Cross-dimensional Semantic Fusion (CSF) module. The heterogeneous encoder integrates the initial convolutional layers of ResNet-50 with the hierarchical attention mechanism of Swin Transformer to efficiently capture both local details and long-range dependencies. Specifically targeting the characteristics of distant objects—low pixel occupancy but high semantic relevance—the CSF module enhances feature aggregation…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
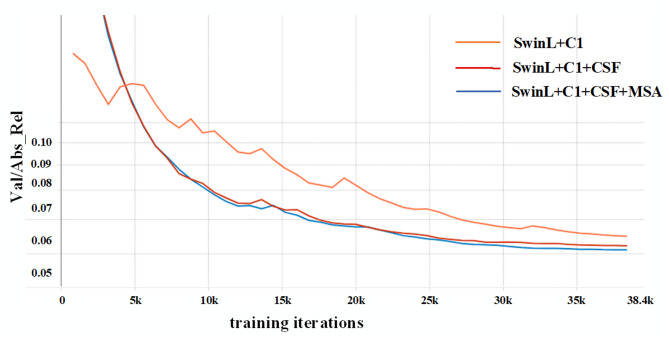 Figure 10
Figure 10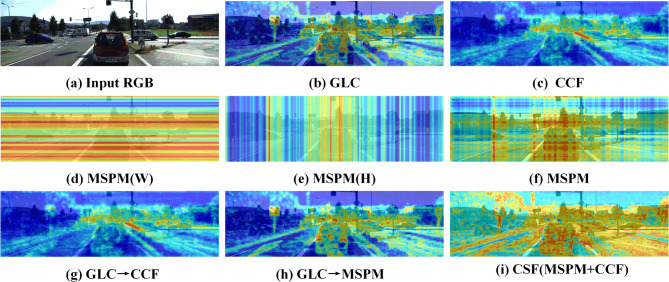 Figure 11
Figure 11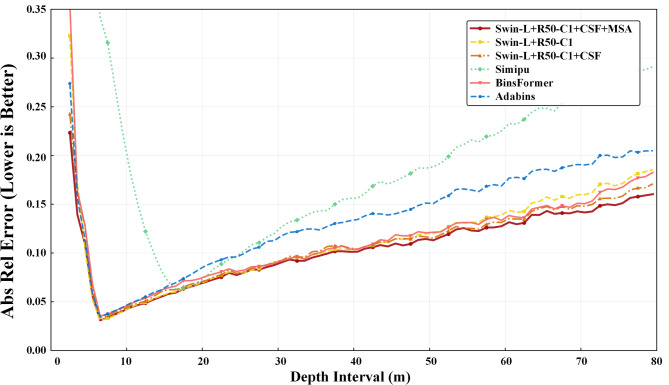 Figure 12
Figure 12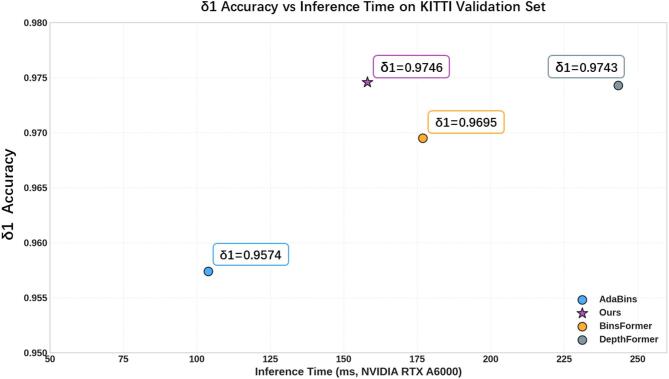 Figure 13
Figure 13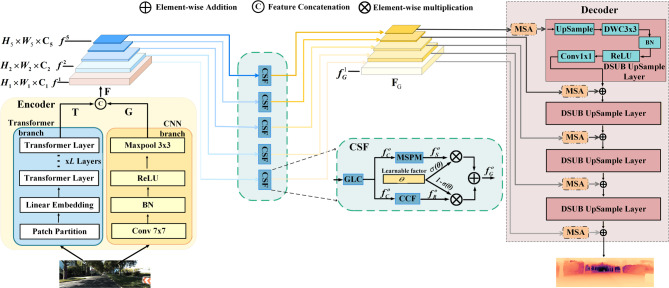 Figure 1
Figure 1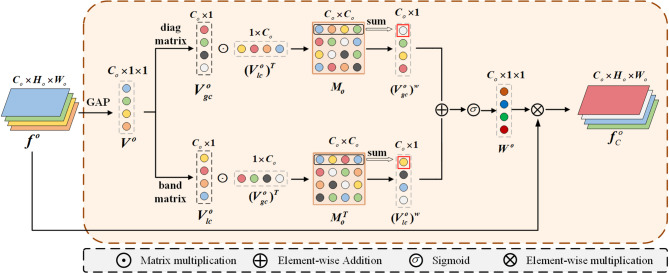 Figure 2
Figure 2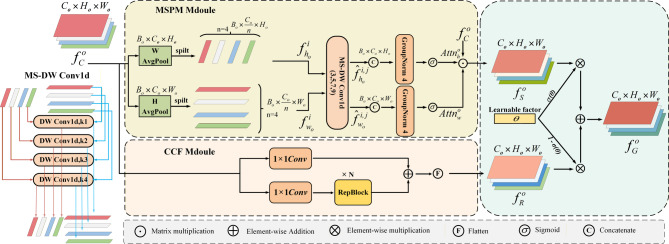 Figure 3
Figure 3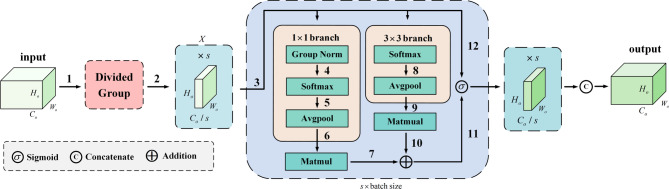 Figure 4
Figure 4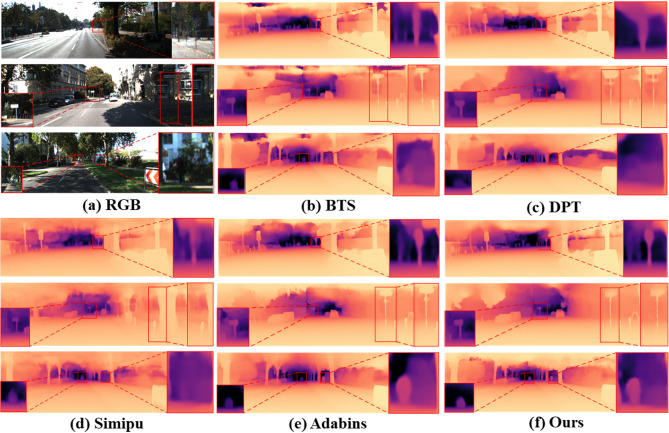 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Vision and Imaging · Advanced Neural Network Applications · Robotics and Sensor-Based Localization