Few-shot annotation correction for lightweight retinal vessel image segmentation
Huazhang Li, Yueming Sun, Daniel Organisciak, Yang Long, Ying Su, Feng Wang

TL;DR
This paper introduces a lightweight method to correct errors in retinal vessel annotations, improving segmentation accuracy despite noisy labels.
Contribution
A novel few-shot U-Net-based framework for annotation correction and noise robust learning in retinal vessel segmentation.
Findings
Performance degrades as label displacement increases, as shown on the DRIVE dataset.
The method achieves high accuracy (96.51-97.54) and AUC (98.01-98.45) on CHASE_DB1 and STARE.
It demonstrates robustness to noisy labels and competitive performance against state-of-the-art methods.
Abstract
Retinal vessel segmentation underpins quantitative analysis in ophthalmology and is widely used for screening and diagnosis. In practice, manual annotations for thin and tortuous vessels are error-prone, yet the effect of positional label noise on segmentation quality remains underexplored. We address this gap with a lightweight few-shot U-Net-based framework for annotation correction and noise robust learning. Analyses on DRIVE reveal clear performance degradation as label displacement increases. Cross-dataset validation shows that the proposed method attains an Accuracy of 96.51, an AUC of 98.01, and an F1 of 83.55 on CHASE_DB1 and an Accuracy of 97.54, an AUC of 98.45, and an F1 of 83.11 on STARE, achieving competitive performance against state-of-the-art methods. These results quantify the sensitivity of vessel segmentation to positional annotation errors and demonstrate practical…
Click any figure to enlarge with its caption.
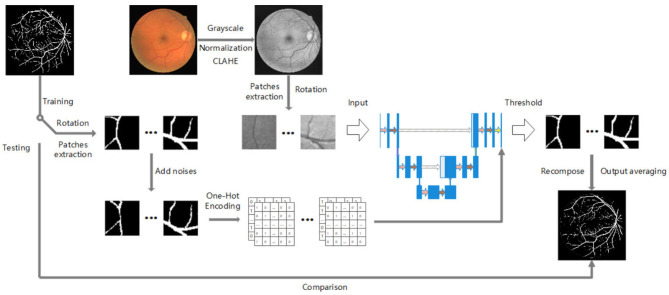 Figure 1
Figure 1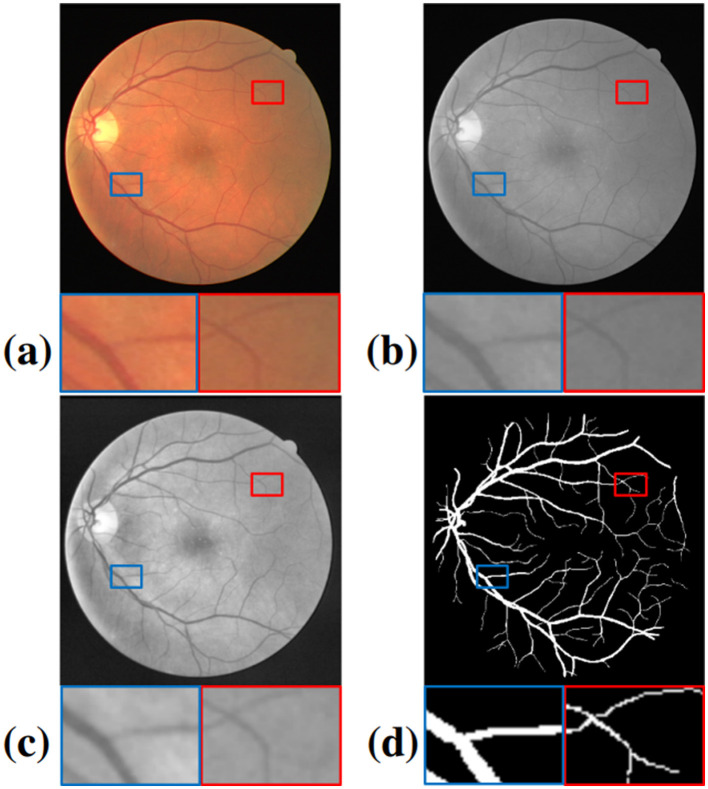 Figure 2
Figure 2 Figure 3
Figure 3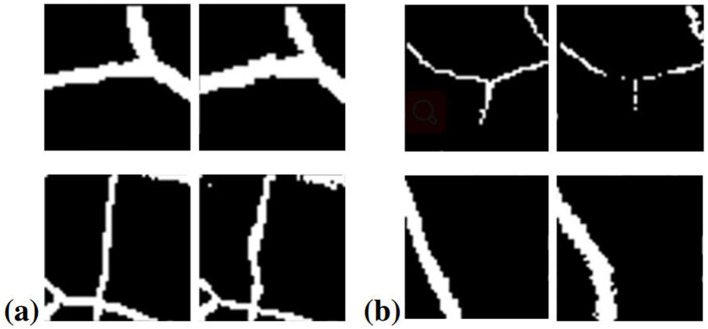 Figure 4
Figure 4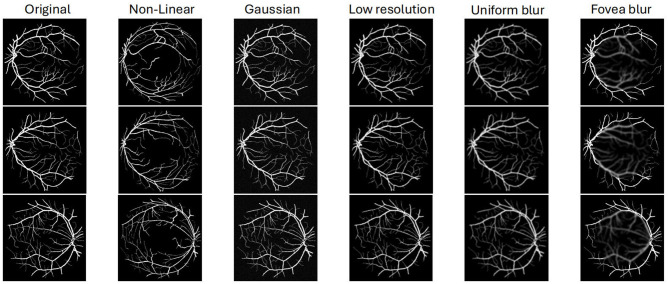 Figure 5
Figure 5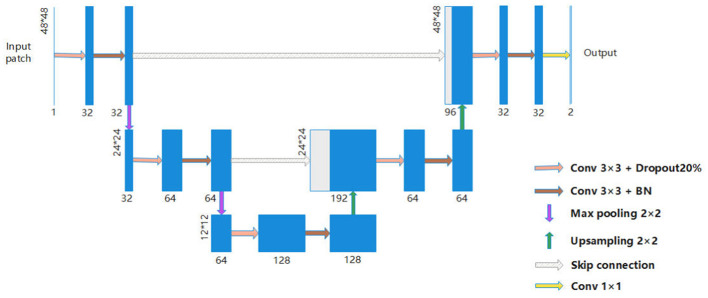 Figure 6
Figure 6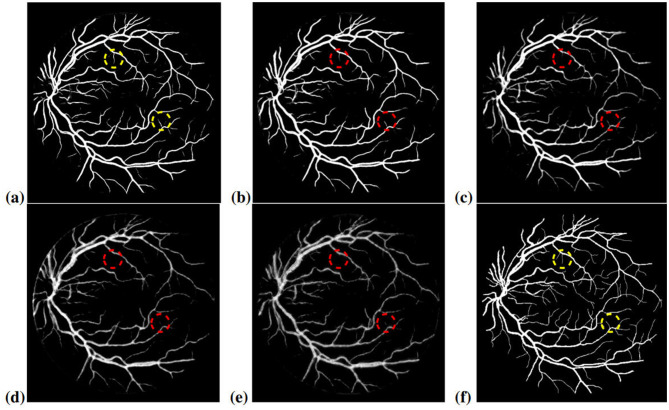 Figure 7
Figure 7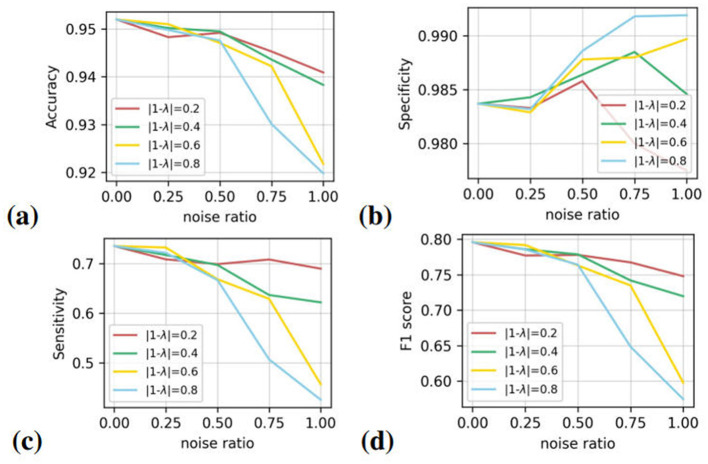 Figure 8
Figure 8|
|
|---|
| 1. Obtain input sequence |
| 2. Compute Query |
| |
| 3. Compute Key |
| |
| |
| 4. Compute the attention scores |
| |
| 5. Compute the context vector |
| |
| 6. Concatenate context vector |
| |
| 7. Pass |
| output = |
| 8. Update the decoder state |
|
|
|---|
| 1. Extract overlapping patches { |
| 2. Extract corresponding label patches { |
| 3. Noise injection (labels): for each label patch |
| 4. Let center |
| 5. If |
| 6. Obtain noisy label |
| 7. Recombined probability map |
|
|
|
|
|
|---|---|---|---|
| Baseline (no gamma, no CLAHE) | 92.08 | 96.81 | 81.15 |
| γ = 1.2, CLAHE (2.0, 8 × 8) | 92.71 | 97.19 | 81.97 |
| γ = 1.4, CLAHE (2.0, 8 × 8) | 93.06 | 97.58 | 82.88 |
| γ = 1.6, CLAHE (2.0, 8 × 8) | 93.53 | 98.03 | 83.57 |
| γ = 1.6, CLAHE (4.0, 8 × 8) | 93.41 | 97.93 | 83.21 |
| CLAHE, γ = 1.6 (2.0, 8 × 8) | 93.18 | 97.69 | 82.96 |
|
|
|
|
|
|
|
|---|---|---|---|---|---|
| R2U-Net++ | 2018 | 4.06 | 63.26 | 1.65 | 1.07 |
| UNet++ | 2018 |
|
| 1.53 | 1.02 |
| Attention UNet | 2018 | 34.88 | 266.53 | 3.55 | 2.59 |
| UNet | 2019 | 7.76 | 54.85 |
| 0.86 |
| DU-Net | 2019 | 4.88 | 53.03 | 1.86 | 1.55 |
| NR-UNet | 2023 | 5.72 | 235.92 | 5.10 | 3.58 |
| FSG-Net | 2023 | 10.52 | 44.74 | 1.13 | 0.77 |
| DSAE-Net | 2025 | 5.08 | 44.76 | 1.30 |
|
| Our | 2025 |
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|
| Baseline (no noise) | 0.9558 | 0.9820 | 0.7758 | 0.8170 |
| Baseline (seamless) | 0.9498 | 0.9829 | 0.7232 | 0.7858 |
| U-Net with λ = 0.2 | 0.9409 | 0.9775 | 0.6894 | 0.7479 |
| U-Net with λ = 0.4 | 0.9383 | 0.9846 | 0.6215 | 0.7196 |
| U-Net with λ = 0.6 | 0.9218 | 0.9897 | 0.4566 | 0.5978 |
| U-Net with λ = 0.8 |
|
|
|
|
|
|
|
|
|
|---|---|---|---|
| Non-linear |
|
|
|
| Gaussian | 93.10 | 97.70 | 83.10 |
| Low resolution | 92.35 | 96.95 | 81.80 |
| Uniform blur | 92.88 | 97.30 | 82.40 |
| Fovea blur | 92.70 | 97.15 | 82.10 |
|
|
|
| ||||
|---|---|---|---|---|---|---|
|
|
|
|
|
|
| |
| R2U-Net ( | 95.56 | 97.84 | 81.71 | 95.29 | 97.68 | 81.79 |
| U-Net ( | 95.78 | 97.72 | 77.83 | 95.01 | 97.81 | 79.46 |
| DU-Net ( |
|
| 80.37 |
|
| 80.64 |
| Unet++ ( | 96.15 | 97.98 | 83.25 | 96.50 | 97.64 |
|
| Attention U-Net ( | 96.08 | 97.98 |
| 96.37 | 97.79 | 82.36 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| ||
|---|---|---|---|---|---|---|
|
|
|
|
| |||
| 0.25 | R2U-Net ( | 0.7216 | 0.7853 | Cleaned | 0.7421 | 0.7980 |
| U-Net ( | 0.7222 | 0.7853 | Cleaned | 0.7395 | 0.7964 | |
| DU-Net ( | 0.7212 | 0.7847 | Cleaned | 0.7408 | 0.7971 | |
| UNet++ ( | 0.7231 | 0.7865 | Cleaned | 0.7440 | 0.7992 | |
| Attention U-Net ( | 0.7212 | 0.7853 | Cleaned | 0.7453 | 0.8001 | |
| NR-UNet ( | 0.7061 | 0.7726 | Cleaned | 0.7453 | 0.8010 | |
| t-vMF ( | 0.7081 | 0.7770 | Cleaned |
|
| |
| T-Loss ( | 0.7168 | 0.7857 | Cleaned | 0.7479 | 0.8018 | |
| Ours | 0.7319 | 0.7917 | Cleaned |
|
| |
| 0.5 | R2U-Net ( | 0.6487 | 0.7239 | Cleaned | 0.6618 | 0.7315 |
| U-Net ( | 0.6564 | 0.7321 | Cleaned | 0.6649 | 0.7332 | |
| DU-Net ( | 0.6531 | 0.7314 | Cleaned | 0.6605 | 0.7326 | |
| UNet++ ( | 0.6428 | 0.7246 | Cleaned | 0.6662 | 0.7360 | |
| Attention U-Net ( | 0.6395 | 0.7128 | Cleaned | 0.6637 | 0.7341 | |
| NR-UNet ( | 0.6659 | 0.7362 | Cleaned | 0.6704 | 0.7391 | |
| t-vMF ( | 0.6635 | 0.7248 | Cleaned | 0.6723 | 0.7395 | |
| T-Loss ( | 0.6317 | 0.7275 | Cleaned |
|
| |
| Ours | 0.7019 | 0.7617 | Cleaned |
|
| |
| 0.75 | R2U-Net ( | 0.5196 | 0.5638 | Cleaned | 0.5417 | 0.6124 |
| U-Net ( | 0.5241 | 0.5549 | Cleaned | 0.5483 | 0.6187 | |
| DU-Net ( | 0.5162 | 0.5611 | Cleaned | 0.5379 | 0.6073 | |
| UNet++ ( | 0.5037 | 0.5462 | Cleaned | 0.5448 | 0.6195 | |
| Attention U-Net ( | 0.5208 | 0.5566 | Cleaned | 0.5526 | 0.6311 | |
| NR-UNet ( | 0.5094 | 0.5381 | Cleaned |
|
| |
| t-vMF ( | 0.5149 | 0.5367 | Cleaned | 0.5718 | 0.6423 | |
| T-Loss ( | 0.5173 | 0.5592 | Cleaned | 0.5751 | 0.6486 | |
| Ours | 0.6319 | 0.6917 | Cleaned |
|
| |
|
|
|
|
|
|---|---|---|---|
| NR-UNet ( |
|
| 0.8974 |
| t-vMF ( |
| 0.8121 |
|
| T-Loss ( | 0.8255 | 0.8096 | 0.9045 |
| DSAE-Net ( | 0.8244 | 0.7986 |
|
| FSG-Net ( | 0.8420 | 0.8173 | 0.9044 |
| Proposed methods | 0.8632 |
| 0.9042 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRetinal Imaging and Analysis · Advanced Neural Network Applications · Medical Image Segmentation Techniques
Introduction
1
Retinopathy is remarkably related to many cardiovascular and ophthalmologic diseases such as age-related macular degeneration, glaucoma, hypertension, and arteriosclerosis (1). Hemorrhages and exudates can serve as the primary distinguishing signs of retinopathy. They usually occur around the blood vessels and damage their morphological characteristics. As the retinal vascular tree is easily photographed non-invasively (2), the analysis based on retinal fundus images helps doctors identify cases. The traditional way to extract retinal vessels is manual segmentation. However, it is a laborious task that requires experienced specialists for accuracy. Developing accurate and automatic blood vessel segmentation methods is essential to realize the large-scale clinical screening of the population with retinopathy.
Challenges in retinal vessel segmentation
1.1
Although there have been many advanced segmentation algorithms, vascular segmentation remains a challenging task due to the limitations in obtaining medical data, the weak contrast of fundus images, and the complex geometric structure of retinal vessels. The general reasons can be summarized into the following factors:
Insufficient fundus images: Training deep learning models requires a large volume of data to generalize well, and a lack of data usually results in overfitting. This problem is particularly acute in shallow models, which struggle to extract high-level features necessary for accurate predictions in complex tasks, such as medical image analysis (3). Consequently, insufficient medical images have consistently posed a significant challenge in the development of reliable computer-aided diagnosis systems. Public datasets commonly used for retinal vessel segmentation, such as the DRIVE (4) dataset, which consists of only 40 images, and the STARE (5) and CHASE_DB1 (6) datasets, each containing just 20 images. These small datasets limit the ability to apply advanced data augmentation techniques or transfer learning methods effectively. The scarcity of labeled data further exacerbates this issue, making it difficult to develop robust models capable of performing well across different patient populations and imaging conditions (7).Accurately segmenting retinal vessels from fundus images is a time-consuming and labor-intensive task requiring expertise from experienced clinicians. Due to the complexity involved, producing high-quality, densely annotated labels is challenging. The manual process is not only slow but also prone to variability among annotators, leading to potential inconsistencies in the labeled data (5, 8). The small size of these datasets further exacerbates the issue, as incomplete or inaccurately labeled data can hinder the performance of deep learning models (4, 6). As a result, these models may struggle to learn robust and generalizable features, complicating the development of reliable computer-aided diagnosis systems (4).Indistinguishable capillaries: The weak contrast caused by poor or overexposed illumination often leads to blurred or non-sharp boundaries of blood vessels in fundus images, making it difficult for models to accurately differentiate between vessels and the surrounding tissue (8). This challenge is particularly pronounced in cases where retinal lesions are present, as these can further obscure vessel boundaries. Moreover, the width of retinal vessels varies significantly, ranging from several dozen pixels for larger vessels to just a few pixels for capillaries. This kind of fine structure increases the difficulty of the capillary recognition by models. However, the pooling layer commonly used in convolutional neural networks (CNNs) tends to remove this fine structure, which is crucial for accurate segmentation, while it is hard to rebuild during up-sampling.
Motivation and contribution
1.2
Most of the previous studies focused on the quantity and quality of the fundus images. They did little research on the inaccurate labeling problem. In fact, manual segmentation is error-prone and inevitably brings bias to the training of a deep learning model. Currently, some research has analyzed the effect of noisy labels on model performance (9). There are also some studies that proposed advanced algorithms to alleviate the impact of noisy labels on training (10–12). In the field of image segmentation, (13) has quantitatively studied the variation in accuracy of inaccurate annotations in the segmentation of large organs such as lungs and heart. However, the study of the impact of distorted annotations on retinal vessel segmentation tasks is still rare. In this study, we present a Few-Shot deep learning model, designed for annotation correction in lightweight retinal vessel image segmentation. This model provides advanced data-cleaning functionalities for time-saving labeling with minimal manual effort, even when working with noisy annotations. The contributions of this study include:
We adopt several image processing methods and design a U-Net-based model to improve the accuracy and robustness of the segmentation.We apply a non-linear transformation strategy to the labels to simulate the mislabeled problem commonly encountered in real-world scenarios.We quantitatively evaluate the sensitivity of the model to inaccurate retinal vessel positions and analyze the impact of these inaccuracies on segmentation performance.
Quantitative experiments substantiate that our approach effectively addresses the error-prone nature of manual retinal vessel annotations, delivering noise-robust retinal segmentation and explicitly quantifying the impact of positional label distortions on vessel topology.
Related studies
2
Plenty of previous studies have been done in automatic retinal vessel segmentation. With the outstanding performance that convolutional neural networks have made in image recognition tasks (14, 15), and the great success of CNN-based architectures like FCN (16) and U-Net (17) in pixel-wise segmentation, deep learning-based approaches have been widely applied to retinal vessels segmentation in recent research. The variants used by (18–22) are based on these fundamental architectures that have good performance. To reduce the spatial loss in the U-Net model, Wang et al. (21) integrated two feature refinement paths to the encoder and decoder. Their framework complemented spatial information through bilinearly up-sampling and down-sampling, and achieved high average accuracy. Liu et al. (23) introduce a multiscale U-Net augmented with spatial positional attention to better capture small vessels and boundary details, reporting improved retinal vessel segmentation on standard benchmarks. Jin et al. (22) introduced deformable convolutional blocks to a U-shaped architecture. The blocks learn receptive fields adaptively through diverse offsets and therefore model the retinal vessels of various thicknesses. In order to overcome the overfitting problem, Wang et al. (20) replaced traditional convolution with a high-frequency convolution to reduce the parameters by avoiding redundant background information. Besides, data enhancement is also an essential step. It is a common method to extract patches from images instead of training full images (8, 24, 25). In 2018, Oliveira et al. (26) proposed a rotation strategy that brought new context information to FCN. In (25, 27), a non-linear transformation had been applied to training images, which greatly enriched the input data, although it brought bias to the model.
However, noisy labels have been largely overlooked in retinal vessel segmentation, even though inaccurate annotations are common in practice. By contrast, other medical imaging areas have begun to address this issue. For example, Xiao et al. mitigate annotation noise in cardiac MRI using a dual-teacher (CNN+Transformer) semi-supervised framework with uncertainty to filter noisy pseudo-labels, and Light3DHS improves robustness to imaging noise and low contrast in 3D hippocampus MRI via a multiscale convolutional-attention encoder coupled with a lightweight ViT to enhance local–global features. Overall, explicit treatment of label noise remains rare in retinal segmentation. Zhang et al. (9) pointed out that wrong labels will seriously reduce the generalization of the model, thus resulting in the decline of accuracy. To solve this problem, some robust networks against noise have been proposed (28–30). Liu et al. (30) introduced a dual-network for medical image classification. The noise-tolerant framework can update labels from easy to difficult. Nevertheless, these effective image classification and detection approaches are not applicable to segmentation because of the additional spatial information within the images. In segmentation tasks, Zhang et al. (13) proposed a Tri-network that can mine valuable information from low-quality (non-expert) annotations, so as to counteract the effect of noise on large organ segmentation. In 2019, Shu et al. (31) proposed a spatial transformation strategy to corrode the segmentation boundary. However, due to the blood vessels' special spindly morphological feature, it cannot be applied to retinal vessel labels. In Zhou's work (32), the annotations were synthesized into the incomplete map by erasing thinner vessels directly, without considering the deviation of the position of blood vessels caused by manual segmentation. Several publicly available datasets have been commonly used for retinal vessel segmentation tasks, each offering unique characteristics that aid in advancing research.
Methodology
3
In this section, the procedure of the proposed approach is introduced in detail, including image preprocessing, patch extraction, label transformation, and model architecture. Figure 1 presents the overall pipeline of our proposed method.
The overall pipeline of our project.
Formalization
3.1
The algorithm outlined in Table 1 describes the dynamic attention mechanism. This framework enables the model to adaptively adjust its attention weights based on the varying input sequence X = [x1, x2, …, xn]. Inspired by this principle of dynamic, input-adaptive weighting, we propose a novel training paradigm using noise injection. We construct input sequences that intentionally intermix clear and noisy image samples. During training, the model is compelled to learn a more robust representation by dynamically attending to and distinguishing between informative clean signals and misleading noise. The objective is to train the model to develop an explicit awareness of noisy labels, thereby improving its generalization and robustness when encountering real-world, imperfect data distributions.
We formalize the model training and test task as below. The training set consists of visual data and annotations. Let it be represented by (x1, y1), ..., (xn, yn) ⊆ 𝒳 × 𝒴 , where the N is the number of training data. The represents the D-dimensional feature space, while share the same dimension. During the data preprocessing, the data will be transferred to , where N1 and D1 represent the dataset size and data dimension after the preprocessing process. This progress can be represented by 𝒳_p_ = A( 𝒳 ) where A means the data mapping between 𝒳_p_ and 𝒳 . The training progress aims to learn f: 𝒳_ptrain_ → 𝒴 where the 𝒳_ptrain_ is the training part in 𝒳_p_. We can transfer it to the following Equation:
where P is the projection matrix, ℒ is the loss function. At the test stage, the aim is to compare the model output f(𝒳_ptest) with annotation 𝒴test, which can be represented by C(f(𝒳ptest), 𝒴test_).
As the key idea of this project is to compare the model performance in different noise levels, here we introduce noise no1, ..., non ⊆ 𝒩 into 𝒴_train. Then the training labels for model will be 𝒴_𝒩 = 𝒴_train+noi, where noi_ ∈ 𝒩. Which means each noise level noi is related to a label set 𝒴_𝒩i_, and using each training set can learn a model fi: 𝒳_ptrain_ (with label set 𝒴_𝒩i_ → 𝒴 ). We can transfer the comparison of the model performance into C(fi(𝒳ptest), 𝒴_test).
Image pre-processing
3.2
Retinal fundus images are 3-channel RGB images. To alleviate the shortage of computational resources and the adverse effects of inhomogeneous illumination intensity, the images are converted into 1-channel grayscale images, then normalized by Equation 2:
where I and I′ denote, respectively, the original and converted pixel values, and μ and σ denote the mean value and standard deviation of all pixels in the grayscale images (Figure 2). Even so, the images are in low contrast, with detailed information near the edge of the retina disappearing. In this study, contrast-limited adaptive histogram equalization (CLAHE) (33) and gamma adjustment are adopted to address this issue. CLAHE can rearrange the lightness distribution according to the pixel value histograms while avoiding overamplifying noise by dividing the images into blocks. The pixel value in any range with a frequency greater than 2 will be evenly distributed among the other ranges. After the equalization, the total number of pixel values remains the same, but they are distributed more widely. This redistribution helps to enhance both the subtle features and overall contrast of the image, making finer details more apparent.
Comparison of the preprocessing results for the key steps: (a) Original image; (b) Grayscale image; (c) Normalization + CLAHE + Gamma adjustment; (d) Ground truth. The blue and red circles represent a light and dark region, respectively.
We apply Contrast-limited adaptive histogram equalization (CLAHE) to find a trade-off between vessels and noise. Specifically, CLAHE divides an image into a grid of tiles with size controlled by the tile grid parameter t×t, where t denotes the number of tiles along each spatial dimension. A histogram is computed and equalized independently in each tile, and bilinear interpolation is then used between adjacent tiles to suppress block boundary artifacts. To prevent the over-amplification of noise in homogeneous regions, CLAHE introduces a clip limit c, which caps the maximum height of each local histogram bin; the clipped excess counts are redistributed across all bins before equalization. In general, a larger t (smaller tiles) strengthens local enhancement and can highlight thin vessels but may amplify noise, whereas a smaller t yields smoother enhancement. Similarly, a larger c produces stronger contrast enhancement with a higher risk of noise amplification, while a smaller c enforces more conservative, noise-suppressed enhancement.
Gamma adjustment is one of the global tone reproduction operators (34). The operation is expressed as:
where J and I denote the original pixel values and the values after adjustment. In our experiments (shown in Table 3), γ is greater than 1, enhancing the contrast in the darker areas while reducing the contrast in the lighter areas through exponential transformation (Figure 2). This approach ensures that both bright and dark regions are well represented, which is critical for accurately visualizing retinal structures. Additionally, the combination of CLAHE and gamma adjustment provides a balanced enhancement across the entire image, making it easier to distinguish fine details such as small blood vessels and subtle pathological changes. These preprocessing steps are crucial for improving the input quality for the segmentation model, ultimately leading to more reliable and accurate segmentation results. Moreover, by standardizing the preprocessing pipeline, we ensure that the model's performance is consistent across different images, regardless of variations in lighting conditions or image quality.
Patch extraction
3.3
Deep learning models usually have poor performance on small datasets. They quickly tend to overfit because they are unable to learn enough features. Training with patches instead of full images brings more information to the model. Oliveira et al. (26) mentioned that more patches in a larger image benefit the model. In this study, there are 2200 overlapping patches extracted from each image during training. To balance global and local information, the size of the patch is set to 48 × 48 through experience. Besides, each patch is rotated by the angle of 90°, 180°, and 270° respectively. By doing so, the input data has been tremendously enlarged. In addition, all the pixels in the patch are guaranteed inside the FOV.
In the retinal vessel segmentation tasks, the low accuracy of the prediction is mainly due to the insufficient segmentation ability on small blood vessels. In order to ease the problem, we randomly extract 1,000 patches from each image and count the number of white pixels (pixel value = 1) in each patch. The frequency distribution histogram is shown in Figure 3c. It has 20 bins and a heavy tail. We also visualize the patches having different ranges of white pixels, and empirically treat the patches with 0–200 white pixels as the patches containing capillary and small vessels. The proportion of small vessels to all vessels is 0.37, calculated by the first three bins of the histogram. It is plausible to believe that the data is imbalanced between small vessels and thick vessels. Therefore, to increase the extraction proportion of small vessels, assuming that the patches with a ratio of P of total patches are randomly selected, and the rest are only extracted from patches with 0-200 white pixels. Then the proportion of small vessels is roughly increased to 0.5. It can be expressed as Equation 4.
The pixel value distribution and sample patches: (a) Sample patches containing 0–200 white pixels; (b) Sample patches containing 200–800 white pixels; (c) The frequency distribution histogram of the number of white pixels of 1,000 randomly extracted patches.
P is 0.8 after calculation. Thus, in our experiments, we randomly extract 80% patches, and the remaining 20% only contain small vessels.
In the test, test images are cut into patches. The usual way to do this is to seamlessly cut the image from left to right, top to bottom, in order. However, in the work by Liu et al. (35), the authors pointed out that seamless cut brings bias when combining segmentation maps of patches into the full segmentation masks. Here, we adopt their approach to cut the overlapping patches with a stride of 10 pixels in both height and width, which means most of the pixels in the image are predicted multiple times. We provide the sample patchs in Figure 3. The final results are the average of multiple predictions. This also further improves the segmentation performance.
Noise injection
3.4
Unlike eroding and expanding the segmentation boundary as in Zhang et al. (13) and Shu et al. (31), or directly erasing the small branches of the vessel segments in Zhou et al. (32), in our study, the method used to add noise to the labels is a non-linear transformation, which changes the position of blood vessels in the segmentation. Compared to applying traditional noise injection methods (shown in Figure 4), our noise injection strategy explicitly mimics manual annotation errors, enabling the model to learn in a more targeted manner. Every patch extracted from ground truth is transformed on a pixel level, simulating the inaccurate labeling problem existing in medical datasets, especially the errors caused by manual labeling.
Sample transformed patches showing the effects of different β values. β = 1.5: The left pictures (a) denote ground truth; the right pictures (b) denote transformed patches.
Formally, let a patch be defined on coordinates (x, y) with center c = (cx, cy) and radius R (set to half of the shortest side of the patch, i.e., R = 24 in our experiments). For each pixel p = (x, y), we compute its distance to the center
and apply a non-linear radial transformation
where β controls the deformation strength. When β > 1, the central region is effectively zoomed in; when β < 1, it is zoomed out. The new coordinate p′ = (x′, y′) is then obtained by
for pixels satisfying r ≤ R, and p′ = p otherwise, where ε is a small constant to avoid division by zero. In practice, we compute two 2D offset matrices Δx = x′−x and Δy = y′−y corresponding to the horizontal and vertical displacements of each pixel, and obtain the noisy label patch by sampling the original ground-truth mask at locations (x′, y′).
In Table 2 we provide overall noise injection pipeline. The transformation region is thus a circle in the center of the patch, where the deformation ability in the central area is strongest and decreases when radiating outward. This approach allows for a more realistic simulation of annotation errors by introducing positional shifts rather than simply modifying pixel values. It preserves the structural integrity of the vessel shapes and maintains the visual context of the vessels within the retinal image. Additionally, this type of noise injection ensures that the resulting noisy labels still resemble plausible anatomical structures, which is crucial for effective model training. Some sample results are illustrated in Figure 5.
Illustration of various noise injection methods applied to the clear image. The corruptions (Non-linear, Gaussian noise, Low resolution, Uniform blur, Fovea blur) degrade image quality by introducing noise, lowering resolution, or simulating manual annotation.
Overall pipeline
3.5
The model is based on the U-Net proposed by Ronneberger et al. in 2015 (17). This extraordinary architecture was specially designed for biomedical image segmentation. The traditional convolutional network can extract high-level information from input images and feature maps, and reduce dimensions successfully by pooling layers, while losing detailed information. The features containing compact and positional information are challenging to reconstruct in deeper layers. However, more than recognizing objects in pictures, U-Net achieved pixel-wise segmentation by providing a symmetric structure with skip-connection, which combines both low- and high-level information. Our architecture is illustrated in Figure 6. It consists of a contracting path (on the left side) and an expanding path (on the right side). The input layer is the extracted source image and annotation. The application of two 3 × 3 convolutions repeats every step in the contracting path to summarize features from neighboring pixels, a 20% dropout layer to prevent overfitting (36). We also apply batch normalization to each step, which speeds up the training. Followed by that is a downsampling operation (max pooling layer) with a stride of 2. The size of input data in each step remains the same with the use of zero padding, and shrinks four times after max pooling, while the number of input channels is doubled. In the expanding path, the feature maps begin to be reconstructed in the same way as in the contracting path, but in the opposite direction. In every step, the input features are concatenated with the corresponding feature maps from the contracting path after 2 × 2 upsampling. The number of input channels is halved in convolutions. Finally, the dimension of the feature maps is reduced to 2 × 48 × 48 for the two-class probability in this case. The activation function used in each convolution is Rectifier Linear Unit (ReLU), and softmax is used for calculating the loss.
The network architecture used in our work. Blue blocks refer to multi-channel feature maps. The shape of each feature map is shown by the side of the block. Gray blocks refer to copied shallow feature maps. Arrows in different colors represent different operations.
In our implementation, the U-Net backbone is supervised using one-hot encoded labels. For each input image patch, the encoder produces a sequence of hidden feature vectors H = [h1, …, hn] at a given scale, while the current decoder feature map at the corresponding scale is summarized into a decoder state d. This attention-enhanced decoder feature map is finally upsampled and passed through the output layer to predict per-pixel class logits. The corresponding ground-truth vessel masks are transformed into one-hot encodings Y ∈{0, 1}^H×W×C^ (with C = 2 for vessel and background), and a pixel-wise cross-entropy loss between the logits and the one-hot labels is used to train the entire U-Net with dynamic attention end-to-end.
As illustrated in Figure 1, our pipeline starts from the original color fundus images and their corresponding binary vessel annotations. The RGB fundus image is first converted to grayscale, followed by intensity normalization and CLAHE enhancement to improve vessel contrast. From the preprocessed grayscale image, overlapping patches are extracted and further augmented by rotations; these patches are then fed as input to a U-Net–like encoder–decoder network enhanced with dynamic attention. Specifically, the encoder produces multi-scale feature maps, which are passed through a dynamic attention module at the bottleneck to adaptively reweight spatial and channel responses conditioned on each input patch. In addition, before concatenation with the decoder features, the skip-connection feature maps are refined by lightweight dynamic attention blocks, allowing the model to selectively emphasize informative vessel patterns while suppressing noisy background structures. In parallel, the ground-truth vessel maps undergo the same rotation and patch extraction steps, after which artificial noise is added to the label patches to simulate noisy annotations. The noisy label patches are transformed into one-hot encodings and used to supervise the dynamically attended feature maps during training. Concretely, let denote the one-hot label at pixel (i, j) of a patch and the corresponding softmax probability vector predicted by the network, where C is the number of semantic classes. We optimize the standard pixel-wise cross-entropy loss
where H×W is the spatial resolution of each patch. At inference time, the network outputs probability maps for each input patch; these are converted into binary vessel masks by thresholding, and the predicted patch-wise masks are recomposed into a full-size retinal vessel map, where overlapping regions are merged by output averaging to obtain the final segmentation result.
Experiment settings
4
Datasets
4.1
We consider three widely used retinal vessel benchmarks—DRIVE (37), STARE (5), and CHASE_DB1 (38)—which exhibit diverse forms of imaging and annotation noise. The DRIVE (Digital Retinal Images for Vessel Extraction) dataset consisted of 400 diabetic subjects between 25 and 90 years of age; forty photographs were randomly selected, divided into a training and a test set, both containing 20 images. The dataset was collected in a diabetic retinopathy screening program and consists of color fundus photographs acquired with a non-mydriatic 3CCD camera and stored in compressed JPEG format. This acquisition protocol introduces several sources of imaging noise: the blue channel is often nearly empty or dominated by acquisition noise, so that reliable vessel information is essentially confined to the green channel, and JPEG compression artifacts together with local illumination variations make very thin or low-contrast vessels difficult to distinguish from background texture. In addition, the ground-truth vessel masks were obtained by multiple human observers who were instructed to label pixels they judged to be vessels with at least a certain subjective confidence level; as a result, there is noticeable inter-observer disagreement, especially on subpixel-width vessels and on boundary pixels where it is ambiguous whether they belong to the vessel or to the background. These factors mean that DRIVE implicitly contains both imaging noise and annotation noise, particularly in regions of fine vasculature and near pathological structures.
The STARE (STructured Analysis of the REtina) dataset was explicitly designed to include both normal and pathological retinal images, and thus exhibits a broader and more challenging spectrum of noise and ambiguity. In abnormal cases, bright and dark lesions such as hemorrhages, exudates, drusen, and optic disc boundaries share similar local color, contrast, and curvilinear structure with blood vessels, so that a matched-filter response intended to enhance vessels also responds strongly to non-vessel structures. This leads to substantial overlap between the response distributions of vessel and non-vessel pixels and a much higher false-positive rate in the presence of pathology. Even in the hand-labeled ground truth, the authors report that pixels on vessel boundaries, very small vessels, and vessels adjacent to lesions are “less easily labeled,” and a second expert observer systematically annotates more vessel pixels than the first, reflecting genuine uncertainty in where vessels begin and end. Consequently, STARE captures both strong structured background “noise” from pathological tissue and significant inter-observer variability in the vessel labels.
The CHASE_DB1 dataset extends retinal vessel analysis to a multi-ethnic cohort of school children imaged with a hand-held fundus camera, and its images are characterized by particularly challenging noise conditions. The authors emphasize pronounced inter- and intra-image variability in background pigmentation, nonuniform background illumination, and generally poor vessel-to-background contrast, which together make small and peripheral vessels difficult to resolve. Moreover, wider arterioles often exhibit a strong central light reflex, producing a bright strip along the vessel centerline that distorts the expected Gaussian intensity profile and can confuse both human observers and automated methods attempting to delineate vessel boundaries. Compared to DRIVE and STARE, CHASE_DB1 therefore introduces additional acquisition-related artifacts specific to pediatric imaging (hand-held camera motion, pigmentation differences) and accentuates structured noise in the form of uneven illumination and central vessel reflexes, further increasing ambiguity in vessel annotation despite the availability of dual manual segmentations.
Training
4.2
The primary purpose of this project is to thoroughly evaluate the variation tendency of the U-Net model's performance as the proportion of noisy labels increases in the retinal vessel segmentation task, with the goal of understanding the model's robustness and the potential impact of noise on segmentation accuracy and reliability.
As described in the previous section, the main experiments are conducted on the DRIVE database. For few-shot settings, 40 photographs are randomly selected and split into 20 for training and 20 for testing. Only the results from the test set are evaluated. We also conduct cross-validation on CHASE_DB1 and STARE datasets to test generalization. To keep the same few-shot settings, we also randomly select 20 images for training and 20 images for testing. During training, 2200 patches are extracted from each image, among them 80% are randomly selected, 20% are from the region containing small vessels. Then the number of patches is quadrupled by rotation. Finally, there are a total of 176000 patches in size 48 × 48 obtained for the training set. The input annotation patches are converted to noisy labels by applying a non-linear transformation. In the five experiments, the degree of deformation is chosen in sequence of [0,0.2,0.4,0.6,0.8], where the number in the list represents the distance of p between non-deformation and deformation. We set 1−p as the noise level. The reason for doing so is that we only care about the influence brought by the displacement of the vessel from its original position, rather than the direction of transformation. Beyond that, we also conduct 3 sub-experiments for each experiment. We mix the ground truth and noisy labels in different proportions so as to further quantitatively evaluate the change in model performance with increasing noise ratio.
In the test, the output patches are regrouped to a full-size segmentation with averaging. The threshold is 0.5. Pixels with values greater than 0.5 are classified as blood vessels (1), less than 0.5 are classified as background (0).
Experimental setup
4.3
All the tests are conducted on a laptop equipped with an Intel Core i7-10750H CPU, an NVIDIA GeForce GTX 1650 Ti GPU, and 32GB of RAM. U-Net is used as the network model, implemented by Keras 2.3.1 with Tensorflow backend. Every model is trained for 20 epochs, with a mini-batch size of 32, using Stochastic Gradient Descent (SGD) with a 0.1 learning rate and 0.9 momentum as the optimizer. It is worth noting that the model does not stop learning after 20 epochs but tends to become very stable, demonstrating minimal improvement in performance beyond this point. Training takes about 20 min with a model size of 8.94M parameters. The choice of 20 epochs is a compromise to save training time because the segmentation task is not the main work in this study.
The training process also involves data augmentation techniques, including random rotations and shifts, to enhance the model's ability to generalize from limited training data. Each patch is augmented four times by rotating it at 90-degree intervals, effectively increasing the diversity of the dataset and reducing overfitting. This approach ensures that the model learns robust features for vessel segmentation, regardless of orientation and position within the retinal image. Model efficiency, including per-epoch training time, is summarized in Table 4. Compared with the fastest baseline, our model incurs only a modest increase in training time, while achieving the lowest parameter cost and delivering substantial performance gains (see the Results section).
Additionally, the training is conducted with a cross-validation strategy to ensure the reliability and robustness of the model's performance across different subsets of data. The DRIVE database is split into training and validation sets, with the model's hyperparameters fine-tuned based on validation performance to prevent overfitting. This setup helps in establishing a balance between training time and model accuracy, ensuring that the results are both credible and reproducible.
Throughout the training, we monitor the loss function and accuracy on the validation set after each epoch. This monitoring helps in early stopping if the model shows signs of overfitting or if there is no significant improvement in performance, thereby optimizing the computational resources and time.
Evaluation metrics
4.4
We evaluate the output using several statistically significant metrics: accuracy (Acc), specificity (Sp), sensitivity (Sn), and F1 score (F1). These metrics provide a comprehensive assessment of the model's performance in the retinal vessel segmentation task, ensuring that all aspects of classification accuracy are considered. The metrics are defined as follows:
where TP, FN, TN, and FP denote true positive, false negative, true negative, and false positive, respectively. All the indicators range from 0 to 1, with higher values indicating better segmentation performance. Accuracy (Acc) reflects the overall correctness of the model's predictions, while specificity (Sp) measures the proportion of actual negatives correctly identified, which is crucial for minimizing false positives in the background. Sensitivity (Sn), or recall, indicates the model's ability to correctly identify blood vessel pixels, directly reflecting the true positive rate.
Precision measures the accuracy of the positive predictions, crucial for understanding how reliable the detected vessels are. The F1 score combines both precision and sensitivity, providing a balanced metric that is especially useful when the dataset is imbalanced, which is often the case in medical imaging. By using these metrics together, we can gain a well-rounded view of the model's performance, ensuring it accurately identifies vessels while minimizing misclassifications. Additionally, these metrics allow for the comparison of model performance across different noise levels and configurations, facilitating a thorough analysis of how well the U-Net model handles noisy labels in retinal vessel segmentation.
Results
5
Results on noise level
5.1
Table 5 illustrates the results of our main experiments. The first line gives the results generated from the model trained with original annotations. The results in the second line are based on the first model, but the test patches are extracted seamlessly (with a stride of 48), rather than overlapping patches (with a stride of 10). The third to sixth lines show the performance of segmentation with four levels of noise interference. The visual predictions are shown in Figure 7.
The example of segmentation results from different kinds of noise level labels: (a) segmentation with original labels; (b) segmentation with noise level lambda = 0.2; (c) segmentation with noise level lambda = 0.4; (d) segmentation with noise level lambda = 0.6; (e) segmentation with noise level lambda = 0.8; (f) ground truth. The yellow circles mark the segmented capillaries. The red circles mark the capillaries that disappear or become blurred with increasing noise level.
In Table 5, compared with the baseline, which is on the averaging of multiple patch predictions, the use of seamless output recombination is obviously not practical. Meanwhile, the other experiments quantify the influence of inaccurate annotations on retinal vessel segmentation. Most of the indicators decline as expected when the noise level increases, except specificity. It presents a transitory fall and climbs back in the later experiments. Specificity refers to the true negative rate. The higher specificity means a lower proportion of backgrounds misclassified as blood vessels. However, compared to the 3.22% drop in accuracy, the decreasing amplitudes are dramatic in sensitivity and f1 score, being 30.95% and 22.12% respectively. Sensitivity refers to the true positive rate, and the F1 score takes both precision and sensitivity (recall) into account, which is a reliable metric to measure the performance of a classification model. The plunge of these two indicators demonstrates the severe deterioration of the network's identification ability for blood vessels after the noise level reaches 0.6. The model tends to classify pixels as backgrounds, resulting in the rise of specificity. In Figure 7, the segmentation blurs with the increasing noise due to the weaker classification probability on vessels, especially on small vessels. In the red circles, capillaries are faded away with noise interference. Most of them disappear when the noise level reaches 0.6. In Figure 7d, an abnormal edge shows on the left of the segmentation. The network mistakes the color difference between the FOV and outside as a blood vessel, which means the degradation of the model's noise-robust learning ability.
Results on noise types
5.2
Table 6 summarizes the influence of different noise types on retinal vessel segmentation performance. The first row reports the results obtained when training the model with our proposed non-linear positional perturbation of the vessel labels. This setting achieves the highest accuracy, F1 score and AUC, indicating that the non-linear transformation provides a challenging yet still anatomically plausible supervision signal that helps the network learn more robust vessel representations. The subsequent rows correspond to image-level corruptions applied to the fundus images: additive Gaussian noise, low-resolution downsampling, uniform blur, and fovea blur. Among these, Gaussian noise and uniform blur lead to a moderate degradation in performance, suggesting that the model can still recover most vessel structures under global intensity fluctuations and mild smoothing.
In contrast, the low-resolution setting yields the most pronounced drop in all three metrics, reflecting that aggressive downsampling and upsampling severely damage thin and tortuous vessels and thus hinder the network's ability to localize small structures. Fovea blur also reduces performance, but to a lesser extent than the low-resolution case, as the corruption is confined to the central region and leaves peripheral vessels relatively intact. Overall, the ablation demonstrates that different noise types affect the segmentation model in distinct ways: positional label noise can be exploited to regularize training and improve robustness, whereas strong resolution degradation or localized over-blurring primarily impairs the detection of fine capillaries and leads to a more noticeable decline in F1 score and AUC.
Results on noise ratio
5.3
As in many cases, the noises exist as part of the overall data. Here, we conduct several sub-experiments to simulate the actual situation. At every noise level, we evaluate the segmentation performance with different noise ratios at [0, 0.25, 0.5, 0.75, 1], where 0 represents original labels. The results are illustrated in Figure 8.
The segmentation performance under different noise levels with noise ratio at [0, 0.25, 0.5, 0.75, 1]. The figures from left to right represent four evaluation matrices. Four lines in different colors represent for noise ratios. Here, λ denotes the ratio of original images, and 1 − λ denotes the noise ratio.
In the figure, when the noise ratio is less than 0.5, the indicators vary slightly. However, there are striking changes in all the indicators when more than half of the labels are noisy. The lines spread out when the x-coordinate is greater than 0.5. It can be concluded that the segmentation performance of U-Net has no linear correlation with annotation noises (in the form of position offset). Only when the noise dominates the label, the identification ability on vessels of the network is disrupted, apparently. The variation tendency of evaluation metrics is similar to that of the main experiments. The sensitivity and F1 score of the models with the noise level of 0.6 and 0.8 decrease rapidly, while the specificity has a slight rise.
Cross dataset validation
5.4
To assess generalization beyond DRIVE, we evaluate on CHASE_DB1 and STARE (Table 7). We keep the same split setting with the Drive dataset, a random split of 1:1 train and test datasets. Compared to the Drive dataset, the CHASE_DB1 and STARE contain no official train/test splits, so we reimplement all the compared baselines under a fixed split protocol for fair comparison. Our Proposed method achieves the best results on STARE across all three metrics—Acc 97.54%, AUC 98.45%, and F1 83.11%, and ranks second on CHASE_DB1 with Acc 96.51%, AUC 98.01%, and F1 83.55%, closely trailing the best F1 of Attention U-Net and the best Ac/AUC of DU-Net. Compared with the plain U-Net baseline, our method improves F1 by +5.72% on CHASE_DB1 and by +3.65% on STARE, with concurrent gains in Acc and AUC, respectively. Taken together with the noise-level and noise-ratio analyses, these cross-dataset outcomes indicate that the model's robustness to label perturbations translates into better vessel delineation under dataset shift, particularly on STARE, where small-vessel preservation is reflected in the consistently superior F1.
Evaluation of data cleaning
5.5
While we have cross-tested the sensitivity of the model to different noise ratios and levels, there is no advice on data cleaning. To verify the necessity of further noise cleaning, we conduct additional experiments on the data where noise has been removed, keeping other parameters the same. The training data with 25%, 50%, 75% noises in the above experiments are reduced to , and respectively. The results of the same amount of training data are averaged. We select the most representative sensitivity and F1-score as the evaluation matrices. Experiment results are illustrated in Table 8. As the noise ratio increases and the amount of clean data decreases, our method consistently stabilizes performance. This demonstrates strong robustness to noisy annotations as well as effective learning under limited clean supervision (few-shot setting).
In the table, the data in bold represent the best results in the same set of experiments. It is notable that noise-removed data perform significantly better than data with noise, although fewer data points are trained. Meanwhile, even the slightest noise interference in the experiment affects the model's determination. It will not bring additional information, though with more data. We figure that it is productive to clean the noisy data and labels in retinal vessel segmentation tasks.
Discussion
6
The primary goal of this study was to evaluate the impact of noisy labels on the performance of the U-Net model in retinal vessel segmentation tasks. Our experimental results provide valuable insights into how noise levels and noise ratios affect the segmentation accuracy and robustness of the model.
Impact of noise levels on model performance
6.1
The results from Table 5 indicate a clear degradation in model performance as the noise level increases. Specifically, as the noise level p rises from 0 to 0.8, we observe a significant decrease in sensitivity (Sn) and F1 score, which are critical metrics for assessing the accuracy of vessel segmentation. Sensitivity, which measures the true positive rate, plummets from 0.7758 in the baseline to 0.4255 at the highest noise level. This drop reflects the model's declining ability to correctly identify blood vessels when noise is introduced. Similarly, the F1 score, which considers both precision and recall, shows a notable reduction, indicating that the overall quality of the segmentation deteriorates with increasing noise.
Interestingly, the specificity (Sp), which measures the true negative rate, demonstrates an initial decline but then improves at higher noise levels. This rise in specificity, despite the decrease in other metrics, suggests that the model becomes overly conservative in classifying pixels as background when noise is high. As a result, fewer non-vessel pixels are misclassified as vessels, but at the cost of missing actual vessel pixels, which is detrimental to accurate segmentation.
Building on this trend, we further compare against existing noise-robust segmentation frameworks (Table 9). Among the baselines, t-vMF and T-Loss are loss functions integrated into the U-Net. t-vMF attains the highest Dice and Acc (0.8868 and 0.9052), while our proposed method yields the best IoU (0.8506), with NR-UNet close behind on Dice/IoU and T-Loss providing the second-best Acc. This pattern highlights our method's ability to handle noisy labels. Taken together, these results indicate that robustness strategies trade off different aspects of performance under noise, and our method complements the strongest baselines by prioritizing accurate region overlap when sensitivity and F1 begin to decline at higher noise levels.
Effect of noise ratio on model performance
6.2
The analysis of different noise ratios, as shown in Figure 8, reveals that the U-Net model's performance is not linearly correlated with the amount of noise in the data. When the noise ratio is below 0.5, the model maintains relatively stable performance across all evaluation metrics. However, once the noise ratio exceeds 0.5, a steep decline in both sensitivity and F1 score is evident. This indicates a threshold effect, where a certain level of noise saturation leads to a tipping point beyond which the model's ability to accurately segment vessels deteriorates rapidly.
This observation is particularly relevant for practical applications, as it suggests that the U-Net can tolerate a moderate amount of noisy labels without significant loss in performance. However, when noise becomes predominant, the segmentation results are severely compromised. Thus, maintaining a low noise ratio in training data is crucial for achieving reliable model performance.
Significance of cleaning data
6.3
The results from Table 8 highlight the substantial benefits of data cleaning. In all cases, training on noise-free data produced better segmentation results compared to training on noisy data, even when the noisy data set was larger. This underscores the importance of data quality over quantity in machine learning tasks. The presence of noise not only hampers the model's learning process but also introduces biases that degrade its generalization ability.
The experiment further demonstrates that even minimal noise can adversely impact model performance, emphasizing the necessity for meticulous data preparation. Removing noise from the training data significantly improved both sensitivity and F1 score, illustrating that clean data leads to more accurate and reliable models. This finding is crucial for medical image analysis, where high precision and sensitivity are imperative for detecting subtle anatomical structures and pathological changes.
Implications for future work
6.4
Our study suggests several directions for future research. First, exploring more sophisticated noise-handling techniques, such as noise-robust loss functions or advanced data augmentation methods, could further enhance model robustness. Additionally, developing automated methods for noise detection and data cleaning could streamline the preprocessing pipeline, ensuring high-quality input data for training.
In conclusion, our experiments demonstrate the critical impact of noisy labels on retinal vessel segmentation and highlight the importance of data quality in medical imaging tasks. By carefully managing noise levels and ratios and employing effective data cleaning strategies, we can significantly improve model performance and reliability, ultimately contributing to better diagnostic outcomes in clinical practice.
Conclusion
7
This work addresses a largely overlooked problem in retinal vessel segmentation: positional annotation noise in manual labels. Prior retinal studies emphasize data quantity and quality, yet rarely model or measure the impact of positional label distortions on thin-vessel topology. We model realistic positional distortions, quantify performance sensitivity across noise levels and ratios, and introduce a lightweight few-shot annotation-correction framework that improves robustness with minimal labeling effort. On the analysis of the DRIVE dataset, increasing λ from 0 to 0.8 reduces sensitivity from 0.7758 to 0.4255 and F1 from 0.8170 to 0.5746. The method delivers strong generalization on CHASE_DB1 with an Accuracy of 96.51, AUC of 98.01, F1 of 83.55, and on STARE with an Accuracy of 97.54, AUC of 98.45, F1 of 83.11.
In future work, we will test more datasets and advanced segmentation networks in noisy environments by using our quantitative method, and give more general conclusions about the relationship between noise ratio and segmentation performance. Besides, we plan to add a new mechanism to the model that identifies capillaries so that the small vessels are trained separately. We will also propose a method to automatically identify and clean the noise.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abràmoff MD Garvin MK Sonka M. Retinal imaging and image analysis. IEEE Rev Biomed Eng. (2010) 3:169–208. doi: 10.1109/RBME.2010.208456722275207 PMC 3131209 · doi ↗ · pubmed ↗
- 2Patton N Aslam TM Mac Gillivray T Deary IJ Dhillon B Eikelboom RH . Retinal image analysis: concepts, applications and potential. Prog Retin Eye Res. (2006) 25:99–127. doi: 10.1016/j.preteyeres.2005.07.00116154379 · doi ↗ · pubmed ↗
- 3Le Cun Y Bengio Y Hinton G. Deep learning. Nature. (2015) 521:436–44. doi: 10.1038/nature 1453926017442 · doi ↗ · pubmed ↗
- 4Niemeijer M Staal JJ van Ginneken B Loog M Abramoff MD. Comparative study of retinal vessel segmentation methods on a new publicly available database. Proc SPIE - Int Soc Opt Eng. (2004) 5370:648–56. doi: 10.1117/12.535349 · doi ↗
- 5Hoover A Kouznetsova V Goldbaum M. Locating blood vessels in retinal images by piecewise threshold probing of a matched filter response. IEEE Trans Med Imaging. (2000) 19:203–10. doi: 10.1109/42.84517810875704 · doi ↗ · pubmed ↗
- 6Owen CG Rudnicka AR Mullen R Barman SA Wormald R Cook DG . Measuring retinal vessel tortuosity in 20 infants with and without retinopathy of prematurity. Investig Ophthalmol Vis Sci. (2009) 50:1492–9. doi: 10.1167/iovs.08-301819324866 · doi ↗ · pubmed ↗
- 7Shen D Wu G Suk HI. Deep learning in medical image analysis. Annu Rev Biomed Eng. (2017) 19:221–48. doi: 10.1146/annurev-bioeng-071516-04444228301734 PMC 5479722 · doi ↗ · pubmed ↗
- 8Xiao X Lian S Luo Z Li S. Weighted res-unet for high-quality retina vessel segmentation. In: 2018 9th International Conference On Information Technology in Medicine and Education (ITME). Hangzhou: IEEE (2018). p. 327–31. doi: 10.1109/ITME.2018.00080 · doi ↗