Participatory-informed preference optimization (PiPrO): A reinforcement learning simulation study
Tara Templin, Shuyi Song, Sophia Fort, Nasa Sinnott-Armstrong

TL;DR
This paper introduces PiPrO, a method that helps AI models balance community and physician perspectives in healthcare recommendations.
Contribution
PiPrO is a novel framework that explicitly tunes trade-offs between community and clinician inputs using reinforcement learning.
Findings
PiPrO reliably learned stable alpha values and a consistent reward signal.
Alpha shifts toward physician weighting when community feedback is noisier.
Alpha shifts toward community weighting when physician feedback is more biased.
Abstract
Artificial intelligence (AI) has transformative potential in public health, but its impact is limited by models that implicitly prioritize a single stakeholder perspective and do not make explicit and tunable trade-offs between community and clinician endorsement. To address this gap, we introduce Participatory-informed Preference Optimization (PiPrO), a large language model embedding-based calibration framework that generates a single clinical outcome prediction while explicitly accounting for differences between community and physician interpretations of the same scenario. PiPrO takes as input two embeddings derived from a large language model representing a community-facing context and a physician-facing context. It then applies a shared lightweight feedforward predictor to produce per-stakeholder scores which are then mixed using a single global mixing weight (alpha). Alpha controls…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
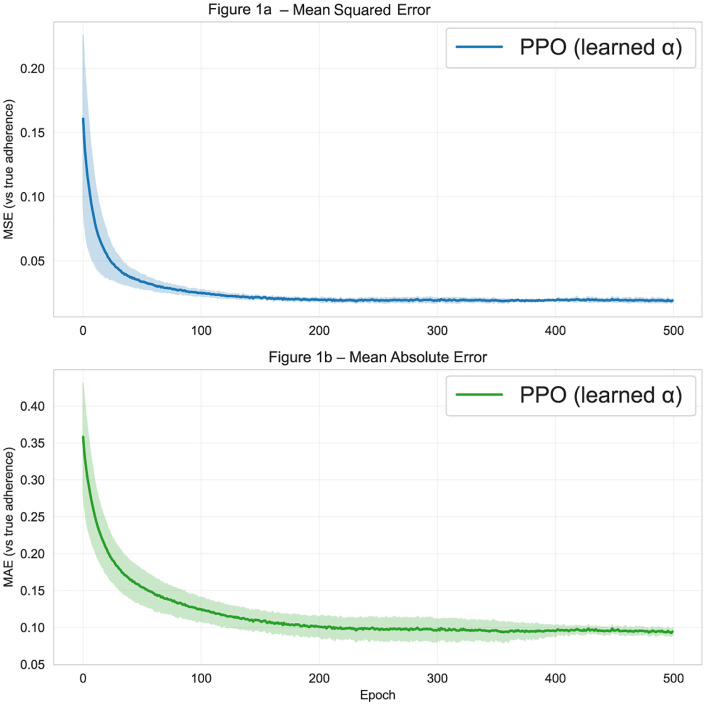 Fig 1
Fig 1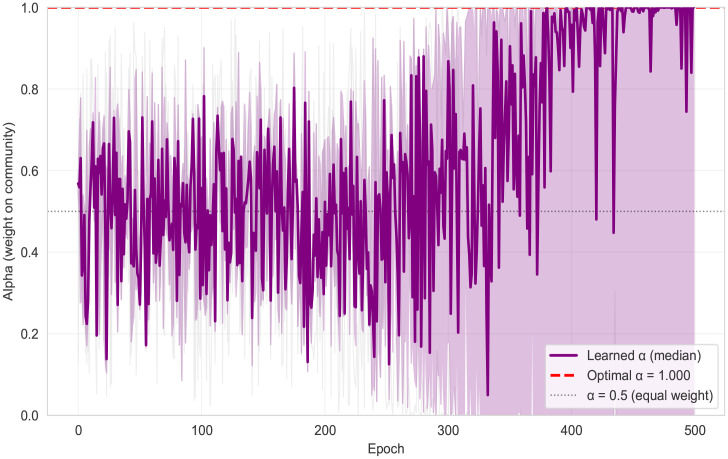 Fig 2
Fig 2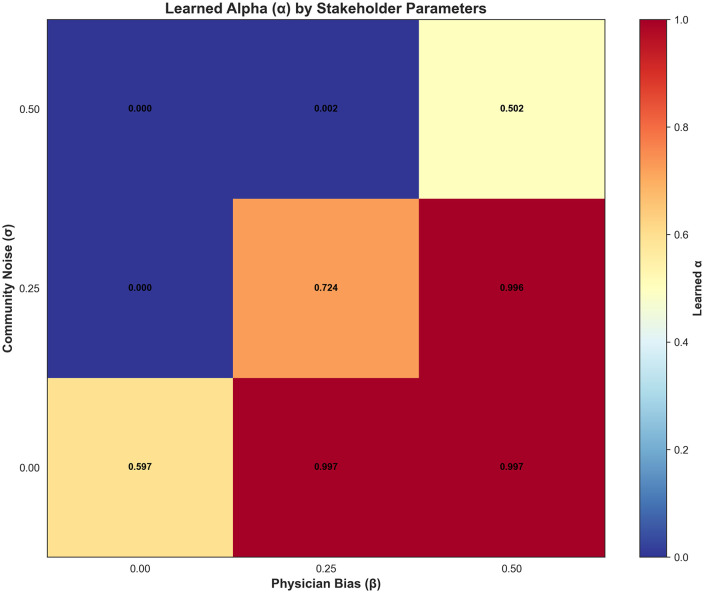 Fig 3
Fig 3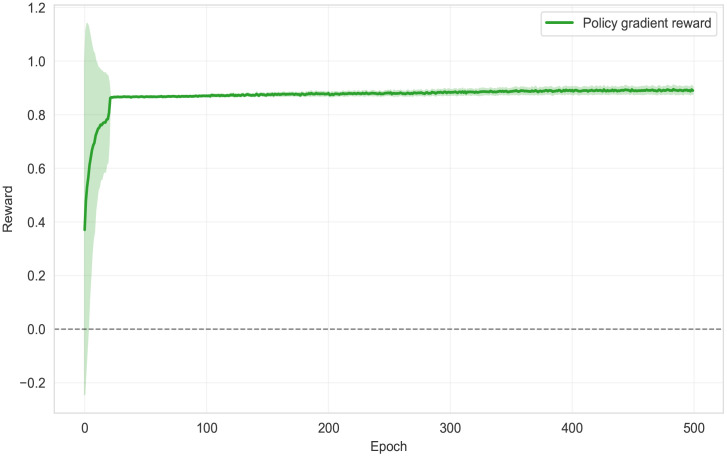 Fig 4
Fig 4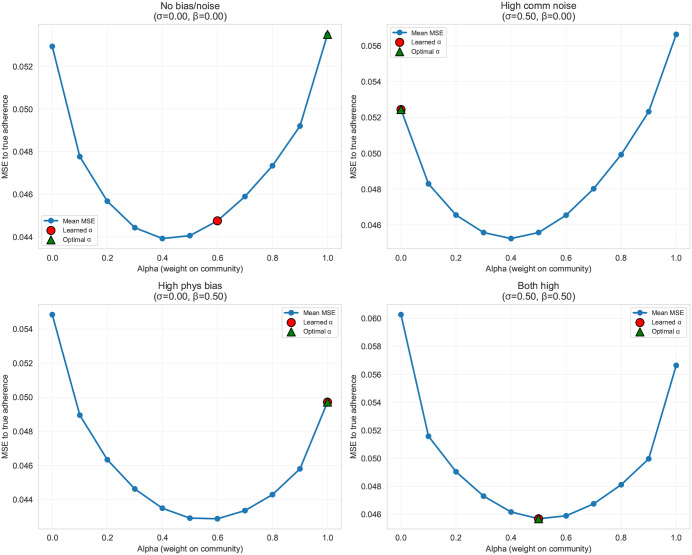 Fig 5
Fig 5- —http://dx.doi.org/10.13039/100000051National Human Genome Research Institute
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Machine Learning in Healthcare · Digital Mental Health Interventions
Introduction
Artificial intelligence (AI) is rapidly changing many aspects of medicine and public health [1]. The application of AI to health is accompanied by several well-documented challenges, including hallucination, bias, and a lack of regulatory oversight [2]. These barriers have been primarily evaluated by healthcare providers and technical experts, leaving a gap in the inclusion of patients and community members [3]. Current AI training processes do not systematically incorporate community perspectives, which is an omission of information that could address real-world public health needs effectively [4].
The field of public health has increasingly recognized the importance of patients and community leaders contributing to and directing research and technology development. This is especially true for contributors to the health of communities that have historically been underrepresented in decision-making [5,6]. Community engagement in public health initiatives can improve relevance of health programs to local needs and values, potentially more effectively addressing health disparities [7].
To address these gaps, we introduce Participatory-informed Preference Optimization (PiPrO). PiPrO is a reinforcement learning methodology designed to incorporate community perspectives. PiPrO is designed to integrate community-derived input alongside clinical expertise via continuous feedback, allowing communities and patients to contribute to care recommendations.
There are four main reasons why PiPrO fills these informational gaps. First, by modeling community preferences and stakeholder expertise, PiPrO mitigates algorithmic biases inherent in AI systems trained on unrepresentative datasets. Second, AI systems aligned with local contexts and patient values have higher acceptability and adoption rates, and PiPrO enables individual communities to directly improve models by reflecting their needs and preferences. For example, community-tailored health messages increase adherence and behavior change [8,9], thereby amplifying the real-world health impact of AI interventions. Third, PiPrO uses stakeholder embeddings and a calibration parameter to fine-tune multi-party responses, offering a computationally simple yet flexible alignment framework that can be easily deployed in a variety of settings. Finally, the structured feedback loops inherent in PiPrO offer both local and general transparency about how community inputs influence AI recommendations, as well as iterative inclusion of community preferences over time. This builds trust in AI systems [10], reduces misinformation [11,12], and ensures accountability [13], all of which are critical components of sustained public engagement and effective public health responses [14].
In this paper, we review relevant literature in AI alignment and community-based participatory research (CBPR), introduce the PiPrO method, and conduct a simulation study to evaluate a proof-of-concept in which simulated patient- and provider-preferences guide joint model calibration. This is meant to represent a wide range of scenarios relevant to medicine and public health. In practice, there is a wide range of discordance levels for interventions between patients and providers, and being able to model this range of responses is useful for designing an internally consistent AI model of healthcare.
Background: AI-driven participatory approaches in public health
While we are primarily focused on presenting our reinforcement learning framework, key methodological choices were made by building on two separate areas of study: AI alignment and community-based participatory research. In this section, we briefly review these two strands of literature and situate our contribution within both. To further situate our contribution, we also provide examples of past AI tools intended for public health applications that explicitly included community feedback and examples where meaningful conflicts may be important to represent within AI systems.
Techniques to update algorithms based on feedback
There are already numerous existing techniques to achieve feedback on model performance. These methods include Reinforcement Learning with Human Feedback (RLHF), [15] Direct Preference Optimization (DPO), [16] Kahneman-Tversky Optimization (KTO), [17] Reinforcement Learning with Expert Feedback (RLEF), [18] Iterative Preference Optimization (IPO), [19] and Simultaneous Preference Integration for Neural Networks (SPINN) [20]. Kumar et al. (2024) introduced a framework for language models to incorporate community-specific preferences using data from Reddit subforums, conditioning each model on prepended community-specific identifiers to reflect the distinct preferences of that community [21]. We detail these existing techniques in Table 1 below. To the best of our knowledge, none of these current techniques directly model patient-vs-provider preference tradeoffs in classification tasks.
Table 1: Overview of techniques to update algorithms based on feedback.
The combination of dynamic treatment regimes and Q-learning that explicitly incorporates patient preferences has been one well-established line of work in statistics and biostatistics. Early work by Butler et al. [22] formalized preference-aware dynamic treatment regimes by balancing competing outcomes through patient-specific utilities, and more recent methods make preferences over multiple outcomes explicit. Survival Augmented Patient Preference Q-Learning (SAPP-Q-Learning) [23] incorporates patient preferences to trade off quality of life and survival under censoring, while Latent Utility Q-Learning (LUQ-Learning) [24] generalizes this approach by modeling preferences as latent utilities over multi-dimensional outcome vectors with flexible elicitation and strong theoretical guarantees. Unlike PiPrO, however, these methods are designed to optimize treatment policies under patient-specific preferences and do not model explicit, potentially conflicting preference labels from multiple stakeholders (e.g., patients and providers). In addition, these reinforcement learning approaches fail to evaluate classification tasks where such preference tradeoffs are central to the practice of medicine**.**
In clinical settings, reviews of reinforcement learning (RL) for decision support emphasize that RL’s key source of flexibility lies in the reward function, and that altering the reward can fundamentally change the policies an algorithm recommends. [25, 25] This flexibility is frequently framed as an opportunity to reflect patient values and support shared decision-making, since different reward formulations can encode different tradeoffs among clinical outcomes (e.g., short-term physiologic stability versus long-term survival). These clinical RL approaches typically treat preferences as implicitly embedded in a scalar reward or utility rather than modeling explicit, potentially conflicting preference signals from multiple stakeholders (such as patients and clinicians) on the same decision task.
Set-valued policy RL (near-optimal SVP/ “clinician-in-the-loop” RL) learns, for each clinical choice, a set of actions whose expected cumulative rewards are provably near-equivalent rather than simply a single best action. By relaxing the objective from strict optimality to ζ-optimality, these methods identify multiple treatment options that perform similarly under a scalar reward (e.g., survival), enabling clinicians or patients to incorporate additional considerations—such as side effects, invasiveness, cost, or individual preferences—when selecting among them [26, 27]. The approach is typically implemented using value-based, model-free reinforcement learning with a near-greedy inclusion rule and worst-case evaluation over the action set, providing theoretical guarantees under mild conditions. While this framework supports human-in-the-loop decision making by preserving flexibility at deployment time, it does not explicitly model or learn from stakeholder-specific preference signals, treating preferences as external to the learning process rather than as structured feedback integrated into the algorithm itself. In addition, it does not allow for selection of actions that are suboptimal, only selection among otherwise equivalent choices on the basis of orthogonal considerations.
In the computer science literature, there is a broad tradition of preference-based reinforcement learning (PbRL) that relaxes the assumption of a fully specified reward function, defining learning objectives through preference comparisons over states, actions, or trajectory segments. [28] Classic work shows that complex behaviors can be learned by fitting a latent reward or utility model from (often non-expert) human pairwise comparisons and then optimizing policies against that learned objective, substantially reducing the need for hand-engineered rewards. A general methodological survey formalizes PbRL as solving RL problems using qualitative preference feedback and categorizes approaches by the type of feedback, the learned representation (policy, preference model, or utility), and the associated optimization strategy. More recent work in treatment recommendation similarly applies preference-based RL to learn rewards that encode tradeoffs across multiple clinical goals (e.g., efficacy versus side effects), primarily in simulation. [29] Compared with PiPrO, these approaches typically collapse all feedback into a single latent utility or reward signal and do not explicitly represent, calibrate, or reconcile simultaneous (and not necessarily consistent) preferences, which potentially conflict with preference signals from different stakeholders.
A parallel strand of work treats clinician behavior itself as a revealed preference signal and uses inverse reinforcement learning (IRL) to infer the latent reward functions that appear to guide practice. In ICU settings, for example, Yu et al. infer clinicians’ implicit tradeoffs in ventilation weaning and sedative dosing from retrospective trajectories, and related reviews frame this approach as learning “clinician preference” by interpreting observed decisions as reward-maximizing behavior [29]. This line of work conceptualizes preference as a single, implicit provider objective recovered from data, without jointly incorporating patient-stated preferences on the same decision tasks, or providing an explicit mechanism to balance or calibrate potentially conflicting patient–provider preference signals under noisy feedback.
There is a more direct “patient vs. doctor preferences” literature that models shared decision-making explicitly as a negotiation problem and uses learning-based or rule-based strategies to reach mutually acceptable treatment plans. In this line of work, Chen et al. (2025) [30] propose an RL-based automated negotiation framework in which doctor and patient agents express preferences over multiple treatment dimensions (including side effects) and iteratively improve negotiation strategies via deep reinforcement learning, while related frameworks employ fuzzy or intuitionistic-fuzzy agent negotiation to manage preference uncertainty and concession behavior. [31] Collectively, these approaches treat preference divergence as a core challenge and seek efficient, fair agreements through sequential offer exchange. However, these methods are negotiation-centric, not on calibrating a predictive model’s outputs using simultaneous, heterogeneous preference signals from multiple stakeholders.
Another related literature that frames personalization and preference alignment as a contextual bandit problem, particularly in just-in-time adaptive interventions (JITAIs). In this line of work, Tewari and Murphy (2017) [32] formalize contextual bandits as a framework for sequential decision-making in which interventions are selected based on time-varying contextual information (e.g., stress, location, physiological signals) and updated using proximal outcome feedback, with the goal of minimizing regret while balancing exploration and exploitation. These approaches emphasize online learning of context-dependent decision rules under uncertainty and have been widely studied under stochastic, adversarial, and partially non-stationary settings. Compared to PiPrO, standard contextual bandit formulations typically assume a single implicit reward signal and do not explicitly model or reconcile preference feedback from multiple stakeholder groups.
Community-based participatory research (CBPR)
CBPR is a model which explicitly aims to make community members equal partners in research.[7,33,34] CBPR projects involve community partners at all stages – from setting the research agenda to designing interventions and disseminating results – and facilitates two-way knowledge exchange between community and researchers [35,36]. Such approaches have been shown to expand the reach of health interventions and influence policies to eliminate disparities.[37–39] Overall, patient and community participation is seen as a catalyst for more effective and equitable public health outcomes, particularly for marginalized groups who often face unique barriers and health inequities [40,41]. PiPrO can serve as one tool to enable faster and easier integration of community feedback into AI development for intervention design so that CBPR-based interventional work is more effective.
Past examples of AI development with community feedback loops
Including feedback from communities in AI tools is not new; indeed it is broadly essential to many reinforcement learning techniques used to fine-tune models (although this is not typically considered community engagement). Prior health-related AI projects have solicited community input in myriad ways. We now detail examples where community input was a key driver of AI development and application in public health.
The first group of examples focus on using AI tools and community engagement to improve prediction of health outcomes. The improvements in prediction involve improvements in timeliness and accuracy. Participatory disease surveillance systems, such as the “Global Flu View” platform [42], aggregate self-reported symptoms from community members to detect outbreaks.These approaches have promise to detect signs of outbreaks earlier than traditional clinic-based reporting [43]. The FAITH! Trial (Fostering African-American Improvement in Total Health) developed an AI tool to improve cardiovascular health through community-based participatory methods [44] and achieved an area-under-curve (AUC) of 0.89 for detecting reduced ejection fraction [45]which was notable since AI-based screening tools trained in academic settings typically perform poorly in real-world populations due to lack of representative data [46]. In environmental health, the “Smell Pittsburgh” initiative [47]enabled residents used sensors and reported pollution odors to generating a dataset of environmental indicators via AI prediction.[48] In the RISE project, community members and scientists collaboratively annotated images of industrial smoke plumes, which were then used to train an AI model to automatically recognize pollution events [49].
AI chatbots for health have been developed with user-centered design, particularly those focused on involving users in testing [50]. A randomized controlled trial demonstrated that the Wysa chatbot, which employs a user-centered AI approach, significantly reduced symptoms of depression and anxiety in individuals with chronic conditions like arthritis and diabetes.[51] Patient-in-the-loop approaches enable further automated model refinement beyond the developer-centric approach that is currently standard [52]. However, the term “patient-in-the-loop” encompasses a range of methods and implementations - and requires more evidence to establish the generalizability and efficacy of these approaches across different healthcare contexts. It also inherently situates researchers as designers and implementers of study questions, with patients acting as alternative model inputs rather than true collaborators in the answering process.
Examples where further method development would add value
We propose two illustrative use cases where a method such as PiPrO that aims to represent different preferences and perspectives might be particularly helpful. We anticipate that even more use cases will arise in this fast-moving field.
Addressing conflicts in preferences: Patients and health providers often rank the same treatments (e.g., drugs) differently. For example, a discrete choice experiment examining the relative importance of six attributes related to lipid-lowering drugs showed that patients prioritized the mode and frequency of drug administration as the second and third most important factors only after the minimization of liver damage risk, while providers ranked these attributes as the two least significant out of the six. [53] Neither perspective is wrong, but they reflect different priorities.
Standard modeling approaches collapse these differences into an average. When patient and provider preferences are pooled together, the model learns what is most often preferred. However, the model cannot explain disagreement, cannot identify which types of cases drive maximal disagreement, and cannot adjust its recommendations based on whose priorities matter more in a given context.
PiPrO is designed to represent this issue directly. At a high level, it treats drug choice as a problem where multiple preference patterns coexist, rather than assuming a single consensus ranking. It allows the model to recognize that certain types of cases tend to follow one set of priorities (e.g., side-effect sensitivity) while other cases follow another (e.g., efficacy dominance), and to indicate which pattern is most influential for a given recommendation. Importantly, it makes the trade-off between patient- and provider-oriented priorities explicit and adjustable, rather than hiding it inside a single opaque prediction.
Addressing Algorithmic Bias and Hallucinations: The integration of AI into digital tools meant to improve health brings ethical considerations such as algorithmic bias, the potential for misinformation, privacy and data security, and questions of accountability and transparency [2].
Algorithmic bias is a well-documented risk in healthcare AI. [54] AI systems trained on data that under-represents certain populations often performs worse for those groups because large language models tend to reflect majority voices present in their training data. [55] Alessandra Bazzano and colleagues (2025) argue that without community engagement, adopting AI in public health exacerbates health inequities, whereas designing AI with community input helps address bias and risks upfront [56].
Involving the community in both development and dissemination of AI can enhance trust and reduce skepticism [57]. This may be particularly true in the detection of plausible but incorrect health information (“hallucinations”) from the AI [58,59]. Such misinformation, if undetected, threatens patient safety [60]. Community feedback loops can serve as an error-correction mechanism [61]. When multiple community members flag a response as inaccurate or harmful, the platform can institute an automatic quarantine of that content until an adjudication process (led by community-elected moderators or domain experts) is completed.
Methods
Framework overview
We propose a machine learning framework aimed at improving health care recommendation accuracy by explicitly accounting for the fact that different stakeholders may endorse different recommendations for the same clinical scenario. In the model, each training case has a single target clinical outcome (for example, an adherence outcome), and the input is represented using two separate compact feature sets (“embeddings”) for the same case derived from a large language model. One embedding represents a community-facing view of the scenario, and the other represents a physician-facing view.
PiPrO generates an intermediate prediction from each embedding stream and then combines them using a single, interpretable global mixing weight, which we refer to as alpha. Conceptually, alpha functions as a “dial” that determines how strongly the final recommendation reflects the community-based signal versus the physician-based signal. Alpha is learned from feedback rather than being fixed in advance, so the model can adaptively balance these two alignment objectives during training while simultaneously training a single “context to prediction” task by sharing weights across stakeholders, such that the only difference in interpretation on a per-stakeholder basis is the context embedding differences between providers. This enables straightforward interpretation of single stakeholder feedback while building a system that can jointly account for everyone’s needs.
Model architecture
In this section we will describe the model architecture at a high level.
PiPrO is implemented as a feedforward network with shared weights. This feedforward network is applied separately to the community and physician embeddings to produce two real values scores - one per embedding. Each forward pass is intentionally lightweight: it uses a fully connected layer followed by batch normalization, a rectified linear activation, dropout regularization, and a final fully connected output layer. The hidden layer size is two units, chosen based on the two different stakeholders in the network. Thus, first layer can be thought of as summarization, and the second as co-learning.
The model then forms a single combined score by taking a linear alpha-weighted blend of the two stack outputs, then converts that combined score into a final predicted probability for the target outcome. This architecture scales straightforwardly to more or fewer stakeholders, including stakeholders who occupy the same roles (e.g., two community feedback or two physician feedback providers), including missing predictions on a per-item level.
Calibration and feedback loop
After producing the predicted probability, PiPrO updates the shared weights of the prediction networks and the global mixing weight alpha using a combined supervised and feedback-driven learning procedure.
The parameter alpha is updated by combining the shared fully connected networks that include both community and physician responses. The two predicted responses are combined into a single reward using the alpha weighting scheme described above. Clinically, this means that alpha shapes both the final recommendation and the contribution of stakeholder endorsement to the learning signal. Alpha is learned with a reinforcement-learning style policy update. The algorithm further samples candidate alpha values per epoch from a Beta probability distribution
We incorporate two stability mechanisms. First, our PiPrO implementation uses a warmup period of 100 epochs in which only the supervised prediction networks are trained; alpha begins updating only after this warmup is complete. Second, it includes a mild regularization term that discourages alpha from collapsing to extreme values unless the endorsement data consistently supports that choice by adding to the loss value for alpha far from equal contribution.
Data generation
We generated a simulated dataset of 10,000 scenarios in which each case has a single underlying target outcome (for example, overall medication adherence) and two fixed-length numeric representations (“embeddings”) of the same scenario derived from textual representations generated from the llama3.1 model: one intended to reflect a community-facing view and one intended to reflect a physician-facing view. These paired embeddings are the only inputs provided to the model.
During training, we simulate two endorsement streams to reflect how feedback differs by stakeholder group. Community feedback is available for every case but is imperfect: it matches the underlying outcome most of the time, with a specified probability of being randomly inverted to represent noisy or inconsistent community endorsement. Physician feedback is higher value but limited: at each training step, only a randomly selected subset of cases is “queried” for expert input, and the physician label is intentionally biased toward high adherence (meaning it is sometimes set to “adherence” regardless of the underlying outcome). The model’s prediction is converted into a yes/no recommendation using a fifty percent cutoff and scored as agreement versus disagreement with each stakeholder. In experiments, we vary the community noise level, the number of physician queries per batch, and the strength of physician bias to stress-test the calibration mechanism under realistic feedback constraints.
Evaluation metrics and visualization
Following model training, we assessed performance on the held-out test set. Outcome prediction performance was summarized with mean squared error (average squared difference between the predicted outcome probability and the target outcome) and mean absolute error (average absolute difference). We report these metrics for PiPrO (with learned alpha). To reflect run-to-run variability, we repeated experiments across multiple random seeds and visualized uncertainty over epochs using aggregated curves (with confidence bands).
To characterize training dynamics and the calibration process, we generated a set of standard diagnostic plots. First, we plotted epoch-by-epoch learning curves for mean squared error and mean absolute error on the held-out set, alongside the baseline reference. Second, we plotted the trajectory of the learned global mixing weight, summarizing alpha across seeds using the median and interquartile range; when available, we also included a reference “optimal alpha” computed from an offline alpha sweep for the same experimental condition. Third, to visualize how model predictions track each stakeholder’s interpretation, we plotted stakeholder-specific mean absolute error curves for the community signal and for the physician signal over training (noting that physician feedback is sparse by design and only present for a queried subset during training). Fourth, we plotted the policy-gradient reward signal used to update alpha, to document the magnitude and stability of the feedback signal driving calibration. Finally, we performed two post-hoc visualizations to contextualize alpha: (i) an alpha sweep plot that evaluates outcome prediction error across a grid of fixed alpha values under multiple noise/bias conditions in comparison to the true data, and (ii) a bias–noise landscape heatmap that summarizes the learned alpha values across combinations of community noise and physician bias settings.
Ethics statement
This study is a simulation study of an algorithmic framework. Thus it does not involve live participants and does not require approval by an Institutional Review Board for a statistical simulation involving no data collection.
Training conditions
Training was performed using NVIDIA L40S GPUs. Each synthetic clinical scenario was converted into an embedding using the Llama 3.1 language model run locally via Ollama in Python.
Results
Fig 1 shows that across epochs, the PiPrO model with policy-gradient alpha learning showed a rapid initial reduction in outcome prediction error followed by a clear plateau. Mean squared error dropped sharply from the initial value (approximately 0.16) to a stable range near 0.02 by roughly 150–200 epochs, with uncertainty bands narrowing over time, indicating reduced variability across seeds as training progressed. Mean absolute error similarly declined from approximately 0.37 to a stable range near 0.09–0.10 by the end of training.
Model learns to predict true adherence.
Fig 2 shows that the learned alpha exhibited substantial exploration early in training in an example of 3 parameter combinations, fluctuating around the equal-weight reference (0.5) with a wide interquartile range across seeds. After the period where alpha began to change systematically, the median alpha increased steadily and then saturated near the upper boundary (approaching 1.0) late in training, indicating convergence toward a community-dominant mixing regime in this parameter slice. The run-level variability was highest during the transition period and narrowed once alpha approached its terminal regime, consistent with stabilization of the policy update.
Learning ɑ (σ_comm = 0.0, β_phys = 0.0).
Fig 3 presents a heatmap summarizing the final learned value of alpha across a grid of stakeholder-feedback conditions. The horizontal axis varies physician bias (the degree to which simulated physician feedback is pushed toward high adherence), and the vertical axis varies community noise (the probability that community feedback is randomly flipped). Each cell reports the learned alpha value for that parameter combination, and the color scale maps alpha from 0 (physician-dominant mixing) to 1 (community-dominant mixing). The main scientific takeaway from Fig 3 is that the learned mixing weight alpha adapts in a directionally appropriate way to the relative reliability of the two feedback streams: when the community signal becomes noisier, the policy shifts alpha downward (placing more weight on the physician stream), and when the physician signal becomes more biased, the policy shifts alpha upward (placing more weight on the community stream). When both stakeholder signals are degraded at the same time, the learned alpha returns toward an approximately equal-weight compromise rather than collapsing to either extreme.
Alignment with community vs. physician interpretations.
Fig 4 shows that the policy-gradient reward signal increased sharply during the earliest epochs (from approximately 0.37 to the high 0.8s within the first few dozen epochs) and then remained stably positive for the remainder of training, with a slow upward drift toward approximately 0.89–0.90. The confidence band was wide early, reflecting high across-seed variability when the model and policy are immature, and then narrowed substantially as training progressed, indicating a stable reward landscape once the system reached its steady-state regime.
Reward signal guiding ɑ learning.
Fig 5 shows that across all four sweep conditions, outcome prediction error as a function of fixed alpha was consistently convex (U-shaped), with the lowest mean squared error occurring at intermediate alpha values (roughly in the 0.4–0.6 range) rather than at the extremes. In contrast, the alpha selected by the learned policy tended to move toward boundary solutions (near 0 or near 1) when only one feedback stream was degraded (high community noise or high physician bias), while it remained near the center (approximately 0.5) when both streams were simultaneously degraded. Operationally, these sweeps demonstrate that the alpha values favored by the feedback-driven policy can diverge from the alpha values that minimize squared error to the true outcome, highlighting a measurable trade-off between optimizing the endorsement-driven objective and optimizing pure outcome prediction performance.
Alpha sweep: finding optimal bias-variance balance.
Ethical considerations in for the Implementation of PiPrO
Calibrating preferences based heavily on community feedback might inadvertently reinforce existing biases, echo chambers, or misinformation present within specific communities, particularly without validation mechanisms or using training strategies not incorporating measures of trust. In this section, we discuss how involving communities through approaches like PiPrO can mitigate or exacerbate risks such as bias and misinformation, and what safeguards are needed to help ensure responsible AI use. PiPrO can also enable inclusion of expert opinions into mostly patient-derived modeling efforts as a means of reducing the effect of misinformation as well.
Kumar et al. (2024) emphasize that while personalizing AI to community preferences has benefits, it must be done with safeguards to avoid creating echo chambers that entrench the community’s own biases.[21] In practice, this might translate to requiring and reweighting diverse community representation in input datasets, forming community advisory boards for AI projects, and continuously monitoring algorithm outcomes. As described by Kumar et al (2024), one approach is tiered training on two major sources of knowledge. Tier 1 consists of universal best practices (e.g., peer-reviewed studies, WHO guidelines) to anchor the model in evidence-based standards. Tier 2 incorporates local data (e.g., health department protocols, regional dialect or cultural knowledge). The system could also use Retrieval-Augmented Generation to ground the AI responses in information from community trusted sources [62]. A future PiPrO implementation could integrate an evidence check; the present simulation addresses only synthetic patient and provider label information and does not incorporate external knowledge bases or topic-specific expertise.
AI-based platforms are susceptible to adversarial misuse [63]. This can arise through manipulative prompts designed to elicit harmful content or through data poisoning attacks, in which false user feedback accumulates to misalign the model [64]. Community participation can indeed mitigate adversarial threats through collective oversight, but it can also inadvertently introduce risks if not carefully managed [65]. Without robust safeguards, open community input can be exploited for data poisoning or coordinated misinformation [66].
Conclusion
In this work, we introduced a calibrated four‑head ensemble that aims to balance patient and provider preferences in a synthetic decision task. Our proof-of-concept demonstrated substantial improvements in aligning recommendations with diverse stakeholder perspectives, particularly when preferences diverge. The simulated community and provider feedback showed the potential for effective refinement of model behavior. This approach holds promise for improving the effectiveness and acceptability of AI-enabled digital health tools.
This work has limitations. The current approach relies on synthetic data generation. Real-world data might contain complex nuances and interactions that synthetic embeddings do not capture, and will likely require larger training (or pre-training) sample sizes to obtain robust results. The simplified binary representation (patient/provider preferences) restricts capturing more nuanced or gradient preferences frequently seen in clinical and community contexts. Feedback loops in this study are simulated, assuming probabilistic interactions. Actual feedback from patients and providers may vary considerably in quality, frequency, and type, even over time. The next step is to generate a community-relevant, stakeholder-aware dataset that allows testing of multiple stakeholder real world problems for AI. To explore human-centered validation in the drug-versus-lifestyle treatment example, we would deploy our framework in a real clinical workflow where clinicians and patients review the recommendation, record their preferences and rationale, and then track downstream patient-centered outcomes (e.g., adherence, symptom control, adverse events, and patient-reported burden) to test whether PiPrO improves welfare-relevant endpoints when preferences conflict. A prospective extension of this application would involve the randomization (or the use of a stepped-wedge rollout) of PiPrO recommendations to establish causal effects and assess usability and trust among patients and clinicians.
The ensemble method introduces computational complexity and may be challenging to scale to larger, high-dimensional datasets or real-time inference situations. We explored only a single hyperparameter (α). Other potentially influential hyperparameters (e.g., network architecture details, learning rates, attention mechanism parameters) were not systematically explored, potentially limiting performance optimization.
Partnering with communities and trusted local leaders is a recurring recommendation in addressing health misinformation in public health [57]. In practice, this means that the development of AI interventions should not occur in isolation. Continuous dialogue with the community must guide what the AI does and how it does it, pointing toward a future of “community-engaged AI development” in public health. Our calibration mechanism, once combined with genuine community feedback and co-design, could illustrate one pathway toward this vision of “community-engaged AI development”, demonstrating how iterative community input can dynamically refine model recommendations, actively balancing community preferences and clinical guidelines.
Supporting information
S1 FileReward function.(PDF)
S2 FileAlgorithm.(PDF)
S3 FileModel architecture diagram.(PDF)
S4 FileEmbedding correlations.(PDF)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Dangi RR, Sharma A, Vageriya V. Transforming healthcare in low-resource settings with artificial intelligence: Recent developments and outcomes. Public Health Nurs. 2025;42(2):1017–30. doi: 10.1111/phn.13500 39629887 · doi ↗ · pubmed ↗
- 2Templin T, Perez MW, Sylvia S, Leek J, Sinnott-Armstrong N. Addressing 6 challenges in generative AI for digital health: A scoping review. PLOS Digit Health. 2024;3(5):e 0000503. doi: 10.1371/journal.pdig.0000503 38781686 PMC 11115971 · doi ↗ · pubmed ↗
- 3Nadarzynski T, Knights N, Husbands D, Graham CA, Llewellyn CD, Buchanan T, et al. Achieving health equity through conversational AI: A roadmap for design and implementation of inclusive chatbots in healthcare. PLOS Digit Health. 2024;3(5):e 0000492. doi: 10.1371/journal.pdig.0000492 38696359 PMC 11065243 · doi ↗ · pubmed ↗
- 4Barony Sanchez RH, Bergeron-Drolet L-A, Sasseville M, Gagnon M-P. Engaging patients and citizens in digital health technology development through the virtual space. Front Med Technol. 2022;4:958571. doi: 10.3389/fmedt.2022.958571 36506474 PMC 9732568 · doi ↗ · pubmed ↗
- 5Sofolahan-Oladeinde Y, Mullins CD, Baquet CR. Using community-based participatory research in patient-centered outcomes research to address health disparities in under-represented communities. J Comp Eff Res. 2015;4(5).10.2217/cer.15.3126436953 · doi ↗ · pubmed ↗
- 6Cyril S, Smith BJ, Possamai-Inesedy A, Renzaho AMN. Exploring the role of community engagement in improving the health of disadvantaged populations: A systematic review. Glob Health Action. 2015;8:29842. doi: 10.3402/gha.v 8.29842 26689460 PMC 4685976 · doi ↗ · pubmed ↗
- 7Morales-Garzón S, Parker LA, Hernández-Aguado I, González-Moro Tolosana M, Pastor-Valero M, Chilet-Rosell E. Addressing health disparities through community participation: A scoping review of co-creation in public health. Healthcare (Basel). 2023;11(7):1034. doi: 10.3390/healthcare 11071034 37046961 PMC 10094395 · doi ↗ · pubmed ↗
- 8Kukula VA, Odopey S, Arthur E, Odonkor G, Awini E, Adjei A, et al. Understanding health worker and community antibiotic prescription-adherence practices for acute febrile illness: A nested qualitative study in the Shai-Osudoku District of Ghana and the development of a training-and-communication intervention. Clin Infect Dis. 2023;77(Suppl 2):S 182-90.10.1093/cid/ciad 327PMC 1036841437490740 · doi ↗ · pubmed ↗