Covariate Adjustment in Basket Trials Borrowing Information Across Subgroups
Jiyang Ren, David S. Robertson, Haiyan Zheng

TL;DR
This paper introduces Bayesian hierarchical models that use ANCOVA to improve treatment effect estimation in basket trials by adjusting for covariates and borrowing information across subgroups.
Contribution
The novelty lies in integrating ANCOVA with Bayesian hierarchical models for basket trials, exploring both with and without treatment-by-covariate interactions.
Findings
Covariate-adjusted BHMs outperformed unadjusted BHMs and frequentist ANCOVA in simulation studies.
The models were successfully applied to the MAJIC study, showing practical benefits in analyzing basket trials.
Incorporating ANCOVA improved estimation precision in the context of patient heterogeneity and small sample sizes.
Abstract
Basket trials are an efficient approach to simultaneously evaluate a single therapy across multiple diseases where patients share a common molecular target. Bayesian hierarchical models (BHMs) are widely used to estimate the treatment effects while accounting for heterogeneity between patient subgroups within a basket trial. However, the use of analysis of covariance (ANCOVA) with treatment‐by‐covariate interaction terms, in this context of patient heterogeneity and small samples, has been largely unexplored, despite the widespread use of ANCOVA for improving estimation precision in traditional settings from a frequentist perspective. In this paper, we propose two covariate‐adjusted BHMs that incorporate ANCOVA into the data model to enhance the estimation precision in basket trials, wherein borrowing of information is permitted across subgroups to a certain extent. Specifically, both…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
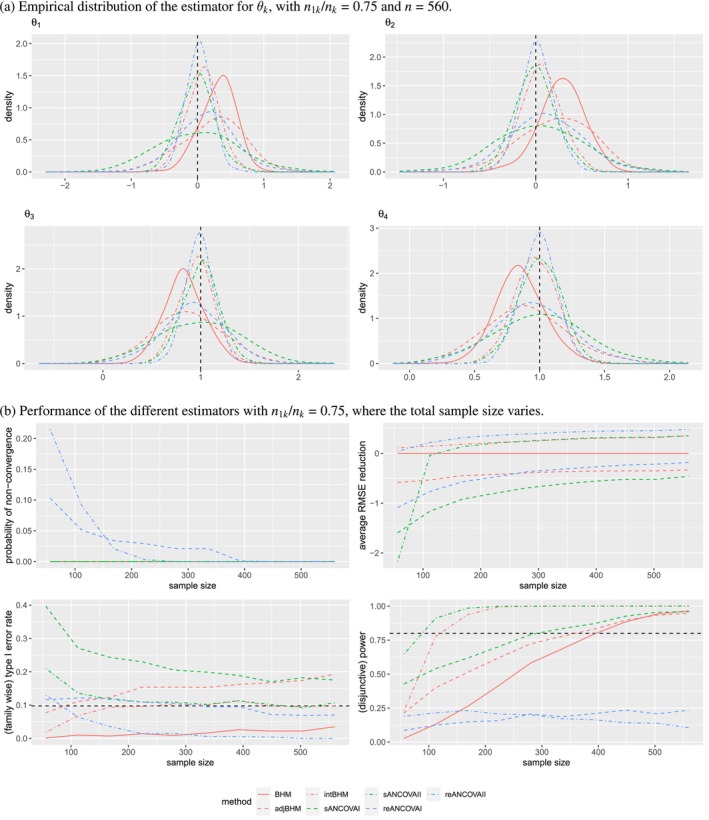 FIGURE 1
FIGURE 1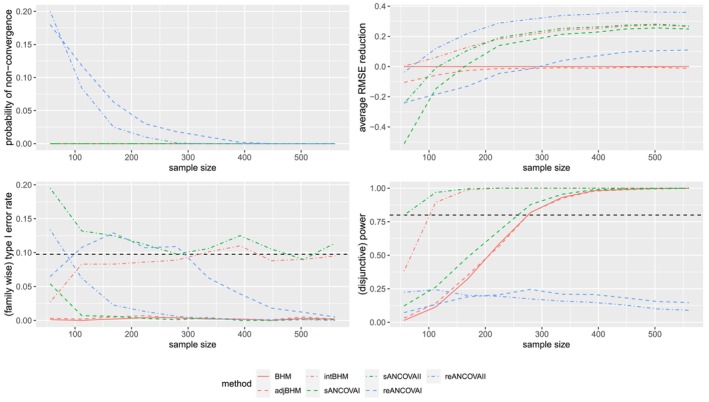 FIGURE 2
FIGURE 2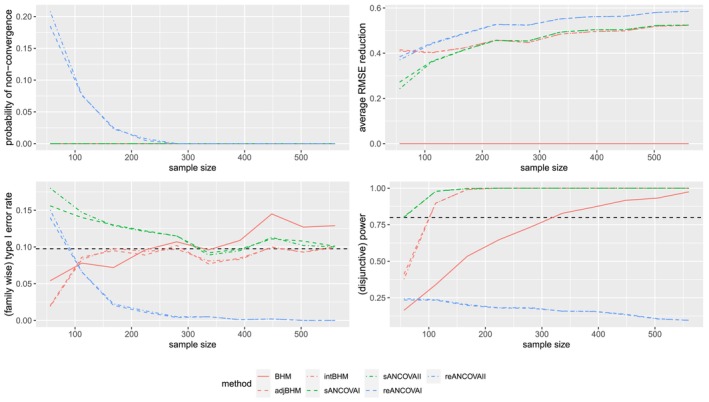 FIGURE 3
FIGURE 3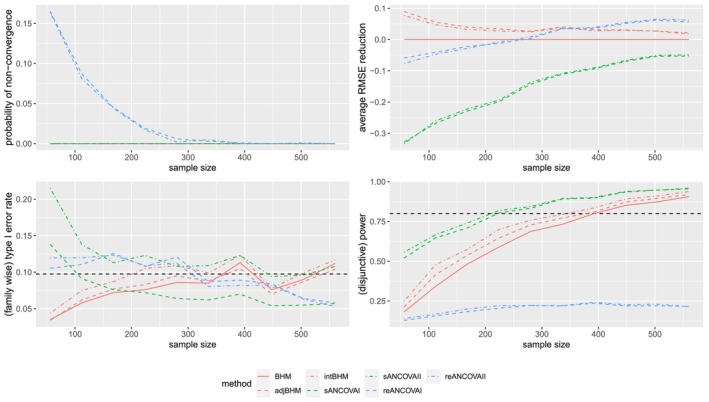 FIGURE 4
FIGURE 4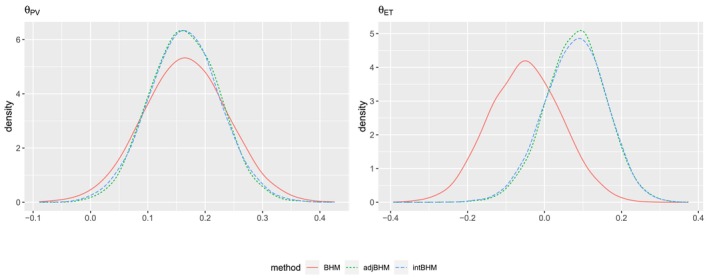 FIGURE 5
FIGURE 5| Data model | Parameter model | |
|---|---|---|
| BHM | Equation ( | |
| adjBHM | ||
| intBHM |
| Abbreviation | Model |
|---|---|
| BHM | Unadjusted BHM with a prior on |
| adjBHM | Covariate‐adjusted BHM without interaction term (ANCOVA I) with a prior on |
| intBHM | Covariate‐adjusted BHM with interaction term (ANCOVA II) with a prior on |
| BHM2 | Unadjusted BHM with a weak prior on |
| adjBHM2 | Covariate‐adjusted BHM without interaction term (ANCOVA I) with a weak prior on |
| intBHM2 | Covariate‐adjusted BHM with interaction term (ANCOVA II) with a weak prior on |
| sANOVA | Unadjusted stratified ANOVA |
| sANCOVAI | Covariate‐adjusted stratified ANCOVA I |
| sANCOVAII | Covariate‐adjusted stratified ANCOVA II |
| reANOVA | Unadjusted random‐effect ANOVA with random slope of |
| reANCOVAI | Covariate‐adjusted random‐effect ANCOVA I with random slope of |
| reANCOVAII | Covariate‐adjusted random‐effect ANCOVA II with random slope of |
| Metrics | Definition | Estimate | MCSE of estimate |
|---|---|---|---|
| Bias | |||
| SD | |||
| RMSE | |||
| RMSE reduction | |||
| Rejection rate |
| Bias | SD | RMSE | RMSE reduction (%) | Rejection rate | ||
|---|---|---|---|---|---|---|
| BHM | 0.308 (0.008) | 0.265 (0.006) | 0.406 (0.007) | — | 0.018 (0.004) | |
| adjBHM | 0.226 (0.015) | 0.473 (0.011) | 0.524 (0.011) | −28.961 (1.82) | 0.105 (0.01) | |
| intBHM | 0.082 (0.008) | 0.244 (0.005) | 0.258 (0.006) | 36.572 (1.308) | 0.047 (0.007) | |
| BHM2 | 0.262 (0.009) | 0.289 (0.006) | 0.39 (0.007) | 4.13 (0.363) | 0.011 (0.003) | |
| adjBHM2 | 0.187 (0.016) | 0.502 (0.011) | 0.536 (0.012) | −31.819 (2.128) | 0.099 (0.009) | |
| intBHM2 | 0.068 (0.008) | 0.249 (0.006) | 0.258 (0.006) | 36.538 (1.337) | 0.045 (0.007) | |
| sANOVA | 0 (0.012) | 0.38 (0.008) | 0.38 (0.009) | 6.561 (1.922) | 0.006 (0.002) | |
| sANCOVAI | 0.004 (0.019) | 0.607 (0.014) | 0.607 (0.014) | −49.406 (3.271) | 0.101 (0.01) | |
| sANCOVAII | −0.004 (0.008) | 0.261 (0.006) | 0.261 (0.006) | 35.689 (1.581) | 0.055 (0.007) | |
| reANOVA | 0.151 (0.007) | 0.233 (0.005) | 0.278 (0.006) | 31.672 (1.119) | 0.016 (0.004) | |
| reANCOVAI | 0.128 (0.014) | 0.437 (0.01) | 0.455 (0.012) | −12.041 (2.394) | 0.066 (0.008) | |
| reANCOVAII | 0.021 (0.006) | 0.191 (0.004) | 0.192 (0.005) | 52.739 (1.122) | 0 (0) | |
| BHM | 0.282 (0.008) | 0.239 (0.005) | 0.369 (0.006) | — | 0.02 (0.004) | |
| adjBHM | 0.216 (0.013) | 0.4 (0.009) | 0.455 (0.009) | −23.177 (1.47) | 0.111 (0.01) | |
| intBHM | 0.061 (0.007) | 0.21 (0.005) | 0.218 (0.005) | 40.926 (1.213) | 0.054 (0.007) | |
| BHM2 | 0.24 (0.008) | 0.254 (0.006) | 0.349 (0.006) | 5.439 (0.313) | 0.015 (0.004) | |
| adjBHM2 | 0.184 (0.013) | 0.417 (0.009) | 0.456 (0.009) | −23.441 (1.688) | 0.1 (0.009) | |
| intBHM2 | 0.05 (0.007) | 0.212 (0.005) | 0.218 (0.005) | 41.006 (1.244) | 0.055 (0.007) | |
| sANOVA | 0.019 (0.009) | 0.297 (0.007) | 0.297 (0.007) | 19.533 (1.603) | 0.002 (0.001) | |
| sANCOVAI | 0.04 (0.015) | 0.47 (0.011) | 0.471 (0.011) | −27.673 (2.646) | 0.081 (0.009) | |
| sANCOVAII | −0.003 (0.007) | 0.215 (0.005) | 0.215 (0.005) | 41.782 (1.404) | 0.056 (0.007) | |
| reANOVA | 0.12 (0.007) | 0.224 (0.005) | 0.254 (0.006) | 31.088 (1.052) | 0.014 (0.004) | |
| reANCOVAI | 0.11 (0.012) | 0.384 (0.009) | 0.399 (0.009) | −8.17 (1.896) | 0.059 (0.007) | |
| reANCOVAII | 0.015 (0.006) | 0.176 (0.004) | 0.177 (0.004) | 52.1 (1.166) | 0 (0) | |
| BHM | −0.165 (0.006) | 0.204 (0.005) | 0.263 (0.005) | — | 0.813 (0.012) | |
| adjBHM | −0.126 (0.011) | 0.352 (0.008) | 0.374 (0.008) | −42.426 (1.829) | 0.766 (0.013) | |
| intBHM | −0.041 (0.006) | 0.176 (0.004) | 0.18 (0.004) | 31.401 (1.536) | 1 (0) | |
| BHM2 | −0.14 (0.007) | 0.216 (0.005) | 0.257 (0.005) | 1.99 (0.309) | 0.807 (0.012) | |
| adjBHM2 | −0.106 (0.012) | 0.366 (0.008) | 0.381 (0.009) | −44.894 (2.055) | 0.765 (0.013) | |
| intBHM2 | −0.033 (0.006) | 0.177 (0.004) | 0.18 (0.004) | 31.376 (1.572) | 1 (0) | |
| sANOVA | −0.005 (0.008) | 0.261 (0.006) | 0.261 (0.006) | 0.651 (1.734) | 0.764 (0.013) | |
| sANCOVAI | −0.016 (0.013) | 0.416 (0.009) | 0.416 (0.009) | −58.541 (2.995) | 0.742 (0.014) | |
| sANCOVAII | 0.003 (0.006) | 0.182 (0.004) | 0.182 (0.004) | 30.758 (1.745) | 1 (0) | |
| reANOVA | −0.076 (0.006) | 0.177 (0.004) | 0.192 (0.004) | 26.872 (1.184) | 0.119 (0.01) | |
| reANCOVAI | −0.067 (0.01) | 0.324 (0.007) | 0.331 (0.009) | −25.881 (2.346) | 0.189 (0.012) | |
| reANCOVAII | −0.01 (0.005) | 0.144 (0.003) | 0.145 (0.003) | 44.903 (1.397) | 0.074 (0.008) | |
| BHM | −0.148 (0.006) | 0.186 (0.004) | 0.238 (0.005) | — | 0.924 (0.008) | |
| adjBHM | −0.104 (0.01) | 0.316 (0.007) | 0.333 (0.007) | −39.682 (1.902) | 0.855 (0.011) | |
| intBHM | −0.034 (0.005) | 0.158 (0.004) | 0.161 (0.004) | 32.317 (1.488) | 1 (0) | |
| BHM2 | −0.125 (0.006) | 0.194 (0.004) | 0.23 (0.005) | 3.181 (0.329) | 0.925 (0.008) | |
| adjBHM2 | −0.086 (0.01) | 0.325 (0.007) | 0.336 (0.008) | −40.997 (2.116) | 0.857 (0.011) | |
| intBHM2 | −0.027 (0.005) | 0.159 (0.004) | 0.161 (0.004) | 32.278 (1.517) | 1 (0) | |
| sANOVA | 0.001 (0.007) | 0.221 (0.005) | 0.221 (0.005) | 7.035 (1.72) | 0.908 (0.009) | |
| sANCOVAI | −0.001 (0.011) | 0.356 (0.008) | 0.356 (0.008) | −49.518 (3.024) | 0.85 (0.011) | |
| sANCOVAII | 0.002 (0.005) | 0.161 (0.004) | 0.161 (0.004) | 32.277 (1.675) | 1 (0) | |
| reANOVA | −0.064 (0.006) | 0.174 (0.004) | 0.185 (0.004) | 22.22 (1.153) | 0.134 (0.011) | |
| reANCOVAI | −0.051 (0.009) | 0.3 (0.007) | 0.304 (0.007) | −27.632 (2.196) | 0.195 (0.013) | |
| reANCOVAII | −0.007 (0.004) | 0.134 (0.003) | 0.135 (0.003) | 43.443 (1.376) | 0.073 (0.008) |
| Estimate | Standard error (SE) | Credible interval | SE reduction (%) | ||
|---|---|---|---|---|---|
| BHM | 0.355 | 0.935 | — | ||
| adjBHM | 0.876 | 0.300 | [0.303, 1.468] | 67.938 | |
| intBHM | 0.884 | 0.313 | [0.284, 1.506] | 66.485 | |
| BHM | −1.626 | 1.184 | — | ||
| adjBHM | 0.811 | 0.363 | [0.067, 1.514] | 69.322 | |
| intBHM | 0.805 | 0.373 | [0.060, 1.521] | 68.508 |
- —Tsinghua Scholarship for Overseas Graduate Studies
- —Medical Research Council10.13039/501100000265
- —Cancer Research UK10.13039/501100000289
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods in Clinical Trials · Statistical Methods and Bayesian Inference · Statistical Methods and Inference
Introduction
1
In recent years, precision medicine has received considerable attention [1, 2, 3]. Particularly in oncology, treatments can be tailored to a patient's biomarkers (e.g., genetic mutations), rather than being solely guided by the tumor's tissue location. This tailored approach to treatment is referred to as ‘targeted therapy’, designed to inhibit the growth of cells that have a particular mutation [4, 5]. The evolution in anti‐cancer treatment has further led to the development of advanced designs and analysis strategies for clinical trials that involve a heterogeneous patient population.
One innovative method for evaluating targeted therapies is known as basket trials. Briefly, basket trials are a well‐used type of master protocol trial [6] designed to test a single targeted therapy across multiple diseases, whilst patients share the common molecular target [7, 8]. A pioneering example of basket trials is the phase II study evaluating vemurafenib in multiple nonmelanoma cancers with BRAF V600 mutations [9]. In this study, 122 cancer patients carrying BRAF V600 mutation were enrolled in six prespecified cancer cohorts and a seventh cohort with all other tumor types. Trial subsets (‘subtrials’ for short) are thus defined with respect to the disease subtypes, such as non‐small‐cell lung cancer, anaplastic thyroid cancer, etc.
Through basket trials, investigators aim not only to assess whether a drug is an effective biomarker‐targeted therapy but also to identify which tumor types are sensitive to the drug [10]. This motivates us to consider both overall efficacy and subtrial‐specific efficacy. Hobbs et al. [11] reviewed 13 pivotal basket trials in oncology and found that the primary analysis pooled data across histologies to evaluate an overall efficacy in seven studies, whereas the remaining six were designed for histology‐specific analyses. In practice, the choice of estimand is not universal and should be determined on a case‐by‐case basis. For example, not all basket trials are suited to targeting overall efficacy; an effective therapy may be deemed ineffective if one or more ineffective histologies are imbalanced in enrollment [10, 11]. Consequently, at the stage of planning basket trials, investigators generally need to consider whether the drug works in most or all subtrials, which leads to different strategies for the design and analysis. Therefore, to maximize applicability across basket trial settings, we focus on subtrial/histology‐specific treatment effects, and we also show in the Appendix that our method can be applied to estimate an overall efficacy in basket trials demonstrating homogeneous treatment effects.
Compared with conducting separate trials for various disease subtypes, basket trials are more efficient in terms of accelerated enrollment and simultaneous evaluation in one study under an overarching trial infrastructure. To acknowledge the commonality shared across subtrials (e.g., same genomic mutation), statistical modelling strategies that allow information borrowing for estimating the subtrial‐specific treatment effects are typically preferred over the approach of no borrowing (referred to as “stand‐alone analysis” below). However, one needs to be cautious about the degree of borrowing in the presence of high heterogeneity of treatment effects across disease subtypes. For instance, it has been observed that V600E BRAF‐mutant melanoma and hairy cell leukemia respond positively to BRAF inhibition, whereas colon tumors with the same BRAF mutation do not [7, 9, 12, 13, 14]. This poses challenges to perform information borrowing to an appropriate extent, which should ideally be determined by the level of heterogeneity.
The statistical literature on carefully handling heterogeneity in the analysis of basket trials is extensive, in both frequentist and Bayesian frameworks. Early proposals mainly concern stand‐alone analyses, that is, to estimate the treatment effects independently for each disease type [15]. While heterogeneity can be fully accounted for, this approach is limited by the small sample size of subtrials and inevitably leads to low‐powered tests. More recent proposals include the so‐called “test‐then‐pool” solution [10, 16, 17, 18], which proceeds with pooling only subtrials that have passed a homogeneity test. Such frameworks, nevertheless, can be prone to the risk of misclassification, and pooling heterogeneous subtrials can lead to biased estimation.
In contrast, Bayesian hierarchical models (BHMs) are advantageous, well‐studied, and widely utilized for information borrowing. In particular, BHMs permit information borrowing through the population parameters; specifically, the population variance captures the between‐subtrial heterogeneity. Thall et al. [19] proposed using BHMs to analyze Phase II clinical trials involving multiple diseases. Berry et al. [20] applied this approach to basket trials based on the assumption of exchangeability, which suggests that there is no prior evidence indicating a superior treatment effect in certain tumor types compared to others. Some research has relaxed this assumption by allowing the possibility of non‐exchangeability [21], employing mixtures of several BHMs [22, 23, 24], and utilizing clustering techniques [25, 26, 27]. Additional extensions—such as calibrated BHM [28], BHM with correlated priors [29], and BHM with commensurate priors [30]—have further generalized BHMs for information borrowing. To address the possibility that the model can be misspecified, Bayesian model averaging methods have been developed [31, 32, 33, 34]. Candidate models that capture the underlying heterogeneity among tumor types are associated with weights for averaging. To the best of our knowledge, however, little attention has been given to explicitly incorporating covariate information that may contribute to the heterogeneity of treatment effects besides tumor (sub)types (the subgroups indicator).
Covariate adjustment using generalized linear models is widely accepted and guided by industry standards as outlined in ICH E9 and the FDA guidance [35, 36], although these guidelines do not specifically address the application in Bayesian frameworks. Covariates typically include both predictive and prognostic factors. Prognostic factors can only affect outcomes, while predictive factors can affect both the outcomes and treatment effects. The FDA guidance notes that “incorporating prognostic baseline factors in the analysis of clinical trial data can result in a more efficient use of data to demonstrate and quantify the effects of treatment with minimal impact on bias or the Type I error rate”, which emphasizes the benefit of covariate adjustment on estimation precision (the variance of the estimator, also known as estimation efficiency). Among methods for covariate adjustment in randomized clinical trials, the analysis of covariance (ANCOVA) without or with treatment‐by‐covariate interaction terms (referred to below as “ANCOVA I” and “ANCOVA II”, respectively) has been extensively studied [37, 38, 39, 40]. The advantages of ANCOVA I and II in studies with simple randomization have been demonstrated [37]. In our review of the literature, ANCOVA I (without treatment‐by‐covariate interaction terms) is more frequently applied than ANCOVA II (with interaction terms) for clinical trials drawing inferences in a Bayesian framework [30, 41, 42, 43, 44]. This has motivated us to revisit this topic. Specifically, it remains unclear if excluding treatment‐by‐covariate interaction terms would result in a loss in precision under BHMs, as was demonstrated from the frequentist perspective [37, 39, 45].
The rest of the paper is organized as follows. Section 2 introduces three data models (i.e., one unadjusted model and two covariate‐adjusted models), followed by a common parameter model, to form BHMs for borrowing of information in basket trials. Section 3 describes a simulation study to evaluate the performance of different methods, including BHMs and frequentist ANCOVA models. Section 4 applies the methods to hypothetical data simulated based on the MAJIC study. Section 5 concludes the paper with a discussion about future research avenues.
Methods
2
Consider a basket trial with K subtrials. Let θk denote the average treatment effect and nk the sample size specific to each subtrial k=1,…,K. Throughout this paper, we consider a randomized controlled setting where the nk patients are randomly assigned between a new treatment and control within each subtrial, with n1k patients in the treatment group and n0k patients in the control group. That is, nk=n1k+n0k. The treatment arms, as well as the randomization ratio (denoted by n1k:n0k), are kept the same across subtrials. For patient i=1,…,nk within subtrial k, let Tik denote the treatment assignment indicator, with Tik=1 representing the treatment and Tik=0 representing the control. Let Yik denote the continuous outcome of interest and Xik the pretreatment (baseline) covariates.
Data Models: Unadjusted, ANCOVA I and ANCOVA II
2.1
To start with, we describe an unadjusted data model that does not consider the covariate information. Assume the relationship between outcome, denoted by Yik, and the treatment, denoted by Tik, can be characterized by a normal linear regression model
where αk is the intercept and θk is the treatment effect parameter of subtrial k. Here, we consider a continuous outcome, but this modelling assumption is not restrictive in the sense that other data types can be covered through the use of a generalized linear model. With an unadjusted analysis strategy,
for each subtrial k=1,…,K.
As noted, baseline covariates can influence the outcome and the treatment effect. Adjusting for the imbalance of covariates in the analysis of randomized trials potentially decreases the asymptotic variance of treatment effect estimators. Basket trials consist of K subtrials, with each implementing a simple randomization mechanism, that is, complete randomization at a fixed ratio. It is hence intuitively appealing to extend the covariate adjustment methods, devised for a homogeneous population with a simple randomization mechanism, to basket trials to improve the estimation efficiency, and accordingly to reduce the asymptotic variance of the estimator.
ANCOVA has been well‐studied for simple randomization under both the super‐population framework and the finite‐population framework [37, 39, 45]. The former concerns the randomness of random sampling and random treatment assignment, while the latter considers random treatment assignment alone. In brief, ANCOVA is divided into two cases: ANCOVA I models regress the outcome on the treatment indicator and covariates to adjust the effect of covariates on the outcome; ANCOVA II models build on the ANCOVA I model to further include interaction terms of the treatment and the covariates, which further adjust the effect of covariates. In a homogeneous population with a simple randomization mechanism, Yang and Tsiatis [37] compared ANCOVA I, ANCOVA II, and the unadjusted method, concluding that:
- ANCOVA II is the most efficient among these three methods;
- Under equal allocation, ANCOVA I is as efficient as ANCOVA II;
- ANCOVA I cannot guarantee efficiency gains compared with the unadjusted method.
For basket trials that involve several subpopulations, we consider two data models extended from ANCOVA I and ANCOVA II, respectively. Note that θk refers to a subtrial‐specific treatment effect. The purpose of covariate adjustment is to adjust for predictive factors within each subtrial, other than for tumor types that define the subtrials.
We first consider the ANCOVA I model, assuming that (prognostic) covariates can affect outcomes while not affecting treatment effects:
where αk is the intercept, θk is the treatment effect, and βk is the effect of covariates on the outcome of subtrial k. For each subtrial k, we have
For the ANCOVA II model, we assume that the (predictive) covariates can affect both outcomes and treatment effects:
where αk is the intercept, θk is the treatment effect parameter, βk is the effect of covariates on the outcome, and γk is the effect of covariates on the treatment effect of subtrial k. For each subtrial k, we have
Note that we need to assume the subtrial‐specific means of covariates equal 0, that is, E(Xik)=X‾k=0 for each k. If this is not met by default, one can use Xik−X‾k for standardization to center around 0 in the data analysis. Otherwise, θk is no longer the subtrial‐specific average treatment effect.
Parameter Model: Borrowing of Information Across Subtrials
2.2
Following Thall et al. [19], we fit a BHM to estimate the subtrial‐specific treatment effects, θ=(θ1,…,θK), by including a parameter model as follows:
where μθ and σθ2 are the unknown population mean and variance. Specifically, μθ influences the locations of the subtrial‐specific treatment effects, and σθ represents the level of heterogeneity between subtrials. Borrowing of information is permitted through an underlying distribution, from which values for σθ are drawn. Here, we have placed a HT(σHT,d) prior on σθ, which denotes a half‐t distribution. That is, a generalized t distribution with a location parameter of 0, a scale parameter of σHT, and d degrees of freedom, truncated to take positive numbers only. The parameter σHT controls the degree of borrowing: the higher the value of σHT, the less information is borrowed between subtrials. For implementation, the hyperparameters, μ,σ,σHT,d, are prespecified. Alternatively, an inverse‐Gamma or Uniform prior can be specified for σθ. Here, we choose a heavily‐tailed half‐t prior, as it is less sensitive to the hyperparameters, based on the simulation results in Cunanan et al. [46]. We refer the interested reader to Gelman [47] and Cunanan et al. [46] for general recommendations on priors for variance parameters.
This parameter model (4) coupled with each of the three data models outlined in Section 2.1, results in three hierarchical models to estimate the substrial‐specific treatment effects θ. To complete the BHMs, we specify priors for the other parameters. Specifically, αk,βk,γk each follow a normal prior, and σy2, the variance of the outcome, follows an inverse‐Gamma prior. Hereafter, we refer to these three hierarchical Bayesian ANCOVA methods as unadjusted BHM (BHM), adjusted BHM without interaction (adjBHM), and adjusted BHM with interaction (intBHM), respectively. A recap of the three BHMs considered is provided in Table 1. We fit the BHMs using Markov chain Monte Carlo (MCMC) to draw samples from the posterior distributions, and then estimate the subtrial‐specific treatment effects θ.
Simulation Study
3
In this section, we conduct a simulation study to evaluate the performance of unadjusted BHM, adjBHM, and intBHM, and two classes of frequentist methods, stratified AN(C)OVAs and random‐effect AN(C)OVAs, in analyzing basket trials with K=4 subtrials.
Design of the Simulation Study
3.1
Aims
3.1.1
We aim to compare the performance of covariate‐adjusted with unadjusted BHM as well as Bayesian with frequentist methods, considering the impact of correctly specified or mis‐specified data‐generating models, different sample sizes, and different treatment allocation ratios.
Data‐Generating Mechanisms
3.1.2
We consider four data‐generating mechanisms. For all, we consider basket trials with K=4 subtrials. The sample size ratio of different subtrials is n1:n2:n3:n4=2:3:4:5. A range of different sample sizes are set for the numerical evaluation so that the total sample size, n=∑k=1Knk, ranges from 56 to 560 in increments of 56. The ratio 2:3:4:5 is motivated by the practical consideration that basket trials often have a varying number of patients involved. We let the heterogenous treatment effects θ=(0,0,1,1) (with a homogeneous scenario with θ=(1,1,1,1) analyzed in Appendix B), and one‐dimensional pretreatment covariate, Xik∼i.i.d.N(0,1),∀k=1,…,4.
We generate the outcomes from using the following three models:
- Yik=1+θkTik−2Xik+4TikXik+ϵik,
- Yik=1+θkTik−2Xik+ϵik,
- Yik=1+θkTik−2Xik+TikXik3+ϵik,
where ϵik are i.i.d. standard normal random noise. Scenario (1) is correctly specified for ANCOVA II but mis‐specified for ANCOVA I, scenario (2) is correctly specified for ANCOVA I and the degenerate ANCOVA II with γk=0, even if ANCOVA II requires estimating one more parameter γk, and scenario (3) is mis‐specified for all of the methods. We consider the most commonly used randomization ratio of 1:1 for each of the K subtrials, that is, a 1:1 allocation of treatment:control; equivalently, n1k/nk=0.5 where n1k denotes the number of patients allocated to the treatment. In order to study whether unequal allocation ratios would affect the consistency of the conclusions, in scenario (1), we also consider a 3:1 allocation of treatment:control, that is, n1k/nk=0.75 for all the subtrials.
Estimands
3.1.3
Our estimands are subtrial‐specific treatment effects θk.
Methods
3.1.4
Each of the three BHMs three stratified AN(C)OVA models, and three random‐effect AN(C)OVA models, is fitted to the simulated trial data to compare the performance of different methods. The specification of different models and their abbreviations are summarized in Table 2.
As noted earlier, we use cluster‐centered covariates Xik−X‾k to perform covariate adjustment. For Bayesian methods, we set an inverse−Gamma(2,20) prior on the variance of the outcome, a N(0,100) prior on μθ, αk, βk, γk, and a HT(2,5) or a HT(100,5) weak prior on σθ. For Bayesian methods, we apply MCMC using a burn‐in of 2000 with a chain of length 10 000 to sample the posteriors and use posterior means with 95% credible intervals symmetric about the posterior mean, to estimate θk. For stratified AN(C)OVA models, we fit linear regression data models in Section 2.1 separately within each subtrial to estimate subtrial‐specific treatment effects. For random‐effect AN(C)OVA models, in the random effect part, we include random intercept and random slope of Tik. In the fixed effect part, the random‐effect ANOVA model (reANOVA) includes treatment only, random‐effect ANCOVA I model (reANCOVAI) additionally includes covariates‐by‐subtrial interaction term, and the random‐effect ANCOVA II model (reANCOVAII) further includes treatment‐by‐covariates‐by‐subtrial interaction term.
Performance Measures
3.1.5
We simulate B=1000 replicates of basket trials following the configuration above to generate the trial data. We compare the performance of these models in terms of the following metrics:
- bias, defined as the absolute difference between the mean of the empirical distribution of θk estimates and the true value used for simulating the data,
- standard deviation (SD), defined as the standard deviation of the estimates for θk,
- root mean squared error (RMSE) of the estimates for θk,
- RMSE reduction with respect to the unadjusted BHM,
- marginal rejection rate, defined as the proportion of simulated (sub)trials rejecting the null hypothesis H0k:θk=0 for each k, that is, where the posterior credible interval or confidence interval does not include the null value,
- family‐wise type I error rate, defined as the empirical probability of rejecting H01 or H02,
- disjunctive power, defined as the proportion of simulated (sub)trials rejecting H03 or H04.
The definitions, estimates, and Monte Carlo standard errors (MCSEs) for various performance metrics, such as bias, SD, RMSE, RMSE reduction for method 2 versus method 1, and marginal rejection rate, are provided in Table 3. To further clarify whether the observed differences in simulation performance stem from methodological differences or simulation error, we also report the MCSE for each of the performance metrics.
Exploration and Visualization of Results
3.2
Results of Scenario (1) With n1k/nk=0.75
3.2.1
Results of scenario (1) with n1k/nk=0.75 are shown in Figure 1 and Table 4. Note that only seven methods (BHM, adjBHM, intBHM, sANCOVAI, sANCOVAII, reANCOVAI, reANCOVAII) are included in the figure to maintain differentiation between the curves and the readability of the plots. From Figure 1a and Table 4, we observe that for large sample sizes, in terms of the bias of the estimators of θk, only stratified AN(C)OVAs have negligible biases in accordance with their theoretical unbiasedness. Except for stratified AN(C)OVAs, all the BHMs and random‐effect AN(C)OVAs have obvious bias; however, these biases can be almost entirely eliminated by using covariate adjustment with an interaction term because of correct specification. For BHMs, a weaker prior of σθ in this heterogenous scenario can help to reduce bias. Second, in terms of SD and RMSE, compared with unadjusted methods, all the covariate adjustments with the interaction term perform better, whereas covariate adjustment without the interaction term performs worse. For example, compared with unadjusted BHM, intBHM reduces the RMSE by 31%–41%, while adjBHM increases the RMSE by 23%–44%. Third, in terms of the marginal rejection rate, unadjusted methods and covariate‐adjusted methods with an interaction term can control the marginal type I error rate at 5% while covariate‐adjusted methods without an interaction term do not. For subtrials k=3 and 4, intBHM has the largest marginal power, whereas random‐effect methods lose power because of the violation of the normality assumption given the small number of subtrials.
Simulation results of the different estimators under scenario (1) with n1k/nk=0.75. The dashed horizontal lines in Panel (b) represent the 9.75% level of (family‐wise) type I error rate and 80% (disjunctive) power, respectively. Only seven methods (BHM, adjBHM, intBHM, sANCOVAI, sANCOVAII, reANCOVAI, reANCOVAII) are included in this figure.
When the total sample size varies from 56 to 560, the performance of these estimators is compared in Figure 1b. We can draw the following conclusions. First, only random‐effect AN(C)OVAs have issues of nonconvergence. As the total sample size increases, random‐effect AN(C)OVAs exhibit decreasing probability of nonconvergence. Second, similar to the conclusions for large sample sizes, except for random‐effect AN(C)OVAs, compared with unadjusted BHM, intBHM, and sANCOVAII reduce the RMSE on average, while adjBHM and sANCOVAI do not. As the total sample size increases, intBHM and sANCOVAII have an increasing RMSE reduction while adjBHM and sANCOVAI have a decreasing RMSE increase. In general, BHMs perform similar or better than stratified AN(C)OVAs in terms of RMSE reduction, especially for small total sample sizes. Third, except for adjBHM and sANCOVAI, all other methods control the family‐wise type I error rates at 9.75% accounting for the inflation due to multiple evaluations, computed as 1−(1−0.05)2, given that the individual null hypothesis type I error rate is controlled at 5%. Moreover, the family‐wise error rate becomes stable as the sample size increases. Finally, in terms of disjunctive power, it increases with the sample size for all the models except for random‐effect AN(C)OVAs, and ANCOVA II (intBHM and sANCOVAII) has the largest power, which is particularly noticeable for smaller total sample sizes.
Results of Scenario (1) With n1k/nk=0.5
3.2.2
Given the results of Yang and Tsiatis [37], it is of interest to understand the efficiency of the Bayesian estimators under equal allocation, which is widely used in clinical trials.
Results under scenario (1) with n1k/nk=0.5 are shown in Figure 2, Table A1 and Figure A1 in Appendix A. Similarly to the results for n1k/nk=0.75, we observe that ANCOVA II has the smaller bias and smaller RMSE compared with unadjusted methods and ANCOVA I for BHMs and reAN(C)OVAs. For example, for large sample sizes, intBHM can reduce the RMSE values by 21%–35% compared with unadjusted BHM. Besides, intBHM also has the largest marginal power with a marginal type I error rate controlled at 5%. In addition, focusing on Bayesian estimators, adjBHM gives very similar posteriors, as well as the quantified RMSE, type I error rate, and power, to unadjusted BHM. This is because both adjBHM and the unadjusted BHM are mis‐specified models under scenario (1). In particular, even if unadjusted BHM and adjBHM have a smaller SD compared with intBHM, intBHM still has the smallest RMSE. The decrease of RMSE for intBHM is largely driven by the decrease in bias, which is benefiting from the correct specification of the true model.
Performance of different estimators under scenario (1) with n1k/nk=0.5, where the total sample size varies. The dashed horizontal lines represent the 9.75% level of (family‐wise) type I error rate and 80% (disjunctive) power, respectively. Only seven methods (BHM, adjBHM, intBHM, sANCOVAI, sANCOVAII, reANCOVAI, reANCOVAII) are included in this figure.
Results of Scenario (2) With n1k/nk=0.5
3.2.3
The true model in scenario (2) is correctly specified for ANCOVA I (adjBHM, sANCOVAI, reANCOVAI) and ANCOVA II (intBHM, sANCOVAII, reANCOVAII), even if ANCOVA II requires estimating one more parameter γk. Results of scenario (2) with n1k/nk=0.5 are shown in Figure 3, Table A2 and Figure A2 in Appendix A. From these figures and tables, we can see that all the ANCOVA I methods and ANCOVA II methods perform very similarly. Compared with unadjusted methods, they have smaller bias and smaller SD. The RMSE is reduced by around 50%. Besides, covariate‐adjusted BHMs have smaller RMSE and family‐wise type I error rate, although also having lower power, than stratified ANCOVAs for small total sample sizes.
Performance of different estimators under scenario (2) with n1k/nk=0.5, where the total sample size varies. The dashed horizontal lines represent the 9.75% level of (family‐wise) type I error rate and 80% (disjunctive) power, respectively. Only seven methods (BHM, adjBHM, intBHM, sANCOVAI, sANCOVAII, reANCOVAI, reANCOVAII) are included in this figure.
Results of Scenario (3) With n1k/nk=0.5
3.2.4
The true model in scenario (3) is mis‐specified for all of the methods. Results of scenario (3) with n1k/nk=0.5 are shown in Figure 4, Table A3 and Figure A3 in Appendix A. First, ANCOVA I and II perform very similar to unadjusted methods in terms of bias, SD, and RMSE. Second, from Table A3 we can see that when θ1=0, all methods control the marginal type I error rate below 5%. However, when θ2=0, there is type I error rate inflation for Bayesian methods. This may be due to a larger sample size in the second subtrial (n2=120). From Figure 4 we can see that the (family‐wise) type I error rate increases with the total trial sample size. The larger sample size can lead to stronger evidence that might not be consistent with what the half‐t prior implies. In other words, under a larger sample size, potential prior‐data conflict could inflate the type I error rate. In terms of marginal power, intBHM performs the best, followed by adjBHM. We also observe a small yet stable increase of disjunctive power for intBHM in Figure 4.
Performance of different estimators under scenario (3) with n1k/nk=0.5, where the total sample size varies. The dashed horizontal lines represent the 9.75% level of (family‐wise) type I error rate and 80% (disjunctive) power, respectively. Only seven methods (BHM, adjBHM, intBHM, sANCOVAI, sANCOVAII, reANCOVAI, reANCOVAII) are included in this figure.
Summary
3.3
Overall, we can draw the following conclusions based on all the simulation results. The results of comparisons between unadjusted model and ANCOVA I or ANCOVA II models are broadly consistent across classes of methods. Comparing different classes of methods, only stratified AN(C)OVAs exhibit negligible bias, consistent with their theoretical unbiasedness, while random‐effect AN(C)OVAs show nonconvergence, resulting in a loss of power. In addition, compared with stratified AN(C)OVAs, BHMs achieve greater RMSE reduction but lower disjunctive power, particularly when the total sample size is small. This may be because, with small sample sizes, BHMs can be unstable in estimating heterogeneity and between‐subtrial variance, which can introduce bias and reduce the ability to detect signals.
Particularly, focusing on Bayesian methods, first, intBHM always has the smallest bias and largest power, and can always reduce (never increase) the RMSE compared with unadjusted BHM. Second, adjBHM can have good finite sample performance when correctly specified and for small sample sizes. However, in some scenarios, it may perform worse than unadjusted BHM, in terms of RMSE. In fact, motivated by the theoretical result of ANCOVA I in Yang and Tsiatis [37] under a frequentist framework, we do not expect adjBHM to always perform better than unadjusted BHM. In summary, we recommend intBHM, covariate adjustment with an interaction term, as it is robust to model mis‐specification and sample size.
Case Study
4
The MAJIC study (ISRCTN: 61925716) is a phase II randomized controlled basket trial designed to assess the long‐term comparative safety and efficacy of Ruxolitinib versus Best Available Therapy (BAT) in patients with Polycythaemia Vera (PV) or Essential Thrombocythaemia (ET), who meet the criteria for resistance or intolerance to Hydroxycarbamide therapy. For simplicity, we refer to the two subtrials as PV and ET. The JAK1/2 inhibitor Ruxolitinib, which targets Janus‐associated kinases (JAKs), specifically JAK1 and JAK2, may alleviate symptoms in patients with Polycythaemia Vera (PV) driven by JAK2 mutations, as well as in patients with Essential Thrombocythaemia (ET), whose mutations result in increased JAK2 signaling. In the PV subtrial, n1=180 patients were randomly assigned to the Ruxolitinib treatment group (n11=93) and BAT control group (n01=87). Similarly, in the ET subtrial, n2=110 patients were randomly assigned to the Ruxolitinib treatment group (n12=58) and BAT control group (n02=52). The primary outcome was the achievement of complete response (CR), as defined by European LeukemiaNet (ELN) criteria, within one year.
We generated hypothetical data that mimics the characteristics and the structure of the original trial, as reported in the trial results publications [48, 49]. We first randomly assign treatments and sample baseline covariates from either a normal distribution or a Bernoulli distribution, with parameters informed by Table 1 (Baseline Features at Study Entry) in Harrison et al. [49] and Table 1 (Baseline characteristics by treatment) in Harrison et al. [48]. Both Harrison et al. [49] and Harrison et al. [48] fitted multivariable logistic regression models to evaluate the effects of treatment and baseline covariates on the primary outcome. Using these results, linear models ((C1), (C2)), as detailed in Appendix C, were used to generate the continuous log‐odds ratios for PV and ET, with a signal‐to‐noise ratio of 10. The coefficients of the linear models are derived from the multivariable logistic regression results reported in Harrison et al. [49] and Harrison et al. [48].
We denote the log‐odds ratio as the continuous outcome of interest by Yik. The covariate‐adjusted estimators were obtained by including three covariates: namely, sex, JAK2V617F mutation status, and baseline haemoglobin. The parameters of interest, θPV and θET, represent the average treatment effects of Ruxolitinib versus BAT on the log‐odds ratio in the PV and ET subtrials, respectively. The data models and parameter models in BHM are multivariable extensions of the models described in Sections 2.1 and 2.2, see Equation (C3) and (C4) in the Appendix. We perform MCMC sampling using a burn‐in of 2000 with a chain of length 10 000 to sample the posteriors. The posterior means are used as point estimates, the posterior standard deviations as standard errors, and 95% credible intervals are also obtained. The results are presented in Figure 5 and Table 5.
Empirical distribution of posterior samples of θPV and θET in the analysis of a hypothetical data generated based on the MAJIC study.
The credible intervals for both θPV and θET using unadjusted BHM contain zero. In contrast, the credible intervals obtained from covariate‐adjusted methods indicate positive effects of ruxolitinib versus BAT in both PV and ET subtrials, demonstrating the superiority of ruxolitinib in achieving CR. Furthermore, compared to the unadjusted BHM, the covariate‐adjusted methods reduce the standard error by 66.5%–69.3%. The two covariate‐adjusted methods perform very similarly because all covariates included are prognostic factors rather than predictive factors. Additionally, we applied the same multivariable logistic regression methods (including the same three covariates as in the Bayesian analyses) used by Harrison et al. [48] and Harrison et al. [49] to analyze this hypothetical data. The estimates of θPV and θET are 0.739 (95% CI: [0.201,1.278]) and 2.433 (95% CI: [0.512,4.353]), respectively. These results support positive effects of ruxolitinib versus BAT in both the PV and ET subtrials, consistent with the covariate‐adjusted BHMs. Specifically, the PV result is similar to that from the covariate‐adjusted BHMs, whereas the ET result shows a noticeably larger point estimate and a wider confidence interval. This is expected because this analysis is stand‐alone and the ET subtrial has a relatively small sample size.
To assess the robustness of the proposed methods, we also use CR as the outcome of interest, sampled from a Bernoulli distribution with log‐odds ratio generated by Equations (C1) and (C2). The parameter models (Equation C4) in the BHM are multivariable extensions of the models outlined in Section 2.2. We consider two types of data models: the normal multivariable linear regression models (Equation C3), and the Bernoulli multivariable logistic regression models (Equation D1), see the Appendix. The covariate‐adjusted methods using normal multivariable linear regression models yield similar results. However, those using Bernoulli multivariable logistic regression models exhibit nonconvergence of the model fitting algorithm of the logistic regression due to 0‐1 separation [50]. Detailed results are provided in Appendices C and D.
Discussion
5
Covariate adjustment in clinical trials is widely accepted and guided by industry standards [35, 36]. However, its application is yet to extend to basket trials where borrowing of information is a critical concern. To fill this gap, this paper explored incorporating covariate adjustment into Bayesian models to analyze basket trials for enhanced estimation precision, providing an analogue to the use of covariate adjustment in traditional randomized controlled clinical trials using frequentist methods. In particular, we propose using ANCOVA models as the data model, coupled with a conventional stipulation of parameter model, to form BHMs for borrowing of information and to estimate the treatment effects. Our simulation results demonstrate that intBHM (with treatment‐by‐covariate interaction terms) achieves the best performance in terms of bias, RMSE, and power. It is also shown to be the most robust to model misspecification. Our exploration covers settings of small to large sample sizes. Furthermore, as illustrated in Appendix B, our method is applicable to estimate the overall treatment effect in basket trials with homogenous effects. Moreover, extensive comparison of different prior beliefs is not the scope of this paper but rather to assess impact of covariate adjustment. Use of more informative priors, if not effectively discounted in situations of a prior‐data conflict, may lead to more bias for methods that permit borrowing of information. This can be perceived from comparing results of the evaluated Bayesian models with different priors (including unadjusted BHMs, adjBHMs, and intBHMs) in Table 4. In practice, when analyzing basket trials using covariate‐adjusted methods, in addition to widely recognized considerations such as variable selection and model selection, we must also account for the convergence of the MCMC algorithm. In addition, because most basket trials are currently conducted as nonrandomized (single‐arm) designs, which is recommended in the FDA guidance [8], one may also consider the applicability of our proposed methods to single‐arm basket trials. Specifically, covariate adjustment without an interaction term (ANCOVA I) could be applied to analyze single‐arm basket trials, helping to control measured confounding; however, unmeasured confounding cannot be eliminated without randomization, regardless of the analytic method. Therefore, when using covariate‐adjusted BHM to analyze single‐arm basket trials, one should be cautious about potential bias arising from unmeasured confounding.
Borrowing of information over coefficients for covariates can be a direct extension of the present work. We note advantages and drawbacks of exploiting borrowing of information on both treatment effects and other coefficients need to be adequately explored. Furthermore, extending our methods for covariate adjustment to establish more advanced Bayesian hierarchical parameter models would also be straightforward. Additional desirable properties may be attained by stipulating a parameter model like one of the EXNEX that accommodates non‐exchangeability distributions, [21], the calBHM allowing the population variance to be calibrated [28], or the discrepancy‐based approach to borrowing more strength between subtrials with high similarity than from others [30].
Another avenue of future research would be to incorporate the efficiency brought about by covariate adjustment into the trial planning stage. Explicitly, building upon the sample size determination by Zheng et al. [51], we could develop new sample size formulae for basket trials to take account of prognostic or predictive baseline covariates. Finally, we note that this paper has focused on the methodological setup and numerical simulation studies. Beyond the scope of this work, theoretical study on efficiency gains achieved by covariate‐adjusted BHMs would be among the valuable topics for further investigation.
Author Contributions
Jiyang Ren: methodology, investigation, writing – original draft, writing – review and editing. David S. Robertson: conceptualization, investigation, methodology, writing – original draft, writing – review and editing. Haiyan Zheng: conceptualization, investigation, methodology, writing – original draft, writing – review and editing.
Funding
This work was supported by the Tsinghua Scholarship for Overseas Graduate Studies (Grant No. 2023026), the UK Medical Research Council (Grant Nos. MC_UU_00002/14 and MC_UU_00040/03), and Cancer Research UK (Grant No. RCCCDF‐May24/100001).
Conflicts of Interest
The authors declare no conflicts of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1E. A. Ashley , “Towards Precision Medicine,” Nature Reviews Genetics 17, no. 9 (2016): 507–522.10.1038/nrg.2016.8627528417 · doi ↗ · pubmed ↗
- 2S. E. Jackson and J. D. Chester , “Personalised Cancer Medicine,” International Journal of Cancer 137, no. 2 (2015): 262–266.24789362 10.1002/ijc.28940 · doi ↗ · pubmed ↗
- 3N. J. Schork , “Personalized Medicine: Time for One‐Person Trials,” Nature 520, no. 7549 (2015): 609–611.25925459 10.1038/520609 a · doi ↗ · pubmed ↗
- 4D. M. Hyman , B. S. Taylor , and J. Baselga , “Implementing Genome‐Driven Oncology,” Cell 168, no. 4 (2017): 584–599.28187282 10.1016/j.cell.2016.12.015PMC 5463457 · doi ↗ · pubmed ↗
- 5J. J. Tao , A. M. Schram , and D. M. Hyman , “Basket Studies: Redefining Clinical Trials in the Era of Genome‐Driven Oncology,” Annual Review of Medicine 69, no. 1 (2018): 319–331.10.1146/annurev-med-062016-050343 PMC 745501129120700 · doi ↗ · pubmed ↗
- 6J. Woodcock and L. M. La Vange , “Master Protocols to Study Multiple Therapies, Multiple Diseases, or Both,” New England Journal of Medicine 377, no. 1 (2017): 62–70.28679092 10.1056/NEJ Mra 1510062 · doi ↗ · pubmed ↗
- 7L. Renfro and D. Sargent , “Statistical Controversies in Clinical Research: Basket Trials, Umbrella Trials, and Other Master Protocols: A Review and Examples,” Annals of Oncology 28, no. 1 (2017): 34–43.28177494 10.1093/annonc/mdw 413PMC 5834138 · doi ↗ · pubmed ↗
- 8FDA , “Master Protocols: Efficient Clinical Trial Design Strategies to Expedite Development of Oncology Drugs and Biologics. Guidance for Industry,” 2022.