Target-enhanced double-pulse LIBS coupled with feature-fused CNN for mechanistic and interpretable coffee origin authentication
Xiaoyong He, Kaiqiang Que, Tingrui Liang, Zhenman Gao, Zenghui Wang, Yufeng Li

TL;DR
A new method combining laser spectroscopy and machine learning accurately identifies coffee origins, outperforming traditional techniques.
Contribution
A novel framework integrating potassium-assisted DP-LIBS with a Feature-Fused CNN for interpretable and accurate coffee origin authentication.
Findings
The Feature-Fused CNN achieved 99.00% classification accuracy for coffee origin.
The model retained >94% accuracy under 30 dB SNR, showing strong anti-interference performance.
SHAP and 1D Grad-CAM++ revealed the model's reliance on synergistic trace elements like Fe, Cr, Cu, and K.
Abstract
Coffee geographical origin authentication is critical for mitigating economically motivated adulteration, yet rapid trace-element analysis in complex organic matrices remains a significant challenge. This study establishes a novel synergistic framework integrating Potassium-assisted orthogonal Double-Pulse Laser-Induced Breakdown Spectroscopy (DP-LIBS) with a Feature-Fused CNN for precise coffee traceability. A high-purity KHCO₃ solid target was employed to facilitate plasma cross-coupling and secondary energy injection, significantly enhancing signal sensitivity. Surmounting the inherent bottlenecks of manual feature engineering, a Feature-Fused CNN architecture was constructed by concatenating normalized spectral data with statistical descriptors, enabling the autonomous extraction of hierarchical spatial-spectral patterns. The proposed model achieved a superior classification…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1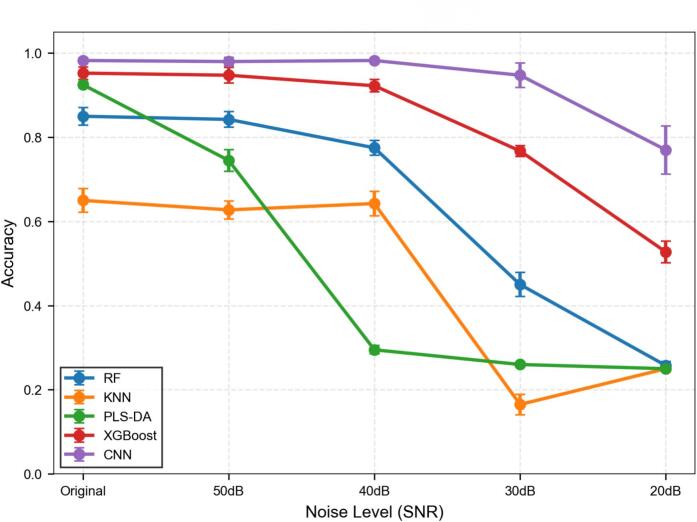 Figure 2
Figure 2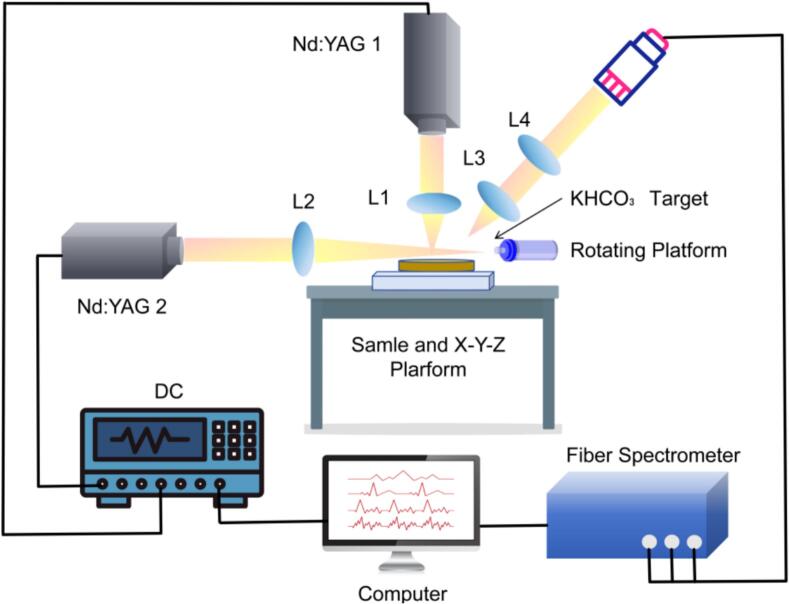 Figure 3
Figure 3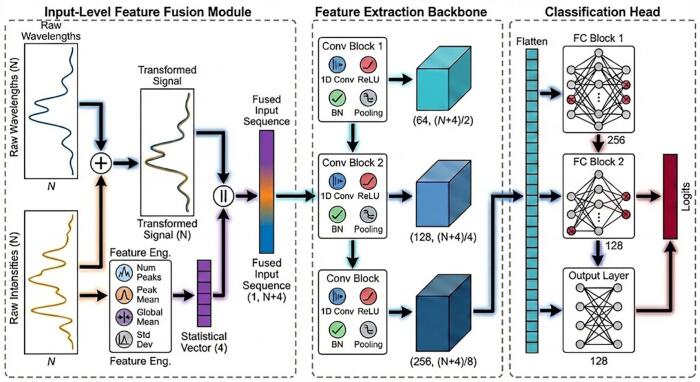 Figure 4
Figure 4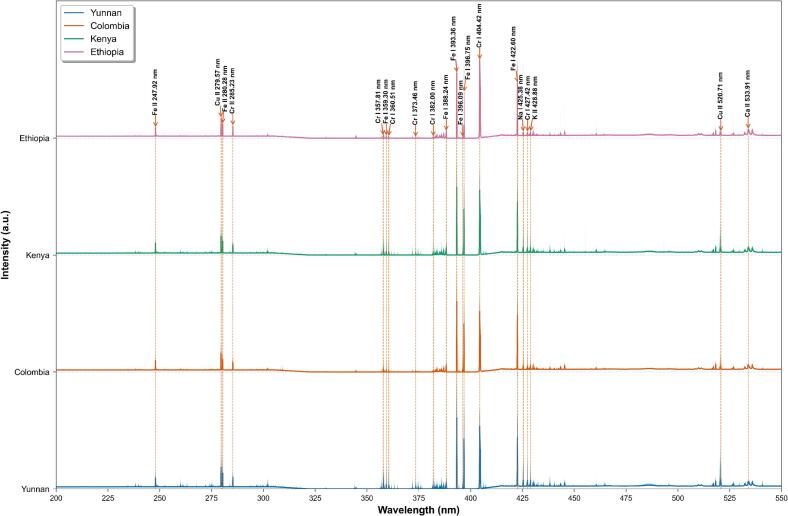 Figure 5
Figure 5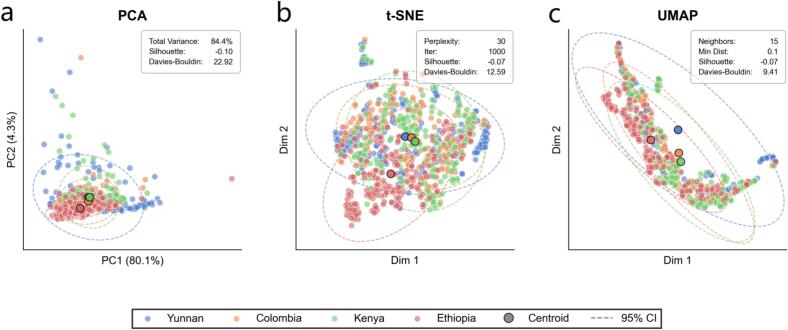 Figure 6
Figure 6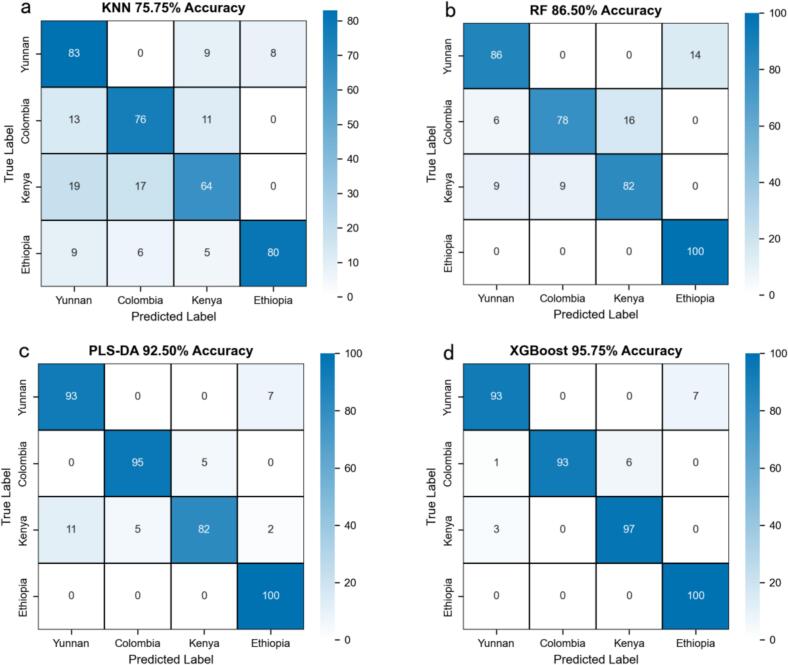 Figure 7
Figure 7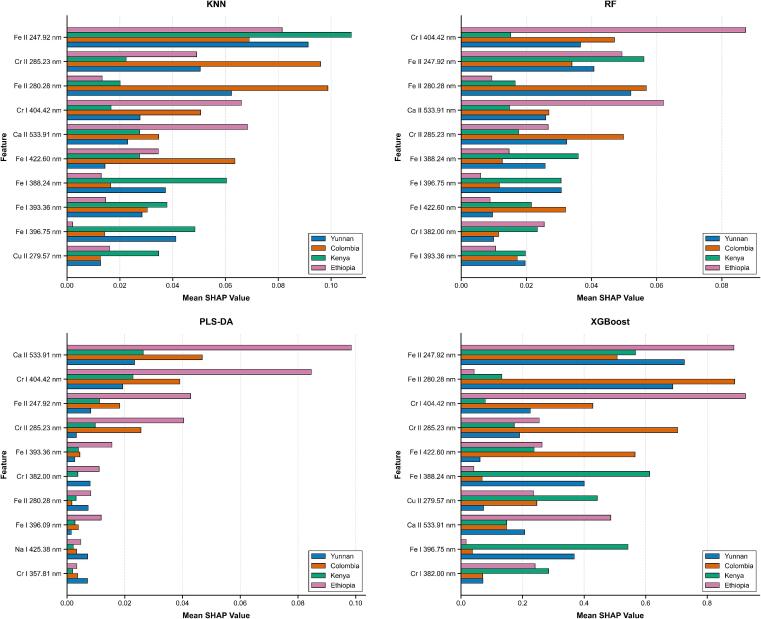 Figure 8
Figure 8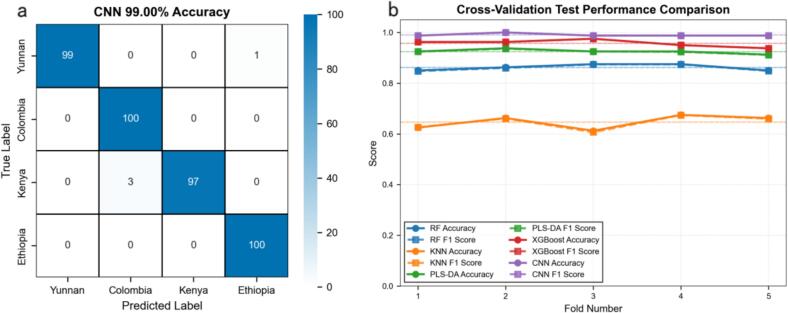 Figure 9
Figure 9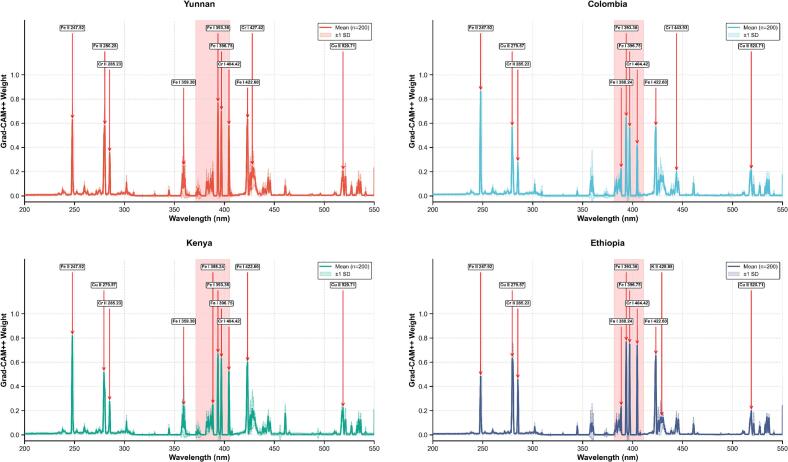 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsLaser-induced spectroscopy and plasma · Spectroscopy and Chemometric Analyses · Melamine detection and toxicity
Introduction
1
Coffee represents a pivotal commodity in global agricultural trade, with its commercial value and organoleptic quality being intrinsically linked to geographical origin(Tieghi et al., 2024). Specifically, Coffea arabica varieties are typically cultivated in high-altitude regions such as the Ethiopian Plateau, the Colombian Andes, and the Yunnan highlands, where environmental conditions favor the accumulation of chlorogenic and citric acids, resulting in characteristic floral and fruity flavor profiles. In contrast, Coffea canephora (Robusta) predominates in low-altitude areas like the Vietnamese Central Plains and Indonesian Java, characterized by higher concentrations of caffeine and trigonelline that contribute to a distinct bitterness (Mendes, Oliveira, Rodarte, Anjos, & Bell, 2024). However, this terroir-driven pricing mechanism is increasingly undermined by economically motivated adulteration, such as the mislabeling of Vietnamese Robusta as Colombian Arabica, which significantly erodes market trust (Mihailova et al., 2022). Although various analytical techniques have been employed to address this challenge, they face inherent limitations: sensory evaluation is prone to subjectivity (Soares, de Alencar, Chiarello, & de Oliveira, 2025); chromatographic and mass spectrometric methods (e.g., GC–MS and LC-MS), despite their precision, require complex and time-consuming sample preparation (Núñez et al., 2025); elemental and isotopic analyses (e.g., ICP-MS) often lack sufficient granularity for fine-scale discrimination (Valentin & Watling, 2013); spectroscopic techniques such as NIR and THz exhibit poor model generalization (Fu, Ren, & Sun, 2024; Mutz et al., 2023); and NMR, while non-destructive, struggles with scalability and high instrumentation costs (Alvarenga et al., 2025).
Laser-Induced Breakdown Spectroscopy (LIBS) has established itself as a premier analytical technique due to its rapid, multi-element detection capabilities and minimal sample preparation requirements (Silva et al., 2017; Silva, Milori, Neto, Ferreira, & Ferreira, 2019). However, conventional single-pulse LIBS (SP-LIBS) often suffers from limited sensitivity, poor limits of detection (LOD), and signal instability caused by matrix effects and plasma shielding (Gautier et al., 2004, Gautier et al., 2005). To address these challenges, Double-Pulse LIBS (DP-LIBS) has been widely adopted as an effective plasma modulation method, significantly enhancing emission intensity through mechanisms such as increased ablated mass, elevated plasma temperature, and elongated plasma lifetime (Noll, Sattmann, Sturm, & Winkelmann, 2004). For instance, Ahmed and Baig achieved a ∼300-fold intensity increase in aluminum alloys using a collinear arrangement (Ahmed & Baig, 2009), while Stratis et al. reported a 30-fold signal enhancement and a 5000 K temperature rise in orthogonal pre-ablation configurations. Furthermore, Wang et al. demonstrated that orthogonal reheating DP-LIBS offers superior stability, reducing the Relative Standard Deviation (RSD) to 2% compared to 5% in SP-LIBS (Wang et al., n.d.). In agricultural and food applications, Nicolodelli et al. utilized DP-LIBS to achieve a 155-fold enhancement for magnesium in fertilizers by increasing the ablated mass (Nicolodelli et al., 2016), and Peng et al. successfully combined reheating DP-LIBS with machine learning for high-accuracy chromium detection in rice leaves (Peng et al., 2019). Despite these advancements, trace element analysis in complex organic matrices like coffee remains challenging due to strong background interference and low ionization efficiency. To overcome this, this study introduces a novel Potassium-assisted orthogonal DP-LIBS system employing a high-purity KHCO₃ solid target. By synchronizing vertical sample ablation with horizontal target excitation to facilitate plasma cross-coupling and secondary energy injection, this method significantly suppresses background noise and enhances trace element sensitivity to the ppb level for precise coffee origin tracing.
Regarding data processing, traditional machine learning methods like KNN and RF are widely used but often struggle with high-dimensional spectral data due to the curse of dimensionality and the loss of local features(Biau, 2012; Boateng, Otoo, & Abaye, 2020). In recent years, the synergistic integration of LIBS with advanced deep learning, multimodal fusion, and explainable artificial intelligence (XAI) has emerged as a frontier research direction in food traceability and environmental monitoring. Recent studies demonstrate the superiority of deep architectures in handling complex matrices. For instance, Iroshan et al. developed the DLIBS-FFNet deep learning framework, which fuses dimensionality-reduced features to achieve superior robustness over traditional methods in the anatomical classification and heavy metal quantification of legumes (Iroshan, Aizezi, & Liu, 2025). Simultaneously, to transcend the limitations of single-source spectral information, Meng et al. proposed a multimodal fusion strategy (LIBS-FLIPA) combining LIBS with laser-induced plasma acoustic signals. By leveraging frame segmentation algorithms to extract complementary features, they significantly enhanced classification accuracy in challenging environments (Meng, Gao, Ye, & Liu, 2025), highlighting the potential of heterogeneous feature fusion. Furthermore, the increasing complexity of models has driven the demand for interpreting “black box” algorithms. Ye et al. successfully constructed a DTEWD-XGBoost-SHAP framework for single-particle aerosol analysis, utilizing SHAP values to quantitatively elucidate the regulatory mechanisms of key chemical components on physical properties (Ye et al., 2025). These advancements underscore the necessity of simultaneously achieving deep feature extraction and model interpretability in high-performance classification tasks.
Consequently, this study establishes a synergistic framework that integrates feature engineering with deep fusion architecture to transcend the performance bottlenecks of conventional methodologies. Specifically, a Feature-Fused CNN model is constructed by concatenating min-max normalized spectral data with four statistical descriptors—peak count, mean peak intensity, mean signal intensity, and standard deviation—into a unified, information-rich input vector. This design enables the autonomous extraction of hierarchical spatial-spectral patterns via convolutional layers, thereby significantly enhancing robustness in coffee authentication. The primary objectives of this research are threefold: (1) developing a KHCO₃-enhanced orthogonal DP-LIBS system with synchronized sample-target motion for augmenting trace-element sensitivity and mitigating background interference; (2) implementing the spectral-statistical feature fusion framework via the Feature-Fused CNN, which is rigorously benchmarked against traditional machine learning models including KNN, RF, PLS-DA, and XGBoost; and (3) elucidating critical spectral markers for geographical authentication through SHAP analysis and Grad-CAM++ visualization, bridging the gap between elemental signatures and soil-climatic factors to provide mechanistic insights into the classification logic.
Materials and methods
2
Sample preparation and data acquisition
2.1
Medium-roasted coffee beans representing four distinct geographical origins—Yunnan, Colombia, Kenya, and Ethiopia—were utilized in this study. Specifically, beans originating from Yunnan and Ethiopia were sourced from Lujiazui Coffee (Baoshan) Co., Ltd.; Colombian beans were purchased from Linyi Chenka Trading Co., Ltd.; and Kenyan beans were obtained from Lipuyao International Trade (Beijing) Co., Ltd. The samples were pulverized using a high-speed multifunctional grinder operating at 35,000 rpm for 2 min. The resulting powder was sieved to pass through a 200-mesh screen and subsequently homogenized. Aliquots of the coffee powder (3.0 g) were compressed into pellets (30 mm diameter; 3.5 mm thickness) under 20 tons of hydraulic pressure. For calibration purposes, KHCO₃ target discs (6.0 g; 30 mm diameter; 4.0 mm thickness) were prepared from analytical-grade powder under identical pressure conditions to ensure surface planarity for optimal laser coupling (Fig. 1). To mitigate hygroscopic effects and ensure chemical stability, all prepared pellets and targets were stored in a desiccator maintained at <10% relative humidity prior to analysis.Fig. 1. Schematic diagram of coffee sample preparation process.Fig. 1
Spectral data acquisition was performed using a target-enhanced orthogonal DP-LIBS system. The first laser pulse (20 mJ) vertically ablated the coffee pellet to generate primary plasma and preheat the sample surface. After a 6 μs delay, the second pulse (60 mJ) horizontally irradiated the KHCO₃ target, exciting potassium-enriched plasma that coupled with the coffee-derived plasma to prolong lifetime and enhance electron-impact excitation efficiency. To ensure homogeneous ablation distribution, the target underwent linear translation at 0.5 mm/s while the coffee pellet rotated at 5 rpm (Fig. 2). Spectrometers were configured with a gate delay of 1.5 μs and gate width of 2 ms. Each spectrum represented an average of five consecutive laser pulses. For each geographical origin, four independent pellets were analyzed, with 50 high-resolution spectra acquired per pellet, yielding a total dataset of 800 independent spectral files. Raw spectral data spanned 200–550 nm, each spectrum comprising 6145 wavelength-intensity data points. All experiments were conducted under controlled environmental conditions (25 ± 1 °C, 50 ± 5% relative humidity). The heavy-metal concentrations presented in Table 1 were validated via ICP-MS to ensure data reliability.Fig. 2. Schematic of the DP-LIBS system.Fig. 2. Table 1Coffee Elemental concentrations (μg/kg).Table 1. Sample NameKenyaEthiopiaColombiaYunnanNa13,421.438167.568481.9011,527.01K11,465,852.2617,195,739.5912,627,503.0115,561,426.92Ca344,222.74532,753.06357,557.97505,804.29Cr372.9193.54209.15118.12Mn38,195.7451,395.2814,992.8178,978.92Fe23,921.6015,891.0712,189.7222,542.08Cu10,888.661539.1715,010.549088.13As2.52<0.1<0.1<0.1Cd1.7836.400.5419.04Hg<0.1<0.1<0.1<0.1
Spectral preprocessing methods
2.2
Addressing the dimensional heterogeneity between spectral wavelength coordinates and intensity magnitudes is a prerequisite for ensuring numerical stability and accelerating convergence in gradient-based optimization. To strictly prevent data leakage and ensure the model's generalization capability on unseen data, a rigorous data isolation protocol was implemented prior to any global normalization. Specifically, the dataset was partitioned into training and independent test sets, with all preprocessing parameters derived exclusively from the training data.
Consequently, a global standardization framework was established across the training spectral domain . To map the disparate ranges of spectral position and radiometric response into a unified latent space, global boundaries and were defined based solely on the extrema of the training dataset:
The normalized spectral vector for both training and testing samples is obtained via a Min-Max scaling transformation using these pre-computed training parameters:
where is a regularization constant to prevent singularity. Crucially, for the validation and test sets, the same and values derived from the training set were applied, ensuring that no information from the test data influenced the feature scaling process.
Following normalization, a fused spectral signature vector was generated by the element-wise summation of the normalized wavelength and intensity vectors ( ). Complementing this continuous spectral representation, discrete statistical descriptors were extracted to capture salient morphological landmarks and global distributional characteristics. A peak detection algorithm was employed to isolate significant diagnostic features, defined as local maxima exceeding a dynamic amplitude threshold of . The set of indices corresponding to these peaks, denoted as , allows for the derivation of the peak count ( ) and the mean peak intensity ( ):
Furthermore, to characterize the overall signal energy and variability—which often correlate with sample concentration and scattering properties—the global mean intensity ( ) and global standard deviation ( ) were computed over all spectral channels:
The final high-dimensional feature vector is constructed by concatenating the fused spectral signature with these statistical moments:
This comprehensive vector design serves a multi-faceted purpose: it preserves the full spectral detail essential for chemical fingerprinting while simultaneously capturing morphological nuances through peak-based parameters. Moreover, by quantifying the distributional patterns of the signal via statistical metrics, the proposed feature set enhances the model's robustness against spectral variations. Ultimately, this approach provides the classifier with a standardized, high-information-density input, significantly elevating classification performance.
Classification methods
2.3
Conventional machine learning algorithms
2.3.1
RF is an ensemble classification method that constructs multiple decision trees and aggregates their predictions through majority voting or averaged probabilities (Fawagreh, Gaber, & Elyan, 2014). Its core mechanism employs bootstrap sampling to generate diverse training subsets while randomly selecting feature subsets at each node split, reducing inter-tree correlation and enhancing generalization. This approach makes RF robust for classification and regression tasks involving high-dimensional data and noisy environments (Ye, Wu, Huang, Ng, & Li, 2013).
KNN is a non-parametric classification algorithm that classifies unlabeled samples based on common similarity metrics, including various distance measures such as Euclidean distance, Manhattan distance, and generalized Minkowski distance (Zhang, Li, Zong, Zhu, & Cheng, 2017). It identifies the k closest training samples and assigns the majority class through voting. The optimal k value balances overfitting and underfitting, typically determined through cross-validation. Despite its simplicity, KNN exhibits sensitivity to high-dimensional data, necessitating feature selection or dimensionality reduction techniques to enhance efficiency in spectral analysis (Wang, An, Chen, Li, & Alterovitz, 2015).
PLS-DA integrates dimensionality reduction with classification in a supervised approach. It extracts latent variables to maximize inter-class variance, projects high-dimensional features into a low-dimensional space, and constructs a linear discriminant model(Lee, Liong, & Jemain, 2018). Particularly effective for scenarios with limited samples but high feature dimensionality such as spectral data, PLS-DA avoids multicollinearity issues by optimizing principal components while balancing feature interpretability and classification accuracy(Saccenti & Timmerman, 2016).
XGBoost iteratively trains gradient-boosted decision trees by optimizing weighted loss functions and fitting residuals. Innovations include L1/L2 regularization for model complexity control, parallel computing support, and sparse data handling, significantly improving training speed and generalization(Chen, 2016). Its robustness in class-imbalanced and nonlinear problems makes it ideal for complex spectral classification(Caramês et al., 2025).
Bayesian optimization is an intelligent hyperparameter tuning algorithm leveraging probabilistic modeling to enhance model performance. It constructs Gaussian process-based probability distributions for objective functions such as validation metrics, iteratively guiding search direction by dynamically refining surrogate models through prior evaluations. The algorithm balances exploration of unknown regions and exploitation of known optima using acquisition functions like Expected Improvement(Snoek, Larochelle, & Adams, 2012). In contrast to traditional grid search, Bayesian optimization leveraging the Tree-structured Parzen Estimator (TPE) algorithm demonstrates significant computational efficiency by navigating high-dimensional parameter spaces to identify optimal configurations with fewer evaluations. In this study, the hyperparameters of the RF, KNN, PLS-DA, and XGBoost models were rigorously optimized over 50 iterations. A composite weighted metric was utilized as the objective function, integrating the F1-score (weight: 0.5) to address precision-recall trade-offs in class-imbalanced scenarios and accuracy (weight: 0.5) for a holistic assessment of predictive capability. The detailed hyperparameter search ranges and configurations are presented in Table 2.Table 2. Optimized hyperparameter tuning ranges for classification models.Table 2. ModelHyperparameterTuning rangeOptionsRFn_estimators50–500Integermax_depth5–30Integermin_samples_split2–20Integermin_samples_leaf1–10IntegerKNNn_neighbors1–30Integerweights–[‘uniform’, ‘distance’]p1–5IntegerPLS-DAn_components2–20IntegerXGBoostn_estimators50–500Integermax_depth3–10Integerlearning_rate0.01–0.3Logarithmic Samplingsubsample0.6–1.0Floatcolsample_bytree0.6–1.0Floatmin_child_weight1–10Integergamma0–5Float
Convolutional neural network with statistical feature fusion
2.3.2
CNN emulate the hierarchical processing of biological visual systems to establish multilevel feature abstraction capabilities. The core architecture comprises convolutional layers extracting spatial features through local receptive fields with weight-sharing mechanisms, nonlinear ReLU activation functions enhancing model expressiveness, pooling layers preserving salient features via downsampling while improving translational invariance, and fully connected layers integrating high-level abstract features for classification decisions. This hierarchical stacking enables CNN to autonomously learn low-to-high-order feature representations from raw data, proving particularly effective for processing spatially correlated spectral signals(Li, Liu, Yang, Peng, & Zhou, 2021).
A feature-fused CNN architecture was developed for spectral data analysis, as illustrated in Fig. 3. The model input consists of a composite feature vector constructed by concatenating the normalized spectral profile with four engineered statistical descriptors: peak count, mean peak intensity, mean signal intensity, and standard deviation. The network backbone comprises three sequential convolutional blocks with increasing channel depths of 64, 128, and 256, respectively. Each block performs a 1D convolution (kernel size = 3, padding = 1), followed by ReLU activation, batch normalization, and max pooling (kernel size = 2) to extract hierarchical spectral features. The resulting feature maps are flattened and propagated through a multi-stage fully connected classifier consisting of dense layers with 256, 128, and 4 nodes. To mitigate overfitting, dropout regularization is applied after the first two dense layers at rates of 0.3 and 0.2, respectively. The model was trained for 50 epochs using the Adam optimizer (learning rate = 1 × 10^−4^) with a Cross-Entropy loss function, modulated by a cosine annealing learning rate scheduler and a batch size of 32.Fig. 3. Schematic diagram of the feature-fused CNN architecture.Fig. 3
Experimental design and computational framework
2.4
Ensuring the rigor and unbiased nature of the experimental evaluation, the raw dataset was initially stratified into an independent test set and a development set. Approximately 10% of the samples were strictly sequestered as the independent test set, which was completely excluded from model training and hyperparameter optimization to serve exclusively for the final verification of generalization performance. The remaining 90% constituted the development set, utilized to execute a 5-fold cross-validation scheme. In this process, data were randomized and partitioned into five mutually disjoint subsets, with four subsets selected for training and one for validation during each iteration to comprehensively assess model stability and generalization. Accuracy and Macro F1-score were established as the core evaluation metrics, while confusion matrices were utilized to visually elucidate the detailed distribution characteristics of classification outcomes.
All computational workflows were executed on a high-performance workstation running Windows 11 Professional, equipped with an Intel Core i5-12500T processor, 64 GB DDR5 RAM, and an NVIDIA RTX A2000 GPU. The software environment operated within Python 3.12.9 hosted by PyCharm Professional 2023.2.8. Traditional machine learning models utilized scikit-learn 1.6.1, whereas the CNN architecture leveraged PyTorch 2.6.0 with CUDA 12.4 for GPU acceleration. Furthermore, systematic hyperparameter optimization was managed via Optuna 4.3.0, with matplotlib 3.10.0 and seaborn 0.13.2 employed for high-resolution data visualization.
Results and discussion
3
Coffee spectral profiles
3.1
LIBS was employed to analyze the elemental composition of coffee samples from multiple geographical origins. As illustrated in Fig. 4, the average LIBS spectra across 200–550 nm exhibited structural similarities, indicating shared fundamental elemental constituents. Key emission lines were identified by referencing the U.S. National Institute of Standards and Technology atomic spectra database (NIST ASD, https://physics.nist.gov/PhysRefData/ASD/lines_form.html) (Cai et al., 2023), Dominant peaks revealed elemental signatures such as Fe, Cr, Na. Despite these overarching similarities, discernible variations in emission intensities at specific wavelengths were observed among origin-specific samples. The inherent spectral complexity characterized by densely overlapping emission lines from multiple elements precluded reliable visual differentiation of geographical origins. Consequently, while spectral fingerprints establish a foundation for origin discrimination, their interpretation necessitates advanced chemometric approaches. Subsequent machine learning or deep learning analysis is essential for extracting latent origin-related information to achieve robust classification.Fig. 4. Spectral profiles of coffee varieties.Fig. 4
Analysis of dimensionality reduction visualizations
3.2
Scrutinizing the intrinsic manifold structure of high-dimensional raw LIBS spectral data necessitated the implementation of three complementary dimensionality reduction techniques including PCA, t-SNE, and UMAP. Preceding the dimensionality reduction, raw spectral intensities underwent Z-score normalization to mitigate amplitude scaling effects and ensure equal contribution of all spectral variables. It is imperative to note that these dimensionality reduction algorithms were employed exclusively for exploratory data visualization and qualitative cluster assessment; they were not utilized as input features for the subsequent supervised classification models. PCA was selected as the linear benchmark to extract orthogonal directions of maximum variance for global topology preservation while quantifying the variance contribution of each component(Maćkiewicz & Ratajczak, 1993; Unnikrishnan et al., 2013). Addressing the complex non-linear relationships inherent in spectral signatures, t-SNE was utilized to maintain local neighborhood structures by minimizing the Kullback-Leibler divergence between probability distributions in high- and low-dimensional spaces(Linderman, Rachh, Hoskins, Steinerberger, & Kluger, 2019; Lopes, Neto, & Martins, 2020). Additionally, UMAP was deployed based on topological data analysis theory to balance the preservation of global structure and local neighborhoods while offering superior computational efficiency(McInnes, Healy, & Melville, 2018; Sainburg, McInnes, & Gentner, 2021). Reproducibility and optimal visualization were guaranteed through precise hyperparameter configuration where PCA extracted the first two principal components, t-SNE was initialized with a perplexity of 30 and 1000 iterations, and UMAP was configured with 15 neighbors and a minimum distance of 0.1. Deterministic execution for all stochastic algorithms was enforced by fixing the random state to 42.
As visualized in Fig. 5a, the linear projection via PCA indicates that the global variance is predominantly captured by the first principal component. PC1 accounts for 80.1% of the total variance while PC2 explains 4.3% which cumulatively represents 84.4% of the spectral information. Despite this high explained variance, the score plot demonstrates severe overlapping among the four coffee origins. The centroids of Yunnan, Colombia, Kenya, and Ethiopia samples are tightly clustered within the central region and exhibit extensive intersection of their 95% confidence ellipses without distinct decision boundaries. Quantitative assessment corroborates this visual indistinguishability as the Silhouette Coefficient is −0.10 and the Davies-Bouldin Index is 22.92. The negative Silhouette score is particularly diagnostic as it reveals that the average intra-class distance exceeds the inter-class distance in the linear space. This confirms that the dominant direction of variance in the raw spectra is driven by factors orthogonal to the chemical differences associated with coffee varieties.Fig. 5. Visualization of dimensionality-reduced coffee spectra: (a) PCA; (b) t-SNE; (c) UMAP.Fig. 5
In pursuit of elucidating latent local structures, t-SNE (Fig. 5b) and UMAP (Fig. 5c) were employed to probe non-linear manifolds. Both methods unveiled a striking phenomenon where the data spontaneously organized into approximately four distinct agglomerations. However, visual inspection of the spatial distribution reveals that these clusters are highly heterogeneous. Within each isolated island, the samples from the four different geographical classes are intermixed rather than stratified by coffee type, and the centroids of the respective classes remain spatially proximal within the dense central regions. Although the structural compactness improved significantly as evidenced by the reduction of DBI from 22.92 in PCA to 12.59 in t-SNE and 9.41 in UMAP, the Silhouette Coefficients remained negative at −0.07 for both methods. This metric discrepancy highlights a critical data characteristic where non-linear algorithms successfully detected strong local manifolds as indicated by the lower DBI, but the basis of this clustering does not correspond to the target labels as indicated by the negative Silhouette score. The observation that t-SNE and UMAP detect distinct data separations unrelated to coffee types points to the prevalence of systematic background variance. This stratification is attributed to physical spectral responses arising from variations in sample granularity, packing density, or minor environmental fluctuations such as humidity and temperature during acquisition. These physical baseline shifts generate a variance magnitude that overshadows the subtle chemical fingerprints of the cultivars. Consequently, unsupervised algorithms which prioritize maximizing global variance like PCA or preserving topological proximity based on raw Euclidean distances like t-SNE and UMAP inherently cluster data based on these dominant physical attributes. This finding provides the fundamental rationale for the supervised Feature-Fused CNN framework proposed in this study. Unlike unsupervised methods, the convolutional layers of the CNN function as adaptive semantic filters, effectively suppressing this high-variance physical background noise to extract the nuanced, discriminative geochemical features required for accurate coffee origin classification.
Comparative performance and interpretative attribution of conventional machine learning
3.3
Benchmarking classification efficacy and error distribution patterns
3.3.1
Comparative analysis of the four machine learning algorithms for coffee variety classification revealed significant performance disparities, as quantified in Fig. 6. Aggregated five-fold cross-validation results generated confusion matrices, with final metrics representing mean values across validation rounds. KNN (Fig. 6a) exhibited the lowest accuracy at 75.75%, demonstrating substantial inter-varietal confusion including 17% of Yunnan samples misclassified as Colombia or Kenya, 24% of Colombia samples erroneously assigned to Yunnan or Kenya, 36% of Kenya samples misclassified as Yunnan or Colombia, and 20% of Ethiopian samples misclassified. RF (Fig. 6b) achieved 86.50% accuracy with flawless identification of Ethiopian samples but displayed a 14% misclassification rate for Yunnan primarily confused with Ethiopia, a 22% misclassification rate for Colombia primarily confused with Kenya, and an 18% misclassification rate for Kenya assigned to Yunnan or Colombia. PLS-DA (Fig. 6c) attained 92.50% accuracy, perfectly classifying Ethiopian samples but misassigning 7% of Yunnan as Ethiopia, 5% of Colombia as Kenya, and 18% of Kenya across the other three origins. XGBoost (Fig. 6d) achieved optimal performance among traditional models at 95.75% accuracy, showing exceptional discriminative power including 100% accuracy for Ethiopia, 93% for Yunnan with 7% misclassified as Ethiopia, 93% for Colombia, and 97% for Kenya with 3% misclassified as Yunnan. The superior precision of ensemble-based XGBoost and dimensionality-reduced PLS-DA stems from their enhanced capacity to model complex spectral relationships and capture subtle varietal differences. Analysis of the prevalent misclassification patterns suggests links to geographical origins, with confusion between the high-altitude origins Yunnan and Ethiopia observed across multiple models potentially reflecting overlapping elemental profiles, and confusion between the mid-altitude origins Colombia and Kenya, possibly arising from comparable spectral characteristics influenced by environmental factors. These performance gaps are not merely a byproduct of algorithmic design but are deeply tied to two interrelated core factors: first, the intrinsic spectral variability of coffee varieties, driven by geo-environmental factors such as soil composition, climate, and altitude, shapes the elemental and chemical composition of coffee beans, giving rise to unique spectral fingerprints that serve as the fundamental basis for varietal classification; second, algorithms differ significantly in their ability to decode these fingerprints—XGBoost, an ensemble model, effectively models nonlinear spectral patterns by aggregating weak learners, PLS-DA retains discriminative features through dimensionality reduction, and RF balances complexity with interpretability, while KNN, a distance-based method, struggles to disentangle subtle environment-induced spectral variations, resulting in inferior performance. The combined effect of these factors explains the performance gradient from KNN to XGBoost, and the higher precision of ensemble-based XGBoost and dimensionality-reduced PLS-DA ultimately stems from their enhanced capacity to model complex spectral relationships and capture subtle varietal differences.Fig. 6. Confusion matrices of conventional machine learning algorithms: (a) KNN; (b) RF; (c) PLS-DA; (d) XGBoost.Fig. 6
SHAP-based spectral feature attribution and geochemical linkages
3.3.2
Aiming to enhance the interpretability and transparency of machine learning classification models, SHAP analysis was performed on the optimal test sets of four trained models: RF, XGBoost, KNN, and PLS-DA. The top-10 significant spectral feature wavelengths extracted from the data served as input variables, and SHAP analysis quantified the contribution of individual spectral features to classification decisions across coffee varieties. TreeExplainer was used for tree-based algorithms RF and XGBoost, as it leverages the hierarchical splitting logic of decision trees to compute exact SHAP values efficiently, avoiding the approximations needed for non-tree models and ensuring alignment with the sequential feature interactions inherent to these ensemble methods(Deb & Smith, 2021), while KernelExplainer was applied to distance-based and linear models KNN and PLS-DA. Since these models lack tree structures, KernelExplainer uses a kernel method to approximate SHAP values, making it compatible with KNN's distance-driven similarity calculations and PLS-DA's linear latent variable projections, thus maintaining methodological consistency with their underlying mechanisms(Bifarin & Fernández, 2024).
As visualized in Fig. 6, the SHAP value analysis illuminated the internal inference mechanisms of the four traditional machine learning models, revealing that while algorithmic strategies differ, geographical discrimination consistently relies on specific trace element fingerprints (Fe, Cr, Na, Cu). KNN (Fig. 7a), which is sensitive to local manifold structures, prioritized Cr II (397.96 nm) and Na II (292.35 nm) as primary discriminators; it effectively characterized Yunnan coffee and Colombia coffee through shared chromium features, while isolating Kenya coffee via a unique sodium signature and differentiating Ethiopia coffee using a dominant chromium profile. The ensemble-based RF (Fig. 7b) captured global spectral variances, establishing Fe I (300.75 nm) as a ubiquitous predictor for Yunnan coffee and Colombia coffee, with critical secondary differentiation provided by Fe II (315.28 nm) for Kenya coffee and Cr II (397.96 nm) for Ethiopia coffee. PLS-DA (Fig. 7c), defining linear boundaries, similarly identified Cr II (397.96 nm) as the dominant separator for Ethiopia coffee and Yunnan coffee, while employing Fe I (405.32 nm) and Cr I (403.33 nm) to characterize Colombia coffee and Kenya coffee. The gradient-boosted XGBoost (Fig. 7d) exhibited a distinct high-gain feature selection strategy, assigning exceptional importance to Fe I (300.75 nm) for classifying Colombia coffee and Yunnan coffee; uniquely, it diverged by identifying Fe II (315.28 nm) as a critical marker for Kenya coffee, while characterizing Ethiopia coffee through a combined profile of Fe I (300.75 nm) and Cu II (300.47 nm). However, despite identifying these discrete markers, traditional machine learning models are inherently limited by their reliance on shallow, linear, or distance-based feature interactions. They often lack the capacity to autonomously extract hierarchical spatial-spectral dependencies or effectively suppress background noise interference in complex matrices, which restricts their robustness compared to deep learning architectures that learn holistic spectral representations.Fig. 7TOP features SHAP values: (a) KNN; (b) RF; (c) PLS-DA; (d) XGBoost.Fig. 7
Feature-fused CNN: algorithmic superiority and mechanistic insights
3.4
Evaluation of classification robustness and computational resource efficiency
3.4.1
Performance evaluation of the proposed CNN algorithm demonstrated exceptional efficacy in classifying coffee varieties, achieving an average test set accuracy of 99.00% and an F1-score of 99.00%, which significantly outperformed all conventional machine learning benchmarks. The CNN model surpassed the best-performing traditional model, XGBoost (95.75%), as well as PLS-DA (92.50%), RF (86.50%), and KNN (75.75%), establishing a robust superiority in discriminating complex spectral signatures. Confusion matrix analysis (Fig. 8a) further corroborated this precision, revealing 99% accuracy for Yunnan samples, 97% for Kenyan samples, and a flawless 100% classification rate for both Colombian and Ethiopian origins. The stability of the model was confirmed via five-fold cross-validation (Fig. 8b), where the CNN consistently maintained near-perfect accuracy across all folds, contrasting sharply with the variability observed in distance-based methods like KNN. This performance leap stems from the CNN's end-to-end architecture, which unifies spatial-spectral feature learning to autonomously capture subtle, non-linear inter-varietal variations that manual feature engineering fails to resolve.Fig. 8CNN performance metrics: (a) Confusion matrix; (b) Comparative line plot of model accuracy.Fig. 8
While the CNN architecture achieved the highest classification accuracy, a rigorous quantitative evaluation of computational resources reveals a distinct trade-off between predictive precision and algorithmic complexity. As presented in Table 3, the deep learning model incurred a substantial computational cost during the training phase, requiring an average of 1194.11 s, which is significantly higher than the rapid training times of shallow algorithms such as PLS-DA (0.92 s) and XGBoost (30.65 s). In terms of deployment efficiency, linear and tree-based models demonstrated superior inference speeds; specifically, PLS-DA and XGBoost achieved ultra-low latencies of 0.0715 ms and 0.1867 ms per sample, respectively, benefiting from their computationally efficient matrix projections and decision tree traversals. In contrast, the CNN exhibited a higher average inference latency of 4.9406 ms due to the dense matrix operations inherent in multi-layer convolutions. However, this latency remains negligible for real-time industrial screening applications, and notably, the CNN maintained a highly compact memory footprint (0.0995 MB), significantly outperforming the memory-intensive PLS-DA (56.4547 MB). Consequently, the increased computational expenditure during the training phase is a justifiable investment. It supports an end-to-end learning paradigm that autonomously extracts hierarchical spatial-spectral features, thereby transcending the performance ceilings imposed by the manual feature engineering and linear assumptions of traditional models to achieve robust, high-precision authentication.Table 3. Comparison of performance metrics among different models.Table 3. ModelTest set accuracy(%)Test set F1-score(%)Average training time(s)Average training memory(MB)Average inference time per sample (ms)RF86.50 ± 2.0986.32 ± 2.168.6927 ± 0.085714.0435 ± 0.00120.3127 ± 0.0056KNN75.75 ± 2.4275.56 ± 2.510.0064 ± 0.00100.0652 ± 0.000034.8779 ± 0.7733PLS-DA92.50 ± 0.7992.39 ± 0.770.9180 ± 0.055456.4547 ± 0.00010.0715 ± 0.0068XGBoost95.75 ± 1.2795.74 ± 1.2830.6517 ± 0.51890.0123 ± 0.00100.1867 ± 0.0176CNN99.00 ± 0.5099.00 ± 0.501194.1127 ± 31.53180.0995 ± 0.05184.9406 ± 0.1424
1D Grad-CAM++ visualization: Elucidating the spectral logic of geographical origin
3.4.2
The 1D Grad-CAM++ technique was implemented to decode the decision-making process of the Feature-Fused CNN and elucidate wavelength-specific contributions to geographical classification. Unlike conventional approaches relying on global average pooling, Grad-CAM++ utilizes pixel-wise weighting coefficients to resolve unweighted localization issues, thereby enhancing the identification of multiple occurrences of class-discriminative features such as repeating emission lines(Cai et al., 2023; Chattopadhay, Sarkar, Howlader, & Balasubramanian, 2018).
Mathematically, let represent the classification score for a specific coffee origin prior to the softmax layer, and denote the -th feature map in the final convolutional layer. The importance weight for the -th feature map is computed by integrating the gradients with a weighting coefficient , formulated as:
Here, represents the weighting coefficient for the -th spectral channel in the -th feature map. This coefficient is derived using a closed-form solution involving second- and third-order partial derivatives of the class score with respect to the feature maps, ensuring a more refined sensitivity to spectral intensity variations:
The final class-discriminative localization map is obtained by the linear combination of weighted feature maps, followed by a ReLU activation to suppress negative contributions:
As visualized in Fig. 8, this methodology enables the precise localization of critical spectral regions. To rigorously quantify the reliability of these spectral fingerprints, the Standard Deviation of the generated activation weights was analyzed across samples. The Standard Deviation serves as a statistical metric for spectral consistency. A low value at a specific wavelength indicates that the CNN consistently activates this spectral region across varying samples of the same origin, identifying it as a robust geochemical marker immune to sample heterogeneity. Conversely, a high value suggests substantial intra-class variability in feature expression, potentially attributable to fluctuations in trace element concentrations, matrix effects, or environmental noise during data acquisition. This dual analysis combining gradient-based localization with statistical stability offers a methodological framework that connects deep learning predictions with spectrochemical interpretability.
The 1D Grad-CAM++ visualization analysis decoded the wavelength-specific contributions to the CNN model's decision-making process, elucidating the spectral logic underpinning geographical classification. For Yunnan coffee (Fig. 9a), the classification was driven by a complex profile where the model prioritized Fe I emissions (393.36, 396.75, 422.60, 359.30 nm) and Fe II lines (247.92, 280.28 nm), further reinforced by specific Cr I (404.42, 427.42 nm), Cr II (285.23 nm), and K II (428.88 nm) signatures as diagnostic markers. Colombian coffee (Fig. 9b) was characterized primarily by a prominent response at Fe II (247.92 nm), supported by a broad spectrum of Fe I activations (393.36, 422.60, 396.75, 388.24 nm); notably, the model identified unique Cu II (279.57, 520.71 nm) emissions combined with Cr I (404.42, 443.93 nm) and Cr II (285.23 nm) to distinguish this origin. Similarly, Kenyan coffee (Fig. 9c) displayed a strong reliance on the Fe II (247.92 nm) emission, yet it was differentiated by the combined influence of specific Fe I peaks (393.36, 396.75, 422.60, 388.24, 359.30 nm) and a distinct interplay of Cr I (404.42 nm), Cr II (285.23 nm), and Cu II (279.57 nm). In contrast, Ethiopian coffee (Fig. 9d) highlighted a unique multi-element fingerprint where Cr I (404.42 nm) emerged as a critical identifier alongside dominant Fe I emissions (393.36, 396.75, 422.60 nm); the concurrent prioritization of Cu II (279.57, 520.71 nm), Cr II (285.23 nm), and K II (428.88 nm), with a relatively lower emphasis on Fe II compared to other origins, suggests a distinct geochemical signature for this region. Quantitative analysis across all varieties indicates that the 391.2–408.8 nm spectral interval consistently accumulated the highest importance weights. These results demonstrate that while ubiquitous Fe I and Fe II emissions serve as general tracers for the organic matrix, the specific variations in Cr, Cu, and K emissions enable precise geographical discrimination correlated with local soil composition and climatic conditions, confirming that the CNN captures meaningful geochemical fingerprints rather than noise. Crucially, these findings demonstrate that the model authenticates geographical origin by recognizing the synergistic covariance of multiple elements rather than relying on isolated spectral peaks. This multi-parametric dependency ensures that the classification is governed by the holistic geochemical fingerprint involving Fe, Cr, Cu, and K. Consequently, this mechanism effectively filters out single-source contamination such as sporadic iron spikes caused by machinery wear because these artificial signals lack the requisite correlation with other terroir-specific markers, thereby guaranteeing the specificity and reliability of the authentication.Fig. 91D Grad-CAM++ visualizations for CNN models: (a) Yunnan; (b) Colombia; (c) Kenya; (d) Ethiopia. Each colored solid line shows the mean weight per wavelength for samples of a given origin. The shaded area of the same color shows the corresponding standard deviation.Fig. 9
Robustness evaluation under noise interference
3.5
A systematic noise injection stress test was implemented to evaluate model reliability under simulated environmental interference. Gaussian white noise at varying signal-to-noise ratios ranging from the original clean signals down to 20 dB was superimposed onto the independent test set spectra. This procedure simulates progressively harsh measurement conditions often encountered in real-world deployment scenarios. The evaluation utilized the ensemble of models derived from the stratified five-fold cross-validation scheme, and the reported metrics represent the mean accuracy with standard deviations across the folds to ensure statistical rigor and eliminate data artifacts.
As shown in Fig. 10, the robustness analysis reveals that the Feature-Fused CNN architecture exhibits exceptional resilience compared to traditional machine learning baselines. Conventional models experience a precipitous decline in classification accuracy when the signal-to-noise ratio falls below 40 dB, whereas the proposed deep learning model maintains a stable performance plateau with accuracy exceeding 94% even at a moderate noise level of 30 dB. This superior stability stems from the dual-stream architecture that effectively fuses spectral morphological features with statistical descriptors, where the convolutional layers function as adaptive filters to suppress high-frequency noise while preserving critical low-frequency characteristic peaks. Crucially, these results carry broader implications for the model's adaptability to complex food matrices beyond mere environmental noise resilience. In industrial processing, the introduction of additives such as sugar or milk typically induces spectral baseline fluctuations and non-linear matrix effects that are analogous to the signal degradation simulated by high-intensity noise. Therefore, the model's sustained high precision under low-SNR conditions serves as a robust proxy validation for its capability to decouple authentic geographical origin fingerprints from the spectral interferences caused by complex matrices, highlighting its potential applicability for processed coffee products.Fig. 10. Robustness evaluation of classification models under varying noise levels.Fig. 10
Conclusions
4
This study successfully validates a novel synergistic framework integrating Potassium-assisted orthogonal DP-LIBS with a Feature-Fused CNN to address the critical challenge of rapid, non-destructive coffee geographical authentication. By employing a high-purity KHCO₃ solid target for plasma cross-coupling alongside a deep architecture that concatenates normalized spectral data with statistical descriptors, the proposed system effectively surmounted the sensitivity limitations of conventional atomic spectroscopy. The Feature-Fused CNN not only achieved a state-of-the-art classification accuracy of 99.00%, significantly outperforming traditional algorithms including XGBoost, PLS-DA, RF, and KNN, but also demonstrated exceptional robustness against signal degradation, maintaining high precision even under simulated matrix interferences. Crucially, this research addresses the intrinsic opacity of deep learning models by implementing a dual-interpretability strategy: SHAP analysis quantified feature contributions for traditional machine learning benchmarks, identifying key markers such as Fe and Cr, while 1D Grad-CAM++ provided unprecedented mechanistic insights into the CNN, visualizing wavelength-specific activation weights. These visualizations confirmed that the model's superior decision-making logic relies on recognizing the synergistic covariance of specific trace elemental fingerprints (Fe, Cr, Cu, and K) rather than isolated spectral peaks, thereby ensuring the geochemical validity of the classification. Future investigations should focus on applying this technology to the fine-scale provenance tracing of high-value agricultural products within a single nation, thereby rigorously evaluating the method's resolution limits under minimal geographical variance. Furthermore, advancing the miniaturization of this framework for portable LIBS instrumentation will foster a transition towards mechanistically transparent and reliable real-time food forensics.
CRediT authorship contribution statement
Xiaoyong He: Writing – review & editing, Supervision, Resources, Project administration, Funding acquisition, Conceptualization. Kaiqiang Que: Writing – original draft, Software, Methodology, Investigation, Formal analysis. Tingrui Liang: Validation, Software, Formal analysis, Data curation. Zhenman Gao: Visualization, Software, Funding acquisition, Data curation. Zenghui Wang: Methodology, Investigation, Formal analysis, Data curation. Yufeng Li: Methodology, Formal analysis, Data curation.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ahmed R.Baig M.A.A comparative study of single and double pulse laser induced breakdown spectroscopy Journal of Applied Physics 1063200910.1063/1.3190516 · doi ↗
- 2Alvarenga Y.A.Boness H.V.M.Sarmento C.S.A.G.Lemos O.L.Matsumoto S.N.Boffo E.F.Exploring Bahia’s coffee diversity: NMR spectroscopy and chemometrics unveil regional variations Food Chemistry 483202514427910.1016/j.foodchem.2025.14427940222133 · doi ↗ · pubmed ↗
- 3Biau G.Analysis of a random forests model The Journal of Machine Learning Research 131201210631095 doi:https://dl.acm.org/doi/abs/10.5555/2503308.2343682
- 4Bifarin O.O.Fernández F.M.Automated machine learning and explainable AI (Auto ML-XAI) for metabolomics: Improving cancer diagnostics Journal of the American Society for Mass Spectrometry 35620241089110010.1021/jasms.3c 0040338690775 PMC 11157651 · doi ↗ · pubmed ↗
- 5Boateng E.Y.Otoo J.Abaye D.A.Basic tenets of classification algorithms K-nearest-neighbor, support vector machine, random forest and neural network: A review Journal of Data Analysis and Information Processing 84202034135710.4236/jdaip.2020.84020 · doi ↗
- 6Cai Z.Huang Z.He M.Li C.Qi H.Peng J.Zhang C.Identification of geographical origins of Radix Paeoniae Alba using hyperspectral imaging with deep learning-based fusion approaches Food Chemistry 422202313616910.1016/j.foodchem.2023.13616937119596 · doi ↗ · pubmed ↗
- 7Caramês E.T.de Moraes-Neto V.F.Bertozzi B.G.da Silva L.P.Villa J.E.Pallone J.A.Correa B.Identification of Fusarium sambucinum species complex by surface-enhanced Raman spectroscopy and XG Boost algorithm Food Chemistry 480202514384810.1016/j.foodchem.2025.14384840117817 · doi ↗ · pubmed ↗
- 8Chattopadhay A.Sarkar A.Howlader P.Balasubramanian V.N.Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks 2018 IEEE winter conference on applications of computer vision (WACV)2018 IEEE 839847