A methodology for integrating AI into embodied human intelligence for the performance of complex tasks
Tamim Ahmed, Thanassis Rikakis

TL;DR
This paper introduces a framework for combining human and AI intelligence to perform complex tasks, using a layered model and dynamic Bayesian networks to enhance human performance.
Contribution
A novel four-layer dynamic Bayesian network framework that models human-AI collaboration for embodied tasks, enhancing performance through bidirectional inference and real-time adaptation.
Findings
The framework achieved high agreement with clinicians in automated rehabilitation assessment (90.8-93.1%).
Clinicians reported increased confidence and efficiency when using AI insights for therapy planning.
Abstract
We propose a theory and methodology for designing human-artificial intelligence (AI) collaboration in complex, embodied tasks. The theory distinguishes human embodied intelligence from computational intelligence and identifies synergies in which AI enhances—rather than replicates or replaces—human performance. We represent observable structures of expert performance as a nested network with four interdependent layers: Environment (space and tools), Activity (what is done), Goals (what is aimed for), and Meaning (how performance is interpreted), all connected by dynamic four-layer edges. A bidirectional Dynamic Bayesian Network (DBN) computes this representation across temporal scales: instants, actions, complete performances, and sequences. The DBN informs the design of digital tools (from sensors to data structures and AI modules) that capture human performance and extract features,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
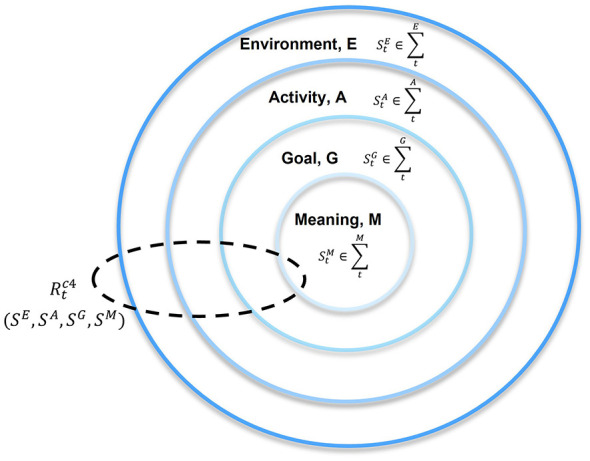 Figure 1
Figure 1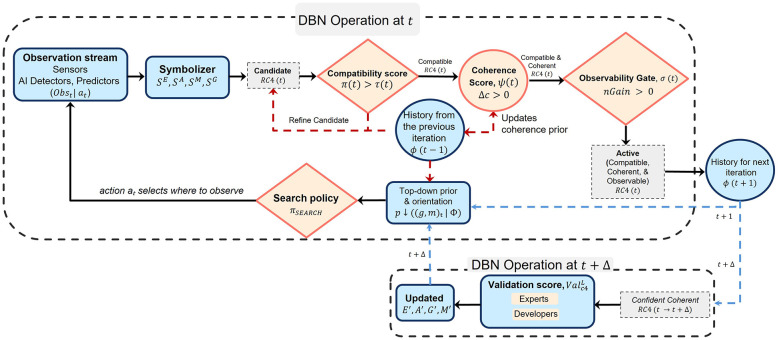 Figure 2
Figure 2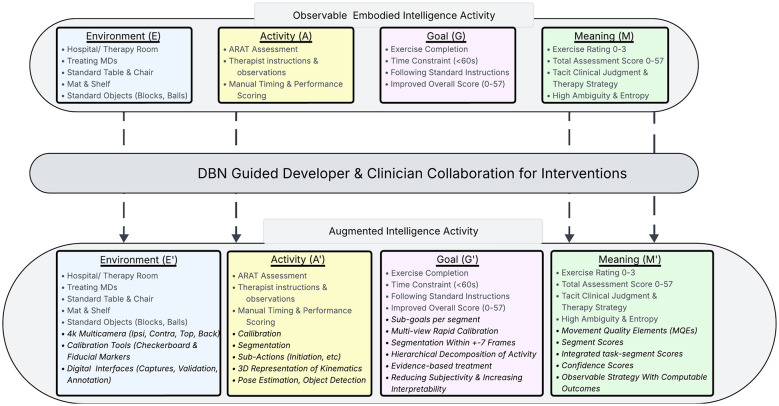 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStroke Rehabilitation and Recovery · Traumatic Brain Injury Research · Artificial Intelligence in Healthcare and Education
Introduction
This study proposes a methodology for exploring and structuring collaborations between human embodied intelligence and artificial intelligence. The methodology focuses on applying artificial intelligence (AI) to complex embodied tasks with formalized, observable structures. The complexity of these tasks requires highly developed embodied intelligence and offers significant opportunities for human-AI collaboration, where technology complements rather than replaces people. The observable and formalized elements of the tasks provide an entry point for computational modeling that can facilitate meaningful human-AI collaboration. The targeted tasks can range from designing a smart product to performing surgery in a modern operating room or conducting a search-and-rescue operation using autonomous agents.
In the background section, we present prior work on embodied human intelligence that links cognitive development to sensorimotor activity and to task performance in the wild. Within this context, human symbol creation and processing are strongly related to the extraction of meaning from interactions in the wild to inform future interactions. Therefore, human symbol processing is well differentiated from, and potentially synergistic with, computational symbol processing. Computation focuses on extracting relationships among symbols rather than on relations between symbols and embodied needs and actions. Humans improve their activities in the wild through constant learning and the development of tools. Our methodology approaches artificial intelligence as a means (a tool) for extending explicit symbol processing within complex embodied actions by humans to inform and enrich these actions.
In the methodology section, we represent human embodied performance in complex tasks as a nested network. The nested network comprises the following layers (listed from containing to contained): environment, human embodied activity, embodied goals, and meaning. The components and interconnections of the nested network are complex and not fully observable because many are embodied and tacit. Furthermore, they change as interaction drives human learning and as the environment evolves. We then facilitate human-AI collaboration by computationally modeling the nested network as a bidirectional Dynamic Bayesian Network (DBN). The DBN (i) translates the expert's symbols and routines (recorded in the nested network) into top–down information needs and bottom–up probabilistic updates; (ii) informs the design of digital tools (from sensors to data structures and AI engines) that can track and analyze task performance; (iii) produces symbolic descriptors and related calibrated likelihoods that increase the coherence and observability of the network and enhance the probability of improved performance; and (iv) assesses enhanced human performance and computational design in an integrative manner. As with all human-made tools, the inclusion of computational tools and intelligence in an activity will alter the embodied activity and its environment, thereby informing subsequent cycles of learning and adaptation. We define the long-term interrelated development of human and computational intelligence across environment, actions, goal setting, and meaning extraction as augmented intelligence (AI).
We present a detailed example of applying this methodology to the automation and augmentation of physical therapy assessment. We worked with 10 clinicians and 105 patients on the project for more than a year. We revealed explicit key components of the clinicians' embodied assessment process and modeled them as a Dynamic Bayesian Network (DBN). The DBN informed the design of a computational ensemble that successfully captured and extracted core elements of patient interactions with the environment and the therapist's assessment of those interactions. We could develop automated assessments that explicitly correlate clinically validated ratings with detailed movement-quality features. Clinicians believed that the enhancements provided by computational insights would help them improve their therapeutic strategies in ways that could be communicated explicitly to patients and other clinicians. Finally, we conclude by outlining key limitations and scaling opportunities for the methodology and discussing future study.
Background and prior work
Interactions between humans and physical environments, as well as with other people, in tasks such as tying a shoelace (Korteling et al., 2021), performing surgery (Cooper and Tisdell, 2020; Kelly et al., 2019), or playing the violin in an orchestra (Proverbio and Valtolina, 2025; Clayton and Leante, 2013) require complex cognitive processes that are deeply intertwined with sensorimotor activities. The development of integrated cognitive and sensorimotor abilities through interactions with the environment enabled us to perform survival functions early in human development (hunting, food cultivation, building shelter, and making tools) and continued to evolve as our goals became more complex (the development of built environments and machines) (Varela et al., 2017). By creating artifacts that influenced our environments, we, in turn, influenced and evolved our interaction techniques (Dourish, 2001; Osiurak et al., 2018). For example, our current auditory scene analysis processes have their origins in human interactions with natural environments, but they have evolved to also address interactions with built environments (McAdams and Bigand, 1993).
Cognition is involved in the direct performance of human interactions with the environment and in the construction and manipulation of symbolic representations of these interactions (Simon, 1990). Symbolic representations facilitate the structured analysis of the components of our experience (Newell et al., 1989) and support the formation of symbolic logic (Pylyshyn, 1988). However, mental representations of an experience, like every form of modeling, rely on simplifying the experience to make it comprehensible, manipulable, and generalizable (Miller and Page, 2009). Furthermore, detailed and controlled analysis of an experience is typically achieved by isolating its components to avoid the complexities arising from their continuous interactions (Krakauer, 2024). This isolation removes much of the essence of that experience (Dewey, 2024). The proliferation of isolated analyses of components of human experience in academia can be partly attributed to the siloed approach of our learning and discovery institutions and structures (Darbellay, 2015) and to human “Descartian Anxiety” for analytic control (Varela et al., 2017). However, the more significant underlying reason may be that the development of symbolic logic and human rational thought is, overall, a more recent component of human evolution and thus comparatively limited (Ackerman, 1991; Korteling et al., 2021). Analysis of isolated components of an experience and the reduction of complexity through symbolic representations are well-suited to the limits of disembodied rational thought (Hutchins, 1995). Conversely, integrated cognitive and sensorimotor abilities for acting in the wild are much older in terms of human evolutionary time and are therefore more suited to engaging the totality of a complete experience (Moravec, 1988; Piaget, 1978; Maturana and Varela, 2012; Barsalou et al., 2003).
Conflating overall human cognition with disembodied symbol processing creates two key limitations. It marginalizes the most complex forms of human intelligence, which are embodied in action in the wild (Iida and Giardina, 2023; Hutchins, 1995; Johnson, 2024). It conflates human and computational intelligence, thereby reducing opportunities to design “non anthropomorphic artificial intelligence” (Korteling et al., 2021) that differs from but can synergize with embodied human intelligence (Monteith et al., 2024; Dave et al., 2023). Symbol-processing-based intelligence has the greatest potential to enrich human experience when integrated into the complex, embodied human experience. This integration can lead to reflection (Dewey, 2024; Varela et al., 2017), enhancing human experience and advancing human potential.
For an example of this integration, we can look to musical notation. Western classical music notation is about 1,000 years old (Burkholder et al., 2006). By the classical and romantic eras (1,700–1,900s), symbols (musical notations) were used to represent notes, dynamics (volume), and articulation in long musical pieces such as symphonies (>30 min in duration). The intelligent and predictable manipulation of symbols by expert musicians in an orchestra (approximately 100 people) could inform the coherent performance of millions of coordinated embodied actions by the musicians for over 30 min, producing a sonic experience that directly engaged and enriched 1,000 or more people in a large concert hall. David Krakauer described this type of integration of symbol processing into a complex experience as an example of “strong emergence in a causal function” that involves “low information source to high information targets” (Krakauer, 2024). There are two obvious cases of this enhanced information flow in the “above music example: the musicians augment the symbolic information given in the musical score in a predictable manner,” and the audience members augment the sonic information received from the symphony orchestra in a predictable manner (Krakauer, 2024). A third inverse information flow is involved in this complex experience: the composer needs to translate their complex experiential intentions into symbols (musical notation) so that the musicians can successfully augment these symbols into sounds that the audience can interpret as a complex and meaningful experience (Dewey, 2024; Burkholder et al., 2006).
The main reason symbols work so well in this type of emergence is that they successfully leverage highly developed forms of embodied human intelligence (Clayton and Leante, 2013). Musical notation and music experiences overall leverage thousandss of years of integrated development of sensorimotor activities and embodied cognition through interaction with the environment and society (Johnson, 2024; Barsalou et al., 2003). This shared embodied intelligence enables each performer to use a small set of common symbols to inform millions of sensorimotor activities that produce the desired sounds and to coordinate those activities with those of the other performers in real-time (Proverbio and Valtolina, 2025). It also allows the composer, the performers, and the audience to receive and interpret complex sequences of organized sound (including harmonic structure, melodic form, rhythmic organization, orchestration, and timbre) in a coherent and predictable manner (McAdams and Bigand, 1993; Clayton and Leante, 2013). But even more importantly, it is the combination of shared and individualized embodied intelligence that allows each audience member to receive and interpret the sounds of a symphony in a predictable manner and map that sonic experience to their own lived experience in a customized manner so they each feel the full strength of the experience (Dewey, 2024).
An art experience is a complex interplay among the expert practice of art-making, the produced artifact, the personal embodied experience of each audience member, and the shared embodied and cultural experiences of a society (Sloboda, 1986). As Vygotsky points out, this complexity surpasses the capacities of analytic thought and gives rise to aesthetics: an ancient Greek word for emotions and meaning arising from integrated multi-sensory perception and cognition (Vygotsky and Cole, 1978). During a recorded conversation with Maximilian Schell in 1972, Bernstein (1975) discusses the beginning of the second movement of Beethoven's Seventh Symphony. He explains that the “magic” of that moment cannot be in the music itself (the notes written on the page) because the musical material at that point is primarily a repeated note. The emergence of what Bernstein calls “magic” is due to the amplification of the simple musical artifact by the embodied experience of the listeners. This emergence would not be possible without the development of intricate and effective symbolic representation (musical notation). However, symbolic representation is neither the reason nor the substance of the experience. The synergy of symbolic representation and multifaceted embodied human intelligence produces a complex and powerful experience that is beyond direct analysis; it is emergent.
We propose that AI can integrate into the embodied human experience a level of symbol processing that has not been possible to date and that exceeds the capabilities of human symbol processing. The goal of this integration would not be to expand disembodied analysis. Instead, it aims to enable the emergence of augmented intelligence, in which human embodied intelligence, computational tools, and lived environments evolve in an integrative manner through complex interplay (Dave et al., 2023; Ehrenfeld, 2022). In the following section, we outline a methodology to advance the integration of AI into the performance of complex, embodied tasks.
Methodology
Representing performance of a complex task as a nested network
To facilitate human-AI collaboration, we focus this methodology on complex embodied tasks that involve multiple interdependent interactions among different people, tools, and environments, integrating predictability with uncertainty. The targeted tasks involve significant simultaneity of interactions at any given instance, along with a latent or explicit hierarchical time structure: instances are compiled into short and meaningful actions; sequences of actions are compiled into a defined performance of a complex task; and sequences of complex task performances enable iterative learning and improvement of performance (Iida and Giardina, 2023; Simon, 2019). The performance of these complex tasks requires specialized forms of embodied intelligence that are correlated with the extended practice of the task (Peña, 2010; Benner, 2004). The long-term collective experience of a community of expert practitioners (Sch'´on, 2017) yields partially formalized performances and assessments that can be tracked. The observable and formalized structures of these complex tasks provide an entry point for modeling and computation, while their latent components offer opportunities for improved performance through human-AI collaboration.
Human-AI collaboration requires an interaction model that is accessible to (and acceptable by) expert performers while also being computable. We propose building this interaction model on a nested network representation of the performance of the targeted complex task. The environment and human activities involved in a complex task include many features visible to both human and computational intelligence, and can thus support human-AI collaboration. Therefore, Environment (E) and Activity (A) form the two external layers of the nested network model. Within complex tasks, the environment and human activity are mutually defined (Varela et al., 2017; Osiurak et al., 2018). The elements of the environment shape the development of integrated human sensorimotor and cognitive strategies for effective performance within it; in turn, the human actor(s) influence the environment to improve performance. In many cases, these mutually defining interactions result in distributed cognition, in which the human actors design work environments, tools, and communication protocols to distribute processing across these components and improve performance (Hutchins, 1995; Dourish, 2001). Piloting large ships and planes and performing surgeries are complex tasks that exhibit the characteristics of distributed cognition (Cooper and Tisdell, 2020; Sergeeva et al., 2020; Hollan et al., 2000). Many of the tools and interactions of distributed cognition are gradually formalized and communicated through structured collections of symbols (i.e., the ship's navigation manual and navigation maps). The formalized interactions of distributed cognition (and the symbols that accompany them) provide key material that can be computationally captured and analyzed to support human-AI collaboration.
The third area of the nested network comprises the actors' goals (G), their embodied needs, and their motivations. Every complex task involves explicit goals and constituent sub-goals. For most formalized complex tasks, training manuals, textbooks, and other aids document the overarching goals and sub-goals of the task, linking these goals to the specific actions that human experts must take in particular situations and environments. For example, the main goals of an airline pilot are to “ensure they reach their destinations safely and securely” (ALPA, 2025). Sub-goals include: “work out the best route using weather reports and air traffic control data, create a flight plan, carry out pre-flight checks, follow procedures for take-off and landing, fly the plane, communicate with air traffic control, communicate with cabin crew and passengers, check data during the flight, and adjust the route if necessary, write reports” (National Careers Service, 2025). There are detailed pilot training manuals and flight manuals that connect these Goals (G) to Actions (A) that need to be taken by the pilot in the context of the immediate Environment (cockpit) and surrounding Environments (e.g., airplane, airports, flight paths) (FAA, 2025). Explicit goal documents and their connections of goals to actions and to structured environments can serve as the core starting point for a computable nested network model that is also readily accessible to expert performers of the task.
However, each complex task also has implicit and tacit goals and sub-goals. In many cases, these are not visible, as this knowledge is gained and shared by experts through their embodied collective practice (Sch'´on, 2017; Koshy et al., 2017; Benner, 2004). Each person's practice is partly driven by individualized needs and motivations. For example, it is critical for lawyers to understand diverse client needs and to present cases differently to different juries and judges. Although these goals and sub-goals are acknowledged in legal education, their achievement is primarily tacit and realized through collective and individualized reflective practice (Casey, 2013). The explicit goal of architects and clients is to design a building. However, different architects and clients may have varying motivations and needs regarding their functional and aesthetic choices (Sch'´on, 2017). Multi-actor complex tasks may involve actors with varied sub-goals and related expertise. For example, a surgical team comprises surgeons, anesthesiologists, nurses, and trainees, with distinct roles that must be coordinated to ensure successful surgical performance (Kelly et al., 2019). A human-AI collaboration model for a complex task needs to account for explicit goals and sub-goals, as well as hidden sub-goals, needs, and motivations of different actors (Prudkov, 2025; Granato and Baldassarre, 2024).
The fourth and innermost layer of the nested network is meaning (M). Since we are dealing with complex and embodied tasks, we use a definition of meaning that is based on related work from pragmatism and phenomenology (Dewey, 2024; Merleau-Ponty et al., 2013). The actor constructs meaning by connecting the different pieces of the integrated sensorimotor and cognitive experience they have while performing the complex task. The pieces that need to be connected for meaning extraction span the Environment, Activity, and Goals layers of our representation and establish multifaceted four-layer connectivity (across the EAGM layers) that is critical to the performance of the task (Fooken et al., 2023). The goal of extracting meaning is continuous improvement in the task, but also generalized learning that enhances the lived experience (Buschman and Miller, 2014; Tenenbaum et al., 2011; Granato and Baldassarre, 2024). Meaning extraction from complex embodied tasks is primarily achieved through reflection-in-action, but also through reflection-on-action (Varela et al., 2017; Dewey, 2024).
The professional development of nurses through training and practice is strongly associated with an increased ability to extract Meaning from complex interactions among Goals, Actions, and the Environment. When a nurse starts her professional career, she will primarily rely on the formal and explicit connections between Goals, Actions, and the Environment defined in the textbooks of her training (Kim, 1999; Peña, 2010). For example, “to determine fluid balance, nursing students are given clear parameters and guidelines: Check the patient's morning weights and daily intake and output for the past three days. Weight gain and intake consistently greater than 500 cc could indicate water retention, in which case fluid restriction should be started until the cause of the imbalance can be found” (Benner, 2004). However, fluid balance decisions are more salient and cannot be fully addressed by such rule-based interactions. As the nurse gains expertise, she must learn to guide her fluid balance decisions by considering a broader range of signs and symptoms (e.g., lethargy, skin turgor, mental status) as well as her interactions with the patient (Benner, 2004). She must also learn to address potential contradictory signals that may arise from the increased number of parameters and the competing needs and instructions from different stakeholders, including attending physicians, the patient, the patient's family, the hospital administration, and insurance (Mantzoukas and Jasper, 2004). Meaning extraction from complex interactions that involve a large number of Environment-Action-Goal parameters can only be achieved when these interactions have been “seen, recognized, and assessed across a range of patients” in actual practice (Benner, 2004).
The diagnoses, related treatment decision notes, and codes entered by the nurse in the EHR will provide an explicit symbolic representation of the Meaning the nurse extracted from a situation, as well as explicit connections of that Meaning to the environment (patient signs and symptoms), Activities (actions the nurse and/or other medical personnel have taken), and the Goals she was trying to achieve through her decision. The nurse's notes, along with other elements of the EHR, constitute the explicit, observable record of the patient's treatment by clinicians. However, many of the salient elements considered in her decision, and the reasons they informed it, may not appear in the EHR. An expert can intuitively explore many potential links between the components of complex task performance and, in many cases, produce new and highly impactful links that are not easily documented through traditional methods (Taylor, 1992). Bennet provides a detailed example of how an expert nurse deals with a situation where “a patient who was hemorrhaging stopped breathing. The links between the patient's condition and actions are sufficiently strong that the nurse attends primarily to actions rather than the assessment of signs and symptoms. This is reasonable because, in extreme circumstances, the possible responses are fewer, but experience is required to make this shift in performance” (Benner, 2004; Kim, 1999).
The tacit knowledge of experts is critical for extracting meaning from complexity and managing adverse (unexpected) events that cannot be captured or recorded in generalizable manuals across many types of complex tasks. The opening chapter of Edwin Hutchins's book “Cognition in the Wild” describes in detail an adverse event in which a large ship loses steam power (and eventually electricity) as it approaches the port (Hutchins, 1995). The experts in the pilothouse must quickly engage backup systems and emergency procedures that they rarely use, and establish new navigation goals, as the ship cannot enter port in its current state. They take actions (like different turns of the rudder) that test the behavior of the environment (the backup guidance mechanisms of the ship and the resulting overall direction of the ship) and use these interactions to extract meaning (calculate how long it would take for the ship to slow down without being able to reverse the engines and how well the ship could be guided with backup systems) and set new immediate goals (define a feasible location where the ship will have slowed down enough to drop anchor). As Hutchins puts it: “the safe arrival of the Palau (ship) at anchor was due in large part to the exceptional seamanship of the bridge crew” (Hutchins, 1995).
Performance of complex tasks by experts involves a combination of “explicit” knowing-that and “tacit” knowing-how (Peña, 2010; Polanyi, 2012). The augmented intelligence architecture we propose in this study leverages the symbolic and explicit connections among Meaning, Goals, Activity, and Environment to gradually reveal the tacit components and compute their dynamic connectivity with the explicit components, thereby increasing the observability of complex tasks performance. This increased observability enables the identification of areas of opportunity where AI can enhance human performance and informs the assessment of that performance. To facilitate this type of human-AI collaboration, the representation of human performance on complex tasks needs to seamlessly integrate the computational enhancements required for capture, processing, and interaction as an integral part of the performance.
We propose that explainable and effective AI enhancements to human performance in complex tasks should be embedded in a four-layer nested network representation (Figure 1) that is computable. The assessment of the enhancement needs to be evident in the computational model and validated by human experts. Our nested network representation of performance on complex tasks shows all four constituent areas of the network as fully nested, indicating strong interdependence among its components. Changes to any component in any of the four areas of the network, whether through AI-based enhancements or other processes, will affect all areas and alter the network's configuration.
The nested network representing the performance of a complex task.
As discussed in the previous section, human performance on a complex task is clearly influenced by generalized learning that occurs outside the environment of the complex task. However, generalized learning connectivity is open and difficult to model in the context of specialized human-AI collaboration relating to the performance of a specific complex task (Tenenbaum et al., 2011). By modeling only the performance of a specialized, complex task, we do not need to represent all learning. Even in this limited case of a complex task, the network representation is dynamic and complex. We have argued that learning a complex, embodied task requires connectivity across all four layers of the network. Connectivity changes throughout the task as human actors and environments co-evolve. In a complex task, actors simultaneously manage a large number of nodes with multifaceted, dynamic connectivity. Almost all complex tasks must deal with unforeseen rare events (Krakauer, 2024).
Human actors manage this complexity in real time by distributing processing across the entire network and by relying on priors shaped by their embodied practice, as well as on the shared, accumulated knowledge of experts who perform and gradually formalize the complex task. Priors shaped by previous experience can be expressed as top-down conditional probabilities that, at any given point, may be affirmed or altered by the bottom-up data being observed (Fooken et al., 2023; Buschman and Miller, 2014; Tenenbaum et al., 2011; Spreng et al., 2010). We thus propose modeling the nested network representation as a bidirectional Dynamic Bayesian Network (DBN). In the next section, we discuss how the DBN can connect human expert performance to a computational ensemble, thereby informing system design and enhancing task performance.
Co-designing the computational Ensemble for human-AI collaboration
The DBN supports system designers and expert task performers in the iterative co-design and implementation of human-AI collaboration for enhanced task performance. The DBN (i) translates the expert's symbols and routines (recorded in the nested network representation) into top–down information needs and bottom–up probabilistic updates; (ii) informs the design of digital tools (from sensors to data structures and AI engines) that can enhance task performance; (iii) produces symbolic descriptors and related calibrated likelihoods that increase the coherence and observability of the EAGM network, enhancing the probability of improved performance; and (iv) assesses enhanced human performance and computational design in an integrative manner.
Co-design of the nested network representation
The first step in the co-design process is to establish trust with experts in complex task performance by emphasizing the collaborative nature of the project. The AI will not attempt to replace the experts. Instead, it will be co-designed by AI developers and task experts to complement and enhance human embodied performance. The co-designers can then work together to define all explicit and observable components of the four layers of the nested network representation—E, A, G, M—and their explicit or potential connectivity. We restrict the model to observable and explicitly defined features at every step. This allows us to compute the E—A—G—M relationships of the nested network (Figure 1) directly in the probability space and to computationally track how AI-based enhancements improve the confidence of the system.
The co-design team should also define an explicit hierarchy of time periods for aggregating information in the nested network: (i) instants t; (ii) actions k (contiguous groups of instances that constitute a short meaningful action); (iii) a performance T (an ordered sequence of actions constituting one complex task performance); and (iv) a sequence ρ (a sequence of complex–task performances) enabling iterative learning across repeated performances.
Translating the observable descriptors and features into computable symbols
Once an initial network representation has been developed, the next step is to establish methods for capturing and annotating the expert performance of the task in a manner that preserves all features of the network representation in as much detail as possible, without interfering with the performance process. The AI designers need to build or select feature extractors that use the captured data to produce explicit mappings from expert descriptors to computable symbols. For example, the expert-defined boundary of an action can be coded as a specific interaction of recorded data fields so that the computer can look for those boundaries automatically. The raw captured streams should also be processed using appropriate AI algorithms (e.g., Transformers/LSTM for time-series analysis and CNNs for image-based analysis) to identify prominent patterns that may be tacitly used by experts but have not been explicitly defined.
Expression of the bidirectional DBN
The vocabulary of symbols created from the outputs of the feature extractors and expert descriptors populates the observation channels of the DBN. At each instant t we map explicit and observable streams to finite vocabularies by symbolizers σ_•_:
Here are observable features or descriptors; σ_•_ may be learned, or rule-based; and (the lexicons) may evolve over time as computational enhancements propose candidates for inclusion that can be accepted or rejected based on the bidirectional DBN processes formalized in the later sections.
Before presenting the detailed mathematical formulation of the DBN, we provided a high-level view of the bidirectional inference cycle illustrated in Figure 2. A single DBN step contains a top-down pass (predict orientation, choose where to look) and a bottom-up pass (observe and symbolize, build cross-layer connectors, update orientation, and gate candidate codes). Combining both passes yields a joint posterior over orientation, symbols, and connecting edges across all four layers of the network. Because the four layers (EAGM) are nested, the bottom-up pass must first decide, at each instant, which four layer combinations (s^E^, s^A^, s^G^, s^M^) are actually in effect, and the top-down pass must read a compact summary of what has been happening across time brackets (actions, tasks, and sequences) to set expectations. Accordingly, we (i) defined how a candidate quadruple becomes an active c4 edge at an instant, and (ii) defined how those instantaneous edges are aggregated into fixed-size summaries that seed the top-down prior and the discovery gates.
Bidirectional DBN operation showing the complete processing cycle. DBN Operation at t (dashed boundary): The top-down pass begins with history Φ(t−1) parameterizing the prior over orientation (g, m)t, which drives the search policy πSEARCH to select action at. The bottom-up pass processes Obs(t∣at) through symbolizers to produce candidate quadruples Rc4(t). Candidates pass sequentially through: (1) compatibility check κ(t) > τ(t), (2) coherence gate ψ(t) requiring ΔC>0, and (3) observability gate σ(t) requiring nGain > 0. Candidates failing any gate (dashed red paths) are refined and re-evaluated; persistent failures update the error list and prior. Candidates passing all gates become Active Rc4(t)—compatible, coherent, and observable—and feed into history Φ(t+1) for the next iteration. DBN Operation at t+Δ: After sufficient iterations, when active candidates have accumulated confidence, they proceed to the validation gate where experts and developers confirm integration. Only validated candidates update the EAGM network (E′, A′, G′, M′), producing confident coherent Rc4(t→t+Δ) that becomes part of the established priors.
The DBN operates through these complementary passes within a gated pipeline that determines which cross-layer quadruples (s^E^, s^A^, s^G^, s^M^) ultimately become active edges (c4) and, after sufficient confidence accumulates, are part of the updated nested network. The top-down pass begins with the accumulated history Φ(t−1) from previous instants, actions, and task performances. This history parameterizes a prior distribution over the current orientation (g, m)t—encoding “what goal (g) are we pursuing” and “how do we currently interpret the unfolding performance (meaning-m).” The orientation drives a search policy π_SEARCH_ that selects an action at to maximize expected information gain. This action conditions the observation that initiates the bottom-up pass.
The bottom-up pass processes the action-conditioned observation Obs(t∣at) through layer-specific symbolizers, yielding candidate symbols . These symbols are assembled into candidate quadruples r = (s^E^, s^A^, s^G^, s^M^), collectively denoted . Each candidate must then pass through a sequence of three gates—compatibility, coherence, and observability—before becoming an active edge. Candidates that fail any gate are routed back for refinement; those that fail repeatedly are moved to an error list that feeds back to update the prior. The bottom-up pass concludes with the orientation update: fusing the top-down prior with the bottom-up evidence (active symbols and c4 edges) to obtain a joint posterior over orientation. This posterior becomes the starting point for the next top-down pass.
Active edges flow into the history for the next iteration Φ(t+1), but they do not immediately update the EAGM network. Instead, they accumulate confidence over a period Δ. Only after sufficient iterations—when the active candidates have gained confidence above a threshold—do they proceed to the validation gate, where experts and developers confirm the integration of the new patterns. Upon validation, the network state (E′, A′, G′, M′) is finally updated, closing the outer loop shown in Figure 2.
We now formalize each component of this cycle.
Top-down pass: orientation prior and search policy
The latent orientation (gt, mt) summarizes “what we are trying to do” (gt: current goal) and “how we currently interpret the unfolding performance” (mt: meaning). This orientation is drawn from a top-down prior:
where encodes the current lexicon state. The conditional is a top-down prior—it is computed before looking at the current evidence at time t. Hence, it conditions on the previous orientation (g, m)t−1, fixed-size summaries Φ_≤ t−1_ from earlier aggregates (actions, tasks, sequences), and the current lexicon state Λ_t_.
The predicted orientation guides where to look next: if certain goals or interpretations are the most uncertain or the most consequential now, the policy selects actions that are expected to be diagnostic for them. This corresponds to the “Search policy π_SEARCH_” defined as:
which maximizes expected information gain minus action cost:
The selected action at conditions the observation stream, yielding Obs(t∣at).
Action cost: constraining search to expected connectivity
We formalize the action cost to reflect a key insight: given the current orientation (gt, mt) derived from history Φ_≤ t−1_, the DBN has well-defined expectations for which Environment–Activity combinations are relevant. Searching outside this constrained space increases both time and uncertainty.
Let denote the expected action set—the computational actions (e.g., sensor orientation, sensor combinations, feature extraction, and computation of feature correlations) that are likely to reveal evidence consistent with the current orientation. This set is derived from the history: given (g, m)t−1 and the coherence prior , the DBN knows which E–A combinations have historically co-occurred with and/or right after the current goal–meaning state.
So, the action cost decomposes into two terms:
Execution time τ(at) captures the resource cost of performing action at—switching sensors, extracting more features, and calculating new feature correlations all consume time and computational resources. The coefficient cτ > 0 weights this base cost.
Deviation from expectations measures how far at lies from the expected action set. We define:
where π_exp_(a∣g, m, Φ) is the probability that action a is aligned with the expected E–A connectivity given orientation (g, m) and history Φ. This probability is derived from the coherence prior:
where the sum is over quadruples r = (s^E^, s^A^, s^G^, s^M^) whose E–A components are accessible via action at. Actions that search within the expected connectivity have high π_exp_ and thus low deviation costs; actions that search randomly have low π_exp_ and incur high costs.
The scalar coefficients (cτ, cdev) are learned from the data, as their optimal values depend on the specific task and the reliability of the coherence prior. Early in co-design (sparse history), cdev should be low to encourage exploration; as the prior stabilizes, cdev increases to exploit accumulated knowledge. This adaptive weighting ensures that the system balances exploration and exploitation as it learns.
Substituting Equation 5 into the search objective (Equation 4), the optimal action is:
This formulation ensures that the search policy prioritizes actions within the expected connectivity space, deviating only when the expected information gain is much higher than anticipated—denoting the possibility of a novel or unknown event in task performance that justifies a momentary increase in time and deviation costs.
Bottom-up pass: action-conditioned symbolization and candidate discovery
The bottom-up pass processes the action-conditioned observation Obs(t∣at) through layer-specific symbolizers, yielding candidate symbols . Critically, the observation at instant t depends on the action at selected by the search policy. Different actions yield different observations, and we make this dependency explicit in the symbolization equations. The action-conditioned observations are converted to symbols:
Here are calibrated observation factors that map action-conditioned observations—obtained from captured data by domain-specific extractors—into distributions over explicit symbols, with quantified uncertainty. The observation reflects what is revealed when action at is taken: different actions expose different aspects of the Environment, Activity, Goals, and Meaning. Predictions from an ensemble of AI modules pertinent to the current state directly parameterize these terms.
When current vocabularies have low confidence in explaining the observed structure, the bottom-up pass also activates a proposal mechanism that generates candidate explicit codes in layer L. Typical triggers include: (i) high residuals in the builder (many near-miss κ_t_ patterns), (ii) stable co-occurrence clusters of partial tuples (e.g., (s^E^, s^A^, *, *)), and (iii) expert-suggested codes from interactions. AI extractors and predictors help in two ways: by surfacing stable feature clusters as proposals and by improving calibration so that the gate's utility and coherence tests are reliable. For the discovery and updating of vocabularies:
The gate decision determines whether a proposed symbol s is accepted into the vocabulary. With symbols in hand—whether from existing vocabularies or newly proposed candidates—we decide which quadruples r = (s^E^, s^A^, s^G^, s^M^) are candidate cross-layer edges at time t, producing the “Candidate ” shown in Figure 2.
Bottom-up pass: the c4 builder and gated pipeline
The c4 builder assembles candidate quadruples and determines which become active edges through a sequence of three gates. Because a c4 edge encodes a strong cross-layer constraint over E–A–G–M, calibrated AI predictors that assign high and mutually consistent probabilities to the symbols in r = (s^E^, s^A^, s^G^, s^M^) increase the compatibility potential κ_t_(r).
Gate 1 (Instantaneous edge activation): compatibility check
Consider a candidate quadruple r = (s^E^, s^A^, s^G^, s^M^). The compatibility score κ_t_(r) evaluates whether the proposed connectivity is compatible with existing connectivity at instant t. Compatibility enforces two fundamental rules:
Rule 1 (Novel elements compatible with existing connectivity): the candidate may propose novel connections for an existing EAGM connectivity pattern (linking elements not previously connected to the pattern); however, those novel connections cannot contradict the well-established Gs and Ms of the connectivity pattern. Thus, the additions of pertinent E and A elements to existing Gs and Ms are allowed, and the additions of pertinent sub-Goals and sub-Meanings are also permitted.
Rule 2 (Novel elements with novel four-layer connectivity): novel elements that do not meet Rule 1 can be suggested as long as they have novel four-layer connectivity (i.e., novel E and A elements with novel G and M connections), thus indicating a new or alternative interpretation of the current events of the task.
These rules ensure that compatibility acts as a filter for genuine novelty: candidates that shift multiple elements together in a way that extends (rather than opposes) the existing network structure pass through, while arbitrary single-element changes or contradictory proposals are rejected.
The probability that r passes the compatibility check and proceeds to the coherence gate is:
where is the compatibility score and τ_t_ ∈ (0, 1) is a threshold. To encourage exploration early and selectivity later within an action or performance, we adopt a monotonic schedule:
where π_t_ ∈ [0, 1] denotes normalized progress within the current action and s:[0, 1] → [0, 1] is an increasing schedule (e.g., s(x) = x^p^, p≥1).
Gate 2 (Aggregated evidence over time): coherence check
Candidates passing the compatibility check proceed to the coherence gate. Unlike compatibility, which is an instantaneous assessment, coherence requires evidence aggregated over time. One cannot assess coherence at a single instant—coherence measures whether a pattern aligns with what has been observed across actions, tasks, and sequences.
After inferring the DBN posterior at time t−1, we compress beliefs into hierarchical summaries that inform the coherence assessment. Let r = (s^E^, s^A^, s^G^, s^M^) index a candidate c4 edge and be the instant-level indicator. Using evidence up to t−1, we form prefix counts at each aggregate level:
Converting counts to probabilities with Dirichlet smoothing:
The coherence prior at instant t is the convex mixture:
with log-odds .
The coherence gate requires a positive coherence gain:
where measures alignment with historically frequent patterns at level X. Candidates with pass the coherence gate and become part of the coherent set.
Gate 3 (Demonstrating increased connectivity): observability check
Candidates passing the coherence gate proceed to the observability gate, which evaluates whether accepting the candidate increases the observable cross-layer connectivity of the network. We define the observability gain:
The numerator is the expected increase in active, compatible c4 edges because the vocabulary was augmented. The denominator normalizes by the ambient search space, rewarding expressivity that manifests rather than raw vocabulary growth.
Candidates with nGain > 0 pass the observability gate and become active edges—compatible, coherent, and observable.
Refinement loop and error handling
Candidates failing any of the three gates are not simply discarded. Instead, they enter a refinement loop (dashed red paths in Figure 2). The system attempts to adjust symbolizer parameters, recalibrate compatibility thresholds, seek additional observations, or modify the candidate by considering alternative symbol combinations.
Candidates cycle through refinement until they either pass all gates or exhaust a maximum number of attempts. Candidates who persistently fail are moved to an error list. Importantly, the error list is not a dead end—it feeds back to update the prior, ensuring that the system learns from failures. Patterns that consistently fail may indicate: (i) sensor or symbolizer miscalibration requiring engineering attention, (ii) genuine edge cases that experts should review, or (iii) noise that should be down-weighted in future assessments.
Bottom-up pass: orientation update via joint posterior
The bottom-up pass concludes by fusing the top-down prior with the bottom-up evidence to obtain a joint posterior over orientation, symbols, and c4 edges. Let denote the history up to t−1 (including the posterior over (g, m)t−1 and the summaries Φ_≤ t−1_). At instant t, the action at is chosen by the search policy (Equation 3), and we condition on this realized at when forming observations.
Define the per-layer symbolization likelihood (Equation 9) and the c4 builder likelihood:
Using the top-down prior (Equation 2) and the per-layer likelihood , the step-t joint posterior over orientation, symbols, and c4 edges, given the realized action and observations, factorizes as:
The instantaneous log-posterior satisfies:
Any improvements that sharpen the symbolization likelihoods or strengthen c4 consistency (higher κ_t_, more informative ) tighten the posterior. This joint posterior represents the fusion of top-down and bottom-up passes at each instant.
We can define the prediction from the top-down prior by averaging over the previous posterior:
Conditioned on the realized action at, symbols, and c4 edges at time t, the posterior kernel over orientation is:
A point estimate for orientation (if needed) is then obtained as follows:
This orientation update completes the bidirectional inference at instant t: the top-down prior set expectations, the bottom-up pass gathered evidence and built active c4 edges, and the joint posterior now reflects both. The updated orientation (gt, mt) becomes the starting point for the next top-down pass.
History update and feedback to instantaneous decisions
Active edges—having passed compatibility, coherence, and observability gates—flow into the history for the next iteration. Let denote the instants in action k, the actions in task T, and Tρ the tasks in sequence ρ. If the instantaneous state is , the summaries are:
Here, Agg pools sufficient statistics within an action (e.g., c4 histograms, dwell times, transitions), and Compose concatenates child summaries carrying cross-boundary information upward. The fixed-size summary:
includes normalized edge histograms {π^act^, π^task^, π^seq^} used to compute the coherence prior for subsequent iterations.
This history feeds back to influence instantaneous decisions in two ways. First, at instant t, the mixture prior and its log-odds bias the selection of E–A–G–M edges toward patterns that have repeatedly co-occurred at the current action k(t), task T(t), and sequence ρ(t) levels. This feedback from history to the coherence prior is demonstrated in Figure 2.
Second, when a new candidate symbol or edge rnew passes all gates, it is promoted to the likelihood. These updates immediately change the next-step evidence:
because (i) the symbolization likelihoods can now assign calibrated probability mass to the new code(s), and (ii) the coherence prior increases for motifs involving rnew (as the aggregated counts rise). Consequently, the posterior tightens around orientations consistent with the newly stabilized E–A–G–M structure. Candidates that fail the gates remain auxiliary (used for learning and calibration) and do not enter , leaving the posterior unchanged by them. Crucially, active candidates update the history Φ(t) → Φ(t+1) but do not immediately update the EAGM network (E′, A′, G′, M′). The network update requires validation.
Validation and network update at t+Δ
Active edges accumulate confidence through repeated activation across iterations. After a period Δ—which may span multiple actions or even tasks—candidates who have maintained active status with confidence above a threshold proceed to the validation gate.
At the validation gate, experts and developers review the accumulated evidence:
Developers verify that the technical implementation (sensors, feature extractors, symbolizers, derivation algorithms) is correctly calibrated and that the observed patterns reflect genuine signals rather than artifacts.Experts confirm that the patterns have domain relevance—that they correspond to meaningful distinctions in complex task performance.
The validation score captures this expert assessment. The complete gate for network update combines accumulated confidence with validation:
where measures accumulated confidence from repeated activation.
Only candidates that pass this validation gate update the EAGM network (E′, A′, G′, M′). This collaboration ensures that: (i) instantaneous decisions respect existing knowledge while remaining open to genuine novelty; (ii) only candidates with demonstrated temporal coherence and observability enter the active set; (iii) experts are not burdened with instantaneous decisions but engage only after patterns have proven stable; (iv) the system now has a new posterior peak and lowest entropy; and (v) the system continuously learns from both successes and failures.
Experiment and results: human AI collaboration in physical therapy assessment
Physical therapy for stroke survivors is a complex task requiring interdependent interactions between therapists and stroke survivors, as well as standardized tools and environments. Therapy may last up to three years, during which multiple therapists work with patients. Patient recovery is influenced by many components beyond therapy sessions, including adherence to home exercises, the use of the affected limb by patients in everyday activities, and the support available for patients during daily living. Because of this variability, the physical therapy field has developed structured and formalized assessment tools that are administered at regular intervals during the lengthy process of therapy to track patient progress and inform therapy customization. The overarching goal of therapy is to support the functional recovery of patients and facilitate reintegration into daily life activities. Thus, therapy assessment tools are expertly structured to assess progress toward functional recovery. The Action Research Arm Test (ARAT) (Yozbatiran et al., 2008) is a clinically validated tool for assessing the upper extremity of stroke survivors. It comprises 19 individual exercises that are generalizable to the functional use of the upper limb during daily living. Therefore, improvements in the ARAT are expected to generalize to improved overall functionality.
Our AI development team, in close collaboration with eight therapists at a major rehabilitation hospital, identified the following common goals for developing human-AI collaboration processes to support augmented ARAT assessment. Augmented assessment would free therapists to focus on delivering therapy. It could also increase the standardization and granularity of observations during therapy without requiring extra time or effort from therapists. Increased standardization and granularity through automation that is intuitively accessible to therapists would make assessments portable across therapists and clinics and inform effective therapy customization. In this context, human-AI collaboration aims to empower and assist (augment) the expert in performing the complex task of physical therapy. It does not aim to replace the expert.
Our second co-design step was to define a nested network representation of the ARAT that would be computable as a DBN. We first co-defined the observable elements of the network. The ARAT has a highly codified environment and tools. It includes a table and a chair, with a shelf of specific dimensions on the table, and a mat of specific dimensions placed in a specific location on the table. The mat includes drawings for placing the ARAT objects and the hands of the patients in standardized positions. The ARAT uses standardized objects with different affordances for each of the 19 exercises. The instructions for each exercise are defined in a manual as a precise interaction between the patient's body and the standardized environment (McDonnell, 2008). Each exercise has a well-specified goal, which is articulated to the patient before they begin the exercise. For example, please start with your arm on the edge of the table, move to grasp the “specific object” at the “specific location” with “specific fingers,” and move it to a “specific location” within 1 min (the “specifics” change per exercise). Thus, defined and observable E-A interactions can be linked to the specified Goals (G) of each exercise.
The ARAT manual (McDonnell, 2008) includes specific instructions on what the therapist needs to observe for the standardized assessment of each of the 19 activities. Based on these observations, the therapist uses a well-defined scoring rubric (included in the manual) to assign a score of 0–3 to each exercise. The rating of each exercise, along with the rating rubric, provides explicit and observable features of Meaning extraction (M) by the therapist that can be connected to specific E, A, and G elements for each exercise assessment. The individual scores across the 19 exercises are summed to yield a total score of 0–57 for the entire complex task (the ARAT), thereby providing an explicit and observable EAGM network for the entire task. Repeated ARAT sessions during long-term therapy allow tracking of the network's evolution across sessions. The ARAT structure can thus be readily aligned with the four information aggregation structures of the DBN: (i) the instance: the smallest unit of high quality observation of the E and A elements of the ARAT, (ii) an individual action of the complex task with a well-defined start and endpoint: an individual exercise of the ARAT, (iii) one performance of the complete complex task—a complete ARAT assessment, and (iv) a sequence of sessions of the complex task—the multiple ARAT sessions.
However, most elements of ARAT performance are hidden. The therapist brings hidden embodied knowledge from training, practice, and everyday living to the assessment process. The detailed meaning of how the ARAT assessment informs the adaptation of therapy to address individual patient needs is embodied in the therapist's expert practice and interactions with each patient and is also hidden (Winstein et al., 2016; Krakauer, 2006). The patient's needs for functional recovery in daily life and their motivations for recovery may be partially revealed to the therapist through their embodied interactions with patients, but in most cases, they remain largely hidden. Furthermore, therapists, like all human beings active in the wild (Brown et al., 2011), observe detailed statistical features of the E and A interactions that are not expressible as a linear sequence of specific individual elements. After all, a significant part of human sensorimotor daily experience (proprioception, motor planning, auditory, and visual scene analysis) is actually statistical and activated through embodied perception action cycles and thus hidden (Wolpert, 2007; Ahlheim et al., 2014).
Instantiating the DBN model for automated ARAT assessment
We now ground the generic, bidirectional DBN within our Augmented ARAT Assessment system. Figure 3 provides a comprehensive visualization of this transformation, illustrating the journey from standard clinical observation (top panel) through DBN-guided co-design (middle panel) to an augmented intelligence approach (bottom panel). Critically, this transformation is not a single redesign but an iterative process in which each proposed computational enhancement must pass through the DBN's gated pipeline—compatibility check, coherence gate, and observability gate—before clinicians and developers validate its integration into the permanent network structure.
Transformation of the ARAT assessment into an Augmented Intelligence Activity. The framework illustrates the translation of the standard clinical observation loop [(Top) Observable embodied intelligence activity with Environment E, Activity A, Goal G, Meaning M] through a DBN-guided co-design process [(Middle) DBN Guided Developer & Clinician Collaboration for Interventions] into a digitized, computational environment [(Bottom) Augmented intelligence activity with enriched E′, A′, G′, M′ layers]. Each enhancement passes through the DBN's gated pipeline—compatibility, coherence, and observability checks—before validation by clinicians and developers leads to permanent network updates.
In the initial version of DBN, Environment symbols S^E^ encode the standardized ARAT setup, Activity symbols S^A^ encode patient activity, Goal symbols S^G^ encode the immediate goal of each ARAT exercise, and Meaning symbols S^M^ encode the explicit ratings provided by the therapist. As the co-design of the Augmented ARAT Assessment system proceeds, the DBN is gradually enriched through human and computational insights. In the following sections of the paper, we outlined each of the core additions that transformed human assessment of the ARAT into an augmented (human-AI collaborative) assessment. We identified the problem the addition aims to address, specified the new codes (lexicon updates) produced by the addition, described the DBN factors the addition modifies, outlined the measured/expected effects on coherence and visibility gain, and presented the resulting DBN posterior updates that lead to uncertainty reduction in the assessment of the ARAT. In general, we expect to see the following changes in entropy (H) and coherence ( ) for an added component x:
Multi-view capture with expert controls: enriching environment (E→E′)
Digitization and symbolization of the Environment and Activity elements of the ARAT require capture methods that do not interfere with the patient or therapist activities. Therapists move during each exercise to improve their detailed observation of its various elements. Therapists do not denote the connections between their movements and the Activity and Environment elements they observe. The features and connections among the therapist, patient, and Environment (E) interactions need to be computed from a multi-view capture of the ARAT. As these connections were not observable, the DBN initially could not establish strong c4 edges. The single-view system left many patient movements ambiguous, flagging high residuals (many near-miss κ_t_ patterns) and low confidence in symbolization. This prompted the developers to propose multi-view capture, along with rapid calibration protocols, as a candidate to enhance E–A layer capture.
The multi-view system proposes new Environment symbols that are compatibly connected to existing A patterns (certain views are systematically better for certain activities) and existing G patterns (specific goals require specific viewing angles). The custom views will help produce more detailed and more confident assessments (M). The compatibility check passed because the proposal enriched the network without contradicting established E–A–G–M patterns. The search/attention policy assigns control at = (vt, zt, st) for view, zoom, and half-speed playback. The integration of the views, kinematic and visual features extracted using computational models, and different viewing features yielded the following effects in our proposed bi-directional DBN.
(i) Observation model p(Obst∣at, et): Multi-view improves two aspects of the likelihood: pixels (fewer occlusions, better SNR) and 3D kinematics (better geometry for triangulation). Since 3D kinematics are computed from video, we model them as conditionally dependent on pixels given (at, et). The full observation factor separates pixel-based evidence from kinematic reconstruction:
with the reconstructed pose/hand–object state. As the kinematic covariance shrinks, downstream inference becomes sharper.
(ii) Symbolizers , : When multi-view reduces , features become less noisy, and the posteriors , become less entropic (more confident). This directly reduces uncertainty at the symbol level and propagates it through the DBN.
(iii) c4 builder : The cross-layer edge r = (s^E^, s^A^, s^G^, s^M^) is activated by a sigmoid that combines local compatibility with historical coherence.
learns that some views are systematically better for certain actions (e.g., contralateral for pre-shaping and ipsilateral for termination). rewards low uncertainty, e.g., . The coherence prior comes from aggregated edge histograms and up-weights historically consistent quadruples. Together, multi-view raises both κ_t_(r) (better match & evidence) and , as view–activity pairs (e.g., contralateral view for pre-shaping and ipsilateral for termination) show stable co-occurrence patterns across actions, tasks, and sequences. The coherence prior increased for historically consistent view–action patterns, yielding and sharper DBN posteriors. Multi-view capture enabled the discovery of new quadruples that were previously unobservable. With improved geometry for 3D triangulation and fewer occlusions, the system could now build c4 edges connecting specific views to specific activities, goals, and meanings: .
A lightweight policy, such as the recommended view vt by action (from π^coh^), exposes zt and st = 0.5 × that are introduced when hand–object events are predicted. The policy objective given by Equation 4 now includes zoom/speed. There is no change in the lexicon, and the improvement comes from better-conditioned evidence for existing symbolizers. The improvement will generate faster disambiguation with fewer redundant looks, satisfying the conditions: at the same or lower action cost; via more consistent, high-quality edges across repeated uses. After the multi-view system demonstrated stable performance across multiple assessment sessions (Δt), clinicians and developers reviewed the accumulated evidence. Clinicians confirmed that the automated view selection aligned with their tacit viewing strategies and that greater control over payback speed would improve video capture for review and, therefore, assessment. The developers verified that the 3D kinematic reconstruction improved the symbolizer's confidence. Upon validation, the Environment layer was permanently updated:
Action segmentation: enriching activity (A→A′)
Multi-view capture and analysis by AI designers and therapists have begun to reveal a critical yet tacit and non-standardized approach to activity segmentation. Therapists use a generalizable segment vocabulary that enables meaningful assessment of specific movement components across different ARAT exercises and can inform therapy customization (e.g., targeting the reduction of trunk compensation during movement initiation across all types of upper-limb activity). Using computational methods and expert input to reveal and standardize segmentation could add explicit, observable EAGM connectivity to the network and improve posteriors. The c4 builder showed stable co-occurrence clusters of partial tuples [e.g., (s^E^, s^A^, *, *)] at specific temporal phases, but these patterns did not connect to explicit Goal or Meaning symbols. This triggered the proposal mechanism to surface explicit segmentation as a candidate enhancement.
It would provide an additional time-aggregation bracket (sub-action) that bridges instant and action aggregate assessments across all ARAT exercises and support tuning EAGM assessments based on the type of sub-action (segment) being performed. The clinicians defined an initial segmentation vocabulary, which was gradually refined through co-design activities that leveraged computational insights from the DBN. The final vocabulary comprises four segments mapped to subactions in the DBN: initiation and progression, termination, manipulation and transportation, and place and release. This vocabulary was proposed as a candidate enhancement to the Activity layer.
The developers added the sub-action vocabulary within A and an automated segmenter that produces spans with types and confidence . Initially, the activity layer used the per-frame activity classifier, with a likelihood . Our segmentation component replaces this with a structured factor that enforces span consistency from the automated segmenter:
The frame evidence maintains the information from the per-frame classifier (what this instant looks like). The temporal/ordering prior encodes legal progressions and smoothness (e.g., Initiation→Progression→Termination), discouraging implausible jumps. A duration bias can be included by augmenting Ψ (semi-Markov) to prefer sub-actions that last multiple frames. Span consistency utilizes the automated segmenter's proposal as a soft constraint: within the proposed span , the labels are encouraged to equal , with strength controlled by confidence . If is high, the span behaves like a nearly fixed sub-action of type ; if it is low, the model falls back to frame evidence and Ψ.
Within a span , the posterior over collapses onto the proposed type (when is high), so the entropy drops across the span. Stable increases the c4 compatibility for the appropriate view–sub–action–goal–meaning, where each segment type is connected to specific Environment configurations (camera views optimal for that segment), specific Goal interpretations (what needs to be achieved during that segment), and specific Meaning indicators (what quality elements matter during that segment). Because the same quadruples activate reliably across repetitions of similar sub-actions in the 19 exercises of the complex task, the aggregate histograms that form π^coh^ concentrate on clinically consistent patterns, which increases the coherence potential used by the builder. The c4 builder achieves many tighter action–goal–view alignments.
Here is one example of the new four-layer connections. If the segmenter proposes frames 30:60 as hand pre-shaping with confidence π^A^ = 0.9, the structured factor will assign (as a child of the Progression sub-Action) unless the frame evidence is overwhelmingly contradictory. A more confident sub-Action recognition will leverage the multi-view c4s to establish a contralateral, zoomed-in view as the preferred view for the frames. This will decrease occlusions, enhance sampling (number of pixels) per tracked finger, and reduce frame jitter. It enables a new sub-goal (assessment of hand-shaping pre-grasp) that can be reliably assessed across all exercises (new Meaning). It thus enables new c4 quadruples connecting segments to views, goals, and meanings that were previously unobservable: . This allows the c4 builder to consistently activate the correct quadruples—producing sharper posteriors for the orientation (gt, mt) and more confident downstream scoring.
After demonstrating stable segmentation across multiple sessions, clinicians confirmed that the four-segment vocabulary captured their tacit assessment structure. Developers verified that automated boundary detection achieved ±7 frame accuracy. The Activity layer was permanently updated:
Segment-focused movement quality: enriching activity and expanding goals (A→A′, G→G′)
With the inclusion of the segment (sub-action) vocabulary, the DBN revealed another gap; the Meaning layer remained ambiguous because different movement quality elements (MQEs) have varying relevance depending on the segment being performed. The system showed high entropy in despite improved Activity symbolization, prompting a proposal for segment-focused MQE weighting. Based on prior collaborative work (Kelliher et al., 2020), we asked the experts to define a small number of movement quality elements that they focus on per type of segment during their practice. Once the MQEs were developed, the team concluded that they introduced a new level of granularity to the observation and assessment of ARAT. The therapists performed such assessments intuitively but could conduct them accurately, explicitly, and in a standardized manner only with the aid of computation. This is a clear example of how EAGM can transform into E'A'G'M', as shown in Figure 3, through the addition of new elements that significantly enhance the explicit cross-layer connectivity. The translation between human observation and AI-enhanced observation is performed by the DBN.
Based on the movement quality elements (MQE) for sub-action vocabulary, symbolizers σ_A, σM_ were updated to classify into the refined lexicons:
We also introduced a focus prior that defines which MQEs m receive attention given segment s^A^, which up-weights the expert-nominated MQEs for the current sub-action and augments the updated compatibility from Equation 27 to recognize these focused co-occurrences, while the coherence potential accumulates support for the resulting c4 edges across actions, tasks, and sequences. For example, when a patient struggles with trunk compensation during initiation, this consistently predicts lower exercise scores. The segment-specific MQE weights accumulated stable evidence:
This targeted weighting aligns the machine's meaning space with clinicians' mental models and measurably reduces ambiguity with sharper MQE posteriors ( ) and clearer orientation (ΔH((g, m)t) < 0) from the DBN. Thus, it increases cross-layer visibility and stability across action/task sequences.
Expert-defined sub-goals and related meaning: enriching goal and meaning (G→G′, M→M′)
The introduction and refinement of a sub-action vocabulary that is valid across all individual exercises of the complex task (ARAT), along with the attachment of a few highly weighted movement quality elements to each sub-action, increased the explicit and observable elements of the DBN. However, this increased observability did not produce the reduction in assessment entropy predicted by the DBN. Our discussions had already identified potential causes of this problem. The clinicians noted that they began to predict the overall meaning (and associated ratings) of an individual ARAT exercise from the performance of its constituent segments. For example, the “Initiation and Progression” segment needs to be completed appropriately for the hand to be able to start the “Terminate” segment for a specific object of an ARAT exercise. We thus concluded that segments (sub-actions) should be assigned specific sub-goals and associated meanings (ratings) that can be aggregated consistently into the overall Goal and Meaning of each ARAT exercise (action).
The clinicians proposed that since each exercise was rated between 0 and 3 using a standardized rubric, the segments should also be rated on the same scale using a similar rubric. Given the speed of each exercise and the many elements to be assessed, the clinicians suggested that the movement quality elements be assessed using a binary classification: 1 for appropriate and 0 for not appropriate. The term “appropriate” connects the Meaning of the assessment of specific movement quality elements to the Meaning of the assessment of a specific sub-goal; in other words, the performance of a movement quality element is appropriate for the segment during which it is performed. In turn, the consistent ratings of segments and exercises connect the Meaning of sub-goal assessment to the Meaning of Goal assessments. It allows the system to derive Augmented Meaning (M′) not as an ambiguous overall rating but as a composite of explicit, confidence-weighted scores of Exercises, segments, and Movement Quality Elements (MQEs).
Building on the focus-weighted compatibility from the previous subsection (Equation 29/ ), we now incorporate expert annotations that make two aspects explicit at the sub-action level j: (i) an ordinal sub-goal rating Ỹ_j_ ∈ {0, 1, 2, 3}; (ii) a binary status mj, q ∈ {0, 1} for each focused movement-quality element (MQE) tied to the sub-action type . These serve as observational factors and drive both symbol learning and c4 edge formation.
Let hj be a learned embedding (from multi-view pixels/kinematics) pooled over instants of sub-action j:
and be the action-level embedding. During training, expert labels supervise Equations 31–33, but at inference, these factors provide calibrated evidence to the DBN that is predicted from automated algorithms:
At each instant , we form per-MQE quadruples , where Gj denotes the (latent/predicted) sub-goal code consistent with Ỹ_j_. We update the focus-aware compatibility from Equation 29
and build edges with coherence-weighted activation using the updated .
With this update to the proposed DBN, each expert label (Ỹ_j, {mj, q}) becomes an explicit code and adds valid, focus-compatible candidates for c4 edges (more observable cross-layer structure; , ). Furthermore, the standardized sub-goal rubrics and binary MQEs shrink hypothesis spaces, tightening posteriors for , , and (g, m)t_ ( , , ΔH((g, m)t) < 0). Thus, action/task/sequence histograms over {preferred view, sub-action, Ỹ_j, mj, q_} concentrate on reusable motifs, increasing ψ^coh^ for those edges and making the top-down prior more predictive regarding subsequent cases. With the clinicians validating that the hierarchical goal-meaning structure captured their reasoning process, both the Goal and Meaning layers were permanently updated:
Computational ensemble development for automated scoring and quality inference
With all EAGM layers enriched through the gated validation process, we developed an AI ensemble that operationalizes the complete transformation. This ensemble connects the DBN to pose estimators, 3D kinematics extractors, and joint transformer/HBM predictors (Ahmed et al., 2024), producing calibrated predictions that feed back into the DBN's gated pipeline.
First, multi-view 4K videos are processed through 2D pose and hand keypoint estimators (Ahmed et al., 2021) and hand-object contact detectors (Lee et al., 2025) to extract body and hand joint coordinates and object locations. View-synchronized triangulation produces 3D kinematics that populate the observation channels: (active view features), (motion and velocity cues), and (hand aperture, wrist orientation, trunk compensation, smoothness, and accuracy in relation to the score).
Second, we trained predictors on clinician-validated data: (i) a multi-view transformer for sub-action span detection and (ii) a fusion of transformer-based activity recognition with hierarchical Bayesian models (HBM) (Ahmed et al., 2024) trained on multi-rater sub-action/action scores with MQEs.
The ensemble outputs replace or augment the learned symbolizers:
where and are fused predictions from the transformer and HBM in the logit space. Crucially, the ensemble's predictions are not directly presented to clinicians. Instead, they enter the DBN as candidate c4 edges that must pass through the same gated pipeline: compatibility with existing patterns, coherence over time, and positive observability gain. Predictions that fail these gates are flagged for refinement or added to the error list.
The final compatibility equation for the ARAT assessment, updated through the complete co-design process, is:
where each term reflects an enhancement that has passed through the gated pipeline and has been validated by clinicians and developers, the result is a transformed EAGM network, where Environment (E′) includes multi-view capture infrastructure with automated view selection, Activity (A′) includes explicit segmentation with a temporal structure, Goal (G′) includes hierarchical sub-goals with segment-level objectives, and Meaning (M′) includes segment ratings, binary MQEs, and confidence scores. The “High Ambiguity/Entropy” that originally characterized the Meaning layer has been replaced by “Observable strategy with computable outcomes”—not by imposing a rigid structure on clinical judgment but by making tacit knowledge explicit through a principled, evidence-driven process that preserves alignment with expert practice.
Study set up and outcomes
Our automated ARATs assessment tool was deployed at a major rehabilitation hospital in the Midwest, where five clinicians used our four-camera multi-view capture system to record routine ARATs assessments of 105 stroke survivors over six months. The clinical study was approved by the IRB, and all participants (patients and clinicians) provided informed consent before data collection, workshops, and group discussions for the co-development of the system. The study produced a dataset of 1,800 exercise performances. The automated segmentation algorithm reached 91% agreement with human boundaries within ±7 frames. The exercise and segment clips were then rated by five expert clinicians using the standardized assessment vocabulary co-developed. Inter-rater agreement among the clinicians was substantial but also exhibited uncertainty characteristic of decisions in complex tasks, which became more pronounced as the granularity increased. Kappa scores for inter-rater agreement for exercises and segments were (κ = 0.748) and (κ = 0.699) respectively, but (κ < 0.600) for movement quality features (MQEs).
We then trained the ensemble models to automate ARAT exercise assessment. The automated assessments matched clinician ratings at 90.8% at the exercise level, 93.1% at the segment level, and 90.6% at the movement quality level for cases where clinicians' ratings were in agreement. With the addition of statistical probabilistic modeling from the HBM and calibrated posteriors aligned with sub-action contexts, the ensemble models disambiguated 92% of cases in which clinicians' ratings disagreed. We validated 400 machine-generated assessments with four expert clinicians who were not part of the system's co-design process. The clinicians agreed with the automated ratings at 90.8%, 93.1%, and 90.56% on the exercise, segment, and movement quality levels, respectively. They also reported a strong fit with their clinical practice. They indicated that the customization of therapy by clinicians can be well informed by access to automated assessments that link an exercise rating to details of the exercise's performance and can illustrate these connections through synchronized multi-view and time-variable displays playback. Details of the automated assessment models and validation study results will be published in an upcoming paper. We also plan to release de–identified data from the study after that publication.
Discussion
The ARAT project illustrates our co-design approach to human-AI collaboration for the emergence of augmented intelligence in complex task performance. Engineers and therapists establish common goals for the project and then begin to collaborate on the components. The therapists provide the explicit symbols for the first version of the EAGM network for Augmented Therapy Assessment. Engineers set up the infrastructure to digitize the explicit elements. This allows for the first computation of the EAGM as a DBN. The DBN identifies opportunities for newly added digital elements or therapist-provided information to enhance the network's observability and confidence. Suggestions can be quickly tested and refined as the DBN makes connections or identifies missed connections between new elements and the nested network, which is observable and quantifiable. The increased observability of the network makes experts' tacit knowledge explicit and guides computational enhancements that improve both explicit and tacit practices among clinicians. The DBN provides the computational agents with concrete, in-the-loop proposals (“switch to contralateral camera, zoom on digits, extract finger relations to object”) that mirror expert habits. The appropriate AI agent(s) can then operationalize the choice and deliver the specific measurements requested by the DBN. In turn, the DBN can justify a computational assessment recommendation to the human expert with a short, symbolic rationale: “the contralateral view of hand pre-shape for secure grasp co-occurs with inadequate aperture; the probability is high given past sessions.”
This AI reasoning and its outcomes are preferable to opaque saliency maps; it speaks the expert's language and is auditable. Experts can confirm and/or correct the computational ensemble predictions and recommendations with minimal effort, thereby integrating them into routine workflows. If the AI recommendation is accepted, the integration of the recommendation into future therapy strategies is left to the expert. When a patient returns for their next ARAT assessment, the computational ensemble can compute detailed changes from the previous sessions and help further inform the therapist about the effectiveness and/or direction of adaptation. The collaborative architecture allows the human performer(s) to readily receive low information, high-pertinence input from the AI agents and amplify the effect of this information to significantly enhance performance. In practice, this means a computational ensemble that keeps up with the expert, offering well–timed, well–founded suggestions that reduce ambiguity and enhance performance on complex tasks without increasing sensorimotor or cognitive load. As the human-AI collaboration advances, the human expert's behavior changes, and the computational ensemble keeps up with those changes.
It may seem counterintuitive that as the amount of information processed by human-AI collaboration increases and becomes more complex, the entropy in performance assessment decreases while confidence in future planning increases. We propose that this occurs because the computational agents are not attempting to increase the degree of explicit standardization in task performance. We have already shown in earlier sections that complex task performance relies on a combination of standardized explicit procedures and tacit embodied procedures that are sensitive to the ever-changing complexities of the task. Therefore, the probabilistic nature of DBNs enables the translation of computational contributions into recommendations for evidence-based adaptation of performance by the embodied intelligence of the expert.
The application of computational ensembles to the ARAT assessment can be adapted to other complex task contexts. For example, in the ARAT, we enhanced observation through multi–view capture, which was linked to the development of a custom sub–action vocabulary. In surgery, one might add laparoscopic view modes linked to procedural phases. In sports, one may add broadcast angles and micro–technique phases. The abstractions of the DBN (explicit symbols, c4 edges, bidirectional inference, coherence priors, discovery/gating) remain constant, and the ensemble of AI modules is domain–specific. In each case, the DBN is the invariant translator; the AI ensemble is the adaptable measurement layer; the co–design loop ensures both remain aligned with expert intent for emerging human-AI collaboration.
Limitations and future work
Our approach emphasizes scalability and generalizability; yet both remain open challenges that we address through several research directions. First, the co-design program we advocate—iterative, participatory, and evidence-driven—requires sustained engagement with domain experts; this yields durable artifacts but does not scale immediately across many sites or tasks. Second, while the bidirectional DBN is domain-agnostic, each deployment requires porting the explicit, observable lexicons (Environment, Activity, Goals, Meaning) of the target complex task, as well as their symbolizers. This means that the methodology is best suited to complex tasks that have been at least partially formalized through expert practice. The methodology relies on these expert practitioners to map AI insights into enhanced practice. For example, in our physical therapy application, it is up to expert clinicians to map augmented assessment into customized therapy. Furthermore, we have tested our methodology only in asynchronous practice; applications where AI agents act synchronously with experts will require significant enhancements to real-time inference and interaction design.
A key opportunity for scalability lies in the transferability of evolved DBN networks. Once a network has been symbolized and validated for a particular complex task, it can serve as a pretrained model for related tasks—similar to how pretrained neural networks provide useful initializations for similar domains. This evolved network could initialize DBNs for related functional assessments in which the underlying EAGM structure exhibits significant overlap. In the context of rehabilitation, this would apply to other assessment instruments (e.g., the Wolf Motor Function Test and the Box and Blocks Test), to the assessment of therapy sessions, and to the development of training assistants for less-experienced therapists. This approach could substantially reduce the burden of co-design in new deployments while preserving the principled, evidence-driven nature of network evolution.
As a next step toward scalability, we will work with our partner clinic to build Explainable Augmented Automated Rehabilitation Assistant (xAARA) to assess therapy sessions in the clinic. xAARA will be explicitly positioned as an assistant, not an authority, and will surface automated assessments that help clinicians adapt therapy in real time. It will also support the integration of assessments and adaptations into the patient record for further analysis. As xAARA matures, we hope to adapt it for the automated assessment of therapy sessions in the home, where the system will provide summaries of patient progress to the therapist and allow the therapist to remotely review progress, adapt the schedule of exercises for the patient, and offer remote input on movement elements that the patient can focus on during therapy. We also plan to test the current ARAT assessment tool in other clinics as an assessment assistant and/or as a therapist training tool. Across these applications, we plan to measure convergence speed and final DBN quality relative to networks initialized from scratch.
In parallel, we will begin testing the porting of the methodology to educational and surgical contexts. Through these diverse applications, we hope to publish a portable “porting protocol” (vocabulary elicitation, view/interaction mapping, capture constraints, uncertainty audits, and network transfer guidelines) that enables new sites and tasks to leverage existing validated networks while adapting them to local contexts. The long-term vision is a library of pretrained DBN networks for families of related complex tasks, enabling rapid deployment of human-AI collaboration systems that inherit accumulated knowledge while remaining open to domain-specific adaptation.
Conclusion
We proposed a theory and a related methodology for designing and implementing human-AI collaboration in the performance of complex tasks. The theory differentiates human embodied intelligence from computational intelligence and hypothesizes opportunities for synergy in which artificial intelligence enhances human performance rather than attempting to replicate or replace it. The methodology leverages observable elements of human expert performance on complex tasks to build a computational ensemble for human-AI collaboration. At the core of this ensemble is a bidirectional Dynamic Bayesian Network (DBN) that computes a nested network representation (Environment, Activity, Goals, Meaning) across multiple temporal scales—from individual instants to actions, complete performances, and sequences of performances. The ensemble enhances explicit observation and analysis of complex task performance and provides recommendations that fit readily into the expert performer's workflow, reduce entropy, and increase performance confidence. The expert performer decides whether and how to apply the recommendations in their practice. Expert validation is fed back into the computational ensemble, improving computational insights and permanently updating the network structure. The methodology was successfully implemented for human-AI collaboration in physical therapy assessment. The methodology is portable to other experts' settings. Planned applications include transdisciplinary educational research (modeling student learning experiences) and surgical outcome prediction (real-time decision support). By combining an interpretable probabilistic translator (DBN) with targeted predictive modules (AI agents) and human embodied intelligence, this theory and methodology offer a practical path to developing AI assistants that are expert-aligned, auditable, and that become more confident—and more useful—with experience. AI is thus recontextualized as a tool to enhance human potential.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ackerman D. (1991). A Natural History of the Senses. New York, NY: Vintage.
- 2Ahlheim C. Stadler W. Schubotz R. I. (2014). Dissociating dynamic probability and predictability in observed actions—an f MRI study. Front. Hum. Neurosci. 8:273. doi: 10.3389/fnhum.2014.0027324847235 PMC 4019881 · doi ↗ · pubmed ↗
- 3Ahmed T. Rikakis T. Kelliher A. Wolf S. L. (2024). A hierarchical Bayesian model for cyber-human assessment of movement in upper extremity stroke rehabilitation. IEEE Trans. Neural Syst. Rehabil. Eng. 32, 3157–3166. doi: 10.1109/TNSRE.2024.345000839186425 · doi ↗ · pubmed ↗
- 4Ahmed T. Thopalli K. Rikakis T. Turaga P. Kelliher A. Huang J.-B. . (2021). Automated movement assessment in stroke rehabilitation. Front. Neurol. 12:720650. doi: 10.3389/fneur.2021.72065034489855 PMC 8417323 · doi ↗ · pubmed ↗
- 5ALPA (2025). Air Line Pilots Association, International. ALPA. Available online at: https://www.alpa.org (Accessed February 3, 2026).
- 6Barsalou L. W. Niedenthal P. M. Barbey A. K. Ruppert J. A. (2003). Social embodiment. Psychol. Learn. Motiv. 43, 43–92. doi: 10.1016/S 0079-7421(03)01011-9 · doi ↗
- 7Benner P. (2004). Using the dreyfus model of skill acquisition to describe and interpret skill acquisition and clinical judgment in nursing practice and education. Bull. Sci. Technol. Soc. 24, 188–199. doi: 10.1177/0270467604265061 · doi ↗
- 8Bernstein L. (1975). Leonard Bernstein Discussing Beethoven's 6th and 7th Symphony. Available online at: https://www.youtube.com/watch?v=Ou YY 1g V 8jh U (You Tube video) (Accessed February 3, 2026).