Sensitivity Analysis for Publication Bias in Diagnostic Meta‐Analysis of Sparsity Using the Copas t‐Statistic Selection Function
Taojun Hu, Yi Zhou, Xiao‐Hua Zhou, Satoshi Hattori

TL;DR
This paper introduces a new method to address publication bias in diagnostic meta-analyses, especially when data is sparse.
Contribution
The paper extends the Copas t-statistic model to the bivariate binomial framework for sparse diagnostic data.
Findings
The proposed method effectively addresses publication bias in sparse diagnostic meta-analyses.
Simulation studies confirm the method's practicality and improved performance over existing approaches.
Real-world applications demonstrate the method's utility in synthesizing diagnostic accuracy.
Abstract
Publication bias (PB) poses a significant threat to meta‐analysis of diagnostic studies, as studies yielding significant results are more likely to be published in scientific journals, leading to the synthesized diagnostic capacity possibly being overestimated. Sensitivity analysis provides a flexible method to address PB by assuming different proportions of unpublished studies. Most existing methods addressing PB in meta‐analysis of diagnostic studies are based on the bivariate normal model using normal approximations. However, they are unsuitable for meta‐analysis with sparse data, which is common in diagnostic studies with high sensitivities or specificities. Alternatively, the bivariate binomial model relies on the exact within‐study model and has better finite sample properties. To address PB in the bivariate binomial model, we model the selective publication process of diagnostic…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
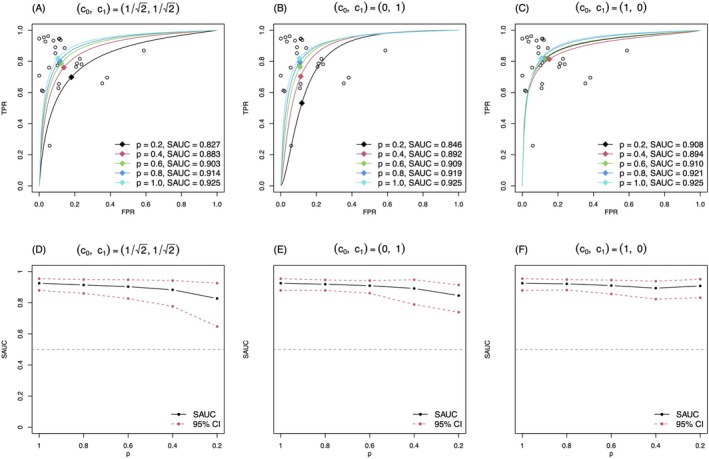 FIGURE 1
FIGURE 1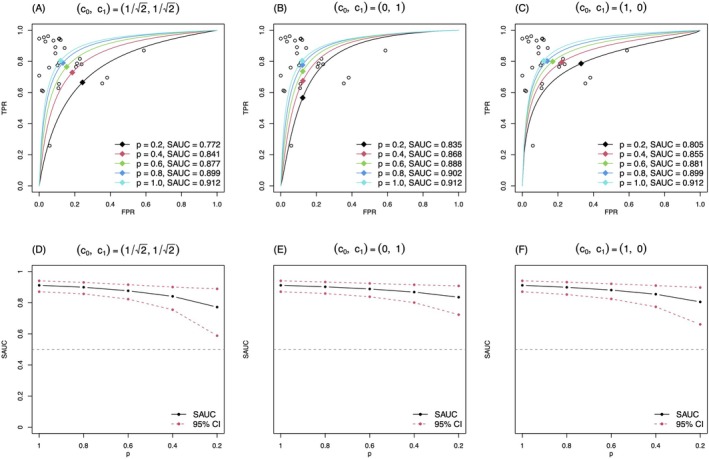 FIGURE 2
FIGURE 2| Study | Author | TP | FP | FN | TN | Cut‐off points |
|---|---|---|---|---|---|---|
| 1 | Icardi | 53 | 6 | 3 | 47 | 1.19 |
| 2 | Cid | 100 | 10 | 15 | 7 | 1.5 |
| 3 | Gamez‐Diaz | 266 | 73 | 138 | 133 | 1.7 |
| 4 | Groselj‐Gren | 13 | 6 | 4 | 23 | 1.86 |
| 5 | Gros | 91 | 16 | 54 | 132 | 2.2 |
| 6 | Bhandari | 89 | 63 | 39 | 102 | 2.3 |
| 7 | Groselj‐Gren | 17 | 0 | 7 | 12 | 2.38 |
| 8 | Groselj‐Gren | 19 | 3 | 10 | 24 | 2.45 |
| 9 | Dilli | 31 | 6 | 4 | 36 | 4.39 |
| 10 | Genel | 40 | 8 | 9 | 27 | 3.05 MFI |
| 11 | Tang | 50 | 10 | 14 | 32 | 8.5 MFI |
| 12 | Hussein | 17 | 2 | 1 | 16 | 43.5 MFI |
| 13 | Mokuda | 14 | 2 | 1 | 23 | 1800 mol |
| 14 | Nishino | 19 | 2 | 6 | 34 | 2000 mol |
| 15 | Doi | 19 | 1 | 12 | 67 | 2000 mol |
| 16 | Tanaka | 28 | 2 | 18 | 93 | 2000 mol |
| 17 | Matsui | 51 | 7 | 4 | 195 | 2000 mol |
| 18 | Allen | 23 | 4 | 4 | 40 | 2000 mol |
| 19 | Cardelli | 50 | 3 | 2 | 57 | 2398 mol |
| 20 | Livaditi | 35 | 0 | 2 | 10 | 2566 mol |
| 21 | Ng | 30 | 7 | 2 | 51 | 4000 mol |
| 22 | Hsu | 49 | 1 | 6 | 10 | 4300 mol |
| 23 | Lam | 107 | 37 | 29 | 137 | 6010 mol |
| 24 | Ng | 72 | 20 | 21 | 175 | 6136 mol |
| 25 | Ng | 91 | 25 | 24 | 198 | 6136 mol |
| 26 | Tillinger | 21 | 2 | 1 | 74 | 10 000 mol |
| 27 | Layseca‐Esp | 8 | 1 | 23 | 16 |
| S = 15 | S = 25 | S = 50 | S = 100 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Experiment | Rate (%) | Full | Published | Full | Published | Full | Published | Full | Published |
| 1 | Zero entries | 21.0 | 19.7 | 20.9 | 19.7 | 20.8 | 19.3 | 21.5 | 20.2 |
| No‐more‐than‐3‐entries | 80.5 | 75.4 | 80.4 | 74.9 | 80.8 | 75.2 | 81.0 | 75.8 | |
| No‐more‐than‐5‐entries | 93.4 | 90.1 | 93.3 | 90.0 | 93.8 | 90.2 | 93.5 | 90.2 | |
| 2 | Zero entries | 0.6 | 0.9 | 0.6 | 0.9 | 0.7 | 1.0 | 0.8 | 1.1 |
| No‐more‐than‐3‐entries | 15.0 | 18.3 | 14.9 | 18.6 | 15.1 | 18.4 | 15.7 | 18.4 | |
| No‐more‐than‐5‐entries | 38.4 | 43.1 | 38.2 | 43.5 | 38.4 | 43.2 | 38.8 | 42.9 | |
| 3 | Zero entries | 5.4 | 6.7 | 5.5 | 6.9 | 5.3 | 6.7 | 5.0 | 6.5 |
| No‐more‐than‐3‐entries | 50.0 | 47.8 | 49.4 | 46.9 | 49.5 | 47.0 | 48.2 | 46.0 | |
| No‐more‐than‐5‐entries | 73.6 | 70.7 | 73.3 | 70.2 | 73.5 | 70.3 | 72.9 | 70.2 | |
| 4 | Zero entries | 15.5 | 23.2 | 15.2 | 23.3 | 15.5 | 23.3 | 14.9 | 22.7 |
| No‐more‐than‐3‐entries | 63.6 | 70.5 | 63.2 | 70.7 | 63.6 | 70.9 | 64.2 | 71.3 | |
| No‐more‐than‐5‐entries | 80.2 | 84.7 | 80.3 | 84.9 | 80.7 | 85.1 | 81.6 | 85.8 | |
| 5 | Zero entries | 1.4 | 3.6 | 1.3 | 3.7 | 1.4 | 3.6 | 1.3 | 4.1 |
| No‐more‐than‐3‐entries | 21.4 | 30.5 | 21.5 | 30.4 | 21.1 | 30.1 | 21.5 | 30.9 | |
| No‐more‐than‐5‐entries | 45.9 | 54.4 | 45.9 | 54.1 | 44.9 | 53.5 | 45.3 | 54.0 | |
| 6 | Zero entries | 4.1 | 10.7 | 4.0 | 11.1 | 3.4 | 10.8 | 3.3 | 10.9 |
| No‐more‐than‐3‐entries | 40.0 | 50.7 | 40.7 | 51.5 | 39.2 | 50.7 | 40.5 | 51.6 | |
| No‐more‐than‐5‐entries | 64.4 | 71.8 | 64.5 | 72.2 | 63.7 | 71.6 | 64.0 | 71.7 | |
| S = 15 | S = 25 | S = 50 | S = 100 | |||
|---|---|---|---|---|---|---|
| Experiment | Method | TRUE | AVE (SD) | AVE (SD) | AVE (SD) | AVE (SD) |
| 1 | MLE with published studies | 83.2 | 87.5 (4.4) | 87.4 (3.5) | 87.6 (2.5) | 87.5 (1.7) |
| Method of Zhou et al. [ | 84.8 (4.3) | 84.8 (3.3) | 85.1 (2.4) | 85.1 (1.7) | ||
| Proposal with | 84.4 (5.8) | 83.9 (4.7) | 83.7 (3.4) | 83.6 (2.5) | ||
| Proposal with | 86.3 (4.9) | 86.3 (3.9) | 86.6 (2.8) | 86.4 (1.9) | ||
| Proposal with | 86.9 (4.8) | 87.4 (3.7) | 87.9 (2.6) | 87.3 (1.8) | ||
| 2 | MLE with published studies | 79.8 | 81.7 (7.4) | 82.7 (5.2) | 83.8 (3.7) | 84.4 (2.7) |
| Method of Zhou et al. [ | 76.2 (9.4) | 76.8 (7.0) | 78.0 (5.1) | 78.3 (3.9) | ||
| Proposal with | 79.1 (8.5) | 79.4 (6.6) | 80.1 (5.0) | 80.5 (3.9) | ||
| Proposal with | 82.0 (7.4) | 82.7 (5.1) | 83.7 (3.6) | 84.2 (2.8) | ||
| Proposal with | 78.6 (7.7) | 78.6 (5.6) | 79.0 (4.0) | 79.4 (2.9) | ||
| 3 | MLE with published studies | 86.9 | 88.8 (3.1) | 89.3 (2.4) | 89.7 (1.5) | 89.7 (1.0) |
| Method of Zhou et al. [ | 84.6 (4.3) | 85.0 (3.6) | 85.6 (2.5) | 85.7 (1.9) | ||
| Proposal with | 87.8 (4.1) | 88.1 (3.4) | 88.2 (2.5) | 88.0 (1.9) | ||
| Proposal with | 89.4 (3.5) | 90.1 (2.6) | 90.7 (1.7) | 91.0 (1.1) | ||
| Proposal with | 87.5 (3.3) | 87.7 (2.5) | 87.9 (1.7) | 87.8 (1.1) | ||
| 4 | MLE with published studies | 83.2 | 84.0 (3.1) | 84.1 (2.2) | 84.3 (1.5) | 84.3 (1.0) |
| Method of Zhou et al. [ | 81.2 (3.3) | 81.1 (2.3) | 81.1 (1.6) | 81.1 (1.1) | ||
| Proposal with | 83.0 (3.8) | 83.1 (2.8) | 83.3 (2.0) | 83.3 (1.3) | ||
| Proposal with | 83.9 (3.3) | 84.0 (2.3) | 84.2 (1.6) | 84.2 (1.1) | ||
| Proposal with | 84.0 (3.2) | 84.1 (2.2) | 84.2 (1.5) | 84.3 (1.1) | ||
| 5 | MLE with published studies | 79.8 | 80.9 (4.3) | 81.4 (3.0) | 81.4 (2.2) | 81.6 (1.5) |
| Method of Zhou et al. [ | 77.3 (5.5) | 77.6 (3.9) | 77.4 (2.8) | 77.4 (2.1) | ||
| Proposal with | 79.6 (5.7) | 80.3 (4.3) | 80.2 (3.4) | 80.3 (2.6) | ||
| Proposal with | 81.0 (4.5) | 81.5 (3.2) | 81.4 (2.3) | 81.4 (1.6) | ||
| Proposal with | 80.1 (4.6) | 80.6 (3.1) | 80.6 (2.3) | 80.7 (1.6) | ||
| 6 | MLE with published studies | 86.9 | 87.3 (2.3) | 87.5 (1.9) | 87.7 (1.3) | 87.8 (0.8) |
| Method of Zhou et al. [ | 84.0 (3.3) | 84.3 (2.5) | 84.4 (1.7) | 84.5 (1.1) | ||
| Proposal with | 87.0 (3.1) | 87.5 (2.7) | 87.8 (2.1) | 88.2 (1.2) | ||
| Proposal with | 87.8 (2.5) | 88.2 (2.1) | 88.5 (1.6) | 88.9 (1.2) | ||
| Proposal with | 86.9 (2.4) | 87.1 (2.0) | 87.2 (1.4) | 87.4 (0.8) |
- —Grant‐in‐Aid for Scientific Research
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMeta-analysis and systematic reviews · Agriculture, Soil, Plant Science · Statistical Methods and Bayesian Inference
Introduction
1
Diagnostic studies have long been utilized to assess the effectiveness of medical tests. These tests aim to determine the presence or absence of certain diseases in patients. For diagnostic studies involving continuous biomarkers, the Receiver Operating Characteristic (ROC) curve and the area under the ROC curve (AUC) offer thorough evaluations of diagnostic accuracy at all possible values of cutoff points of biomarkers. To increase the precision of diagnostic accuracy estimated from individual studies, meta‐analysis plays an important role in synthesizing the reported results from multiple studies and providing a comprehensive understanding of the accuracy of the diagnostic test. Suppose we are interested in the meta‐analysis of diagnostic studies. Diagnostics studies may not report the ROC curve and its AUC and often report only a pair of sensitivity and specificity with some cut‐off value. Since the cut‐off values to define the sensitivity and the specificity are often heterogeneous across studies, they are likely to correlate with each other negatively. Thus, summarizing sensitivity and specificity independently would be less appealing. The Summary Receiver Operating Characteristic (SROC) curve is an alternative way to obtain a summary evaluation of a diagnostic test. The SROC curve consolidates sensitivities and specificities from various studies by portraying the relationship between pairs of sensitivity and 1‐specificity over multiple individual studies [1, 2, 3]. The area under the SROC curve (SAUC) serves as a useful metric to evaluate the synthesized accuracy of diagnostic tests. There are two primary methods to estimate the SROC curve/SAUC. The first one is the bivariate normal model [2], which assumes that the logit‐transformed empirical sensitivity and specificity follow a joint normal distribution, relying on the central limit theorem for asymptotic normality, and estimates the parameters through maximizing the likelihood (ML) which is the product of a series of normal distributions. The other is based on the bivariate binomial model. Bayesian inference [3] and the maximum likelihood method [4] can be used for making inferences with the bivariate binomial model.
Since the bivariate binomial model does not rely on the asymptotic normality of the logit‐transformed empirical sensitivity and specificity in constructing the likelihood function, it enhances finite‐sample performance compared to the bivariate normal model. The bivariate binomial model especially addresses challenges presented by meta‐analysis with sparse data, that is, very few or even zero events occur. Suppose the following situation: we are interested in conducting a meta‐analysis of diagnostic studies with the true sensitivity or specificity being high and nearly 1 and with a small size of diseased or non‐diseased subjects. In such cases, the occurrence of the false positive, the non‐diseased subjects being falsely diagnosed as diseased, or the false negative, the diseased subjects being falsely diagnosed as non‐diseased, may fall into small values or even zero, which is called sparse data in meta‐analysis. The sparse data pose great threats to the bivariate normal model [2]. The reason is twofold: first, in the presence of zero frequencies, the logit‐transformed empirical sensitivity and specificity are not defined. To handle this situation with the bivariate normal model, a continuity correction is necessary and may introduce bias in inference [5]. Second, normal approximations for the logit‐transformed empirical sensitivity and specificity with sparse data are unsuitable. Instead, the bivariate binomial model avoids this issue by using the exact within‐study model, rendering itself more reliable in the presence of sparse data. Thus, the bivariate binomial model is more suitable for sparse meta‐analyses of diagnostic studies. We present examples of real‐world meta‐analyses to show the commonness of sparsity in meta‐analysis of diagnostic studies in Section 4. Note that the two models have been thoroughly compared and discussed in previous studies [6, 7, 8, 9]: Chu et al. [6] suggested the bivariate binomial model can easily replace the bivariate normal model. Harbord et al. [7] showed that the bivariate binomial model and bivariate normal model are highly related under specific parameter transformations. However, Chu et al. [10] commented on their relations and showed that the bivariate binomial model would reduce to the bivariate normal model only given a fixed‐effects alpha parameter. Rosenberger et al. [8] have shown the relative superiority of the bivariate binomial model in sparse data.
Besides the data sparsity, publication bias (PB) is another critical issue that influences the reliability of meta‐analyses. Studies with remarkable findings are more likely to be published, leading to an overrepresentation of positive findings. PB has been extensively studied in the standard univariate meta‐analysis of intervention studies. Methods including graphical methods and quantitative methods based on selection models have been proposed to address PB. We put a brief introduction of these related works in Web Appendix A. Among these methods, Copas [11] introduced a sensitivity analysis method to allow selection functions monotonic with the t‐statistic, or equivalently its p‐value. Studies with significant results, which are strongly related to small p‐values, are more likely published. Thus, Copas t‐statistics selection model is a natural choice. To the best of our knowledge, the only method incorporating the Copas t‐statistics selection model for PB in meta‐analysis of diagnostic studies is based on the bivariate normal model [12]. To make up for the lack of methods for addressing PB in meta‐analysis with sparse data of diagnostic studies, it is necessary to extend the Copas t‐statistics selection model to the bivariate binomial model.
In this paper, we propose a sensitivity analysis method to address PB in sparse meta‐analysis of diagnostic studies based on the Copas t‐statistics selection model with the bivariate binomial model. We derive the conditional likelihood given published studies based on the bivariate binomial model to make inferences about PB. In the iteration steps of maximizing the likelihood, intensive calculations of integrals are required in the calculations of the marginal selection probability. To address this computational issue, we propose approximation methods for calculating the marginal probability with high accuracy and small computational costs. We show the applicability of our proposal with both real‐world meta‐analyses of diagnostic studies of sparsity and simulation studies. The remainder of this article is structured as follows: Section 2 provides a concise overview of the bivariate binomial model without considering PB. Section 3 introduces the proposed sensitivity analysis method, which applies the Copas t‐statistics selection model to the bivariate binomial model; we also elaborate on our inference approaches. In Section 4, we illustrate our proposed sensitivity analysis with real‐world meta‐analyses. In Section 5, we further substantiate the performance of our proposal with simulation studies. Finally, Section 6 summarizes our methods as well as discusses our proposal with the previous related work.
Bivariate Binomial Model
2
Notations
2.1
Let us consider a meta‐analysis encompassing S published diagnostic studies. The number of subjects in the s‐th (s=1,⋯,S) study is represented as n(s). Each study evaluates the diagnostic capacity of the common continuous biomarker to determine the presence of the disease based on study‐specific cut‐off points. Without loss of generality, we assume that larger values of the biomarker indicate that the subject is more likely to contract the disease. Consequently, subjects are classified into the tested positive group, which is denoted by Xi(s)=1, if the biomarker is larger than the given cut‐off point, or the tested negative group, which is denoted by Xi(s)=0, if the biomarker is lower than that. Let the actual disease status of the subject ii=1,…,n(s) in the s‐th study be denoted by Di(s). We denote the number of subjects with test outcome Xi(s)=x and true disease status Di(s)=d as Nxd(s), and its realization as nxd(s), for x=0,1 and d=0,1. Thus, each study is supposed to offer the information of a 2 × 2 contingency table as Table 1. Within the contingency table, the true positive (TP) is n11(s); the true negative (TN) is n00(s); the false negative (FN) and false positive (FP) is n01(s) and n10(s), respectively. The total numbers of subjects with and without disease are denoted by n1(s) and n0(s) respectively.
Bivariate Binomial Model
2.2
Let the study‐specific True Positive Rate (TPR) and False Positive Rate (FPR) be denoted and defined by π1(s)=PXi(s)=1|Di(s)=1 and π0(s)=PXi(s)=1|Di(s)=0 respectively. The bivariate binomial model [3, 4] is defined by
where G(⋅) represents a known cumulative distribution function (c.d.f). A commonly used choice for G(⋅) is the standard logistic function, defined as G(x)=11+exp(−x). Without specific mentions, we use the standard logistic function for G(⋅) in this paper. Model (1) comes from the distributions of the latent biomarker of diseased (Di(s)=1) and non‐diseased subjects (Di(s)=0) following the logistic distribution. The parameter θ denotes the overall location of the biomarker distribution and θ(s) describes the heterogeneity from cut‐off values and some other sources over studies. The parameter α denotes the difference between the mean of the biomarker distributions of diseased and non‐diseased subjects and α(s) represents its heterogeneity over studies. A detailed explanation of parameters and interpretation of the bivariate binomial model was given in Appendix A of Hattori and Zhou [13]. Parameters θ(s) and α(s) are random‐effects, which are assumed to follow the bivariate normal distribution, given by
The within‐study model assumes TP and FP to follow a binomial distribution, defined as N11(s)∼Binomialn1(s),π1(s) and N10(s)∼Binomialn0(s),π0(s), respectively, conditional on θ(s) and α(s). Thus, the likelihood of the bivariate binomial model without accounting for PB is given by
with
where Θ=θ,α,β,σθ,σα. By integrating (1) over θ(s),α(s), the overall sensitivity and specificity are derived as,
The pair of the overall sensitivity and specificity is also called the summary operating point (SOP) [12]. If we let x represent 1‐specificity, then the sensitivity can be formulated as a function of x with respect to the parameters α and β, after eliminating θ. Thus, the SROC curve, which illustrates the relationship between sensitivity and 1‐specificity, is defined by [13]:
and the SAUC is defined by:
Most of the literature refers to the quantities defined by (4) and (5) as HSROC and HSAUC, respectively. In addition, Reitsma et al. [2] proposed another way to describe the relationship between sensitivity and 1‐specificity, named SROC and its SAUC. In Appendix A of Zhou et al. [12], the authors showed the equivalence between these two quantities. Thus, we refer to these quantities in (4) and (5) as SROC and SAUC instead, to avoid the unnecessary proliferation of terminology.
Sensitivity Analysis for Publication Bias
3
Selection Function
3.1
In this section, we aim to address PB with the Copas t‐statistics selection model for the bivariate binomial model. The bivariate nature of diagnostic studies makes it difficult to directly apply the original Copas t‐statistic selection model. In practice, the funnel plot on the lnDOR, which is defined by logit(spe) + logit(sen), is widely used to detect PB [14, 15]. Thus, the significance (or the t‐statistic) of the lnDOR is naturally selected as the key statistic of the selection model. To allow flexibility, we adopt the idea from Zhou et al. [12] that considers the linear combination of logit‐transformed sensitivity (denoted by logit(sen)) and specificity (denoted by logit(spe)) as the key statistic in the selection model, that is
where logit(x) is defined as logx1−x and c0,c1 are non‐negative coefficients indicating the weight of sensitivity or specificity in the selective mechanism. Zhou et al. [12] pointed out that the t‐statistics are scale‐invariant and they constrained c12+c02=1c0,c1∈[0,1] without loss of generality (see Web Appendix B). We followed their settings. For the s‐th study, the empirical key statistic is given by c0logn00(s)/n01(s)+c1logn11(s)/n10(s). The empirical variance for (6) is then derived as
for the s‐th study. Thus, the t‐statistic for (6) is given by
The t‐statistics for the lnDOR, sensitivity, specificity correspond to c0,c1=(1/2,1/2), c0,c1=(1,0), and c0,c1=(0,1), respectively. The selective publication process suggested by the significance of (6) from each study is modeled by the following selection function:
where H(⋅) is an arbitrary non‐decreasing function valued from 0 to 1. The probit function Φ(⋅) is adopted in this paper since it often makes the formula derivation simpler and is widely used in previous studies [11, 12]. Equation (8) indicates that when c0,c1=(1/2,1/2), the selective publication is determined by the significance of the lnDOR; when c0,c1=(0,1) or (1,0), the selective publication is determined by the significance of sensitivity or specificity, respectively. For studies with zero cells in the contingency table, t(s) is undefined. We apply the continuity correction, which is adding 0.5 to all the cells, and then calculate t(s). We note that the continuity correction is only used for calculating the study‐specific t‐statistic in the selection function (8) to model the selective publication and is not used in the exact likelihood of meta‐analysis.
Exact Conditional Likelihood Function and Strategies of Statistical Inference
3.2
In our likelihood‐based sensitivity analysis, we make inferences based on maximizing the likelihood conditional on the published. Previous likelihood‐based sensitivity analysis methods [12, 16, 17] are based on the bivariate normal model, and thus deriving and inferring the conditional likelihood is rather simple based on the nature of the bivariate normal distribution. Our method is based on the bivariate binomial model, where the within‐study model is the exact binomial distribution instead of the normal model. Thus, the likelihood combines both the probability mass function for discrete variables and density functions for continuous variables and involves complex summations of integrals. We need to tackle the computational issues in the estimation.
Based on the bivariate binomial model, the likelihood conditional on the published is derived as
where fPn11(s),n10(s),n01(s),n00(s) refers to P(N11(s)=n11(s),N10(s)=n10(s),N01(s)=n01(s),N00(s)=n00(s)|n1(s),n0(s)) in (2), while fPn1(s),n0(s) denotes the marginal probability mass function of n1(s),n0(s) in the population studies, and the denominator P(select) denotes the marginal selection probability.
We regard the marginal selection probability P(select)=p as the sensitivity parameter in our method. Given a fixed value of p, the probability of n1(s),n0(s) conditional on published is derived as
An equivalent form is
Then, integrating it over n1(s),n0(s) in both sides, we can derive
where EO means the expectation conditional on the published. We consider the empirical version of (11) by replacing the expectation conditional on published with the average over observed studies, that is
Combining with (10), the likelihood conditional on published (9) can be rewritten as
Thus, we can derive the log‐likelihood conditional on the published, that is,
Equation (12) poses a constraint on the likelihood. Parameters Θ,γ0,γ1 can be estimated by maximizing the log‐likelihood (13) with the constraint function (12). The last term of (13) is a constant with respect to the parameters. The first and third terms in the right of the equal sign of (13) are given by (2) and (8), respectively. The term Pselect|n1(s),n0(s) is special to the case of the bivariate binomial model and the corresponding part is of much simpler form in the normal‐approximation‐based models. The conventional normal‐approximation‐based models construct this term conditional on the within‐study standard errors for all studies and assume them to be randomly sampled from an unknown distribution. As the bivariate binomial distribution does not involve the within‐study standard errors in the likelihood, we construct this term conditional on the sample sizes, n1(s),n0(s), and assume that the sample sizes of published studies are random samples from an unknown distribution.
One difficulty of optimizing (13) lies in the calculation of Pselect|n1(s),n0(s) in (13) and (12). Specifically, we can express it by
with
It involves both the selection functions a(⋅) and the probability mass function for the bivariate binomial model fP(⋅). Thus, it is a function of Θ,γ0,γ1. For simplification, we denote tm11,n1(s),m00,n0(s) as t˜(s)m11,m00 in the following. As given in (2), fP(⋅) involves bivariate integration. Thus, we need to calculate many integrals in (14) and sum them up. This calculation is computationally demanding and may also suffer from the issue of error accumulation. We address the problem through an approximation approach. We regard m11,m00 as random variables following binomial distributions, that is, m11∼Binomialn1(s),p1(s) and m00∼Binomialn0(s),p0(s). Then (14) can be re‐expressed by Pselect|n1(s),n0(s)=Et˜(s)m11,m00Hγ0+γ1t˜(s)m11,m00, where Et˜(s)m11,m00 implies the expectation with respect to the distribution of t˜(s)m11,m00. We use the asymptotic normality properties of the statistics t˜(s)m11,m00 to approximate its true distribution and then derive an approximation for Pselect|n1(s),n0(s). While the direct calculation for (14) needs continuity correction to compute t˜(s)m11,m00 if any of m11,n1(s)−m11,m00 or n0(s)−m00 is zero, our approximation method avoids using the continuity correction. The proof of the asymptomatic normality for t˜(s)m11,m00 and the derivation of its asymptomatic expectation and variance are presented in the Web Appendix C.
To make inferences with the constraint (12), we derive the parameter γ0 as a function of the remaining parameters based on the constraint function (12) given the fixed value of p, denoted by γ^0=γ^0Θ,γ1;p. This is because Pselect|n1(s),n0(s) is a function of Θ,γ0,γ1 and it is easy to show that Pselect|n1(s),n0(s) is a monotone function of γ0 given Θ,γ1 based on the monotonicity of a(⋅), ranging from 0 to 1. Thus, γ0 can be expressed as a function of Θ,γ1 by solving (12) when p∈(0,1). After eliminating γ0, the parameters in (13) are left to Θ,γ1. The maximum likelihood estimates (MLE) of the parameters are denoted by Θ^,γ^1. We estimate the asymptomatic variance matrix for the parameters Θ through the inverse of the observed Fisher information matrix, denoted by ∑^. The SROC curve and SAUC in the presence of PB can be estimated through the plug‐in of Θ^ to the expressions of SROC curve (4) and SAUC (5). The resulting estimator for SAUC is denoted by SAUC^=SAUC(α^,β^). The variance of the SAUC can be estimated through the Delta method, that is
where the superscript T means the transpose of the vector and the ∑^α,β is the submatrix of ∑^ corresponding to the components for (α,β).
We construct a 95% confidence interval (CI), which is always within [0,1] by applying the Delta method with some transformation g from (0,1) to (−∞,∞). The asymptomatic expectation and variance of g‐transformed SAUC are given by g(SAUC^) and g′(SAUC^)2Var(SAUC^), respectively, where g′=dg(x)/dx. The reconstructed 95% CI for SAUC can be expressed as
A common choice for g is the logit function, g(x)=log(x/(1−x)). By varying the values of marginal selection probabilities p within 0 and 1, one could know the impact of PB through the changes of estimates for the parameters and the SAUC.
Application
4
We illustrated our sensitivity analysis method with the meta‐analysis conducted by Li et al. [18]. This meta‐analysis evaluated the effectiveness of the neutrophil CD64 expression as a biomarker to differentiate infected patients from non‐infected ones with bacterial infection with 27 individual studies. The data are presented in Table 2. Of the 27 independent studies, two studies (No. 7 and 20) had zero frequencies of FP, and most of the other studies had very low frequencies of FP or FN. In the original paper, Li et al. [18] estimated the SAUC as 0.925 (95% CI: [0.880, 0.954]), highlighting the potential of neutrophil CD64 expression as a promising biomarker for diagnosing bacterial infection. The overall sensitivity and specificity were estimated as 0.819 (95% CI: [0.687, 0.951]) and 0.895 (95% CI: [0.823, 0.967]), respectively. It pointed out that the meta‐analysis suffered much from PB since Egger's test showed a remarkable trend of PB (p<0.001). The original paper did not address how PB could affect the estimate of the SAUC. Zhou et al. [12] used this dataset for their illustration, and the issue of sparsity was overlooked in their analysis. We re‐evaluate the impact of PB in this meta‐analysis using the proposed method. We conducted sensitivity analysis setting p=0.2,0.4,0.6,0.8,1 with three specified selective mechanisms: c0,c1=(1/2,1/2),(0,1) and (1,0). Note that p=1 implies the analysis assumes no selective publication, and the estimates should be the same in the bivariate binomial model and our proposal.
The results of the proposed method are presented in Figure 1. In the upper panels of Figure 1, we depicted the estimated SROC curves under various ps with the three settings of c0,c1. Zhou et al. [12] presented that tracing the SOP, that is the pair of (sensitivity, specificity), over p was useful to characterize what kind of selective process was considered with the supposed selection function. Thus, we also present the SOPs for this purpose. As shown in panel (A) of Figure 1, the plots of the SOPs suggested a selective publication process under which studies around the lower right part of the SROC curve were less likely published. Recall that the SOP of the original analysis (p=1) was (0.819,0.895) and it moved up to (0.755,0.869) with p=0.2. The change of the SROC curve and SAUC suggested that the test accuracy was robust against the selective publication mechanism determined by the significance of the lnDOR. Tracing the SOPs in panels (B) to (C) of Figure 1, one could understand that the selection function with c0,c1=(0,1) and (1,0) modeled different publication mechanisms and the figures indicated that impacts by the selective publication mechanisms determined by only sensitivity or specificity would be minor: SOP was moved to (0.529,0.884) with c0,c1=(0,1) under p=0.2, where specificity only changed by −0.011 from 0.895 to 0.884; and SOP was moved to (0.818,0.891) with c0,c1=(1,0) under p=0.2, where sensitivity only changed by −0.001 from 0.819 to 0.818.
The estimated SROC curves and SAUC under three selective publication mechanisms in CD64 example with the bivariate binomial model (our proposal).
We showed the estimated SAUC with varying p in panels (D) to (F) of Figure 1. The SAUC was 0.925 (95% CI: [0.880, 0.954]) without accounting for selective publication (p=1). With all specified values of p, the lower bounds for SAUCs were larger than 0.5 under all three selective mechanisms, suggesting the effectiveness of neutrophil CD64 expression in diagnosing bacterial infection since SAUC = 0.5 indicated that the diagnostic test result was a random guess. The estimated SAUC under p=0.2 is much lower than that under p=1 under all three selective publication mechanisms, suggesting the potential impact of selective publication for this example; ignoring PB will lead to an overestimation of the SAUC.
We also conducted the sensitivity analysis based on the bivariate normal model by Zhou et al. [12] for comparisons. Although the parameterizations between the bivariate binomial and bivariate normal models are different, Harbord et al. [7] showed there was a correspondence between the parameters of the bivariate normal model and those of the bivariate binomial model. Each model has its definition of the SROC curve and SAUC; the bivariate binomial model naturally leads to the SROC curve (4) and SAUC (5), whereas Reitsma et al. [2] introduced an alternative definition of the SROC with the bivariate normal model. With the correspondence between the parameters of the two models, one may derive the SROC curve/SAUC with (4) and (5) even if the bivariate normal model is used for parameter estimation. The formula to this end is given in Equation (A1) of Zhou et al. [12]. The estimated SROC curves with the bivariate normal model were given in panels (A) to (C) of Figure 2, assuming different selective mechanisms under p=0.2,0.4,0.6,0.8,1; the variation of SAUC was shown in panels (D) to (F) of Figure 2. We could observe that the bivariate normal model obtained lower estimates for the SAUC compared with the bivariate binomial model. The differences between Figures 1 and 2 can be attributed to the ignorance of tackling the sparsity by the bivariate normal model. As shown in Figures 1 and 2, using the exact within‐study model instead of applying normal approximation would give a higher estimate for SAUC in this example. For example, the SAUC by the bivariate binomial model with p=0.2 was 0.827 whereas that by the bivariate normal model was 0.771.
The estimated SROC curves and SAUC under three selective publication mechanisms in CD64 example with the bivariate normal model by Zhou et al. [12].
We also analyzed two additional meta‐analysis datasets of diagnostic studies to show the wide applicability of our proposal. The results were placed in the Web Appendices D and E.
Simulation Studies
5
We evaluated the performance of the proposed methods with simulation studies. We considered three sets of overall sensitivity and specificity in (3): (0.9, 0.5), (0.5, 0.9), and (0.8, 0.8) given the link function G(⋅) as the standard logistic function. With the scale parameter β=0.15 set, we determined three settings of θ and α by solving (3). We set the standard deviation of cut‐off parameters and accuracy parameters σθ,σα=(0.6,1.2),(1.2,0.6) to see if the performance of our proposal would be affected by varying the variance parameters. Thus, we considered 6 scenarios for data generation and the parameters are summarized in the Web Appendix F. We considered simulating small‐scale, medium‐scale, and relatively large‐scale, and large‐scale meta‐analyses with S˜(S˜=15,25,50,100) published and unpublished studies.
Under each scenario, we generated 1000 independent meta‐analyses with S˜ studies. For each dataset, the number of subjects with the disease, n1(s), was sampled from a discrete uniform distribution U(10,30), and the number of subjects without the disease, n0(s), sampled from the U(200,300), mirroring real‐world disparities in subject numbers. The variations in cut‐off and accuracy parameters across studies, θ(s) and α(s), were sampled from normal distributions N0,σθ2 and N0,σα2, respectively. Then we set π1(s) and π0(s) according to (1). n11(s) and n10(s) were generated from binomial distributions Binomialn1(s),π1(s) and Binomialn0(s),π0(s), respectively. The sampled n11(s),n10(s) and n01(s),n00(s)=n1(s)−n11(s),n0(s)−n10(s) constituted the 2 × 2 contingency tables for both published and unpublished studies.
We considered the selection function based on the t‐statistics for the lnDOR, which corresponded to c0,c1=(1/2,1/2) in (7). With the selection parameter γ1 set at 1.5, we sought for γ0 satisfying the 1/S˜∑s=1S˜Pselect|ni1(s),ni0(s)=p as P(select)=∫Pselect|ni1(s),ni0(s)fPni1(s),ni0(s)dni1(s)dni0(s), given the fixed marginal publication probability p as 0.7, indicating that approximately 70% of studies would be selectively published. To simulate the selective publication process, we decided whether an individual study would be published or not by a Bernoulli distribution, BernΦγ0+γ1t(s).
To confirm whether the generated dataset had sparsity, we evaluated the proportion of the studies with zero entries in the 2 × 2 contingency table among all the studies (published and unpublished), as well as among the published studies. In addition, we evaluated the proportion of the studies with cell frequencies of no more than 3 and no more than 5. Their averages over the 1000 simulated datasets are summarized in Table 3. It indicates that we successfully generated meta‐analyses of sparsity.
We applied our proposed method to only published studies and compared our proposal with the sensitivity analysis proposed by Zhou et al. [12] based on the bivariate normal model. Specifying p=0.7 and the t‐statistics with c0,c1=(1/2,1/2) in (7), we summarized the estimates for parameters in the model and the SAUC in Table 4. The average for the SAUC by maximizing the likelihood with the bivariate binomial model with only published studies (denoted as the MLE with published studies) had a non‐ignorable discrepancy with the true value, indicating that PB was a considerable issue for this dataset. Both the proposed method and the method by Zhou et al. [12] successfully reduced biases. Our proposed method had smaller biases than the method by Zhou et al. [12]. In addition, the empirical standard error, which is the standard deviation of point estimators for 1000 independent meta‐analyses [19], of our proposed method continued to decrease as the meta‐analysis size S˜ increased, further validating the superior performance of our proposed method. We also showed the estimated SAUC with two misspecified t‐statistics in the selection function (7) corresponding to c0,c1=(0,1) and (1,0) in Table 4. We observed that the misspecification of the t‐statistics in the selection function could lead to a slightly larger bias compared with that under the correctly specified t‐statistics. Correct specification of the t‐statistics in the selection function could remove the bias. Except for the estimates of SAUC, we showed the estimates of (θ,α) in the bivariate binomial model and the pairs of sensitivity and specificity in Web Table 6. It substantiated that our proposed method could also obtain the least bias for these parameters and statistics among the three methods.
We show the results with simulation datasets under the true selective mechanisms with c0,c1=(0,1) and (1,0) in Web Appendix G.
To validate the robustness under various marginal selection probabilities p, we conducted additional simulation studies with the same setups as the one in this section but changing the marginal selection probability p from 0.7 to 0.5. It reflects a heavier missing publication case where around 50% of studies are supposed to be unpublished. We showed the summary results in Web Appendix H. The average of SAUCs under our proposed method was closer to the true values compared with the method by Zhou et al. [12], suggesting the advantage of the bivariate binomial model in sparse meta‐analysis. In addition, the estimate by our proposed method in Table 4 and Web Table 12 are very close, indicating the robustness of our proposed method across various marginal selection probabilities. In addition, we compared the proposed method with existing ones when the marginal selection probability was misspecified. We applied the proposed and related methods assuming p=0.5 to the simulation datasets, which had p=0.7. The results were summarized in Web Appendix I. We found that even though the SAUC estimated by our proposed method contained unignorable bias under misspecified p, they were still less biased compared to the method by Zhou et al. [12] in most scenarios, indicating the advantage of our proposed method in sparse diagnostic meta‐analyses.
Discussion
6
We proposed an exact likelihood‐based sensitivity analysis method to address PB in meta‐analyses of diagnostic studies with sparse data. Most existing sensitivity analysis methods rely on the normal approximation for the pair of empirical logit‐transformed sensitivities and specificities, while we utilize the bivariate binomial model that uses the exact within‐study binomial model. The bivariate binomial model is more suitable for sparse meta‐analyses and possesses better finite sample performance. To our knowledge, Hattori and Zhou [13] is the only sensitivity analysis method for PB in the bivariate binomial model. They used the Heckman‐type selection function. Their method described a selective publication process under which studies of larger sample sizes and larger AUC were more likely to be published. On the other hand, the method for the SROC was designed to make inferences based on the observations of pairs of sensitivity and specificity, and some studies might not report the AUC. Thus, the publication of such studies would be determined by sensitivity and specificity rather than the AUC. To address this issue, we extended the Copas t‐statistics selection model to the bivariate binomial model. Our selection function defines selective publication processes by the observed statistics of each study and its cut‐off value. Such selective publication based on observed quantities would be more appealing. Since the true structure of the selective publication is unknown, we cannot determine which selection model would be more reliable between the Copas‐Heckman and Copas t‐statistics selection models. It is important to evaluate robustness against various kinds of potential selective publication processes. Our development provides a useful tool to evaluate the potential impacts of selective publication processes alternative to the Copas‐Heckman selection model. The results of the real applications and simulation studies showed the feasibility of our proposal in practical situations, especially for sparse meta‐analyses of diagnostic studies. We consider the selection function as a monotone function with the t‐statistics of the linear combination of logit‐transformed sensitivity and specificity. Our methods can reflect several publication mechanisms including those determined by lnDOR, sensitivity, and specificity. However, the true underlying publication mechanism is not easy to identify or even verify with limited information from only published studies. Thus, we recommend conducting a comprehensive sensitivity analysis with multiple selection functions corresponding to various t‐statistics or c0,c1 in practice. In addition, Zhou et al. [12] proposed a joint estimation of model parameters and c0,c1 in the selection model for the bivariate normal model. We also tried to assume c0,c1 as parameters to estimate rather than hyperparameters and jointly estimate them with other model parameters in the bivariate binomial model. We found the optimization was not stable and often fell into non‐convergence. It is appealing to develop a more robust estimation method to overcome the computational issue so that the c0,c1 can be estimated for sparse meta‐analyses in the future.
Though the use of the bivariate binomial model can avoid continuous correction when a zero cell occurs, we have to apply continuous correction to compute t‐statistics in the selection model. For those studies with zero cells, the sensitivity/specificity/DOR is undefined, thus, the continuity correction is unavoidable to describe the selective mechanism. Thus, from this perspective, our proposal has reduced the effect of continuity correction to a minimum. However, the use of continuity correction will still lead to inductive bias in the results especially in meta‐analysis with a large proportion of studies containing zero cells in the selection function. It is warranted in future research to define relevant selection functions completely free from influential continuity correction.
We took a sensitivity analysis approach with the marginal selection probability p fixed. In reality, p is unknown. Thus, we need to consider several values of the marginal selection probability. Even with this difficulty, which is a common issue in the sensitivity analysis, our simulation study revealed that the proposed method is better suited for sparse meta‐analysis. Li et al. [17] proposed EM algorithms to quantitatively estimate the parameters in the bivariate normal model and the SROC curve/SAUC, adjusting for PB without assuming a given selection probability. Their methods are based on the Copas‐Heckman selection model. It would be interesting to develop methods to adjust for PB in sparse meta‐analysis of diagnostic studies with the Copas t‐statistics selection functions, without specifying the sensitivity parameters and the marginal selection probability. Moreover, in this paper, we modeled the selection function only with t‐statistics. Other study characteristics can influence publication. It would be very important to investigate how to handle the covariate‐specific selection function in future work.
Funding
This work was supported by Grant‐in‐Aid for Scientific Research, 25K03086 from the Ministry of Education, Science, Sports and Technology of Japan.
Conflicts of Interest
The authors declare no conflicts of interest.
Supporting information
Data S1: Supporting Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1L. E. Moses , D. Shapiro , and B. Littenberg , “Combining Independent Studies of a Diagnostic Test Into a Summary ROC Curve: Data‐Analytic Approaches and Some Additional Considerations,” Statistics in Medicine 12, no. 14 (1993): 1293–1316.8210827 10.1002/sim.4780121403 · doi ↗ · pubmed ↗
- 2J. B. Reitsma , A. S. Glas , A. W. Rutjes , R. J. Scholten , P. M. Bossuyt , and A. H. Zwinderman , “Bivariate Analysis of Sensitivity and Specificity Produces Informative Summary Measures in Diagnostic Reviews,” Journal of Clinical Epidemiology 58, no. 10 (2005): 982–990.16168343 10.1016/j.jclinepi.2005.02.022 · doi ↗ · pubmed ↗
- 3C. M. Rutter and C. A. Gatsonis , “A Hierarchical Regression Approach to Meta‐Analysis of Diagnostic Test Accuracy Evaluations,” Statistics in Medicine 20, no. 19 (2001): 2865–2884.11568945 10.1002/sim.942 · doi ↗ · pubmed ↗
- 4P. Macaskill , “Empirical Bayes Estimates Generated in a Hierarchical Summary ROC Analysis Agreed Closely With Those of a Full Bayesian Analysis,” Journal of Clinical Epidemiology 57, no. 9 (2004): 925–932.15504635 10.1016/j.jclinepi.2003.12.019 · doi ↗ · pubmed ↗
- 5T. Stijnen , T. H. Hamza , and P. Özdemir , “Random Effects Meta‐Analysis of Event Outcome in the Framework of the Generalized Linear Mixed Model With Applications in Sparse Data,” Statistics in Medicine 29, no. 29 (2010): 3046–3067.20827667 10.1002/sim.4040 · doi ↗ · pubmed ↗
- 6H. Chu and S. R. Cole , “Bivariate Meta‐Analysis of Sensitivity and Specificity With Sparse Data: A Generalized Linear Mixed Model Approach,” Journal of Clinical Epidemiology 59, no. 12 (2006): 1331–1332.17098577 10.1016/j.jclinepi.2006.06.011 · doi ↗ · pubmed ↗
- 7R. M. Harbord , J. J. Deeks , M. Egger , P. Whiting , and J. A. Sterne , “A Unification of Models for Meta‐Analysis of Diagnostic Accuracy Studies,” Biostatistics 8, no. 2 (2007): 239–251.16698768 10.1093/biostatistics/kxl 004 · doi ↗ · pubmed ↗
- 8K. J. Rosenberger , H. Chu , and L. Lin , “Empirical Comparisons of Meta‐Analysis Methods for Diagnostic Studies: A Meta‐Epidemiological Study,” BMJ Open 12, no. 5 (2022): e 055336.10.1136/bmjopen-2021-055336 PMC 908664435534072 · doi ↗ · pubmed ↗