A multi-dimensional pyramid strategy for limited sample classification of hyperspectral cropland imagery
Mingchao Yang

TL;DR
This paper introduces MDPC-Net, a new method for classifying crops in hyperspectral images using limited samples, achieving high accuracy with lower computational cost.
Contribution
MDPC-Net combines a multi-dimensional pyramid with a Transformer to improve hyperspectral crop classification with limited labeled data.
Findings
MDPC-Net outperforms six classical models in classification accuracy on three datasets.
The method reduces computational complexity while maintaining high performance.
The approach effectively balances accuracy and efficiency in limited sample conditions.
Abstract
Hyperspectral crop classification is often challenged by substantial intra-class spectral variability, high inter-class similarity, and the scarcity of high-quality labeled samples. These issues frequently lead to insufficient feature fusion or excessive computational complexity in conventional classification methods. To address these problems, this study proposes MDPC-Net, a limited sample hyperspectral crop classification method that couples a multi-dimensional pyramid with a Transformer architecture. The model extracts crop features from spectral, spatial, and joint spectral–spatial dimensions to capture fine-grained characteristics. A feature reorganization strategy is further incorporated to effectively reduce dimensional redundancy, while the Transformer modules enhance global dependency modeling, thereby improving the discrimination of crop features in complex environments.…
Click any figure to enlarge with its caption.
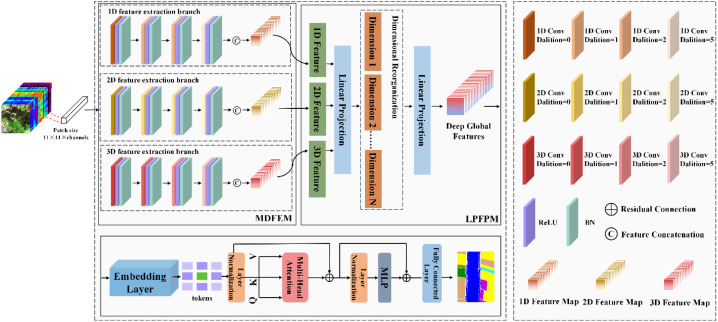 Figure 1
Figure 1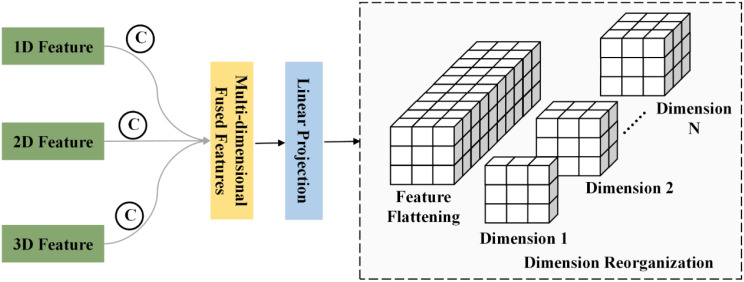 Figure 2
Figure 2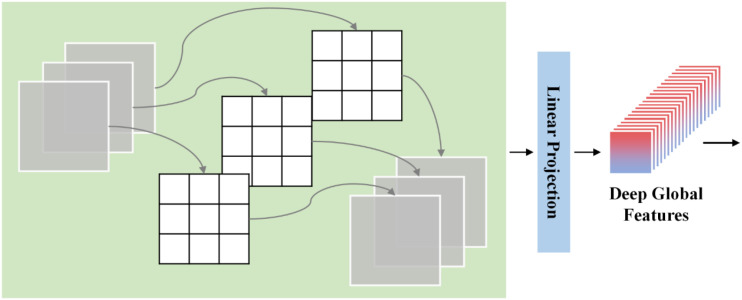 Figure 3
Figure 3 Figure 4
Figure 4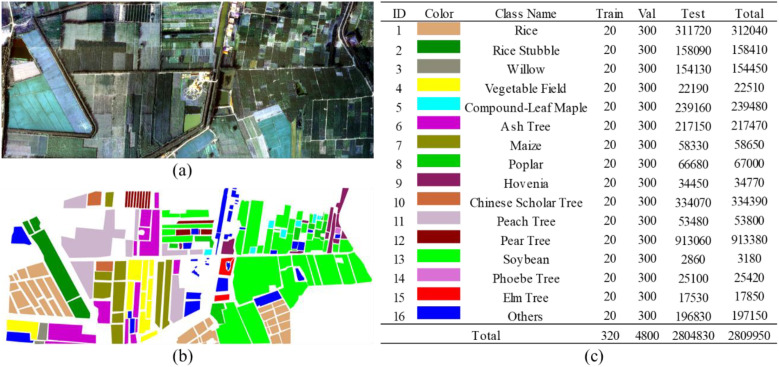 Figure 5
Figure 5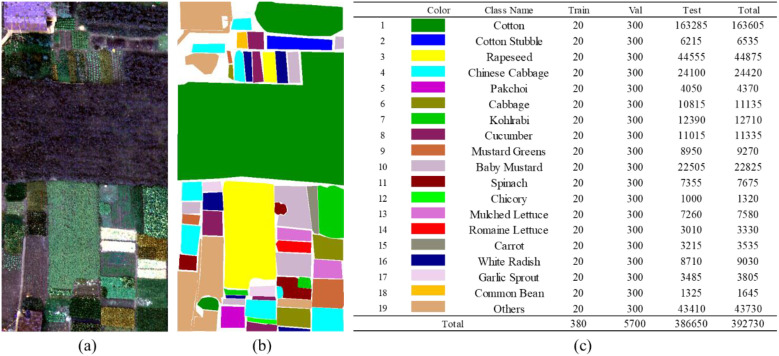 Figure 6
Figure 6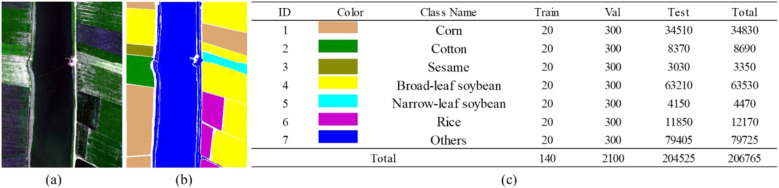 Figure 7
Figure 7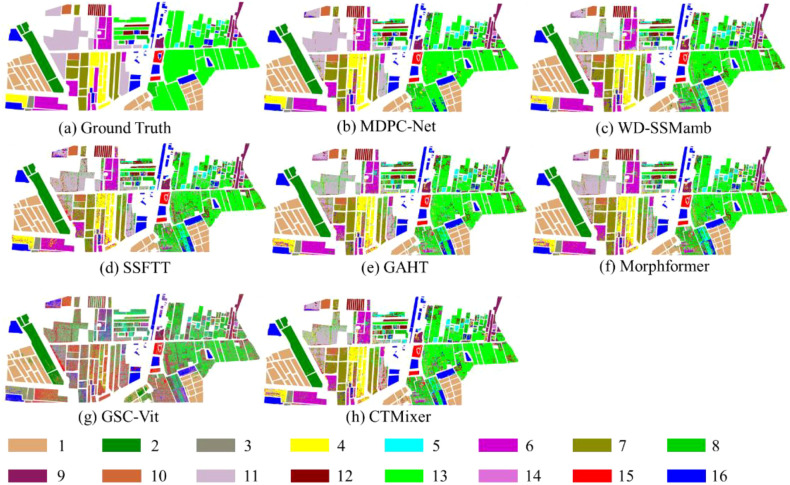 Figure 8
Figure 8 Figure 9
Figure 9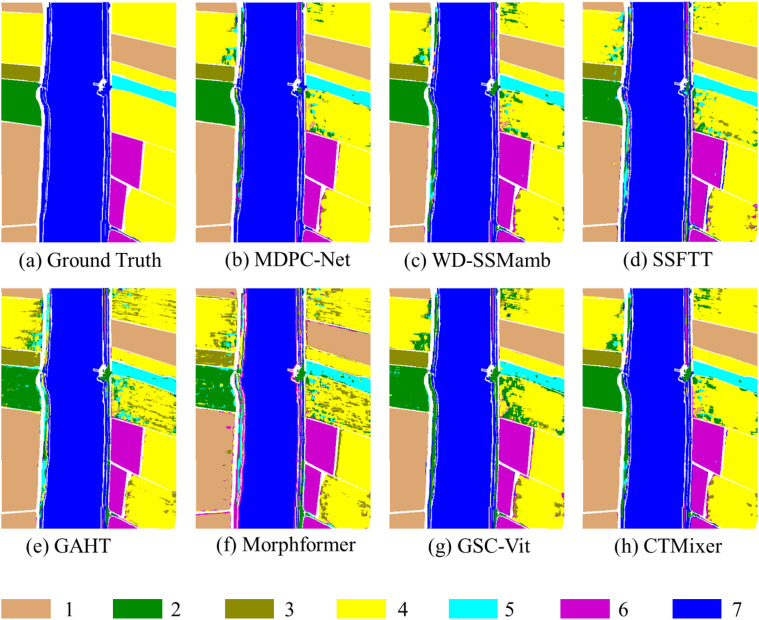 Figure 10
Figure 10| Label | SSFTT | GAHT | Morphformer | GSC-Vit | CTMixer | WD-SSMamb | MDPC-Net | |
|---|---|---|---|---|---|---|---|---|
| 1 | Rice | 98.77 ± 0.52 | 98.48 ± 0.47 | 98.74 ± 0.53 | 98.70 ± 0.43 | 99.36 ± 0.51 | 99.39 ± 1.52 |
|
| 2 | Rice Stubble | 99.43 ± 0.37 | 99.37 ± 0.50 | 99.16 ± 0.62 | 98.93 ± 1.02 | 99.63 ± 0.33 | 99.41 ± 1.08 |
|
| 3 | Willow | 85.01 ± 1.30 | 81.84 ± 1.72 | 79.10 ± 1.78 | 81.78 ± 1.85 | 86.56 ± 2.19 | 96.02 ± 1.65 |
|
| 4 | Vegetable Field | 77.17 ± 4.18 | 76.52 ± 3.42 | 73.38 ± 1.07 | 77.37 ± 4.53 | 78.22 ± 2.54 | 92.24 ± 1.89 |
|
| 5 | Compound-Leaf Maple | 76.78 ± 1.16 | 73.10 ± 2.04 | 73.21 ± 2.28 | 74.94 ± 3.12 | 81.52 ± 2.05 | 91.43 ± 1.12 |
|
| 6 | Ash Tree | 74.18 ± 2.31 | 76.50 ± 4.24 | 76.29 ± 1.68 | 77.15 ± 3.85 | 81.14 ± 2.71 | 90.45 ± 0.74 |
|
| 7 | Maize | 74.82 ± 2.75 | 73.34 ± 4.05 | 71.50 ± 2.92 | 70.64 ± 4.11 | 81.68 ± 2.01 | 89.82 ± 0.84 |
|
| 8 | Poplar | 88.44 ± 1.14 | 88.29 ± 1.89 | 87.14 ± 2.00 | 87.20 ± 0.79 | 89.33 ± 2.10 | 94.96 ± 1.20 |
|
| 9 | Hovenia | 89.02 ± 2.18 | 91.61 ± 1.48 | 90.54 ± 1.45 | 90.87 ± 0.98 | 92.96 ± 2.80 | 98.19 ± 0.63 |
|
| 10 | Chinese Scholar Tree | 68.28 ± 2.67 | 68.25 ± 1.67 | 66.27 ± 4.78 | 66.42 ± 3.79 | 70.11 ± 5.26 | 87.98 ± 1.92 |
|
| 11 | Peach Tree | 87.65 ± 2.10 | 88.09 ± 2.99 | 86.10 ± 2.81 | 88.94 ± 3.63 | 89.35 ± 1.64 | 97.05 ± 1.15 |
|
| 12 | Pear Tree | 62.14 ± 1.65 | 59.46 ± 2.81 | 57.38 ± 2.87 | 59.85 ± 7.02 | 62.46 ± 3.61 | 78.35 ± 0.55 |
|
| 13 | Soybean | 99.44 ± 0.78 | 98.74 ± 0.78 | 99.02 ± 0.26 | 99.09 ± 0.52 | 99.51 ± 0.52 | 99.47 ± 1.64 |
|
| 14 | Phoebe Tree | 96.77 ± 0.50 | 96.64 ± 1.15 | 96.72 ± 0.69 | 97.49 ± 0.80 | 96.65 ± 0.52 | 98.5 ± 0.70 |
|
| 15 | Elm Tree | 96.24 ± 0.39 | 96.06 ± 1.27 | 94.10 ± 1.19 | 94.28 ± 0.88 | 96.97 ± 1.06 | 98.97 ± 0.66 |
|
| 16 | Others | 84.99 ± 1.32 | 83.70 ± 1.26 | 84.85 ± 1.34 | 84.60 ± 1.20 | 86.52 ± 1.19 | 90.2 ± 1.04 |
|
| OA | 76.47 ± 0.36 | 75.16 ± 1.28 | 74.03 ± 1.04 | 78.26 ± 1.76 | 75.26 ± 3.14 |
|
| |
| AA | 84.95 ± 0.19 | 84.38 ± 0.83 | 83.34 ± 0.73 | 87.00 ± 0.69 | 84.26 ± 1.32 |
|
| |
| K×100 | 73.11 ± 0.38 | 71.64 ± 1.39 | 70.46 ± 1.12 | 75.12 ± 1.91 | 71.80 ± 3.35 |
|
| |
| Label | SSFTT | GAHT | Morphformer | GSC-Vit | CTMixer | WD-SSMamba | MDPC-Net | |
|---|---|---|---|---|---|---|---|---|
| 1 | Cotton | 93.55 ± 2.00 | 93.32 ± 1.86 | 95.67 ± 1.20 | 95.68 ± 1.69 |
| 94.94 ± 1.42 | 96.24 ± 1.42 |
| 2 | Cotton Stubble | 91.54 ± 2.95 | 90.43 ± 2.73 | 92.73 ± 3.86 | 92.18 ± 3.06 | 92.28 ± 1.42 | 95.09 ± 1.8 |
|
| 3 | Rapeseed | 91.44 ± 1.85 | 87.64 ± 2.96 | 89.79 ± 3.13 | 88.93 ± 1.50 | 90.73 ± 2.34 | 93.96 ± 1.67 |
|
| 4 | Chinese Cabbage | 66.10 ± 5.30 | 61.54 ± 4.91 | 61.99 ± 2.90 | 67.10 ± 3.97 | 66.70 ± 2.57 | 72.85 ± 1.38 |
|
| 5 | Pakchoi | 68.72 ± 3.09 | 57.23 ± 7.23 | 67.85 ± 10.04 | 64.05 ± 6.77 | 68.20 ± 5.79 |
| 80.27 ± 3.86 |
| 6 | Cabbage | 97.23 ± 1.51 | 94.29 ± 2.57 | 97.41 ± 0.40 | 95.59 ± 1.70 | 97.25 ± 1.15 | 97.53 ± 1.0 |
|
| 7 | Kohlrabi | 85.55 ± 3.12 | 73.83 ± 4.55 | 84.16 ± 6.87 | 78.18 ± 3.61 | 81.19 ± 2.88 | 87.40 ± 1.54 |
|
| 8 | Cucumber | 69.61 ± 4.29 | 62.71 ± 4.51 | 66.54 ± 6.25 | 70.78 ± 5.38 | 72.29 ± 5.08 | 80.21 ± 1.89 |
|
| 9 | Mustard Greens | 74.27 ± 4.62 | 70.36 ± 7.12 | 74.11 ± 4.86 | 75.62 ± 5.61 | 73.58 ± 2.97 | 77.42 ± 1.06 |
|
| 10 | Baby Mustard | 67.55 ± 5.04 | 61.71 ± 5.88 | 66.78 ± 6.48 | 67.15 ± 3.30 | 63.53 ± 4.72 | 71.23 ± 1.17 |
|
| 11 | Spinach | 90.09 ± 2.71 | 77.24 ± 4.75 | 88.17 ± 0.90 | 81.52 ± 4.81 | 87.00 ± 1.80 | 93.38 ± 0.72 |
|
| 12 | Chicory | 97.30 ± 1.72 | 95.50 ± 4.15 | 95.90 ± 3.53 | 94.80 ± 3.04 | 96.60 ± 2.52 | 96.48 ± 1.56 |
|
| 13 | Mulched Lettuce | 92.07 ± 3.00 | 89.71 ± 3.61 | 92.44 ± 3.90 | 90.45 ± 2.45 | 93.06 ± 2.06 | 93.73 ± 1.2 |
|
| 14 | Romaine Lettuce | 92.66 ± 3.47 | 92.99 ± 3.58 | 95.32 ± 3.00 | 94.52 ± 3.99 | 95.15 ± 2.75 | 96.99 ± 1.39 |
|
| 15 | Carrot | 92.53 ± 2.19 | 87.34 ± 3.91 | 91.63 ± 3.47 | 92.72 ± 2.67 | 93.16 ± 3.32 | 96.15 ± 1.33 |
|
| 16 | White Radish | 90.36 ± 2.34 | 83.04 ± 4.73 | 85.15 ± 2.20 | 86.06 ± 4.11 | 87.99 ± 4.38 | 91.38 ± 0.55 |
|
| 17 | Garlic Sprout | 93.46 ± 1.91 | 94.09 ± 3.01 | 93.17 ± 2.97 | 93.92 ± 2.31 | 96.76 ± 2.20 | 97.07 ± 1.09 |
|
| 18 | Common Bean | 96.08 ± 2.41 | 90.49 ± 6.98 | 95.70 ± 3.19 | 94.11 ± 2.20 | 94.49 ± 4.48 | 97.12 ± 1.21 |
|
| 19 | Others | 75.57 ± 1.87 | 76.66 ± 3.28 | 78.20 ± 3.48 | 77.46 ± 1.71 | 77.57 ± 2.99 | 78.94 ± 1.55 |
|
| OA | 86.33 ± 1.11 | 83.89 ± 1.17 | 86.76 ± 1.33 | 86.65 ± 1.12 | 87.50 ± 0.70 | 88.98 ± 1.48 |
| |
| AA | 85.56 ± 0.85 | 81.06 ± 0.95 | 84.88 ± 1.71 | 84.25 ± 1.02 | 85.49 ± 0.46 | 88.99 ± 0.88 |
| |
| K×100 | 82.84 ± 1.32 | 79.82 ± 1.39 | 83.32 ± 1.64 | 83.19 ± 1.35 | 84.21 ± 0.83 | 86.83 ± 0.51 |
| |
| Label | SSFTT | GAHT | Morphformer | GSC-Vit | CTMixer | WD-SSMamb | MDPC-Net | |
|---|---|---|---|---|---|---|---|---|
| 1 | Corn | 98.66 ± 0.59 | 98.21 ± 0.61 | 96.97 ± 2.01 | 98.42 ± 1.11 | 99.30 ± 0.28 | 99.03 ± 1.29 |
|
| 2 | Cotton | 98.58 ± 0.61 | 89.65 ± 5.76 | 96.63 ± 2.83 | 95.07 ± 2.16 | 95.79 ± 2.60 |
| 97.29 ± 1.10 |
| 3 | Sesame | 97.66 ± 0.70 | 96.30 ± 0.90 | 94.55 ± 4.09 | 98.55 ± 0.69 | 98.25 ± 0.71 | 99.12 ± 0.87 |
|
| 4 | Broad-leaf soybean | 91.13 ± 2.20 | 87.07 ± 3.29 | 87.32 ± 3.05 | 87.03 ± 2.71 | 90.38 ± 2.14 | 99.25 ± 1.45 |
|
| 5 | Narrow-leaf soybean | 94.07 ± 2.48 | 89.59 ± 5.28 | 92.67 ± 4.48 | 94.51 ± 3.72 | 94.36 ± 1.46 | 95.24 ± 1.76 |
|
| 6 | Rice | 98.52 ± 1.45 | 99.54 ± 0.32 | 97.80 ± 0.42 | 99.58 ± 0.22 | 98.39 ± 1.04 | 99.18 ± 0.92 |
|
| 7 | Others | 92.56 ± 2.04 | 92.08 ± 2.05 | 88.69 ± 2.31 | 92.08 ± 2.32 | 94.19 ± 1.93 | 95.37 ± 0.76 |
|
| OA | 93.84 ± 0.64 | 91.91 ± 1.50 | 90.69 ± 2.27 | 92.29 ± 1.33 | 94.25 ± 0.30 | 94.72 ± 0.87 |
| |
| AA | 95.88 ± 0.54 | 93.21 ± 1.62 | 93.52 ± 2.43 | 95.03 ± 0.47 | 95.81 ± 0.45 | 95.84 ± 0.56 |
| |
| K×100 | 91.63 ± 0.84 | 89.07 ± 1.94 | 87.50 ± 2.95 | 89.58 ± 1.73 | 92.15 ± 0.41 | 93.54 ± 0.76 |
| |
| Datasets | 1D/2D/3D | MDFEM | LPFPM | OA | AA | K×100 |
|---|---|---|---|---|---|---|
| Matiwan Village | ✔ | ✔ | 85.82 ± 2.49 | 92.67 ± 0.88 | 84.16 ± 2.61 | |
| ✔ | ✔ | 86.11 ± 1.67 | 93.25 ± 0.79 | 85.63 ± 1.78 | ||
| ✔ | ✔ |
|
|
| ||
| WHU-HongHu | ✔ | ✔ | 84.90 ± 0.47 | 82.03 ± 1.30 | 81.00 ± 0.60 | |
| ✔ | ✔ | 87.50 ± 0.70 | 85.49 ± 0.46 | 84.21 ± 0.83 | ||
| ✔ | ✔ |
|
|
| ||
| WHU-LongKou | ✔ | ✔ | 92.88 ± 1.05 | 93.89 ± 0.86 | 90.35 ± 1.37 | |
| ✔ | 93.83 ± 0.67 | 95.66 ± 0.48 | 91.61 ± 0.88 | |||
| ✔ | ✔ |
|
|
|
| Datasets | Methods | Parameters/M | FLOPs/M |
|---|---|---|---|
| Matiwan Village | SSFTT | 1.190 | 62.557 |
| GAHT | 1.498 | 181.149 | |
| Morphformer | 0.244 | 45.698 | |
| GSC-Vit | 0.708 | 49.073 | |
| CTMixer | 0.612 | 74.314 | |
| WD-SSMamba |
|
| |
|
| 0.295 | 33.506 | |
| WHU-HongHu | SSFTT | 1.255 | 65.999 |
| GAHT | 1.515 | 183.100 | |
| Morphformer | 0.256 | 48.206 | |
| GSC-Vit | 0.711 | 49.506 | |
| CTMixer | 0.613 | 74.364 | |
| WD-SSMamba |
|
| |
|
| 0.306 | 34.807 | |
| WHU-LongKou | SSFTT | 1.254 | 65.998 |
| GAHT | 1.514 | 183.100 | |
| Morphformer | 0.255 | 48.205 | |
| GSC-Vit | 0.711 | 49.506 | |
| CTMixer | 0.612 | 74.362 | |
| WD-SSMamba |
|
| |
|
| 0.305 | 34.806 |
- —National Key Research and Development Program of China10.13039/501100012166
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRemote-Sensing Image Classification · Remote Sensing in Agriculture · Advanced Image Fusion Techniques
Introduction
1
Precise crop classification forms the foundation for agricultural production management (Tang et al., 2024), policy formulation, and food security, providing essential information for decision support in agricultural systems (Guerri et al., 2024). Hyperspectral imagery (HSI), with its exceptionally high spectral resolution, captures subtle reflectance variations across continuous wavelength ranges, and has therefore been widely employed in hyperspectral image–based crop classification (HSICC) (Khan et al., 2024; Ullah et al., 2025).
However, crop classification remains challenging due to the intrinsic variability of agricultural ecosystems (Aasen et al., 2018). Growth-stage differences and stress conditions within the same crop species often lead to the “same object, different spectra” phenomenon, whereas spectral similarity among different crops in certain wavelength regions results in the “different objects, same spectrum” problem (Gallo et al., 2023). Both issues substantially reduce inter-class separability. Meanwhile, acquiring large quantities of high-quality, pixel-level annotated samples in farmland environments is costly and labor-intensive, making data scarcity a persistent bottleneck for supervised HSICC and motivating increasing interest in limited sample learning paradigms (Gao et al., 2017). Traditional machine learning approaches rely heavily on handcrafted spectral indices and texture descriptors for feature extraction and dimensionality reduction (Ali et al., 2023), followed by statistical or shallow learning algorithms such as support vector machines (SVM), random forests (RF), k-nearest neighbors (KNN), linear discriminant analysis (LDA), and naïve Bayes (NB) for classification. These methods depend strongly on expert experience in feature engineering and are prone to the “curse of dimensionality” when dealing with high-dimensional spectral data (Hamidi et al., 2021). Moreover, they typically treat spectral and spatial information independently and lack end-to-end joint learning capabilities (Konduri et al., 2020; Khan et al., 2023). As a result, they fail to model deeper spectral–spatial relationships, making it difficult to distinguish spectrally similar crop types in complex agricultural environments and limiting their ability to achieve fine-grained classification in real-world farmland scenes.
Deep learning methods have been increasingly applied to HSICC tasks in recent years and have achieved remarkable progress (Chandrasekharan et al., 2016). By constructing multi-layer nonlinear mappings, deep learning establishes an end-to-end learning mechanism capable of automatically capturing intricate spectral features and spatial contextual dependencies in hyperspectral data (Agilandeeswari et al., 2022). Convolutional neural networks (CNNs) are widely used to extract spectral–spatial features of crops. One-dimensional CNNs (1D-CNNs) focus primarily on spectral sequence modeling while neglecting spatial neighborhood information (Hu et al., 2015), limiting their ability to differentiate spectrally similar crops in farmland scenes with blurred boundaries or mixed pixels. Two-dimensional CNNs (2D-CNNs) can extract spatial textures but are insufficient in modeling complex inter-band spectral dependencies, which constrains their ability to capture subtle spectral differences among crop varieties (Nazeri et al., 2019). Three-dimensional CNNs (3D-CNNs) jointly extract spectral–spatial features but suffer from high computational complexity and require large amounts of high-quality annotated samples—conditions often unmet in real agricultural environments—thereby restricting their practical applicability (Fernandes et al., 2019). Moreover, CNN-based methods inherently emphasize local neighborhood information and often fail to capture global dependencies, making their predictions susceptible to salt-and-pepper noise.
To alleviate the dependence on large-scale labeled data, limited sample learning has recently emerged as an effective paradigm for remote sensing image classification limited sample limited sample approaches can be broadly categorized into three groups. Metric-based methods learn embedding spaces in which samples are classified based on similarity measures, enabling knowledge transfer from base classes to novel classes with limited samples. Meta-learning-based approaches aim to acquire task-agnostic initialization or learning strategies that can rapidly adapt to new classes under limited sample settings. More recently, transformer-inspired limited sample frameworks have been explored to leverage global contextual modeling and attention mechanisms for improved feature generalization. Despite their success in natural image domains, these methods face notable challenges when applied to hyperspectral data, including high spectral dimensionality, complex spectral–spatial coupling, and severe intra-class variability, which often lead to degraded generalization performance under extremely limited training samples.
To overcome these limitations and enhance global feature modeling in HSICC, researchers have explored improved CNN variants and Transformer-based architectures. (Roy et al. (2020) proposed HybridSN (Roy et al., 2020), a hybrid spectral CNN that integrates 3D-CNN and 2D-CNN layers to improve spectral–spatial feature representation while controlling model complexity. SqueezeNet (Iandola et al., 2016) employs pointwise convolutions to reduce feature dimensionality, followed by multi-scale convolutions, significantly compressing parameter counts. MobileNets (Howard et al., 2017) utilize depthwise separable convolutions to build lightweight neural networks by applying a single filter to each input channel, greatly reducing computational costs. Although these models achieve lower computational complexity, their classification accuracy remains limited. To enhance global context modeling, Wang et al. (2023) introduced ESSAN (Wang et al., 2023), which incorporates dilated convolutions and Transformer modules to improve large-scale feature perception and contextual representation (Tu et al., 2022). further introduced a pixel aggregation strategy that groups homogeneous regions and integrates them into a hierarchical Transformer framework, enabling adaptive multi-scale feature construction and more effective modeling of local spatial semantics (Michelon et al., 2023; Liang et al., 2024). These developments improve the model’s ability to perceive field shapes, crop distribution patterns, and critical spectral bands.
Despite recent advances, existing HSICC methods still struggle to simultaneously ensure low computational complexity and high classification accuracy. The growing demand for efficient and precise crop mapping in precision agriculture poses new challenges for model design and feature organization. SANet (Zhang et al., 2024) integrates spectral and contextual information while emphasizing intra-spectral autocorrelation. By combining spatial–spectral non-local blocks with multi-scale spectral self-attention (SSA), SANet allocates more attention resources to spatial and spectral dimensions and models inherent spectral–spatial correlations, thereby strengthening the representation of contextual structures and key spectral dimensions (Al Duhayyim et al., 2023) (Chen et al., 2024). introduced FrFSSPN, a frequency–spectral–spatial prototype network based on fractional Fourier transform, which integrates frequency-domain information with spectral–spatial representations to enlarge inter-class separability while preserving intra-class consistency. CMTNet (Guo et al., 2025) further enhances model robustness under limited sample conditions by incorporating a spectral–spatial feature extraction module for shallow features and enforcing cross-level constraints to improve classification stability (Lu et al., 2024; Guo et al., 2025).
Although these methods partially address data scarcity and global dependency modeling, most existing limited sample HSICC frameworks still rely on fragmented feature extraction pipelines or incur substantial computational overhead when integrating multi-dimensional information. In particular, the extremely high spectral resolution of hyperspectral imagery poses challenges for attention-based mechanisms, which may overemphasize long-range dependencies while neglecting local spectral–spatial structures. These limitations highlight the need for a unified and efficient architecture that can effectively balance representation capability and computational efficiency under limited sample settings.
Although these methods utilize CNN variants and Transformers to capture global dependencies and consider crop-specific growth variability, significant challenges remain for multi-channel hyperspectral tasks. Current HSICC models still suffer from fragmented feature extraction pipelines, making it difficult to effectively integrate features across multiple dimensions and thereby limiting their ability to capture complex spectral–spatial characteristics of crops. Moreover, as network depth increases, feature fusion modules often lead to substantial computational overhead, which restricts their adaptability to practical applications. Due to the extremely high spectral resolution of HSI, the multi-head self-attention (MHSA) mechanism may focus excessively on long-range global dependencies while overlooking local spatial structures. These limitations highlight the need for a unified architecture capable of balancing representation ability and computational efficiency.
To address these challenges, this study proposes a novel HSICC framework named MDPC-Net (Multi-Dimensional Pyramid Coupling Transformer Network), which integrates a multi-dimensional progressive feature extractor, a linear-projection pyramid fusion module, and Transformer-based global semantic modeling. First, three parallel progressive dilated convolution branches—1D, 2D, and 3D—are designed to extract spectral, spatial, and joint spectral–spatial features from different data dimensions. Second, the linear-projection feature pyramid reorganizes and fuses multi-dimensional features while reducing computational cost. Finally, Transformer modules leverage multi-head self-attention and multilayer perception mechanisms to capture global semantic dependencies across spectral–spatial domains.
The main contributions of this work are summarized as follows:
A multi-dimensional feature extraction backbone based on progressive dilated convolutions is proposed. Three parallel branches (1D, 2D, and 3D) capture hyperspectral features from different dimensions, while progressive dilation enables multi-level receptive field aggregation.A linear-projection feature pyramid fusion module is designed. This module employs multi-scale depthwise separable convolutions to extract spatial features at different scales and reorganizes these features into a unified representation, enhancing multi-scale perception.A unified architecture combining the multi-dimensional feature backbone, linear-projection pyramid, and Transformer is developed. This design effectively models global spectral–spatial dependencies and strengthens the discrimination of crops with similar spectral signatures. Experiments on three datasets demonstrate that MDPC-Net achieves high classification accuracy while maintaining low computational complexity.
Methods
2
Overall architecture of MDPC-net
2.1
The overall architecture of MDPC-Net is illustrated in Figure 1. The model consists of three components: A multi-dimensional feature extraction backbone based on progressive dilated convolutions, a linear-projection feature pyramid for multi-branch feature fusion, and an embedding and Transformer-based feature integration module for final representation learning and classification.
The overall network architecture of MDPC-Net.
First, for each pixel in the original HSI, an image patch of size is extracted and used as the basic processing unit. The patch is simultaneously fed into three parallel branches—1D, 2D, and 3D—to extract features from different data dimensions. All three branches employ progressive dilated convolutions, where zeros are inserted between convolutional kernel elements to gradually enlarge the receptive field without increasing the number of parameters or computational cost. This design enables the model to capture fine-grained local details while progressively learning broader global dependencies.
The feature maps obtained from the three branches are then forwarded to the linear-projection feature pyramid module. Through a linear mapping, features from all branches are projected into a unified dimensional space. The multi-dimensional features are then partitioned along the channel dimension into several groups for structural reorganization. A subsequent linear projection aggregates these reorganized groups to form deep, globally enriched representations.
Finally, the resulting global features are transformed into token sequences via an embedding layer and fed into the Transformer module. The Transformer captures long-range dependencies and facilitates comprehensive feature interactions across different scales, further enhancing the model’s ability to interpret complex spectral–spatial characteristics of crops in hyperspectral imagery.
Multi-dimensional feature extraction module
2.2
Conventional convolution is a fundamental operation in convolutional neural networks, where a kernel slides over the input with a predefined stride, and each kernel element is multiplied with the corresponding input element and summed to produce the output. The receptive field of standard convolution is determined by the kernel size. When larger-scale contextual information is required, the kernel size must be increased, which inevitably leads to a substantial growth in the number of parameters and computational cost. Furthermore, standard convolution extracts features at a single scale, making it insufficient for inputs containing multi-scale structures, as it may fail to capture comprehensive feature information.
Dilated convolution extends standard convolution by inserting zeros between kernel elements, where the dilation rate controls the spacing between sampled positions. This mechanism enlarges the receptive field without increasing the kernel size or parameter count, enabling the model to capture broader contextual information. However, using a fixed dilation rate restricts the receptive field to a single scale, potentially missing information at other scales and leading to the so-called “gridding effect,” which degrades feature extraction performance.
Equations 1, 2 present the effective kernel size and receptive field (RF) size of dilated convolution, respectively:
where denotes the effective kernel size, represents the size of the original convolution kernel, and is the dilation rate. denotes the receptive field size of the -th dilated convolution layer, and represents the stride of the -th layer.
The Multi-Dimensional Feature Extraction Module (MDFEM) adopts a multi-scale representation strategy based on Progressive Dilated Convolution (PDC). The core idea of PDC is to construct hierarchical receptive fields through an increasing sequence of dilation rates. In our design, a dilation rate sequence of is employed, which mathematically forms a receptive field pyramid. To further enhance the model’s capability in capturing diverse characteristics of hyperspectral data, three parallel branches—1D, 2D, and 3D—are incorporated to extract features from different dimensional perspectives.
The 1D branch applies one-dimensional convolution to focus on spectral-domain features, enabling the extraction of subtle variations along the spectral signatures. The 2D branch employs two-dimensional convolution to learn spatial information, such as structural patterns and textural details within hyperspectral imagery. The 3D branch uses three-dimensional convolution to jointly model the spectral and spatial dimensions, thereby capturing integrated spectral–spatial representations. The outputs from the three branches are flattened along the spatial dimension and concatenated to form a unified feature tensor. The fused feature representations of each branch are formulated in Equations 3–5, respectively.
where , , and denote the feature maps extracted from the 1D, 2D, and 3D branches, respectively. , , and represent the outputs of the 1D, 2D, and 3D convolutions with dilation rates , respectively.
Linear-projection feature pyramid module
2.3
The core idea of the Linear-Projection Feature Pyramid Module (LPFPM) is to capture spatial features at multiple scales through depthwise convolutions (DC) and to fuse these features to enhance the model’s ability to perceive multi-scale information. Specifically, the multi-dimensional feature maps , , and produced by the MDFEM are first concatenated to obtain the fused representation . The formulation is given in Equation 6:
Next, is passed through a linear projection layer to reduce its feature dimensionality, yielding . This dimensionality reduction step effectively decreases the computational cost of the subsequent convolutional operations and improves overall efficiency. The process is formulated in Equation 7.
Subsequently, the reduced feature representation is flattened and partitioned into groups along the channel dimension, forming feature maps with different dimensional configurations. Each group is processed by convolutional layers of different scales, as illustrated in Figure 2. This operation is formulated in Equation 8:
Feature fusion and reorganization.
where denote the groups of feature vectors obtained after channel-wise partitioning.
Finally, depthwise pointwise convolution (DPC) is applied to the feature maps of different dimensional groups. Depthwise convolution is a special form of grouped convolution in which the number of groups is equal to the number of input channels, meaning that each channel is processed independently with its own convolution kernel while the number of output channels remains unchanged (Figure 3). Since no cross-channel interaction is involved and each channel uses a separate filter, this decomposition significantly reduces the number of parameters and computational cost.
Depthwise pointwise convolution.
Assuming that the input feature map is , a standard convolution with a kernel size of and output channels results in a computational cost , as defined in Equation 9. In comparison, the computational cost of depthwise pointwise convolution (DPC) is denoted as , as shown in Equation 10.
After applying DPC, the reduction in the number of parameters, denoted as , is calculated as shown in Equation 11.
Transformer encoder
2.4
The Transformer encoder consists of an embedding layer, a multi-head self-attention (MHSA) mechanism, and a multi-layer perceptron (MLP), as illustrated in Figure 4. First, the deep global features extracted by the LPFPM are transformed into a sequence of tokens that can be processed by the Transformer architecture. The tokens are then passed through a layer normalization operation to stabilize the feature distribution prior to attention computation. The encoder follows a standard Transformer architecture, configured with a token dimension of 64, a depth of 1 layer, 8 attention heads, an MLP hidden dimension of 8, and a dropout rate of 0.1.
Transformer architecture.
First, the spectral-spatial features extracted by the parallel 2D, 1D, and 3D convolutional branches are fused by the Multi-scale Receptive Field Fusion (MRFP) module. The MRFP employs three parallel depth-wise convolutions at different scales (original, downsampled, and upsampled) to capture multi-contextual information, followed by feature concatenation and a pointwise convolution for fusion. These fused deep global features are then projected and transformed into a sequence of tokens for processing by the Transformer. Specifically, the tokenization process is implemented via two sets of learnable projection matrices, which compress the spatial-spectral feature sequence into a fixed number of 4 tokens, each with a dimension of 64. The tokens, along with a prepended learnable classification token, are subsequently passed through a layer normalization operation to stabilize the feature distribution prior to attention computation.
In the MHSA module, each pixel-level feature vector is projected into three independent subspaces—query (Q), key (K), and value (V)—allowing the model to capture feature relationships across different representation subspaces. The outputs from multiple attention heads are then concatenated and linearly transformed to project them back into the output space, which reduces dimensionality while retaining essential information. The similarity between the query and key vectors is computed as shown in Equation 12:
The dot-product operation between and reflects the similarity between the two vectors. To obtain normalized attention weights, a softmax function is applied, converting the similarity matrix into an attention weight matrix. The resulting attention weights are then multiplied with the value vectors , enabling each token to attend to other tokens and capture complex relationships such as “different spectra within the same region” and “similar spectra across different regions,” thereby uncovering intrinsic spectral variations within crops.
The MLP is a fundamental feed-forward neural network that ensures unidirectional information flow. Data enter from the input layer, are processed through one or more hidden layers, and finally pass to the output layer, with no feedback connections between layers. The output of the MLP layer is formulated in Equation 13:
where , and , represent the weights and biases of the two linear transformations, respectively, and denotes the nonlinear activation function. To mitigate covariate shift and provide more stable gradient signals, normalization layers are introduced before both the MHSA and MLP blocks.
Data sources
3
In this section, we introduce the three hyperspectral datasets used in our experiments. The original HSI images and the corresponding ground-truth label maps are illustrated in Figures 5–7. For all datasets, non-crop categories are uniformly assigned to an “other” class.
Original image and sample labels of the matiwan village dataset. (a) Original image. (b) Sample labels. (c) Color mapping of categories and pixel counts of training, validation, and test sets.
Original image and sample labels of the WHU-HongHu dataset. (a) Original image. (b) Sample labels. (c) Color mapping of categories and pixel counts of training, validation, and test sets.
Original image and sample labels of the WHU-LongKou dataset. (a) Original image. (b) Sample labels. (c) Color mapping of categories and pixel counts of training, validation, and test sets.
Matiwan Village dataset
3.1
The first dataset was acquired from aerial hyperspectral imagery collected in Matiwan Village, Xiong’an New Area, Baoding City, Hebei Province, China. The dataset contains 256 spectral bands covering a wavelength range of 400–1000 nm, with a spectral resolution of 2.1 nm. The spatial resolution of the imagery is 0.5 m, and the scene consists of 3750 × 1580 pixels. A total of 18 land-cover categories are present in the dataset, among which 16 crop types are selected as the target classes for this study, while the remaining categories are grouped into an “other” class.
WHU-HongHu dataset
3.2
The second dataset was collected on November 20, 2017, in Honghu City, Hubei Province, China. During data acquisition, parts of the UAV-based hyperspectral imagery were slightly affected by cloud occlusion. The dataset covers a spatial extent of 940 × 475 pixels with a spatial resolution of 0.043 m and contains 270 spectral bands. It consists of a variety of complex crop types, with certain categories (e.g., Chinese cabbage and bok choy) exhibiting high spectral similarity. A total of 22 land-cover classes are included in the dataset, among which 19 crop types are selected as the target categories for this study, while the remaining classes are grouped into an “other” category.
WHU-LongKou dataset
3.3
The third dataset was acquired on July 17, 2018, using UAV-based hyperspectral imaging in Longkou Town, Hubei Province, China. Weather conditions during acquisition were clear, with no cloud or rainfall interference. The dataset has a spatial size of 400 × 550 pixels with an approximate spatial resolution of 0.463 m. It contains 270 spectral bands spanning a wavelength range of 400–1000 nm. A total of nine land-cover categories are present in the dataset, among which seven crop types are selected as the target classes for this study, while the remaining categories are assigned to an “other” class.
Experimental settings and results
4
Experimental settings
4.1
(1) Parameter settings: To ensure fairness and reproducibility, all experiments were conducted on a workstation equipped with an Intel(R) Core(TM) i9-14900KF CPU, an NVIDIA GeForce RTX 5090 GPU, and 128 GB RAM. All models were implemented and trained using the PyTorch deep learning framework. The number of training epochs was set to 500. Each experiment was repeated five times, and the average performance was reported to improve the reliability of the results.
(2) Patch size configuration: Considering the trade-off among computational cost, classification accuracy, and the ability to capture both local details and contextual information within hyperspectral imagery, an input patch size of was selected for all experiments.
(3) Sample proportion settings: For the WHU-LongKou and WHU-HongHu datasets, an equal number of training samples was adopted for fairness. Specifically, five random groups of samples were selected, with each group containing 20 pixels for training and 300 pixels for validation, while the remaining pixels were used as the test set. For the Matiwan Village dataset, five random groups were also selected, each containing 100 pixels for training and 300 pixels for validation, with the remaining pixels used for testing. This setting allows us to evaluate the model’s performance under balanced limited sample scenarios.
(4) Learning rate settings: In this study, five learning rates— , , , , and —were tested on the three datasets. After extensive experimentation, a learning rate of was determined to be the optimal choice.
(5) Evaluation metrics::Overall accuracy (OA), average accuracy (AA), and the Kappa coefficient are widely used metrics for evaluating classification performance.
OA measures the percentage of correctly classified pixels relative to the total number of pixels in the test set, reflecting the overall classification performance. It is computed as (Equation 14):
where denotes the number of crop categories, represents the number of correctly classified pixels for class , and is the total number of pixels in the test set.
AA represents the arithmetic mean of the classification accuracy of each class, helping to reduce the influence of class imbalance. It is defined as (Equation 15):
where refers to the number of true pixels belonging to class in the test set.
The Kappa coefficient is an agreement measure that evaluates the consistency between classification results and ground truth while accounting for agreement occurring by chance. A higher Kappa value indicates more reliable classification performance. It is calculated as (Equation 16):
where the expected agreement under random classification is given by (Equation 17):
Here, denotes the number of pixels predicted as class in the classification results.
Experimental results
4.2
We compare the proposed method with six state-of-the-art deep learning–based HSI classification approaches, including conventional CNN-based models such as 3D-CNN (Zunair et al., 2020), However, since the classification accuracy of 3D-CNN for each category lags behind that of other advanced models, it is not included in the comparison table. As well as Transformer-based methods such as SSFTT (Sun et al., 2022), MorphFormer (Roy et al., 2023), GAHT (Mei et al., 2022), GSC-ViT (Zhao et al., 2024), CTMixer (Zhang et al., 2022), and WD-SSMamba (Zhang et al., 2025).
SSFTT captures spectral–spatial representations and higher-level semantic features through a spectral–spatial feature tokenization transformer. MorphFormer is a learnable spectral–spatial morphological network that improves interaction between structural and shape-related information in HSI labeling. GAHT introduces a group-aware pixel embedding module that constrains MHSA within local spectral–spatial contexts. GSC-ViT incorporates a grouped separable convolution (GSC) module that significantly reduces convolutional parameters while effectively capturing local spectral–spatial information. CTMixer adopts a dual-branch architecture combining CNNs and Transformers to jointly extract local and global hyperspectral features. Mamba-based models, including WD-SSMamba, utilize a state-space model architecture, which dynamically captures long-range dependencies while reducing computational complexity through efficient token generation. The Mamba framework facilitates lightweight and effective modeling of spectral and spatial features in hyperspectral image classification tasks.
Matiwan Village dataset
4.2.1
The classification performance of MDPC-Net and the six comparison models on the Matiwan Village dataset is summarized in Table 1. MDPC-Net achieves an OA of 88.82%, an AA of 94.20%, and a Kappa coefficient of 0.8702 across 16 crop categories, demonstrating strong overall classification capability under limited-sample conditions. MDPC-Net attains the highest classification accuracy for 15 out of 16 crop types, confirming the effectiveness of the proposed multi-dimensional feature coupling strategy.
Nevertheless, a small number of spectrally similar classes still exhibit relatively lower classification accuracy. For instance, the accuracies for pear tree and Chinese scholar tree are 78.50% and 88.29%, respectively. This performance degradation can be primarily attributed to substantial spectral overlap between these vegetation types, which share similar canopy structures, biochemical compositions, and phenological characteristics in the Matiwan Village region. Under such conditions, even high-dimensional hyperspectral features provide limited inter-class separability, making precise discrimination inherently challenging. Although MDPC-Net still outperforms most comparison models on these classes, the remaining performance gap highlights an intrinsic limitation imposed by spectral similarity rather than model insufficiency. From a methodological perspective, this observation suggests that classification performance for highly spectrally similar crops may benefit from incorporating additional discriminative cues, such as multi-temporal information, fine-grained texture descriptors, or domain-specific prior knowledge (e.g., phenological constraints). Future extensions of the proposed framework could explore temporal-aware feature modeling or adaptive class-specific refinement mechanisms to further enhance discrimination among such challenging categories. The qualitative classification results are illustrated in Figure 8. Compared with the ground-truth map (Figure 8a), methods such as WD-SSMamba (Figure 8c) and SSFTT (Figure 8d) tend to generate fragmented predictions in large homogeneous regions, erroneously splitting continuous crop fields into multiple categories. This phenomenon indicates limited robustness in maintaining spatial consistency, particularly under complex agricultural layouts. GSC-ViT (Figure 8g) better captures large-scale structural patterns but still suffers from noticeable loss of local details, especially near field boundaries.
Sample classification results of different models on the matiwan village dataset. The numerical labels and their corresponding color patches indicate distinct crop categories, with the specific crop type for each label detailed in Figure 5.
In contrast, MDPC-Net (Figure 8b) demonstrates superior spatial coherence and structural fidelity. Its predictions exhibit strong alignment with the ground truth across diverse spatial patterns, including large continuous green regions, regular purple and brown block-like fields, and smaller scattered blue and red patches. This improvement can be attributed to the proposed multi-dimensional progressive feature extraction and linear-projection pyramid fusion, which jointly preserve both global contextual semantics and fine-grained local structures.
Furthermore, Mamba-based models, such as WD-SSMamba (Figure 8c), show noticeable improvements over conventional CNN- and Transformer-based approaches by more effectively modeling long-range dependencies while maintaining computational efficiency. However, compared with MDPC-Net, their spatial predictions still exhibit occasional inconsistencies in boundary delineation and local detail preservation. This comparison highlights that while Mamba-based architectures provide an efficient mechanism for global dependency modeling, the explicit multi-dimensional feature coupling and hierarchical fusion strategy employed by MDPC-Net is more effective in addressing the complex spectral–spatial characteristics of agricultural scenes.
WHU-HongHu dataset
4.2.2
The classification performance on the WHU-HongHu dataset is summarized in Table 2. MDPC-Net achieves an OA of 89.95%, an AA of 89.63%, and a Kappa coefficient of 0.8730 across 18 crop categories, demonstrating strong overall performance on this large-scale and fine-grained agricultural dataset. MDPC-Net outperforms the six comparison methods for most crop types, confirming its robustness under complex class distributions and limited training samples.
However, several spectrally and morphologically similar categories remain challenging to distinguish. For example, the classification accuracy for cotton is slightly lower than that of CTMixer, whereas cotton residues achieve higher accuracy than CTMixer. This phenomenon is mainly attributed to the high spectral similarity and transitional characteristics between cotton and cotton residues, especially during post-harvest stages, where residual vegetation and soil background introduce mixed spectral responses. Although MDPC-Net effectively leverages multi-dimensional contextual information, such subtle intra-class variability and inter-class overlap inherently limit discriminability under a single-date hyperspectral setting. Similarly, confusion is observed between Chinese cabbage and baby mustard choy, as well as mustard and small mustard, which exhibit closely related spectral signatures and comparable canopy structures. These crop types often share similar biochemical compositions and growth stages, leading to overlapping spectral–spatial representations. While MDPC-Net still outperforms several baseline methods for these classes, the reduced performance relative to other crop categories highlights intrinsic classification difficulty driven by semantic proximity, rather than deficiencies in the proposed framework. From a methodological perspective, these observations suggest that further performance improvements for such confusing classes may require additional discriminative cues beyond single-scene spectral–spatial features. Potential extensions include incorporating multi-temporal hyperspectral observations to exploit phenological differences, integrating object-level structural priors, or introducing class-adaptive feature refinement strategies that emphasize subtle intra-class variations. These directions could further enhance discrimination among crops with high spectral and morphological similarity.
The qualitative classification results are illustrated in Figure 9. Compared with the ground-truth map (Figure 9a), MDPC-Net (Figure 9b) consistently produces classification maps with higher spatial coherence and visual fidelity than all comparison models. Among the Mamba-based methods, such as WD-SSMamba (Figure 9c), improved modeling of structural patterns and spatial relationships can be observed when compared with traditional CNN-based approaches. Nevertheless, Mamba-based models still fall short of MDPC-Net in terms of fine-grained detail preservation and boundary accuracy.
Sample classification results of different models on the WHU-HongHu dataset. The numerical labels and their corresponding color patches indicate distinct crop categories, with the specific crop type for each label detailed in Figure 6.
Specifically, while WD-SSMamba exhibits clearer region continuity and reduced noise, it still shows limitations in accurately delineating complex field boundaries and small, irregular plots. In contrast, MDPC-Net achieves more precise class transitions at field boundaries and maintains high correspondence with fine-scale ground-truth structures. This advantage is primarily attributed to the LPFPM module, which constructs a multi-scale feature pyramid through multi-dimensional residual connections and linear projections. By effectively integrating spectral, spatial, and spectral–spatial features across scales, LPFPM enhances the model’s adaptability to the heterogeneous and multi-scale characteristics inherent in real-world agricultural landscapes.
WHU-LongKou dataset
4.2.3
The accuracy evaluation of MDPC-Net and six competing models on the WHU-LongKou dataset is presented in Table 3. MDPC-Net achieves an OA of 95.70%, an AA of 97.22%, and a Kappa coefficient of 0.9411, indicating an overall high level of classification performance on this dataset. Among the six crop types, MDPC-Net yields slightly lower accuracy than SSFTT only for cotton, while achieving superior or comparable performance for the remaining categories.
In addition, the classification accuracies for broad-leaf soybean and narrow-leaf soybean are relatively lower than those of other classes. This behavior can be primarily attributed to the strong spectral similarity and morphological resemblance between these two soybean varieties, which often share overlapping spectral signatures due to similar biochemical composition and growth conditions. Although these classes are spectrally distinguishable from other crops, their intra-group confusion poses a significant challenge for fine-grained classification. Notably, compared with other competing models, MDPC-Net demonstrates a markedly improved capability to discriminate between these two confusing categories, suggesting that the proposed multi-dimensional feature coupling strategy enhances sensitivity to subtle spectral–spatial variations. From a broader perspective, the remaining confusion between soybean subtypes reflects an intrinsic limitation of single-date hyperspectral imagery, where spectral similarity dominates class separability. Future extensions of the proposed framework could explore the integration of multi-temporal observations, phenology-aware representations, or class-specific adaptive refinement modules to further improve discrimination among closely related crop varieties. Across all evaluated models, MDPC-Net also exhibits the lowest standard deviation for most classes, indicating that its predictions are more stable and less sensitive to within-class variability, such as the same crop type appearing across different plots or under slightly varying environmental conditions. This stability highlights the robustness of MDPC-Net and suggests that the learned representations generalize well across spatially heterogeneous agricultural parcels.
Qualitative comparisons between the ground-truth map (Figure 10a) and the classification result produced by MDPC-Net (Figure 10b) further support these findings. The overall color distribution and field boundaries are highly consistent with the reference labels. The “others” category exhibits clear and continuous boundaries, while the spatial locations and shapes of corn, cotton, rice, and sesame are accurately preserved, with no evident large-scale misclassification artifacts. Minor errors are mainly observed at the boundaries of broad-leaf soybean fields, where some pixels are misclassified as narrow-leaf soybean or cotton.
Sample classification results of different models on the WHU-LongKou dataset. The numerical labels and their corresponding color patches indicate distinct crop categories, with the specific crop type for each label detailed in Figure 7.
In contrast, several competing methods suffer from noticeable loss of detail in small-area classes, particularly cotton, resulting in fragmented or incomplete field representations (Figures 10c–h). These results indicate that MDPC-Net more effectively preserves global spatial structure, field morphology, and class distribution consistency, enabling more reliable modeling of crop associations in complex agricultural scenes.
Ablation experiments
4.3
To thoroughly validate the effectiveness of the innovative components in our proposed method, we conducted ablation experiments on all three datasets. The ablation study is divided into two parts: Evaluating the contribution of single-branch feature extraction versus the three-branch MDFEM module; and assessing the effectiveness of the LPFPM module.
The results are summarized in Table 4. For each dataset, the first row reports the average accuracy obtained from the 1D, 2D, and 3D single-branch extractors combined with MDFEM; the second row presents results using MDFEM alone (without LPFPM); and the third row corresponds to MDFEM combined with LPFPM, i.e., the full MDPC-Net.
Individual modules vs. combined modules
4.3.1
Across all ablation configurations and on all three datasets—Matiwan Village, WHU-HongHu, and WHU-LongKou—adding either LPFPM or MDFEM alone consistently improves OA, AA, and Kappa. This demonstrates the independent effectiveness of both modules.
However, the performance improvement achieved by combining MDFEM + LPFPM is substantially greater than the sum of the improvements contributed by each module individually. This indicates that the two modules do not simply provide additive functional benefits; rather, they synergistically enhance feature representation.
Specifically, MDFEM strengthens the discriminability of multi-dimensional features (e.g., through enhanced spectral–spatial fusion), while LPFPM refines the hierarchical transmission within the feature pyramid. When integrated, these two components enable the network to more accurately capture agricultural category variations—such as crop-specific spectral differences and spatial distribution patterns—leading to more precise recognition results.
Robustness across heterogeneous datasets
4.3.2
The three datasets represent varying levels of scene complexity: Matiwan Village corresponds to large heterogeneous farmlands, WHU-HongHu to medium-complex mosaicked fields, and WHU-LongKou to small and relatively simple plots.
In all cases, the combined MDFEM + LPFPM configuration yields consistent and superior improvements in OA, AA, and Kappa compared to individual modules alone (Table 5). This demonstrates that the proposed modules effectively adapt to different crop spectral variations and farmland scales across diverse agricultural landscapes.
The combined architecture therefore exhibits strong robustness to cross-region and cross-scale crop recognition, maintaining reliable performance despite substantial variations in field size, crop type, and scene composition.
Computational complexity analysis
4.4
Beyond accuracy, MDPC-Net demonstrates clear advantages in computational efficiency. We computed the number of parameters (Parameters) and floating-point operations (FLOPs) for MDPC-Net, WD-SSMamba, and the six comparison models across all three datasets.
In terms of parameter count, WD-SSMamba contains significantly fewer parameters than MDPC-Net across all datasets. For example, on the Matiwan Village dataset, WD-SSMamba has 0.153M parameters, which is less than half the parameters of MDPC-Net (0.295M parameters). Similarly, WD-SSMamba has 0.152M parameters on WHU-HongHu and 0.161M parameters on WHU-LongKou, both of which are lower than MDPC-Net’s 0.305M parameters. This reduction in parameter count highlights the lightweight design of WD-SSMamba, which is based on advanced wavelet convolutions and the Mamba architecture for efficient feature extraction and representation. Regarding computational cost, MDPC-Net still exhibits a lower FLOPs value than WD-SSMamba in most cases, particularly on the WHU-LongKou dataset, where WD-SSMamba has 24.790M FLOPs, compared to MDPC-Net’s 34.806M FLOPs. While WD-SSMamba benefits from fewer parameters, the complexity of its frequency-domain feature extraction results in higher FLOPs than MDPC-Net in some scenarios. Specifically, on Matiwan Village and WHU-HongHu, WD-SSMamba’s FLOPs (34.667M and 34.712M, respectively) are still lower than the FLOPs of some other models, but they are still higher than MDPC-Net’s FLOPs in those datasets. This comparison highlights MDPC-Net’s superior balance of computational efficiency and accuracy, making it particularly well-suited for large-scale remote sensing tasks that demand both high accuracy and low computational overhead. WD-SSMamba, with its lighter parameter count, excels in compactness but at the cost of a slightly higher computational cost in certain configurations, demonstrating a trade-off between model efficiency and accuracy.
Conclusion
5
In this study, we proposed MDPC-Net, a hyperspectral image crop classification (HSICC) framework that achieves high classification accuracy while maintaining low computational complexity. By integrating multi-dimensional feature extraction, a linear-projection feature pyramid, and Transformer-based global modeling, MDPC-Net demonstrates strong and stable performance across diverse agricultural scenes.
First, the MDFEM module adopts a three-branch architecture with progressive dilated convolutions to jointly capture spectral, spatial, and spectral–spatial characteristics. This design effectively alleviates long-standing challenges such as “same spectrum, different objects” (e.g., broad- vs. narrow-leaf soybeans) and “same object, different spectra” (e.g., rice vs. rice stubble). Second, the LPFPM module reorganizes and fuses multi-dimensional features through depthwise separable convolutions and linear projection, constructing a feature pyramid that reduces hyperspectral redundancy while enabling multi-scale information fusion. This mechanism supports accurate modeling across spatial scales, from fine-grained plot boundaries (e.g., sesame field edges) to large-scale semantic patterns (e.g., corn distribution). Finally, the Transformer component captures long-range contextual dependencies via self-attention, further enhancing global consistency and boundary delineation in complex agricultural environments.
Importantly, the proposed framework is sensor-agnostic in design and does not rely on sensor-specific handcrafted features, making it readily adaptable to hyperspectral data acquired from different platforms, including airborne, UAV-based, and satellite-borne sensors, with varying spectral resolutions and band configurations. The use of linear projection and multi-dimensional feature coupling allows MDPC-Net to flexibly accommodate differences in spectral dimensionality and spatial resolution, which is critical for real-world deployment across heterogeneous data sources. Moreover, MDPC-Net is not tailored to a specific crop type or region, and its effectiveness across three benchmark datasets with distinct crop compositions and planting patterns suggests strong generalization potential to other agricultural regions. This makes the proposed framework particularly suitable for large-scale agricultural mapping and cross-regional applications, where crop types, field geometries, and management practices vary significantly. Experimental results on three representative benchmark datasets consistently demonstrate that MDPC-Net outperforms all comparison models, validating both its effectiveness and robustness under limited-sample conditions.
In future work, MDPC-Net may be further enhanced through additional lightweight optimization and the integration of spatiotemporal information, such as multi-temporal hyperspectral observations. These extensions would further improve adaptability to different sensors and support dynamic crop monitoring, thereby strengthening the practical value of MDPC-Net for precision agriculture and large-scale agricultural management.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Aasen H. Honkavaara E. Lucieer A. Zarco-Tejada P. J. (2018). Quantitative remote sensing at ultra-high resolution with UAV spectroscopy: A review of sensor technology, measurement procedures, and data correction workflows. Remote Sens. 10, 1091. doi: 10.3390/rs 10071091, PMID: 41725453 · doi ↗
- 2Agilandeeswari L. Prabukumar M. Radhesyam V. Phaneendra K. L. N. B. Farhan A. (2022). Crop classification for agricultural applications in hyperspectral remote sensing images. Appl. Sci. 12, 1670. doi: 10.3390/app 12031670, PMID: 41725453 · doi ↗
- 3Al Duhayyim M. Alsolai H. Ben Haj Hassine S. S. Alzahrani J. S. Salama A. Motwakel A. . (2023). Automated deep learning driven crop classification on hyperspectral remote sensing images. Comput. Mater. Contin. 74, 3167–3181. doi: 10.32604/cmc.2023.033054, PMID: 40612875 · doi ↗
- 4Ali I. Mushtaq Z. Arif S. D. Algarni A. F. Soliman N. El-Shafai W. (2023). Hyperspectral images-based crop classification scheme for agricultural remote sensing. Comput. Syst. Sci. Eng. 46, 303–319. doi: 10.32604/csse.2023.034374, PMID: 40612875 · doi ↗
- 5Chandrasekharan S. Gomez K. Al-Hourani A. Kandeepan S. Rasheed T. Goratti L. . (2016). Designing and implementing future aerial communication networks. IEEE Commun. Mag. 54, 26–34. doi: 10.1109/MCOM.2016.7470932, PMID: 41116384 · doi ↗
- 6Chen M. Feng S. Zhao C. Qu B. Su N. Li W. . (2024). Fractional fourier-based frequency-spatial–spectral prototype network for agricultural hyperspectral image open-set classification. IEEE Trans. Geosci. Remote Sens. 62, 1–14. doi: 10.1109/TGRS.2024.3386566, PMID: 41116384 · doi ↗
- 7Fernandes F. C. Faramarzi E. Li X. Ma Z. Ducloux X. (2019). Mobile display power reduction for video using standardized metadata. IEEE Trans. Mob. Comput. 18, 165–178. doi: 10.1109/TMC.2018.2829185, PMID: 41116384 · doi ↗
- 8Gallo I. Ranghetti L. Landro N. La Grassa R. Boschetti M. (2023). In-season and dynamic crop mapping using 3D convolution neural networks and sentinel-2 time series. ISPRS J. Photogramm. Remote Sens. 195, 335–352. doi: 10.1016/j.isprsjprs.2022.12.005, PMID: 41756733 · doi ↗