Modular, On-Site Solutions with Lightweight Anomaly Detection for Sustainable Nutrient Management in Agriculture
Abigail R. Cohen, Yuming Sun, Zhihao Qin, Harsh S. Muriki, Zihao Xiao, Yeonju Lee, Matthew Housley, Andrew F. Sharkey, Rhuanito Soranz Ferrarezi, Jing Li, Lu Gan, Yongsheng Chen

TL;DR
This paper introduces a modular system for real-time nutrient monitoring in agriculture, balancing efficiency and accuracy to reduce waste and improve sustainability.
Contribution
A novel tiered pipeline for lightweight anomaly detection and nutrient estimation using multispectral imaging and machine learning.
Findings
Anomaly detection achieved 73% accuracy for low-fertilizer samples with low energy use.
Vision transformers outperformed random forests in estimating phosphorus and calcium.
The system enables edge deployment for sustainable nutrient management.
Abstract
Efficient nutrient management is critical for crop growth and sustainable resource consumption (e.g., nitrogen and energy). Current approaches require lengthy analyses, preventing real-time optimization; similarly, imaging facilitates rapid phenotyping but can be computationally intensive, preventing deployment under resource constraints. This study proposes a flexible, tiered pipeline for anomaly detection and status estimation (fresh weight, dry mass, and tissue nutrients), including a comprehensive energy analysis of approaches that span the efficiency–accuracy spectrum. Using a nutrient depletion experiment with three treatments (T1–100%, T2–50%, and T3–25% fertilizer strength) and multispectral imaging, we developed a hierarchical pipeline using an autoencoder for early warning. Further, we compared two status estimation modules of different complexity for more detailed analysis:…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 1
1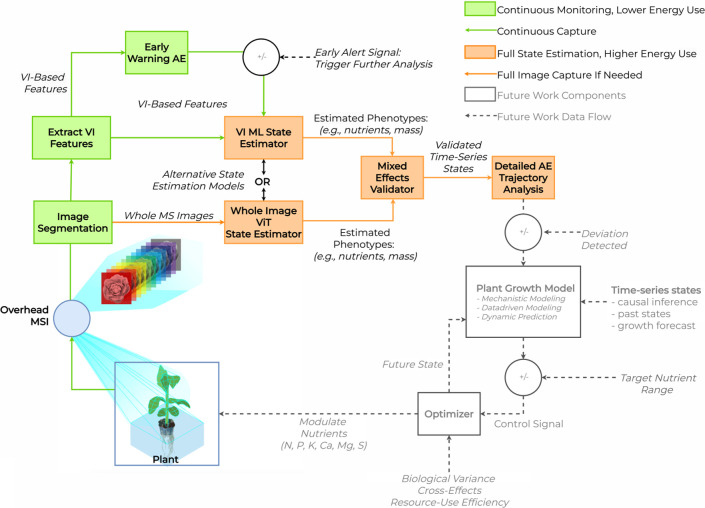 2
2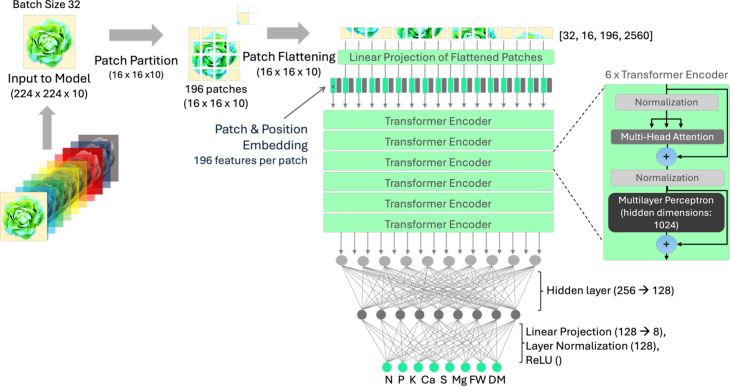 3
3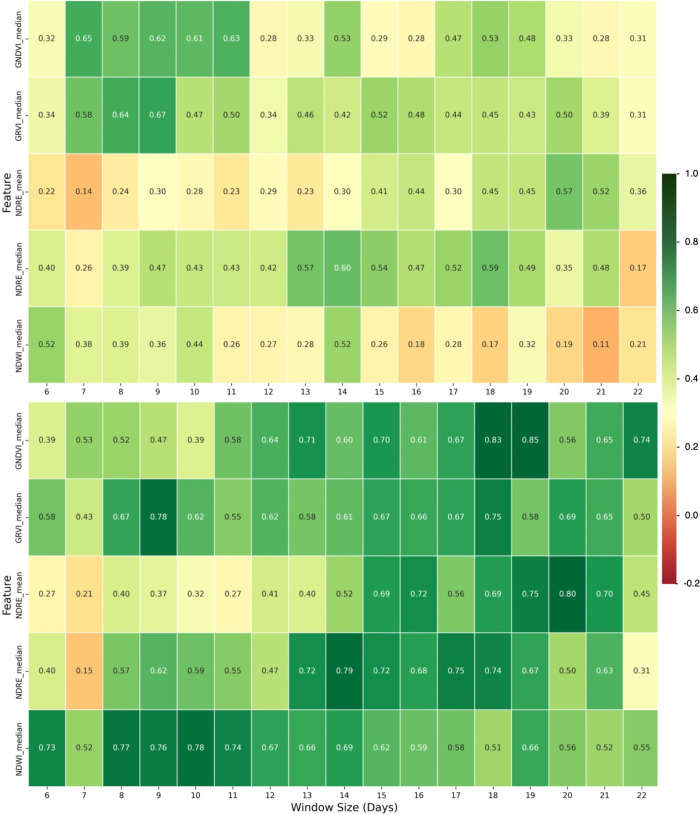 4
4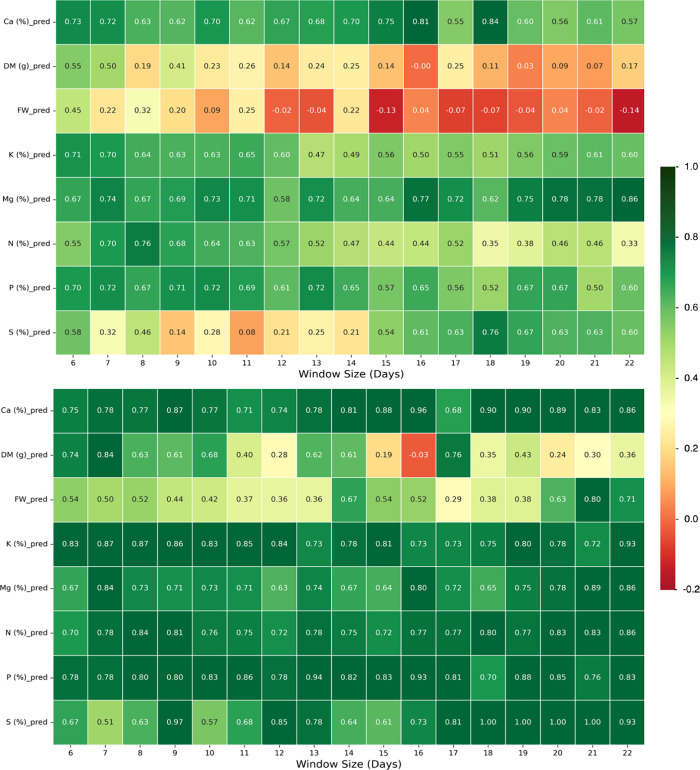 5
5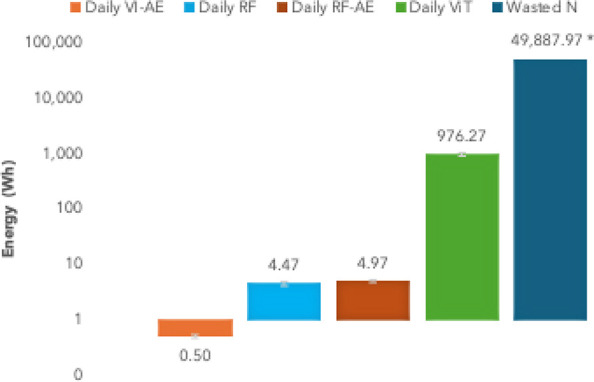 6
6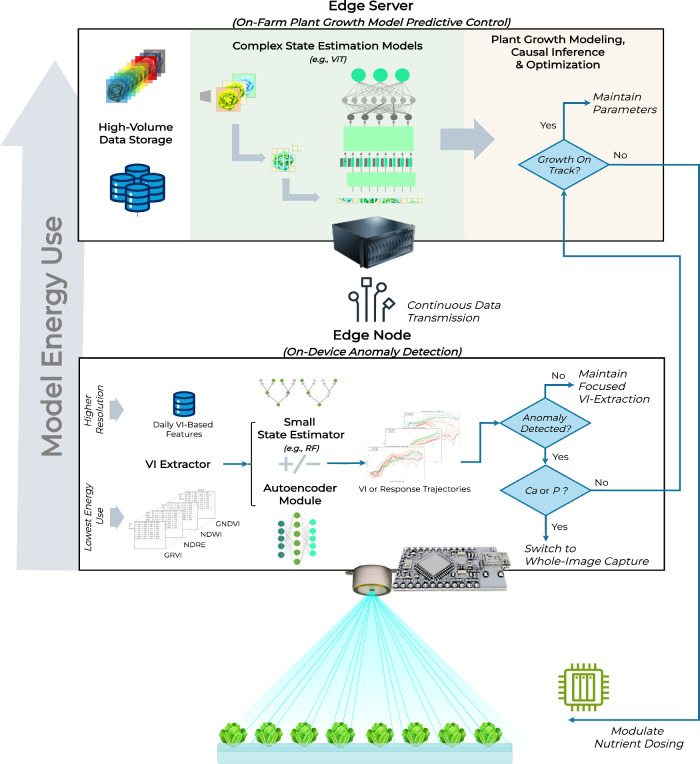 7
7|
|
|
|---|---|
| 1 (blue, 463, 475, 488) | important wavelengths
identified for detecting nitrogen concentrations (400–550 nm) (source), as reflectance at 460
nm or 670 result from electron transitions in chlorophyll a and b, |
| 2 (cyan, 484, 497, 513) | 470 to 520
nm is correlated to Ca concentrations |
| 3 (green, 510, 526, 545) | Green is used in many phenotyping tasks and is associated with all our selected RGB and multiple MSI indices. |
| 4 (amber, 594, 603, 609) | Phosphorus, potassium, and
calcium concentrations have been
found in regions of 570–600 nm. |
| 5 (red, 629, 640, 647) | 620–720 nm is associated with nitrogen estimation. |
| 6 (deep red, 651, 665, 672) | Reflectance at or around 670 nm is associated with chlorophyll a and b. |
| 7 (far red, 717, 740, 752) | Mg is associated with red edge (∼710 nm). |
| 8 (NIR-850, 835, 855, 867) | associated with phosphorus, potassium, and calcium concentrations (860–990 nm) |
| 9 (NIR-940, 920, 949, 972) | strongly
related to nitrogen concentration (960–990 nm), |
| 10 (white, broad spectrum) | important for visualization, preprocessing, and quality control |
|
|
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|---|---|
| n_estimators | 100 | [500–1600] | 900 | 1300 | 900 | 900 | 900 | 1300 | 900 | 900 |
| max_depth | none | [5–16] | 14 | 12 | 14 | 14 | 14 | 12 | 14 | 14 |
| min_samples_split | 2 | [2, 3] | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| min_samples_leaf | 1 | [1, 2, 3] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| max_features | 1.0 (equiv. to using all features) | ['sqrt', 'log2'] | 'sqrt' | 'sqrt' | 'sqrt' | 'sqrt' | 'sqrt' | 'sqrt' | 'sqrt' | 'sqrt' |
| bootstrap | true | [true, false] | false | false | false | false | false | false | false | false |
| criterion | 'squared_error' | ['squared_error', 'absolute_error'] | squared_error | squared_error | squared_error | squared_error | squared_error | squared_error | squared_error | squared_error |
|
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|---|
| random forest on VI-based features | |||||||||
| Avg. | 0.69 ± 0.06 | 0.79 ± 0.06 | 0.71 ± 0.1 | 0.82 ± 0.03 | 0.58 ± 0.06 | 0.76 ± 0.04 | 0.28 ± 0.07 | 0.35 ± 0.09 | 0.55 ± 0.09 |
| RMSE ± SD | 24.95 ± 3.59 | 0.72 ± 0.14 | 0.49 ± 0.04 | 0.10 ± 0.01 | 0.86 ± 0.07 | 0.04 ± 0.005 | 0.17 ± 0.02 | 0.02 ± 0.003 | |
| ViT on whole MS images | |||||||||
| Avg. | 0.53 ± 0.12 | 0.7 ± 0.16 | 0.29 ± 0.11 | 0.79 ± 0.15 | 0.61 ± 0.15 | 0.65 ± 0.14 | 0.24 ± 0.08 | 0.49 ± 0.15 | 0.44 ± 0.12 |
| RMSE ± SD | 13.3 ± 1.50 | 0.91 ± 0.06 | 0.33 ± 0.06 | 0.07 ± 0.01 | 0.87 ± 0.08 | 0.03 ± 0.003 | 0.12 ± 0.08 | 0.03 ± 0.002 | |
| parameter |
|
|
|
|---|---|---|---|
| training
power, | 65.69 | 0.30 | 0.46 |
| inference power, | 69.94 | 0.24 | 0.34 |
| training time per sample, | 2.0 e–6 | 2.35 e–7 | 11.82 |
| inference time per sample, | 2.55 e–8 | 1.74 e–9 | 6.83 |
| training energy per sample, | 1.31 e–4 | 1.55 e–5 | 11.83 |
| inference energy per sample, | 1.78 e–6 | 1.22 e–7 | 6.84 |
| state estimation model | training time (h) | inference time (h) | training energy (Wh) | inference energy (Wh) |
|---|---|---|---|---|
| RF on VIs | 9.20 e–3 | 6.00 e–4 | 1.21 ± 0.14 | 0.05 ± 3.90 e–3 |
| ViT on whole MSI images | 0.673 ± 1.87 e–4 | 0.167 ± 2.5 e–4 | 66.53 ± 3.37 | 11.5 ± 0.83 |
| model | input data | average | training GPU energy (Wh/sample) | inference GPU Energy (Wh/Sample) | relative inference energy intensity |
|---|---|---|---|---|---|
| AE on VI-based feature | selected VI-based features | N/A (anomaly detection) | 1.54 e–4 | 1.45 e–6 | 1 (baseline) |
| RF on VI-based features | 20 selected VIs | 0.69 | 1.24 e–3 | 1.60 e–5 | 8.95× |
| ViT on whole MSI | whole MSI (10 channels) | 0.53 | 6.38 e–2 | 3.49 e–3 | 1956× |
- —National Science Foundation10.13039/100000001
- —National Science Foundation10.13039/100000001
- —National Science Foundation10.13039/100000001
- —Agricultural Research Service10.13039/100007917
- —Agricultural Research Service10.13039/100007917
- —Agricultural Research Service10.13039/100007917
- —Agricultural Research Service10.13039/100007917
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSmart Agriculture and AI · Remote Sensing in Agriculture · Insect Pheromone Research and Control
Introduction
1
Agriculture requires sizable amounts of energy-intensive inputs (e.g., nutrients). ?,? The industrial fixation of nitrogen (N) for fertilizers is an energy-intensive process that consumes 35–50 MJ per kilogram. ?,? However, the efficiency of this applied nitrogen is low, with a global average N use efficiency (NUE) of only 46%.? This means more than half of applied N remains in agricultural discharge waters, which contributes to eutrophication downstream and generates 65% of global emissions of nitrous oxide (N_2_O), a potent greenhouse gas. ?,? Improved nutrient management can be achieved through precision agriculture (PA), and automation can save time and labor expenses. ?−? ? PA depends on efficient monitoring systems capable of quickly detecting problems, backed by the necessary computing infrastructure to continuously evaluate and optimize. However, if detection accuracy does not prevent meaningful crop loss, the system is too computationally intensive to offset efficiency gains, or the data infrastructure cannot be supported in resource-constrained environments, sustainable PA will not scale. With a diverse range of environmental parameters and highly variable biological responses inherent to agriculture, increasingly complex management systems could lead to higher computing and equipment costs. For these reasons, efforts should be made to create efficient, fit-for-purpose models that work in edge environments.
Nondestructive, dynamic plant monitoring has the potential to allow growers to maximize productivity, minimize resource use, and adhere to effluent standards without relying on heuristic-based or threshold-based simulations that may still result in luxury conditions. ?−? ? To these ends, imaging [e.g., red, green, blue (RGB) and multispectral imaging (MSI)] and modeling [e.g., machine learning (ML)] show promise in direct, noninvasive phenotyping. Whole images can be analyzed directly for color and shape features, or reflective intensity features, such as vegetation indices (VIs) can be easily extracted. RGB-VIs can monitor plant growth by relating green bands with red or blue, while MSI can improve estimation by measuring bands beyond the visual spectrum [e.g., Red Edge (RE), Near-Infrared (NIR) and Short-Wave Infrared (SWIR)]. VIs have been used to assess field crop biomass, water status, among others using UAV and satellite imagery. ?−? ? ?
Once images are captured, modeling approaches typically involve dimensionality reduction [e.g., principal component analysis (PCA) or band filtering] followed by traditional regression or ML. ?−? ? ? More recently, given advancements in graphics processing units (GPUs) and superior computing infrastructure, scientists have also applied deep learning (DL) to specific extracted features or whole images. ?−? ? ? However, the resource intensity required for DL can be prohibitive for deployment in resource-constrained environments. Additionally, most nutrient analyses focus either on classification, ?−? ? ? estimating instantaneous phenotypes, ?,? or constructing time-series diagnostic curves for a single nutrient.? Moreover, wide biological variance in plant response variables (RVs) (e.g., tissue nutrient concentration, mass) can make instantaneous diagnosis challenging, ?,? meaning growth must be evaluated against the desired evolution of parameters to support management or automation. Therefore, control optimization requires models that can make sense of biologically variable time-series data to support automated decision-making. ?,?
While these studies advance biofeedback-enabled management, analysis bridging resource intensity and nutrient management remains limited. Computing costs and energy use increase with model complexity,? and the rapid pace of adoption of energy-hungry large language models (LLMs),? the sustainability of AI has come under scrutiny. ?,? Not only do different modeling phases (i.e., training and inference) have variable energy demands (and by extension water use and CO_2_ emissions), but different frameworks (e.g., TensorFlow and PyTorch) differ in impact intensity.? When dealing with high-dimensionality MSI data, there can also be trade-offs between performance, interpretability, complexity, and the scale of training samples, with simpler models sometimes outperforming more complex ones.? While some recent reviews show the possible benefits of AI in agricultural resource use, ?,? the net impacts remain understudied with respect to nutrient management. Moreover, recent shifts toward edge computing, TinyML, and distributed microcontroller deployment require critical evaluation of model approaches and the development of efficient, modular, task-specific models for resource-constrained environments. ?,?
This study provides a framework for efficient, adaptable, nondestructive nutrient intervention through anomaly detection, while evaluating the accuracy and efficiency of nutrient status modules. We introduce a tiered pipeline for MSI nutrient management, integrating a lightweight autoencoder (AE) for direct anomaly detection to circumvent labor-intensive spot checks followed by two potential state estimation modules ranging in complexity (random forest, RF, and vision transformer, ViT). To highlight performance and environmental impact trade-offs in these approaches, we evaluate accuracy, computation time, and energy use for each module. This integration of advanced imaging, real-time data, and established analytical methods provides a nuanced understanding of nutrient management modeling, filling the critical gap in understanding the relative impacts of model complexity compared to the potential gains of nutrient use minimization.
Materials and Methods
2
Experiment Overview
2.1
To aid in the evaluation of nutrient management modeling approaches, we conducted a pilot-scale imaging experiment, testing the limits of N removal efficiency (NRE, applied N minus effluent N), which also provided rich imaging and plant growth data.
Plant Cultivation and Sampling
2.1.1
An experiment was conducted using a deep-water culture (DWC) system in a glass-covered greenhouse at the University of Georgia (College of Agriculture and Environmental Sciences, Department of Horticulture, CEA Crop Physiology and Production Laboratory) during Fall, 2024. Rex lettuce (Lactuca sativa) was grown for 30 days after transplanting (DAT) using a depletion fertilization strategy, where water was replenished as needed, 2–3 times per week. Three treatment groups with successively diluted nutrient solution concentrations, 100% (control, T1), 50% (T2), and 25% (T3), were prepared in triplicate (216 plants per treatment) using a modified Sonneveld solution (MSS)? recipe as the control (Section SI 1.1).
Plant tissue analysis was performed to provide ground-truth (GT) labels by Waters Agricultural Laboratories (Camilla, GA). Five whole-head samples (cut just above the substrate-bound root ball) from each of the nine tanks were sampled on days 11, 14, 18, 21, 23, 25, and 26. Shoot samples were weighed to obtain fresh weight (FW) and packaged whole for analysis. Samples were analyzed for dry weight (DW), total carbon, N, P, potassium (K), calcium (Ca), magnesium (Mg), and sulfur (S). Water samples from the start and end of the experiment were analyzed by Waters Agricultural Laboratories (Camilla, GA). Further details of the growth conditions, tissue analysis, and water analysis are found in the Supporting Information (Section SI 1.1).
Image Acquisition and Computing System
2.1.2
Plant growth was continuously monitored using a WiFi-connected (Simple Mobile Moxee 4G Mobile Hotspot, Simple Mobile; Miami, USA) imaging system (RAYN Vision Systems, Middletown, FL, USA). Overhead multispectral images were captured every hour beginning at 10 pm (eight images per night) using five MSI cameras from 4 days after transplantation (DAT), for a total of 880 overhead images. Images were captured overnight to accommodate hardware specifications and reduce incident lighting interference from daylight in the greenhouse. For illumination, the imaging system is manufactured with integrated lighting, which includes the nine narrow band LEDs and white LEDs (5700 K), automated sequentially to capture the bands of interest. The MSI output included 1280 × 800 pixel images with a depth of 10 channels (blue, cyan, green, amber, red, deep red, far red, NIR-850, and NIR-940), which correspond to important wavelengths found in literature and selected through research by the manufacturer for plant phenotyping tasks (Table).
1: Multispectral Wavelengths Captured by the Equipment and Their Biochemical Significance
A diagram and photographs of the overhead imaging setup are shown in Figure.
Approximate coverage for The RAYN Vision System (RVS) Multispectral Camera for 4 of 5 cameras (top left); a photo of the imaging setup (top right); photographs of the grow setup (center row); and two example MSI images (bottom row) to show coverage for T13 (bottom left) and T32 and T31 (bottom right). T11, T12, T21, and T22 had similar coverages to T32 and T31.
The computing system used in this experiment deployed two NVIDIA RTX 6000 Ada Generation graphics processing units (GPUs), each equipped with 48 GB of VRAM. The GPUs were paired with a 64-core AMD Ryzen Threadripper Pro 7985WX CPU, which facilitated masking, resizing, and data conversion.
The entire system ran on a Linux Ubuntu 22.04.5 LTS using Python 3.9.19, leveraging CUDA 12.4 for GPU acceleration to optimize performance during model training and inference.
Preprocessing and Vegetation Indices
2.1.3
Following data collection, overhead images were first segmented to isolate each lettuce sample image using the Segment Anything Model (SAM).? As optimized, edge-enabled segmentation was out of scope for this study, and an automated approach was selected for model proof-of-concept. SAM is an automated “zero-shot” tool developed to segment natural images that maintains high accuracy without the need for post-training or fine-tuning.? Images were converted into pseudo-RGB images, and then, usable plant samples were identified (selecting only complete samples that were not cut off in the frame) and labeled for each. Next, SAM was applied to each overhead image using point-based input prompts to generate individual binary masks for each lettuce ID, which were then applied to the MSI data.
Following segmentation, sample images were saved for use in ViT model and VIs were extracted along with their mean, median, and standard deviation for each foliar surface for use later in the RF and AE. Three data sets were prepared for each sample and saved to the server for further analysis: (1) a whole segmented sample image for end-to-end ViT; (2) a single daily VI value for each index feature using the 11 pm image; and (3) a daily average for each index-based feature. The VI-based feature set consisted of 106 VI-based input features. A table of indices and their calculations is found in Section SI 1.6 along with our VI calculation pipeline details.
Tiered Nutrient Monitoring
2.1.4
Our study employed a multidimensional approach that included a VI-based early warning protocol with an AE architecture trained on healthy trajectories to flag deficient trajectories, bypassing continuous state estimation in resource-constrained situations. The AE was followed by two alternative state estimation modules that ranged in complexity from ML (RF) to DL (ViT) for state estimation. In parallel, a high-resolution RF-AE was proposed for change point detection (CPD) in estimated RV trajectories. A control block diagram for the parallel pipeline is found in Figure.
Nutrient monitoring system control block diagram with three parallel pathways: (1) lightweight continuous early warning system using autoencoder (AE) on vegetation index (VI)-based features; (2) machine learning model (random forest, RF) for state estimation using VI-based features; and (3) whole image deep learning vision transformer (ViT) state estimation. To demonstrate automation opportunities, state estimation results pass through the AE for detailed trajectory analysis.
This tiered approach, including the AE anomaly detection and state estimation module energy analysis, along with a system-level integration and validation approach using a mixed effects model (MEM), provides a framework for enhanced nutrient management sustainability in a range of operating environments.
Anomaly Detection Using Autoencoder (AE)
2.2
One of the core contributions of this study is the demonstration of a modular AE anomaly detection approach. AE is a neural network designed to learn latent representations of input data through unsupervised learning to optimize the reconstruction of the input.? The AE architecture contains two primary components: (1) an encoder learns to compress input data into low-dimensional latent representations and (2) a decoder reconstructs the original data from these learned representations. Through this encoder-decoder framework, AEs capture underlying data patterns and structures of trajectories they have seen before and struggle to reconstruct new anomalous trajectories.
The AE proposed in this study adapts a simple autoencoder architecture, which consisted of a fixed-dimension 64–32–64 encoder–decoder, using the nn.Module in PyTorch. ?,? To illustrate its adaptability, two implementations of the AE were evaluated: (1) an early warning module using VI-based features extracted from one MSI image of each sample per day, starting at 4 DAT. All 106 VI-based features were analyzed using the AE, and the top 5 was selected for visualization. (2) A high-resolution module using RF-estimated response variable trajectories as inputs to the AE model, generated using the daily averaged VI-based feature data set (not used for RF training) to produce pseudolabels.
The models were each trained over 100 epochs on exclusively “healthy” T1 trajectories, VI-based feature trajectories for the early warning module, or RF-estimated trajectories for the high-resolution module using the Adam optimizer with a learning rate of 0.001. During inference, growth trajectories of lettuce heads (y _ t _) at time t were reconstructed as ŷ _ t _ with a reconstruction error threshold of 1.5 times the mean reconstruction error observed in the training data set at the final training epoch, serving as the indicator for anomaly detection.
Windows from 6 to 22 days long, starting at 4 DAT, were used to evaluate the optimal length of time needed for the model to differentiate between healthy (T1) and deficient (T2) or highly deficient (T3) trajectories. The models were each trained on the first 40 (or as many as available given destructive sampling) of the T1 trajectory segments of the same length, and then, each window was tested on the remaining T1 trajectories along with the T2 and then T3 trajectories, to evaluate the net detection accuracy (true detection rate minus false detection rate). Performance metrics evaluated for the AE included the net detection rate (true detection minus false detection) and GPU energy consumption.
Deeper Analysis: State Estimation Module Options
2.3
Nutrient management intervention and automation require a balance between accurate state estimation and efficient deployment. For the state estimation modules used in this study, RF and ViT models were evaluated using the single 11 pm image (for ViT) and VI calculation of this image (for RF). The data set was divided for both models with the same training, validation, and testing data splits. For each approach, images were divided into two categories: (1) labeled images with ground truth (GT) analysis and (2) unlabeled images.
To evaluate performance while maintaining tank and treatment representation and avoiding data leakage, a manual 27-fold cross-validation scheme was developed and replicated for both RF and ViT. Each fold represented a unique permutation of tanks, maintaining two tanks from each treatment class for testing and the remaining for training (80%) and validation (20%) to ensure consistent and comprehensive coverage of the data set. The test set contained only labeled data. Unlabeled images from each training and validation tank were assigned pseudolabels using the average RV values from their respective tanks using the GT values of the 5 destructive samples from that DAT.
Finally, Weights and Biases? was integrated into the pipeline to enable real-time tracking of training metrics and visualizations of model performance over time. This tool also facilitated reproducibility by maintaining a detailed record of each experiment’s configuration and results.
Vegetation Indices with Machine Learning
2.3.1
Among traditional ML approaches, random forest (RF) produces reliable predictions using nonlinear decision trees, and when used for regression analysis, RF is robust to multicollinearity. ?,? Compared to other ML approaches, RF has been successful at a variety of phenotyping tasks and has been found to be fast with relatively low computational intensity. ?,? RF was used for two tasks in this pipeline. First, it served as a feature selection module. Second, it was used to determine instantaneous phenotypes for each lettuce sample RV (FW, DM, and tissue N, P, K, Ca, S, and Mg) with VI-based input features. All modeling, including the feature selection procedures, was implemented by using the scikit-learn library in Python. The modeling workflow was applied independently to each RV target.
RF feature selection was conducted in three stages within each fold: (1) recursive feature elimination (RFE); (2) removal of low-importance features; and (3) correlation pruning. Additional details of the feature selection are found in Section SI 2.1.1. Selected features were aggregated across the 27-fold scale and ranked based on frequency and median importance, with the top 20 features selected as the fixed feature set. Each fold was subsequently rerun using these 20 features with the tuned hyperparameters identified previously (Table). In this final training, the selected features underwent a final round of correlation pruning with the same criteria.
2: Default, Ranges Searched, and Final Hyperparameter Settings for Each Prediction Target for the Random Forest Model
The final model was retrained using the pruned feature set and corresponding hyperparameters, and predictions were generated for the test set. SHAP (SHapley Additive exPlanations) was used to interpret the final RF models and quantify the contribution of each selected vegetation index to the predictions. In addition, out-of-fold (OOF) test predictions were collected by aggregating the predicted values from all test folds, enabling an overall out-of-fold evaluation of the model performance.
In addition to the above hyperparameters, the following defaults were also used and remained unmodified: random_state was set to none (with a fixed seed of 50), oob_score was set to false, verbose was set to 0, warm_start was set to false, ccp_alpha was set to 0.0, max_samples was set to none, and monotonic_cst was set to none.
Whole Image Analysis with Deep Learning
2.3.2
The second state estimation model selected for analysis was a DL vision transformer (ViT) using multitask learning to predict all RVs simultaneously. ViT was selected for its reputation as both a state-of-the art computer vision approach and a highly complex model that has not been widely explored for use in nutrient state estimation but shows promise for precision agriculture. ?,? It was also selected over more commonly deployed architectures such as convolutional neural networks (CNN) like ResNet due to ViT’s ability to make use of spatial and spectral relationships using self-attention mechanisms.? ViTs process images as sequences of patches, unlike CNNs, which focus on local spatial features, which makes ViTs adept at recognizing global relationships across whole images.
Using the labeled and unlabeled data in the same manner as the RF, the ViT model was adapted to use raw multispectral images with a suitable feature space, using all 10 spectral channels afforded by the MS imager from the original 3-channel input. The original ViT architecture (Figure) was adapted by modifying the input channel dimension directly in the embedding convolution layer from the original 3 channels to the 10 spectral channels from the MSI datacubes.
ViT architecture for the DL state estimation module. Figure adapted from the hyperspectral domain.
The ViT had 2 main components: (1) a ViT component (implemented using vit_pytorch),? which processed patches through multiple self-attention layers and discovers spatial and spectral patterns to estimate instantaneous tissue nutrient concentration and mass,? and (2) a fully connected layer that converted the output of the ViT followed by rectified linear unit (ReLU) activation functions, which reduce the dimensionality and introduce nonlinearity into the data set for more accurate predictions. The model was trained using a batch size of 32 with a variable learning rate (initialized at 0.0001) and run for 100 epochs to output the 8 target response variable attributes (six nutrient concentrations, FW, and DM). The architecture included 16 attention heads and a multilayer perceptron (MLP) with hidden dimensions of 1024, while the patch embedding dimension was 256. The ViT backbone also used six transformer encoder layers, which passed an output of 256 to a fully connected layer (FCL). This FCL reduced dimensionality from 256 to 128 in a hidden layer and then further from 128 to the 8 response variables. More details of the model architecture are found in Section SI 2.1.2.
Performance Metrics and Validation
2.4
Efficient, biologically accurate, modular models are becoming increasingly important for edge computing and deployment in resource-constrained environments. To evaluate the different modules in the tiered pipeline in this context, we measured the accuracy and GPU energy usage for each module. We then evaluated the biological validity of results based on treatment effects using mixed effects modeling.
State Estimation Accuracy Metrics
2.4.1
To evaluate and compare the two state estimation modules, we calculated the coefficient of determination (R^2^) and root mean squared error (RMSE) for each fold, training and inference times, and energy usage for model training/validation and inference. Per-nutrient R^2^ and global R^2^ values were calculated for each fold, from which the average and standard deviation across the manual cross validation 27-fold were determined. RMSE was calculated to measure the prediction accuracy of each response variable estimation at each time point, indicating the average magnitude of the model’s prediction errors.
Energy Measurement Methodology
2.4.2
The computational efficiency of each module was calculated using GPU power monitoring for benchmarking purposes, running each model on one of the two GPUs (GPU 0 or 1) to streamline monitoring and documentation. For longer-running models (ViT), Weights and Biases was used to extract power consumption data (watts) in real time directly from the nvidia-smi, which uses NVIDIA Management Library (NVML), an interface for monitoring and managing NVIDIA GPU states.? For the very short runs of the RF and AE models, NVML was accessed directly to monitor average power consumption over the course of the runs, which returns the power draw (±5 W) averaged over one second. To determine uncertainty for power use, a larger value was used (standard deviation or 5 W). Note: since the RF was developed using the scikit-learn library, which uses CPU exclusively, we needed to rerun the RF using the cuml.RandomForestRegressor library to force it to run on the GPU for even hardware comparison.
Power consumption was multiplied by the total runtime to calculate energy consumption for the run (Wh). ?,? GPU energy consumption and computing time were recorded during both the training and inference phases, where each training phase included all steps involved in model training, validation, and hyperparameter tuning (excluding the RFE for RF), while the inference covered final prediction on the entire available data set (with exception of the AE, which only had training and testing sets). For per-sample estimates, training and inference energy was calculated for each sample and multiplied by run duration to find an average per-sample consumption. Additional energy considerations such as RAM and CPU use were out of the scope of this study.
Mixed Effects Modeling to Evaluate Treatment
Effects
2.4.3
Following estimation, mixed effects modeling (MEM) was deployed to evaluate the source of variance in the growth response and to validate the underlying assumptions. MEM was applied to both GT and RF-estimated trajectories using a linear MEM model implemented by python (mixed.lm). ?,? The model used a basic two-tier nested structure with three compartments: treatment (fixed effect), tank-within-treatment, and residual effects (random effects).
The MEM served three major functions in our analysis: First, for experimental design validation, confirming treatment dominates the variance in GT data. Next, the MEM serving as a state estimation fidelity assessment to validate the biological signal reliability of our estimation models was preserved in our estimated RV trajectories. Finally, we used the analysis as an intervention trigger validation to confirm that the anomaly detection signal was related to treatment.
Results and Discussion
3
A shift from centralized computation toward soft sensors and edge computing in agriculture will require a thorough evaluation of model complexity, efficacy, and efficiency. Our analysis provides a novel evaluation of nutrient management model energy use in the context of avoided embodied energy from nutrient waste, proposing a tiered approach to nutrient management that includes efficient anomaly detection followed by deeper trajectory analysis.
The results from this experiment are presented in three parts: (1) individual module performance and energy use, including the early warning system using AE model on the raw VI-based features and a performance comparison of the two state estimation modules (RF and ViT); (2) an integrated system using AE on the RF-estimated trajectories to demonstrate that modular, fit-for-purpose DL trajectory analysis can be deployed at multiple stages; and (3) analysis and discussion of how energy use might scale for industrial implementation as compared to the potential to offset embodied nitrogen use from abated waste.
Individual Module Performance
3.1
Lightweight Anomaly Detection Using VI-AE
3.1.1
Early warning of nutrient application issues can save operators significant time and labor expenses. First, our results using the VI-AE demonstrate that selecting the appropriate VI is crucial to the model’s success and that even the top features evolve in their detection efficacy over the course of the experiment (Figure).
Net detection rate (true positive minus false positive) heatmap of the top 5 features for the early warning autoencoder for T2 (top) and T3 (bottom) by day from 4 to 11 DAT through 4–25 DAT.
Different VIs may be better suited for monitoring anomalies at different growth stages, with the NDWI median showing the most promise for early growth periods (with 71% average net detection of T3 until window length 12) and the GNDVI median for later growth (73% average net detection of T3 for the longest five windows). Although net detection rates of T2 were lower than those of T3, with a 65% net detection using GNDVI for a 7-day window and a 67% net detection using GRVI with a 9-day window, significant losses could be averted using this early warning protocol prior to deeper analysis.
Early plant growth can be especially sensitive to nutrient and water stress, when small leaves are thin and will allow shorter wavelengths to be reflected by biochemical constituents, making indicators like NDWI promising for the detection of differences.? Similarly, GRVI is sensitive to early changes in green color,? which may explain why it shows promise as an early detection indicator, reaching 78% net detection of T3 and 67% net detection of T2 by 9 DAT. By contrast, studies exploring the use of GNDVI have found it to be an especially successful indicator of plant health during intermediate and later growth stages when the canopy is dense, when other metrics, such as the NDVI, may saturate.? This may explain its increasing detection accuracy using the AE early warning system. Finally, the red edge channel shows promise in anomaly detection:? its use in the calculation of NDRE may explain the success of NDRE as a feature for differentiation between deficient and healthy trajectories as plants reach maturity, remaining above 50% net detection of T3 from 19 to 25 DAT, peaking at 80% at 24 DAT.
Performance of State Estimation Module Options
3.1.2
Nutrient management intervention and automation require a balance between accurate state estimation and efficient deployment. In this section, we present the accuracy and GPU energy use of two potential state estimation models ranging in complexity from ML (RF) to DL (ViT). Table displays the results for the state estimation models, including average R ^2^ and RMSE across the 27-fold range along with time and energy consumption for training and inference.
3: State Estimation Model Performance
RF outperforms ViT in R ^2^ by 6 of 8 (80%) of the phenotypes response variables with much more stable results (average R ^2^ standard deviation of 0.07 vs ViT’s 0.13). Overall, the models perform similarly with respect to N, with R ^2^ values of 0.79 ± 0.15 and 0.82 ± 0.03 for ViT and RF, respectively, and for P, with 0.61 ± 0.15 for ViT and 0.58 ± 0.06 for RF, and both models struggle with Mg, a commonly troublesome nutrient for image-based estimation. However, ViT significantly outperforms RF in the estimation of tissue Ca, with a 40% increase in R ^2^ (0.49 vs RF’s 0.35). For context, one study deploying HSI reported R ^2^ as high as 0.94 for Ca and 0.987 for nitrate.? Our approach provided the opportunity to evaluate the efficacy and efficiency of more affordable equipment (MSI vs HSI) in state estimation under field-like conditions that likely led to weaker signals for individual tissue nutrient concentrations but more closely approximate industrial deployment. We also varied the nutrient solution strength, providing a complement to existing studies that vary nutrients independently, while imaging with MSI throughout the growth period to overhead characterize whole lettuce in vivo at the pilot scale.
Our results also show that the standard deviation of many of the indices works more effectively than the mean or median value of the index over the foliar surface. This suggests that the distribution of the index values provides more information about the growth of the plant in comparison to the index value. This provides critical insight into spatial characteristics of nutrient deficiency: variation across the foliar surface, lost when averaging over the sample, is highly correlated with lower tissue concentrations. While ViT is typically leveraged for its ability to merge spectral and spatial information, our results demonstrate that through careful feature engineering that captures spatial characteristics combined with simple model architectures, it can be more effective and much more computationally efficient than complex end-to-end approaches on whole images. Additional details about feature importance are found in the Supporting Information (Section SI 3.2.1).
GPU Energy Use Across Modules
3.1.3
Trajectory analysis is of critical importance for MPC and PA, facilitating dynamic, tailored control of nutrient use and the optimization of yield while maintaining the possibility of integration into edge environments. There must be continuous or intermittent monitoring of growth and phenotype trajectories to indicate success or to flag that a deviation from the desirable growth trajectory necessitates input modulation. Table shows the energy analysis for the AE.
4: Energy Use for Training and Inference for the Autoencoder Model for One Feature
Sample trajectories were also divided by window length to evaluate if the length of the trajectory impacted energy use, but a significant increase in coefficients of variation in per-day energy use demonstrated that window length was not a dominant driver of energy use variation. Training and inference computational cost metrics for the state estimation module alternatives are reported in Table.
5: Training and Inference Time and Energy Use for the State Estimation Module Alternatives
Our analysis shows that increased computational intensity does not always lead to improved accuracy across all nutrients. The RF pipeline uses 1.6 × 10^–5^ ± 1.1 × 10^–6^ GPU energy for inference per sample with an average model R ^2^ of 0.69 ± 0.06. By contrast, the deep learning modeling approach modeled here (MSI-ViT) uses 3.49 × 10^–3^ ± 2.5 × 10^–4^ Wh for inference per sample, with an overall R ^2^ of 0.53 ± 0.12. Per sample, energy comparisons across modules are found in Table.
6: Performance and Energy Use across Model Complexity, Including AE on Raw VI-Based Features, RF on Daily VI-Based Features, and ViT on Whole MSI Images
The results show trade-offs in efficiency and accuracy for some nutrients. For example, MSI-ViT has 42% R ^2^ improvement for Ca over the RF (0.49 vs 0.35) but at nearly 2000 times the inference energy per sample. Given the importance of Ca dosing accuracy and its impact on tipburn, which can result in significant economic losses for growers, Ca could be managed much more effectively with this increased accuracy for Ca estimation. This would allow growers to avoid other measures, such as reducing daily light integrals to avoid this costly occurrence.? While the training per sample for RF was only 80% of the AE training, the inference energy used for AE is less than half that of RF.
Though the accuracy of the deep learning state estimation approaches presented here shows room for improvement in future work with hyperparameter tuning and modifications to architecture, this framework for evaluation demonstrates the need to consider the computational intensity of the modeling approach and material efficiency trade-offs within the broader context of resource intensity. Our results suggest that while complex deep autoencoder-LSTM (long, short-term memory) classification approaches can achieve high classification accuracy (94%),? simpler autoencoder architectures may be sufficient for early warning implementations with careful feature engineering. Future analysis should include sensitivity analysis investigating the trade-offs in model performance and energy use across different modeling approaches with modifications to architecture, training sample sizes, and hyperparameter values.
High-Resolution Trajectory Analysis and Validation
3.2
While status estimation is ultimately necessary for nutrient optimization, trajectory analysis is critical for fully automated modulation. Given the low inference energy required by the RF, we also deployed the autoencoder on the RF-estimated trajectories, demonstrating the applicability in automation and potential for further resolution while still using low GPU energy.
Trajectory Analysis of RF-Estimated Response
Variables
3.2.1
To facilitate automated decision making, the autoencoder architecture shows promise for detecting differences in estimated tissue nutrient concentration trajectories, especially in more highly differentiated treatments (T3 compared with the T1 control). In the moderate-energy detection pipeline, which begins with VI feature extraction, followed by RF state estimation, the estimated response trajectories are then run through an autoencoder (AE) at increasing window lengths (6–22 days long) from 4 DAT (Figure).
Net detection rate (true positive minus false positive) for the estimated 50% (T2) trajectories (top) and estimated 25% (T3) trajectories (bottom) by response variable success rate for window sizes (6–22), with all windows beginning at 4 DAT.
As may be expected, the RF-AE has a higher net detection rate than VIs alone and greater success differentiating between healthy (T1) trajectories and extreme nutrient restricted treatments (T3) (Figure bottom) as compared to T2 trajectories (Figure top). Nutrient response variables elicit particularly high net detection of T3 treatments throughout the measured windows, from 4 to 10 DAT (window size 6) through 4–26 DAT (window size 22). This is especially true for Ca (which averaged 81.6%), K, N, and P. The high false detection of the T1 trajectories when tested against T2 trajectories demonstrates that the model performs better when the trajectories are highly differentiated. The weakening evolution of the T2 detection accuracy may be explained by two compounding challenges: (1) the number of training samples decreases as the window lengths increase from 6 (with 40 samples) to 22 (16 samples) with destructive sampling and (2) the signal-to-noise ratio increases with increasing variance as plants mature.
This can be seen from the differences between S and FW detection in the later growth stages: there is strong reconstruction and net detection rate at later growth stages for T3 S trajectories (with 100% net detection by 22 DAT), even though the absolute separation between T1 and T3 trajectories is small (with mean separation of 13%), while the FW detection rate is much lower, with higher absolute separation (57% mean separation) (see estimated trajectory visualizations in Section SI 3.2.3). This emphasizes AE sensitivity to trajectory shape more than the values of the response variables, as it struggles with smoother, parallel curves of the weight response variables. While T3 and T2 trajectories differ in value, each shows an increase that levels off in parallel over time following logistic growth.
Variance Validation Using the Mixed Effect
Model
3.2.2
Following integrated state estimation and trajectory analysis, MEM was conducted to validate assumptions and assess the onset of treatment effects during the growth period. The results show that treatment dominates the variance across FW, DM, and tissue N concentration for all samples on all 7 sampling days. Apart from magnesium, treatment is the dominant source of variance for the remaining response variables on 6 of the 7 sampling days.
The treatment effects across nutrients and time (p ≤ 0.05) (S3.3) reveal that treatment was a significant driver of variance for all variables on all modeled days apart from day 26 for Mg. These results also demonstrate that the biological signal of variance due to treatment is not lost in the RF state estimation model. Further, this result in estimated states’ treatment effects validates the RF-AE, for which all days and windows display statistically significant treatment effects (p ≤ 0.05) apart from Mg on 24 DAT.
Balancing Considerations for Resource Use
in Digital Agriculture
3.3
Despite increased scrutiny facing AI’s energy use, agricultural research lacks grounded benchmarking of computational approaches to evaluate against potential sustainability gains. Digital agriculture offers great promise for sustainability and material use efficiency,? but its implementation requires a balance between the material or energy use offsets with the computational and resource intensity of the modeling approaches used to achieve them. In this section, we provide scaled GPU energy comparisons between the different modules and contextualize the relative energy use as compared to the potential mitigated embodied energy from N use reduction.
Scaling Potential Impacts of Nutrient Use
Reduction
3.3.1
The results of our depletion experiment add to the body of evidence that plants can achieve significantly improved NRE when fed less than the industry standard.? While the destructive sampling design of this experiment prevented precise estimation of nutrient use efficiency (i.e., bioaccumulated N divided by applied N, or NUE), treatment-level comparisons offer promising insight into NRE and potential to reduce wasted N. The final fresh weight of the T2 plants, despite being exposed to initial N concentrations 50% of the control (T1) plants, averaged 78.9% (±9.6%) of the control FW, with tissue N concentrations averaging 4.9% (±0.2%) of DM, within the published thresholds for healthy tissue nitrogen levels (4.0–5.6%).? Moreover, the T2 plants achieved this without any remaining effluent N, showing 100% NRE, while the T1 plants retained 40 mg/L N in the effluent. This effluent disparity, coupled with the health and vigor achieved by the T2 plants, reveals the potential for avoided downstream impacts in addition to upstream embedded emissions avoidance.
To contextualize the energy trade-offs at scale, we calculated inference GPU energy use and estimated the embodied energy in wasted nutrients for a facility growing 10,000 heads of lettuce over a 28 day growth period and compared them (Figure).
*GPU energy use (Wh) for 28 days of daily inference on 10,000 lettuce samples for VI-AE, RF, RF-AE, and ViT compared to embodied energy in wasted N over the same period. Average value (11.11 kWh kg–1 N) used from literature. , Log scale y-axis to display all values for comparison.
It should be noted that Figure uses a log scale for the y-axis to display all values in one graphic. If run every day on successively longer windows, the early warning monitoring system (AE-VI) would require a total of 0.5 ± 0.03 Wh for the month. Since the inference GPU energy required by RF is still low (4.47 ± 0.32 Wh), a combined RF-AE system would only use 4.97 Wh over that period if run each day for a higher-resolution analysis. Meanwhile, the higher-complexity model requires significantly more inference energy under the same circumstances (MSI-ViT: 0.98 ± 0.07 kWh). However, this computational energy consumption pales in comparison to the wasted embodied energy from excess N application. Seeing that global NUE averages 46%,? our experimental scenario (with total average T1 tissue N 0.383 g ± 0.052), scaled to the same 10,000 heads of lettuce, would require 8.32 ± 1.13 kg N, of which 4.49 kg ± 0.61 N would be wasted as effluent. At 9.7–13.9 kWh per kg of N for artificial N-fixation, the wasted embodied energy is between 38 and 64 times the projected GPU energy used running ViT inference on MSI images over the same period. Since this global NUE estimate uses predominantly field data, it should be noted that these are just benchmarks to evaluate the potential savings in a hydroponic greenhouse scenario, where case studies have found N-wasting for some crops can exceed 59% of applied N.? The ViT inference GPU energy may be completely offset by a reduction of just 2% in wasted N.
N-use optimization could yield tremendous savings in avoided embodied carbon, eutrophication burden for aquatic ecosystems, and N_2_O emissions from unused N in effluent solutions without compromising yield.? A dynamic, biofeedback-enabled nutrient monitoring system, such as the early warning VI-AE, coupled with higher-resolution state estimation models, such as RF or ViT, could significantly reduce the harmful impacts of N mismanagement.
Integrating Results for Practical Guidance
and Future Directions
3.3.2
Nutrient management using digital agriculture will become increasingly important for operators of both controlled environment agriculture (CEA) and row crops. As it is not physically or economically feasible to collect samples for analysis (and farmers need all their yield for sale), anomaly detection and state estimation approaches will facilitate nondestructive, dynamic nutrient management in real-time. Here, we synthesize the tiered approach to inform the application of the proposed modular architecture (Figure).
Proposed end-to-end implementation of the nutrient management automation architecture, including lower-energy modules such as VI-AE and RF-AE, which could be deployed on edge devices, and complex state-estimation approaches such as ViT and future plant growth models, which would be run on edge servers for on-farm MPC.
First, for lower computing cost and lower-energy nutrient monitoring, a lightweight VI-AE module demonstrates 78% net early detection of T3 by 10 DAT, which could result in significant reduction of expensive losses due to substrate supply challenges (e.g., tube clogs and uneven nutrient distribution in the grow media). Further, the approach used much less data, using a small, stored data array (VI-based feature array, 5.5 MB total for our experiment) rather than raw images (10.7 MB per image). Future implementations leveraging multiple VIs into a multivariate detection platform would likely lead to improved, robust detection over the duration of the grow out. For example, joining VI features that are more sensitive to early deficiencies such as NDWI with those that are sensitive to later changes like GNDVI along with midstage detection indices (NDRE) could lead to sustained detection.
In larger farming operations with strict discharge limits, a higher accuracy P detection performance of the ViT may improve operators’ compliance at scale. In such operations, energy differences may be justified by the increased P-estimation accuracy. Similarly, in a growing environment particularly susceptible to calcium issues and tipburn, such as those using artificial lighting, ?,? the benefits of the ViT may outweigh the energy costs. By contrast, smaller farming businesses may opt for event-based detection and use a deeper analysis or investigation only when triggered. Decoupling the state estimation model from the initial anomaly detection will provide these operators with the ability to monitor deviations from plant status before they become costly mistakes.
Future efforts should optimize RF and AE modules for canopy-level VIs extracted from unsegmented images to adapt the approach for full end-to-end edge device capability. Next, different change point detection architectures should be evaluated for performance and energy use and then optimized based on these results, while the plant state estimation models should be optimized for performance across nutrients with weaker results such as Mg and Ca and with respect to energy use to further the efficiency and sustainability gains. Future work is also needed to extend the system boundary to include CPU and RAM energy use and to evaluate the embodied emissions of computing and controller systems through full life cycle and technoeconomic analyses that include the cost of deploying distributed models in a farm environment. Finally, root cause analysis is needed to bridge these early warning systems with causal inference-based plant growth models to close the loop on automated decision support with course correction once deviations are detected.
Conclusions
4
The nutrient monitoring pipeline proposed in this work demonstrates the potential to utilize MSI-measured indicators and feature engineering to dynamically assess nutrient use throughout lettuce growth. We provide a novel contextualization of model energy costs against embodied nutrient waste energy, establishing an adaptable hierarchical early warning approach to nutrient management. By evaluating different modules for their potential accuracy and efficiency, we provide evidence that ML-enabled nutrient estimation can achieve significant sustainable nutrient management gains. Our benchmarking study revealed that DL-enabled modeling may be able to substantially reduce negative impacts of fertilizer mismanagement in agriculture, with the most complex model evaluated requiring roughly 38–64× less GPU energy than the embodied energy of wasted N from over application. We demonstrate that the use of temporal and feature optimization, combined with nutrient-specific feature engineering for the RF and AE, achieves biologically grounded anomaly detection and nutrient estimation without sacrificing accuracy (with an average R ^2^ of 0.81 for FW and N, and net anomaly detection surpassing 80% for severe nutrient deprivation). Further, we show the flexibility of the phenotyping model-agnostic AE module, first as a lightweight early warning system that triggers further analysis only when necessary and then a more integrated system-level tool when combined with a state estimation module for higher-resolution trajectory analysis. This modular approach has the potential to improve the operational efficiency and adaptability in a range of environments and operating conditions.
This research has broad implications for the deployment and discovery. First, it supports phenology research to uncover dynamic uptake patterns and dose responses in agriculture with the potential to facilitate the optimization of growth parameters that are currently not possible with destructive sampling workflows. Next, the flexible VI-based AE module can be adapted for deployment in combination with increasingly high-resolution phenotyping models as part of alternative automation pipelines to save operators time and labor costs associated with high-frequency manual spot checks. Given the broad indications of VI-based features, this has potential applicability for pest management, water use optimization, and more. This integrated analysis of model accuracy and energy efficiency provides a framework for resource-aware nutrient management and sustainability in agriculture.
Supplementary Material
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ouikhalfan M.Lakbita O.Delhali A.Assen A. H.Belmabkhout Y.Toward Net-Zero Emission Fertilizers Industry: Greenhouse Gas Emission Analyses and Decarbonization Solutions Energy Fuels 20223684198422310.1021/acs.energyfuels.2c 00238 · doi ↗
- 2Rosa L.Gabrielli P.Energy and Food Security Implications of Transitioning Synthetic Nitrogen Fertilizers to Net-Zero Emissions Environmental Research Letters 202318101400810.1088/1748-9326/aca 815 · doi ↗
- 3Shapouri, H. ; Duffield, J. A. ; Wang, M. The Energy Balance of Corn Ethanol: An Update; 2002.
- 4Xie M.Shon H. K.Gray S. R.Elimelech M.Membrane-Based Processes for Wastewater Nutrient Recovery: Technology, Challenges, and Future Direction Water Res.20168921022110.1016/j.watres.2015.11.04526674549 · doi ↗ · pubmed ↗
- 5Zhang X.Zou T.Lassaletta L.Mueller N. D.Tubiello F. N.Lisk M. D.Lu C.Conant R. T.Dorich C. D.Gerber J.Tian H.Bruulsema T.Maaz T. M. C.Nishina K.Bodirsky B. L.Popp A.Bouwman L.Beusen A.Chang J.Havlík P.Leclère D.Canadell J. G.Jackson R. B.Heffer P.Wanner N.Zhang W.Davidson E. A.Quantification of Global and National Nitrogen Budgets for Crop Production Nat. Food 20212752954010.1038/s 43016-021-00318-537117677 · doi ↗ · pubmed ↗
- 6Tahir N.Li J.Ma Y.Ullah A.Zhu P.Peng C.Hussain B.Danish S.20 Years Nitrogen Dynamics Study by Using APSIM Nitrogen Model Simulation for Sustainable Management in Jilin China Sci. Rep 20211111750510.1038/s 41598-021-96386-534471165 PMC 8410903 · doi ↗ · pubmed ↗
- 7Desloover J.Vlaeminck S. E.Clauwaert P.Verstraete W.Boon N.Strategies to Mitigate N 2O Emissions from Biological Nitrogen Removal Systems Curr. Opin Biotechnol 201223347448210.1016/j.copbio.2011.12.03022244791 · doi ↗ · pubmed ↗
- 8Cowan N.Ferrier L.Spears B.Drewer J.Reay D.Skiba U.CEA Systems: The Means to Achieve Future Food Security and Environmental Sustainability?Front. Sustainable Food Syst.2022689125610.3389/fsufs.2022.891256 · doi ↗