LinkML: an open data modeling framework
Sierra A T Moxon, Harold Solbrig, Nomi L Harris, Patrick Kalita, Mark A Miller, Sujay Patil, Kevin Schaper, Chris Bizon, J Harry Caufield, Silvano Cirujano Cuesta, Corey Cox, Frank Dekervel, Damion M Dooley, William D Duncan, Tim Fliss, Sarah Gehrke, Adam S L Graefe

TL;DR
LinkML is an open framework that helps standardize and share scientific data, making it easier to integrate and reuse across different fields.
Contribution
LinkML introduces a flexible and accessible data modeling language that supports FAIR data standards and promotes interoperability.
Findings
LinkML enables the creation of standardized data models that can be shared and reused across disciplines.
The framework supports complex data structures and integrates with existing systems, reducing data heterogeneity.
LinkML has been adopted in diverse fields like biology, biomedicine, and engineering to standardize data at the source.
Abstract
Scientific research relies on well-structured, standardized data; however, much of it is stored in formats such as free-text lab notebooks, nonstandardized spreadsheets, or data repositories. This lack of structure challenges interoperability, making data integration, validation, and reuse difficult. LinkML (Linked Data Modeling Language) is an open framework that simplifies the process of authoring, validating, and sharing data. LinkML can describe a range of data structures, from flat, list-based models to complex, interrelated, and normalized models that utilize polymorphism and compound inheritance. It offers an approachable syntax that is not tied to any one technical architecture and can be integrated seamlessly with many existing frameworks. The LinkML syntax provides a standard way to describe schemas, classes, and relationships, allowing modelers to build well-defined, stable,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
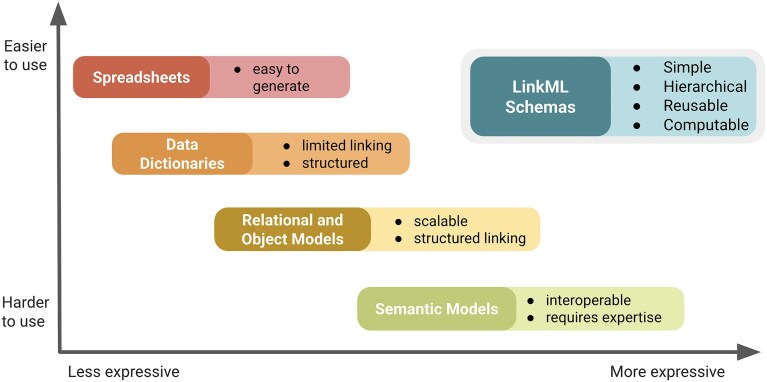 Figure 1
Figure 1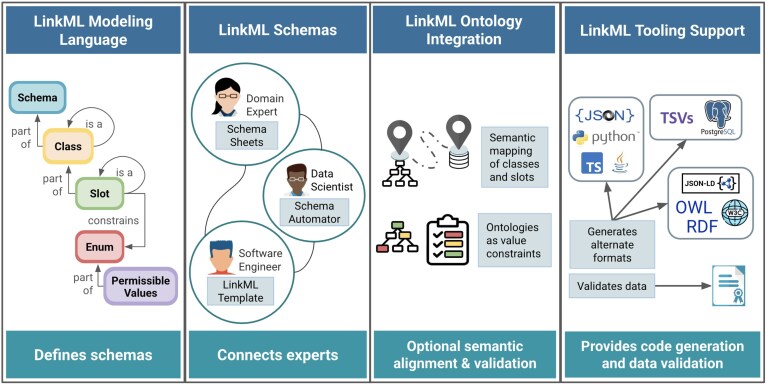 Figure 2
Figure 2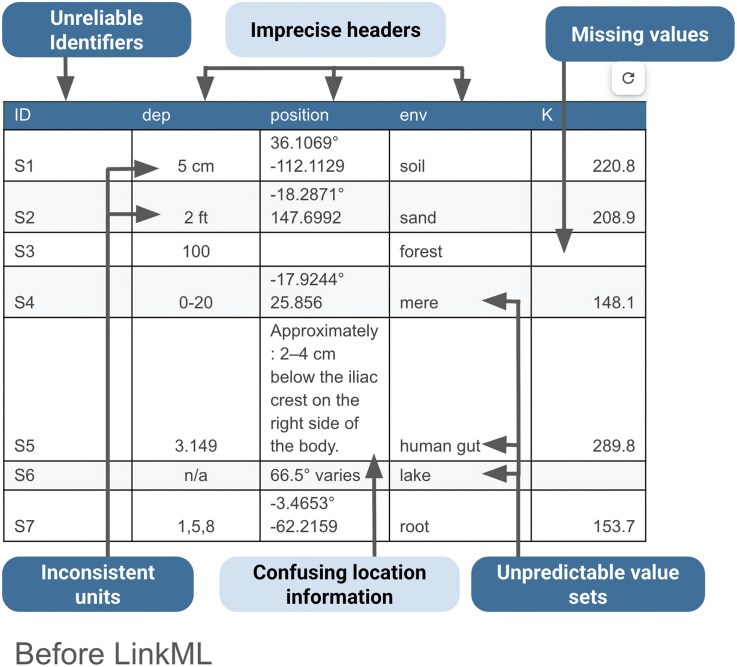 Figure 3
Figure 3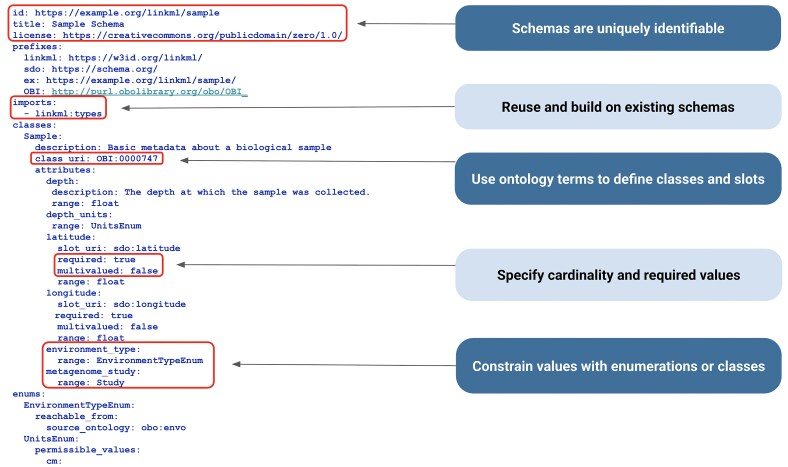 Figure 4
Figure 4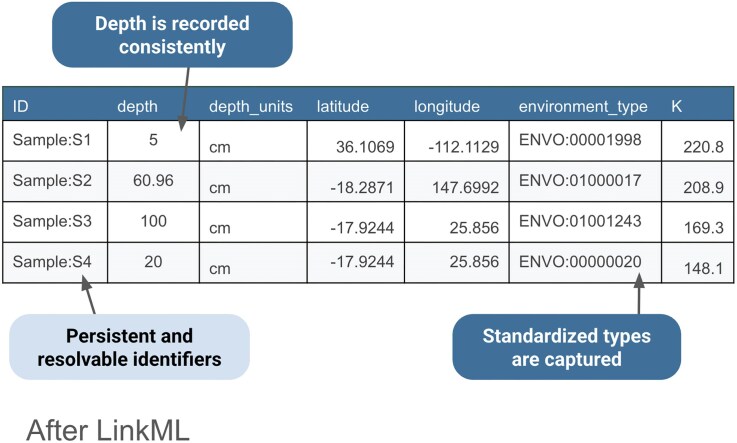 Figure 5
Figure 5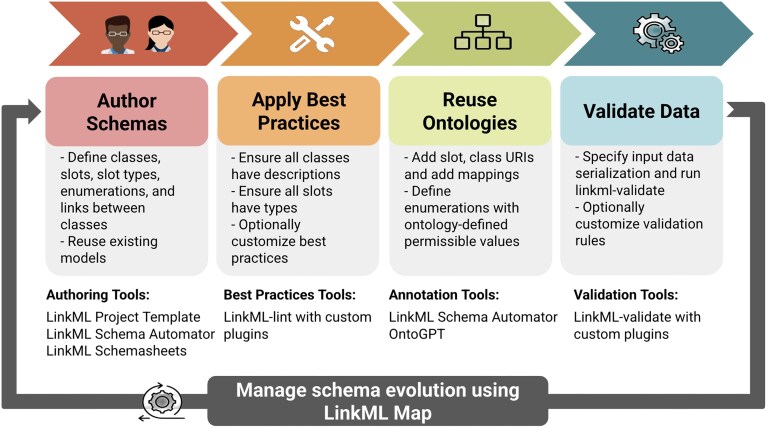 Figure 6
Figure 6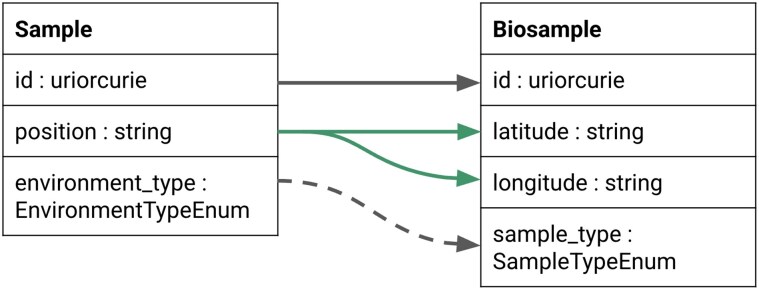 Figure 7
Figure 7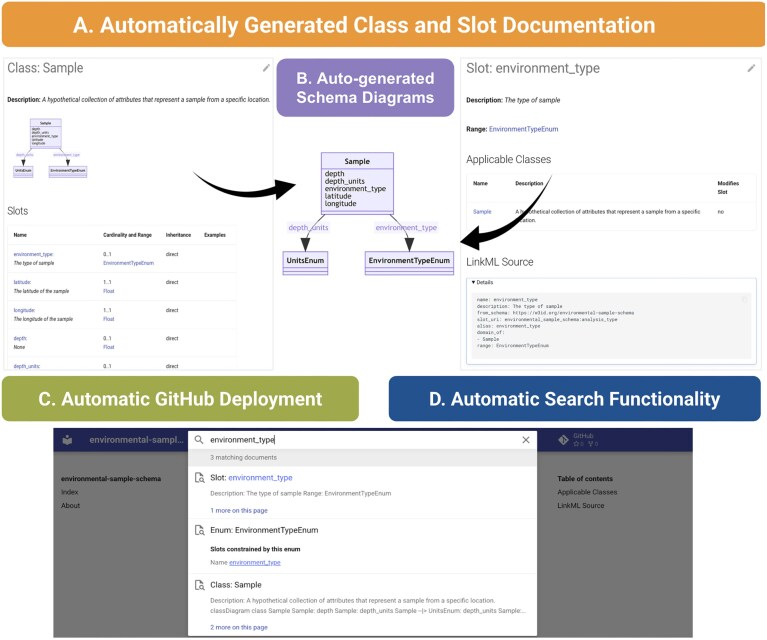 Figure 8
Figure 8| Elements | Description | Examples |
|---|---|---|
|
| Defines the overall structure of a data model, including metadata, prefixes, and imports. | Sample schema with prefixes like NMDC |
|
| Represent entities or concepts in the model, which can be linked to each other via slots. | Sample, study |
|
| Attributes or properties of classes, which describe their characteristics and relationships. | Latitude, longitude, analysis_type, metagenome_study |
|
| Define data types that slots can hold, such as strings, integers, or enumerations. | String, integer, float, boolean, class, enumeration |
|
| Controlled vocabularies to constrain slot values or link to external ontologies. | environment_type: Environment Ontology terms |
|
| Link schema elements to external standards or ontologies via URIs. | class_uri: nmdc:Biosample, slot_uri: MIXS:0000009 |
| Tool name | Description | Life cycle stage |
|---|---|---|
|
| A copier-based starter project to scaffold new LinkML schemas with recommended structure | Create Schema |
|
| Define schemas in spreadsheet format and convert them into LinkML YAML | Create Schema |
|
| Auto-generates LinkML schemas from source artifacts such as spreadsheets or JSON data | Create Schema |
|
| Serializes Python classes that reflect the schema structure, for runtime validation, serialization, and type enforcement | Create Schema |
|
| Serializes LinkML model as RDF triples using RDFS and SKOS to represent schema structure and semantics | Create Schema |
|
| Converts the schema into JSON Schema for validating JSON data files and outputs JSON-LD context files to support semantic annotation and Linked Data compatibility | Create Schema |
|
| Validates schema conformance to community best practices using customizable linting rules | Apply Best Practices |
|
| Suggests ontology mappings and value sets by prompting large language models, such as GPT | Reuse Ontologies |
|
| Validates input data against a LinkML schema; supports extensions via custom plugins | Validate Data |
|
| Supports schema alignment, transformation, and evolution across versions or related models | Manage Schema Evolution |
|
| LinkML-Store adds a layer of abstraction between data models and underlying technologies, making it easier to migrate or adapt backends without changing the model itself | Manage Schema Evolution |
|
|
- —U.S. Department of Energy10.13039/100000015
- —National Human Genome Research Institute10.13039/100000051
- —National Institute of Mental Health10.13039/100000025
- —National Institutes of Health10.13039/100000002
- —National Cancer Institute10.13039/100000054
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsResearch Data Management Practices · Scientific Computing and Data Management · Semantic Web and Ontologies
Introduction
Data integration in the sciences is challenging due to heterogeneity, complexity, the proliferation of ad hoc formats, and poor compliance with the FAIR (Findable, Accessible, Interoperable, and Reusable) guidelines.[1]. Data are often published in unstructured, text-based formats that lack a standardized, reusable structure and element definitions. Without a formal schema to convey the data generator’s intent, downstream reuse is difficult, time-consuming, and prone to misinterpretation. Reuse is further hindered by poorly structured formats, missing units or values, unlinked records, and the lack of standardized identifiers or curated relationships. While tools like JSON Schema, relational database schemas, and spreadsheets offer partial solutions, such as structural validation and type enforcement, they lack native support for linking to shared vocabularies or aligning with external data models. These frameworks define data structure but not domain meaning, limiting their ability to ensure that terms, concepts, and relationships used in one dataset are understood in the same way as those in another.
LinkML addresses this gap by providing a unified, schema-driven framework that supports both structural and semantic modeling (Fig. 1).
LinkML is both expressive and easy to use. LinkML balances ease of authoring with support for semantic clarity, interoperability, and reuse, enabling users to create structured models without requiring extensive technical expertise while allowing for expressive and standards-aligned representations.
The LinkML framework
LinkML is an open and extensible data modeling framework that provides a simple and structured way to describe and validate data. As illustrated in Fig. 2, LinkML facilitates cross-domain collaboration between experts to create shared data models. It includes a schema language (the LinkML metamodel) for defining data elements and their relationships, as well as tools to convert models to widely used data modeling formalisms like JSON Schema [2], SQL [3], Resource Description Framework (RDF) [4], OWL [5], SHACL [6], and Python [7]. Rather than replacing current tools, LinkML augments them with shared semantics, machine-readable documentation, and cross-platform interoperability, making FAIR data easier to produce, validate, and reuse across domains.
LinkML framework components. The LinkML modeling framework provides a flexible way to organize information, author data models, and reuse existing standards like ontologies and linked data frameworks. It can help validate data for schema conformance, foster expert collaboration, and translate between LinkML and other technical modeling frameworks. The modeling language and tooling can be explored at [8]. Panel 1: LinkML schemas consist of hierarchical classes with attributes (slots) that describe them. Panel 2: LinkML’s data model creation tools are accessible to users with varying levels of expertise. Users can bootstrap a LinkML data model from existing data using Schemasheets or SchemaAutomator or start with the LinkML Template. Panel 3: LinkML can bridge model semantics across formats by reusing knowledge in ontologies, mapping schema elements to ontology terms, and providing translators between representations, such as the Relational Database Management System and OWL. Panel 4: LinkML generates schemas in several popular formats and validates data.
LinkML supports a wide range of data structures, from simple spreadsheets and data tables to complex, interlinked models. It helps reduce data inconsistency and complexity while aligning with FAIR data standards [1] by promoting well-defined, persistently identified, and ontology-annotated data structures. It balances ease of use with semantic clarity, offering a powerful alternative to both low-barrier formats like spreadsheets and high-complexity models like RDF/OWL. By combining structured linking, ontology reuse, and human-readable syntax, LinkML enables interdisciplinary teams to build computable, reusable models without sacrificing accessibility or interoperability.
Motivating example
To illustrate LinkML’s capabilities, we use biological microbiome sampling as a representative example. Microbiome studies involve collecting samples from diverse environments, such as air, water, organisms, and soil, to perform analyses that characterize these habitats and their associated microbial communities. These analyses may include physicochemical measurements, contaminant testing, and genomic sequencing. Once published, sampling data can be repurposed for many applications, such as building machine learning models to predict microbial community functions, tracking contamination patterns across ecosystems, constructing knowledge graphs that link samples to biological and chemical data (such as pathways or genomic features), or integrating data into centralized repositories like the National Microbiome Data Collaborative [9].
To appreciate the need for LinkML, consider the typical state of microbiome sampling data. In Fig. 3, an example dataset is shown. The data are in a spreadsheet, but they lack consistency and clarity. For example, the “dep” field (what is “dep”? It is not defined) has entries that employ a variety of formats and units, so they cannot be easily compared with each other, let alone with other data sources. Terms are not tied to an ontology or terminology, so it is not clear what they cover. For example, can “sand” refer to any type of sand? Do empty cells mean “not specified,” “not required,” or “mistakenly blank”? And combining latitude and longitude into a single “position” field makes it harder to query or validate locations.
An example of sampling data before the use of LinkML. This “before” example highlights the kinds of inconsistencies and uncertainties researchers face when working with sampling data without a standardized schema. The data are in a spreadsheet, but they are not FAIR. They lack consistency and clarity and require human intervention to interpret, harmonize, and parse objectively.
The LinkML standard
The LinkML framework provides a flexible data modeling language built around 4 core element types: schemas, classes, slots, and enumerations. These core language elements allow users to define and organize information in a structured, machine-readable way. A LinkML schema specifies the meaning, relationships, and constraints of a dataset. Within a schema, classes represent conceptual entities (e.g., samples, genes, publications), slots define the attributes or fields associated with these classes, and enumerations (analogous to dropdown menus) constrain slot values to controlled vocabularies. Basic data types, such as strings or integers, are defined by types, and enumerations can be created locally or imported from external ontologies. Building upon these core language constructs, the LinkML metamodel (or standard) is itself expressed as a LinkML schema that precisely defines how schemas, classes, slots, enumerations, and types should be described. This enables LinkML to be self-describing, facilitates tooling, and supports mapping schema elements to existing standards and ontologies (Table 1).
LinkML provides powerful mechanisms for linking knowledge, including (i) connecting model classes within a schema through typed relationships, (ii) establishing class hierarchies that support the specialization of concepts, and (iii) mapping to existing data standards and ontologies to enhance interoperability. For example, a representative Sample class can be linked to related classes, such as Sample Site or Metagenomic Study, using defined slots that describe relationships like “collected from” or “associated with.” Class hierarchies enable schema developers to define general concepts and then specialize them through subclasses. For instance, an Air Sample Site subclass can inherit all properties of a general Sample Site while adding air-specific details, such as humidity or PM2.5 levels. Figure 4 further describes the LinkML syntax used in this example. For more detailed information, refer to the LinkML tutorial [10], documentation [11], and metamodel specification [12].
Example of a LinkML schema. This snippet shows part of a Sample schema written in YAML [13] using LinkML. The schema begins with a unique identifier in the form of a URL, along with metadata such as title and license. It defines a set of prefixes to incorporate existing models and uses an “imports” section to bring in other LinkML schemas, promoting reuse instead of reinventing common structures. Existing classes and types are leveraged within the class definition. For instance, the Sample class draws on the Ontology for Biomedical Investigations (OBI) [14], and the latitude slot draws on the schema.org [15] definition. Slot properties such as required and multivalued specify cardinality of the property or slot, while enumerations provide controlled vocabularies that tie allowed values to well-defined semantics.
In LinkML, a mapping refers to the alignment of schema elements, such as classes, slots, or enumerations, with terms from established ontologies, typically referencing the ontology term’s Uniform Resource Identifier (URI). For example, a slot representing the area or type of an environment from which the sample was collected can be constrained to values from the Environment Ontology (ENVO) [16] by defining an enumeration whose permissible values are derived from a subset of ENVO. In exposure and toxicology modeling, this same approach can be used to constrain a slot, such as “exposure stimulus,” to terms from the Exposure Ontology (ECTO) [17]. This enables the reuse of ontology branches, allowing for the validation and interpretation of data based on domain semantics encoded in the ontology. A practical application of this approach can be seen in the National Microbiome Data Collaborative (NMDC) schema [18], which utilizes ENVO terms in enumerations to facilitate the standardization of environmental context annotations in microbiome sample collection data [19].
In LinkML, the attributes of a class are defined using slots, which are analogous to database fields or spreadsheet columns. Each slot describes a particular characteristic or property that class instances can have. The slot range—such as a string, integer, boolean, or a more complex structure like another LinkML class or an enumeration—determines the kind of data that the slot can hold. Slots can also be extensively annotated with metadata, such as textual definitions, usage notes, and mappings to external standards or ontologies. When slots are assigned globally unique identifiers (URIs), they can be referenced reliably in other schemas or external systems. Minimal information about any sequence (MIxS) schema [20], which uses LinkML to standardize the annotation of genomic samples and sequences, organizes related slots into checklists, which are structured collections tailored for specific sample types or environmental contexts. Each checklist defines a group of attributes (slots) that describe relevant metadata, such as environmental conditions, host-associated information, and geolocation data. These slots capture the presence of certain data and enforce structure and semantics through their associated types and annotations.
LinkML is designed with reuse and extensibility in mind. Classes, slots, and entire schemas can be imported or extended across schemas, enabling modular modeling and consistent reuse of domain concepts. In addition to these built-in mechanisms, schema alignment, transformation, and evolution can be supported using LinkML-Map [21]. LinkML-Map provides a declarative syntax for expressing changes across schema versions or between related models, including subsetting, renaming, restructuring, and aligning schemas to new standards.
Many real-world projects have adopted LinkML to leverage its core features. For example, the Biolink Model [22] is built using LinkML to define a comprehensive, ontology-aligned schema that connects concepts across diverse biological domains, enabling interoperability among tools, datasets, and knowledge graphs. The National Center for Advancing Translational Science Biomedical Data Translator [23] project builds on this by using the Biolink Model to harmonize data from over 300 sources. The Alliance of Genome Resources (AGR) [24] uses a LinkML schema to integrate data from multiple model organism databases, applying class hierarchies, semantically defined slots, and ontology mappings to handle complex biological relationships and species-specific constraints as their data models evolve.
Returning to the example spreadsheet shown in Fig. 3, we can see how applying the LinkML schema from Fig. 4 to structure the sample data results in a clearer, more interoperable dataset in Fig. 5. Using consistent units as dictated by the schema for the depth column eliminates ambiguity, ensures rows are directly comparable, and avoids errors that can arise from interpreting mixed units. LinkML makes it easy to specify identifiers with namespaces and resolvable URIs; these unique and persistent identifiers allow data consumers to unambiguously reference the same entity across time, systems, and studies. The LinkML-structured dataset references environment types using ENVO ontology term identifiers, rather than free text. This standardizes meanings, reduces misinterpretation, and enables computational tools to link samples to broader ecological knowledge.
After using LinkML to structure the “before” data shown in Fig. 3. A unique and persistent identifier enables each sample to be unambiguously referred to; the depth field is formatted consistently and uses the same units, enabling comparison; the environment type is identified by identifiers from the ENVO environment ontology.
LinkML builds resolvable, persistent identifiers directly into its core modeling framework. The syntax requires explicit identifiers for every schema element and provides built-in mechanisms for prefix management and CURIE-to-URI expansion. LinkML’s tooling further supports this by resolving namespace prefixes (via Bioregistry.org and other resolver services), validating CURIEs, and ensuring consistent URI generation. The ecosystem also applies these practices to its own metamodel. Each element of the LinkML metamodel is assigned a persistent identifier that resolves through the w3id permanent identifier service. LinkML’s end-to-end use of resolvable identifiers serves as a model for how LinkML schemas can achieve long-term, stable, FAIR-aligned identification. By using LinkML to define and publish both data and schema metadata, researchers can establish clear, shared definitions of entities and their attributes, such as samples, collection sites, or measurement types, ensuring that data are interpretable, comparable, and reusable. This approach benefits not only microbiome studies but also any field that relies on integrating diverse data sources into larger knowledge frameworks.
LinkML data life cycle
The LinkML data life cycle is summarized in Fig. 6, which provides an overview of how LinkML facilitates data modeling from schema creation to validation and integration. Tools in the LinkML framework that support each phase of the data life cycle are summarized in Table 2.
The 5 stages of the LinkML data life cycle. The LinkML data life cycle encompasses 5 main stages: schema creation and reuse, applying best practices, reusing ontologies, validating data, and managing schema evolution. Each stage is supported by a suite of LinkML tools designed to simplify and enhance the process of developing interoperable data models.
Author schemas
LinkML aims to be accessible to nontechnical users (such as domain experts), as well as data modelers and software developers, by providing multiple authoring approaches. Users can directly edit schemas using the default YAML syntax (Fig. 4) or take advantage of the LinkML project template system, which provides scaffolding for a new LinkML schema project with preconfigured tooling for schema development, documentation, and maintenance.
For users who prefer to author in a tabular format, LinkML Schemasheets [25] allow modelers to define classes, slots, and other LinkML elements and schema syntax row by row in a spreadsheet (Table 3), which LinkML tools can automatically convert to a YAML representation. Additionally, the LinkML SchemaAutomator tool supports users migrating from other modeling formalisms by converting various sources, such as TSV files, HTML tables, SQL databases, JSON Schemas, and OWL/RDF files, into the LinkML format.
Deriving schema serializations
LinkML provides extensive schema generation and serialization tools that convert schemas from the default YAML syntax into various formats, including JSON Schema, Python Pydantic classes, SQL DDL, RDF, OWL, ShEx(see Fig. 2). This ability to produce polyglot outputs ensures compatibility acrossdifferent technical environments. However, conversions are constrained by the expressiveness of the target framework and may result in some loss of information.
Applying best practices
Once developers have created a schema, LinkML encourages them to apply best practices through its linting tool. While LinkML is generally permissive about model style, the linter promotes consistency and clarity by ensuring schemas include clear descriptions, follow naming conventions (e.g., CamelCase for classes, snake_case for slots), specify appropriate slot ranges, and define enumerations with permissible values. Users can customize these checks by configuring their linting rules and tailoring the validation process to their specific requirements.
Optional ontology integration
Using ontologies in LinkML is optional but can significantly improve semantic clarity and interoperability when needed. For users who do not require formal semantics, LinkML works effectively without the need for ontology integration. However, when precision or alignment with external standards is desired, LinkML provides lightweight and flexible mechanisms to reference ontologies, such as annotating slots or classes with URIs, or declaring mappings (e.g., skos:exactMatch, broadMatch, narrowMatch) to established vocabularies.
A common use case is defining permissible values for a slot using terms from an ontology. For instance, a schema describing microbiome samples might constrain the environmental_material slot to values from a specific branch of the ENVO, such as terms under “soil” or “marine water.” This enables data from different projects to use a shared set of values, while still allowing schema authors to subset or annotate the ontology to meet their local needs. When applied in practice, as in the NMDC submission schema, this approach has helped harmonize environmental context annotations across thousands of samples contributed by multiple labs, enabling federated search, filtering, and comparative analysis.
Validating data
Effective data validation is essential to ensuring interoperability. The LinkML validator verifies that data conform to a specified schema, including those schemas that integrate external ontologies [26] as enumerated value sets or range constraints. Through its plugin-based architecture, the validator supports a variety of validation strategies, including JSON Schema validation, SHACL for semantic validation, and SQL database constraints for ensuring relational data integrity. The LinkML validator allows model designers to declare all constraints within the schema itself, independent of the underlying data storage format, thereby enhancing the flexibility and extensibility of the validation process. This approach also ensures compatibility with existing validation frameworks and provides a mechanism for confirming the correctness of data and compliance with models [27].
Managing schema evolution
The final life cycle stage addresses the ongoing need to adapt schemas as data standards, best practices, and use cases evolve. For example, a project may decide to merge 2 fields into 1 to align with community standards or restructure parts of a schema to support a new type of analysis. In the Monarch Initiative [28], this challenge is addressed by reusing a focused subset of the broader Biolink Model schema to support research on rare diseases, demonstrating how existing models are often adapted to meet project-specific needs.
LinkML-Map [21] supports schema evolution by allowing modelers to define transformations through a declarative mapping syntax. These transformations can include subsetting a schema, flattening a normalized model for downstream systems, or modifying slot and class definitions, such as changing data types or cardinalities (Fig. 7). While the Simple Standard for Sharing Ontology Mappings [29] focuses on mapping individual identifiers and ontology terms at the entity level, LinkML-Map extends these principles to structural schema elements, enabling automated, transparent, and maintainable schema evolution. This approach facilitates data migrations across a range of storage systems, including JSON and CSV files, SQL databases, document stores, and graph databases.
Example of the LinkML-Map tool tracking changes to a model. The LinkML-Map software can help manage type and name transformations, as well as more extensive merge operations. In the example here, the position field in the source schema is split using LinkML-Map rules into separate fields for latitude and longitude, respectively. Additionally, the environment_type is relabeled to sample_type to align with the terminology used in the target project.
Documenting and Sharing LinkML Schemas
Effective sharing and deployment of data models are essential for promoting data reuse. However, without standardized mechanisms for distributing models and their metadata, it can be difficult to accurately understand, implement, and reuse data. Model documentation is frequently fragmented, described in disparate and often noncomputable formats such as PDFs, plain text documentation pages, SQL dumps, or API annotations, each with varying levels of detail and accessibility. LinkML addresses this challenge by providing a unified, automated documentation system that ensures models are consistently presented in a clear, accessible format (Fig. 8). Documentation is deployed to a predictable, web-based location, making it easily discoverable. The schema documentation remains uniform across projects—it is fully indexed, searchable, and visually represented in diagrams. LinkML enables customization of documentation appearance and layout to suit the specific needs of a project, ensuring flexibility without sacrificing consistency.
LinkML’s automated documentation system. (A) Each schema class (e.g., Sample) is presented with detailed metadata, including slot descriptions, cardinalities, ranges, and inheritance. (B) LinkML auto-generates interactive visual schema diagrams to show the relationships between classes, slots, and enumerations (e.g., environment_type linked to EnvironmentTypeEnum). (C) The documentation site is automatically deployed to GitHub Pages, ensuring schema updates are reflected without manual publishing steps. (D) A full-text search interface enables quick discovery of schema components (slots, classes, enums) using labels, descriptions, or identifiers. The documentation also includes URIs, mappings to external standards, and links to the schema source.
Generative Artificial Intelligence Integrations
LinkML’s structured framework complements the growing capabilities of generative artificial intelligence (AI), particularly large language models (LLMs). By providing clearly defined schemas, LinkML serves as a bridge between human engineers, LLMs, and computational tools. The human-readable YAML format that LinkML uses makes schemas easy to author and maintain while providing a structured foundation that LLMs can interact with to enhance data extraction and generation processes. Meanwhile, LinkML makes data AI- and analysis-ready [30] by providing clear, well-defined features and labels, allowing for the linking and contextualization of scientific data.
For instance, the OntoGPT platform [31] utilizes LinkML schemas to define the data entities and relationships that users want to extract from unstructured text. These schemas are translated into LLM prompts through OntoGPT’s LinkML-based code infrastructure, effectively guiding the LLM to generate structured outputs that adhere to the defined schema. This process demonstrates how LinkML enables users to leverage LLMs for tasks that require structured data extraction without sacrificing schema consistency or interoperability. By setting clear expectations about the structure and content of generated outputs, LinkML schemas enhance the usability and reliability of LLM-driven data generation. This alignment between structured schemas and AI-generated content enables a practical, scalable approach to integrating LLMs into existing data ecosystems.
The LinkML Community
LinkML has a growing community of users and developers building on its open framework. The software is cloned hundreds of times a week, and the main LinkML GitHub repository has over 400 stars as of October 2025. Guided by the Open Data, Open Code, and Open Infrastructure principles for sustainable open-source development [32], the LinkML community fosters collaboration through regular community meetings, open discussions, and transparent development practices. Monthly meetings hosted by community members provide a forum for sharing updates, gathering feedback, and exploring diverse use cases. Development primarily takes place in open GitHub repositories, where pull requests, reviews, and discussions drive the ecosystem forward. LinkML is widely adopted, with hundreds of public GitHub projects using it, reflecting its flexibility and broad applicability. Current applications span genomic standards [20], microbiome science [18], clinical genomics, model organism research [24], biological pathway modeling [23], knowledge graphs [23], ontology mappings [29], and even large-scale data initiatives like Gaia-X, an effort to build a transparent, federated data infrastructure that also leverages LinkML-based schemas [33].
Community contributions (hundreds of pull requests from over 90 people so far) continue to expand LinkML’s capabilities. For example, Data Harmonizer [34], a spreadsheet-like data authoring service, converts LinkML modeling elements into checkable constraints on a web-based data entry form, providing an accessible interface for data entry. Projects such as the NMDC actively use Data Harmonizer. Another example is the community-supported development for representing multidimensional arrays in LinkML [35], which enabled the use of LinkML in projects such as Neurodata Without Borders.
The LinkML Registry [36] serves as a curated collection of schemas created using LinkML, similar in purpose to the Open Biological and Biomedical Ontologies Foundry’s [37] approach to organizing interoperable ontologies. The registry provides diverse examples that can be used and adapted for new data modeling projects.
Conclusions
While expressive frameworks such as RDF and Labeled Property Graphs offer semantically rich ways to represent data, most datasets are still shared in simpler formats like SQL dumps, CSV/TSV files, and spreadsheets. These define structure but not domain meaning, making it challenging to ensure that terms and relationships are interpreted consistently across datasets. They persist because they are easy to use, but they fall short when it comes to interoperability, semantic clarity, and model reuse. Community-driven frameworks such as ISA-Tools for experimental metadata [38] and Frictionless Data [39] provide valuable solutions for tabular data and predefined schemas. Formats like Croissant [40] standardize dataset-level metadata. Similarly, Maggot [41] offers an extensible schema, web interface, and storage-linked metadata management for datasets, aligned with data management plans. LinkML complements these approaches by enabling self-authored, customizable tabular schemas, hierarchical classes, ontology integration, multiformat data exchange, and automated code generation. But LinkML goes further: it models not only the metadata about a dataset but also the structure and relationships among the entities within it, enabling consistent representation of both datasets and their contents [42].
LinkML fills an important gap by offering a modeling language that is intuitive for domain experts yet expressive enough for ontology-aware, structured data integration. It provides a single source of truth: models are defined once and translated consistently into various formats, including JSON, YAML, RDF, Python, and SQL. Its metamodel supports human-readable and machine-interpretable definitions of classes, properties, relationships, and constraints, making it well suited for heterogeneous systems. As an open-source framework with an active community, LinkML continues to evolve alongside emerging standards. By enabling schema-driven development across diverse tooling ecosystems, LinkML helps teams collaboratively build models that are reusable, computable, and aligned with modern data-sharing goals. Rather than forcing a choice between simplicity and semantic rigor, LinkML offers both, making it a pragmatic solution for projects and communities aiming to make their data more reusable and interoperable.
Availability of Supporting Source Code and Requirements
Project name: LinkML
Project homepage: https://linkml.io (documentation), https://github.com/linkml (source code)
Operating system(s): Platform independent
Programming language: Python and others
Other requirements: Python ≥ 3.9 as of 27 June 2025
License: a mixture of BSD-3 and Apache 2.0
RRID: RRID:SCR_027188
Abbreviations
AI: artificial intelligence; ECTO: Exposure Ontology; ENVO: Environment Ontology; LLM: large language model; MIxS: minimal information about any sequence; NMDC: National Microbiome Data Collaborative; RDF: Resource Description Framework; URI: Uniform Resource Identifier.
Supplementary Material
giaf152_Authors_Response_To_Reviewer_Comments_original_submission
giaf152_GIGA-D-25-00274_original_submission
giaf152_GIGA-D-25-00274_Revision_1
giaf152_Reviewer_1_Report_original_submissionLarry Lannom, MLS -- 7/28/2025
giaf152_Reviewer_2_Report_original_submissionDaniel Jacob -- 8/4/2025
giaf152_Reviewer_2_Report_Revision_1Daniel Jacob -- 11/24/2025
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wilkinson M D, Dumontier M, Aalbersberg IJJ, et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data. 2016;3:160018. 10.1038/sdata.2016.18.26978244 PMC 4792175 · doi ↗ · pubmed ↗
- 2JSON Schema . https://json-schema.org/. Accessed 5 Jan 2026.
- 3Wikimedia Foundation. SQL:2023 . https://en.wikipedia.org/wiki/SQL:2023. Accessed 5 Jan 2026.
- 4RDF—Semantic Web Standards.. https://www.w 3.org/RDF/. Accessed 5 Jan 2026.
- 5OWL—Semantic Web Standards. https://www.w 3.org/OWL/. Accessed 5 Jan 2026.
- 6Shapes Constraint Language (SHACL) . https://www.w 3.org/TR/shacl/. Accessed 5 Jan 2026.
- 7Python.. https://www.python.org/. Accessed 5 Jan 2026.
- 8Link ML. https://w 3id.org/linkml. Accessed 6 Jan 2026.