A general framework for adaptive nonparametric dimensionality reduction
Antonio Di Noia, Federico Ravenda, Antonietta Mira

TL;DR
This paper introduces a framework that adapts dimensionality reduction methods by automatically choosing optimal local structures, improving data projections.
Contribution
The novel contribution is using an intrinsic dimension estimator to automatically tune neighborhood sizes in nonparametric dimensionality reduction.
Findings
The adaptive framework significantly improves projection methods on real and simulated datasets.
Improvements are measurable via quantitative metrics and visualization quality.
The method optimizes hyperparameters for algorithms relying on local neighborhood structures.
Abstract
Dimensionality reduction is a fundamental task in modern data science. Several projection methods specifically tailored to take into account the non-linearity of the data via local embeddings have been proposed. Such methods are often based on local neighbourhood structures and require tuning the number of neighbours that define this local structure, and the dimensionality of the lower-dimensional space onto which the data are projected. Such choices critically influence the quality of the resulting embedding. In this paper, we exploit a recently proposed intrinsic dimension estimator which also returns the optimal locally adaptive neighbourhood sizes according to some desirable criteria. In principle, this adaptive framework can be employed to perform an optimal hyper-parameter tuning of any dimensionality reduction algorithm that relies on local neighbourhood structures. Numerical…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
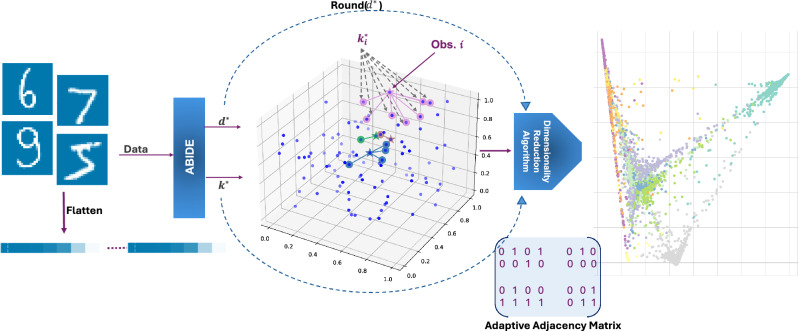 Figure 1
Figure 1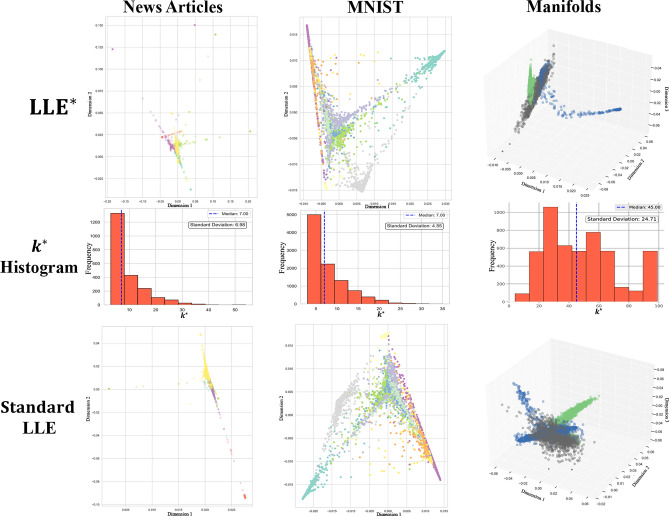 Figure 2
Figure 2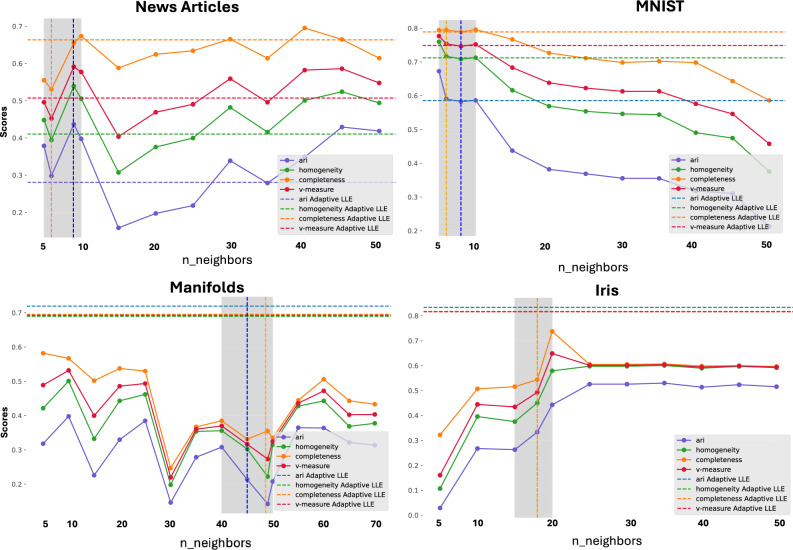 Figure 3
Figure 3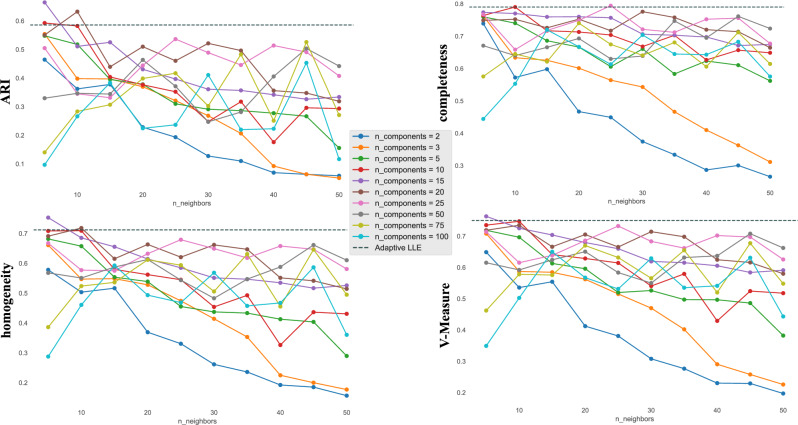 Figure 4
Figure 4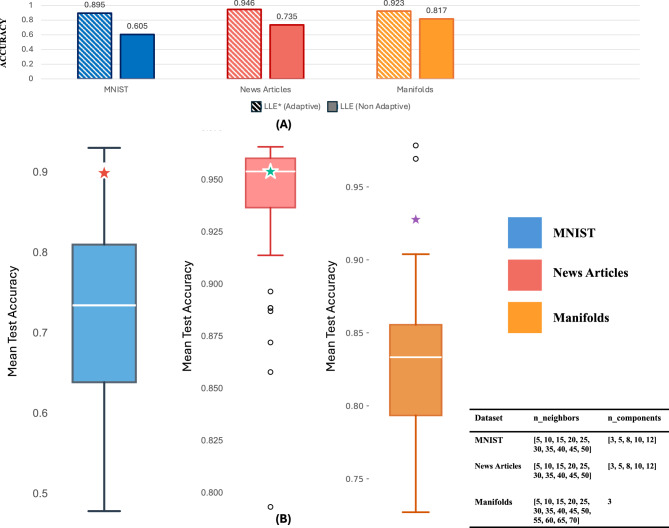 Figure 5
Figure 5 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFace and Expression Recognition · Stochastic Gradient Optimization Techniques · Statistical Methods and Inference
Introduction
Background
The explosion of data production in recent years has created huge amounts of information in many fields, such as medicine, finance, social media, and e-commerce. Such data often has many features or variables, making it high-dimensional. The analysis and visualisation of high-dimensional data is a challenging task because of physical and computational constraints. Dimensionality reduction techniques are essential tools that help make high-dimensional data analysis feasible. These methods aim to reduce the number of features while keeping the relevant information. The main goals of dimensionality reduction are to speed up computations, improve model accuracy, and help data visualisation. A complete and recent survey is given in^1^.
Low-dimensional representations can be based on both parametric and nonparametric methods; see^2^. A famous example of a parametric technique is Principal Component Analysis (PCA)^3^, which maps the data into a lower-dimensional space using projections onto linear subspaces. Parametric methods are simple and effective for many data analysis tasks, but may not work well for complex data with strongly nonlinear structures.
Nonparametric approaches are specifically tailored to take into account the strong nonlinearities of the data. A large class of nonparametric methods in statistics is based on Nearest Neighbours (NN). NN methods allow the development of flexible models tailored for several different scopes, that range from density estimation, regression, classification and dimensionality reduction; see^4^. In nonparametric dimensionality reduction NN methods are adopted to build locally adaptive neighbourhood structures, and the choice of the locally adaptive NN order is fundamental to performing the projection onto a lower-dimensional space^5^. We mention some celebrated and popular methods: the isometric mapping (Isomap)^6^, the Locally Linear Embedding (LLE)^7^, spectral embedding^8^, and Uniform Manifold Approximation and Projection (UMAP)^9^ that have been successfully employed to capture nonlinear structures and more complex patterns in the data. However, these methods can be very computationally demanding and hard to tune.
Contributions
In this paper, we introduce a novel nonparametric dimensionality reduction framework that leverages the intrinsic dimension (ID) (see^10,11^ for recent reviews) estimator recently proposed in^12^. This estimator jointly estimates the ID of the data and the optimal number of NN, ensuring that the underlying probability distribution of the data is approximately uniform in such a neighbourhood. By automatically identifying the optimal locally adaptive neighbourhood structure for each data point, our method adapts to the local structure of the data, enhancing the performance of NN-based projection methods. This adaptive approach can be integrated into several well-known nonlinear projection methods, e.g. LLE, spectral embedding and UMAP, demonstrating significant improvements in their performance. Our method’s adaptability is particularly beneficial in preserving the geometric structure of data, leading to more accurate and meaningful low-dimensional representations.
Through extensive numerical experiments, we evaluate the proposed method across various learning tasks, including classification, clustering, and data visualisation. The results show that our approach not only enhances the accuracy and robustness of nonparametric dimensionality reduction methods but also reduces computational complexity by optimising the neighbourhood selection process.
Organisation of the paper
The paper is organised as follows: In “Methods”, we briefly describe the algorithm for estimating the ID and for identifying optimal neighbourhoods for each data point. Successively, we explain how this integrates with nonlinear dimensionality reduction methods such as LLE and Isomap. In “Numerical experiments”, we show that our framework significantly improves classical nonparametric dimensionality reduction methods for various learning tasks on both real and simulated data. In “Discussion”, some concluding remarks are offered.
Methods
In machine learning, most approaches developed in both supervised and unsupervised settings involve several hyper-parameters to be tuned. These can be set a priori by a domain expert based on the available data type, or can be tuned using Hyper-Parameter Optimisation approaches^13^. Since optimisation algorithms are generally computationally expensive and time-consuming, different techniques have been explored to efficiently search the hyper-parameter space, including Grid Search ^14^, Random Search ^15^, and Bayesian Optimization ^16^. In particular, in dimensionality reduction algorithms, the nature of hyper-parameters is critical, as it significantly influences how observations are mapped into the reduced space and affects the trade-off between preserving the original local and global structure. However, it must be pointed out that hyper-parameter tuning in unsupervised approaches poses a significant challenge, as the absence of ground truth labels prevents direct performance validation^13^. For instance, in LLE and other dimensionality reduction approaches that leverage a neighbourhood structure for the data, the number of components into which the original observations are mapped (n_components) and the number of neighbours to consider (n_neighbours) are the two main hyper-parameters of the algorithms.
In the following, data-driven versions of classical NN-based dimensionality reduction methods are introduced, where hyper-parameters are autonomously estimated by the ID estimator introduced in Di Noia et al.^12^ and incorporated within such dimensionality reduction approaches, avoiding further time- and cost-consuming hyper-parameter tuning optimisation. As mentioned, we remark that we adopt such an ID estimation framework, because it naturally adapts to NN-based dimensionality reduction methods.
Intrinsic dimension and uniform neighbourhoods
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_1,\dots ,X_n$$\end{document} be a random sample taking values in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {R}^D$$\end{document} . In the following, we use the compact notation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_{1:n}$$\end{document} for the sample and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{1:n}$$\end{document} for its realisation. Moreover, suppose that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_{1:n}$$\end{document} are sampled in a small neighbourhood of a d-dimensional \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C^1$$\end{document} manifold embedded in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {R}^D$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d<D$$\end{document} ; i.e. the manifold hypothesis is satisfied. Let us consider two open balls \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B(x,r_A)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B(x,r_B)$$\end{document} with radii \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_A$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_B$$\end{document} such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_A<r_B$$\end{document} and centred at the same point on the manifold tangent space. Next, we consider a (spatial) Poisson process on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {R}^D$$\end{document} with intensity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h:\mathbb {R}^D\rightarrow \mathbb {R}_+$$\end{document} and locally homogeneous on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B(x,r_B)$$\end{document} . It follows that the number of realizations belonging to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B(x,r_B)$$\end{document} , denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_B$$\end{document} , is Poisson distributed with parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho \mu (B(x,r_B))$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu$$\end{document} is the Lebesgue measure on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {R}^D$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho$$\end{document} is the value attained by the intensity function h on the set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B(x,r_B)$$\end{document} . As a consequence, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_A|k_B \sim \textrm{Binomial}(k_B,p)$$\end{document} , where, for a sufficiently small outer ball B, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p\approx (r_A/r_B)^d = \tau ^d$$\end{document} , with d corresponding to the ID. Now, let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_{A,i}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_{B,i}$$\end{document} be, respectively, the number of points in the open balls \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B(x_i,r_A)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B(x_i,r_B)$$\end{document} , where we do not count \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_i$$\end{document} since we condition on it. If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_{A,1:n}$$\end{document} are independent conditionally on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_{B,1:n},\tau$$\end{document} , the likelihood of d reads
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L(d)= \prod _{i=1}^n \left( {\begin{array}{c}k_{B,i}\\ k_{A,i}\end{array}}\right) (\tau ^d)^{k_{A,i}} (1-\tau ^d)^{k_{B,i}-k_{A,i}} \end{aligned}$$\end{document}and is maximised at
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \widehat{d} = \frac{\log ( (\sum _{i=1}^n k_{A,i}) /(\sum _{i=1}^n k_{B,i}) )}{\log \tau }. \end{aligned}$$\end{document}The estimator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{d}$$\end{document} is called Binomial ID Estimator (BIDE). It is immediately noticeable that it depends on the choice of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_A$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_B$$\end{document} , thus, these radii must be selected.^12^ proposes an adaptive procedure that exploits a likelihood ratio test to enlarge the neighbourhood of each data point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_B$$\end{document} while ensuring that the local homogeneity of the underlying Poisson process still holds. This makes the procedure more efficient and, most importantly, more robust to noise. The task is turned into the selection of the largest NN of each data point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_i$$\end{document} to consider. More precisely, let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_{i,j}$$\end{document} be the distance between point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_i$$\end{document} and its j-th NN and introduce the hyper-spherical shells
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} v_{i,j}: = \mu (B(x_i,r_{i,j})\setminus B(x_i,r_{i,j-1})) =\Omega _d (r^d_{i,j}-r^d_{i,j-1}), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Omega _d = (2\Gamma (3/2))^d/\Gamma (d/2+1)$$\end{document} is the volume of a unit d-dimensional hyper-sphere with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Gamma$$\end{document} denoting the Euler’s Gamma function. When the underlying Poisson process is homogeneous on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B(x_i, r_{i,j})$$\end{document} with intensity constantly equal to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho _i$$\end{document} , then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_{i,1},\dots ,v_{i,k}$$\end{document} are independent and identically distributed (i.i.d.) draws from an exponential law with rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho _i$$\end{document} . Therefore, the log-likelihood reads
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{i,k}(\rho _i) := k \log \rho _i -\rho _i V_{i,k}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_{i,k}=\sum ^k_{j=1} v_{i,j}$$\end{document} . The likelihood ratio test compares two models: the first where it is assumed that the intensity of the process at point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_i$$\end{document} and its \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k+1$$\end{document} NN are different, say \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho _i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho _i'$$\end{document} , and the second where they are assumed to be equal. Thus, the test statistic
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} D_{i,k}= -2 \Big (\underset{\rho _i>0}{\max }\ (L_{i,k}(\rho _i)+L_{k+1,k}(\rho _i))-\underset{\rho _i,\rho '_i>0}{\max }\ (L_{i,k}(\rho _i)+L_{k+1,k}(\rho '_i))\Big ), \end{aligned}$$\end{document}can be employed to test \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_0: \rho _i=\rho _i'$$\end{document} against \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_1: \rho _i\ne \rho _i'$$\end{document} . More specifically, the optimal k for each point i is selected as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} k^*_i = \min \{k: D_{i,k}\ge q_{1-\alpha ,1}=:D_\text {thr} \} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q_{1-\alpha ,1}$$\end{document} is the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(1-\alpha )$$\end{document} -quantile of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi _1^2$$\end{document} distribution. Note that small values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} imply the identification of larger neighbourhoods. This choice is strongly related to the disentanglement of signal and noise, and it is usually a choice of the researcher.
From (2), it is clear that such a selection procedure depends on d, however,^12^ combined it into an iterative algorithm that starts from an initial estimate of d, and improves it through (3) and (1) until convergence. Under mild conditions, the algorithm is shown to terminate with small numerical tolerance for n large, and the resulting ID estimator is named Adaptive BIDE (ABIDE). In^12^ it is proven to be consistent and an expression for its approximate asymptotic variance is provided. The ABIDE workflow outputs the estimated ID and the set of optimal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_{1:n}^*$$\end{document} obtained at the convergence of the iterative procedure, which can be regarded as the identified optimal locally adaptive neighbourhood structure. For the purposes of this paper, unless differently specified, we implicitly consider the ID as the nearest integer to the ABIDE estimate and we denote it by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${d}^*$$\end{document} .
Adaptive nonparametric dimensionality reduction
As already mentioned, the observed data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_{1:n}=x_{1:n}$$\end{document} satisfy the manifold hypothesis. As a consequence, there exists a map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f: \mathbb {R}^d\rightarrow \mathbb {R}^D$$\end{document} such that, locally, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f^{-1}(x_{1:n}) = y_{1:n}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{1:n}$$\end{document} is the set of low-dimensional data that we aim to recover. Dimensionality reduction can be seen as the inverse problem of learning the inverse map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g:=f^{-1}$$\end{document} based on the realisation of a random sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_{1:n}$$\end{document} ; see^17^. The problem is ill-posed, and it can be approached by imposing various restrictions on f. A huge literature on different approaches naturally stems from this fact. A large number of dimensionality reduction methods are based on performing the inversion, preserving local properties of the data and of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g$$\end{document} . In the realm of local-preserving methods, very successful procedures that have been proposed are based on local neighbourhood structures induced by NN methods. Notable examples are LLE, Spectral Embedding, and Isomap. Such a class of methods can be cast into algorithms of the type
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} y_{1:n}=\widehat{g} (x_{1:n}; k_{1:n}, d^\text {proj}) \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_{1:n}$$\end{document} is the set of local neighbourhoods’ sizes expressed in terms of NN orders and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^{\text {proj}}$$\end{document} is the dimension of the space where the researcher aims to project the data. For visualisation purposes, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^{\text {proj}}=2,3$$\end{document} , while for modelling purposes it can be larger, and the optimal value is the unknown ID d. Note that in nonparametric dimensionality reduction methods, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{g}$$\end{document} does not have an explicit expression, with the advantage of being more flexible. In “Methods”, we stressed the fact that the ID is fundamentally related to the size of uniform neighbourhoods. Such framework allows us to select \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_{1:n}$$\end{document} and d in (4) in an optimal and self-consistent way, i.e. for a given dimensionality reduction of the type (4) we consider its locally adaptive version
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} y_{1:n}=\widehat{g}^* (x_{1:n}; k^*_{1:n}, d^*) \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^*$$\end{document} is the nearest integer to the ABIDE estimate and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*_{1:n}$$\end{document} is the associated set of sizes for the uniform neighbourhoods of each data point.
Application to LLE: adaptive LLE
Here, we briefly exemplify how the introduced adaptive framework applies to the LLE method (visually represented in Fig. 1). Although several variants of LLE have been proposed (e.g.^18,19^), we adopt the original formulation of^7^; see^20^ for a review of its variants. The (locally) adaptive LLE method indirectly induces the map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{g}^*$$\end{document} in (5) through the following algorithm composed of three steps:
In Step 1, given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_{1:n}^*$$\end{document} , we build a neighbourhood graph where, for each statistical unit i, we find its j-th nearest neighbour for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j=1,\dots ,k_i^*$$\end{document} , according to the Euclidean metric. We represent such graph by an adaptive adjacency matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A \in \{0,1\}^{n\times n}$$\end{document} , defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} A_{ij} = {\left\{ \begin{array}{ll} 1 & \text {if } x_j \text { is among the } k_i^* \text { nearest neighbours of } x_i,\\ 0 & \text {otherwise.} \end{array}\right. } \end{aligned}$$\end{document}In Step 2, we reconstruct each unit \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_i$$\end{document} via a weighted linear combination of its neighbours. The local reconstruction weights of each point in the D-dimensional space, denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{w}_i$$\end{document} , are obtained by solving
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \widetilde{w}_i = \arg \min _{w \in \mathbb {R}^{k_i^*}} \Big \Vert x_i - \sum _{j: A_{ij}=1} w_j x_j \Big \Vert _2^2, \quad \text {subject to } \sum _{j: A_{ij}=1} w_j = 1. \end{aligned}$$\end{document}In Step 3, we define the global weight matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W \in \mathbb {R}^{n\times n}$$\end{document} as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} W_{ij} = {\left\{ \begin{array}{ll} (\widetilde{w}_i)_j & \text {if } A_{ij} = 1,\\ 0 & \text {otherwise,} \end{array}\right. } \quad i,j=1,\dots ,n. \end{aligned}$$\end{document}Finally, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^*$$\end{document} -dimensional embedding is obtained by solving
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} y_{1:n} = \text {LLE}^*(x_{1:n}; k_{1:n}^*, d^*) =&\arg \min _{y_1,\dots ,y_n \in \mathbb {R}^{d^*}} \sum _{i=1}^n \Big \Vert y_i - \sum _{j=1}^n W_{ij} y_j \Big \Vert _2^2,\\&\text {subject to} \quad \frac{1}{n} \sum _{i=1}^n y_i y_i^\top = I, \quad \sum _{i=1}^n y_i = 0, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_i \in \mathbb {R}^{d^*}$$\end{document} are the embedded points and I is the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^*\times d^*$$\end{document} identity matrix.
It is at once apparent that our adaptive version has a strong advantage over the classical LLE because the locally linear reconstructions in Step 1 are much more accurate on local neighbourhoods where the sampling distribution is approximately uniform and, additionally, the size of such neighbourhoods adapts to local variations of the distribution. In “Numerical experiments”, we show that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} outperforms the standard LLE in both supervised and unsupervised learning tasks, as well as in graphical representations.Fig. 1. Representation of the main \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} steps.
Numerical experiments
Datasets
To evaluate the effectiveness of the proposed method, various datasets with different characteristics are used, allowing for an in-depth exploration across a wide spectrum of data types. In Table 1, we refer to some characteristics of each dataset.
Iris
Iris^21^ is a simple and widely used dataset in literature, consisting of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=150$$\end{document} samples from three species of flowers - Virginia, Versicolor, and Setosa - where each sample contains \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D=4$$\end{document} features.
MNIST
MNIST^22^ is a dataset of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$28\times 28$$\end{document} pixel grayscale images of handwritten digits. It contains 10-digit classes (from 0 to 9) with a total of 70000 images. For this analysis, each image is treated as a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D=784$$\end{document} -dimensional vector ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$28 \times 28 = 784$$\end{document} pixels). To better assess the method’s performance on a more manageable subset, only the test portion of the dataset is used, which consists of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=10000$$\end{document} images. The specific dataset subset used in our experiments is available in the GitHub repository.
Simulated manifolds
We consider \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=5100$$\end{document} points confined on three different manifolds in the 3D space: a torus, a spiral, and a sphere. Subsequently, we generate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D=20$$\end{document} Gaussian variables. The first three of these variables are added to the manifold points, while the other 17 become additional (noise) coordinates. In total, there are 5100 observations with 20 variables, of which we already know the true de-noised ID ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d = 3$$\end{document} ). This synthetic dataset allows us to test the method’s ability in a controlled environment where we already know the labels and the ID of the manifolds.
News articles
A text classification dataset contains \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=2225$$\end{document} text samples across five categories of documents: politics, sports, technology, entertainment, and business. Starting from the textual content, we generate semantic embeddings using a pre-trained SBERT model^23^, specifically the sentence-t5-base model. These generated \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D=768$$\end{document} -dimensional vectors become the input for the dimensionality reduction approach.Table 1. Main characteristics of the datasets used, namely the data type, number of variables, number of observations, number of labels, the estimated ID \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^*$$\end{document} , the approximate standard deviation of the ID estimator, and the ABIDE’s execution time (measured in seconds), which represents the additional computational cost introduced by the adaptive mechanism compared to its non-adaptive counterpart.DatasetSyntheticType# of vars (D)# of obs (n)# of labels \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^*$$\end{document} Std( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^*$$\end{document} ) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta _{time}$$\end{document} Iris✗Tabular415032.550.060.02MNIST✗Image784100001011.560.051.01Manifolds✓Tabular20510033.300.010.23News articles✗Text7682225510.940.090.13
In Table 1, we also reported \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta _{time}$$\end{document} , which represents the execution time of ABIDE (measured in seconds) required to estimate the optimal number of neighbours and the intrinsic dimension. The value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta _{time}$$\end{document} therefore represents the additional computational cost, measured on a Mac equipped with an M2 chip, introduced by the adaptive versions relative to the non-adaptive ones.
Unsupervised learning
In the following subsections, we evaluate the quality of the representations generated in a fully unsupervised context. The adaptive extension we propose can be used both in data preprocessing contexts, where the ID estimation and neighbourhood structure are used jointly to map the original data into a low-dimensional space, and in a data visualization scenario, fixing the dimension of the target space, leveraging only the adaptive structure inferred by the ID estimator.
Qualitative evaluation
To qualitatively evaluate the representations of the adaptive model, we map the observations into a 2D space for the MNIST and News Articles datasets, and into a 3D space for the Manifolds dataset, of which we know the true ID.Fig. 2. Data visualisation in the reduced space using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} (first row) and the standard version (third row). The second row shows histograms of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} , with summary statistics displayed for median values and standard deviation.
In Fig. 2, we observe the representations generated by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} , the histograms related to the estimated values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} , and the representations generated by LLE using the median value of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} distribution as the fixed number of neighbours (n_neighbours). We observe that in the case of MNIST, the two representations are very similar to each other. We anticipate that this similarity will carry over to how the two approaches perform when clustering is applied to the reduced data obtained with the adaptive and non-adaptive LLE methods. Concerning News Articles, we observe that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} produces more compact clusters with well-identified boundaries, while standard LLE shows significant overlap that obscures the underlying data structure. In Manifolds, the representation obtained with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} improves the identification of clusters. In this case, we also examine the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} histograms, which differ significantly from the previous ones. While the previous distributions were unimodal and positively skewed with low variability, here the standard deviation is much larger, indicating that the data density is strongly non-uniform. As a result, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} adaptive approach is better suited to capture local variations.
Quantitative evaluation
To quantitatively assess the quality of representations generated by adaptive methods compared to their non-adaptive counterparts, we compare the results obtained from clustering algorithms applied to the low-dimensional representations. We use a simple and widely used clustering approach, K-Means ^24^, to group data into as many clusters as the number of labels in the considered datasets. Once we obtain the output from the clustering approach, we compare the predictions with the ground truths, as reported in the original datasets. We evaluate the clustering performance using metrics adapted for scenarios where clustering is performed with known true labels. The metrics used are Adjusted Rand Index (ARI)^25^, Completeness, Homogeneity, and V-measure^26^. In particular, the ARI measures clustering similarity, ranging from -1 to 1, with 1 indicating perfect agreement with true labels. Completeness assesses if members of the same true class are in the same cluster, while Homogeneity evaluates how pure or homogeneous each cluster is with respect to a single class label. The V-measure balances homogeneity and completeness, calculated as their harmonic mean. All these metrics range from 0 to 1 (except ARI), with 1 being the optimal score.
As mentioned, the proposed approach allows for autonomously optimising the hyper-parameters by exploiting the locally adaptive neighbourhood structure of the data, independently finding the best hyper-parameters for the number of neighbours (n_neighbours) and the dimension on which to map the original variables (n_components).Table 2. Clustering performance metrics based on MNIST, news articles, and manifolds dataset. We compared \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {LLE}^*$$\end{document} with the default configuration of sklearn of the standard LLE implementation and the modified one. Best results for each metric are highlighted in bold.ModelsARIHomogeneityCompletenessV-measureMNIST \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${ {LLE}}^*$$\end{document} 0.5860.7120.789****0.749LLE0.4650.5780.7390.649LLE modified0.3520.5430.6910.608News articles \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${ {LLE}}^*$$\end{document} 0.2810.4110.664****0.507LLE0.2060.2920.4970.369LLE modified0.0010.0050.2270.010Manifolds \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{LLE}}^*$$\end{document} 0.7190.6890.695****0.692LLE0.3180.4220.5820.489LLE modified0.1010.2010.3940.266
In Table 2, we report the results of LLE* together with those obtained using the default hyper-parameter configuration of the standard LLE implementation from the scikit-learn Python package and the modified version of LLE^19^ . This comparison is motivated by the scenario in which a practitioner, unaware of the most suitable hyper-parameter settings, would typically rely on the default configuration provided by standard software packages.Fig. 3. Visualisation of performance metrics of ARI, homogeneity, completeness, and V-measure as the number of considered neighbours varies, fixing the dimension of the target space \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^*$$\end{document} , returned by ABIDE, for the 4 datasets considered. Horizontally, in dashed lines, we report the metrics of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} . Vertically, the median (in orange) and the mean (in blue) of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} are shown. The grey shaded area represents an arbitrary neighbourhood around these summary measures (mean and median) to highlight the proximity of the adaptive results to these reference values. With respect to the Iris dataset, the mean and median coincide.
In Fig. 3, we compare the performance of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} (horizontal dashed lines) with the performance of LLE as the number of neighbours varies (continuous lines) for all 4 chosen metrics. We create a combination of possible hyper-parameter values explored through grid search. This allows us to evaluate how \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} behaves compared to different choices of numbers of neighbours (n_components is fixed and equal to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^*$$\end{document} ). We explore neighbours from 5 to 50 with a step size of 5, except for Manifolds, where, since the average \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} is close to 50, we extend the exploration up to 70 neighbours. Vertical dashed lines are also drawn to highlight the mean (blue) and the median (orange) of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} distribution. We observe that in most cases, the results obtained by varying the number of neighbours are smaller, and thus worse, or close to the results obtained with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {LLE}^*$$\end{document} .
Another interesting observation is that when we fix the number of neighbours as the mean or the median—or we consider a neighbourhood around these summary statistics (represented by the gray area in Fig. 3)—of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} distribution, the results obtained for some metrics are comparable to those obtained by using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} for the MNIST, Iris, and News Articles datasets. Regarding the Manifolds dataset, this trend is not visible: as previously discussed, looking at Fig. 2, we can see how the distribution of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} is much more variable compared to that of the other datasets, which indicates that the data density varies significantly across different regions of the manifold. Therefore, if we take the median of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} , we possibly introduce systematic biases due to sub-regions where the density exhibits strong irregularities.
These insights allow us to make some remarks on how to handle the possible modelling scenarios:
- When the data density of points varies considerably, the locally adaptive structure enables us to effectively describe the local neighbourhoods of observations, avoiding the introduction of bias during the projection phase into the low-dimensional space.
- For data with more regular density, on the other hand, imputing a fixed k as the median \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} already leads to acceptable results. However, since the data distribution is unknown, we recommend always using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} because it leads to accurate and robust results independently of the roughness of the data density. Fig. 4. Visualisation of the performance of the 4 considered metrics ARI, Homogeneity, Completeness, and V-Measure for different choices of n_components and n_neighbours in LLE on MNIST dataset. The horizontal dashed lines represent the results of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} .
For the sake of completeness, in Fig. 4, we observe how performance varies as the two hyper-parameters n_components and n_neighbours change for the MNIST dataset. Again, we observe that the choice of the adaptive method leads to better results for almost all the possible configurations of hyper-parameters explored and for all the considered metrics. For some metrics, the best results are obtained with combinations of n_components = 10 and 15 and n_neighbours = 5, values that are comparable to those obtained with the ID estimate ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^*$$\end{document} = 11.56) and the median number of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} of 7.
Beyond LLE: application to spectral methods
The adaptive framework introduced for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} naturally extends to many other NN based dimensionality reduction methods. As a proof-of-concept, we test the performance of our adaptive paradigm in Spectral Clustering (SC)^8^. In SC, a similarity graph is constructed using a fixed number of NNs, followed by eigendecomposition of the graph Laplacian and k-means clustering on the resulting spectral embedding. We develop an adaptive version of Spectral Clustering ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {SC}^*$$\end{document} ) that leverages the ABIDE estimator to automatically determine both the optimal neighbourhood structure and the embedding dimensionality for spectral graph construction. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {SC}^*$$\end{document} replaces the fixed neighbourhood parameter with the data-driven \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} values obtained from ABIDE, while using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^*$$\end{document} to determine the spectral embedding dimensionality. The most basic adaptive version of SC can be obtained by simply plugging the adaptive adjacency matrix A introduced in (6) of “Methods” into the standard spectral embedding workflow. For comparison, SC corresponds to the scikit-learn implementation configured to build the similarity graph using nearest neighbours instead of the default RBF kernel, while keeping all the other hyper-parameters at their default values.Table 3. Clustering performance metrics based on MNIST, news articles, and manifolds dataset. We compared \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {SC}^*$$\end{document} with the default version of sklearn. Best results for each metric are highlighted in bold.ModelsARIHomogeneityCompletenessV-measureMNIST \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${ {SC}}^*$$\end{document} 0.5890.7250.845****0.780SC0.5630.7010.7220.712News articles \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${ {SC}}^*$$\end{document} 0.539****0.5850.694** 0.635SC0.4470.5570.7040.622Manifolds** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${ {SC}}^*$$\end{document} 0.6730.6940.713****0.703SC0.2630.3670.5330.435
Experimental evaluation on MNIST, News Articles, and Manifolds datasets in Table 3 demonstrates the effectiveness of this adaptive approach. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {SC}^*$$\end{document} achieves substantial improvements over standard SC on MNIST and News Articles, and particularly dramatic gains on the Manifolds dataset, where the non-uniform density distribution makes the locally adaptive neighbourhood selection crucial.
Beyond LLE: application to UMAP
UMAP (Uniform Manifold Approximation and Projection) is a nonparametric dimensionality reduction method based on manifold learning and topological data analysis^9^. The algorithm constructs a fuzzy topological representation of the data in the high-dimensional space and then optimizes a low-dimensional embedding to preserve this structure. A critical hyper-parameter in UMAP is the number of nearest neighbours (n_neighbours) used to construct the local neighbourhood graph, which directly influences the balance between preserving local and global structure.
We introduce a simple adaptive version of UMAP, denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {UMAP}^*$$\end{document} , that leverages the locally adaptive neighbourhood structure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*_{1:n}$$\end{document} obtained from the ABIDE estimator. Adopting the notations introduced in “Methods” and following the standard UMAP workflow^9^, we introduce local scaling parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _i$$\end{document} such that
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _{j: A_{ij}=1} \exp \Big (-\frac{\max (0,\Vert x_i-x_j\Vert _2-\rho _i)}{\sigma _i}\Big ) = \log _2 k_i^*,$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho _i$$\end{document} is the distance to first non-coincident nearest neighbour. Next, the local fuzzy weight vectors are computed as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\widetilde{w}_i)_j = \exp \Big (-\frac{\max (0,\Vert x_i-x_j\Vert _2-\rho _i)}{\sigma _i}\Big ), \quad \text { for all } j: A_{ij}=1,$$\end{document}and the global weighted adjacency matrix is obatined as in (8):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_{ij} = {\left\{ \begin{array}{ll} (\widetilde{w}_i)_j & \text {if } A_{ij}=1, \\ 0 & \text {otherwise,} \end{array}\right. } \quad i,j=1,\dots ,n.$$\end{document}The sparse weight matrix W defines the fuzzy simplicial set used by the UMAP workflow. Thus, following the standard UMAP procedure, W is symmetrized, and its symmetrized version defines the fuzzy topological representation of the data in the high-dimensional space, where the locally varying neighbourhood sizes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*_{1:n}$$\end{document} naturally adapt to regions of varying data density. Finally, as in UMAP, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {UMAP}^*$$\end{document} constructs a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d^*$$\end{document} -dimensional representation by minimizing the fuzzy set cross-entropy between the high-dimensional and low-dimensional fuzzy representations.Table 4. Clustering performance metrics based on MNIST, news articles, and manifolds dataset. We compared \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {UMAP}^*$$\end{document} with the default version of uwot package. Best results for each metric are highlighted in bold.ModelsARIHomogeneityCompletenessV-measureMNIST \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${ {UMAP}}^*$$\end{document} 0.7530.8180.840****0.829UMAP0.7480.8100.8310.813News articles \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${ {UMAP}}^*$$\end{document} 0.641****0.7290.7750.760UMAP0.6180.7270.7960.760Manifolds \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${ {UMAP}}^*$$\end{document} 0.7880.7680.777****0.773UMAP0.4470.4690.4910.480
Based on Table 4, we observe that the adaptive model ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {UMAP}^*$$\end{document} ) achieves better performance on the considered datasets compared to the default hyper-parameter configuration of the uwot package. For MNIST, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {UMAP}^*$$\end{document} consistently outperforms standard UMAP across all the considered evaluation metrics, demonstrating that the locally adaptive neighbourhood structure better captures the local variations of the underlying data distribution. The improvement is even more pronounced for the Manifolds dataset, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {UMAP}^*$$\end{document} achieves markedly higher clustering accuracy and structure preservation. This result highlights once again the advantage of using locally adaptive neighbourhoods when the data density varies strongly across regions of the manifold, allowing the model to flexibly adjust to local variations and avoid distortions in the low-dimensional embedding. For the News Articles dataset, the performance gap between the two variants is less pronounced, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {UMAP}^*$$\end{document} showing a slight improvement in ARI and Homogeneity, while maintaining comparable V-Measure scores.
Supervised learning
For supervised learning tasks, we must address the challenge of extending our adaptive framework to out-of-sample points not present during the training phase. We develop a local reconstruction approach that maintains the adaptive neighbourhood structure for test data. For each test point, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${x}_{test}$$\end{document} , we temporarily augment the training data including it, estimate its optimal neighbourhood size, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${k}^*_{test}$$\end{document} using the intrinsic dimension learned during training, and compute locally adaptive reconstruction weights based on its \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k_{test}^*$$\end{document} nearest neighbours. The test point is then projected into the embedding space using a weighted combination of its neighbours’ embeddings. See Algorithm 1 for the detailed procedure.
Algorithm 1Out-of-sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} for supervised learning.
In a supervised context, the projections obtained as output from dimensionality reduction algorithms are often fed to supervised models. This is done to avoid possible complications due to the high dimensionality of the data, e.g., the curse of dimensionality^27^, to avoid overfitting, to decrease the computational burden of high-dimensional datasets, and ultimately to improve model performance^28,29^.
To evaluate the quality of the representations in a supervised context, we use the MNIST, Manifolds, and News Articles datasets and assess the performance in terms of accuracy and F1 score. To do this, we use m-fold cross-validation, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m = 3$$\end{document} , where a Logistic Regression model is fitted on the reduced space representations. The hyper-parameters used are the same as the default ones from the sklearn implementation, except for the penalty parameter which is set to None, to ensure that the model performance depends solely on the quality of the dimensionality reduction rather than regularization effects.Fig. 5**(A)** The results of the accuracy score for the datasets considered are shown for different configurations of LLE, adaptive ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} ) and non-adaptive (LLE). (B) Boxplots of accuracy scores comparing adaptive and non-adaptive dimensionality reduction approaches across MNIST, News Articles, and Manifolds datasets. The Boxplots show the distribution of scores from the hyper-parameter grid search, while the stars represent the adaptive method results. Results are averaged using an 80%–20% holdout approach over three different runs. The table on the bottom right shows the hyper-parameter grid used for the non-adaptive approach, exploring different combinations of n_neighbours and n_components values.
In Fig. 5A, we report the results for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} , and LLE implemented in sklearn . We observe that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} leads to the best results for all the datasets considered. Compared to the default sklearn implementation, which can be used as an easy-to-go choice, our adaptive approach achieves significantly better results in terms of accuracy, without any hyper-parameter tuning.
In order to extend the comparison between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hbox {LLE}^*$$\end{document} representations and their non-adaptive counterparts, we compare \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {LLE}^*$$\end{document} with LLE by varying the number of components and neighbours, exploring all possible combinations in a grid-search-like approach. In Fig. 5B, we show the boxplots of accuracy scores based on different hyper-parameter-value combinations explored (shown in the bottom right table in Fig. 5B). We observe that the use of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {LLE}^*$$\end{document} approach allows us to achieve among the best results for the MNIST and Manifolds datasets, while for News Articles, the results are very close to the median, as they are already high. Also in this case, we empirically observe how the use of an adaptive approach consistently leads to robust and competitive results without the need for hyper-parameter tuning.
Discussion
We introduce a general framework for hyper-parameter tuning in non-linear NN-based dimensionality reduction methods, where the selection of the neighbourhood structure and the dimension of the projection space are often arbitrary. Our method is based on intrinsic dimension estimation and locally adaptive uniform neighbourhood selection, which are performed jointly. We show that our approach leads to a significant improvement in the performance and graphical visualisation of LLE, a very popular dimensionality reduction method in statistics and machine learning, whenever employed in unsupervised and supervised learning tasks on both simulated and real benchmark datasets. As a proof of concept, we also extend our approach to Spectral Clustering and UMAP, achieving excellent results in an unsupervised context. The framework can be naturally extended to all dimensionality reduction methods that require neighbourhood structure (n_neighbours) and target space dimensionality (n_components) as input to compute the projection. More broadly, the locally adaptive \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k^*$$\end{document} -based paradigm can be extended to all unsupervised, semi-supervised, and supervised algorithms that leverage neighbourhood relationships (i.e., DBSCAN, Label Propagation, K-Nearest Neighbours, etc.).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Gérard, B. & Luc, D. Lectures on the Nearest Neighbor Method. Vol. 246. (Springer, 2015).
- 2Joshua, B. et al. A global geometric framework for nonlinear dimensionality reduction. Science 290(5500), 2319–2323 (2000).10.1126/science.290.5500.231911125149 · doi ↗ · pubmed ↗
- 3Roweis, S.T. & Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 290(5500), 2323–2326 (2000).10.1126/science.290.5500.232311125150 · doi ↗ · pubmed ↗
- 4Leland, M., John, H. & James, M. Umap: Uniform manifold approximation and projection for dimension reduction. ar Xiv preprintar Xiv:1802.03426 (2018).
- 5James, A.D., Binnie, P., Dłotko, J., Harvey, J. M. & Ka Man, Y. A survey of dimension estimation methods. ar Xiv preprintar Xiv:2507.13887 (2025).
- 6Di Noia, A., Macocco, I., Glielmo, A., Laio, A. & Mira, A. Beyond the noise: Intrinsic dimension estimation with optimal neighbourhood identification. ar Xiv preprintar Xiv:2405.15132 (2024).
- 7La Valle, S.M., Branicky, M.S. & Lindemann, S.R. On the relationship between classical grid search and probabilistic roadmaps. Int. J. Robot. Res.23(7-8), 673–692 (2004).
- 8James, B. & Yoshua, B. Random search for hyper-parameter optimization. J. Mach. Learn. Res.13(2) (2012).