AI applications in lumbar and lumbosacral pedicle screw placement: a systematic review of limited evidence and future directions
Pakpoom Thintharua, Ratchaphon Prabrai, Anuyut khamsiriwatchara, Rohan Sethi, Sorayouth Chumnanvej

TL;DR
This paper reviews how AI can help with placing screws in the spine during surgery, highlighting benefits like faster operations and reduced errors.
Contribution
The paper systematically categorizes and analyzes current AI applications for pedicle screw placement in spine surgery.
Findings
AI reduces operation time and improves accuracy in identifying anatomical landmarks.
AI applications help reduce radiation exposure and image errors during surgery.
Limited training data and lack of diversity hinder AI model generalization and robustness.
Abstract
Artificial intelligence (AI) is a general term that refers to the use of a computer to simulate intelligent behavior with minimal human intervention. Currently, AI can be applied to various spine surgery approaches. This review aims to provide a clearer picture of AI’s applicability for the perioperative period and enhance outcomes for pedicle screw fixation (PS). The PRISMA guideline was applied, which identified 14 studies regarding AI applications in PS. We categorized the AI application to PS into segmentation, object detection, image registration, and other categories, such as improved quality and converted images. Then, an analysis and discussion of the current trends and applications of various AI models in PS methods was performed. The effects of AI performance included a reduction in the time required for operations and planning, automatic identification of screws and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
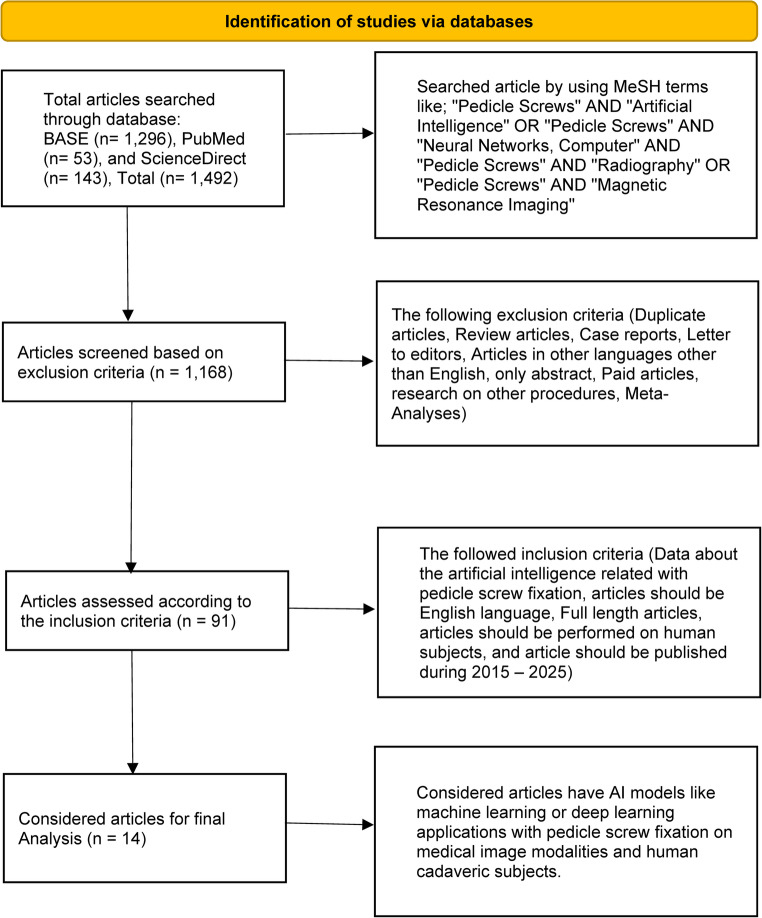 Figure 1
Figure 1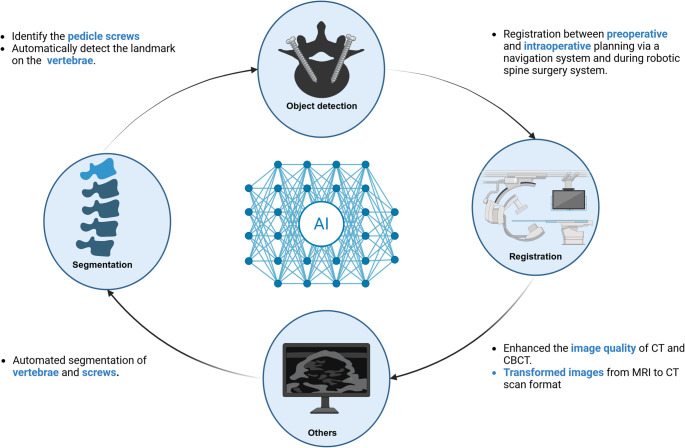 Figure 2
Figure 2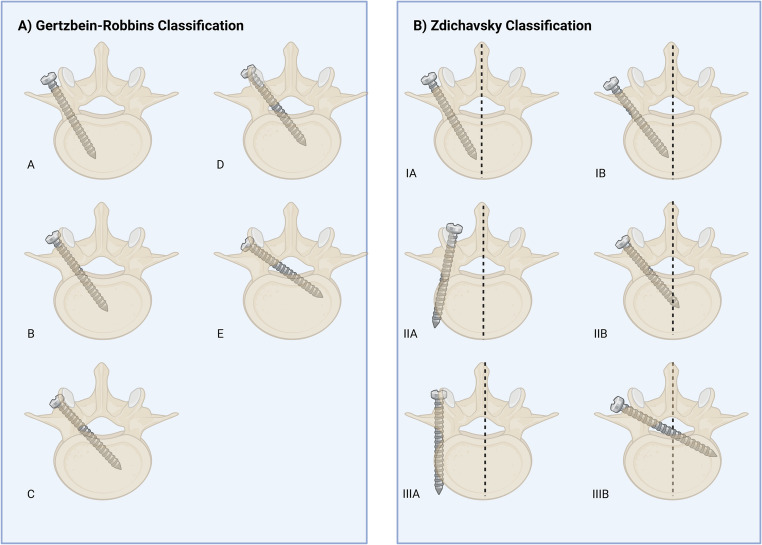 Figure 3
Figure 3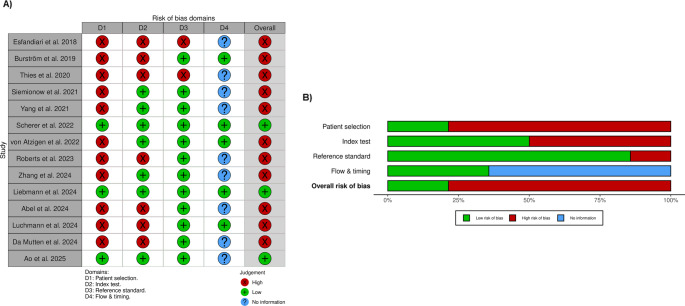 Figure 4
Figure 4- —Mahidol University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpinal Fractures and Fixation Techniques · Medical Imaging and Analysis · Spine and Intervertebral Disc Pathology
Introduction
Artificial Intelligence (AI) lets computers act like people by analyzing data and making smart decisions [1]. It is transforming spine surgery by making it easier to assess patients before surgery and predict the postoperative outcomes [2, 3]. It is also improving the quality of medical research [4]. AI also makes surgical workflows and data tracking more efficient [2, 3] and directly helps with better performance during surgery [2, 5]. The medical image speed and quality analysis can be improved by AI while lowering cost [4, 6]. It also integrates robotics to assist—rather than replace—surgeons in delivering safer care [3].
Pedicle screw fixation (PS) remains challenging, as placing screws near vital nerves involves significant risk [5]. Reports reveal that manual placement is difficult, with breach rates ranging from 8% to 50% [7, 8]. While the freehand technique is cost-effective, it relies heavily on the surgeon’s experience and lacks real-time feedback [9]. To address these limitations, AI helps to improve image quality, automate trajectory planning, and enhance screw detection [11–15], making this error-prone process more efficient [10]. Although wider studies on AI in spine surgery exist [2–4], there is currently no systematic review that focuses solely on AI applications for PS.
This is the first systematic review to examine current trends and applications of AI models in PS. Specifically, this systematic review aims to: [1] categorize current AI applications in pedicle screw fixation [2], evaluate their performance metrics and clinical outcomes [3], assess methodological quality, and [4] identify evidence gaps requiring future research. By synthesizing these findings, this study seeks to bridge the gap between technical innovation and clinical practice, helping surgeons select the optimal tools for safer outcomes.
Materials and methods
Article collection
The Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guideline 2020 was utilized for the systematic review of literature. We searched the research articles based on three databases, including BASE: Pedicle Screws AND (Artificial Intelligence OR Neural Networks, Computer) AND Pedicle Screws AND (Radiography OR Magnetic Resonance Imaging) [January 15, 2025], PubMed: (((“Pedicle Screws“[Mesh]) AND (“Artificial Intelligence“[Mesh])) OR ((“Pedicle Screws“[Mesh]) AND (“Neural Networks, Computer“[Mesh]))) AND (((“Pedicle Screws“[Mesh]) AND (“Radiography“[Mesh])) OR ((“Pedicle Screws“[Mesh]) AND (“Magnetic Resonance Imaging“[Mesh]))) [January 15, 2025], and ScienceDirect: ((“Pedicle Screws” AND “Artificial Intelligence”) OR (“Pedicle Screws” AND “Neural Networks, Computer”)) AND ((“Pedicle Screws” AND “Radiography”) OR (“Pedicle Screws” AND “Magnetic Resonance Imaging”)) [January 16, 2025]. The articles were collected over ten years, from 2015 to 2025. The exclusion and inclusion criteria were set for selecting the appropriate research articles for references. The comprehensive search approach utilizing database-specific syntax is shown in Table S1 (Supplementary). The review focused on AI applications for pedicle screw fixation primarily in the lumbar and lumbosacral spine, as these represent the most common sites for pedicle screw instrumentation.
Inclusion criteria
This review article focuses on the application of AI models with pedicle screw fixation, which improves the surgical strategies. Articles should be written in the English language, full-length articles should be performed on human subjects, and articles should be published between 2015 and 2025. Furthermore, selected studies must have focused primarily on lumbar or lumbosacral pedicle screws, or on whole-spine applications where data for the lumbar/lumbosacral segments could be independently extracted.
Exclusion criteria
The types of articles, like review articles, case reports, letters to editors, only abstracts, paid articles, research on other procedures, and meta-analyses, were excluded from this literature. Articles without information regarding both pedicle screw fixation (PS) and its relationship with AI.
Article screening process
A two-stage screening process was used. Studies were first screened independently by two authors by title and abstract. Then, we performed an in-depth review of the selected articles to find any potentially eligible studies. Any disagreements at each stage were re-evaluated by two reviewers to reach a conclusive consensus.
Data extraction and reporting
Data from selected studies were extracted and compiled using Google Sheets (Google Inc., California, USA). Extracted variables included study characteristics (author, year, journal), methodological details (study design, population, sample size, perioperative phase, imaging modality), technical specifications (AI models, architectures), and key findings. Due to substantial heterogeneity in AI architectures, imaging modalities, outcome measures, and study designs, meta-analysis was not feasible. We conducted structured narrative synthesis using the PICO framework to systematically organize and compare findings. We organized and analyzed the data extracted using the PICO format. P: population (pedicle screws and spinal surgery), I: intervention (AI applications to pedicle screw fixation), C: comparison (AI and traditional approaches), and O: outcome (accuracy, precision, safety, and time-consuming).
Quality assessment
All 14 studies were rated using the Quality Assessment of Diagnostic Accuracy Studies-2 (QUADAS-2) technique. Patient Selection, Index Test (AI model performance), Reference Standard (clinical grading systems), and Flow and Timing were examined by two authors for bias and applicability issues. A third reader was consulted if there was a disagreement; otherwise, judgments were determined by consensus.
Statistical analysis
Cohen’s Kappa (k) was used to measure the inter-rater reliability between the two separate reviewers. There was a lot of agreement (95.0% and a k-value of 0.89 in the first Stage 1 screening of the Title and Abstract. For the Full-Text review (Stage 2), dependability went up to a lot of agreement (k = 0.94; 97.8% agreement). All differences at both stages were worked out in a consensus discussion to make sure the final list of studies was correct.
Results
Search results
The MeSH terminology was used to identify 1,492 articles in total that were searched from various online sources, including BASE (1,296), PubMed (53), and ScienceDirect (143), respectively. 1,168 articles remained after implementing the exclusion criteria, and 91 articles after using the inclusion criteria. From 91 articles, we selected only 14 for organization and analysis using the PICO format. We applied the systematic reviews and meta-analyses (PRISMA) for the study selection process, as shown in the flow diagram in Fig. 1.Fig. 1PRISMA flow diagram of systematic review
All the selected articles were retrospective studies at 64.29% and prospective studies at 35.7%. Of the studies, 12 (85.7%) focused only on the lumbar or lumbosacral segment, whereas 2 (14.3%) included the whole spine but provided data relevant to the lumbar region. The perioperative period was observed, and it was found that the intraoperative phase was at 50.0%, followed by the preoperative phase at 28.6%, the postoperative phase at 14.3%, and both the pre- and intraoperative phases at 7.1%, respectively. The most common image modalities for AI applications in pedicle screw fixation were CT and CBCT scans at 35.7%, followed by radiography at 21.4%, the combination of at least two modalities at 21.4%, and MRI at 7.1%, respectively. In addition, 14.3% came from RGB or RGBD video sources and stereo camera images. The relevant characteristics of the included studies, including study designs, population, sample size, perioperative phase, image modalities, AI models, applications, and key findings, are presented in Table 1. Furthermore, what is the basic principle of each AI model, and why does it fit this task? was shown in Table 2.Table 1. Technical Performance and Clinical Analysis of AI Models in Spinal SurgeryAuthorsStudy designPopulationSample sizeSegmentsPhaseImage modalitiesAI modelsApplicationsPrimary MetricPerformance RangeClinical SignificanceStudy Limitations Burström et al. 2019 [5]PTHuman cadavers21 cadaversLumbar/LumbosacralIOCBCTML (unidentified)SegmentationAccuracy (Planning)86.1% (Auto) – 95.4% (Clinical)Rapid automated planning (11 ± 4 s per 5 vertebrae).Performance relies on excluding severe deformities and prior surgeries. Esfandiari et al. 2018 [9]RTPatients undergoing PS40 patientsLumbar/LumbosacralPOX-raysFCNSegmentationSegmentation Accuracy93% (Synthetic) vs. 83% (Clinical)High precision in pose estimation (1.93° discrepancy).Significant accuracy drops when moving from synthetic to clinical data. Thies et al. 2020 [11]RTChest CT scans from TCIAn/aLumbar/LumbosacralIOCT, CBCTModified VGG architectureImproved quality of the imageImage QualityQualitative improvementEnables online C-arm trajectory adjustment without interruption.Sample size and quantitative metrics not reported. Siemionow et al. 2021 [12]RTPatients (unidentified)20 patientsLumbar/LumbosacralPrO, IOCTAutonomous pedicle screw planner (ML), CNNSegmentation, landmark detectionGrading Agreement100% (Zdichavsky); 99% (Gertzbein Grade A)Matches standard clinical grading systems (Ravi grading).Small sample size (N = 20). Scherer et al. 2022 [13]RTPatients were derived from a consecutive registry of navigated spinal instrumentations179 patientsLumbar/LumbosacralIOCTnnU-NetSegmentationMean Absolute Difference (MAD)Screw tip MAD: 4 mm; Dice: 0.6110x speed compared to manual planning.Dice coefficient (0.61) suggests segmentation overlap is moderate. Zhang et al. 2024 [14]RTPatients undergoing PS282 patientsLumbar/LumbosacralPrOCTModified U-Net (combined with ResNet34) or VGG16 (limited data availability) architecturesLandmarks detectionPercentage of Correct Key points (PCK)> 93% (at 3 mm threshold)High inter-rater reliability (ICC 0.82–0.98) with clinicians.Limited data availability noted for the VGG16 comparison arm. Liebmann et al. 2024 [15]PTSpineDepth dataset and cadavers for validationn/a (Dataset + Cadavers)Whole-spineIORGB or RGBD video sourcesU-NetRegistrationTarget Registration Error (TRE)Median TRE: 2.7 mm; Success: 100%Fast registration process ( 1.5s total duration).Exact sample size not fully defined in summary. Yang et al. 2021 [16]RTThe patients who had lumbar spine one-segment instrument surgery2894 lumbar spineLumbar/LumbosacralPOX-raysResNet34 model with ImageNet pretrained weights, Google AutoML, Apple Create MLObject detectionAccuracy/PrecisionResNet: ~97–98%; AutoML: ~87–98%Demonstrated high accuracy using transfer learning (ImageNet).Commercial tool “Apple Create ML” showed significantly lower recall (73%). von Atzigen et al. 2022 [17]PTHuman cadavers8 cadaversLumbar/LumbosacralIOStereo camera imagesSNNObject detectionAverage Error/Time5.43 mm error; Bending time 231sMarker-free AR reduced surgical bending time by ~ 50%.Small cadaveric sample (N = 8). Roberts et al. 2023 [18]RTPatients who had CT and MRI scans performed within 30 days20 patientsLumbar/LumbosacralPrOMRISupervised 3D cycleGanConvert the type of image (MRI to CT)Intraclass Correlation (ICC)Sagittal error < 10%; Axial error up to 34%Enables CT-like planning from MRI (radiation-free).High error rate (34%) in axial plane measurements; unreliable IVDH. Abel et al. 2024 [19]RTAdult patients who planned for initial lumbar spine fusion surgery16 patientsLumbar/LumbosacralPrOCT, MRIDL (unidentified)SegmentationGeometric ReliabilityHigh reliability (general)Validates MRI usage for 3D geometric planning.Failed to measure vertebral body length at L1, L2, and L4. Luchmann et al. 2024 [20]PTHuman cadavers6 cadaversLumbar/LumbosacralIOX-raysDL (unidentified)SegmentationBreach Rate21% (AI) vs. 24% (Freehand)Reduced radiation exposure (33 mGy vs. 49 mGy).Very small sample (N = 6); marginal improvement in breach rate. Da Mutten et al. 2024 [21]RTThree different data sets from VerSe (spine), MSD T10 (liver), and COVID-19 (chest)214 patients for the training set and 40 CT scans for validationWhole-spinePrOCTYOLOv8m, 2D-U-NetObject detection, segmentationmAP/Dice ScoreDice: 0.76–0.79; mAP: 0.63 (Int) to 0.09 (Ext)Segmentation generalized well to external validation.Object detection failed to generalize externally (mAP dropped to 0.09). Ao et al. 2025 [22]PTAdult humans with different BMIs5 adultsLumbar/LumbosacralIOCT, MRI, USSafeRPlan (Deep Reinforcement Learning)RegistrationSafety Rate99% SafetyImproved safety by 5% over existing methods.Extremely small sample size (N = 5).Augmented reality (AR), computed tomography (CT), cone beam computed tomography (CBCT), convolutional neural network (CNN), fully convolutional network (FCN), intervertebral disc height (IVDH), intraclass correlation coefficient (ICC), intraoperative (IO), machine learning (ML), mean average precision calculated at varying IoU thresholds (mAP), not available (n/a), pedicle screw fixation (PS), percentage of correct key points (PCK), postoperative (PO), preoperative (PrO), prospective study (PT), retrospective study (RT), stereo neural network (SNN), target registration error (TRE), the cancer imaging archive (TCIA), and ultrasound (US)Table 2. Technical principles of AI models in spinal surgeryModelTypeCore Working Principle (The “How”)Why does it fit this task?CNN (Convolutional Neural Network)Foundational ArchitectureFeature filtering: Small windows (filter) are moved over an image to find patterns. First, it finds lines or edges, then forms, and finally vertebrae.It functions like human eyes, so the computer can “see” body shapes and features in CT or X-ray images instead of reading pixel values.VGG16Deep CNN BackboneUniform Stacking: A very deep stack of simple 3*3 convolution filters. It relies on depth (16 layers) to learn increasingly complex features.It’s very simple: a consistent structure makes it a reliable “feature extractor” for improving image quality or detecting landmarks.ResNet34Deep CNN BackboneResidual Learning (Skip Connections): When networks are deep, data usually gets lost. ResNet adds layers with “skip connections” that let data go around certain levels. This keeps the original signal.It can train much deeper networks (34 layers) without slowing down, which makes it a great tool for finding subtle fractures or features in X-rays.ImageNetLarge-Scale DatasetTransfer Learning: This is not a model, but a “school.” Models like ResNet are first taught on ImageNet (14 M distinct photos) to learn what “edges” and “shapes” look like.Pre-training: By the time the model sees a spine X-ray, it already knows how to see. It only needs to “fine-tune” its knowledge for bones, saving massive amounts of training time.FCN (Fully Convolutional Network)Segmentation NetworkPixel-wise Classification: FCNs describe every pixel as “bone” or “background,” while normal CNNs just say “this image has a spine.” It replaces dense layers with convolutional ones, so it can work with images of any size.It makes a “mask” over the vertebrae, which lets you divide the vertebrae more precisely than with just a bounding box.U-NetSegmentation NetworkEncoder-Decoder with Bridges. It’s shaped like a “U.” The “where” part of the left side (Encoder) makes the picture smaller to get context. The right side (Decoder) builds it back up to exact information (“what”). Skip connections and keep sharp edges by connecting both sides.For Medical, even with a few training images, it is great at tracing the exact outlines of organs and bones.2D-U-NetSegmentation NetworkSlice-by-Slice Processing: Uses the U-Net design on one 2D slice of a CT scan at a time instead of the whole 3D volume.It needs less computer memory than the 3D versions, so it’s easier to run on regular hospital computers.nnU-Net (No-New-Net)Auto-ML FrameworkSelf-Adaptation: This is a “smart” U-Net that looks at the dataset (for example, image resolution and spacing) and instantly figures out the best way to set up the network (layer depth and patch size) without anyone having to guess.It removes human error in design. In the study, it achieved 10x speed because it was perfectly optimized for the specific CT variation used.SNN (Stereo Neural Network)Depth EstimationDisparity Matching: In this study, SNN stands for Stereo and not Spiking. It uses two pictures, like left and right “eyes,” and figures out depth by looking at how things move between the two views.It makes it possible to move through 3D space with basic cameras in place of costly CT machines that use radiation during surgery.YOLOv8m (You Only Look Once)Object DetectionSingle-Shot Grid: It divides the image into a grid. For every cell, it predicts “Is there an object center here?” and “How big is the box?” simultaneously. It does this in one single pass.Real-Time Speed: Because it only looks once (unlike older models that look hundreds of times), it is fast enough to track surgical tools or vertebrae in live video.Supervised 3D CycleGANGenerative Adversarial Network (GAN)Cycle Consistency: It uses two competing networks: a Generator (creates fake CTs from MRI) and a Discriminator (tries to catch the fakes). It ensures that if you convert MRI >>> CT >>> MRI, you get the original image back.It allows surgeons to “see” a CT scan (good for bone) derived from an MRI (good for nerves) without exposing the patient to the radiation of an actual CT scan.SafeRPlanDeep Reinforcement Learning (DRL)Constrained Agent: An AI “agent” learns by trial and error in a simulated environment. Unlike standard RL, SafeRPlan adds hard “penalties” or constraints preventing it from ever choosing a path that touches vital organs.It automates the planning of screw trajectories. It doesn’t just “see” the spine; it decides the best path to drill.
Moreover, we found that 78.6% of the AI models included in the strategy were identifiable, whereas 21.43% were unidentified models, which referred to deep learning (DL) or machine learning (ML). The researchers selected architecture, which was a subset of DL, at a rate of 92.9%. U-Net-based architecture was the most prevalent DL model, representing 28.6%. Approximately 71.4% of articles effectively implemented their strategy with a singular model without integration with others. Furthermore, half of the overall research articles utilized AI models for image segmentation in comparison to other applications. We divided the successful application of AI models related to PS into four different categories, as illustrated in Fig. 2.Fig. 2. The application of AI models related to PS has been divided into four main categories: segmentation, object detection, registration, and others
Various AI models were applied to automate surgical tasks. These are divided into four groups: Segmentation (outlining bones), Detection (localizing landmarks or implants), Registration (aligning preoperative plans with intraoperative anatomy), and Others (such as image enhancement and modality synthesis), as shown in Table 1; Fig. 2. The results are described below.
Segmentation
Various model types were identified, including FCN, nnU-Net, and 2D-U-Net, alongside unspecified ML and DL architectures. In terms of pure accuracy, results varied by data source. As an example, Burström et al. [5] found an automated segmentation accuracy of 86.1%, which increased up to 95.4% when patients with severe spinal deformities were not evaluated. Similarly, the FCN model by Esfandiari et al. [9] achieved 93.0% accuracy on synthetic X-rays, though this dropped to 83.0% on clinically realistic images.
Pose Estimation and Geometric Accuracy beyond simple segmentation, the spatial accuracy of these models was critical. Esfandiari et al. found a 3D angular discrepancy of 1.93° ± 0.64° between the estimated screw axis and the measured tunnel axis, with a Euclidean distance error of 1.92 ± 0.55 mm. Using nnU-Net, Scherer et al. [13] found a bit higher mean absolute differences (MADs): 4.61 ± 2.27 mm for the point of the screw head and 5.51 ± 3.64° for the direction of the screw. Even though there were some differences, the clinical safety was high. Using the Gertzbein-Robbins system, 3.8% of the screws were Grade B (not completely within boundaries) and 96.2% were Grade A (completely within boundaries), as shown in Fig. 3A [23].Fig. 3. Classification systems for assessing pedicle screw placement accuracy. (A) The Gertzbein-Robbins classification system categorizes screw placement based on the degree of cortical breach. Grades A and B are generally considered clinically acceptable. (B) The Zdichavsky classification provides a more detailed assessment of perforation direction and severity. Both systems are widely used in clinical practice and research to evaluate pedicle screw placement safety. Pedicle screw placement accuracy classification systems. Panel A: Gertzbein-Robbins Classification; Grade A: The screw is fully within the pedicle (without breach), Grade B: ≤ 2 mm perforation, Grade C: 2< x ≤ 4 mm perforation, Grade D: 4< x ≤ 6 mm perforation, and Grade E: > 6 mm perforation. Panel B: Zdichavsky Classification; Grade IA: ≥ 50.0% of screw within the pedicle AND ≥ 50.0% of pedicle screw within the vertebral body, Grade IB: > 50.0% of pedicle screw lateral outside the pedicle AND > 50.0% of pedicle screw within the vertebral body, Grade IIA:≥ 50.0% of pedicle screw within the pedicle AND > 50.0% of pedicle screw lateral outside the vertebral body, Grade IIB: ≥ 50.0% of pedicle screw within the pedicle and tip of pedicle screw crossing the midline of the vertebral body, Grade IIIA: >50.0% of pedicle screw lateral outside the pedicle AND >50.0% of pedicle screw lateral outside the vertebral body, and Grade IIIB: >50.0% of pedicle screw medial outside the pedicle and tip of pedicle screw crossing midline of the vertebral body
Generalization and Validation: newer models tested robustness across different datasets. Da Mutten et al. [21] showed that a 2D-U-Net could generalize well, achieving a Dice score that actually increased from internal validation (0.76 ± 0.12) to external validation (0.79 ± 0.17).
Efficiency Gains: A consistent finding across studies [5, 12, 19, 20] was the reduction in processing time. Most notably, Scherer et al. demonstrated a 10-fold increase in speed, reducing the planning time from 6.41 min (manual) to just 41.8 s (automated) per case. Burström et al. similarly reported a mean time of 11± 4 s for 5 vertebrae.
Clinical Workflow: Accurate segmentation is merely the prerequisite for 3D reconstruction and trajectory planning [20, 29]. As these studies highlight, while automated segmentation significantly accelerates the preoperative workflow by replacing manual plotting, clinical validation (post-validation) remains essential to ensure these time gains do not come at the cost of geometric precision.
Landmark and object detection
High-Precision Landmark Detection: A safe plan for the trajectory depends on correctly identifying the anatomical landmarks. In controlled studies, AI models demonstrated exceptional reliability. At a 3 mm distance threshold, Zhang et al. [14] utilized a modified U-Net and ResNet34 architecture that could automatically find the landmark on the lumbar vertebrae. It had a PCK of more than 93%. Additionally, the intraclass correlation coefficients (ICC) for seven parameters, including pedicle axial angle, screw path length, pedicle width, and interpedicular distance, were 0.82–0.98, supporting the clinician’s assessment.
Screw and Implant Detection: AI can detect each pedicle screw implant, and its application is effective for spinal implant identification. Yang et al. reported a comparison of three AI models. They found the ResNet34 model, with ImageNet pre-trained weights and transfer learning, achieved 97.0% accuracy and a 96.7% recall for anteroposterior (AP) radiography, as well as a 98.7% accuracy and a 98.2% recall for lateral (Lat) radiography. Google AutoML demonstrated 91.4% precision and 87.4% recall for AP radiography, whereas Lat radiography showed 97.9% precision and 98.4% recall. In Apple Create ML, AP radiography demonstrated 76.0% precision and 73.0% recall, while Lat radiography revealed 89.0% precision and 87.0% recall [16].
Safety and Grading Validation: Several studies moved beyond simple detection to clinical safety verification. Siemionow et al. [12] used a CNN to grade screw placement, reporting that 100.0% of 208 samples were classified as Zdichavsky Grade [24] IA (no perforation), as shown in Fig. 3B. Similarly, under the Gertzbein-Robbins system, as shown in Fig. 3A, 99.0% (206/208) were Grade A.
The Generalization Challenge: Despite these successes, robustness remains a critical issue when models face external data. Da Mutten et al. used the YOLOv8m model for object detection, achieving the average of the mean average precision calculated at varying IoU thresholds, ranging from 0.50 to 0.95 (mAP50-95) values of 0.64, 0.63, and 0.09 for training, internal validation, and external validation, respectively. Then they utilized another model for automatic segmentation. This drastic drop suggests that while AI can “memorize” specific hospital datasets, it may struggle to detect spinal objects in images from different machines or protocols without further training [21].
Emerging Technologies: Stereo Vision: To eliminate X-ray dependence, von Atzigen et al. [17] used a Stereo Neural Network (SNN) to autonomously locate pedicle screws with an average inaccuracy of 5.43 mm. In addition, SNN can reconstruct the rod’s shape in real time for an accurate 3D shape estimate and rod shape evaluation.
Registration
Registration and Real-Time Navigation: Computer-assisted surgery's most significant difficulty is the "registration bridge"—fitting preoperative planning to intraoperative anatomy. Liebmann et al. [15] addressed this using a U-Net architecture to assist navigation. The median registration success rate was 100.0%, with a median Target Registration Error (TRE) of 2.7 mm, Trajectory Error (TrEr) of 1.6°, Entry Point Error (EpEr) of 2.3 mm, and Average Distance Difference (ADD) of 2.6 mm.
Speed and Efficiency: Beyond accuracy, Liebmann et al. [15] highlighted the efficiency of AI-driven registration. The median duration for the registration step is 1475 ms, while the pose update step takes 20 ms.
Robotic Safety and Path Planning: Ao et al. [22] demonstrated the preoperative planning system called “SafeRPlan” for robotic spine surgery, which used preoperative and intraoperative registration, combining real-time observation for continuous path planning for PS. They found that it improved safety by 5.0% compared to existing methods for placing pedicle screws, with 99.0% safety rates based on an evaluation of the real ultrasound (US) reconstruction dataset.
Clinical Significance: This study [15, 22] shows that AI can aid virtual planning and physical implementation of the “handshake”. Preoperative planning specifies the course, but perfect registration keeps the instrument on it. For robotic and guided spine surgery, AI is improving at hard, real-time spatial alterations. Very low error rates (TRE < 3 mm) and high safety margins (99.0%) show this.
Others
Image Enhancement and Modality Synthesis: Beyond segmentation and navigation, AI models are increasingly used to overcome the inherent limitations of medical imaging hardware. Thies et al. [11] improved intraoperative imaging by removing metal artifacts with a modified VGG architecture. CT scans often show a “starburst” visible from screws and rods in revision operations. These hid the bone next to them. The model improves body part visibility during challenging revisions. By selecting these things, the user can adjust the C-arm’s path online.
Cross-Modality Synthesis (MRI to CT): A more severe approach is to take diagnostic images without radiation. From MRI data, Roberts et al. [18] created “virtual” CT scans using a Supervised 3D CycleGAN. This allows clinicians to use MRI’s enhanced soft-tissue contrast and bone detail for surgery planning without radiation from a CT scan.
Accuracy vs. Safety Trade-offs: While the concept of synthetic CTs is promising, current reliability varies significantly by plane. Roberts et al. found that while sagittal plane measurements were accurate (errors < 10.0%), axial plane measurements suffered errors of up to 34.0%. Since pedicle screw width and trajectory are primarily determined in the axial plane, this high error rate presents a significant safety barrier. This discrepancy was reflected in the Intraclass Correlation Coefficients (ICC), where synthetic CTs (ICC 0.60–0.92) failed to match the reliability of real CTs (ICC 0.80–0.96), with Intervertebral Disc Height (IVDH) showing the lowest reliability.
Risk of Bias Assessment
The quality assessment of the included studies revealed significant sources of bias, particularly concerning study design, as shown in Fig. 4. High-risk patient selection was found in 11 (78.6%) of 14 studies. Because the data were retrospective and the researchers used convenience sampling, which may limit the generalizability of the findings. For the Index Test, 7 research studies (50.0%) were high risk because they didn’t have criteria for evaluating models, which could mean that the performance metrics were too optimistic. In contrast, the Reference Standard domain exhibited the least bias because proven clinical grading systems (e.g., Gertzbein-Robbins) were consistently utilized to confirm surgical outcomes, ranking 12 research studies (85.7%) as low risk. Finally, because the duration between the first test and the reference standard confirmation and patient loss was not clearly documented, the risk of bias related to flow and timing was generally unknown in 9 studies (64.3%).Fig. 4. Risk of bias assessment using the Robvis risk of bias tool. (A) The risk of bias summary displays the review author’s judgment regarding each risk of bias item for every included study. (B) Risk of bias graph showing the review author’s judgment about each risk of bias item presented as percentages across all included studies
Performance metrics reported
Most of the studies (10 out of 14, or 71.4%) used technical numerical scores, but four studies (28.6%) used only clinical grading. For segmentation tasks, half of the studies reported results, but only three clearly said they used the Dice coefficient. Precision and Recall were also rare; they only showed up in two papers. Most of the people who answered (57.1%) focused on spatial accuracy instead of these usual AI measures. They talked about errors in millimeters or degrees. No study showed AUC/ROC graphs, as shown in Table S3.
Discussion
The evolution of navigation, from robotics to AI
Various AI models were utilized within the perioperative period (pre-, intra-, and postoperative) of PS to enhance surgical outcomes and minimize complications. In general, the medical image analysis methods can be grouped into five categories, including registration, localization, classification, detection, and segmentation [6]. But we classified the AI applications from 14 articles into segmentation [5, 9, 12, 13, 19–21], landmark and object detection [12, 14, 16, 17, 21], registration [12, 16], and other fields, including quality image improvements [11] and image transformation [18]. Currently, the AI implementation for PS remains limited, requiring further studies to close these gaps. Traditional freehand PS requires experienced surgeons to ensure screw accuracy and avoid complications. The development of robotic-assisted systems (RAS) applied to preoperative planning (PrO) and intraoperative guidance (IO) is improving surgical accuracy and reducing surgical complications [25, 26]. However, RAS demonstrated limitations, including registration errors, spine movement post-registration, patient body habitus, artifacts from metallic implants, poor bone differentiation, skiving, soft-tissue interference, and physical constraints [26], and took a lot of time [13]. Therefore, different researchers explored solutions to these problems; AI was one approach that was utilized to improve each step of the perioperative period.
Segmentation, workflow efficiency vs. clinical Generalization
Medical image segmentation is now emerging as an important research area in the field of computer vision, which uses technology for processing computer images to analyze and process 2D or 3D images to achieve segmentation, extraction, and 3D reconstruction [27]. Several studies used AI models for segmentation to diagnose and treat pathological conditions, such as brain tumor segmentation [28], lung segmentation [29], liver tumor segmentation [30], and others [27]. The accuracy of the segmentation of image modalities such as CT, MRI, and X-rays of spines is also critical for the treatment and diagnosis of pathological diseases of spines, which enhances the PrO phase [31]. While Scherer et al. reported a 10-fold reduction in planning time, the clinical impact depends on whether this time saving translates to reduced operative time or improved patient outcomes—neither of which was measured. This proposed method has the potential to improve workflows in spine surgery when integrated into RAS [13]. Several studies have shown that AI models enhance accuracy, decrease time consumption, and minimize radiation exposure in comparison with traditional methods [5, 12, 19–21]. Moreover, Esfandiari et al. reported the screw segmentation, demonstrating high accuracy using a human X-ray dataset, but the proposed model shows high accuracy only when using the synthetic X-rays; meanwhile, lower accuracy when tested with Realistic X-rays. They also evaluated the angle of the segmented screws in the PO phase compared with the real screws in a porcine specimen analog, which showed high accuracy. Additionally, pose estimation must be evaluated in real clinical settings using real patient X-rays [9]. However, the small number of samples and lack of diversity in the dataset impaired the model’s generalization and efficacy. These are the weaknesses that must be addressed in future studies.
Landmark detection and the generalization challenge
Landmark and object detection using AI models were applied to a variety of medical image modalities for diagnosis and surgical planning, including colon polyp detection, gallstone detection, cervical cancer detection, mandible fracture detection, stroke lesion detection, pulmonary tuberculosis detection, COVID-19 detection, and others [32]. The automated localization of whole-spine lateral radiographs using DL architecture demonstrated a high degree of accuracy in agreement with manual measurements reported by Yeh et al. [33]. In contrast with the PS approach, the AI applied to screw instruments, not anatomical structures or lesions. AI models applied the pedicle screw position, orientation, length, diameter, and screw structures, revealing high detection accuracy [12, 16, 17]. However, the anatomical structure detection, like vertebrae and point landmarks detection for PrO, was reported [14, 21]. According to the articles, researchers showed that AI applications had many benefits. For example, they could cut down on the time needed for PrO image-guided surgery while maintaining a highly accurate measurement for the procedure [12], help clinicians find spinal implants, improve clinical practice, and patient care [16], and more. Furthermore, some limitations of the study were discovered. In some studies, the sample set used only lumbar and sacral spines. This may lead to low diversity and accuracy for the model.
Bridging the gap, registration and real-time navigation
Image registration allows the direct comparison and integration of data acquired from different sources. In medical image analysis, it enables the integration of information from different temporal points and/or imaging modalities. The example demonstrated a fully automated DL framework for 3D multimodal medical image registration of CT and MRI images of the head [34]. Nonetheless, registration remains an error-prone process that may lead to unsafe planning [22]. Liebmann et al. conducted automated image registration between the PrO and IO using a navigation system guided by augmented reality and employing a U-Net architecture. This method was evaluated on a public dataset, achieving a 100.0% success rate in registration, fast implementation, and absence of radiation exposure [15]. Furthermore, a study conducted by Ao et al. established a safe deep reinforcement learning (DRL) planning approach (SafeRPlan) based on registration concepts, relying on the alignment of PrO to the IO anatomy for robotic spine surgery for PS, resulting in safety rates superior to baseline approaches by over 5.0% [22]. The advantages of AI applications for registration include more precise feature detection, improved intensity matching, especially between different types of images, and faster, more accurate alignment [35]. From the clinical implications for resource-limited settings, x-ray-based AI applications demonstrate the accuracy and precision for the localization of the target.
Image enhancement and modality synthesis
AI is helping with medical imaging hardware, localization, and guidance. Implant metal makes “starburst” lines on CT/CBCT scans. These stripes obscure bone and complicate revision procedures [36, 37]. The VGG design was updated by Thies et al. [11] to filter artifacts in real time. Improvements include easier visibility and online C-arm orientation changes without surgical interruption. A more radical application is cross-modality synthesis, aiming to eliminate ionizing radiation. Roberts et al. [18] made “virtual” CT scans from MRI data using a Supervised 3D CycleGAN. This method uses MRI’s better soft-tissue contrast and CT’s clearer bone clarity without using radiation. Don’t forget to be careful. The model had 34.0% axial plane errors, even though the sagittal reconstruction was correct. Synthetic CTs aren’t good for high-risk instrumentation because they aren’t very accurate when it comes to geometry. The axial image is what mostly determines the width of the pedicle screw.
Implications for practice and research
Democratizing spine surgery: X-ray-based AI in resource-limited settings
This study found that using X-ray images instead of costly CT or MRI machines could provide accurate outcomes with the assistance of various types of AI models. In Low- and Middle-Income Countries (LMICs), access to intraoperative CT (O-arm) or MRI navigation is often nonexistent. Our analysis suggests that AI can effectively “upgrade” standard radiography to fill this gap. Esfandiari et al. [9] and Yang et al. [16] demonstrated that standard X-rays, when augmented by AI, could achieve segmentation and implant detection accuracies exceeding 90.0%. Furthermore, Luchmann et al. [20] showed that an X-ray-based deep learning system (X23D) actually reduced breach rates (21.0% vs. 24.0%) and radiation exposure compared to conventional freehand fluoroscopy.
Barriers to implementation in Southeast Asia
It might help democracy, but using it in therapy is hard to do, especially in Southeast Asia. Our study has found four main reasons that prevent more people from using these tools. First, the price is still too high. Software can be scaled up or down, but AI-based robotic systems cost between 500,000, which is too expensive for state hospitals in poor countries. Second, most of these places don’t have the AI technology they need, like high-performance computers and data tools that can work together to run these models intraoperatively. Third, rules for businesses are often out of date compared to technology. Thailand hasn’t accepted many advanced AI-driven guiding systems. This makes it legally and technically risky for people who start using them first. Finally, a lack of local vendor support makes technical downtime worse because local engineers sometimes don’t have the skills to work on AI-robotic systems that only some companies build. These problems show that AI can work in places with few resources, but it usually doesn’t have what it needs to work.
The economic and infrastructure advantage
AI systems that use X-rays have a number of advantages. For example, they are much cheaper than CT or MRI-based navigation systems (standard X-ray machines vs. intraoperative CT/CBCT systems). They also offer a simpler setup, reduced running costs (no maintenance contracts or costly consumables), and are easier to procure in rural locations where X-rays are the main imaging option. However, our review identified important limitations of X-ray-based AI systems.
The accuracy trade-off and future directions
However, this accessibility comes at the cost of geometric precision. A distinct “performance gap” remains: X-ray-based segmentation accuracy (83.0–93.0%) lags behind CT-based systems (95–98.0%) [5, 13]. Complex 3D anatomical assessment is difficult using 2D projection X-rays, especially in malformed spines. Image quality reduction in high BMI patients impairs AI effectiveness because X-rays cannot detect neuronal structures, blood vessels, or soft tissue pathology that may compromise surgical planning. Scoliosis, kyphosis, and severe degenerative changes diminish X-ray-based AI accuracy, and full assessment requires two orthogonal views, increasing radiation exposure. Future Direction: Focus on hybrid AI models that maximize X-ray accuracy in future research. This will maximize clinical value in low-resource areas. They should also construct inexpensive, portable fluoroscopy devices with AI navigation, confirm that X-ray-based AI systems operate for everyone (even spinal abnormalities), and compare and contrast AI navigation with standard methods in resource-poor areas. The globe could have safe and correct PS placement with these adjustments. This would reduce health-based variations in spine surgery outcomes.
Quality of evidence and risk of bias
Risk of bias assessment
Existing evidence must moderate enthusiasm for these technologies. Our rigorous quality assessment found major biases that would invalidate the results. Through retrospective data and convenience sampling, 11 (78.6%) of 14 studies identified high-risk patient selection. This increases selection bias, suggesting models were trained on “clean” or “ideal” cases rather than sequential, real-world patient groups. In addition, 50.0% of Index Test investigations were high risk because they lacked pre-specified criteria for model performance evaluation, raising concerns that accuracy measures may be optimistic or overfit. The Reference Standard shows that 85.7% of studies had low bias due to the consistent use of proven clinical grading systems (e.g., Gertzbein-Robbins) to confirm surgical outcomes. Challenges in Standardization: Dice, AUC, and precision aren’t always available, making it challenging to compare AI systems and acquire repeatable results. Since they’re the most used instruments, current research focuses on making measures usable in surgery (mm/degrees) and clinical grading (Gertzbein-Robbins) rather than standardizing computations. This feature makes it clinically valuable, but without rigorous scientific reporting, algorithms cannot be objectively compared. Future research needs “dual-reporting” standards. This requires technical measures for validation and clinical grading for usefulness. Clinical Readiness Assessment: Of 14 studies, only 5 (35.7%) involved prospective design, and none were randomized controlled trials comparing AI-assisted vs. traditional approaches. Consequently, before routine clinical adoption, the following are essential: [1] prospective multicenter trials [2], head-to-head comparisons with conventional navigation [3], long-term patient outcome data [4], cost-effectiveness analyses [5], external validation across diverse populations.
Limitations and methodological quality
The quality of the proof we have must temper our excitement about these technologies. Our methodical study finds three major problems that make it hard to use this in clinics: Anatomical Bias: A big problem is that most datasets leave out the thoracic spine. There is a big problem with how widely the results can be applied because only two studies looked at vertebrae in the chest. Because thoracic pedicles are quite a bit smaller and differently shaped compared to lumbar pedicles, AI performance metrics based on lumbar datasets probably rate the accuracy of the thoracic area too highly. Heterogeneity and Standardization: Substantial heterogeneity in AI models, datasets, and outcome measures precluded quantitative synthesis. A major limitation of current literature is the paucity of standardized algorithmic performance metrics. Only 64.3% of studies reported objective AI metrics (precision, recall, Dice coefficient), while 35.7% relied solely on clinical grading systems. This prevents meaningful comparison across studies and assessment of whether AI performance improvements translate to clinical benefit. For example, high Gertzbein-Robbins Grade A rates may reflect conservative screw planning rather than AI algorithmic accuracy. However, our structured narrative approach using the PICO framework allows systematic comparison of findings and identification of evidence gaps. Lack of Pathological Diversity: The reliance on small datasets from the past means that complicated conditions like severe scoliosis, osteoporosis, or revision cases are often left out. Because there isn’t any variety, the model gets overfit, which makes it less robust in difficult real-world situations. The “Sim-to-Real” Gap: This is a problem in technology—models that are taught on clean, synthetic data don’t work well when they’re used on clinical images from the real world that have noise, artifacts, and soft-tissue interference.
Authors’ experience & pilot study
We’re using AI-assisted methods in our clinical workflow to overcome this review’s issues, especially the lack of pre-study data. Despite the learning curve, AI-driven pre-planning helps detect complicated defects that 2D fluoroscopy misses. Personal evidence isn’t enough. After completion, the IRB will approve our school’s pilot project. The study directly compares AI-assisted planning versus manual planning. This prospective study in Thai tertiary care will assess accuracy (breach rates), operation duration, and radiation exposure. We think region-specific statistics are vital to demonstrate that modernizing spine surgery in Southeast Asia is worth the costs and permissions.
Conclusion
This systematic review of 14 studies demonstrates that AI applications in lumbar pedicle screw fixation show promise for automated planning, improved accuracy, and reduced operative time, but current evidence remains insufficient for routine clinical adoption. AI-based segmentation reduces planning time tenfold while maintaining accuracy, and detection algorithms achieve > 93% landmark identification. However, all studies have significant methodological limitations, including retrospective designs, small sample sizes, limited diversity in datasets, and the absence of prospective comparative trials. Before clinical implementation, rigorous multicenter randomized trials comparing AI-assisted versus conventional techniques are essential, along with validation across diverse patient populations and spinal pathologies. Currently, AI should be viewed as an emerging educational and planning tool rather than a replacement for surgeon expertise and established navigation methods.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary file 1 (DOCX 1.48 MB)