On Window Mean Survival Time With Interval‐Censored Data
Takuto Iijima, Tomotaka Momozaki, Shuji Ando

TL;DR
This paper introduces a new method for analyzing survival data in cancer trials, especially when survival curves cross or show late differences, using window mean survival time with interval-censored data.
Contribution
The paper proposes a novel WMST inference method for interval-censored data using one-point imputations and Turnbull's method.
Findings
The proposed WMST method using mid-point imputation performs comparably to Turnbull's method for interval-censored data.
WMST testing has higher power than RMST in late difference and early crossing survival scenarios.
WMST maintains higher power than RMST even when the pre-specified time point is not clinically optimal.
Abstract
In recent years, cancer clinical trials have increasingly encountered non proportional hazards (NPH) scenarios, particularly with the emergence of immunotherapy. In randomized controlled trials comparing immunotherapy with conventional chemotherapy or placebo, late difference and early crossing survival curves scenarios are commonly observed. In such cases, window mean survival time (WMST), the area under the survival curve within a pre‐specified interval τ0,τ1, has gained increasing attention due to its superior power compared to restricted mean survival time (RMST), the area under the survival curve up to a pre‐specified time point. Considering the increasing use of progression‐free survival as a co‐primary endpoint alongside overall survival, there is a critical need to establish a WMST estimation method for interval‐censored data; however, sufficient research has yet to be…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
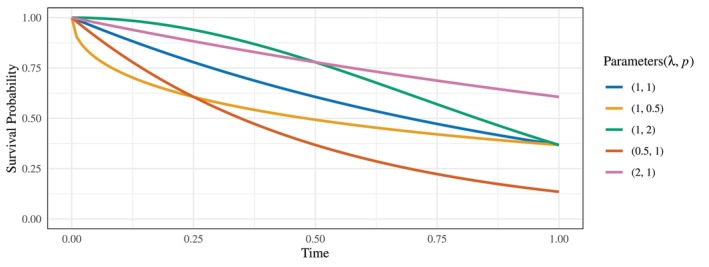 FIGURE 1
FIGURE 1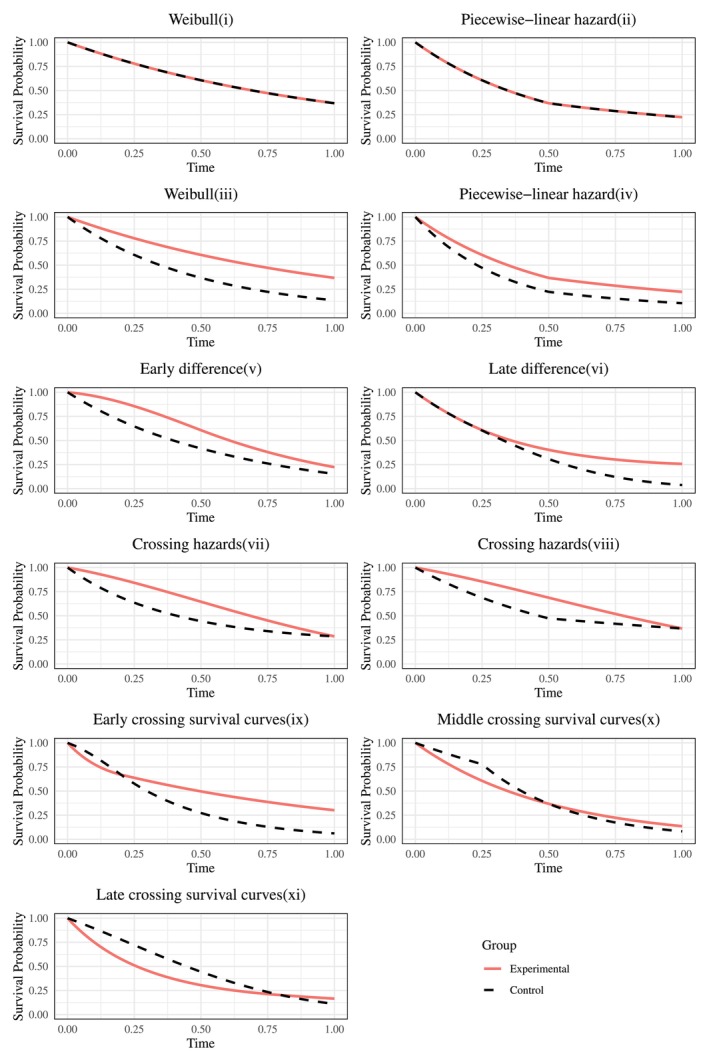 FIGURE 2
FIGURE 2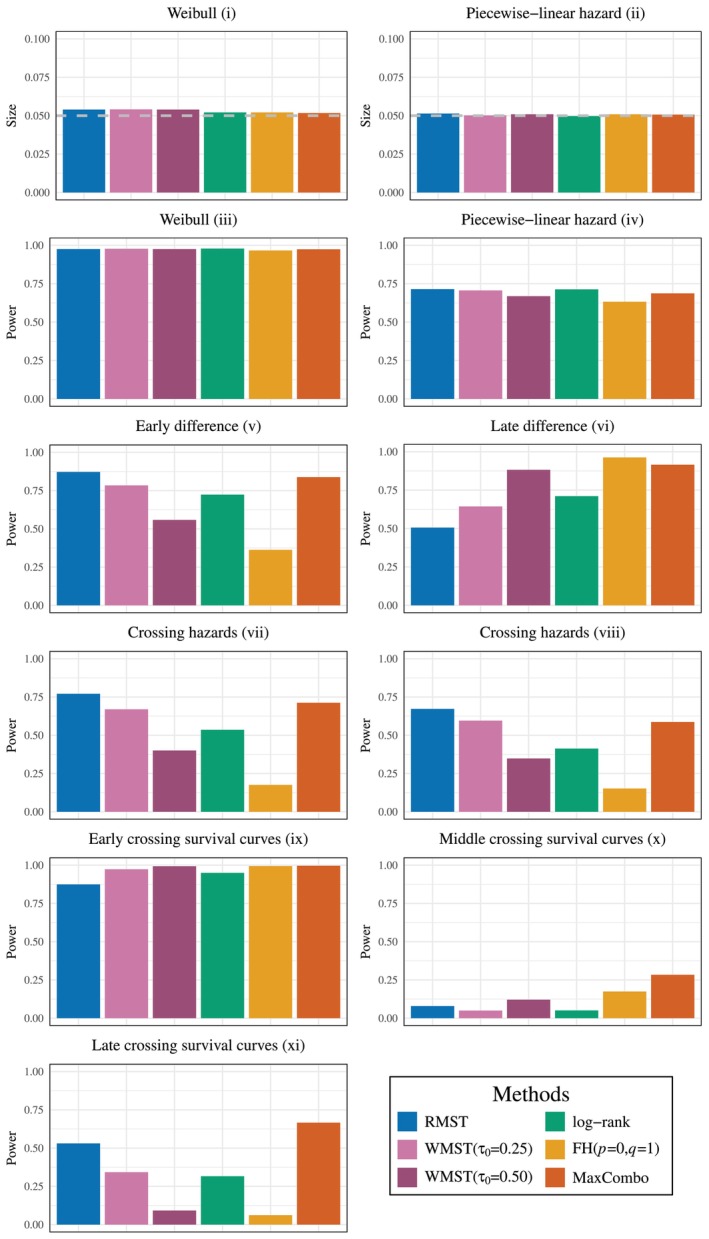 FIGURE 3
FIGURE 3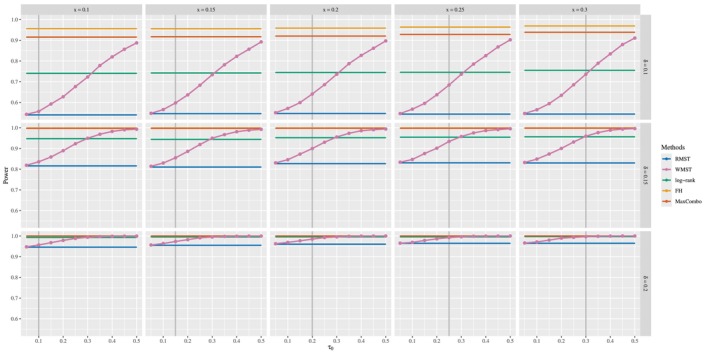 FIGURE 4
FIGURE 4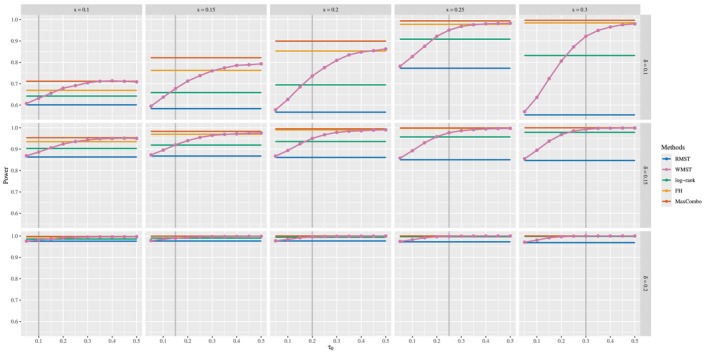 FIGURE 5
FIGURE 5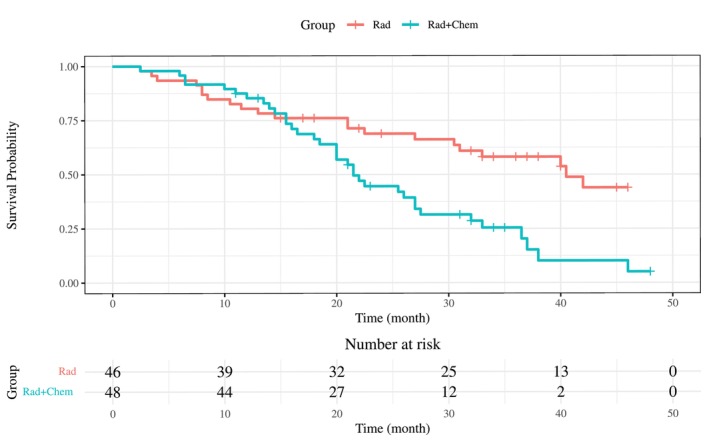 FIGURE 6
FIGURE 6| Mid‐point + KM | Right‐point + KM | Turnbull | Mid‐point + KM | Right‐point + KM | Turnbull | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameter | rBias | MSE | rBias | MSE | rBias | MSE | rBias | MSE | rBias | MSE | rBias | MSE |
| Weibull (, ) | ||||||||||||
| Weibull (1, 1) |
| 0.0949 | 0.0024 |
|
| 0.0727 | 0.0008 |
| ||||
| Weibull (1, 0.5) |
| 0.0727 | 0.0018 | 0.0013 |
| 0.0382 |
|
| ||||
| Weibull (1, 2) | 0.0008 | 0.0848 | 0.0024 |
|
| 0.0965 | 0.0012 |
| ||||
| Weibull (0.5, 1) |
| 0.2397 | 0.0039 |
|
| 0.2032 | 0.0009 |
| ||||
| Weibull (1, 2) |
| 0.0393 | 0.0040 | 0.0009 |
| 0.0266 |
|
| ||||
| None |
| 0.0739 | 0.0019 | 0.0011 |
| 0.0642 | 0.0008 |
| ||||
| Low |
| 0.0862 | 0.0022 | 0.0011 |
| 0.0717 | 0.0008 |
| ||||
| High |
| 0.0957 | 0.0024 | 0.0012 |
| 0.0605 | 0.0007 |
| ||||
| 200 |
| 0.0969 | 0.0020 |
|
| 0.0759 | 0.0006 |
| ||||
| 400 |
| 0.0977 | 0.0018 |
|
| 0.0771 | 0.0005 |
| ||||
| 3 |
| 0.1111 | 0.0029 | 0.0012 | 0.0007 | 0.0762 | 0.0009 |
| ||||
| 10 |
| 0.0602 | 0.0015 |
|
| 0.0516 | 0.0006 |
| ||||
| 20 |
| 0.0329 | 0.0012 |
|
| 0.0297 | 0.0006 |
| ||||
| 0.2 |
| 0.0691 | 0.0017 |
|
| 0.0466 |
|
| ||||
| 0.5 |
| 0.0303 |
|
| 0.0006 | 0.0074 |
| 0.0006 | ||||
| 1.0 |
|
|
|
|
|
| ||||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Statistical Methods in Clinical Trials · Advanced Causal Inference Techniques
Introduction
1
In randomized controlled trials (RCTs) where the outcome is survival time, the log‐rank test has been widely used to evaluate differences in survival times between two groups. The log‐rank test is uniformly most powerful when the proportional hazards (PH) assumption holds. However, Uno et al. [1] have pointed out that the log‐rank test is closely related to the PH assumption, and when the PH assumption is clearly violated, may lack sufficient power to detect differences in survival times between two groups. Furthermore, an empirical analysis by Horiguchi et al. [2], which compare the log‐rank test with other testing methods, including restricted mean survival time (RMST) and weighted log‐rank tests, using data from recent Phase III cancer RCTs (69 trials for overall survival [OS] and 59 trials for progression‐free survival [PFS]), finds that the log‐rank test do not always exhibit superior empirical power. One potential reason for this result is the inclusion of trials in which the PH assumption does not hold. In fact, approximately 7% of the OS trials and approximately 33% of the PFS trials violated the PH assumption. In subgroup analyses focusing on trials where the PH assumption holds and PFS is the primary endpoint, the log‐rank test exhibits the highest empirical power. Additionally, a study by Trinquart et al. [3] reports that, as of 2016, 24% of oncology studies exhibited non‐proportional hazards (NPH), indicating an increasing number of cases where routine application of the log‐rank test may not be appropriate.
Based on these facts, alternative methods to the log‐rank test that do not rely on the assumption have gained renewed attention in recent years. Among them, RMST, the area under the survival curve up to a pre‐specified time point, is preferred due to its ease of clinical interpretation compared to existing statistical testing methods. Discussions on RMST have begun to appear in medical journals such as the “Journal of Clinical Oncology” [3], and RMST has already been used as a summary measure for primary endpoints in some studies [4, 5, 6, 7]. Although RMST is robust and interpretable even in NPH scenarios, it is not without its drawbacks. A reported limitation is its reduced power in cases where survival curves diverge in the late phase of a trial (late difference) or cross in the early phase (early crossing survival curves) [8].
A notable example of scenarios leading to late difference or early crossing survival curves is cancer immunotherapy, which has attracted significant attention in recent years. Due to its therapeutic mechanisms, many trials involving cancer immunotherapy, particularly when comparing with placebo or chemotherapy groups, have observed late differences or early crossing survival curves [9, 10]. Furthermore, the immuno‐oncology drug development pipeline has expanded rapidly, increasing approximately 2.5 times between 2017 and 2020 [11], highlighting the growing need for testing methods capable of maintaining power in late difference and early crossing survival curves scenarios. In this context, window mean survival time (WMST) [12], which is equivalent to long‐term RMST [13, 14, 15], has been proposed as a summary measure, maintaining the interpretability of RMST, outperforms RMST in cases involving late difference and early crossing survival curves. As the name suggests, WMST corresponds to the area under the survival curve within a clinically relevant window of time. Unlike RMST, WMST allows clinicians to construct a window of time during the later phase of a study when late difference or early crossing survival curves are anticipated. This enables focused analysis to determine whether the new treatment improves the mean survival time within that specific window of time. In fact, numerical simulations by Paukner and Chappell [12] demonstrate that WMST achieve higher statistical power than RMST in late difference and early crossing survival curves scenarios with right‐censored data.
In Phase III trials targeting advanced cancer, PFS, defined as the time to disease progression or death (whichever occurs first), is increasingly being used not only as a secondary endpoint but also as a primary endpoint [16, 17, 18]. For solid tumors, progression is defined by the revised RECIST guidelines [19] as tumor growth exceeding a certain threshold or the appearance of new lesions. Since progression is identified only by a medical test, such as CT, the exact time point of the progression event is unknown. Instead, it is known that the progression event occurred within the interval (l,r], where is the time of l is the last examination without progression, and r is the time when progression is confirmed. Data representing the time to an event in interval form are referred to as interval‐censored data. Kaplan–Meier (KM) method [20] cannot directly estimate survival functions using interval‐censored data. To address this, imputation methods such as right‐point imputation or mid‐point imputation are used to approximate interval‐censored observations as single time points, allowing KM methods to estimate survival functions. Additionally, Turnbull's method has been developed as a non‐parametric approach to estimate survival functions directly from interval‐censored data [21]. Although right‐point imputation is frequently used in oncology and other fields, its statistical justification remains unclear. Nishikawa and Tango [22] compare the exactness of the survival rate estimation at different times using the three methods introduced above. They find that for estimating PFS rates, the method with the smallest mean squared error (MSE) at the majority of time points is KM estimation following mid‐point imputation. However, no studies have compared these methods for estimating the accuracy of WMST.
The challenge of interval censoring extends beyond clinical trials to the rapidly expanding domain of electronic health records (EHRs) in epidemiologic research. EHRs have become invaluable sources for assembling large cohorts, with millions of patient records now being analyzed for real‐world evidence generation [23, 24]. In this setting, interval censoring is effectively inevitable since disease events can only be detected during discrete healthcare visits with irregular intervals—a fundamental characteristic that cannot be eliminated through study design. Moreover, recent EHR studies have documented non‐proportional hazards patterns, including delayed treatment effects with early crossing survival curves [25], precisely the scenarios where WMST has shown advantages over traditional methods.
Zhang et al. [8] discuss an estimator for RMST for interval‐censored data. In their approach, the survival function is estimated using Turnbull's method, and the area under the survival curve is calculated using the linear smoothing method. However, this method cannot express the standard error in a closed form, requiring the use of perturbation‐resampling methods like the bootstrap method to calculate the standard error, making the computation less straightforward. On the other hand, single‐point imputation methods, including right‐point imputation or mid‐point imputation, can express the standard error in a closed form, allowing for easier computation. In this study, we evaluate the performance of three methods for WMST estimation designed for interval‐censored data: (1) KM estimation following mid‐point imputation (mid‐point + KM), (2) KM estimation following right‐point imputation (right‐point + KM), and (3) Turnbull's estimation. Based on the results of the comparison, the most effective method is used to construct a class of WMST estimators and tests. Furthermore, this test method is compared with existing testing methods such as RMST test, the log‐rank test, and the Fleming‐Harrington test (FH test).
The remainder of this article is organized as follows. Section 2 describes the definitions of RMST and WMST, estimation methods and the testing procedure for WMST considering interval‐censored data. Section 3 conducts numerical experiments to perform one‐sample estimation and assess the exactness of the estimation. Subsequently, two‐sample tests are conducted to compare WMST with existing testing methods such as RMST, weighted log‐rank tests, and others. Additionally, under survival scenarios considering the value of τ0 (set prior to data collection) and the difference in the areas under two survival curves, the detection power of WMST is compared and evaluated against existing testing methods, including RMST, the log‐rank and FH tests. Section 4 applies WMST test to real‐world data and compares it with existing testing methods, as in Section 3. Finally, Section 5 provides the conclusions.
WMST for Interval‐Censored Data
2
This section introduces WMST, which provides interpretable results even under NPH scenarios, along with its estimation methods. RMST is presented as a special case of WMST. We describe hypothesis testing procedures using WMST and propose estimation methods specifically designed for interval‐censored data.
Estimation for Right‐Censored Data
2.1
Let S(t) denote the survival probability at time t≥0. WMST of survival time T is defined as the area under the survival function S(t) from τ0 to τ1 [12], that is,
When τ0=0, WMST reduces to the well‐known RMST, which represents the area under the survival curve up to a specific time point τ1 [26], that is,
Let S0(t) and S1(t) denote the survival probabilities for the control group and the treatment group, respectively. The difference in WMST between the two groups is expressed as
For the special case of RMST (τ0=0), this becomes
With observed k ordered event times denoted as t1<⋯<tk, the estimators of WMSTτ0,τ1 and Δτ0,τ1 can be obtained as
respectively, where ti*=maxti,τ0, ti+1*=minti+1,τ1, tj,i*=maxtj,i,τ0, tj,i+1*=mintj,i+1,τ1, and tj,i is the ordered ith event times in group j (j∈{0,1}). S^0(⋅) and S^1(⋅) denote the survival functions estimated by KM method for each group. For RMST estimation (τ0=0), the formulas simplify to
Remark 1For selecting τ1, several discussions have been presented in the context of RMST and long‐term RMST [27, 28, 29, 30]. Tian et al. [30] propose a condition for empirically selecting τ1 as the smaller of the maximum observed times between the two groups. For selecting τ0, methods have been proposed to select the time point at which the two survival curves begin to diverge or the time at which WMST difference becomes significantly different from zero [31]. In this study, τ0 is set to a predefined value based on the anticipated survival scenario prior to the start of the trial. For example, in immunotherapy trials where delayed treatment effects are expected, τ0 can be informed by the anticipated onset of clinical benefit from early‐phase studies or biological considerations [12]. τ1 is selected as the smaller of the maximum observed times between the two groups for hypothesis testing.
Hypothesis Testing With WMST
2.2
The estimator for the variance of WMST can be obtained as
where
derived using Greenwood's formula, with the number of events dk and the number of individuals at risk rk (those in the risk set) at time t=tk. Therefore, under the assumption that S0(t) and S1(t) are independent, the estimator for the variance of the difference in WMST, Δ^τ0,τ1, can be obtained as
where σ^02 and σ^12 are the estimators for the variance of WMST for each group.
When comparing WMST for the control and treatment groups, the following null hypothesis and alternative hypothesis are used:
Under the null hypothesis H0, the following test statistic is given as
This test statistic, due to the asymptotic normality of Z, can be evaluated against the standard normal distribution under large‐sample conditions.
WMST Estimate Designed for Interval Censoring
2.3
Since this study involves survival time data with interval censoring, KM method cannot be directly applied. To this end, we use right‐point or mid‐point imputation to handle the interval‐censored observations, estimate the survival function using KM method, and then calculate WMST. These methods are straightforward to implement in R using the existing survWMST package, where the wmst() function directly calculates both WMST estimates and their standard errors. Additionally, we compare these approaches with Turnbull's method [21], which directly estimates the survival function from interval‐censored data using non‐parametric maximum likelihood estimation (NPMLE) without requiring imputation, and then calculates WMST from the estimated survival function.
A key practical advantage of our proposed imputation approaches is that they enable the direct use of existing WMST software without requiring modifications to the underlying functions. In contrast, implementing WMST with Turnbull's method requires custom programming to handle the unique survival function structure produced by NPMLE, and computational techniques such as bootstrap methods are required to estimate the variance, whereas the imputation‐based methods allow for the explicit expression of standard errors. These factors make our imputation approaches considerably more practical and computationally efficient for applied researchers. Our approach to handling interval censoring is summarized as follows.
- Mid‐point + KM: The survival function is estimated with KM method after imputing the interval‐censored observations li,ri by
- 2Right‐point + KM: The survival function is estimated with KM method after imputing the interval‐censored observations li,ri by
- 3Turnbull's algorithm: Let ti (i=1,…,n) denote survival times that follow the survival function S(⋅), where the interval‐censored observation of ti is given as the interval li,ri. Then the likelihood function can be expressed as
and the survival function is estimated by maximizing this likelihood. For computational implementation, we use the icfit() function from the R package interval [32], which computes the NPMLE via Turnbull's iterative algorithm.
Compared to the Turnbull method, the methods combining mid‐point and right‐point imputations with KM estimation are easier to implement, requiring only simple data preprocessing.
Simulation Studies
3
This section begins with a description of the settings common to all numerical simulations. It then outlines the settings and results used to evaluate estimation accuracy, as well as those for assessing test size and power. Finally, to examine the robustness of WMST with interval‐censored data, the section investigates the impact of RMST difference δ, the starting point of WMST, τ0, and the divergence or crossing point of the survival curves x on the tests, focusing on survival scenarios frequently observed in cancer immunotherapy trials, such as early crossing survival curves and late difference.
Simulation Settings
3.1
The interval‐censored data used in the simulations are generated following Zhang et al. [8]. The procedure for simulating a scenario where interval censoring arises in PFS is described below. For each subject, a baseline examination is conducted at time g0, followed by K periodic follow‐up examinations gk=g0+k×1/(K+1) at equally spaced intervals. Additionally, to account for the practical situation in clinical trials where subjects may miss scheduled visits, a dropout probability vector Pdropout of length K is introduced. It is assumed that all subjects complete the baseline examination. Furthermore, to investigate how the proportion of interval censoring in observed events impacts the performance of WMST, a parameter pexact is introduced. The following steps are repeated for i=1,…,n.
Step 1. Generate the baseline examination time g0(i) from Unif(0,1/(K+1)) and construct the examination schedule g0(i),g1(i),…,gK(i).
Step 2. Generate the event time ti from a specific distribution described later. Additionally, based on the dropout probability vector Pdropout, determine whether the examination is missed at time gj(i) (j=1,…,K). Generate a random flag ξi from Bernoullipexact to specify whether the event is death (ξi=1) or progression (ξi=0).
Step 3. Based on the random flag ξi, determine the type of event and construct the interval‐censored observation:
- If ξi=1 (death event): Set the observed interval as li,ri=ti−ϵ,ti, where ϵ is a small positive number close to 0. This represents an exact event time.
- If ξi=0 (progression event): Identify the examination interval containing the true event time ti. Specifically, find consecutive examination times gk(i) and gl(i) (where k<l) such that gk(i)<ti≤gl(i) and neither examination was missed due to dropout. Set the observed interval as li,ri=gk(i),gl(i). This simulates the clinical scenario where progression is detected at examination gl(i) but was not present at the previous examination gk(i).
Step 4. If the event occurs after the final examination time gK(i) or if the progression event cannot be confirmed due to missed examinations, set ri=∞ and treat it as right‐censored.
Evaluation of Estimation
3.2
In the numerical simulations for evaluating estimation methods, various parameter settings are examined to assess the performance of WMST estimator, taking interval censoring into account. First, for the dropout probability vector Pdropout, the following four dropout scenarios are considered. In this case, the probability of missing any given examination, except for the final examination, is assumed to be equal across all follow‐up examinations, while the dropout probability for the final examination is set to be twice as high. Namely,
- None :Pdropout,k=0 for k=1,…,K;
- Low :Pdropout,k=0.1 for k=1,…,K−1 and Pdropout,K=0.2;
- Medium :Pdropout,k=0.2 for k=1,…,K−1 and Pdropout,K=0.4;
- High :Pdropout,k=0.3 for k=1,…,K−1 and Pdropout,K=0.6.
Event times have the Weibull distribution with the probability density function
We considered the five combinations of scale parameter λ and shape parameter p
taking into account survival scenarios where the risk of death is constant, decreasing, or increasing over time, as well as scenarios with high or low mortality risk. Figure 1 shows the survival curves of the Weibull distributions examined.
Survival curves of five Weibull distributions with parameters (λ,p)∈{(1,1),(1, 0.5),(1,2),(0.5, 1),(2,1)}. These true distributions, differentiated by color, represent constant, decreasing, and increasing hazard scenarios used for generating simulated data in the estimation evaluation.
The simulation parameters also include sample sizes n∈{100, 200, 400}, the number of follow‐up examinations K∈{3, 5, 10, 20}, and the proportion of death events among all observed events pexact∈{0, 0.2, 0.5, 1.0}. The numerical simulations are conducted with the event time distribution set to Weibull(λ=1,p=1), the dropout probability vector Pdropout,k set to Medium, n=100, K=5, and pexact=0 as a default setting. The influence of each parameter is evaluated by varying one parameter at a time while keeping the others fixed. For the WMST estimation evaluation, we examine two different values of τ0 (0.25 and 0.50), and τ1 is selected as the smaller of the maximum observed times between the two groups [30]. For each parameter configuration, 10 000 numerical simulations are performed, and the estimation accuracy is examined in terms of relative bias (rBias) and mean squared error (MSE)
where μ^sτ0,τ1 is estimated WMST during the sth numerical simulation.
Table 1 shows that the mid‐point + KM and Turnbull had a smaller MSE compared to right‐point + KM overall. However, the difference in MSE between mid‐point + KM and Turnbull is negligible. When τ0=0.50, the difference in MSE between the mid‐point + KM and Turnbull is also negligible, but in terms of the absolute value of rBias, Turnbull outperforms the mid‐point + KM. Regarding the distribution of survival time T, for Weibull(λ=1,p=2), MSE is nearly identical between the mid‐point + KM and Turnbull, but Turnbull shows higher accuracy than the mid‐point + KM in terms of the absolute value of rBias. Conversely, for Weibull(λ=0.5,p=1), mid‐point + KM outperforms Turnbull in the absolute value of rBias.
This pattern can be explained by differences in the survival time distributions. Among the five distributions examined, Weibull(λ=1,p=2) is characterized by increasing hazards toward the later stages of the trial. Under such conditions, Turnbull demonstrates higher accuracy in terms of the absolute value of rBias. To further compare the estimation accuracy of the mid‐point + KM and Turnbull under a distribution with even higher hazards in the later stages, Weibull(λ=1,p=3) is also considered. The results show that while the MSE values are almost identical, Turnbull demonstrates higher accuracy in terms of the absolute value of rBias compared to the mid‐point + KM. In the most notable case among the 10 000 numerical simulations, Turnbull accurately estimates the true survival curve, whereas the mid‐point + KM underestimates the survival curve for most of the trial duration, particularly near the end of the trial period, leading to a significant divergence. This discrepancy likely contributes to the increase in the absolute value of rBias for the mid‐point + KM. However, in the field of cancer immunotherapy, where WMST is particularly relevant, survival scenarios such as Weibull(λ=1,p=2), with increasing hazards in the last part of the trial period, are considered uncommon.
As n increases, the absolute value of rBias decreases for both the mid‐point + KM and Turnbull, while it shows little change for the right‐point + KM. When the parameter K decreases, the interval width of the interval‐censored data increases. However, even with small values of K, the MSE values for the mid‐point + KM and Turnbull remains nearly unchanged. Similarly, the parameter Pdropout, which also affects the width of the interval, shows little impact on the MSE values for the mid‐point + KM and Turnbull. In contrast, for the right‐point + KM, the MSE values varies depending on changes in K and Pdropout. Furthermore, even with an increased proportion of interval censoring, the MSE values for the mid‐point + KM and Turnbull remains nearly constant.
Based on these simulation results, we recommend the mid‐point + KM method for practical applications. Despite achieving comparable estimation accuracy to Turnbull's method, the mid‐point + KM approach offers substantial practical advantages. As detailed in Section 2.3, implementation requires only simple interval midpoint calculation followed by direct application of the well‐established wmst() function in the survWMST package. In contrast, implementing WMST with Turnbull's method requires researchers to compute the NPMLE using appropriate software and then develop custom code to process the resulting survival function structure, which is a non‐trivial task for applied researchers.
Furthermore, the mid‐point + KM method provides closed‐form variance estimates. Turnbull's method, conversely, requires bootstrap resampling for variance estimation to obtain accurate variance estimates, substantially increasing computational burden. Conducting the hypothesis testing evaluations in Sections 3.3 and 3.4 with bootstrap‐based variance estimation would have required prohibitive computational time. Additionally, implementing and interpreting bootstrap procedures correctly requires statistical expertise that may present barriers for some applied researchers. Therefore, the mid‐point + KM method offers the optimal balance of statistical rigor and practical utility, making it our recommended approach for WMST estimation with interval‐censored data.
Evaluation of Hypothesis Test
3.3
The mid‐point imputation method is used throughout the following hypothesis testing evaluations, as it provides the best balance between statistical accuracy (Section 3.2) and computational efficiency (Section 2.3) required for our comprehensive simulation studies. The survival function estimated using KM method is then used to calculate WMST, and hypothesis testing based on WMST is evaluated.
Harrington and Fleming [33] introduce FH test as a type of weighted log‐rank test (WRT). FH test uses the weight function
for p≥0 and q≥0, where S^(t−) represents the left‐continuous survival function estimated at time t using the pooled survival time data from both groups using KM method. By appropriately selecting the hyperparameters p and q, it is possible to assign greater weight to differences occurring in either the early or late stages of the study period. In this study, we focus on survival scenarios such as late difference and early crossing survival curves, where the survival curves of the two groups diverge significantly in the later stages of the trial. Therefore, the hyperparameters are set to p=0 and q=1.
In addition to the single weighted log‐rank tests, combination tests have gained attention as robust alternatives under non‐proportional hazards. The MaxCombo test and related work [34, 35, 36, 37] combines multiple FH weighted log‐rank statistics to achieve robust power across various survival scenarios. Specifically, MaxCombo typically uses the maximum of test statistics from FH (0,0), FH (0,1), FH (1,0), and FH (1,1), which are sensitive to proportional hazards, late differences, early differences, and middle differences, respectively [38]. This versatile testing approach has become increasingly common in immunotherapy trials where the timing of treatment benefit is uncertain [39].
Under the null and alternative hypotheses, 10 000 numerical simulations are repeated to calculate and evaluate the test size or power. Following the settings of Pan [40], the numerical simulation of the two‐sample WMST test is conducted under the PH and NPH assumptions. Similarly to the evaluation of the estimation methods, the generation of interval‐censored data follows the method of Zhang et al. [8]. However, in this subsection, all simulation settings are based on the default settings from the previous section, with only the distribution parameters for survival time T being replaced.
Figure 2 illustrates the survival scenarios under the null and alternative hypotheses and demonstrates the diverse patterns of treatment effects that can occur in clinical practice. The null hypothesis scenarios show identical survival curves between control and experimental groups: (i) exponential distribution and (ii) piecewise‐linear hazard, serving as baselines for evaluating Type I error control. Additional null scenarios—including decreasing (p=0.5) and increasing (p=2) Weibull hazards, and time‐dependent piecewise‐linear hazards—are presented in Appendix A for comprehensive validation across diverse baseline conditions. The alternative hypotheses encompass both proportional hazards (PH) and non‐proportional hazards (NPH) patterns. The PH scenarios (iii–iv) include Weibull distributions with constant hazard ratio λ1p/λ0 and piecewise‐linear hazard functions maintaining a hazard ratio of 1.5 throughout the study period. Additional PH scenarios with varying shape parameters and time‐dependent hazards are detailed in Appendix A.
The survival time scenarios used in the numerical simulations for hypothesis testing. H0: (i)–(ii), H1(PH): (iii)–(iv), H1(NPH): (v)–(xi).
Most importantly for our study, the NPH scenarios (v–xi) are classified as early difference, late difference, crossing hazards, and crossing survival curves, capturing the complex survival patterns frequently observed in cancer immunotherapy trials [41, 42, 43, 44, 45]. The early difference scenario (v) shows initial treatment benefit that diminishes over time, while the late difference scenario (vi) represents delayed treatment effects that become apparent only after an initial period—a hallmark of immunotherapy responses. The crossing hazards scenarios (vii–viii) exhibit hazard functions that intersect over time, leading to changing hazard ratios throughout the study period. The crossing survival curves scenarios (ix–xi) are particularly relevant to immunotherapy studies, where initial harm or lack of benefit may be followed by substantial long‐term advantages. These diverse scenarios enable comprehensive evaluation of WMST's performance across clinically relevant survival patterns, particularly those challenging for traditional methods. The distributions or hazard functions of survival times under each scenario for both the null and alternative hypotheses are as follows.
-
Null hypotheses
-
–PH
-
∘Weibull
-
i. T0,T1∼Weibull(λ=1,p=1)
-
∘Piecewise‐linear hazard
-
ii. h0(t)=h1(t)=2 (t∈[0,0.5)); h0(t)=h1(t)=1 (t∈[0.5,1])
-
Alternative hypotheses
-
–PH
-
∘Weibull
-
iii. T0∼Weibull(λ=0.5,p=1),T1∼Weibull(λ=1,p=1)
-
∘Piecewise‐linear hazard
-
iv. h0(t)=3,h1(t)=2 (t∈[0,0.5)); h0(t)=1.5,h1(t)=1 (t∈[0.5,1])
-
–NPH
-
∘Early difference
-
v. h0(t)=1.75, h1(t)=3t+0.25 (t∈[0,0.5)); h0(t)=h1(t)=t+1.25 (t∈[0.5,1])
-
∘Late difference
-
vi. h0(t)=h1(t)=2 (t∈[0,0.2)); h0(t)=4t+1.2, h1(t)=−2t+2.4 (t∈[0.2,1])
-
∘Crossing hazards
-
vii. h0(t)=−1.5t+2, h1(t)=1.5t+0.5 (t∈[0,1])
-
viii. h0(t)=1.5, h1(t)=t+0.5 (t∈[0,0.5)); h0(t)=0.5, h1(t)=t+0.5 (t∈[0.5,1])
-
∘Crossing survival curves
-
ix.Early: h0(t)=10t+1, h1(t)=−10t+3 (t∈[0,0.2)); h0(t)=3, h1(t)=1 (t∈[0.2,1])
-
x.Middle: h0(t)=1, h1(t)=2 (t∈[0,0.25)); h0(t)=3, h1(t)=2 (t∈[0.25,1])
-
xi.Late: h0(t)=2.5t+1, h1(t)=−2.5t+3, (t∈[0,0.8)); h0(t)=3, h1(t)=1 (t∈[0.8,1])
Figure 3 presents a comprehensive comparison of test performance across various survival scenarios. Under the null hypothesis scenarios (i) and (ii), all testing methods maintain Type I error rates close to the nominal significance level of α=0.05.
Size and power comparison of WMST tests with existing methods (RMST, Log‐rank, FH, and MaxCombo) across 11 survival scenarios. H0: (i), (ii), H1 (PH): (iii), (iv), H1 (NPH): (v)–(xi) [complete results in Appendix B].
Under the alternative hypothesis with proportional hazards (PH) assumptions in scenarios (iii) and (iv), as well as in all PH scenarios presented in Appendix A, the log‐rank test exhibits the highest statistical power, as expected given its optimality under PH. Notably, both WMST and RMST tests achieve power levels remarkably close to the log‐rank test, while consistently outperforming FH (p=0,q=1) and MaxCombo tests across all PH scenarios. This consistent superiority of WMST over FH and MaxCombo under PH represents a crucial advantage, as PH violations in practice are often less extreme than anticipated during trial design. The slightly reduced power of MaxCombo relative to the optimal test (which in PH scenarios is the log‐rank test, equivalent to FH (0,0)) is consistent with the findings of Lin et al. [37], attributable to the inherent model selection penalty when combining multiple test statistics.
In non‐proportional hazards (NPH) scenarios, MaxCombo demonstrates superior power in most cases, which is expected given its design to combine multiple weight functions (FH (0,0), FH (0,1), FH (1,0), and FH (1,1)) that are sensitive to different patterns of survival differences [38]. For late difference scenarios such as (vi), where treatment effects manifest predominantly in later follow‐up periods, the FH (0,1) test, which assigns greater weight to later events, achieves the highest power. Similar to the PH scenarios, MaxCombo shows slightly reduced power compared to the optimal single test due to the multiplicity adjustment inherent in combination testing.
Of particular interest are the late difference (vi) and early crossing survival curves (ix) scenarios, where WMST consistently outperforms RMST. Furthermore, with appropriate selection of τ0, WMST achieves power comparable to both FH (0,1) and MaxCombo tests while maintaining its interpretability advantage. This demonstrates that WMST can effectively balance statistical efficiency with clinical interpretability in scenarios where treatment effects are delayed or when survival curves cross.
In contrast, for scenarios including early difference (v), crossing hazards (vii, viii), and late crossing survival curves (xi), we observe a consistent power hierarchy: RMST > WMST (τ0=0.25) > WMST (τ0=0.50). This pattern can be attributed to the decreasing magnitude of the WMST difference between treatment groups as τ0 increases (see Table B1 in Appendix B), making treatment effects more difficult to detect. Similarly, in the middle crossing survival curves scenario (x), the minimal WMST difference of 0.003 results in correspondingly low statistical power, highlighting the importance of window selection in relation to the anticipated timing of treatment effects. Notably, even in these scenarios where WMST underperforms relative to RMST, FH (0,1) tests exhibit even lower power. Beyond these power limitations, FH tests suffer from additional critical drawbacks: the lack of interpretable effect measures [37, 39] and elevated false positive rates in crossing hazards scenarios [12, 46]. These comprehensive limitations demonstrate that WMST maintains both statistical and methodological advantages over weighted log‐rank approaches.
These power comparisons reveal an important trade‐off in test selection. While MaxCombo and optimally‐selected FH tests may achieve higher power in certain NPH scenarios, they provide only p‐values and test statistics without clinically meaningful effect estimates [37, 39, 47]. In contrast, WMST provides the mean survival time within a specified window, which is easier to interpret compared to the hazard ratio under the NPH [48, 49, 50, 51]. This enables clinicians to communicate treatment effects clearly—for example, “treatment A provides an average of X additional months of survival between months Y and Z.” This advantage extends beyond clinical trials and enables even clinicians or patients without advanced statistical knowledge to make informed and confident decisions about treatment plans or drug choices based on a clear understanding.
Given that test selection must be pre‐specified before trial commencement, WMST represents a practical choice that balances statistical performance with clinical utility. It maintains competitive power across diverse survival patterns—consistently outperforming weighted tests under PH and achieving reasonable power under various NPH scenarios, while providing interpretable effect estimates essential for regulatory decisions and clinical practice. This combination of stable statistical performance and direct clinical interpretability positions WMST as particularly valuable in modern clinical trials where clear communication of treatment benefits is as important as their detection.
Altering Choice of τ0, Crossing Point and Difference of RMST
3.4
The setting of τ0 is determined prior to the collection of trial data in actual clinical trials. In this study, numerical simulations are conducted to investigate how the pre‐specified value of τ0 affects the power to detect differences when the divergence or crossing point of the two survival curves derived from the trial data occurs at different points. In addition, the impact of the true difference in RMST on power is examined. Focusing on the late difference and early crossing survival curves scenarios, where WMST shows superior results to RMST in the previous subsection, the divergence or crossing point x of the two survival curves is set at {0.10,0.15,0.20,0.25,0.30}, τ0 at {0.05,0.10,0.15,0.20,0.25,0.30,0.35,0.40,0.45,0.50}, and the difference of RMST δ is set at {0.10,0.15,0.20}. For all 5×10×3 combinations, 5000 numerical simulations are conducted to calculate the power. As in the previous subsection, all other parameters are kept in their default settings.
Figures 4 and 5 present comprehensive power comparisons for the late difference and early crossing survival curves scenarios, respectively, revealing distinct patterns that inform optimal window selection strategies for WMST analysis. In Figure 4 (late difference scenario), several critical observations emerge. First, WMST (pink line) consistently demonstrates superior power compared to RMST (blue line) across all combinations of parameters, with the WMST power curves consistently positioned above those for RMST regardless of the values of τ0 and x. While this superiority is maintained throughout, the absolute power of WMST increases as τ0 increases, reflecting the benefit of focusing the analysis window on later time periods where treatment differences are more pronounced in the late difference scenario. Second, the magnitude of the difference of RMST δ dramatically influences the power of both methods, with larger values of δ leading to substantial power gains. The vertical progression across panels in Figure 4 shows that as δ increases from 0.10 to 0.20, the power curves shift upward dramatically, with WMST achieving near‐perfect power (>0.99) for δ=0.20 when τ0 is sufficiently large (typically τ0≥0.30), regardless of the divergence point x. Notably, while RMST (blue line) also improves with increasing δ, its power remains consistently lower than WMST, and this gap persists across all effect sizes. Third, a notable feature evident in Figure 4 is the robustness of WMST to variations in the divergence point x. Examining horizontally across the panels for fixed δ, the WMST power curves (pink) maintain similar shapes and levels despite changes in x. This property has important practical implications: in actual clinical trials, the precise timing when treatment effects begin to manifest (x) is unknown at the design stage. The robustness of WMST to variations in x provides protection against this uncertainty, maintaining statistical power regardless of when the survival curves actually diverge.
Power for WMST tests based on τ0, the divergence point (x) of survival curves and difference of RMST under the late difference scenario, compared to three existing methods: RMST, log‐rank, FH, and MaxCombo [complete results in Appendix B].
Power for WMST tests based on τ0, the crossing point (x) of survival curves and difference of RMST under the early crossing survival curves scenario, compared to three existing methods: RMST, log‐rank, FH, and MaxCombo [complete results in Appendix B].
Figure 5 (early crossing survival curves scenario) reveals distinctly different power dynamics. When δ=0.10, WMST achieves moderate power levels that depend both on τ0 and the crossing point x. In contrast, as the effect size increases (δ=0.15 and δ=0.20), WMST (pink) achieves consistently high power (often exceeding 0.90) with a much weaker dependence on the specific values of τ0 and x, providing substantial tolerance for uncertainty in window placement. Importantly, when the effect size is small (δ=0.10), setting τ0 before the crossing point x can substantially reduce the power, potentially leading to false negative results—failing to detect a treatment effect that actually exists. This reduction occurs because the analysis window primarily captures the pre‐crossing period where the treatment group performs worse, diluting or masking the subsequent modest benefit. Therefore, when early crossing is anticipated with small‐to‐moderate treatment effects, choosing a conservative (later) value for τ0 may be preferable to avoid missing true treatment effects. Throughout all effect sizes and crossing points, WMST maintains its consistent advantage over RMST (blue), with the gap between them generally widening as τ0 increases.
Examining the performance patterns across Figures 4 and 5 reveals important insights about the relative strengths of different testing methods. When τ0≥x, WMST (pink) generally outperforms the log‐rank test (green) in both late difference and early crossing scenarios, demonstrating the advantage of focusing the analysis window on periods where treatment effects are most pronounced. The FH (0,1) (yellow) and MaxCombo (orange) tests represent the current best practices for handling non‐proportional hazards, achieving consistently high power across both scenarios. Remarkably, when τ0≥x, WMST achieves power comparable to these optimized methods and can even exceed FH performance, especially in the early crossing scenario. This competitive statistical power becomes more consistent as the effect size increases, with WMST approaching MaxCombo's performance for δ=0.20. Notably, RMST (blue) fails to achieve this level of performance, highlighting the substantial efficiency gain from focusing on a carefully selected time window. Crucially, WMST achieves this strong statistical performance while providing a directly interpretable expected survival time within the window, which rank‐based methods cannot offer. This combination of competitive power and clinical interpretability positions WMST as an attractive method for analyzing interval‐censored data under non‐proportional hazards, offering both the rigor needed for regulatory decisions and the clarity needed for clinical communication.
Application
4
This section demonstrates the results of applying the WMST method to real data with interval censoring. Similarly to the previous section, the interval‐censored data are imputed using the mid‐point imputation method, after which the survival function is estimated with KM method. WMST is then estimated and tested, and the results are compared with existing testing methods. The real data used in this study are from the “bcos” dataset available in the interval package of R software [52]. The bcos dataset contains interval‐censored survival times for 46 patients who underwent radiation therapy and 48 patients who received a combination of radiation therapy and chemotherapy, with the survival endpoint defined as cosmetic deterioration. The survival curves estimated with KM method after the mid‐point imputation are shown in Figure 6. The two survival curves intersect around 15 months, corresponding to the early crossing survival curves scenario discussed in the previous section.
KM curves estimated by using the mid‐point imputation method on interval‐censored data in the BCOS dataset, where “Rad” represents the radiotherapy group and “Rad + Chem” represents the group that received radiotherapy with adjuvant chemotherapy.
The p‐values for each test compared in the previous section are as follows: 0.0091 (RMST), 0.0010 (WMST (τ0=15)), 0.0011 (log‐rank), and 0.0001 (FH). As in the previous section, WMST is tested by shifting τ0 around the intersection point of the survival curves (τ0∈{12.5,17.5}). The resulting p‐values are 0.0021 (WMST (τ0=12.5)) and 0.0004 (WMST (τ0=17.5)). As a result, the p‐values for all tests are below 0.05, indicating a significant difference in survival rates between the radiation‐only group and the combination therapy group. It is well known that under the NPH, the log‐rank test and FH test cannot provide the clinically meaningful interpretation of the difference between the survival curves of the two groups. In contrast, for RMST, the difference between the groups is estimated to be 7.06 (95% CI [1.76,12.37]), and for WMST, the difference between the groups is estimated to be 7.53 (95% CI [3.06,12.00]). Furthermore, in this case, as the survival curves crossed early, the p‐value for WMST is lower than that for RMST.
Conclusion
5
In recent years, the NPH survival scenarios have been steadily increasing in cancer clinical trials. In particular, cancer immunotherapies, which have gained significant attention, often exhibit late differences and early crossing survival curves scenarios. Furthermore, in phase III trials targeting advanced cancers, the PFS is increasingly being adopted as a co‐primary endpoint alongside the OS. In response to these trends, we propose a class of methods for the estimation and testing of WMST designed for interval‐censored data and conduct extensive numerical simulations to compare their performance with conventional methods.
Through numerical simulations, WMST estimation method that uses mid‐point imputation followed by KM estimation (mid‐point + KM) demonstrates estimation accuracy comparable to that of WMST estimation method with Turnbull, which is the NPMLE. Unlike the frequently used right‐point + KM method in clinical practice, WMST estimation methods based on the mid‐point + KM and Turnbull are shown to be robust to both the proportion of interval‐censored cases and the interval widths of the interval‐censored data. Considering these findings, we establish WMST estimation based on mid‐point + KM as the standard approach. While achieving comparable statistical accuracy to Turnbull's method, this approach offers decisive practical advantages: it provides closed‐form variance estimation through Greenwood's formula, enables direct use of existing WMST software packages, and avoids the computational burden of bootstrap procedures. These characteristics make interval‐censored WMST analysis accessible for routine clinical research.
Numerical simulations for hypothesis testing show that even in the presence of interval‐censored data, WMST maintains higher power than FH (0,1) under the PH survival scenarios. More importantly, our comprehensive comparisons with the MaxCombo test—which represents current best practice for handling non‐proportional hazards in immunotherapy trials—reveal that while MaxCombo may achieve higher power in certain scenarios, WMST offers competitive performance with the distinct advantage of providing clinically interpretable effect estimates. Furthermore, WMST outperforms RMST in terms of power under late difference and early crossing survival curves scenarios, which are frequently observed in cancer immunotherapy trials. In the late difference and early crossing survival curves scenarios, the impact of selecting τ0 is investigated. It is found that when τ0 is appropriately selected relative to the divergence or crossing point of the two curves, WMST demonstrates improved power that, in certain scenarios, approaches that of MaxCombo, with the crucial benefit of maintaining clinical interpretability through its expected survival time estimate. Even when τ0 is set earlier than the optimal point, WMST maintains higher power than RMST for interval‐censored data. Our findings highlight that the proposed method represents a valuable addition to the methodological toolkit for assessing PFS in cancer immunotherapy trials, particularly under late difference and early crossing survival curves scenarios, by successfully balancing statistical efficiency with clinical interpretability.
An important direction for future research would be the development of versatile WMST methods specifically designed for interval‐censored data. As demonstrated by Paukner and Chappell [47] for right‐censored data, versatile testing approaches that combine multiple window specifications can substantially improve robustness against window misspecification. However, extending these approaches to interval‐censored data presents significant methodological and computational challenges, requiring comprehensive evaluation across numerous window combinations and censoring patterns. This represents a substantial research undertaking that warrants dedicated investigation in future work.
In this study, we employ the mid‐point imputation for handling interval‐censored data. However, the mid‐point imputation assigns a single value to all subjects whose disease progression (DP) is observed within the same interval. This means that all DP events within the same interval occur on the same day, which is unrealistic. To address this issue, Nakagawa and Sozu [53] propose an enhanced mid‐point imputation, and their numerical simulations demonstrate that the enhanced method provides more accurate estimates of the survival function compared to the standard mid‐point imputation. While applying the enhanced method in our study could lead to better WMST estimation accuracy and statistical power, a rigorous evaluation of these potential improvements remains an open question for future research.
Author Contributions
All authors contributed equally to all aspects of this research, including conceptualization, methodology development, formal analysis, writing, and revision of the manuscript. T.M. served as the corresponding author and handled project administration. S.A. provided supervision. All authors have read and approved the final manuscript.
Funding
The authors have nothing to report.
Conflicts of Interest
The authors declare no conflicts of interest.
Supporting information
Data S1: Supporting Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1H. Uno , B. Claggett , L. Tian , et al., “Moving Beyond the Hazard Ratio in Quantifying the Between‐Group Difference in Survival Analysis,” Journal of Clinical Oncology 32, no. 22 (2014): 2380–2385.24982461 10.1200/JCO.2014.55.2208 PMC 4105489 · doi ↗ · pubmed ↗
- 2M. Horiguchi , M. J. Hassett , and H. Uno , “Empirical Power Comparison of Statistical Tests in Contemporary Phase III Randomized Controlled Trials With Time‐to‐Event Outcomes in Oncology,” Clinical Trials 17, no. 6 (2020): 597–606.32933339 10.1177/1740774520940256 · doi ↗ · pubmed ↗
- 3L. Trinquart , J. Jacot , S. C. Conner , and R. Porcher , “Comparison of Treatment Effects Measured by the Hazard Ratio and by the Ratio of Restricted Mean Survival Times in Oncology Randomized Controlled Trials,” Journal of Clinical Oncology 34, no. 15 (2016): 1813–1819.26884584 10.1200/JCO.2015.64.2488 · doi ↗ · pubmed ↗
- 4J. Song , Q. Ma , W. Gao , et al., “Matching‐Adjusted Indirect Comparison of Blinatumomab vs. Inotuzumab Ozogamicin for Adults With Relapsed/Refractory Acute Lymphoblastic Leukemia,” Advances in Therapy 36, no. 4 (2019): 950–961.30758745 10.1007/s 12325-019-0873-7PMC 6824351 · doi ↗ · pubmed ↗
- 5H. P. Guimaraes , R. D. Lopes , d. B. Silva , et al., “Rivaroxaban in Patients With Atrial Fibrillation and a Bioprosthetic Mitral Valve,” New England Journal of Medicine 383, no. 22 (2020): 2117–2126.33196155 10.1056/NEJ Moa 2029603 · doi ↗ · pubmed ↗
- 6S. Qin , J. Li , Y. Bai , et al., “Nimotuzumab Plus Gemcitabine for K‐Ras Wild‐Type Locally Advanced or Metastatic Pancreatic Cancer,” Journal of Clinical Oncology 41, no. 33 (2023): 5163–5173.37647576 10.1200/JCO.22.02630 PMC 10666986 · doi ↗ · pubmed ↗
- 7A. J. Birtle , R. Jones , J. Chester , et al., “Improved Disease‐Free Survival With Adjuvant Chemotherapy After Nephroureterectomy for Upper Tract Urothelial Cancer: Final Results of the POUT Trial,” Journal of Clinical Oncology 42, no. 13 (2024): 1466–1471.38350047 10.1200/JCO.23.01659 PMC 11095877 · doi ↗ · pubmed ↗
- 8C. Zhang , Y. Wu , and G. Yin , “Restricted Mean Survival Time for Interval‐Censored Data,” Statistics in Medicine 39, no. 26 (2020): 3879–3895.32767503 10.1002/sim.8699 · doi ↗ · pubmed ↗