Assessing image quality in photoacoustic imaging: A metric-based and deep learning-based evaluation
Melle Van Der Brugge, Kalloor Joseph Francis, Navchetan Awasthi

TL;DR
This paper benchmarks image quality assessment methods for photoacoustic imaging, showing that structure-based metrics and deep learning models can improve automated quality evaluation.
Contribution
The first large-scale benchmark of IQA in PA imaging, evaluating 13 metrics and deep learning models across nearly one million images.
Findings
Structural similarity-based metrics like SSIM reliably capture image quality differences in PAI.
Deep learning models, especially PAQNet, achieve high correlations with reference-based scores for no-reference quality estimation.
Conventional metrics like PSNR and existing NR metrics correlate poorly with reconstruction improvements.
Abstract
Photoacoustic (PA) imaging offers high-resolution functional imaging in vivo, but image quality varies with acquisition hardware, reconstruction methods, and scanning conditions. Reliable image quality assessment (IQA) is therefore critical for evaluating new PA technologies and ensuring reproducible research. IQA metrics originally proposed for natural images are widely used; however, their relevance to PA imaging has not been systematically benchmarked. We present the first large-scale benchmark of IQA in PA imaging, evaluating 11 full-reference (FR) metrics and 2 no-reference (NR) metrics across nearly one million PA images from five independent datasets. These datasets span phantoms, preclinical small-animal scans, and challenging ex vivo and in vivo acquisitions with controlled degradations across multiple commercial imaging systems. Metric scores were analyzed statistically to…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6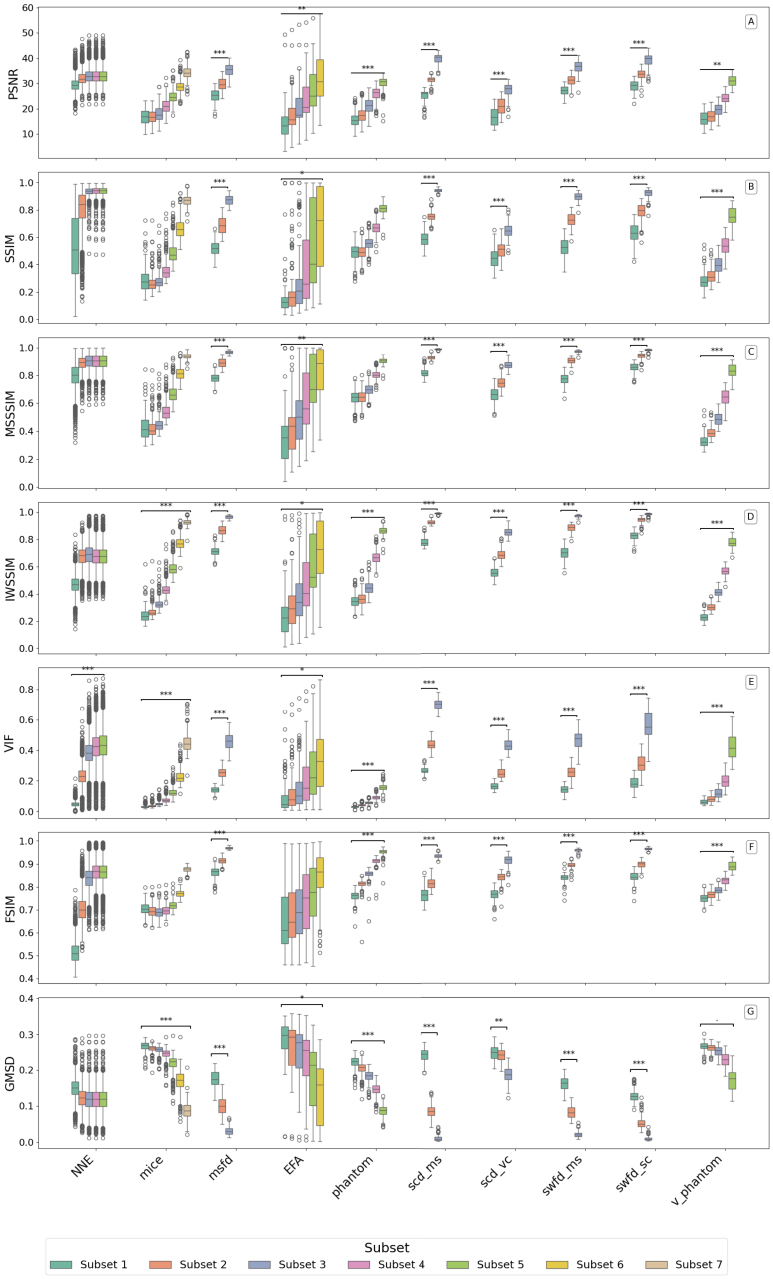 Figure 7
Figure 7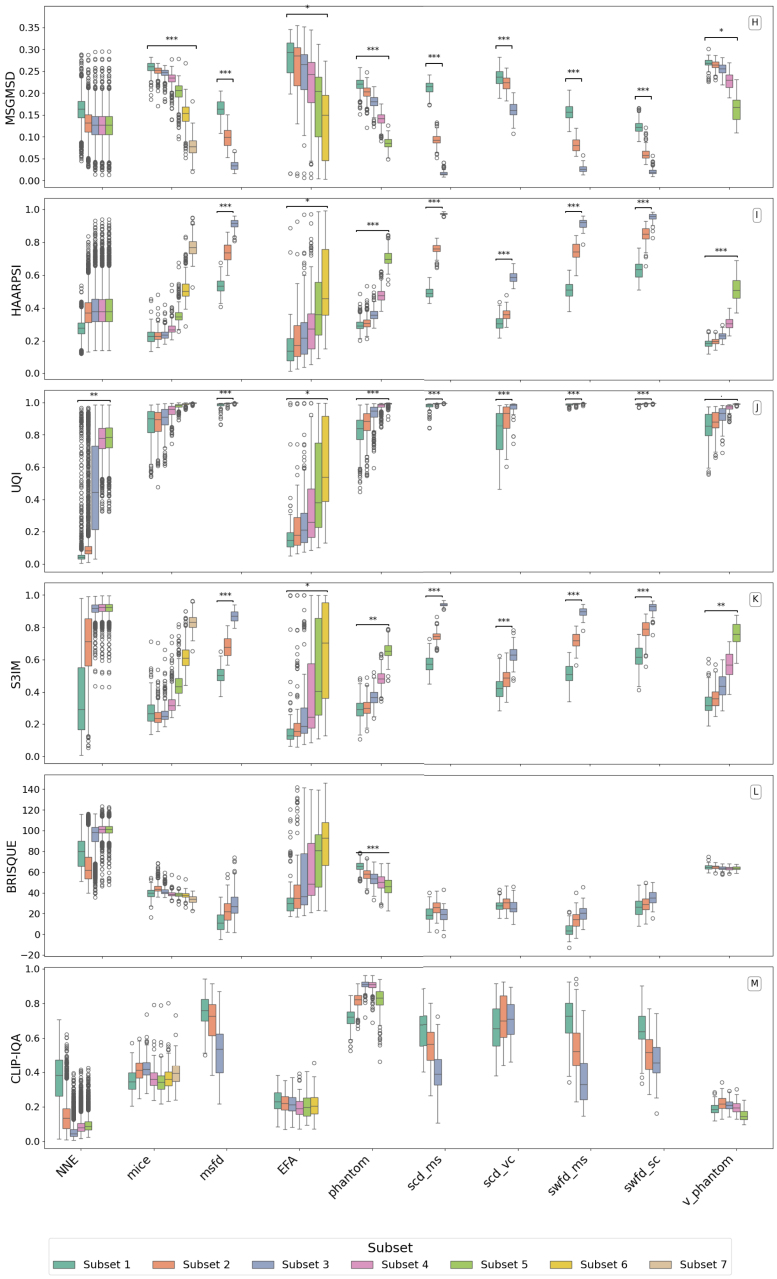 Figure 8
Figure 8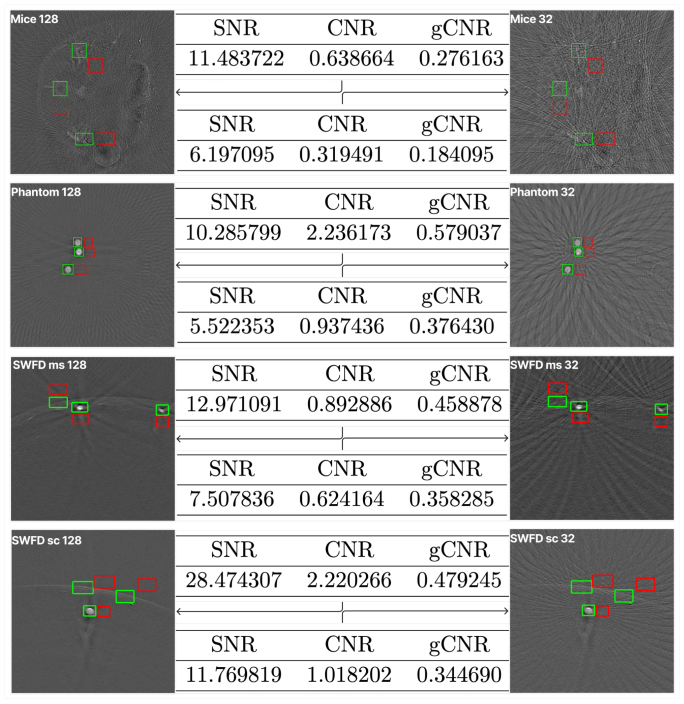 Figure 9
Figure 9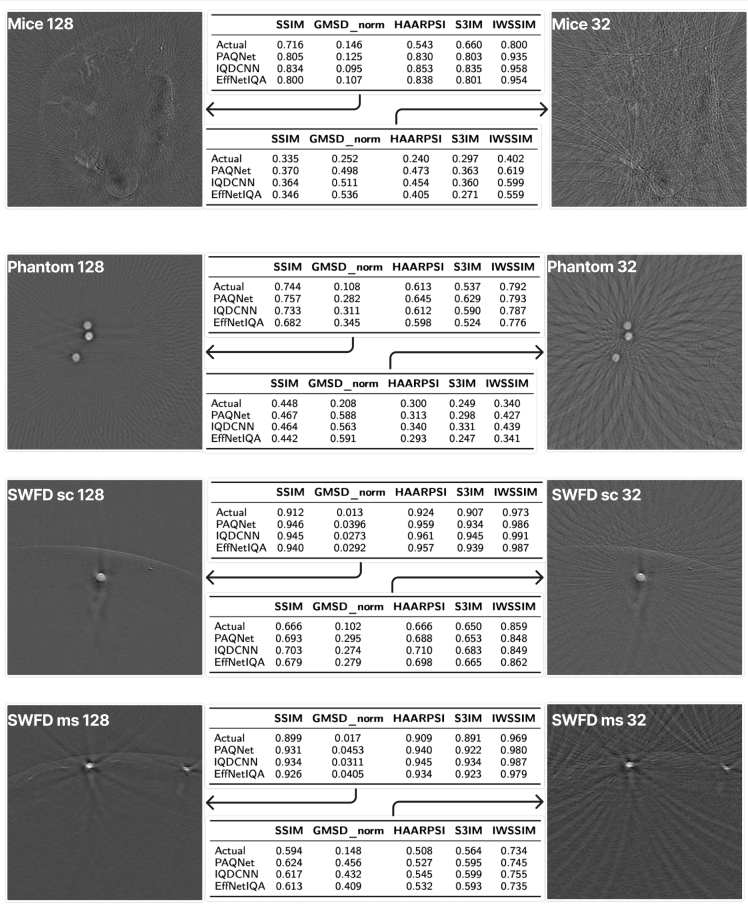 Figure 10
Figure 10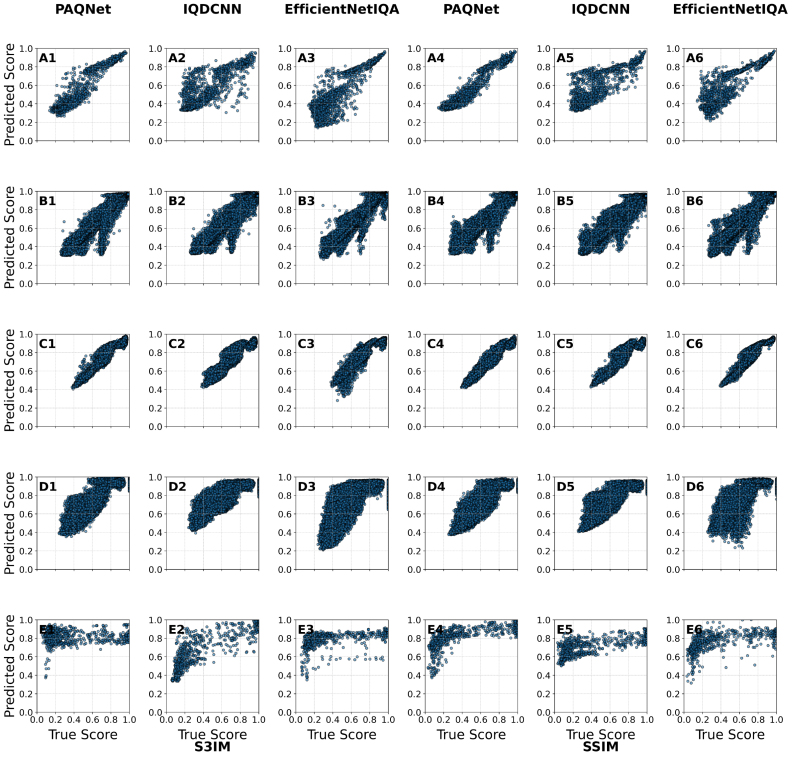 Figure 11
Figure 11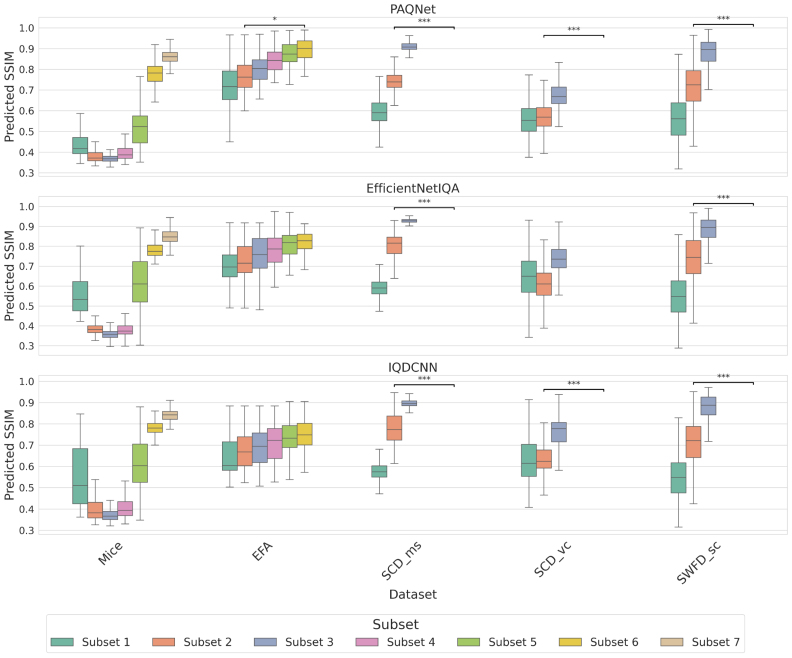 Figure 12
Figure 12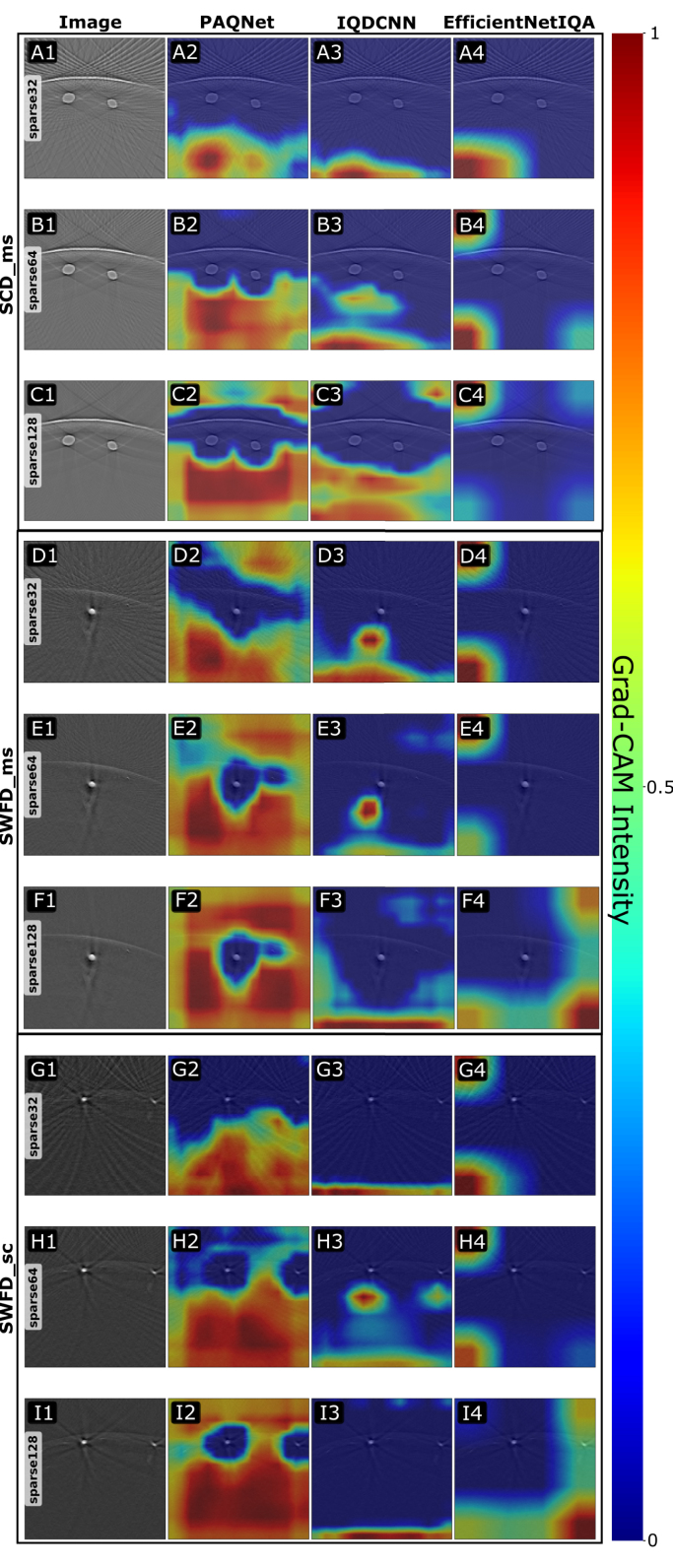 Figure 13
Figure 13Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPhotoacoustic and Ultrasonic Imaging · Thermography and Photoacoustic Techniques · Infrared Thermography in Medicine
Introduction
1
Photoacoustic imaging (PAI) combines optical absorption contrast with ultrasonic resolution and penetration, enabling multiscale, multiparametric imaging from microscopy to tomography [1], [2], [3]. PAI has been demonstrated for many clinical applications, yet image quality assessment (IQA) in PAI is not standardized [4], [5]. Most conventional IQA measures, for example, Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), etc., are originally designed for natural photographs [6], [7] and might not be suitable for diagnostic medical imaging, including PAI [8]. PAI further exhibits modality-specific degradations, for example, limited-view and band-limited artefacts, streaking artefacts from sparse sampling, clutter from out-of-plane signals, sidelobes from beamforming, depth-dependent attenuation, and spectral coloring, which are not well captured by natural-image statistics [9], [10], [11], [12]. Hence, there is a need for IQA methods for PAI.
For PAI, researchers have relied on a mix of signal-based quality measures and conventional IQA metrics. Signal-based measures such as SNR, CNR, contrast ratio, signal-to-background ratio, and spatial resolution are widely used by the PAI community [13], [14]. These are no-reference metrics, but require manual region selection. Inspired by ultrasound imaging, a PAI-specific detectability metric, the generalized contrast-to-noise ratio (gCNR), has gained interest because it avoids dynamic-range and thresholding limitations of classical contrast and CNR, and better reflects target detectability [15]. Multiple works now report gCNR alongside SNR and CNR to quantify visibility gains from beamforming or reconstruction [14], [16]. Although SNR, CNR, and gCNR are considered no-reference metrics, they depend on manual selection of target and background regions. These metrics can be partially automated through region detection algorithms for a specific dataset, but their spatial variation across different target locations makes it difficult to produce a single representative quality score for an image. The need for no-reference metrics that do not rely on manual region selection or reference images is the gap addressed in this work. Palma-Chavez et al. [4] presented a comprehensive review of consensus test methods and current practices in photoacoustic image quality assessment, emphasizing phantom-based evaluation of spatial resolution, geometric accuracy, imaging depth, sensitivity, and contrast. These methods rely on manual region selection and are essential for standardizing imaging systems. Our study complements this work by introducing a framework for automated quality assessment that predicts image quality directly from the reconstructed images without the need for reference data or manual region definition, enabling scalable and objective comparison of image quality across datasets, reconstruction methods, and imaging systems.
At the same time, full-reference evaluation in PAI has been constrained by the scarcity of trusted references in vivo. Obtaining a ground truth image for experimental PAI is challenging. However, researchers have developed approaches to overcome this using twin phantoms, controlled targets, and test methods for image quality and oximetry accuracy [17], [18], [19]. This is still limited to a controlled test environment. Several PAI reviews have also focused on clinical PAI and have highlighted the need for IQA practices and the gap between current metrics and clinical needs [4], [5].
Learning-based IQA, which has matured rapidly in natural and medical imaging, offers a route to modality-aware, no-reference quality prediction [6], [7], [20]. In PAI, deep learning has predominantly targeted reconstruction, artefact removal, and denoising under sparse or limited-view sampling [11], [21], [22], [23], [24], with quality judged by a mixture of PSNR, SSIM, and signal-based metrics, and PSNR has been shown not to correlate with expert opinion [8]. Hence, benchmarking existing imaging quality metrics and developing learning-based IQA for PAI for no-reference quality assessment are urgent requirements for clinical translation.
In this work, we first benchmark a broad range of full-reference and no-reference metrics on diverse PAI datasets, including phantoms and in vivo images, to identify which metrics best reflect differences in perceptual quality. Second, from the top-performing metrics, we train and analyze learning-based no-reference predictors that map PA images to predict the quality scores. Using nearly one million examples spanning simulated, phantom, in vivo, and clinically inspired images, we study generalization, out-of-distribution behavior, and model interpretability. Our contributions are (i) a quantitative comparison of eleven FR and two NR metrics across multiple datasets and acquisition regimes, (ii) three NR-IQA models, PAQNet, IQDCNN, and EfficientNetIQA, trained to mimic the top-ranked metrics and explored in multi-task settings, and (iii) an interpretability analysis via Grad-CAM based analysis to probe what image regions drive quality predictions. Our work is the first on large-scale IQA in PAI with images from multiple commercial systems, targets, and applications, benchmarking the highest number of metrics so far, a step towards learning-based no-reference quality assessment, and providing an open-source resource to the community.
Datasets
2
To capture a wide range of image qualities and artefacts, we compiled several PAI datasets spanning simulations, phantoms, small animal imaging, and human-inspired scenarios. Each dataset includes reference “high-quality” reconstructions and corresponding lower-quality images produced by altering imaging parameters (such as number of detectors, view angle, or Signal-to-Noise Ratio). Below we outline each dataset and its key characteristics.
OADAT dataset
2.1
We utilized the OADAT open-access collection [25], which provides both experimental and synthetic optoacoustic data. In particular, we used from the OADAT dataset:
- •Simulated Cylinders Dataset (SCD): This consists of simulated tomographic reconstructions using a circular transducer geometry (full 360° view). This also includes variants including a full-view reference and a sparse-view reconstruction with fewer detection angles (e.g., half-circle or quarter-circle coverage). The sparse configurations introduce angular undersampling artefacts.
- •Multispectral Forearm Dataset (MSFD): This configuration consists of a multi-segment arc transducer geometry, with data from forearm imaging [25]. This dataset contains multiple wavelength acquisitions (700–850 nm) but for our purposes we use a representative wavelength (760 nm) to focus on spatial quality. The reconstructions are available for a full multisegment array (reference) and sparser sampling configurations (e.g., using only a subset of segments), leading to spatial sparsity artefacts. The MSFD subset is one of the largest datasets, contributing to the order of reconstructed images.
- •Single Wavelength Forearm Dataset (SWFD): This consists of a simulated linear-array geometry with a wide field of view, including both a full-view detector reference and sparser versions (e.g., skipping detectors or reducing aperture). We utilized both a multi-segment (ms) linear configuration and a single-segment (or semi-circular, sc) configuration [25]. These allow testing metric sensitivity to different coverage; the semi-circular case is particularly challenging as the limited view induces significant reconstruction blurring in the reconstructed images.
All OADAT-sourced images are reconstructed optoacoustic tomographic slices with known ground truth references (the full-sampling or full-view cases). The simulated data has the advantage of a very large number of images (hundreds of thousands across parameter variations), facilitating robust statistics. We applied preprocessing to these datasets, including bandpass filtering (0.1–6 MHz) and intensity normalization [25], [26], [27], to ensure consistency before metric computation. All images were reconstructed using a delay-and-sum backprojection algorithm with a fixed speed-of-sound, following the standard reconstruction pipeline provided with the dataset.
Experimental phantom and in vivo data
2.2
We also utilized PAI data from controlled phantom experiments and small animal imaging, which was captured using a tomography system (full-ring 512-element transducer).
- •The Phantom dataset consists of tissue-mimicking phantoms with embedded structures (e.g., printed vascular patterns on polyurethane films) imaged in a water tank. Reference images were acquired with a full 512-element ring for 360° coverage, and degraded versions were generated by using only a subset of the detection elements (e.g., 8, 16, 32, …, 128 evenly spaced detectors) to simulate sparse-sampling reconstructions [28]. As expected, image quality improves as more detectors are used (sparse8 being poorest, sparse128 closer to reference) [28].
- •A Virtual Phantom dataset was similarly created, but using simulated data of a digital phantom through the same ring geometry. The Virtual Phantom (“V Phantom”) helps examine whether trends observed in real phantom data persist in an idealized simulation of a phantom [28].
- •The Mice dataset consists of in vivo whole-body mouse scans [28]. Mice were imaged with the full ring array (providing a ground truth reconstruction) and with progressively sparser angular sampling. We denote reconstructions by the number of virtual projections (e.g., sparse4, sparse8, …, sparse256) used in the image formation [28]. This dataset presents realistic biological variability (heterogeneous tissues, blood vessels, etc.) and thus tests metric performance under more complex, natural image features. For instance, deeper structures and higher noise in mice images pose challenges that may differ from the phantom case.
All experimental data were preprocessed similarly to simulations (bandpass filtered and min–max normalized per image). For the in vivo data, we ensured any irrelevant borders or imaging artefacts (e.g., coupling medium boundaries) were cropped out prior to analysis, so that metrics focus on the actual anatomical region of interest. Following the reconstruction pipeline provided with the dataset, images in the Phantom and in vivo mouse datasets were reconstructed using a universal backprojection algorithm. Prior to reconstruction, the raw signals were bandpass filtered. For in vivo mouse imaging, the reconstruction was adapted to account for a heterogeneous speed-of-sound distribution between the animal and the surrounding coupling medium, while for phantom experiments a uniform speed of sound was assumed.
Experimental frame averaging (EFA) dataset
2.3
To assess performance under noise-induced degradation, we used the Experimental Frame Averaging (EFA) dataset [29]. The dataset is acquired with the handheld LED-based AcousticX system (Cyberdyne Inc., Tsukuba, Japan), which integrates a pulsed 850 nm LED array and a 128-element linear ultrasound transducer (center frequency 7 MHz) in a handheld probe configuration [30]. Image quality was varied by changing the number of frame averages during acquisition: fewer averages yielded lower Signal-to-Noise Ratio (SNR) with stronger noise, while higher averaging produced smoother, high-SNR reference images.
The dataset includes five phantoms and three in vivo human extremity scenes:
- •Phantoms: Vascular network phantoms with vessel-like structures, one Derenzo resolution test pattern, and one angular sensitivity test pattern. Each target was ink-printed on 60 µm polyurethane films [17].
- •In vivo: Images of human extremities (e.g., fingers, arms) highlighting vascular structures [9].
Each phantom and in vivo target was acquired at seven frame-averaging levels: 25 600 (used as reference), 128, 256, 384, 640, 1280, and 2560 frames, referred to as PA1 to PA7. Thus, the dataset provides controlled degradations in SNR and speckle appearance while preserving anatomical or phantom structure.
Prior to metric computation, all EFA images were intensity- normalized, and uniform background regions (e.g., above the tissue surface) were cropped to prevent bias. This dataset is particularly suited for evaluating how well metrics capture quality degradation due to noise and averaging. Images in the EFA dataset were reconstructed using a Fourier-domain reconstruction method followed by envelope detection [31].
Neurovascular network explorer (NNE) dataset
2.4
The NNE dataset consists of high-resolution 2-photon vessel diameter measurements from the mouse S1 cortex. In this study, the data were used to generate simulated and experimental photoacoustic (PA) images for fluence compensation analysis. Using the AcousticX LED-based imaging system and digital phantom printing onto polyurethane films, the dataset includes realistic reconstructions with ground truth acquired in both water and tissue-mimicking media. Images were reconstructed under various noise conditions (10–50 dB), enabling the evaluation of deep learning-based models [32]. NNE images were reconstructed using time reversal reconstruction approach followed by envelope detection [33].
Across all datasets, we set aside appropriate training, validation, and testing splits for the deep learning experiments (as detailed in Section 3). In total, our compiled data spans on the order of images, making this one of the largest studies of PAI image quality to date.
Methods
3
In this section, we describe the methods for assessing image quality in PAI, including the definitions of the image quality metrics, the statistical evaluation approach for metrics, and the design and training of deep learning models for quality prediction. We also outline the experimental protocol for model training, validation, and testing.
Image quality metrics
3.1
We evaluated a broad set of established IQA metrics, covering full-reference metrics, which require a ground truth image for comparison, and no-reference metrics, which operate on the image alone. All metrics are computed on a per-image basis. For full-reference metrics, each reconstructed image from a dataset was compared to its corresponding high-quality reference image, considered as the “ground truth”. For no-reference metrics, the score is computed from the reconstructed image itself. First, we will discuss the FR metrics in detail.
Full-reference (FR) metrics
3.1.1
To establish a benchmark for assessing image fidelity, reference-based metrics are used to compare the reconstructed images to the ground truth. Eleven image quality metrics are used to evaluate the PA images. All full-reference metric computations are performed using the PyTorch Image Quality (PIQ) library [26], [27], a modern and GPU-compatible package for reproducible image quality assessment in deep learning environments. The metrics S3IM, UQI, and FSIM are not implemented in PIQ and were therefore computed using custom implementations based on their published formulations.
PSNR
Peak Signal-to-Noise Ratio (PSNR) will quantify the difference between the reference image ( ) and the reconstructed image ( ) by comparing the maximum possible signal power to the power of corrupting noise. PSNR is defined as :
where is the maximum possible pixel value of the image (defined by the data range) and MSE is defined as:
where is the total number of elements (pixels) in the images. and are the intensity values of the th pixel in images (reference) and (reconstructed), respectively.
A higher PSNR score indicates a higher quality of the reconstructed image compared to the ground truth, indicating less noise in the input image [34].
SSIM
Structural Similarity Index Measure (SSIM) will be used to measure the structural similarity between the reconstructed photoacoustic image and the ground truth, focusing on luminance, contrast, and structure. SSIM is defined as:
where and are the mean intensity of images and , respectively. and are the variance of images and , respectively. is the covariance of images and . is a stabilizing constant to avoid division by zero, derived from (default 0.01) and (data range). is also a stabilizing constant to avoid division by zero, derived from (default 0.03) and (data range) [35], [36].
MS-SSIM
Multi-Scale Structural Similarity (MS-SSIM) extends SSIM by comparing image structures at multiple spatial resolutions. It decomposes the image into different scales using low-pass filtering and downsampling, combining luminance, contrast, and structure comparisons at each level. MS-SSIM is defined as:
where is the number of scales, and , , and represent luminance, contrast, and structure comparisons respectively. MS-SSIM improves robustness against resolution and viewing condition changes [37].
IW-SSIM
Information-Weighted SSIM (IW-SSIM) weights the local SSIM scores by the local information content, giving more importance to regions with higher entropy. It aims to reflect human visual sensitivity to structural information by emphasizing perceptually important regions during averaging [38].
Sparse SSIM (S3IM)
S3IM evaluates structural similarity only within informative regions rather than across the entire image. This is achieved by generating adaptive masks that highlight vascular or edge-like structures, while suppressing homogeneous background regions that are less informative in photoacoustic images. The method can be described in three steps:
- 1.Adaptive mask generation. For both the reference and predicted image, a Gaussian local thresholding method is applied using a neighborhood size proportional to the image resolution:
where is the image height. A sensitivity parameter ( ) controls the threshold level. This creates binary masks ( ) that mark significant structures (e.g., vessels, high-contrast regions).
- 2.Mask combination and application. The masks from the reference and predicted image are combined using a logical OR, ensuring that any structure present in either image is included. The resulting mask is applied to both images, zeroing out background pixels:
- 3.SSIM computation on masked regions. The standard SSIM map is computed between the masked images. The S3IM value is then obtained as the mean SSIM restricted to the masked regions:
By focusing exclusively on sparse, informative regions, S3IM reduces the influence of noise-dominated background and improves sensitivity to structural fidelity. This is particularly relevant for PA images, where vascular structures occupy only a small fraction of the image domain [39].
HAARPSI
Haar Perceptual Similarity Index (HaarPSI) leverages Haar wavelets to model the early stages of human visual processing. It computes local similarities in the wavelet domain and aggregates them with perceptual weights. HAARPSI is defined as:
where is a sigmoid function and is the local similarity in Haar bands. HaarPSI is designed for high correlation with human perception at low computational cost [40].
FSIM
Feature Similarity Index (FSIM) will be used to assess the perceptual similarity between the reconstructed photoacoustic image and the ground truth, focusing on phase congruency and gradient magnitude to capture structural and textural details. FSIM is defined as:
where is the combined similarity measure of phase congruency (PC) and gradient magnitude (GM). is the phase congruency similarity between the original and predicted images at pixel . is the gradient magnitude similarity between the original and reconstructed images at pixel . are the phase congruency maps of the original and reconstructed images, respectively. are the weights for the relative importance of and (default is 1). are stabilizing constants for and , respectively [41], [42].
GMSD
Gradient Magnitude Similarity Deviation (GMSD) uses image gradients to assess structural differences. It calculates a pixel-wise similarity map between gradients and uses its standard deviation as the quality score. GMSD is defined as:
where and are gradient magnitudes of the reference and reconstructed images. A lower GMSD implies higher similarity [43].
MS-GMSD
Multi-Scale GMSD (MS-GMSD) extends GMSD to multiple resolutions. Similar to MS-SSIM, it averages GMSD scores across scales to better capture human visual perception over various image details and distortions [43].
VIF
Visual Information Fidelity (VIF) will be used to evaluate the amount of visual information preserved in the reconstructed photoacoustic image compared to the ground truth, focusing on the human visual system’s sensitivity to signal fidelity and noise. VIF is defined as:
where is a gain factor that represents the relation between the original and reconstructed image pixel values for pixel . is the variance of the image signal at pixel . is the variance of the visual noise (default value is 2). The numerator represents the information fidelity of the distorted image. The denominator represents the information fidelity of the original image [44].
UQI
Universal Image Quality Index (UQI) will be used to evaluate the similarity between the reference image ( ) and the reconstructed photoacoustic image ( ), focusing on luminance, contrast, and structural distortions using a localized sliding window approach. UQI is defined as:
where and are the local means of and , respectively, calculated over a sliding window of size . and are the local variances of and , respectively, also computed within the sliding window. is the local covariance between and . The numerator combines luminance similarity and contrast similarity , capturing the joint distribution of the two images. The denominator normalizes the metric to account for scaling, ensuring is bounded between −1 and 1, with values closer to 1 indicating higher similarity [45].
No-reference (NR) metrics
3.1.2
Next, we will discuss the NR metrics utilized in this work.
BRISQUE
Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE) is a no-reference image quality assessment metric that evaluates the perceptual quality of an image based on natural scene statistics (NSS) in the spatial domain. Unlike full-reference methods, BRISQUE does not require a ground truth image for comparison. Instead, it analyzes the image’s statistical properties to predict distortions such as noise, blur, and compression artefacts. BRISQUE is computed in three main steps:
- 1.Mean Subtracted Contrast Normalization (MSCN): The image is processed to remove local mean intensity variations and normalize contrast:
where is the local mean, is the local standard deviation, and is a small constant to avoid division by zero.
- 2.Pairwise Product Computation: Four directional spatial relationships are computed to capture structural distortions:
- 3.Feature Extraction and Quality Prediction: Statistical features are extracted from the MSCN coefficients and pairwise product images. These features are fitted to a generalized Gaussian distribution (GGD) and an asymmetric generalized Gaussian distribution (AGGD) to form a 36-dimensional feature vector. The final BRISQUE score is obtained by feeding these features into a support vector machine (SVM) trained on human-labeled image quality datasets.
BRISQUE produces a quality score in the range of 0 to 100, where lower values indicate higher image quality and higher values suggest a more distorted image. This metric is useful for assessing real-world image degradations without requiring a reference image [46].
CLIP-IQA
CLIP-IQA is a recent no-reference image quality assessment method that leverages the contrastive vision-language representations of the CLIP model. Instead of computing traditional quality scores, CLIP-IQA uses image-text similarity to align degraded images with textual quality descriptions. The method involves embedding both the image and a set of predefined quality-related text prompts using CLIP, and computing their cosine similarity:
where denotes the CLIP embedding function, is the input image, and is the set of textual prompts (e.g., “This is a high-quality image”). This approach allows CLIP-IQA to generalize across multiple distortion types without requiring a reference image or specialized training on IQA datasets. It has shown competitive performance in both full-reference and no-reference IQA settings [47].
Region-based detectability metrics
3.1.3
To complement the full-reference and no-reference analyses, we computed region-based detectability metrics, namely Signal-to-Noise Ratio (SNR), Contrast-to-Noise Ratio (CNR), and generalized CNR (gCNR), on representative reconstructions from multiple datasets (Mice, Phantom, SWFD_sc, SWFD_ms). For each image, three signal regions of interest (ROIs) were placed on three visible targets, and three corresponding local background ROIs of identical size were placed adjacent to each target. The mean and standard deviation were computed for each region. All region-based metrics were computed on beamformed images in linear scale. The SNR was defined as [4]:
where is the mean pixel value within a target ROI, and is the standard deviation of pixel values within the paired background ROI.
We report CNR as:
where is the mean pixel value within a signal ROI, and and are the mean and standard deviation within the paired background ROI.
Generalized CNR (gCNR) quantifies the separability of signal and background pixel-value distributions and is robust to dynamic-range and thresholding effects [15]. Let and denote the normalized histograms of the signal and background ROIs, estimated with a fixed number of bins over the joint pixel-value range of the paired ROIs. gCNR is given by:
which equals 1 when the distributions do not overlap and 0 when they are identical.
For each image, metrics were computed for each of the three signal background pairs and then averaged to obtain one SNR, one CNR, and one gCNR per image.
Statistical evaluation of metrics
3.2
We evaluated each metric based on its ability to distinguish between reconstruction qualities under varying acquisition and processing settings. Known configuration differences within each dataset (e.g., 32 vs. 128 detectors, or 128 frame vs. 25600 frame averaging) were used as ground-truth ordinal relationships, where the configuration with more detectors or greater averaging was expected to yield higher quality. We assume that increasing the number of transducers and the amount of frame averaging leads to higher photoacoustic image quality. Our primary goal is to test whether an IQM can reliably separate these predefined quality levels [48]. This should be regarded as a surrogate for human observer studies, not a replacement for direct assessment of perceived image quality or diagnostic performance. Using these pairings, we performed the following evaluations:
- •Pairwise significance testing: For each configuration pair within a dataset (e.g., sparse32 vs. sparse128 in Phantom, or 2-frame vs. 7-frame in EFA), we applied a two-sided t-test to the metric values. Differences were considered significant at .
- •Significant Count (SC): For each metric, we counted the number of image subset pairs with statistically significant differences. A higher count indicates greater sensitivity to quality variations.
- •Normalized Mean Difference (NMD): For significant comparisons, we computed the absolute difference in mean metric values, normalized by the metric’s value range, followed by computing the mean value. This quantifies effect size, i.e., how strongly the metric separates reconstruction qualities on average.
- •Composite Score (CS): Finally, we defined a composite score as the product of the Significant Count and the Normalized Mean Difference:
This provides a unified ranking criterion, favoring metrics with both high sensitivity and strong effect size.
In addition to the formal tests, we examined metric distributions via boxplots and their correlations with each other to see if some metrics are redundant. Where appropriate, we also computed Spearman’s rank correlation between metric scores and the known “quality level” (such as number of detectors) as another check on monotonic behavior.
For all metrics, the absolute value of the normalized mean difference was used, ensuring that metrics where lower values indicate higher image quality (e.g., GMSD) are treated equivalently to metrics whose values increase with quality. Hence, composite scores quantify sensitivity to quality changes independent of metric directionality.
All statistical analyses were performed using Python (SciPy and pandas libraries). Given the very large sample size ( 100k images for some metrics), even small differences often yield significant -values; therefore, our focus was on patterns of consistency and effect sizes rather than just significance.
Deep learning models for quality prediction
3.3
We also designed three deep learning models to predict image quality from PA images. Each model takes a single reconstructed PA image (grayscale, 128 × 128 pixels after preprocessing) as input and outputs one or more scalar quality scores for the image metric. During training, these models were supervised with “ground truth” quality values provided by one or multiple FR metrics. In essence, the networks learn to mimic a given image quality metric, enabling no-reference prediction of that metric. The three models evaluated in this work are described below. PAQNet is newly proposed in this work, while IQDCNN and EfficientNetIQA are adapted for PA imaging but have not been used for this purpose before.
PAQNet
3.3.1
We developed a custom convolutional neural network specifically for this task. It consists of four convolutional layers with increasing filters (32, 64, 128, 256) and 5 × 5 or 3 × 3 kernels, each followed by ReLU activation and 2 × 2 max pooling. This is followed by two fully connected layers (128 units each with ReLU) and a final linear output node for regression. The model has around 2.5 million parameters, making it relatively lightweight. We initialized weights randomly and optimized the design via extensive hyperparameter search and -fold cross-validation on the training set. PAQNet was trained using a MAE loss and ADAM optimizer with learning rate of .
Fig. 1. Deep learning architectures used for photoacoustic image quality prediction. (a) Proposed PAQNet, a lightweight custom CNN. (b) IQDCNN, adapted from prior medical NR-IQA work [48]. (c) EfficientNetIQA, based on EfficientNet-B0 with a regression head.Fig. 1(a)PhotoacousticQualityNet (PAQNet): 4×Conv+ReLU with pooling, flatten, two FC layers, and a scalar regression output.(a)(b)IQDCNN: 4×Conv layers (32 filters, 5 × 5), followed by 3 FC layers (1024 units, dropout 0.3), and regression output.(b)(c)EfficientNetIQA: EfficientNet-B0 backbone with modified first layer (grayscale input) and regression head (128-unit FC + output node).(c)
IQDCNN
3.3.2
This is a deep CNN model adapted from a prior no-reference IQA approach for medical images [48]. The architecture is a deep network with four convolutional layers (each 32 filters of size 5 × 5) followed by three fully connected layers of 1024 units. We use ReLU activations and dropout (rate 0.3) on the fully connected layers (see Fig. 1). IQDCNN was originally proposed for MRI quality assessment [48], and we repurposed it for PAI. It has around 3.8 million parameters. We trained it with an MAE loss (absolute error) and Adam optimizer, learning rate of . IQDCNN serves as a baseline deep regression model for comparison with the proposed model.
EfficientNetIQA
3.3.3
This is a model based on EfficientNet-B0 [49], a modern convolutional network architecture known for its efficiency and strong performance on image tasks. We modified EfficientNet-B0 to accept single-channel input (by averaging the weights of the initial RGB filters) and replaced the top classification layers with a regression head. The regression head consists of a fully connected layer with 128 units (ReLU activation) and an output node (see Fig. 1). EfficientNetIQA has roughly 4.2 million parameters, the largest of the three models, and a significantly deeper feature extraction part (with many more layers than the custom CNNs). We used the Adam optimizer with a learning rate of and an MAE loss for training. This model was expected to capture more complex feature relationships for quality prediction, potentially improving accuracy at the cost of more computation.
Training procedure and evaluation protocol
3.3.4
All models were implemented in PyTorch. We trained each model to predict specific metric scores. In our primary experiments, we trained separate instances of the models for each of five representative FR metrics (SSIM, HAARPSI, IW-SSIM, S3IM, and GMSD). These metrics were chosen to span different types (structural, perceptual, gradient-based) and because they showed strong reliability in our metric benchmark (see Section 4, Results). For example, a “PAQNet-SSIM” model was trained using SSIM scores of images as ground truth. The models thus learn a mapping from an input image to the quality score that a given metric would assign.
We also explored training models to predict multiple metrics simultaneously (multi-output models, described below) as an ablation to see if joint learning helps in better prediction of the IQMs. The dataset was split into training, validation, and test sets with careful consideration to avoid overfitting and ensure robust evaluation. Datasets with a large number of images, such as MSFD and SWFD (multisegment), were used for training to provide a rich and diverse learning set. Smaller or more specialized datasets, such as NNE (Denoising) and V-Phantom, were assigned to the validation set to support reliable hyperparameter tuning without overlapping with training data.
To maintain a strict separation between training and evaluation, several datasets were excluded entirely from both training and validation. These include SCD (both multisegment and virtual circle configurations), SWFD (semicircle), Mice, and the PA Experiment dataset (EFA), which were reserved exclusively for testing. This strategy enables the evaluation of model generalization to unseen datasets and imaging conditions.
Importantly, evaluation is performed separately per dataset rather than on the combined test set. This allows for a more nuanced analysis of model performance across different data characteristics and acquisition setups. The use of distinct datasets for training and validation was a deliberate design choice to test cross-domain generalization. OADAT contains substantially more samples and many highly similar consecutive slices, so using it for both training and validation would risk information leakage and overly optimistic performance estimates. Under this protocol, validation loss is used to monitor trends and detect overfitting rather than to provide an in-domain performance measure (see Table 1).
We performed -fold cross-validation (with ) on the training set when tuning hyperparameters for PAQNet. For IQDCNN and EfficientNetIQA, we adopted hyperparameters from literature or initial trials and then made minor adjustments based on validation performance. Early stopping was employed based on validation loss, to avoid overfitting.Table 1. Image counts per dataset used for training, validation, and testing in the deep learning experiments.Table 1. Dataset (Split)Number of imagesTrainMSFD453,600SWFD (ms)156,912Phantom2345Total Train612,857ValidationNNE (Denoising)25,420V-Phantom490Total Validation25,910TestSCD (vc + ms)160,000SWFD (sc)156,912Mice1918EFA711Total Test****319,541
During training, images were fed in batches of 16. The training was run on NVIDIA A100 GPUs (40 GB memory); each model took on the order of a few hours to train until convergence when using 612k training images. We utilized the PyTorch Lightning framework for streamlined training and checkpointing.
Each trained model was evaluated on the test set by computing the mean absolute error (MAE) between predicted and true metric values, as well as the Spearman and Pearson correlation coefficients. These statistics were computed for each dataset in the test set to quantify how well the model predicts quality in seen vs. unseen domains. In particular, we report performance on (i) the OADAT-derived test images (which are similar in distribution to much of the training data), (ii) the Phantom and Mice images (somewhat similar but with real experimental variability), and (iii) the EFA images (distinct distribution with LED illumination and high noise, not seen in training).
Multi-output quality prediction
3.3.5
In an ablation experiment, we trained “multi-output” versions of the above models that predict multiple quality metrics at once. The architectures were identical to their single-output counterparts except that the final fully connected layer had outputs (with or 5 in our experiments, corresponding to combinations of metrics). For example, a PAQNetMulti model was trained to output both SSIM and GMSD scores simultaneously for each input image. The idea is that by learning to predict two complementary metrics, the model’s internal representation might become more robust and general (e.g., focusing on features relevant to both structural similarity and gradient fidelity). We tried two pairwise combinations (SSIM+GMSD, SSIM+HAARPSI) and one 5-metric combination (SSIM + GMSD + HAARPSI + S3IM + IW-SSIM) to push the limit of joint learning.
During multi-output training, we used a joint loss equal to the average of the individual metric losses (all metrics were normalized to comparable scales for stability). We monitored the validation loss for each output as well as the average. The multi-output models were otherwise trained with the same settings as single-output. After training, we evaluated whether the multi-metric models achieved lower error on each metric compared to models trained on that metric alone.
Grad-CAM based interpretability analysis
3.3.6
We used Gradient-weighted Class Activation Mapping (Grad-CAM) to visualize the regions that influenced each model’s quality predictions. Grad-CAM provides a spatial importance map by weighting the activation maps of the final convolutional layer with the gradients of the target output [50]. We generated Grad-CAM maps across three sparsity levels (sparse32, sparse64, and sparse128) using the same slice. These maps reveal which regions most strongly influence model predictions of image quality.
Computational resources
3.4
All training and evaluation experiments were executed on a high-performance computing cluster. Each model training typically utilized a single NVIDIA A100 40 GB GPU. Training the largest model (EfficientNetIQA) on the full training set took roughly 10 h. In total, our study consumed approximately 1200 GPU-hours for training and hyperparameter searches across all models. Inference for a single image is fast (on the order of 1–10 ms for the CNN models, and slightly longer for EfficientNetIQA), indicating that once trained, these models could be deployed for real-time quality monitoring in PAI systems.
Results
4
We first present the results of the objective metric evaluation, comparing how well each IQA metric reflects known image quality differences in PAI data (Section 4.1). Next, we report the performance of the deep learning models in predicting quality scores, including both in-distribution and out-of-distribution tests (Section 4.2). We then summarize insights from the ablation studies on multi-metric training and interpretability (Section 4.3).
Benchmarking image quality metrics
4.1
This section evaluates how well different image quality metrics distinguish between reconstruction configurations or settings across multiple datasets. The metric results are visualized in Fig. 2, Fig. 3, and summarized using a composite ranking in Table 3. In Fig. 2, Fig. 3, each dataset has subsets with different configurations or settings resulting in different quality levels as explained in Table 2. Fig. 2, Fig. 3 plot each IQM across these subset ladders, in the left to right order shown in Table 2. Significant pairwise differences are marked in the figures, and the overall separability is summarized by the composite ranking in Table 3.
Table 2. Subset ladders corresponding to the box plots in Fig. 2, Fig. 3. Within each dataset, subsets are ordered from lower to higher expected image quality.Table 2. DatasetSubset ladder (left to right = higher expected quality)NNESNR 10 dB, 20 dB, 30 dB, 40 dB, 50 dBMICEsparse4, sparse8, sparse16, sparse32, sparse64, sparse128, sparse256PHANTOMsparse8, sparse16, sparse32, sparse64, sparse128V_PHANTOMsparse8, sparse16, sparse32, sparse64, sparse128EFAPA2, PA3, PA4, PA5, PA6, PA7 (PA1 shown as reference only)MSFD (OADAT)sparse32_w760, sparse64_w760, sparse128_w760SCD_MS (OADAT)sparse32, sparse64, sparse128SCD_VC (OADAT)sparse32, sparse64, sparse128SWFD_MS (OADAT)sparse32, sparse64, sparse128SWFD_SC (OADAT)sparse32, sparse64, sparse128Table 3Ranking of image quality metrics on PAI datasets. Metrics are sorted by the composite score (Significant Count × Normalized Mean Diff). FR = full-reference, NR = no-reference. Higher values indicate better ability to distinguish reconstruction quality differences. SC = Significant Count, NMD = Normalized Mean Difference and CS = Composite Score (CS = SC × NMD).Table 3. MetricSCNMDCSS3IM (FR)840.23719.89SSIM (FR)830.23519.48IW-SSIM (FR)790.24119.03GMSD (FR)820.19616.10MS-GMSD (FR)830.19115.83HAARPSI (FR)810.19415.73MS-SSIM (FR)810.18615.04VIF (FR)830.15913.20UQI (FR)790.13410.62FSIM (FR)740.1007.39PSNR (FR)770.0927.06BRISQUE (NR)400.0522.09CLIP-IQA (NR)240.0571.38Table 4An example from MSFD dataset showing how SC, NMD, and CS differ between PSNR and SSIM across three quality configurations (ms,ss32 (Low), ms,ss64 (Med.), ms,ss128 (High)). SC = Significant Count, NMD = Normalized Mean Difference and CS = Composite Score (CS = SC × NMD).Table 4PSNRSSIMQuality levelLowMed.HighLowMed.HighMean value25.20229.80335.4520.5180.6860.872SC ( )3/33/3NMD (avg.)0.0850.236CS0.2560.708
Metric performance overview
4.1.1
Composite scores from each dataset in Fig. 2, Fig. 3 are computed using the number of times the metric provided statistically significant difference between subsets and the normalized mean differences. The significance count (SC), normalized mean difference (NMD) and composite scores (CS) are provided in Table 3. Table 4 illustrates how the three indicators, SC, NMD and CS capture differences in statistical separability between metrics on MSFD dataset. As a representative example, PSNR and SSIM are compared across three image quality levels (Low, Medium, High). Although both metrics increase as image quality improves, PSNR values overlap substantially between levels, whereas SSIM values are more distinctly separated. Consequently, SSIM detects significant differences in all three pairwise comparisons (SC = 3/3) and shows larger mean shifts (higher NMD), resulting in a higher composite score. This example demonstrates that two metrics can follow the same trend yet differ in how strongly they distinguish adjacent quality levels. A similar analysis applies to other metrics evaluated in this study, where differences in variance and effect size across quality configurations explain variations in their final ranking. We observe that full-reference (FR) metrics dominate the top of the ranking. The best-performing metric overall is S3IM, with the highest composite score of 19.89, closely followed by SSIM (19.48) and IW-SSIM (19.03). These three are SSIM variants, indicating that structural similarity metrics are particularly effective in capturing degradation across reconstruction settings in photoacoustic imaging.
Beyond SSIM variants, the gradient-based metrics GMSD (16.10) and MS-GMSD (15.83) also perform well, ranking fourth and fifth, respectively. These metrics appear to be particularly sensitive to high-frequency structural changes and artefacts, which are common in undersampled or noisy reconstructions. HAARPSI, which approximates perceptual similarity based on wavelet responses, also achieves a reasonably good composite score. Traditional metrics such as PSNR and FSIM show weaker performance, both ranking near the bottom of the FR group. Surprisingly, VIF, despite being theoretically grounded in information fidelity, underperforms relative to more structure-aware metrics.
Among the no-reference (NR) metrics, BRISQUE (2.09) and CLIP-IQA (1.38) rank lowest overall. These metrics show poor ability to detect consistent differences across configurations, suggesting that current NR-IQA methods may not generalize well to the artefact types and modalities present in photoacoustic data.
Region-based detectability results
4.1.2
Fig. 4 summarizes region-based detectability metrics. Increasing the number of receive channels from 32 to 128 consistently improved SNR, CNR, and gCNR across all datasets. The SNR increased by +5.28 for Mice (6.20 vs. 11.48), +4.77 for Phantom (5.52 vs. 10.29), +5.46 for SWFD_ms (7.51 vs. 12.97), and +16.70 for SWFD_sc (11.77 vs. 28.47). Corresponding increases in CNR were +0.31, +1.30, +0.27, and +1.20, respectively. The gCNR exhibited smaller increases of +0.10, +0.20, +0.10, and +0.14, consistent with its reduced sensitivity to local variance estimates.
Fig. 2. Boxplot of metric distributions (page 1 of 2) on various datasets with subsets representing different configurations or settings resulting in different quality levels.Fig. 2. Fig. 3Boxplot of metric distributions (page 2 of 2) on various datasets with subsets representing different configurations or settings resulting in different quality levels.Fig. 3. Fig. 4Region-based detectability analysis with manually selected signal (green) and local background (red) ROIs. Numbers report mean (SD in bracket) across images for SNR, CNR, and gCNR. Higher values indicate better target detectability.Fig. 4
Dataset-specific differences
4.1.3
IQM significance varied across the different datasets utilized in this work. For example, on the extremely noisy EFA dataset, most metrics struggled to differentiate frame averaging levels, unless the difference was large; only VIF and UQI consistently detected quality differences at intermediate averaging levels. On the high-quality Phantom and Virtual Phantom datasets, IW-SSIM and HAARPSI had a slight edge, suggesting that those metrics might be particularly attuned to subtle structural differences in cleaner images. Meanwhile, on the complex in vivo Mice images, which have more structure, noisy, and differences in reconstruction artefact, SSIM and S3IM showed strong alignment with quality levels with sparse sampling, while metrics like GMSD and MS-SSIM were slightly less correlated. This variability across datasets indicates that while a few top metrics are generally robust, no single metric is perfect for all scenarios.
The top metrics in our study were those capturing structural similarity (SSIM variants) and local perceptual fidelity (HAARPSI, GMSD). These metrics consistently flagged quality improvements across different datasets: for instance, S3IM and SSIM had high sensitivity in the OADAT subsets (MSFD, SCD, SWFD) as well as in Phantom and Mice datasets. In contrast, metrics focusing purely on pixel error (PSNR) or pre-trained natural image statistics (BRISQUE) underperformed, underscoring the importance of structure-aware criteria for PAI. The variance of different image quality metrics motivated our development of learning-based predictors, which can provide top-performing quality metrics in a no-reference way.
Fig. 5. Example test images from different datasets with their corresponding full-reference and predicted metric scores per model.Fig. 5
Deep learning model performance
4.2
Five best-performing image quality metrics (IQMs) are modeled using deep learning, and the results are presented in this subsection. We compared full-reference metrics (SSIM, HAARPSI, IW-SSIM, S3IM, and GMSD) across five datasets, evaluated with PAQNet, IQDCNN, and EfficientNetIQA. Fig. 5 shows example images with the corresponding full-reference scores and model predictions, and Table 5 reports mean absolute error (MAE) between predicted and ground-truth scores. Overall, the lowest errors are observed for the OADAT-derived test sets, SWFD_sc and SCD_ms, which are closest to the training distribution, followed by Mice with slightly higher but still low errors. This likely reflects shared acquisition characteristics in OADAT, including similar transducer responses and reconstruction methods, and indicates that the models generalize across applications, target tissue and transducer configurations, when the acquisition settings resemble the training data. In contrast, EFA, acquired with LED illumination and a linear array at a different center frequency, shows markedly higher MAE for all models and metrics, highlighting the challenge of transferring to a distinct imaging setup.
Across models, EfficientNetIQA achieves the best average performance in terms of MAE on HAARPSI (0.1599) and GMSD (0.1421), and remains competitive on SSIM (0.1437) and S3IM (0.1451). It is outperformed on IW-SSIM, where PAQNet (0.1894) and especially IQDCNN (0.1408) achieve lower MAE. PAQNet performs well overall, obtaining the lowest average SSIM error (0.1335) and often ranking among the top two across datasets, for example 0.0248 SSIM MAE on SWFD_sc and 0.0276 on SCD_ms. IQDCNN is strongest on EFA, achieving the lowest MAE for four of the five metrics, including 0.3022 on S3IM and 0.3314 on IW-SSIM.Table 5. Mean Absolute Error (MAE) across image quality metrics and deep learning model (Grouped by Dataset). The highest performing model in bold.Table 5. DatasetModelSSIMHAARPSIIW-SSIMS3IMGMSDMicePAQNet0.08310.23640.23310.09150.2379IQDCNN0.12230.22700.22460.11840.2191EfficientNetIQA0.11180.1681****0.20600.09740.2116SWFD_scPAQNet0.02480.03680.02850.02200.0313IQDCNN0.02650.03580.03300.02670.0353EfficientNetIQA0.02690.02700.02440.0193****0.0297SCD_vcPAQNet0.07790.18410.11040.10430.1715IQDCNN0.11950.19700.09910.13980.1627EfficientNetIQA0.11340.15240.11100.13100.1318EFAPAQNet0.45430.46360.55910.48360.5217IQDCNN0.38080.33200.3314****0.30220.3745EfficientNetIQA0.43520.41000.45590.44070.2766SCD_msPAQNet0.02760.04900.01610.0241****0.0465IQDCNN0.03760.04890.01610.04010.0625EfficientNetIQA0.03110.0420****0.01330.03710.0607AveragePAQNet0.13350.19400.18940.14510.2018IQDCNN0.13730.16810.1408****0.12540.1708EfficientNetIQA0.14370.15990.16210.14510.1421
Beyond prediction accuracy, we compared the computational footprint of the three deep models. As summarized in Table 6, PAQNet uses substantially fewer parameters and FLOPs than IQDCNN and EfficientNetIQA, and achieves the shortest inference time and lowest peak memory usage under identical hardware and input settings. Combined with the similar MAE reported in Table 5, this confirms that PAQNet provides competitive quality prediction while remaining a lightweight and deployment-efficient option for PAI applications.
Fig. 6 shows scatter plots of predicted versus reference scores for S3IM (columns 1 to 3) and SSIM (columns 4 to 6) across datasets and models. For the in-distribution datasets, SWFD_sc and SCD_ms, all three models cluster tightly along the diagonal, indicating high predictive accuracy and low error. On SSIM for SCD_ms (C4 to C6), PAQNet and IQDCNN exhibit slightly less dispersion than EfficientNetIQA, suggesting more stable predictions. On the Mice dataset, EfficientNetIQA shows less deviation compared to the true value (diagonal), than the other models for both SSIM and S3IM (A3, A6), consistent with its lower MAE in Table 5. In contrast, the EFA dataset shows the weakest correspondence for all models (E1 to E6), with broader spread and bias from the diagonal, matching the higher errors in Table 5. Across datasets, PAQNet tends to yield tighter SSIM distributions (right panels), while EfficientNetIQA is competitive for S3IM (left panels), indicating that predictive reliability depends on both dataset and metric.Table 6. Computational efficiency of PAQNet, IQDCNN, and EfficientNetIQA for 128 × 128 grayscale inputs (batch=1). Operation counts are tool-estimated per forward pass; inference time measured on an NVIDIA GPU (CUDA).Table 6. ModelParameters (M)FLOPs (G)Inference Time (ms)Memory (MB)PAQNet****2.500.2460.59 ± 0.12****19IQDCNN3.780.1520.64 ± 0.0121EfficientNetIQA4.170.1267.05 ± 0.2273Fig. 6Scatter plots comparing predicted vs. true values for three models (columns) across five datasets (rows). Left side shows S3IM results, and right side shows SSIM results. Datasets are arranged as: (A) Mice, (B) SWFD_sc, (C) SCD_ms, (D) SCD_vc, and (E) EFA.Fig. 6
The correlation results in Table 7 further support the observed performance trends. For the in-distribution datasets (SWFD_sc, SCD_ms, Mice), correlations between predicted and true scores are consistently high. In particular, SWFD_sc shows near-perfect agreement across all models, with Pearson and Spearman . On the SCD_ms dataset, EfficientNetIQA achieves the highest correlations for SSIM ( , ), while PAQNet leads slightly on S3IM ( , ). Similarly, on the Mice dataset, PAQNet obtains the strongest correlations for both S3IM ( , ) and SSIM ( , ), highlighting its stability in this setting.Table 7. Spearman and Pearson correlation between predicted and true S3IM and SSIM values across datasets.Table 7. ModelMiceSWFD_scSCD_msSCD_vcEFA**Spearman (S3IM)PAQNet0.91070.97990.68090.8716−0.0059IQDCNN0.78560.96480.59890.84450.8429EfficientNetIQA0.76860.98140.77420.86010.6608Pearson (S3IM)PAQNet0.94600.98080.69810.92620.0596IQDCNN0.82270.97660.60450.88980.8084EfficientNetIQA0.87840.98700.75410.83130.4490Spearman (SSIM)PAQNet0.92300.97460.91660.88510.8202IQDCNN0.82600.96720.90400.86540.6645EfficientNetIQA0.82580.97550.95840.86420.6865Pearson (SSIM)**PAQNet0.96530.98110.98190.93040.6462IQDCNN0.85310.97510.95840.88200.6763EfficientNetIQA0.88710.97380.97010.90230.4633
In contrast, the EFA dataset shows markedly reduced correlations, reflecting the domain gap caused by its different imaging setup. Note that model prediction uncertainty remains higher for out-of-distribution data (EFA), confirming limits of domain generalization. For S3IM, IQDCNN generalizes best ( , ), while both PAQNet and EfficientNetIQA show weak or inconsistent correlations ( and 0.6608 respectively). For SSIM, PAQNet achieves the highest correlations ( , ), whereas EfficientNetIQA lags behind ( , ).
All three models effectively reproduce full-reference metric scores for in-distribution PAI images, with EfficientNetIQA generally leading in SSIM correlations and competitive on S3IM. However, their ability to generalize to unseen domains such as EFA is limited, underscoring the need for more diverse training data or domain adaptation strategies.
Fig. 7 shows predicted SSIM across datasets, grouped by subsets that reflect increasing image quality, consistent with the configuration order in Fig. 2, Fig. 3 and the dataset definitions in Section 4.1.1. PAQNet and IQDCNN recover the expected ordering with clear separation for SCD_ms, SCD_vc, and SWFD_sc, consistent with their in-distribution status relative to OADAT. For SCD_vc, EfficientNetIQA does not preserve the full subset order. On Mice, ordering is less consistent, with the first subset predicted higher than subsequent ones before increasing again, deviating from the full-reference trends in Fig. 2, Fig. 3. For EFA, the monotonic trend with increasing frame averaging is largely preserved, and PAQNet shows several significant differences between subsets. Notably, this occurs despite higher overall error on EFA, indicating that models can still track relative quality changes even when absolute prediction accuracy degrades. This behavior aligns with the correlation patterns in Table 7, which are strong in-distribution and reduced for EFA.Fig. 7. Predicted SSIM scores using PAQNet, EfficientNetIQA and IQDCNN across datasets, with subset labels explained in Table 2.Fig. 7
Grad-CAM Analysis: To examine the features influencing our quality prediction model, we generated Grad-CAM visualizations for reconstructions obtained with 32, 64, and 128 detectors for the SWFD_ms dataset, shown in Fig. 8. For the proposed model, PAQNet, the maps mainly highlighted noise-dominated regions. In the 32 detector reconstructions, where structural detail is limited, they emphasized areas with reduced signal consistency. For the 64 and 128 detector cases, where anatomical structures are better recovered, the attention remained on background noise and showed low response to anatomy. This indicates that the model bases its predictions on noise-related degradations and is also sensitive to streaking artefacts. In contrast, the attention maps for IQDCNN and EfficientNetIQA rely on restricted regions, often at the corners or lower parts of the image, which makes their quality estimates less reliable.
Fig. 8. Grad-CAM intensity maps of images from three different datasets SWFD_sc, SWFD_ms, and SCD_ms with three different sparse transducers levels 32, 64 and 128. Red areas indicate strong positive Grad-CAM activations (intensity ) while blue areas indicate weak activations (intensity ). Each panel shows the original reconstruction and Grad-CAM overlays for PAQNet, IQDCNN, and EfficientNetIQA.Fig. 8
Ablation studies: Multi-metric training and model interpretability
4.3
Multi-metric Training: As shown in Table 8, multi-metric training does not consistently lead to lower MAE (L1) losses compared to training on single metrics. Here, we define (MAE of combination) (mean MAE of corresponding single metrics). Thus, negative values indicate that the combined training performed better than the average of the individual metrics. The results in Table 9 show that PAQNet benefits slightly from all three two-metric pairings ( , , ), while EfficientNetIQA improves for ( ) and ( ).
In contrast, IQDCNN shows small gains only for ( ) and performs worse when all five metrics are combined ( ). Overall, targeted pairings can provide modest benefits, but combining many metrics indiscriminately offers little advantage and can even harm performance.Table 8MAE loss per dataset and metric combination (Grouped by model).Table 8. DatasetModelSSIM GMSDSSIM HAARPSIGMSD HAARPSISSIM GMSD HAARPSI S3IM IW-SSIMMicePAQNet0.16230.14310.23130.1606IQDCNN0.15160.17660.24580.1805EfficientNetIQA0.12600.15250.25080.2135SWFD_scPAQNet0.03210.03010.03680.0307IQDCNN0.03360.03810.03740.0442EfficientNetIQA0.02130.02060.0286****0.0257SCD_vcPAQNet0.11860.13990.16740.1299IQDCNN0.14650.14650.18060.1487EfficientNetIQA0.12810.13380.19130.1165EFAPAQNet0.45820.44930.48480.5085IQDCNN0.39830.3652****0.35850.4831EfficientNetIQA0.36360.40870.40230.4722SCD_msPAQNet0.04260.03130.03990.0325IQDCNN0.04920.03250.05450.0559EfficientNetIQA0.04170.03880.05830.0447AveragePAQNet0.16220.15800.19130.1728IQDCNN0.15560.15180.17550.1821EfficientNetIQA0.1363****0.15070.20670.1749Table 9Average difference ( ) in MAE loss between multi-metric training and the mean of the corresponding single-metric trainings. A negative indicates that the combination achieves lower (better) loss.Table 9. ModelSSIM+GMSDSSIM+HAARPSIGMSD+HAARPSIAll FivePAQNet−0.0055−0.0058−0.00660.0004IQDCNN0.0016−0.00080.00610.0336EfficientNetIQA−0.0066−0.00110.05570.0243
Discussion
5
This work represents, to our knowledge, the first systematic study of image quality assessment (IQA) in photoacoustic imaging (PAI). By benchmarking a wide set of metrics and introducing learning-based models, we establish which approaches are most effective and where major challenges remain.
Implications for PAI quality assessment
5.1
Our findings show that metrics emphasizing structural similarity, such as SSIM and its variants, are the most reliable for PAI. This reflects the importance of preserving vascular and edge detail in reconstructions. In contrast, intensity-based measures like PSNR do not capture clinically relevant differences, for example distinguishing blur from noise. For objective reporting and comparison of reconstructions, metrics such as SSIM, S3IM, IW-SSIM, GMSD or HAARPSI are therefore the most suitable.
The ROI-based analysis confirms that increasing the number of receive channels improves target detectability in practice. SNR and gCNR rose consistently in all datasets, with the largest gains in SWFD_sc, indicating clearer separation of targets from their local background. The small and sometimes negligible changes in CNR are expected because CNR scales with the background variance and is less sensitive when both signal and background fluctuate together. In contrast, gCNR reflects distribution overlap, so it tracks detectability more faithfully and aligns with the improvements seen in our full-image metrics. These findings show that the ROI-based metrics can be used as no-reference metric. The primary limitation of these metrics is that manual region selection is required in this case. Hence, these metrics can be used when automated region selection is possible. We found that SNR and gCNR are more effective in highlighting the quality differences. These metrics can be used as no-reference metrics when the targets are well-known and can be automatically selected.
Generic no-reference (NR) metrics from natural imaging, such as BRISQUE or CLIP-IQA, performed poorly. Their assumptions about natural scene statistics do not hold in PAI, where background noise, wavelength dependence, and depth-related attenuation dominate. This underscores the need for NR metrics tailored to PAI characteristics and artefacts.
Learning-based NR models, particularly EfficientNetIQA, successfully predicted FR metric scores on in-distribution data, enabling reference-free quality assessment. Such models could provide real-time quality feedback during acquisition. Effective deployment will require training on broader datasets or adopting domain adaptation methods. Although the models do not predict the exact absolute metric values, they effectively mimic the trend of full-reference (FR) scores, consistent with their intended use as no-reference (NR) estimators. For in-distribution datasets such as Mice, SWFD, and SCD, PAQNet achieves low mean absolute errors (e.g., MAE = 0.083–0.038) and high correlation with true scores (Spearman 0.88, Pearson 0.93), demonstrating strong alignment between predicted and actual metric trends. The scatter plots in Fig. 6 further confirm this correspondence, showing tight clustering along the diagonal for in-distribution data. Only the EFA dataset exhibits larger deviations, which is expected given its distinct imaging conditions and unseen domain characteristics. This highlights the current limitation in domain generalization and supports the need for explicit domain adaptation.
Interpretability analysis showed that models often attend to meaningful structures but occasionally misinterpret artefacts as quality features. This mismatch indicates that high numerical correlation with FR metrics does not guarantee clinically aligned judgments. Improving interpretability should be a priority to ensure safe application in medical contexts.
Limitations and future directions
5.2
Our models were trained on FR metrics, which themselves are proxies for human perception and diagnostic utility. While necessary in the absence of large-scale subjective ratings, this constrains what the models can learn. The datasets, although extensive, lack clinical patient images and therefore may not cover the variability present in real clinical practice. Finally, our exploration of multi-metric training was limited to a few combinations, leaving room for more systematic investigation.
A key limitation of our ranking framework is the absence of an external ground truth based on human observers or diagnostic tasks. We implicitly treat the acquisition induced quality levels as reference categories and evaluate how consistently each metric separates them. Although this approach enables systematic, large scale comparison across multiple datasets and artefact types, it does not replace subjective quality assessment with human subjects. Future work should therefore complement the present analysis with expert studies and application specific performance metrics.
Future work should prioritize the development of PAI-specific NR metrics, either through analytic approaches informed by domain knowledge or through models trained on human preference and task-performance data. Integrating IQA into reconstruction algorithms is another promising direction, allowing systems to optimize parameters based on predicted quality during acquisition. To improve generalization, domain adaptation and multi-domain training strategies should be pursued. Enhancing interpretability through architectures designed for transparent decision-making will also be important for clinical acceptance. Finally, since IQA scores vary across datasets from different systems, combining multiple metrics into a single learning-based composite score may provide a more robust and transferable assessment.
Broader impact
5.3
Reliable IQA will be central to advancing PAI towards clinical translation. Embedding automated quality assessment into imaging systems would allow non-technical users to monitor and optimize acquisitions in real time. Standardized, objective quality measures will also accelerate fair comparison of algorithms and hardware. Automated and interpretable quality prediction can support clinical adoption by detecting low-quality acquisitions early and by quantifying improvements. More broadly, this study shows that although no single metric captures all aspects of image quality, carefully designed machine learning approaches can provide practical and generalizable solutions when trained on diverse data.
Conclusion
6
We presented a comprehensive evaluation of image quality assessment (IQA) methods for photoacoustic imaging, combining traditional full-reference metrics with recent learning-based models. Using nearly one million PA images from diverse datasets, we benchmarked eleven full-reference and two no-reference metrics, and trained three deep neural networks to perform no-reference quality prediction by mimicking full-reference measures. The results show that structural similarity metrics such as SSIM, S3IM, and IW-SSIM were the most reliable in capturing reconstruction quality, surpass intensity-based metrics like PSNR and generic image statistics. In contrast, general-purpose no-reference metrics such as BRISQUE and CLIP-IQA correlated poorly with reconstruction quality, highlighting the need for PAI-specific or learned approaches. Our deep learning models, particularly EfficientNetIQA, achieved strong performance with correlations up to 0.95 against reference-based scores, providing a practical full-reference proxy without requiring reference images. However, performance decreased when models were applied across different data distributions, such as across different PAI systems, indicating that generalization remains a challenge and will require broader training strategies or domain adaptation. Finally, while combining multiple metrics within a single training framework yielded marginal improvements in isolated cases, it did not consistently enhance prediction accuracy and sometimes degraded it, suggesting that selective integration of complementary metrics is preferable. This study establishes a foundation for both benchmarking and advancing no-reference IQA methods tailored to PAI, with deep learning models offering a promising path towards reference-free quality assessment in practical applications.
CRediT authorship contribution statement
Melle Van Der Brugge: Writing – original draft, Visualization, Validation, Software, Methodology, Investigation, Formal analysis, Data curation. Kalloor Joseph Francis: Writing – review & editing, Validation, Supervision, Resources, Project administration, Methodology, Investigation, Conceptualization. Navchetan Awasthi: Writing – review & editing, Validation, Supervision, Resources, Project administration, Methodology, Investigation, Conceptualization.
Funding
This work has received financial support from the Dutch Research Council (NWO) for the project NWO-VENI (19165), 10.13039/501100001826ZonMw for the project Off Road (04510012210042).
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wang L.V.Hu S.Photoacoustic tomography: in vivo imaging from organelles to organs Science 33560752012145814622244247510.1126/science.1216210 PMC 3322413 · doi ↗ · pubmed ↗
- 2Manohar S.Razansky D.Photoacoustics: a historical review Adv. Opt. Photon.842016586617
- 3Park J.Choi S.Knieling F.Clingman B.Bohndiek S.Wang L.V.Kim C.Clinical translation of photoacoustic imaging Nat. Rev. Bioeng.332025193212
- 4Palma-Chavez J.Pfefer T.J.Agrawal A.Jokerst J.V.Vogt W.C.Review of consensus test methods in medical imaging and current practices in photoacoustic image quality assessment J. Biomed. Opt.2692021090901–09090110.1117/1.JBO.26.9.090901 PMC 843414834510850 · doi ↗ · pubmed ↗
- 5Dimaridis I.Sridharan P.Ntziachristos V.Karlas A.Hadjileontiadis L.Image quality improvement techniques and assessment adequacy in clinical optoacoustic imaging: a systematic review Biosensors 121020229013629103810.3390/bios 12100901 PMC 9599915 · doi ↗ · pubmed ↗
- 6Moorthy A.K.Bovik A.C.Blind image quality assessment: From natural scene statistics to perceptual quality IEEE Trans. Image Process.20122011335033642152166710.1109/TIP.2011.2147325 · doi ↗ · pubmed ↗
- 7Mittal A.Soundararajan R.Bovik A.C.Making a “completely blind” image quality analyzer IEEE Signal Process. Lett.2032012209212
- 8Breger A.Biguri A.Landman M.S.Selby I.Amberg N.Brunner E.Gröhl J.Hatamikia S.Karner C.Ning L.A study of why we need to reassess full reference image quality assessment with medical images J. Imaging Inform. Med.202512610.1007/s 10278-025-01462-1PMC 1270120440126854 · doi ↗ · pubmed ↗