Artificial intelligence in the diagnosis and prognosis of ocular trauma: a systematic review
Zahra Abbasi Dolatabadi, Mahdi Nabi Foodani, Mohammad Fayyazi Farkhad, Faezeh Golvardi-Yazdi

TL;DR
This systematic review explores how artificial intelligence can help diagnose and predict outcomes for eye injuries, finding that deep learning models show high accuracy.
Contribution
The paper provides the first comprehensive synthesis of AI applications for diagnosing and predicting outcomes in ocular trauma.
Findings
Deep learning models like DenseNet-169 and UNet achieved up to 96% diagnostic accuracy and AUC values of 0.99.
ANNs outperformed traditional scoring systems in prognostic prediction with up to 93% accuracy.
ChatGPT-4 showed 100% diagnostic accuracy but had 30% inconsistency in treatment decisions.
Abstract
Ocular trauma is a leading cause of acquired monocular blindness worldwide, requiring prompt and accurate diagnosis and prognosis. While artificial intelligence (AI) has shown growing potential in medicine, a comprehensive synthesis of its applications in Diagnosis and Prognosis of Ocular Trauma is still lacking. Therefore, this systematic review aims to comprehensively synthesize the current evidence on the diagnostic and prognostic performance of artificial intelligence in ocular trauma. This study is a systematic review conducted in accordance with the PRISMA 2020 guidelines. A comprehensive search was performed in PubMed, Scopus, and Web of Science from inception to May, 2025. Original studies using artificial intelligence (AI) for the diagnosis or prognosis of ocular trauma, applying human clinical data, and reporting performance metrics were included. Review articles and animal…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
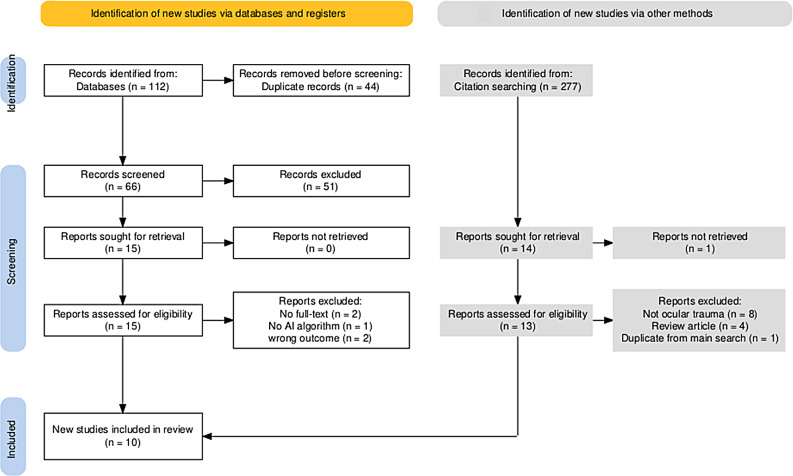 Figure 1
Figure 1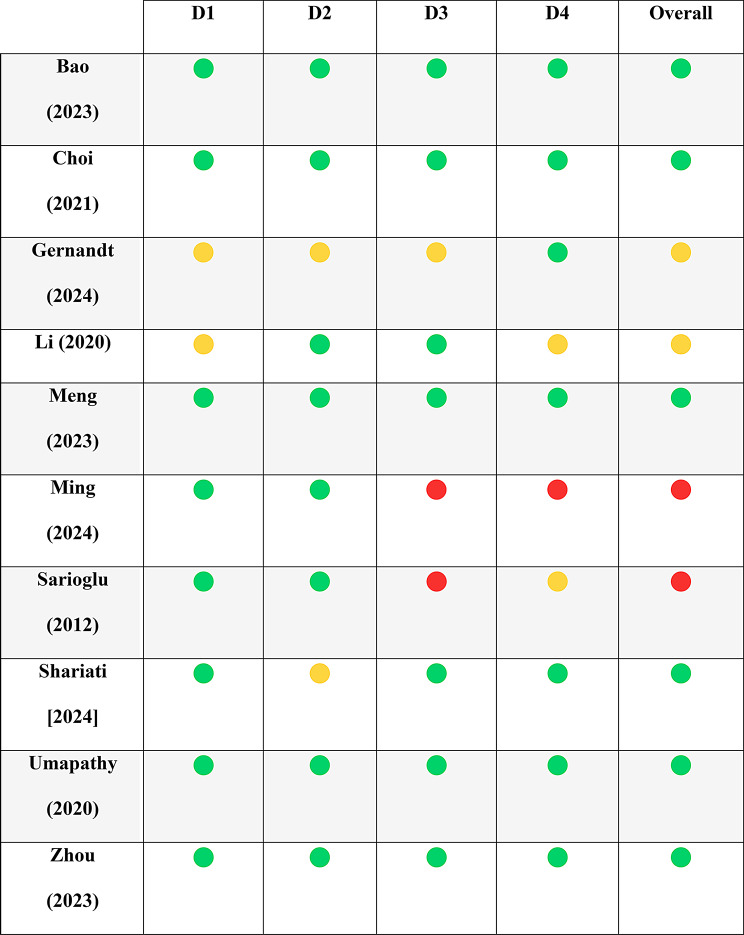 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTraumatic Ocular and Foreign Body Injuries · Facial Trauma and Fracture Management · Ocular Disorders and Treatments
Introduction
Ocular trauma represents one of the most frequent and vision-threatening emergencies encountered in ophthalmic and emergency care settings. It remains the leading cause of acquired monocular blindness worldwide, affecting both children and adults across diverse geographical and socioeconomic contexts [1, 2]. Such injuries arise from a wide range of mechanisms—including blunt and penetrating trauma, intraocular foreign body, chemical or thermal exposure, falls, assaults, and motor vehicle accidents—and present with high heterogeneity in severity and clinical manifestations. The urgent nature of these injuries, combined with the complexity of ocular anatomy and potential for rapid deterioration, underscores the importance of prompt and accurate diagnosis to avoid irreversible vision loss [3, 4].
Although standard clinical guidelines exist for the management of ocular trauma [5–7], delays in diagnosis or misinterpretation of key findings may critically compromise functional outcomes. Globally, more than 19 million individuals are estimated to experience monocular blindness due to ocular injuries, reflecting the substantial healthcare and socioeconomic burden associated with traumatic eye conditions [8–10]. Globally, approximately 19 million individuals suffer from monocular blindness caused by traumatic eye injuries, which poses a heavy burden on public health systems because of both high treatment costs and socioeconomic consequences [9, 10].
Parallel to the growing clinical challenges associated with ocular trauma, the field of ophthalmology has undergone rapid transformation driven by advances in artificial intelligence (AI). Since its conceptual introduction by John McCarthy in 1956, AI has evolved from basic rule-based systems to sophisticated machine learning (ML) and deep learning (DL) models capable of processing complex datasets, identifying intricate patterns, and generating predictive outputs with remarkable consistency and accuracy [11–13].
These techniques have been widely adopted in ophthalmic diagnostics, particularly for automated detection of diabetic retinopathy, age-related macular degeneration, retinal detachment, and glaucoma progression, often demonstrating expert-level or superior performance across various imaging modalities [14, 15].
Compared with other ophthalmic diseases, the application of AI in ocular trauma is relatively recent but expanding rapidly [16]. Traumatic injuries pose unique diagnostic challenges due to obscured visualization, concurrent hemorrhage or edema, and the need for rapid interpretation of imaging studies such as computed tomography (CT). In recent years, diverse AI models—including convolutional neural networks for orbital fracture detection and segmentation [17], ML-based algorithms for predicting visual outcomes [18], and natural language processing (NLP) tools and large language models (LLMs) for clinical reasoning—have been developed to enhance both diagnostic precision and prognostic accuracy in ocular trauma cases [14]. Studies applying deep convolutional neural networks to orbital CT imaging report high classification accuracy, often approaching or exceeding traditional observer performance in fracture detection tasks [17]. Furthermore, emerging studies evaluating LLMs like ChatGPT demonstrate promising capability in diagnostic reasoning and triage support, though inconsistencies remain in treatment decision-making [14].
Despite these advances, the current body of evidence remains fragmented. Studies vary substantially in their methodological quality, data sources, AI techniques, performance metrics, and clinical endpoints. Moreover, no previous systematic review has provided a comprehensive synthesis of diagnostic and prognostic performance across AI models used in ocular trauma. As a result, clinicians, researchers, and policymakers lack clear and consolidated evidence regarding the reliability, clinical utility, and limitations of AI-based tools in this domain.
To address this gap, the present systematic review critically synthesizes the existing evidence on artificial intelligence–based models applied to ocular trauma. Specifically, this review aims to [1] characterize the range of AI methodologies employed for diagnostic and prognostic tasks [2], summarize reported model performance across different trauma types and data modalities without direct quantitative comparison, and [3] identify key methodological limitations, challenges, and opportunities for future development and clinical integration. By providing a comprehensive and descriptive evidence synthesis, this review seeks to support informed decision-making regarding the potential adoption of AI-based tools in emergency and ophthalmic trauma care, while highlighting priorities for advancing research and clinical translation.
Methods
This study is a systematic review conducted in accordance with the PRISMA 2020 guidelinesA comprehensive search was performed in PubMed, Scopus, and Web of Science between April and May 2025, with no restriction on publication date.Original studies using artificial intelligence (AI) for the diagnosis or prognosis of ocular trauma, applying human clinical data, and reporting performance metrics (e.g., accuracy, sensitivity, specificity) were included. Review articles and animal studies data were excluded. Two reviewers independently screened the studies, extracted relevant data, and assessed the risk of bias using The Prediction model Risk Of Bias ASsessment Tool (PROBAST). Due to heterogeneity among the included studies, no meta-analysis was conducted, and results were synthesized narratively.
The protocol of this review was registered in the International Prospective Register of Systematic Reviews as CRD420251043768 (https://www.crd.york.ac.uk/PROSPERO/view/CRD420251043768.) and conducted in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 guidelines [19]. A completed PRISMA checklist is provided in Appendix Table 1 to ensure comprehensive and transparent reporting of the review process.
Selection criteria
Studies were included if they applied artificial intelligence for the diagnosis or prognosis of ocular trauma, used human clinical data, reported model performance metrics such as accuracy, sensitivity, specificity, or area under the curve (AUC), were published in English, and had full-text available. Studies were excluded if they were review articles, used only animal or in vitro data.
Search strategy
The search strategy combined relevant keywords and controlled vocabulary terms related to ocular trauma, artificial intelligence, and clinical outcomes. The final search string was as follows:
(“ocular trauma” OR “eye trauma” OR “ocular injur*” OR “eye injur*” OR “close* globe injur*” OR “open* globe injur*” OR “orbital fracture” OR “chemical burn) AND (“artificial intelligence” OR “machine learning” OR “deep learning” OR “AI” OR “neural network”) AND (“diagnosis” OR “prognosis” OR “prediction” OR “predictive model” OR “triage” OR “classification”). Table 1.
Table 1. Search strategyNo.DatabaseResults1PubMed322Web of Science423Scopus38TotalPubMed, WOS and Scopus112DuplicatesPubMed, WOS and Scopus46TotalPubMed, WOS and Scopus66 PubMed: National Library of Medicine #QueryResults1(“ocular trauma” OR “eye trauma” OR “ocular injur*” OR “eye injur*” OR “close* globe injur*” OR “open* globe injur*” OR “orbital fracture” OR “chemical burn”)21,6002(“artificial intelligence” OR “machine learning” OR “deep learning” OR “AI” OR “neural network”)817,4973(“diagnosis” OR “prognosis” OR “prediction” OR “predictive model” OR “triage” OR “classification”)6,314,4654#1 AND #2 AND #332 Web of Science Core Collection #QueryResults1(((((((ALL=(ocular trauma)) OR ALL=(eye trauma)) OR ALL=(ocular injur*)) OR ALL=(eye injur*)) OR ALL=(close* globe injur*)) OR ALL=(open* globe injur*)) OR ALL=(orbital fracture)) OR ALL=(chemical burn)9,9852((((ALL=(artificial intelligence)) OR ALL=(machine learning)) OR ALL=(deep learning)) OR ALL=(AI)) OR ALL=(neural network)2,326,8183(((((ALL=(diagnosis)) OR ALL=(prognosis)) OR ALL=(prediction)) OR ALL=(predictive model)) OR ALL=(triage)) OR ALL=(classification))5,623,8204#1 AND #2 AND #338Scopus#QueryResults1TITLE-ABS-KEY(“ocular trauma” OR “eye trauma” OR “ocular injur*” OR “eye injur*” OR “close* globe injur*” OR “open* globe injur*” OR “orbital fracture” OR “chemical burn”)40,2022TITLE-ABS-KEY(“artificial intelligence” OR “machine learning” OR “deep learning” OR “AI” OR “neural network”)2,574,0733TITLE-ABS-KEY(“diagnosis” OR “prognosis” OR “prediction” OR “predictive model” OR “triage” OR “classification”)9,551,4244#1 AND #2 AND #357
The search strategy was tailored for each database and last updated on May 3, 2025.
Data extraction
Data were independently extracted by two Researcher via a predesigned Excel sheet on the basis of the review protocol. The extracted information included the study characteristics, AI model type, type of ocular trauma, data source, outcome type (diagnosis or prognosis), and related metrics, such as accuracy, sensitivity, specificity, and AUC, as well as the study population, sample size, country, and model performance indicators. Disagreements were resolved through discussion.
Data analysis
Because of the heterogeneity in study designs, AI models, and reported outcome measures, a quantitative meta-analysis was not performed. Instead, a structured narrative synthesis was conducted following PRISMA 2020 guidelines. Extracted data were analyzed descriptively according to three predefined domains aligned with the review objectives: type of ocular trauma, AI methodology, and predicted clinical outcome. Studies were organized within these categories to identify patterns and trends in AI performance. Model metrics, including accuracy, sensitivity, specificity, and AUC, were compared across subgroups, and imaging-based models were descriptively compared with those relying on clinical data to assess differences in diagnostic and prognostic accuracy. Any inconsistencies or variations across studies were qualitatively interpreted in relation to study design, data source, and risk of bias.
Results
Study selection
A comprehensive search across multiple databases identified 112 records. After 46 duplicates were removed, 66 records remained for title and abstract screening. Following this screening, 51 studies were excluded because they did not meet the inclusion criteria. The full texts of 15 articles were assessed for eligibility, and 10 studies [14, 17, 18, 20–26] met the inclusion criteria and were included in this systematic review. The study selection process is summarized in the PRISMA flow diagram is shown in Fig. 1.
Fig. 1PRISMA Flow diagram of study
Risk of bias in studies
The risk of bias across four domains was assessed via the PROBAST tool: participants, predictors, outcomes, and analysis. Most studies showed low to moderate risk in the participant and predictor domains; however, some exhibited high risk in the outcome and analysis domains, primarily due to a lack of clarity in outcome definitions, inappropriate handling of missing data, and limited information on model overfitting and performance evaluation. The detailed evaluation of individual PROBAST questions per study is provided in Tables 2 and 3, while Table 4 summarizes the risk of bias assessments with color coding for clarity (green = low risk, yellow = moderate risk, red = high risk).
Study characteristics
The included studies were cohort [17, 18, 21], cross-sectional [20, 22], and retrospective [14, 23–26] in design and were conducted in various countries, including the USA [23, 25], China [17, 20–22, 26], Iran [24], the Republic of Korea [18] and Switzerland [14]. A total of ten studies met the inclusion criteria, with sample sizes ranging from 100 to 3705 participants. To facilitate comparison, the included studies were categorized based on type of ocular trauma, AI methodology, and predicted clinical outcome. By trauma type, most studies focused on open-globe injuries [18, 21, 24, 25], three examined orbital fractures [14, 17, 20] and the remainder addressed mixed ocular trauma cases [22, 23, 26]. When categorized by AI methodology, deep learning–based models were predominantly used for diagnostic imaging tasks, with convolutional neural networks (CNNs) representing the most frequently employed architectures [17, 18, 20, 25]. Prognostic modeling of visual outcomes more commonly utilized traditional machine learning approaches, including artificial neural networks (ANNs) and other supervised learning algorithms [21, 24, 26]. Three recent studies [14, 22, 23] evaluated conversational AI models such as ChatGPT-4 for diagnostic reasoning and treatment decision-making. By data modality, imaging-based studies (CT or fundus photographs) [17, 20, 23, 25, 26] generally demonstrated higher diagnostic accuracy (AUC 0.90–0.99) compared to those using solely clinical features (AUC 0.78–0.85) [14, 18, 21, 22, 24]. The predicted outcomes across studies included fracture localization, segmentation of affected areas, prediction of final visual acuity, and evaluation of diagnostic or triage accuracy.A detailed, categorized summary of study characteristics is presented in Table 5.
Study characteristics and types of AI models
The ten included studies employed a wide range of artificial intelligence (AI) approaches, thereby directly addressing the first objective of this review. Overall, the identified methods were classified into three main categories: deep learning, classical machine learning, and natural language processing with large language models (NLP/LLMs).
Deep learning approaches included architectures such as DenseNet-169, InceptionV3, MRes-UNET2D, and UNet and its modified variants. Classical machine learning methods comprised XGBoost, random and decision forests, support vector machines (SVMs), and artificial neural networks (ANNs). In addition, NLP and LLM-based techniques were represented by systems such as MedLEE and ChatGPT-4.
The heterogeneity of these AI methodologies highlights the multifaceted nature of AI applications in ocular trauma, encompassing image analysis, predictive modeling based on clinical data, extraction of relevant information from textual records, and clinical reasoning supported by large language models.
AI performance across trauma types and data modalities
Across included studies, imaging-based deep learning models consistently demonstrated superior diagnostic performance for various ocular trauma types. DenseNet-169 achieved AUC of 0.99 and 98% accuracy in orbital fracture detection (Bao et al.) [20], while combinations of InceptionV3 and XGBoost reported AUCs of 0.957 [17]. Modified UNet architectures effectively segmented injured ocular structures, achieving Dice scores of 0.95 [25]. These results indicate that deep learning excels in detecting structural abnormalities across trauma types and image modalities, fulfilling the objective of evaluating performance across both trauma types and data modalities.
In parallel, natural language processing (NLP) and large language models (LLMs) were assessed for their diagnostic interpretation capabilities. Sarioglu et al. applied NLP to CT radiology reports and, using filtered NLP + SVM models, achieved high diagnostic accuracy with F-scores of 0.97(CI:95%) [23]. Similarly, ChatGPT-4 correctly identified all orbital fracture cases, but agreement with clinical management decisions was only 70% (Gernandt et al.) [14]. These findings demonstrate that NLP and LLMs are highly effective for extracting diagnostic information from textual reports, but therapeutic decision-making remains less reliable, highlighting modality-specific strengths and limitations.
For prognostic applications, machine learning models incorporating clinical variables showed substantial improvements over traditional scoring systems. ANN models predicted final visual acuity after ocular trauma with 93% accuracy and AUC 0.96(CI:95%) (Shariati et al.) [24], outperforming conventional tools such as the Ocular Trauma Score. Boosted decision trees yielded AUCs up to 0.97 in open globe injury prognosis (Choi et al.) [18], and the VisionGo NLP-based model achieved preoperative AUC 0.75 and intraoperative AUC 0.90, surpassing both clinician predictions and OTS benchmarks (Meng et al.) [21]. These results suggest that ML-based prognostic models, particularly those using structured clinical features, offer meaningful enhancements in outcome prediction.
Patterns in AI performance across data types
A consistent pattern across studies was that imaging-based deep learning demonstrated superior diagnostic performance (AUC: 0.90–0.99) compared with models relying solely on clinical features (AUC: 0.78–0.85). Conversely, prognostic models incorporating clinical variables, especially those using ANN and boosted algorithms, outperformed imaging alone for predicting final visual acuity. NLP and LLM-based models showed promise for text interpretation, particularly for extracting structured information from unstructured reports.
These findings underscore the importance of matching AI model types to the clinical task:
Deep learning: best for diagnosis of structural abnormalities.
Machine learning: best for prognosis based on clinical features.
LLMs/NLP: best for decision support and textual data interpretation.
Discussion
The findings of this study indicate that artificial intelligence (AI) has considerable potential in the diagnosis and prognostication of ocular trauma. This systematic review revealed that deep learning models such as DenseNet-169 and UNet demonstrated high performance in detecting orbital fractures, with reported AUC values reaching 0.99 and accuracies exceeding 96% in the study by Xiao-li Bao (2023) [20]. These results show that deep learning can be very helpful in improving diagnosis speed and accuracy in trauma cases.
Additionally, predictive models such as artificial neural networks (ANNs) have shown acceptable performance in stratifying final visual acuity into different levels. In the study by Shariati (2024), the ANN model achieved an accuracy of 93% and an AUC of 0.96 in predicting visual outcomes, reflecting its strong discriminative ability(CI:95%) [24]. This highlights the potential use of ANN models in early decision-making and outcome prediction in eye injuries.
However, beyond reporting high performance metrics, a critical appraisal of model validation strategies and generalizability is necessary to contextualize these findings. Most included studies primarily reported model performance based on internal validation or cross-validation, with limited evidence of external validation using independent datasets. While these approaches are useful for assessing model consistency within a given dataset, they may overestimate real-world performance when models are applied across different populations, imaging protocols, or clinical environments. External validation, which is essential for evaluating model robustness and transportability, was infrequently performed. Consequently, the high accuracy and AUC values reported in several studies should be interpreted cautiously, as their generalizability to routine clinical practice remains uncertain.
In addition, apparent high diagnostic performance may partly reflect methodological limitations, including class imbalance and an over-reliance on discrimination metrics such as AUC. Many studies did not report complementary measures of model calibration or clinical utility, such as calibration slope, Brier score, or Matthews correlation coefficient. In imbalanced datasets, high AUC values may obscure poor predictive performance for less frequent but clinically critical outcomes. The absence of calibration reporting further limits assessment of whether predicted probabilities accurately reflect observed risks, which is essential for clinical decision-making. Future AI studies in ocular trauma should therefore integrate both discrimination and calibration metrics and prioritize validation across diverse and clinically relevant subgroups.
Recent literature within the past two years reflects significant advances in artificial intelligence applications in ophthalmology. Multi-modal AI approaches that integrate multiple data types such as imaging and clinical variables have demonstrated promising performance beyond single-modality models, suggesting enhanced diagnostic and prognostic utility across diverse ocular conditions [27, 28]. In addition, large language models with visual and textual input capabilities, such as GPT-4 V, have shown potential for combined analysis of ocular images and clinical context, representing an emerging direction for AI-assisted decision support in ophthalmic practice [29]. These developments indicate that contemporary AI research in ophthalmology is rapidly evolving toward more comprehensive and robust multimodal systems.
The nature of diagnosis by humans and AI is fundamentally different. Human diagnostic performance is influenced by factors such as clinical experience, environmental conditions, and subjective interpretation, whereas AI models when properly programmed and adequately trained can interpret input data consistently and efficiently, delivering results in less time and at a broader scale. The findings suggest that the ANN model in Shariati’s study outperformed traditional tools such as the OTS. The ANN model functions independently of human intervention, relying solely on structured clinical features [24]. In contrast, the OTS system, designed primarily for binary outcome prediction (vision vs. no vision), has limited precision in multiclass predictions and is heavily reliant on clinical judgment [30, 31]. This suggests that AI models can reduce human error and offer more detailed outcome predictions compared to traditional scoring tools.
Although ultrasonography has demonstrated high diagnostic accuracy for ocular trauma when performed by experienced clinicians [32, 33], its operator-dependent nature and required expertise limit consistency across settings. AI-based imaging approaches may help address these limitations by providing more standardized and reproducible diagnostic support.
Moreover, a retrospective study by Gernandt (2023) demonstrated that ChatGPT-4 successfully diagnosed all cases of orbital fracture with 100% accuracy. However, its treatment recommendations (surgical vs. conservative) align with actual clinical decisions in only 70% of cases [14]. This means that although AI can help in diagnosis, it still needs improvement when used for making treatment decisions.
In addition to ocular trauma, recent studies have demonstrated the high efficacy of deep learning in diagnosing maxillofacial fractures. For example, Warin et al. (2023) evaluated CNN-based models including DenseNet-169, ResNet-152, YOLOv5, and Faster R-CNN on CT images. The overall accuracy of DenseNet-169 in multi-class classification is reported to be 0.7, and the accuracy of the Faster R-CNN model in identifying failure locations is reported to be 0.78 [34]. Furthermore, Dashti et al. (2024) conducted a meta-analysis on deep learning algorithms applied to panoramic radiographs for mandibular fracture detection, reporting pooled sensitivity of ~ 97% and specificity of ~ 81% [35]. These findings show that AI models used in eye injuries can also work well in detecting other types of trauma, like jaw or facial fractures.
From a comparative perspective, our review identifies clear performance differences across AI model types. Image-based deep learning models such as DenseNet and UNet demonstrated superior performance in CT-based diagnostic tasks compared to traditional machine learning approaches like logistic regression or decision trees. In terms of prognostic modeling, ANNs trained on diverse clinical variables consistently outperformed algorithms such as support vector machines and decision forests, as observed in Shariati et al. (2024) [24]. Choosing the right model based on the type of data and clinical goal is important for achieving the best results.
NLP-based models like ChatGPT-4 were highly effective in processing narrative clinical data for diagnostic hypothesis generation but showed limitations in decision-making accuracy. Importantly, model interpretability remains a key issue in clinical AI. While most high-performing deep learning models function as “black boxes,” tools like VisionGo (Meng et al., 2024) incorporated SHAP (Shapley Additive Explanations) to enhance transparency and explainability [21]. This trade-off between model complexity and interpretability is a critical factor when considering real-world deployment. AI models that are easier to understand and explain will likely be more accepted in clinical practice, especially in serious or high-risk cases.
Overall, the selection of AI models must align with the clinical objective diagnosis, prognosis, or decision support and should be guided by input data type, performance needs, and the clinical context. Imaging-based models remain most effective for detection, while clinical-feature-based ANNs offer robust outcome prediction. NLP models are best suited for triage support and case analysis but currently require further refinement for therapeutic recommendation tasks.
Strengths and limitations
This systematic review was conducted with a rigorously designed methodology to ensure the identification and inclusion of all relevant studies. To maintain the highest standards of academic integrity, two independent reviewers systematically performed abstract screening, full-text evaluation, data extraction, and bias assessment. To mitigate potential publication bias and ensure comprehensive coverage of the literature, an extensive search strategy was implemented across multiple databases.
interpretability remains a key limitation in the clinical application of AI, as many explainability techniques such as SHAP—originally proposed as a unified framework for feature attribution in complex models [36]—are inconsistently applied across studies. Furthermore, explainability has been identified as critical for clinician trust and adoption in ophthalmic AI, since transparent reasoning enhances acceptance and safe implementation in practice [37]. In contrast, large language models such as ChatGPT-4 have recently shown potential for clinical reasoning and decision support in orbital fracture diagnosis, although domain-specific validation remains limited [14].
Despite promising findings, the evidence reviewed in this study has several limitations. Some studies had small sample sizes or relied on single-center data, which may limit the generalizability of the results. In several studies that used AI-based chatbots such as ChatGPT, there was insufficient transparency regarding the type of input data, sample selection criteria, and model testing conditions. Additionally, several studies did not assess external validity, and models were often tested in retrospective or controlled environments, limiting the generalizability of the results to real-world clinical settings.
Another important issue is the high variability in data types (including images, clinical features, and textual data) and performance metrics (such as accuracy, AUC, F1 score, and MCC), making direct comparisons between studies difficult.
The review process itself also has limitations. Some relevant studies may have been excluded due to language restrictions, unavailability of full-text articles, or the use of nonstandard terminology in databases. The lack of uniform reporting standards for AI model performance further complicated the synthesis and interpretation of the findings. Although a comprehensive search strategy was applied, the possibility of selection bias or missing unpublished research cannot be entirely ruled out.
Implications for clinical practice, policy, and future research
This study underscores the potential of artificial intelligence in enhancing diagnostic accuracy, clinical decision-making, and prognostic prediction for patients with ocular trauma. AI-based tools may serve as valuable adjuncts to human expertise, particularly in resource-constrained settings or high-volume clinical environments, by improving diagnostic efficiency and reliability. These technologies could complement clinical judgment, especially in domains reliant on structured data or image-based assessments.
For widespread AI implementation, healthcare systems must establish robust ethical frameworks and data privacy safeguards to ensure patient information security. Future research should prioritize multicenter, real-world validation studies with larger datasets while exploring optimal human-AI collaboration models. Additionally, comparative studies evaluating AI performance against human clinicians in ocular trauma management are needed to objectively assess the clinical utility of this technology and define its optimal scope of application.
Conclusion
The findings of this systematic review indicate that AI has significant ability in identifying the type and location of ocular fractures, predicting final visual acuity, and assisting with treatment decisions on the basis of imaging and clinical data. AI systems may closely rival, or in some instances, surpass human performance. However, the optimal clinical use of AI likely lies in its integration as a collaborative and complementary tool alongside human expertise.
Appendix
Table 1PRISMA 2020 ChecklistSection and TopicItem #Checklist itemLocation where item is reportedTITLETitle1Identify the report as a systematic review.Title includes “A Systematic Review”Page:1 Line:1 ABSTRACT Abstract2See the PRISMA 2020 for Abstracts checklist.Structured abstract includes background, objectives, methods, results, and conclusion.Page: 2–3 Line:19–50 INTRODUCTION Rationale3Describe the rationale for the review in the context of existing knowledge.Rationale is clearly discussed in the Introduction; highlights lack of systematic reviews on AI in ocular trauma.Page: 4–6Objectives4Provide an explicit statement of the objective(s) or question(s) the review addresses.Objectives are explicitly stated at the end of the Introduction.Page: 5–6 METHODS Eligibility criteria5Specify the inclusion and exclusion criteria for the review and how studies were grouped for the syntheses.Eligibility criteria (inclusion/exclusion) are defined in the Methods section.Page: 7 Line: 141–145Information sources6Specify all databases, registers, websites, organisations, reference lists and other sources searched or consulted to identify studies. Specify the date when each source was last searched or consulted.PubMed, Scopus, and Web of Science were searched up to May 3, 2025.Page: 7 Line:140Search strategy7Present the full search strategies for all databases, registers and websites, including any filters and limits used.Full search strategy with Boolean operators is described in the Methods.Page: 8–10Selection process8Specify the methods used to decide whether a study met the inclusion criteria of the review, including how many reviewers screened each record and each report retrieved, whether they worked independently, and if applicable, details of automation tools used in the process.Two reviewers independently screened studies; PRISMA flow diagram is included.Page: 10–11 Line:Data collection process9Specify the methods used to collect data from reports, including how many reviewers collected data from each report, whether they worked independently, any processes for obtaining or confirming data from study investigators, and if applicable, details of automation tools used in the process.Data were independently extracted by two Researcher via a predesigned Excel sheet on the basis of the review protocol.Page: 10 Line: 172Data items10aList and define all outcomes for which data were sought. Specify whether all results that were compatible with each outcome domain in each study were sought (e.g. for all measures, time points, analyses), and if not, the methods used to decide which results to collect.Outcomes include model performance (accuracy, AUC, sensitivity, specificity, etc.).Page: 10 Line: 173–17610bList and define all other variables for which data were sought (e.g. participant and intervention characteristics, funding sources). Describe any assumptions made about any missing or unclear information.Other variables include study design, trauma type, AI model, input type, sample size, country, etc.Page: 10 Line: 173–176Study risk of bias assessment11Specify the methods used to assess risk of bias in the included studies, including details of the tool(s) used, how many reviewers assessed each study and whether they worked independently, and if applicable, details of automation tools used in the process.Risk of bias was assessed using the PROBAST tool by two independent reviewers.Page: 12 Line: 199–206Effect measures12Specify for each outcome the effect measure(s) (e.g. risk ratio, mean difference) used in the synthesis or presentation of results.Effect measures were model performance metrics: AUC, accuracy, precision, sensitivity, specificity.Page: 10–11 Line: 183–187Synthesis methods13aDescribe the processes used to decide which studies were eligible for each synthesis (e.g. tabulating the study intervention characteristics and comparing against the planned groups for each synthesis (item #5)).Studies were grouped and described by AI model type and Trauma Types and Data Modalities.Page: 12–1513bDescribe any methods required to prepare the data for presentation or synthesis, such as handling of missing summary statistics, or data conversions.No data conversions were needed; full data available from included studies.13cDescribe any methods used to tabulate or visually display results of individual studies and syntheses.Results were tabulated in summary tables and explained in narrative format.Page: 12–15, 35–5213dDescribe any methods used to synthesize results and provide a rationale for the choice(s). If meta-analysis was performed, describe the model(s), method(s) to identify the presence and extent of statistical heterogeneity, and software package(s) used.No meta-analysis conducted due to heterogeneity; narrative synthesis was used.Page: 10 Line: 17813eDescribe any methods used to explore possible causes of heterogeneity among study results (e.g. subgroup analysis, meta-regression).No formal heterogeneity analysis was conducted.Page: 10 Line: 17813fDescribe any sensitivity analyses conducted to assess robustness of the synthesized results.No sensitivity analysis was conducted.Page: 10 Line: 178Reporting bias assessment14Describe any methods used to assess risk of bias due to missing results in a synthesis (arising from reporting biases).Reporting bias was not formally assessed.Certainty assessment15Describe any methods used to assess certainty (or confidence) in the body of evidence for an outcome.Certainty of evidence was not assessed using tools like GRADE. RESULTS Study selection16aDescribe the results of the search and selection process, from the number of records identified in the search to the number of studies included in the review, ideally using a flow diagram.Study selection process is presented with PRISMA flow diagram and counts.Page: 1116bCite studies that might appear to meet the inclusion criteria, but which were excluded, and explain why they were excluded.Excluded studies and reasons for exclusion are listed.Page: 11 Line: 190–192Study characteristics17Cite each included study and present its characteristics.Characteristics of included studies are summarized in a table and narrative.Page: 12–15, 35–52Risk of bias in studies18Present assessments of risk of bias for each included study.Risk of bias results are reported in narrative and visual format.Page: 12, 30–34Results of individual studies19For all outcomes, present, for each study: (a) summary statistics for each group (where appropriate) and (b) an effect estimate and its precision (e.g. confidence/credible interval), ideally using structured tables or plots.Results for each study (metrics and AI models) are summarized in tables and narrative.Page: 12–15, 35–52Results of syntheses20aFor each synthesis, briefly summarise the characteristics and risk of bias among contributing studies.Findings from grouped studies are summarized narratively.Page: 12–1520bPresent results of all statistical syntheses conducted. If meta-analysis was done, present for each the summary estimate and its precision (e.g. confidence/credible interval) and measures of statistical heterogeneity. If comparing groups, describe the direction of the effect.No statistical synthesis or meta-analysis was conducted.20cPresent results of all investigations of possible causes of heterogeneity among study results.No subgroup or heterogeneity analysis performed.20dPresent results of all sensitivity analyses conducted to assess the robustness of the synthesized results.No sensitivity analyses performed.Reporting biases21Present assessments of risk of bias due to missing results (arising from reporting biases) for each synthesis assessed.No formal assessment of reporting bias was conducted.Certainty of evidence22Present assessments of certainty (or confidence) in the body of evidence for each outcome assessed.No formal assessment of certainty of evidence was performed. DISCUSSION Discussion23aProvide a general interpretation of the results in the context of other evidence.Overall findings interpreted in the context of existing literature.Page: 15–1823bDiscuss any limitations of the evidence included in the review.Limitations of the included studies are discussed.Page: 18–1923cDiscuss any limitations of the review processes used.Limitations of the review process (e.g., search scope) are described.Page: 19 Line: 363–36823dDiscuss implications of the results for practice, policy, and future research.Implications for practice and future research are clearly outlined.Page: 19–20 OTHER INFORMATION Registration and protocol24aProvide registration information for the review, including register name and registration number, or state that the review was not registered.Registered in PROSPERO: CRD420251043768.Page: 7–8 Line: 149–15024bIndicate where the review protocol can be accessed, or state that a protocol was not prepared.Protocol described in the Methods sectionPage: 7–8 Line:148–15224cDescribe and explain any amendments to information provided at registration or in the protocol.No amendments were made after registration.Support25Describe sources of financial or non-financial support for the review, and the role of the funders or sponsors in the review.No financial or institutional support received.Competing interests26Declare any competing interests of review authors.Authors declared no competing interests.Availability of data, code and other materials27Report which of the following are publicly available and where they can be found: template data collection forms; data extracted from included studies; data used for all analyses; analytic code; any other materials used in the review.All data are from publicly available published studies.
Table 2PROBAST questions for risk-of-bias assessment Participants 1.1 Were appropriate data sources used, e.g., cohort, RCT, or nested case-control study data?1.2. Were all inclusions and exclusions of participants appropriate? Predictors 2.1. Were predictors defined and assessed in a similar way for all participants?2.2. Were predictor assessments made without knowledge of outcome data?2.3. Are all predictors available at the time the model is intended to be used? Outcome 3.1. Was the outcome determined appropriately?3.2. Was a prespecified or standard outcome definition used?3.3. Were predictors excluded from the outcome definition?3.4. Was the outcome defined and determined in a similar way for all participants?3.5. Was the outcome determined without knowledge of predictor information?3.6. Was the time interval between predictor assessment and outcome determination appropriate? Analysis 4.1 Were there a reasonable number of participants with the outcome?4.2. Were continuous and categorical predictors handled appropriately?4.3 Were all enrolled participants included in the analysis?4.4. Were participants with missing data handled appropriately?4.5. Was selection of predictors based on univariable analysis avoided?4.6. Were complexities in the data (e.g., censoring, competing risks, sampling of control participants) accounted for appropriately?4.7. Were relevant model performance measures evaluated appropriately?4.8. Were model overfitting, underfitting, and optimism in model performance accounted for?4.9. Do predictors and their assigned weights in the final model correspond to the results from the reported multivariable analysis? ?
Table 3. Risk-of-bias assessment of each study by PROBAST questionsStudy1.11.22.12.22.33.13.23.33.43.53.64.14.24.34.44.54.64.74.84.9Overall riskBao (2023)PYYYNIYYYYYNIYYPYPYNIYYPYYY-Choi (2021)YPYYYYYYYYYYNIYYPYYYYYY-Gernandt (2024)NINININIYYYYPYNIPYPYYYNIYNIYNIY±Li (2020)YNIYYYPYYYYYPYNIYYPYYYYPYY±Meng (2023)YYYYPYYYYYYYYPYYPYYYYYY-Ming (2024)PYYYNIYYYYYPNNIPYNIYYNINIYPNNI+Sarioglu (2012)YYYNIYYYPYYPNNIYYYPYNINIYPYNI+Shariati (2024)PYYYNIPYYPYYYNIPYYYYPYYYYPYY-Umapathy (2020)YYYYPYYYYYYPYPYYYYYYYYPY-Zhou (2023)YYYNIYYYYYNIPYYYYPYYYYYY-Abbreviations: N, not for low risk of bias; n.a., not assessed; NI, no information for risk of bias assessment; PN, probably not for low risk of bias; PY, probably yes for low risk of bias; Y, yes for low risk of bias; +, indicated high risk of bias; -, indicated low risk of bias; ±, indicated unclear risk of bias
Table 4. Risk of Bias assessment with color coding
Table 5. Data Extraction Table - Ocular Trauma & AI Studies N First Author, YearStudy TypeTrauma TypeAI MethodInput DataOutcome PredictedSample SizeCountryPerformance MetricsConclusionOverall Risk of Bias (PROBAST)1Xiao-li Bao, 2023(20)Development and internal validationorbital blowout fractures (OBFs)Deep learning networks (DenseNet-169 and UNet)CT imagesfracture side distinguishment and fracture area segmentation3016 orbital CT images(497 cases)ChinaEvaluation of DenseNet-169 for Fracture Identification:Accuracy:0.96Sensitivity:0.97Specificity:0.95Precision:0.98AUC:0.99Evaluation of DenseNet-169 for Fracture Side Distinguishment:Accuracy:0.98Sensitivity:0.97Specificity:0.99Precision:0.99AUC:0.99the developed AI system can automatically identify and segment orbital blowout fractures (OBFs). This advancement has the potential to enhance diagnostic accuracy and improve the efficiency of 3D printing-assisted surgical repairs for OBFs.Low2Seungkwon Choi, 2021(18)Retrospective Cohort StudyOpen Globe Injuries (OGI)9 Different algorithm36 Clinical Features (e.g., retinal detachment, wound location, initial VA)To predict final visual acuity and analyze significant factors influencing open globe injury prognosis. (Success: VA ≥ 0.1, Failure: VA < 0.1)171 casesRepublic of Korea Support Vector Machine Accuracy: 0.831Precision: 0.856Recall: 0.915F Score: 0.884AUC: 0.867 Averaged Perceptron Accuracy: 0.850Precision: 0.881Recall: 0.910F Score: 0.894AUC: 0.891 Boosted Decision Tree Accuracy: 0.899Precision: 0.916Recall: 0.944F Score: 0.929AUC: 0.971 Bayes Point Machine Accuracy: 0.855Precision: 0.878Recall: 0.930F Score: 0.902AUC: 0.902 Decision Forest Accuracy: 0.885Precision: 0.914Recall: 0.925F Score: 0.919AUC: 0.947 Decision Jungle Accuracy: 0.880Precision: 0.912Recall: 0.922F Score: 0.916AUC: 0.936 Locally Deep Support Vector Machine Accuracy: 0.852Precision: 0.867Recall: 0.937F Score: 0.899AUC: 0.887 Logistic Regression Accuracy: 0.841Precision: 0.865Recall: 0.922F Score: 0.892AUC: 0.893 Neural Network Accuracy: 0.844Precision: 0.848Recall: 0.948F Score: 0.895AUC: 0.898The POTS model demonstrated high performance in predicting final visual acuity and was made available as a web-based tool.Low3Steven Gernandt, 2024(14)retrospective observational studyorbital fracturesChatGPT-4Age and gender of patient,Mechanism of injury, Current medical history, pertaining to the event, Relevant past medical history and comorbidities, Physical examination findings, Diagnostic imagery findingsassess the accuracy of ChatGPT-4 in the diagnosis and management of orbital fractures compared to the actual clinical decisions madeUnclearSwitzerland Diagnosis Accuracy 100% (Correctly diagnosed fractures in all cases) Management Discrepancy 30% (Overall mismatch in treatment choice: conservative vs. surgical) Specificity 100% (Perfect identification of patients needing surgery) Sensitivity 57% (Moderate performance in identifying cases for conservative management0 Positive Predictive Value (PPV) 100% (All predicted surgical cases truly needed surgery) Negative Predictive Value (NPV) 50% (Only half of predicted conservative cases truly suited it)The ChatGPT-4 model can be a useful tool in the diagnosis and management of orbital fractures; however, further studies are needed to evaluate its generalizability and clinical applicability.Moderate4Lunhao Li, 2020(17)Retrospective Cohort Studyorbital facturesInception V3 (CNN) + XGBoost convolutional neural networksOrbital CT scansDetection of Orbital Fractures188 CT scans (94 fracture, 94 controlChinaAccuracy: 92% (single-image), 87% (patient-level), AUC: 0.957The model showed good performance (high AUC), but external validation with multicenter data is needed.Moderate5Xiangda Meng, 2023(21)Multicenter Retrospective Cohort + Prospective Validationopen globe injury (OGI)-no light perception (NLP)Machine Learning (XGBoost with Nested Cross-Validation)16 Clinical Features (e.g., wound length, vitreous status, retinal detachment)predict the visual outcomes of vitrectomy for OGI-NLP eyes (Visual Recovery (NLP vs. Light Perception/Improved Vision))531 Patients (459 Training + 72 External Validation + 27 Prospective)ChinaAUC: 0.75 (Pre-Vitrectomy), 0.90 (Intra-Vitrectomy)The VisionGo model outperformed the traditional OTS system and ophthalmologists, and offered high interpretability using SHAP.Low6Shuai Ming, 2024(22)A cross-sectional studyEye diseaseArtificial intelligence (AI)chatbots (chat GPT)Medical history (Hx) + examination findings (Hx + Ex) in textual formatinvestigate the performance of AI chatbots in recommending ophthalmic outpatient registration and diagnosing eye diseases within clinical case profiles.208 casesChinaRegistration Suggestion Accuracy (Hx profiles only):GPT-3.5:66/104 → **63.5%**GPT-4.0: 81/104 → **77.9%**Residents: 72/104 → 69.2%P value: 0.07Top-performing subspecialties: Ocular trauma, retinal diseases, and strabismus/amblyopia.ChatGPT (especially GPT-4.0) showed moderate performance in residency recommendations and disease diagnosis, but further validation is needed for clinical useHigh7Efsun Sarioglu, 2012(23)Retrospectivetraumatic orbital injuryNatural Language Processing (NLP) with MedLEE + Topic Modeling (LDA)Emergency CT scan textual reportsDiagnosis of orbital fracture (positive/negative)3705 cases (463 positive, 3,242 negative)USA CI:95%
Decision Tree Precision: 0.947Recall: 0.948F Score: 0.948NLP - All:Precision: 0.955Recall: 0.956F Score: 0.955NLP - Filtered:Precision: 0.970Recall: 0.970F Score: 0.970 SVM Precision: 0.959Recall: 0.960F Score: 0.959NLP - All:Precision: 0.968Recall: 0.969F Score: 0.968NLP - Filtered:Precision: 0.971Recall: 0.971F Score: 0.971NLP with UMLS code filtering showed the best performance. Topic modeling was useful for dimensionality reduction, but binary classification performed poorly.High8Mehrdad Motamed Shariati, 2024(24)Analytical-observational (retrospective)Open Globe Injuries (OGI)Different machine learning models(MLR, SVM, KNN, DT, RF, ADA, BG, WGB, ANN, PPV, BC, MCV)12clinical features (age, gender, type of trauma, initial VA, RAPD, injury zone, ocular complications such as RD, TON, IOFB, etc.)Final visual acuity (VA) in three classes: poor (0–0.1), moderate (0.1–0.7), good (0.7–1)301 casesIran CI:95%
SVM AUC-ROC: 0.86AUC-PRC: 0.75PPV: 0.812Sensitivity: 0.764Accuracy: 0.885F1 Score: 0.787MCC: 0.709Brier Score (BS): 0.433The ANN model showed the best performance (AUC-ROC: 0.96, Accuracy: 93%)Low Naïve Bayes AUC-ROC: 0.84AUC-PRC: 0.72PPV: 0.857Sensitivity: 0.705Accuracy: 0.885F1 Score: 0.774MCC: 0.704Brier Score (BS): 0.634 XGB AUC-ROC: 0.88AUC-PRC: 0.82PPV: 0.923Sensitivity: 0.705Accuracy: 0.901F1 Score: 0.800MCC: 0.744Brier Score (BS): 0.395 ADA AUC-ROC: 0.86AUC-PRC: 0.74PPV: 0.750Sensitivity: 0.705Accuracy: 0.852F1 Score: 0.727MCC: 0.626Brier Score (BS): 0.643 Bagging AUC-ROC: 0.89AUC-PRC: 0.79PPV: 0.764Sensitivity: 0.764Accuracy: 0.868F1 Score: 0.764MCC: 0.673Brier Score (BS): 0.412 Multinomial Logistic Regression AUC-ROC: 0.84AUC-PRC: 0.75PPV: 0.866Sensitivity: 0.764Accuracy: 0.901F1 Score: 0.812MCC: 0.748Brier Score (BS): 0.439 KNN AUC-ROC: 0.81AUC-PRC: 0.69PPV: 0.750Sensitivity: 0.705Accuracy: 0.852F1 Score: 0.727MCC: 0.626Brier Score (BS): 0.476 Decision Tree AUC-ROC: 0.85AUC-PRC: 0.75PPV: 0.785Sensitivity: 0.647Accuracy: 0.852F1 Score: 0.709MCC: 0.617Brier Score (BS): 0.413 Random Forest (RF) AUC-ROC: 0.92AUC-PRC: 0.86PPV: 0.866Sensitivity: 0.764Accuracy: 0.901F1 Score: 0.812MCC: 0.748Brier Score (BS): 0.311 Artificial Neural Network (ANN) AUC-ROC: 0.96AUC-PRC: 0.91PPV: 0.894Sensitivity: 0.819Accuracy: 0.930F1 Score: 0.855MCC: 0.811Brier Score (BS): 0.2019L Umapathy, 2020(25)RetrospectiveOcular trauma (specifically globe injuries)Deep learning using a 2D Modified Residual UNET (MRes-UNET2D)CT imagesAutomated segmentation of globe contours and volume quantificationTraining on 80 subjects without globe injuries; testing on two cohorts: 18 subjects in the first cohort and 9 subjects in the second cohortUSA First Test Cohort 9n = 18) Dice Score: 0.95Precision: 96%Recall: 95%Second Test Cohort (n = 9)MRes-UNET2DDice Score: 0.95Human Interobserver Dice Score: 0.94The MRes-UNET2D model enables fast and reliable segmentation and volume estimation of globes in orbital CT images. Its performance is comparable to human experts, and it can serve as a quantitative tool in ocular trauma assessment.Low10Zhi-Lu Zhou, 2023(26)retrospective analysis experimentocular traumamachine learning models (XGB, SVR, BYR, RFR)clinical data, OCT images and fundus photographsassessment of VA after ocular trauma100 eyesChina CI:95% Sensitivity: 0.83Precision: 0.92Specificity: 0.95Accuracy: 0.90Predicting BCVA using machine-learning models in patients with treated ocular trauma is accurate and helpful in the identification of visual dysfunction.Low
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bao XL, Zhan X, Wang L, Zhu Q, Fan B, Li GY. Automatic identification and segmentation of orbital blowout fractures based on Artificial Intelligence. Translational Vis Sci Technol. 2023;12(4).10.1167/tvst.12.4.7PMC 1008238337022710 · doi ↗ · pubmed ↗
- 2Shariati MM, Eslami S, Shoeibi N, Eslampoor A, Sedaghat M, Gharaei H et al. Development, comparison, and internal validation of prediction models to determine the visual prognosis of patients with open globe injuries using machine learning approaches. BMC Med Inf Decis Mak. 2024;24(1).10.1186/s 12911-024-02520-4PMC 1110697038773484 · doi ↗ · pubmed ↗