An Association Test for Ordinal Outcomes in Clustered Data With Informative Cluster Size
Hasika K. Wickrama Senevirathne, Sandipan Dutta

TL;DR
This paper introduces a new statistical test for analyzing ordinal outcomes in clustered data where cluster size might influence the results.
Contribution
A novel nonparametric method is proposed to handle ordinal outcomes in clustered data with informative cluster size.
Findings
The new test outperforms existing methods in identifying significant ordinal associations when cluster size is informative.
The proposed method performs comparably to existing methods when cluster size is not informative.
The method was successfully applied to real-world cluster-randomized clinical trial data.
Abstract
In cluster‐correlated data, the number of observations in a cluster can be associated with the outcome from that cluster. This phenomenon is known as informative cluster size which can occur in cluster‐randomized clinical trial data. Several studies have found that ignoring the issue of informative cluster size can produce biased results in the analysis of clustered data. Most of the existing methods for addressing informative cluster size are suited to continuous outcomes. However, ordinal outcomes and covariates are often encountered in clustered data obtained from large clinical studies. The existing methods for ordinal association testing in clustered data can produce suboptimal results in the presence of informative cluster size. In this article, we propose a new nonparametric method for testing marginal association between ordinal variables in clustered data that can account for…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
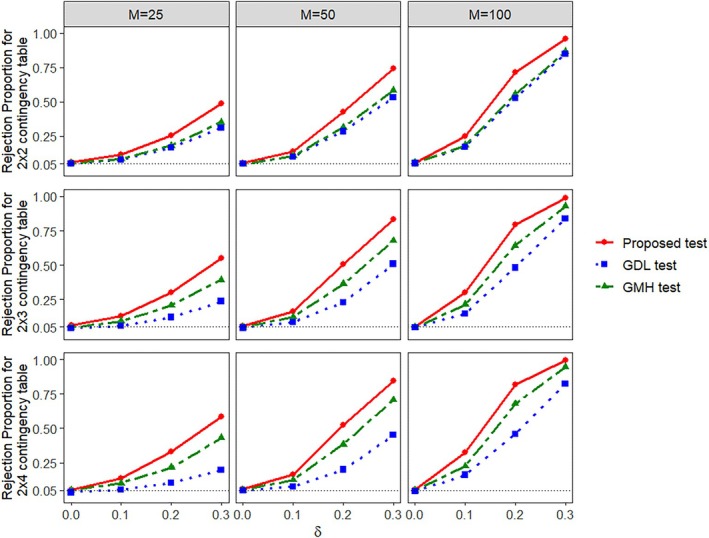 FIGURE 1
FIGURE 1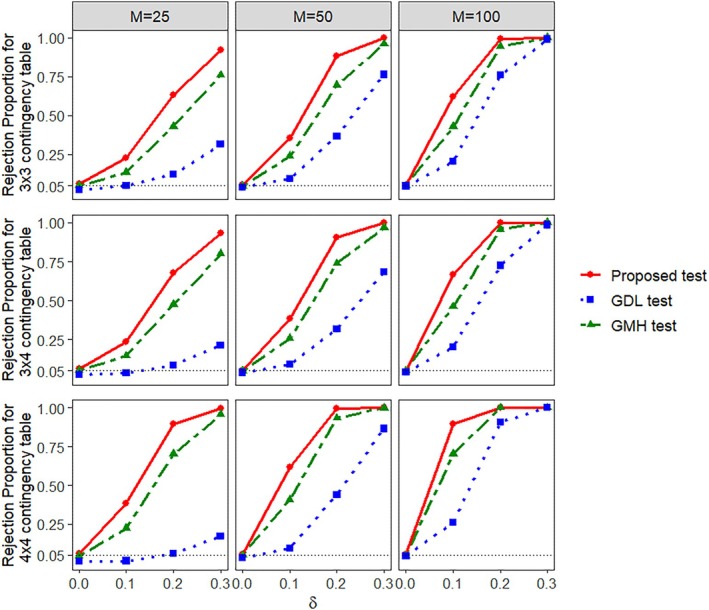 FIGURE 2
FIGURE 2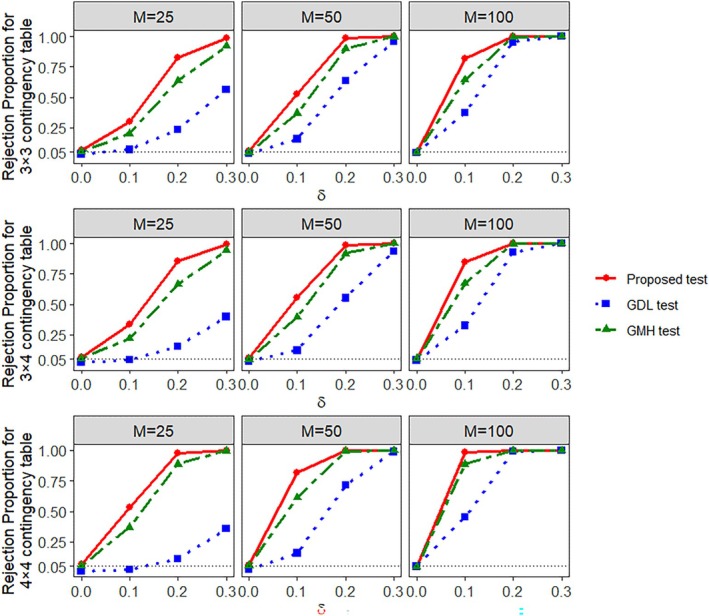 FIGURE 3
FIGURE 3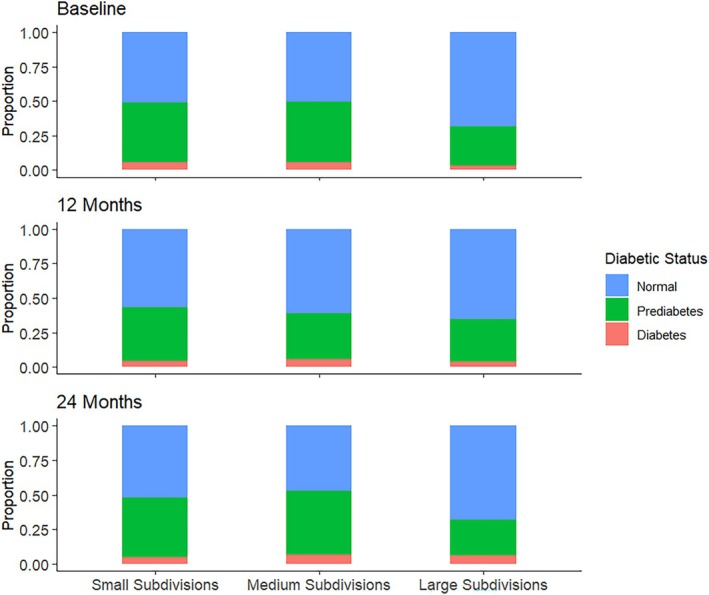 FIGURE 4
FIGURE 4| Proposed test | GMH test | GDL test | ||
|---|---|---|---|---|
| 25 | 0.060 (0.050, 0.070) | 0.056 (0.046, 0.066) | 0.050 (0.040, 0.059) | |
| 0.061 (0.051, 0.071) | 0.045 (0.036, 0.054) | 0.041 (0.032, 0.050) | ||
| 0.055 (0.045, 0.065) | 0.050 (0.040, 0.060) | 0.035 (0.027, 0.043) | ||
| 50 | 0.053 (0.043, 0.063) | 0.044 (0.035, 0.052) | 0.049 (0.039, 0.058) | |
| 0.058 (0.048, 0.068) | 0.049 (0.040, 0.058) | 0.044 (0.035, 0.052) | ||
| 0.058 (0.048, 0.068) | 0.052 (0.042, 0.062) | 0.049 (0.039, 0.058) | ||
| 100 | 0.058 (0.048, 0.068) | 0.058 (0.048, 0.068) | 0.053 (0.043, 0.062) | |
| 0.051 (0.041, 0.061) | 0.049 (0.040, 0.058) | 0.048 (0.039, 0.057) | ||
| 0.052 (0.042, 0.062) | 0.050 (0.040, 0.060) | 0.044 (0.035, 0.053) |
| Proposed test | GMH test | GDL test | ||
|---|---|---|---|---|
| 25 | 0.061 (0.051, 0.071) | 0.050 (0.040, 0.060) | 0.024 (0.017, 0.031) | |
| 0.062 (0.051, 0.072) | 0.051 (0.041, 0.061) | 0.024 (0.017, 0.031) | ||
| 0.061 (0.051, 0.071) | 0.045 (0.036, 0.054) | 0.009 (0.005, 0.013) | ||
| 50 | 0.053 (0.043, 0.063) | 0.047 (0.038, 0.056) | 0.041 (0.032, 0.050) | |
| 0.051 (0.041, 0.061) | 0.048 (0.039, 0.057) | 0.038 (0.030, 0.046) | ||
| 0.054 (0.044, 0.064) | 0.049 (0.040, 0.058) | 0.033 (0.025, 0.041) | ||
| 100 | 0.049 (0.040, 0.058) | 0.050 (0.040, 0.060) | 0.047 (0.038, 0.056) | |
| 0.046 (0.036, 0.055) | 0.051 (0.041, 0.061) | 0.040 (0.031, 0.049) | ||
| 0.057 (0.047, 0.067) | 0.047 (0.038, 0.056) | 0.042 (0.033, 0.051) |
| Proposed test | GMH test | GDL test | ||
|---|---|---|---|---|
| 25 | 0.064 (0.053, 0.075) | 0.054 (0.044, 0.063) | 0.034 (0.026, 0.042) | |
| 0.065 (0.054, 0.075) | 0.056 (0.045, 0.066) | 0.026 (0.019, 0.033) | ||
| 0.068 (0.057, 0.078) | 0.054 (0.044, 0.063) | 0.009 (0.005, 0.013) | ||
| 50 | 0.059 (0.048, 0.069) | 0.047 (0.038, 0.056) | 0.036 (0.028, 0.044) | |
| 0.062 (0.051, 0.073) | 0.047 (0.038, 0.056) | 0.029 (0.022, 0.036) | ||
| 0.060 (0.049, 0.070) | 0.052 (0.042, 0.061) | 0.024 (0.017, 0.031) | ||
| 100 | 0.055 (0.045, 0.065) | 0.048 (0.038, 0.057) | 0.046 (0.037, 0.055) | |
| 0.051 (0.041, 0.061) | 0.053 (0.043, 0.062) | 0.041 (0.032, 0.050) | ||
| 0.051 (0.041, 0.061) | 0.044 (0.035, 0.052) | 0.048 (0.039, 0.057) |
| Variable | Trial phase |
| |
|---|---|---|---|
| Proposed test | GMH test | ||
| BMI | Baseline | 0.665 (0.117) | 0.073 (1.795) |
| 24‐month | < 0.001 (0.956) | 0.002 (3.089) | |
| Vigorous work | Baseline | 0.053 (−0.486) | 0.745 (−0.326) |
| 24‐month | 0.045 (−0.560) | 0.064 (−1.854) | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Bayesian Inference · Bayesian Methods and Mixture Models · Data-Driven Disease Surveillance
Introduction
1
Clustered data is a type of correlated data where the observations within a cluster are correlated while observations between different clusters are assumed to be independent. Clustered data are frequently encountered in clinical and biomedical studies, especially in longitudinal studies, dental studies, and cluster‐randomized clinical trials. In such data, the cluster size, that is, the number of units present in a cluster, can vary among different clusters. Moreover, this cluster size can be associated with the outcome from that cluster. This phenomenon is known as informative cluster size [1, 2]. In such scenarios of informative cluster size (ICS), it has been seen that estimators based on averaging over participants, ignoring their cluster identities, may produce substantially different results than cluster‐averaged estimators [2, 3]. As for an example, ICS can occur in the data obtained from multiple clinic visits of cancer patients, where the number of clinic visits (cluster size) of a patient (cluster) can indicate the severity of the disease in that patient. In the context of cluster‐randomized clinical trials where hospitals (clusters) are randomized to treatment arms, larger hospitals may have superior (or inferior) outcomes than smaller hospitals, irrespective of the treatment arm, due to the quality of the staff involved, hospital location, type of patients admitted, number of patients served and many other factors. As a result, it is possible that the outcomes averaged over hospitals may produce different conclusions than the outcomes averaged over patients. This is due to the impact of ICS. This needs to be taken into account for determining the appropriate choice of the average treatment effect [3].
Two pioneer approaches for addressing this ICS in the marginal analysis of outcomes in clustered data were by Hoffman et al. [4] and Williamson et al. [5] Following these, several statistical methods have emerged that implement these two approaches for analyzing varied types of outcomes in clustered data [6, 7, 8, 9, 10]. Moreover, the idea of ICS has been extended to additional layers of informativeness arising from the number of units in a group or a subcluster within a cluster [11, 12, 13].
Most of the methods developed so far, in the context of ICS, involve continuous or numerical outcomes. However, in health studies, non‐continuous categorical outcomes are also frequently encountered. For instance, in a multinational mental health research, DSM‐IV disorder severity was assessed on an ordinal scale (e.g., mild, moderate, and serious) with data clustered by country [14]. Similarly, patient‐reported outcomes in multi‐center oncology trials—such as symptom severity or adverse events—are often recorded using categorical measures, resulting in a clustered ordinal data structure [15]. Other notable examples include the use of the modified Rankin Scale (mRS) to measure functional recovery in multi‐center stroke studies [16] and the grading of diabetic retinopathy severity within multi‐ethnic cohort studies [17]. Despite such prevalence, research on non‐continuous outcomes, in the area of ICS, has been very limited with a few recent exceptions [18, 19]. One of these recent works by Gregg et al. [19] suggests a nonparametric model‐free testing of marginal association between categorical outcomes in clustered data with ICS. Their work is analogous to the Pearson independence test for bivariate categorical outcomes in the context of clustered data with ICS. However, this approach ignores any ordinality that may be present in the categories of the outcome variable. Therefore, the method of Gregg et al. [19] can produce suboptimal inference for association testing of ordinal outcomes, especially when a large observational study or a cluster‐randomized clinical trial produces multiple ordinal outcomes of interest. Selman et al. [20] enlists a large number of recent clinical trials which used ordinal outcomes as primary and secondary endpoints. These include cluster‐randomized clinical trials [21] that generated clustered ordinal outcomes. In such cases of clustered clinical data, the common approach for testing marginal ordinal association turns out to be the classical generalized (stratified) Mantel–Haenszel trend test [22, 23] that treats clusters as strata. Being an ad‐hoc solution for analyzing stratified data, the generalized Mantel–Haenszel trend test is ignorant to the presence of ICS in clustered data. Therefore, an appropriate robust model‐free marginal association testing method for ordinal variables has been missing in the ICS paradigm for clustered data. Motivated by the need to fill this void, in this article, we propose a novel nonparametric test, free of any model‐based assumptions, for testing association between ordinal outcomes in clustered data that can address ICS.
The rest of the article is organized in the following way. In Section 2, we develop our new test for testing marginal association between two ordinal variables in clustered data with an emphasis on ICS. In Section 3, we evaluate the performance of the proposed test in simulated data and compare it with the existing alternative tests. Section 4 demonstrates the applicability and usefulness of our proposed method through real‐world cluster‐randomized clinical trial data involving a diabetes intervention. The article ends with a discussion in Section 5.
Methodology
2
Background and Notations
2.1
We first discuss a standard mechanism of testing association between two ordinal categorical variables. Based on that, we develop our test statistic of ordinal association testing in a clustered data setting with the primary focus on ICS.
Let X and Y be two ordinal categorical variables having K ordered categories and G ordered categories, respectively. In a classical setting, this categorical data can be represented through a K×G contingency table with the ordered categories of X and Y as rows and columns, respectively. For testing the association between two such ordinal variables in a K×G contingency table, one of the most popular approaches is the Mantel–Haenszel test (MH test) for linear trend as described in Agresti [23], and Mantel and Haenszel [24]. In this approach each category of a variable is assigned a numerical score in such a way that the ordered structure of the categories within a variable is preserved in the scores assigned. Let u1≤u2≤…≤uK denote the assigned scores for the K categories of the X variable and v1≤v2≤…≤vG denote the assigned scores for the G categories of the Y variable. This leads to a two‐way contingency table with K rows and G columns where the cell frequency of a typical cell k,g represents the number of observations having the scores uk and vg for the X and Y variables respectively. The classical MH test uses the correlation coefficient ρ between the two sets of scores for testing whether the two ordinal variables X and Y are associated or not (H0:ρ=0). While this approach is known to identify the linear association between the two sets of scores, its interpretation for measuring, or identifying, the strength of association between the two underlying ordinal variables would depend on the choice of the scores used. Since the choice of numerical scores could be arbitrary, e.g., equally spaced versus unequally spaced scores, the accuracy of the results from this approach could depend on the subjective choice of the investigator [24]. One way of circumventing this issue is to use the ranks of the scores, instead of the scores themselves, for both categories. This approach would preserve the ordered nature of the scores and identify any monotonic association while alleviating the problem of subjectivity of the score choices and interpretations. In our method, we use this approach of score selection. One of the main assumptions of the MH test is that all the observations in the data are independent, i.e., every frequency count in each cell of the K×G contingency table is coming from independent sampling units. This assumption of independence becomes invalid in clustered data where observations within a cluster are correlated. Therefore, we need to modify the standard MH test to account for the correlated observations in clustered data. We would formulate the new test statistic based on the following notations.
Suppose there are M clusters in the data. A cluster i has ni++ units, i.e., the cluster size is ni++ for the cluster i. Let Xij denote the X‐category and Yij denote the Y‐category for a unit j in a cluster i where 1≤j≤ni++ and 1≤i≤M. Then, all the information in the cluster i can be represented through Vi=ni++XijYij1≤j≤ni++ while V1,V2,…,VM are i.i.d. Now, let us consider the two‐way contingency table within each cluster i. Let nikg be the number of observations belonging to the row (X‐category) k and the column (Y‐category) g in the cluster i. In other words, the cell frequency for the cell k,g in the cluster i is nikg=∑j=1ni++IXij=kYij=g), for 1≤k<K, 1≤g≤G, with I. being a binary indicator function. Here, the cluster size ni++=∑k∑gnikg. Moreover, in the cluster i, the kth row frequency is nik+=∑g=1Gnikg and the gth column frequency is ni+g=∑k=1Knikg. We define π^ikg=nikgni++, π^ik+=nik+ni++, and π^i+g=ni+gni++.
Test for Ordinal Association in Clustered Data
2.2
Development of the Test Statistic
2.2.1
The classical MH test, discussed in the previous section, would not be applicable for this clustered data as the units within a cluster are not independent. In this case, we can use the idea of within‐cluster‐resampling [4] technique to implement the MH test in this data. Considering there are ni++ paired outcomes XijYij1≤j≤ni++ in every cluster i, we randomly select one outcome pair, say XiYi, with equal probability 1/ni++ from the cluster i. This procedure is repeated for each of the M clusters, resulting in a resampled data set X1Y1X2Y2…(XMYM). Note that this set of M resampled observations are independent since each of them is obtained from a different cluster. Therefore, based on this set of M independent pairs, we can compute the MH test statistic [23]
where
Here, π^kg*=nkgM, nkg=∑i=1MIXi*=kYi*=g, π^k+=nk+M, π^+g=n+gM, u¯=∑kukπ^k+, and v¯=∑gvgπ^+g.
In the abovementioned MH statistic W*, all the M clusters contribute equally by providing one outcome pair each. This alleviates the unequal contributions from differently sized clusters. However, this W*, despite being a valid test statistic, is inefficient for testing the association between the ordinal variables for this clustered data. This is because, in the construction of W*, only one pair of observation is being considered from the whole cluster and, hence, the value of W* would heavily depend on the pair being selected and subjected to wide sampling fluctuations. To overcome this limitation due to the imposed randomization, we use a marginalization principle [5] where we average the statistic, specifically ρ^, based on resamples across all possible resampled realizations of XiYi* values given the observed data. To achieve this for the ratio statistic ρ^, we replace all resampled components in ρ^ with the corresponding averages, or conditional expectations, given the complete clustered data V1V2…VM. Therefore, our proposed new estimator of association between the ordinal variables in clustered data is
where
The detailed calculations for obtaining the above expression of ρ^c can be found in Appendix A.
Then, our proposed test statistic, extending the idea of the MH test, for testing ordinal association in clustered data is Wc=M−1ρ^c.
Variance Estimation and Testing Procedure
2.2.2
The classical MH test statistic, W*, is supposed to have an asymptotic standard normal distribution, for large M, under the null hypothesis, H0, of no association between the ordinal variables [23]. Asymptotic normality of the statistics based on the within‐cluster resampling and the equivalent marginalization procedures have also been established in previous research works [4, 5]. While our proposed estimator, ρ^c, can be shown to be asymptotically (for large M) unbiased under H0 (see the Supplementary Web Material for an empirical justification), to implement a large sample testing, similar to the aforementioned tests, we need to estimate the variance of our proposed test statistic Wc. To obtain this variance estimate, V^Wc, we employ a ‘delete‐1‐cluster’ jackknife‐based variance estimation [12].
Let Wci be the value of the test statistic obtained after deleting the ith cluster. In other words, The jackknife variance estimate of Wc is
where
Then, the standardized test statistic Zc=Wc/V^Wc, which would follow a standard normal distribution for large M under H0, can be used to carry out the test of association between the two ordinal variables in a clustered data. The empirical performance of this proposed test has been evaluated in the next section.
Simulation Studies
3
In this section, we evaluate the performance of the proposed test through empirical type‐I error rate and power calculations in different simulated settings of clustered data. We also compare it with two existing alternative nonparametric tests for clustered categorical data. One of the tests is the generalized Mantel–Haenszel (GMH) test [22] which uses clusters as strata while carrying out the MH test. The other test is the association test by Gregg, Datta, and Lorenz [19] developed for clustered categorical data which would be referred to as the GDL test. Note that, while GDL test can be implemented with different choices for the variance estimator, we have used the method of moments version of the GDL test following the recommendation in the original article [19]. We considered a variety of simulation settings that varies in terms of the number of X‐categories and Y‐categories, i.e., K and G. In each setting, we consider three different choices of the number of clusters (M), namely, 25, 50, and 100 representing small, moderate, and large sample scenarios, respectively. The chosen nominal (target) size or type‐I error rate is 0.05. The empirical size (type‐I error rate), along with its 95% confidence interval, and the power results, are based on 2000 Monte‐Carlo iterations.
Clustered Data With ICS
3.1
In this simulation setting, we have two ordinal categorical variables (X and Y) measured in each of the M clusters. In a cluster i, 1≤i≤M, two independent variables ai and qi are generated where aiNormal0,1 and qiNormal0,0.01. For the same cluster, the cluster size ni++ is generated from a Poisson distribution, ni++−1Poisson20exp0.5aiqi. We generate Xij, the ordinal category score of the X variable for the unit j of cluster i, by discretizing Qij=ai+eijX into one of the K ordered categories. Here, eijXNormal0.1,1 independently for all j=1,2,3…,ni++. In the discretization procedure, the cut points defining the K ordered categories of the X variable are based on the empirical equal‐probability quantiles that ensure balanced frequencies across all the categories. Here, Xij is assigned a value from 1,2,3…,K equivalent to the rank of the X‐category. Then, we generate Yij, the ordinal category score of the Y variable for the unit j of cluster i. This is done, similar to Xij, by the discretization of Pij=qi+eijY+δXij into one of the G ordered categories through empirical equal‐probability quantiles. Here, eijY~Normal0,2 independently for all j and δ is the parameter controlling the degree of association between the two ordinal variables X and Y. In case of δ=0, we have no association between the two ordinal variables which represent our null hypothesis. On the other hand, with an increase in the absolute value of δ, the strength of the association between the two variables increases. In this simulation, we have considered different choices of δ. Also, Yij is assigned a value from 1,2,3…,G equivalent to the rank of the Y‐category. In this way, we generate ni++ pairs of XijYij in each cluster i where 1≤i≤M. Note that the cluster size ni++, in a cluster i, is correlated with the variables X and Y through the random cluster effects ai and qi, respectively. This results in a clustered ordinal data with informative cluster size.
In this simulated setting, we have considered different choices for the number of clusters M, namely, 25, 50, and 100, which would represent small, moderate, and large sample scenarios, respectively. For each of the three choices of M, we have considered different choices for the number of X and Y categories, i.e., K and G. In this section we present the results in terms of K×G contingency tables by choosing values of both K and G from the set 2,3,4. This allows us to have a variety of contingency table settings that include equal as well as unequal number of categories in the two ordinal variables. In each of these simulated settings, we obtain the empirical size or type‐I error rate and the empirical power of our proposed test along with that of the competing GMH and GDL tests. The empirical type‐I error rate of a test is calculated as the proportion of rejections (p‐value < 0.05) in the Monte‐Carlo iterations when the data is generated under the null hypothesis model, i.e., δ=0. The empirical power of a test is obtained as the proportion of rejections, in the Monte‐Carlo iterations, for a value of δ≠0, i.e., under the alternative hypothesis. The results from this simulation setting are presented as two different cases as follows.Case 1At least one of the two ordinal variables is binary.
Here, we consider the situation where the value of K is 2, i.e., the variable X is binary. The other variable can have two or more ordered categories, i.e., G can have any value from the set 2,3,4. In these combinations, the ordering of the two categories of the binary variable X is not expected to have any additional significant impact on the testing of association or independence. Additionally, this set of choices for the two‐way contingency table would include the 2×2 scenario where both variables have only two categories and they can be essentially treated as two nominal categorical variables disregarding their ordinality. Hence, this setting is in line with the GDL test since GDL test assumes the variables to be nominal categorical variables without considering any specific ordering of its categories.
Table 1 shows the empirical size (type‐I error rate), along with its 95% confidence interval, for all three tests under study for different choices of M and K×G combinations. From this table, we find that the empirical size of the proposed test is close to the nominal size of 0.05 for the different combinations of K×G in small, moderate, and large number of clusters. The GMH test is also consistent in maintaining the nominal size of 0.05. On the other hand, the GDL test tends to be more conservative than the other two tests, especially for the small M and G>2. Figure 1 shows the empirical power performances of all the three tests. The empirical power curve is computed as a function of the association strength measure δ. Power values of all the three tests increase with increase in the values of δ and M. From this figure, we see that the power of our proposed test, for any δ≠0, is always the highest among the three tests for all the choices of M and G. The GDL test has the lowest power in all the scenarios apart from the 2×2 scenarios where the power performances the GMH test and the GDL test are similar. Overall, in this setting, our proposed test is the one with the highest power while maintaining the nominal type‐I error rate.Case 2Both ordinal variables have more than two categories.
**TABLE 1: Empirical size (95% confidence interval) of the proposed test, GMH test, and GDL test from Section 3.1 when K
2 and G≥2 in clustered data with ICS.**
Empirical power (rejection proportion) of the proposed test, GMH test, and GDL test from Section 3.1 when K=2 and G≥2 in clustered data with ICS.
Here, we consider the results of the simulation scenarios consisting of 3×3, 3×4, and 4×4 contingency tables. Table 2 shows the empirical size (type‐I error rate), and the corresponding 95% confidence interval, of all three tests under study for different choices of M. From this table, we find that our proposed test closely maintains the target type‐I error rate for different numbers of clusters and contingency table configurations. The same can be said about the GMH test. However, the GDL test seems overly conservative, particularly when dealing with a small or moderate number of clusters and many ordinal categories. Figure 2 shows the empirical power performances of the three tests for different number of clusters and contingency table settings. The power values of all the three tests increase with the increase in the number of clusters as well as with an increasing δ. However, our proposed test dominates the other two tests, in terms of power, with its power values being higher than the other two in all the three contingency table settings for any given choice of δ≠0 and M. The GDL test has the lowest power values among the three tests in all the scenarios with its power being extremely low for the setting M=25. This highlights that GDL test may not be a suitable candidate in case of a small number of clusters, especially for M<30, and it needs a larger M than the other two tests to reach its asymptotic power.
Empirical power (rejection proportion) of the proposed test, GMH test, and GDL test from Section 3.1 when K>2 and G>2 in clustered data with ICS.
In conclusion, through these simulations we find that our proposed test is the best performing method maintaining the nominal type‐I error rate while producing higher power than the existing alternative tests for identifying association between ordinal variables in a clustered data with informative cluster size.
Clustered Data Without ICS
3.2
For this simulation setting we generate the cluster size ni++, in a cluster i, in a different way from the previous simulation setting 3.1 so that there are no impacts of the random cluster effects ai and qi on the cluster size. Specifically, for 1≤i≤M, ni++−1~Poisson20exp0.5 while the two sets of ordinal scores, Xij and Yij (1≤j≤ni++), are generated in the same way as in the previous simulation setting 3.1. Since the random cluster effects, ai and qi, were the only sources of association between the cluster size and the ordinal categorical variables in the previous simulation setting, generating ni++ independent of ai and qi made the outcome variables independent of the cluster size in a cluster i. Hence, the clustered data generated in this simulation setting is devoid of ICS.
Table 3 shows the empirical size (type‐I error rate), with its 95% confidence interval, of the proposed test as well as that of the GDL test and the GMH test in clustered data without any ICS. We see that our proposed test and the GMH test have comparable size values, although the proposed test appears to be more liberal at M=25 compared to the higher values of M. On the other hand, the GDL test continues its pattern of conservative performance with its empirical size consistently remaining way below the target 0.050 mark, especially for M=25 and 50. This is further reflected in Figure 3 where we compare the power performances of the three tests for different choices of δ. The GDL, unsurprisingly, has the lowest power out of the three, while our proposed test has the highest power values, for all choices of the effect size δ in all the combinations of K×G and different number of clusters (M). While the power of the GMH test is still less than that of our proposed test even in the absence of ICS, the differences between the two sets of power values appear to have reduced in case of large samples (M=100) when compared to the results of the clustered data with ICS. This difference, however, continues to be substantial in small and moderate samples.
Empirical power (rejection proportion) of the proposed test, GMH test, and GDL test from Section 3.2 when K>2 and G>2 in clustered data without ICS.
Therefore, in conclusion, our proposed test is the best performing method even if the cluster sizes are not informative and, hence, can be trustfully used for ordinal association testing in any clustered data.
Real Data Analysis
4
In this section, we illustrate the application of our proposed test using a real‐world cluster‐randomized clinical trial data. The data analyzed in this section arises from the Kerala Diabetes Prevention Program (K‐DPP) [25]. This is a lifestyle‐intervention program that aimed to prevent the disease progression of, or reduce the degree of morbidity associated with, Type‐2 diabetes mellitus (T2DM) in an at‐risk population in a populated district of the state of Kerala in India. This study was adapted to a rural India population with the goal of benefiting from lifestyle intervention cures in a low‐income or middle‐income population similar to that achieved in the evidence‐based peer‐driven lifestyle intervention programs in high‐income countries like Australia, Finland, and United States. In the K‐DPP trial, the primary outcome was diabetes status or incidence, while several other secondary outcomes or variables including, clinical or biochemical outcomes (e.g., body‐mass index, blood pressure, cholesterol levels etc.), behavioral variables (e.g., alcohol consumption, tobacco usage, physical work), and sociodemographic measures (e.g., education level, occupation) were also considered. In this trial, 60 polling areas or subdivisions were randomized into the two arms, control and intervention, under equal allocation ratio. This resulted in 30 subdivisions, having 507 participants, being randomized to the control arm while the other 30 subdivisions, with 500 participants, receiving the intervention. Therefore, the subdivisions were treated as clusters with 30 clusters in each arm of the trial. Data was collected at baseline, 12 months, and 24 months. In our analysis, we focus on studying the association of the primary diabetes outcome with two other ordinal variables, namely, BMI category and physical work status.
Being a cluster‐randomized trial, all the participants belonging to a given cluster (subdivision) are placed in the same arm of the trial. However, the number of participants in a cluster, i.e., the cluster size, varied from one cluster to another ranging from 9 to 24. Therefore, clusters with more participants, i.e., larger subdivisions, contribute more data points to the marginal analysis than smaller clusters or subdivisions. In this case, if an outcome, say, diabetes incidence, is correlated to the cluster size, then there would be an imbalance or bias in the contributions between the diabetic population and the non‐diabetic populations. This is where the cluster size becomes informative, i.e., we can have ICS in the clustered data. This is a possible scenario in the K‐DPP trial data since the quality of lifestyle and healthcare vary widely among the different subdivisions (clusters) of a state. An indication of ICS in this trial can also be seen in Figure 4. We have used the primary outcome of diabetes status which has three ordinal categories (levels): “Normal,” “Prediabetes,” and “Diabetes,” based on the American Diabetes Association (ADA) classification. In Figure 4, we have categorized the 60 subdivisions into three categories of “small,” “medium,” and “large” subdivisions, using the tertiles of the cluster (subdivision) sizes. It can be observed from the stacked bar charts in Figure 4 that the proportion of individuals having diabetes or prediabetes tend to be decreasing with the increase in the subdivision size. In other words, the smaller subdivisions tend to have higher proportions of diabetes and prediabetes than the larger subdivisions. This pattern is consistent in all the three time points (baseline, 12 months, and 24 months) of the study. Hence, we can suspect that the clustered data generated from the K‐DPP trial has a potential ICS scenario. This feature needs to be taken into account when testing association between diabetes status and other important ordinal variables.
Figure showing the distributions of diabetes status categories by subdivision sizes at different time points of the K‐DPP trial.
We apply our proposed methodology, that can account for ICS, for testing association of diabetes status and different ordinal outcomes mentioned before. We also apply the traditional GMH test for ordinal association testing to check the extent to which both methods agree or disagree in their results. In all the analyses, a p‐value less than 0.050 was assumed to be significant while a p‐value between 0.050 and 0.100 was considered as marginally significant. We have tested the associations, based on the 60 clusters combining the two arms of the trial. We test these associations at baseline and at the last follow‐up (24 months). The diabetes status has three ordered categories of “Normal” or non‐diabetes, “Prediabetes,” and “Diabetes.” The body‐mass index or BMI categories are normal, overweight, and obese. The physical work status involves two categories, namely, vigorous and non‐vigorous work. The results of the association testing are given in Table 4. From the diabetes‐BMI association testing at baseline, the GMH test shows marginally significant association while our proposed test does not show any significant association. However, at 24‐months, both GMH and the proposed test identify significant association between diabetes status and BMI levels. At this point, positive values of both test statistics indicate that higher BMI levels tend to be associated with worse diabetes outcomes. From the association testing results of diabetes and vigorous physical activity status, in Table 4, we find that, at baseline, the new test shows marginally significant association between the two ordinal variables, while the GMH test does not show any form of significance. On the other hand, from the 24‐months trial data, our test identifies significant association between diabetes status and physical activity while the GMH shows marginal significance. Based on the 24‐month data, it appears that vigorous physical work is associated with better (lower) diabetes outcomes as indicated through the negative test statistic values for both tests.
Discussion
5
In this article, we have proposed a new nonparametric test for testing association between two ordinal variables in clustered data. Our test can address the complex issue of informative cluster size (ICS) where the outcome from a cluster is correlated with its cluster size. None of the existing nonparametric tests for marginal ordinal association account for ICS, resulting in biased or suboptimal inference in clustered data as shown in our simulation studies. Our test outperforms the classical marginal ordinal association test as well as the existing test for the association of categorical (nominal) outcomes in clustered data with ICS. Even if the cluster size is not informative, our proposed test has been shown to be competitive with the existing tests in terms of accurately detecting ordinal association. We have also demonstrated a real‐life application of our proposed test using cluster‐randomized trial data for a diabetes intervention.
In the construction of the new test, we have applied the idea of identifying monotonic ordinal associations through rank‐based correlations. An alternative approach of identifying association between ordinal variables could be based on Kendall's τb measure. A comparison between the tests implementing the rank‐based measure and the Kendall's τb measure would be an interesting future project in the context of clustered ordinal association testing under ICS.
In some clustered data, there could be another level of informativeness, in addition to ICS, due to the presence of multiple groups of units within the same cluster. In that case, the number of units belonging to a group in a cluster can be correlated with the outcome from that group in that cluster. This scenario is known as the informative intra‐cluster group size [12, 26]. We plan to extend our ordinal testing mechanism for ICS to clustered data with informative intra‐cluster group size in a future project.
In this article, we introduced a new nonparametric test of association between ordinal variables in clustered data that accounts ICS while remaining robust and model‐free. However, if a researcher's aim extends beyond marginal ordinal association to include modeling an ordinal outcome in clustered data with ICS while adjusting for other continuous or non‐categorical covariates (or their effects), the method of Mitani et al. [18], which is based on a proportional odds model assumption, is an appropriate choice. While our current article is limited to testing only the marginal association between ordinal variables, in future work, we plan to extend this procedure to incorporate the effects of other continuous and non‐categorical covariates, potentially via a model‐based approach comparable to the Mitani et al. [18] method.
Funding
The authors have nothing to report.
Conflicts of Interest
The authors declare no conflicts of interest.
Supporting information
Table S1: Average bias (Monte‐Carlo based) of the proposed ordinal association estimator ρ^c, under true H0 of no association, for different choices for 𝑀 and the combinations of 𝐾×𝐺 contingency table under the simulation from Section 3.1. Table S2: Average jackknife estimate of the bias of the proposed ordinal association estimator ρ^c, under true H0 of no association, for different choices for 𝑀 and the combinations of 𝐾×𝐺 contingency table under the simulation from Section 3.1.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1J. Nevalainen , H. Oja , and S. Datta , “Tests for Informative Cluster Size Using a Novel Balanced Bootstrap Scheme,” Statistics in Medicine 36, no. 16 (2017): 2630–2640.28324913 10.1002/sim.7288 PMC 5461221 · doi ↗ · pubmed ↗
- 2S. R. Seaman , M. Pavlou , and A. J. Copas , “Methods for Observed‐Cluster Inference When Cluster Size Is Informative: A Review and Clarifications,” Biometrics 70 (2014): 449–456.24479899 10.1111/biom.12151 PMC 4312901 · doi ↗ · pubmed ↗
- 3B. C. Kahan , F. Li , B. Blette , V. Jairath , A. Copas , and M. Harhay , “Informative Cluster Size in Cluster‐Randomised Trials: A Case Study From the TRIGGER Trial,” Clinical Trials 20, no. 6 (2023): 661–669.37439089 10.1177/17407745231186094 PMC 10638852 · doi ↗ · pubmed ↗
- 4E. B. Hoffman , P. K. Sen , and C. R. Weinberg , “Within‐Cluster Resampling,” Biometrika 88 (2001): 1121–1134.
- 5J. M. Williamson , S. Datta , and G. A. Satten , “Marginal Analyses of Clustered Data When Cluster Size Is Informative,” Biometrics 9 (2003): 36–42.10.1111/1541-0420.0000512762439 · doi ↗ · pubmed ↗
- 6S. Datta and G. A. Satten , “Rank‐Sum Tests for Clustered Data,” Journal of the American Statistical Association 100, no. 471 (2005): 908–915.
- 7S. Datta and G. A. Satten , “A Signed‐Rank Test for Clustered Data,” Biometrics 64, no. 2 (2008): 501–507.17970820 10.1111/j.1541-0420.2007.00923.x · doi ↗ · pubmed ↗
- 8D. Lee , J. K. Kim , and C. J. Skinner , “Within‐Cluster Resampling for Multilevel Models Under Informative Cluster Size,” Biometrika 106, no. 4 (2019): 965–972.