Recovering missing features in nonnegative matrix factorization via generalized singular value decomposition
Youdong Guo, Timothy E. Holy

TL;DR
This paper introduces a new method to recover missing components in nonnegative matrix factorization using generalized singular value decomposition, improving efficiency and accuracy.
Contribution
GSVD-NMF efficiently recovers missing components in under-complete NMF without rerunning from scratch, using generalized singular value decomposition.
Findings
GSVD-NMF effectively recovers multiple missing components in under-complete NMF.
The method reaches better local optima and is compatible with various NMF algorithms.
Efficient rank expansion is achieved by augmenting components rather than rerunning NMF.
Abstract
Nonnegative matrix factorization (NMF) is widely used to separate mixed sources into components. Algorithms for NMF require choosing the rank in advance, and if the results are unsatisfying, one typically executes NMF again with a different rank. To make NMF more interactive, here we introduce GSVD-NMF, a method that proposes new components based on the generalized singular value decomposition (GSVD) to address discrepancies between initial under-complete NMF results and the SVD of the original matrix. Simulation and experimental results demonstrate that GSVD-NMF often effectively recovers multiple missing components in under-complete NMF, with the recovered NMF solutions frequently reaching better local optima. The results further show that GSVD-NMF is compatible with various NMF algorithms and that directly augmenting components is more efficient than rerunning NMF from scratch with…
Click any figure to enlarge with its caption.
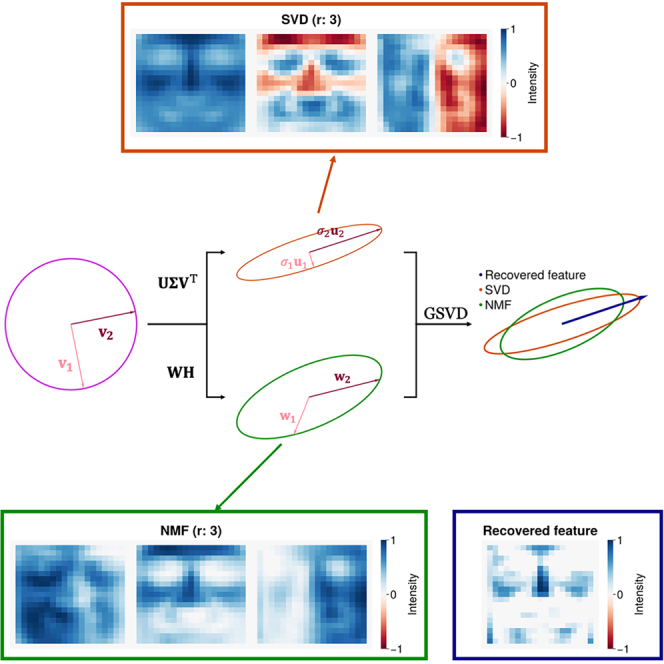 Figure 1
Figure 1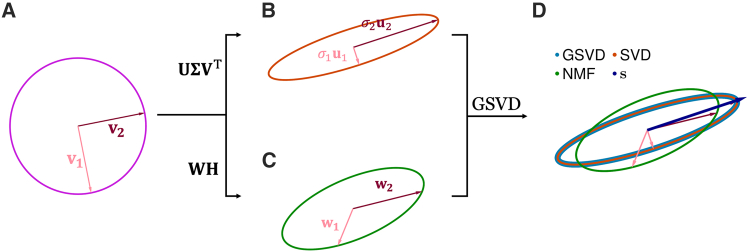 Figure 2
Figure 2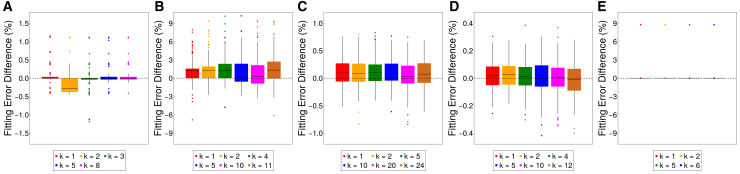 Figure 3
Figure 3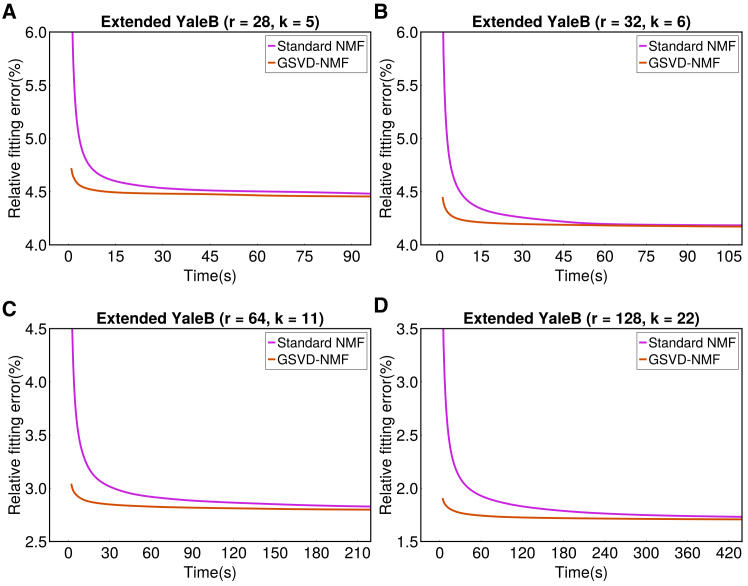 Figure 4
Figure 4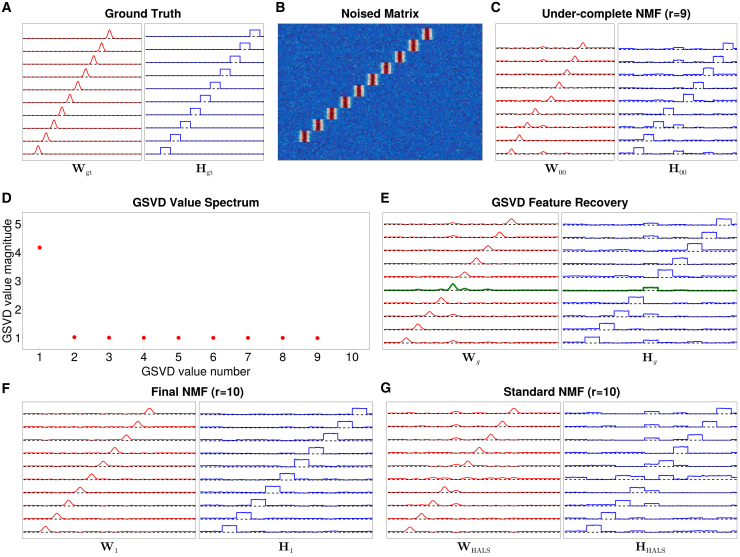 Figure 5
Figure 5 Figure 6
Figure 6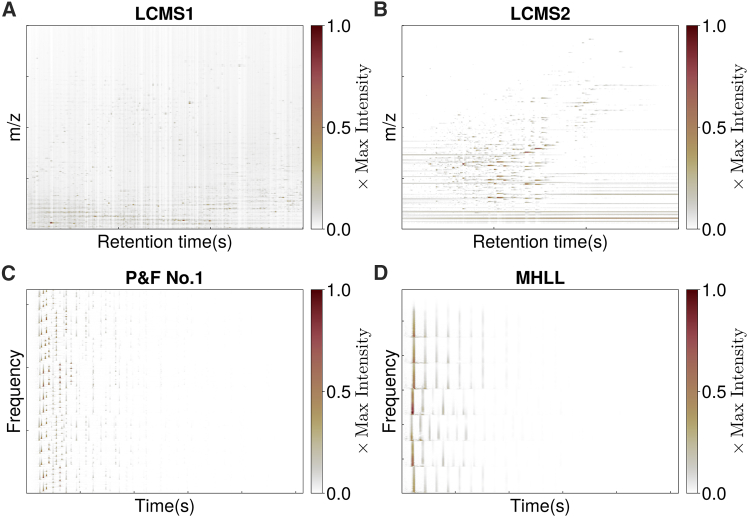 Figure 7
Figure 7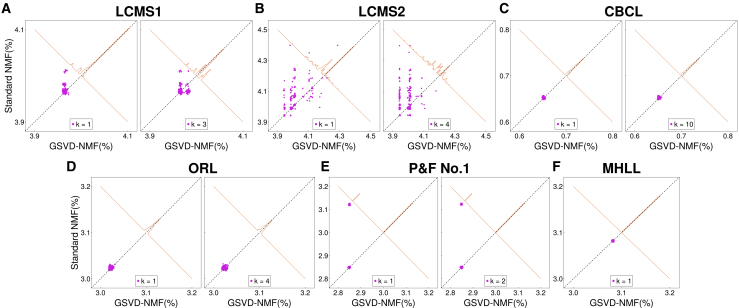 Figure 8
Figure 8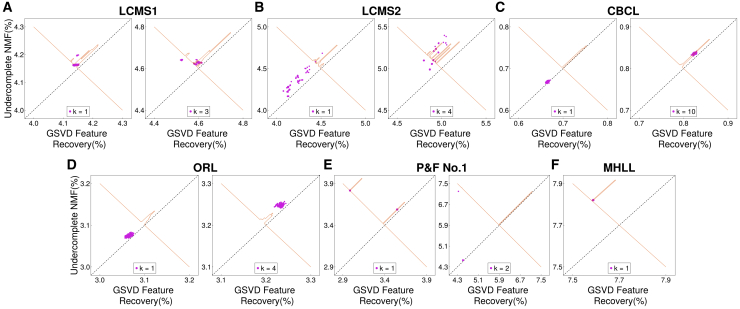 Figure 9
Figure 9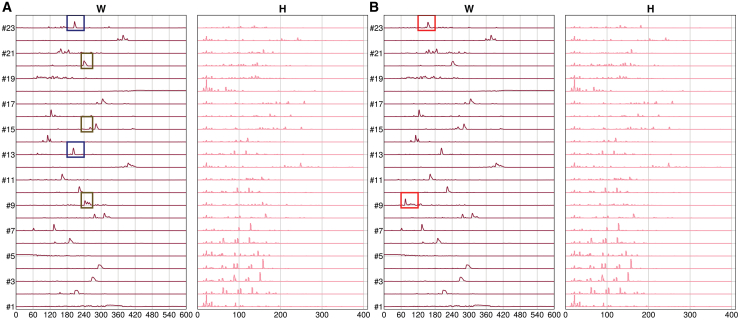 Figure 10
Figure 10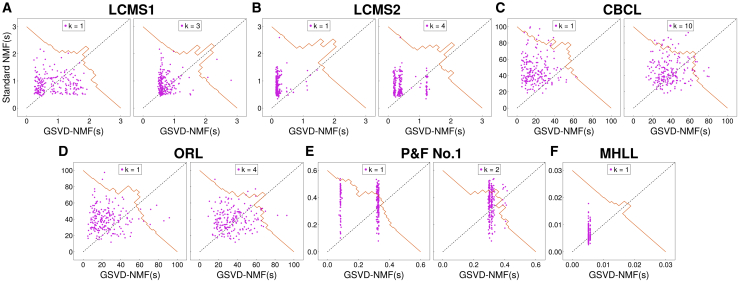 Figure 11
Figure 11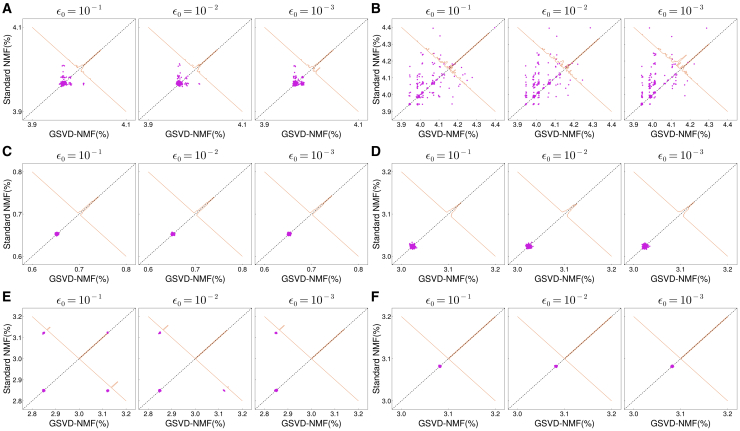 Figure 12
Figure 12Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTensor decomposition and applications · Face and Expression Recognition · Matrix Theory and Algorithms
Introduction
The exponential growth of data, driven by high-throughput technologies, represents a significant opportunity and challenge. To uncover hidden structures within these high-dimensional datasets, nonnegative matrix factorization (NMF) has become a widely-used tool. NMF is an effective unsupervised machine learning approach for extracting latent features in circumstances where plausible features, and their loadings, are constrained to be nonnegative. It has been widely used in the analysis of many types of data.1^,^2^,^3^,^4^,^5^,^6^,^7^,^8^,^9^,^10^,^11^,^12 Compared to other widely used source separation methods, such as PCA and ICA, NMF offers two key advantages: it does not require the assumption that components are uncorrelated or independent, and its results are intuitive and easy to interpret.13 Mathematically, an NMF is given by
where and are two nonnegative matrices. is the number of components, which ideally represents the actual number of features in the data matrix. For example, individual features can refer to attributes such as the pixel-wise intensity of a cell in a microscopic image,14 the ion-count vs. mass-to-charge ratio of a compound in a mixed mass profile15 or the participation of brain areas in a particular network in cortical functional magnetic resonance imaging.16 To obtain and in Equation 1, here we focus on NMF without any additional regularization, minimizing the Squared Euclidean Distance (SED) of the original matrix and the factorization
where . The SED is one of the most widely used objective functions for NMF, and a variety of algorithms have been developed to minimize it.1^,^17^,^18^,^19
Although NMF is widely used, in some circumstances it can fail to identify an accurate and comprehensive representation of the data features. NMF is NP-hard15^,^20 and performing an NMF-based analysis requires the determination of a suitable factorization rank. Various methods have been proposed to learn the factorization rank , but no known procedure results in an unambiguous answer.10^,^20^,^21 In practice, researchers often explore a range of component numbers to identify the most interpretable or meaningful results.22^,^23^,^24 Moreover, we recognize that in real-world problems, the correct number of components may be undefined, and the usefulness of the decomposition is assessed in part by how well the resulting components explain the underlying phenomena under study. For example, in calcium imaging microscopy, different regions of a cell may exhibit distinct temporal dynamics, and thus a factorization where the number of components equals the number of cells may actually fail to assign one component per cell, if highly-active cells are poorly described with a single component. If changing component number means that NMF has to be restarted from scratch, producing stable and meaningful features can require considerable trial-and-error, and thus be time-consuming for large datasets.
Given that the “true” factorization rank is poorly defined, in this manuscript we focus on a more practical problem: supposing that one decides to change the rank of an existing factorization, how might one do so efficiently? Several methods start with an excess number of components and then prune them. Sparse regression-based NMF pruning removes unnecessary components through sparsity constraints.25 These methods do not heavily rely on robust estimation of the number of components, as unnecessary components are effectively reduced to zero. However, they introduce an additional sparsity coefficient, which must be learned or tuned separately. Moreover, different approaches may produce varying results when applied to real-world datasets.26^,^27^,^28 Another approach that relies on starting with excess components was recently developed by Guo et al.,29 which progressively merges redundant components to achieve better local optima while dynamically reducing the factorization rank.
The alternative to rank-reduction is rank-expansion, i.e., to begin with a smaller set of components which grows as needed. With an initially undercomplete representation, features may be missed or integrated into other components, so this approach requires the ability to add features in a manner that addresses deficits in the current factorization. Rank-one nonnegative matrix underapproximation19^,^30 (NMU) incrementally adds one component to an existing and , and then re-optimizes the augmented factorization. Supposing and satisfy , NMU recursively expands the rank by one, adding minimizing
where and . This rank-expansion is performed for . With NMU, the residual is required to be nonnegative, which must be enforced as a constraint during optimization.19^,^31^,^32 Because of these constraints and the recursive nature of updating, NMU is computationally expensive, and its convergence remains undemonstrated.33
In this paper, we introduce an alternative to NMU called GSVD-NMF, which uses the generalized singular value decomposition (GSVD) to incrementally grow and augment components for an existing under-complete NMF solution. We use the GSVD to discover the main directions of discrepancy (corresponding to generalized singular values most different from one) between the SVD of the data matrix and the existing NMF of the same rank. As SVD provides a globally optimal matrix factorization, and GSVD identifies conjugate directions that extremize the signal-to-signal ratio, this approach is maximally informative about discrepancies within the subspace spanned by the SVD. We employ a similar truncation as used in NNDSVD34 to enforce the nonnegativity of the augmented components.
Compared to NMU, GSVD-NMF introduces two important innovations: (1) We employ GSVD to propose new directions and refine them using standard NMF, providing a deterministic initialization to the missing-component problem. (2) Using nonnegative least squares, we introduce the “new” components while modulating the amplitude of “old” components, thus making room for the new components to contribute substantively to the factorization without any need for constrained optimization.
Although we use the word “incremental” our method is incremental in rank, not data: we assume that the underlying reference matrix remains constant. This is different from incremental (online) NMF,35^,^36^,^37^,^38^,^39^,^40^,^41^,^42^,^43^,^44^,^45 where new data points arrive over time and the model is updated while keeping the rank fixed or adjusting it based on the newly added samples. Given that these are two distinct uses of the word “incremental” we do not compare our method to ones which focus on online data.
The entire pipeline is tested through simulations and on multiple real-world datasets with different NMF algorithms for source separation. The results demonstrate that our method effectively initializes new components for under-complete NMF, with the augmented solutions achieving better local optima and greater efficiency than standard NMF approaches. Moreover, starting from under-complete NMF (deliberately setting rank number smaller than the number of features in ), the proposed method can help NMF converge to better local optima. A key practical advantage is that the under-complete NMF can be computed with a relaxed convergence tolerance, greatly reducing runtime while still enabling accurate feature recovery. Finally, the proposed method allows one to efficiently expand the number of components, which can be convenient and effective for interactive analysis of large-scale data.
Results
The mathematical foundation of GSVD-NMF is described in STAR Methods. In this section, we demonstrate the effectiveness of GSVD-NMF and compare its performance with standard NMF on synthetic and real-world data.
Concept and illustrative examples
Our concept is most easily understood by viewing matrices as linear transformations that act on vectors in the domain space, which in Figure 1 will be represented as points in the unit disc (magenta). Figure 1B represents the action of the SVD of on a unit disc and Figure 1C is action of the NMF of on the unit disc, projected into the subspace spanned by the SVD. We model an imperfect NMF, given by and , which is a relatively poor approximation of our chosen . This is revealed as a difference between the resulting ellipses in the range-space (Figure 1D). Our primary objective is to identify new directions that can reshape the NMF solution to more closely approximate the SVD solution, as exemplified by the vector in Figure 1D.Figure 1. Concept of GSVD-based feature recovery for NMF ( case)(A) A unit disk (magenta) and its basis vectors , .(B) Under multiplication by , points in the magenta disk map to points in the brown ellipse; key elements of ’s SVD are denoted.(C) An inexact NMF factorization maps to a slightly different ellipse (dark-green), indicating an imperfect match to .(D) GSVD-NMF suggests new directions that maximally capture the discrepancy between the true mapping (SVD ellipse) and the NMF mapping. Under multiplication by , the magenta disk is mapped to the blue ellipse (GSVD), which aligns with the true SVD ellipse.
The direction shown in Figure 1D corresponds to the new column in produced by solving Equations 5 and 14. Together with adjustments in the amplitudes of the existing components, the augmented solution maps the unit disc onto the blue ellipse (GSVD), perfectly replicating the SVD ellipse (brown). The perfect recovery in this case is an artifact of restricting ourselves to two dimensions for visualization, but it does demonstrate that the GSVD step can perfectly recover the missing feature direction in this example.
For a slightly more realistic example, we illustrate the ability of GSVD-NMF to discover “missing” components on synthetic data with 10 ground truth components, which are shown in Figure 2A. Running HALS,17 one of the most accurate and widely-used NMF algorithms,20^,^46 with 10 components initialized using NNDSVD,34 on with Gaussian noise (as shown in Figure 2B) resulted in an inaccurate solution (Figure 2G). The solution included multiple feature components and a noise component, with one feature failing to capture an independent component.Figure 2A synthetic example used to illustrate GSVD-NMF for feature recovery , displaying and (A) Ground truth (each line depicting one column) and (each line depicting one row) with 10 features.(B) generated as with added Gaussian noise.(C) Standard NMF results (HALS) with 9 components.(D) The generalized singular value spectrum from Equation 7.(E) Feature recovery results ( , ), with the new component in green.(F) Final NMF results ( , ).(G) Standard NMF results initialized with NNDSVD. Despite knowing the correct number of components, several features are incompletely separated, and the solution is much worse than (F).
To exploit GSVD-NMF, we started from the solution returned by HALS with 9 components, one less than the number of ground truth components, obtaining the result shown in Figure 2C. One sees that several components of the ground truth are blended, Figure 2C. To test for missing information, we compared the 9-component NMF with a 9-component SVD using GSVD as described in STAR Methods. This identified a “missing” direction related to the first (large-magnitude) generalized singular value, Figure 2D. Note that this analysis provides support for only one additional component. The component recovered by the feature recovery step in the pipeline (Figure S1) is shown in green in Figure 2E. After using HALS to optimize this 10-component augmented factorization, the final NMF result, shown in Figure 2F, faithfully represents each ground truth component. Therefore, GSVD-NMF can recover the missing component from under-complete NMF, and in this case performs better than naive HALS even when the correct number of components is known and a high-quality initialization strategy is used.
For an even more realistic example, Figure 3 illustrates the process of adding a single component to a rank-3 NMF of the CBCL face image dataset. The new component (green box, panel (a)) captures meaningful facial structures (principally, the nose and cheeks) that were under-emphasized in the rank-3 NMF solution. Subsequent NMF refinement (panel (b)) redistributes features among the four components, while maintaining an obvious connection to the initial state in panel (a). This example clearly demonstrates how GSVD-NMF can reveal and separate features that standard NMF fails to distinguish at lower ranks.Figure 3GSVD-NMF feature recovery illustrated on the CBCL face image dataset ( component)(A) A rank-3 NMF is augmented with one additional component (green box), while scaling the old components (orange box) by (Equation 13).(B) Final NMF result obtained by refining the initialization in (A).
Experimental results
Datasets
We also tested the performance of GSVD-NMF on seven real-world datasets: two liquid chromatography mass spectrometry (LCMS) datasets, three face image datasets, and two audio datasets. The LCMS datasets are shown in Figures 4A and 4B. Two of the face image datasets, the MIT CBCL face images47 and the ORL face images from AT&T Laboratories Cambridge, were analyzed systematically using the same procedures as for the LCMS and audio datasets. The audio datasets feature the first 30 s of “Prelude and Fugue No.1 in C major” by J.S. Bach, played by Glenn Gould and the first measure of “Mary had a little lamb”, both of which are taken ifrom Leplat et al., Cichocki and Phan, Lin8^,^17^,^18 and illustrated in Figures 4C and 4D. The third face image dataset, Extended YaleB face images, is used as an example of “big data”. To demonstrate the computational advantages of GSVD-NMF; for this dataset, we only report results with deterministic initialization and compare the resulting convergence trajectories.Figure 4. Four of the real-world datasets used for experiments(A) LCMS1.(B) LCMS2.(C) The amplitude spectrogram of “prelude and fugue no.1 in C major”.(D) The amplitude spectrogram of “Mary had a little lamb.” The colorbar label represents the intensity at each pixel, normalized by the maximum intensity of the matrix. For the LCMS data, the intensity corresponds to the ion count. Higher values indicate a greater number of ions.
Details about all seven real-world datasets are presented in Table 1 and the column lists the “real” number of features we selected for this paper. Where possible, these choices were based on previous literature with the same datasets.8 For the LCMS datasets not previously studied, we tested several rank-selection methods.10^,^20^,^48 Because these methods gave divergent answers, ultimately we selected one among the recommended values based on visual inspection.Table 1. Description of datasetsNo.DatasetsSize 1LCMS1 172LCMS2 233MIT CBCL face images 494ORL face images 255Prelude and Fugue No.1 in C major (P&F No.1) 136Mary had a little lamb (MHLL) 37Extended YaleB face images (large matrix test) 28, 32, 64, 128
GSVD-NMF recovers components for under-complete NMF
While the illustrations above used a direct approach—solving Equations 5 and 14—to initialize new rows in and columns in , this approach was computationally expensive on larger datasets. Henceforth, we adopt an alternative accelerated initialization for : starting with Equation 16 and following the pipeline shown in Figure S1).
The comparison of local optima achieved by standard NMF and GSVD-NMF is given in Figure 5 (comparison with HALS) and Figure S2 (comparison with (GCD, ALSGrad, and MU) in the supplementary materials. Here, we show the results for (a single new component) and (recovering of the number of components in the under-complete NMF). Both are evaluated via relative fitting error, with the horizontal axis representing GSVD-NMF and the vertical axis standard NMF.Figure 5. Comparing the fitting error of standard NMF (HALS) and GSVD-NMF on real-world data(A–F) Left and right panels corresponds to a different number of components recovered by GSVD-NMF. (A) LCMS1. (B) LCMS2. (C) CBCL. (D) ORL. (E) prelude and fugue no.1 in C major. (F) Mary had a little lamb. The scatterplot compares the relative fitting errors of standard NMF and GSVD-NMF against the original matrix across different NMF algorithms. Each magenta scatter point represents an individual comparison from a single random initialization, with its position indicating the relative fitting error for standard NMF (vertical axis) and GSVD-NMF (horizontal axis). The brown line illustrates the histogram of the perpendicular distances from the scatter points to the diagonal, summarizing the overall distribution of error differences. For most tests, GSVD-NMF produces an equal or better fit.
Figures 5 and demonstrate that NMF converges to single or multiple stationary points across all datasets using all four algorithms. Most are local minima, but for the MU algorithm some clusters in Figure S2C contained solutions that could be substantially improved via HALS; since HALS optimizes Equation 2 strictly by descent, these MU-solutions did not lie at the bottom of a local basin. For all algorithms, most points in Figures 5 and are above or along the diagonal line, indicating that the recovered solution from under-complete NMF by GSVD-NMF either matches or improves the convergence of NMF in the majority of cases. This conclusion was true both when adding a single component or when adding multiple components simultaneously .
Although we show in the STAR Methods section that the fitting error cannot increase after inserting new components—because the under-complete NMF solution is always embedded within the augmented solution—we empirically verify this property here. The scatterplots in Figures 6 and S3 (supplemental information) compare the fitting errors of the re-initialized solutions (after component insertion but before NMF refinement) with those of the under-complete NMF results. Empirically, the figure shows that GSVD-based component injection never increases the fitting error, and subsequent NMF refinements converge quickly from these initializations. Although the improvement can be subtle in some datasets, the re-initialized solutions consistently achieve equal or lower error than the under-complete NMF, as indicated by points lying above the diagonal (e.g., the case for “Prelude and Fugue No. 1 in C major”). This confirms that no case arises in which all newly added components collapse to zero.Figure 6. Improvement in objective value using the GSVD-NMF featuresLeft and right panels corresponds to a different number of components recovered by GSVD-NMF(A) LCMS1.(B) LCMS2.(C) CBCL.(D) ORL.(E) Prelude and fugue no.1 in C major.(F) Mary had a little lamb.
We also evaluated whether GSVD-NMF could achieve gains over existing approaches when using deterministic initialization methods such as NNDSVD, NNDSVDa, and NNDSVDar.34 The results are shown in Tables 2 and S1. The NMF solutions recovered by GSVD-NMF are comparable to or better than standard NMF across all datasets and all tested NMF algorithms, whether recovering single or multiple components simultaneously. This outcome demonstrates the perhaps surprising point that GSVD-NMF can improve NMF even when the same SVD components have already been used to initialize NMF.Table 2GSVD-NMF vs. standard NMF (HALS) with deterministic initializationDatasetsFitting error (%): Standard NMF/GSVD-NMF RandomNNDSVDNNDSVDaNNDSVDarLCMS11713.97 0.01/3.97 0.003.97/3.973.97/3.973.97/3.9733.97 0.01/3.97 0.013.97/3.973.97/3.973.97/3.97LCMS22314.06 0.08/4.01 0.064.05/3.994.07/4.01****4.05/3.9944.06 0.08/3.99 0.044.05/4.014.07/4.01****4.05/4.01CBCL4910.65 0.00/0.65 0.000.65/0.650.65/0.650.66/0.65100.65 0.00/0.65 0.000.65/0.650.65/0.650.66/0.65ORL2513.02 0.00/3.02 0.003.02/3.023.03/3.023.02/3.0243.02 0.00/3.02 0.003.02/3.023.03/3.023.03/3.02P&F No.11312.90 0.11/2.85 0.002.85/2.852.85/2.852.85/2.8542.90 0.11/2.85 0.002.85/2.852.85/2.852.85/2.85MHLL313.08 0.00/3.08 0.003.08/3.083.08/3.083.08/3.08Bold entries indicate lower fitting error for GSVD-NMF than standard NMF.
Even when the improvement in relative fitting error over HALS may seem modest (e.g., approximately 3% on LCMS2), it results in substantial differences in the extracted components. Since obtaining these components is typically the actual goal of performing NMF, such improvements may have substantial impact on downstream analyses. Figure 7 presents a comparison between the components derived from standard NMF (HALS) and GSVD-NMF (performed in the recursive way) on the LCMS2 dataset. Specifically, components #9 and #23 (marked with green boxes in Figure 7B) are clearly recovered by GSVD-NMF but are missing in the HALS results. In the HALS decomposition, the features corresponding to component #9 are fragmented across components #20, #15, and #3 (blue boxes in Figure 7A), while GSVD-NMF preserves these components individually. Likewise, component #23 is entangled with component #13 in the HALS output, whereas GSVD-NMF distinguishes #13 as an independent feature (brown box in Figure 7A).Figure 7. Comparison of the factorized components ( , ) obtained from NMF on LCMS2 data using HALS with NNDSVD initializationThe red boxes highlights components captured by GSVD-NMF but missed by standard NMF. The blue and brown boxes indicate a single feature that is split across multiple components in the standard NMF results, whereas GSVD-NMF successfully captures it as a single component. (A) Standard NMF. (B) GSVD-NMF.
Comparison to nonnegative matrix underapproximation (NMU)
As mentioned in the introduction, GSVD-NMF can be compared to NMU, which also iteratively grows the rank of the factorization. To ensure a fair comparison, we started GSVD-NMF with two components and incrementally added one component at each step, matching the sequential nature of NMU. The results are summarized in Table 3, with the full error trajectories versus the number of components shown in Figure S5 of the Supplementary Materials. These trajectories indicate that GSVD-NMF consistently maintains a lower fitting error as the rank increases. GSVD-NMF outperforms all NMU algorithms on all datasets, and matches or beats HALS on all datasets. We suspect NMU’s worse performance on Equation 2 is due to the additional constraint , which may restrict its optimization flexibility.Table 3GSVD-NMF vs. nonnegative matrix underapproximationDatasetsFitting error (%)RNMULNMUPNMUNMU-ADMMGSVD-NMFLCMS16.145.816.038.553.97LCMS26.216.666.4710.723.94CBCL3.031.662.374.090.65ORL5.086.664.5313.563.02P&F No.14.875.374.798.892.85MHLL6.115.606.3010.293.08
Computational performance: GSVD-NMF finds high-quality solutions more quickly
Aside from the quality of solutions, many applications of NMF are sensitive to computational performance. Superficially, one might imagine that GSVD-NMF would increase the computational cost, given the extra steps that include additional optimization runs. To investigate this issue, we measured the time required to augment an existing under-complete solution and compared it to the time required to run NMF again with more components. Specifically, starting from the same initialization we performed NMF twice: once to measure the average time per iteration (which varies with dataset and number of retained components), and a second time to measure the objective value after each iteration until convergence. Measuring these two quantities separately was necessary because computation of the objective value takes much longer than a single iteration of NMF.
The results for random initialization are presented in Figure 8, as a scatterplot comparing the time required to augment components in under-complete NMF by GSVD-NMF versus the time to run NMF from scratch with additional components. The title of each panel within the subplot provides the name of the dataset. Similar to Figure 5, each dot represents a single NMF run with a specific initialization (now measuring run-time rather than objective value), while the brown lines indicate the distribution of distances between each dot and the diagonal. Figure 8 shows that in most cases, initializing new components by GSVD-NMF is generally more efficient than rerunning NMF with extra components. As suggested by the thin vertical clusters that frequently appear in these plots, the time taken for GSVD-NMF augmentation was relatively consistent for each under-complete local minimum, while the times for running NMF from scratch with additional random components varied significantly. The CBCL and ORL face image datasets provide an exception: their GSVD-NMF runtimes do not form tight vertical clusters. This is because the under-complete NMF solutions for these datasets contain many distinct local optima with similar fitting errors, as noted in the study by Guo et al.29 Nevertheless, even in these cases, GSVD-NMF remains more efficient than rerunning NMF from scratch, as indicated by the fact that more points lie above the diagonal.Figure 8. Total runtimes of standard NMF vs. GSVD-NMF with different random initializations(A–F) Each point represents the runtime for standard NMF plotted against the runtime for GSVD-NMF; points above the diagonal indicate shorter runtime for GSVD-NMF. The brown line shows the histogram of the perpendicular distances from the diagonal, summarizing the overall distribution of time differences. (A) LCMS1. (B) LCMS2. (C) CBCL. (D) ORL. (E) Prelude and fugue no.1 in C major. (F) Mary had a little lamb. For most datasets, GSVD-NMF converged to high-quality solutions more quickly.
For deterministic initializations (SVD-based initialization), Figure S4 in the Supplementary materials show the traces of objective value versus time for different initialization methods across four datasets. Each panel’s caption includes the dataset name and the number of new components added. The GSVD-NMF trace represents the final NMF phase used for refinement. The first element in each trace represents the objective value after one iteration. Figure S4 indicates that the final NMF in GSVD-NMF converges faster than standard NMF for both LCMS datasets, face image datasets and “Mary had a little lamb.” In contrast, for “prelude and fugue no.1 in C major,” the convergence performance is similar to or slightly worse than that of standard NMF.
Further zooming into the region around the intersection of the two strategies’ traces reveals that for , the proposed method behaves similarly to standard NMF. However, for , it achieves a slightly lower objective value after a period of slow progress, indicating a minor advantage in the final objective, albeit with slower convergence.
In conclusion, we find that it is generally more efficient to augment a prior solution by GSVD-NMF than it is to run standard NMF from scratch with additional components. Thus, on average, GSVD-NMF improves upon both quality and computational performance.
The performance of each stage in GSVD-NMF is documented in Table 4. It is evident that the “feature recovery” step is highly efficient, representing an essentially negligible portion of the total time across all datasets. Therefore, the efficiency of GSVD-NMF primarily depends on the time allocated to the NMF step in the pipeline. In other words, (or the maximum number of iterations) serves as the main control parameter for the runtime performance of GSVD-NMF.Table 4. Time (mean std) of each stage of GSVD-NMFDatasetsTime Feature RecoveryFinal NMFStandard NMFLCMS11710.0015 0.00010.8561 0.49390.9039 0.338030.0013 0.00010.7209 0.29500.9039 0.3380LCMS22310.0020 0.00020.2220 0.19240.8355 0.317940.0018 0.00020.4750 0.36910.8355 0.3179CBCL4910.0338 0.010219.6774 10.976646.3339 16.4238100.0734 0.087137.9356 13.419846.3339 16.4238ORL2510.3322 0.167724.5752 14.976840.0731 13.982740.4761 0.185834.7749 14.939640.0731 13.9827P&F No.11310.0011 0.00010.2461 0.11330.3616 0.101420.0015 0.00010.3125 0.02290.3616 0.1014MHLL310.0001 0.00000.0052 0.00030.0063 0.0024Bold entries indicate that the GSVD feature recovery step requires substantially less time than the NMF stage.
The choice of ϵ0
A potential additional optimization is based on the observation that GSVD-NMF runs standard NMF twice: once for the initial under-complete NMF and again for the final NMF (Figure S1). So far, we employed the same convergence criterion, in Equation 21, for both NMF runs. Here, we investigate whether one can reduce computation time by relaxing the tolerance of the initial under-complete NMF without sacrificing overall quality.
The effects on solution quality of reducing the stringency of the under-complete NMF steps are shown in Figure 9. Here, we present the results from HALS for NMF with . The tolerance had little effect on the “Mary had a little lamb” dataset. For the other three datasets, the advantages of GSVD-NMF increase with the stringency of , particularly evident in the “prelude and fugue no.1 in C major” dataset. Overall, these results demonstrate that in GSVD-NMF, the under-complete NMF can be run at higher tolerance (lower stringency) but with higher risk of landing in worse local optima. However, at all tested stringencies GSVD-NMF outperforms or matches standard NMF in aggregate. Therefore, based on the results of this section and Figure 5, GSVD-NMF could be considered a general pipeline for performing NMF.Figure 9. The effect of convergence tolerance on final results of GSVD-NMF(A–F) Panels should be compared to those of Figures 5 and , which used . (A) LCMS1. (B) LCMS2. (C) CBCL. (D) ORL. (E) Prelude and fugue no.1 in C major. (F) Mary had a little lamb.
The choice of k
It should be noted that all of the above experiments set or , both of which appear to be broadly successful. In practice, we may wish to add more components simultaneously, rather than iteratively adding one component at a time, to make the whole pipeline more efficient. Thus, it is valuable to investigate the role of on the final results.
The experiment for Figure 5 (200 random initialized trials) was conducted with different . Figure 10 illustrates the difference between the fitting error of standard NMF and that of GSVD-NMF. Consistent with the results in Figure 5, GSVD-NMF finds superior local optimum in most cases on both LCMS datasets and “prelude and fugue no.1 in C major” regardless of . Thus, the choice of is not critical, as a wide range of choices (at least for fairly small values of ) work well.Figure 10. The effect of different (A) LCMS1.(B) LCMS2.(C) CBCL.(D) ORL.(E) Prelude and fugue no.1 in C major. This figure compares the difference in relative fitting error between GSVD-NMF and standard NMF ( - ) across different numbers of augmented components. The boxplot summarizes the distribution of fitting error differences for each case. The box spans the interquartile range (IQR), with the midline marking the median, and the whiskers extending to 1.5 IQR.a Positive values indicate that GSVD-NMF achieves a better fit, while negative values suggest that standard NMF performs better.
Application on large-scale matrix
To further demonstrate the computational advantage of expanding rank via GSVD-NMF rather than re-running NMF from scratch, we conducted an additional experiment on a genuinely large matrix: one pose from the Extended YaleB face dataset (#7 in Table 1), with size (approximately 78 million entries). We tested several target ranks to provide a comprehensive comparison across different factorization sizes. Figure 11 reports the convergence trajectories (objective value vs. time) for GSVD-NMF and standard NMF (300 iterations). The runtime of the GSVD feature-recovery step is included, which shifts the GSVD-NMF curves slightly to the right; however, this overhead corresponds to only one or two NMF iterations (as shown in the Methods section) and is negligible relative to the full optimization. Across all tested ranks, GSVD-NMF converges substantially faster than re-running standard NMF from scratch, and the advantage becomes more pronounced at higher ranks. Overall, the large-scale results are fully consistent with our findings on small and medium-sized datasets: augmenting a prior solution with GSVD-NMF is more efficient than restarting NMF with a larger rank, especially on large matrices where re-initializing and re-optimizing from scratch is costly.Figure 11. Runtimes of standard NMF and GSVD-NMF with NNDSVD initialization on the extended YaleB dataset (large matrix)The plot shows convergence trajectories (objective value vs. time), demonstrating that GSVD-NMF converges faster than re-running standard NMF from scratch.
Discussion
In this work, we introduced GSVD-NMF, a framework for recovering missing features in under-complete NMF. By leveraging the GSVD between the under-complete NMF result and the SVD of the original data, the method identifies latent subspace directions that the under-complete NMF fails to capture and incrementally augments the components to recover these missing features. Experiments on synthetic and real-world datasets demonstrate that GSVD-NMF effectively restores omitted features, achieves comparable or lower reconstruction error than re-running NMF from scratch, and remains robust across a range of added component numbers. Expanding the rank with GSVD-NMF is therefore substantially more efficient than performing a full NMF recomputation. A further practical advantage is its tolerance to relaxed convergence in the initial under-complete NMF. Because GSVD-NMF depends primarily on the subspace structure rather than exact coefficient estimates, the initial factorization can be computed with a loose tolerance, greatly reducing runtime without compromising recovery accuracy. This property makes the method both efficient and flexible for large-scale or exploratory analyses where rank selection and full convergence are expensive. Overall, GSVD-NMF provides an effective and principled mechanism for incrementally expanding the rank of NMF solutions, bridging SVD-based subspace analysis with NMF. It offers a practical route toward adaptive rank growth, improved interpretability, and enhanced computational efficiency in large-scale matrix factorization problems.
Limitations of the study
Our work demonstrates the advantages of GSVD-NMF for adding new components. However, several points remain worthy of further investigation.
First, in this work we used a simplistic criterion for choosing how many components to add, e.g., adding 20% additional components. One promising enhancement might be to monitor the generalized singular value spectrum and identify an “elbow” point that indicates diminishing returns in added components.
Second, as described in the STAR Methods section, the procedures “init H” and “init W″ do not guarantee nonnegativity of the newly added rows and columns in and . To address this, the NNDSVD truncation is applied to enforce nonnegativity of the new components. Developing alternative high-quality truncation strategies, or extending the current approach to ensure nonnegativity more directly, represents a promising direction for future work. One possible strategy is to retain both the positive and negative parts during the NNDSVD truncation stage, re-initialize intermediate components, and subsequently apply the component-merging procedure proposed in29 to reduce them to effective components.
Third, the current formulation assumes continuous-valued input matrices and optimizes the fitting under the SED. For discrete data types, such as count matrices (common in text mining or genomics) or binary matrices (e.g., presence/absence data), the SED may not accurately reflect the underlying statistical noise model. In principle, the GSVD-based feature recovery framework could be extended to these settings by incorporating appropriate objective functions—such as KL divergence objectives—within the same rank-expansion scheme. Investigating such extensions of GSVD-NMF may be another important direction for future research.
Resource availability
Lead contact
Requests for further information and resources should be directed to and will be fulfilled by the lead contact, Youdong Guo ([email protected]).
Materials availability
Not applicable.
Data and code availability
- •Code: all code required for this paper is open-source and available at https://github.com/HolyLab/GsvdInitialization.jl.
- •Data: The datasets analyzed during the current study are available in the Zenodo repository, https://doi.org/10.5281/zenodo.17844816. Original source: LCMS1: available at massIVE: dataset identifiers MSV000089200 and https://doi.org/10.25345/C5KP7TV9T. LCMS2: available at massIVE: dataset identifiers MSV000089747 and https://doi.org/10.25345/C58C9R77T.
- •All other items: Any additional information required to reanalyze the data reported in this paper is available from the lead contact upon request.
Acknowledgments
This work was supported by 10.13039/100000002NIH grants R01DC020034 and R01DC010381 (T.E.H.), and Imaging Science Pathway Fellowship (Y.G., PI: Joseph P. Culver).
Author contributions
Y.G. and T.E.H. developed the method, Y.G. conducted the experiments. Y.G. and T.E.H. analyzed the results. All authors reviewed the manuscript.
Declaration of interests
The authors declare no competing interests.
Declaration of generative AI and AI-assisted technologies in the writing process
During the preparation of this work, ChatGPT was used to refine English usage. After using this tool, the authors reviewed and edited the content and take full responsibility for the content of the publication.
STAR★Methods
Key resources table
REAGENT or RESOURCESOURCEIDENTIFIERDeposited dataThe datasets used for benchmarkhttps://doi.org/10.5281/zenodo.17844816LCMS1, LCMS2, CBCL, ORL, Maryhadalittlelamb, Prelude, CroppedYaleB, RandomSeedsSoftware and algorithmsJulia 1.10.8https://julialang.org/downloads/oldreleases/Programing languageGsvdInitialization.jlhttps://github.com/HolyLab/GsvdInitialization.jlJulia codeNMF.jlhttps://github.com/JuliaStats/NMF.jlJulia codeTSVD.jlhttps://github.com/JuliaLinearAlgebra/TSVD.jlJulia codeLinearAlgebra.jlhttps://github.com/JuliaLang/LinearAlgebra.jlJulia code
Experimental model and study participant details
Omitted as our study does not involve biological models.
Method details
GSVD-based feature recovery
GSVD has been used to solve the quadratic optimization problem in maximum signal fraction analysis (MSFA),49^,^50^,^51^,^52 which seeks a set of projection directions that maximize the ratio of signal energy to noise energy, formulated as the Rayleigh quotient
where is the observed data matrix. The matrix approximates the noise component under the additive model , with representing the unobserved source signal. Although MSFA does not guarantee exact recovery of the sources, it linearly projects the observed signal onto directions that emphasize components with high signal-to-noise ratio. A theoretically equivalent solution to the optimization problem can be obtained by computing the GSVD between and .
Given that , where and denote the components wait to be recovered, the GSVD of a pair of matrices identifies conjugate directions that maximize the oriented signal-to-signal ratio. Naively, similar to maximizing variance for principal component analysis (PCA), one might imagine that the new direction could be obtained by maximizing
where . Equation 5 formalizes the process illustrated in Figure 1, the generalized Rayleigh quotient quantifies how much residual variance remains outside the NMF subspace, and its maximization effectively “reshapes” the current factorization toward the missing directions. We model in the column space of and instead optimize a variant of Equation 5 that projects the NMF result down to the SVD subspace:
where , and . This is equivalent to optimizing the generalized Rayleigh Quotient. Since and are symmetric, the extreme values of Equation 6 satisfy a generalized eigenvalue problem53
where . Equation 7 can be solved to higher numerical precision by the GSVD of and , resulting in
The matrices are unitary and . Here, the matrices and are given by
where are real, diagonal matrices and denotes the rank of . is identity matrix. Plugging Equation 8 into Equation 7 yields
Letting , we need to solve
and are real, nonnegative diagonal matrices. Assume that and . If the rank of is , all generalized singular values are finite; conversely, if , the generalized singular values are infinite for and finite thereafter. When is finite , the corresponding are the unit coordinate vectors. Thus, and the new directions are given by
is the -th column of . When , is infinite , we similarly select using the -th column of . These represent directions that are missing entirely from the factorization.
Typically, GSVD-NMF has the capacity to suggest missing directions only for rank-2 NMF and higher. For rank-1 factorizations, NMF algorithms find the global optimum, and since the first component in the SVD of a nonnegative matrix is nonnegative, the rank-1 NMF solution should already be equivalent to the first SVD component.
After fixing , the corresponding additional components for (defined as ) are derived from a least-squares problem by minimizing
where , is the -th column in , is the -th row in and . Here is required to be nonnegative in order to preserve the nonnegativity of the original components . The vector is introduced to modulate the magnitude of the pre-existing components, thereby improving the adaptability of the matrix in the minimization of Equation 13. The joint optimization problem over and in Equation 13, can be formulated as a standard Non Negative Least Squares (NNLS) problem. By defining the variable vector as the concatenation of the column-flattened and , the minimization becomes
where is the columnwise flattening of , , the coefficient vector , where is the column-flattened . Prior to solving the NNLS problem, must be made nonnegative. We employ a truncation strategy where the nonnegative residual matrix is , and the truncated result for the -th row in is
where denotes the 1-norm of the vector . This truncation maximizes the alignment (1-norm) of the resulting nonnegative component with the nonnegative residual , thus ensuring the effective in minimizing the remaining error. This single NNLS problem achieves a global optimum for and given a fixed without any other step. However, the computational cost is significant, particularly for large datasets. The temporal complexity of forming is , which can be equivalent to hundreds of iterations of NMF algorithms(HALS). Solving the resulting NNLS problem in Equation 14 incurs additional cost.
Given this substantial computational burden, especially when the dimensions and are large, we propose an alternative, decoupled approach to accelerate the initialization process in practice. Expanding Equation 13 as
where with . with , , . and are a block matrices, where and , is an identity matrix. Details about obtaining and Equation 16 are presented in Supplementary Materials. The stationary point of Equation 16 with respect to is
Substituting Equation 17 into Equation 16 yields
where . Since Equation 18 is derived from a NNLS problem 16, the quadratic in Equation 18 must be positive semidefinite, and thus this problem is convex and admits a deterministic solution.54^,^55
Unlike the standard SVD, where singular vectors form orthogonal bases, the new components derived through GSVD-based feature recovery are not guaranteed to be orthogonal. The suggested components are unique, up to scaling, if the generalized singular values are distinct. GSVD-NMF cannot make the solution worse:
Lemma 1. Given a data matrix and an existing approximate factorization , the optimal solution to Equation 16 cannot increase the fitting error.
Proof. This follows from the fact that the solution lies within the solution space:
We note that if the initial factorization is exact, then all generalized singular values are 1, is arbitrary, will be zero, and the fitting error will not be decreased. Thus we cannot guarantee a decrease in error, but we can at least guarantee a non-increasing error.
To impose nonnegativity constraints on and from Equation 17 and Equation 18 without significantly increasing the computational demand, we use the truncation step of NNDSVD, which generates the best nonnegative approximation of each new component.34 While ensuring the nonnegativity, in principle this comes with a risk: what if truncation results in an all-zero new component? In this circumstance, no useful work would be done. Here, we demonstrate that this cannot occur:
Lemma 2. Given a data matrix and an existing locally-optimal nonnegative factorization for which , the nonnegative solution minimizing Equation 16 strictly reduces the error.
Proof. The residual between the original matrix and the existing under-complete NMF solution, given by , contains both positive and negative values.19 Let be a specific entry satisfying , and let and . This has positive components and reduces the sum-of-squares of the residual even in the sub-optimal case of . Thus, there exists a nontrivial nonnegative component that will reduce the residual. Since the GSVD improves on this ansatz, and NNDSVD provides its optimal nonnegative rank-1 approximation, this procedure cannot return an all-zeros component unless the residual is itself zero.
Since the truncation alters the entries in and , we let and , all components in and are re-optimized together by minimizing
where , . , are the -th column and -th row in , respectively. Equation 20 is also a NNLS problem and thus convex. Moreover, this step also guarantees that the fitting error in Equation 20 does not exceed that of the under-complete NMF, following an analysis analogous to Equation 19. The final step is refinement via NMF, initialized with and . The GSVD-based feature recovery is summarized in Algorithm 1.Algorithm 1GSVDFeatureRecoveryInput: Output: Compute , , , , by solving Equation 8 and Equation 9
columns in corresponding to the largest values in Compute with Equation 17 and Equation 18 Compute , by truncating , (Truncation step in NNDSVD)
Compute with Equation 20
If the SVD in Equation 6 has more components than the NMF, it is guaranteed that some singular values will be infinite, and our strategy will first select directions missing from the NMF. When adopting this strategy, the schematic in Figure 1 depicting the polishing of existing directions is no longer relevant.
Temporal complexity analysis
The GSVD-based feature recovery is a one-shot procedure that requires no iterative optimization. To analyze its temporal complexity, we divide it into three main components.
For initializing new columns in (denoted as “init H” in Figure S1), the dominant computational terms arise from (i) computing in Equation 7, (ii) performing the GSVD in Equation 8, and (iii) evaluating in Equation 12. The temporal complexities of these steps are , , and , respectively. Consequently, the overall complexity of this step can be summarized as . Given that , the dominant complexity simplifies to approximately .
For initializing new rows in (“init W” in Figure S1), the major computations include evaluating the coefficients and in Equation 18, solving the nonnegative least-squares problem in the same equation, and forming new rows according to Equation 17. The coefficient computation in Equation 18 dominates, with a temporal complexity of as detailed in the Supplementary Materials. Minimizing Equation 18 requires time, where denotes the number of iterations—typically on the order of tens—thus negligible compared to the coefficient computation. Constructing new rows via Equation 17 costs . Therefore, the overall dominant temporal complexity of “init W” is .
For the amplitude multiplication step, which is analogous to solving the nonnegative least-squares problem for initializing new rows in , the temporal complexity is , where is the number of iterations (typically in the order of dozens).
In summary, the overall dominant temporal complexity of the GSVD-based feature recovery is , which is comparable to the complexity of a single iteration of the HALS algorithm for NMF.17 Empirically, the total runtime of the GSVD-based feature recovery corresponds to roughly two to three iterations of the NMF algorithm. Therefore, this method is significantly more efficient than restarting NMF from scratch. Moreover, as shown in later experiments, since the NMF algorithm converges rapidly when initialized with our GSVD-based recovery, expanding the rank of NMF using our approach is substantially more efficient than reinitializing NMF entirely.
The whole pipeline
The whole pipeline of the proposed method is given in Figure S1 in Supplementary Materials. Given that standard NMF typically yields local optima and SVD constitutes a global optimum of matrix factorization, our core concept involves identifying features captured by SVD but absent in an existing approximate factorization. These identified features are then incorporated as new components into the existing NMF results. and are the results of under-complete NMF with components. We use , and to denote the results of rank- approximate SVD, which is the global optimum of rank- matrix factorization of . Using the GSVD, we compare the results of under-complete NMF and rank- SVD, and on that basis propose new rows (denoted ) for and new columns (denoted ) for . The matrices and are not guaranteed to be nonnegative, so NNDSVD truncation34 is applied to preserve the nonnegative approximation. Additionally, the amplitudes of the original and newly added components are jointly adjusted using a nonnegative least-squares approach to balance the power between the existing and new components. Finally, all components are polished by NMF to produce the final factorization. The pseudo-code for the full GSVD-NMF pipeline is provided in Algorithm 2. We use the notation “NMF ” to denote running NMF on matrix with components and convergence relative tolerance , initialized with and . The procedure “GSVDFeatureRecovery ”, detailed in the next subsection and in Algorithm 1, performs the GSVD-based component augmentation. If an under-complete NMF solution ( , ) is already available, rank expansion can be performed directly by invoking “GSVDFeatureRecovery ”.Algorithm 2GSVD-NMFInput: ;Output:
It can be seen that a truncation step occurs in the GSVD-based feature-recovery stage. However, the Multiplicative Update (MU) algorithm is known to be sensitive to zero entries and scaling effects, which can prevent the newly introduced components from being properly activated and normalized.56 To mitigate this issue, when using MU or MU-related NMF algorithms, we add a small perturbation to all components before the final NMF refinement.
Quantification and statistical analysis
On real-world data, in addition to HALS we also analyzed Greedy Coordinate Descent (GCD),57 Alternating Least Squares Using Projected Gradient Descent (ALSPGrad),18 and Multiplicative Updating (MU).58 After establishing efficacy with a variety of algorithms, later analysis on computational efficiency and influence of parameters is performed just with HALS. To determine convergence, here we monitor the maximum relative change in the Frobenius norm of the columns of and the rows of (given in Equation 21), and stop iterating when
for , for some choice of . In these expressions, and are the -th column and -th row in and on the -th iteration, respectively. Unless otherwise specified, was used. Throughout, the maximum number of iterations for NMF was set so high that termination was triggered only by the -criterion. The relative fitting error between and the input matrix , , was used to evaluate the local optima of NMF. This measures how well the factorization fit the input matrix.
Since the ground truth components of real-world data are undetermined, we assessed methods in terms of the value of the objective Equation 2, with smaller values indicating better solutions. For each random initialization, we compared the final solution from GSVD-NMF against standard NMF with the same number of components. Standard NMF was initialized with a random rank- solution, with given in Table 1. The under-complete NMF was initialized with the first components of this same initialization, and then new components were added by GSVD-NMF to achieve rank . Thus, the two solutions start from as much of a shared initialization as can be achieved given their differences in initial rank. This comparison addresses whether it is more effective and efficient to directly augment components for an existing under-complete NMF solution or to rerun NMF from scratch with additional components. Solution objective values are compared in scatter plots, where each dot represents a single random initialization, and brown lines represent the histogram of perpendicular distances between points and the diagonal (a.k.a., equal performance) in the figure. The total number of random initializations in this experiment is 200.
In addition to comparing the GSVD-NMF pipeline with standard NMF algorithms, we also evaluated it against other NMF methods that incrementally increase the rank, including Recursive NMU (RNMU),59 Global NMU (LNMU),19 Prior NMU (PNMU)32 and NMU-ADMM.31
The simulation and experiments were performed using Julia 1.10 on Washington University in St. Louis RIS scientific computing platform with Intel_Xeon_Gold6242CPU280GHz 8G RAM.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Lee D.D.Seung H.S.Learning the parts of objects by non-negative matrix factorization Nature 401199978879110.1038/4456510548103 · doi ↗ · pubmed ↗
- 2Feng X.R.Li H.C.Wang R.Du Q.Jia X.Plaza A.Hyperspectral unmixing based on nonnegative matrix factorization: A comprehensive review IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens.1520224414443610.1109/JSTARS.2022.3175257 · doi ↗
- 3Qu K.Li Z.A fast sparse NMF optimization algorithm for hyperspectral unmixing IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens.1720241885190210.1109/JSTARS.2023.3341583 · doi ↗
- 4Chen Y.Zhang H.Liu R.Ye Z.Lin J.Experimental explorations on short text topic mining between LDA and NMF based schemes Knowl. Base Syst.163201911310.1016/j.knosys.2018.08.011 · doi ↗
- 5Huang C.Zhu F.Zhang H.Wang N.Huang Q.Identification of S 1PR 4 as an immune modulator for favorable prognosis in HNSCC through machine learningi Science 26202310769310.1016/j.isci.2023.107693 PMC 1048031437680482 · doi ↗ · pubmed ↗
- 6Ikeda K.Nakada T.A.Kageyama T.Tanaka S.Yoshida N.Ishikawa T.Goshima Y.Otaki N.Iwami S.Shimamura T.Detecting time-evolving phenotypic components of adverse reactions against BNT 162b 2 SARS-Co V-2 vaccine via non-negative tensor factorizationi Science 25202210523710.1016/j.isci.2022.105237 PMC 951500836188188 · doi ↗ · pubmed ↗
- 7Parekh J.Parekh S.Mozharovskyi P.d’Alché Buc F.Richard G.Listen to interpret: Post-hoc interpretability for audio networks with nmf Adv. Neural Inf. Process. Syst.3520223527035283
- 8Leplat V.Gillis N.Ang A.M.S.Blind audio source separation with minimum-volume beta-divergence NMFIEEE Trans. Signal Process.6820203400341010.1109/TSP.2020.2991801 · doi ↗