Permutation Tests Based on the Copula‐Graphic Estimator and Their Use for Survival Tree Construction
Pauline Baur, Markus Pauly, Takeshi Emura

TL;DR
This paper introduces a new survival tree algorithm using a copula-graphic estimator to handle dependent censoring, improving survival analysis in clinical data.
Contribution
A novel permutation test based on the copula-graphic estimator is introduced for survival tree construction under dependent censoring.
Findings
The new permutation test shows good type I error and power in simulations with varying group sizes and censoring.
Survival trees using the new test outperform logrank-based trees in certain simulation scenarios.
The method is successfully applied to real clinical trial data.
Abstract
Survival trees are popular alternatives to Cox or Aalen regression models that offer both modeling flexibility and graphical interpretability. This paper introduces a new algorithm for survival trees that relaxes the assumption of independent censoring. To this end, we use the copula‐graphic estimator to estimate survival functions. This allows us to flexibly specify shape and strength of the dependence of survival and censoring times within survival trees. For splitting, we present a permutation test for the null hypothesis of equal survival. Our test statistic consists of the integrated absolute distance of the groups' copula‐graphic estimators. A first simulation study shows a good type I error and power behavior of the new test. We thereby assess simulation settings of various group sizes, censoring percentages, and grades of dependence generated by Clayton and Frank copulas. Using…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
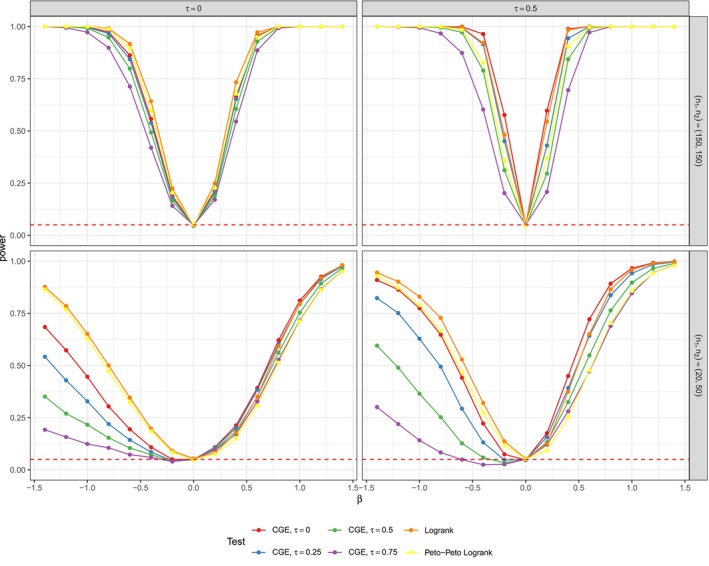 FIGURE 1
FIGURE 1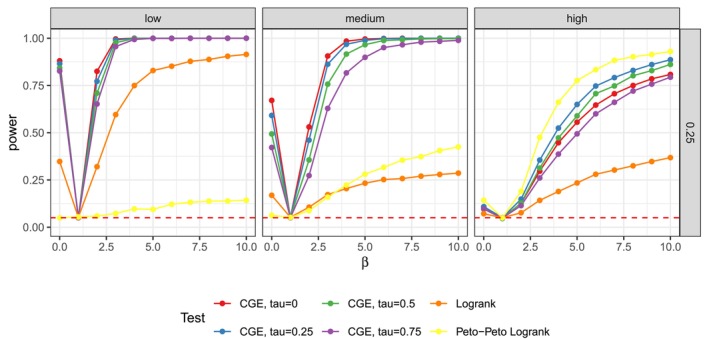 FIGURE 2
FIGURE 2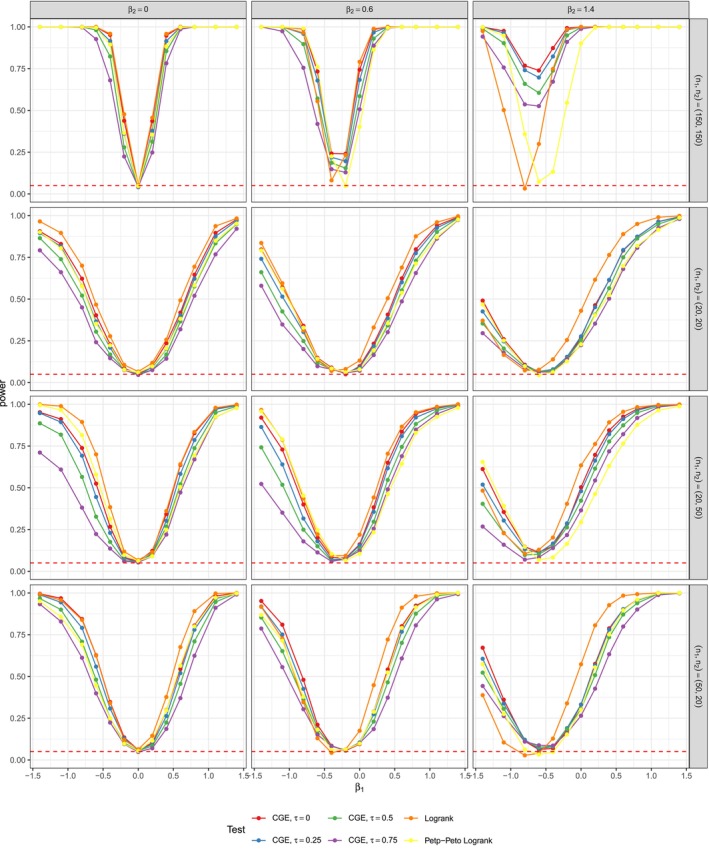 FIGURE 3
FIGURE 3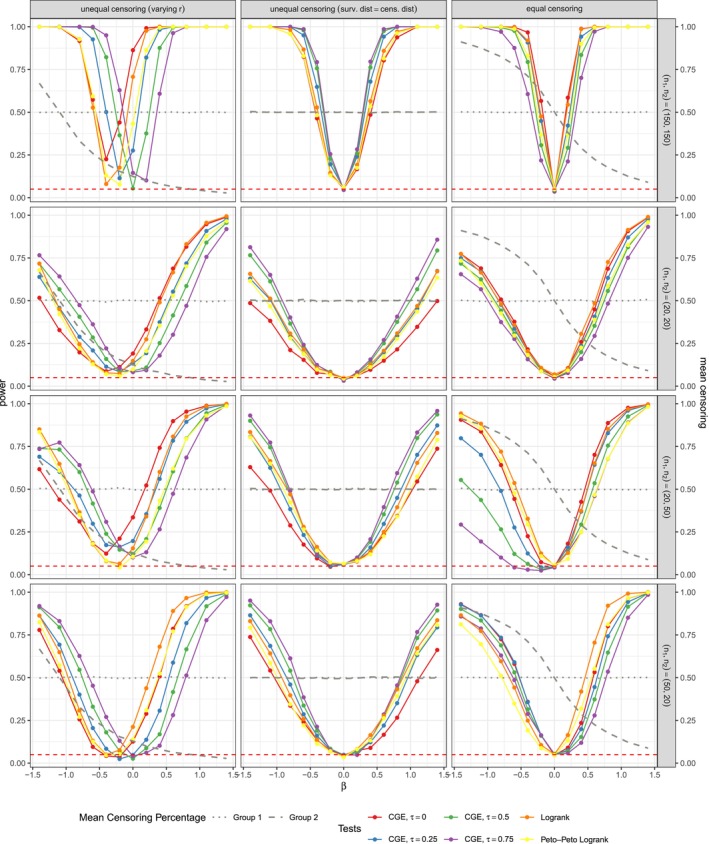 FIGURE 4
FIGURE 4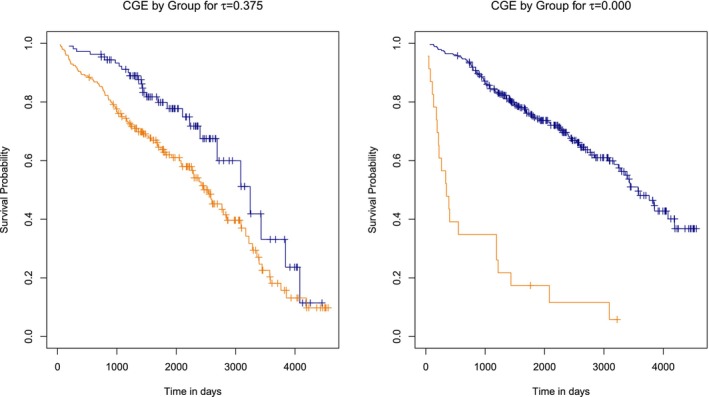 FIGURE 5
FIGURE 5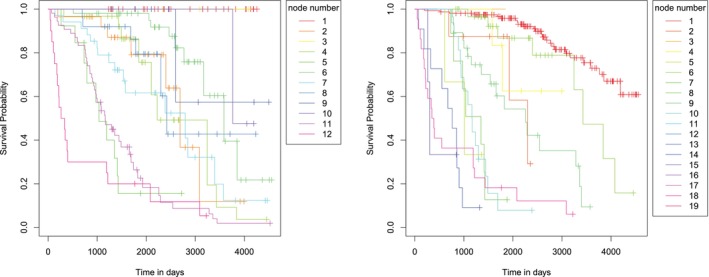 FIGURE 6
FIGURE 6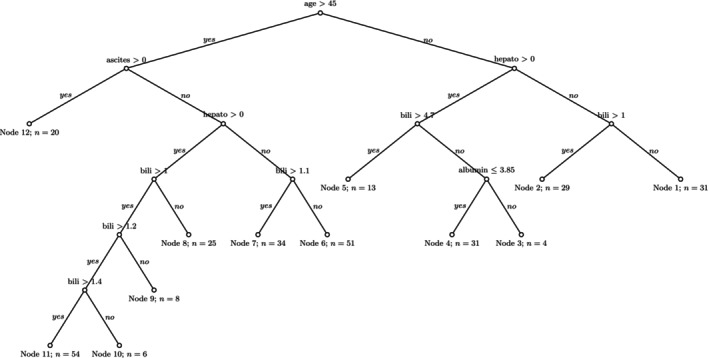 FIGURE 7
FIGURE 7| Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. |
|---|---|---|---|---|---|
| 0.9700 | 1.0000 | 1.0000 | 0.9997 | 1.0000 | 1.0000 |
| Copula‐graphic estimator | |||||||
|---|---|---|---|---|---|---|---|
| Logrank | |||||||
| low cens. | term. nodes | 15.800 |
| 15.760 | 15.920 | 24.450 | |
| Precision% | 0.765 | 0.762 |
| 0.752 | 0.619 | ||
| 0.715 | 0.712 | 0.711 | 0.715 |
| |||
| KM | 0.127 | 0.120 | 0.118 |
| 0.241 | ||
| CGE | 0.358 |
| 0.356 | 0.354 | 0.420 | ||
| high cens. | term. nodes |
| 13.480 | 13.550 | 13.750 | 17.660 | |
| Precision% |
| 0.789 | 0.762 | 0.778 | 0.650 | ||
| 0.730 |
| 0.732 | 0.733 | 0.728 | |||
| KM |
| 0.288 | 0.296 | 0.286 | 0.340 | ||
| CGE |
| 0.492 | 0.531 | 0.528 | 0.526 | ||
| low cens. | term. nodes | 46.520 | 46.410 |
| 46.480 | 65.810 | |
| Precision% |
| 0.681 | 0.669 | 0.666 | 0.529 | ||
| 0.712 | 0.715 | 0.712 | 0.715 |
| |||
| KM | 0.109 | 0.108 |
| 0.107 | 0.214 | ||
| CGE | 0.396 | 0.420 |
| 0.422 | 0.521 | ||
| high cens. | term. nodes | 39.280 | 38.760 |
| 38.810 | 46.300 | |
| Precision% |
| 0.680 | 0.681 | 0.674 | 0.557 | ||
| 0.740 | 0.738 | 0.742 | 0.744 |
| |||
| KM | 0.289 | 0.291 |
| 0.292 | 0.355 | ||
| CGE |
| 0.555 | 0.566 | 0.576 | 0.601 | ||
| Terminal nodes with subjects | |||||
|---|---|---|---|---|---|
| CGE tree () | 0 | 0 | 2 | 16 | |
| 0 | 0 | 4 | 43 | ||
| Logrank tree | 4 | 5 | 0 | 12 | |
| 10 | 11 | 12 | 31 | ||
| of CGE | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Tree | Logrank | 0.000 | 0.125 | 0.250 | 0.375 | 0.500 | 0.625 | 0.750 | 0.875 |
| term. nodes | 27.3 | 19.3 | 19.9 | 20.3 |
| 19.3 | 20.9 | 19.4 |
|
| KM | 0.192 |
| 0.189 | 0.201 | 0.194 | 0.203 | 0.203 | 0.211 | 0.212 |
|
| 0.791 | 0.769 | 0.782 | 0.790 | 0.801 | 0.796 | 0.789 | 0.772 | |
- —Studienstiftung des Deutschen Volkes10.13039/501100004350
- —Deutsche Forschungsgemeinschaft10.13039/501100001659
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Financial Risk and Volatility Modeling · Statistical Methods in Clinical Trials
Introduction
1
In survival analysis, censoring is a common phenomenon, occurring, for example, when participants are lost to follow‐up in a clinical trial. Typically, both censoring times and survival times are random [1]. Many common survival analysis methods are derived under the assumption of independent censoring and survival times [1, 2]. However, this assumption may not always be realistic, potentially introducing bias into the survival analysis [3, 4]. For example, Klein and Moeschberger (1987) [5] explain this issue for the case of the Kaplan‐Meier estimator.
Dependent censoring can arise, for instance, when study dropouts occur due to adverse events or lack of improvement from the study medication [6], since a patient's health status affects both these events and the expected survival time. In case of a positive dependency between survival and censoring times, subjects censored at a time t have a smaller expected survival compared to subjects censored at a time greater than t. Consequently, statistical methods assuming independent censoring can overestimate the survival time. The opposite is true for negative dependency [7]. This bias is especially problematic when two groups with varying censoring proportions are compared. One such scenario is a clinical placebo‐controlled trial, where the verum group has a higher dropout rate due to study‐drug‐related adverse events. If the independent censoring assumption is violated, applying biased survival time estimation can lead to overly optimistic survival estimates for the verum group [3, 8]. Hence, survival analysis methods that can model dependent censoring are often necessary.
Copulas are a common tool in such methods. They specify the joint distribution of random variables [9, chapter 2], in our case event and censoring times. Furthermore, copula models can be used to analyze the bias introduced by false independent censoring assumptions, as Emura and Chen (2016) [4] show for univariate feature selection using Cox‐regression. Zheng and Klein (1995) [10] introduce a copula‐based estimator for survival distributions, the copula‐graphic estimator. It can be considered an extension of the Kaplan–Meier estimator that incorporates dependence using a pre‐specified copula model. Many applications of this estimator exist: Lo and Wilke (2010) [11] extend the copula‐graphic estimator for data with more than two competing risks using the class of Archimedean copulas. Huang and Zhang (2008) [3] apply the work of Zheng and Klein to a regression setting. They model marginal competing risks using Cox proportional hazard models, while the joint distribution is modeled on an assumed copula. Many further applications of the copula‐graphic estimator in survival regression settings have been explored, including frequentist approaches [12, 13] as well as Bayesian methods [6].
The present paper uses the copula‐graphic estimator to derive nonparametric survival trees that allow for dependent censoring. Traditional classification and regression trees, which both are nonlinear regression models, were introduced by Breiman et al. (1984) [14]. Various extensions of their work to survival analysis under the independent censoring assumption have been developed [15]. In the present paper, we extend the idea behind conditional inference trees [16] and the work of Emura et al. (2023) [17] to the setting of dependent censoring. We will construct trees of binary splits on single covariates using p‐values of significance tests for survival difference as a splitting criterion. We will modify existing tree algorithms, such as logrank trees [18], by using a significance test that does not assume independent censoring. In doing so, we present a new survival analysis method that is straightforward to implement, easy to interpret and free from assumptions of parametric regression models.
To this end, we propose a permutation test with the integrated, absolute distance of the copula‐graphic estimators of two groups as a test statistic for the null hypothesis of equal survival distributions, assuming equal censoring distributions across groups. Permutation tests are a common tool in survival analysis [16, 19, 20] and similar approaches to ours already exist: Pepe and Fleming (1989) [21] introduce a class of Kaplan‐Meier estimator based statistics. They extend their statistic by various weighting functions that reduce the impact of observations towards the end of a study when only few events are observed. Moradian et al. (2017) [22] use a statistic of absolute distances of Kaplan‐Meier estimators as a splitting criterion in a survival forest. They later extend their work using the copula‐graphic estimator to create a survival forest that can account for dependent censoring [23]. As detailed in Section 2.3, we propose a standardized version of the distance proposed by Modarian et al. (2019) [23]. In addition, our proposed approach is based on p‐values, which provide a statistically more meaningful measure than the distance itself.
The rest of the paper will be structured as follows: Section 2 will review the copula‐graphic estimator and survival trees and then propose a survival tree algorithm for dependently censored survival data. Section 3 and 4 will assess the algorithm's performance in two simulation studies. Lastly, in Section 5 we will apply the survival tree algorithm to real‐world data from the Mayo Clinic Primary Biliary Cholangitis clinical trial. Section 6 concludes the paper with a discussion.
Methods
2
Notation
2.1
We consider right‐censored survival data for n subjects. Event times are modeled by non‐negative random variables Ti, corresponding censoring times by non‐negative Ci
with continuous, strictly increasing distribution functions F and G, respectively. For each subject i, only Xi=min(Ti,Ci) and the censoring status Δi=1(Xi=Ti) can be observed with 1() being the indicator function. The Xis are assumed to be independent, identically distributed random variables. In addition, we observe p covariates, which are a realization of the random vector Zi=(Zi1,…,Zip)⊤. Thus, the observed dataset is {(xi,δi,zi);i=1,…,n} with lowercase letters denoting the realizations of the respective random variables. Throughout, vectors are denoted using bold font. The probability of subject i surviving past a time t>0 is given by the survival function ST(t)=Pr(Ti>t)=1−F(t), which is continuous and strictly decreasing [24, chapter 2]. The corresponding censoring function is defined analogously as SC(t)=Pr(Ci>t)=1−G(t). Let T and C denote independent copies of Ti and Ci, respectively.
Copula‐Graphic Estimator
2.2
In the following, T and C are not independent, instead their dependency will be modeled using bivariate copulas. These will be defined based on survival functions, rather than cumulative distribution functions, to fit our survival setting. The general properties of copulas remain valid [25, chapter 3]. The joint survival function of T and C is
with 𝒞 being the copula. A feasible copula function 𝒞 has to fulfill 𝒞(u,0)=𝒞(0,v)=0, 𝒞(u,1)=u and 𝒞(1,v)=v for every u,v∈[0,1]. Furthermore, we require 𝒞 to yield a probability mass on every rectangle in [0,1]2, by ensuring 𝒞(u2,v2)−𝒞(u2,v1)−𝒞(u1,v2)+𝒞(u1,v1)≥0 for all u1,u2,v1,v2∈[0,1] with u1≤u2 and v1≤v2 [9, chapter 2].
The scope of this paper will be restricted to the class of Archimedean copulas, which have a closed‐form expression and thus are convenient to work with. Archimedean copulas are generated by a function φ via
for φ:[0,1]→[0,∞] being continuous and strictly decreasing to φ(1)=0 with pseudo‐inverse
Equation (1) defines a copula, if φ is convex. One example for an Archimedean copula is the Clayton copula, which is generated by φ(u)=u−θ−1/θ for a parameter θ∈[−1,∞)∖{0} [9, chapter 4].
Copulas provide an easy‐to‐interpret way of modeling the dependence structure, specifically the concordance of T and C. On a realization level, a concordant pair of observations (t1,c1) and (t2,c2) fulfills (t1−t2)(c1−c2)>0; a discordant one (t1−t2)(c1−c2)<0. On the population level, the scale‐invariant Kendall's τ measures association between i.i.d. vectors (T1,C1) and (T2,C2) with
which is the difference of the probability of concordance and the probability of discordance. For random variables ST(T) and SC(C) with dependence structure 𝒞, Kendall's τ can alternatively be calculated as
with the last equation (∗) holding true for Archimedean 𝒞 [9, chapter 5]. Thus, the association depends on the copula, but not the respective marginal distributions. For the Clayton copula, Equation (2) simplifies to τ=θ/(θ+2), yielding a straightforward way to specify the level of concordance [9, chapter 5]. Consequently, the Clayton copula's limiting case of θ→0 is the independence copula, which models independent event and censoring times as 𝒞ST(t),SC(s)=Pr(T>t)Pr(C>s). It can be generated from Equation (1) by choosing φ(u)=−log(u) [9, chapter 4].
As explained in the introduction, the well‐known Kaplan‐Meier estimator does not consider a dependency of survival and censoring times. For scenarios, where the independent censoring assumption is not realistic, Zheng and Klein (1995) [10] introduced an alternative estimator, the copula‐graphic estimator (CGE), which estimates the survival function under a known dependence structure described by a copula. Rivest and Wells (2001) [26] extend this work by deriving a closed‐form expression of the CGE for survival and censoring functions under the assumption of an Archimedean copula with twice‐differentiable generator φ. They start by requesting the naive estimate for the survival function π^(t)=1/n∑i=1n1(Xi>t) at time t>0 to be equal to the Archimedean copula structure from Equation (1) based on estimators of ST and SC, rather than the theoretical survival and censoring function. This can be denoted as
with Ŝ and Ĉ being the CGEs of the survival and censoring function, respectively. Solving this equation for Ŝ and considering n observations, yields the CGE of the survival function:
It is a right‐continuous, decreasing step‐function. Ŝ(0) equals 1. Subsequently, there are negative jumps at each xi associated with an event (δi=1). Using the generator of the independence copula φ(u)=−log(u) in Equation (3), the CGE Ŝ(t) equals the Kaplan‐Meier estimator for t<max(X1,…Xn) [10, 26].
For instance, under a Clayton copula, the CGE is given by: [12]
A visualization of the CGE and the influence of the assumed dependency through the copula model can be found in Figure B1 on page 95 in the Appendix B.
Proposed Test
2.3
In the following paragraphs, we propose a permutation test assessing differences in survival time distributions between two groups using a randomization technique for the exact control of the type I error rate. The notation introduced in Section 2.1 will be extended to cover a two‐sample problem. For group j∈{1,2}, the event and censoring time variables will be
with respective distributions Fj and Gj. Censored data Xji=min(Tji,Cji) and Δji=1(Xji=Tji) are adapted accordingly. The null and alternative hypotheses for a difference in survival distributions of the two samples are given by
The censoring distributions for both groups, G1 and G2, are assumed to be identical, such that the Xij are exchangeable under the null hypothesis. We will use the CGE for Archimedean copulas to construct a test statistic for a non‐parametric permutation test. The test statistic is similar to the one proposed by Moradian et al. (2019) [23], who used a similar statistic as a measure of prognostic difference between groups for determining optimal splits in a survival random forest. We slightly modify the statistic and will introduce a permutation test and corresponding splitting criterion.
Intuitively, the statistic is derived from the absolute difference of the CGEs of groups 1 and 2 and should increase with differing ST11 and ST21. For an observation vector x=(x1⊤,x2⊤)⊤ with observations in group j being xj=min(tj1,cj1),…,min(tjnj,cjnj)⊤ and censoring indicator vector δ=(δ1⊤,δ2⊤)⊤, the statistic is
The normalization of the integrated difference by the observed time span t∗=min(max(x1),max(x2)) is a modification compared to the statistic used by Moradian et al. (2019) [23]. This has two purposes: First, it makes the test statistic primarily reflect the magnitude of differences between groups during the common observation window rather than the overall study length. Second, truncation at t∗ limits the influence of a few extreme observations in the longer‐followed group that could otherwise inflate the CGE difference. The resulting statistic is a time‐normalized average CGE difference. This adjustment addresses situations where one group has a substantially shorter follow‐up with a rapidly declining CGE and a small maximum observed time, while the other group has longer observed survival times: Without normalization, the integral may be small solely due to the short integration range, even when the between‐group survival difference is large.
Since the theoretical probability distribution of L1 is difficult to be derived analytically, we will evaluate it using a randomization approach.
To find the permutation distribution of L1 and calculate corresponding p‐values, we consider the finite permutation group
of size |𝒢|=n! for any permuting function π:{1,…,n}→{1,…,n}. Note that each observation's event time and censoring indicator are permuted jointly, ensuring that an observed event time always remains an event time and cannot be permuted into a censoring time and vice versa. Furthermore, the group sizes n1 and n2 stay the same.
Enabled by the assumption of exchangeability and equal censoring distributions across groups, the distribution of (X,Δ) with X=X11,…,X1n1,X21,…,X2n2 is invariant to permutations in 𝒢 under the null hypothesis. In this case, the following test ψ based on statistic L1 is an exact level α test for H0 as in Equation (4), that is, E(ψ(X,Δ))=α: [27, chapter 17]
L1(x,δ) is the test statistic on the observed data and critical value L1(k)(x,δ) is derived by calculating the test statistics for all |𝒢| permutations, ordering them to L1(1)(x,δ)≤L1(2)(x,δ)≤⋯≤L1(n!)(x,δ) and considering the k=(n!−⌊n!α⌋)th value. By setting randomization probability a(x,δ)=αn!−|{j:L1(j)(x,δ)>L1(k)(x,δ)}|·|{j:L1(j)(x,δ)=L1(k)(x,δ)}|−1,j∈{1,…n!}, we ensure that ψ is an exact level‐α‐test.
In most cases, a systematic calculation of all n! permutations would be computationally infeasible. Even for moderate sample sizes of n1=n2=50, we would already have to consider 100!=9.332622×10157 permutations. Exploiting the test statistic's symmetry reduces this to an effective number of n1+n2n1 distinct permutations, which still becomes infeasible quickly, for example, with 50+5050=1.008913×1029 for n1=n2=50. We therefore resort to nperm≤n! random data permutations. We consider the observed data and nperm−1 further permutations, since the observed group assignment has to be part of the group of considered permutations to obtain positive Monte Carlo p‐values. This yields a valid test, in the sense that under H0 (exchangeability) the probability of seeing a p‐value as small as some p∈(0,1) is at most p. However, under the alternative hypothesis the test may be slightly less powerful than an exact (fully permuted) permutation test [28, chapter 3.5].
The resulting algorithm for its p‐value computation is given below:
ALGORITHM 1 p‐value of introduced randomization test.
Survival Trees
2.4
We will construct survival trees using recursive partitioning, which repeatedly splits the covariate space into two disjoint sub‐spaces, yielding increasingly homogeneous survival outcomes within and heterogeneous outcomes between groups. A basic method of tree building uses binary splits based on a single covariate at a time [15]. Each node partitions the data into child nodes {i:zij≤q} and {i:zij>q} based on the jth covariable and some cutoff value q, for i∈{1,…,n} and j∈{1,…,p}.
Each split is chosen to maximize the prognostic survival difference between the resulting groups. Ciampi et al. (1986) [18] use a logrank test as a measure for prognostic difference. Performing a grid search over all covariates and feasible cutoff values, logrank test p‐values are calculated for all possible splits. The optimal split is chosen as the split that maximizes the test statistic among all significant tests to some pre‐defined p‐value threshold. Nodes are split until no feasible split with a p‐value smaller than the threshold can be found. Emura et al. (2023) [17] generally adapt this approach, but select the split that minimizes the p‐value after variance stabilization. We will follow their approach, but use the test introduced in Section 2.3 instead of a logrank test, in order to account for possibly dependent censoring. Moradian et al. (2019) [23] already used a similar statistic to construct survival trees, however, their statistic was not evaluated within a statistical test and they constructed a random forest rather than a single tree.
Typically, median survival time and Kaplan–Meier estimator of the resulting terminal nodes are reported. We will supplement this by the CGE. For ideal interpretation of the tree, we aim to order the terminal nodes by survival prognosis from left to right.
To do so, the test statistic in (5) is calculated without absolute values, resulting in
A positive value of L˜1 indicates a longer survival in group 1. Based on the sign of L˜1, group 1 is assigned to either the left or the right child node, ensuring that subjects with better survival prognosis always move to the right side of the tree. This yields the following tree algorithm (Algorithm 2):
ALGORITHM 2Construction of survival tree.
Choice of Copula Model and Dependency Parameter
2.5
Since the true marginal distribution of survival and censoring times is not identifiable from an observed competing risk dataset [29], additional assumptions have to be made prior to estimation. One assumption providing identifiability is the copula assumption [10] introduced above. Therefore selecting a sensible copula generator φ and dependence τ in Equation (3) will be a crucial and challenging step for our data analysis.
Zheng and Klein (1995) [10] evaluate the robustness of the CGE under a misspecified copula model. They find that, as long as the strength of dependency between survival and censoring times is estimated well, the CGE is relatively robust towards misspecification of the copula class. Therefore, we will decide on one copula class, namely the Clayton copula, prior to our data analysis. The Clayton copula can model positive and negative dependency and specifies a straightforward and easy to interpret connection between its parameter θ and Kendall's τ [9, chapter 4,5]. Furthermore, the Clayton copula has successfully been used in previous research to model dependency in survival times, for instance showing good results in modeling the time to metamorphosis for salamander larvae [30], or in analyzing adherence to tuberculosis treatment [6]. Lastly, due to the Clayton copula's simple generator function, we were able to implement a completely vector and matrix‐based algorithm version of the permutation test in Algorithm 1 in R, which saved computing time.
While there are approaches of estimating the dependency parameter from the data, these approaches typically lead to estimators with large variances, especially for small sample sizes [31]. However, there is research on how sensitive statistical inference is to wrongly assumed independence of survival and censoring times. For instance, Siannis et al. (2005) [32] provide bounds around the estimated median survival (calculated under the assumption of independent censoring), depending on the strength and type of dependence between survival and censoring times. Although this can give an idea on how much estimates are biased by wrongly assumed independence, it cannot provide a guideline on how to select the optimal τassum. for the proposed test. Instead, a sensitivity analysis can be applied by varying the dependence parameter, evaluating model performance and then using the results to draw conclusions on the underlying dependence structure [7]. Emura and Chen (2016) [4], who introduce an extension of univariate Cox regression for dependent censoring, recommend selecting τ using a cross‐validated Harrell's C‐index. They build their model for various assumed τ, estimate Harrell's C for each model and then choose the model with the largest C‐index. We will use the same approach for our model selection and add the Integrated Brier Score as an additional performance measure. More details can be found in Section 4.1, where the setup of our survival tree study is explained.
Simulation Study: Tests
3
Simulation Design
3.1
The following simulation study aims to show that the proposed test indeed is a level‐α test with good power and type I error properties. Furthermore, we identify scenarios where the proposed test might fail. To do so, we will simulate data with proportional as well as non‐proportional hazards and perform sensitivity analysis regarding the assumption of equal censoring distributions across groups.
We compare the performance of the permutation test introduced in Section 2.3 using the Clayton copula and assumed concordance parameter θassum.∈{0.000,0.6‾,2,6}, which corresponds to τassum.∈{0.000,0.25,0.5,0.75}.1 Since logrank test‐based survival trees are commonly found in literature, [15, 18] we additionally included the logrank test. Furthermore, we included the Peto–Peto test that weights the logrank statistic by an estimate of the pooled survival function of both groups, [24, chapter 7] but will only report its results, when they deviate from the traditional logrank test. Both tests were evaluated using the R‐package survival [33].
We set the desired type I error to α=0.05. The type I error, or power, from nsim rounds of simulations is estimated as power^=1/nsim∑i=1nsim1(ppermi≤α) for ppermi being the p‐value from the ith simulation. The uncertainty of performing a simulation study with a finite number of repetitions is given by the empirical or Monte‐Carlo standard error (SE) as 1/nsim(power^×(1−power^)) [34]. Thus, for an estimated type I error of 0.05 from nsim=2000 repetitions, the Monte‐Carlo standard error estimate would be 0.005. During power estimation its upper bound is given by 0.5/nsim [35], which is 0.011 for nsim=2000 and 0.016 for nsim=1000.
The additional insecurity of calculating a permutation test on nperm rather than all n! permutations can approximately be quantified by a factor of 1.2 that is added to the Monte‐Carlo standard error [36]. Both for the type I error and maximal error based on 1000 or 2000 permutations, this seems acceptable for the purpose of getting a general idea of our test's performance. Thus, we choose nsim=1000 for calculating power curves and nsim=2000 for type I error analysis, where the exact maintenance of the error rate seems relevant. A permutation number of nperm = 1000 is chosen for both cases, which is well above the suggestion of 8nsim by Boos and Zhang (2000) [36].
To further confirm our choices of nsim and nperm, we re‐ran parts of the type I error and power analysis with larger nsim=nperm=5000. The results can be seen in Tables A1, A2 and Figures 1, 2, with the results corresponding to Tables A3, A4 and Figures B3, B12 in the Appendices A and B. The results from the sensitivity analysis regarding type I errors show only minor deviations from the main study. While individual estimates differ slightly from the main study (as expected due to Monte Carlo variability), we observe no systematic deviation that would indicate an over‐ or underestimation of the type I error with smaller simulations. The same holds true for the power analysis.
Power estimates with theoretical dependency of event and censoring times of τtheor.=0.0001 (left), and τtheor.=0.5 (right) for n1=n2=150 (top) and n1=20,n2=50 (bottom). r=0.5 for all Figures. The simulations were performed with nsim=5000 and nperm=5000. The results are almost identical to simulations with small nsim=nperm=1000 in Figure B3.
For type I error analysis, we consider all group sample sizes in (n1,n2)∈{20,50,100,200}×{20,50,100,200}, to cover small to moderately large sample sizes as well as both balanced and unbalanced group sizes. For the computationally more extensive power analysis, which evaluates a larger grid of effect sizes and censoring/data‐generation settings, we consider sample sizes in (n1,n2)∈{20,50,150}×{20,50,150} ({20,50,150} for the non‐proportional hazards setting), again including balanced and unbalanced settings. These sample size choices are motivated by our PBC study in Section 5, which includes a total of 312 patients that we repeatedly want to split into two groups. Finally, the selected sample sizes are consistent with sample sizes used in other simulation studies on two‐sample survival tests [37, 38].
The software R in version 4.2.1 was used for all calculations [39] and visualizations were made using the ggplot2 package [40].
Proportional Hazards
3.1.1
To simulate survival times from a Cox proportional hazard model, [24, chapter 2] we condition survival times on a one‐dimensional observed covariate z and receive ST(t|z)=exp−H0(t)exp(βz) for a parameter β∈ℝ and cumulative baseline hazard function H0. Since exp−H0(T)exp(βz)∼Unif[0,1] for survival time T, we solve this term for T, generate uniform random variables U and then simulate our survival times as T=H0−1(−log(U)exp(−βz)) [41]. Since previous simulation studies on survival data showed censoring rates to influence results much more than underlying statistical distributions, we choose simple distributions and focus on modeling our test's properties under various censoring rates [37]. To achieve this, we generate survival times using an exponential model with scale parameter λ=1, such that H0(t)=λt and T=−log(U)exp(−βz).
The generation of survival times depending on covariates is inspired by studies assessing properties of classification models [4, 17, 23], and provides simulation settings that can be generalized to datasets as described in Section 2.1. For the major part of the study, we consider binary covariates with zi=0 for subjects from group 1 and zi=1 for subjects from group 2. Parameter β varies on [−1.4,1.4], with β=0 representing the null hypothesis. Trial simulations indicated that the interval of [−1.4,1.4] is large enough to observe a power close to 1 towards the edge of the considered β‐interval.
Besides the described regression‐inspired designs with survival times depending on some βz, we additionally assess power on alternatives with varying covariate generating mechanisms between groups and β=1 for both groups, to mimic datasets like the one we will study in Section 5 with survival times possibly depending on various clinical covariates. Namely, we consider:
- 1.Normally distributed covariates with mean μ=0 in group 1, μ=γ in group 2 and standard deviation σ=1 in both groups. Parameter γ is varied on [−1.5,1.5] with γ=0 describing the null hypothesis.
- 2.Normally distributed covariates with variance σ=1 in group 1, σγ in group 2 and mean μ=0 in both groups. Parameter γ is varied on [0.00001,10] with γ=1 describing the null hypothesis.
- 3.Poisson distributed covariates with parameter λ=1 in group 1 and parameter λ=1+γ in group 2. Parameter γ is varied on [−0.9,1.5] with γ=0 describing the null hypothesis.
Censoring times are generated by drawing a second set of times as described above, and setting the minimum of event and censoring time as the observed value [42]. The scale parameter is set to λ=(1/(1−r))−r, such that for β=0 and independent survival and censoring times, the resulting survival data will have a censoring percentage of 100r % [43]. This leads to censoring time C=−log(V)·((1/(1−r))−r)−1 for uniform V. Three stages of censoring are simulated by choosing r∈{0.1,0.25,0.5}. Hence, censoring times are generated independently from covariates and β, to ensure equal censoring distributions across groups, as requested in Methods Section 2.3 (see Section 3.2.3 for a sensitivity analysis regarding the violation of this assumption).
To model dependent survival and censoring times, U,V∼Unif[0,1] are drawn according to a pre‐specified copula model using the R‐package Copula.surv [44]. All simulation settings are tested under two different censoring‐event dependencies, namely the Frank and the Clayton copula, which span notably different dependence regimes within the Archimedean family. While Clayton copulas allow us to model lower‐tail dependence, Frank copulas have no tail dependence. We used the true theoretical dependency parameters τtheor.∈{0.0001,0.25,0.5,0.75}. Furthermore, we run simulations with τtheor.=0.95 to understand the behavior of our test under extreme values of τtheor..
Non‐Proportional Hazards
3.1.2
To investigate the performance of our test under non‐proportional hazards, we use a Gompertz baseline hazard function h(t)=exp(γt+β1z+β2zt) to generate time‐dependent effects, resulting in non‐proportional hazards. This hazard function can be analytically integrated and inverted to generate survival times as: [42]
We simulate data for β1∈[−1.4,1.4], β2∈{0,0.6,1.4}, γ=1, group sizes n1,n2∈{20,50,150}, censoring parameter r∈{0.1,0.5} and dependency of censoring and survival times τtheor.∈{0.0001,0.5}.
Simulation Results
3.2
Proportional Hazards
3.2.1
In the following, the results of type I error and power analysis will be shown. Unless stated otherwise, the described results in this subsection refer to the settings with Clayton copula modeled dependence and binary covariates. Numbers will be rounded to three digits after the decimal sign.
Under proportional hazards, all tests maintain the type I error rate of 0.05 relatively well in all settings, with 90% of type I error estimates falling into the interval of [0.043,0.060] and all estimates being within [0.037,0.0685]. The median type I error estimate is 0.051. An overview of the estimated type I error rates for moderate sample sizes (n1=n2=50) on data generated by the Clayton copula, which in our case is the correctly specified copula class, can be seen in Table A3 in the Appendix A. While the CGE‐based tests show acceptable type I error estimates in all cases, Table A3 does not display any coherent patterns across varying τtheor. and censoring scenarios. Similar findings were made for other sample sizes.
The logrank test's type I error does not increase substantially when its assumption of independent survival and censoring times is violated. For small sample sizes (n1=20 or n2=20) and a high dependency parameter of τtheor.=0.75 all tests, but in particular the logrank test, are slightly too liberal. The logrank test has type I error estimates up to 0.067 (SE of 0.006), which can be seen in Table A4 in the Appendix A. For larger n, this problem vanishes, as Table A5 illustrates.
We did not find any systematic difference of type I errors between tests on data generated using a Clayton copula and tests on Frank copula data, which result in a misspecified model. Both copula scenarios had a median type I error of 0.051 over all considered simulation settings, with 90% of the type I errors falling into [0.0435,0.0588] for the Clayton copula and into [0.043,0.060] for the Frank copula, respectively. Figure B2 in the Appendix B gives more insight into this and compares type I error rates across copula models by test, sample size and theoretical dependence τtheor. The data displayed in the graphic is generated with censoring parameter r=0.5, yielding a mean censoring proportion of 0.500. The considered misspecifications of the copula class do not seem to cause inflated or too conservative type I error rates. Furthermore, no trend in type I error rates for varying τtheor. is visible for data from either copula model. In particular, our study results do not show a superior maintenance of the type I error rates, when the true τtheor. and the assumed τassum. coincide. Again, the logrank test is slightly more liberal than the CGE‐based test. The results for r∈{0.1,0.25} are similar.
Overall, we are satisfied with the type I error of the proposed test and move on to power analysis.
The power estimates for large sample sizes of n1=n2=150, binary covariates and simulated dependency of τtheor.∈{0.0001,0.5} can be seen in the upper part of Figure 1. The data for the graphic was generated with high censoring parameter r=0.5. Two things have to be noted: Firstly, the censoring distributions of both groups are identical and independent of β. However, the survival time distributions on the alternative hypothesis vary between groups. Our observations were generated as x=min(t,c) for survival times t and censoring times c. Therefore, the mean censoring percentage of our simulated data in group 1 (which has survival times not affected by β) is constantly around 0.500, but the mean censoring percentage in group 2 varies with β. The deviations in the censoring proportion in both groups range from minor ones (e.g., 0.499 vs. 0.435 for β=0.2 and τtheor.=0.5) to major ones (e.g., 0.501 vs. 0.327 for β=1). More detailed information on censoring percentages of the data from Figure 1 can be found in Table A6. Secondly, the censoring mechanism seems to not be completely independent from τtheor.. Censoring proportions rise with τtheor. for negative β (e.g., 0.591 for τtheor. = 0.0001 and 0.646 for τtheor. = 0.5 for β=−0.6 and r=0.5) and decrease for positive τtheor. (e.g., 0.425 for τtheor. = 0.0001 vs. 0.351 for τtheor. = 0.5 for β=0.6). Thus, while a comparison of the tests within each sup blot in Figure 1 is possible, since the powers were estimated on the same datasets, only a limited interpretation of the performance for varying dependence is reasonable.
All in all, the tests were able to detect deviations from the null hypothesis β=0 and for large |β|, their power estimates are close to 1. In all cases, the CGE tests with lower τassum. performed better with the τassum.=0‐test having the best power. The logrank and Peto–Peto tests perform similarly.
Exemplary, for τtheor.=0.5 and β=−0.4, the CGE‐based test with τassum.=0 has an estimated power of 0.960 (SE of 0.001). The test for τassum.=0.5 has a power of 0.783 (SE of 0.013) and the test with τassum.=0.75 is at 0.587 (SE of 0.016).
All tests showed a faster increase with positive β than with negative β, which partially could be attributed to the varying mean censoring percentages described in Table A6. In both displayed scenarios with n1=n2=150 of Figure 1, the logrank test and the CGE‐based test for τassum.=0 perform similarly. While for τtheor.∈{0.0001,0.25}, the logrank test has higher power, the CGE test has a higher power for τtheor.=0.5. For simulation settings with balanced, but smaller group sizes, the power rises slower than for the case of n1=n2=150, but the performance of the test relative to each other remains the same. See Figures B4 and B7 in the Appendix B for details.
The lower part of Figure 1 illustrates deficits of the CGE tests in unbalanced, small sample size settings. In the case of n1=20 and n2=50, the logrank test's power rises steadily with β<0 increasing in absolute value. However, the CGE‐based test's power, especially for large τassum. increases much slower and even falls to 0.030 (SE of 0.005) at β=−0.4 for the test with τassum.=0.75. For β<0, group 2 is expected to have longer survival times. This leads to scenarios, where the latest observed time in smaller group 1, max(x1), is a lot lower than the latest time max(x2) in group 2. An example of a single dataset from our simulation study illustrates this in Figure B5 in the Appendix B. The logrank test is able to detect the longer survival of group 2 with a p‐value of 0.031. However, the CGE‐based statistic, only comparing survival curves up to min(max(x1),max(x2)), misses out on the fact that there is a large difference in max(x1) and max(x2) and yields a p‐value of 0.170. Apparently, for this setting, the division of the absolute distance in between the CGEs by observation time span min(max(x1),max(x2)) is not enough to counteract this. The issue occurred for various values of τtheor. (see Figure B6), but was less present for lower censoring parameters r (see Figure B8).
The problem vanishes when group 1 has a larger sample size compared to group two, for example, for n1=50 and n2=20. The larger sample size in group 1 with expected shorter survival leads to smaller differences of max(x1) and max(x2) and thus a larger proportion of the study time is accounted for in the CGE‐based test statistic. In some settings, the CGE tests outperform the logrank test, such as the case of β=−0.2, where the logrank test has a power of 0.057 (SE of 0.007) and the four CGE‐based tests have powers in between 0.089 (SE of 0.009) and 0.098 (SE of 0.009). Again, an illustration of an exemplary dataset is shown in Figure B5.
In the following paragraphs, we will discuss results from the three settings with alternative covariate structures. In setting 1. additional variance is added to simulated times by adding normal covariates of varying means to group 2. Still, the means of the covariates generating the survival times are varied across the same range as β was for binary covariates. Hence, the results of setting 1. are very similar to the results described above. All tests increase in power for large sample sizes in both groups. Again, the logrank test outperforms the CGE‐based tests in almost all settings. For unbalanced designs with lower n1 and smaller covariates in group 1 (i.e., γ<0), the same problems described for binary covariates with β<0 occur and the CGE tests perform worse than the logrank test. The problems vanish if both groups have a smaller sample size. These power properties are illustrated in Figure B9 for the case of τtheor.=0.25 and r=0.5.
Setting 3. has Poisson distributed covariates with parameter λ=1+γ and γ being varied on [−0.9,1.5] to consider various alternative hypotheses. Thus, mean and variance of the survival time generating covariates differ across groups. Still, all tests are able to maintain the type I error well and the power rises steadily with |γ| and achieves values close to one for large |γ| for all tests. For sample sizes of n1=n2=150, this is illustrated in Figure B10. In all settings, the logrank test's power is higher than that of CGE‐based tests, with power curves being clearly separated for all γ. For large sample sizes, the CGE‐based tests have an almost identical performance for all considered τassum..
Lastly, setting 2. has normal covariates and alternative hypotheses of standard deviation 1 in group 1 and varying deviation γ in group 2. The mean of the covariates is the same for both groups. CGE‐based tests generally had higher power, since the logrank test was only able to achieve acceptable power for large n and low censoring rates. For n1=n2=150, dependency τtheor.=0.25, γ=10 and a censoring proportion of 0.257 (r=0.1), all four CGE tests have a perfect power estimate of 1.000 (SE of 0.000). For a higher mean censoring proportion of 0.501, the CGE‐based tests lose power and for example, have power estimates between 0.789 (SE of 0.013) and 0.892 (SE of 0.010) at τtheor.=0.25 and γ=10. The logrank test however only has a power estimate of 0.912 (SE of 0.009) and 0.382 (SE of 0.015) in these two settings. This setting is one of the few, where the behavior of the Peto–Peto test strongly differs from the logrank test's. Specifically, the test performs poorly when the censoring percentage is low, but achieves the best performance among all tests when censoring is high. To illustrate this pattern, Figure B11 shows an exemple dataset for each of the three censoring settings at β=7.5. From the displayed CGEs of the two study groups, we see that the difference in observed times between the two groups early on in the study rises with censoring parameter r. Because the Peto–Peto test places greater weight on early survival differences when computing its statistic, this explains its strong performance under high censoring and poorer performance under low censoring.
Setting 2. is the only setting where CGE‐based tests with higher τassum. repeatedly show greater power than the CGE test with τtheor.=0, as can be seen in Figure 2. In the case of n1=n2=50, τtheor.=0.5 and r=0.5 the CGE‐based test with τtheor.=0.75 even has the highest power estimates, which we don't see for any other covariate distributions. See Figure B13 for details. Looking at exemplary datasets from this settings, such as the one displayed in Figure B20, we see that the longest observed times in both groups are similar for large γ. However, in group 2, survivals and censorings are completely separated, meaning that all observed survival times are lower than any observed censoring time. Consequently, the curve of the CGE is at a relatively high level, since the censoring times do not affect the estimator's path at all. The CGE of group 1 on the other hand, especially with large τassum., strongly weights censorings in group 1 and falls to a much lower value. Thus, there is a good separation between the estimators of the groups, resulting in a small p‐value. It should be noted that the dataset from Figure B20 was an extreme example regarding the separation of survival and censoring times in group 2, which was not the case for all rounds of simulation.
Power estimates for normal covariates with varying standard deviation between groups, n1=n2=150 and τtheor.=0.25. Censoring percentages vary across columns from 0.258 and r=0.1 on the left to 0.501 and r=0.5 on the right. The simulations were performed with nsim=5000 and nperm=5000. The results are almost identical to simulations with small nsim=nperm=1000 in Figure B12.
Similar to our findings on type I error rates, misspecifying the copula class does not seem to reduce the test's power. To illustrate this, we exemplarily study the settings from Figures 1 and 2, and assess how the Clayton Copula–based test's power changes, if we misspecify the copula class. On the left of Figures B14 and B15, dependence between survival and censoring times is generated using a Clayton copula; on the right, we use a Frank copula, which leads to a misspecification of the copula class.
The resulting power curves of the Clayton‐CGE test are very similar, and we do not observe a systematic loss of power when the data are generated from the misspecified (Frank) copula. Small differences occur in individual configurations: For instance the CGE test with τassum.=0.75 has a power of 0.653 for the Clayton‐based data and a power of 0.704 for the Frank copula generated data (setting of binary covariates, n1=20, n2=50, β=0.8, censoring parameter r=0.5 and τtheor.=0.5). However, this could also be due to a relatively small number of simulations per setting of nsim=1000 or slightly varying censoring percentages across copula models (in this case 26.590% for the Clayton and 27.273% for the Frank copula).
Non‐Proportional Hazards
3.2.2
For the data generated under non‐proportional hazards, we additionally report the results of the Peto–Peto test, since they sometimes differ from those of the logrank test. Under non‐proportional hazards with β2=0 and a low censoring proportion generated with r=0.1, all tests perform well and very similarly to each other, as can be seen in Figure B17 in the Appendix B. For higher censoring with r=0.5, the tests still have a type I error of about 0.05 and a steadily increasing power with β1, but the tests' power differs slightly, as seen in Figure 3. The logrank test overall has the best performance and the performance of the CGE tests decreases as τassum. increases.
Power estimates with theoretical dependency of event and censoring times of τtheor.=0.5 and censoring parameter r=0.5. The data was generated with non‐proportional hazards.
While all tests generally exhibit reasonably high power when |β1| differs considerably from zero, deviations from H0 due to β2>0 are not always detected. For example, consider the setting with β1=−0.8 and β2=1.4. Under r=0.5 and τtheor.=0.5, the CGE tests for small sample sizes (n1=n2=20) have very low power between 0.085 and 0.107 (see Figure 3, column 3, row 2). Only for the largest sample sizes considered (n1=n2=150, column 3 row 1) are the CGE tests able to detect deviations from H0, with estimated power ranging from 0.536 (for τassum.=0.75) to 0.768 (for τassum.=0). In contrast, the logrank and Peto–Peto tests perform poorly across all sample sizes, with a power of 0.073 for n1=n2=20 and only 0.032 for n1=n2=150.
These issues can be explained by the way the survival times are generated. We can denote the times as a function of U∈Unif[0,1]:
Now, there are some parameter settings, where T(u,γ,β1,β2,0) (group 1 due to z=0) and T(u,γ,β1,β2,1) (group 2 with z=1) are very similar, even though the parameter values of β1 and β2 differ from 0. This results in very similar survival times being generated for both groups, even though H1 is true. Figure B16 illustrates this for the above mentioned parameter values of β1=−0.8,β2=1.4 and β1=0.8,β2=0.6, where in contrast the generated survival times for the two groups are clearly separated.
As Figures 3 and B17 show, the type I error, which should be 0.05, is generally well maintained. Some deviations from 0.05 exist for all tests, including the logrank and Peto–Peto tests. Since they show no clear pattern across τtheor. and censoring parameter r, they might at least partially be caused by the small number of simulated datasets at nsim=1000. More details for the setting of n1=n2=150 can be seen in Table A7 in the Appendix A.
In conclusion, we see that our test is able to provide an accurate type I error to control all considered non‐proportional hazard settings, while it only provides a high power in some of the considered settings. However, the CGE test's power in the setting where it was not ideal, was still comparable and oftentimes better than that of the traditional testing procedures.
Sensitivity Analysis: Censoring Distributions
3.2.3
During the simulations, we observed differences in censoring proportions between the two groups. Although the censoring distributions were identical across groups, group‐specific survival time distributions under H1 resulted in different proportions of censored observations. These issues were especially prominent for large τtheor. and β, which we further investigated for extreme parameter settings τtheor.=0.95 and β∈{−5,5}. Furthermore, we performed a sensitivity analysis to see how our test performs when the assumption of equal censoring distributions for both groups made in Section 2.3 is violated. All Figures shown in this subsection display the mean censoring proportion in both groups in addition to the test's power.
For the sensitivity analysis, we again simulated data with proportional and non‐proportional hazards. We considered violations from the assumption of equal censoring distributions in two ways:
1: Group‐specific censoring parameters ( r varies by group): Censoring times were generated as described in Section 3.2.1, but r differs for both groups with r∈{0.1,0.5} for group 1 and r∈{0.25} for group 2.
2: Censoring distribution matches survival distribution: Censoring times are generated the same way that survival times are generated. Consequently, under H1 the censoring distributions of the two groups differ.
Results for the proportional hazards setting with τtheor.=0.5 are shown in Figure 4. In the setting with equal censoring distributions (left column), censoring times in both groups were generated with r=0.5. For the setting of varying r across groups, censoring in group 2 was generated with r=0.25.
Power estimates with theoretical dependency of event and censoring times of τtheor.=0.5 and proportional hazards. The data was generated with r=0.5 in group 1 and r=0.25 in group 2 (left column), with identical censoring and survival distribution (middle column), and with equal censoring distribution with r=0.5 (right column).
When the censoring distribution equals the survival distribution (middle column), all tests across all sample sizes show a good type‐I error and a steadily increasing power with |β|. In some cases, the test's power is lower compared to the setting with equal censoring distribution, but this could be caused by a higher mean censoring rate in group 2. Overall, our test appears not to be too sensitive to this particular violation of the equal censoring assumption.
However, when censoring distributions differ due to varying values of r, all tests, including the logrank test, perform worse, especially with respect to the type I error control. For the largest sample size considered (n1=n2=150), only the CGE test with τassum.=0.5 maintains an accurate type I error of 0.054. In contrast, the CGE test with τassum.=0 exhibits the largest type I error (0.863), while the logrank test also shows a substantial type I error inflation of 0.707. Notably, although censoring proportions are lower in this setting than in the case of equal censoring, the tests still perform worse. This indicates that the tests are highly sensitive towards this violation of the assumption of equal censoring distributions.
For survival times generated under non‐proportional hazards, this issue is less prominent, as can be seen in Figure B18 in the Appendix B. For n1=20, n2=50, τtheor.=0.5, and the same values of r as above, the type I error under censoring with varying r across groups ranges from 0.044 for the CGE test with τassum.=0.75 to 0.143 for the CGE test with τassum.=0. As before, we observe that the power of the tests remains low when β2≠0, which is consistent with the behavior already seen in Section 3.2.2, where the assumption of equal censoring distributions was not violated.
Overall, the sensitivity of our test to violations of the equal censoring distribution seems to depend on the exact form of the deviation. Some violations led to inflated type I error. However, in these settings the traditional logrank and Peto–Peto tests also failed to control the type I error.
To assess the effects of extreme values of τtheor., we simulated data with τtheor.=0.95, again considering equal as well as unequal censoring distributions between groups. While the mean censoring proportion in group 1 remained constant at 0.5 for uniform censoring times, the censoring proportion in group 2 varies substantially, ranging from nearly 100% for β<0 to almost 0% for β>0. In the setting with equal censoring distributions across groups, this large difference in mean censoring proportions apparently helps all tests to detect differences between the groups and the power improves compared to the setting with τtheor.=0.5.
For the setting with unequal censoring distributions due to varying r, the tests also show acceptable power for β≠0, which slightly improves with increasing τtheor.. However, the issues with inflated type I error rates discussed above persist. Overall, the CGE tests appear robust to extreme values of τtheor., even though these induce large differences in mean censoring proportions under our model assumptions. The full results can be seen in Figure B19 in the Appendix B.
To assess the influence of extreme values of β, we simulated data with β∈{−5,5} for the proportional hazards model for all parameter settings (with respect to n,r,τtheor. and censoring distribution) discussed in Section 3. This led to extreme censoring proportions for data generated under the assumption of equal censoring distributions, with censoring in group 2 close to 100% for β=−5 and close to 0% for β=5. Nevertheless, all CGE tests achieved a power close to 1 across the considered settings, as reflected by the summary statistics for the estimated power shown below (Table 1):
Therefore, we assume that our tests are quite robust towards great deviations in censoring proportions under extreme values of β.
Simulation Study: Trees
4
Simulation Design
4.1
In a second simulation study, we compare the performance of the trees introduced in Section 2.4 to those of the logrank tree regarding prediction ability and ability to select relevant covariates. The study design is motivated by Emura et al. (2012) [45] who generate datasets of survival times and according informative and non‐informative covariates to study methods for compound covariate prediction.
For each round of simulation, we simulate a training and a testing dataset with n=100 subjects each as follows: For subject i, the covariate vector
is drawn with each entry following a continuous uniform distribution with mean 0 and standard deviation 1. The covariates are separated into three blocks (1 to q, q+1 to 2q and 2q+1 to p). Covariates of the first two blocks have a pairwise correlation of ρ within their block; the remaining genes are uncorrelated. Our data generation mechanism is motivated by Scenario 2 (gene pathway) from Emura et al. (2012) [45]. The underlying idea is that covariates can be grouped into blocks representing biological pathways, where each pathway consists of q correlated genes that jointly affect survival in a coherent direction. Restricting pairwise interactions to occur within blocks reflects the common assumption that interactions are more likely among functionally related variables (e.g., genes within the same pathway), and allows us to study the behavior of the tests under a controlled and easy to interpret correlation structure. This block‐structured approach of simulating survival data was used in multiple prior works [4, 45, 46]. We use the X.pathway function from the R‐compound.Cox package to generate datasets of this format [47].
To mimic a clinical dataset consisting of categorical patient data and laboratory biomarker assessments, half of the genes in each block are transformed to a binary scale by calculating mediani(zij) for each covariate j∈{1,…,p} and setting the new, binary covariate to z˜ij=1{zij≥mediani(zij)}. Subsequently, all covariates are rounded to one digit after the decimal point, which reduces the size of possible cutoff‐values within survival trees and thus greatly speeds up the simulation study. Survival and censoring time are generated analogously to Section 3.1, using a multidimensional parameter
to generate T=−log(U)exp(−β⊤zi) for uniform U and one‐dimensional auxiliary parameter β. Note that only the first 2q covariates actually affect the survival times. Again, the Clayton copula with parameter τtheor. is used to generate dependency between survival and censoring times. We compare the performance of CGE‐based trees for τassum.∈{0.0001,0.25,0.5,0.75} and the logrank tree using the implementation of the uni.survival.tree package [48]. We consider larger sample sizes of n∈{100,300}, in order to have more subject observations than the number of covariates, which was chosen as p=50. As this is only a small simulation study, all other parameter values are not varied, but approximately set in the middle of their respective feasible ranges, which leads to β=0.5, ρ=0.5, p‐value threshold p˜=0.01, and τtheor.=0.25. Two censoring scenarios are considered leading to mean censoring proportion of 0.135 and 0.464, respectively. nsim=100 simulation rounds were performed and the number of permutations for the permutation tests was set to nperm=1000, which allows us to conduct the study in a manageable amount of time. The trees are evaluated regarding three criteria:
- 1. Selection ability: We evaluate, how many of the tree's splits are based on the informative covariates 1 to 2q. We provide the precision, which is the proportion of non‐terminal nodes that split depending on one of the informative covariates. It can take values between 0 and 1, with 1 indicating perfect precision [17].
-
Prognostic ability: We use Harrell's C‐index to measure, if a tree's terminal nodes are able to order the test dataset's survival times correctly into groups from low to high survival. The terminal nodes are numerated from right to left with low numbers indicating low risk. For any two patients, the index describes, if the patient with the lower terminal node number survived longer than the patient with the higher node number [49]. The index is computed by a pairwise comparison over all test subjects, where one certainly had an event before the other one. If (tn#)i denotes the terminal node number of subject i, with a low number indicating long survival, the numbers of concordant (CC), discordant (DC) and tied (TR) pairs of all comparable subjects i,j=1,…,n are given by: [50]
The resulting index
can take values in [0,1], with high values indicating good prognostic ability [50]. The survival package was used to calculate Harrell's C [33].
- 3. Prediction ability: The Brier Score is used to evaluate, how accurately a tree predicts the survival of a subject from the testing dataset at a given timepoint. We predict the survival of a subject in terminal node (tn#) at time t as the value of the CGE calculated on subjects in node (tn#) from the training dataset at time t. We calculate the CGE using the same τassum. used to construct the respective tree, and use τassum.≈0, that is, the Kaplan–Meier estimator for the logrank tree predictions. Graf et al. (1999) [51] provide a version of the Brier score that incorporates censoring by weighting deviations of predicted survival from true survival with an estimator of the censoring distribution. This score can then be integrated over the study period to yield the Integrated Brier Score (IBS), which is
with Ŝ and Ĉ describing estimators of survival or censoring function, respectively [50]. Common choices are Kaplan‐Meier estimators. We additionally provide the IBS using CGEs with τassum.=τtheor., which in the case of this simulation study is known to us. The integral from Equation (7) is estimated over a grid of timepoints t˜1,…,t˜m as
It is sufficient to choose t˜ as the timepoints observed in the testing or training dataset, since the step‐function like estimators will not fluctuate in between these points.2
Simulation Results
4.2
Table 2 displays the study results. The performance of the four CGE‐based trees is very similar in all settings regarding the number of terminal nodes as well as all accuracy measures introduced in Section 4.1. No noticeable trends related to τassum. can be seen.
The logrank trees have more terminal nodes than the CGE trees. For instance, the CGE tree with τassum.=0.25 has 15.7 terminal nodes on average for n=100 and low censoring of 0.135%, while the logrank tree has 24.450, which is the 1.557‐fold. As n rises from 100 to 300, the number of terminal nodes increases with a factor of about 3 for the CGE trees (e.g., factor 2.926 for τassum.=0.5 and low censoring) and a factor around 2.7 for the logrank tree (2.692 for low censoring). These large numbers for n=300, especially seen for the logrank trees, might diminish the easy and practical interpretability of survival trees. Adjusting the threshold p‐value p˜ or adding a minimum nodesize threshold to allow an additional split to the tree algorithm would solve this problem. Lastly, the trees are smaller for higher censoring, which aligns with the results from Section 3.2, where we saw that both logrank and CGE‐based tests lose power with higher censoring and therefore find fewer significant splits.
The precision of the CGE trees is over 0.666 in all settings. Hence, the majority of covariates is selected correctly. The logrank tree's precision is lower in all settings. For all trees, the precision decreases with higher n (e.g., from 0.762 for n=100 to 0.681 for n=300 for τassum.=0.5), which might be partially caused by a higher number of cutoff values and thus the higher number of possible splits that comes with larger n. In all settings except for n=100 and low censoring, the CGE test with τassum.=0 has the largest precision ranging between 0.682 and 0.799. However, the differences are small (e.g., 0.710 for τassum.=0 vs. 0.681 for τassum.=0.5 for n=300 and high censoring).
Both the traditional IBS and the CGE adjusted score have higher values for higher censoring, indicating less prediction ability. For instance, the score increases from 0.120 for low censoring to 0.288 for high censoring for the CGE test with τassum.=0.25 and n=100. In most settings, the logrank test shows the highest values for both versions of the IBS.
Between n=100 and n=300 changes in the Kaplan‐Meier estimate based IBS can be seen, and for multiple trees the values increase. For instance, the logrank test's IBS increases from 0.34 for n=100 to 0.355 for n=300 under high censoring, while its C‐index improves. As the size of the trees (measured as the number of terminal nodes) also increases from n=100 to n=300, this indicates a trade‐off between model complexity and predictive accuracy. However, we believe the effect is driven less by the absolute size of the trees per se, and more by the occurrence of terminal nodes with very few observations (i.e., very small terminal nodes), which occurs more frequently in larger trees.
The IBS itself is computed from subject‐specific survival predictions obtained from the terminal node model fitted on the training data, that is Kaplan‐Meier for the logrank tree and CGE‐based prediction for the CGE trees. When terminal nodes contain only very few training observations, these node‐level survival estimates can become unstable, which can inflate IBS for test subjects assigned to such nodes. This phenomenon is particularly pronounced for the larger logrank trees as can be seen in Table 3.
The CGE‐based IBS showed larger increases from n=100 to n=300, for example, from 0.354 to 0.422 for low censoring and the test with τassum.=0.75. In addition to the large number of small terminal nodes mentioned above, this could also be caused by the CGE Score putting higher weights on individuals with very high observed times, which more frequently occur in larger datasets. Details can be found in Appendix C.
For Harrell's C‐index, the row‐wise values of all trees are comparable. In particular, the logrank trees have the highest C‐index in three out of four settings (for instance a value of 0.732 for n=300 and low censoring). All C‐indices are well over 0.500, which would indicate trees that order subjects no better than random assignment. The C‐indices are slightly higher in the high censoring scenario, but do not change much with n.
Illustrative Data Analysis
5
In this section, we will apply the proposed tree algorithm to real‐world data. We will use the Primary Biliary Cholangitis (PBC) dataset provided by the survival package [33]. PBC is a progressive liver disease causing inflammations in the liver that lead to cirrhosis, destroy the bile ducts and eventually result in death. The dataset is from a randomized Mayo Clinic trial conducted between 1974 and 1984 testing D‐penicillamine, a possible treatment for PBC [53, chapter 3].
The full dataset contains data from 418 subjects. However, 106 did not participate in the randomized trial and consequently have many missing values in variables potentially very relevant to survival, in particular the variable Treatment. Thus, these 106 subjects are removed prior to our data analysis, leaving us with a sample size of 312.
In addition to each patient's event or censoring time, 17 covariates are provided. These include seven binary or categorical variables such as Presence of Ascites and Presence of Hepatomegaly or Enlarged Liver. Furthermore, ten continuous variables, mostly biomarkers, such as Serum Bilirubin or Serum Cholesterol are provided. Before analysis, we rounded the variable Age to full years to reduce the value of feasible cutoff values and save computation time.
1.080% of covariate observations are missing, especially of the variables Serum Cholesterol (8.974% missing) and Triglycerides (9.615% missing). So far, the proposed tree cannot handle missing values. Consequently, these two variables were removed from the dataset prior to our analysis. After this, only six subjects with missing values in one or more variables were left. These subjects were removed as well, leaving 306 subjects for the following analysis.
Of the remaining patients, 123 died during the study, 164 were censored due to lost follow‐up and 19 had a liver transplantation. For this illustrative data example, these patients are considered censored as well, since the transplantation prevented a death through PBC.
It is reasonable to assume, that a patient's health status, and with it their underlying survival time distribution, affected the decision, if a liver transplantation was necessary [7]. Thus, we suspect that the dataset was generated by positively dependent survival and censoring times, making it a suitable dataset to test our method.
Before constructing a survival tree, we evaluate the performance of the tree construction algorithms by cross‐validation. We evaluate the performance of the CGE trees using the Clayton copula with Kendall's τassum.∈{0.0001,0.125,0.250,0.375,0.500,0.625,0.750,0.875} and the logrank tree. We use a p‐value threshold of p˜ = 0.01, the number of permutations nperm.=5000 and apply the metrics introduced in Section 4.1 to evaluate the tree algorithms. The performance measures are computed using 10‐fold cross‐validation [54, chapter 7].
The results can be seen in Table 4. The logrank tree has 27.3 terminal nodes on average, which is slightly more than the CGE trees, which have between 19.2 terminal nodes for τassum.∈{0.375,0.875} and 20.9 terminal nodes for τassum.=0.625. The larger size of the logrank tree was also seen in the simulation study in Section 4.2. The mean C‐index of the CGE‐trees ranges from 0.769 to 0.801, with no clear trend in relation to τassum. visible. The logrank tree had the highest C‐index of 0.816.
The Kaplan–Meier–based IBS increases almost monotonously with τassum. Only the trees with τassum.=0 and τassum.=0.125 have a lower Score than the logrank tree at 0.192, while the CGE tree with τassum.=0.375 almost ties the logrank tree at a Score of 0.194.
The analysis of performance measures does not indicate one CGE tree that is superior to the other ones. This result is confirmed by a visualization of the CGE‐based tree's metrics in Figure B21 in the Appendix B. In the following, we will choose the tree with τassum.=0.375 for a more detailed analysis, since it provides a compromise of relatively small mean tree size, large C‐index and an IBS similar to the logrank tree's. We will compare this tree's properties to that of the logrank tree. Both trees are re‐calculated on the full dataset.
The resulting trees are again larger than the ones seen during cross validation due to increased n. This results in a CGE tree with 22 and a logrank tree with 30 terminal nodes. Both trees seem overfitted. Half of the CGE tree's terminal nodes have under five subjects. The logrank tree has 18 terminal nodes with under five and ten with only one subject. As described in Section 2.4, we ordered the tree's terminal nodes such that terminal nodes with a high number have the worst survival prognosis. However, no clear separation of the survival curves of the terminal nodes was visible and patterns in survival across terminal nodes could not be seen clearly. See Figure B22 in the Appendix B for details. Both trees use multiple variables repeatedly for splitting in subsequent splits. We thus re‐calculate both trees using a smaller p‐value threshold of p˜=0.001. The new trees were considerably smaller with 12 terminal nodes for the CGE tree and 19 terminal nodes for the logrank tree. We will describe these trees for the remaining part of this section:
The separate group survival curve estimates at the first split of both trees can be seen in Figure 5. The CGE tree splits the data into {Age≤45} and {Age>45}, with the first group showing longer survival. Figure 5 indeed shows a clear separation of the CGEs of the two group's survival, with the older group having the lower estimates. The first split of the logrank tree is by {Presence of Ascites>0} and {Presence of Ascites≤0}. The separated groups by the logrank test are uneven, with only 23 of 306 subjects being in the second group. Moreover, the censored subjects are distributed among groups very unevenly with only two of 183 censored subjects being in the group with lower expected survival.
Survival curve estimates after the first split for the CGE tree with τassum.=0.375 (left) and the logrank tree using the Kaplan‐Meier estimator (right).
We continue our analysis by looking at the survival curve estimators of the PBC data by terminal node in Figure 6. Still, no clear separation of estimates is visible, but there is a tendency for nodes with lower numbers to have longer survival times. The graphic for the CGE tree shows several groups that consist only of censored individuals with overlapping CGEs constantly at 1. We can also see that the terminal node sizes for the CGE tree are distributed relatively evenly by taking values between 6 and 54. The logrank tree's final node sizes differ more from each other. One terminal node contains 157, more than half, of the study subjects. Eight terminal nodes only contain one subject, and their survival estimators cannot be displayed in Figure 6. The more even distribution of subjects over terminal nodes speaks in favor of the CGE tree here.
Survival curve estimates of terminal nodes, with node 1 indicating highest survival probability. CGE tree with τassum.=0.375 (left) and the logrank tree using the Kaplan–Meier estimator (right). The trees were calculated with p˜=0.001. High node numbers indicate shorter survival.
To end our analysis, we display the full CGE classification tree for τassum.=0.375 in Figure 7. Many of the tree's splits seem reasonable, such as categorizing older patients (Age
45) or patients with Presence of Hepatomegaly or Enlarged Liver (hepto) in higher risk groups. Nine of the twelve terminal nodes have a parent node that splits according to Serum Bilirubin. While this points out the importance of the biomarker for liver health, it also indicates that the tree might be overfitted. In further analysis, we could, for instance, find a systematic way to summarize node 8 to 11, which result from repeatedly splitting the data according to Serum Bilirubin.
CGE survival tree with τassum.=0.375 and p˜=0.001. High node numbers indicate shorter survival.
Discussion
6
In this paper, we introduced a permutation test for the null hypothesis of equal survival distributions in two groups under the assumption of equal censoring distributions. The introduced test is based on the copula‐graphic estimator, such that form and strength of a dependence between survival and censoring times can be incorporated. Assuming a Clayton copula and various dependence parameters corresponding to values of Kendall's τ between 0 and 0.75, we assessed the test's type I error and power in a simulation study. We found that the test maintains a desired type I error of α=0.05 relatively well for all considered sample sizes and censoring scenarios. Furthermore, it was robust to a misspecification of the copula model when the data was generated from a Frank copula. We were overall satisfied with the test's power, which was generally robust except in scenarios with highly unbalanced group sizes and significant censoring. Here, the logrank test demonstrated higher power than our proposed test, even under conditions of dependent censoring. The most notable power advantage of our proposed test compared to the logrank test was observed in cases with heteroscedasticity.
In practice, the problem of selecting a suitable dependence parameter τassum. for the test remains challenging. In our simulation studies, we saw that in almost all cases the power of the CGE test decreases with τassum. and the test with τassum.=0 had the highest power overall. Few exceptions were seen, for instance under proportional hazards with normal covariates, varying variances across groups and high censoring (see Figure 2). However, this effect vanishes for the same setting with less censoring. Furthermore, when the assumption of equal censoring distribution across groups was violated and the censoring distribution was the same as the survival distribution, the CGE‐tests with higher τassum. performed slightly better (see Figure 4). These findings could potentially assist the search for a good τassum. and we suggest the following practical guidance: First, when the focus is predictive modeling via tree construction, τassum. can be treated as tuning parameter and selected via cross‐validation during training. Second, when inference with the CGE‐based permutation test is the primary goal, we recommend τassum.=0 as the default choice. In situations with heavy (and possibly unequal) censoring and/or heteroscedasticity, a τassum.>0 may be pre‐specified from domain knowledge; alternatively, results for several τassum.>0 values may be reported in a sensitivity analysis without selecting one post‐hoc.
The permutation test was then implemented as a splitting criterion in a survival tree algorithm, that was tested on simulated data as well as on real‐world data from the Mayo Clinic Primary Biliary Cholangitis clinical trial. While the trees' survival predictions demonstrated satisfactory concordance in all settings, with Harrell's C‐indices exceeding 0.7, the IBS was rather high with values of over 0.28, especially for data with a high censoring rate above 46%.
We decided to only consider a single survival tree to benefit from its straightforward interpretability and low computation time. Moreover, a single survival tree provides an explicit set of decision rules that partitions patients into subgroups with distinct estimated survival curves. Such rule‐based decision paths are easier to read and communicate clinically, particularly in comparison with the random survival forest (RSF) [55], where predictions are aggregated across many trees and no single decision path exists. Nonetheless, tree ensembles such as survival forests [55] are often shown to have much higher predictive ability. Furthermore, during 10‐fold cross validation we noticed differences in the ten resulting trees, their number of terminal nodes and chosen covariates. This instability could also be reduced using an ensemble method. Although a survival forest may increase computational time and reduce interpretability, its potential predictive benefits could justify the trade‐off. Beyond the classical RSF, many other implementations exist, see for example Section 3 of Bou‐Hamad et al. (2011) [15] for an overview.
Compared with Cox‐regression, our approach avoids proportional hazards assumptions, can capture non‐linearities, and allows detection of various effect types, which can be clinically informative. On the other hand, the Cox model remains advantageous when proportional hazards is plausible: It offers direct effect size estimation and direct coefficient‐based interpretability. In a single tree, effect magnitudes are less straightforward to quantify and expressed implicitly via subgroup survival curves rather than coefficients.
Limitations
6.1
While we were able to implement and apply the proposed survival tree, some limitations of the method and of our simulation study should be noted:
One limitation of the proposed method is the assumption of equal censoring distributions of both groups. While this assumption (and the resulting exchangeability of survival times under the null hypothesis) is required to mathematically derive an exact test, it is not a realistic assumption and limits the use of our work on real‐world data. In the sensitivity analysis in Section 3.2.3, we found that certain violations of this assumption can degrade the test's performance. However, traditional methods such as the logrank test exhibited similar sensitivity. Other authors [38, 56] suggest an alternative permutation approach that does not require exchangeability under the null hypothesis by applying a studentization. They studentize their test statistic by adding a (co)variance estimator to the test statistic that is calculated on the same data permutations as the rest of the statistic. This studentized permutation strategy was subsequently applied to inference in factorial designs [20]. A similar studentization approach could also be derived for our statistic. Moreover, we could also think about other tests for splitting, for example, based on ideas from omnibus tests [37, 38, 56] or based on interpretable estimands like the restricted mean survival time [57].
During the evaluation of the simulation study in Section 4.2 we saw that the considered trees tend to overfit towards the training data, resulting in trees with many terminal nodes only containing a small number of training subjects and low predictive accuracy. Furthermore, this number was often larger than the number of covariates and took away some of the interpretability of our trees that we had hoped for. Currently, we address overfitting in two ways: First, we assess predictive performance out‐of‐sample on independent test data. Second, the tree growth procedure includes an explicit stopping rule (the p‐value threshold) that determines whether a split of the data into two groups is considered significant and leads to the addition of two new sub‐nodes to the tree. This regularizes tree growth and is applied consistently to ensure a fair comparison. Additional strategies against overfitting like post‐hoc pruning or imposing a minimum terminal‐node size would also be of interest. Furthermore, we could add an amalgamation step to our algorithm that reduces the number of terminal nodes by recursively grouping similar terminal nodes together [15, 58].
The logrank tree had even more terminal nodes than the copula‐graphic estimator based trees across all study settings. One reason for this is given by our p‐value threshold of 0.01 that was set for all trees before the start of the simulation study. A detailed study on its calibration for both types of trees would be necessary to properly evaluate this issue.
Moreover, we saw a problem of copula‐graphic estimator trees finding splits with large absolute differences between the group's estimators by choosing one group consisting of almost exclusively censored subjects. This resulted in one group's CGE having values close to 1 over the whole study period and led to large test statistic values. To prevent splits like the one seen in Figure B23, we could add a maximum censoring threshold for each descendant group.
A further issue of the proposed permutation‐based trees was long computation time, caused by the nesting of the iterative permutation test into the iterative tree algorithm. To solve this problem, we could try to adapt a computationally efficient, matrix‐based algorithm [17] for a survival tree splitting based on score tests. While a direct transfer of this algorithm to our proposed test does not seem possible, since we use a permutation test, some modification of the proposed algorithm might be applicable for our setting.
Beyond the aforementioned limitations of the survival tree algorithm, the simulation studies and data example used to assess its performance also have limitations: During our simulation studies in Sections 3 and 4 we generated survival data with two different censoring‐event dependencies, using a Clayton and a Frank copula. Exploring a broader range of copulas is an interesting extension. For instance, considering copula families with strong upper‐tail dependence (e.g., the Gumbel copula in case of late events) could potentially lead to different empirical split patterns.
In our simulation study assessing the performance of CGE trees on simulated data in Section 4, we generated survival times depending on blocks of informative and non‐informative covariates. We restricted pairwise interaction to covariates within the same block, to mimic a pathway of genes. Since real‐world data may exhibit more complex interaction patterns (including interactions spanning across blocks), we acknowledge that our simulation setting is limited in this respect. While this may affect the absolute performance of specific models, our primary goal was an initial, controlled comparison of the tree algorithm under a structured pathway‐like setting, such that the results remain informative for relative method comparison. Nevertheless, further studies with more complex covariate patterns would be valuable.
Lastly, this paper only considers one real‐world clinical data example. While this case study provides a first illustration of the method's applicability, a multi‐dataset benchmarking study is another important direction for future work.
Funding
The authors have nothing to report.
Disclosure
The authors have nothing to report.
Conflicts of Interest
The authors declare no conflicts of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1K. M. Leung , R. M. Elashoff , and A. A. Afifi , “Censoring Issues in Survival Analysis,” Annual Review of Public Health 18, no. 1 (1997): 83–104, 10.1146/annurev.publhealth.18.1.83.9143713 · doi ↗ · pubmed ↗
- 2E. L. Kaplan and P. Meier , “Nonparametric Estimation From Incomplete Observations,” Journal of the American Statistical Association 53, no. 282 (1958): 457–481, 10.2307/2281868. · doi ↗
- 3X. Huang and N. Zhang , “Regression Survival Analysis With an Assumed Copula for Dependent Censoring: A Sensitivity Analysis Approach,” Biometrics 64, no. 4 (2008): 1090–1099, 10.1111/j.1541-0420.2008.00986.x.18266895 PMC 4037927 · doi ↗ · pubmed ↗
- 4T. Emura and Y. H. Chen , “Gene Selection for Survival Data Under Dependent Censoring: A Copula‐Based Approach,” Statistical Methods in Medical Research 25, no. 6 (2016): 2840–2857, 10.1177/0962280214533378.24821000 · doi ↗ · pubmed ↗
- 5J. P. Klein and M. Moeschberger , “Independent or Dependent Competing Risks: Does It Make a Difference,” Communications in Statistics ‐ Simulation and Computation 16, no. 2 (1987): 507–533, 10.1080/03610918708812602. · doi ↗
- 6S. Schneider , R. C. P. dos Reis , M. M. F. Gottselig , P. Fisch , D. R. Knauth , and Á. Vigo , “Clayton Copula for Survival Data With Dependent Censoring: An Application to a Tuberculosis Treatment Adherence Data,” Statistics in Medicine 42, no. 23 (2023): 4057–4081, 10.1002/sim.9858.37720988 · doi ↗ · pubmed ↗
- 7N. D. Staplin , A. C. Kimber , D. Collett , and P. J. Roderick , “Dependent Censoring in Piecewise Exponential Survival Models,” Statistical Methods in Medical Research 24, no. 3 (2015): 325–341, 10.1177/0962280214544018.25038073 · doi ↗ · pubmed ↗
- 8A. J. Templeton , E. Amir , and I. F. Tannock , “Informative Censoring — A Neglected Cause of Bias in Oncology Trials,” Nature Reviews Clinical Oncology 17, no. 6 (2020): 327–328, 10.1038/s 41571-020-0368-0.32273582 · doi ↗ · pubmed ↗