Closed-form feedback-free learning with forward projection
Robert O’Shea, Bipin Rajendran

TL;DR
This paper introduces Forward Projection, a fast and interpretable method to train neural networks without backpropagation, achieving good performance on biomedical data.
Contribution
A novel feedback-free training method using random projections and closed-form solutions for interpretable and efficient learning.
Findings
FP achieves comparable generalization to gradient-based methods with a single forward pass.
FP-trained networks produce interpretable layer-wise predictions and highlight clinically relevant features.
FP outperforms backpropagation in few-shot learning by generating more generalizable models.
Abstract
State-of-the-art backpropagation-free learning methods employ local error feedback to direct iterative optimisation via gradient descent. Here, we examine the more restrictive setting where retrograde communication from neuronal outputs is unavailable for pre-synaptic weight optimisation. We propose Forward Projection (FP), a randomised closed-form training method requiring only a single forward pass over the dataset without retrograde communication. FP generates target values for pre-activation membrane potentials through randomised nonlinear projections of pre-synaptic inputs and labels. Local loss functions are optimised using closed-form regression without feedback from downstream layers. A key advantage is interpretability: membrane potentials in FP-trained networks encode information interpretable layer-wise as label predictions. Across several biomedical datasets, FP achieves…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
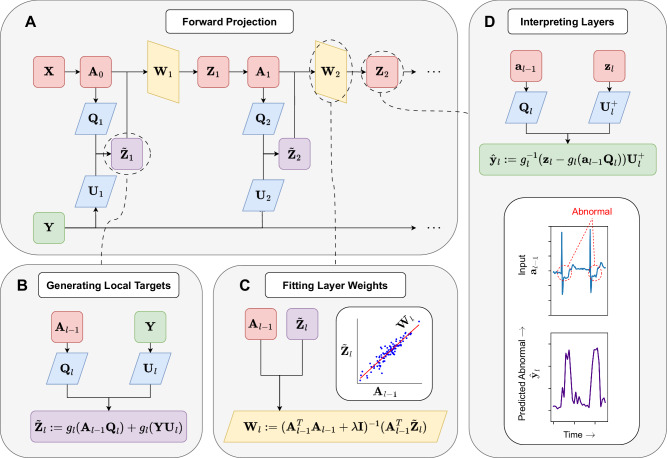 Figure 1
Figure 1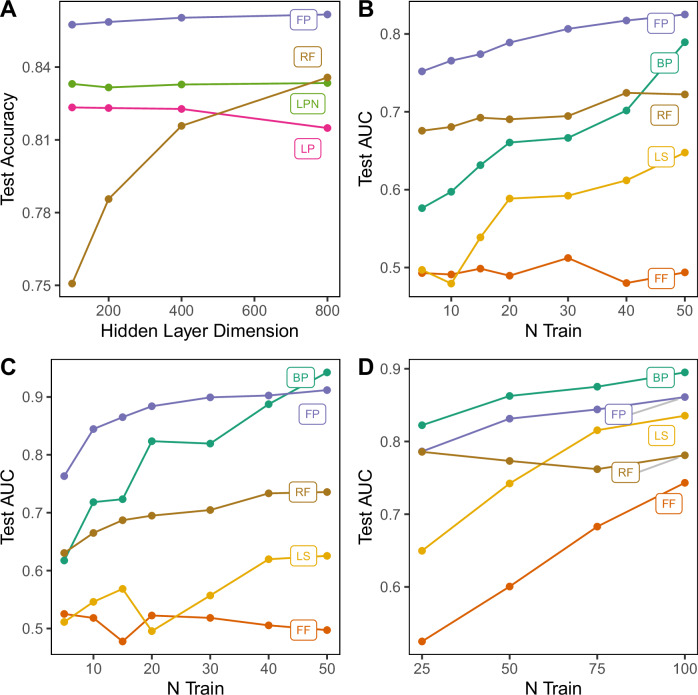 Figure 2
Figure 2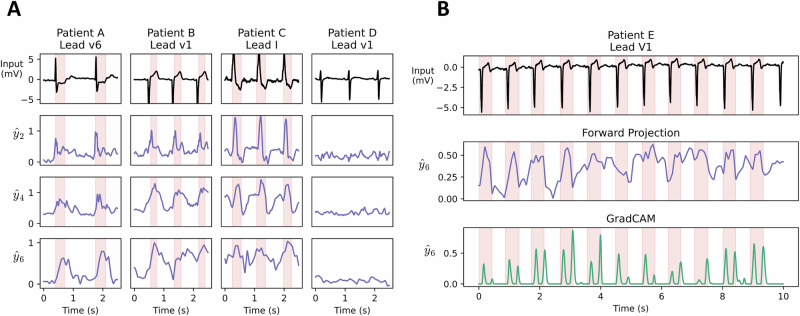 Figure 3
Figure 3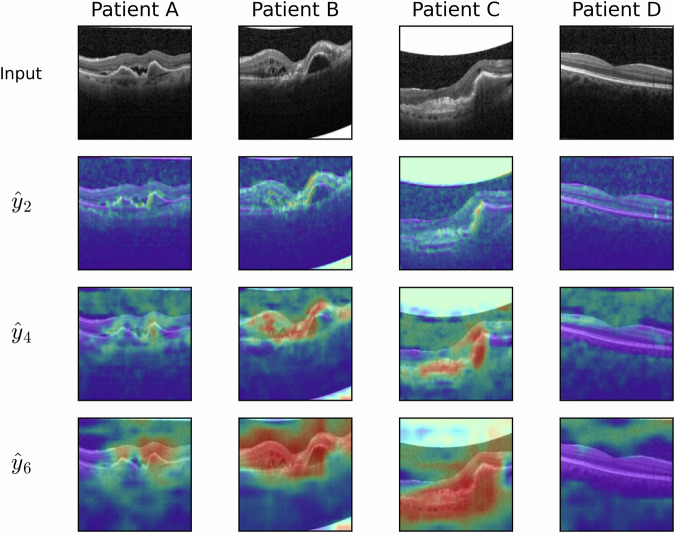 Figure 4
Figure 4- —501100000266RCUK | Engineering and Physical Sciences Research Council (EPSRC)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Memory and Neural Computing · Neural Networks and Reservoir Computing · Neural dynamics and brain function
Introduction
A core task in neural network training is synaptic “credit assignment” for error in downstream layers^1–3^. Although backpropagation has been established as the standard approach to this problem, its biological plausibility has been questioned^3–5^. Backpropagation requires bidirectional synaptic communication, which is incompatible with the unidirectional transmission of neural action potentials^3^. Consequently, backpropagation would require either symmetric neural connectivity or a parallel retrograde network for error feedback to earlier layers^3,6,7^. The backward pass traverses layers in reverse order of activation, leading to temporal discordance between forward and backward operations and necessitating storage of hidden activations. Furthermore, gradient descent requires hidden neural activations to be differentiable throughout. To approximate backpropagation in a more biologically plausible way, approaches such as Predictive Coding^5,8^ and Difference Target Propagation^1^ seek to align forward neural activity with a backward network that mirrors the forward architecture, effectively implementing an inverse model. Various strategies have been proposed to address the credit assignment problem with reduced retrograde communication requirements. Auxiliary loss functions computed on the activations of individual layers have been proposed to shorten the backward pass^9–12^. A prominent example is the layer-wise greedy optimisation method that aims to minimise the costs of backpropagation by applying local supervision (LS) at each layer^9,13^. Extensions of this approach include deep continuous local learning^10^ and single-layer updating^14^. Hebbian learning rules using asymmetric feedback weights have been explored, allowing for independent updates for forward and feedback pathways^15^.
Recent approaches have also explored using two forward passes to facilitate communication between upstream and downstream neurons^16–19^. The “Forward-Forward” (FF) learning algorithm^16^ is an approach in which data and label hypotheses are combined as inputs, with optimisation seeking to upregulate neural response to correctly labelled inputs and subdue responses to spuriously labelled inputs. However, inference under the original Forward-Forward algorithm requires a forward pass for each hypothesised label, presenting issues for tasks with large label spaces^19^. The “PEPITA" algorithm employed a preliminary forward pass to predict a label, which is used to generate spurious data-label instances for training^17^.
The central issue with local learning methods in deep neural networks is that the optimal activity of hidden neurons is unknown during training, preventing direct observation of local error. Pre-defining activity targets for hidden neurons allows for heuristic local optimisation. However, target definition strategies are a topic of ongoing research^20^. Techniques such as local-representation alignment and target propagation introduce target values for hidden activations using limited retrograde communication from downstream neurons^1,11,20–22^. Alternatively, target activities can be set as fixed random label projections computed during the forward pass, thereby permitting direct measurement of the error during the forward pass^11^. However, this approach may lead to highly correlated neuronal activity – a problem known as informational collapse^13^. Although additive noise permits maximal decorrelation of target potentials^1^, it is uninformative with respect to the label, potentially impeding model fitting. Approaches such as random neural network features^23^ forgo optimisation of hidden nodes entirely, instead projecting inputs to a random high-dimensional non-linear feature space. However, random feature layers require exponential scaling with respect to the input dimension to support downstream learning^24^.
The “Predictive Coding” paradigm provides a perspective on the collective functionality of intermediate neurons, proposing that local neural learning processes optimise the prediction of pre-synaptic neural inputs, minimising the “surprise” of out-of-distribution stimuli^5^. Approaches such as the “Difference Target Propagation”^1^ reframe network layers as a series of autoencoders, where intermediate activations represent a series of encodings, transitioning from input information to label information. The issue of informational collapse in locally supervised SGD-trained models has been addressed by optimising the retention of information on the pre-synaptic activity^13^. “Prospective configuration” of target activities reformulates learning under the presumption that idealised adjustments to neuronal activity should be generated via energy minimisation before synaptic adjustment^20^. Synaptic weights may be modified to realise the predetermined activities in response to the given input stimuli^20^, thereby transitioning from input information to label information through model layers. “Local neural synchronisation" generates target neural activity for hidden layers by projecting neuronal activity onto periodic basis vectors representative of class labels^25^.
Going beyond these approaches, we propose the use of random nonlinear projections of both pre-synaptic inputs and target labels to generate local target activities in the forward pass. The objective of this approach is to develop a neural network training algorithm that requires no retrograde communication. Closed-form regression techniques are applicable in this setting, permitting single-step layer weight computation without error feedback. Thus, weight parameters are determined without backward communication from neuronal outputs or downstream layers. Further advantages of this method include the direct interpretability of hidden neurons with respect to local label predictions and stability in the few-shot setting.
Results
We consider a dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{D}}}}={\{({{{{\bf{x}}}}}_{i},{{{{\bf{y}}}}}_{i})\}}_{i=1}^{N}$$\end{document} from the joint distribution ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X,Y$$\end{document} ). The task is to learn a feed-forward neural network function mapping \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X \to Y$$\end{document} . The model has L layers, with dimensions m0, …, mL, and activations a0, …, aL, where a0 = x and aL = y. Each layer is equipped with weights Wl to generate membrane potentials zl = al−1Wl, and activation function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${f}_{l}:{\mathbb{R}}\to {\mathbb{R}}$$\end{document} to generate neuronal outputs al = fl(zl). The model prediction is defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{{{{\bf{y}}}}}=\left.{f}_{L}({{{{\bf{W}}}}}_{L}(\ldots {f}_{1}({{{{\bf{W}}}}}_{1}{{{\bf{x}}}})))\right)$$\end{document} .
Forward projection (FP)
To generate target membrane potentials for hidden neurons, we present the Forward Projection (FP) algorithm (Fig. 1A). We propose to combine pre-synaptic inputs and labels using random non-linear projections to generate targets (Fig. 1B). For each training sample, the target potential \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widetilde{{{{\bf{z}}}}}}_{l}\in {{\mathbb{R}}}^{1\times {m}_{l}}$$\end{document} is generated from pre-synaptic inputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{a}}}}}_{l-1}\in {{\mathbb{R}}}^{1\times {m}_{l-1}}$$\end{document} and labels \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\bf{y}}}}\in {{\mathbb{R}}}^{1\times {m}_{L}}$$\end{document} using fixed random projection matrices \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{Q}}}}}_{l}\in {{\mathbb{R}}}^{{m}_{l-1}\times {m}_{l}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{U}}}}}_{l}\in {{\mathbb{R}}}^{{m}_{L}\times {m}_{l}}$$\end{document} such that
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widetilde{{{{\bf{z}}}}}}_{l}={g}_{l}({{{{\bf{a}}}}}_{l-1}{{{{\bf{Q}}}}}_{l})+{g}_{l}({{{\bf{y}}}}{{{{\bf{U}}}}}_{l}),$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${g}_{l}:{\mathbb{R}}\to {\mathbb{R}}$$\end{document} is an element-wise non-linear transformation. It is noted here that gl is not necessarily equal to fl, the neural activation function. Ql and Ul are fixed linear projections drawn from random Gaussian distributions, which are pre-defined before training. The target potential \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widetilde{{{{\bf{z}}}}}}_{l}$$\end{document} allows a local auxiliary loss function to be defined with respect to the actual membrane potential, zl, realised during the forward pass. The randomised combination of pre-synaptic inputs with the target label is inspired by the high-dimensional computing paradigm^26^, where fixed random projections are employed to encode information from multiple vector inputs, approximately preserving relative distances according to the Johnson-Lindenstrauss lemma^26^. Accordingly, it is noted that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widetilde{{{{\bf{z}}}}}}_{l}$$\end{document} approximately encodes both al−1 and y (see section S.8 in SI). By generating target potentials in a forward manner, the mix of information encoded in each layer is expected to transition incrementally from predominantly input information in early layers to label information in later layers. We propose to define a local loss function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\mathcal{L}}}}}_{l}:=\parallel {{{{\bf{Z}}}}}_{l}-{\widetilde{{{{\bf{Z}}}}}}_{l}\parallel$$\end{document} , which may be employed as an objective to optimise Wl. Synaptic weights for each layer can be computed in a closed-form forward manner, using ridge regression (Fig. 1C), such that
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{W}}}}}_{l}:={({{{{\bf{A}}}}}_{l-1}^{\top }{{{{\bf{A}}}}}_{l-1}+\lambda {{{\bf{I}}}})}^{-1}({{{{\bf{A}}}}}_{l-1}^{\top }{\widetilde{{{{\bf{Z}}}}}}_{l}).$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{A}}}}}_{l-1}\in {{\mathbb{R}}}^{N\times {m}_{l-1}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widetilde{{{{\bf{Z}}}}}}_{l}\in {{\mathbb{R}}}^{N\times {m}_{l}}$$\end{document} are matrices of pre-synaptic activities and target potentials, respectively, collected over the N samples in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{D}}}}$$\end{document} . λ is a regularisation term, and I is the identity matrix. Observe that the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{A}}}}}_{l-1}^{\top }{{{{\bf{A}}}}}_{l-1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{A}}}}}_{l-1}^{\top }{\widetilde{{{{\bf{Z}}}}}}_{l}$$\end{document} terms in (2) may be computed sequentially over instances \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{{{{{\bf{a}}}}}_{1,l-1},\ldots,{{{{\bf{a}}}}}_{N,l-1}\}\subset {{\mathbb{R}}}^{1\times {m}_{l-1}}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{{\widetilde{{{{\bf{z}}}}}}_{1,l},\ldots,{\widetilde{{{{\bf{z}}}}}}_{N,l}\}\subset {{\mathbb{R}}}^{1\times {m}_{l}}$$\end{document} (see section S.7 in SI). Therefore, memory requirements are independent of N, depending only on ml−1 and ml. Note, weights are computed once only, after the single training epoch. The approach of encoding information on both inputs and labels in the hidden layers is inspired by the Predictive Coding and Target Propagation paradigms^1,5,9^. However, unlike previous approaches, no backward communication is required from neuronal outputs to pre-synaptic inputs to achieve the FP fit. As a consequence of this fitting approach, neural membrane potentials in hidden layers of FP-trained models may be interpreted as label predictions (Fig. 1C).Fig. 1. Graphical overview of forward projection.A Forward projection algorithm for fitting layer weights W1, …, Wl to model labels Y from data X. B Procedure for generating the l-th layer target potentials \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widetilde{{{{\bf{Z}}}}}}_{l}$$\end{document} . Pre-synaptic inputs Al−1 and labels Y are projected with fixed matrices Ql and Ul, respectively, before applying non-linearity gl. C Optimising Wl to predict \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widetilde{{{{\bf{Z}}}}}}_{l}$$\end{document} from Al−1 by ridge regression with penalty λ. D Interpreting membrane potentials zl as a local label prediction \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{{{{\bf{y}}}}}}_{l}$$\end{document} given pre-synaptic inputs al−1 and projection matrices Ql and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{U}}}}}_{l}^{+}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{U}}}}}_{l}^{+}$$\end{document} is the pseudo-inverse of Ul.
Forward projection performance
Forward Projection was compared to other local learning methods, including random features (RF)^24^, Local Supervision (LS)^9^, and Forward-Forward (FF)^16^ in multiple tasks using equivalent model architectures (Table 1). The Fashion MNIST (FMNIST) image classification task was modelled on a multi-layer perceptron (MLP). Forward Projection achieved higher test accuracy than other local learning methods in this task, approaching the performance of the backpropagation reference standard. Two large-scale biomedical sequence modelling tasks were also evaluated with one-dimensional convolutional neural network (1D-CNN) architectures. The Promoters task required the identification of human non-TATA promoters, a class of gene promoter regions that increase transcription of DNA sequences^27,28^. Forward projection yielded higher test performance than all other local learning methods in this task. The PTBXL-MI task^29^ required diagnosis of myocardial infarction (MI), a heart condition commonly known as “heart attack", from 12-channel electrocardiogram (ECG) recordings. FP and LS performed comparably in this task. FP also outperformed all other methods in the optimisation of models with more complex neuronal activations such as modulo and polynomial activation functions (see section S.14 in SI). Backpropagation performance benchmarks on the PTBXL-MI and Promoters tasks were consistent with previous studies^28,30^. For the CIFAR10 classification task without data augmentation, two-dimensional convolutional neural networks (2D-CNNs) trained by FP underfitted, but still outperformed all other local learning methods, whereas standard backpropagation overfitted the model. FP was implemented in a transformer architecture to discriminate the first two classes of the CIFAR10 dataset ("CIFAR2"), outperforming RF.Table 1. Test performance of various learning methods across different datasetsMethodFP (ours)RFLSFFPCDTPBP (ref.)DatasetMetricFMNIST MLPAUC98.3 ± 0.098.0 ± 0.098.7 ± 0.198.5 ± 0.198.2 ± 0.197.8 ± 0.299.0 ± 0.0Acc86.3 ± 0.184.0 ± 0.283.1 ± 2.085.6 ± 0.883.0 ± 0.479.3 ± 2.088.4 ± 0.3Promoters 1D-CNNAUC88.7 ± 0.580.0 ± 1.186.6 ± 1.183.5 ± 0.779.7 ± 1.778.8 ± 0.894.1 ± 0.3Acc81.8 ± 0.572.2 ± 1.479.7 ± 1.275.3 ± 3.670.5 ± 3.669.3 ± 3.387.4 ± 0.7PTBXL-MI 1D-CNNAUC95.5 ± 0.594.7 ± 1.897.3 ± 0.389.3 ± 3.886.0 ± 0.986.4 ± 2.299.3 ± 0.0Acc86.5 ± 1.183.4 ± 2.186.1 ± 4.069.4 ± 8.264.2 ± 5.070.1 ± 5.894.9 ± 0.6CIFAR2 2D-ViTAUC91.5 ± 0.583.1 ± 0.596.1 ± 0.4Acc83.5 ± 0.575.9 ± 0.689.2 ± 0.7CIFAR10 2D-CNNAUC85.1 ± 0.281.4 ± 0.587.7 ± 0.557.9 ± 1.774.5 ± 0.364.5 ± 2.389.8 ± 0.7Acc48.8 ± 0.340.6 ± 1.048.4 ± 1.113.1 ± 1.928.5 ± 0.915.3 ± 3.054.8 ± 1.5The FMNIST dataset was modelled with a multi-layer perceptron; Promoters and PTBXL-MI datasets were modelled using 1D convolutional neural networks (1D-CNNs); CIFAR2 (first two CIFAR10 classes only) was modelled using vision transformers, and CIFAR10 was modelled with 2D-CNNs.BP backpropagation, DTP difference target propagation, FF forward-forward, FP forward projection, LS local supervision, PC predictive coding, RF random features.
Alternative feedback-free approaches
To assess the value of the FP target generation function, we compared the performance of closed-form regression models fitted to targets generated by alternative functions, including simple label projection ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widetilde{{{{\bf{Z}}}}}}_{l}:={{{{\bf{yU}}}}}_{l}$$\end{document} ) and label projection with additive noise \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left({\widetilde{{{{\bf{Z}}}}}}_{l}:={{{{\bf{yU}}}}}_{l}+{{{\bf{E}}}}\right)$$\end{document} . To evaluate the capability of feedback-free training methods to handle information “bottlenecks", they were applied to optimise MLP architectures for FMNIST classification. MLPs were generated with 1000 hidden neurons in the first and second layers (m1 = m2 = 1000), and m3 ∈ {100, 200, 400, 800} neurons in the final hidden layer. FP outperformed other feedback-free approaches (Fig. 2A). The performance of RF deteriorated in models with small penultimate layers, as relevant information was less likely to be represented by random projection^24^. The performance of simple label projection deteriorated in models with large penultimate layers, a result that may be attributable to rank deficiency (see section S.6 in SI). Noisy label projection maintained steady performance, but at a lower level than FP.Fig. 2. Performance of Forward Projection with backpropagation and local learning approaches.A Comparison of feedback-free fitting methods on FMNIST. MLP architectures had 1000 neurons in the first and second layers and 100, 200, 400 or 800 neurons in the final hidden layer. B–D Test performance of few-shot trained 2D-CNN models. Mean test AUC is reported over 50 few-shot training experiments. B Chest X-ray (CXR) task. C Optical Coherence Tomography (OCT) task. D CIFAR2 task in which models were required to classify the first two classes (aeroplane and automobile). Models were fitted with N ∈ {5, 10, 15, 20, 30, 40, 50} training samples from each class in CXR and OCT tasks and N ∈ {25, 50, 75, 100} samples per class for the CIFAR2 task. Predictive Coding and Difference Target Propagation are plotted separately in Supplementary Fig. S3. BP backpropagation, FF Forward-Forward, FP Forward Projection, LS Local Supervision, RF Random Features.
Few-shot learning
"Few-shot" learning is a constrained learning scenario in which the number of data samples available for training is small. High-dimensional data, such as images, pose a challenge for few-shot learning, as many spurious features may exist. Thus, successful few-shot training methods must select generalisable features in the presence of these confounders. Few-shot learning was assessed in image classification tasks using a 2D-CNN architecture. The optical coherence tomography task (OCT)^31^ required that the model discriminate images of healthy retinas from those with choroid neovascularization, a pathology that affects the eye and manifests mainly as abnormal growth of blood vessels behind the retina. The paediatric chest X-ray (CXR) task^31^ required the model to discriminate between images of viral pneumonia, bacterial pneumonia, or healthy controls. The CIFAR2 task required the model to discriminate between the first two CIFAR10 classes (aeroplane and automobile). Few-shot training datasets were generated by subsampling, with N ∈ {5, 10, 15, 20, 30, 40, 50} training examples from each class for OCT and CXR tasks, and N ∈ {25, 50, 75, 100} training examples per class for the CIFAR2 task. Data augmentation was not employed. Model generalisability was assessed on all test data (CXR: Ntest = 431; OCT: Ntest = 327; CIFAR2: Ntest = 2000). Forward Projection-trained models demonstrated the greatest few-shot generalisability in CXR (Fig. 2B) and OCT (Fig. 2C), outperforming all other methods, including backpropagation, in all the tasks with N ≤ 40 training samples. In the CIFAR2 few-shot task, Forward Projection achieved the best performance of any local learning method in experiments with N ∈ {50, 75, 100}, being outperformed only by backpropagation. With as few as N = 10 training samples, Forward Projection fitted discriminative models for the classification of OCT (test AUC: 84.5 ± 5.8) and CXR (test AUC: 76.6 ± 5.8). CXR and OCT datasets highlighted two distinct vulnerabilities of backpropagation training in few-shot conditions. In the N = 5 setting on OCT, backpropagation overfitted the training samples (Train AUC: 86.8 ± 13.2; Test AUC: 61.8 ± 17.4), as models integrated noise into decision functions. On the other hand, backpropagation failed to achieve adequate model fitting in the N = 10 setting on CXR (Train AUC: 69.0 ± 8.1; Test AUC: 59.7 ± 6.2). Random features performed comparably to backpropagation in tasks with the fewest training samples, but performance improved only slightly with larger sample sizes. Random Features models could not overfit within convolutional layers, as these contained no free parameters. However, Random Features had a limited capacity to learn structural features in larger training samples. The improvement that Forward Projection provided over Random Features is therefore attributable to structural feature learning within hidden convolutional layers. Label Projection and Noisy Label Projection failed to converge in few-shot training (training AUC ≈ 0.50). Neither Local Supervision nor Forward-Forward training matched the baseline generalisability of Random Features in OCT and CXR tasks; however, Local Supervision achieved comparable test discrimination to Forward Projection in the CIFAR2 task when *N *≥ 75. Predictive coding and Difference Target Propagation yielded uninformative models in few-shot learning tasks (Supplementary Fig. S3). Few-shot performance is tabulated in Supplemental Table S2.
Feature interpretability
Explainability is a central issue with backpropagation-based learning, as relationships between hidden activations and model predictions may be non-monotonic, complicating the interpretation of hidden neural activities^32^. An important advantage of Forward Projection is the interpretability of hidden neuron activity with respect to label predictions (see section S.8 in SI). Assuming \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{z}}}}}_{l}\approx {\widetilde{{{{\bf{z}}}}}}_{l}$$\end{document} , neural potentials may be interpreted as a local label prediction \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{{{{\bf{y}}}}}}_{l}$$\end{document} (Fig. 1D), such that
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{{{{\bf{y}}}}}}_{l}:={g}_{l}^{-1}({\widetilde{{{{\bf{z}}}}}}_{l}-{g}_{l}({{{{\bf{a}}}}}_{l-1}{{{{\bf{Q}}}}}_{l})){{{{\bf{U}}}}}_{l}^{+}.$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{U}}}}}_{l}^{+}$$\end{document} is the Moore-Penrose generalised inverse of the label projection matrix. Likewise, pre-synaptic inputs are encoded in neural pre-activation potentials, with an analogous reconstruction function (see section S.8 in SI). It is noted that (3) may be uninformative if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\parallel {{{{\bf{z}}}}}_{l}-{\widetilde{{{{\bf{z}}}}}}_{l}\parallel }{\parallel {\widetilde{{{{\bf{z}}}}}}_{l}\parallel }$$\end{document} is large – i.e., if Wl did not achieve a good fit. Measurement of local error in training data may provide insights into the reliability of (3) during inference. Interpretation of pre-activation potentials zl is simplified by the selection of bijective functions for gl so that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${g}_{l}^{-1}$$\end{document} exists everywhere. In practice, a surrogate approximation to the functional inverse was observed to suffice in our experiments; for example, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${g}_{l}^{-1}(\cdot )\approx \tanh (\cdot )$$\end{document} was employed as a surrogate inverse for gl( ⋅ ) = sign( ⋅ ). In our experiments, hidden neurons of models fitted with Forward Projection were interpretable as label predictions. In the FMNIST task, test accuracy of layer explanations was observed to improve between early layers and subsequent layers (Supplementary Fig. S2-A), demonstrating progressive learning. In the PTBXL-MI task, applying the surrogate layer explanation function (described in equation (3)) to the convolutional layers identified various clinically salient features for diagnosing myocardial infarction (MI). MI, a clinical condition characterised by damage to heart muscles due to poor blood flow, may manifest in ECG data with various electrophysiological abnormalities. Consequently, the model must learn several distinct pathological waveform features, including elevation of the “ST" segment, or inversion of the “T" wave. Fig. 3A shows the layer explanations as a function of time in four patients, three of whom were diagnosed with myocardial infarction. Patient A demonstrates ST-segment depression in lead II, which is temporally consistent with peaks in the model explanation functions at each layer. Likewise, the model explanation functions peak during ST-segment elevation in Patient B and during QRS widening and T-wave inversion in Patient C. In contrast, the model explanation function is near zero in Patient D, who had normal ECG morphology. Forward Projection model explanations derived using (3) from the sixth convolutional layer ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{y}}_{6}$$\end{document} ) were compared with GradCAM outputs of backpropagation-trained networks. The first 15 MI-positive test instances in the PTBXL dataset were annotated by a medical doctor to segment the diagnostically relevant subsequences. Layer explanations derived by Forward Projection achieved similar discrimination performance (AUC: 0.61 ± 0.14, AUPR: 0.52 ± 0.19) to GradCAM (AUC: 0.59 ± 0.12, AUPR: 0.55 ± 0.13) (Fig. 3B).Fig. 3. Forward Projection layer interpretations for electrocardiogram analysis.A Visualisation of layer explanations over time in a 1D-convolutional neural network trained by Forward Projection to detect myocardial infarction (MI) in electrocardiograms (ECGs) from PTBXL data. Patients A, B, C, E (diagnosed with MI) and patient D (no disease) were extracted from test data. Explanations were extracted from the second, fourth and sixth convolutional layers ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{y}}_{2},{\widehat{y}}_{4},{\widehat{y}}_{6}$$\end{document} ) using equation (3). Explanations increase with MI features (highlighted in red), including ST-segment depression (Patient A), ST-segment elevation (Patient B) and QRS widening with T-wave inversion (Patient C). B Comparison of Forward Projection with GradCAM. Top: ECG data from Patient E (diagnosed MI), showing ST-segment elevation. Middle: Sixth convolutional layer explanation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{y}}_{6}$$\end{document} ) from a model trained by Forward Projection. Below: GradCAM output for the sixth convolutional layer of a model trained by backpropagation.
Choroid neovascularization (CNV) is the growth of abnormal blood vessels behind the retina due to diseases such as age-related macular degeneration^33^. In OCT images, CNV may be represented by various image features, including hyper-reflective dots and detachment of the retinal pigment epithelium^34^. In the OCT task, the model’s layer explanation functions identified regions of interest related to CNV (Fig. 4). 2D-CNN models trained with only 100 instances per class learned to localise fine-grained CNV features, including retinal/subretinal fluid (Patients A-C), hard exudates (Patient B), and fibrosis (Patient C).Fig. 4. Visualisation of layer explanations over space in 2D-CNNs trained by Forward Projection to detect choroid neovascularization (CNV) in the OCT task.Ensemble average of five models shown. Patients A–C (diagnosed with CNV) and patient D (no disease) were extracted from test data. Explanations were extracted from the second, fourth and sixth convolutional layers ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{y}}_{2},{\widehat{y}}_{4},{\widehat{y}}_{6}$$\end{document} ), using (3). CNV heat-maps demonstrate high values (red) over CNV features, including retinal/subretinal fluid (Patients A–C) and hard exudates (Patient B), and fibrosis (Patient C), with low values (blue) over the healthy retina (Patient D).
Training complexity
We now analyse the complexity of training with the Forward Projection algorithm for a classification task by estimating the storage and computational requirements for a densely connected m × m hidden layer. We consider a dataset of N training samples, with label dimension mL. Note that FP model weights can be obtained in one pass over the N training samples, while all other methods require each training sample to be fed to the network for several epochs (denoted Ne). The training procedure for each layer is presented in Supplementary Fig. S1.
The memory requirement for Forward Projection is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}({m}^{2})$$\end{document} for the layer weights, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}({m}^{2})$$\end{document} for the Q matrix, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}(m{m}_{L})$$\end{document} for the U matrix. As the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{A}}}}}_{l-1}^{\top }{{{{\bf{A}}}}}_{l-1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{A}}}}}_{l-1}^{\top }{\widetilde{{{{\bf{Z}}}}}}_{l}$$\end{document} terms in (2) can be accumulated sequentially over data batches (See section S.7 in SI), two m × m matrices suffice for their storage, thereby avoiding storage of the N × m matrices Al−1 and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widetilde{{{{\bf{Z}}}}}}_{l}$$\end{document} . As with all methods, Forward Projection requires \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}({m}^{2})$$\end{document} multiply-and-accumulate (MAC) operations to calculate the activations for the downstream layer in the forward pass. To generate target potentials during the forward pass, Forward Projection also requires \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}({m}^{2})$$\end{document} additional MAC operations to project through Q and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}(m{m}_{L})$$\end{document} MAC operations to project through U. Computation of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{A}}}}}_{l-1}^{\top }{{{{\bf{A}}}}}_{l-1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{A}}}}}_{l-1}^{\top }{\widetilde{{{{\bf{Z}}}}}}_{l}$$\end{document} terms requires \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}(N{m}^{2})$$\end{document} MAC operations each. After all samples have been observed, computation of model weights using equation (2) requires \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}({m}^{3})$$\end{document} operations to invert the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{{\bf{A}}}}}_{l-1}^{\top }{{{{\bf{A}}}}}_{l-1}$$\end{document} term and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}({m}^{3})$$\end{document} operations for matrix multiplication to complete the regression; however, this happens only once for each layer. Furthermore, Forward Projection requires no backward pass.
For backpropagation, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}({m}^{2})$$\end{document} memory is required for storing layer weights, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}({m}^{2})$$\end{document} for accumulated gradients, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}(m)$$\end{document} for activations. Here, the computation requirements scale as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}({N}_{e}{m}^{2})$$\end{document} MACs each for the forward pass, backward pass, and weight update calculations. Hence, in the typical setting where m ≫ mL, we note that Forward Projection and backpropagation have similar memory requirements, scaling as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}({m}^{2})$$\end{document} . Notably, compute scales as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}({m}^{3})$$\end{document} for FP versus \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{O}}}}({N}_{e}{m}^{2})$$\end{document} for BP. For example, training a dense hidden layer with 1000 inputs and 1000 outputs on the FMNIST dataset (N = 60, 000, mL = 10) by Forward Projection requires a total of 1.2 × 10^11^ MAC operations for the forward pass and 1.2 × 10^11^ MAC operations for the weight update. Training the same layer via 100 epochs of backpropagation requires 6.0 × 10^12^ MAC operations for forward passes and 1.8 × 10^13^ operations for weight updates. Forward projection requires only a single training epoch, reducing overall computation time accordingly. Note that Local Supervision and Forward-Forward algorithms have similar computational and memory requirements as backpropagation (Table 2 and Table S3). We also present the wall-clock time for full training of an MLP with 3 × 1000 hidden neurons on FMNIST, demonstrating a 66 × speedup with Forward Projection in this example. Further timing results are provided in Supplementary Table S3. Computations were run using the Google Colab service with an NVIDIA T4 graphics processing unit. Training complexities of other methods are discussed in section S.13 in SI.Table 2. Training complexity for a single hidden layer with m inputs and m outputs, given a label with dimension mLComputeMemoryFMNIST trainingMethodTraining epochsForward passWeight updateModel parametersWeight updateTime (s)EpochsBackprop-agationNeNeN**m^2^3NeN**m^2^m^2^m^2^ + 2m22.43 ± 4.811.6 ± 2.7Local SupervisionNeNeN (m^2^ + m**mL)2NeN (m^2^ + m**mL)m^2^ + m**mLm^2^ + 2m46.9 ± 12.510.8 ± 3.56Forward-ForwardNe2NeN**m^2^4NeN**m^2^m^2^m^2^ + 2m172 ± 5640.2 ± 13.8Predictive CodingNeNeN**m^2^3NeN**m^2^2m^2^2m^2^ + 2m150 ± 6125.4 ± 10.2Difference Target Prop.NeNeN**m^2^8NeN**m^2^2m^2^2m^2^ + 4m72.7 ± 26.413.6 ± 5.3Forward Proj. (Ours)1N (2m^2^ + m**mL)2N**m^2^ + 2m^3^2m^2^ + m**mL2m^2^0.34 ± 0.11N: training sample size. Ne: epochs, all parameters except activations are per layer. For simplicity, we assume batch size B = 1 and that predictive coding trains for k = 1 iteration. Complexity is detailed in section S.13 in SI.
Discussion
We present the Forward Projection algorithm, which enables learning in a single pass over the dataset using random projections and closed-form optimisation. Compared to state-of-the-art local learning methods that require observing post-synaptic neuronal outputs to optimise synaptic weights via error-based gradient descent, Forward Projection operates under a stricter constraint, fitting weights using just the pre-synaptic neuronal activity and labels.
The target generation function proposed here for Forward Projection promotes input and label encoding in neural membrane potentials (see section S.8 in SI). Joint encoding of labels with pre-synaptic activity alleviates the degenerate neural activity which results from local modelling of simple label projections, whilst avoiding the introduction of uninformative noise (see section S.6 in SI). In this analysis, a simple non-linearity was employed for target generation. The utility of more complex nonlinearities for target generation is a subject for further research.
Explainability of neural network models is an important limitation in decision-critical fields such as biomedicine, where errors such as confounded decisions may lead to significant consequences^35^. FP-trained layers may be interpreted without downstream information, providing insight into model reasoning in hidden layers. FP interpretation yielded informative outputs in three model architectures, identifying clinically salient features in ECG sequences and OCT images. An important advantage of FP training is that saliency maps may be generated before downstream fitting, permitting on-the-fly inspection of intermediate layers for sufficiency or confounding. Thus, expert scrutiny of hidden layer performance may be conducted even before the downstream architecture is finalised.
Few-shot learning is ubiquitous in biological systems, which exhibit rapid neuronal adaptation to changing environments^36^. In our experiments, Forward Projection demonstrated clear performance advantages over backpropagation and local learning approaches in few-shot learning tasks, presenting a plausible method for learning new tasks rapidly. In this setting, convolutional features learned by Forward Projection yielded more generalisable models than backpropagation, which overfitted in some experiments and underfitted in others, even underperforming random features in some cases. Forward Projection also maintained reasonable performance on activation functions that were untrainable by SGD-based methods (see section S.14 in SI).
The closed-form Forward Projection fit is computable in a single pass over the data for each layer, presenting an opportunity to expedite training and reduce environmental footprint. The efficiency of FP training is attributable to a substantially different operational sequence from that employed in SGD-based approaches. Firstly, FP training collects a Gram matrix of pre-synaptic activity over a single epoch, which is subsequently inverted during a one-step weight matrix computation. Secondly, FP completes fitting for each layer before initialising successive layers. In contrast, SGD-based approaches fit all the layers in the network iteratively, using feedback from neuronal outputs and downstream layers. FP training requires no retrograde communication between neural output activations and presynaptic connections, enabling direct training on hardware with unidirectional synaptic and neuronal communication. This differs from current iterative local learning methods, which require backward communication from neuronal outputs to optimise pre-synaptic parameters (see section S.2 in SI). Although FP addresses the feedback-free constraint inherent in biological learning systems, the biological plausibility of one-step learning via matrix inversion remains uncertain. Iterative fitting via gradient descent in sequential, batch-based learning offers a practical and scalable approach for aligning weights with locally generated targets, as defined in (1) (see section S.11 in SI). Although closed-form optimisation remains a challenge for recurrent architectures, future research will explore integrating iterative training with random temporal convolutions to generalise the FP framework to dynamic models and expand its applicability to temporal learning tasks. This backpropagation-free strategy holds promise for biologically inspired computing systems, such as spiking neural networks, where non-differentiable activation functions preclude standard backpropagation^37–39^. FP training may be applicable as a pre-training step to reduce the number of training epochs required for backpropagation. In conclusion, FP is an efficient approach for neural network optimisation, employing techniques from randomised projective embedding and linear regression to fit weight matrices in one epoch using a single-step solution. Interpretability of hidden neurons in FP-trained models may be employed to improve the explainability of neural network predictions.
Methods
Generalisability of machine learning methods to real-world datasets requires robustness to adverse modelling conditions such as class imbalance and noise, which often impede performance^40^. To assess the applicability and generalisability of Forward Projection and local learning methods in diverse real-world conditions, performance was evaluated in benchmark tasks from four biomedical domains described below.
PTBXL-MI
The PTB-XL dataset contains 12-lead electrocardiography (ECG) recordings from 18,889 participants^29,41^. ECG recordings of ten-second duration and 100Hz sample rate were used in our experiments. The predictive task was to discriminate ECG recordings with normal waveform morphology (Ntrain = 6, 451; Ntest = 721) from those diagnosed as myocardial infarction (Ntrain = 2, 707; Ntest = 268) by a cardiologist. Data instances with uncertain diagnoses were excluded from this analysis. Following recommendations of the dataset authors who provided predefined participant-disjoint dataset splits, the tenth fold was held out for model testing^29^. The first 15 MI-positive ECGs in the test set were annotated by a medical doctor to identify diagnostically relevant sections for quantitative explainability evaluation.
Promoters
The Human Non-TATA Promoters dataset ("Promoters") was extracted from the GenomicBenchmarks repository^28^. Data was originally published in ref. ^27^. 36,131 nucleotide sequences of 251 bases each were analysed. Nucleotide sequences were converted to 4-channel one-hot vectors indicating adenine, cytosine, guanine and thymine. Indeterminate bases were represented with zero vectors. Models were required to classify the promoter functionality of the sequence as “promoter" (Ntrain = 12,355; Ntest = 4119) or “non-promoter" (Ntrain = 14, 742;Ntest = 4915).
CXR
The paediatric pneumonia chest X-ray dataset ("CXR") is a retrospective cohort of patients aged between one and five years, recorded in Guangzhou Women and Children’s Medical Center, Guangzhou, originally published in ref. ^31^. Chest X-ray images were recorded as part of routine care during diagnostic workup for suspected lower respiratory tract infection. During data collection, clinicians screened the images for quality and excluded those with severe artefacts or corruption. Images were annotated by two expert physicians. Local institutional review board approvals were obtained. Images were loaded in greyscale, rescaled to the [0, 1] intensity range and resized to 128 × 128 pixels by bilinear interpolation. Models were required to classify images as “normal" (Ntrain = 1349; Ntest = 234), “viral pneumonia" (Ntrain = 2538; Ntest = 242), or “bacterial pneumonia" (Ntrain = 1345; Ntest = 148).
OCT
The optical coherence tomography dataset ("OCT") is a retrospective cohort of adult patients from five ophthalmology institutions in the USA and China recorded between 2013 and 2017 during routine care, originally published in ref. ^31^. Images were initially annotated by local medical students, who had received OCT interpretation training. Subsequent annotation was performed by four ophthalmologists and two independent retinal specialists. Horizontal foveal cut images were available in portable network graphics image format. Images were loaded in greyscale, rescaled to the [0, 1] intensity range, and resized to 128 × 128 pixels by bilinear interpolation. Models were required to classify images as either “normal" (Ntrain = 2926; Ntest = 149) or “choroid neovascularisation" (Ntrain = 791; Ntest = 178).
Model training
The FMNIST dataset was modelled using an MLP with 3 × 1000 hidden ReLU-activated neurons. Sequential datasets (PTBXL-MI and Promoters) were modelled by a 1D-CNN architecture of four convolutional blocks. Each convolutional block included two convolutional layers with kernel dimensions 3 and strides of 1 and 2, respectively. Convolutional layers in the l-th block had 32 × 2^l−1^ filters. Convolutional implementation is detailed in Supplementary section S.3. Convolutional outputs were aggregated by global average pooling in the penultimate layer. For gradient-descent-based learning algorithms, batch normalisation layers were included between convolutional blocks. CIFAR2 modelling in Table 1 used a vision transformer architecture^42^ operating on image patches of dimension 4 × 4, with a sequential stack of four multi-headed attention layers, each having 8 heads, embedding dimension 64, and MLP dimension 64. 2D-CNN architectures had kernel dimension 3 × 3 and the l-th convolutional block had 16 × 2^l−1^ filters (CXR and OCT), 32 × 2^l−1^ filters (CIFAR2), or 64 × 2^l−1^ filters (CIFAR10). The sign function was employed to generate target activations for Forward Projection models, such that
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widetilde{{{{\bf{z}}}}}}_{l}={{{\rm{sign}}}}({{{{\bf{a}}}}}_{l-1}{{{{\bf{Q}}}}}_{l})+{{{\rm{sign}}}}({{{{\bf{yU}}}}}_{l}).$$\end{document}Data augmentation was not performed in our experiments. Models were fitted using the PyTorch library. For SGD-based methods, early stopping was performed according to validation loss. Model weight initialisation was random, and optimisation was performed with the Adam optimiser with a learning rate of 0.001, training to minimise validation loss by early stopping with a patience of five epochs. In few-shot experiments, the learning rate was reduced to 0.0001 for SGD-based models, and a patience of ten epochs was employed. It is acknowledged that direct comparison of gradient-descent-based training with closed-form solutions is not strictly “like-for-like". However, all efforts were made to ensure experimental conditions were otherwise equivalent. Models were fitted to minimise categorical or binary cross-entropy as appropriate. Implementations of Forward-Forward, Local Supervision, Difference Target Propagation and Predictive Coding methods are detailed in supplementary section S.5.
Explainability analysis
Model architectures for explainability analysis were equivalent to those used for the main experiments. Pre-activation potentials in hidden neurons were interpreted as local label predictions using (3) with the following approximation
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\widehat{{{{\bf{y}}}}}}_{l}:=\tanh ({{{{\bf{z}}}}}_{l}-{{{\rm{sign}}}}({{{{\bf{a}}}}}_{l-1}{{{{\bf{Q}}}}}_{l})){{{{\bf{U}}}}}_{l}^{+}.$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tanh (\cdot )$$\end{document} is employed as a surrogate inverse for the sign function used to generate the target potentials.
Ethics approval and consent to participate
This study involves no new data collection or experiments on human or animal subjects. All clinical data used in this study was publicly available in previous publications^27–29,31^.
Supplementary information
Supplementary Information Transparent Peer Review file
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Lee, D. et al. Difference target propagation. (eds Appice, A. et al.) In Machine Learning and Knowledge Discovery in Databases—European Conference, ECML PKDD 2015, Porto, Portugal, September 7–11, 2015, Proceedings, Part I, Vol. 9284 of Lecture Notes in Computer Science, 498–515c. 10.1007/978-3-319-23528-8_31. (Springer, 2015).
- 2Lillicrap, T. P., Cownden, D., Tweed, D. B. & Akerman, C. J. Random synaptic feedback weights support error backpropagation for deep learning. Nat. Commun. 7. 10.1038/ncomms 13276 (2016).10.1038/ncomms 13276 PMC 510516927824044 · doi ↗ · pubmed ↗
- 3Millidge, B., Seth, A. K. & Buckley, C. L. Predictive coding: a theoretical and experimental review. Preprint at https://arxiv.org/abs/2107.12979 (2021).
- 4Akrout, M., Wilson, C., Humphreys, P. C., Lillicrap, T. P. & Tweed, D. B. Deep learning without weight transport. (eds Wallach, H. M. et al.) In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, Neur IPS 2019, December 8–14, 2019, Vancouver, BC, Canada. 974–982. https://proceedings.neurips.cc/paper/2019/hash/f 387624 df 552cea 2f 369918 c 5e 1e 12bc-Abstract.html. (2019).
- 5Bengio, Y., Lamblin, P., Popovici, D. & Larochelle, H. Greedy layer-wise training of deep networks. (eds Schölkopf, B., Platt, J. C. & Hofmann, T.) In Advances in Neural Information Processing Systems 19, Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, Vancouver, British Columbia, Canada, December 4–7, 2006, 153–160 https://proceedings.neurips.cc/paper/2006/hash/5da 713a 690c 067105 aeb 2fae 32403405-Abstract.html. (MIT Press, 2006).
- 6Kaiser, J., Mostafa, H. & Neftci, E. Synaptic plasticity dynamics for deep continuous local learning (decolle). Front. Neurosci. 14. 10.3389/fnins.2020.00424 (2020).10.3389/fnins.2020.00424 PMC 723544632477050 · doi ↗ · pubmed ↗
- 7Frenkel, C., Lefebvre, M. & Bol, D. Learning without feedback: fixed random learning signals allow for feedforward training of deep neural networks. Front. Neurosci. 15. 10.3389/fnins.2021.629892 (2021).10.3389/fnins.2021.629892 PMC 790285733642986 · doi ↗ · pubmed ↗
- 8Nøkland, A. & Eidnes, L. H. Training neural networks with local error signals. (eds Chaudhuri, K. & Salakhutdinov, R.) In Proceedings of the 36th International Conference on Machine Learning, Vol. 97 of Proceedings of Machine Learning Research. 4839–4850. https://proceedings.mlr.press/v 97/nokland 19a.html. (PMLR, 2019).