Statistical Feature Engineering for Robot Failure Detection: A Comparative Study of Machine Learning and Deep Learning Classifiers
Sertaç Savaş

TL;DR
This paper compares machine learning and deep learning methods for detecting robot failures using sensor data and finds that statistical features significantly improve classification performance.
Contribution
The study introduces three novel feature engineering approaches and provides a comprehensive comparison of ML and DL classifiers for robot failure detection.
Findings
The Naive Bayes classifier achieved the highest accuracy (93.85%) using the Baseline feature set.
The Domain-12 feature set consistently improved performance across multiple algorithms.
Skewness features from Fx and Fy sensors were identified as the most critical for failure detection.
Abstract
Industrial robots are widely used in critical tasks such as assembly, welding, and material handling as core components of modern manufacturing systems. For the reliable operation of these systems, early and accurate detection of execution failures is crucial. In this study, a comprehensive comparison of machine learning and deep learning methods is conducted for the classification of robot execution failures using data acquired from force–torque sensors. Three different feature engineering approaches are proposed. The first is a Baseline approach that includes 90 raw time-series features. The second is the Domain-6 approach, which consists of 6 basic statistical features per sensor (36 in total). The third is the Domain-12 approach, which comprises 12 comprehensive statistical features per sensor (72 in total). The domain features include the mean, standard deviation, minimum, maximum,…
Click any figure to enlarge with its caption.
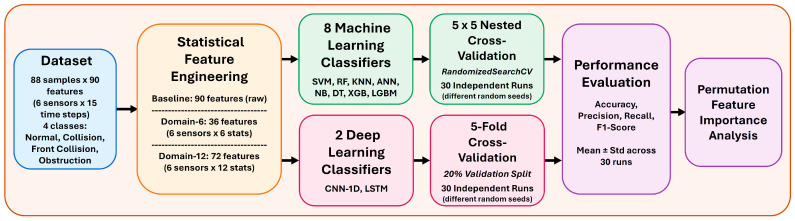 Figure 1
Figure 1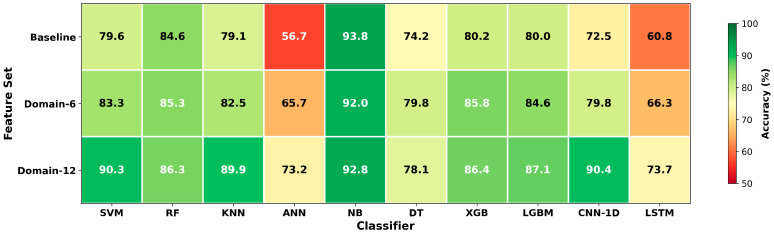 Figure 2
Figure 2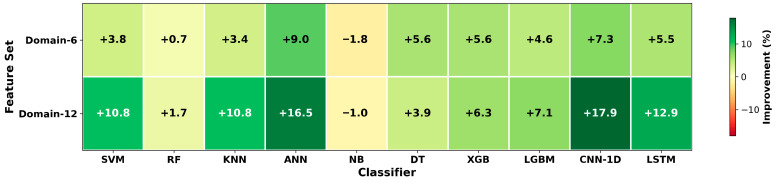 Figure 3
Figure 3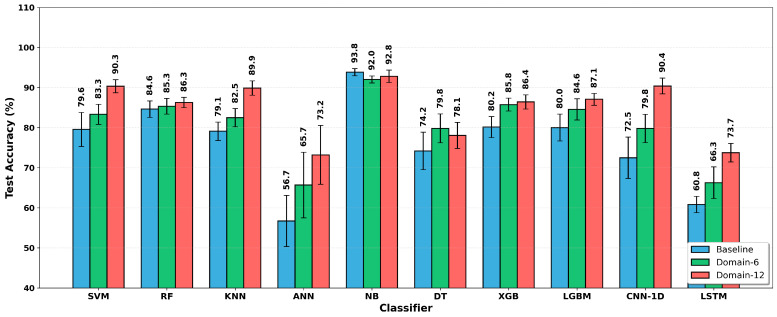 Figure 4
Figure 4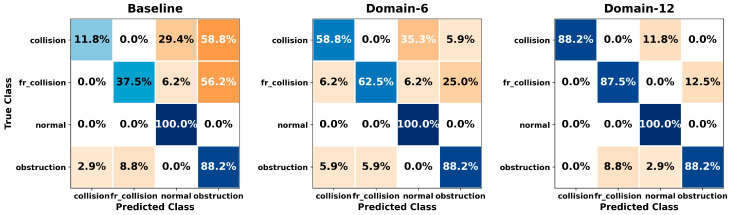 Figure 5
Figure 5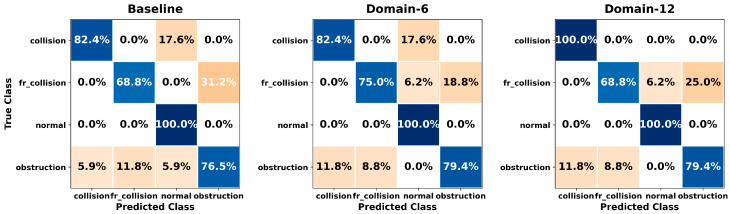 Figure 6
Figure 6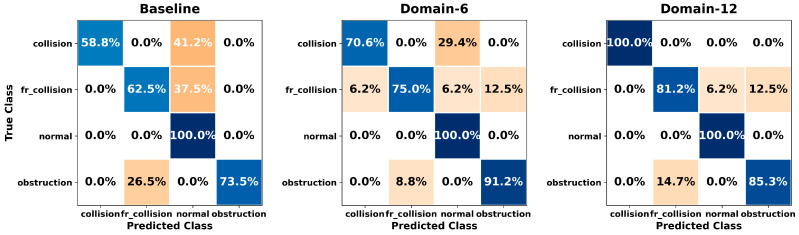 Figure 7
Figure 7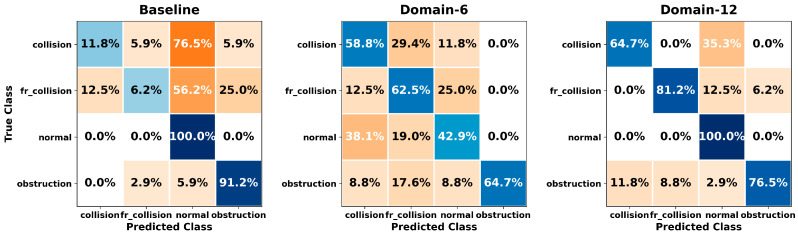 Figure 8
Figure 8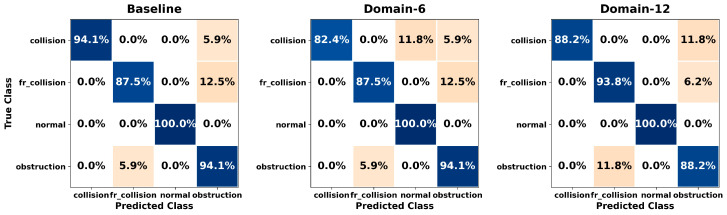 Figure 9
Figure 9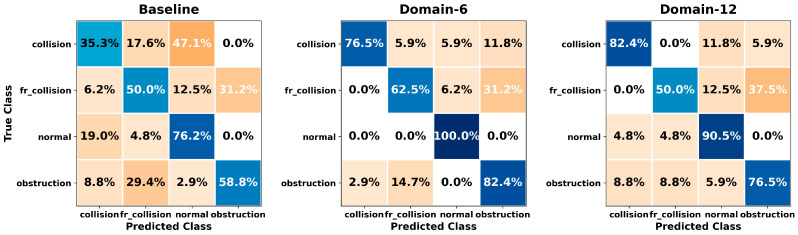 Figure 10
Figure 10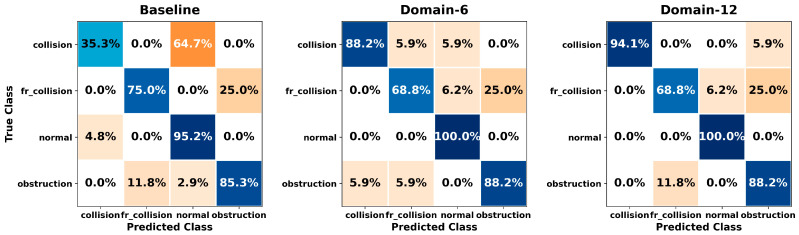 Figure 11
Figure 11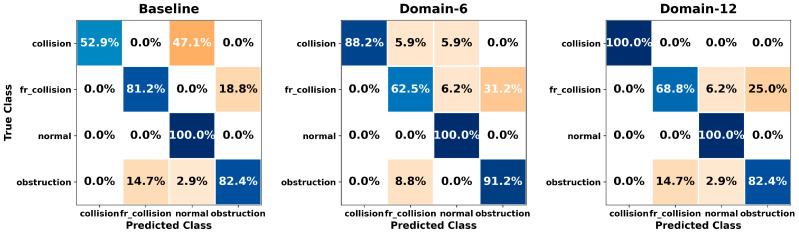 Figure 12
Figure 12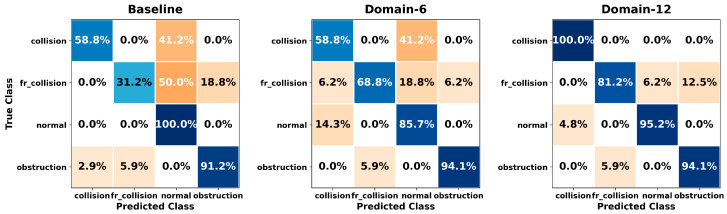 Figure 13
Figure 13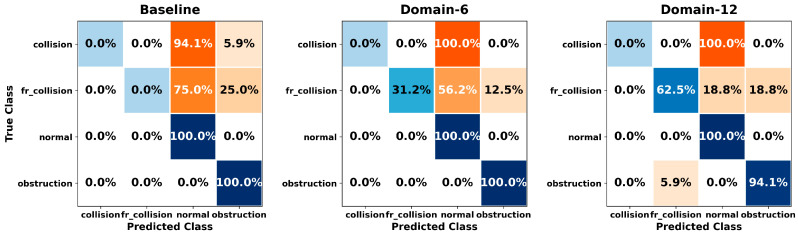 Figure 14
Figure 14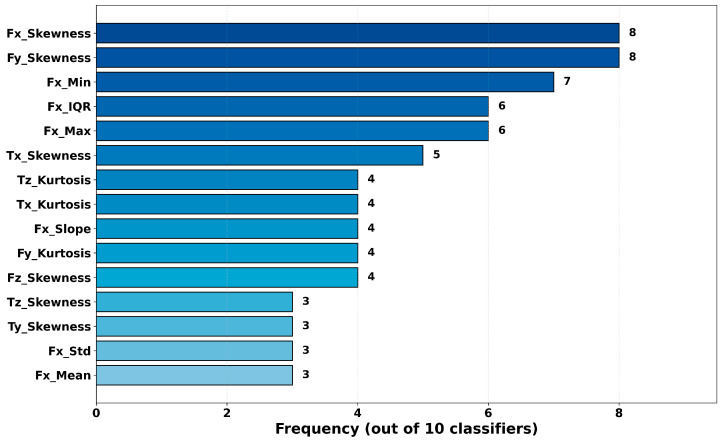 Figure 15
Figure 15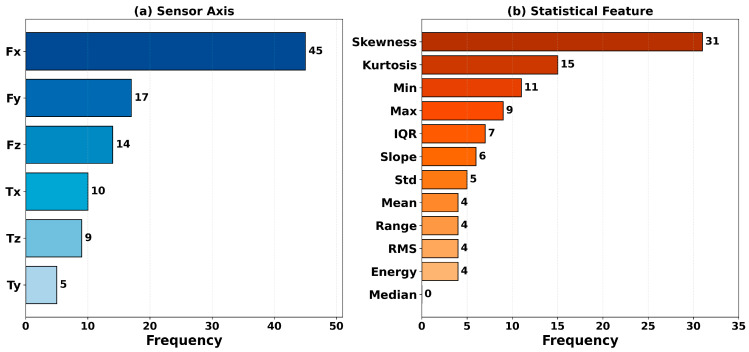 Figure 16
Figure 16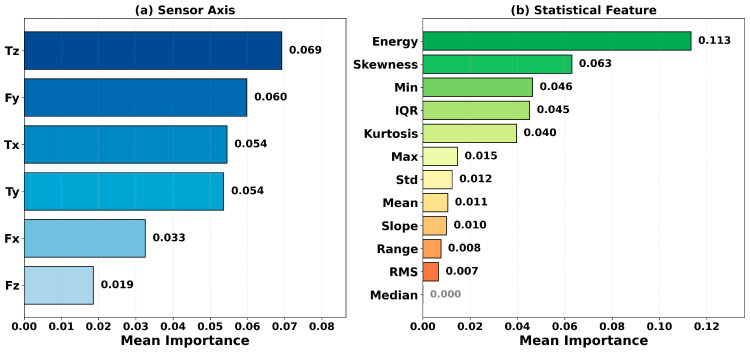 Figure 17
Figure 17Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Fault Diagnosis Techniques · Time Series Analysis and Forecasting · Anomaly Detection Techniques and Applications
1. Introduction
Industrial robots have become indispensable components of modern manufacturing systems. The reliability of these systems—widely deployed in applications such as assembly, welding, painting, and material handling—is critical for production efficiency and occupational safety. Failures in robotic systems can lead to production downtime, quality defects, and potential safety hazards. Therefore, early and accurate detection of robot failures is a fundamental requirement for the effective management of industrial automation systems.
Force–torque sensors play an important role in detecting failures in robot execution. By measuring interactions between the robot arm and its environment, these sensors enable differentiation between normal operation and abnormal conditions. However, extracting meaningful information from sensor signals and performing failure classification requires appropriate feature engineering and careful selection of classification algorithms. In conventional approaches, raw sensor data are used directly, which often results in high dimensionality and increased computational complexity.
In the study using the robot execution failure dataset introduced by Seabra Lopes and Camarinha-Matos [1], various feature transformation strategies were evaluated for robot failure classification. Windowed averages, derivatives, and monotonicity measures were used, yielding substantial improvements in accuracy. However, that study was conducted with a limited set of algorithms, such as SKIL and OC1, and it did not assess modern machine learning techniques. Today, powerful classifiers—including support vector machines, random forests, gradient boosting methods, and deep learning algorithms—are widely used in fault detection problems. A comprehensive evaluation of the effectiveness of these modern approaches for robot failure classification would therefore represent a meaningful contribution to the field. In addition, performing classification using statistical features spanning both basic and advanced descriptors offers an important perspective on feature engineering.
The literature on fault detection and predictive maintenance in industrial robots has evolved within a broad framework that emphasizes approaches focusing on robot subcomponents (e.g., motor drives and joints), deep learning-based feature extraction from sensor data, and Internet of Robotic Things (IoRT)-based online monitoring architectures. Eang and Lee [2] developed a CNN-RNN (Recurrent Neural Network) hybrid observer framework for predictive maintenance and fault detection in DC motor drives of industrial robots, aiming to learn dynamic characteristics from sensor data to support early fault identification and maintenance. Bilal et al. [3] proposed an IoRT-based monitoring architecture for online fault diagnosis in industrial robot joints; their approach employed a Transfer Learning (TL)-assisted deep learning model to identify joint fault conditions across varying operating regimes reliably. Liu et al. [4] introduced a Dilated-CNN-based method for cross-axis fault diagnosis in multi-axis industrial robots, strengthening the model with Self-Attention and using TL to adapt it to different axis data to mitigate limited-data challenges. Pan et al. [5] developed a data-driven Deep Convolutional Neural Network (DCNN) approach for diagnosing sensor and actuator faults in robot joints, aiming to classify different fault types by learning discriminative representations from fused sensor–actuator data. Sabry et al. [6] proposed a fault detection approach for industrial robots based on comparing power consumption and encoder data between a “healthy reference” and real-time measurements, aiming to distinguish joint/encoder degradations by representing power-consumption patterns with a simple modeling scheme. Shi et al. [7] developed an Interacting Multiple Model-based Adaptive Control System for stable steering of distributed-drive electric vehicles under various road excitations, aiming to reduce instabilities (e.g., oversteer/understeer) by adapting the vehicle model to conditions while preserving yaw and longitudinal stability. Li et al. [8] proposed a deep learning approach supported by Data Augmentation (DA) for fault diagnosis in rotating machinery, aiming to improve diagnostic performance with limited labeled data by generating richer training samples via simple signal-level augmentation operations.
Similarly, the fault diagnosis literature for industrial power transmission elements, such as rotating machinery and bearings, has focused on addressing limited-labeled-data issues through data augmentation, leveraging hybrid CNN–LSTM architectures to exploit time and frequency information jointly, and achieving reliable diagnosis via signal-based methods such as Motor Current Signature Analysis (MCSA). Fu et al. [9] developed a parallel CNN–LSTM deep learning model for bearing fault diagnosis from vibration signals, aiming to achieve more robust feature extraction and reliable diagnosis by jointly leveraging time and frequency information. Chen et al. [10] proposed a Multi-Scale CNN–LSTM model to automatically learn features directly from raw vibration data for bearing fault diagnosis. Han et al. [11] aimed to jointly learn spatiotemporal features by combining CNN, LSTM, and Gated Recurrent Unit (GRU) architectures for bearing fault diagnosis. Rohan et al. [12] investigated the diagnosis of Rotate Vector (RV) reducer faults in industrial robots using motor current signals and MCSA. Raouf et al. [13] proposed an MCSA-based data-driven classification approach for identifying robotic RV reducer faults from motor current. Fu et al. [14] presented a lightweight, edge-deployable real-time fault-diagnosis method for power transformers based on acoustic signals. Li et al. [15] proposed an MCSA-based approach for local fault diagnosis in robotic rotary vector reducers.
In this study, a comprehensive classification investigation is conducted for detecting robot execution failures. The main contributions can be summarized as follows: (1) Inspired by the modern signal processing literature, a new time-domain feature set is proposed, including statistical descriptors such as mean, standard deviation (std), minimum, maximum, range, slope, median, skewness, kurtosis, root mean square (RMS), energy, and interquartile range (IQR). (2) A total of ten classifiers are comprehensively compared, including eight conventional machine learning methods (SVM, RF, KNN, ANN, NB, DT, XGBoost, LGBM) and two deep learning models (CNN-1D, LSTM). (3) For reliable performance evaluation, 5 × 5 nested cross-validation and 30 independent runs are used for conventional machine learning models. In contrast, for deep learning models, 5-fold outer cross-validation with early stopping is employed, again with 30 independent runs. (4) Feature-related outcomes are analyzed within the Permutation Feature Importance framework.
2. Materials and Methods
This section presents the study’s methodological framework in detail. First, the dataset is introduced. In the domain-based feature extraction subsection, three feature sets (Baseline, Domain-6, and Domain-12) are described, and the mathematical formulations of the 12 statistical features are provided. Next, the theoretical foundations and operating principles of the ten classification algorithms are summarized. Within the cross-validation strategy, nested cross-validation and k-fold cross-validation approaches are explained. Finally, the hyperparameter search spaces and the most frequently selected parameter values are reported, and the evaluation metrics used for performance assessment—accuracy, precision, recall, and F1-score—are defined. The methodological flow diagram of the study is shown in Figure 1.
2.1. Dataset Description and Preprocessing
In this study, the “Robot Execution Failures” dataset available in the UCI Machine Learning Repository is used [16]. The dataset was obtained from experiments conducted on an industrial robot arm, where force–torque sensor data were collected during a pick-and-place macro-operation. In this work, the LP1 (Approach to Grasp) subset is considered. This subset contains failures occurring while the robot approaches a part to grasp it, and its main characteristics are summarized in Table 1.
The matrix in Equation (1) represents the input sample structure of the dataset.
where to denote the temporal evolution of the force component within the observation window; the same notation applies to , , and the torque components. Overall, the raw input contains 90 features (6 sensor channels × 15 time steps). The class distribution of the dataset is reported in Table 2. The dataset includes normal operation and three different failure types.
Z-score standardization is applied for feature normalization, transforming each feature to have zero mean and unit variance. To prevent data leakage, normalization is performed separately for each fold within the cross-validation loop: the StandardScaler parameters (mean and standard deviation) are computed exclusively from the training data, and then the transform is applied to both training and test sets. This approach ensures that test data do not contribute to the calculation of scaling parameters, thereby preserving cross-validation integrity. The normalization formula is given in Equation (2).
Here, denotes the raw feature value, is the feature mean, is the standard deviation, and represents the normalized value.
2.2. Domain-Based Feature Extraction
In this study, the term domain features refers to handcrafted time-domain statistical descriptors extracted from each force–torque sensor channel, rather than raw time-series samples. The Baseline set uses raw measurements directly, whereas the Domain-6 and Domain-12 sets are obtained by computing statistical features per sensor channel. Domain-6 includes first-order statistics that are simple to compute and interpret (mean, standard deviation, minimum, maximum, range, and slope), while Domain-12 extends these with distribution-shape measures (skewness and kurtosis), robust statistics (median and IQR), and signal-energy measures (RMS and energy). In the context of robot execution failure detection, these statistics can be considered domain-informed because they capture physically meaningful characteristics of force–torque signals and provide a more compact and interpretable representation than raw samples. The feature sets and their dimensions are summarized in Table 3, and the complete list of statistical features is provided in Table 4.
The mean feature represents the central tendency of the time series and is computed using the arithmetic mean definition given in Equation (3).
where is the -th sample value, is the number of samples, and denotes the mean. The standard deviation, given in Equation (4), measures the dispersion of the data around the mean.
where is the standard deviation, is the mean, is the -th sample, and is the number of samples. The minimum feature in Equation (5) denotes the smallest observation in the sequence, the maximum feature in Equation (6) denotes the largest observation, and the range feature in Equation (7) is defined as the difference between the maximum and minimum values.
where is the minimum observation, is the maximum observation, and is the range value (i.e., the max–min difference). The slope feature is computed by fitting a first-order polynomial (linear fit) to the time-series data using the least-squares method. The slope coefficient is obtained via the linear regression slope expression in Equation (8).
where is the slope coefficient, is the -th time sample, is the -th measurement, is the mean of the time indices, and is the mean of the measurements. The median is the middle value of the ordered data. For odd/even sample sizes, the median is computed using the piecewise definition given in Equation (9).
where denotes the -th element of the sorted data, is the number of samples, and is the median. The -th central moment is a fundamental quantity used to compute shape descriptors such as skewness and kurtosis, and it is defined as in Equation (10).
where is the -th central moment, is the moment order, is the -th sample, and is the mean. Skewness measures the asymmetry of the distribution and is obtained by normalizing the third central moment with the second central moment, as given in Equation (11).
where is the skewness coefficient, is the second central moment, and is the third central moment. Kurtosis measures the tail heaviness of the distribution. The excess kurtosis is computed by normalizing the fourth central moment with the second central moment and subtracting 3, as given in Equation (12).
where denotes the excess kurtosis, is the fourth central moment, and is the second central moment. The RMS represents the effective magnitude of the signal and is computed using the root-mean-square definition in Equation (13).
where is the -th sample and is the number of samples. The energy feature is defined as the sum of squared sample values and is computed as in Equation (14).
where is the total energy and is the -th sample. Finally, the IQR robustly measures the central spread of the distribution and is computed as the difference between the third and first quartiles. This is given in Equation (15).
where is the first quartile (25th percentile) and is the third quartile (75th percentile).
2.3. Classification Algorithms
In this study, ten classification algorithms representing different learning paradigms are evaluated. The algorithms are considered under two main categories: conventional machine learning and deep learning.
SVM is a kernel-based classifier that aims to find the optimal hyperplane maximizing the separation margin between classes. For non-linearly separable problems, kernel functions map the data into a higher-dimensional space to enable linear separation. During hyperparameter optimization, radial basis function (RBF), linear, and polynomial kernels are examined, and the RBF kernel is selected most frequently. Owing to its ability to capture local patterns, the RBF kernel provided the most suitable performance for this dataset. It measures similarity between two samples via an exponential transformation of the Euclidean distance, while the gamma ( ) parameter controls the flexibility of the decision boundary [17].
RF is an ensemble learning method that combines multiple decision trees using bagging (bootstrap aggregating). Each tree is trained independently using a random subset of the training data and a random subset of features. This randomness reduces variance and mitigates overfitting. The final classification is obtained by majority voting across trees; i.e., the class predicted by the largest number of trees is assigned as the output [18].
KNN is an instance-based learning algorithm that does not require explicit model training. For a test sample, the closest training samples are identified, and the majority class among these neighbors is assigned as the prediction. Performance depends on the choice of and the distance metric; small values increase sensitivity to noise, whereas large values may blur class boundaries [19].
ANNs are feedforward networks inspired by biological neural systems and consist of one or more hidden layers. In this work, a Multi-Layer Perceptron (MLP) architecture is used. Each neuron computes a weighted sum of its inputs and applies a nonlinear activation function. The Rectified Linear Unit (ReLU) activation improves computational efficiency and gradient propagation by setting negative values to zero. Network weights are updated iteratively using backpropagation [20].
NB is a probabilistic classifier based on Bayes’ theorem. It operates under the “naive” assumption that features are conditionally independent given the class label. Although this assumption rarely holds exactly in practice, NB often performs surprisingly well in real-world problems. The Gaussian Naive Bayes variant assumes that continuous features follow a normal distribution within each class and computes posterior probabilities accordingly [21]. In this implementation, prior probabilities are computed from class frequencies in the training set; that is, the prior probability of each class equals the proportion of training samples belonging to that class. Given the class imbalance in the dataset, larger classes have higher prior probabilities, which may influence posterior probability calculations. However, the stratified cross-validation approach employed in this study preserves class proportions in each fold, systematically controlling this effect.
DTs are rule-based classifiers that recursively partition the data according to feature values. Starting from the root node, each split is determined by the most informative feature, and class decisions are made at leaf nodes. In the Classification and Regression Trees (CART) framework, split quality is evaluated using criteria such as Gini impurity or entropy. Gini impurity quantifies the class homogeneity at a node, with lower values indicating purer (more homogeneous) nodes [22].
XGBoost is a high-performance, scalable implementation of gradient boosting. It constructs a strong ensemble by adding weak learners (decision trees) sequentially, where each new tree focuses on correcting errors made by the previous ensemble. XGBoost controls overfitting via regularization terms and accelerates optimization using a second-order Taylor approximation. Practical features such as parallel processing and native handling of missing values contribute to its wide adoption [23].
LGBM is an efficient gradient boosting method optimized for large-scale datasets. It reduces memory usage and speeds up training through histogram-based learning, which discretizes continuous values into bins. Unlike level-wise tree growth, LGBM employs a leaf-wise strategy that splits the leaf that yields the largest reduction in loss. While leaf-wise growth can converge faster, constraints such as maximum depth and number of leaves are important to prevent overfitting [24].
CNN-1D architectures are designed to automatically extract local patterns from time series and signal data. Convolutional layers slide learnable filters (kernels) over the input to detect local features, while pooling layers reduce the dimensionality of the feature map to lower computational cost and introduce translational invariance. In this study, a two-convolution-layer architecture is adopted to capture temporal patterns in the force–torque sensor signals [25].
LSTM networks are specialized recurrent neural networks (RNNs) capable of learning long-term dependencies in sequential data. To address the vanishing gradient problem in conventional RNNs, LSTM introduces a cell state and gating mechanisms (forget, input, and output gates). The forget gate decides which information to discard, the input gate determines what new information to store, and the output gate controls what information is passed to the next time step. This architecture is well-suited for problems where temporal dependencies are critical, such as robot failure detection [26].
2.4. Cross-Validation Strategy and Training Settings
In this study, nested cross-validation (NCV) is employed for model evaluation and hyperparameter optimization of the conventional machine learning algorithms (SVM, RF, KNN, ANN, NB, DT, XGBoost, and LGBM) [27]. Unlike standard cross-validation, NCV uses separate loops for hyperparameter selection and performance estimation, thereby providing more reliable generalization estimates. The adopted NCV scheme follows a 5 × 5 configuration. The outer loop uses 5-fold stratified cross-validation to assess generalization performance, where in each outer fold 80% of the data are used for training and 20% for testing. The inner loop is used for hyperparameter optimization by splitting the training set again into 5 folds and selecting the best hyperparameter configuration. Hyperparameter search is conducted using RandomizedSearchCV, with 20 random combinations evaluated from the predefined search space for each algorithm.
To improve statistical reliability, the entire experimental procedure is repeated over 30 independent runs. In each run, the data are shuffled using a different random seed, enabling robust reporting of results that are less sensitive to random variation.
For the deep learning models (CNN-1D and LSTM), a different evaluation strategy is adopted due to the small dataset size (N = 88). Because deep learning hyperparameter tuning on small datasets is prone to overfitting, a fixed-architecture approach is preferred instead of nested cross-validation. On extremely small datasets (N = 88), hyperparameter optimization in nested CV would evaluate configurations on only ~14 validation samples per inner fold, risking overfitting to fold-specific characteristics. The architectures employed are based on established designs from time-series classification literature. Moreover, since this study’s focus is isolating the effect of feature engineering rather than maximizing DL performance, using the same architecture across all feature sets ensures that performance changes reflect feature quality rather than architecture–feature interactions.
As the outer evaluation loop, 5-fold stratified cross-validation is applied, and in each fold, 20% of the training split is reserved for validation. To mitigate overfitting on the small dataset, several strategies are employed: (1) early stopping monitors validation loss and terminates training when no improvement is observed for 5 consecutive epochs, preventing the model from continuing to fit training data after generalization plateaus; (2) 30 independent runs with different random seeds ensure that results are not artifacts of a particular train-test split; (3) stratified 5-fold cross-validation ensures that all samples are used for testing exactly once, providing robust performance estimates. The moderate standard deviations observed in the Results Section across runs indicate consistent generalization rather than memorization. The deep learning training parameters are set to a maximum of 50 epochs and a batch size of 32.
The applied cross-validation strategy and the main training parameters are summarized in Table 5.
2.5. Hyperparameter Optimization
For the conventional machine learning algorithms, hyperparameter optimization is performed within the inner loop of nested cross-validation using RandomizedSearchCV. For each algorithm, 20 random configurations are sampled from the predefined search space and evaluated using 5-fold cross-validation. For the deep learning models, due to the small dataset size, a fixed-architecture strategy is adopted, and overfitting is mitigated via early stopping (patience = 5). The hyperparameter ranges and the most frequently selected settings for the machine learning algorithms are presented in Table 6, while the deep learning model architectures are given in Table 7.
2.6. Performance Metrics
In this study, model performance is evaluated using four metrics. Accuracy indicates overall success by measuring the proportion of correctly classified samples among all samples. Precision reflects how many of the predicted positive instances are truly positive, thereby capturing the effect of false positives. Recall quantifies the proportion of actual positive instances correctly identified, measuring the model’s ability to detect positive samples. F1-score is the harmonic mean of precision and recall and represents the balance between these two measures; it is particularly important for a more reliable assessment of performance on imbalanced datasets. The metrics and their formulations are provided in Table 8.
Here, TP (True Positive) denotes correctly predicted positives, TN (True Negative) correctly predicted negatives, FP (False Positive) incorrectly predicted positives, and FN (False Negative) incorrectly predicted negatives.
3. Results
3.1. Classification Results
This section presents the classification results obtained for three feature sets (Baseline, Domain-6, and Domain-12) and ten classification algorithms. For the Baseline feature set, accuracy, precision, recall, and F1-score values, together with the total computation times, are reported in Table 9. Similarly, the corresponding performance metrics and total computation times for the Domain-6 feature set are provided in Table 10, while the results obtained using the Domain-12 feature set are presented in Table 11. In all tables, the metrics are reported as mean ± standard deviation [minimum, maximum], and the reported values represent the outcomes of 30 independent runs for each combination. In Table 9, Table 10 and Table 11, “Total Time” indicates the cumulative computation time (in minutes) for all 30 independent runs of the respective algorithm, including nested cross-validation with RandomizedSearchCV (for ML) or 5-fold CV with early stopping (for DL).
The code is implemented in Python 3.13.5 and executed on a computer running Windows 10 (64-bit) equipped with an Intel Core i7-7700HQ CPU @ 2.80 GHz, 16 GB RAM, and an NVIDIA GTX 1050 (4 GB) GPU and all models are executed using GPU-accelerated implementations.
When the classification results obtained for the three feature sets are examined, it is evident that the performance of the algorithms varies substantially depending on the feature representation. With the Baseline feature set, Naive Bayes achieves the highest accuracy (93.85%), while commonly used algorithms such as RF also produces competitive results. When switching to the Domain-6 feature set, overall improvements are observed for most classifiers, except for Naive Bayes. The Domain-12 feature set, which incorporates advanced statistics such as skewness, kurtosis, energy, and IQR, yields consistent performance gains across many algorithms. In particular, SVM, KNN, and ANN achieve notable improvements with Domain-12. Among the deep learning models, CNN-1D performed relatively poorly with the Baseline feature set; however, with Domain-12, it achieves 90.4% accuracy, second only to Naive Bayes. Overall, the lowest standard deviation values are observed for Naive Bayes and SVM, indicating that these algorithms are more stable across different data splits.
Figure 2 presents the accuracy values for the three feature sets and ten classifiers in a heatmap. Dark green tones indicate high accuracy, whereas red tones represent low accuracy.
Figure 3 shows the percentage improvements in the Domain-6 and Domain-12 feature sets relative to Baseline. Positive values (green) indicate performance gains, while negative values (red) indicate performance drops. In the figures, XGB denotes XGBoost.
Figure 4 provides a comparative bar chart of the three feature sets across all classifiers. The error bars represent the standard deviation over 30 independent runs.
In Figure 2, the consistently dark-green appearance of the Naive Bayes row across all columns indicates strong generalization performance, largely independent of the feature set (approximately 92–94%). The red tones observed for ANN and LSTM reflect learning difficulties on small datasets. As shown in Figure 3, substantial improvements are observed for CNN-1D, ANN, LSTM, SVM, and KNN. It is also clear that these gains increase markedly as the number of statistical features grows. Figure 4 further shows that, except for NB and DT, most algorithms exhibit some improvement with Domain-6 and considerably larger improvements with Domain-12. This effect elevates models such as SVM and KNN to higher performance levels and enables CNN-1D to move from relatively low performance to outperform several conventional algorithms.
Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12, Figure 13 and Figure 14 present the confusion matrices of the SVM, RF, KNN, ANN, NB, DT, XGB, LGBM, CNN-1D, and LSTM classifiers, respectively, for the Baseline, Domain-6, and Domain-12 feature sets. Blue cells indicate correct classifications, while orange cells indicate misclassifications. Darker shading corresponds to higher percentages of correct or incorrect predictions.
The confusion matrices in Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12, Figure 13 and Figure 14 provide a detailed, class-wise view of each classifier’s prediction performance across the three feature sets. Diagonal entries represent correct classifications, whereas off-diagonal entries indicate confusion between classes. In general, Normal and Obstruction classes achieve the highest recognition rates across most algorithms, likely due to their larger sample sizes. In contrast, frequent confusion is observed between Front Collision and Collision, suggesting that these two failure types produce similar force–torque signatures. Notably, this confusion is reduced with Domain-6 and decreases substantially with Domain-12, accompanied by higher prediction rates. The overall increase in diagonal values and the decrease in off-diagonal values for Domain-12 confirm that advanced statistical features strengthen inter-class separability. Moreover, the more balanced diagonal distribution achieved by CNN-1D compared to LSTM indicates that the convolutional architecture captures local patterns in the force–torque signals more effectively.
3.2. Permutation Feature Importance Analysis
Permutation feature importance is a model-agnostic interpretability technique that assesses how strongly a model’s predictive performance depends on a given feature. In this approach, the values of a feature are randomly shuffled, breaking the original relationship between the feature and the target, and the resulting performance drop is measured. The larger the drop, the more critical the feature is considered. In practice, the model is first trained and a reference accuracy is computed on the test set. Then, the values of the selected feature in the test set are randomly permuted and the model is re-evaluated on this corrupted data. The difference between the reference and post-permutation accuracies constitutes the feature importance score. This process is repeated for all features to obtain a comprehensive ranking of importance.
In this study, permutation importance is computed for all classifiers using the Domain-12 feature set. For each classifier, the top 10 features with the highest importance scores are identified, and the results are analyzed from two perspectives: frequency analysis and mean-importance analysis. Frequency analysis evaluates the general relevance of a feature by counting how many classifiers include it in their top-10 list. In contrast, mean-importance analysis measures absolute impact by averaging the accuracy decrease attributable to that feature across classifiers. Considering these two measures jointly enables identification of features that are both consistently important and associated with large effect sizes. The most frequently occurring features across all classifiers are shown in Figure 15, the frequency distribution by sensor axis and statistical feature type is shown in Figure 16, and the average feature importance values are presented in Figure 17.
To clarify the terminology: “frequency by sensor axis” refers to how many times features derived from a particular sensor channel (Fx, Fy, Fz, Tx, Ty, Tz) appear in the top-10 importance lists across all classifiers. For example, as shown in Figure 16, features derived from the Fx axis exhibit the highest frequency among all sensor axes, indicating that this sensor axis carries critical information for failure detection. Similarly, “frequency by statistical type” indicates how many times a particular statistical descriptor (mean, std, skewness, kurtosis, etc.) appears in the top-10 lists across all classifiers.
As shown in Figure 15, Fx_Skewness and Fy_Skewness appear in the top-10 lists of 8 out of 10 classifiers, exhibiting the highest frequency. This finding indicates that skewness plays a critical role in characterizing failure conditions, suggesting that the asymmetry of the force distribution is an important discriminative cue between normal operation and failures. Figure 16 shows that the dominance of Fx and Fy among sensor axes implies that horizontal-plane forces are more informative for failure detection than vertical forces and torques. Among statistical features, the prominence of skewness and kurtosis highlights the discriminative power of distribution-shape descriptors. Figure 17 provides a complementary perspective by reporting mean importance scores rather than frequencies. Notably, the energy feature exhibits the highest average importance (0.113). Although it does not rank among the most frequent features, it has a significant impact in the models that include it. This points to the presence of “sparse but strong” features and underscores the value of comprehensive feature evaluation. As a notable finding, only 15 out of 72 features (21%) in the Domain-12 feature set appear in the top-10 list of more than two classifiers. This result indicates that not all statistical features are equally discriminative, and distribution shape descriptors such as skewness and kurtosis are particularly critical for robot failure detection. This finding supports that the domain-based feature engineering approach, unlike random feature generation, produces physically meaningful and discriminative features.
Also, the dominance of skewness features (Fx_Skewness, Fy_Skewness) over energy-based features (energy, RMS) deserves physical interpretation. Skewness measures force distribution asymmetry, which encodes the temporal structure of robot–environment interactions. During normal operation, force profiles tend to be symmetric as the robot executes smooth movements. Failure conditions–collisions, obstructions, front collisions—introduce characteristic asymmetries: sharp unidirectional force spikes followed by gradual decay (positive skewness) or sustained buildup followed by abrupt release (negative skewness). In contrast, energy and RMS measure signal magnitude, which can be similar across different states (e.g., moving heavy payloads vs. collision forces). Thus, skewness captures the character of interactions rather than just their magnitude, explaining its superior discriminative power.
4. Conclusions and Discussion
In this study, a comparative classification framework is conducted to identify robot failures using data collected from force–torque sensors. The results clearly demonstrate that feature engineering has a critical impact on classification performance. The consistent improvements achieved by the Domain-12 feature set across many algorithms indicate that statistical features inspired by modern signal-processing literature provide more discriminative representations than raw time-series inputs. In particular, incorporating advanced statistics such as skewness, kurtosis, and energy captures the characteristic signatures of failure conditions more effectively.
The source of performance improvement observed between Baseline (90 raw features) and Domain-12 (72 statistical features) requires careful analysis. This improvement cannot be explained solely by dimensionality reduction, as random selection of 72 features would not produce similar results. The fundamental sources of improvement are: (1) Domain knowledge: Skewness reflects the asymmetry of force distribution, kurtosis captures sudden changes, and energy represents signal power—these features capture the physical characteristics of failure conditions. (2) Noise filtering: Statistical features naturally filter measurement noise by being computed over 15 time steps. (3) Discriminative power: Permutation importance analysis reveals that only 15 out of 72 features (21%) show consistent importance, and these features (skewness, energy) are advanced statistics specific to Domain-12. These findings demonstrate that the proposed feature engineering approach, unlike random feature selection, produces domain-informed features that carry critical information for failure detection.
When algorithmic performance is considered, the consistently strong results of the Naive Bayes classifier across all feature sets are noteworthy. The strong NB performance despite force–torque sensors being inherently correlated warrants explanation. NB can succeed even when independence is violated because optimal classification requires only correct ranking of posterior probabilities, not accurate probability estimates. Moreover, domain features (Fx_Skewness, Tz_Median, etc.) exhibit lower correlation than consecutive raw time steps, partially addressing the violation. The finding that only 21% of features are consistently important suggests NB relies on a relatively independent feature subset. Gradient-boosting methods (XGBoost and LightGBM) also achieve substantial performance, especially with richer feature sets, corroborating the effectiveness of ensemble learning in modeling complex decision boundaries. Among deep learning models, the clear superiority of CNN-1D over LSTM indicates that extracting local patterns from force–torque signals is more beneficial than modeling long-term dependencies in this setting. Moreover, SVM and KNN achieved around 90% classification accuracy with the Domain-12 feature set, ranking among the top four methods alongside NB and CNN-1D.
The potential impact of class imbalance on classification performance should also be considered. In the dataset, the Collision and Front Collision classes are smaller in size compared to the Obstruction class. This may increase the tendency of smaller classes to be misclassified into larger classes, particularly in classifiers that rely on prior probabilities such as Naive Bayes. The confusion matrices in Figure 9 partially reflect this pattern. Nevertheless, the main finding of the study—the consistent improvement provided by the Domain-12 feature set—is observed across all classifiers and all classes. This indicates that the proposed feature engineering approach is effective regardless of class distribution. In future work, a more detailed examination of this effect using class balancing techniques (SMOTE, class weighting) is planned.
When comparing with previous studies in the literature, methodological differences should be considered. In the original study [1] that introduced the LP1 dataset, feature transformations such as windowed averages and derivatives were used with SKIL and OC1 algorithms. However, since different feature representations, different algorithms, and different evaluation protocols were used, direct accuracy comparison is not methodologically appropriate. The value of this study lies not in absolute accuracy values but in the controlled experimental design: Under the same dataset and same evaluation protocol, improvements achieved by merely changing the feature representation reveal the isolated effect of feature engineering. This approach demonstrates the effectiveness of domain-based statistical features in robot failure detection, independent of accuracy competition with previous studies.
Permutation importance analysis reveals that skewness features derived from the Fx and Fy channels are the most critical variables for failure detection. The dominant contribution of horizontal-plane forces suggests that anomalies along these axes best reflect failure-related interactions between the robot arm and its environment. In addition, the observation that the energy feature has the highest average importance, despite not ranking among the top in frequency, highlights the need for comprehensive feature evaluation. Overall, this study demonstrates that domain-based statistical feature engineering offers an effective approach for robot failure classification and that substantial improvements can be achieved in both conventional machine learning and deep learning models when appropriate feature representations are employed.
The study also has some limitations. The relatively small size of the dataset used (N = 88, 4 classes) restricts deep learning models from fully realizing their potential. The generalizability of results obtained on small datasets is limited, and validation studies on different datasets are required. Nevertheless, this limitation does not affect the main contribution of the study: On the same limited dataset, improvements are achieved by merely changing the feature representation. These findings demonstrate that feature engineering is critically important even under limited data conditions. Since collecting labeled failure data in industrial robotics applications is typically costly and time-consuming, the ability to achieve high performance with small datasets is practically valuable.
Finally, future work should therefore consider evaluations on larger and more diverse datasets, further investigate transfer learning strategies, and validate real-time deployment feasibility. Regarding computational efficiency, Domain-12 requires additional computation for sorting (median, IQR) and higher-order moments compared to Domain-6, but remains computationally lightweight for typical embedded systems. For real-time applications, feature subset selection—using only the 15 most important features identified by permutation importance—can significantly reduce latency while retaining most discriminative power. Hardware acceleration (FPGA/GPU) offers further optimization opportunities for ultra-low-latency scenarios.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Seabra Lopes L. Camarinha-Matos L.M. Feature Transformation Strategies for a Robot Learning Problem Feature Extraction, Construction and Selection Liu H. Motoda H. The Springer International Series in Engineering and Computer Science Springer Boston, MA, USA 1998 Volume 45310.1007/978-1-4615-5725-8_23 · doi ↗
- 2Eang C. Lee S. Predictive Maintenance and Fault Detection for Motor Drive Control Systems in Industrial Robots Using CNN-RNN-Based Observers Sensors 2025252510.3390/s 25010025 PMC 1172299039796814 · doi ↗ · pubmed ↗
- 3Bilal H. Obaidat M.S. Shamrooz Aslam M. Zhang J. Yin B. Mahmood K. Online Fault Diagnosis of Industrial Robot Using Io RT and Hybrid Deep Learning Techniques: An Experimental Approach IEEE Internet Things J.202411314223143710.1109/JIOT.2024.3418352 · doi ↗
- 4Liu Y. Chen C. Wang T. Cheng L. An attention enhanced dilated CNN approach for cross-axis industrial robotics fault diagnosis Auton. Intell. Syst.202221110.1007/s 43684-022-00030-6 · doi ↗
- 5Pan J. Qu L. Peng K. Sensor and Actuator Fault Diagnosis for Robot Joint Based on Deep CNN Entropy 20212375110.3390/e 2306075134203708 PMC 8232324 · doi ↗ · pubmed ↗
- 6Sabry A.H. Nordin F.H. Sabry A.H. Abidin Ab Kadir M.Z. Fault Detection and Diagnosis of Industrial Robot Based on Power Consumption Modeling IEEE Trans. Ind. Electron.2020677929794010.1109/TIE.2019.2931511 · doi ↗
- 7Shi K. Cheng D. Yuan X. Liu L. Wu L. Interacting multiple model-based adaptive control system for stable steering of distributed driver electric vehicle under various road excitations ISA Trans.2020103375110.1016/j.isatra.2020.03.02132216986 · doi ↗ · pubmed ↗
- 8Li X. Zhang W. Ding Q. Sun J.-Q. Intelligent rotating machinery fault diagnosis based on deep learning using data augmentation J. Intell. Manuf.20203143345210.1007/s 10845-018-1456-1 · doi ↗