Defect-Intent Ambiguity Addressing for Training-Free Deterministic PCB Defect Localization via Template Selection and Dissimilarity Mapping
Saiyan Saiyod, Woottichai Nonsakhoo, Zhengping Li, Piyanat Sirisawat

TL;DR
This paper introduces a training-free method for detecting defects in PCBs using reference images and image processing techniques, achieving high precision and recall.
Contribution
A novel, training-free deterministic framework for PCB defect localization using template selection and dissimilarity mapping.
Findings
The method achieves high precision (0.9663) and recall (0.9987) with minimal false positives.
Average precision reaches 0.984 under the box-matching protocol.
The framework uses interpretable parameters and avoids machine learning models.
Abstract
Automated optical inspection (AOI) for printed circuit boards (PCBs) requires localizing small, sparse defects under illumination drift and minor placement misalignment, while supporting fast, auditable pass/fail decisions. This paper presents a training-free, reference-based digital image processing framework with no learning/training stage that compares each defective query image with a small library of defect-free reference templates (for the same PCB layout/revision) using a small set of interpretable control parameters. A reference is selected by coarse-to-fine matching (fast pre-screening followed by SSIM refinement on a central region), and an optional global alignment is applied only when it increases SSIM to limit defect-driven over-correction. Defects are highlighted by a defect-likelihood field that fuses an SSIM-derived structural dissimilarity map with a normalized…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
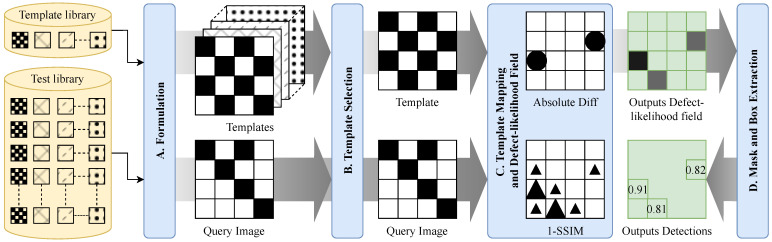 Figure 1
Figure 1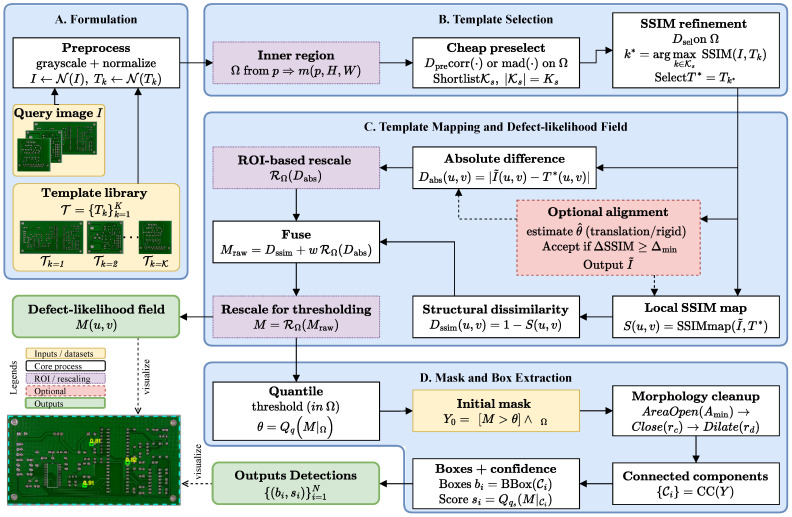 Figure 2
Figure 2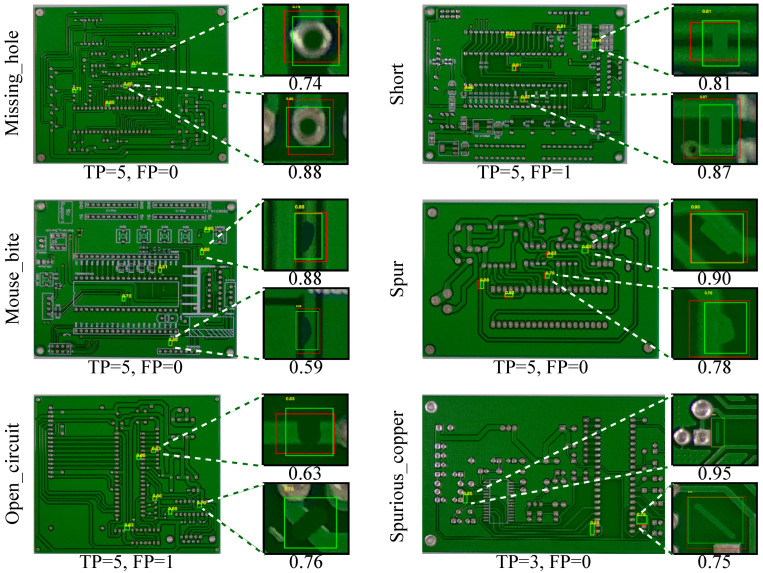 Figure 3
Figure 3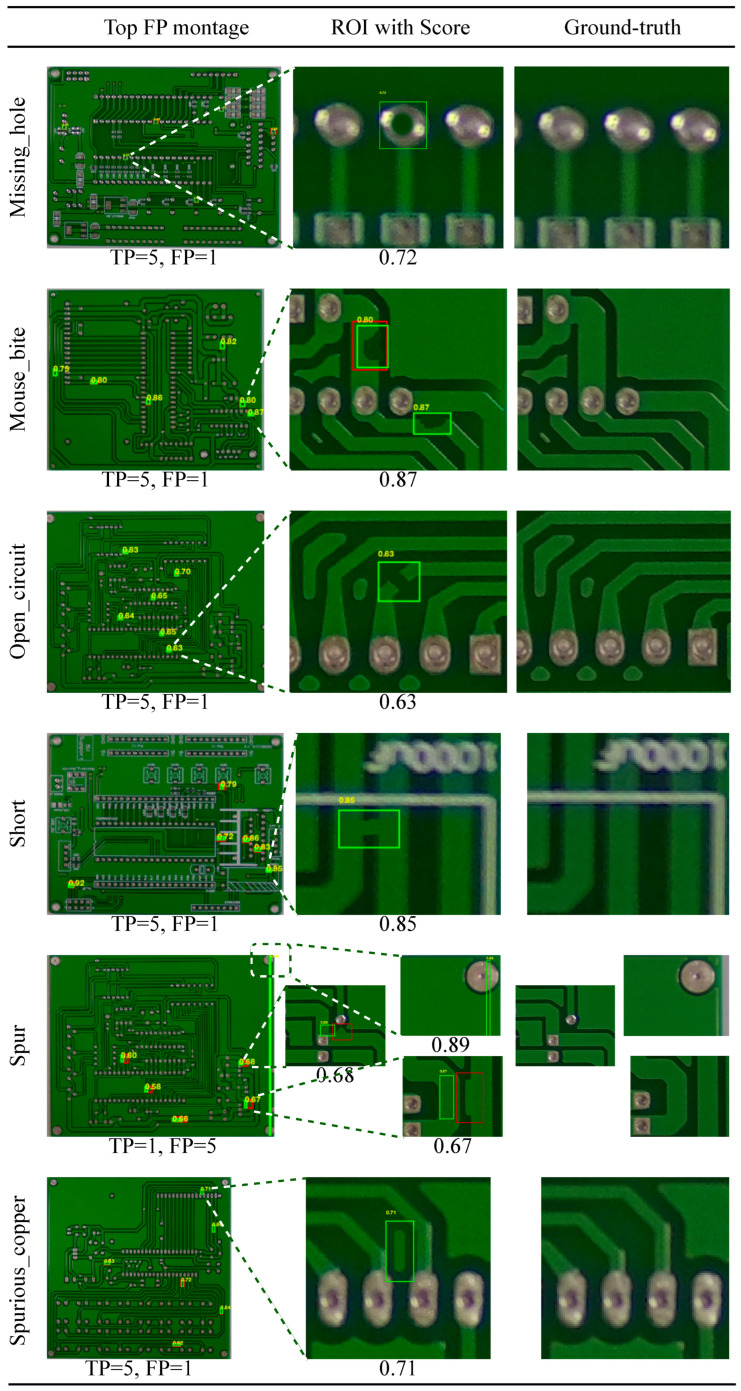 Figure 4
Figure 4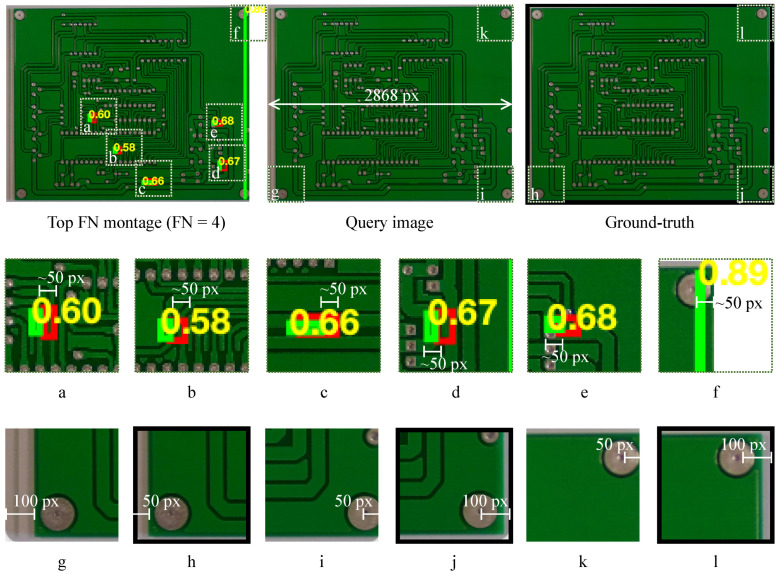 Figure 5
Figure 5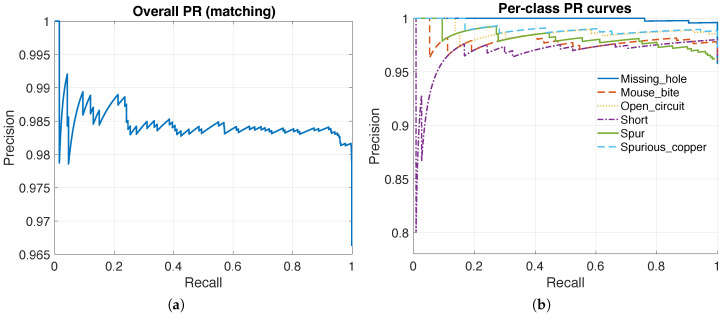 Figure 6
Figure 6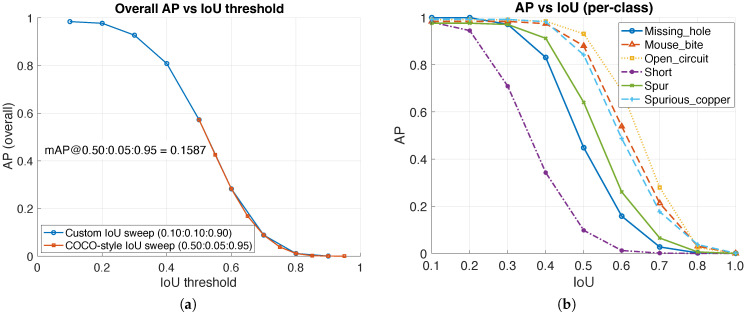 Figure 7
Figure 7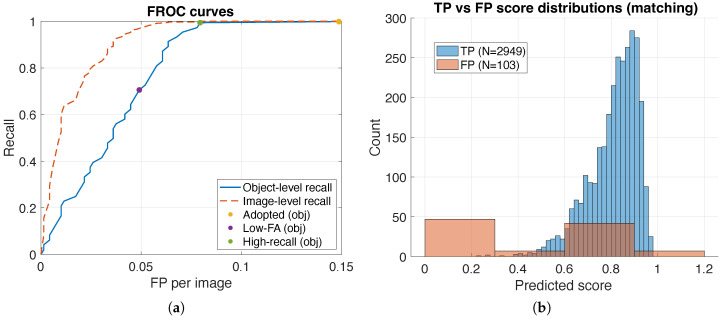 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsIndustrial Vision Systems and Defect Detection · Advanced Neural Network Applications · Advancements in Photolithography Techniques
1. Introduction
Automated optical inspection (AOI) is a core quality fcontrol stage in printed circuit board (PCB) manufacturing, where decisions must be made reliably at production speed [1,2]. In practice, true defects are sparse and localized (e.g., missing copper, spurious copper, scratches, and pinholes), yet benign variability in illumination and minor board-placement changes is common [3]; therefore, a useful inspection method must suppress nuisance variability while remaining sensitive to subtle, localized structural deviations. AOI is typically positioned inside a broader in-line quality strategy that aims to reduce scrap and rework while keeping false alarms manageable in production [4].
In many industrial quality control (QC) workflows, the primary decision is pass/fail (accept/reject): if any verified defect is present, the board is rejected. Therefore, reliable defect localization and evidence are central, while fine-grained defect-type classification (e.g., Missing_hole, Mouse_bite, Short) is often optional and can be treated as a downstream step for reporting, process monitoring, or root-cause analysis [5]. At the same time, surveys of PCB defects and inspection practices highlight that defect taxonomies and visual manifestations can vary across processes and products, which complicates universal classification claims and emphasizes the value of interpretable evidence [6].
A key practical disparity is that the notion of a “defect” can be ambiguous without context from the intended design [7]. In PCB engineering, many localized copper features are introduced deliberately to satisfy electromagnetic interference and compatibility (EMI/EMC) and signal/power integrity (SI/PI) constraints rather than to “look clean” in an image [7,8,9,10]. For example, an apparent copper bridge may be an unintended short in one location but an intentional connection, net-tie, or controlled strap in another. Likewise, patterns that resemble spurious copper in isolation can be purposeful copper pours and fills (e.g., ground pours for shielding and controlled return-current paths), via stitching and via fences to reduce radiation and crosstalk, guard traces, copper thieving/balancing for manufacturability, or local tuning structures used to manage impedance, ringing, and high-frequency noise.
Spur-like features and short stubs can also be intentional (e.g., test access, reinforcement/teardrops, thermal relief, or current-spreading structures), even though similar geometries may be considered defects in other contexts. Because these intent-driven features may be small and localized, appearance-only inspection can confuse design intent with anomaly [6,11].
This defect-versus-intent ambiguity motivates reference-based inspection: comparing a query board against a defect-free exemplar of the same layout provides the necessary design-context baseline [12]. The template encodes the intended routing, copper distribution, and layout-specific structures used for EMI/EMC and SI/PI, allowing the inspection decision to focus on deviations from the intended reference (true defects) rather than on visually unusual but intentional patterns [7,8].
In production, the primary constraint is often not peak accuracy in a curated benchmark but predictable behavior under everyday drift and change [4,13]. Practical AOI systems are judged by time-to-deploy on a new board, validation burden, compute footprint, and the ability to explain failures when they occur [13]. End-to-end learning-based models are widely used; however, in some deployment settings their internal decision logic can be harder to audit and their lifecycle cost can include labeling, retraining, monitoring, and re-qualification [5,14]. When an inspection decision is disputed, it is valuable to attribute the response to concrete causes such as illumination shift, residual misalignment, template mismatch, or a true localized defect [15,16].
Accordingly, a recurring deployment theme is to reduce manual labeling burden and model maintenance effort while still improving robustness, which motivates both training-free pipelines and low-label learning regimes [17,18].
These constraints motivate a complementary design point: analysis-first, physics- and mathematics-grounded image processing that exposes its decision signal. Classical industrial inspection continues to rely on deterministic components such as thresholding, morphology, and template matching because they are auditable and controllable [19,20]. In this view, a defect-free template functions as a measurement reference standard: inspection becomes change detection against the intended layout rather than category recognition.
The main obstacle is that simple subtraction is sensitive: small geometric mismatch and brightness drift can dominate the difference image and produce widespread false positives [15]. Robust reference-based inspection therefore benefits from structural similarity measures and careful handling of alignment [21]. The structural similarity index (SSIM) [22] emphasizes structure rather than raw intensity and can be evaluated locally to form an SSIM map that highlights localized changes. Alignment can further reduce nuisance differences, but in defect localization it must be used carefully because defects can bias the estimated transform; a pragmatic safeguard is to accept alignment only when it yields a measurable similarity improvement [23].
Related work on PCB AOI spans broad surveys and focused PCB-specific reviews that summarize classical image processing pipelines and, more recently, deep learning-based approaches [1,2,6,11,14,24]. Classical AVI/AOI surveys establish the foundational problem setting and recurring algorithmic motifs (preprocessing, registration/matching, and post-processing for decision rules) [25]. More recent reviews focus on electronics manufacturing and PCB inspection specifically, including the rise of deep learning and the associated practical considerations (data requirements, interpretability, and lifecycle/maintenance cost) [11,14,24]. Across these perspectives, a consistent theme is that production deployment often rewards predictable behavior and actionable diagnostics, which keeps reference-based inspection relevant even when learning-based models are available.
Beyond RGB surface imagery, inspection and monitoring can also involve specialized imaging and task-specific pipelines, for example in solder-joint and electronic assembly defect analysis, where the sensing modality and measurement objective differ from bare-board surface AOI [26,27].
A long-standing and still common formulation is reference/template-based change detection, where the query is compared to a defect-free exemplar and differences are extracted using similarity measures and post-processing [12,20,21]. In this family, normalized cross-correlation and related similarity measures are widely used to compare a query against a template, both for alignment/matching and for highlighting likely change regions [12,28]. Because AOI images can differ by small shifts, rotations, and illumination drift, many works explicitly study robustness of similarity/dissimilarity measures and the sensitivity of subtraction-based signals to misregistration [15,29]. Feature-based matching and alternative similarity measures (beyond raw subtraction) are also widely explored as ways to increase tolerance to nuisance variation while preserving localized change cues [16,30,31]. Rotation or uncertainty-aware designs further emphasize that handling geometric variability is a practical requirement rather than a corner case [32]. This practical issue is directly aligned with our use of structural similarity and alignment safeguards: the goal is to suppress broad, nuisance-driven responses while preserving localized defect evidence [22,23].
Within classical (training-free) inspection, several works explicitly combine subtraction/matching with deterministic operators for categorization and reporting [19,21,33]. For example, an algorithmic scheme for concurrent detection and classification applies fuzzy c-means segmentation after image subtraction and then uses arithmetic/logic operations, the circle Hough transform, morphological reconstruction, and connected-component labeling to assign defect categories; it reports 100% detection and 99.05% classification accuracy in its experimental setting [33]. In a similar spirit, other subtraction-based pipelines target both detection and defect-type decisions by combining difference images with hand-designed operators (e.g., morphology, logical operations, and component analysis), illustrating the long-standing appeal of deterministic, auditable processing in PCB AOI [19].
In parallel, deep learning has been widely adopted for PCB defect detection and classification, commonly borrowing generic object-detection backbones and adapting them for small, low-contrast defects and industrial constraints [24,34,35,36,37]. One line of work applies one-stage object detectors (often YOLO-family variants) and proposes architectural changes to improve localization of tiny PCB defects while keeping inference efficient [38,39,40,41,42,43,44]. Additional one-stage variants integrate backbone and attention refinements for feature reuse and improved localization under clutter [45,46,47,48]. Another line adapts two-stage and feature-pyramid designs (e.g., Faster R-CNN/FPN-style components) to improve multi-scale defect detection where targets are small and the background is cluttered [49,50,51]. Beyond detector backbones, several studies emphasize lightweight deployment, attention/feature-fusion refinements, and context modeling to trade off accuracy and throughput in practical settings [52,53,54]. Deep learning is also used for related PCB inspection tasks including defect classification, reconstruction/autoencoder-based inspection signals, and component-level understanding such as PCB segmentation for recognition [55,56,57]. Transformer- and DETR-inspired detectors are another recent direction, motivated by global context modeling and end-to-end detection design [58,59]. Beyond standard detector framing, learning-based approaches also include alternative objectives and cues (e.g., energy-based or edge-guided signals), domain adaptation strategies to handle distribution shift [60], and PCB-specific designs for bare-board defects [61,62,63].
Because labeled defect samples can be scarce and production distributions can drift, recent work also explores semi-supervised, unsupervised, and few-shot settings for PCB inspection [17,18,64]. These directions aim to reduce annotation burden and improve adaptability by leveraging unlabeled data, uncertainty modeling, or meta-learning-style transfer from limited support examples [17,18,64].
An important practical gap in PCB inspection is defect-versus-intent ambiguity. Appearance-only cues can confuse intentional layout features with true defects unless a layout-specific reference is available. Motivated by this, this work presents a training-free, reference-based image processing framework that retains the operational advantages of template inspection while improving robustness to everyday nuisance variation. While end-to-end learning-based defect detectors are widely used in industrial inspection across product domains, the proposed pipeline provides an auditable and controllable alternative that does not require a training lifecycle [65,66]. The method is computationally efficient and operationally transparent: it produces interpretable intermediate fields (similarity and difference maps) and relies on controllable operators whose behavior can be inspected and tuned without retraining.
The main contribution of this work lies in a training-free framework design that combines classical operators with explicit robustness safeguards targeting defect-versus-intent ambiguity under everyday nuisance variability. In particular, we emphasize ROI-based template selection, SSIM-gated alignment acceptance, and a fused defect-likelihood mapping that yields confidence-ranked detections for deployment-oriented PR/FROC threshold selection. The key contributions are as follows:
- Coarse-to-fine reference selection with central-region similarity: a fast pre-screening stage plus SSIM refinement computed on a central region to suppress border/outlier effects, with caching and downscaling for throughput.
- SSIM-gated alignment acceptance: an explicit validation rule that applies a global warp only when SSIM improves on the same central region, mitigating defect-driven over-correction.
- Fused, auditable defect-likelihood and operational evaluation: an explicit defect-likelihood field that fuses structural dissimilarity and normalized absolute difference with central-region-based rescaling for stable thresholding, producing confidence-ranked candidates that are characterized via PR/FROC and IoU-sensitivity rather than a single tuned threshold.
The remainder of this paper is organized as follows: Section 2 details the proposed method, Section 3 presents the experimental results and analysis (including the evaluation protocol), Section 4 discusses limitations and practical considerations, and Section 5 concludes this paper.
2. Proposed Methods
This section presents a training-free PCB defect-localization pipeline. For each query image, it selects a defect-free reference template and outputs (i) an interpretable defect-likelihood field and (ii) confidence-ranked bounding boxes. At a high level, the pipeline performs coarse-to-fine template selection, constructs the defect-likelihood field by fusing SSIM-based structural dissimilarity with normalized absolute difference, applies global alignment only when it improves SSIM, and extracts sparse candidates via quantile thresholding, morphology, and connected-components analysis (Figure 1).
2.1. Formulation
This work considers reference-based PCB inspection in which, for each defective query image, one or more defect-free exemplars of the same PCB layout are available. Let I denote a defective query image and denote a library of defect-free templates. Here, templates refer to defect-free reference images for the same PCB layout/revision (not defect-type templates that enumerate defect categories). Consequently, the localization stage is class-agnostic across defect categories: any defect that manifests as a localized deviation from a valid defect-free reference can yield a response in the defect-likelihood field.
The goal is to output the following: (i) a spatial defect-likelihood field (higher values indicate more likely defect) and (ii) a set of N axis-aligned bounding boxes with confidence scores , where each denotes the top-left corner and the box width/height , and is a confidence score.
To stabilize similarity computation and threshold estimation, statistics are evaluated on a central image region parameterized by a margin with m pixels on all sides. The margin m is computed from an area-avoidance ratio , which specifies the fraction of the total image area to ignore.
2.2. Template Selection
All images are converted to grayscale and normalized to by an affine intensity rescaling. Scalar SSIM is denoted by [22]. Pixel coordinates are (column, row) and the image domain is .
Similarity and thresholds are evaluated on an inner region parameterized by a symmetric margin m determined from an area-avoidance ratio , where 0.95 is an experimental upper limit to ensure a nontrivial inner region. With a margin m on all four sides, the central area is and the remaining area is
Setting this equal to yields the (smaller) quadratic root
and is used as an integer padding. The inner region is
In implementation, this continuous expression is converted to an integer ROI with explicit rounding and safety clamping; see Appendix A.1.
Given a query image I and template library , the template is selected by maximizing SSIM on the inner region at a designated selection resolution. Let denote isotropic resizing to satisfy and let denote grayscale+normalization. At selection scale ,
To reduce computation, similarity is evaluated only within . Denoting cropping by , the selection objective is
and the chosen template is .
To reduce selection time, a two-stage scheme is used: (i) a cheap preselect score at a smaller max dimension to shortlist candidates and (ii) SSIM refinement computed only on that shortlist. Two suitable preselect scores are as follows:
where are vectorized values in after mean subtraction ( ) or are directly compared ( ). Correlation-style matching is a standard building block for template-based inspection and fast preselection [12,28,67]. Further details and implementation considerations (including complexity, shortlist logic, and caching of preprocessed templates to amortize decoding/resizing across queries) are provided in Appendix A.2.
2.3. Template Mapping and Defect-Likelihood Field
After selecting , a defect-likelihood field is constructed on a processing grid. To control runtime, expensive stages (alignment, SSIM-map, and morphology) may be downsampled by selecting a target long-side processed length and defining an isotropic scale
This yields
If needed, the query is resized to match the template grid. The implementation also supports resolution presets and scales morphology/area parameters consistently with the processing scale; see Appendix A.3.
Although the proposed framework can operate without explicit alignment, in practical AOI settings a lightweight global alignment is highly recommended whenever small placement shifts or mild rotations are expected. Because the defect-likelihood field is computed pixel-wise, even minor global misalignment can produce widespread responses that resemble false defects.
Let denote a parametric global warp (translation or rigid) with parameters , and let the warped query be . The alignment is estimated by maximizing an intensity-based similarity inside the inner region ,
where is a correlation-like similarity and denotes inner-region masking, i.e., pixels outside are set to zero. More general geometric matching formulations exist (e.g., via epipolar-geometry constraints), but a lightweight global warp is sufficient under the fixture-controlled imaging assumed in AOI lines [68].
Because defect content can bias the estimated warp, the transform is not applied unconditionally. Instead, the candidate warp is validated using SSIM gain on the inner region,
The alignment is accepted if (a user-controlled safeguard); otherwise it is rejected. Accordingly, the aligned (or unaligned) query is defined as
This acceptance rule makes alignment a practical robustness aid while limiting over-correction in the presence of true defects.
To prevent outliers outside the central region from compressing the dynamic range used for thresholding, a min–max rescaling is used whose extrema are computed over only. Define and . The operator therefore performs min–max normalization using extrema computed over pixels in only, which prevents values outside from compressing contrast in the region used for threshold selection. The stabilizer ensures numerical safety when .
A local SSIM map is computed between and . For a window centered at , let be local means, let be local variances, and let be the local covariance. The SSIM map value can be written as
where stabilize the ratio. This is converted to a structural dissimilarity map,
In our implementation, the SSIM map is computed using MATLAB R2023a’s SSIM function with explicitly specified parameters (window size/weighting and stabilizing constants) for reproducibility; the exact values are reported in Appendix A.4. An absolute-difference map is also computed
An additive fusion with weight w is used, followed by rescaling for stable thresholding:
In this interpretation, is a defect-likelihood signal: localized defects produce concentrated peaks, while nuisance global mismatch (wrong template) tends to produce broad responses.
2.4. Mask and Box Extraction
Defects are sparse, so a high-quantile threshold is chosen using pixels in only:
where is a sensitivity parameter.
For a finite set of values , the q-quantile is any value such that at least a fraction q of samples are and at least a fraction are . Using a high quantile to set is robust in this setting because true defects typically occupy only a small fraction of pixels within .
The initial binary mask is
To suppress speckle noise and consolidate defect blobs, a sequence of set operators is applied to within the inner region. Let denote a disk structuring element of radius r, and let remove connected components smaller than . The sequence is
where • is morphological closing, ⊕ is dilation, and ∧ is pixel-wise AND with the inner-region mask .
Connected components of Y are converted to axis-aligned bounding boxes . Each component is assigned a confidence score using a robust statistic of M inside the component. A stable choice is a high quantile:
Boxes are sorted by and mapped back to the original resolution if the processing scale . For the exact connected-component scoring rule and supported alternatives (e.g., quantile/max/mean scoring), see Appendix A.5. Therefore, the final output of this stage is a confidence-ranked set of detections
where each is an axis-aligned bounding box, and is its confidence score derived from the defect-likelihood field. In summary, the mask-and-box stage is controlled by a small set of interpretable parameters: threshold quantile q, minimum area , closing radius , dilation radius , and confidence quantile (default ). These parameters jointly control the false-positive/false-negative trade-off and the coarseness of the resulting boxes.
2.5. Algorithm Summary
The proposed framework takes a defective query image and selects a reference template from a small library using a coarse-to-fine strategy (cheap pre-screening followed by SSIM refinement). If enabled, a global alignment is applied with an explicit acceptance test based on SSIM gain on the inner region, limiting transforms biased by defect content. A defect-likelihood field is then constructed by fusing an SSIM-derived structural dissimilarity map with a normalized absolute-difference map and applying an -based rescaling. Finally, high-quantile thresholding and simple morphological post-processing yield connected components that are converted into confidence-ranked bounding boxes. Algorithm 1 summarizes the full procedure, while the mathematical operators and data products are summarized in Figure 2. Algorithm 1 Template selection and defect localization
- Require: Query image I, templates ,
- parameters
- Ensure: Detections and defect-likelihood field M
- 1:Compute central region from area-avoidance ratio p
- 2:Preselect shortlist (size ) using a cheap score at resolution
- 3:Select template by maximizing SSIM on over at resolution
- 4:Set processing scale s from and build processed images
- 5:Optional alignment: estimate transform and compute SSIM gain on ; accept if
- 6:Define aligned query (either warped or )
- 7:Compute SSIM map between and
- 8:Compute dissimilarity maps and
- 9:Fuse and rescale to obtain defect-likelihood field M
- 10:Threshold:
- 11:Initial mask:
- 12:Cleanup:
- 13:Connected components → boxes and scores
- 14:Map boxes back to original scale (if )
Computational Complexity
Let K be the number of available templates and be the shortlist size after preselection. Let denote the maximum long-side resolutions used for (i) the cheap preselect score, (ii) SSIM refinement for template selection, and (iii) the downstream processing grid, respectively. Using the common square-grid proxy, the number of evaluated pixels scales as at resolution D. Restricting computations to the central region (via ROI cropping/masking) primarily changes constants. Per query image, the coarse-to-fine template selection cost is
where the first term corresponds to evaluating a cheap preselect score over all templates at , and the second term corresponds to SSIM refinement over the shortlist at (dominant when enabled). After selecting , the downstream stages operate on the processing grid at : (i) optional global alignment uses a correlation-based registration objective (translation/rigid) and in practice scales near-linearly in the number of processed pixels (often with FFT-accelerated correlation), (ii) the SSIM map uses a fixed window size (constant window operations per pixel), and (iii) difference-map construction, -based rescaling, quantile thresholding, morphology with fixed structuring-element radii, and connected-components labeling are all up to small multiplicative constants. Overall, the per-image runtime scales as
and the dataset runtime is linear in the number of evaluated images. In practice, template preprocessing (grayscale/normalization/resizing) can be cached, and choosing with keeps selection tractable even for moderate template libraries.
2.6. Experimental Setup and Evaluation Protocol
Experiments use the PKU-Market-PCB dataset [3]. Defect classes are used only for class-wise reporting; the localization pipeline itself is class-agnostic across defect categories (while assuming a valid defect-free reference template for the same layout/revision). The dataset folder organization (templates, defective images, and Pascal Visual Object Classes (VOC) annotations) is described in Appendix A.6. The proposed method is implemented in MATLAB R2023a, and experiments are run on an Apple M1 processor with 8GB RAM. The implementation configuration and hyperparameters are reported in Appendix A.7
2.6.1. Dataset
Although the proposed method employs training-free image processing that produces an explicit defect-likelihood field and interpretable intermediate maps, the final outputs are evaluated using standard box-level localization metrics, which facilitates comparison with established benchmarks in the AOI and object-detection literature. For broader context on automated optical inspection in electronics manufacturing and recent perspectives on PCB defect detection, see the comprehensive surveys in [69,70]. Table 1 summarizes the evaluated dataset, including image resolution and annotation statistics.
2.6.2. Detections and Confidence
For each query image, the method outputs a set of axis-aligned detections , where each is the bounding box of a connected component extracted from a thresholded version of (Section 2.4). Each detection is assigned a confidence score computed as a robust statistic of M values inside the component (a high-quantile score is used so that a higher indicates stronger evidence of a localized peak). For the exact component-to-box confidence definition used in the implementation, see Appendix A.5.
2.6.3. Ground Truth and Intersection-over-Union (IoU) Matching
Ground-truth annotations are axis-aligned Pascal VOC boxes. For each query image, let denote the set of ground-truth boxes. Detections are matched to ground truth using a greedy one-to-one assignment within each image: detections are processed in descending confidence order, and a detection is matched to an as-yet-unmatched if (each detection matches at most one ground-truth box and vice versa). Unmatched detections are counted as false positives, and unmatched ground-truth boxes are counted as false negatives.
Unless noted otherwise, is used because detections are derived from thresholded connected components rather than tight box regression.
2.6.4. Fixed Operating Point (Counts and F1)
Given a score threshold t, detections with are retained and dataset-level counts (after per-image one-to-one matching) are computed: true positives , false positives , and false negatives . Precision, recall, and F1 are
where is a small numerical stabilizer (e.g., ) used only to avoid division-by-zero in degenerate cases (e.g., when ); it does not affect results when denominators are nonzero.
For completeness, we also report a detection accuracy that does not require defining true negatives (TN), which are not well-defined for variable-length detection outputs:
2.6.5. Avoiding Threshold Selection on the Reported Set
To avoid optimistic bias from selecting t on the same set used for reporting, operating-point metrics are reported using K-fold cross-validation: in each fold, the score threshold is chosen to maximize on the calibration split (the union of the other folds), and precision/recall/F1 are then computed on the held-out fold using this fixed threshold. This work reports the mean ± standard deviation across folds. For continuity with the original submission and to aid interpretation of class-wise behavior, this also includes a reference operating point obtained by selecting on the full evaluated set; this reference is explicitly labeled and is not used as the primary estimate of generalization performance. Implementation details for the cross-validated operating point selection are provided in Appendix B.1.
2.6.6. Threshold-Sweep Metrics (PR/AP, AP-Versus-IoU, and FROC)
To summarize performance across confidence thresholds, the precision–recall curve is constructed by ranking all detections across the dataset by confidence and sweeping down this global ranked list. True/false positives are determined using the matching protocol described above at the specified [71,72]. Average precision (AP) is computed from this PR curve using a precision envelope and piecewise integration over recall (the VOC07 11-point approximation is disabled in the evaluation script).
To quantify sensitivity to localization stringency, AP is also computed across multiple IoU thresholds. In particular, (i) a custom sweep and (ii) a COCO-style sweep are reported. When multiple IoU thresholds are considered, mean Average Precision is reported as the mean AP across the specified thresholds.
For operational analysis, free-response receiver operating characteristic (FROC) curves are reported by sweeping score thresholds. For a threshold t, let be the number of evaluated images, let be the total number of ground-truth boxes, and let be the number of images containing at least one ground-truth box. The following quantities are defined:
where is the number of ground-truth-containing images for which at least one detection is a matched true positive (TP) at threshold t. In this paper, FROC plots and operating-point tables use object-level recall versus ; image-level recall is included for completeness. The exported threshold grid and image-level recall computation used to generate the FROC bundle are described in Appendix B.2.
At the dataset level, ; therefore, and are numerically equivalent. Accordingly, is used in the FROC definition to emphasize the object-level nature of the curve.
For completeness, explicit definitions for IoU on boxes and the AP computation used in our evaluation are provided in Appendices Appendix B.3 and Appendix B.4.
3. Experimental Results and Analysis
This section reports qualitative examples and quantitative localization performance under the experimental setup and evaluation protocol described in the previous subsection. The method produces confidence-ranked detections from an explicit defect-likelihood field ; therefore, results are presented both at a fixed operating point (counts and precision/recall/F1) and across confidence thresholds (precision–recall, AP, and FROC).
All quantitative results in this section are reported on 693 evaluated query images under the adopted IoU matching protocol (Section 2.6). Threshold-sweep curves (PR/AP/FROC) are computed on the full set. For fixed-threshold operating-point metrics, this work reports K-fold cross-validated results (mean ± std) to avoid selecting thresholds on the same set used for reporting.
For reference and continuity with prior results, the manuscript also reports descriptive counts at a reference best-F1 threshold selected on the full evaluated set (explicitly labeled as reference).
3.1. Qualitative Results and Failure Modes
Figure 3 shows representative TP cases where the proposed mapping produces localized peaks in that translate into axis-aligned bounding boxes overlapping the annotated defects. While the boxes are not optimized to tightly fit the defect boundary (they are derived from thresholded connected components), they consistently localize the defect region and provide a monotonic confidence score for ranking.
Figure 4 shows representative false positive (FP) cases. In practice, FPs tend to arise from nuisance variability that produces structured responses in the SSIM/difference maps, such as residual global misalignment, illumination drift, or local texture/reflectance changes that are not labeled as defects. A qualitative review of these cases suggests that many FPs stem from two primary sources: (i) structured nuisance variability such as residual global misalignment, illumination drift [73], or local texture changes that are not true defects, and (ii) actual defects that are present in the images but are missing from the corresponding Pascal VOC XML annotation files. Because this work operates strictly under the provided ground-truth labels without resorting to relabeling or manual verification, all reported metrics faithfully reflect the adopted box-matching protocol and evaluation set. The presence of unlabeled defects in the FP set underscores the importance of careful annotation in benchmark datasets and suggests that true recall may be higher than reported. These observations underscore the value of the optional alignment safeguard and careful template selection, which are most influential in reducing nuisance-driven artifacts. Moreover, the confidence-ranked outputs and FROC curves (Section 3.6) enable operational threshold selection based on a tolerable false-alarm budget in production, allowing practitioners to adjust operating points according to their acceptable FP/image rate and trade recall for lower false-alarm burden when necessary.
Figure 5 provides representative visual evidence for the observed Spur false negatives (all four FNs in the per-class breakdown). These cases are consistent with thin/fragmented structures producing a weaker or spatially discontinuous response under the current high-quantile thresholding and morphology settings, which can suppress small components or yield boxes that fail the one-to-one IoU matching criterion. Because the pipeline is deterministic and controlled by interpretable parameters , this behavior reflects an explicit operating trade-off that can be adjusted (as also summarized by the FROC curve in Section 3.6).
3.2. Template Selection Quality and Practical Failure Causes
The exported per-image diagnostics show that template selection is typically highly stable (template SSIM values are near 1.0 for the majority of images), but rare outliers can occur, which are consistent with occasional template mismatch or nontrivial capture variation. On the 693 evaluated images, the per-image template SSIM has median (p5 ), while a small number of outliers fall below 0.99 (4/693 images) and one extreme case reaches as low as . These outliers are practically important because low similarity can inflate structured responses in and therefore increase false positives under fixed post-processing parameters.
3.3. Quantitative Summary at the Adopted Operating Point
Table 2 reports per-class detection counts (TP/FP/FN) and the resulting precision/recall/F1 under the adopted IoU matching protocol at a reference best-F1 operating point selected on the full evaluated set. Overall, the method achieves TP = 2949, FP = 103, FN = 4, yielding Precision = 0.9663, Recall = 0.9987, and F1 = 0.9822 at this reference threshold. Cross-validated operating-point results (mean ± std across folds), which avoid threshold selection on the reported set, are provided in Table 3. In this revision, we treat these cross-validated operating-point results as the primary generalization-oriented summary, while the full-set best-F1 operating point is retained only as a clearly labeled reference point.
Across defect types, performance is broadly consistent. The main deviations are informative: all four missed defects (FN = 4) occur in the Spur class, suggesting a small subset of cases where the defect response is weaker or more fragmented under the current post-processing parameters. This behavior is expected in a deterministic pipeline and can be addressed by adjusting the interpretable parameters for the desired false-positive/false-negative trade-off.
3.4. Precision–Recall Characteristics Across Confidence Thresholds
Because detections are confidence-ranked by , varying the acceptance threshold induces a precision–recall (PR) trade-off. Figure 6 reports the overall PR curve and the per-class PR curves, summarizing how precision changes as recall increases and which defect types degrade earlier as the threshold is lowered.
In AOI practice, this view is useful because the operating point is chosen based on the acceptable false-alarm burden in production. In addition, the PR curves validate that the proposed confidence score is informative: a meaningful ranking yields a PR curve that maintains high precision over a wide recall range.
3.5. Sensitivity to Matching Stringency (AP Versus IoU)
Figure 7 reports average precision as a function of the IoU threshold. As the IoU requirement becomes stricter, AP decreases because the proposed detections are derived from thresholded map components and are not explicitly optimized to tightly fit the ground-truth boxes. In particular, because our boxes are obtained by extracting connected components and enclosing them with axis-aligned rectangles, should be interpreted as a permissive matching criterion for region-level localization (component fragmentation/merging can yield looser boxes even when the detected region overlaps the defect). Consequently, the decline in AP at higher IoU thresholds primarily reflects box tightness/placement mismatch rather than an inability to detect defect regions. Quantitatively, the exported AP–IoU sweep shows high AP at the adopted low-stringency regime (overall AP ≈ 0.984 at IoU = 0.10) but a pronounced decline at stricter thresholds (overall AP ≈ 0.572 at IoU = 0.50), approaching near-zero at very strict IoU (e.g., ≥0.80). This plot is therefore included to transparently characterize localization-stringency sensitivity rather than to claim pixel-tight bounding-box regression.
For completeness, Table 4 first summarizes representative overall AP values at selected IoU thresholds, and Figure 7 then visualizes the full AP-versus-IoU behavior, including both the overall curves (custom and COCO-style sweeps) and the per-class curves.
3.6. False-Alarm Rate Versus Recall (Or FROC)
For deployment, a key question is how many false alarms must be tolerated to achieve a target recall. Figure 8 reports FROC curves, which summarize recall as a function of the false positive rate (e.g., false positives per image) as the confidence threshold varies. This view complements PR curves by emphasizing the operational cost of additional recall.
At the adopted operating point (Table 2), the system attains Recall = 0.9987 with FP/image ≈ 0.149. In practice, Figure 8 is used to choose an operating threshold based on an allowed FP/image budget; the exported FROC curve enables selecting alternative thresholds to trade a small recall reduction for a lower false-alarm burden.
3.7. Score Separability of True and False Detections
Figure 8 compares the confidence-score distributions of true positives and false positives. A clear separation indicates that the confidence score provides a meaningful ranking signal, enabling threshold selection to trade precision for recall. Overlap between TP and FP score distributions highlights ambiguous cases (e.g., residual misalignment or illumination-driven artifacts) that can be addressed by improving template selection, enabling alignment when appropriate, or adjusting the mask-and-box parameters.
3.8. Quantitative Runtime Breakdown
Beyond asymptotic scaling, an empirical runtime breakdown of the reference implementation by stage is reported in Table 5.
4. Discussion
The proposed framework targets practical AOI where defect-free references are available and decisions must be reliable, auditable, and deployable without a training lifecycle. Operating-point metrics are summarized using K-fold cross-validation to avoid selecting thresholds on the reported set (Table 3), while a reference best-F1 operating point on the full set is retained for descriptive continuity (Table 2). Under the adopted IoU matching protocol, confidence-ranked outputs support operational interpretation via PR/FROC sweeps (Figure 6 and Figure 8) and IoU-sensitivity via AP-versus-IoU analysis (Figure 7).
4.1. Why the Method Works in Practice
Robustness comes from explicitly controlling nuisance variability and using structure-aware comparison: template selection reduces systematic mismatch, optional alignment is gated by SSIM gain to avoid defect-driven over-correction, and the fused defect-likelihood field combines SSIM-derived structural dissimilarity with normalized absolute difference to handle both structural and radiometric changes (e.g., illumination drift). Together, these choices yield a confidence score that is informative for ranking, consistent with the PR and FROC behavior.
4.2. Class-Wise Behavior and Failure Modes
Per-class performance is broadly consistent; the main deviation is that the only missed defects (FN = 4) occur in the Spur class (Table 2), where responses can be weaker or more fragmented under the current post-processing. This is expected in a deterministic connected-components-to-box stage (threshold/area/morphology can suppress fine structures), and recall can be increased by adjusting with the resulting FP/image quantified by the FROC curve.
4.3. Operating-Point Selection and Localization Stringency
Operating-point metrics are reported using K-fold cross-validation to avoid selecting thresholds on the same set used for reporting (Section 2.6). In practice, deployment typically selects thresholds based on an allowable false-alarm budget; Figure 8 and Table 6 make this trade-off explicit. Accordingly, FROC (object-level recall versus FP/image) is recommended as the primary operational view, with PR as a complementary precision summary. The adopted matching threshold reflects that detections are derived from thresholded connected components rather than tight box regression; consequently, AP decreases as IoU becomes stricter (Figure 7), indicating a design choice favoring reliable region localization for QC over pixel-tight boxes. To avoid over-interpreting performance under low-stringency matching, the Results section summarizes AP at representative moderate IoU thresholds and provides the full AP-versus-IoU sweep. If tighter boxes are required, a lightweight post-processing refinement (e.g., contour-based tightening) can be added without changing the detection ranking.
4.4. Limitations and Practical Considerations
The method assumes defect-free templates of the same PCB layout/revision, which is realistic in many manufacturing settings and helps resolve defect-versus-intent ambiguity; however, this assumption also defines the primary limitations:
- Layout/revision mismatch or wrong template: if the selected template does not correspond to the same board revision (or if no valid template exists), reference comparison can yield structured false-positive regions that mimic defects. Coarse-to-fine template selection mitigates mild mismatch, but it cannot correct true design changes; in such cases, the correct remedy is updating the template library (or enforcing recipe-based template selection in fixed-product lines).
- Perspective/projective distortion and nonrigid deformation: the SSIM-gated alignment improves robustness to small global shifts/rotations, but larger viewpoint/perspective changes remain out of scope. When the imaging geometry is not fixture-controlled, residual misregistration can dominate difference/SSIM maps and reduce localization quality.
- Heavy illumination non-uniformity and reflectance drift: normalization and the fused SSIM/difference design reduce sensitivity to global brightness drift; however, strong spatially varying illumination (e.g., vignetting, hotspots, and specular highlights) can still introduce structured responses in the defect-likelihood field and increase false positives.
- ROI-based statistics and border effects: evaluating thresholds and similarity on the central region improves robustness to border artifacts, but defects near the excluded border can have reduced influence on thresholding statistics. If border defects are critical, the ROI margin should be reduced (with the expected trade-off of higher nuisance sensitivity).
- Component-derived boxes are not tight boundaries: detections are produced from thresholded connected components, so bounding boxes are intended for reliable region localization rather than pixel-tight boundaries. This is why AP drops at stricter IoU thresholds (Figure 7); if tighter boxes are required, a lightweight contour-based tightening step can be added without changing the detection ranking.
Finally, this revision does not include trained deep learning baselines; because training-based results can be sensitive to split definition and training/engineering choices, we treat such comparisons as out of scope here and instead report explicit PR/AP/FROC and IoU-sensitivity analyses under a fully specified protocol.
4.5. Future Work
Future work includes the following: (i) automatic threshold recommendation for a specified FP/image budget from the exported FROC curve; (ii) lightweight box tightening to improve IoU without retraining; (iii) broader alignment models (e.g., rigid/affine) while retaining an SSIM-gain acceptance gate; (iv) per-template caching and template-library management for scale; and (v) computational/implementation optimizations (early exits, efficient SSIM/difference computation, downsampling-aware parameter scaling, and fixed-point/embedded-friendly variants) with evaluation on single-board computers or microcontrollers.
5. Conclusions
This work addresses defect–intent ambiguity in PCB AOI by presenting a training-free, reference-based defect localization framework designed for deployments where interpretability and controllable false-alarm rates are critical. The method selects a compatible defect-free reference via coarse-to-fine matching, applies global alignment only when it increases SSIM (to avoid defect-driven over-correction), and forms a defect-likelihood field by fusing SSIM-derived structural dissimilarity with normalized absolute differences; confidence-ranked detections are then produced via connected-component extraction.
To support deployment-oriented decision making, we report precision–recall and FROC curves rather than advocating a single universal threshold. At the adopted operating point, the method achieves 0.9987 recall at 0.149 FP/image, and operating-point metrics are additionally reported using K-fold calibration/test thresholding to avoid selecting thresholds on the same set used for reporting (with a full-set best-F1 threshold retained only as a clearly labeled reference point). Under the adopted box-matching protocol with , average precision reaches 0.984, and AP-versus-IoU sweeps transparently characterize sensitivity to stricter localization requirements. The primary limitation is the need for defect-free templates of the same PCB layout/revision; within this setting, the approach provides a reproducible and auditable alternative to training-based inspection by flagging only statistically and structurally supported deviations for review.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Chin R.T. Harlow C.A. Automated Visual Inspection: A Survey IEEE Trans. Pattern Anal. Mach. Intell.1982 PAMI-455757310.1109/TPAMI.1982.476730922499630 · doi ↗ · pubmed ↗
- 2Moganti M. Ercal F. Dagli C.H. Tsunekawa S. Automatic PCB Inspection Algorithms: A Survey Comput. Vis. Image Underst.19966328731310.1006/cviu.1996.0020 · doi ↗
- 3Peking University Open Lab on Human-Robot Interaction PKU-Market-PCB Dataset Available online: https://robotics.pkusz.edu.cn/resources/dataset/(accessed on 26 January 2026)
- 4Azamfirei V. Psarommatis F. Lagrosen Y. Application of automation for in-line quality inspection, a zero-defect manufacturing approach J. Manuf. Syst.20236712210.1016/j.jmsy.2022.12.010 · doi ↗
- 5Chen X. Wu Y. He X. Ming W. A Comprehensive Review of Deep Learning-Based PCB Defect Detection IEEE Access 20231113901713903810.1109/ACCESS.2023.3339561 · doi ↗
- 6Sankar V.U. Lakshmi G. Sankar Y.S. A Review of Various Defects in PCBJ. Electron. Test.20223848149110.1007/s 10836-022-06026-7 · doi ↗
- 7Kim M. Meander-DGS Effect on Electromagnetic Bandgap Structure for Power/Ground Noise Suppression in High-Speed Integrated Circuit Packages and PC Bs Electronics 20221121110.3390/electronics 11020211 · doi ↗
- 8Ott H.W. Electromagnetic Compatibility Engineering Wiley Hoboken, NJ, USA 2009