HL-Mamba: A High–Low Frequency Interaction Mamba Network for Hyperspectral Image Classification
Yehong Teng, Shu Gan, Xiping Yuan

TL;DR
This paper introduces HL-Mamba, a new neural network for classifying hyperspectral images by combining global structures and edge details in the frequency domain.
Contribution
HL-Mamba introduces a high–low frequency interaction Mamba network with decomposition and cross-frequency modules for improved HSI classification.
Findings
HL-Mamba outperforms eight methods on four datasets with overall accuracies up to 95.28%.
The decomposition module effectively separates global structures and edge details for better feature representation.
Ablation studies confirm the effectiveness of the core components like frequency alignment loss and cross-frequency interaction.
Abstract
Deep-learning-based methods have achieved remarkable success in hyperspectral image (HSI) classification tasks due to their promising ability. However, the high dimensionality and spectral–spatial correlations of HSIs usually lead to information redundancy and feature entanglement, limiting the classification performance. To address these issues, we propose a novel high–low frequency interaction Mamba network, called HL-Mamba, which achieves effective decoupling and interaction between global structures and edge details of HSIs in the frequency domain, thereby improving spectral–spatial representation for HSI classification. Specifically, a high–low frequency decomposition Mamba module is designed to decompose the HSI into low-frequency structural and high-frequency edge detail components, which allows the model to learn global structures and fine-grained details, enhancing…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
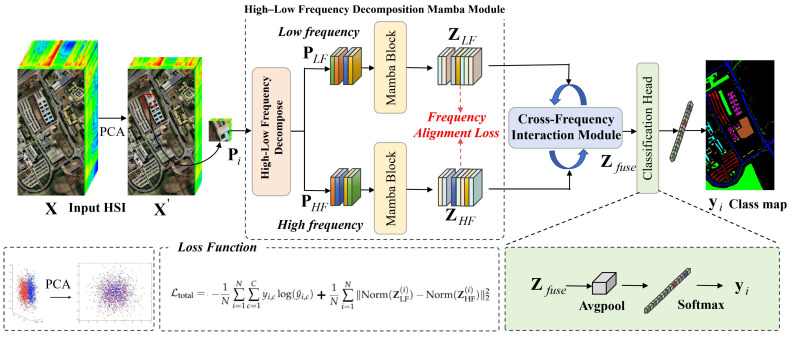 Figure 1
Figure 1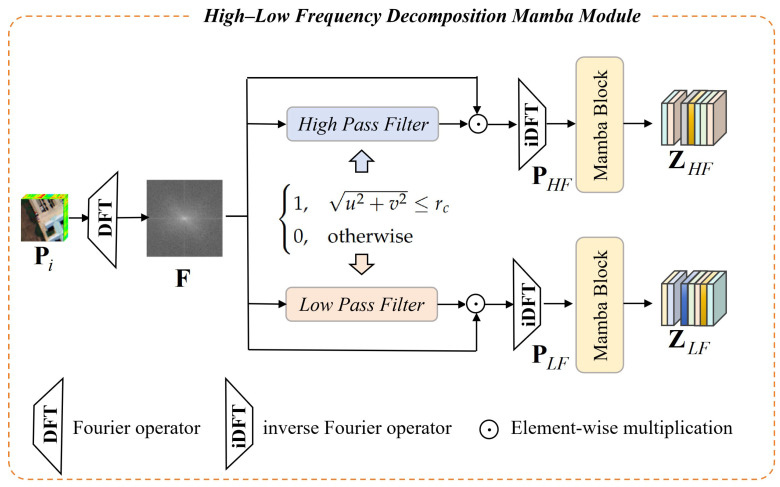 Figure 2
Figure 2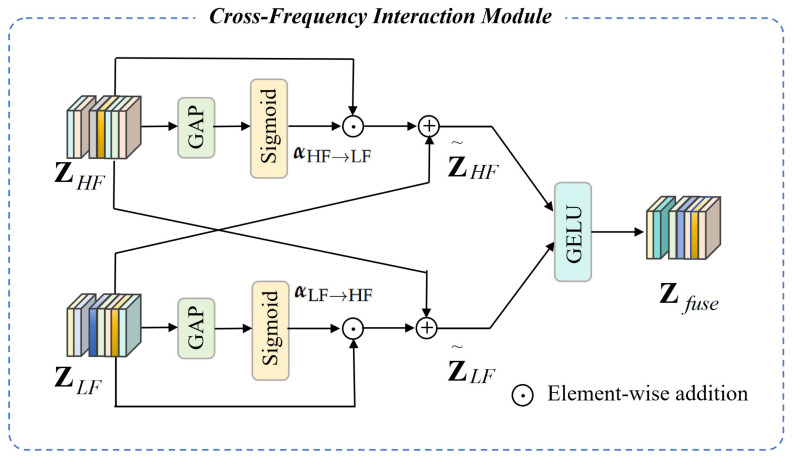 Figure 3
Figure 3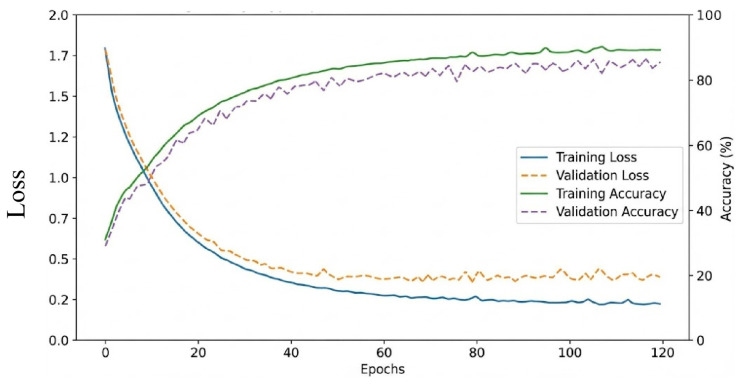 Figure 4
Figure 4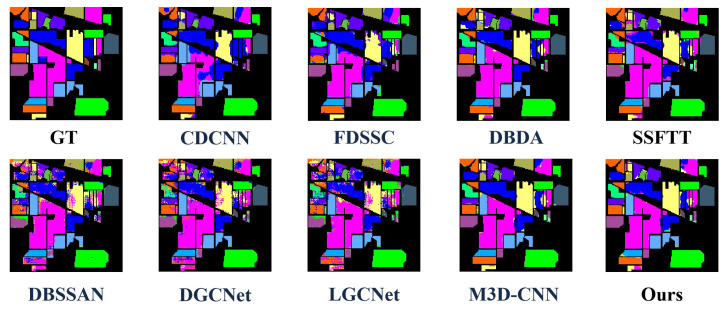 Figure 5
Figure 5 Figure 6
Figure 6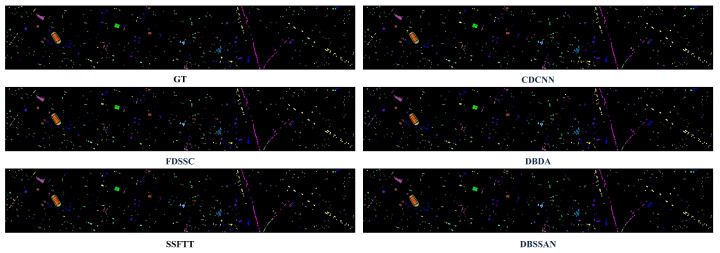 Figure 7
Figure 7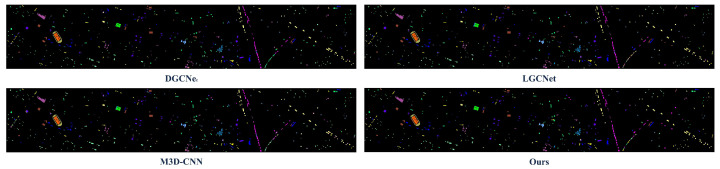 Figure 8
Figure 8 Figure 9
Figure 9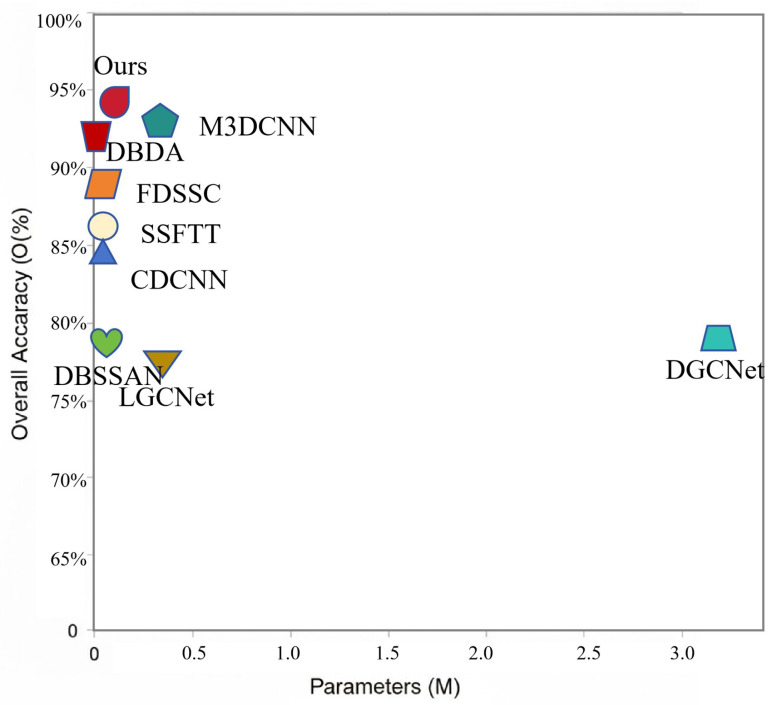 Figure 10
Figure 10- —National Natural Science Foundation of China
- —Kunming University of Science and Technology
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRemote-Sensing Image Classification · Geochemistry and Geologic Mapping · Domain Adaptation and Few-Shot Learning
1. Introduction
Hyperspectral imaging technology has emerged as one of the most significant research topics in remote sensing, as it provides rich spectral and spatial information through hundreds of contiguous spectral bands [1,2]. The remarkable potential of hyperspectral images (HSIs) plays a pivotal role in diverse applications, such as environmental monitoring [3], agricultural management [4], mineral exploration [5], and urban planning [6]. HSI classification serves as the most critical step in many of these applications, aiming to assign a distinct land cover category to each pixel [7].
Over the past decade, numerous methods have been proposed to enhance the performance of HSI classification [8]. Early methods mainly relied on traditional machine learning techniques such as support vector machines [9], k-nearest neighbors [10], and random forests [11], which primarily focused on spectral information. However, these methods often ignored spatial correlations, leading to spectral confusion and classification errors in complex scenes. To mitigate this limitation, spatial–spectral feature extraction methods are introduced, incorporating local spatial context via morphological profiles, Markov random fields [12], or principal component analysis (PCA)-based dimensionality reduction [13]. Nevertheless, these hand-crafted spatial–spectral feature extraction strategies still suffer from limited capability to adaptively capture the complex nonlinear relationships embedded in HSI data.
With the rapid advancements in deep learning, numerous deep-learning-based models have been proposed to improve HSI classification by jointly learning hierarchical spectral–spatial representations, which have shown significant superiority over traditional hand-crafted feature methods [14,15]. Among them, convolutional neural networks (CNNs) have gained significant attention due to their strong ability to capture local spatial–spectral dependencies of HSIs [16]. For instance, 2D CNNs and 3D CNNs are widely employed to learn hierarchical feature representations from pixel values and spectral reflectance sequences [17]. Yang et al. proposed an enhanced multiscale feature fusion network, which extracts multiscale features from parallel multipath structures across three stages to boost classification performance [18]. In addition to CNNs, recurrent neural networks and long short-term memory networks have been applied to HSI data to model sequential dependencies along the spectral dimension, fully leveraging the intrinsic correlation between contiguous spectral bands [19,20,21]. More recently, Transformer-based models, known for their powerful self-attention mechanisms, have also been adapted for HSI classification, achieving promising results by capturing long-range dependencies between spectral bands and spatial regions [22,23]. For example, Yang et al. proposed a center-to-surrounding interactive learning network via integrating Transformer architecture for more effective spectral–spatial feature learning [24]. However, the self-attention mechanism in standard Transformers incurs a quadratic computational complexity with the number of pixels, resulting in substantial computational redundancy and limiting its efficiency in processing HSI data.
To alleviate the above computational redundancy issue, subsequent studies have explored a series of efficient model designs, including CNN variants with depthwise separable convolutions [25], compact RNN architectures with gated mechanisms, and improved Transformer models with sparse attention or linear attention [26]. These methods reduce computational overhead for HSI classification tasks, enabling efficient processing of high-dimensional HSI data [27]. Meanwhile, state space models (SSMs) represented by Mamba have also been introduced into HSI classification recently, due to their linear computational complexity and efficient long-range dependency modeling capability. For instance, Wang et al. proposed MambaHSI+, a framework that integrates bidirectional state-space modeling with spectral trajectory learning for HSI classification [28]. Liu et al. proposed a dual-classification-head self-training network that performs class-wise feature alignment across domains, achieving strong cross-domain classification performance [29]. Despite their success in efficiency and accuracy, these deep-learning-based methods still face nonnegligible limitations. They rely on complex network architectures and large-scale training data, and more importantly, they inherently entangle global structural features with fine-grained edge details in the feature learning process, leading to redundant and suboptimal feature representations, and making it difficult to simultaneously capture both global structural information and local fine-grained textures.
To address the feature entanglement between global structure and local details, frequency-based methods have recently emerged as a promising paradigm for HSI classification, by explicitly decomposing HSI data into different frequency components corresponding to structural and detail information, respectively [30]. Early attempts at frequency-based analysis for HSI classification mainly adopted Fourier transform and wavelet transform to decompose HSI into multiresolution frequency components, enabling multiscale feature extraction [31]. Wavelet-based methods have shown unique advantages in handling the high dimensionality of HSIs, as they support the decomposition of spectral and spatial features at different scales [32]. However, these methods typically rely on hand-crafted frequency decomposition and feature extraction strategies, which may limit their generalization and performance when dealing with complex and diverse HSI datasets. To overcome this limitation, recent studies have combined deep learning techniques with frequency-domain representations, integrating frequency decomposition into end-to-end networks [33]. These frequency-based deep learning models take the decomposed frequency components as part of the input to CNNs, enabling the model to learn discriminative frequency-domain representations in an end-to-end manner [34], and have achieved significant improvements in classification accuracy [35]. For example, Yang et al. proposed the ITER method for weakly supervised HSI classification, which employs a high-frequency-aware self-attention in a high-enhanced transformer to refine detailed feature representation for pixel-level prediction [36]. However, a critical limitation of existing frequency-based methods is the lack of effective interaction between different frequency components, failing to fully exploit the complementary properties of high- and low-frequency features.
To address aforementioned core challenges of computational redundancy, feature entanglement between global structure and local details, and insufficient cross-frequency interaction in existing methods, we propose a high–low frequency interaction Mamba network (HL-Mamba) framework, tailored for HSI classification. This framework innovatively integrates frequency-domain feature decoupling with the efficient long-range modeling capability of Mamba to tackle the core pain points in HSI classification. First, a high–low frequency decomposition Mamba module is designed to decompose HSI into low-frequency structural and high-frequency detail components. The low-frequency branch efficiently captures long-range dependencies in global structures, while the high-frequency branch focuses on modeling fine-grained textures and edges. This frequency-wise separation manner enables the network to learn complementary features without mutual interference between global structural and edge details. Furthermore, a dynamic cross-frequency interaction module is proposed to establish bidirectional information flow. Thus, low-frequency structural features guide high-frequency detail aggregation, while high-frequency textures refine global structural representations, yielding more discriminative spectral–spatial features for HSI classification. To enhance feature consistency, and complementarity, a frequency alignment loss is designed, enhancing the classification performance. The main contributions of this article can be summarized as follows:
- 1.A high–low frequency interaction Mamba network is proposed, which innovatively integrates frequency-domain feature decoupling with the efficient long-range modeling capability of Mamba to tackle the core issues of feature entanglement and computational redundancy in HSI classification.
- 2.A dynamic cross-frequency interaction module is designed, where low-frequency structural features guide aggregation of discriminative high-frequency details and high-frequency textures refine global structural representations, yielding more discriminative spectral–spatial features for HSI classification.
- 3.A frequency alignment loss is designed to constrain the consistency and complementarity of distribution between the high- and low-frequency components, further enhancing the discriminability of classification.
2. Materials and Methods
2.1. Dataset Description
Four benchmark datasets are selected to ensure experimental diversity across different sensors. The detailed number of training and testing samples is summarized in Table 1.
1.Indian Pines dataset [37]: Captured over northwestern Indiana, USA, this dataset has a spatial resolution of 20 m and 220 spectral bands. The spatial size of image is 145 × 145 pixels, containing 16 land-cover classes dominated by agricultural crops (e.g., corn, soybean), forests, and low-density residential areas. The strong spectral similarity between corn, soybean, and grass species poses a significant challenge for HSI classification.2.Pavia University dataset [38]: Acquired by the ROSIS sensor over Pavia, Italy, this dataset features a high spatial resolution of 1.3 m and 103 spectral bands. A spatial size of 610 × 340 pixels and 9 urban surface classes (e.g., asphalt, meadows, bare soil, self-blocking bricks), it is ideal for evaluating the fine-grained spatial discrimination capability of models due to its rich spatial details.3.Houston dataset [39]: Released by the IEEE GRSS Data Fusion Contest 2013, this dataset includes 349 × 1905 pixels and 144 spectral bands, covering 15 complex urban and suburban classes (e.g., roads, parking lots, vegetation, buildings). High intra-class variability and mixed pixels caused by shadows and structural occlusions make it a challenging benchmark for urban HSI classification.4.WHU-Hi-HanChuan dataset [40]: A large-scale dataset captured by the Wuhan University airborne hyperspectral sensor over Hanchuan, China. It covers 1100 × 5100 pixels with 270 spectral bands and a fine spatial resolution of 1 m. The 16 land-cover categories include agricultural crops (strawberry, soybean, sorghum), vegetation, water bodies, and built-up areas. The vast scene size and high spectral diversity enable a rigorous test of the model’s generalization to real-world scenarios.
2.2. Data Processing Methods
To ensure fair comparison with HSI classification methods, we adopt the widely accepted training–test split protocols consistent with mainstream works for the four datasets, randomly selecting a fixed proportion of labeled samples per land cover category as the training set and using remaining labeled samples as the independent test set, with the random seed fixed throughout the splitting process to guarantee result reproducibility and avoid data leakage. For data preprocessing, we first perform per-band min–max normalization on raw HSI data to map reflectance values to the range of [0, 1]. We then apply PCA with the transformation matrix fitted only on the training set. To construct standardized model inputs, we adopt a center-pixel neighborhood cropping strategy with a uniform spatial window size of for all datasets to balance local spatial context capture and computational efficiency, and use padding for edge pixels to supplement missing neighborhood information and ensure valid input patches for all pixels without introducing extra noise.
3. Proposed Method
In this section, the details of the HL-Mamba are presented. The core idea is to separate HSI into low-frequency and high-frequency components, enabling complementary feature learning via the Mamba network. A cross-frequency interaction module is also designed for feature interaction and learning.
3.1. Mamba: State Space Model for Sequence Modeling
Mamba, a novel state space mode proposed for sequence modeling, has recently shown remarkable superiority in processing long-range sequential data due to its linear computational complexity ( ) and efficient state propagation mechanism [28]. Different from traditional transformer-based architectures relying on self-attention, Mamba captures temporal and spatial dependencies by modeling the evolution of hidden states through a continuous-time SSM, which is particularly suitable for HSI classification tasks where spectral–spatial features exhibit sequential characteristics along spectral bands.
The core of Mamba is the discrete-time state space update, defined as:
where denotes the hidden state at position t, is the input feature, represents the output, and , , , are learnable parameter matrices. To adapt to HSI’s multidirectional feature propagation, the diagonalized version of (denoted as ) is adopted to accelerate computation, leading to the simplified inference formula:
where denotes element-wise exponential operation and converts a vector to a diagonal matrix. This design enables Mamba to efficiently model the long spectral sequences of HSI pixels while maintaining low computational cost, making it a promising backbone for HSI classification.
3.2. Overall Framework
HSI classification faces two core challenges, i.e., spectral–spatial feature entanglement and computational redundancy in long-range dependency modeling. Traditional HSI classification methods mainly rely on convolutions or self-attention mechanisms for feature learning [17,23]. However, convolutions are limited in capturing long-range dependences, while self-attention suffers from quadratic computational complexity. In addition, these methods treat the spectral–spatial features of HSIs as spatial domain, ignoring the inherent frequency properties of HSIs. Different frequency components preserve sharp edges and global structural features that are crucial for distinguishing similar classes. To address the above issues, an HL-Mamba is proposed (Figure 1). It integrates frequency-domain decomposition and long-range modeling of Mamba to explicitly process high- and low-frequency features. This reduces feature entanglement and computational redundancy, while boosting the discriminability of spectral–spatial representations for HSI classification.
Given an input HSI cube , where H, W, and B denote the spatial height, width, and number of spectral bands, respectively, we first apply principal component analysis (PCA) [41] to reduce spectral redundancy and preserve the most informative bands:
where represents the reduced spectral dimension.
For pixel-wise HSI classification, 3D patches centered at each pixel are extracted as input samples:
where K denotes the spatial window size and is the local spatial–spectral cube of the i-th sample.
Each patch is processed by the proposed HL-Mamba, whose core components include a high–low frequency decomposition Mamba module, a cross-frequency interaction module, and a classification head. The overall forward process is defined as:
where and denote the low- and high-frequency feature extraction branches, represents the cross-frequency interaction module, and is the final classification head output with C classes corresponding to the number of land-cover types.
This framework achieves frequency decomposition, long-range feature modeling, and adaptive interaction, ensuring that the model can simultaneously capture fine-grained edge features and global structural information, thus achieving high-precision HSI classification.
3.3. High–Low Frequency Decomposition Mamba Module
HSI contains rich but redundant spectral–spatial information, and directly feeding deep networks leads to entangled feature learning. Moreover, the complex spatial–spectral correlation in HSI requires the model to have strong long-range dependency modeling capabilities, but traditional methods (convolutions or self-attention) are difficult to balance modeling effectiveness and computational redundancy. To address these problems, a high–low frequency decomposition Mamba module is designed (Figure 2), which first explicitly disentangles HSI to global structural representations and fine-grained texture representations, and then employs two parallel Mamba branches to model long-range dependencies under different frequency components.
Given a patch , we perform a 2D discrete Fourier transform (DFT) along the spatial dimensions to convert the spatial domain information into the frequency domain:
where is the DFT operator. In the frequency domain, each spatial frequency component corresponds to different levels of spatial variation and structural smoothness. Low-frequency components are distributed in the central region, corresponding to smooth global structures and semantic information, while high-frequency components are distributed in the peripheral region, corresponding to sharp edges and local texture details.
To accurately separate high- and low-frequency components, we define two complementary frequency masks based on the distance from the frequency domain center:
where denotes the cutoff radius determining the low–high frequency boundary, which is a learnable hyperparameter adjusted according to different HSI datasets.
The high- and low-frequency components in the frequency domain are reconstructed back to the spatial domain via inverse DFT to facilitate subsequent feature extraction and modeling:
where ⊙ is element-wise multiplication. and , respectively, represent the low-frequency structural component and high-frequency detail component of the original patch.
To fully capture the distinct characteristics of different frequency components, each frequency component is fed into an independent Mamba network for long-range dependency modeling and feature enhancement:
where and are the low-frequency structural feature map and high-frequency detail feature map, respectively. D is the channel dimension after Mamba network.
The Mamba architecture, based on selective state-space modeling, efficiently captures long-range dependencies with linear complexity. Compared with Transformer-based models, Mamba reduces computational costs, allowing better feature representation for HSI classification.
3.4. Cross-Frequency Interaction Module
Although low-frequency and high-frequency branches capture complementary information, processing them independently may lead to insufficient representation. To address this, a cross-frequency interaction module is designed that enables bidirectional information exchange and adaptive feature fusion (Figure 3).
We first summarize global information from each branch using global average pooling (GAP) and project it through linear layers:
where denotes the sigmoid activation function, and are learnable projection matrices, and represents the global average pooling operation. measures the contribution of low-frequency structural features to high-frequency detail feature enhancement, and measures the contribution of high-frequency texture features to low-frequency structural feature refinement.
Based on the generated dynamic attention weights, adaptive feature enhancement on each frequency branch is performed to achieve bidirectional information interaction:
After bidirectional enhancement, the two frequency feature maps are concatenated and project them through a fusion layer to generate the final integrated spectral–spatial feature map:
where denotes concatenation, represents a GELU activation, and is a learnable fusion matrix. The GELU activation is mathematically defined as:
where is the cumulative distribution function of the standard normal distribution, and erf denotes the Gaussian error function. Unlike traditional piecewise activation functions (e.g., ReLU), GELU introduces soft stochasticity by weighting input values based on their probability of being active, which effectively alleviates overfitting and improves the generalization ability of deep learning models fo feature learning.
Finally, the integrated feature map is input into the classification head to obtain the final classification prediction. The classification head consists of a global average pooling layer, a fully connected layer, and a softmax activation function:
where is the global average pooling operation and and are the weight matrix and bias vector of the fully connected layer, respectively. To avoid noise addition during cross-frequency interaction, we adopt the dynamic attention weights generated by global average pooling which can adaptively weight the contribution of different frequency features, reducing the impact of noise. In addition, the GELU activation function in the fusion layer has a slight regularization effect, suppressing the propagation of noise components.
3.5. Frequency Alignment Loss
Although the cross-frequency interaction module promotes information exchange between high- and low-frequency features, during the training process, the two frequency branches may still converge to disjoint feature subspaces due to differences in the characteristics of the structural and texture features. To address this issue, a frequency alignment loss function is designed to explicitly constrain the distribution consistency and feature complementarity between high- and low-frequency features.
The total loss function of the HL-Mamba is a weighted combination of the cross-entropy loss ( ) and the frequency alignment loss ( ). Among them, the cross-entropy loss is used to supervise the classification performance of model, ensuring that the integrated features can accurately distinguish different land-cover classes:
where N is the number of training samples and and denote the ground truth label and predicted probability of the i-th sample for the c-th class, respectively.
The frequency alignment loss is designed to constrain the distribution consistency of high- and low-frequency features. We first normalize the high- and low-frequency feature maps to eliminate the impact of different feature scales, then calculate the L2 distance between the normalized features, and finally take the average of all samples as the alignment loss:
where denotes the normalization operation and and are the low-frequency and high-frequency feature maps of the i-th sample, respectively. Minimizing this loss can force the high- and low-frequency features to be distributed in similar subspaces, ensuring semantic consistency, while the differences in features are retained to maintain complementarity.
The total loss function of the network is defined as:
where is a hyperparameter controlling the balance between the classification accuracy and the inter-frequency feature coherence. Through experiments, we set to ensure that the frequency alignment loss can effectively promote feature consistency without compromising the classification performance.
4. Results
4.1. Experimental Setup
All experiments are implemented using PyTorch 2.2 and are conducted on a NVIDIA RTX 4090 GPU. The Adam optimizer is used for model training with an initial learning rate of and a batch size of 64. During data preprocessing, PCA is used to reduce the spectral dimension to 30 to preserve key spectral information while reducing redundancy. The network depth is configured as three Mamba modules, with a total of six Mamba modules for feature extraction in the dual branches. The loss weight in the total loss function is adjusted through experiments, and the value was set to 0.2. The training curves of the Indian Pines dataset are shown in Figure 4. All models are trained for a maximum of 100 epochs, and the model with the highest validation accuracy is selected for testing.
4.2. Evaluation Metrics
Three metrics are used to quantitatively evaluate the classification performance, i.e., overall accuracy (OA), average accuracy (AA), and Kappa coefficient. OA measures the global classification performance as the ratio of correctly classified pixels to the total number of pixels, which is mathematically defined as:
where C denotes the total number of land cover categories, represents the number of pixels correctly classified into class i, and is the number of pixels belonging to class i but predicted as class j. AA addresses category imbalance by calculating the arithmetic mean of class-wise accuracies, reflecting the model’s ability to classify each category evenly. Its formulation is given by:
The Kappa coefficient is a robust metric that evaluates the agreement between predicted results and ground truth while eliminating the impact of random classification, providing a more reliable assessment beyond mere chance. It is calculated as:
where is the expected accuracy due to random chance, and is the total number of test pixels.
4.3. Performance Comparison
To further validate the performance of HL-Mamba, we compare it with eight HSI classification methods, including CNN-based methods (CDCNN [42], FDSSC [43], M3D-CNN [44], DGCNet [45], LGCNet [46]) and spectral–spatial feature fusion methods (DBDA [47], DBSSAN [48], SSFTT [22]). The quantitative results on the four datasets are summarized in Table 2, Table 3, Table 4 and Table 5, and the qualitative classification maps are shown in Figure 5, Figure 6, Figure 7 and Figure 8. The optimal values for OA, AA, and Kappa are indicated in bold. The second-best values are indicated with double underlines, and the third-best values are indicated with a single underline.
4.3.1. Quantitative Results and Analysis
1.Indian Pines Dataset: As shown in Table 2, HL-Mamba achieves the highest OA (94.07%), AA (90.40%), and Kappa (93.25%) among all compared methods. Compared with the second-best method DBDA (OA = 93.44%), HL-Mamba improves OA by 0.63%. The key reason is that the high–low frequency decomposition effectively separates the global structure and edge details of crops, and the cross-frequency interaction module enhances the discriminability of spectrally similar classes (e.g., Alfalfa and Oats), which is difficult for comparison methods to achieve. Notably, HL-Mamba shows significant advantages in class-level accuracy for challenging classes with high spectral similarity. For example, the accuracy of Alfalfa (a minority class) reaches 53.78%, which is 2.45% higher than DBDA (51.33%) and far superior to CDCNN (0.89%) and FDSSC (24.00%). For Oats, HL-Mamba achieves 79.47% accuracy, outperforming M3DCNN (78.42%) and DBDA (73.16%). This indicates that the frequency-aware feature learning of HL-Mamba effectively enhances the discrimination of spectrally similar classes.2.Pavia University Dataset: Table 3 presents the quantitative results of HL-Mamba and comparison methods on the Pavia University dataset. This dataset is characterized by high resolution and large samples for most classes, which demands models to effectively capture fine-grained spatial details in processing large-scale data. HL-Mamba achieves the highest AA of 90.66% and Kappa of 91.79%. In terms of class-level accuracy, HL-Mamba shows remarkable performance in classes with similar spatial textures and spectral properties. For example, the Asphalt and Bitumen classes, which are easily misclassified due to their similar gray-scale textures in spatial images, HL-Mamba achieves accuracies of 90.82% and 95.18%, respectively. For the Shadows class, a typical low-frequency structural class with large intra-class variability, HL-Mamba achieves an accuracy of 82.72%. This advantage comes from the low-frequency branch’s efficient modeling of global structural context, which accurately identifies shadow regions. For the high-resolution urban scene of Pavia University, the key advantage lies in the HLFDMM’s ability to capture fine-grained spatial details (via high-frequency branch) and global structural consistency (via low-frequency branch). For example, the Asphalt class (easily confused with Bitumen due to similar gray textures) achieves 90.82% accuracy, and the Shadows class (with large intra-class variability) reaches 82.72% accuracy, far higher than M3DCNN’s 63.55%. This is because the low-frequency branch models the global context of shadow regions, while the cross-frequency interaction module refines edge details of urban structures, effectively mitigating misclassification caused by spatial similarity.3.Houston Dataset: The Houston dataset is a challenging urban hyperspectral dataset with complex mixed pixels, shadows, and occlusions, requiring models to extract spectral–spatial feature better. As shown in Table 4, HL-Mamba achieves the highest OA of 87.32%, AA of 88.18%, and Kappa of 86.29%. The dataset’s challenges (mixed pixels, shadows, occlusions) are addressed by the synergy of CFIM and FAL: for the Commercial class (affected by high-rise building shadows), HL-Mamba’s accuracy (63.68%) is 3.45% higher than DBDA (60.23%); for the Parking Lot 2 class (small-scale and easily mixed with roads), accuracy reaches 86.90%, outperforming the second-best FDSSC (80.80%). The FAL enhances feature invariance to illumination variations, while the CFIM fuses structural (low-frequency) and texture (high-frequency) features, making the model robust to urban interference factors. For classes affected by shadows and occlusions, such as Commercial and Railway, HL-Mamba shows significant advantages. The Commercial class, which is often misclassified due to the shadow of high-rise buildings, achieves an accuracy of 63.38% with HL-Mamba, 3.45% higher than DBDA (92.48%). This is because the frequency alignment loss enhances the invariance of features to illumination variations, making the model less sensitive to shadow-induced spectral distortions.4.WHU-Hi-HanChuan Dataset: As a large-scale agricultural and suburban hyperspectral dataset, WHU-Hi-HanChuan features a vast scene size and high spectral diversity, testing the model’s performance. Table 5 presents the quantitative results, where HL-Mamba achieves the highest OA of 95.28%, AA of 89.81%, and Kappa of 94.47%, outperforming the second-ranked M3DCNN (OA = 94.26%, Kappa = 993.28%). For crop classes with overlapping spectral bands (e.g., Soybean and Sorghum), HL-Mamba achieves 92.70% and 97.42% accuracy, respectively, benefiting from HLFDMM’s effective decomposition of spectral–spatial features. For the Water-spinach class (a minority crop with sparse samples), accuracy reaches 85.78%, 15.31% higher than DBDA (70.75%), as the cross-frequency interaction module aggregates discriminative details from high-frequency features, compensating for the lack of training samples. For agricultural crop classes with similar spectral characteristics, such as Soybean and Sorghum, HL-Mamba achieves accuracies of 97.42% and 85.78%, respectively. This demonstrates that the frequency-aware feature learning effectively extracts discriminative spectral features from overlapping spectral bands of different crops.
4.3.2. Visualization Results and Analysis
Figure 5, Figure 6, Figure 7 and Figure 8 illustrate classification maps generated by the proposed method and baselines. Visually, the proposed method yields smoother boundaries and fewer misclassified pixels, especially along class edges and shadowed regions. The high-frequency branch captures subtle texture transitions, while the low-frequency branch preserves large-area semantic consistency. The resulting maps exhibit clear object details.
1.Indian Pines Dataset: Qualitatively, Figure 5 visualizes the classification maps of HL-Mamba and comparison methods on the Indian Pines dataset, which is dominated by agricultural land cover with similar crop types. The classification map of the HL-Mamba exhibits sharp edge details across the entire scene. In contrast, CDCNN and FDSSC suffer from severe salt-and-pepper noise in minority class regions, and their classification results show blurred boundaries between Oats and surrounding grassland classes. For the Grass-pasture-mowed class, a sparse category prone to misclassification, HL-Mamba clearly demarcates its distribution with minimal pixel confusion. This visual superiority stems from the CFIM and frequency-aware feature learning of HL-Mamba. The high-frequency branch captures fine texture differences between similar crops, while the low-frequency branch anchors the global structural distribution of sparse classes.2.Pavia University: Qualitatively, the classification map of HL-Mamba (Figure 6) shows clear edge details and minimal misclassification noise compared to other methods. For instance, in the buildings, HL-Mamba accurately distinguishes the classes with no obvious mixed pixels, while CDCNN and FDSSC exhibit slight misclassification in these edge regions. Additionally, HL-Mamba effectively suppresses the “salt-and-pepper” noise in the classification map of the Gravel class, which is attributed to the CFIM integration of global and local features, enhancing the spatial consistency of classification results.3.Houston Dataset: Figure 7 presents the qualitative classification results on the Houston dataset, a complex urban scene with mixed pixels. The classification map of HL-Mamba accurately delineates the boundaries of distinct urban functional areas, with no obvious mixed pixels in the transition zones. For shadow-affected regions, HL-Mamba maintains consistent classification accuracy without spectral distortion-induced misclassification, while DBDA and M3DCNN show scattered misclassified pixels in these shadowed areas. Notably, HL-Mamba precisely identifies small-scale high-texture objects embedded in complex urban landscapes, with clear and complete details of their shapes. Additionally, for the Healthy grass and Stressed grass classes with high intra-class variability, HL-Mamba’s classification map shows smooth spatial transitions between the two grass types, reflecting the effective fusion of global structure and local details via the CFIM.4.WHU-Hi-HanChuan Dataset: Qualitatively, Figure 8 shows that HL-Mamba’s classification map accurately captures the large-scale distribution of agricultural crops and urban areas, with no obvious misclassification in the transition zones between Strawberry fields and Soybean fields. Compared to CDCNN and FDSSC, HL-Mamba’s classification map has better spatial continuity, especially in the Water class, where the boundaries of water bodies are clearly delineated without being affected by surrounding vegetation shadows. This confirms that HL-Mamba is well-suited for large-scale HSI classification tasks.
4.3.3. Computational Complexity
To evaluate the efficiency of HL-Mamba, we analyzed its model parameters, computational complexity (FLOPs), and test time on the Indian Pines dataset and compared them with eight methods under the same hardware platform. As shown in Table 6, HL-Mamba achieves an excellent balance between classification performance and model efficiency. The visualization results of the number of parameters and the of OA for each method in the Indian Pines dataset are shown in Figure 9. It has a compact parameter count of 0.2957 M, a low FLOP count of 0.0354 G, and a fast average test time of 0.2934 s, which demonstrates its lightweight and high-efficiency characteristics for HSI classification. Compared with other methods, HL-Mamba shows obvious advantages in reducing computational overhead and accelerating inference. HL-Mamba significantly reduces both model parameters and inference latency, which benefits from the linear-complexity Mamba backbone, frequency decomposition-based redundant computation reduction, and a lightweight cross-frequency interaction mechanism. Although slightly higher in parameters and FLOPs than some extremely lightweight methods (e.g., DBDA with 0.0389 M parameters, M3DCNN with 0.0095 G FLOPs), HL-Mamba outperforms these methods by a large margin in classification accuracy (OA) on the Indian Pines dataset, which verifies its trade-off of performance and efficiency.
5. Discussion
To validate the effectiveness of key components in HL-Mamba and the influence of critical hyperparameters, we carried out ablation experiments on the Indian Pines dataset. The Indian Pines dataset was selected due to its high class diversity and spectral similarity challenges, which can effectively highlight the performance of model. Two sets of ablation experiments were designed. The first was a sensitivity analysis of hyperparameter and the number of Mamba modules. The second was module ablation. These experiments aimed to validate the contributions of the high–low frequency decomposition Mamba module (HLFDMM), CFIM, and frequency alignment loss (FAL).
5.1. Sensitivity Analysis of Hyperparameter
To investigate the sensitivity of the model’s classification performance to the number of Mamba modules, experiments were conducted with the number of Mamba modules set to 2, 3, 4, and 5, respectively. The results are presented in Table 7. It can be observed that the classification metrics exhibit a trend of first increasing and then decreasing with the increase in the number of Mamba modules. When the number of Mamba modules is 3, the model achieves the optimal performance, with OA reaching 94.07%, AA 90.40%, and Kappa 93.25%. This indicates that an appropriate increase in the number of Mamba modules can enhance the model’s ability, thereby improving HSI classification accuracy. However, when the number of modules exceeds 3, all metrics show a decline. This phenomenon may be attributed to the excessive complexity of the model caused by redundant Mamba modules, leading to overfitting and a reduction in feature representation efficiency. Therefore, the optimal number of Mamba modules for the proposed model is determined to be 3.
The loss weight balances the classification loss and the frequency alignment loss . To determine the optimal , experiments are conducted with varying from 0 to 0.6 at intervals of 0.1. The results are summarized in Table 8. When (i.e., no frequency alignment loss), the OA is 92.86%, AA is 88.57%, and Kappa is 91.85%. With the increase of from 0 to 0.2, all metrics gradually improve, reaching the highest performance (OA = 94.07%, AA = 90.40%, Kappa = 93.25%) at . This indicates that the frequency alignment loss effectively enhances the consistency and complementarity between high- and low-frequency features, thereby improving HSI classification performance. However, when exceeds 0.2, the metrics begin to decrease. For example, when , OA drops to 92.53%, which is lower than the result at . This is because a large over-constrains the feature distribution of the two frequency branches, leading to the loss of complementary details between high- and low-frequency features. Thus, setting achieves the optimal balance between classification accuracy and inter-frequency feature.
5.2. Module Ablation
To validate the contributions of the high–low frequency decomposition Mamba module (HLFDMM), CFIM, and frequency alignment loss (FAL), module ablation experiments were conducted, as shown in Table 9. The baseline model without any of the three modules achieves an OA of 89.25%, AA of 84.11%, and Kappa of 87.98%. Specifically, enabling only HLFDMM yields the most significant standalone performance improvement (OA = 92.86%), confirming its core role in decomposing HSIs into discriminative high–low frequency features to capture global structures and fine-grained details. In contrast, enabling only CFIM improves OA to 90.18% by facilitating cross-frequency feature interaction, while enabling only FAL raises OA to 89.76% by aligning feature distributions across frequency branches; both exhibit limited standalone gains because CFIM merely establishes interaction without relying on effective frequency decomposition and FAL lacks the support of decoupled high–low frequency features. Furthermore, among dual-module combinations, the HLFDMM + CFIM configuration performs best (OA = 93.69%), as CFIM can fully exploit the discriminative value of HLFDMM-decomposed features to enhance inter-frequency complementarity, while the HLFDMM + FAL combination also delivers solid results (OA = 93.24%) by integrating decomposition and alignment. Notably, activating all three modules achieves the optimal performance (OA = 94.07%, AA = 90.40%, Kappa = 93.25%), demonstrating that only when combined with HLFDMM, whose frequency decomposition lays the foundation for discriminative feature learning, can CFIM fully leverage the complementary advantages of different frequency features and FAL effectively enhance the consistency of decoupled features, ultimately achieving synergistic performance improvement in HSI classification.
5.3. Limitations
Despite the promising performance of the proposed HL-Mamba model demonstrated by the above experiments, it still has limitations. The frequency decomposition strategy adopted in HLFDMM is fixed, and it lacks adaptability to different types of ground objects in HSIs, which may restrict the model’s ability to capture task-specific frequency features.
6. Conclusions
This study makes three key contributions that integrate frequency-domain decomposition and Mamba to effectively address feature entanglement and computational redundancy, designing a CFIM to achieve bidirectional information complementation between high- and low-frequency features, and designing an FAL to enhance feature consistency. Specifically, by decomposing HSI into complementary low-frequency structural components and high-frequency edge detail components, and employing parallel Mamba branches to model different frequency component, the proposed method mitigates the problems of feature entanglement and information redundancy. Furthermore, through the bidirectional information flow between different frequency features established by the cross-frequency interaction module, and the consistency enhancement of frequency-domain features by the frequency alignment loss, HL-Mamba is able to learn more discriminative spectral–spatial representations and significantly enhance the HSI classification capability. Extensive experiments conducted on four public benchmark datasets demonstrate that the proposed HL-Mamba consistently achieves state-of-the-art classification performance while maintaining high computational efficiency, benefiting from the linear-complexity Mamba backbone and lightweight cross-frequency interaction module. Ablation studies and visualization analyses further confirm the effectiveness of each core component of the overall framework. Future research will focus on developing adaptive frequency separation schemes, exploring multi-scale frequency fusion, and extending the model to large-scale or real-time remote sensing applications.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Yang X. Cao W. Lu Y. Zhou Y. Hyperspectral image transformer classification networks IEEE Trans. Geosci. Remote Sens.202260552871510.1109/TGRS.2022.3171551 · doi ↗
- 2Ahmad M. Ghous U. Usama M. Mazzara M. Wave Former: Spectral–spatial wavelet transformer for hyperspectral image classification IEEE Geosci. Remote Sens. Lett.202421550240510.1109/LGRS.2024.3353909 · doi ↗
- 3Rajabi R. Zehtabian A. Singh K.D. Tabatabaeenejad A. Ghamisi P. Homayouni S. Hyperspectral imaging in environmental monitoring and analysis Front. Environ. Sci.202411135344710.3389/fenvs.2023.1353447 · doi ↗
- 4Avola G. Matese A. Riggi E. An overview of the special issue on “precision agriculture using hyperspectral images”Remote Sens.202315191710.3390/rs 15071917 · doi ↗
- 5Booysen R. Lorenz S. Thiele S.T. Fuchsloch W.C. Marais T. Nex P.A.M. Gloaguen R. Accurate hyperspectral imaging of mineralised outcrops: An example from lithium-bearing pegmatites at Uis, Namibia Remote Sens. Environ.202226911279010.1016/j.rse.2021.112790 · doi ↗
- 6Yuan J. Wang S. Wu C. Xu Y. Fine-grained classification of urban functional zones and landscape pattern analysis using hyperspectral satellite imagery: A case study of Wuhan IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens.2022153972399110.1109/JSTARS.2022.3174412 · doi ↗
- 7Mei S. Song C. Ma M. Xu F. Hyperspectral image classification using group-aware hierarchical transformer IEEE Trans. Geosci. Remote Sens.202260553901410.1109/TGRS.2022.3207933 · doi ↗
- 8He L. Li J. Liu C. Li S. Recent advances on spectral–spatial hyperspectral image classification: An overview and new guidelines IEEE Trans. Geosci. Remote Sens.2017561579159710.1109/TGRS.2017.2765364 · doi ↗