Real-Time Pose Measurement Framework of Wind Tunnel Aircraft Models Based on a Monocular Time-of-Flight Camera
Jianqiang Huang, Cui Liang, Shuai Zhao, Tengchao Huang

TL;DR
This paper introduces a real-time, high-precision pose measurement system for wind tunnel aircraft models using a monocular Time-of-Flight camera.
Contribution
A novel framework combining global and local registration techniques for accurate and efficient pose estimation in wind tunnel experiments.
Findings
The proposed method achieves single-axis rotation angle errors below 0.03° at over 40 FPS.
The framework reduces rotation angle errors by 9% to 39% compared to existing global registration methods.
The study reveals an 'axis-sensitivity' phenomenon in monocular ToF-based pose estimation.
Abstract
Precise and real-time acquisition of aircraft model attitude is fundamental for aerodynamic analysis in wind tunnel experiments, yet achieving high-precision non-contact measurement remains a significant challenge. To address this, this paper proposes a pose measurement framework based on a monocular Time-of-Flight (ToF) camera that fuses keyframe global registration with non-keyframe local registration. First, a novel hand-crafted local feature based on three-plane encoded height and density is introduced. When combined with the Two-stage Consensus Filtering RANSAC (TCF-RANSAC) algorithm, this feature achieves robust global registration of keyframes, providing reliable initial pose estimates for the system. Subsequently, leveraging the continuity constraint of model motion, fast incremental local registration of non-keyframes is performed using the Generalized Iterative Closest Point…
Click any figure to enlarge with its caption.
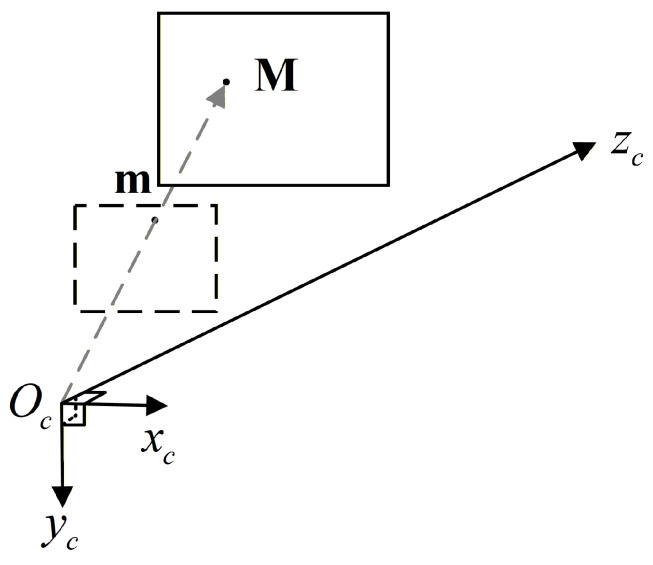 Figure 1
Figure 1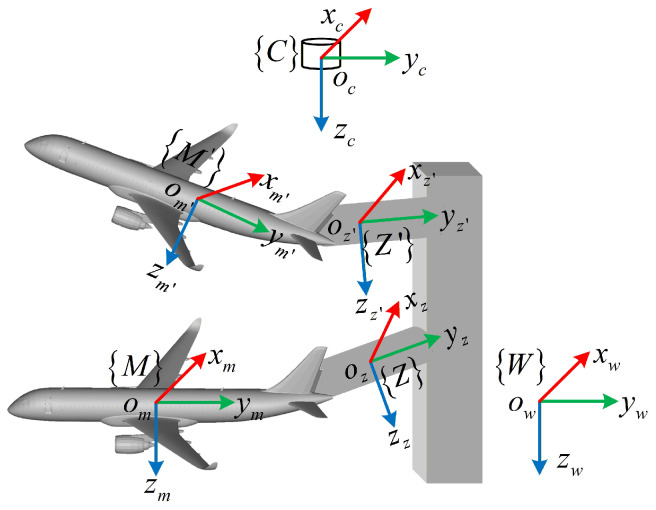 Figure 2
Figure 2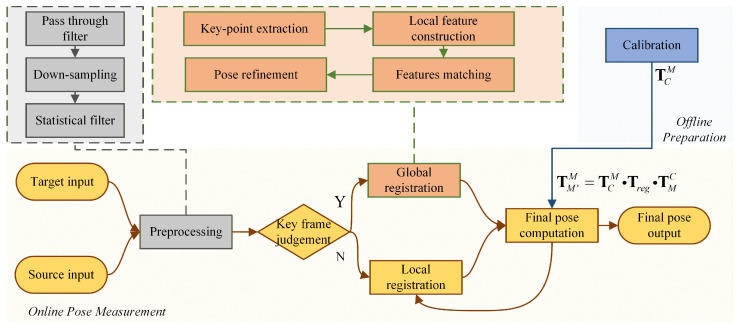 Figure 3
Figure 3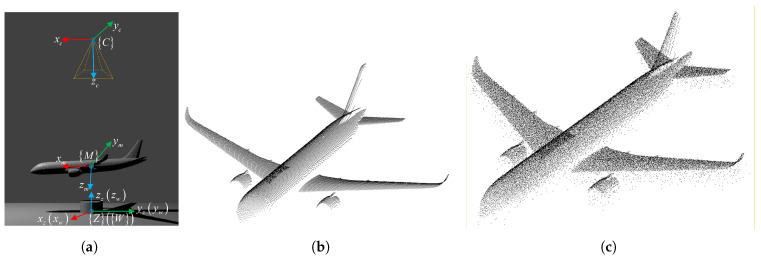 Figure 4
Figure 4 Figure 5
Figure 5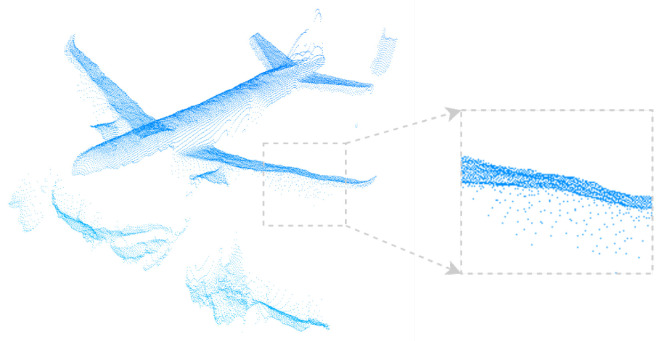 Figure 6
Figure 6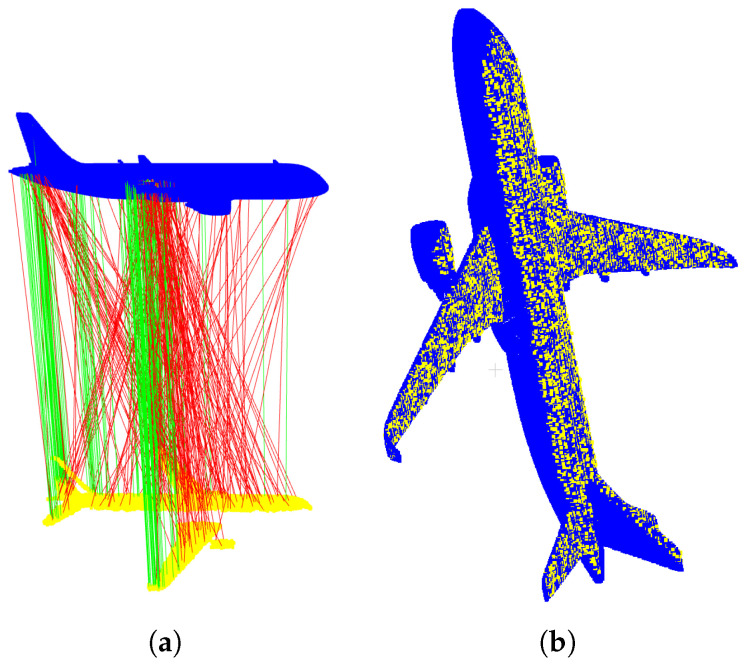 Figure 7
Figure 7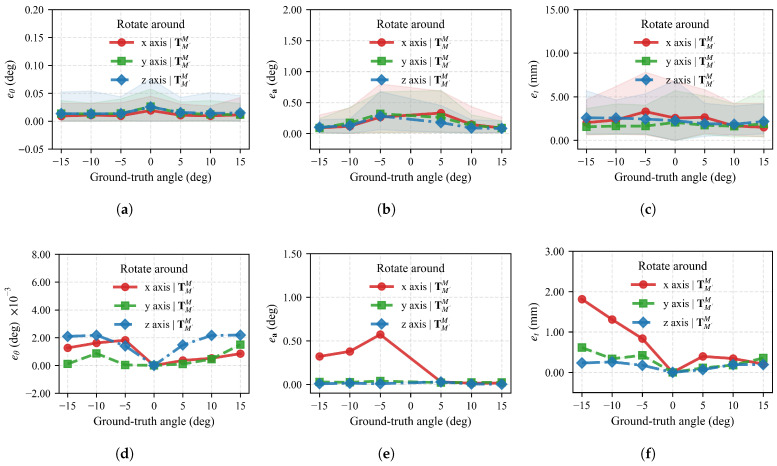 Figure 8
Figure 8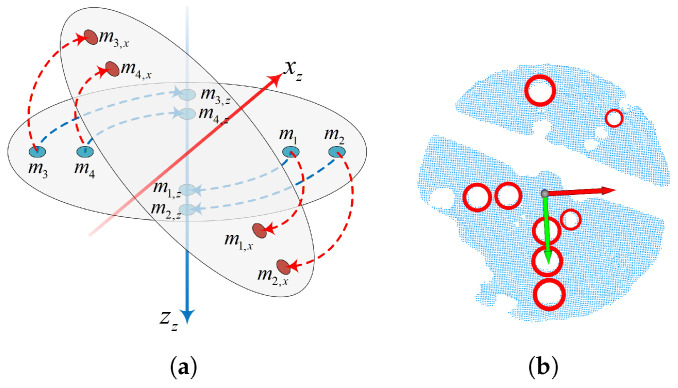 Figure 9
Figure 9 Figure 10
Figure 10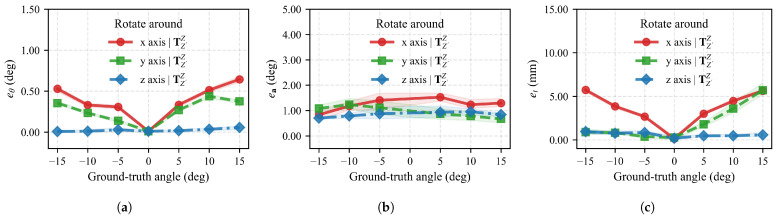 Figure 11
Figure 11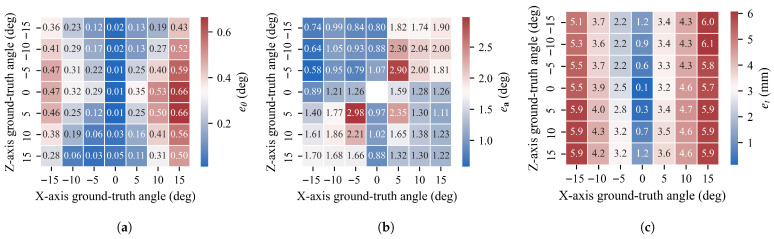 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14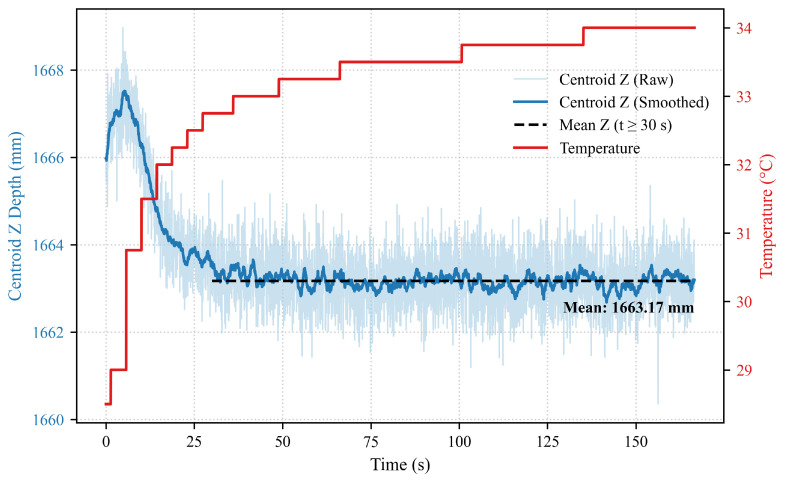 Figure 15
Figure 15- —“Pioneer” and “Leading Goose” R&D Program of Zhejiang
- —Key Research and Development Program of Jiaxing
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAerospace and Aviation Technology · Robotics and Sensor-Based Localization · Inertial Sensor and Navigation
1. Introduction
Wind tunnel experiments involving aircraft [1,2], automobiles, and other targets [3,4] are pivotal for equipment development in the aerospace and transportation sectors. By synchronizing timestamps, it is possible to obtain the pose, pressure, and other physical parameters of different targets simultaneously. Therefore, achieving fast and accurate target pose measurement is of significant importance [5].
Traditional pose measurement methods can be categorized into two types: contact-based and non-contact. Contact-based methods typically implement pose measurement by rigidly attaching inertial measurement units (IMUs) to the target [6]. Although these methods provide high-rate attitude outputs with relatively low algorithmic complexity, they require additional experimental setup and suffer from cumulative drift, which limits long duration accuracy. In contrast, non-contact methods acquire target geometry using optical devices, such as RGB cameras, laser-based vision systems, and Time-of-Flight (ToF) cameras, and estimate pose through image or point cloud processing algorithms [7,8,9]. Marker-based vision systems are widely used in wind tunnel experiments due to their high accuracy and maturity, but they require careful marker placement and are sensitive to occlusion at large angles of attack. Markerless vision-based approaches reduce surface preparation requirements but are sensitive to illumination changes, background interference, and partial occlusion; moreover, monocular RGB-based methods provide only indirect depth cues, limiting achievable three-dimensional pose accuracy. According to reported wind tunnel experiments, conventional aerodynamic measurements generally require attitude accuracy on the order of 0.05–0.1°, while advanced aeroelastic and flow–structure interaction studies demand higher precision, typically better than 0.02–0.03°, with update rates exceeding 30–50 Hz to ensure reliable synchronization with other sensors [1,3,4], which poses significant challenges for existing inertial-based and vision-based methods.
Point clouds are a widely used 3D data representation in computer vision and graphics, typically acquired from devices such as LiDAR, ToF cameras, and structured light cameras [10,11,12]. Focusing on pose measurement scenarios for wind tunnel models, two key considerations emerge. First, wind tunnels are typically large-scale environments, requiring 3D imaging devices with sufficient working distance that maintain consistent precision across varying ranges. Second, to achieve temporal alignment with other sensor data, algorithms must enable real-time pose measurement, necessitating devices capable of high-speed point cloud acquisition. Considering these requirements, structured light systems are limited by light source power and constrained working distances; while capable of sub-millimeter precision, they operate slowly and struggle with fast-moving targets. Compared to structured light, LiDAR achieves significantly greater working distances but typically offers only centimeter-level precision and near-real-time scanning. However, ToF cameras typically achieve an 8–10 m working distance with millimeter-level precision while enabling real-time point cloud acquisition, making them an optimal choice for this application. Table 1 summarizes this comparison.
Through point cloud registration, targets from multiple coordinate systems can be aligned to a unified frame to determine camera or target pose changes. Early representative work includes the Iterative Closest Point (ICP) algorithm [13] and its variants [14,15,16]. To improve registration precision and robustness, Segal et al. proposed the Generalized ICP (GICP) algorithm [17]. GICP unifies point-to-point and point-to-plane metrics by introducing covariance matrices for each point to model local surface geometry, essentially implementing a plane-to-plane probabilistic registration framework that significantly improves performance in structured environments. However, both ICP and GICP are local algorithms and typically require good initial alignment to converge to the correct solution. To overcome this, the Go-ICP algorithm employs branch-and-bound methods for global search but suffers from low computational efficiency [18]. Methods based on hand-crafted local feature descriptors like SHOT [19], TOLDI [20], and FPFH [21] can provide good initializations for ICP and GICP, serving as widely used coarse registration approaches that avoid local optima. Nevertheless, hand-crafted descriptors rely on human intuition and consequently suffer from inherent limitations in feature representation capability [22,23].
Recent years have witnessed significant progress in deep learning-based feature description and point cloud registration [24,25,26]. Methods such as SpinNet [27] and Geo-Transformer [28] achieve robust registration in large-scale indoor and outdoor scenes, substantially improving feature representation. However, deep learning-based methods still face challenges, including high memory usage, substantial computational overhead, and the requirement for large training datasets. These issues impede their practical deployment in wind tunnel experimental scenarios.
Whether hand-crafted or deep learning-based, descriptor-based registration methods inevitably produce numerous false matches due to limited local feature distinctiveness, noise, and repetitive structures. Therefore, it is necessary to filter for high-quality correspondences to provide a reliable initial alignment for fine registration methods like ICP [29,30]. The maximal clique method relaxes the constraints of previous graph-based approaches, achieving significant progress in improving inlier rates, and has been applied to various scenarios [31,32]. However, this method is sensitive to the number of initial correspondences, and graph construction is time-consuming, limiting its utility in time-critical applications. RANSAC is the most common method for handling outliers [33], generating and validating hypotheses through repeated sampling. However, the required number of iterations grows exponentially with the outlier ratio, rendering it significantly less efficient than ideal. The recently proposed Two-stage Consensus Filtering RANSAC (TCF-RANSAC) applies multi-level filtering, substantially improving computational efficiency while maintaining high accuracy, thus enabling real-time applications [34].
Previous work on point cloud-based pose measurement has often treated two consecutive frames as independent datasets, neglecting model motion constraints [8]. In wind tunnel trials, models typically do not undergo abrupt large-scale motion over short periods. Therefore, this paper addresses the pose measurement problem for aircraft in wind tunnels by first analyzing pose representation across multiple coordinate systems and then proposing a framework that fuses keyframe global registration with local registration. For keyframe global registration, a novel hand-crafted local feature is utilized; initial correspondences obtained through feature matching are refined using TCF-RANSAC for robust estimation, followed by fine-tuning with the GICP algorithm. For non-keyframe local registration, incremental pose updates are implemented by using the pose output from the previous frame as the initialization for the current frame, thereby bypassing the computational burden of global registration. Finally, the proposed method demonstrates high accuracy and efficiency when evaluated on both simulated and real datasets.
We select the hand-crafted local descriptor + TCF-RANSAC + GICP combination mainly to satisfy real-time requirements and practical deployment constraints in single-view ToF wind tunnel measurements. Learning-based descriptors and registration frameworks can achieve strong representation, but they typically require training data, incur higher memory/compute cost, and may generalize poorly to ToF point clouds with sensor-specific noise, sparse sampling, and limited viewpoint coverage. In contrast, a hand-crafted descriptor is training-free and deterministic, which facilitates repeatable experiments and rapid integration. TCF-RANSAC is adopted for correspondence filtering because it improves hypothesis verification efficiency under high outlier ratios while maintaining robustness, which is important when smooth surfaces and ToF noise reduce descriptor distinctiveness. Finally, GICP is used for fine registration because its covariance-based formulation provides a probabilistic plane-to-plane metric that is robust to anisotropic ToF ranging noise and yields accurate refinement with reasonable initialization.
The framework is intended for wind tunnel experiments requiring non-contact, full six-degree-of-freedom pose measurement of rigid aircraft models, such as attitude monitoring during angle-of-attack sweeps and aerodynamic force and moment measurements where fiducial markers or onboard sensors are undesirable. Its practical applicability is constrained by the intrinsic parameters of the employed monocular ToF camera, including working distance, field of view, spatial resolution, and ranging accuracy, and it requires the model to remain within the camera’s field of view to ensure sufficient point cloud overlap. The method is not limited to static pose estimation; by combining keyframe-based global registration with efficient local registration on subsequent frames, it supports real-time continuous pose tracking of smoothly moving models, provided that abrupt large-scale motion and severe self-occlusion are avoided.
The main contributions of this work are summarized as follows:
- A complete real-time pose measurement pipeline: We propose a comprehensive framework fusing keyframe global registration (using a novel three-plane encoded feature and TCF-RANSAC) with incremental local updates (GICP), achieving a rotation error of less than 0.03° at speeds exceeding 40 FPS.
- Characterization of sensing limitations: The error distribution of monocular ToF measurement is systematically analyzed, revealing an “axis-sensitivity” phenomenon where optical axis rotation offers superior precision. This finding provides essential theoretical guidelines for optimal camera deployment in aerodynamic testing.
2. Problem Formulation
Let the model point cloud acquired by the camera at time 0 be and at time t be , both represented in the camera coordinate system C. The objective is to estimate the rigid body transformation (with rotation and translation ) to obtain the model pose change in the camera coordinate system by rigid registration. Subsequently, the estimated pose in C is converted to an equivalent pose representation in the model coordinate system M or the wind tunnel/world coordinate system W.
This section outlines the theoretical foundations of the proposed method. First, the projection geometry and data acquisition characteristics of the sensor are modeled to define the relationship between 3D spatial points and the image plane. Subsequently, the mathematical principles governing the alignment of 3D point clouds are detailed to formulate the core registration objective. Finally, the spatial relationships between the camera, the model, and the mechanism are formalized through coordinate system transformations, deriving the necessary geometric constraints for accurate pose estimation and error evaluation.
2.1. ToF Camera Model
The process of point cloud acquisition by a ToF camera can be described using the pinhole camera model. As shown in Figure 1, let a 3D point in the world coordinate system be represented as and its projection point on the pixel plane be . The imaging model can be expressed as follows:
where is the camera intrinsic matrix, defined as
where and are focal lengths in the x and y directions, respectively, and are the principal point, and d is the depth measured by the ToF camera.
2.2. Point Cloud Registration
A point cloud is a collection of 3D spatial coordinates. We denote the source point cloud as and the target point cloud as . The objective of rigid point cloud registration is to find a homogeneous transformation that minimizes the alignment error between and [13]:
where is a 3D rotation matrix, is a 3D translation vector, and is the set of matched point pairs, where each pair consists of a source point and a target point . The homogeneous transformation can be written as
Furthermore, can be written as
In most cases, is unknown. Within the ICP framework, it is typically assumed that the nearest point in to a point in forms a matched pair, with iterations yielding and that minimize residuals. However, this assumption makes the algorithm susceptible to initial values and falling into local optima. A good solution is to use initial matched points and the initial transformation obtained through feature matching as initial values to improve robustness.
2.3. Coordinate System Definition and Transformation
Figure 2 illustrates the coordinate system definitions for ToF camera-based pose measurement of aircraft. The model coordinate system M and mechanism coordinate system Z are moving, while the camera coordinate system C and world coordinate system W are stationary. We adopt the convention that the transformation from coordinate system C to coordinate system M is denoted as . Since the model is rigidly attached to the mechanism, the transformation from M to Z remains constant during measurement. In the wind tunnel scenario, M is fixed to the aircraft body as the visual observation target, while Z is fixed to the mechanical support providing the kinematic reference; thus, the coordinate systems before and after motion refer to the temporal states of these rigidly coupled systems at the initial time and the current measurement time t.
Let the model point cloud acquired by the camera at time 0 be and at time t be . Then,
where is the transformation matrix from the point cloud at time 0 to time t.
For the same physical point on the model, its coordinates in the model coordinate system remain invariant:
Therefore,
where is the transformation matrix from the camera coordinate system to the model coordinate system at time 0. The transformation from model coordinate system at time t to model coordinate system M at time 0, denoted , is as follows:
Clearly, and are similar. Furthermore, , , and form a complete relational network through similarity transformation, describing the same physical motion represented in different coordinate systems.
When evaluating the accuracy of using the mechanism’s pose transformation ,
which also implies the following:
Similarly, the model’s pose transformation in the wind tunnel coordinate system also satisfies the following:
3. Methodology
Figure 3 illustrates the proposed framework, which fuses keyframe global registration with incremental local tracking. To balance computational efficiency and robustness against local optima, the system processes the initial frame (keyframe) using a global registration pipeline to establish a reliable pose baseline. Subsequent frames (non-keyframes) are then aligned using fast local registration, initialized by the previous time-step’s pose. This strategy leverages the motion continuity of wind tunnel models to achieve real-time performance. The detailed procedure is outlined below and summarized in Algorithm 1. Algorithm 1 Proposed pose measurement pipeline.Input: Current point cloud ; Reference point cloud ; Previous registration result (if ); Calibration .Output: Model pose change (in Model coordinate system).1: Preprocessing: Apply pass-through filter, grid downsampling, and statistical outlier removal on (Section 3.1).2: Registration (Obtain ): If t is a Keyframe then (Global Registration + Refinement) 2.1: Extract keypoints and construct local features on and . 2.2: Perform feature matching and apply TCF-RANSAC to get coarse pose . 2.3: Pose Refinement: Apply GICP initialized with to minimize: (Equation (22)). 2.4: Update . else (Local Registration) 2.5: Set initialization (Motion Continuity). 2.6: Tracking: Apply GICP initialized with to solve for . end if3: Final Pose Computation: 3.1: Convert pose to Model coordinate system using Equation (9): .4: Output: Return .
3.1. Preprocessing
In the preprocessing step, the point cloud is , where N is the number of source points. We first remove invalid points through a pass-through filter:
where is the original point cloud set, is the filtered point cloud set, and , , , , , and are user-defined minimum and maximum thresholds along the x-, y-, and z-axes, respectively.
Subsequently, we apply grid downsampling to reduce the point cloud size and apply statistical filtering to further remove point cloud noise.
3.2. Global Registration
3.2.1. Keypoint Extraction
Keypoints, as a subset of the point cloud, are extracted for constructing local features. Keypoint selection methods are numerous [35,36]. Here, instead of deliberately selecting keypoints, we randomly select a fixed proportion to avoid having too many or too few keypoints.
3.2.2. Local Feature Construction
We employ a previously proposed hand-crafted local feature construction method based on three-plane encoded height and density [22]. The construction steps are briefly described as follows:
For point cloud and an extracted keypoint on , we first construct a local reference frame (LRF) within a spherical neighborhood of radius r around to achieve rigidity invariance of local features [37].
Specifically, given the neighborhood point set , the z-axis of the LRF is obtained as the eigenvector corresponding to the smallest eigenvalue of the covariance matrix of the de-centered neighborhood points. The sign ambiguity of the z-axis is resolved by enforcing consistency with the dominant direction of the neighborhood.
Subsequently, all neighborhood points are projected onto the plane orthogonal to the z-axis. On this projected point cloud, local height information along the z-axis is encoded and fused with planar distance information to construct a second covariance matrix, from which the x-axis is determined after sign disambiguation. Finally, the y-axis is computed as the cross product of the x-axis and the z-axis, forming a right-handed orthonormal basis centered at .
The neighborhood point cloud at yields an LRF:
where K is the number of points in the neighborhood, and form an orthonormal basis centered at keypoint .
Subsequently, we transform neighborhood points to the local reference frame to obtain . We extract local features from three orthogonal projection planes of the LRF. Taking the plane as an example, we partition the plane into angular sectors and radial rings. For each region, we compute average density and average height :
where s is the number of points in the region, c is the centroid of points in the region, and is the local height, defined as the z-component of points in the region.
Similar to the existing literature, we further obtain a Gaussian-encoded average density:
where is a bandwidth control parameter, and and are the maximum and minimum average densities across all regions, respectively. Average height is treated similarly. Additionally, we quantize the Gaussian-encoded average density:
where is the quantization bit depth. Average height is handled similarly. Finally, we concatenate the quantized average densities and quantized average heights from all partitions on the three planes to form the local feature F.
3.2.3. Feature Matching
After obtaining local features for all keypoints, we use kdtree to find nearest neighbor matches between source and model point clouds, constructing the initial correspondence set :
where and are keypoints on the source and model point clouds, respectively, and is the number of initial correspondences.
However, due to ToF camera point cloud noise and limited viewpoint causing self-occlusion, the constructed local features have insufficient representation capability. Consequently, initial correspondences often contain many false matches requiring further filtering.
We use TCF-RANSAC to perform robust estimation on initial correspondences. TCF-RANSAC comprises three stages of progressive filtering. In the first stage, we randomly select a correspondence pair and iteratively construct a maximum consensus set :
where is a subset of , i is the current iteration, is the L2 norm, and is the distance constraint threshold. Note that for any correspondence , we denote its constituent points in the source and target clouds as and , respectively.
In the second stage, building upon the first stage, we further introduce angle constraints. From , we randomly select two correspondences and , first satisfying the following equation:
Then, we iteratively construct a more robust consensus set :
where is the filtered subset of , i denotes the current iteration, represents the angular consistency metric, and is the adaptive angle constraint threshold derived from the distance constraint .
Finally, in the third stage, we employ standard RANSAC on to obtain the final consensus set as the correct correspondence set. For keypoints in the filtered correspondence set, we use SVD decomposition to obtain the initial pose.
3.3. Pose Refinement and Local Registration
The pose estimated from local feature matching serves as a coarse alignment but can be inaccurate due to monocular ToF depth noise and non-uniform sampling, which degrade feature distinctiveness on the smooth aircraft surface.
To refine this coarse alignment, we adopt GICP instead of standard ICP or NDT [38]. GICP models local surface geometry using per-point covariance matrices, yielding a probabilistic plane-to-plane metric that is more robust to anisotropic ToF noise.
The registration problem is formulated as estimating a rigid-body transformation that minimizes the Mahalanobis distance between corresponding points in the source cloud and the target cloud :
where is the residual vector, and and are the local covariance matrices around and , respectively. Solving Equation (22) requires an iterative non-linear least squares method (e.g., Gauss-Newton) with an initialization . In this work, we use the following:
- Initial refinement (keyframe): , where is the coarse pose estimated from feature matching.
- Temporal tracking (non-keyframe): , where is the optimized pose from the previous frame.
3.4. Calibration
In most cases, we aim to obtain the pose change of the model in its own model coordinate system, namely . Therefore, it is necessary to transform the computed through Equation (9). This requires obtaining the transformation from model coordinate system M to camera coordinate system C at time 0. In our framework, is obtained by applying the aforementioned global registration procedure to register the CAD model (in M) with the time 0 point cloud (in C).
The model coordinate system uses the right-hand body axis convention with origin at the aircraft center of gravity: x-axis points along the fuselage toward the nose, y-axis points toward the right wing, and z-axis points toward the fuselage bottom. In practical measurement, CAD models of measurement targets are readily available. Therefore, registering the model point cloud in the camera coordinate system acquired at time 0 with the CAD model of the measurement target yields .
Furthermore, to obtain the model’s pose change in the wind tunnel coordinate system or in the mechanism coordinate system , one only needs to calibrate the transformation between the camera coordinate system and wind tunnel coordinate system W at time 0, or the transformation with mechanism coordinate system Z.
4. Experiments and Results
4.1. Experimental Setup
4.1.1. Datasets
Two datasets are used for performance evaluation: a simulated dataset and a real-world dataset.
The simulated dataset was generated in Blensor [39] by rendering noiseless single-view point clouds and subsequently introducing three types of synthetic noise: Gaussian noise, flying point noise, and simulated multipath interference (MPI). Specifically, 1% of the points were displaced by 5 pr to simulate flying points, where pr is point cloud resolution (the average distance between adjacent points in the point cloud). MPI was emulated by offsetting points along the sensor-to-point ray direction with a delay distance equal to 15% of the original range, blending the original and delayed distances with weights of 60–80% and 20–40%, respectively. This was followed by the addition of Gaussian noise with an intensity of 0.5 pr.
To simulate the wind tunnel mechanism, a cylinder with a radius of 1 m and a height of 1 m was placed in the world coordinate system. An aircraft model resembling the C919, with dimensions of m × m × m, was rigidly attached to the cylinder. The attachment incorporated a rotation defined by XYZ Euler angles and a 2 m translation along the world z-axis. The ToF camera was positioned at world coordinates m with a XYZ Euler misalignment to simulate installation error. The simulated scene and point clouds are shown in Figure 4.
We rotate the cylinder about its three axes individually with step size in the range , acquiring 100 frames at each angle step to form the simulated dataset.
To evaluate the proposed framework under realistic conditions, a real-world dataset was collected using the physical measurement platform shown in Figure 5, consisting of a ToF camera, a three-axis turntable, an aircraft model, and a computer. The camera was positioned approximately 1.2 m above the model. The ToF camera has a working distance of 8.3 m, a field of view of , and a spatial resolution of pixels. The aircraft model represents a generic passenger aircraft configuration (length 0.78 m, wingspan 0.71 m, and height 0.24 m).
The ToF camera and turntable are connected to the computer for data acquisition. To ensure consistency with the simulation experiments, the aircraft model was rotated around three axes (pitch, yaw, and roll) ranging from to with a step size of . At each step, 100 frames of point cloud data were collected to ensure statistical reliability. The ground truth poses were provided by the high-precision turntable. In the real experimental setup, the physical model is manufactured using rigid material and rigidly mounted on the turntable mechanism. Due to single-view acquisition and surface reflectance variations, the captured point clouds mainly cover the upper fuselage, wings, and part of the empennage, which is consistent with typical wind tunnel measurement scenarios. Figure 6 shows the model point clouds acquired by the ToF camera. Compared to simulated noise, the real-world acquired model point clouds exhibit more noise due to environmental factors and model surface material properties, including partial shape deficiencies and even local deformations.
It should be noted that in the real experiment, the transformation from camera coordinate system to mechanism coordinate system Z at time 0 and the transformation from model coordinate system M to mechanism coordinate system Z are both unknown.
4.1.2. Implementation Details
Our framework and algorithms run on a computer configured with an Intel Core Ultra 7 255H CPU and 32 GB of memory. Our algorithms are implemented based on the Point Cloud Library (PCL) [40] with multi-threading acceleration but without GPU acceleration. The first frame is selected as the keyframe. The algorithm parameters used in our experiments are summarized in Table 2. To ensure the method’s applicability to general scenarios, scale-dependent parameters (such as downsampling grid size) are defined relative to the point cloud resolution (pr). This dynamic scaling allows the pipeline to adapt to varying working distances and sensor resolutions. The quantization bit depths (16 for density; 24 for height) were empirically selected to balance feature distinctiveness and computational efficiency across both tested aircraft models [22].
4.1.3. Evaluation Metrics
Since similarity transformation preserves rotation angle while changing the rotation axis, for the rotation component, we first extract the rotation angle and rotation axis from :
where is the trace of . We then compute errors and between estimated rotation angle and rotation axis and their ground truth values, as well as the translation error:
4.2. Accuracy Analysis
4.2.1. Simulated Experiment Results
Since coordinate system transformations are known in simulated experiments, we evaluate the final pose estimation error in the model coordinate system, where the influence of calibration errors is inherently included. The transformation from model coordinate system M to camera coordinate system C at time 0, as mentioned, is obtained through registration of the model with the acquired point cloud. Registration results are shown in Figure 7.
We compiled statistics for rotation angle error and translation error across all angles for different rotation axes, as shown in Figure 8 and Table 3. Results demonstrate that the proposed pose measurement method achieves high measurement precision and good stability. Under noiseless conditions, mean rotation angle errors for all three axes are below 1.60 × 10^−3∘^, with standard deviations all being zero, indicating excellent convergence precision and repeatable measurement results in ideal conditions. Mean translation errors are at most 0.70 mm, with the standard deviations also being zero.
When noise is introduced, rotation angle error means increase to – , which are below , with standard deviations around – , indicating some measurement variation but overall being controllable. Translation error mean increase to 1.73–2.29 mm with standard deviations around 0.82–1.10 mm, showing moderate variation relative to means. Overall, the algorithm maintains good measurement precision and stability under noisy conditions, demonstrating strong robustness to the added point cloud noise.
4.2.2. Real Experiment Results
In real experiments, transformations between coordinate systems are unknown except at time 0, which can be obtained through model–point cloud registration. However, both from the model to mechanism coordinate system and from the camera to mechanism coordinate system require additional calibration. We calibrate and evaluate after similarity transformation to the mechanism coordinate system.
Since turntable rotary tables typically have high-precision threaded holes drilled by manufacturers, we attach fiducial points to these holes. The turntable rotates to n positions about the z-axis and x-axis; at each position, the ToF camera acquires turntable surface images, fitting fiducial points using established algorithms. Through circular arc fitting, we obtain the and axes of the turntable coordinate system; is obtained through cross product, as shown in Figure 9.
Successful keyframe registration scenarios and example ToF-acquired model point clouds are shown in Figure 10. Compared to simulated point clouds, real point clouds contain substantially more noise.
Rotation angle error and translation error across all angles for different axes are shown in Figure 11. Unlike simulated results, rotation around the z-axis yields the smallest error, while rotations around the x and y axes show rotation angle and translation errors increasing with rotation angle. Since model rotation around the z-axis approximates rotation around the camera optical axis, we term this phenomenon “axis sensitivity.” We analyze the causes of axis sensitivity in the Section 5.
Mean rotation angle error and standard deviation of the mean across all rotation angles are presented in Table 4. For rotation around the z-axis, the mean rotation angle deviation is . In contrast, for model rotations around x and y axes, mean rotation angle errors reach and , respectively. Standard deviations for rotations around all three axes are 0.01°.
To further analyze real-world effectiveness with multi-axis rotations, we calculated poses when the turntable rotates simultaneously about z and x axes at different angles, with results in Figure 12. As rotation angles increase around the x-axis, both rotation angle error and translation error increase, while rotation around the z-axis maintains relatively consistent errors when the x-axis rotation angle is fixed. Minimum rotation angle error across all stages is only , with a minimum translation error of only 0.1 mm.
Overall, the framework’s effectiveness is thoroughly validated, particularly achieving the highest precision when rotating around the z-axis.
4.3. Computational Efficiency
Our framework’s computational performance is summarized in Table 5. Real-world dataset input point clouds contain approximately 88,000 points, reduced to approximately 3800 points after preprocessing. Local feature construction is the most time-consuming step for keyframes. Total keyframe processing time, including a comprehensive global registration pipeline, is less than 120 ms. More importantly, all subsequent non-keyframe processing time is less than 25 ms, achieving pose output frame rates exceeding 40 FPS. Since global registration is executed only once on the initial frame, our framework easily enables real-time continuous pose measurement.
The computational cost is dominated by filtering and voxel downsampling, local feature construction and matching, and GICP-based local registration. When point density increases, the runtime of the nearest-neighbor search and correspondence evaluation typically grows rapidly if the raw point count is left uncontrolled. In our framework, voxel downsampling provides an explicit mechanism to bound the number of points, enabling an accuracy–speed trade-off by adjusting the grid size. For higher frame rates commonly required in large wind-tunnel facilities, the inter-frame motion is smaller, which generally benefits the convergence of local registration; therefore, the non-keyframe branch can maintain tracking as long as the per-frame point count is controlled. Finally, the main computational kernels (kNN search, descriptor computation, and GICP iterations) are amenable to parallelization; multi-threading is already used in our implementation, and further acceleration using SIMD/GPU or approximate nearest-neighbor structures can be adopted when higher resolution or >100 Hz update rates are required.
4.4. Comparison with Other Methods
Having validated our method’s performance, we further compare our proposed framework with mainstream methods in terms of accuracy, speed, and robustness. We selected several prevalent point cloud registration methods. Global registration methods include classical FPFH and recent MDCS [41] and TPSH [42], while local registration methods include classical ICP, GICP, and recent VGICP. FPFH uses PCL implementations, GICP and VGICP use author-provided source code, and TPSH and MDCS are implemented by us. All common parameters are kept consistent, with method-specific parameters using the original authors’ defaults. The characteristics of different local features are shown in Table 6.
Comparisons on keyframes from real-world experiments with model rotation around the z-axis are performed, computing each result 10 times and averaging, with results shown in Table 7.
The experimental results indicate that the proposed method achieves the highest registration accuracy, yielding the lowest errors across rotation angle, rotation axis, and translation metrics. In terms of efficiency, it ranks second overall, offering an optimal trade-off compared to competing methods. Specifically, while MDCS excels in feature construction speed (approx. 40% of ours), its matching process is significantly slower (approx. 3.9×) due to high feature dimensionality. Conversely, although FPFH achieves the fastest matching, its limited descriptive power results in substantial registration errors. Consequently, the proposed framework strikes the best balance between descriptive capability and computational cost, delivering superior precision with competitive real-time performance.
Local registration method comparison results are shown in Table 8. Initial values for each method are computed using our approach. GICP shows the shortest computation time and smallest registration error on our dataset, validating the reasonableness of our local registration method selection.
4.5. Evaluation of Different Geometric Shapes
To evaluate the generalization capability of the proposed framework across different objects, we introduced a second aircraft model (referred to as Model 2) in addition to the original model (Model 1, resembling the C919). As shown in Figure 13, Model 2 resembles a B-2 bomber configuration and exhibits a geometry significantly different from Model 1, particularly characterized by a flatter profile.
Experiments were conducted in an environment with a temperature of 22.4 °C and an illuminance of 11 Lux. Model 2 was rigidly mounted on the turntable and rotated around the z-axis to positions of , , and . For each angle, 100 frames were collected. The comparative results of rotation angle error, rotation axis error, and translation error for both models are presented in Table 9.
The mean rotation angle error for Model 2 across the three angles is , compared to for Model 1, indicating a difference of approximately . Both models exhibit the maximum rotation angle error at . The rotation axis error remains approximately . Although the translation error for Model 2 is slightly larger than that of Model 1, the error trends are consistent: errors are minimal at and increase as the rotation angle increases.
The mean and standard deviation values for Model 2 are generally higher than those for Model 1. This can be attributed to variations in geometric observability. Since Model 2 exhibits a “flatter” profile along the z-axis, the eigenvalues of its Hessian matrix in that direction are reduced. This implies that the optimization landscape becomes flatter, making the pose estimation more susceptible to noise and resulting in higher uncertainty. Nevertheless, the algorithm maintains a high level of accuracy for both geometries.
4.6. Evaluation of Real-World Environmental Factors
To assess the robustness of the algorithm under varying environmental conditions, we analyzed the effects of ambient illuminance and temperature.
4.6.1. Impact of Ambient Illuminance
First, with the environmental temperature controlled at 22.4 ± 0.2 °C, experiments were conducted under three different illuminance levels: 0 Lux (dark), 11 Lux (dim), and 343 Lux (bright), as shown in Figure 14.
Model 2 was rotated to around the z-axis. The pose errors under different lighting conditions are summarized in Table 10. The results indicate that the three error metrics remain consistent across different illuminance levels. This robustness is attributed to the ToF camera operating in the near-infrared (NIR) spectrum (850 nm), which mitigates interference from visible light. This characteristic makes the system highly adaptable to indoor environments with controllable lighting, such as wind tunnels.
4.6.2. Impact of Temperature and Drift Analysis
Next, under a constant illuminance of 11 Lux, we evaluated the performance at two different environmental temperatures: 16.4 °C and 22.4 °C. Model 2 was rotated to around the z-axis. The results are shown in Table 11.
The errors remain consistent across different temperatures. ToF ranging errors are primarily influenced by internal sensor heat generation rather than ambient temperature. Ambient temperature mainly affects the heat dissipation efficiency. Once the ToF camera operates for a warm-up period, its internal temperature stabilizes, and the internal compensation mechanism ensures stable distance measurements, thereby maintaining registration accuracy.
To verify this, we monitored the z-axis depth of the scene centroid over a 3-min period, as depth stability is critical for point cloud generation. The relationship between the measured distance and the internal temperature of the camera over time is illustrated in Figure 15.
At the beginning of data collection, the internal temperature of the ToF camera rises rapidly, accompanied by an increase in the measured distance. Subsequently, the internal compensation mechanism activates, and the measured distance gradually stabilizes. As shown in the data, the centroid distance tends to reach equilibrium after approximately 30 s. Table 12 presents the stable centroid distances ( s) under different environmental and initial internal temperatures.
It can be observed that under different environmental temperatures but similar initial internal temperatures, the difference in mean distance is minimal (e.g., 0.03 mm). However, variations in internal temperature significantly affect the distance measurement (exceeding 0.1 mm). This confirms that the ranging error is dominated by internal thermal drift. It should be noted that all experimental data reported in this paper were collected after the device had reached thermal equilibrium (warm-up period > 30 s).
5. Error Analysis and Discussion
5.1. Axis-Sensitivity Analysis
In real experiments, we observed that when the model rotation axis approximately aligns with the camera optical axis—in our experiments, the turntable z-axis approximately aligns with the camera axis—registration precision significantly outperforms rotations where the axis is approximately perpendicular to the optical axis, namely turntable X/Y axis rotations. This “axis sensitivity” results from the combined effects of single-view geometric observability differences and anisotropic ToF depth measurement noise.
Taking point-to-plane ICP and GICP’s equivalent quadratic approximation near convergence as an example, residuals are expressed as [17]:
with objective function . Here, denotes the residual for point pair i, represents the surface normal, and are the rotation and translation components, and and are corresponding points in the source and target clouds, respectively. Linearizing around convergence point with pose perturbation , the Gauss-Newton Hessian approximation is , where is the weight matrix, and is the Jacobian of residuals with respect to pose perturbation. Censi provides a classical closed-form covariance estimation framework for ICP, emphasizing observability analysis under under-constrained conditions [43]. At a common first-order approximation, pose increment uncertainty is expressed as follows:
where characterizes point cloud measurement noise statistics, including depth noise, outliers, and quantization effects. From Equation (26), the spectral structure of —specifically its eigenvalue magnitudes and condition number—determines constraint strength for different degrees of freedom. Larger eigenvalues correspond to stronger constraints and smaller variance; conversely, flat valley bottoms result in high noise sensitivity and degeneracy, indicating weak observability.
ToF camera errors are not isotropic. Extensive surveys and evaluation work show that ToF depth measurement error along the range direction, approximately along , typically significantly exceeds lateral error projected from pixel angular resolution to and planes [44]. This error varies with distance, incident angle, and reflectance and produces structured errors including flying pixels—also known as mixed pixels—and multipath interference arising from multiple reflections, commonly abbreviated as MPI.
When model rotation approximately aligns with the camera optical axis, the point cloud produces significant tangential displacement on the image plane, more constrained by lateral resolution and contour geometry, with weaker coupling to ToF depth noise. Therefore, typically has larger eigenvalues in the rotation freedom direction, yielding smaller rotation uncertainty and more stable convergence. In contrast, rotation around or significantly changes many points’ depth values, while ToF depth noise and MPI, along with flying point error, are stronger in this direction, causing eigenvalues to decrease and making rotation estimation more noise-sensitive. Additionally, single-view rotations around or more easily cause self-occlusion, reducing effective overlap and destabilizing correspondences.
Consequently, geometric observability—determined by visible surface and shape distribution—combined with ToF anisotropic noise, jointly determines estimation difficulty for different rotation axes. This provides guidance for wind tunnel camera placement: if experimental motion is primarily single-axis rotation, the rotation axis should approximate alignment with the camera optical axis; if unavoidable large rotations around or occur, multi-view coverage, increased overlap, or backend optimization are needed to compensate for weak observability directions.
5.2. Error Sources and Propagation
Final pose error in our framework results from the combined effects of sensor errors, registration errors, calibration errors, and systematic errors, propagating, coupling, and amplifying through coordinate transformation chains. At the sensor level, ToF point cloud measurement errors primarily stem from depth random noise and systematic bias, often exhibiting anisotropic distribution. At the algorithmic level, coarse registration suffers from noise and missing data, reducing local feature discriminability, causing initial value bias; fine registration more easily falls into local minima or exhibits unstable convergence in weakly observable directions. At the calibration level, CAD models are ideal, complete geometric models, while actual ToF point clouds are noisy, incomplete, single-view observations, making the CAD–point cloud registration matrix prone to systematic bias. Additionally, the camera–mechanism calibration matrix relies on fitting limited, spatially constrained fiducial points, with precision bounded by point cloud quality and geometric conditioning, introducing inherent errors in mechanism coordinate system pose and origin. Furthermore, at the system level, temperature drift and model micro-vibrations during experiments effectively manifest as pose disturbances.
To uniformly describe these errors and analyze propagation, we employ the Lie group multiplicative perturbation model, where denotes the special Euclidean group representing rigid body transformations. For any pose , the nominal value is , and the perturbation is , where denotes the Lie algebra representing infinitesimal motion. Using the left perturbation model from Equation (10), and since is the inverse of , we express the first two terms as left perturbations:
Let . At first-order approximation,
where denotes the adjoint representation of transformation , which describes how perturbations transform between coordinate frames. Assuming independence of two perturbations, covariance propagation is as follows:
where . Equations (28) and (29) show that calibration and registration uncertainties couple to downstream coordinate systems through similarity transformation. In particular, when the camera and model have large translation and rotation perturbations, they are significantly coupled to translation errors.
In this work, we use only the first frame as a keyframe for global registration and perform local tracking for subsequent frames. This design is justified by the smooth-motion assumption in typical wind-tunnel tests, which limits inter-frame pose changes and enables stable convergence of local registration. For longer experiments or cases with larger pose variations (e.g., abrupt motion, severe occlusion, or drift accumulated over time), relying on a single initial keyframe may increase the risk of tracking degradation and local-minimum convergence. In such situations, the framework can be extended by introducing an adaptive keyframe strategy, e.g., triggering re-initialization when the registration residual, overlap ratio, or inlier count indicates reduced alignment quality, or by periodically inserting keyframes at a fixed interval. These mechanisms would improve long-term robustness at the expense of occasional increases in latency.
6. Conclusions
This paper addresses pose measurement for aircraft in wind tunnels, proposing and implementing an efficient measurement framework fusing keyframe global feature matching with non-keyframe local fine registration. By analyzing ToF camera imaging models and aircraft motion constraints, we design a complete pipeline including point cloud preprocessing, global coarse registration based on improved hand-crafted features, and local fine registration based on temporal continuity. Experiments and error analysis demonstrate that while ensuring real-time output, the system achieves rotation angle errors as low as and translation errors of 0.61 mm at over 40 FPS, demonstrating accurate and real-time pose measurement.
The research reveals that constrained by geometric constraints and depth noise coupling, the system exhibits pronounced axis sensitivity, where rotation precision around the optical axis (z-axis) significantly exceeds rotations around horizontal axes ( -axes). This finding provides theoretical reference for wind tunnel camera placement: model rotation axes should approximate alignment with the camera optical axis.
Future work will focus on three main directions:
- Extended real-world validation and generalization: The proposed framework will be further validated in operational wind tunnel environments through long-duration experiments under airflow-induced vibration and environmental disturbances. In addition, its generalization capability will be evaluated on aircraft models with different geometries, scales, and surface characteristics to assess robustness beyond a single model.
- Robustness under high-dynamic and extreme motion conditions: While the current framework targets typical wind tunnel motion patterns, future studies will investigate its performance under more challenging scenarios, including rapid rotations, high-frequency vibrations, and transient disturbances, to better characterize system limits and error behavior.
- System-level comparison and performance scaling: Future work will include direct comparisons with multi-camera photogrammetry-based pose measurement systems under identical experimental setups, as well as GPU-accelerated and parallel implementations of key modules to enable higher frame rates (e.g., >100 FPS) for high-speed measurement applications.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Liang J. Chen G. Li L. Zhang G. Wang J. High-Precision Attitude Measurement of Free-Drop Testing of Aircraft in Wind Tunnel with Self-Correcting Camera Extrinsic Opt. Laser Technol.202619311416510.1016/j.optlastec.2025.114165 · doi ↗
- 2Kasula P. Whidborne J.F. Rana Z.A. Quaternion-Based Attitude Estimation of an Aircraft Model Using Computer Vision Sensors 202424379510.3390/s 2412379538931579 PMC 11207717 · doi ↗ · pubmed ↗
- 3Nietiedt S. Wester T.T.B. Langidis A. Kröger L. Rofallski R. Göring M. Kühn M. Gülker G. Luhmann T. A Wind Tunnel Setup for Fluid-Structure Interaction Measurements Using Optical Methods Sensors 202222501410.3390/s 2213501435808509 PMC 9269804 · doi ↗ · pubmed ↗
- 4Xiang X. Wang S. Cheng X. Zhang J. Meng F. Current Status and Prospects of Computer Vision-Based Attitude and Deformation Measurement Applications in Wind Tunnels Sci. Rep.2025151189010.1038/s 41598-025-96000-y 40195507 PMC 11976945 · doi ↗ · pubmed ↗
- 5Khaleel H.Z. Ahmed A.K. Al-Obaidi A.S.M. Luckyardi S. Husaeni D.F.A. Mahmod R.A. Humaidi A.J. Measurement Enhancement of Ultrasonic Sensor Using Pelican Optimization Algorithm for Robotic Application Indones. J. Sci. Technol.2024914516210.17509/ijost.v 9i 1.64843 · doi ↗
- 6Curriston D.A. Taylor M. White E.B. Use of MEMS Sensors for Inertial Corrections in Wind Tunnel Testing Proceedings of the AIAA SCITECH 2024 Forum, Orlando, FL, USA, 8–12 January 2024 American Institute of Aeronautics and Astronautics Reston, VA, USA 202410.2514/6.2024-0733 · doi ↗
- 7Liu W. Ma X. Li X. Chen L. Zhang Y. Li X. Shang Z. Jia Z. High-Precision Pose Measurement Method in Wind Tunnels Based on Laser-Aided Vision Technology Chin. J. Aeronaut.2015281121113010.1016/j.cja.2015.05.009 · doi ↗
- 8Gómez Martínez H. Giorgi G. Eissfeller B. Pose Estimation and Tracking of Non-Cooperative Rocket Bodies Using Time-of-Flight Cameras Acta Astronaut.201713916517510.1016/j.actaastro.2017.07.002 · doi ↗