Full-Spectrum Hyperspectral Modeling of Leaf Dry Matter Content Using a Stacked Ensemble Framework
Reinis Alksnis, Ina Alsina, Mara Duma, Laila Dubova, Uldis Gross, Tetiana Harbovska

TL;DR
This study uses hyperspectral data and machine learning to accurately predict leaf dry matter content across various crops and conditions.
Contribution
A stacked ensemble framework is introduced to improve prediction accuracy of leaf dry matter content using full-spectrum data.
Findings
Narrow-band spectral indices showed limited predictive performance for leaf dry matter content.
A stacked ensemble model achieved an R2 of 0.896, outperforming individual models.
The approach improves accuracy and robustness in estimating leaf biochemical properties.
Abstract
The objective of this study was to assess the predictability of leaf dry matter content across a diverse range of plant species using hyperspectral reflectance data. The dataset encompassed leaves from multiple crops, including potatoes, beans, wheat, maize, peas, tomatoes, basil, and cucumbers, collected under varying growth conditions, cultivation systems, seasonal contexts, and developmental stages. As an initial benchmark, commonly used narrow-band spectral indices and their combinations were evaluated, but they exhibited limited predictive performance for dry matter content. Consequently, several full-spectrum machine learning models were trained and compared to assess their individual predictive ability. Given their complementary strengths, these models were integrated into a stacked ensemble framework to enhance overall accuracy. The resulting ensemble, combining the outputs of…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
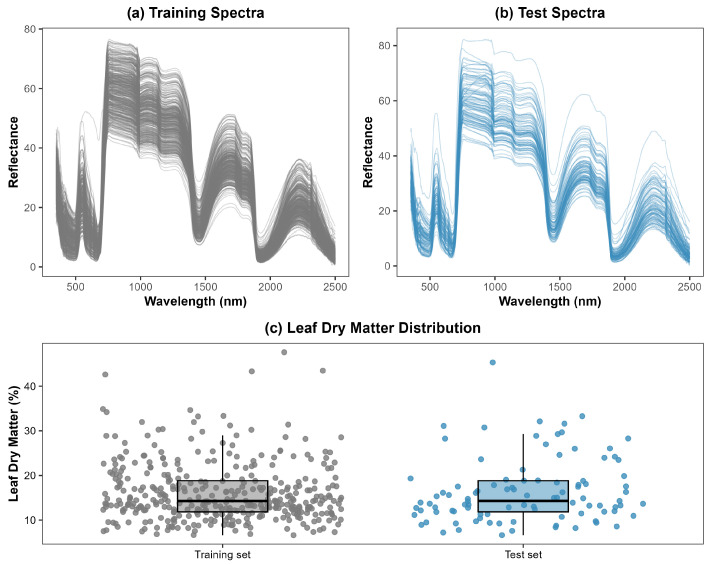 Figure 1
Figure 1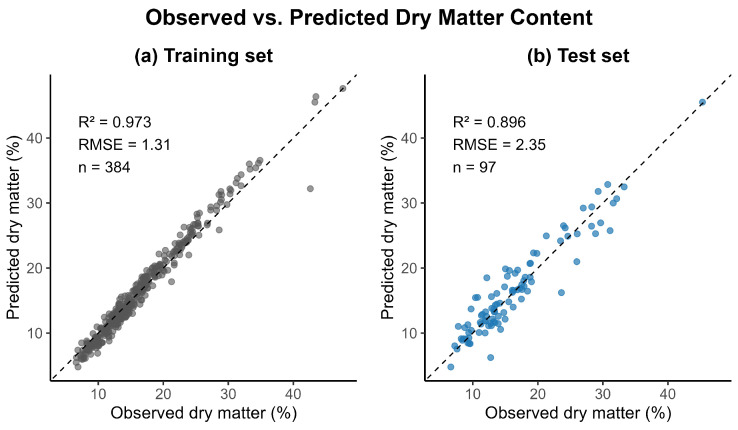 Figure 2
Figure 2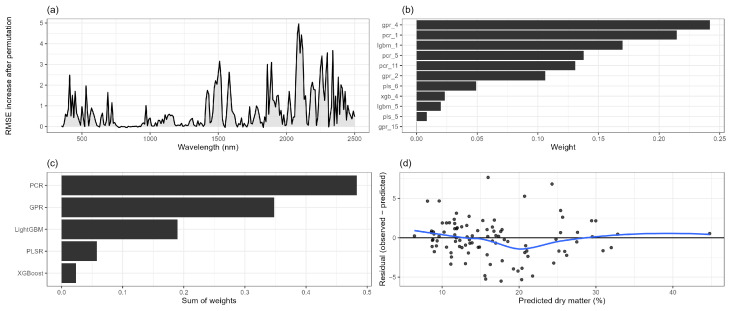 Figure 3
Figure 3- —The Recovery and Resilience Facility
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRemote Sensing in Agriculture · Smart Agriculture and AI · Leaf Properties and Growth Measurement
1. Introduction
Dry matter in plants is produced primarily through photosynthesis. During this process, leaves convert light energy into chemical energy and synthesize carbohydrates from carbon dioxide and water. These assimilates contribute to the formation of structural and storage components of the plant and serve as key indicators of plant growth, water-use efficiency, and potential yield [1,2]. Formed compounds are transported to leaves, stems, roots, and reproductive structures, leading to increased biomass and dry matter accumulation over time. The total amount of dry matter is influenced by different factors such as light intensity, water availability, and nutrient supply as well as leaf area development and pigment (especially chlorophyll) content [3].
Dry matter content and water content in plants are closely related, as they together form the total biomass: water is essential for photosynthesis, nutrient transport and cell growth, while dry matter characterizes the organic and inorganic compounds that are produced as a result of photosynthesis [1]. An optimal amount of water allows plants to synthesize carbohydrates and other compounds, increasing the accumulation of dry matter, while water deficit can limit photosynthesis and reduce the formation of dry matter [3].
The ratio of dry matter to water content is an important indicator of both plant growth and plant stress. Water content and dry matter accumulation are affected by factors such as soil moisture, temperature, plant species, plant age, etc. Scientists have found that plants affected by drought stress sometimes have a higher percentage of dry matter, despite a lower total biomass [4].
Gravimetric analysis is a classic chemical method used to determine dry matter content by measuring the weight change between fresh and dried leaves, but it is a destructive, time-consuming and energy-consuming method. Non-destructive methods are often considered superior to biochemical methods because these methods offer advantages in terms of sample preservation, long-term monitoring, minimal impact and cost-effectiveness [5,6].
Reflectance spectroscopy is widely used in plant stress studies [7,8], as the spectra obtained can characterize the health status of plants, stress level, productivity and even the content of certain components, such as chlorophyll or flavonoids. For example, reflectance spectra containing information about pigments are found in the visible (VIS) or infrared region, while changes in leaf structure are characterized by spectra in the near infrared (NIR) region [9]. Readings in the near-to-mid-infrared region are recommended to obtain information about dry matter/water content [9]. Reflectance spectroscopy and hyperspectral reflectance measurements have been widely used to estimate water content in plants [10] and are valuable tools for assessing the water content of a variety of materials, including soils, plants, and water bodies [11].
Recent studies on dry matter estimation in plants and crops have highlighted the need to develop non-destructive and high-throughput methods for biomass and dry matter estimation, replacing traditional destructive detection methods. Studies using unmanned aerial vehicles (UAVs) equipped with RGB and hyperspectral sensors combined with machine learning have shown promising accuracy in estimating dry matter and forage yield in grasslands and crops, offering practical tools for precision agriculture [12]. Remote sensing approaches that combine vegetation indices with phenological variables have been successfully applied to estimate biomass in cereals, reflecting the integration of spectral data and crop growth models [13]. Studies have also shown that hyperspectral spectroscopy combined with artificial intelligence can effectively model dry matter and nutrient content, highlighting wavelength regions that are sensitive to biomass components [4]. There are studies that confirm that dry matter content modeling can serve as an estimator of total biomass production, aiding in ecological and agricultural monitoring. Collectively, these advances illustrate how combining remote sensing, machine learning, and phenotypic data improves the accuracy, speed, and applicability of dry matter estimation in diverse plant systems [14].
Because hyperspectral reflectance data are inherently high-dimensional and exhibit strong collinearity across neighboring wavelengths, dry matter estimation is typically formulated as a multivariate regression problem. Classical chemometric approaches such as principal component regression (PCR) and partial least squares regression (PLSR) have long been used to relate spectral features to biochemical and structural plant traits, while more recent studies increasingly rely on machine learning algorithms including random forests, gradient boosting, kernel methods, and neural networks. These models are capable of capturing nonlinear responses and complex feature interactions distributed across the spectrum and have repeatedly demonstrated improved predictive performance compared with single-index approaches in vegetation spectroscopy and plant-trait retrieval studies [15,16,17]. However, comparative studies also show that no single algorithm consistently performs best across datasets, species groups, and measurement conditions, suggesting that different learners capture complementary aspects of the spectral signal.
One principled way to exploit such model complementarity is ensemble learning, where predictions from multiple base models are combined into a single meta-model. Among ensemble strategies, stacked generalization, introduced by Wolpert [18], has been shown to reduce generalization error by learning how to optimally combine heterogeneous base learners through a second-level model. Different types of base learners can be used in the first level, among those all the models mentioned above. Generally, in this first level, it is useful to include models that complement each other. For instance, linear models capturing general linear associations should be complemented with nonlinear models to capture higher, more nuanced nonlinearities. Stacking ensemble learning has gained popularity in recent years with applications, among others, in agriculture and remote sensing. Fu et al. (2019) [19] combined partial least squares regression (PLSR), random forests (RF) and Gaussian process regression (GPR) to build a model for predicting photosynthetic capacity from hyperspectral reflectance spectra of tobacco leaves. Yoosefzadeh-Najafabadi et al. (2021) [20] used a stacking model with support vector regression, random forests and neural networks as base learners to predict soybean yield from hyperspectral reflectance and associated physiological traits. Chen et al. (2022) [21] proposed a stacked ensemble extreme learning model by integrating kernel-based and tree-based models to predict nitrogen, phosphorus and potassium concentrations in apple tree leaves using canopy hyperspectral data. Dumancas and Adrianto (2022) [22] stacked partial least squares, support vector machines and artificial neural networks to predict biomass composition from near-infrared spectroscopy data. Fei et al. (2023) [23] introduced a feature splitting regression technique, conceptually related to stacking, for predicting plant biochemical traits from high-dimensional reflectance data. Sharma et al. (2024) [24] extended the stacking concept to integrate convolutional neural networks with ensemble regression models for predicting grapevine physiological parameters from hyperspectral data. Abukmeil et al. (2026) [25] developed a multivariate stacked regression model for predicting correlated macro- and micronutrient concentrations in potato plants using visible and near-infrared reflectance. Li et al. (2025) [26] proposed a stacking ensemble combined with a one-dimensional convolutional neural network model for chlorophyll content prediction in Stellera chamaejasme leaves. These are just a few instances of the vast literature from recent years establishing that stacked ensemble learning is an effective strategy for hyperspectral-reflectance-based predictions of various plant biochemical traits. Thus, our strategy is also to combine linear models (PCR, PLSR, Enet) and nonlinear models (RF, XGBoost, LightGBM, GPR) with the idea that stacking would capture complementary variance structures and thus enhance predictions accuracy, improving the one obtained by the base learners given above.
The aim of this study is to evaluate the predictive limits of hyperspectral data for estimating leaf dry matter by testing a broad range of regression algorithms applied to spectral principal components. Specifically, we investigate whether combining complementary learners in stacked ensembles can yield more robust and accurate predictions than individual models. To achieve this, we integrate both classical and modern regression approaches, ultimately constructing a stacked ensemble framework capable of capturing diverse spectral–dry-matter relationships across multiple crop species.
2. Materials and Methods
2.1. Plant Cultivation and Sampling
The experiments were established in 2024 and 2025 at the experimental field (EF), vegetation polygon (VP), greenhouses (GHs), and growth chamber (GC) of the Institute of Soil and Plant Sciences of the Latvia University of Life Sciences and Technologies. Both field experiments (FEs) and experiments in vegetation containers (VCs) were conducted. Various types of experiments (Table 1) were set up:
- Fertilizers (F): mineral (FM), organic (FO), and organic granulated (FG) fertilizers were balanced according to the nitrogen dose, F0—no additional fertilizer, F1—N dose 50 g m^−2^, F2—100 g m^−2^.
- Plant irrigation regimes (W): WS sprinkler irrigation, WN without additional irrigation, W1 irrigated each second day, W2 irrigated once a week.
- Different light conditions (L): L1 blue and red light together made up more than of visible light, L2 blue and red light together made of visible light, L3 blue and red light together made of visible light.
- Microbial preparation (M) Priestia megaterium was added to substratum (M1), without microbial preparation (M0).
- Soil management methods (S) reduced tillage (without soil conversion) (S0) and conventional tillage (ploughing) (S1).
2.2. Reflectance Spectra and Dry Matter Analysis
Reflectance spectra of plant leaves were obtained using an RS-3500 portable spectroradiometer (Spectral Evolution Inc., Haverhill, MA, USA). Reflectance was measured with 1 nm resolution in the 350–2500 nm range. The leaf was detached, and reflectance in three replicates were immediately measured directly from the leaf surface. The same leaves were immediately weighed and placed in a thermostat for dry matter analysis. Leaves were dried at 60 °C for 24–48 h until a constant weight was achieved. Dry matter (DM) content of leaves was measured by weighing the leaves before ( ) and after drying ( ) and calculated as follows (1):
2.3. Data
The total dataset comprised 482 leaf samples, each characterized by spectral reflectance values measured from 350 to 2500 nm and the corresponding leaf dry matter content (%). The dataset was randomly partitioned into training ( ) and testing ( ) subsets to enable model calibration and independent performance evaluation (see Figure 1). For reproducibility, the random number generator was initialized using set.seed(2025) in R prior to splitting the dataset, ensuring that the same training and testing subsets could be obtained in repeated analyses. Samples were randomly partitioned into training and test sets to evaluate generalization within the pooled dataset. Metadata identifying crop species, year, and growth conditions were not retained at the individual-sample level in the modeling table; therefore, we could not perform species or condition-blocked validation. As a result, the random split may partially share species- or batch-related structure between training and test sets; thus, the reported metrics should not be interpreted as strict cross-species or cross-experiment generalization. The reported performance should be interpreted as within-protocol generalization for spectra acquired using the same instrument and measurement setup.
To ensure comparability between training and testing subsets, the distributional properties of the dry matter content were statistically examined (see Table 2). The Shapiro–Wilk test was first applied to assess normality. The results indicated significant deviations from normality in both subsets (training: W = 0.8915, p < 0.001; testing: W = 0.8877, p < 0.001) suggesting a non-normal distribution of dry matter values. Visual inspection of histograms revealed positive asymmetry. Next, the Fligner–Killeen test was used to evaluate the homogeneity of variances between training and testing subsets. The test ( , p = 0.374) indicated no significant differences in variances between the two subsets. Finally, a Mann–Whitney U test (Wilcoxon rank-sum test) was applied to compare the central tendency of dry matter between the subsets. The test showed no statistically significant difference between the groups (W = 18,460, p = 0.894), confirming that the training and testing samples were drawn from comparable distributions. Overall, these results demonstrate that the training and testing subsets did not significantly differ in terms of distribution of variance.
2.4. Preprocessing and Feature Extraction
Reflectance spectra were recorded from 350 to 2500 nm at 1 nm resolution, resulting in 2151 spectral predictors per sample. Prior to modeling, data were visually inspected for outliers and missing values. Spectra were visually inspected for measurement artifacts, including abnormal reflectance magnitude, discontinuities, or physically implausible spectral shapes. One spectrum exhibited a clear anomaly characterized by an irregular reflectance pattern inconsistent with typical leaf optical properties, likely due to improper sensor–leaf contact during acquisition. This observation was therefore removed prior to analysis. No additional automated multivariate outlier detection procedures (e.g., Mahalanobis distance or Cook’s distance) were applied, as no further spectra displayed extreme leverage or atypical structure. All reflectance variables were mean-centered and standardized to unit variance to ensure equal contribution of each wavelength. To evaluate whether noise reduction could improve predictive performance, spectra were optionally smoothed using a Savitzky–Golay (SG) filter (polynomial order 2; window sizes 7, 9, 11, and 13 bands). Although SG filtering is commonly used to suppress high-frequency sensor noise while preserving absorption features, it did not improve cross-validated performance for any of the evaluated models and in most cases slightly degraded accuracy. This is likely because the raw reflectance spectra, acquired under controlled laboratory conditions, already exhibited a high signal-to-noise ratio, and smoothing may have attenuated subtle SWIR features associated with dry-matter-related structural absorption.
Although plants were cultivated under diverse environmental and treatment conditions (Table 1), all spectral measurements were acquired under controlled laboratory conditions using a fixed leaf-clip geometry and identical instrumentation. Consequently, no atmospheric or scatter corrections (e.g., SNV or MSC) were applied; standardization and PCA-based modeling were sufficient to control for scale differences and collinearity.
2.5. Spectral Indices and SWIR Feature Benchmarking
Before fitting machine learning models, we first evaluated whether dry matter content could be predicted using simple spectral indices derived from known water-sensitive wavelength regions. This step also allowed us to set a benchmark for more complex prediction methods. We examined a set of commonly used reflectance indices and SWIR-based structural proxies (Table 3).
The evaluated indices encompassed a broad range of spectral contrasts sensitive to leaf water status, biochemical composition, and structural properties (Table 3). These included water-related indices targeting absorption features near 970 nm and in the shortwave infrared (e.g., NWI, NDWI, NDII, NDWI-1640, NDWI-Hyperion), lignin- and cellulose-sensitive indices such as the Normalized Difference Lignin Index (NDLI) and the Cellulose Absorption Index (CAI), as well as several stress-oriented ratio indices derived from visible and SWIR bands (e.g., SWSI and DWSI families). In addition, two indices explicitly designed to capture dry matter variation were included, the Normalized Dry Matter Index (NDMI) and the Dry Matter Content Index (DMCI), both of which exploiting reflectance differences in the SWIR region associated with changes in leaf structural and biochemical constituents. Index values were computed separately for the training and test samples. Regression coefficients were estimated exclusively on the training set and subsequently applied to the independent test set to evaluate predictive performance.
2.6. Base Learners
Machine learning regression models can be broadly grouped into several categories, each with distinct strengths and weaknesses. Linear models assume a linear relationship between predictors and response, making them interpretable and computationally efficient, but they often struggle with complex, nonlinear patterns. Ensemble methods combine multiple learners to improve prediction accuracy. For instance, bagging approaches, such as random forests, reduce variance by averaging many models trained in parallel on bootstrap samples, while boosting algorithms, such as XGBoost, sequentially correct the errors of previous models, reducing bias but at the risk of overfitting if not tuned carefully. Kernel-based methods (e.g., support vector regression, Gaussian process regression) can capture complex nonlinearities through flexible similarity functions, offering high accuracy but with increased computational cost and less transparency. Neural networks, including deep learning architectures, are highly expressive and can model intricate feature interactions, yet they require larger datasets, careful regularization, and as black-box algorithms are difficult to interpret. In practice, these categories often complement one another: ensembles can capture nonlinearities missed by linear models, kernel methods can achieve similar flexibility without deep architectures, and neural networks can learn directly from raw, high-dimensional data when simpler models reach their limits.
In this study, eight supervised regression approaches were compared for predicting leaf dry matter content from hyperspectral reflectance data. All models were trained on identically preprocessed predictors. Reflectance spectra were first standardized to zero mean and unit variance and subsequently transformed using principal component analysis (PCA). The number of retained components K was treated as a tunable hyperparameter, with an upper bound chosen to capture at least of the cumulative spectral variance. Model hyperparameters, including K, were optimized using repeated 10-fold cross-validation (with 3 repeats) on the training set. For each method, the configuration with the lowest cross-validated root-mean-square error (RMSE) within one standard error of the minimum was selected.
For each base learner, a broad hyperparameter search space was defined (Table 4). Final model performance was evaluated on a held-out independent test set using RMSE and the coefficient of determination ( ). All modeling was conducted in R (v4.4.1) [42] using the tidymodels framework [43] and associated packages.
We should note that deep learning architectures such as one-dimensional convolutional neural networks (1D-CNNs) have been successfully applied in hyperspectral trait prediction [26]. However, such models typically require substantially larger training datasets to achieve stable generalization due to their high parameterization. Given the moderate sample size in the present study (n = 481), we prioritized regression approaches with established robustness in limited-sample, high-dimensional settings. Future work will evaluate deep learning models within the stacking framework when larger datasets become available.
We now give a brief description of each of the learners used. Partial Least Squares Regression (PLSR) is a linear method that projects predictors to a low-dimensional latent space maximizing covariance with the response [44]. It is widely used in chemometrics for spectral data due to its robustness to multicollinearity. PLSR is one the most frequently applied algorithm for modeling biological trait as a function of light reflectance spectrum [45]. As a method that focusses on feature space reduction, it is very useful when the number of independent variables is large compared to the number of observations, as in this study with 2151 variables—light reflectance at each nanometer from 350 to 2500. Principal Component Regression (PCR) is a closely related method. It is a two-stage linear method where predictors are first transformed by PCA and then used in a standard linear regression [46]. Unlike PLSR, PCR does not use the response to guide the component extraction. Elastic Net Regression is a linear model with both L1 (lasso) and L2 (ridge) penalties, allowing variable selection and shrinkage simultaneously [47]. Gaussian Process Regression (GPR) is a non-parametric Bayesian method that defines a prior over functions, updated with observed data via a kernel function [48]. GPR can capture complex nonlinear relationships but scales poorly with large datasets. Random Forest Regression (RF) is an ensemble of decision trees trained on bootstrap samples, with random feature selection at each split [49]. RF handles nonlinearities and interactions well and is robust to overfitting. Extreme Gradient Boosting (XGBoost) is a gradient boosting implementation optimized for speed and accuracy [50]. XGBoost builds trees sequentially, with each tree correcting the residuals of its predecessors, and includes strong regularization. Light Gradient Boosting Machine (LightGBM) is another gradient boosting algorithm [51].
3. Results
3.1. Spectral Index and Feature Benchmarking
To establish a baseline for predictive performance, simple linear regression models were first evaluated using each spectral index as a single predictor of leaf dry matter content. Across the 26 narrow-band and SWIR-derived indices considered (Table 3), predictive performance on the independent test set was generally limited (Table 5). The strongest individual predictive power was obtained for indices specifically designed to capture dry matter and cellulose-related absorption features. In particular, the Normalized Dry Matter Index (NDMI) achieved the lowest error (RMSE = 5.63 percentage points) leading to the highest coefficient of determination ( ), followed by the Dry Matter Content Index (DMCI) with RMSE = 6.13 and . Structural and greenness-related indices, such as CAI and NDVI, exhibited weaker but still measurable associations with dry matter content, while several shortwave stress indices (e.g., DWSI-3, DWSI-4, SWSI-2) explained only a modest fraction of variance ( ). In contrast, many commonly used water-related indices, including NDII, NDWI-1640 and MSI, showed negligible predictive power when used in isolation.
Overall, these results suggest that variation in leaf dry matter content cannot be attributed to a single dominant absorption feature or index. Instead, the signal appears to arise from a combination of biochemical composition, structural characteristics, and water-related properties that are expressed across different parts of the spectrum. The modest and highly variable performance of individual indices underscores the limitations of relying on isolated spectral contrasts. This, in turn, points to the need for modeling approaches that can integrate complementary information from multiple spectral features, providing a stronger motivation for multiple regression and full-spectrum machine learning methods.
Because individual spectral indices captured only a small fraction of the variability in leaf dry matter content, we next investigated whether combining all indices within a single regression framework could improve predictive performance. A multiple linear regression including all indices simultaneously, however, gave unstable coefficient estimates due to strong multicollinearity among indices derived from overlapping spectral regions. To address this, we employed elastic net regression, a regularized linear modeling approach that combines the properties of ridge and lasso penalties. Elastic net minimizes a penalized least squares criterion, shrinking regression coefficients toward zero and setting some of them exactly to zero, thereby stabilizing the model in the presence of correlated predictors and performing implicit variable selection. All indices were standardized (zero mean, unit variance) prior to model fitting so that the resulting coefficients were directly comparable in magnitude. The fitted Elastic Net model retained 18 of the 26 indices as predictors
On the independent test set, the Elastic Net model based on spectral indices achieved an RMSE of 4.01 percentage points and an of 0.69, representing a substantial improvement over single-index regressions. The fitted coefficients indicated that predictive signal was distributed across multiple biochemical and water-related spectral contrasts rather than being dominated by a single feature. The strongest positive effects were assigned to cellulose- and dry-matter-related SWIR features, particularly the Cellulose Absorption Index (CAI; ), together with positive contributions from NDII ( ) and the dry-matter-oriented NDMI ( ). In contrast, several indices linked to absorption features in the SWIR and water-sensitive ratios were assigned negative coefficients, including NDLI ( ), NDWI-Hyperion ( ), DMCI ( ), the Water Index ( ), SRWI ( ), and SWSI2 ( ). Overall, the coefficient pattern supports the view that dry matter estimation benefits from combining indices sensitive to structural constituents (cellulose/lignin-related absorption features) with indices capturing hydration-related variation, yielding a markedly stronger predictive baseline than any single index alone.
3.2. Single-Model Baselines
Taken together, the index-based analyses indicated that while targeted spectral indices captured some aspects of dry matter variability, they provided an incomplete representation of the underlying signal. Even when combined within a multivariate framework, these hand-crafted features did not fully exploit the richness of the hyperspectral measurements. This naturally motivated the use of more flexible regression approaches that could draw on a much broader portion of the spectral information. Accordingly, we next considered models trained on dimension-reduced representations of the full reflectance spectrum, which allowed complex and potentially nonlinear relationships between spectral features and dry matter content to be learned while mitigating issues related to high dimensionality and strong inter-band collinearity.
To support the ensemble modeling strategy, a range of regression approaches was considered, including latent-variable linear models (PCR, PLSR), regularized regression (Elastic Net), kernel-based learning (Gaussian Process Regression), and tree-based ensemble methods (Random Forest, XGBoost, and LightGBM). The intention was not to compare these methods in isolation but to assemble a diverse set of base learners that brought different strengths to the problem. Models that emphasize a broad, global structure in the spectrum were combined with others that are better suited to capturing localized or nonlinear relationships, increasing the likelihood that complementary information contained in the hyperspectral data could be effectively leveraged through ensemble learning.
The predictive performance of the individual regression models is summarized in Table 6. Among the evaluated approaches, LightGBM achieved the highest accuracy on the independent test set ( ), followed closely by latent-variable linear models, including PCR, PLSR, and Elastic Net, all of which exhibited nearly identical performance. These results suggest that a substantial fraction of the dry matter signal is encoded in broad, approximately linear spectral structures that are effectively captured by dimension-reduction methods. The near-identical test performance of PCR and Elastic Net ( ) was expected under the present modeling setup because both models were trained on the same PCA-transformed predictors. When the predictive signal is concentrated in a limited number of principal components, ordinary least squares on selected components (PCR) and a regularized linear model (Elastic Net) can converge to very similar fitted functions, particularly when cross-validation selects weak regularization. In this setting, regularization provides little additional benefit beyond dimensionality reduction, resulting in comparable generalization performance for the two methods.
Nonlinear models showed more heterogeneous behavior. Random Forest and Gaussian Process Regression provided moderate improvements over index-based approaches but did not outperform the best linear or boosting-based models, while XGBoost exhibited the lowest predictive accuracy among the tested learners. This variability indicates that no single modeling paradigm fully captures the complexity of the hyperspectral–dry-matter relationship. Instead, different algorithms appear to extract complementary information from the same spectral data, motivating their integration within a stacked ensemble framework.
3.3. Stacked Ensemble
A stacked ensemble model was constructed to combine the predictive outputs of multiple tuned base learners into a single, integrated regression framework. Candidate models from each regression family were first optimized using cross-validation and subsequently combined at the prediction level using a regularized linear meta-learner. The meta-learner was implemented as a non-negative LASSO regression, which assigns weights to individual base learners while enforcing sparsity to limit redundancy and overfitting. The final ensemble therefore represents a weighted combination of complementary models rather than reliance on a single best-performing approach.
The resulting stacked model achieved strong predictive performance for dry matter estimation (see Figure 2). On the training dataset ( ), the ensemble attained a coefficient of determination of with a root-mean-square error (RMSE) of 1.31 percentage points. Importantly, this performance generalized well to the independent test dataset ( ), yielding and an RMSE of 2.35. These results indicate that the stacked ensemble improved predictive accuracy relative to individual base learners while maintaining robust generalization to unseen data.
Although overall accuracy provides a useful summary of model performance, it does not reveal how the ensemble arrives at its predictions. Additional insight can be obtained by examining the structure of the stacked model itself, in particular which base learners are retained by the meta-learner and the configurations they represent. This perspective helps to clarify how different modeling approaches contribute to the final predictions and which types of information from the hyperspectral data are most influential within the ensemble.
Table 7 summarizes the base learners retained by the meta-learner together with their corresponding hyperparameters and weights. Although only a subset of candidate models received non-zero weights, these retained learners spanned multiple model families, indicating that the ensemble benefited from structurally diverse representations of the hyperspectral signal. To further interpret how these retained models collectively behave, Figure 3 provides a diagnostic and interpretative view of the final stacked ensemble.
Figure 3 provides a detailed interpretation of the internal behavior and diagnostic properties of the final stacked ensemble model. Together, the four panels offer insight into which spectral regions drive predictive performance, how individual base learners contribute to the ensemble, and whether systematic prediction errors are present.
Panel (a) reveals a strongly structured spectral sensitivity pattern for the stacked ensemble, indicating that predictive performance is driven by distinct wavelength regions rather than being uniformly distributed across the spectrum. The largest increases in RMSE after permutation occur in the shortwave infrared (SWIR), with pronounced sensitivity peaks spanning approximately 1400–1600 nm and 1900–2300 nm. These regions coincide with major absorption features associated with leaf water content, cellulose, lignin, and overall dry matter composition, underscoring their central role in dry matter estimation. Secondary sensitivity peaks are observed in the red-edge and near-infrared region (approximately 700–900 nm), suggesting an additional contribution from the leaf internal structure and canopy scattering effects. In contrast, the visible spectrum below roughly 600 nm exhibits comparatively low sensitivity, indicating that reflectance in this range provides limited independent information for dry matter prediction once longer wavelengths are taken into account. Overall, the spectral importance profile demonstrates that the stacked model relies predominantly on SWIR wavelengths linked to biochemical and water-related absorption processes, while integrating complementary structural information from the red-edge and near-infrared regions. This pattern is consistent with established physical interpretations of hyperspectral reflectance in vegetation and supports the use of full-spectrum modeling approaches for dry matter estimation.
Panels (b) and (c) summarize the composition of the stacked ensemble in terms of meta-learner weights. Panel (b) shows the weights assigned to individual retained base learners, while panel (c) aggregates these contributions at the model-family level. The results demonstrate that the meta-learner allocates substantial weight to multiple Gaussian process regression and principal component regression candidates, alongside additional contributions from partial least squares regression and gradient-boosted tree models. Notably, several models from the same family are retained, indicating that distinct hyperparameter configurations can capture complementary aspects of the hyperspectral signal even within a single modeling paradigm. In contrast, Elastic Net regression and Random Forest models were not retained in the final ensemble, suggesting that their predictive information was largely redundant with that provided by other learners. For Elastic Net, this likely reflects the dominance of latent-variable representations in capturing linear structure, while for Random Forests, the lack of retention may be attributed to overlap with more expressive boosting-based models that better exploit nonlinear interactions in high-dimensional spectral data. Overall, the ensemble composition highlights the benefit of combining latent-variable models, which emphasize the global spectral structure, with nonlinear learners capable of modeling localized interactions.
Panel (d) presents residuals plotted against predicted dry matter values for the test set, with a LOESS (Locally Regression) smoother included to facilitate visual assessment of potential systematic trends. Residuals are centered around zero across the prediction range, with no strong evidence of heteroscedasticity or systematic bias. A slight tendency toward underestimation at higher dry matter values is visible, which is common in hyperspectral regression problems where extreme observations are relatively scarce. Nevertheless, the absence of pronounced trends or variance inflation suggests that the stacked ensemble provides a stable and well-calibrated fit on unseen data.
Taken together, Figure 3 indicates that the stacked model achieves its improved predictive performance by integrating complementary spectral information across wavelength regions and leveraging structurally diverse base learners, while maintaining robust generalization and well-behaved residuals.
4. Discussion
The results of this study indicate that simple narrow-band spectral indices are generally insufficient for robust prediction of leaf dry matter content across heterogeneous samples. In the present dataset, even the best-performing physiologically motivated index (NDMI) explained only a limited fraction of the variance, while water-sensitive indices yielded near-zero predictive power. This behavior is consistent with long-standing spectroscopic theory and empirical evidence showing that dry-matter-related absorption features arise from cellulose, hemicellulose, and lignin, which produce broad and overlapping absorption complexes in the SWIR region rather than isolated spectral features [52,53]. As a consequence, ratio-type indices targeting individual bands tend to saturate quickly and fail to generalize when spectral or structural variability increases. The limited performance of narrow-band water and structural indices in the present study is not inconsistent with the well-established presence of water absorption features in the near- and shortwave-infrared regions. Rather, it reflects the heterogeneous structure of the dataset. The sampled leaves differed not only in water status but also in species identity, anatomical structure, developmental stage, and growth conditions. Under such conditions, reflectance variation arises from overlapping contributions of water absorption, cellulose and lignin content, internal leaf scattering, and thickness-related structural effects. Ratio-type indices targeting isolated wavelength pairs are therefore unable to disentangle these interacting sources of variability. Previous studies reporting strong correlations between SWIR indices and dry matter content were typically conducted within relatively homogeneous species groups or controlled experimental conditions, where structural variability is constrained. As biological heterogeneity increases, the predictive stability of narrow-band indices decreases, while multivariate full-spectrum approaches become more robust.
At the same time, previous studies have shown that simple dry-matter-sensitive spectral indices can exhibit moderate to strong associations with dry matter content under constrained conditions. For example, Wang et al. (2013) [40] reported strong pairwise correlations between normalized SWIR indices (e.g., NDMI, DMCI) and dry matter-related variables in relatively homogeneous vegetation samples, particularly when water absorption effects were accounted for. However, these relationships were evaluated as within-dataset associations rather than as independently validated predictive models, and their robustness is therefore expected to decrease as biological and structural heterogeneity increases. A similar pattern has been observed for more physically based approaches. The PROSPECT model, a physically based leaf radiative transfer model that simulates leaf reflectance and transmittance spectra as a function of biochemical constituents and structural properties, provides a mechanistic framework for estimating leaf traits through model inversion. PROSPECT-based inversions and physically motivated index formulations have demonstrated good performance for dry-matter-related traits under controlled experimental conditions, particularly when prior constraints on leaf structure and water content are imposed [54]. However, these studies also report increased uncertainty and reduced transferability when models are applied across species or experimental conditions, indicating that the robustness of index-based and inversion approaches is strongly dependent on the validity of their underlying assumptions.
In contrast, multivariate models that exploit information across the full hyperspectral feature space consistently yield higher predictive accuracy than narrow-band approaches. Linear latent-variable methods such as Partial Least Squares Regression (PLSR) have demonstrated strong performance for structurally driven leaf traits when applied to full-spectrum data. For example, Serbin et al. (2019) [15] reported coefficients of determination approaching for leaf mass per area across biomes and functional groups, highlighting the effectiveness of multivariate spectral representations for complex structural traits, while earlier spectroscopic work emphasized the necessity of multivariate analysis to capture broad and overlapping absorption features associated with dry matter constituents [52]. Recent studies have further shown that nonlinear machine learning models can provide additional improvements by capturing higher-order interactions and local spectral structure. For instance, Yang et al. (2020) [6] demonstrated that machine learning approaches using multivariate spectral inputs substantially reduced prediction errors for dry matter estimation relative to single-index methods. Similarly, Casas et al. (2014) [17] and Kothari et al. (2023) [16] reported consistent gains from nonlinear learners when predicting structurally driven leaf traits across species and functional groups. In line with these findings, the multivariate models evaluated here outperformed narrow-band baselines.
Importantly, no single multivariate learner consistently dominated across validation folds in the present study, indicating that different model classes captured partially distinct aspects of the spectral–trait relationship. Similar behavior has been noted in hyperspectral trait modeling studies, where model rankings vary across datasets and trait types, especially when structural and biochemical signals overlap [6,16]. This complementarity motivated the use of stacked ensemble learning in the present work.
Although the stacked model achieved very high performance on the training data (R^2^ = 0.973), the reduction to R^2^ = 0.896 on the independent test set reflects expected generalization behavior in high-dimensional regression problems. Ensemble models can closely approximate training data due to their ability to combine complementary base learners; however, some reduction in performance on unseen data is consistent with the standard bias–variance trade-off. In the present study, several mechanisms mitigate excessive overfitting, including prior dimensionality reduction, regularization within individual base learners, and constrained weight estimation at the stacking stage. The observed performance gap is therefore moderate and indicative of normal generalization dynamics rather than severe overfitting.
The absolute performance gain from stacking over the strongest individual model was modest, but this is consistent with ensemble learning theory. When base learners are already well tuned and individually strong, stacked ensembles typically provide incremental improvements by reducing model-specific bias and variance rather than dramatically increasing peak accuracy [18,49]. In the present study, the primary benefit of stacking was improved consistency across validation folds and better integration of complementary linear and nonlinear representations of the spectral signal, rather than a large increase in headline performance metrics.
Taken together, these results reinforce a conceptual distinction between traits dominated by sharp, spectrally localized absorption features and those characterized by distributed biochemical structure. While water content can often be approximated using targeted indices with high accuracy, dry matter content emerges as a spectrally diffuse trait that generally requires multivariate modeling of the full reflectance signal. Within this context, stacked learning provides a rigorous framework for integrating complementary linear and nonlinear representations of hyperspectral information, yielding more robust predictions without reliance on a single modeling assumption.
Reliable, non-destructive assessment of leaf dry matter content is important for crop monitoring and precision agriculture applications. The present results demonstrate that full-spectrum hyperspectral data combined with machine learning can provide accurate estimation of this trait across heterogeneous plant material. Nevertheless, practical deployment remains challenging because Vis–NIR reflectance is influenced by multiple interacting factors, including pigment concentrations, biochemical composition, and leaf structural characteristics. For operational use, future research should focus on identifying spectral regions most strongly and consistently associated with dry matter content across species, developmental stages, and environmental conditions. Clarifying the underlying spectral response mechanisms would support the design of simplified and cost-effective sensing systems, thereby facilitating high-throughput trait monitoring and improved crop management strategies.
5. Conclusions
Leaf dry matter content cannot be reliably predicted using narrow-band spectral indices or hand-crafted SWIR features, with the best set explaining only of variance ( ).Combining multiple indices using Elastic Net regression improves performance ( ) but remains insufficient for accurate dry matter estimation.Full-spectrum machine learning models capture substantially more information, with a stacked ensemble of PLSR, GPR, and gradient boosting achieving on the test set.Ensemble performance arises from combining latent linear structures with nonlinear refinements, highlighting the complementary strengths of different algorithms.The trait cannot be reduced to a single wavelength, and integrating information across the hyperspectral signal provides both methodological and mechanistic advantages.The approach is suitable for high-throughput trait estimation and can be extended to other traits or environmental conditions. Future work will focus on improving model transferability and incorporating uncertainty quantification for operational plant monitoring.Transfer of the modeling approach to data acquired with different spectrometers may require recalibration and retraining using representative samples, as differences in spectral resolution, wavelength alignment, and noise characteristics can affect predictions. However, the stacked ensemble framework and preprocessing strategy remain applicable, and dimensionality reduction helps capture spectral structure that is robust across measurement systems.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Yang Y. Guo X. Liu G. Liu W. Xue J. Ming B. Xie R. Wang K. Hou P. Li S. Solar Radiation Effects on Dry Matter Accumulations and Transfer in Maize Front. Plant Sci.20211272713410.3389/fpls.2021.72713434603357 PMC 8481901 · doi ↗ · pubmed ↗
- 2Zhang H. Chen X. Xue D. Zhang W. Li F. Teng A. Zhang C. Lei L. Ba Y. Dry Matter Accumulation, Water Productivity and Quality of Potato in Response to Regulated Deficit Irrigation in a Desert Oasis Region Plants 202413192710.3390/plants 1314192739065454 PMC 11280481 · doi ↗ · pubmed ↗
- 3Wen L. Meng M. Liu K. Zhang Q. Zhang T. Chen Y. Liang H. Effect of Photoperiod on Dry Matter Accumulation and Partitioning in Potato Agriculture 202414115610.3390/agriculture 14071156 · doi ↗
- 4Nishikawa H. Oenema J. Sijbrandij F. Jindo K. Noij G.-J. Hollewand F. Meurs B. Hoving I. Van Der Vlugt P. Bouten M. Dry Matter Yield and Nitrogen Content Estimation in Grassland Using Hyperspectral Sensor Remote Sens.20231541910.3390/rs 15020419 · doi ↗
- 5Spomer L.A. Techniques for Measuring Plant Water Hort Science 1985201021102810.21273/HORTSCI.20.6.1021 · doi ↗
- 6Yang B. Lin H. He Y. Data-Driven Methods for the Estimation of Leaf Water and Dry Matter Content: Performances, Potential and Limitations Sensors 202020539410.3390/s 2018539432967134 PMC 7570687 · doi ↗ · pubmed ↗
- 7Katsoulas N. Elvanidi A. Ferentinos K.P. Kacira M. Bartzanas T. Kittas C. Crop Reflectance Monitoring as a Tool for Water Stress Detection in Greenhouses: A Review Biosyst. Eng.201615137439810.1016/j.biosystemseng.2016.10.003 · doi ↗
- 8Lu Y. Saeys W. Kim M. Peng Y. Lu R. Hyperspectral Imaging Technology for Quality and Safety Evaluation of Horticultural Products: A Review and Celebration of the Past 20-Year Progress Postharvest Biol. Technol.202017011131810.1016/j.postharvbio.2020.111318 · doi ↗