MTL_TX: A Multi-Task Transformer Model for Improved Radiation Time-Series Estimation
Hongfang Zhang, Adam Stavola, Hal Ferguson, Bence Budavari, Hongyi Wu, Chiman Kwan, Jiang Li

TL;DR
This paper introduces MTL_TX, a transformer-based model that improves radiation dose estimation at JLab using historical sensor data.
Contribution
The novel MTL_TX model integrates hierarchical feature embedding and multi-level decomposition attention for enhanced radiation time-series estimation.
Findings
MTL_TX achieved an R2 score of 0.8584 on 2018 data and 0.8831 when generalizing to 2016-2019 datasets.
The model outperformed existing state-of-the-art methods in radiation dose estimation accuracy.
Abstract
Controlling radiation doses at potential radioactive facilities is critical to ensuring the safety of both personnel and the public. At the Thomas Jefferson National Accelerator Facility (JLab), multiple sensors are deployed around the three experimental halls to monitor key parameters, including single-beam current, energy levels, current leakage, and radiation values during accelerator operations. In this study, we developed a Multi-task Transformer model, MTL_TX, to accurately estimate radiation doses at sensor locations based on historical data, with the aim of enhancing safety in accelerator facilities and surrounding public areas. To improve estimation accuracy, we integrated two innovative components into the proposed model: hierarchical feature embedding (HFE) and multi-level decomposition attention (MDA). Additionally, the multi-task learning (MTL) framework effectively…
Click any figure to enlarge with its caption.
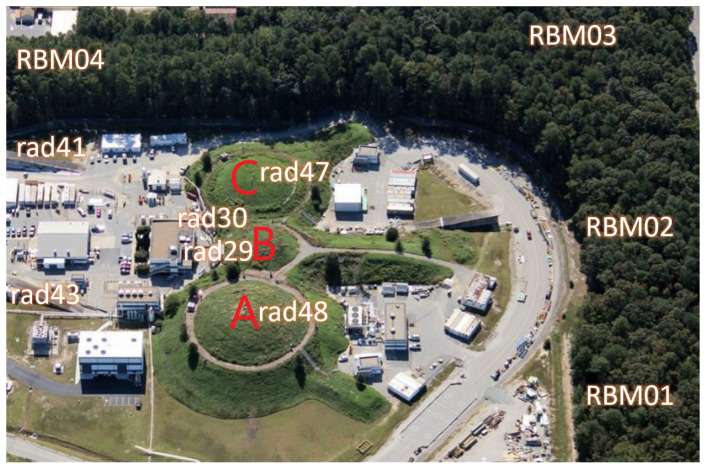 Figure 1
Figure 1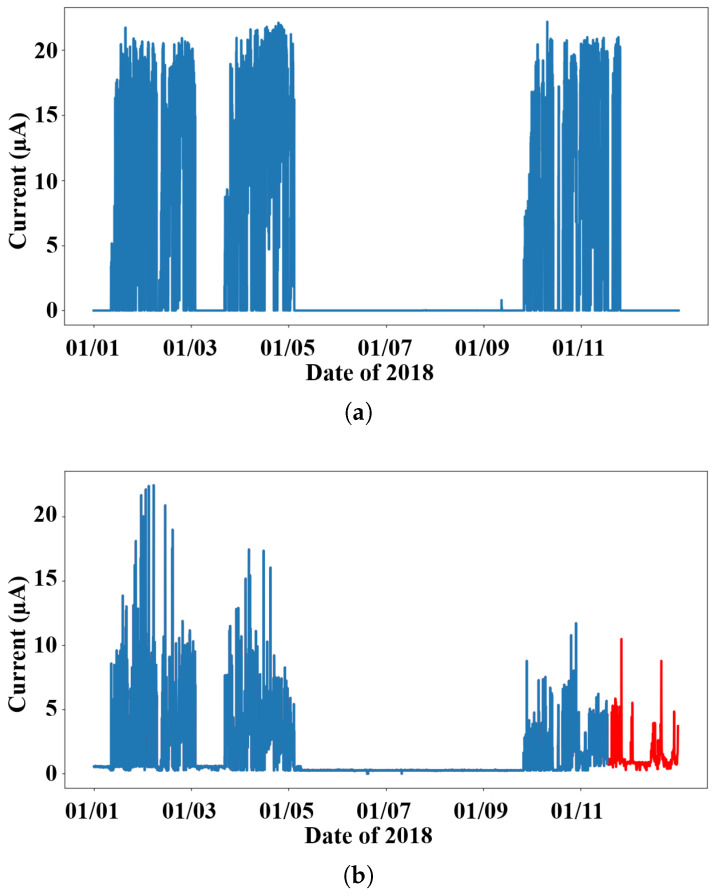 Figure 2
Figure 2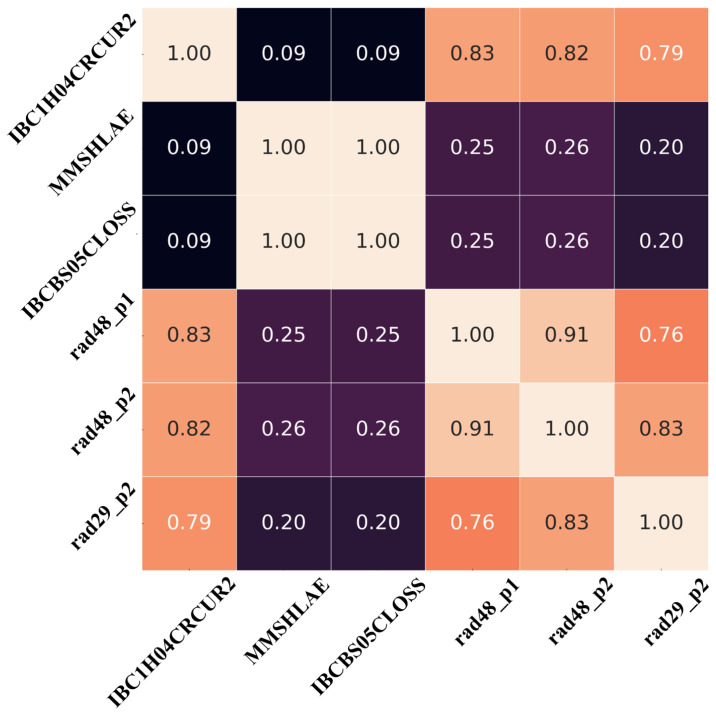 Figure 3
Figure 3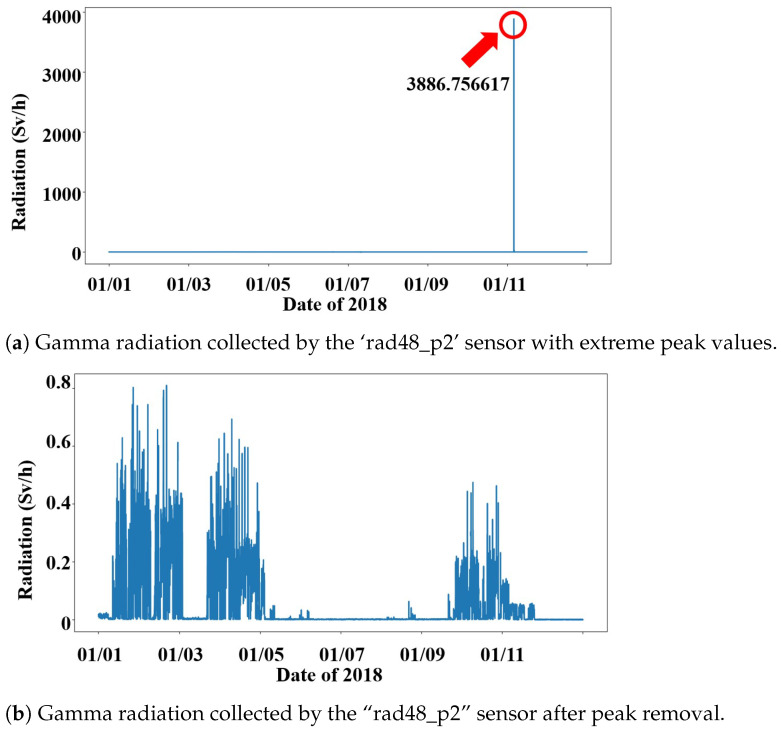 Figure 4
Figure 4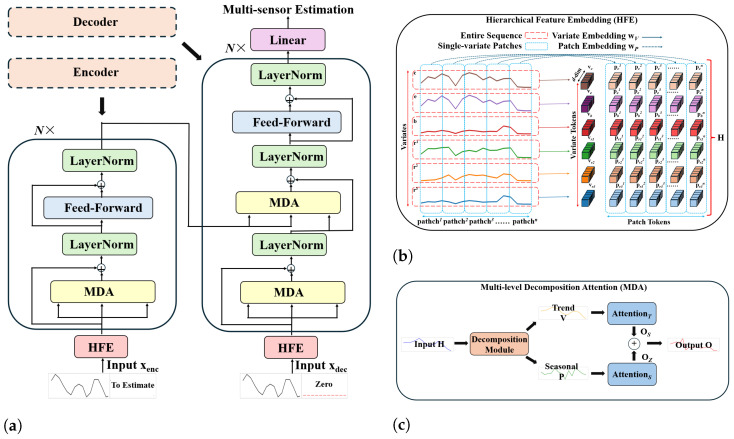 Figure 5
Figure 5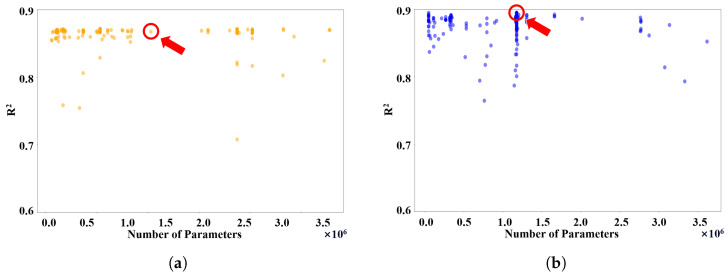 Figure 6
Figure 6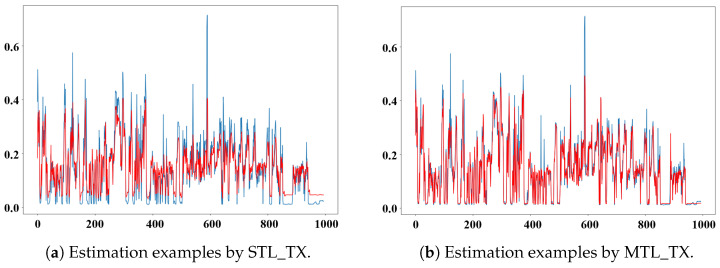 Figure 7
Figure 7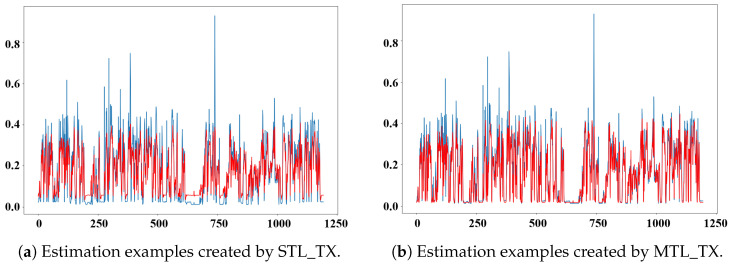 Figure 8
Figure 8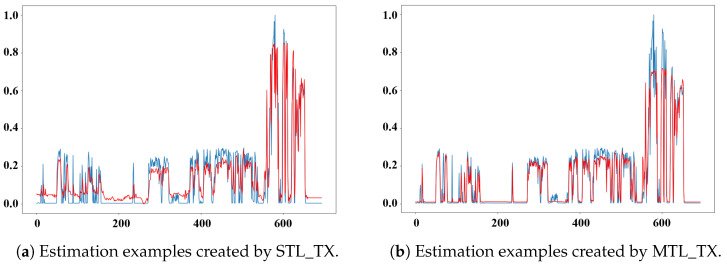 Figure 9
Figure 9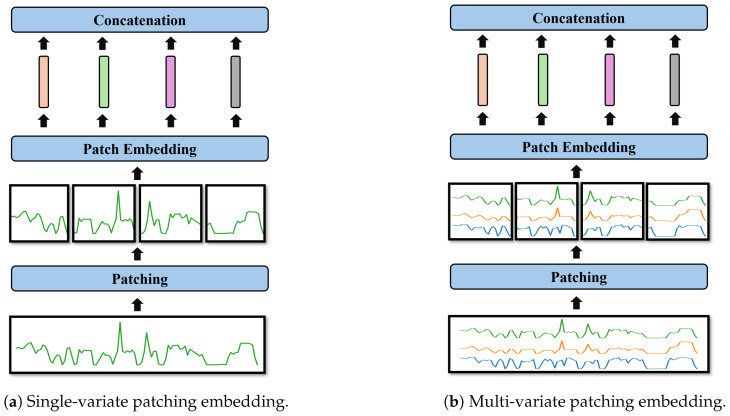 Figure 10
Figure 10- —U.S. Department of Energy, the Office of Science Continuation Funding for SBIR/STTR
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAir Quality Monitoring and Forecasting · Radioactive contamination and transfer · Fire Detection and Safety Systems
1. Introduction
Radiation estimation is a critical aspect of controlling radiation dispersion in accelerator facilities. The Department of Energy (DOE) mandates that radiation exposure in such facilities complies with legal standards to protect personnel, the public, and the environment [1]. At the Thomas Jefferson National Accelerator Facility (JLab), administrative control policies are implemented to maintain radiation exposure as low as reasonably achievable (ALARA), limiting annual doses for unmonitored personnel and the public to 10% of the federal limit (0.1 mSv or 10 mrem). Therefore, minimizing radiation exposure for personnel within the facility without compromising operational efficiency is essential. Traditional methods of controlling radiation exposure primarily focus on controlling radiation sources and improving protective measures between sources and personnel. To ensure compliance with radiation safety regulations, facilities typically rely on active and passive real-time monitoring using radiation sensors to assess both on-site and off-site radiation fields. However, this approach often requires significant resources for effective radiation exposure management, creating challenges for optimizing safety and operational efficiency.
Deep learning (DL) models have demonstrated superior performance in radiation analysis across various radiation sources [2,3,4,5]. In our previous work, we developed a multi-task learning (MTL) framework based on accelerator data characteristics, utilizing long short-term memory (LSTM) and convolutional neural network (CNN) architectures as backbones for effective radiation estimation [6]. Leveraging DL models for automated radiation dose estimation reduces operational costs and enables real-time monitoring, ensuring regulatory compliance for accelerator configurations. Transformers [7] have been extensively studied and have proven to outperform traditional neural networks in time-series analysis, offering enhanced capabilities for capturing both short-term and long-term dependencies. However, there are no existing Transformer-based models specifically designed for radiation estimation in high-energy accelerator environments, which leaves a gap in benchmark comparisons. This paper aims to develop an MTL deep learning model, named MTL_TX, which is based on the Transformer architecture to enhance radiation estimation.
MTL_TX is designed to capture correlations among historical readings across all sensors and provide synchronized, real-time radiation estimates across multiple sensor locations. It is important to clarify that the proposed framework is not intended to model the underlying radiation physics or radiation transport mechanisms of accelerator facilities. Instead, this work addresses the problem of multi-sensor radiation estimation, where reliable real-time estimation must be achieved under noisy, incomplete, and heterogeneous sensing conditions. Building on existing innovations in Transformer architectures, we introduce novel components tailored to the unique characteristics of the collected data, with further enhancement of radiation estimation performance. The proposed model is comprehensively compared with previously developed deep learning frameworks and several other competing methods. Experimental results demonstrate that MTL_TX achieves state-of-the-art performance. Our main contributions are summarized as follows:
- Radiation monitoring at high-energy accelerator facilities is formulated as a multi-sensor estimation problem, and a unified Transformer-based multi-task framework is constructed to jointly estimate radiation values at multiple sensor locations.
- Two novel components, hierarchical feature embedding (HFE) and multi-level decomposition attention (MDA), are specifically tailored for radiation estimation.
- Extensive experiments demonstrate the superior performance of the proposed model, particularly in estimating radiation doses on unseen datasets.
The HFE component integrates global variate embeddings and local patch embeddings into a hierarchical representation to capture inter-sensor dependencies, and the MDA component decomposes input sequences into trend and seasonal components to model multi-level temporal patterns. In summary, MTL_TX achieved = 0.8584 and = 0.2353 on unseen data from the same year, and an average = 0.8831 with = 0.2263 across different years.
The remainder of this paper is organized as follows: Section 2 reviews the related work. Section 3 describes the proposed methodology. Section 4 outlines the experimental setup. Section 5 analyzes the experimental results. Section 6 discusses implications and limitations. Finally, Section 7 concludes the study and outlines directions for future research.
2. Related Work
2.1. Radiation Monitoring at JLab
The main research facility at JLab is the continuous electron beam accelerator facility (CEBAF), which consists of a polarized electron source, an injector, and a pair of superconducting radiofrequency linear accelerators [8]. This facility is capable of accelerating electrons (negatively charged subatomic particles) to nearly the speed of light. The beam delivered to Halls “A”, “B“, and “C“ reaches approximately 11 GeV after five full passes [9]. The electron beam is delivered to four experimental halls, labeled “A”, “B“, and “C“, as shown in Figure 1. The facility is located in Newport News, Virginia. Each hall is equipped with specialized spectrometers to record the products of collisions between the electron beam or real photons and stationary targets; these interactions generate radiation exposure during operation.
Multiple radiation sensors are deployed around the experimental halls to monitor both accessible and non-accessible areas in real time. For instance, sensors labeled “rad##“ represent on-site monitors, while sensors labeled “RBM##“ indicate Radiation Boundary Monitors (RBMs), where “##“ denotes the specific location number. The boundary sensors play a crucial role in monitoring radiation exposure in public areas adjacent to the accelerator facility. Each on-site monitoring sensor is equipped with two channels: gamma and neutron, whose data are archived in the system as “_p1“ and “_p2“, respectively. This study focuses on analyzing the radiation doses in Hall “A”, utilizing data from nearby sensors “rad29“, “rad43“, and “rad48“. These sensors provide essential real-time radiation data, supporting both operational safety and regulatory compliance at JLab.
On-site gamma radiation sensors, referred to as Continuous Area Radiation Monitors (CARM), utilize commercially available probes (Canberra^®^/RemRad^®^ IP100 series ionization chambers) with a typical dose measurement range of 100 µSv/h to 1 Sv/h (0.1 mrem/h to 1 R/h). Neutron radiation is measured using BF3 probes inside Anderson–Braun-type moderators. The effective dose measured by these instruments quantifies the biological risk associated with specific radiation levels. Each radiation sensor independently measures neutron and gamma radiation, and the total radiation dose received by personnel on-site is calculated as the sum of these two components.
Radiation data are collected on a rolling basis with an interval typically not exceeding one minute. The instruments are equipped with internal settings to convert count rates into dose rates (e.g., µSv/h) and to store the collected dose rates in the JLab archival system. This system provides programmatic access to historical data spanning several years and facilitates temporal alignment of outputs from multiple sensors through data resampling. In this study, we focus on data archived from 2016 to 2019, with a resampled interval of one hour.
2.2. Transformer Framework
Transformer models have revolutionized deep learning by replacing traditional recurrent and convolutional operations with self-attention mechanisms [7]. This architectural shift enables efficient parallel computation and the capture of long-range dependencies, making Transformers highly effective in natural language processing, computer vision, and speech recognition. Recent advancements highlight their success across various domains, including BERT [10] and GPT-3 [11] in language modeling, Vision Transformer (ViT) [12] in image analysis, and Speech-Transformer [13] in audio processing. In time-series analysis, Transformers have gained attention for their ability to model complex temporal dependencies. Various studies have refined the Vanilla Transformer to address domain-specific challenges. Informer [14] addressed the inefficiencies of standard attention mechanisms by introducing sparse self-attention and a ProbSparse strategy, enabling long-sequence forecasting with reduced computational overhead. Autoformer [15] extended this approach by incorporating decomposition-based attention mechanisms, separating trend and seasonal components to improve interpretability and estimation accuracy. FEDformer [16] integrated frequency-domain modeling through Fourier and wavelet transforms, effectively capturing both local and global temporal patterns.
2.3. Time-Series Embedding
Recent advancements in embedding strategies have enhanced feature representation and inter-variable relationships in time-series models. PatchTST [17] segments each variable into non-overlapping patches, effectively capturing local temporal patterns. iTransformer [18] inverts the embedding dimension, mapping a single variable’s entire sequence into a high-dimensional feature space (Variate Tokens), allowing the attention mechanism to naturally model multivariate correlations. These studies improve the efficiency and scalability of Transformers in handling complex time-series data. Our previous work has preliminarily examined the impact of different embedding methods and attention mechanisms on JLab-specific tasks [19,20]. Transformers have also shown promise in specific applications such as anomaly detection [21], energy forecasting [22], and industrial IoT data analysis [23]. However, the application of Transformers to datasets in high-energy accelerator facilities remains unproven.
2.4. Multi-Task Learning
Multi-task learning (MTL) enhances machine learning models by leveraging shared representations across related tasks, improving generalization and reducing overfitting compared to single-task learning (STL) [24]. In time-series analysis tasks, MTL enables simultaneous learning from multiple correlated sequences. MTTrans [25] introduced a multi-task Transformer model with shared attention blocks and task-specific decoders to balance knowledge sharing and task differentiation. Crossformer [26] extended this approach with cross-dimension attention, capturing variable interdependencies while supporting multi-task predictions. Transformer models also perform well in cross-domain MTL by utilizing shared attention layers. Perceiver [27] leverages latent space representations to handle multi-modal and multi-task data, offering a flexible framework for diverse inputs. In healthcare, TransMTL [28] applies Transformers to jointly predict patient outcomes across multiple clinical tasks, demonstrating their ability to integrate task-specific nuances with shared temporal patterns.
3. Methodology
3.1. Data Pre-Processing and Selection
This study utilizes archived datasets collected at JLab from 2016 to 2019 and focuses on radiation sensors deployed near Hall A to address the challenge of real-time radiation estimation. Table 1 summarizes the radiation sensors deployed around Hall A, each monitoring distinct physical parameters: a sensor for injected current (labeled “IBC1H04CRCUR2”), a sensor for energy measurement (labeled “MMSHLAE”), a beam loss monitor (BLA, labeled “IBCBS05CLOSS”), and radiation sensors for monitoring gamma and neutrons (labeled “rad48”, “rad43”, and “rad29”). The data usage of each sensor in the model is also indicated in the table.
Figure 2a presents the hourly injected beam current values for Hall A during the 2018 experimental period, while Figure 2b shows the gamma radiation recorded by the “rad48_p1” sensor above Hall A. The archived radiation data contains noise arising from missing beam-related measurements, sensor malfunctions, and operational transitions. To ensure physical consistency, radiation readings whose corresponding injected beam current is missing or unchanged were treated as invalid. Anomalous readings of the “rad48_p1” sensor at the end of 2018 have been removed due to their irrelevance to the corresponding beam current values, as highlighted in red in Figure 2b. Table 2 summarizes the distribution of data segments used in this study. Based on data continuity and noise conditions, where most remaining periods exhibit only near-zero fluctuations, segments were selected according to intervals containing sustained and physically meaningful radiation responses. The 2018 dataset was divided into three segments for model training and testing. The 2016, 2017, and 2019 datasets contained only one usable segment that satisfied these criteria due to higher noise levels and data discontinuities and were used to assess the model’s generalization capabilities.
The “rad43_p1” and “rad43_p2” sensors were excluded from this study due to excessive noise in their recorded data, while the “rad29_p1” sensor was excluded due to significant data gaps. Figure 3 illustrates the correlation matrix for sensor data recorded in Hall A during 2018, including injected single-beam current, energy, beam loss accounting (BLA), and radiation values. The matrix employs Pearson correlation coefficients [−1, 1] to quantify relationships between variable pairs: values near ±1 indicate strong correlations, while those close to 0 suggest weak or no linear dependency. The injected beam current shows a clear correlation with all radiation values, as it is the primary source of radiation. Although BLA exhibits a relatively low correlation with other sensor data, it measures beam current loss in the injector and provides an underlying physical link between current and energy. To estimate current radiation values at “rad48_p1”, “rad48_p2”, and “rad29_p2”, the model leverages historical and concurrent data from Hall A’s beam current, injected energy, BLA, and past radiation measurements.
Radiation data collected in accelerator environments occasionally exhibits extreme spikes that exceed normal radiation levels by several orders of magnitude. As shown in Figure 4a, the “rad48_p2” sensor in 2018 contains multiple abnormal peaks, with the maximum reaching 3886.76 Sv/h. These values are physically implausible under normal beam operation and are not accompanied by corresponding changes in beam current or energy, indicating data logging errors. To mitigate their impact on model training while preserving temporal continuity, such peak values were not removed but set to zero. After this handling, the radiation series returns to a stable and physically reasonable range, as illustrated in Figure 4b. This strategy prevents extreme outliers from dominating the loss function and was applied consistently across all datasets.
3.2. Radiation Estimation
The proposed deep learning model takes historical sensor readings as input and outputs the estimated radiation values for the sensors at the current time step. Let , , and represent the time series of injected current, energy, and beam loss accounting (BLA) recorded at JLab, respectively, where each sequence has a length of T. Similarly, let denote the radiation time series recorded by sensors “rad48_p1”, “rad48_p2”, and “rad29_p2”, where j indexes the specific sensor and each sequence also has a length of T. The model estimates the radiation values aat the current time step, t, , by leveraging the previous m time steps of data from C, E, B, and . This task can be formulated using either single-task learning (STL) or multi-task learning (MTL) frameworks.
Before constructing supervised learning samples for radiation estimation, the raw sensor time series are processed through a deterministic preprocessing pipeline. This pipeline enforces physical consistency, removes spurious extreme values, and extracts contiguous beam-on segments suitable for model training and evaluation. The overall preprocessing procedure is summarized in Algorithm 1. Algorithm 1 Data preprocessing pipeline for radiation time-series modeling.
- 1.Input: Raw multivariate time series , and signal-specific peak thresholds .
- 2.Output: Cleaned contiguous time series for STL and MTL model training and evaluation.
- 3.Missing-data handling: Construct a validity mask
All time indices with are discarded, and the remaining samples are re-indexed to form a valid timeline.
- 4.Peak detection and suppression: Define signal-specific thresholds
For any signal , a peak is detected if
Detected peaks are suppressed by zero replacement:
- 5.Segment selection: Define the set of beam-on indices
Let and denote the start and end of a contiguous beam-on interval. The set of maximal beam-on segments is
Short or unstable segments are discarded, and the remaining segments in are used for modeling.
3.2.1. STL Task
For the sensor, an independent model is trained to estimate the radiation value :
where denotes the estimated radiation value for sensor j at time t; and , , represent the historical and current values of current, energy, and BLA over a sliding window of size m; denotes the historical radiation values, where “0“ represents the current radiation value, to make all input variables the same length. The function is a model trained specifically for the sensor, and represents the set of parameters.
3.2.2. MTL Task
In this context, an MTL model is trained to simultaneously estimate radiation values for all three radiation sensors at time t,
where represent the estimated radiation values for sensors “rad48_p1”, “rad48_p2” and “rad29_p2” at the current time t, respectively. The function denotes the proposed MTL model, parameterized by .
3.3. Proposed MTL_TX Model
Figure 5 illustrates the MTL_TX model, where the model first embeds input variables using the hierarchical feature embedding (HFE) module. The embedded vectors are then processed through the multi-level decomposition attention (MDA) module. Subsequently, the generative decoder utilizes the processed vectors to estimate radiation values for all sensors simultaneously. The HFE module combines global variate tokens and localized patch tokens to capture both long-term trends and short-term patterns, while the MDA module decomposes inputs into trend and seasonal components, thereby enhancing the model’s ability to capture complex temporal dependencies.
3.3.1. Hierarchical Feature Embedding (HFE)
In the literature, iTransformer [18] introduced channel embedding (variate) to capture the global temporal features of time series, while PatchTST [17] proposed patch embedding to capture localized temporal patterns. In the HFE module, we integrate these two approaches to combine global and local features, capturing the hierarchical characteristics of radiation estimation.
Given the input matrix , where , a global variate token and multiple localized patch tokens are computed for each input variable separately. Using as an example, the global variate token is computed as
where , and is a learnable weight matrix that projects to a d-dimensional variate token. The input variable is then divided into non-overlapping patches of length p, as follows:
Each patch is mapped to a high-dimensional embedding space as
where , and is a learnable weight matrix. The final embedding for is obtained by concatenating the global variate token with all patch embeddings.
The same process is repeated for each input variable, and the final embedding input matrix, , is
3.3.2. Multi-Level Decomposition Attention (MDA)
The MDA module consists of two attention mechanisms: the Trend Attention mechanism and the Seasonal Attention mechanism. Let , where
The Trend Attention mechanism processes to extract long-term dependencies and inter-variable relationships.
where are the learnable weight matrices for the query , key , and value , and denotes the projected feature dimension. The Seasonal Attention mechanism processes to capture localized variations.
where are the learnable weight matrices. The final output of the MDA module is obtained by combining the Trend and Seasonal Attention outputs as follows:
MDA integrates global trends and localized seasonal features, enabling MTL_TX to effectively capture multivariate correlations and multi-level temporal dependencies.
3.3.3. Inputs to Encoder and Decoder
The proposed MTL_TX adopts an encoder–decoder architecture in which radiation measurements are modeled as intrinsic system state variables rather than independent driving inputs. In accelerator environments, radiation levels exhibit coupled temporal dynamics influenced by beam current, energy, beam loss, and facility-specific operational conditions. Historical radiation measurements therefore encode the instantaneous system state from which future radiation levels can be inferred.
During training, the encoder receives the multivariate historical sequence
The encoder aggregates beam-related inputs and radiation histories to form a global representation of the coupled system state and its long-range temporal dependencies.
The decoder input design is inspired by generative decoding in Informer [14]. Specifically, the decoder is fed with
where denotes the historical radiation measurements of the sensor j, augmented with a zero-valued placeholder that masks the radiation value at the current time step t. The decoder generates the estimated radiation values
Providing historical radiation measurements to the decoder serves two purposes in the MTL framework. First, they initialize the generative decoding process by supplying the most recent system state, enabling the modeling of short-term radiation dynamics that are not fully observable from beam parameters alone. Second, in the multi-output setting, the joint radiation history guides synchronized prediction across tasks, encouraging coherent multi-sensor estimation within a single forward pass. Beam-related variables ( , , and ) are incorporated exclusively through encoder–decoder attention, allowing the decoder to focus on radiation state evolution conditioned on the encoded global context.
3.3.4. Loss Functions
We utilize the mean squared error (MSE) loss with the Elastic Net regularization [29] to train the proposed model. Elastic Net incorporates regularization (LASSO), which induces sparsity by shrinking coefficients of less relevant features to zero, and incorporates regularization (Ridge), which prevents overfitting by penalizing large coefficients:
where the first term represents the MSE computed over the three sensors over the dataset, and denote the and regularization terms, respectively, and control the strength of the regularization to balance feature sparsity and smoothness.
3.4. Evaluation Metrics
In this study, we use Relative Absolute Error (RAE), Relative Squared Error (RSE) [30], Mean Absolute Error (MAE), Root Mean Squared Error (RMSE) [31], and the coefficient of determination ( ) [32] to assess the performance of the proposed model. RAE represents the ratio of the absolute error to the actual value, while RSE measures the ratio of the squared error to the squared deviation of the actual value, both of which are used to assess the deviation between estimated and actual values. MAE computes the average of the absolute errors between the estimated and actual values, and RMSE quantifies the root mean square of the squared errors, representing the estimation errors produced by the model. For RAE, RSE, MAE, and RMSE, lower values indicate higher estimation accuracy.
The metric, also known as the coefficient of determination, evaluates the goodness-of-fit of the model. Higher values indicate better model performance and represent the ratio of the explained variance to the total variance in the regression task. The formulas for these metrics are defined as follows:
where represents the mean of actual values. These metrics provide a comprehensive evaluation of the model’s accuracy and robustness in estimating radiation values.
3.5. Choice of Competing Models
We compare MTL_TX with several baseline models, including STL models proposed in [6], such as linear regression (LR) [33], random forest (RF) [34], multilayer perceptron (MLP) [35], support vector regressor (SVR) [36], STL CNN [37], STL LSTM [38], and STL Vanilla Transformer (STL_TX). Each STL model was optimized using the Optuna optimizer [39], a Bayesian hyperparameter optimization framework designed to identify optimal configurations efficiently. For the RF model, grid search was employed to determine the best parameter settings. We also compared the proposed model with the MTL bypass-path framework, where CNN and LSTM are selected as backbones.
4. Experimental Setups
4.1. Experiments
To validate the effectiveness of the proposed MTL framework for time-series radiation estimation for JLab-specific tasks, we conducted the following four experiments.
4.1.1. Hyperparameter Optimization
In the first experiment, we performed hyperparameter optimization for STL_TX and MTL_TX using JLab’s 2018 dataset. STL_TX focuses on estimating radiation values exclusively for the “rad48_p1” sensor using data from Hall A sensors, while MTL_TX simultaneously estimates radiation values for three sensors: “rad48_p1,” “rad48_p2,” and “rad29_p2”. We employed the Optuna optimizer [39] to identify the optimal hyperparameter configurations, aiming to maximize the score on the training data. Both models utilized a historical window size of . To ensure fairness, we adjusted the configurations to maintain a similar parameter count for both models.
4.1.2. Comparison Study with Competing Models
As illustrated in Figure 2, the recorded data from 2018 were divided into three segments. The second segment was used to train all competing models due to the inclusion of significant variations in input current. The first and third segments were then used for model evaluation. All competing models underwent a parameter search using Optuna to determine optimal architectures. The MTL LSTM and MTL CNN models from previous work retained their original configurations as reported in [6]. All models were configured with the same input settings, leveraging historical data from multiple sensors to estimate the current radiation values for each sensor.
4.1.3. Model Generalization Testing on Data from Different Years
The three data segments from 2018 exhibit similar distribution characteristics and are highly correlated. Consequently, evaluating model performance solely on these segments is insufficient to demonstrate the models’ robustness. To further assess generalization capabilities, all trained competing models were tested on archived data from the years 2016, 2017, and 2019. As shown in Table 2, the datasets from these years comprise one segment due to substantial noise, with only relatively clean segments included for testing. Evaluating performance on these datasets provides a comprehensive assessment of the robustness of the competing models.
4.1.4. Ablation Study
Ablation Study for Different Architectures
The architecture ablation study evaluates the roles of the encoder, decoder, and cross-sensor information modeling. Three architectural variants were considered. (1) Encoder-only: the model directly maps beam-related variables, including injected current , energy , and BLA , together with cross-sensor historical radiation sequences , to estimate the current radiation values. (2) Encoder–decoder without cross-sensor radiation in the encoder: the encoder is restricted to beam-related inputs , while the decoder is conditioned on historical radiation sequences to perform estimation. (3) Proposed full encoder–decoder: the encoder jointly models beam conditions and cross-sensor radiation histories, and the decoder performs conditioned temporal generation based on radiation sequences.
Ablation Study for Different Decoder Inputs
The decoder input ablation study investigates the role of historical radiation conditioning in the decoder while keeping the encoder identical to the full MTL_TX configuration. Three decoder input settings are evaluated.
(1) Full radiation conditioning:
where denotes the historical radiation sequence of sensor j.
(2) Zero-sequence conditioning:
which removes radiation information while preserving temporal structure.
(3) Zero-token conditioning:
which collapses the decoder input to a constant non-informative sequence.
For all configurations, the model outputs the multi-sensor radiation estimates at the current time step t.
Ablation Study for the Components in the Proposed Method
The component-wise ablation study evaluates the contribution of individual modules in MTL_TX. The baseline model was a Vanilla Transformer, serving as a reference for performance comparison. The proposed components were incrementally added to the baseline model. First, Elastic Net was introduced into the baseline model to enforce sparsity and mitigate overfitting. Next, the HFE module replaced the standard temporal embedding, introducing high-dimensional representations that capture both global and local sequence features. Finally, the MDA module was integrated to construct the fully optimized MTL_TX model, enabling the decomposition of input sequences into trend and seasonal components within the attention mechanism. Notably, MDA is designed to complement HFE, as the hierarchical structure provided by HFE enhances the effectiveness of decomposition-based attention.
4.2. Implementation Details
All models in this study were implemented using the Keras 3.8.0 [40] and the PyTorch 2.6.0 [41] frameworks. Hyperparameter optimization was performed using the Optuna optimizer, with 300 trials used to identify an optimal historical window size of . For all deep learning models, the Adam optimizer was used with an initial learning rate of 0.001, a weight decay of 1 × , a batch size of 256, and a maximum of 100 epochs. Early stopping was applied with a patience of 10 epochs to prevent overfitting. MTL_TX was configured with four attention heads, a hidden dimension of 128, and a feedforward network dimension of 256. A dropout rate of 0.1 was used to enhance generalization. Elastic Net regularization was applied with to control the overall regularization strength, while the scaling factor was used to ensure a balanced contribution from (sparsity) and (smoothness) regularization. All experiments were conducted on the high-performance computing cluster at Old Dominion University, utilizing NVIDIA A100 GPUs to accelerate training.
5. Results
5.1. Hyperparameter Optimization Results
Figure 6 illustrates the hyperparameter search results for STL_TX and MTL_TX. The X-axis represents the number of parameters in each trial, while the Y-axis denotes the corresponding score. On average, the MTL_TX model outperformed the STL_TX model over 300 trials. For a fair comparison, we selected STL_TX and MTL_TX configurations with approximately 12,000 parameters for subsequent experiments, as highlighted in Figure 6. Notably, trials with similar parameter counts exhibited variations in scores due to random parameter initialization, thereby leading to different local optima. We evaluated STL_TX and MTL_TX on the first and third segments of the 2018 archived dataset, with the results presented in Table 3. MTL_TX achieved the best performance, with an RSE of 22.0956%, RAE of 32.4656%, MAE of 0.1464, RMSE of 0.2353 and an score of 0.8584, significantly outperforming STL_TX.
5.2. Comparative Results on Data Collected in 2018
Table 4 presents the average test results for all competing models on the first and third segments of the 2018 dataset. All models were trained on the second segment of the data. MTL_TX achieved the best performance across all metrics. Notably, it significantly outperformed the MTL LSTM model of our previous work, demonstrating clear improvements. It is also worth mentioning that STL_TX performed comparably to the MTL LSTM model, further highlighting the remarkable capability of the Transformer architecture in handling time-series modeling. Additionally, MTL models consistently outperformed STL models, showcasing the advantage of the MTL approach in capturing valuable inter-sensor correlations. This is particularly crucial for JLab’s radiation estimation tasks, where data collected from multiple sensors exhibits inherent dependencies.
5.3. Generalization Results on Data from Different Years
Table 5 presents the average test results of all competing models on datasets from 2016, 2017, and 2019, where all models were trained on the second segment of the 2018 data. MTL_TX achieved the best performance, with an average RSE of 37.2067%, RAE of 21.2411%, MAE of 0.1407, RMSE of 0.2263, and an score of 0.8831, demonstrating its superior generalization capability in estimating radiation values across different years. This is particularly critical for JLab’s radiation estimation tasks, where data characteristics can vary significantly due to operational or environmental factors. The findings further confirm that the MTL framework effectively leverages inter-sensor correlations and temporal dependencies, enabling reliable estimation on unseen datasets.
5.4. Ablation Study Results
5.4.1. Architecture Ablation Study
Table 6 summarizes the architecture ablation results. The encoder-only model achieves moderate performance, with an of 0.5859, indicating that joint modeling of beam-related variables and cross-sensor radiation history captures part of the radiation state. In contrast, removing cross-sensor radiation inputs from the encoder leads to a substantial performance degradation ( ), suggesting that beam-related signals alone are insufficient for reliable radiation estimation. The proposed full encoder–decoder architecture achieves the best performance ( ), demonstrating that accurate estimation requires both cross-sensor state representation in the encoder and conditioned temporal generation in the decoder.
5.4.2. Decoder Input Ablation Study
Table 7 reports the results of the decoder input ablation study. When historical radiation information is removed from the decoder, performance degrades substantially. Both the zero-token and zero-sequence configurations yield limited accuracy, with values of 0.5802 and 0.6127, respectively. In contrast, full historical radiation conditioning achieves significantly better performance ( ). The relatively small gap between zero-token and zero-sequence settings indicates that preserving temporal structure alone is insufficient without meaningful radiation-based state information. These results confirm that historical cross-sensor radiation conditioning is essential for effective decoder operation.
5.4.3. Component-Wise Ablation Study
Table 8 presents the results of this component-wise ablation study. The results demonstrate that the incremental addition of each component progressively improved model performance. The final MTL model with all components achieved the best results, reaching an of 0.8584. Notably, the inclusion of the HFE component provided the most significant performance improvement, underscoring the effectiveness of combining variate and patch embeddings for the data collected at JLab. Our results confirm the effectiveness of the proposed components within the MTL_TX framework. Each component contributes to the overall improvement of the model, with HFE and MDA playing critical roles in enhancing the handling of multivariate time-series data.
5.5. Case Study on Radiation Estimation
To visually evaluate the radiation estimation performance of the MTL_TX model, we compared the estimations of STL_TX and MTL_TX using data from the “rad48_p1” sensor. Figure 7 illustrates the training results of both models on the second segment of the 2018 data from the “rad48_p1” sensor. The red curve represents the radiation values estimated by the models, while the blue curve shows the ground truth. MTL_TX clearly demonstrates superior performance, particularly in regions where the radiation level approaches zero and at sharp local extrema. Figure 8 shows the testing results of the two Transformer models on the first segment of the 2018 data for the same sensor. MTL_TX continues to outperform the STL_TX, providing better overall fits. In particular, MTL_TX demonstrates improved peak fitting accuracy and reduced deviations around near-zero radiation levels, indicating stronger robustness under low-signal and rapidly varying conditions. In near-zero regimes, STL_TX tends to collapse toward mean-dominated predictions, whereas MTL_TX maintains stable tracking behavior. This advantage can be attributed to the multi-task learning mechanism, in which correlated radiation sensors jointly contribute to a shared state representation, thereby alleviating the low signal-to-noise challenges encountered by single-task models. However, both models fail to accurately estimate a sudden peak in the data. Further investigation revealed that this peak was caused by a recording error, which introduced an abrupt jump that cannot be effectively learned by the models.
Figure 9 presents estimation examples from both trained STL_TX and trained MTL_TX on data collected in 2016. It can be observed that the data collected in 2016 exhibit a distinctly different distribution pattern, particularly with noticeable increases in radiation values during certain periods. The estimation results of STL_TX show significant deviations from the actual radiation data, indicating poor generalization to unseen datasets. In contrast, MTL_TX demonstrates superior generalization capability, effectively adapting to distributional changes in the 2016 dataset.
In some peak regions of the dataset (Figure 9), STL_TX appears to capture sharper peaks than MTL_TX. This behavior can be attributed to the fact that STL_TX is trained to fit a single radiation sensor and is therefore more sensitive to large-magnitude variations, which can lead to more accurate fitting of isolated peaks. In contrast, MTL_TX enforces cross-sensor consistency through shared representations, producing smoother and more robust estimates that suppress sensor-specific fluctuations unsupported by other measurements. Overall, MTL_TX consistently outperforms STL_TX, achieving excellent performance across datasets from different years. This further validates the effectiveness of the proposed components within MTL_TX.
6. Discussions
This study aims to develop a Transformer-based MTL model to simultaneously estimate radiation values for sensors within the JLab facility. Two novel components, hierarchical feature embedding (HFE) and multi-level decomposition attention (MDA), were integrated into the proposed model, and it was compared against multiple competing models to evaluate its estimation performance. All of the competing models were tested on datasets collected by JLab from 2016 to 2019. MTL_TX demonstrated the best overall estimation performance. On the 2018 dataset, it achieved average scores of RAE = 32.4656%, RSE = 22.0956%, MAE = 0.1464, RMSE = 0.2353, and = 0.8584. In addition, it exhibited superior generalization performance on unseen data from other years, with average scores of RAE = 31.2067%, RSE = 21.2411%, MAE = 0.1407, RMSE = 0.2263, and = 0.8831.
Compared to STL models, MTL_TX significantly enhances its own ability to extract latent correlations and features from multivariate time-series data, as shown in Figure 10. The STL models are limited to feature extraction for a single radiation sensor and cannot be directly generalized to achieve high-accuracy radiation estimation for other sensors. Each radiation sensor requires a separate STL model, leading to an inefficient deployment strategy that consumes substantial computational resources and increases costs. The primary advantage of the MTL framework lies in its ability to process data from all sensors deployed around Hall A and simultaneously estimate radiation values for multiple sensors. By leveraging the MTL approach, the proposed model provides significant advantages, including reduced computational redundancy, enhanced feature extraction, and improved estimation accuracy.
All three components—ElasticNet, HFE, and MDA—play a crucial role in the proposed model. ElasticNet introduces constraints to mitigate overfitting. HFE integrates variate embedding and univariate patch embedding to capture both global and local information from the input time-series data. The global embeddings provide a comprehensive view of the dataset, while the local embeddings capture localized temporal information within each individual variable channel. Both embeddings enhance the MDA component’s ability to learn multivariate correlations effectively. Results from the ablation study clearly demonstrate the significant contributions of ElasticNet (improving from 0.7792 → 0.8086), HFE ( 0.8068 → 0.8377), and MDA ( 0.8377 → 0.8584).
The novelty of this work lies in integrating Transformer-based multi-task learning into radiation monitoring by formulating the problem as a multi-sensor estimation task rather than radiation transport physics modeling. The proposed MTL_TX framework targets robust radiation estimation under noisy, incomplete, and heterogeneous sensor conditions encountered in operational accelerator environments. By jointly modeling multiple radiation sensors within a unified framework, MTL_TX enables effective cross-sensor information sharing and consistent state estimation that cannot be achieved by independent single-task models.
From a deployment perspective, the final MTL_TX configuration contains approximately trainable parameters and performs radiation estimation through a single forward pass without iterative decoding. In our implementation, a single forward pass requires approximately 10.596 ms. Given the hourly sampling interval, the inference cost is orders of magnitude smaller than the data acquisition interval, making it negligible in practice. As a result, MTL_TX readily satisfies near-real-time requirements while offering reliable, scalable, and low-overhead deployment for radiation monitoring systems.
MTL_TX has a substantial number of parameters, and this significantly contributes to its superior performance. However, we observed that increasing the number of encoder and decoder layers only yielded a slight improvement in performance while dramatically increasing the number of parameters and the training time. To balance model efficiency and performance, MTL_TX in this study comprises two encoder layers and two decoder layers. With advancements in hardware technology and increasing computational power of graphics processing units (GPUs), training time is expected to decrease significantly in the future [42]. Future work may involve adjusting the model architecture to fully exploit the potential of evolving hardware capabilities.
We conducted extensive experiments on both model architecture and input design to investigate the impact of structural choices and information sources on radiation estimation performance. Specifically, we explored encoder-only configurations, encoder–decoder variants with restricted information flow, and multiple decoder input conditioning strategies. Across all evaluations, the full encoder-decoder architecture consistently achieved the best performance. The results indicate that effective radiation estimation requires both explicit cross-sensor state representation in the encoder and conditioned temporal generation in the decoder. Cross-sensor radiation information plays a critical role in capturing shared operational states and inter-sensor dependencies, which cannot be reliably inferred from beam-related variables alone. These findings highlight the importance of jointly modeling beam conditions and cross-sensor radiation histories within a unified framework for robust multi-sensor radiation estimation.
This study has several limitations. First, the performance of MTL_TX depends on the quality and availability of archived multi-sensor data from JLab. The historical data is sparse, noisy, and peak-containing. We utilized simple methods to eliminate these peaks as anomalies; more advanced techniques will be explored for preprocessing. Second, this study used hourly-sampled data for model training and testing. However, JLab also collects data with finer temporal resolution, such as 10 min or 1 min intervals, which capture more detailed radiation fluctuations. Future work will explore multiple temporal resolutions to evaluate the adaptability of MTL_TX to finer-grained time scales. Third, the proposed model was validated using sensor data from JLab’s accelerator facility only. We will apply it to datasets from other DOE accelerator facilities to further evaluate its generalization capability.
7. Conclusions
We propose a Transformer-based MTL model for estimating radiation values from multiple sensors deployed at JLab’s accelerator facility. We introduce two innovative components, including hierarchical feature embedding and multi-level decomposition attention, to boost the performance of the proposed model. The proposed model was thoroughly evaluated against several baseline models, including both single-task and multi-task approaches, using archived radiation data collected from 2016 to 2019 at JLab. Experimental results demonstrated that the proposed model achieved superior performance in estimating radiation values, with the highest and the lowest error metrics on both the dataset from the training year and unseen datasets from other years. In conclusion, the proposed MTL_TX model represents a significant advancement in JLab radiation estimation applications. Future work will focus on further enhancing the model’s capabilities and validating its effectiveness across diverse datasets and operational scenarios.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wallo A. Domotor S. Vazquez G. US Department of Energy policies, directives, and guidance for radiological control and release of property Health Phys.20069152652810.1097/01.HP.0000232649.16529.9517033468 · doi ↗ · pubmed ↗
- 2Liu C.H. Gu J.C. Yang M.T. A simplified LSTM neural networks for one day-ahead solar power forecasting IEEE Access 20219171741719510.1109/ACCESS.2021.3053638 · doi ↗
- 3Liu Z. Sullivan C.J. Prediction of weather induced background radiation fluctuation with recurrent neural networks Radiat. Phys. Chem.201915527528010.1016/j.radphyschem.2018.03.005 · doi ↗
- 4Jin H. Ma H. Butala M.D. Liu E.X. Li E.P. EMI radiation prediction and structure optimization of packages by deep learning IEEE Access 20197937729378010.1109/ACCESS.2019.2927160 · doi ↗
- 5Cho C. Kwon K. Wu C. On weather data-based prediction of gamma exposure rates using gradient boosting learning for environmental radiation monitoring Sensors 202222706210.3390/s 2218706236146409 PMC 9501500 · doi ↗ · pubmed ↗
- 6Zhang H. Stavola A. Ferguson H. Budavari B. Kwan C. Wu H. Li J. Deep Multi-task Learning Models for Radiation Estimation at High Energy Accelerator Facility IEEE Trans. Nucl. Sci.2024711966197710.1109/TNS.2024.3423695 · doi ↗
- 7Vaswani A. Shazeer N. Parmar N. Uszkoreit J. Jones L. Gomez A.N. Kaiser L. Polosukhin I. Attention is all you need Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017 Curran Associates Inc.Red Hook, NY, USA 2017
- 8Leemann C.W. Douglas D.R. Krafft G.A. The continuous electron beam accelerator facility: CEBAF at the Jefferson Laboratory Annu. Rev. Nucl. Part. Sci.20015141345010.1146/annurev.nucl.51.101701.132327 · doi ↗