VistaScan: Optimizing Internet-Wide Scanning Through Visibility-Aware Distributed Task Allocation
Luolin Hu, Fan Shi, Yi Shen, Chengxi Xu, Pengfei Xue, Bingyang Guo

TL;DR
VistaScan is a new system that improves internet-wide scanning by using visibility patterns to reduce redundant work and increase coverage efficiently.
Contribution
VistaScan introduces a visibility-aware distributed scanning system that leverages CIDR block visibility consistency for efficient task allocation.
Findings
VistaScan achieves near-optimal coverage (97.95%, 99.05%, and 97.58%) across global, regional, and special-block tasks.
It reduces probe volume by 64–93% and shortens completion time by 13–19× compared to conventional scanners.
The visibility matrix from one port generalizes to other TCP ports with coverages of 91.09% and 87.95%.
Abstract
Internet-wide scanning is indispensable for security research and network measurement, yet its efficacy remains limited by significant visibility heterogeneity across global networks. Traditional centralized scanners suffer from single-point failures and offer a constrained perspective, while naive distributed approaches fail to intelligently leverage visibility variations, leading to redundant effort and incomplete coverage. This paper presents VistaScan, a novel distributed scanning system based on node visibility awareness, demonstrating that the visibility pattern among IP addresses is highly consistent within CIDR blocks, enabling a lightweight method for efficient and scalable quantification of per-node visibility. It first constructs a Visibility Matrix through efficient anchor probing, then employs a load-aware task allocation mechanism that assigns each block to the most…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
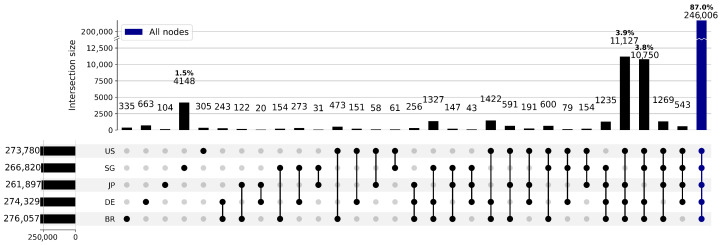 Figure 1
Figure 1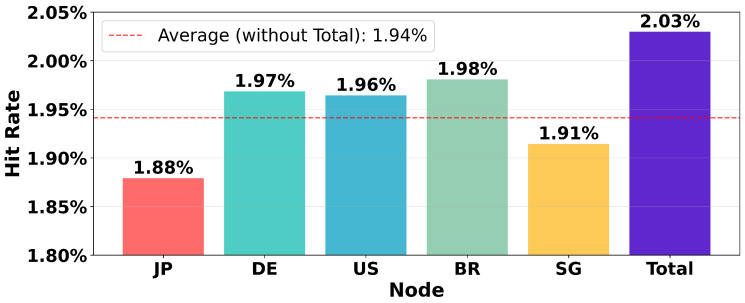 Figure 2
Figure 2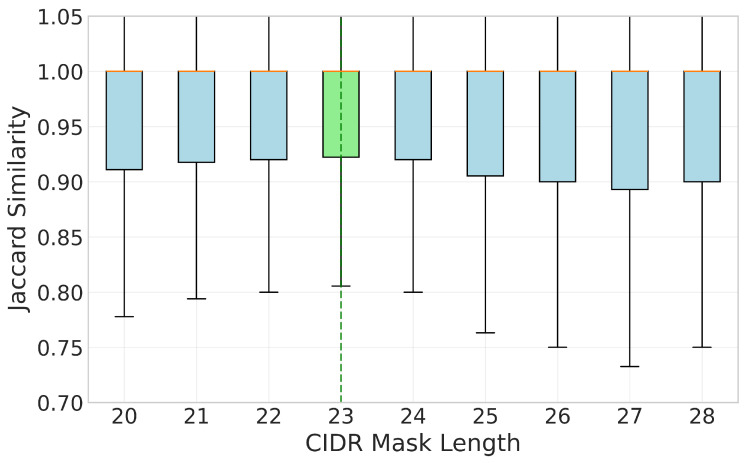 Figure 3
Figure 3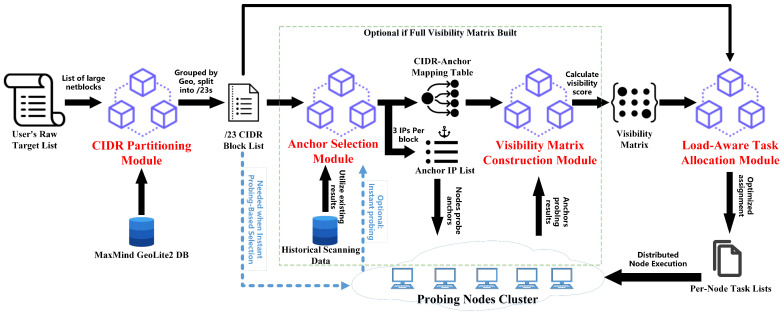 Figure 4
Figure 4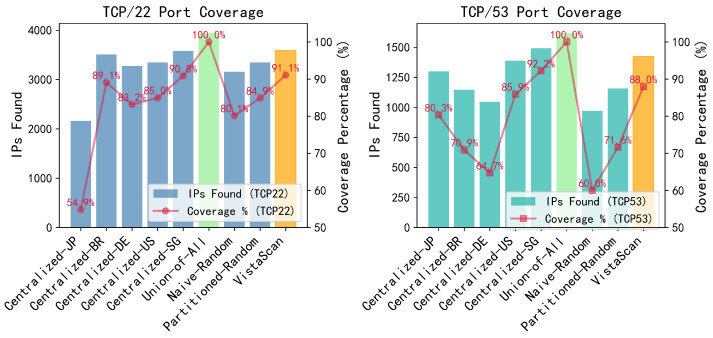 Figure 5
Figure 5 Figure 6
Figure 6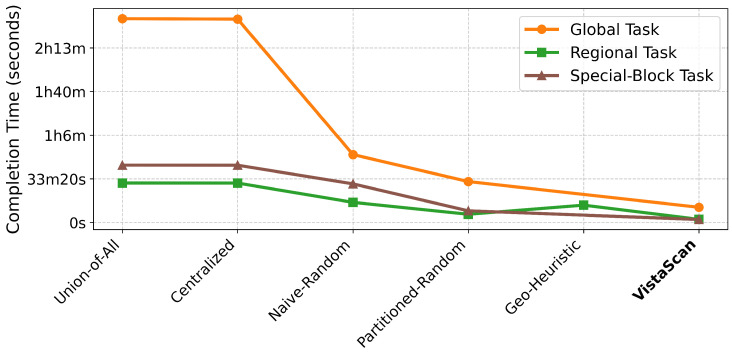 Figure 7
Figure 7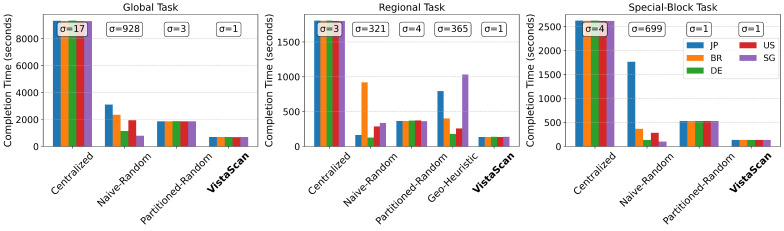 Figure 8
Figure 8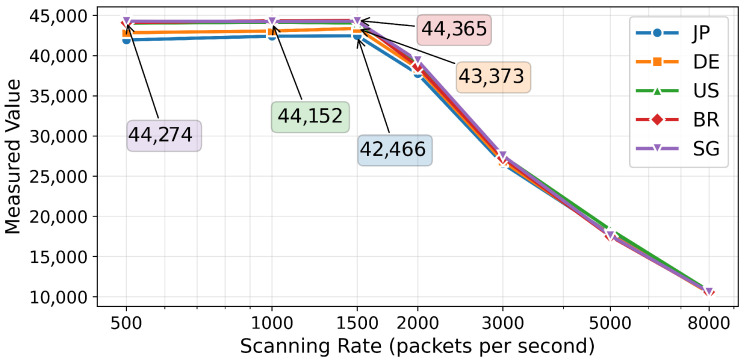 Figure 9
Figure 9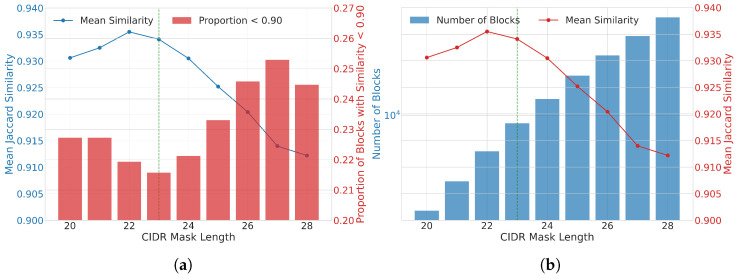 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSoftware-Defined Networks and 5G · Network Traffic and Congestion Control · Software System Performance and Reliability
1. Introduction
With the continuous proliferation of devices connected to the Internet, ensuring robust cybersecurity has become an imperative [1]. Internet-wide scanning plays an important role in cybersecurity analysis and network asset detection. This measurement technique has been used to study security vulnerabilities [2,3,4,5], host liveness [6,7,8,9], service deployment [10,11,12,13,14,15,16], network topology [17,18], uncover protocol weaknesses [19,20,21], and more. Internet-wide scanning works by initiating network connections with services on a set of given ports. So open port scanning is universally recognized as the critical first step in various types of network research. However, the scale of modern IPv4 and IPv6 networks makes exhaustive scanning a monumental task. Although modern scanning tools like ZMap [22], Masscan [23] and Nmap [24] employ centralized high-speed scanning from a single vantage point, this approach faces inherent limitations: the limited efficiency of a single node [12], network access restrictions [3,25] and IP blacklisting [9]. The research community has also recognized the fundamental constraint that no single node can see everything, and different geographical and network locations offer different views of the Internet [3,25,26,27,28].
To reduce the time overhead of large-scale scanning and detection, distributed technology was introduced in scanning and detecting network assets [29,30,31,32]. They improve probing efficiency by breaking down large-scale scanning tasks and distributing them across multiple nodes for execution. However, their task allocation strategies are often simplistic, treating different subtasks and probing nodes as interchangeable, and fail to account for the critical issue of nodal visibility divergence. Blindly assigning a CIDR block to any random node often results in insufficient coverage. If we missed certain ports from the very beginning, this omission can have significant negative implications for subsequent research, potentially resulting in the neglect of security vulnerabilities, the omission of critical assets, and a misjudgment of the overall security posture. Therefore, a more intelligent task allocation strategy is required to maximize coverage and minimize completion time.
In this paper, we present VistaScan, an intelligent visibility-aware distributed scanner for Internet-wide scanning. VistaScan is the first system that quantifies probing node visibility and, accordingly, performs task allocation and probing, the core idea of which is to assign probing tasks of different network blocks to the best-suited probing nodes. Our solution stems from a key empirical observation: Although nodes differ vastly in their global visibility (heterogeneity across nodes), a single node’s visibility of IPs within a specific CIDR block is highly consistent (consistency within blocks), which we formally define as the Visibility Consistency. Based on this, the visibility of representative anchor IPs by a node can characterize its visibility of the entire block. This allows for the assessment of a node’s capability without the need for a full-block exhaustive probe. Prior to executing the distributed probing, each node first performs a pre-scan of the representative IPs. The visibility scores of each node for each block are then calculated to construct a visibility matrix. Subsequently, the probing tasks are allocated in a targeted manner based on this matrix. This approach improves coverage effectiveness, reduces the total number of probe packets, shortens the overall scanning duration, and improves load balance in a distributed scanning scenario. Our core contributions are as follows.
The first formalization and large-scale validation of Visibility Consistency. We discover and formally characterize the phenomenon that visibility remains consistent within blocks, enabling the use of a few representative IPs to infer whole-block visibility. We formulate this concept using Jaccard similarity and empirically establish /23 blocks as the optimal task allocation unit.A lightweight method for efficient and scalable quantification of per-node visibility. We show that using three anchor IPs from different probing sources is a practical and effective heuristic for characterizing block-level visibility. We also propose two anchor selection methods and construct a node–CIDR visibility matrix, where each value in the continuous range [0,1] reflects a node’s proficiency in probing a block.The design and implementation of the VistaScan system. VistaScan comprises four modules: CIDR Partitioning, Anchor Selection, Visibility Matrix Construction, and Load-Aware Task Allocation, significantly improving the performance of distributed Internet measurement by streamlining evaluation, quantifying capability, optimizing assignment, and pruning infeasible work.
We evaluated VistaScan with five baseline methods (Centralized, Union-of-All Nodes, Naive-Distributed-Random, Partitioned-Distributed-Random, Geo-Heuristic) in four metrics (Global Coverage, Total Completion Time, Total Packets Sent, Node Load Balance) across three scanning scenarios (global, regional, and challenging special block tasks). The results show that it achieves near-optimal coverage (97.95%, 99.05%, and 97.58% respectively) while reducing the total number of probes by 64–95% and overall completion time by 13-19x compared to centralized and naive distributed baselines. Crucially, we demonstrate that the visibility matrix derived from one port (TCP/80) is highly effective for scanning other TCP ports (TCP/22, TCP/53), achieving 91.09% and 87.95% coverage, which preliminarily underscores the generalizability of our approach.
The remainder of the paper is organized as follows. Section 2 details the background and motivation for this project. Section 3 describes the architecture of VistaScan. Section 4 reports the experimental setup and evaluation results, followed by a discussion of the results and limitations in Section 5. Section 6 presents the related work. Finally, Section 7 concludes this paper.
2. Background and Motivation
Distributed scanning leverages multiple geographically or topologically distinct vantage points to conduct large-scale network measurements in a parallel and coordinated manner. It offers increased scanning throughput, improved resistance to blocking, and, most importantly, diverse network perspectives. Compared to single-source methods, this approach significantly reduces scan time while enhancing fault tolerance and scalability. However, the transition to a distributed model replaces the technical challenge of high-speed packet generation with new algorithmic challenges, such as intelligent task allocation and coordination overhead. We begin by briefly summarizing current Internet-wide scanning systems and the key challenges they face.
2.1. Heterogeneity in Node Visibility
Prior studies have identified discrepancies in scanning results arising from different probing sources [3,25,26,27]. The paper [28] further showed that scanning from a single vantage point achieve limited coverage (miss an average 1.6–8.4% of HTTP, 1.5–4.6% of HTTPS, and 8.3–18.2% of SSH hosts) and that aggressive scanners experience significant blocking. Due to permanent and temporary blocking, probing nodes from different geographical and network locations would obtain different views of the Internet. They advise scanning from 2 to 3 sufficiently diverse vantage points to improve coverage, but this comes at the cost of a two-to-threefold increase in probing overhead.
To better understand the impact of nodal visibility on distributed probing, we designed a global-scale scanning experiment based on the MaxMind GeoLite2 database. We constructed a task list comprising 100 randomly selected CIDR blocks from each of 18 countries on six continents (excluding Antarctica) and performed scans from five geographically distributed nodes using ZMap. Each node operated at a calibrated rate of 1500 packets per second (pps), which is established in Appendix B to balance packet loss and resource usage. To reduce temporal bias, all nodes shared the same ZMap seed, ensuring target probing at approximately the same time. The experiment was repeated three times to mitigate the effects of the transient network, and the results were aggregated through a union between repetitions. This controlled setup allows us to isolate and quantify the effect of node location on visibility, independent of hardware or configuration artifacts, and provides a foundation for developing customized task allocation strategies.
The results are presented in Figure 1 and Figure 2. Figure 1 reveals significant and systematic disparities in the results of the investigation of the same targets between nodes located in different regions, indicating that each node has a unique and partial view of the Internet. On average, a single node can only detect about 95% of the total assets, with the node JP having the lowest coverage at 92%. Only 87% of the target IPs were visible to all nodes. The remaining 13% exhibited distinct node-specific visibility patterns, with approximately 2% of the assets accessible only from a single probing source. This implies that these IPs can only be discovered if assigned to that specific node. Although this proportion may appear small, in absolute terms, it translates to 36,875 IPs that could be missed due to inappropriate node selection - and this is only within the 1800 CIDR blocks sampled. Given that the full MaxMind database contains 629,757 CIDR blocks, the number of potentially overlooked assets in an Internet-wide scan cannot be overlooked. If such visibility heterogeneity is ignored during distributed scanning and tasks are assigned indiscriminately, the impact on coverage could be substantial.
Moreover, the remarkably low average hit rate of only 1.94% shown in Figure 2 indicates that a significant portion of the blocks and IPs in the IPv4 address space remain inactive, and the active IPs are highly sparse. If we can take advantage of this sparsity and detect these inactive blocks in advance, the probing overhead could be significantly reduced.
2.2. Limitations of Existing Allocation Strategies
Despite the critical importance of accounting for visibility heterogeneity in distributed probing, existing task allocation strategies often fail to adequately leverage these differences, which may cause insufficient coverage, redundant probing, and ineffective measurements.
Random allocation: The most common baseline; it treats all nodes as equal and distributes targets randomly. This approach does not attempt to match targets with nodes that can see them, leading to suboptimal coverage and inefficient use of resources, as demonstrated in our evaluation (Section 4). Previous studies have proposed various distributed scanning frameworks [29,30,31]. These systems focus primarily on achieving load balance, improving overall efficiency, and improving the flexibility and scalability of the system. However, they share a common limitation: treating both nodes and subtasks as homogeneous and interchangeable. Their task allocation strategies are typically randomized, involving either a central controller assigning tasks uniformly or nodes automatically claiming subtasks based on their current load.
Geographic heuristics: The paper [32] showed that the regional characteristics of scanners greatly affect the scan rate and the port connection latency within the same country or region is lower than between countries and regions. Therefore, they cluster scanners based on geographical location and further assign tasks regionally using historical average latency tables, thereby reducing average detection delay and improving task completion efficiency. However, the resources of the probing node are limited; we cannot always rely on nodes located within the target region. Assigning subtasks based solely on geographic clusters also overlooks the heterogeneity of IP responsiveness within regions. Additionally, constructing an average latency table requires historical full-coverage probing data, which incurs significant computational and management overhead. However, the resources of probing nodes are limited, and we cannot always guarantee the availability of nodes within the target region. Assigning sub-tasks based solely on geographical distribution also overlooks the heterogeneity of IP responsiveness within the same region. Furthermore, constructing an average latency table relies on historical full-coverage probing data, which entails significant computational and management overhead.
Therefore, it is imperative to develop a lighter method for evaluating distributed node capabilities and an intelligent task allocation strategy that effectively leverages limited probing resources to maximize coverage and accuracy.
2.3. Problem Formalization and Key Insight
The Distributed Scanning Task Allocation Problem can thus be formalized as follows. Given a set of targets C (e.g., a list of IP addresses or CIDR blocks) and a set of distributed nodes N, find an assignment that maximizes the number of responsive targets found, minimizes the total completion time, and balances the workload across N, subject to the constraint that a node can only probe the targets it can reach. Therefore, a pivotal and urgent task is to define the theoretical foundation for intelligent task allocation.
The key principle is to assign tasks based on node specialties to ensure workload equilibrium, and the primary challenge is to quickly and efficiently quantify and evaluate the coverage capacity of each node. Our proposed system, VistaScan, solves this problem by the key insight that while nodes exhibit vastly different visibility globally, the visibility pattern within a specific CIDR block remains highly consistent from any single node’s perspective. We formalize this property as Visibility Consistency and formally validate it in Appendix C.
Definition 1(Visibility Consistency). For a given CIDR block and a set of distributed probing nodes , we define visibility vector for an IP address as a binary vector , where indicates the visibility of from node . The degree of Visibility Consistency within block B is then quantified as the average pairwise Jaccard similarity between the visibility vectors of all IP pairs in B:
where is the Jaccard similarity coefficient:
A higher consistency score indicates that the visibility patterns of IPs within the block are more homogeneous, justifying the use of representative anchor IPs for the entire block. We also quantify the Visibility Consistency of various sizes of CIDR blocks and one of the figures is shown as Figure 3, indicating that /23 is the optimal block size for overall consistency (see Appendix C.3 for details).
3. VistaScan System Design
The core idea of the VistaScan system is to assign the probing tasks of different network blocks to the best-suited probing nodes. Based on the principle of Visibility Consistency, the visibility of representative anchor IPs by a node can characterize its visibility of the entire block. This allows for the assessment of a node’s capability without the need for a full-block exhaustive probe.
The architecture of VistaScan, shown in Figure 4, is structured as a modular orchestration designed to transform a raw set of scanning targets into an optimally distributed task assignment. The system begins with CIDR Partitioning Module, which ingests user-defined targets and leverages the MaxMind GeoLite2 database to group them by autonomous system or geography before systematically splitting them into consistent /23 CIDR blocks. These standardized blocks then pass to the Anchor Selection Module, which identifies a small set of representative IP addresses (anchors) for each block in two optional ways. Subsequently, the Visibility Matrix Construction Module coordinates a lightweight validation probe where all distributed nodes probe these anchors, resulting in a visibility matrix that quantifies the coverage effectiveness of each node for each block. Finally, the Load-Aware Task Allocation Module consumes this matrix to intelligently assign each CIDR block to the most capable node while maintaining global load balance across the entire system. If a network-wide visibility matrix is already available, the two modules within the dashed box can be skipped, and the partitioned user tasks can be directly allocated based on this pre-built matrix, thereby further reducing system overhead. This orchestrated workflow ensures that the expansive scanning task is decomposed and allocated in a manner that maximizes coverage and efficiency by explicitly accounting for the inherent network visibility constraints of each probing node in a distributed probing scenario.
3.1. CIDR Partitioning
The CIDR Partitioning Module preprocesses the user’s raw input targets, which may be a list of individual IP addresses or large netblocks (e.g., a /12), and transforms them into a canonical set of mainly /23 CIDR blocks optimized for high Visibility Consistency, forming the foundational unit for subsequent processing of anchor selection and task allocation. This module optimizes load balance by refining subtasks into finer-grained units and operates in two stages.
1.IP-to-Country Mapping: Each IP address is mapped to its corresponding country or region using the MaxMind GeoLite2 database. This initial grouping takes advantage of the premise that IPs within the same geographic region are more likely to share network infrastructure and visibility characteristics.2.Canonical Splitting: Address blocks larger than a /23 prefix are split into /23 CIDR blocks. This specific size was selected based on the analysis in Appendix C.3, which found it to be the optimal trade-off between Visibility Consistency and management overhead.
3.2. Anchor Selection
The target IP space is divided into no more than /23 blocks. For each block, we select a small set of anchor IPs to characterize its visibility. In our experiments, using three anchor IPs from different probing sources per block proved to be a practical and effective heuristic, balancing representativeness, robustness, and probing overhead. The theoretical criteria for anchor selection are detailed in Appendix D, and are supported by prior work that leverages limited sampling to infer broader network characteristics [7,12,28,33,34,35,36,37,38]. The optimal number of anchors may vary depending on network conditions and consistency levels, and is a subject for future parameter tuning. The selection of representative anchor IPs can be accomplished through two primary methods:
- 1.Historical Data-Based Selection: This approach utilizes existing probing results, requiring no additional probing overhead beyond the main task. Although computationally efficient, its main limitation is the potential lack of timeliness in anchor IP availability, as the historical data may not reflect the current network state.
- 2.Instant Probing-Based Selection: This method involves initiating a targeted, rapid random probe for a single IP within each target CIDR block by pre-configured nodes. The results of these probes are then aggregated to generate the final anchor list. The principal advantage of this method is the strong timeliness and freshness of the anchors obtained. However, it introduces additional probing overhead and latency before the main scan can begin.
For probing tasks with stringent timeliness requirements—such as post-incident assessments or scans in highly dynamic network environments—users can perform instant anchor scanning and visibility matrix construction on a per-task basis, accepting a modest increase in probing overhead in exchange for maximum freshness. This flexibility ensures that VistaScan can be tailored to a wide range of operational contexts.
Algorithm 1 demonstrates the efficient retrieval and anchor generation process based on historical data. Its core operation involves, for each block, performing an efficient lookup to find belonging IPs from each node’s perspective, randomly selecting one candidate IP per node, and finally deduplicating and sampling up to three unique IPs to serve as the final anchors for that block. The process outputs a comprehensive list of all representative IPs and a mapping of each CIDR block to its anchors. The instant probing method differs only in its data source, consuming a live stream of probe results from each node instead of querying static historical files. Algorithm 1 Historical Data-Based Anchor IP SelectionRequire: Set of distributed nodes: Require: Sorted IP lists from each node’s scan results: Require: List of target CIDR blocks: CEnsure: Representative IP list REnsure: Mapping M from CIDR blocks to representative IPs 1: ▹ Initialize representative IP list 2: ▹ Initialize CIDR-to-IP mapping 3: for each CIDR block in C do 4: ▹ Initialize set for candidate IPs per block 5: for each node in N do 6: ▹ Binary search for IPs in CIDR 7: if then 8: ▹ Random selection per node 9: ▹ Add to candidate set 10: end if 11: end for 12: ▹ Preserve order while removing duplicates 13: if then 14: ▹ Select up to 3 unique IPs 15: ▹ Add to final representative list 16: for each IP in F do 17: ▹ Add to CIDR-to-IP mapping 18: end for 19: end if 20: end for 21: return
This algorithm takes sorted IP lists from historical scanning data from different nodes and a list of target CIDR blocks as input. Its design directly addresses the core requirements of representativeness and diversity by leveraging a key insight: the collective historical data from all nodes provide the most unbiased view of a block’s visibility landscape. By performing an efficient lookup into each node’s sorted IP list, it ensures computational scalability. The strategy of randomly selecting one candidate IP from each node’s perspective inherently incorporates the necessary discriminative power and mitigates single-point visibility bias, as the final anchor set is distilled from a pool that reflects the heterogeneous nature of the network. Finally, the deduplication and sampling step robustly handles real-world data imperfections, enforcing a multi-anchor strategy to balance robustness with low overhead. This synergy of efficiency, built-in diversity, and practical robustness makes the algorithm a critical component for building the foundational data structures of our distributed scanning system.
3.3. Visibility Matrix Construction
The Visibility Matrix M is a core data structure that encodes the visibility score for each node–block pair , where is a node and is a CIDR block. The score is defined as the fraction of anchor IPs in block c that node n can successfully probe, formalized as:
where is the set of anchor IPs for block c and denotes the result of node n probing anchor a.
Algorithm 2 outlines the construction process. It first precomputes a reverse lookup table to efficiently map any anchor IP back to its parent CIDR block (lines 1–3). The reverse mapping IP-to-Block ensures that determining the parent block of any visible IP is an O(1) operation, which is crucial given the scale of Internet-wide scanning. For each node n, it processes the set of anchor IPs visible to n ( ). For each visible IP, it uses the map to increment a counter for the corresponding block (lines 5–9). Finally, the visibility score for each block is computed by normalizing the count of visible anchors by the total number of anchors in that block (lines 10–13). Algorithm 2 Build Visibility Matrix MRequire: ▹ Map: Block c to its anchor lists 1: ▹ Map: Node n to its set of visible anchors 2: ▹ Lists of all nodes and CIDR blocksEnsure: Visibility Matrix 3: ▹ Initialize IP-to-Block mapping 4: for do 5: for do 6: 7: end for 8: end for 9: for do▹ For each node 10: ▹ Initialize per-block counter 11: for do▹ For each anchor visible to node n 12: if then 13: 14: 15: end if 16: end for 17: for do▹ Compute final scores 18: 19: end for 20: end for
This process efficiently transforms raw probe results into a quantitative suitability matrix, which is the final, critical input for the subsequent task allocation stage.
3.4. Load-Aware Task Allocation
The central component of VistaScan before probing is its intelligent task allocation algorithm, which optimally assigns CIDR blocks to distributed nodes based on pre-computed visibility scores while maintaining load balance. The algorithm maximizes coverage probability by leveraging the Visibility Consistency property and ensures efficient resource utilization through dynamic load-aware scheduling.
Algorithm 3 encapsulates the main allocation logic. Process each CIDR block by first checking if any node has positive visibility ( ). For such blocks, it identifies the node(s) with the highest visibility score . If multiple nodes achieve the maximum score, the algorithm selects the currently least-loaded node to maintain the load balance. The selected node is assigned to the block c and its load count increases.
The algorithm separates blocks into two queues based on the availability of visibility information. The priority queue ( ) contains blocks with established visibility patterns, which are assigned to nodes that have demonstrated the highest historical visibility scores. Tie-breaking based on current load ensures balanced distribution, which prevents node overload and ensures efficient resource utilization. Additionally, the algorithm maintains the linear time complexity , guaranteeing scalability for large-scale Internet-wide scanning tasks. Our system and algorithm are fully scalable to a larger number of nodes. Algorithm 3 Load-Aware Task AllocationRequire: : List of CIDR blocks 1: : Visibility matrix ( nodes × blocks) 2: : List of distributed nodesEnsure: : Block-to-node assignment 3: : Node load counts 4: , for all 5: ▹ Blocks with 6: ▹ Blocks not in or with 7: for each block do 8: if then 9: 10: else 11: ▹ For future implementation 12: end if 13: end for 14: for each block do 15: 16: 17: if then 18: 19: else 20: 21: end if 22: , 23: end for 24: return ,
Currently, we only perform the priority allocation for CIDR blocks that are present in the visibility matrix. Those blocks not included in the matrix indicate that no node currently has visibility in them and are therefore discarded directly, a decision grounded in our nodes’ capability and the sparsity of active IPs (as shown in Figure 2). The fallback queue ( ) is reserved for blocks lacking visibility data, providing a framework for future work on complete coverage strategies.
4. Evaluation
We present a comprehensive quantitative evaluation of VistaScan against multiple baselines in Global, Regional, and Special-Block tasks. Section 4.1 covers the experimental environment. Section 4.2, Section 4.3 and Section 4.4 demonstrate the performance of VistaScan.
4.1. Experimental Setup
To thoroughly evaluate the performance of VistaScan, we conducted extensive experiments in a variety of scenarios. Our testbed, target selection, and evaluation methodology were designed to ensure a fair and comprehensive comparison against established baselines.
Testbed. Our distributed probing infrastructure consisted of five nodes strategically deployed throughout the world using commercial cloud services. The details of each node are summarized in Table 1. All nodes were equipped with identical hardware specifications and a 100 Mbps network interface to eliminate performance disparity caused by resource differences. This homogeneous configuration allows us to isolate and attribute any performance variations solely to our task allocation strategy and network visibility, rather than to raw computational or network power.
Scanning Rate. To ensure fairness and prevent measurement artifacts caused by local congestion or packet loss, all experiments used a fixed scanning rate of 1500 pps per node. This value was determined to be the optimal global rate by the calibration process described in Appendix B.
Scanning Tasks and Targets. Table 2 summarizes the three scanning tasks designed to thoroughly evaluate VistaScan under different conditions. The Global task consisting of 3 countries from each of 6 continents was designed to assess worldwide coverage. The Regional task focused on the regions where our nodes are located. The targets of these two tasks were randomly selected from the MaxMind GeoLite2 database to ensure unbiased and generalizable results. The Special-Block task was designed to stress-test the system’s ability to handle challenging blocks where node visibility is highly heterogeneous, in which the targets were manually selected based on our scanning experience.
Baseline Comparisons. We implemented five baseline methods for a comprehensive and rigorous comparison. This design allows us to dissect and isolate the contribution of each individual component within VistaScan.
Centralized: A single node (e.g., US) scans the entire target list. This baseline highlights the advantages of a distributed architecture over a traditional centralized approach.Union-of-All: All five nodes independently and simultaneously scan the entire target set. The final result is the Union-of-All their outputs. This provides the absolute upper bound for the coverage achievable by any distributed system with these five vantage points, serving as a key reference for evaluating the coverage efficiency of VistaScan and other methods.Naive-Distributed-Random: The original, unsplit target list of IPs is randomly and uniformly assigned to the five nodes. This evaluates a simple distributed strategy without intelligent partitioning or allocation.Partitioned-Distributed-Random: The target IP space is first partitioned into /23 CIDR blocks using the VistaScan CIDR partitioning module. Then, this list of blocks is randomly and uniformly assigned to the five nodes. This baseline isolates the performance gain that is only attributable to the CIDR partitioning step.Geo-Heuristic: Targets are assigned to the geographically closest node to them (for example, Brazilian IPs to the BR node). This baseline is only used for the Regional task and represents a common geographic-driven heuristic.
Evaluation Metrics. We evaluated the performance of each method based on the following metrics:
- Global Coverage: The total number of unique IP addresses that respond. To contextualize this absolute value and measure the efficiency of a method’s coverage, we also report it as a percentage of the total unique IPs found by the Union-of-All baseline. This relative measure indicates how close a method gets to the theoretical maximum coverage achievable with the given set of vantage points.
- Total Packets Sent: The aggregate number of probe packets sent by all nodes, indicating the overall network overhead and efficiency of the method.
- Total Completion Time: The wall-clock time from the start of the first probe to the completion of the last probe across all nodes.
- Node Load Balance: The standard deviation of the number of scanning IP addresses assigned to each node, quantifying the fairness workload distribution.
4.2. Coverage Analysis
The paramount goal of a distributed scanning system is to maximize coverage. Our evaluation demonstrates that VistaScan consistently achieves near-optimal coverage across all scenarios, a direct result of its core design principle: Intelligently assigning each CIDR block to the node with the highest probability of seeing it.
As synthesized in Table 3, VistaScan’s coverage remains exceptionally high and stable, reaching 97.95%, 99.05%, and 97.58% in the Global, Regional, and Special-Block tasks, respectively. This performance places it within 2-3% of the theoretical maximum (Union-of-All) and significantly outperforms all centralized and naive distributed baselines. Notably, in the Regional task, VistaScan matches the performance of Geo-Heuristic (99.05% vs. 99.35%) with significantly lower scanning overhead time consumption and without relying on external geographical databases, demonstrating the sufficiency of its empirically measured visibility matrix.
The Special-Block task serves as a stress test. These blocks exhibit poor Visibility Consistency, comprising targets with pronounced visibility heterogeneity. VistaScan’s robust performance here (97.58%) underscores its effectiveness even in the most challenging network environments. Crucially, this high coverage is not achieved by brute force, but through precision: the system allocates tasks based on the visibility matrix, ensuring each block is probed by its most capable node. Our method can also effectively avoid assigning tasks to nodes with poor coverage capabilities for specific blocks, such as the JP node.
VistaScan also features Cross-Port Applicability. As shown in Figure 5, we found that the visibility matrix constructed from one TCP port (TCP/80) is applicable to other TCP ports. When applied to scanning TCP/22 and TCP/53 ports, VistaScan maintained a high coverage of 91.09% and 87.95%, respectively. Within the scope of the TCP protocol that we probed, this cross-port applicability indicates that visibility patterns exhibit cross-port generalization capabilities. It enhances the practicality of VistaScan, as a single profiling phase can optimize subsequent scans for multiple TCP services, dramatically reducing operational overhead.
4.3. Efficiency Analysis: Overhead and Completion Time
Beyond coverage, VistaScan’s paramount advantage is its revolutionary efficiency, simultaneously minimizing two critical resources: network overhead and completion time. As shown in Figure 6 and Figure 7, VistaScan consistently demonstrates orders-of-magnitude improvements in efficiency.
Network Overhead: As illustrated in Figure 6, VistaScan drastically reduces the total number of packets sent. Compared to the baseline methods that scan all targets (approx. 2.7 M–39.2 M packets, depending on the task), VistaScan reduces the network overhead by 64% to 93%. This reduction is the direct consequence of its decisive filtering strategy: any CIDR block with no visible anchor IPs in the visibility matrix is pruned from the task list entirely. This avoids futile probing of network blind spots, constituting a fundamental shift from exhaustive scanning to targeted, intelligent probing.
Completion Time: Figure 7 shows the total completion time. VistaScan completes scans 13 to 19 times faster than centralized baselines. This speedup is a compound effect of (1) reduced total workload (fewer packets to send) and (2) highly efficient parallelization due to excellent load balance (analyzed in Section 4.4). For example, in the Global task, VistaScan was completed in 11 min and 34 s, compared to over 2.5 h for the centralized approaches. This efficiency enables near-real-time Internet-scale scanning, opening new possibilities for frequent monitoring and rapid incident response.
Cost of Pruning: While pruning blocks with no visible anchors drastically reduces probe volume, it inevitably forgoes scanning some IPs. To assess the potential loss of coverage, we examined the pruned blocks in our Global task. Among these blocks, the proportion of responsive IPs was extremely low—less than 0.005% of the IPs in these blocks responded to the probes, and the vast majority of pruned blocks contained no active hosts at all. In practice, VistaScan incurs only about a 2.0% coverage loss compared to the Union-of-All baseline (which represents the theoretical maximum achievable with our five vantage points). Importantly, this loss already includes the inherent coverage deficit of any single node scan (as seen in the Centralized baselines). Therefore, the additional coverage loss attributed to pruning is negligible while yielding substantial savings in probing overhead.
4.4. Load Balance Analysis
The efficiency of a distributed system depends on how well it balances workload across its nodes. Poor load balance leads to resource idle time and becomes the bottleneck for completion time.
Our analysis reveals that VistaScan’s allocation algorithm achieves near-perfect load balance. As depicted in Figure 8, task completion times between all five nodes are virtually identical in all VistaScan scenarios. This is because its allocation algorithm is not only visibility-aware, but also load-aware; when multiple nodes have similarly high visibility scores for a block, the algorithm assigns it to the currently least-loaded node.
In stark contrast, other distributed strategies show a severe imbalance. The Naive-Random method leads to a highly skewed distribution of work, with the slowest node taking up to 3.8 times longer than the fastest to finish its assigned segment. The Geo-Heuristic method also exhibits a significant imbalance in the Regional task, as geographical proximity does not perfectly correlate with scan workload or link quality, nor does it guaranty balanced task allocation across regions. Compared to Naive-Distributed-Random, the Partitioned-Distributed-Random method equipped with the CIDR Partitioning Module achieves a more uniform distribution of tasks, significantly reduces the overall completion time, and exhibits superior load balance.
5. Discussion and Limitations
Our experimental results demonstrate that VistaScan achieves significant performance improvements in various scanning scenarios. In the global scenario, VistaScan achieves higher coverage than all other methods while requiring only 36.7% of packets and 7.4% of the time compared to single-point centralized robing. In regional scanning, VistaScan achieves a nearly identical hit rate to Geo-Heuristic while using only 37% of its probe packets and 17.4% of its time, along with a more balanced node load. In addition, our method excels particularly at Special-Block tasks, outperforming all other approaches across all metrics and approaching the theoretical maximum coverage. The success of our system hinges on two validated core principles: the Visibility Consistency phenomenon within CIDR blocks and the systematic heterogeneity of visibility across geographically distributed nodes. By quantifying the latter into a Visibility Matrix and leveraging the former to make this matrix efficient to construct, VistaScan enables an intelligent task allocation strategy that is both precise and practical, moving the field from ad hoc and static allocation strategies to a data-driven and adaptive framework, fundamentally improving the efficiency and effectiveness of distributed Internet measurement. VistaScan’s advantages can be summarized as follows:
- Streamlining Evaluation: The Visibility Consistency principle enables the inference of full-block visibility from a few anchor IPs, dramatically lowering the assessment overhead through targeted probing rather than full-block scanning.
- Quantifying Capability: We design two anchor selection methods and then build the Visibility Matrix through lightweight probing of anchor IPs, in which are the per-node visibility scores for each block.
- Optimizing Assignment: Using the Visibility Matrix to assign each block to the node with the highest probability of seeing it (the “most capable” node), while simultaneously balancing the load.
- Pruning Infeasible Work: Intelligently discarding blocks for which no node has significant visibility, thus eliminating ineffective probing.
However, we acknowledge several limitations of our current work that point to future research directions.
Anchor Freshness and Matrix Validity: A fundamental assumption of VistaScan is that the visibility matrix provides a reasonably stable representation of the network state. Although network paths are generally stable, events such as routing changes, outages, or filtering updates could stale the matrix over time, leading to task misassignment or erroneous block pruning. To address this, a production system requires lightweight mechanisms for periodic or triggered re-validation—dynamically adjusting probing frequency based on observed network dynamics (e.g., failure rates). Our future work will systematically address temporal robustness along two directions: we plan to evaluate the effective duration of a single constructed visibility matrix over longer time scales, and explore two lightweight update mechanisms—periodic active probing of anchor IPs (e.g., weekly), and online learning that refines visibility scores using incidental observations from main scans. Together, these approaches will enable VistaScan to adapt to gradual network changes while preserving efficiency, ensuring its viability for sustained real-world deployment.
Coverage–Completeness Trade-off: The strategy of pruning blocks with no visible anchors is the primary driver of efficiency gains. However, it inherently sacrifices absolute completeness (as achieved by the Union-of-All baseline) for efficiency. This is a deliberate and beneficial engineering trade-off for most scanning use cases. Nevertheless, for applications where finding every single responsive host is critical, our method could be extended to include a fallback mechanism where pruned blocks are periodically scanned by a random node or all nodes at a very low rate to check for changes. This is why we maintain the fallback queue ( ) mentioned in Section 3.4. Subsequently, a low-frequency scanning and update mechanism will be established for it.
Anchor Count Selection and Extension to UDP Scanning: While our empirical results demonstrate the effectiveness of using three anchors per block (each from a diverse source), the optimal number warrants further investigation, as it may depend on factors such as block size, network stability, and the trade-off between accuracy and overhead. Future work could explore adaptive anchor selection mechanisms that dynamically adjust the anchor count based on intra-block consistency estimates or historical data. In addition, UDP’s connectionless nature, reliance on ICMP, and distinct firewall handling may produce visibility patterns that differ from TCP. While VistaScan currently focuses on TCP, future work should explore its extension to UDP. This requires addressing challenges in probing strategy, response ambiguity, and timeout handling, as well as validating whether Visibility Consistency holds for UDP services. Such research would broaden the applicability of visibility-aware distributed scanning.
Handling of Ultra-Low Consistency Blocks: No real-world system can rely on perfect statistical regularity, and our design pragmatically exploits the strong statistical trend of Visibility Consistency while handling outliers gracefully. We acknowledge that a small subset of blocks exhibit very low intra-block consistency, typically due to complex network configurations such as multihoming or fine-grained, IP-specific filtering policies. For such blocks, a single optimal node may not provide adequate coverage, as visibility can vary significantly even within a /23 prefix. Two promising directions for future work can address this limitation: (1) further subdividing these blocks into smaller granularities (e.g., /24 or /25) to restore high consistency with minimal overhead; and (2) employing multi-node coordinated probing, where tasks are distributed among a set of complementary nodes to maximize coverage. We plan to explore these optimizations in future work.
6. Related Works
Our work is based on and intersects with several key areas of Internet measurement and distributed systems research.
Centralized High-Speed Scanning. Modern scanning tools such as Nmap [24], ZMap [39], Masscan [23], Zippier ZMap [40], ZGrab2 [41], and LZR [42] revolutionized Internet-wide scanning by demonstrating that the entire IPv4 address space can be scanned in minutes from a single machine. With the support of high-performance I/O frameworks such as PF-RING [43], Packetshader [44] and netmap [45], port scanning time can be significantly reduced. VistaScan does not seek to replace these tools, but rather to extend their centralized paradigm. We address their inherent limitations: single-point visibility blind spots, susceptibility to IP blocking, and the physical bottleneck of a single source. VistaScan adopts their high-performance probing engines, but distributes the effort intelligently across nodes.
Distributed Measurement Systems. Distributed scanning technology reduces the time required for large-scale scanning and detection by decomposing scanning tasks and distributing them across multiple nodes. The research community has developed several distributed scanning systems [29,30,31,32]. However, their native task allocation mechanisms are often simplistic, relying on random assignment or geographic heuristics. VistaScan contributes a novel, automated, and intelligent allocation layer that could be deployed on such platforms to dramatically increase the efficiency and coverage of experiments run on them.
Efficient Predictive Scanning Systems. Predictive scanning offers a novel approach to improving the efficiency of large-scale scanning operations. In contrast to distributed scanning systems that minimize scanning duration through probing resource expansion and task partitioning, predictive scanning operates by narrowing the target space via a pregenerated prediction list. Previous works such as Smart Internet Probing [46] by training a unique XGBoost classifier [47], GPS [12], PMap [48], and IPREDS [10] have attempted to develop efficient predictive scanning systems capable of forecasting port activity on target hosts, thereby reducing the time required to discover a sufficient number of valid targets. However, after generating the prediction list, they still face the problem of determining which specific node(s) should execute the actual scanning tasks. VistaScan can act as the core distributed probing engine of these predictive systems, increasing the accuracy of their predictions effectively. Our system integrates the strengths of both distributed and predictive scanning, which not only increases available probing resources but also reduces the probing space, while intelligently assigning tasks to the most suitable nodes.
Studies of Network Visibility. Previous work has documented and analyzed the heterogeneity of views from different organizations [26,27], different scanning origins [28], different probing tools [40] and different probes [3], and the paper [25] further showed that web-based geoblocking is increasingly common. We have taken a step further by systematically investigating the extent to which the location of probing nodes influences the results of distributed measurements. In addition, VistaScan goes beyond observation to application. We are the first to formalize the “Visibility Consistency” hypothesis and use it as the foundational principle for building a practical, optimized distributed scanning system. Our work shows that these observed biases are not just noise to be accounted for, but a signal that can be exploited for significant performance gains.
In summary, VistaScan distinguishes itself by introducing a formal model of Visibility Consistency, which enables a lightweight node’s capabilities evaluation methods and a novel task allocation algorithm that are both more efficient and provide higher coverage than existing distributed approaches, while overcoming the visibility and efficiency limitations of centralized scanners.
7. Conclusions
In this paper, we introduced VistaScan, a novel system for optimizing distributed Internet-wide scanning based on the key insight of Visibility Consistency, that the visibility pattern among IP addresses is highly consistent within CIDR blocks. This principle enabled the construction of a lightweight Visibility Matrix via anchor-based probing and informed the design of a load-aware task allocation algorithm. Our comprehensive evaluation across Global, Regional, and challenging Special-Block tasks demonstrates that VistaScan consistently outperforms existing methods, achieving superior coverage by matching blocks to the most capable nodes while significantly improving efficiency through the pruning of unreachable targets and intelligent load balancing. In particular, the visibility matrix derived from one TCP port (TCP/80) proved highly effective for scanning other TCP ports (TCP/22, TCP/53), preliminarily underscoring the generalizability of our approach. VistaScan shows how a deeper understanding of network structure can lead to substantial practical gains, opening new avenues for building efficient, large-scale distributed measurement systems that are fine-grained, low-impact, and resource-efficient.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kaur J. Ramkumar K. The recent trends in cyber security: A review J. King Saud-Univ.-Comput. Inf. Sci.2022345766578110.1016/j.jksuci.2021.01.018 · doi ↗
- 2Durumeric Z. Clark H. Cody J. Cubit E. Ellison M. Izhikevich L. Mirian A. Censys: A Map of Internet Hosts and Services Proceedings of the ACM SIGCOMM 2025 Conference Coimbra, Portugal 8–11 September 2025147163
- 3Durumeric Z. Adrian D. Stephens P. Wustrow E. Halderman J.A. Ten years of zmap Proceedings of the 2024 ACM on Internet Measurement Conference Madrid, Spain 4–6 November 2024139148
- 4Beurdouche B. Bhargavan K. Delignat-Lavaud A. Fournet C. Kohlweiss M. Pironti A. Strub P.Y. Zinzindohoue J.K. A messy state of the union: Taming the composite state machines of TLS Commun. ACM 2017609910710.1145/3023357 · doi ↗
- 5Checkoway S. Niederhagen R. Everspaugh A. Green M. Lange T. Ristenpart T. Bernstein D.J. Maskiewicz J. Shacham H. Fredrikson M. On the practical exploitability of dual {EC} in {TLS} implementations Proceedings of the 23rd USENIX Security Symposium (USENIX Security 14)San Diego, CA, USA 20–22 August 2014319335
- 6Bano S. Richter P. Javed M. Sundaresan S. Durumeric Z. Murdoch S.J. Mortier R. Paxson V. Scanning the internet for liveness ACM SIGCOMM Comput. Commun. Rev.2018482910.1145/3213232.3213234 · doi ↗
- 7Cai X. Heidemann J. Understanding block-level address usage in the visible internet Proceedings of the ACM SIGCOMM 2010 Conference New Delhi, India 30 August–3 September 201099110
- 8Padmanabhan R. Dhamdhere A. Aben E. Claffy K. Spring N. Reasons dynamic addresses change Proceedings of the 2016 Internet Measurement Conference Santa Monica, CA, USA 14–16 November 2016183198