Communication Signal Modulation Recognition Method Based on Multi-Feature Multi-Channel ResNet and BiLSTM Neural Network
Xi Li, Xuan Geng, Yanli Xu, Fang Cao

TL;DR
This paper introduces a new deep learning method for accurately recognizing communication signal modulations using a combination of ResNet and BiLSTM networks.
Contribution
The novel MF-MC ResNet-BiLSTM model improves recognition accuracy by fusing multi-format signal features and using adaptive attention mechanisms.
Findings
The proposed method achieves 95.67% recognition rate in low SNR environments.
It outperforms existing models like MMF, FGDNN, and LightMFFS in terms of accuracy and robustness.
The model demonstrates strong generalization and feature extraction capabilities.
Abstract
To deal with the insufficient recognition accuracy of traditional signal modulation recognition methods, this paper proposes a new communication signal modulation recognition method with a deep neural network that integrates a multi-feature multi-channel ResNet and BiLSTM neural network (MF-MC ResNet-BiLSTM). By converting the original modulation data into three different vector formats, which are IQ format, AP format, and FFT format, we obtained the model inputs which contain various feature information. After inputting three types of vector signals into the multi-channel feature fusion module, the network converts these input signals into a high-dimensional feature space for feature fusion, and extracts features we need from different signal sources. Meanwhile, we designed a multi-channel model that integrates ResNet-BiLSTM to perform feature fusion, extracting key features of the…
Click any figure to enlarge with its caption.
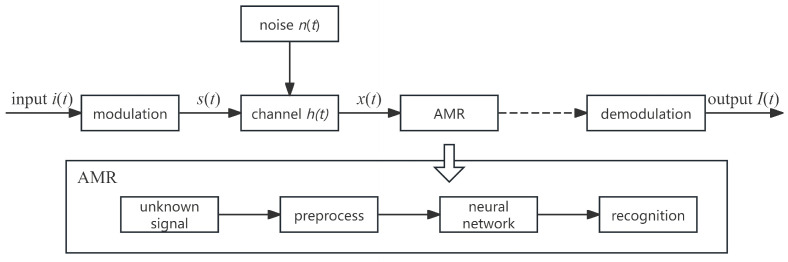 Figure 1
Figure 1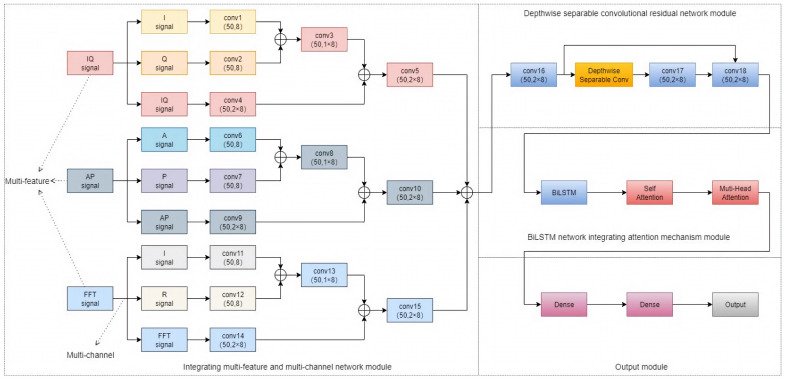 Figure 2
Figure 2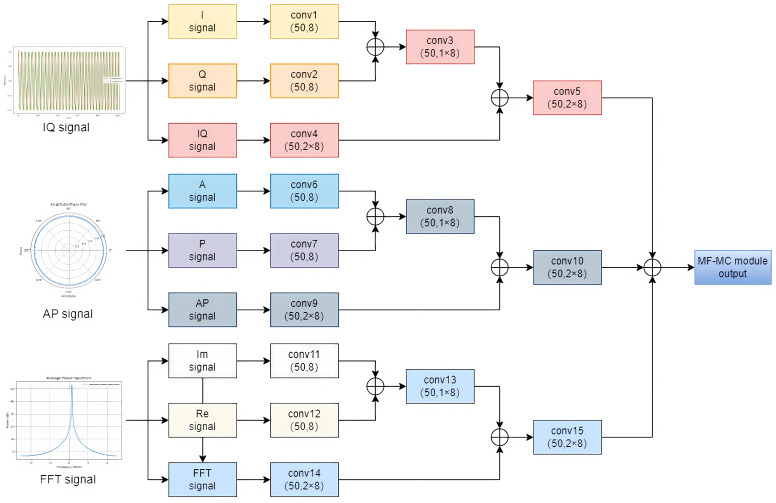 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5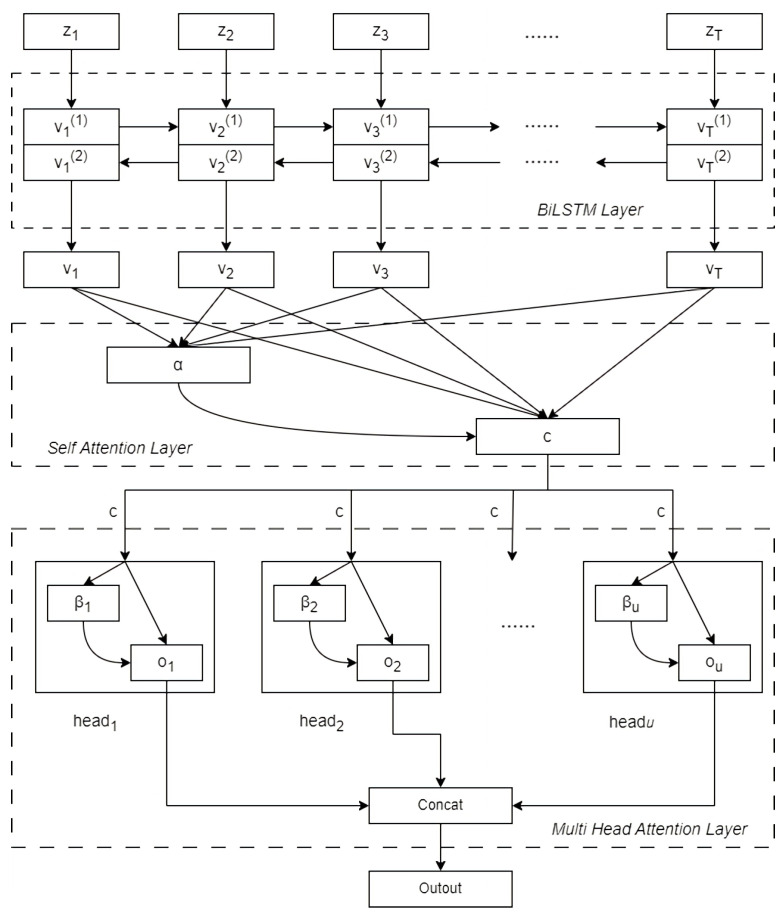 Figure 6
Figure 6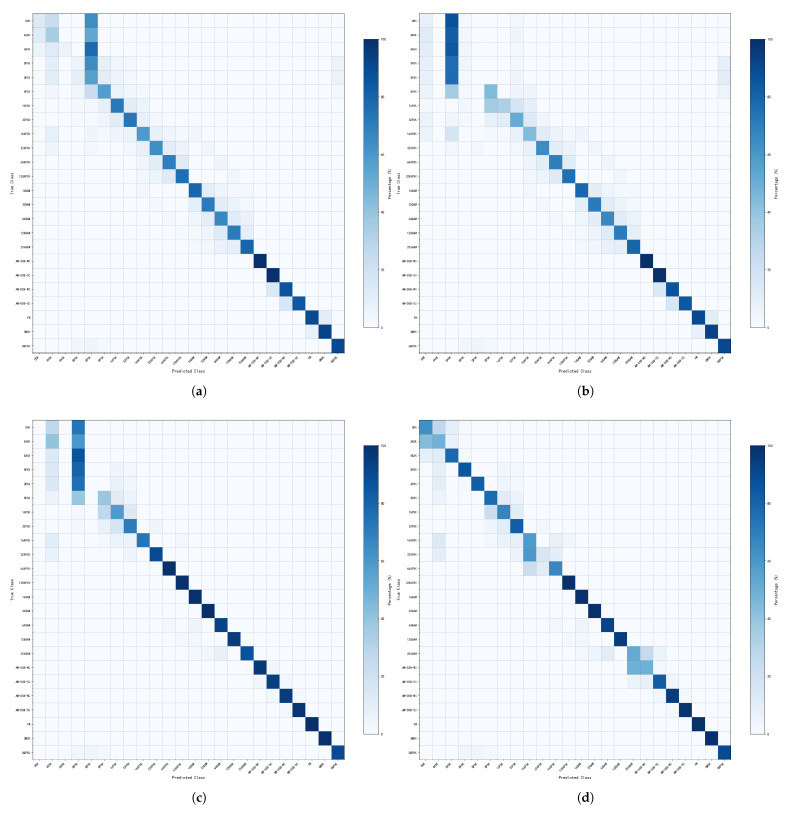 Figure 7
Figure 7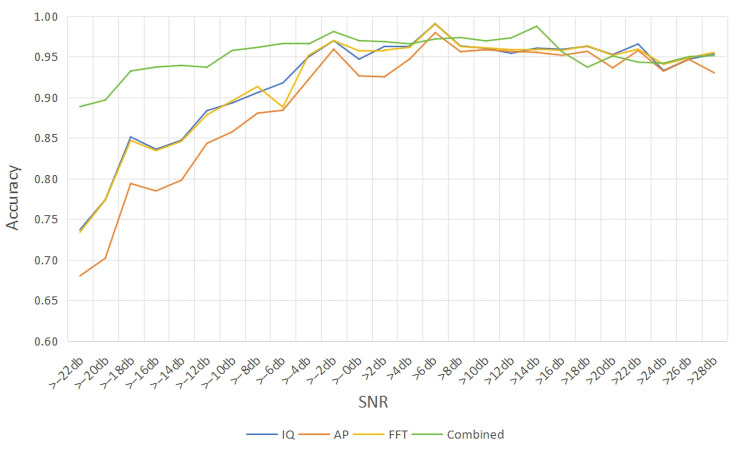 Figure 8
Figure 8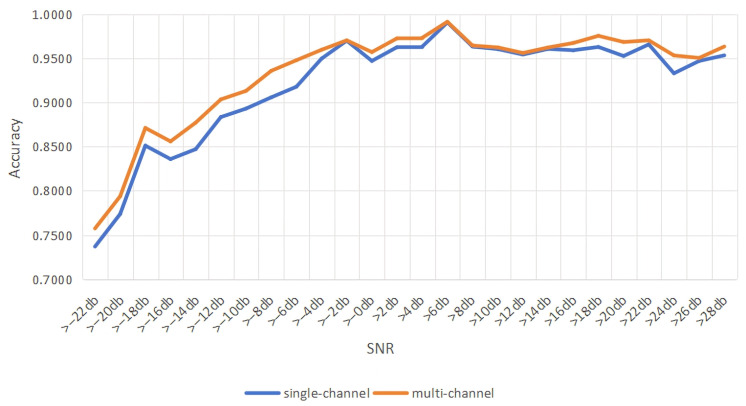 Figure 9
Figure 9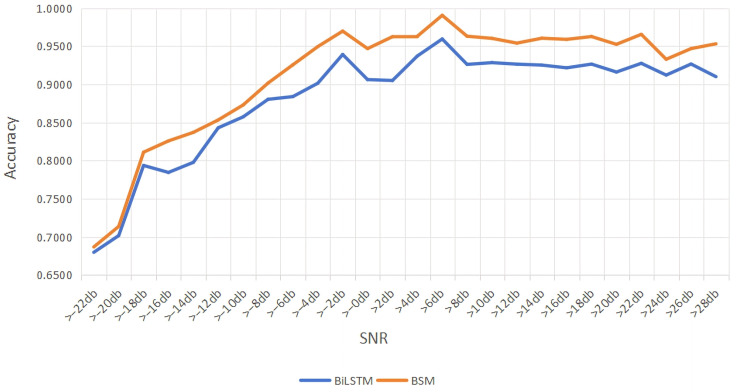 Figure 10
Figure 10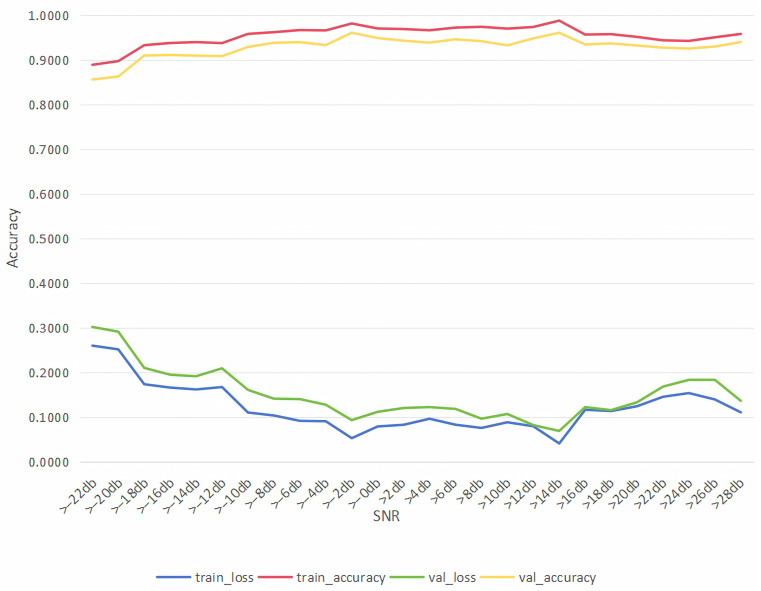 Figure 11
Figure 11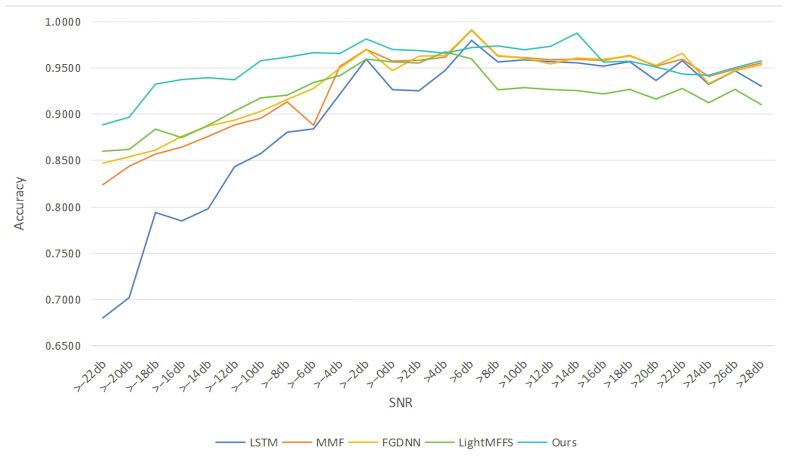 Figure 12
Figure 12- —the Soft Science Project of Shanghai
- —the Key Research and Development Program of Shanghai
- —the Joint Funds of the National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsWireless Signal Modulation Classification · Advanced Neural Network Applications · Telecommunications and Broadcasting Technologies
1. Introduction
Automatic Modulation Recognition (AMR) is a technology that identifies the modulation type of the received signal automatically by analyzing its characteristics in the case that prior information is unknown, serving as a crucial means for monitoring and managing spectrum resources [1]. However, it usually requires a large amount of computing resources and has a high dependence on manually designed features, which limits the ability to express features [2].
Currently, most deep learning-based Automatic Modulation Classification (AMC) methods rely on one-dimensional signal information, failing to fully exploit the characteristics across different signal dimensions. To address this, multi-modal techniques have been widely adopted in the AMC field in recent years and their effectiveness in improving recognition accuracy has been confirmed. Zhang et al. [3] pointed out that fusion of diverse features can enhance the effectiveness of modulation recognition. Deng et al. [4] indicated that multi-modal feature fusion can improve the joint utilization of features to boost classification accuracy. Liu et al. [5] proposed a multi-modal technique based on contrastive learning and demonstrated its effectiveness on the RML2016.10a dataset. Sun et al. [6] introduced a method combining Gated Recurrent Units (GRU) and Convolutional Neural Networks (CNN). They utilized the IQ data and Amplitude-Phase (AP) data for feature extraction and classification, achieving excellent performance on the RML2018.01a dataset. Pathak et al. [7] proposed a parallel multi-channel learning framework to process both IQ and AP modal information, using Long Short-Term Memory (LSTM) networks to extract temporal information and fully connected layers for classification. Wang et al. [8] presented a multi-stream neural network utilizing spatial attention and multi-head attention mechanisms. This method enhanced the dynamic weight allocation capability for spatial and temporal features extracted by the CNN and Bidirectional Gated Recurrent Unit (BiGRU).
In order to address the low SNR and shortcomings of the classification of signals that are easily confused in current models, we proposes a modulation signal classification and recognition algorithm that integrates a multi-feature multi-channel ResNet and BiLSTM neural network. Firstly, the original modulated data are converted into three different vector formats as model inputs including IQ signal, AP signal and FFT signal. Secondly, a multi-channel network architecture is designed to extract multi-dimensional features of input signals. Then, the ResNet network combining depthwise separable convolutional network (DSC) is designed to optimize computational efficiency. Finally, an adaptive multi-head attention network with weighted integration extraction capabilities combining BiLSTM is designed to further improve modulated signal recognition performance. Experimental results show that this method achieves a recognition rate of 95.67% and a recall rate of 94.56% in low SNR environments (−22 dB–2 dB), significantly outperforming existing mainstream network models like MMF, FGDNN, and LightMFFS.
2. Model of Automatic Signal Modulation System
The deep learning-based automatic modulation recognition system model [9] is shown in Figure 1.
First, the input signal is modulated to be After that, the is transmitted through channel and is affected by noise interference and channel fading . The receiver receives the signal as , and the received signal can be expressed by Equation (1).
where is the transmitted signal, which can be expressed as follows.
where is the sampling symbol of which is . is the pulse shaping function. is the symbol period. is the carrier frequency, and is the initial phase. Since the dataset used in this paper is in IQ vector format, it can also be expressed by Equation (3).
where is the in-phase component of and is the quadrature component of , and the phase .
The is the channel impulse response, modeled as the effect of multi-path effects and fading which is as follows.
where and denote the fading coefficient and delay of the first l path, respectively. is additive Gaussian white noise (AWGN), obeying the Gaussian distribution .
In a discrete sampling system, the received signal can usually be expressed as a sequence of in-phase/quadrature (I/Q) components in complex form.
where N is the number of samples and and are the discrete samples of the in-phase and quadrature components, respectively.
The processing of the received signal at the receiver is mainly divided into two stages. Firstly, the received signal is preprocessed to derive a high-quality signal representation. Secondly, deep learning algorithms such as residual networks and long short-term memory networks are utilized to achieve automatic extraction of signal features and prediction of the modulation type of the signal.
3. Modulated Signal Classification and Recognition Algorithm Based on Fusion Multi-Feature Multi-Channel ResNet and BiLSTM Network
3.1. Network Model Design
We propose a modulated signal classification and recognition algorithm based on the fusion multi-feature multi-channel ResNet and BiLSTM network (mf-mc ResNet-BiLSTM) and automatic modulation recognition model, and the designed network model is as follows.
Firstly, the training dataset is produced, where the original modulated signal is performed as IQ vectors and then the IQ vectors are converted into AP and FFT signals respectively. After inputting three types of vector signals into the multi-channel feature fusion module, the processing module converts these input signals into a high-dimensional feature space for feature fusion and extracts useful features from different signal sources [10].
Then we designed the residual neural network (ResNet) based on depthwise separable convolution, which serves as a lightweight module to process spatial sequences which can further accelerate the training process. After that, we designed the feature extraction and fusion network. We proposed the model which combines DSC with bidirectional long short-term memory networks (BiLSTM) to extract temporal features of the signals. Finally, we designed a self-attention mechanism, which can focus on the temporal feature extraction in BiLSTM. To deal with the problem that the self-attention mechanism has low expressive ability, we designed the multi-head attention mechanism (MHA) to increase the model’s expressive ability and capture long-range dependence between features, which achieved the goal of network optimization.
Through the DNN network, the extracted temporal features are input into the data in a one-dimensional format, and after two full-connectivity layer dimensionality reductions, the final output is the recognition results of signal modulation categories. The category predicted by the neural network is , and the cross-entropy function is used to measure the difference between the predicted category and the real category y. The parameter update is carried out with the goal of minimizing the cross-entropy loss function and the expression of the loss function.
where N is the total number of samples, is the true category label of the ith sample, and is the predicted value of the ith sample given by the model. The overall architecture of the algorithm is shown in Figure 2.
3.2. Input Data Design
Currently, the deep learning schemes mainly use single-vector signal inputs, such as IQ signals or frequency domain FFT signals. But the characterization ability of IQ signals and FFT signals significantly decreases in low SNR environments, and the recognition accuracy of the model is greatly reduced under noise interference.
In this paper, we propose a fusion model using IQ vectors, AP vectors and FFT vectors to formulate the input data. In this model, the IQ vectors retain the original temporal characteristics. AP vectors strengthen the temporal and spatial correlation between amplitude and phase in the form of polar coordinates, and FFT vectors provide the global spectral features through the extraction of the frequency domain.
3.2.1. IQ Vector
The IQ vector is obtained by multiplying the I-channel signals with and the Q-channel signals with . Then, we superimpose them to get the modulation signal , where the in-phase component is and the quadrature component is , denoted as follows.
3.2.2. AP Vector
The AP vector refers to the joint amplitude-phase characterization, which is converted by the IQ vector to get the amplitude and phase data .
Its calculation equation is as follows.
where is the phase data of AP vector and is the amplitude data of AP vector. After the transformation, the vector formats of and are the same as the IQ vectors before the transformation, which can be uniformly input into the same model structure without additional operations, greatly simplifying the complexity of the model.
3.2.3. FFT Vector
The FFT vector is the mapping of the IQ vector from the time domain to the frequency domain as shown in Equation (10).
First of all, is a complex signal representation of the IQ channel.
The discrete Fourier transform is then applied to the complex signal , which can be written as follows.
Finally, after obtaining the spectral signal , we divided the spectral signal into two channels, real and imaginary, as the input to the neural network.
3.3. Multi-Feature and Multi-Channel Network
In order to fully utilize the multi-dimensional information of the signal and improve the accuracy and robustness of the modulation recognition, we designed and integrated the multi-feature network (MF) and the multi-channel network (MC) [11]. MF refers to the strategy which employs three formats as inputs, including the raw IQ signal, amplitude-phase (AP) vector, and frequency vector, to extract signal features. MC refers to the parallel processing of signals through multiple independent channels. Each channel can extract different features of the signal and then fuse these features to enhance recognition. The multi-feature and multi-channel network architecture is shown in Figure 3.
We take the FM signal as an example, as shown in Figure 3. Firstly, in the MF module, three vector formats of FM signals are input, which contain different amplitude, phase, and frequency domain information.
Secondly, we put the fused signals into the MC module. The IQ channel uses as the main channel and splits the IQ data into in-phase and quadrature components to obtain the I and Q channels in the format of . The I and Q channels are used as auxiliary channels, which can be effectively supplemented with features for the main channel. In this way, the main channel and the auxiliary channel complement each other, reducing the possibility of missing features and making the feature characterization more stable and diversified. The multi-channel network parameters are shown in Table 1. Since the AP, FFT signals and IQ signals have similar processing methods, we take IQ data as an example to describe in detail.
Finally, we put the fused signals into the MC module. This module converts different types of input signals into a high-dimensional feature space and performs feature fusion, making the network able to extract useful features from different signal sources and combine the features to improve classification performance. After feature fusion, the system classifies three different vector and calculates the corresponding probabilities for each class.
3.4. Depth Separable Convolution Based Residual Network and BiLSTM Incorporating Attention Mechanism
3.4.1. Depth Separable Convolution Based Residual Network
In order to make the network learn deeper feature representations and effectively deal with gradient vanishing in deep networks, we designed a network combining Depthwise Separable Convolution (DSC) and Residual Network (Residual Network based on Depthwise Separable Convolution, RNDSC). This module can reduce the size of the model and the number of parameters to improve the speed of the model and the computational efficiency at the same time.
The DSC is an important technique used in convolutional neural networks to optimize computational efficiency, which can be decomposed into two steps including of depthwise convolution and pointwise convolution. For DSC, depthwise convolution is used to extract spatial features, while pointwise convolution is employed to extract channel features. DSC performs grouped convolution in feature dimensions, applying independent depthwise convolution to each channel, and then aggregates all channels using a 1 × 1 convolution before the output. The number of parameters and computation amount is the sum of the number of parameters and computation amount of the two steps of depthwise convolution and pointwise convolution. The parameter ratio and computation complexity ratio of the conventional and DSC are as follows.
where and are the parameter count of DSC and conventional convolution. and are the computation complexity of DSC and conventional convolution. N is the number of convolution kernels and is the size of the convolution kernel. From Equation (13), the parameter and computational complexity of DSC are much smaller than that of Conv. Therefore, DSC is adopted to achieve a lightweight network structure.
Meanwhile, we designed a new ResNet based on the DSC which is shown in Figure 4. Firstly, the network extracts features through two-dimensional convolution on MF-MC input features. Secondly, the output features is processed by depthwise convolution, and then the pointwise convolution is employed for dimensionality reduction and fusion. Finally, the fused feature is output by RNDSC. This structure enables the model to learn the features of input data and enhances the robustness and generalization ability of the model.
3.4.2. BiLSTM Incorporating Attention Mechanism
The features which are the output of ResNet need to be processed in the temporal feature part, so we proposed the BiLSTM with fusion attention mechanism which connects Self-Attention and Multi-Head Attention. We named this module BSM, and its structural diagram is shown in Figure 5.
The feature sequence generated by DSC is shown as follows.
Z is the vector of length T and is the Tth valued feature vector. After inputting Z into a BiLSTM recurrent network, we used two LSTM networks to scan along the forward and backward directions of the sequence. The hidden states of the two LSTM networks will be concatenated at each position, where denotes the forward output of the hidden layer unit at the time of t. denotes the gate control of LSTM in forward propagation. The output is controlled by the memory unit at the time of and the forward output at the time of . Similarly, denotes the backward output of the hidden layer unit at the time of t and the parameter in the forward and backward LSTM network is shared. Then the output of the hidden layer unit at the time of t can be expressed as a cascade of the hidden states of the forward and backward LSTM network, and the long-term dependency of the feature sequences can be better captured and prevent information loss, which is expressed as follows.
Then, we calculated the attention probability distribution value E determined by the output V from the BiLSTM, which is represented as follows.
where U, W is the weight coefficient and b is the bias coefficient. The output V from the BiLSTM denotes .
After training to obtain the weight vector corresponding to each output vector , the weights are applied to the hidden states output by BiLSTM. Then the output of the self-attention layer c is a weighted summation of the weights, which is represented as follows.
where is the regularized weight of attention probability distribution value E, and its formula can be expressed as .
Then, we put the output of the self-attention mechanism c into the multi-head attention module. The multi-head attention mechanism is set as u head, represented by the attention mechanism unit , and the attention mechanism is performed from within different attention units to learn different relevant features, where the output of the ith attention unit is represented as follows.
where is the regularized weight of the attention unit and the sum of the weights of under the attention mechanism unit is 1.
The output feature result is concatenated and then linearly transformed to get the final output of the attention expressed as follows.
The output of the attention layer is passed into the dense layer twice to realize the dimensionality reduction and generate a k-dimensional matrix, and finally the discrimination type of the modulated recognized signal is obtained by argmax operation. The detailed process of the bidirectional long short-term memory network structure algorithm incorporating the attention mechanism is shown in Figure 6.
3.5. Model Training
The DSC can simplify the training and the ResNet can solve the gradient vanishing [12] or gradient bursting. Meanwhile, the BSM can comprehensively capture the features. Therefore, the modulation recognition accuracy of the signal can be significantly improved by combining these modules.
In order to speed up the training process, we adopt the mini-batch approach to process the data. That means the training set is divided into n batches and each batch contains training samples. During the training process, one batch is selected at one time. The loss function for constructing the model is shown as follows.
The optimization algorithm is selected as the Adam optimizer, and the parameter updates follow a scheduling function that dynamically adjusts the learning rate. We summarize the training process as shown below.
(1)Initialize the network model parameters and set the learning rate.(2)Randomly divide the training samples into n batches.(3)Randomly select a batch .(4)Input the sample into the multichannel network in multi-vector format.(5)Use RNDSC to simplify the training. Then use BSM to train the network on the feature sequence Z which is the output of the multi-feature multi-channel network. Finally, we use as the output.(6)Use Softmax to obtain the predictive probability distribution of the model .(7)Calculate the loss function by substituting the value of into Equation (6)(8)Update the parameters using Adam’s algorithm .(9)Repeat steps (2) to (9) until the loss function converges.
4. Experimental Results and Discussion
4.1. Experimental Setup and Dataset
In this experiment, Python3.7 is used as the development language, and TensorFlow-GPU 2.5.0 is used as the computing framework, which utilizes Keras 2.5.0 as the built-in high-level neural network API. CUDA8.0 is used for computing acceleration. The CPU used in the experiment is Intel (R) Xeon (R) Gold 5418Y, and the GPU is RTX 4090.
The RML2018.01a dataset was used as the input data for this experiment [13]. This dataset is generated by GNU Radio over a complex channel and contains the main impairments of wireless signals in a real-world environment, as well as 24 signal modulation types with a sampling rate of 64 kHz and a maximum sampling rate offset of 50 Hz. Each signal consists of 1024 samples, including a total of 2,555,904 signal samples with SNR ranging from −20 dB to 30 dB, 2 dB intervals. The specific parameters are shown in Table 2.
The simulation experiments are partially constructed using the Keras in Python. To optimize the network parameters effectively, the simulation uses the Adam optimizer. The dataset is divided into a training set, validation set, and test set, in which the training set accounts for 64%, the validation set accounts for 16%, and the test set accounts for 20%, and such a division is helpful for cross-validation and performance evaluation during model training. The specific parameter settings of the model are shown in Table 3.
4.2. Experiments Results for Multi-Feature Inputs
4.2.1. Confusion Matrix Analysis
In this study, several different types of signal inputs are used, including IQ vector, AP vector and FFT vector. The effect of recognizing modulated signals under different types of signal inputs is further verified by using them as single-vector signal inputs and multi-vector signal inputs respectively. Figure 7 gives the confusion matrix of all signals under the inputs of IQ vector, AP vector, FFT vector and multi-vector inputs. The SNR range is −20–30 dB.
As can be seen from Figure 7, the diagonal lines of the confusion matrix of QAM, AM-SSB, AM-DSB, FM, GMSK, and OQPSK are relatively clear for both the single-vector and multi-vector signal inputs, which indicates that they can distinguish various modulated signals more accurately. For signals such as ASK, BPSK, QPSK, PSK, and APSK, the confusion matrices of the single-vector signal inputs show more misclassification cases, and the classification boundaries are more blurred. In contrast, the confusion matrices for multi-vector signal inputs have relatively clear diagonal lines in these signals, indicating that they are able to distinguish various types of modulated signals more accurately.
4.2.2. Noise Resistance Analysis
To explore the recognition performance changes of the multi-vector signal input in the environment of different SNRs. We fused the original signals of different SNR and obtained the signals with a certain range of SNRs to replace the single SNR signal as the input in order to better suit the actual environment. We take the >24 dB in Figure 8 as an example, which refers to the signal input which is composed of all the signals in the 26 dB, 28 dB, and 30 dB SNR for the signals. Figure 8 gives the accuracy of the modulated signal under the SNR with −20–30 dB for the single-vector signal input and the multi-vector signal input.
As shown in Figure 8, before >6 dB, the FFT vector signal has the lowest accuracy at the beginning but has the fastest increase in accuracy. The IQ vector signal and AP vector signal have lower and closer accuracy, and the increase in accuracy is also more rapid and smooth. The multi-vector signal inputs investigated in this paper have higher accuracy than single-vector signal inputs before >6 dB. Meanwhile, the multi-vector signal inputs can achieve an accuracy of 95% after >−10 dB. After >6 dB, the accuracy of single-vector and multi-vector signal inputs is not much different and the trend is relatively smooth; both can reach about 95%.
4.3. Multi-Channel Network Performance Analysis
To further verify the improved performance of multi-channel networks [14] in recognizing modulated signals, we take the IQ vector signals as an example to compare the accuracy obtained by multi-channel and single-channel networks, resectively. Firstly, we use the original IQ signal as a single-channel input model. Then, we input the I channel, Q channel, and IQ channel into the model at the same time for the experimental simulation and comparison. The results of the simulation are shown in Figure 9.
As shown in Figure 9, the multi-channel network has an improvement in accuracy compared to the single-channel network [15]. Since dividing the IQ signal into I-component, Q-component and IQ-component can make it easier for the model to identify and analyze the features of each component, the multi-channel network can extract the features more adequately for >0 dB before. Meanwhile, the FFT and AP signals have a similar principle to the IQ signal and also have a significant improvement in accuracy.
4.4. Performance Analysis of BiLSTM Networks with Attention Mechanisms
In order to verify the effectiveness of the fused multi-head attention mechanism, we designed a comparison experiment after the RNDSC module. We verify the necessity of incorporating a fusion multi-head attention mechanism [16] by comparing the changes in recognition accuracy before and after BSM module. The simulation results are shown in Figure 10.
From Figure 10, it can be seen that the BiLSTM model has ability in extracting signal features. But due to its relatively simple structure, it cannot fully capture the features of complex signals which are not easy to extract, and its recognition accuracy is only 93%. Introducing the attention mechanism and the adaptive mechanism with multiple heads into BiLSTM significantly enhances the model’s ability to extract important features. Meanwhile, BSM can better handle complex signals, and its recognition accuracy is improved to 95.5%.
4.5. Number of Parameters Analysis
In this section, we discuss the number of parameters of each module, which is shown in Table 4.
As can be seen in Table 4, the BiLSTM serves as the backbone module, accounting for 48.1% of the total with 0.25M parameters, and reflecting the high computing cost required for modeling complex bidirectional temporal dynamics. The Depthwise Separable Convolutional Residual Network (DSC-ResNet) contributes 28.8% with 0.15M parameters, and its relatively economical parameter consumption validates the efficiency of modern lightweight convolutional designs in feature refinement tasks. Meanwhile, the multi-head attention mechanism achieves dynamic selection and enhancement of critical information segments at a minimal cost of only 0.07M parameters (13.5%). Overall, The model places more than three-quarters of its parameters (76.9%) in the BiLSTM and DSC-ResNet modules. These components are responsible for fundamental feature extraction and temporal modeling, giving the system a solid and capable foundation. Simultaneously, it utilizes the attention mechanism as a lightweight and critical component. Ultimately, a hierarchical and focused high-efficiency recognition system was constructed with a total parameter count of 0.52M.
4.6. Ablation Study
In order to verify the performance of the MC-MF-RNDSC-BSM which is proposed in this paper, the experiments are conducted to combine the schemes of several modules. These modules include the following:
Module1: Multi-feature Fusion Preprocessing Module;
Module2: Multi-Channel Network Module;
Module3: Depth Separable Convolution-based Residual Network Module;
Module4: Bi-directional Long Short-Term Memory Network incorporating Attention Mechanism.
The classification recognition rates of the different methods are derived and the results are shown in Table 5. In this table, Method1 is Baseline with Module1. Method2 is Baseline with Module1 and Module2. Method3 is Baseline with Module1, Module2 and Module3. Ours contains all modules.
As can be seen in Table 5, the Baseline cannot fully capture the features of complex signals, and its recognition accuracy is only 88.33%. After the introduction of the multi-feature fusion preprocessing module and the multi-channel network module, the ability of the model to extract important features is significantly enhanced so that it can better handle complex signals, and the recognition accuracy is increased to 92.91% and the recall rate is also increased to 92.32%.
When the fusion multi-feature multi-channel network is combined with the residual network based on depth-separable convolution, the gradient problem is avoided by simplifying the model through parameter reduction and combining it with the residual network to efficiently transfer the gradient. This results in a recognition accuracy of 93.43% and a recall of 92.59%.
Finally, the combination of fused multi-feature multi-channel ResNet and BiLSTM neural network proposed in this paper can comprehensively capture the features and improve the accuracy rate to 95.67%, which is an improvement of 2.24%, and the recall rate can also reach 94.56%.
4.7. Training and Validation Performance
To validate whether overfitting is present, we give the training and validation performance in the Figure 11.
As shown in the Figure 11, the training and validation losses decrease simultaneously and gradually converge. Meanwhile, the training and validation accuracies improve in parallel and then stabilize, with only a small gap of approximately 3–5% between them. This limited difference indicates balanced learning behavior and good generalization performance, suggesting that no evident overfitting occurs.
4.8. Comparison Experiments
To validate the performance of our model, we conducted comparision experiments with LSTM, MMF (multimodal fusion) [17], FGDNN (fusion GRU deep learning neural network) [6] and LightMFFS (lightweight multi-feature fusion structure) [18]. The accuracy of signal recognition is shown in the Figure 12.
As shown in Figure 12, before >2 dB, the accuracy of the network which we proposed has a significant improvement compared to the previous models because our network can fully extract the complex features. After >8 dB, the average precision of our network can also remain at a high level compared to the previous models. Overall, our network has significant advantages compared to previous networks.
5. Conclusions
In order to solve the problems of the insufficient feature expression of modulated signals and the poor effect of traditional neural networks on the classification of confusing signals, we proposed a modulated signal classification algorithm based on a multi-feature multi-channel network. By fully exploiting the interaction and diversity among different features, the richness of the dataset is enhanced and the problem of insufficient feature expression of modulated signals is effectively solved. Meanwhile, a multi-channel network structure is designed to optimize the feature extraction process for the confusing characteristics between signals, which solves the problem of the poor classification of confusing signals by traditional neural networks. In order to deal with the feature extraction inflation triggered by the increase in signal samples, we adopted a multi-head attention network to optimize the feature extraction and processing through the attention system, which ensures the high efficiency and accuracy of the model. Experimental results show that this algorithm excels in classification performance and significantly improves the accuracy and robustness of modulated signal classification. Its accuracy can reach 95.67% and the recall rate can reach 94.56%. Additionally, its accuracy has a significant improvement in low SNR environments (−22 dB–2 dB).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Guo Q. Nie M. Qi L. Kaliuzhnyi M. Automatic Modulation Recognition Based on Single-channel Multi-scale Graph Neural Network J. Electron. Inf. Technol.2023451575158410.11999/JEIT 220840 · doi ↗
- 2Lin C. Yan W. Zhang L. Wang Y. A review of communication signal modulation identification J. Chin. Acad. Electron. Sci.20211610741085
- 3Zhang X. Li T. Gong P. Liu R. Zha X. Modulation recognition of communication signals based on multimodal feature fusion Sensors 202222653910.3390/s 2217653936080996 PMC 9460658 · doi ↗ · pubmed ↗
- 4Deng W. Wang X. Huang Z. Xu Q. Modulation classifier: A few-shot learning semi-supervised method based on multimodal information and domain adversarial network IEEE Commun. Lett.20232757658010.1109/LCOMM.2022.3225566 · doi ↗
- 5Liu F.G. Pan J.Y. Zhou R.L. Contrastive learning-based multimodal fusion model for automatic modulation recognition IEEE Commun. Lett.202428788210.1109/LCOMM.2023.3336049 · doi ↗
- 6Sun S.Q. Wang Y.Y. A novel deep learning automatic modulation classifier with fusion of multichannel information using GRUEURASIP J. Wireless Commun. Netw.202320236610.1186/s 13638-023-02275-y · doi ↗
- 7Pathak N.K. Bajaj V. Automatic modulation classification using bimodal parallel multichannel deep learning framework for spatial multiplexing MIMO system Phys. Commun.20235910207110.1016/j.phycom.2023.102071 · doi ↗
- 8Wang X. Liu D. Zhang Y. Li Y. Wu S. A spatiotemporal multi-stream learning framework based on attention mechanism for automatic modulation recognition Digit. Signal Process.202213010370310.1016/j.dsp.2022.103703 · doi ↗