Predicting Car-Engine Manufacturing Quality with Multi-Sensor Data of Manufacturing Assembly Process
Xinyu Yang, Qianxi Zhang, Junjie Bao, Xue Wang, Nengchao Wu, Qing Tao, Haijia Wu, Li Liu

TL;DR
This paper introduces a framework using sensor data to predict car-engine manufacturing quality, reducing rework and improving defect detection.
Contribution
A novel edge-deployable framework combining SAE, CSWE, and ARSR for high-dimensional sensor data analysis in manufacturing.
Findings
Sparse Autoencoder reduces noise in 12,000+ manufacturing parameters.
Class-Specific Weighted Ensemble improves defect recall by 7.72%.
Adaptive Regime-Switching Regression lowers prediction error by 12%.
Abstract
Car engine quality control is fundamentally hindered by extremely high-dimensional, noisy, and imbalanced multi-sensor data. To overcome these challenges, this paper proposes an edge-deployable diagnostic and predictive framework. First, a Sparse Autoencoder (SAE) maps over 12,000 distributed manufacturing parameters into a robust latent space to filter instrumentation noise. Second, for defect classification, a Class-Specific Weighted Ensemble (CSWE) tackles extreme class imbalance by aggressively penalizing majority-class bias, improving defect interception recall by 7.72%. Third, for transient performance tracking, an Adaptive Regime-Switching Regression (ARSR) replaces manual phase selection with unsupervised regime routing to dynamically weight local experts, reducing relative prediction error by 12%. Rigorously validated across three diverse public datasets (NASA C-MAPSS, AI4I,…
Click any figure to enlarge with its caption.
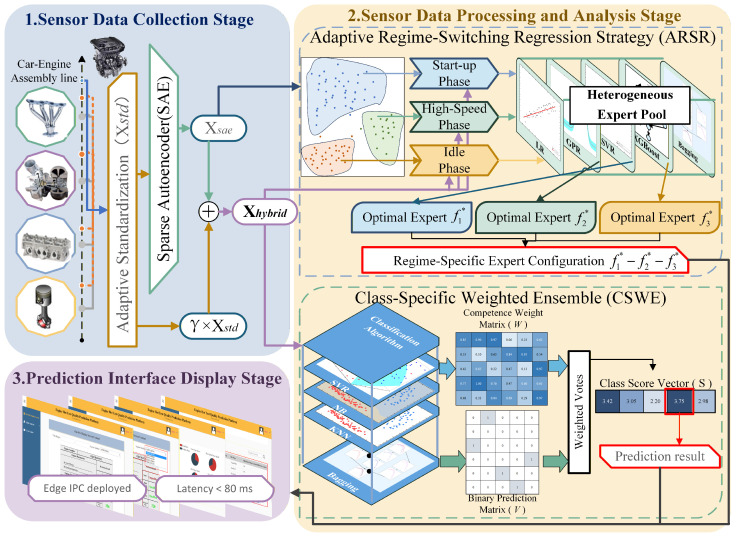 Figure 1
Figure 1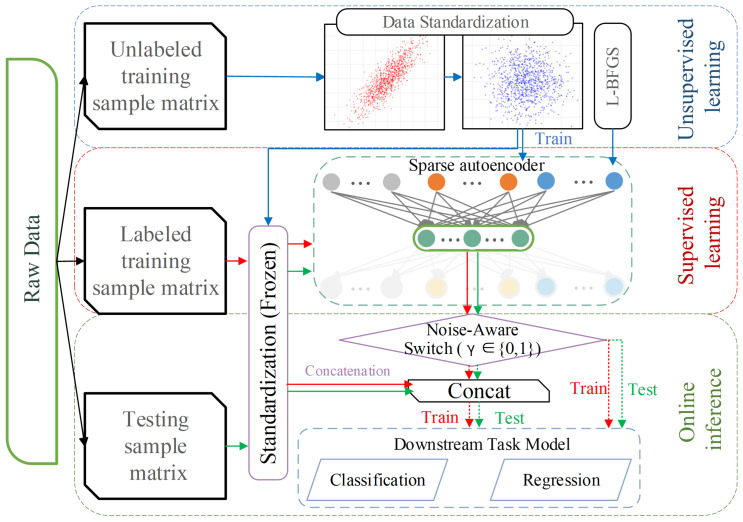 Figure 2
Figure 2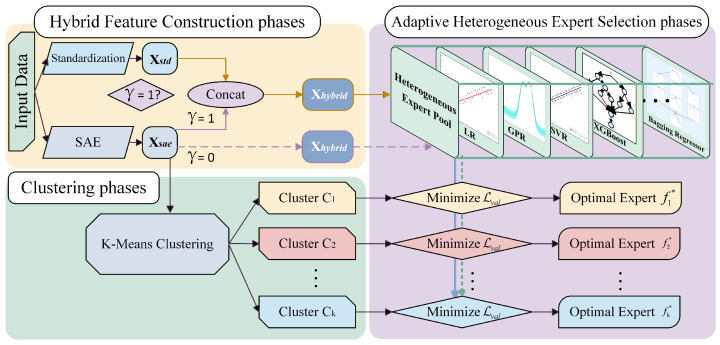 Figure 3
Figure 3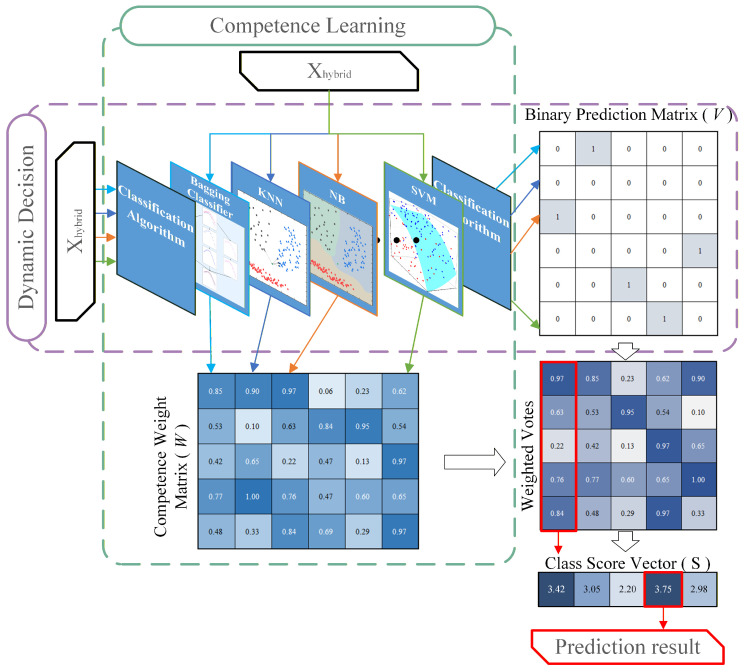 Figure 4
Figure 4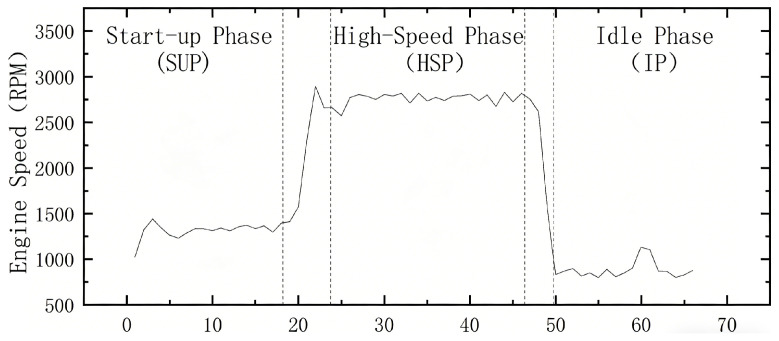 Figure 5
Figure 5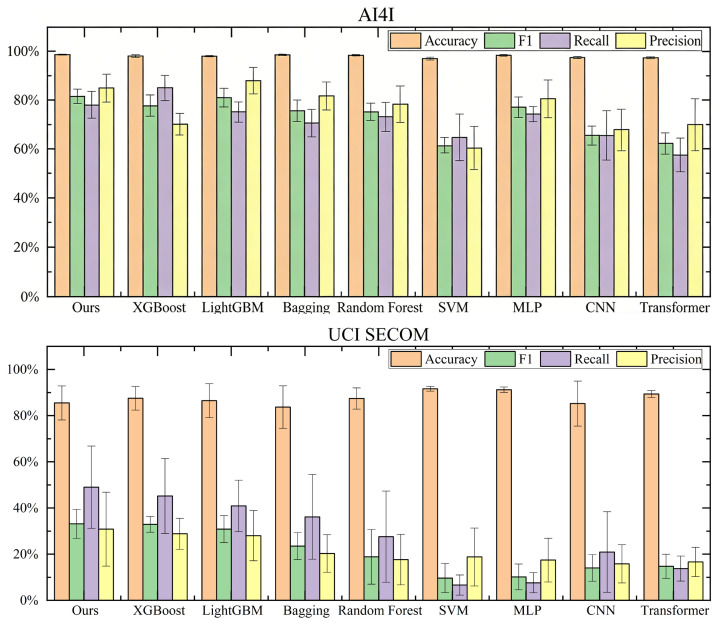 Figure 6
Figure 6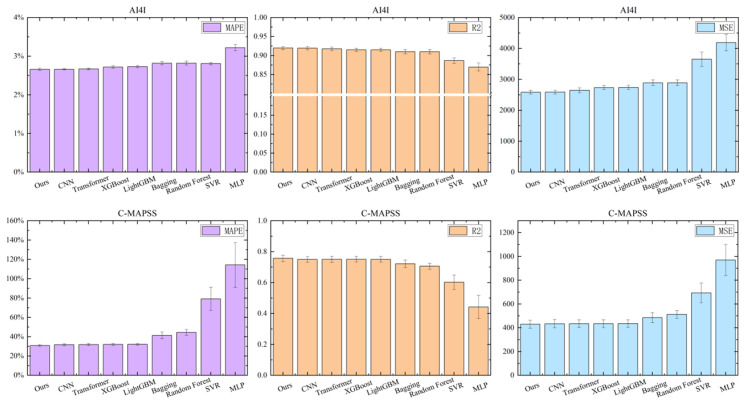 Figure 7
Figure 7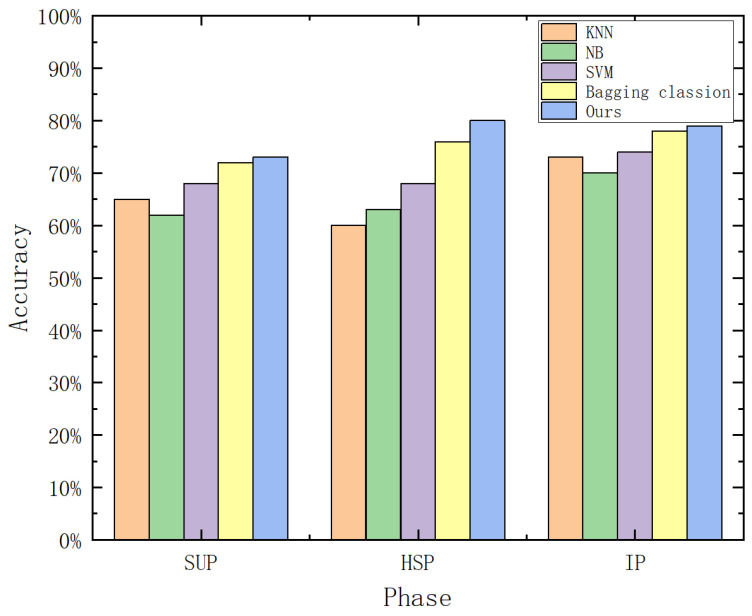 Figure 8
Figure 8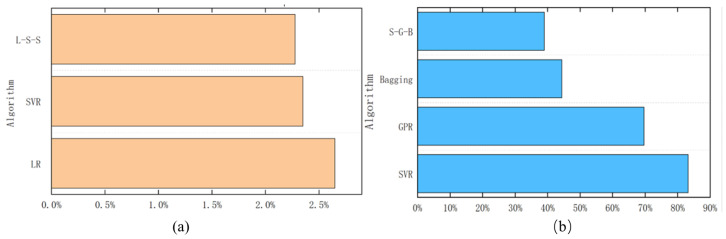 Figure 9
Figure 9 Figure 10
Figure 10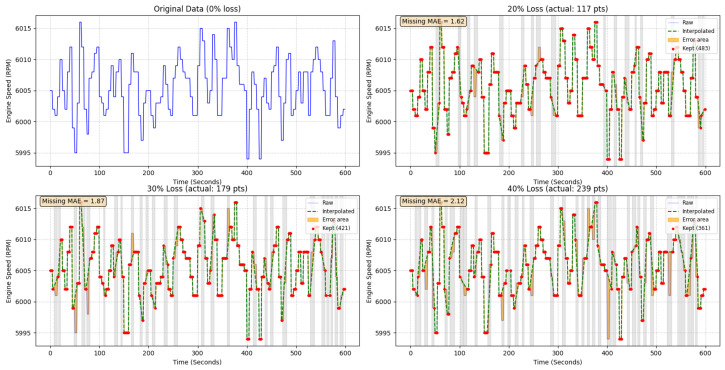 Figure 11
Figure 11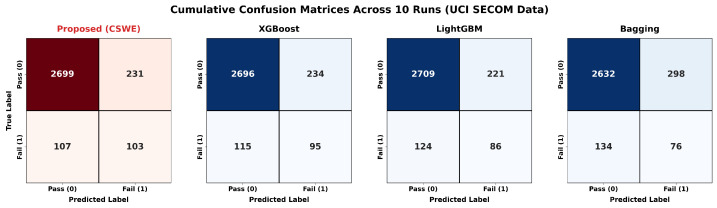 Figure 12
Figure 12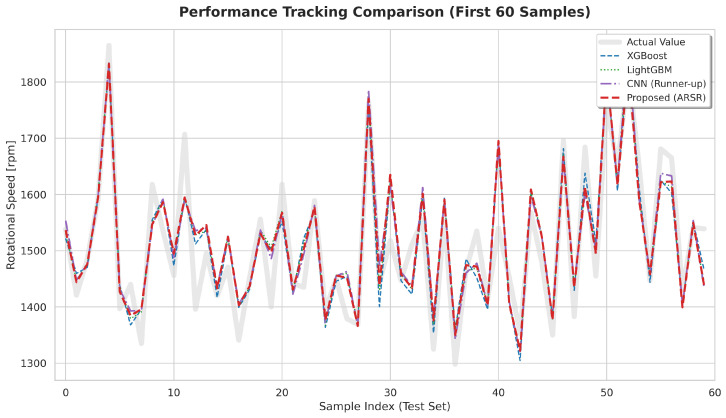 Figure 13
Figure 13- —Chongging Municipal Economy and Information Technology Commission
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Fault Diagnosis Techniques · Anomaly Detection Techniques and Applications · Data Stream Mining Techniques
1. Introduction
Automobiles are a cornerstone of modern discrete manufacturing [1,2]. As the core power unit of a vehicle, the internal combustion engine’s assembly quality directly dictates the holistic performance, safety, and manufacturing cost of the final product [3]. In contemporary production environments, predicting and verifying engine manufacturing quality at the End-of-Line (EOL) testing stage is critical. Early identification of mechanical or thermodynamic anomalies effectively minimizes rework overhead, optimizes production efficiency, and prevents defective units from escaping into the market [4,5].
However, engine assembly lines face profound challenges due to the extreme heterogeneity of multi-sensor data. Modern test benches generate massive, high-frequency data streams encompassing disparate physical domains, such as dynamic torque, rotational speed, oil pressure, and pneumatic leakage rates. These heterogeneous sensors exhibit massive scale discrepancies (e.g., kPa vs. Nm) and varying degrees of non-stationary electromagnetic interference. Traditional quality control protocols, which predominantly rely on rigid empirical thresholds or manual expert inspection, are fundamentally inadequate for deciphering the high-dimensional, non-linear correlations embedded within such complex data. Consequently, developing intelligent, data-driven diagnostic models has become a primary objective for advancing smart manufacturing.
Leveraging this heterogeneous data presents two primary algorithmic bottlenecks. First, the raw sensor arrays are characterized by high dimensionality and severe multicollinearity (redundant features) [6,7,8], demanding robust feature extraction methodologies that can filter noise without discarding critical transient physical indicators. Second, effective data fusion is heavily impeded by the non-stationary nature of engine testing. Engines undergo deterministic, discrete phase transitions (e.g., from Start-up, to High-speed, to Idle) [9]. Existing global approximation models typically struggle to adapt to these abrupt statistical shifts, and their reliance on complex deep learning architectures often exceeds the computational and latency constraints of industrial line-side edge servers.
To bridge these gaps, this study proposes a unified, lightweight, and highly adaptive diagnostic framework tailored for complex engine assembly lines. We integrate Adaptive Standardization with a Sparse Autoencoder (SAE) optimized via the L-BFGS algorithm. This combination effectively unifies physical scales, suppresses background noise, and extracts compact latent features while maintaining strict edge-computing viability. Furthermore, to address the distinct requirements of defect classification and continuous performance tracking, we propose two specialized diagnostic strategies designed to handle extreme class imbalance and non-stationary operating regimes.
The primary contributions of this study are summarized as follows:
- Unified High-Dimensional Feature Extraction: We developed a robust pipeline utilizing a Sparse Autoencoder (SAE) to project extreme high-dimensional ( 12,000), heterogeneous sensor data into a scale-unified latent space. This module effectively filters out industrial electromagnetic interference while preserving critical mechanical dynamics, without relying on complex, latency-heavy deep network architectures.
- Class-Specific Weighted Ensemble (CSWE) for Asymmetric Defect Detection: To address the severe class imbalance inherent in modern automotive quality control (where defect rates are intrinsically extremely low), we introduce the CSWE strategy. Unlike standard ensemble methods, CSWE utilizes a mathematically rigorous, recall-oriented objective function designed to aggressively penalize majority-class bias, thereby significantly maximizing the recall rate for identifying rare defective engines without compromising overall stability.
- Adaptive Regime-Switching Regression (ARSR) via Unsupervised Routing: To overcome the underfitting limitations of global monolithic models under non-stationary dynamics, we designed the ARSR framework. For latent or unlabelled environments, ARSR employs an unsupervised regime routing mechanism (via K-Means clustering on SAE latent features) to automatically discover hidden operational phases and dynamically weight the optimal local experts, providing a principled adaptive architecture.
- Physics-Informed Edge-Optimized Deployment: The proposed framework was successfully deployed as a real-time system on a physical automotive assembly line. For this specific physical application, the regime routing utilizes deterministic, physics-based hard-switching (RPM boundaries) as a deliberate architectural simplification. This strict edge-optimization ensures an ultra-low inference latency of under 80 ms (satisfying Takt time constraints) and has practically demonstrated its engineering viability by reducing the engine rework rate by 7.2%.
The remainder of this paper is organized as follows to ensure clarity and logical progression: Section 2 reviews related work in data preprocessing and multi-sensor fault detection. Section 3 details the proposed methodology, including the SAE, CSWE, and ARSR modules. Section 4 describes the industrial data acquisition and experimental setup. Section 5 presents the objective experimental results on both public benchmarks and the industrial dataset. Section 6 provides an in-depth discussion of the framework’s mechanisms, engineering boundaries, and physical interpretations. Finally, Section 7 concludes the paper.
2. Related Work
2.1. Data Preprocessing
Preprocessing heterogeneous multi-sensor data is essential for engine assembly line fault diagnosis, as it directly impacts data integrity and feature interoperability [10]. Despite extensive research, industrial environments continue to grapple with high dimensionality, sparse labeling, and significant feature redundancy [6].
To manage high-dimensional complexity, traditional statistical methods and emerging deep learning techniques offer different trade-offs. For instance, PCA-based variants like PCA-DP and CMPCA-DP have been utilized to balance privacy with data utility through effective aggregation and noise reduction [11]. Similarly, graph-representation-based feature selection has shown promise in improving efficiency and mitigating overfitting [12]. However, a persistent bottleneck remains: standard linear transformations often fail to resolve the complex non-linear couplings in sensor streams, while graph-based architectures frequently demand computational resources that exceed the limitations of real-time industrial deployment [13,14].
In the realm of noise suppression, specialized algorithms such as enhanced genetic algorithms, hybrid SEMD–ISSA–KELMC frameworks [15], and Krylov subspace techniques [16] have successfully addressed interference in electromagnetic or vibration datasets. Yet, these signal-specific solutions are often ill-equipped for the extreme scale inconsistencies—such as the vast dimensional gaps between torque (Nm) and fluid pressure (kPa)—intrinsic to engine assembly data. Furthermore, they rarely explore the deep, cross-modal correlations necessary for holistic manufacturing quality prediction.
Recent advances in anomaly detection, such as the MAGMM algorithm [17] and the BBTGO meta-heuristic [13], attempt to capture non-linear features while preserving critical spatial information. Nevertheless, the high computational complexity of these frameworks hinders their execution on resource-constrained edge servers, where sub-100ms latency is a hard requirement [13]. This operational gap necessitates a more lightweight yet robust solution, such as the SAE framework optimized via L-BFGS proposed in this study.
The scarcity of labeled samples presents another critical hurdle [18]. While optimization paradigms involving DWT, SSA, or adaptive three-stage strategies have improved signal quality [19,20,21], many remain tethered to rigid prior assumptions about data distribution. In actual industrial settings, these methods often fail to adapt to extremely sparse annotations or leverage the massive, continuous streams of unlabeled sensor data.
Current fusion techniques, ranging from wavelet-PCA combinations [22] to improved MPGA-ACO-BP neural networks [6], have made strides in integrating multi-source data. However, these systems often struggle with physical domain alignment (e.g., mechanical vs. thermodynamic) and lack the dynamic weight allocation required to handle abrupt signal fluctuations across the engine’s discrete operating phases [10]. This study addresses these gaps by introducing an unsupervised feature learning approach that capitalizes on unlabeled data while maintaining high-precision, phase-adaptive modeling.
2.2. Multi-Source Sensor Data Fault Detection Algorithms
Although existing multi-sensor fault diagnosis methods have advanced significantly, they exhibit critical limitations in heterogeneous feature fusion and dynamic adaptability. Deep learning architectures, such as ResNet18 [23], CNN-LSTM [24], Transformer-based frameworks [25,26], and Digital Twin models [27], have facilitated cross-source data interaction. However, they share two primary drawbacks: First, they often struggle with physical scale disparities (e.g., mechanical torque versus sealing leakage) during multi-modal data fusion, which leads to model bias towards high-value features and limits fusion accuracy. Second, when attempting to capture dynamic features under fluctuating production conditions, these methods typically rely on overly complex hierarchical architectures, imposing severe computational overheads that are unsuitable for real-time industrial edge deployment [28].
Regarding dynamic scene adaptation, methods employing DBNs, improved particle filters, or EMD-ANFIS have shown strong performance in non-stationary environments [29,30,31]. Yet, these approaches generally treat dynamic changes as random continuous drifts. Engine testing, conversely, involves discrete, deterministic phase transitions (e.g., Start-up to High-speed). Existing methods lack rapid response mechanisms for such abrupt state switching, resulting in prediction lags.
To bridge these operational gaps—specifically addressing scale inconsistency, edge-computing latency, and deterministic regime switching—the proposed CSWE and ARSR strategies are specifically designed to handle localized classification boundaries and phase-adaptive dynamic tracking.
3. Methodology
3.1. Overall Framework
In this section, we detail a unified diagnostic and predictive framework specifically engineered for the high-precision requirements of automotive engine assembly lines. As illustrated in Figure 1, the architecture is designed to overcome the inherent challenges of industrial cold-test environments, such as heterogeneous sensor noise and non-stationary operational regimes, through a logically cohesive pipeline.
The pipeline initiates by mapping high-dimensional, multi-modal sensor streams—including dynamic torque, fluid pressure, and rotational speed—into a robust latent space. To mitigate the curse of dimensionality while preserving critical physical transients, we implement a Sparse Autoencoder (SAE) augmented with a noise-aware residual fusion mechanism. This dual-path feature extraction architecture generates unified hybrid features that successfully leverage both deep latent fault patterns and raw physical characteristics.
Building upon this robust feature representation, the framework bifurcates into two specialized algorithmic pathways to execute critical quality gate functions. For continuous performance tracking, we propose an Adaptive Regime-Switching Regression (ARSR) strategy. This regression module employs a divide-and-conquer paradigm to dynamically assign specialized local experts to distinct non-linear operating regimes, specifically the start-up, idle, and high-speed phases. Concurrently, to address the discrete defect detection task, we introduce a Class-Specific Weighted Ensemble (CSWE) strategy. By utilizing a competence-based weighting mechanism, this classification branch effectively navigates the extreme class imbalance of rare engine defects and optimizes the interception of highly variable failure modes.
Ultimately, the framework bridges the gap between algorithmic inference and industrial operation through an edge-deployed prediction interface. Hosted on line-side industrial PCs, the system provides real-time feedback to assembly line operators via a comprehensive human-machine interface (HMI). Operating with an optimized average inference latency of under 80 ms, this deployment supports instantaneous go/no-go quality decisions while enabling long-term defect tracing based on unique engine identification numbers to facilitate root cause analysis.
3.2. Feature Extraction
Due to the high dimensionality and scale inconsistencies of heterogeneous multi-sensor data, direct supervised learning is prone to overfitting and gradient instability. To address this, we propose a robust two-stage feature extraction pipeline: an Adaptive Standardization Mechanism for scale unification and a Sparse Autoencoder (SAE) augmented with Noise-Aware Residual Fusion for non-linear feature compression.
3.2.1. Data Standardization
To guarantee an unbiased assessment and prevent data leakage, we implemented a strict data isolation protocol. The overall semi-supervised learning workflow, including the Noise-Aware Residual Fusion mechanism, is systematically illustrated in Figure 2.
To eliminate scale inconsistencies among heterogeneous sensors and ensure numerical stability for the SAE, we enforce a strict standardization protocol before feature learning. As illustrated in the pipeline, this module standardizes the input matrix X.
Given the varying degrees of feature correlation in different datasets, the standardization implementation is configured as follows: For the industrial sensor data, which exhibits severe multicollinearity (e.g., strong coupling between torque and pressure), we employ PCA Whitening. This transformation, defined as
simultaneously standardizes the variance and decouples feature correlations to provide an isotropic input space. For benchmark datasets where feature independence is relatively high, we simplify the process to standard Z-Score or Min-Max scaling. This maps inputs to the sensitive region of the activation function (e.g., ) while preserving the original feature manifold.
To prevent data leakage, all statistics (e.g., mean , eigenvector matrix ) are computed solely from the unlabeled training set and strictly applied to the validation and test sets.
3.2.2. Sparse Autoencoder with Noise-Aware Residual Fusion
Following standardization, a Sparse Autoencoder (SAE) is employed to extract latent patterns. As illustrated in Figure 2, the network compresses the high-dimensional input into a compact feature vector ( ).
Unlike standard Autoencoders, we enforce a sparsity constraint to suppress background instrumentation noise. The network parameters W and b are optimized by minimizing a composite cost function :
where the three terms represent the reconstruction fidelity (MSE), the L2 weight decay (weighted by ), and the sparsity penalty (weighted by ), respectively. The Kullback–Leibler (KL) divergence constrains the average activation to a low sparsity target , effectively filtering out non-salient noise artifacts.
To ensure fast convergence on resource-constrained edge devices, we utilize the L-BFGS algorithm (Limited-memory Broyden–Fletcher–Goldfarb–Shanno). This quasi-Newton method approximates the inverse Hessian matrix to achieve superlinear convergence, making it superior to standard SGD for high-dimensional industrial optimization.
While SAEs are effective at extracting non-linear patterns, the compression process may inevitably filter out high-frequency physical details. To address this, we introduce a conditional Residual Feature Fusion mechanism. To ensure comprehensive representation, the hybrid feature vector is constructed as:
where is a dual-purpose gating parameter determined by both the signal-to-noise ratio (SNR) and the intrinsic dimensionality ( ) of the input space. represents the deep latent features extracted by the SAE, and denotes the standardized physical signals.
Mode I: Compression & Denoising ( ). For the industrial dataset, which is characterized by extremely high dimensionality ( 10,000) and significant noise, we strictly set . This setting enforces the dimensionality reduction capability of the SAE (10,000 ), preventing the “curse of dimensionality” and overfitting while filtering out background interference.Mode II: Information Maximization ( ). For standard benchmarks (e.g., CMAPSS) with low dimensionality ( ) and high signal fidelity, we set . In this low-dimensional regime, overfitting is not the primary constraint. Thus, the residual connection allows the model to leverage both the deep abstract features and the raw physical signals, maximizing predictive precision.
3.3. Quality Verification and Performance Prediction Modules
3.3.1. Adaptive Regime-Switching Regression Strategy
To address the non-stationary multi-stage patterns inherent in complex mechanical equipment, we propose an Adaptive Regime-Switching Regression Strategy (ARSR). This framework discards the reliance on a single monolithic model; instead, it decomposes the prediction task into local sub-problems across multiple stages, automatically identifying operating regimes and assigning the most adaptive “Expert Algorithm” to each.
The workflow consists of three tightly coupled phases, as illustrated in Figure 3.
In the Hybrid Feature Integration Phase, the ARSR module directly ingests the residual-fused features generated from Stage 1 (Section 3.2). This comprehensive hybrid representation ensures that the downstream regression experts are provided with a panoramic view of the equipment’s dynamic status, capturing both explicit physical magnitudes ( ) and implicit non-linear correlations ( ).
In the Clustering Phase, to address the challenge of unsupervised structure discovery in industrial regression scenarios, we utilize K-Means clustering to uncover the intrinsic data structure. We apply K-Means clustering specifically to the latent feature subspace ( ) of the hybrid representation to partition the data into K independent operating regime sets .
In the Adaptive Heterogeneous Expert Selection Phase, since different models exhibit varying performance across different data distributions, we construct a heterogeneous expert pool containing algorithms with diverse inductive biases (e.g., LR, SVR, XGBoost, GBR). For each identified cluster , the system performs an internal competition. The data within is split into training and validation sets. The optimal local expert is selected by minimizing the validation error:
where denotes the optimal expert selected for regime . The selection is performed by iterating through every candidate model f within the heterogeneous pool and identifying the one that minimizes the validation loss on the regime-specific validation set .
During the inference phase, a query sample is first assigned to a cluster via the nearest cluster centers, and the final prediction is generated by the corresponding optimal expert.
3.3.2. Class-Specific Weighted Ensemble Classification
Parallel to the regression task, the End-of-Line (EOL) defect detection (classification) relies on the same hybrid features ( ) extracted from Stage 1. However, relying on a single global classifier is risky due to the distinct decision boundaries of different defect types. For instance, distance-based models (e.g., KNN) may excel at clustering geometric faults, while probability-based models (e.g., Naive Bayes) might perform better on statistical anomalies. Standard majority voting overlooks these specific competencies and tends to bias toward the majority class in imbalanced industrial datasets.
To resolve this, we propose a Class-Specific Weighted Ensemble (CSWE) strategy. Instead of assigning a uniform weight to a classifier globally, we dynamically assign voting weights based on each classifier’s historical validation performance for specific defect categories.
The implementation of CSWE consists of two logically coupled phases:
In the Competence Learning Phase, we construct the expert knowledge base by integrating multiple heterogeneous algorithms (e.g., SVM, KNN, Gaussian Naive Bayes, and Bagging). Let m be the number of algorithms and n denote the total number of target defect classes. We construct the Competence Weight Matrix , defined as:
where each row represents the performance profile of the j-th classifier. To populate this matrix, we utilize the Class-Specific F1-Score on the validation set:
where (typically ) ensures numerical stability. This matrix W (shown in the bottom-left of Figure 4) is frozen after learning.
In the Dynamic Decision Phase, when a query sample (represented by the hybrid feature vector ) is input into the system, the decision process follows three steps:
- Binary Prediction: The classifiers generate a Binary Prediction Matrix (Top-right of Figure 4), where indicates model j predicts class k.
- Weighted Voting: The system computes the Weighted Votes by taking the element-wise product of the dynamic binary predictions (V) and the static competence weights (W).
- Score Aggregation: Finally, we calculate the Class Score Vector by summing the weighted votes column-wise:
The final prediction is the index corresponding to the maximum value in the score vector S:
4. Data Description and Experimental Setup
4.1. Industrial Dataset Construction and Preprocessing
The industrial dataset utilized in this study is derived from the H4 assembly line of a leading automotive manufacturer, specifically focusing on the JL478QEA-AJ engine model. To ensure comprehensive monitoring, we implemented a structured retrieval protocol within the Engine Test Data Management Database. By adopting the unique engine identification number (Engine ID) as the primary association key, we integrated heterogeneous records across three distinct physical domains: Process Data, Quality Data, and Performance Data.
The collected industrial dataset is characterized by extreme high-dimensionality ( 12,000) and multi-source heterogeneity, which is physically mapped to a distributed sensor suite across the H4 assembly line following the hierarchical sequence from OP10 to OP130. As illustrated in Table 1, the data is organized into a three-tier hierarchical structure.
Specifically, the Process Data ( 11,000) is primarily derived from high-frequency torque and angle encoders at fastening stations (e.g., OP10–OP90), where continuous mechanical traces are recorded at a uniform sampling frequency of 5 Hz to capture transient assembly dynamics. The Quality Data ( ) originates from specialized pressure transducers and flow meters at intermediate testing units, such as OP60 for leakage tests and OP100 for fuel-rail integrity. Finally, the Performance Data comprises 29 functional metrics (e.g., engine speed and torque) collected via high-precision tachometers and dynamometers at the End-of-Line (EOL) hot-test bench (OP130). This mapping ensures that the high-dimensional feature space accurately reflects the latent physical states of the entire manufacturing trajectory.
During the data extraction process, records were pulled from the database utilizing the inspection time and the unique Engine ID as query keys. For each engine sample, the retrieved attributes encompass the Engine ID, inspection time, hierarchical data categories (which encode the specific workstation and process stage), specific inspection items, and their corresponding numerical values. To accurately reconstruct the chronological assembly trajectory, the raw data was strictly sorted based on a hierarchical priority: Engine ID → Category (Workstation) → Inspection Time. An illustrative example of this exported data structure is presented in Table 2.
Once the raw chronological trajectories were reconstructed, the next critical step was formulating the predictive modeling tasks by assigning reliable ground truth labels. This was achieved through a rigorous dual-verification process. Primary labels (e.g., Pass/Fail for defect classification, and continuous RPM/Torque values for regression) were automatically recorded by the certified EOL test bench. Furthermore, to address potential labeling noise near decision boundaries, a specific subset of samples underwent manual re-inspection by senior quality engineers.
Following label assignment, the raw sensor streams underwent a rigorous preprocessing pipeline. This process consists of four synchronized stages: (1) Outlier Removal to filter discrete anomalies; (2) Gap Imputation using numerical interpolation; (3) Noise Reduction via smoothing filters; and (4) Standardization to normalize physical scales. To guarantee data quality, a strict sparsity threshold was enforced: any sensor channel or sample instance exhibiting a missing data rate exceeding 30% was discarded. The justification for this specific threshold is further analyzed in Section 6.
Before quantifying the final dataset for model training, the continuous engine test cycle must be segmented to align with the proposed regime-switching architecture. As shown in Figure 5, the dynamic operational profile is deterministically partitioned into three fundamental phases based on RPM thresholds and thermodynamic states: (1) the Start-up Phase (SUP), characterized by a rapid, linear transient acceleration; (2) the High-Speed Phase (HSP), exhibiting complex, non-linear high-frequency vibrations; and (3) the Idle Phase (IP), representing low-amplitude, steady-state dynamics.The transient states between these conditions were excluded to minimize non-stationary switching noise.
Consequently, the final experimental dataset distribution is independently quantified across these three operational phases, as detailed in Table 3. To prevent data leakage during model evaluation, strict stratification by engine serial number was enforced, ensuring that samples from the exact same physical engine do not appear simultaneously in the training and testing sets.
4.2. Public Benchmark Datasets
While the proprietary industrial dataset described in Section 4.1 establishes a rigorous experimental environment with explicit physical constraints and deterministic operational phases, relying exclusively on it limits the assessment of the framework’s broader applicability. To ensure a comprehensive evaluation of its generalization capability—particularly concerning latent regime discovery, extreme class imbalance, and high-dimensional noise—we extended the experimental setup to include three widely recognized public benchmark datasets.
Rather than evaluating the framework holistically on a single dataset, these public benchmarks were strategically selected to isolate and stress-test specific algorithmic components under diverse industrial constraints. As summarized in Table 4, the selected datasets introduce critical data challenges that are pervasive in complex manufacturing environments, serving as targeted testbeds for both the defect detection (classification) and performance tracking (regression) modules.
4.3. Experimental Setup and Evaluation Protocol
To ensure both computational efficiency during training and practical viability during deployment, the experiments were conducted across two distinct hardware platforms. Model training, public benchmark evaluations, and ablation studies were executed on a high-performance server equipped with an Intel Xeon Gold 6430 CPU and an NVIDIA RTX 4090 GPU (24 GB VRAM), ensuring the rapid convergence of complex deep learning architectures. Conversely, the real-world industrial validation was deployed on the actual line-side edge computing cluster powered by legacy Intel Xeon E5-2680 v4 processors, explicitly validating the framework’s low-latency inference capabilities in resource-constrained manufacturing environments. The software stack was standardized on Python 3.8, utilizing PyTorch 2.0.0 for deep neural networks (SAE, Transformer, CNN) and Scikit-learn 1.0 for traditional machine learning models.
To rigorously evaluate the superiority of the proposed framework within this environment, we selected a comprehensive set of state-of-the-art and conventional baseline models. As summarized in Table 5, these comparative methods are systematically categorized into ensemble learning, deep learning, and traditional algorithms, each serving a specific evaluative purpose in addressing high-dimensional industrial data.
To provide a comprehensive and statistically robust assessment of model performance, we report the Mean ± Standard Deviation of the evaluation metrics summarized in Table 6. To ensure strict reproducibility, the global random seed was fixed at 42. The reported results represent the average of 10 independent runs for the classification tasks and the AI4I tool wear dataset. Due to the high computational cost associated with lengthy time-series sequences, results for the NASA C-MAPSS dataset were averaged over 5 independent runs.
Regarding task-specific evaluation, the classification analysis (defect detection) strategically prioritizes maximizing Recall (to strictly prevent defective engines from escaping to the market) and the F1-Score (to ensure balanced assessment under extreme class imbalance). For the regression task (performance tracking), we utilize Mean Squared Error (MSE), the Coefficient of Determination ( ), and Mean Absolute Percentage Error (MAPE). This combination precisely captures the model’s sensitivity to physical outliers, validates the goodness-of-fit to underlying thermodynamic trends, and interprets scale-independent relative errors across vastly different RPM regimes (e.g., Start-up versus Idle phases).
5. Experimental Results
We present a comprehensive quantitative evaluation of the proposed framework. The experimental validation is structured into three parts: First, we assess the framework’s generalization capability and state-of-the-art (SOTA) competitiveness on widely recognized public benchmarks (Section 5.1). Second, we conduct an ablation study to analyze the contribution of core components such as noise-aware residual fusion (Section 5.2). Finally, we demonstrate the framework’s practical engineering performance in the real-world automotive assembly line (Section 5.3).
5.1. Generalization Performance on Public Benchmarks
To verify the robustness of the proposed method against challenges such as high-dimensional noise, class imbalance, and latent operating regimes, we compared our framework with state-of-the-art baselines, including Random Forest, XGBoost, LightGBM, CNN, and Transformer. The comparison encompasses traditional machine learning models (Random Forest, SVM), ensemble methods (XGBoost, LightGBM), and deep learning architectures (CNN, Transformer).
5.1.1. Defect Detection Performance (Classification)
For the classification tasks on the AI4I 2020 (Imbalance Challenge) and UCI SECOM (High-Dimensionality Challenge) datasets, the primary objective is to evaluate whether the proposed Class-Specific Weighted Ensemble (CSWE) can identify minority class failure samples more effectively than traditional methods.
Figure 6 illustrates the comparative performance across different algorithms. Table 7 details the quantitative metrics.
On the AI4I 2020 dataset, the proposed method achieved the highest F1-Score (81.55%), slightly outperforming the second-best model (LightGBM, 81.05%) and significantly exceeding XGBoost (77.22%). While XGBoost exhibited the highest Recall (85.74%), its Precision (70.29%) was considerably lower than ours, indicating a higher rate of false alarms. In contrast, our method achieved a more robust and balanced performance, maintaining a high Precision (85.70%) while sustaining strong recall. This balance is critical in industrial manufacturing to prevent the unnecessary downtime and costs associated with false positive failure predictions.
On the UCI SECOM dataset, which represents an extreme case of high dimensionality and noise, deep learning models such as Transformer and CNN struggled to converge, yielding extremely low F1-Scores. Our method, leveraging the noise-aware SAE for feature extraction, achieved the best Recall (49.05%) and F1-Score (33.17%), demonstrating superior robustness in sparse, noisy feature spaces.
5.1.2. Degradation Prediction Performance (Regression)
For regression tasks, we evaluated the framework on the AI4I 2020 (Tool Wear) and NASA C-MAPSS FD002 (Remaining Useful Life prediction) datasets, with results shown in Figure 7. We selected the more complex FD002 subset as a key benchmark, as its core challenge lies in the presence of six distinct operating conditions. We compared performance using Mean Squared Error (MSE), , and Mean Absolute Percentage Error (MAPE), as detailed in Table 8.
For the AI4I Tool Wear task, our method achieved an MSE of 2584.88, slightly outperforming the 1D-CNN (2589.83) and significantly beating traditional regressors such as SVR (3651.86). The low standard deviation across metrics further evidences the consistency of the results.
On the NASA C-MAPSS FD002 dataset, tabular Transformer and MLP models failed to model the complex multi-regime manifold, resulting in high MSE values (970.55 and 692.97, respectively). In contrast, our framework achieved the lowest MSE of 424.49, surpassing the best baseline (Bagging, MSE = 433.81) and XGBoost (MSE = 434.01). This demonstrates the effectiveness of the adaptive regime-switching strategy, which dynamically assigns optimal local experts to distinct latent regimes.
5.2. Ablation Study: Impact of Key Components
To rigorously evaluate the contribution of each module within the proposed framework, we conducted an ablation study on the UCI SECOM (Classification) and NASA FD002 (Regression) datasets. We compared the full model against three variants:
- w/o Sparsity (AE): Replaces the Sparse Autoencoder with a standard dense Autoencoder, removing the penalty in the loss function.
- w/o SAE (Raw): Removes the feature extraction module entirely, feeding raw standardized sensor data directly into the ensemble models.
- w/o Partitioning: Removes the K-Means clustering and dynamic switching mechanism, training a single global expert pool on the entire dataset.
The quantitative results are summarized in Table 9.
On the UCI SECOM dataset, the “w/o SAE (Raw)” variant achieved the highest Accuracy (88.60%) but suffered from a significantly lower Recall (40.48%) compared to the Full Model (49.05%). This phenomenon occurs because the high-dimensional noise in raw features causes the model to bias towards the majority class (non-defective), leading to missed detections.
Furthermore, removing the sparsity constraint (“w/o Sparsity”) caused the F1-Score to drop drastically from 33.17% to 23.94%. This validates that the Sparse Autoencoder is not merely performing dimensionality reduction, but is actively filtering out incoherent sensor noise through the sparsity penalty, which is crucial for identifying latent fault patterns in complex manufacturing data.
The impact of the Adaptive Regime-Switching Regression (ARSR) Strategy is evident in the NASA FD002 regression task. When the clustering-based partitioning was removed (“w/o Partitioning”), the model was forced to fit a single global function to the six distinct operating conditions, resulting in a degradation of MSE from 424.49 to 474.45. The Full Model, by “dividing and conquering” the latent regimes, effectively minimized the prediction error, confirming the necessity of the multi-expert architecture for complex industrial processes.
5.3. Industrial Field Performance (Edge Deployment)
Following the theoretical validation on public benchmarks, the proposed framework was deployed on the JL478QEA-AJ automotive engine assembly line to evaluate its engineering viability.
To satisfy the strict real-time constraints (<100 ms Takt time) and limited computational resources of the line-side edge devices (Intel Xeon E5), we implemented two strategic optimizations. First, we replaced the unsupervised K-Means clustering within the ARSR module with deterministic, physics-based RPM thresholds (Start-up, High-speed, and Idle). This eliminates iterative computational overhead while ensuring entirely consistent regime assignment. Second, to mitigate memory bandwidth bottlenecks caused by the massive raw data dimensionality (>10,000), we operated the feature extraction module strictly in Mode I ( ). By utilizing only the compact SAE latent representations for downstream inference, the framework drastically reduces the feature footprint while intrinsically filtering high-frequency instrumentation noise.
5.3.1. Task I: Defect Classification
The industrial classification dataset comprises 2090 unlabeled samples for SAE pre-training and 520 labeled samples for supervised validation. We evaluated the Class-Specific Weighted Ensemble (CSWE)—here instantiated as a Region-Weighted Ensemble to handle phase-specific defect patterns—against standard base classifiers and Bagging ensembles.
Figure 8 illustrates the accuracy comparison. The proposed method consistently outperforms baseline approaches, particularly in the High-speed Phase (HSP), where it maintains a stability margin of approximately 5% over competing methods.
Table 10 presents the quantitative metrics. While the improvement in Precision is modest (+1.63%), the most significant gain is observed in the Recall rate, which surged from 69.20% (Bagging) to 76.92% (Ours). In the context of industrial Quality Assurance (QA), Recall is the most critical metric as it represents the system’s ability to intercept defective engines. An improvement of 7.7% implies a substantial reduction in the risk of defective products escaping to the market.
5.3.2. Task II: Continuous Performance Regression
It should be clarified that the regression target is not the engine speed as a variable of driver demand, but rather the engine’s functional response under a fixed test-bench load protocol. By predicting the expected mean speed and its standard deviation, the framework establishes a dynamic baseline for ‘normal’ behavior. Consequently, any significant deviation from these predicted values serves as a micro-indicator to identify latent mechanical friction anomalies or ECU calibration faults that might otherwise remain undetected during standard steady-state monitoring.
In this task, the ARSR module dynamically assigned the optimal expert model to each physical phase based on their distinct data manifolds.
For the Mean Engine Speed prediction task, as illustrated in Figure 9a, the framework automatically selected Linear Regression (LR) for the linear Start-up phase, and Support Vector Regression (SVR) for the highly non-linear High-speed and Idle phases. This dynamic switching strategy (L-S-S) achieved a comprehensive MAPE of 2.276%, outperforming both standalone LR (2.646%) and SVR (2.350%). This confirms that the regime-based switching mechanism effectively captures the varying linearity of the engine’s thermodynamic speed curve.
Conversely, Figure 9b presents the prediction results for the Engine Speed Standard Deviation (STD), which acts as a micro-indicator for transient stability. Compared to global baseline models like Bagging (44.33%) and GPR (69.67%), our proposed phase-adaptive S-G-B combination (SVR-GPR-Bagging) achieved the lowest overall MAPE of 39.00%.
Table 11 summarizes the performance metrics. We observe notably higher MAPE values during the Idle Phase (IP), particularly for Speed STD. This is an inherent artifact of the metric rather than model failure: since the ground truth STD values in the idle phase approach zero, small absolute errors result in disproportionately large percentage errors. Despite this numerical sensitivity, the absolute precision remains within acceptable industrial tolerances.
It is important to address the seemingly high MAPE values in the STD prediction. During the Idle Phase, the ground-truth STD values are numerically minute (approaching absolute zero). Due to the mathematical formulation of the MAPE metric, dividing by such infinitesimal denominators inherently inflates the percentage errors, even for negligible absolute deviations. From a strict engineering perspective, the absolute prediction error during this phase remains well within the industry-standard tolerance limits (±10 RPM). This validates the system’s operational reliability and its capability to accurately distinguish between normal mechanical vibration noise and actual transient stability defects.
5.3.3. System Efficiency and Economic Impact
The optimized framework was deployed on the edge computing cluster. By adopting deterministic regime switching and setting (Pure SAE Mode), the system achieved an average inference latency of 80 ± 3 ms per engine. By bypassing the massive matrix multiplications required by deep global architectures, this lightweight configuration securely maintained the processing time within the strict 100 ms Takt Time boundary.
Following a three-month pilot run (interface shown in Figure 10), statistical analysis confirms that the engine repair rate decreased by 7.2%. This demonstrates that the edge-optimized “Lightweight” configuration of our framework successfully balances theoretical sophistication with engineering practicality.
6. Discussion
6.1. Mechanism Interpretability and Data Heuristics
The selection of the 30% rejection threshold represents a deliberate trade-off between data fidelity and statistical representativeness, constrained by the 5 Hz sampling rate. At this frequency (0.2 s per interval), exceeding 30% loss in a workstation window results in continuous blind spots of 0.8–1.0 s. As demonstrated in Figure 11, since critical transient events—such as the 6000 RPM peak in performance tests—occur within a narrow 1.5–2.0 s window, such gaps lead to the complete erasure of original mechanical signatures.
The choice of 30% also prevents prohibitive data attrition. Setting a more stringent threshold (e.g., <10%) in a harsh industrial environment would lead to the rejection of over 40% of the captured samples. Such aggressive filtering not only restricts the training volume required for deep feature extraction but also introduces survivor bias, where the model only learns from “ideal” sensor conditions and fails to recognize rare defect patterns that often occur during unstable, noisy operational states.
The 30% boundary therefore serves as a optimal point. It maintains a sufficiently diverse training corpus while ensuring that the resulting synthetic artifacts remain within a manageable limit. While the SAE’s sparsity constraint ( ) is highly effective at filtering random high-frequency instrumentation jitter, it is susceptible to the structured, overly-smooth curves generated by excessive interpolation. These artifacts mimic coherent physical patterns and can deceive the SAE into encoding “hallucinated” dynamics as valid latent features. By maintaining the 30% limit, we ensure that the SAE performs its primary role—extracting salient non-linear features and reducing dimensionality—without being contaminated by non-physical interpolated trends.
Furthermore, regarding the exclusion of transient conditions, it is essential to note the physical context of End-of-Line (EOL) testing. In industrial assembly, the steady-state phases (Start-up, High-speed, and Idle) serve as the primary indicators of assembly integrity and thermodynamic stability. Transient switching points often contain significant stochastic noise coupled with the test bench’s mechanical response rather than the engine’s intrinsic build quality. Therefore, focusing on these deterministic, stabilized regimes allows the framework to achieve more reliable defect interception by isolating high-fidelity quality signatures from environmental instrumentation artifacts.
6.2. Cost-Sensitive Diagnostics and Recall Prioritization
In the field of industrial quality assurance (QA), defect containment is of paramount importance. The financial penalty of a missed detection (False Negative) far outweighs the operational cost of a manual re-inspection triggered by a false alarm (False Positive). Missing even a minor micro-structural anomaly can lead to costly batch failures.
When confronted with extremely imbalanced and high-dimensional noise, traditional global baselines often adopt conservative decision boundaries that favor overall accuracy over minority class detection. As illustrated in the cumulative confusion matrices (Figure 12), baselines like LightGBM and Bagging successfully identified only 86 and 76 faults out of 210, respectively. While XGBoost performed better by intercepting 95 faults, it generated 234 false alarms.
In contrast, our proposed CSWE framework successfully recalled 103 true faults—achieving the highest detection rate—while simultaneously producing fewer false alarms (231 False Positives) than the strongest baseline. By leveraging SAE for robust feature extraction and localized routing, CSWE penetrates high-dimensional noise to establish a mathematically verified and practically deployable safety net: maximizing the capture of minority failure modes without inflating the manual inspection overhead.
This philosophy of localized, adaptive routing is equally critical for continuous state monitoring. As shown in the regression tracking comparison (Figure 13) on the AI4I 2020 dataset, state-of-the-art global baselines already exhibit a strong capacity to capture the highly non-linear dynamics of rotational speed. While the ARSR module performs visually similarly to these powerful baselines, it maintains a subtly tighter adherence to the ground truth during rapid mechanical transients. This improved structural stability is quantitatively validated by a distinct reduction in Mean Squared Error (MSE) compared to all baselines. By more effectively suppressing the micro-transient errors (such as overshooting or undershooting) that could otherwise mask imminent mechanical instabilities, ARSR provides a more reliable continuous state estimation. Coupled together, CSWE’s robust defect interception and ARSR’s precise tracking establish a comprehensive, dual-layered safety guarantee for modern automated assembly lines.
6.3. Engineering Boundaries and Edge-Computing Viability
Transitioning from public benchmarks to industrial deployment requires context-aware optimization. Replacing computationally expensive K-Means clustering with explicit physics-based gating rules (predefined RPM thresholds) enables zero-latency regime assignment.
Crucially, edge-computing compatibility dictates the selection of downstream regression experts. While state-of-the-art Tabular Transformers exhibit formidable representational capacity, their global self-attention mechanisms inherently introduce a quadratic computational complexity with respect to feature dimensionality. On resource-constrained edge devices lacking dedicated GPU acceleration, accommodating such high FLOPs and memory bandwidth pressure is theoretically prohibitive and fundamentally incompatible with the strict Takt time constraints (<100 ms) of automated assembly lines. Our lightweight SAE-expert architecture resolves this bottleneck, maintaining an optimal Pareto balance between deep diagnostic capabilities and an ultra-low inference latency of 80 ± 3 ms.
Despite these optimizations, defining acceptable performance thresholds reveals the physical ceiling of single-modal tabular data. Industrial Quality Assurance rigorously prioritizes Recall (ideally > 95%) to prevent defective engines from entering the market. While our edge-deployed framework establishes a robust mathematically verified baseline with a 76.92% Recall and an 81.63% Precision, bridging the gap to near-absolute detection limits requires overcoming unrecorded manual variations and sensor base-noise. Future frameworks must transition to multi-modal sensory fusion, integrating Acoustic Emission (AE) sensors and real-time visual tracking to capture the microscopic structural anomalies that tabular data inherently fails to resolve.
7. Conclusions
In this study, we developed a robust diagnostic and predictive framework to address the inherent complexities of multi-sensor data in automotive engine assembly. By integrating a Sparse Autoencoder (SAE) for non-linear noise filtration with a Class-Specific Weighted Ensemble (CSWE) and an Adaptive Regime-Switching Regression (ARSR) strategy, the proposed approach effectively overcomes the persistent industrial challenges of extreme class imbalance and non-stationary operating dynamics.
Extensive experimental validation has demonstrated the profound algorithmic superiority of this methodology. For defect detection, the CSWE mechanism strategically prioritized minority failure modes, improving the defect interception recall rate by 7.72% over standard ensemble baselines, thereby minimizing the risk of defective engines escaping to the market. Simultaneously, for continuous performance tracking, the phase-adaptive ARSR strategy successfully decoupled the complex thermodynamic baseline, reducing the relative prediction error for transient stability indicators by approximately 12%.
Beyond theoretical accuracy, the framework proved highly efficient and economically valuable in a live production environment. By operating entirely on compact latent features and explicit physics-based routing rules, the edge-deployed system maintained an ultra-low average inference latency of ms, strictly satisfying the line-side Takt time constraints. Furthermore, a three-month longitudinal pilot run validated its practical engineering impact, yielding a 7.2% reduction in overall engine repair rates and establishing a highly scalable paradigm for smart manufacturing quality assurance.
8. Limitations and Future Work
While the proposed framework demonstrates significant industrial applicability and establishes a robust baseline, we acknowledge several limitations that outline critical directions for future research.
First, and most fundamentally, relying exclusively on single-modal tabular process data (e.g., dynamic torque and fluid pressure) imposes a theoretical ceiling on defect detection precision. As addressed in our discussion, approaching a near-100% diagnostic accuracy limit is currently constrained by inherent sensor base-noise, microscopic tolerance stack-ups, and unrecorded manual operational variations. Therefore, a primary direction for future work is transitioning toward multi-modal sensory fusion. Integrating high-frequency Acoustic Emission (AE) sensors and real-time visual tracking data will be essential to capture the microscopic structural anomalies that low-frequency tabular data inherently fails to resolve.
Second, regarding regression evaluation metrics in low-amplitude regimes, the Mean Absolute Percentage Error (MAPE) exhibits extreme numerical sensitivity during the engine’s Idle phase, where ground-truth values for speed standard deviation approach zero. Although the relative performance of our regime-switching model remains superior, the inflated absolute MAPE values indicate that deterministic point-forecasting metrics may be inadequate for stability indices in near-zero scenarios. Future research will explore probabilistic forecasting and confidence interval analysis (e.g., Bayesian Neural Networks) to provide more robust, uncertainty-aware quantification in these low-amplitude operational zones.
Finally, the current framework operates on a static training paradigm, utilizing data collected during a specific production stabilization phase. However, real-world industrial environments are highly susceptible to concept drift caused by progressive tool wear, seasonal ambient temperature shifts, or supplier material batch changes. Currently, the model lacks a continuous online learning mechanism to dynamically adapt to these gradual distribution shifts. Future iterations will incorporate domain adaptation and online learning algorithmsto automatically fine-tune the decision boundaries in real-time. Additionally, validating the framework’s generalization capability across heterogeneous engine models and distinct assembly lines will be prioritized to establish a broader, universally applicable benchmark for industrial quality prediction.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Toy S. Whitmarsh L. Sun Y. Zero-car households—Constraint or lifestyle choice? A systematic literature review of the factors affecting non-car ownership Transp. Rev.20254539041210.1080/01441647.2025.2457091 · doi ↗
- 2Van Eenoo E. Car dependence in research: Navigating its contemporary relevance Transp. Rev.20254528230010.1080/01441647.2025.2457094 · doi ↗
- 3Yang M. Li C. Tang Y. Wu W. Lv Y. Multi-stage hybrid algorithm-enabled optimization of sequence-dependent assembly line configuration for automotive engine J. Manuf. Syst.202366132610.1016/j.jmsy.2022.11.014 · doi ↗
- 4Boysen N. Schulze P. Scholl A. Assembly line balancing: What happened in the last fifteen years?Eur. J. Oper. Res.202230179781410.1016/j.ejor.2021.11.043 · doi ↗
- 5Tremblet D. Yelles-Chaouche A.R. Gurevsky E. Brahimi N. Dolgui A. Optimizing task reassignments for reconfigurable multi-model assembly lines with unknown order of product arrival J. Manuf. Syst.20236719020010.1016/j.jmsy.2023.02.001 · doi ↗
- 6Sun Y. Huang S. Zhang Y. Lin J. An efficient preprocessing method to suppress power harmonic noise for urban towed transient electromagnetic measurement data Measurement 202118611017110.1016/j.measurement.2021.110171 · doi ↗
- 7Xia Y. Wang J. Wei D. Zhang Z. Combined framework based on data preprocessing and multi-objective optimizer for electricity load forecasting Eng. Appl. Artif. Intell.202311910577610.1016/j.engappai.2022.105776 · doi ↗
- 8Zhang X. Zhang X. Liu Q. Xie W. Tang S. Wang Z. TBM big data preprocessing method in machine learning and its application to tunneling J. Rock Mech. Geotech. Eng.2024174762478310.1016/j.jrmge.2024.11.011 · doi ↗