Deep Learning-Based Contact Force Control for a Robotic Leg
Hyoseok Lee, Dongmin Baek, Hyeokjun Kwon, Hyun-min Joe

TL;DR
This paper introduces a deep learning-based controller that improves contact force control in robotic legs, enabling more stable and efficient humanoid robot movement.
Contribution
A novel deep neural network-based inverse model combined with a PI controller for improved contact force control in robotic systems.
Findings
The proposed controller reduced overshoot by 96% and settling time by 61% compared to an admittance controller.
Force-tracking RMSE was decreased by 66.3% across step and sinusoidal experiments.
Abstract
This paper proposes a learning-based contact force controller using deep neural networks (DNN) and a PI controller. Stable contact force control between the foot and the ground is essential for humanoid robots to maintain balance during bipedal walking. While admittance controllers have been extensively employed for contact force control in humanoid robots, their performance is limited by the high nonlinearity inherent in robot systems. To overcome these limitations, we propose a deep neural network (DNN)–based inverse model, which leverages input–output data that inherently capture system nonlinearities. The proposed learning-based contact force controller computes the target foot height based on the target force, measured force, and measured foot height, without relying on a dynamic model of the articulated robotic leg. Furthermore, a PI controller is integrated to mitigate…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
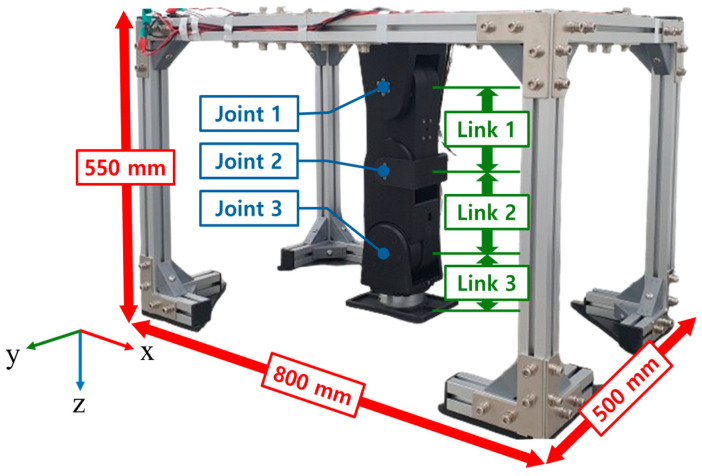 Figure 1
Figure 1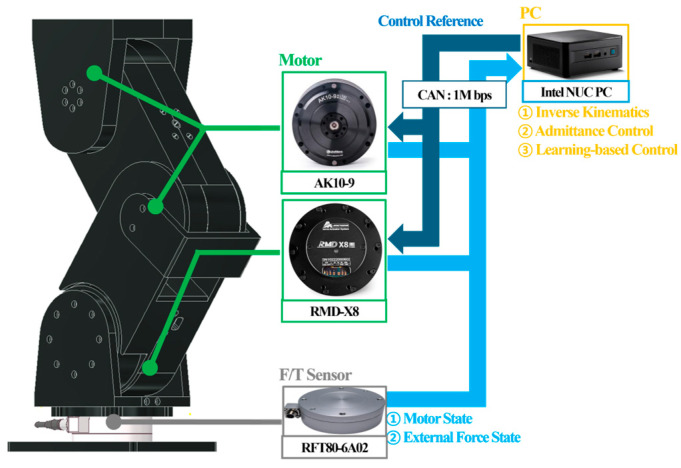 Figure 2
Figure 2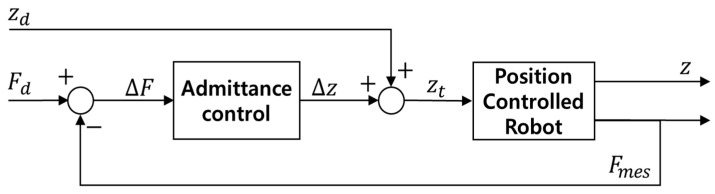 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5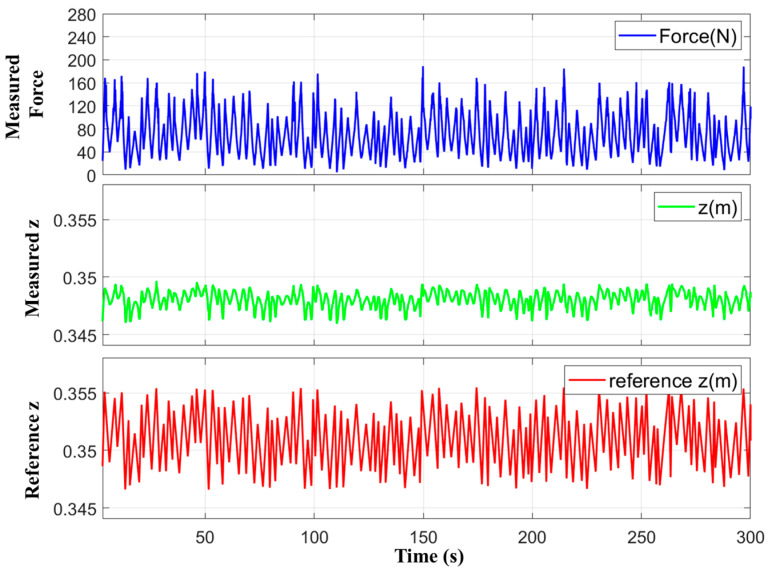 Figure 6
Figure 6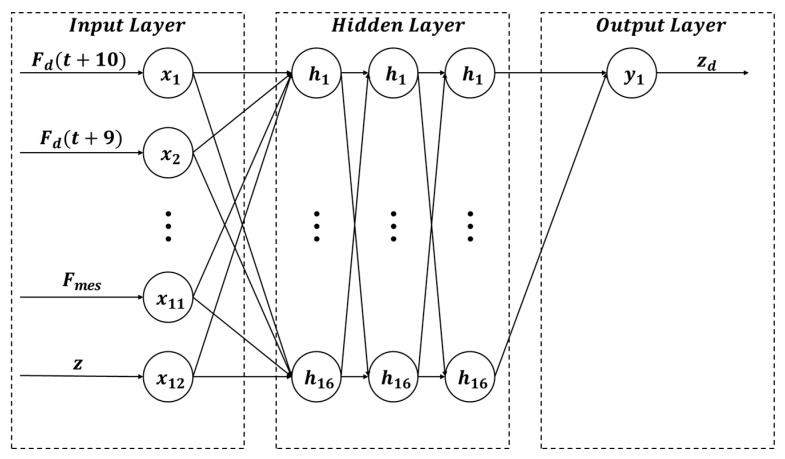 Figure 7
Figure 7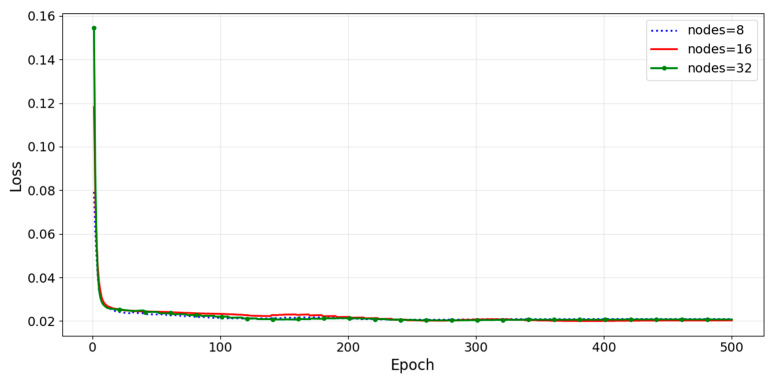 Figure 8
Figure 8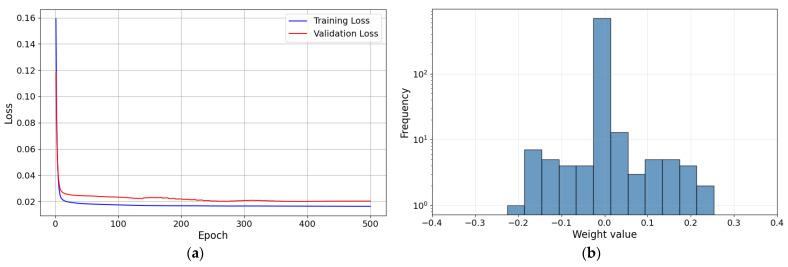 Figure 9
Figure 9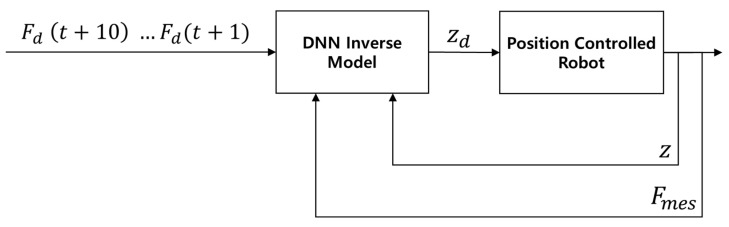 Figure 10
Figure 10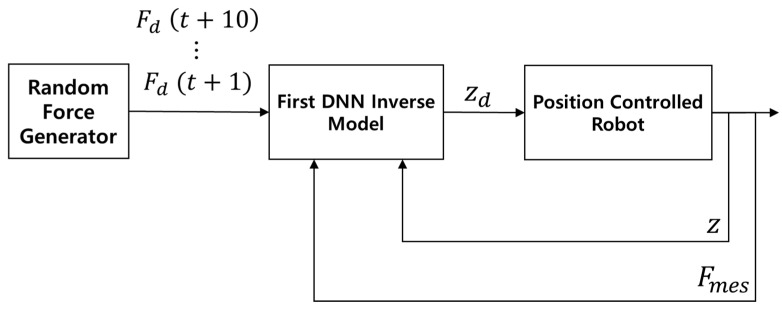 Figure 11
Figure 11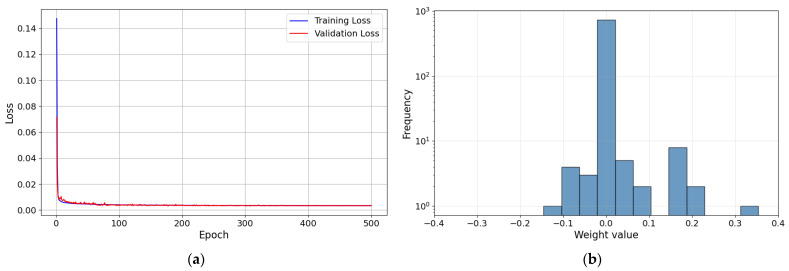 Figure 12
Figure 12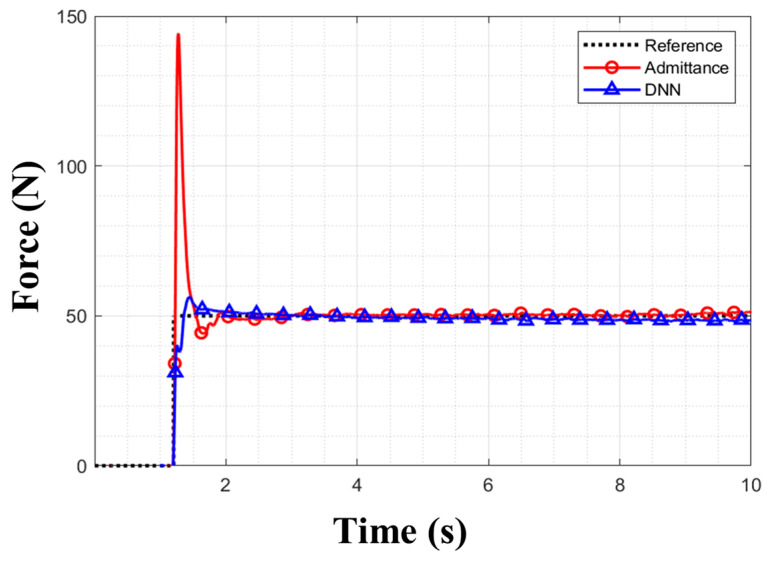 Figure 13
Figure 13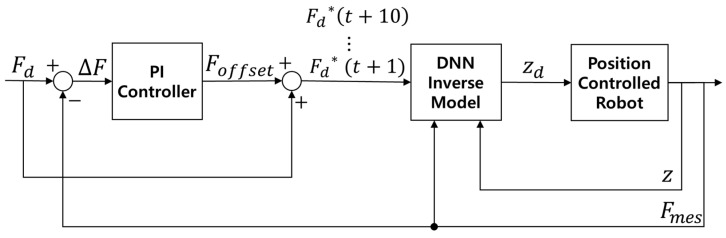 Figure 14
Figure 14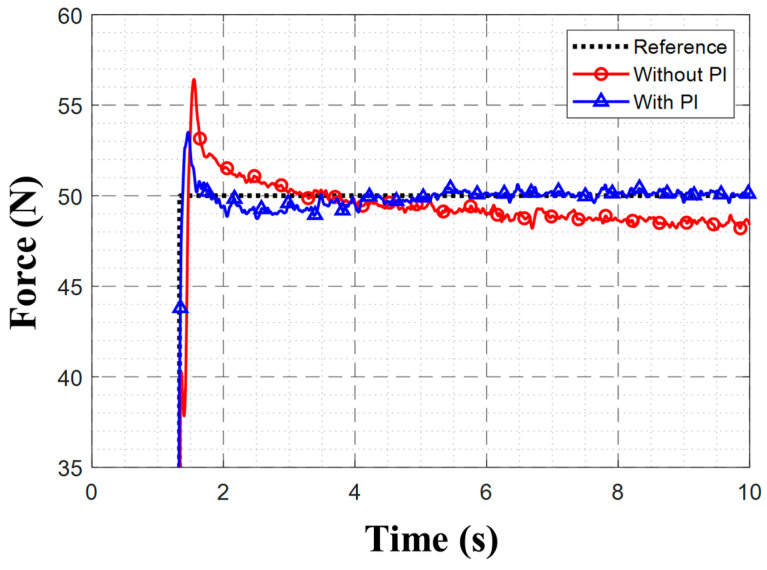 Figure 15
Figure 15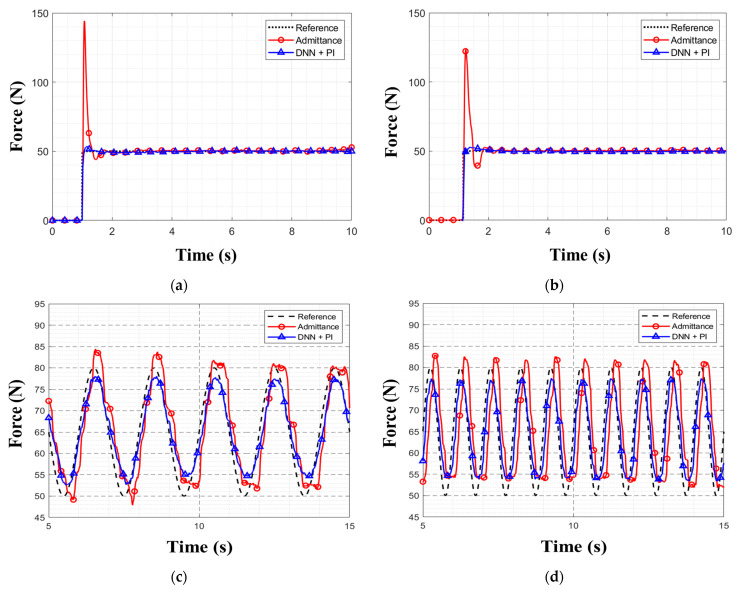 Figure 16
Figure 16- —Korea Basic Science Institute (National research Facilities and Equipment Center)
- —Ministry of Science and ICT
- —Korea Planning & Evaluation Institute of Industrial Technology (KEIT)
- —Ministry of Trade, Industry and Energy
- —National Research Foundation of Korea (NRF)
- —Korea government (MSIT)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotic Locomotion and Control · Prosthetics and Rehabilitation Robotics · Muscle activation and electromyography studies
1. Introduction
Stable control of the contact force between the foot and the ground is essential for humanoid robots to maintain balance and achieve robust bipedal locomotion. To address this challenge, previous studies have focused on mechanical design and control algorithms. Mechanical design–based methods typically incorporate elastic materials or structures into robot hardware to absorb shocks during walking. The Honda P2 humanoid robot has employed a rubber material as a mechanical filter in the foot to absorb shocks from contact with the ground [1]. A study emulated the arch structure of the human foot, incorporating springs to absorb impacts on the humanoid robot’s foot from the ground [2]. Series elastic actuators mitigated shocks through elastic materials placed serially between motors and robot links [3]. Buchner et al. presented an electrohydraulic musculoskeletal robotic leg with tunable stiffness and capacitive self-sensing that achieved agile, energy-efficient hopping over diverse terrains using a single open-loop force-control command set [4]. However, these approaches are highly specialized and hardware-intensive, which can limit their generalizability. Moreover, modifying the mechanical design alone does not guarantee precise control over the ground reaction force and can even increase system nonlinearity due to the complexity and elasticity of the robot structure.
Compliance control algorithms have been widely adopted to regulate contact forces. The BHR-6P humanoid robot has utilized a viscoelastic model for ankle compliance control [5]. A typical example of compliance control is admittance control, which adjusts the system’s position and speed in response to external disturbances [6]. Admittance controllers have been utilized in compliance control for the feet of robots such as KAIST’s DRC HUBO [7] and the HRP-4 by AIST and Kawada [8]. However, challenges in parameter selection for highly nonlinear systems compromise the performance of this technique.
Model predictive control (MPC) has also been widely studied for contact force control of legged robots because it can explicitly handle dynamic and contact-related constraints in an optimization framework [9]. Romualdi et al. proposed an online nonlinear centroidal MPC with step adjustment for humanoid locomotion, enabling real-time adaptation of motion and foothold planning under changing contact conditions [10]. Sombolestan and Nguyen presented an adaptive force-based control method for dynamic legged locomotion over uneven terrain, showing robust contact-force regulation against terrain-induced disturbances [11]. Since MPC requires solving an optimization problem at each control cycle, the achievable control rate is limited by computation and latency, and performance is sensitive to model mismatch.
To overcome the limitations of traditional controllers in nonlinear systems, learning-based approaches such as reinforcement learning and deep neural networks have been widely investigated. Reinforcement learning optimizes a control policy through trial-and-error interactions with the environment to maximize a defined reward function. Portela et al. proposed RL for direct force control in legged manipulation and demonstrated compliant whole-body behavior on a quadruped manipulator platform [12], while Zhang et al. introduced FALCON, a dual-agent RL framework for force-adaptive humanoid loco-manipulation under 3D end-effector force interaction and external force disturbances [13]. However, reinforcement learning requires complex reward shaping or sophisticated sim-to-real transfer techniques to ensure stability.
Therefore, deep neural network (DNN)–based control methods have been utilized because they can effectively learn system dynamics from collected data [14]. Data collection for neural network training can be performed using online or offline methods. The online method continuously updates the model’s weights in real time. Some studies have explored the online training of DNN models to dynamically adjust admittance control coefficients [15], as well as lifelong deep learning to enhance the trajectory-tracking performance of manipulators [16]. Phan et al. proposed a disturbance-observer-based adaptive neural backstepping integral sliding-mode controller for a flexible-joint robot with hydraulic actuator dynamics, in which neural-network parameters are updated in real time to compensate for model uncertainties and external disturbances [17]. However, since this research integrates multiple control components, it introduces many tuning parameters, increasing implementation complexity. Furthermore, online methods risk converging to local minima, potentially impacting the model’s generalizability. The offline method computes and updates weights based on the entire collected dataset, ensuring broader generalization and, thus, versatility for various systems.
DNN-based control can be classified into indirect and direct methods. Indirect methods involve using neural networks for system modeling [18], whereas direct methods utilize the neural network itself as a controller. Direct control using DNNs has demonstrated improved force control performance in nonlinear hydraulic actuators [19] and enabled robust force control in nonlinear twisted-string actuators [20]. However, direct control approaches suffer from steady-state errors.
In this study, we propose a deep neural network (DNN)–based inverse model to address nonlinearities arising from contact between an articulated robotic leg and the ground. Furthermore, a PI controller is integrated with the DNN-based inverse model to eliminate steady-state errors, constituting a learning-based contact force controller.
The main contributions of this research are as follows:
- A DNN-based inverse model is proposed to track the target force via direct methods.
- A PI controller is incorporated to resolve steady-state errors by compensating for the input values of the DNN-based inverse model.
- Reference force–tracking experiments are conducted to evaluate the performance of the proposed learning-based contact force controller.
The remainder of this paper is structured as follows: Section 2 describes the design of the robotic leg, the admittance controller, and the learning-based contact force controller. Section 3 details the experiments conducted to compare the performance of different controllers. Section 4 discusses the experimental results. Finally, Section 5 presents the conclusions from the study.
2. Methodology
2.1. Articulated Robotic Leg Design
A three-degree-of-freedom (3-DOF) robotic leg was designed and fabricated to serve as the hardware system for the contact force control experiments. Figure 1 illustrates the hardware configuration of the robotic leg fixed on an aluminum-frame testbed. The link lengths are L1 = 0.15 m, L2 = 0.15 m, and L3 = 0.11 m, and the total weight of the robotic leg is 5.25 kg. The leg is equipped with three motors and a single force/torque (F/T) sensor. The links of the robotic leg were 3D-printed using Onyx as the printing material. The frame had a rectangular parallelepiped shape with dimensions of 800 mm × 500 mm × 550 mm.
Figure 2 illustrates the hardware control system of the robotic leg. The leg used 1 Mbps CAN to communicate with the control PC (Intel; Santa Clara, CA, USA), which handled both the high-level and low-level control tasks. High-level control includes kinematic calculations, admittance control, and learning-based contact force control, whereas low-level control includes motor control and the reception of measurement values from the motor and F/T sensor. Table 1 lists the specifications of the motor and F/T sensor for each joint. For low-level joint control, we utilized the actuators’ built-in position controllers with factory default PID gains, which were maintained constant throughout all experimental conditions.
2.2. Admittance Controller
The equation for the admittance controller is as follows:
where M is the mass coefficient, B is the damping coefficient, K is the spring coefficient; , , and represent the changes in acceleration, velocity, and position, respectively, in the z-direction; and represents the force error. As this study focuses on regulating contact force exclusively along the vertical z-axis to ensure stable ground interaction, the admittance controller was intentionally designed as a 1-DOF baseline along the same axis. The admittance controller was tuned to follow a step response of 50 N when the robotic leg encountered an obstacle 0.06 m high. The coefficients of the admittance controller were M = 2, B = 200, and K = 80. Figure 3 presents a block diagram of the robotic leg equipped with the admittance controller, where , , and represent the target force, measured force, and force error, respectively, while , , , and denote the change in height, the contact height corresponding to the robotic leg and the obstacle, the input height, and the measured height, respectively. constitutes the input to the admittance controller, while is its output; is added to to calculate , which serves as the basis for the robot’s position control.
2.3. First Learning-Based Contact Force Controller
The fundamental objective of force control is to minimize the error , where is the target force and is the measured force. In conventional approaches, such as admittance control, the control input is typically generated based on this error through a feedback law:
where represents the controller transfer function. In contrast, the proposed method is based on a data-driven inverse model. It directly computes the required target position from the target force , measured force , and measured height , effectively functioning as a feedforward controller. To implement this learning-based controller, the development process involved acquiring the system dynamics through data collection and subsequent training.
The proposed controller’s operation involved data collection and training in two stages. In the first stage, the data to train the first DNN-based inverse model were collected. As shown in Figure 4, a height-adjustable obstacle was positioned beneath the retracted robotic leg; the obstacle’s height was set to 0.06 m. The end effector of the robotic leg was lowered at 0.0215 m/s. Upon contact with the obstacle, indicated by the F/T sensor’s z-directional measurement exceeding 30 N, the robotic leg’s target height was randomly selected through linear interpolation, according to the following equation:
where is the height set for the robotic leg, is the current time, is the height in the initial state, is the time in the initial state, is a random height, and is a random time. When and were randomly selected within the defined range, was applied to the robotic leg for a duration of . When the time exceeded , and were updated to new random values, and the previous values were used as and for the next interpolation. The range of was 0.5–2.5 s, while that of was 0 to −0.009 m relative to the contact height corresponding to the robotic leg and the obstacle. To ensure maximal diversity in the selection of within the defined range, the next value was constrained to differ from the previous value by at least 0.004 m upon each update. Figure 5 illustrates the process where the random height generator provides directly into the robot to output data for the training of first the DNN-based inverse model.
Data were collected at a frequency of 500 Hz for a total duration of 5 min, which yielded a dataset comprising 150,347 data points. The collected data included the target height input to the robotic leg, the measured force, and the measured height. A low-pass filter with a 10 Hz cutoff frequency was applied to the sensor measurements to mitigate noise. Figure 6 presents graphs of the collected data. The equations of the first DNN-based inverse model are defined:
where is the input vector, is the future target force trajectories, is the measured force, and is the measured height. The function represents the affine-linear functions, are the weight matrices, are the bias vectors, is the activation function, is the number of layers, , and (t) is the target height. The neural network is represented by the function The number of steps for the future target force trajectory was set to 10, following an existing approach for similar systems [21].
Figure 7 illustrates the architecture of the first DNN-based inverse model, which consists of an input layer, three hidden layers, and an output layer. Following prior studies on nonlinear inverse modeling [19,22], the network depth was fixed to three hidden layers. To determine the hidden-layer width, we evaluated 8, 16, and 32 neurons per layer. The minimum validation losses were and , respectively, as illustrated in Figure 8. Therefore, 16 neurons were applied across all layers [23]. The Rectified Linear Unit (ReLU) was employed as the activation function to ensure training stability [24]. The collected data were normalized using the z-score method before being input into the network.
The other hyperparameters are shown in Table 2. L1 and L2 regularization were employed to regulate the weights for each layer. The learning rate was multiplied by 0.90 if the validation loss did not improve for 10 epochs. Moreover, early stopping was implemented to prevent overfitting if the validation loss did not improve by more than 0.0001.
During optimization, a gradient clipping of 0.1 was used to prevent gradient explosion. The batch size during training was 128. Furthermore, we adopted the Huber loss function [25], which uses mean squared error (MSE) for small errors and mean absolute error (MAE) for large errors. Equation (8) defines the Huber loss function:
where represents the difference between the predicted and actual values, and is the threshold value. The Huber loss function is sensitive to small errors while remaining robust against outliers. Thus, it increases the stability of neural network training and minimizes the loss value during the training process. The total number of parameters in the proposed neural network was 769. The validation loss was measured to be 0.02 after training.
As shown in Figure 9, both training and validation losses decrease rapidly in the early stage and then converge to stable plateaus without divergence. In addition, the learned weight distribution is concentrated around zero with limited tails, and no evidence of weight explosion is observed. This supports the stability of the optimization process. Figure 10 illustrates the structure of the first learning-based contact force controller, which integrates a DNN-based inverse model. represents the measured force; represent the target force trajectory; and and are the target height and measured height, respectively. The target forces were arranged sequentially in time, yielding a 10-step target-force trajectory. The target force trajectory, measured force, and measured height were then input to the DNN-based inverse model to produce the target height, which is used to control the robotic leg.
2.4. Second Learning-Based Contact Force Controller
During the collection of training data for the first learning-based contact force controller, the target height was randomly controlled while the robotic leg remained in contact with the obstacle, and the corresponding force was measured. The intended measured force was determined by experimentally setting the height range for the robotic leg. Adjusting the height of the contacted obstacle during training could alter the range of the intended measured force. To avoid this, the model was trained considering a fixed obstacle height. Therefore, the first learning-based contact force controller exhibited considerable steady-state errors when the obstacle height differed from the value during training. To address this problem, additional data were collected with the first learning-based contact force controller applied, and a new inverse model was trained.
With the first learning-based contact force controller active, random target forces were input through linear interpolation. Equation (9) represents the linear interpolation for the target force:
where is the current target force applied to the robotic leg, is the current time, is the target force in the initial state, is the time in the initial state, is a random target force, and is a random time. The ranges of and were set to 1–5 s and 15–120 N, respectively. The next value was constrained to differ from the previous value by at least 70 N. During data collection, the obstacle height was manually raised by 1 mm/min for 10 min and then lowered by 5 min. During this process, the obstacle height ranged from 0.06 m to 0.07 m. Figure 11 illustrates the process where a random force generator provides ,…, . These are processed by the first DNN-based inverse model to generate which drives the robot to yield and , thereby completing the data collection set ( ) for the training of the second DNN-based inverse model. The input/output configuration and hyperparameters of the second DNN-based inverse model were identical to those of the first model. The block diagram of the second learning-based contact force controller is the same as that in Figure 10. As illustrated in Figure 12, the second DNN-based inverse model also exhibited stable learning behavior, with smoothly converging training/validation losses and no sign of weight explosion.
3. Experiments
3.1. Experimental Scenarios
To evaluate the performance of the proposed controller, comparative experiments were conducted against an admittance controller. The end-effector of the robotic leg contacted an obstacle at a speed of 0.172 m/s. The controller was activated when the F/T sensor of the robotic leg detected a z-directional force exceeding 15 N. Each experiment lasted up to 18 s, whereafter the robotic leg returned to its initial position. There are four distinct experiment scenarios: step-force tracking at 50 N with a 0.06 m obstacle, step-force tracking at 50 N with a 0.07 m obstacle, sinusoidal-force tracking with with a 0.06 m obstacle, and sinusoidal-force tracking with with a 0.06 m obstacle. The verification criteria for the step-response experiment were root MSE (RMSE), overshoot, and settling time (within a 5% error). For the sinusoidal tracking experiment, the verification criterion was RMSE.
3.2. PI Controller
Table 3 shows the experimental results obtained when a target force of 50 N was applied at a height of 0.06 m. Figure 13 presents the corresponding force-tracking graph for each controller. While the proposed controller tracks reference force substantially better than admittance, it exhibited characteristics of a feedforward controller, which causes steady-state errors of 2 N. To overcome this, a PI controller was utilized to compensate for the steady-state error. The PI controller was applied for both the first and second learning-based contact force controllers.
Figure 14 illustrates the structure of the learning-based contact force controller, which integrates a DNN-based inverse model and PI controller. , , and represent the target force, measured force, and force error, respectively; denotes the PI controller’s output; … represent the compensated target force trajectory; and and are the target height and measured height, respectively. The difference between and , i.e., , was input to the PI controller, which generated the output . The compensated target force was calculated by summing and , and a trajectory of 10 compensated target forces was generated. The compensated target force trajectory, measured force, and measured height were then input to the DNN-based inverse model to produce the target height, which is used to control the robotic leg. The PI gains were selected heuristically through step-response tests. Since the primary objective of the PI controller is to eliminate the steady-state error that the DNN-based inverse model cannot track, the I gain was prioritized and set relatively higher than the P gain. The P gain was increased until a fast response was achieved without excessive overshoot or oscillation, after which I gain was raised to remove the steady-state error. The P and I gains of the PI controller were set to 1.1 and 1.7 for the first learning-based contact force controller, respectively, and 0.1 and 1.0 for the second learning-based contact force controller, respectively.
To evaluate the impact of the PI controller on contact force control performance, we conducted a step-response experiment that involved tracking a 50 N target force with and without the PI controller enabled.
Table 4 shows the experimental results for a 50 N target force applied at a 0.06 m height, highlighting that the incorporation of the PI controller reduced the RMSE, overshoot, and settling time substantially. Figure 15 shows the force-tracking graphs with and without the PI controller. Integrating the PI controller eliminated the steady-state error, driving the measured force to converge to the 50 N target.
3.3. Evaluation of Performance for the Learning-Based Contact Force Controller with PI Controller
Table 5 summarizes the tracking performance of the admittance controller and the proposed controller (DNN + PI) across step and sinusoidal tests. In Figure 16a,b depict step responses at obstacle heights of 0.06 m and 0.07 m, respectively, while (c) and (d) show 0.5 Hz and 1 Hz tracking, respectively. As evident from the data, the proposed controller achieved a considerably lower RMSE, overshoot, and settling time than the admittance controller in step responses. For the sinusoidal tests at 0.06 m, the proposed controller achieved lower RMSEs than the admittance controller for both 0.5 Hz and 1 Hz.
4. Discussion
Based on the results of the step-response experiment comparing the proposed controller with and without the PI controller, the incorporation of the PI controller enhanced performance across all metrics. Whereas a steady-state error of 2 N was observed without the PI controller, the integration of the PI controller eliminated this error, reduced the overshoot, and enabled rapid convergence to the target force. This is because the PI controller generated a compensated force trajectory based on the error between the target force and the measured force, which was input into the DNN-based inverse model.
In the step-response experiment, the proposed controller outperformed the admittance controller across all of RMSE, overshoot, and settling time. The admittance controller struggled to respond to sudden shocks because its coefficients were fixed. In contrast, as the proposed controller had learned the dynamic characteristics of the system, it could ensure more precise control performance under shocks. Due to its feedback-loop control characteristic, the admittance controller adjusted the output depending on the current force error, which led to a delay in tracking the target force. Hence, it exhibited a rapid overshoot during the experiments. In contrast, the proposed controller, by utilizing the currently measured force and the future target force trajectory as inputs, achieved stable control even during sudden force changes.
In the sinusoidal tracking experiment, the proposed controller again achieved lower RMSEs than the admittance controller for both the 0.5 Hz and 1 Hz forces. The admittance controller showed irregular peak values during the 0.5 Hz experiment. As mentioned earlier, the admittance controller’s slower tracking performance was due to its feedback-loop control. In contrast, the proposed controller could respond immediately to the input, thus achieving rapid tracking of the target value. In future work, we plan to extend the proposed controller to legged locomotion by implementing it on the legs of a bipedal robot.
5. Conclusions
This study proposed a DNN-based inverse model to address the limitations of admittance controllers for nonlinear systems. Furthermore, to eliminate the steady-state errors inherent in direct control with inverse models, we integrated a PI controller into our DNN-based inverse model to establish a learning-based contact force controller. To evaluate the performance of the proposed method, we designed a robotic leg and implemented the controllers on the developed platform to conduct comparative experiments. A step-response experiment on a robotic leg verified that augmenting the DNN-only inverse model with a PI controller successfully removed the steady-state error. The proposed controller was then evaluated against an admittance controller through step-response and sinusoidal-tracking experiments. The proposed controller outperformed the admittance controller, achieving a 66.3% average reduction in RMSE and, in step-response tests, 96% lower overshoot and 61% faster settling time on average.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hirai K. Hirose M. Haikawa Y. Takenaka T. The development of Honda humanoid robot Proceedings of the 1998 IEEE International Conference on Robotics and Automation (Cat. No. 98CH 36146), Leuven, Belgium, 20 May 1998 IEEE New York, NY, USA 199813211326
- 2Lee J. Joe H.-M. Design of humanoid robot foot to absorb ground reaction force by mimicking longitudinal arch and transverse arch of human foot Int. J. Control Autom. Syst.2023213519352710.1007/s 12555-023-0387-6 · doi ↗
- 3Pratt J.E. Krupp B.T. Series elastic actuators for legged robots Unmanned Ground Vehicle Technology VISPIE Bellingham, WA, USA 2004135144
- 4Buchner T.J.K. Fukushima T. Kazemipour A. Gravert S.-D. Prairie M. Romanescu P. Arm P. Zhang Y. Wang X. Zhang S.L. Electrohydraulic musculoskeletal robotic leg for agile, adaptive, yet energy-efficient locomotion Nat. Commun.202415763410.1038/s 41467-024-51568-339251597 PMC 11385520 · doi ↗ · pubmed ↗
- 5Li Q. Yu Z. Chen X. Meng L. Huang Q. Fu C. Chen K. Tao C. A compliance control method based on viscoelastic model for position-controlled humanoid robots Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021 IEEE New York, NY, USA 202035183524
- 6Sharkawy A.-N. Koustoumpardis P.N. Human–robot interaction: A review and analysis on variable admittance control, safety, and perspectives Machines 20221059110.3390/machines 10070591 · doi ↗
- 7Joe H.-M. Oh J.-H. A robust balance-control framework for the terrain-blind bipedal walking of a humanoid robot on unknown and uneven terrain Sensors 201919419410.3390/s 1919419431569700 PMC 6806214 · doi ↗ · pubmed ↗
- 8Caron S. Kheddar A. Tempier O. Stair climbing stabilization of the HRP-4 humanoid robot using whole-body admittance control Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019 IEEE New York, NY, USA 2019277283