Global Path Planning Methods Based on the Relationship Between Traversability Capability and Terrain Matching
Zengbin Wu, Hongchao Zhang, Zhen Zhang, Da Jiang, Shuhui Li, Yunlong Sun

TL;DR
This paper presents a new global path planning method for unmanned ground vehicles in challenging terrains by integrating traversability analysis and terrain matching.
Contribution
The novel contribution is a unified planning strategy that combines road network expansion with vehicle mobility limits for improved navigation in degraded environments.
Findings
A grid-based traversability evaluation was developed to assess terrain features.
A road network expansion algorithm was introduced to densify critical segments.
The proposed framework improves operational efficiency of high-mobility vehicles in unstructured environments.
Abstract
In contrast to structured urban settings, road networks in post-disaster or unstructured wildland environments are often incomplete or compromised. Navigation in these contexts requires navigating complex terrains and mitigating potential hazards that impede unmanned ground vehicles (UGVs). While high-mobility off-road vehicles are specifically designed to traverse challenging features like ditches and steep slopes, traditional path planning algorithms often fail to exploit these capabilities. These algorithms typically suffer from a binary focus, either relying strictly on road networks or ignoring them altogether, thereby neglecting the synergy between infrastructure and vehicle mobility. This chapter introduces a global path planning method based on traversability analysis and terrain matching to bridge this gap. The methodology incorporates a grid-based traversability evaluation, a…
Click any figure to enlarge with its caption.
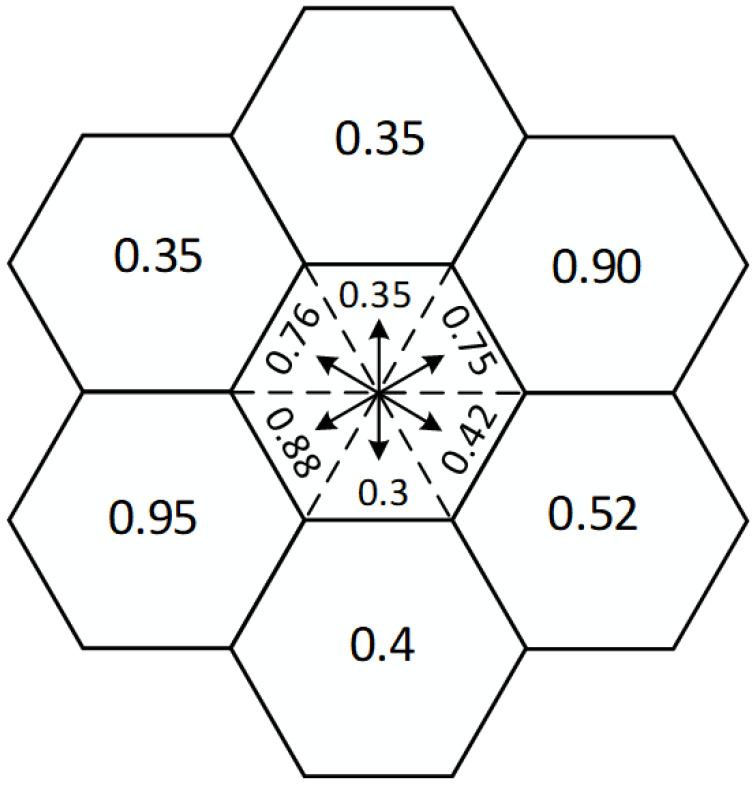 Figure 1
Figure 1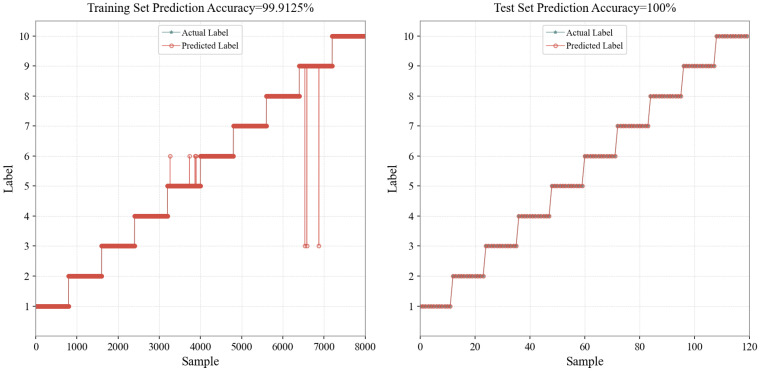 Figure 2
Figure 2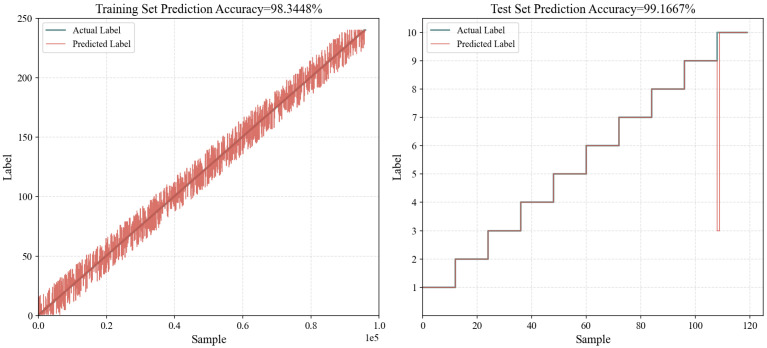 Figure 3
Figure 3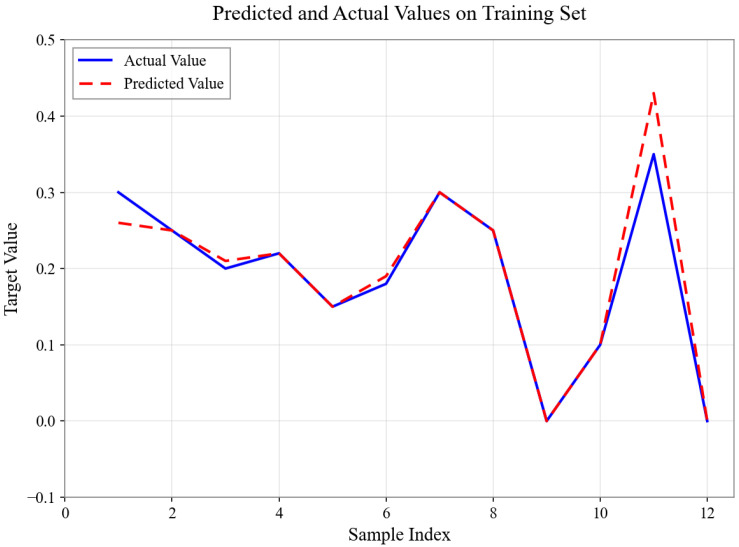 Figure 4
Figure 4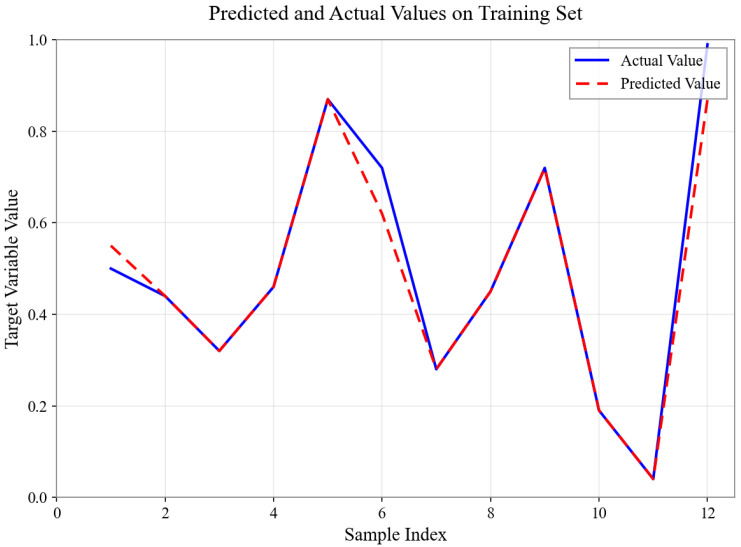 Figure 5
Figure 5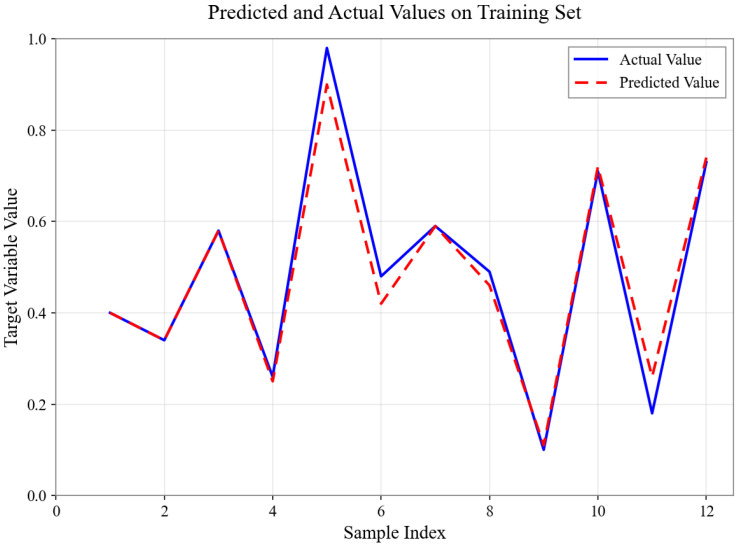 Figure 6
Figure 6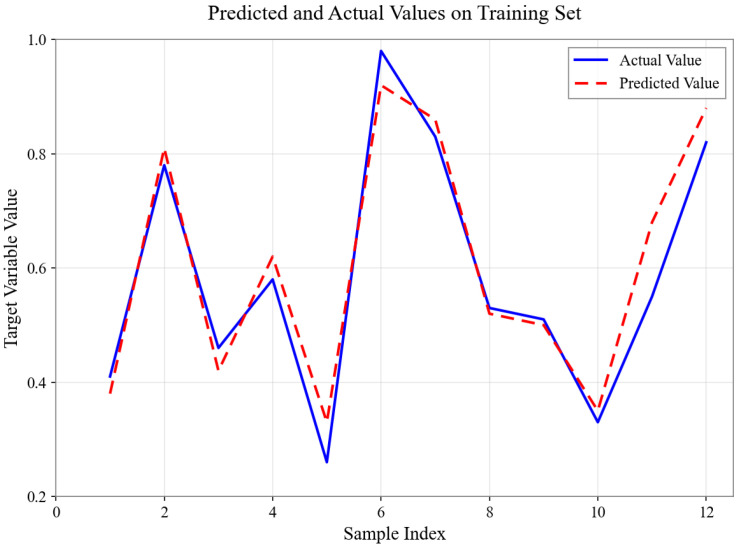 Figure 7
Figure 7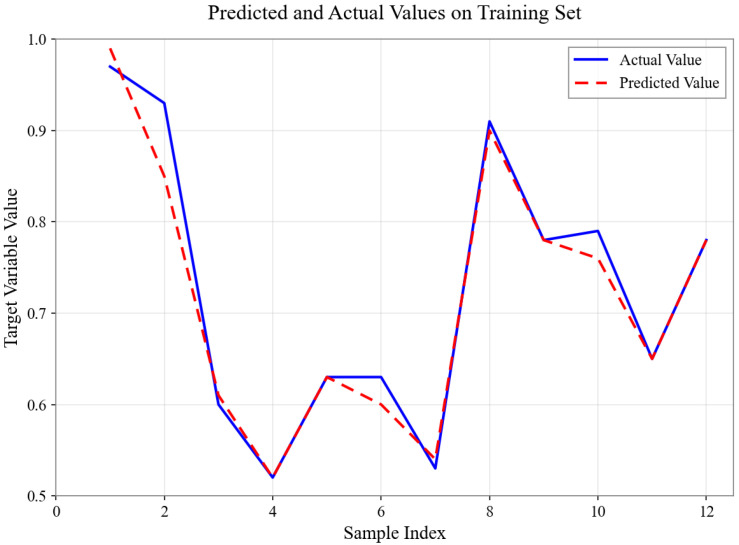 Figure 8
Figure 8 Figure 9
Figure 9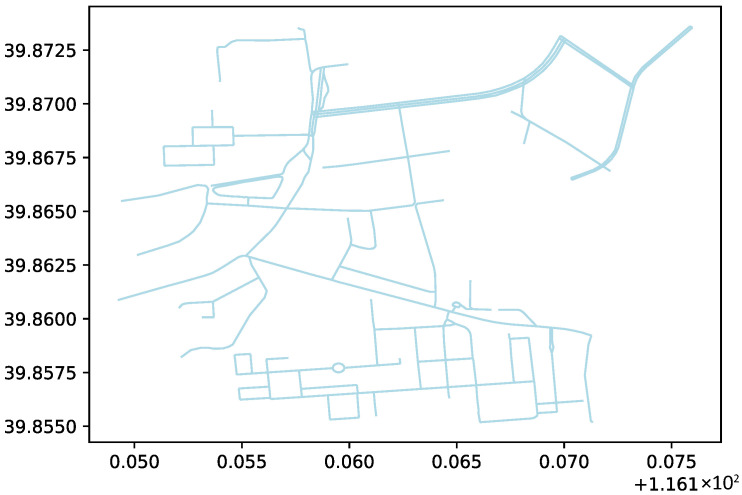 Figure 10
Figure 10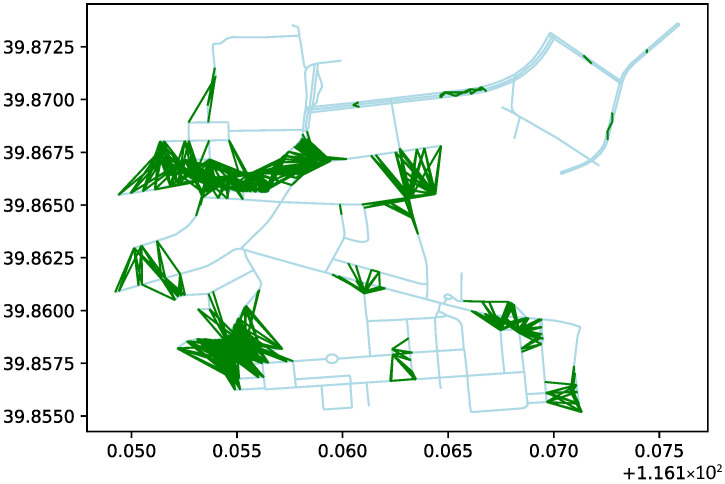 Figure 11
Figure 11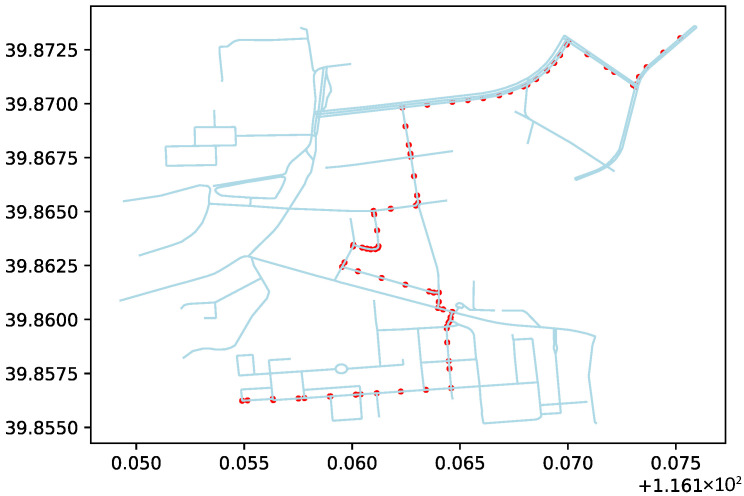 Figure 12
Figure 12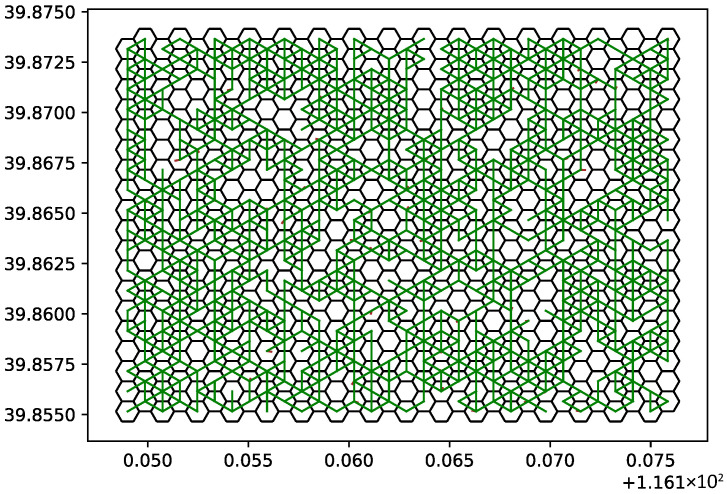 Figure 13
Figure 13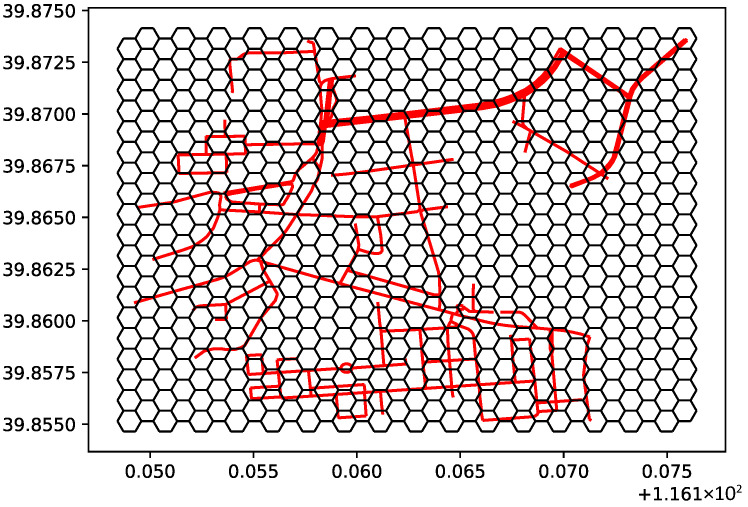 Figure 14
Figure 14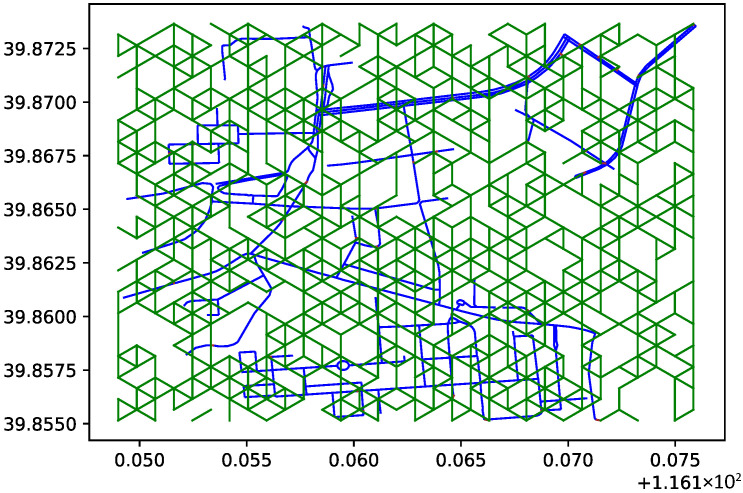 Figure 15
Figure 15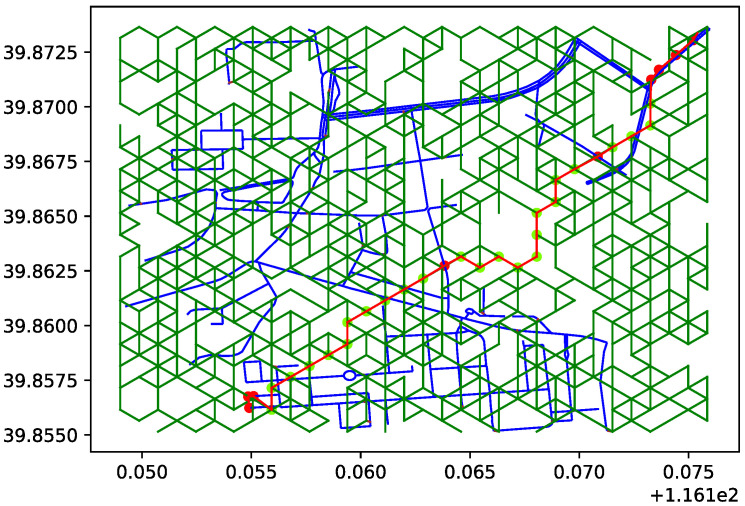 Figure 16
Figure 16| Value | Traversability Coefficient | Mapping Relationship |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 0 |
|
| Value | Traversability Coefficient | Mapping Relationship |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 0 |
|
| Value | Traversability Coefficient | Mapping Relationship |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 0 |
|
| Value | Traversability Coefficient | Mapping Relationship |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 0 |
|
| Value | Traversability Coefficient | Mapping Relationship |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 0 |
|
| Value | Traversability Coefficient | Mapping Relationship |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 0 |
|
| Value | Traversability Coefficient | Mapping Relationship |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 0 |
|
| Value | Traversability Coefficient | Mapping Relationship |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 0 |
|
| Value | Traversability Coefficient | Mapping Relationship |
|---|---|---|
|
| 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 0 |
|
| Soil Type | Value | Traversability Coefficient | Mapping Relationship |
|---|---|---|---|
| Gravel Soil |
|
|
|
| Sandy Soil |
|
|
|
| Loam |
|
|
|
| Clay |
|
|
|
| Soil Type | Value | Traversability Coefficient | Mapping Relationship |
|---|---|---|---|
| Gravel Soil |
|
|
|
| Sandy Soil |
|
|
|
| Loam |
|
|
|
| Clay |
|
|
|
| Value | Traversability Coefficient | Mapping Relationship |
|---|---|---|
|
| 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| Value | Traversability Coefficient | Mapping Relationship |
|---|---|---|
|
| 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsWildlife-Road Interactions and Conservation · Robotic Path Planning Algorithms · Robotics and Sensor-Based Localization
1. Introduction
Path planning, a pivotal research area in intelligent systems, has received extensive attention and demonstrated broad application potential across aerial, terrestrial, and underwater domains [1,2]. In complex terrestrial environments, global path planning for autonomous ground vehicles (UGVs) aims to generate safe, efficient, and kinematically feasible trajectories. This process necessitates a systematic integration of multidimensional factors, including unstructured environmental constraints, vehicle kinematic limits, and safety regulations. To solve collision-free path search problems from initial to goal configurations, prevailing methodologies primarily leverage graph search-based and sampling-based algorithms.
Regarding traversability analysis in complex environments, field operations must account for the inherent challenges of unstructured terrain. Off-road environments, such as mountainous regions, wetlands, and deserts, lack well-defined boundaries and artificial landmarks. Consequently, traversability assessment in these areas encounters significant difficulties due to irregular topography, environmental stochasticity, and nonlinear vehicle–terrain interaction. Traditional assessment methods often rely on rigid geometric thresholds—such as defining traversability based solely on a maximum slope of 30°. However, such deterministic approaches struggle to accommodate the requirements of multimodal data fusion and dynamic operational conditions [3,4].
Current research in terrain traversability is transitioning from single-feature heuristics toward comprehensive evaluation frameworks that integrate multi-source data and multidimensional metrics [5]. Researchers have significantly enhanced the precision and reliability of assessment outcomes by optimizing algorithmic models and employing machine learning and deep learning techniques to quantitatively analyze key factors, including terrain gradient, surface roughness, and obstacle distribution [6]. Concurrently, the research paradigm has shifted from static assessment to real-time dynamic evaluation. From a technical perspective, the widespread adoption of high-resolution remote sensing, 3D LiDAR scanning, and multispectral sensors has provided robust tools for high-fidelity terrain data acquisition [7]. Furthermore, advancements in edge and cloud computing have facilitated the efficient processing and real-time analysis of massive datasets, further advancing the state-of-the-art in terrain traversability assessment [8].
Driven by the rapid advancement of robotics, autonomous driving, and unmanned systems, terrain traversability assessment (TTA) methodologies are continuously evolving to address increasingly diverse operational requirements. Current state-of-the-art approaches are broadly categorized into geometry-based, appearance-based, hybrid, learning-based, and physics-driven methods, each offering distinct perspectives for robust traversability analysis. Geometry-based methods are extensively employed when explicit terrain elevation data is available. This paradigm evaluates traversability by correlating topographic features with a vehicle’s mechanical constraints, such as its maximum approach/departure angles and ground clearance [3]. Prevailing techniques include grid-based discretization, which partitions the environment into cells to compute local morphological properties [9], and statistical modeling, which utilizes Gaussian distributions or kernel functions (e.g., Radial Basis Functions) to characterize terrain irregularities [10]. While these methods provide high computational efficiency and clear physical interpretability—making them suitable for real-time navigation in structured settings—they rely heavily on high-fidelity geometric data. Consequently, they often exhibit limited sensitivity to non-geometric hazards, such as yielding soil or compressible vegetation, which poses significant challenges in complex natural environments [11].
Appearance-based methods primarily utilize RGB imagery or infrared data to delineate navigable regions based on visual cues such as color and texture [12]. Classical computer vision approaches leverage HSV color space analysis and Local Binary Patterns (LBP) for terrain classification [13]. Conversely, modern deep learning architectures employ Convolutional Neural Networks (CNNs), such as ResNet, for high-level feature extraction and semantic segmentation of terrain images [14]. These methods are less dependent on precise geometric information and excel in texture-rich environments like forests and deserts. Nevertheless, their performance is highly contingent on ambient conditions; environmental fluctuations, such as varying illumination and shadows, can degrade classification reliability and compromise overall assessment accuracy [15].
To mitigate the inherent limitations of unimodal approaches, hybrid frameworks have emerged to fuse disparate data sources. These methods integrate geometric and appearance-based information—such as LiDAR point clouds combined with RGB imagery—or incorporate multi-modal sensor data including inertial and tactile feedback to enhance robustness [7]. Representative architectures include semantic-geometric fusion, where LiDAR-derived elevation maps are augmented by semantic labels from RGB segmentation to generate comprehensive cost maps [16]. Additionally, multimodal learning paradigms utilize deep neural networks to extract joint representations from heterogeneous data [17]. While hybrid methods effectively synthesize multidimensional information to navigate complex terrains like muddy slopes, the underlying fusion algorithms are computationally intensive and demand substantial onboard processing resources [18].
Machine learning and deep learning (ML/DL) paradigms have demonstrated significant potential in terrain traversability assessment. Historically, classical ML models such as Support Vector Machines (SVM) and Random Forests were predominantly employed for discrete classification tasks [19]. With the advent of deep learning, CNN-based processing of elevation maps has achieved classification accuracies surpassing 90%, while Transformer architectures have further enhanced the modeling of long-range spatial dependencies [20]. Beyond simple binary classification, contemporary research has transitioned toward multi-objective regression, enabling the continuous prediction of performance metrics such as attainable speed, energy consumption, and acceleration. These advancements transcend the limitations of traditional discrete labels. Furthermore, sim-to-real transfer techniques, bolstered by domain adaptation, allow models trained on synthetic datasets to be effectively deployed in real-world environments, thereby broadening the operational scope of autonomous systems [21].
Physics-driven methods are grounded in terramechanics and vehicle dynamics, evaluating traversability by formulating coupled mechanical-kinematic equations [22]. For instance, the cone index (CI) method quantifies the impact of soil strength on tracked vehicle mobility and generates traversal costs by incorporating terrain gradients—a methodology successfully applied in complex terrain studies, such as those involving the Tibetan Plateau [23]. Additionally, multibody dynamics (MBD) frameworks leverage simulation environments like ADAMS or RecurDyn to model high-fidelity vehicle–terrain interactions. These simulations generate precise physical data that serve as a rigorous foundation for mobility assessment [24]. Despite their accuracy, physics-based approaches are often characterized by high modeling complexity and the inherent difficulty of acquiring precise physical parameters in situ, which can constrain their real-time applicability in highly dynamic or unstructured scenarios [25,26].
Traversability analysis in battlefield environments must account for both geographical terrain characteristics and hostile threat factors; however, publicly accessible information regarding the latter remains notably limited. In scenarios with deterministic map data, graph-search methodologies—specifically the traditional Dijkstra algorithm and its priority-queue-optimized variants—are common selections. The standard Dijkstra algorithm, however, suffers from high time complexity due to its exhaustive traversal of unvisited vertices. In large-scale path planning, this computational inefficiency becomes increasingly problematic, resulting in excessive latency that fails to meet the real-time requirements of dynamic environments [3]. While the A* algorithm enhances search efficiency by incorporating a heuristic function, accurately designing an appropriate heuristic for complex terrains is non-trivial. It demands profound environmental insights and domain expertise, which increases the difficulty and uncertainty of algorithmic implementation [6].
For complex environments that are difficult to model precisely, sampling-based algorithms, such as the Rapidly-exploring Random Tree (RRT), have become prevalent. However, due to their inherent stochasticity, these methods often yield inconsistent trajectories characterized by low search efficiency and variable path optimality. In safety-critical scenarios requiring high-quality paths—such as disaster response and emergency rescue—standard RRT variants may fail to satisfy operational constraints. Consequently, additional path-smoothing and optimization steps are typically required, which inevitably increases the overall algorithmic complexity and computational load [7]. To address multi-constraint challenges across diverse domains, Reinforcement Learning (RL) has gained prominence for its robust adaptability in uncertain settings [8]. Nevertheless, RL-based approaches are often hindered by data-intensive training processes, slow convergence, and a susceptibility to local optima, presenting significant hurdles for their practical deployment in real-world tasks.
The core architecture of graph-search path planning primarily comprises graph construction, node expansion strategies, and path evaluation/optimization. These components provide the necessary framework for achieving efficient and precise global navigation. Specifically, graph construction and expansion strategies can be synthesized into a unified design to address planning problems in distinct environmental contexts. Based on their application, existing algorithms are generally categorized into two paradigms: those optimized for structured road networks and those tailored for unstructured off-road environments. Path planning algorithms tailored for road networks are predominantly applied in urban transportation and logistics distribution. To enhance the performance and practicality of these algorithms within complex urban infrastructures, researchers have explored innovative graph construction methodologies. A notable approach involves generating dynamic graphs by integrating Geographic Information System (GIS) data with real-time traffic streams [9]. In this framework, static topology and node locations are derived from GIS, while edge weights are dynamically updated to reflect current traffic conditions—such as adjusting travel costs based on congestion levels—ensuring the graph realistically mirrors the network state. Regarding the attribute definition of nodes and edges, recent studies have moved beyond conventional metrics like distance and travel time to incorporate multidimensional constraints, including speed limits, lane configurations, and traffic regulations [10]. By annotating graph components with these attributes, algorithms can comprehensively account for operational constraints, ensuring the legality and feasibility of the planned paths.
To address the challenges of graph construction in unstructured field environments, various methodologies have been proposed to handle the lack of predefined topologies. Recognizing the critical influence of topography on traversability, several studies leverage Digital Elevation Model (DEM) data to generate terrain-aware graph structures [11]. By processing DEM data, the environment is discretized into distinct regions, each functioning as a node within the graph. Connectivity between nodes is determined by physical factors such as slope gradients and surface roughness. For regions with gentle slopes and uniform terrain, connections are established with low edge weights to reflect minimal traversal costs. Conversely, for high-risk areas—such as steep cliffs and ravines—connections are either pruned or assigned prohibitive edge weights to ensure avoidance. To enhance obstacle representation fidelity, alternative approaches integrate multi-modal perception from LiDAR and visual sensors to detect and model obstacles precisely [12]. This occupancy information is embedded into the graph; specifically, connectivity in obstacle-dense zones is restricted, or traversal costs are artificially inflated to guide the algorithm toward safer trajectories.
Regarding grid discretization, researchers have introduced multi-resolution and adaptive grid techniques to mitigate the issues of excessive graph size and high computational overhead inherent in uniform partitioning [13]. Multi-resolution strategies apply variable grid granularity based on environmental complexity: fine-grained grids are deployed in areas with abrupt terrain changes or dense obstacles to enhance precision, while coarse grids are utilized in open, flat terrain to improve computational efficiency. Similarly, adaptive grid partitioning dynamically adjusts grid density based on feedback during the search process, aligning the discretization resolution with the actual requirements of the path search and thereby optimizing overall algorithmic performance.
To address the challenges posed by rugged and complex terrain, researchers have introduced various enhancements to traditional graph-search algorithms. Hierarchical graph-based methods partition the environment based on elevation profiles and obstacle distributions, establishing inter-layer transitions that allow the algorithm to navigate across multi-layered architectures. This approach enhances search flexibility and helps the algorithm circumvent local optima. For instance, in mountainous search-and-rescue (SAR) operations, terrain can be categorized into semantic strata—such as the base, slopes, and summits—with distinct graph structures for each level. Transitions between these layers enable the search to resume even if it encounters a local optimum within a single stratum, ensuring the identification of a globally optimal path [14]. Furthermore, multi-scale search algorithms employ a coarse-to-fine strategy: an initial rapid search on a large-scale graph determines a global trajectory corridor, followed by a refined search on small-scale local graphs. This significantly improves both computational throughput and planning precision. To handle dynamic environments, modern algorithms incorporate real-time monitoring and online replanning mechanisms [15]. Onboard sensors facilitate instantaneous data acquisition, triggering replanning upon detecting dynamic obstacles. Incremental search techniques are often employed to optimize resource consumption by restricting updates to local regions affected by environmental changes rather than recomputing the entire global path [7]. Additionally, path-smoothing algorithms eliminate sharp turns to satisfy the vehicle’s kinematic constraints, ensuring the safe operation of rescue platforms in complex settings.
Despite these global advancements, existing methodologies remain insufficient for the urgent requirements of specialized rescue vehicles in post-disaster scenarios where road networks are compromised or severed. While current research incorporates natural terrain and infrastructure [16], the integrated assessment of rapid-onset dynamic hazards—such as secondary structural collapses, landslides, and signal degradation—alongside terrain traversability remains neither timely nor sufficiently accurate. This inability to identify high-risk zones in real-time jeopardizes the safety of rescue platforms. Furthermore, regarding vehicle performance, although the impact of varying kinematic capabilities is recognized [17], there is a lack of systematic integration of the unique off-road characteristics of specialized vehicles under extreme conditions. Specifically, factors such as soil-bearing capacity, geometric clearance, and maneuverability limits in hazardous environments are frequently overlooked. This deficiency prevents the precise quantification of vehicle traversal limits, thereby compromising the overall accuracy of global path planning. The main contributions of this work are summarized as follows:
- (i)Fine-grained traversability evaluation based on vehicle–terrain matching:Addressing the inability of conventional algorithms to distinguish between structured roads and unstructured terrain, we propose a high-fidelity traversability evaluation framework. By discretizing the environment into grid cells and mapping topographic features against vehicle-specific mobility metrics—such as trench-crossing and climbing capacities—this method provides a quantitative assessment of passability, enabling autonomous platforms to fully leverage their inherent off-road capabilities.
- (ii)Hybrid global path planning for compromised infrastructure: To navigate the fragmented or incomplete road networks typical of disaster zones, we develop a hybrid global path planning algorithm that synergistically integrates road-network expansion with unstructured off-road planning. This methodology densifies the road network in critical segments to optimize travel efficiency while facilitating seamless transitions to off-road modes when infrastructure is severed, effectively unifying structured and unstructured navigation.
- (iii)Theoretical stability and convergence guarantees: A rigorous theoretical analysis is established to guarantee the stability of the learning components within the planning system. We provide a convergence theorem for the neural network utilized in traversability cost estimation, proving that the updated parameters—including weights and structural coefficients—converge to an optimal and consistent solution. This mathematical foundation ensures the reliability of navigation decisions within complex optimization landscapes.
- (iv)Empirical validation in complex rescue scenarios: Extensive simulation experiments are conducted to validate the proposed framework. The results demonstrate that our approach significantly outperforms traditional road-centric or pure off-road algorithms in terms of path feasibility and transit efficiency. Specifically, the method exhibits superior adaptability in extreme rescue environments characterized by steep gradients, deep fissures, and severely degraded road networks.
The rest of the paper is organized as follows. In Section 2, we describe the accessibility evaluation method based on hierarchical overlay. Section 3 details the multi-layer fusion framework for passability evaluation. We provide the proof of neural network convergence in Section 4. Section 5 presents the numerical experiments and comparative analysis. Finally, conclusions and future works are discussed in Section 6.
2. Accessibility Evaluation Method Based on Hierarchical Overlay
As mentioned previously, numerous factors affect unmanned vehicle traversability on land battlefields. The area requiring traversal is divided into a grid-based format, and map attribute feature layers are constructed based on evaluation factors. Each layer is generated according to a specific evaluation factor, and finally an overlay algorithm is employed to fuse multiple layers into a traversability characteristic map to support subsequent path planning.
In the single-factor traversability coefficient analysis, by defining the traversability coefficient (where larger K values indicate better traversability), natural wilderness environmental factor values are mapped into three categories: easily passable, passable, and impassable. Prior to the derivation of these formulas, all raw data underwent a comprehensive pre-processing stage, including normalization, to ensure consistency across varying environmental conditions. The value ranges for these three categories are represented in Table 1. The analytical expressions for traversability presented in Table 2, Table 3, Table 4, Table 5, Table 6, Table 7, Table 8, Table 9, Table 10, Table 11, Table 12, Table 13 and Table 14 were established through a combination of inherent vehicle performance specifications and empirical data collected from multiple rounds of rigorous testing.
(1) Impact of Altitude on Unmanned Vehicle Traversability
Altitude directly affects engine power output. Higher altitudes result in thinner air, which can lead to incomplete fuel combustion, reduced engine power, and decreased mobility performance of vehicle equipment. The vehicles be designed to operate continuously at altitudes below 3000 m and requires wheeled vehicles to generally possess the capability to operate normally at altitudes up to 4700 m. Based on practical engineering considerations, an altitude of 3000 m represents the mandatory requirement for tracked vehicles, while an altitude of 4700 m represents the mandatory requirement for wheeled vehicles.
The relationships between traversability coefficients and altitude for tracked vehicles and wheeled vehicles are constructed as shown in Table 2 and Table 3, respectively.
From Table 2, we define a monotonically decreasing linear relationship between the input factor X (e.g., altitude) and the traversability coefficient K. This negative correlation is consistent with empirical physical laws; for instance, as altitude increases, the engine performance or environmental safety typically degrades, leading to a reduction in vehicle throughput capacity. For the specific case of altitude in Table 2, the mapping relationship is defined as:
This approach represents a preliminary macro-scale exploration of traversability. Currently, we employ the control variable method, where each coefficient K is calculated based on its correlation with a single dominant factor to maintain computational efficiency and clarity in grade classification.
(2) Impact of Terrain on Unmanned Vehicle Traversability
Terrain is decomposed into several aspects: step terrain, trench terrain, and gentle slope terrain, where gentle slopes are further divided into longitudinal slopes and lateral slopes. These terrain types typically do not exist simultaneously. The off-road vehicles usually need overcome vertical wall obstacles of no less than 0.8 m, while other tracked vehicles should overcome obstacles of no less than 0.6 m. The mapping relationship between height difference and traversability coefficient for tracked equipment is established as shown in the following Table 4:
The wheeled vehicles generally overcome vertical obstacles of no less than 0.4 m. The mapping relationship between height difference and traversability coefficient for wheeled equipment is established as shown in the following Table 5:
It is required that wheeled vehicles generally overcome trenches with widths of no less than 0.8 m. For 6 × 6 equal-wheelbase vehicles, the trench crossing width should generally be no less than 1.2 m, while for 8 × 8 vehicles it should be no less than 1.8 m. The mapping relationship between trench width and traversability coefficient for wheeled equipment is established as shown in the following Table 6:
The maximum climbing gradient for ground assault vehicles and combat service vehicles should be no less than 30°. The maximum climbing gradient for wheeled vehicles should generally be no less than 30°. The mapping relationship between gradient and traversability coefficient for equipment is established as shown in the following Table 7:
The maximum lateral slope gradient for wheeled vehicles should generally be no less than 17°. The mapping relationship between slope gradient and traversability coefficient for equipment is established as shown in the following Table 8:
Water bodies are decomposed into two aspects: water depth and water surface width. It is required that the fording depth of vehicles should generally be no less than 1.3 m. Therefore, the mapping relationship between water depth and traversability coefficient for equipment is established as shown in the following Table 9:
There are no explicit regulations for the water surface width that vehicles can ford. Based on engineering practice, except for amphibious vehicles, during testing, the water surface width is comparable to the vehicle length. Increasing water surface width poses risks of failures during traversal. The mapping relationship between water surface width and traversability coefficient for equipment is established as shown in the following Table 10:
Typical surface covers include human-made cement roads and asphalt roads, as well as naturally formed grasslands, shrublands, forests, and exposed soil, where exposed soil significantly affects unmanned vehicle traversability depending on material composition and moisture content. Ice and snow are also included in the surface cover category. By default, human-made roads serving social life have a traversability coefficient of 0.9, grasslands have a traversability coefficient of 0.6, shrublands have traversability coefficients of 0.1 (wheeled) and 0.5 (tracked), and ice/snow surfaces have traversability coefficients of 0.4 (wheeled) and 0.6 (tracked). For forest traversability analysis, three aspects are mainly considered: tree spacing, diameter at breast height, and canopy closure. Having combat unmanned vehicles challenge trees is unwise; therefore, only the impact of tree spacing on traversability needs to be considered.
For dry hard road surfaces, the larger the soil particles, the worse the soil compressibility, and the more difficult it is for equipment to traverse. The mapping relationship between dry soil particle diameter and traversability coefficient for equipment is established as shown in the following Table 11:
For water-containing soil, the smaller the soil particles, the worse the soil permeability, the higher the degree of road muddiness, and the more difficult it is for equipment to traverse. The mapping relationship between water-containing soil particle size and traversability coefficient for equipment is established as shown in the following Table 12:
For tracked vehicles, the vehicle width is generally no greater than 4 m, and the vehicle length is generally no greater than 10 m. Considering vehicles traversing through gaps between trees, the mapping relationship between tree spacing and traversability coefficient for tracked equipment is established as shown in the following Table 13:
For wheeled vehicles, the vehicle width is generally no greater than 3 m, and the vehicle length is generally no greater than 8 m. Considering vehicles traversing through gaps between trees, the mapping relationship between tree spacing and the traversability coefficient for wheeled equipment is established as shown in the following Table 14:
As for the hexagonal grid-based layering overlay method. However, this method has some limitations, as it overlooks the directional impact of path orientation on accessibility. Factors such as longitudinal slope, side slope, vertical obstacles, and trenches analyzed earlier all have directional characteristics. Therefore, in this paper, the hexagonal grid is extended to incorporate directional features, as illustrated in Figure 1. The hexagonal grid is divided into 6 directions, and the obstacle characteristics formed by these 6 directions are coupled with the passability of the unmanned vehicle. This analysis results in an evaluation of passability for each direction. As a result, the hexagonal grid is extended into a directed graph, which facilitates accurate path planning.
3. Multi-Layer Fusion for Passability Evaluation
To evaluate the factors affecting passability, a quantitative assessment is performed on the hexagonal grid, resulting in layered evaluation values. The issue of how to perform multi-layer fusion is a key challenge. Traditional methods such as minimum value selection, averaging, or multiplication followed by remapping have limitations and cannot meet the complex needs of passability evaluation in wilderness environment conditions. Therefore, based on the principle of layering and by drawing inspiration from the Mixture of intelligent model, a neural network-based fitting method is proposed to learn from datasets obtained from simulation software, achieving multi-layer fusion.
During the preprocessing phase, individual evaluations are conducted as described earlier. Based on the results of these individual evaluations, classification is performed, and an inference model is established for each class. The inference model uses a BP (Backpropagation) neural network trained on the dataset. Compared with traditional multi-factor overlay analysis methods based on physical models, this model can cover all ground categories and factors, and it offers higher computational efficiency. As mentioned earlier, there are 16 factors that affect the passability of unmanned vehicles in the battlefield. However, these 16 factors are not independent; they still exhibit coupling relationships. For example, if water is present, the terrain will not be in an icy or dry state. Therefore, the coupling relationships among the 16 factors need to be studied and categorized.
Vertical obstacles, trenches, longitudinal slope, and side slope represent terrain features and are grouped into three categories, as shown in Table 15.
In the table, ‘1’ indicates that the corresponding factor does not exist, indirectly suggesting that the factor does not have an impact. The term ‘rand’ means that the parameter is variable and determined based on the local wilderness environment and the evaluation method described earlier, thus possessing randomness.
Water depth, surface width, structural road surfaces, grassland, shrubs, snow and ice, dry ground, and water-containing surfaces are eight factors that characterize surface features, and they exhibit coupling relationships. These factors are grouped into 10 categories, as shown in Table 16. In this table, ‘1’ indicates the absence of a corresponding factor, indirectly suggesting no impact of the factor. The term ‘rand’ represents a variable parameter, determined based on the local wilderness environment and the evaluation method described earlier, thus possessing randomness.
Additionally, altitude is independent and generated randomly. The vegetation spacing factor is categorized into two types: one with trees and one without. In the case with trees, the impact factor is calculated based on the tree spacing, while in the case without trees, the factor is set to 1, indicating no impact on passability. As a result, the wilderness environment is classified into 240 categories.
3.1. Support Vector Machine Classification Model
Support Vector Machine (SVM) is used to construct an optimal hyperplane to realize classification or regression tasks. Its main advantage lies in its ability to efficiently process high-dimensional feature spaces for classification tasks, especially in scenarios requiring high-dimensional classification, such as terrain, water, and wilderness environments. This makes it an ideal choice for classification tasks in complex wilderness environments.
For a continuous dataset , where is the feature vector, and is the class label, the model can be expressed by an error-correcting output code (ECOC) framework. In this framework, the SVM is used to solve multi-class classification tasks. At the same time, in constructing the dataset, it is important to evaluate the influence of differences in the class labels on the model’s ability, and use the class-specific feature vectors to normalize the output of the communication evaluation results, ensuring the model’s standardization.
In SVM, the kernel function and the selection of its parameters are crucial for optimizing the model’s training process. Currently, the radial basis function (RBF) kernel is widely used. The parameters of the RBF kernel are highly sensitive to the data. If appropriate settings are not selected, the model may overfit or underperform. The Sigmoid kernel also satisfies the Mercer’s condition, indicating that it is a valid kernel function. Additionally, polynomial kernels, such as the Polynomial Kernel, can map features to higher-dimensional spaces, and the function is expressed as:
where is a kernel parameter, is a constant term, and d is the polynomial degree. The kernel parameters must be self-adjusted according to the dataset, with , where is the median distance between data points. This adjustment allows the kernel function to be adapted to the dataset and helps improve the model’s classification performance. Moreover, the influence of higher-dimensional spaces on the feature distribution can be better captured by non-linear kernel functions, enhancing the model’s ability to handle non-linear data.
From the experimental results shown in Figure 2, it can be observed that the Support Vector Machine (SVM) model achieves a prediction accuracy of 99.9125% on the training set, and 100% accuracy on the testing set so that some lines overlapped. Specifically, the training set consists of 8000 data points, with 7 misclassified samples, indicating that the model has a strong fitting ability for the training data. When the trained model was used to predict the testing set, consisting of 120 independent samples collected from real wilderness environments, all the samples were correctly classified.
To verify the robustness of the model in training with a large number of categories, a dataset similar to the one in Table 16 was created with 240 categories. For each category of wilderness environment, 400 data samples were generated to form the training set. To test the robustness of the model, the testing set used the same data. The results after training are shown in Figure 3. Any minor uncertainties in the classification stage are smoothed during the regression stage, preventing drastic fluctuations in the final path cost calculation. This integration ensures that the navigation system remains reliable even in complex transitional environments.
3.2. Backpropagation Neural Network
The Backpropagation Neural Network (BP Neural Network) is used here to approximate the nonlinear relationship between factors. The goal is to use the model to establish a predictive model for various wilderness environment factors. Specifically, including classes 24, 41, 52, 67, 79, and 188, were selected to build the model, validating the neural network’s generalization ability. Table 17 provides the initial data for the 24 category.
Since the optimization of each class’s feature variables differs, the input vector is , where each input point is in the range for . The BP neural network structure is used to model the nonlinearity, with a hidden layer having 10 neurons, and a second hidden layer containing 5 neurons. The neural network’s learning strategy is based on the backpropagation algorithm, using the purelin activation function for the output layer, and the sigmoid activation function for the hidden layers. The dataset was partitioned into training, validation, and testing sets with a distribution of 80%, 10%, and 10%, respectively. To ensure the robustness of the learning process and mitigate the impact of random data partitioning, a 10-fold cross-validation protocol was implemented. All performance metrics reported in this study represent the mean values obtained across these ten folds and were further validated over multiple random seeds to ensure statistical stability.
The activation function used here maps the input values to the range [−1, 1], which is similar to the Sigmoid function. The output of the function is centered around 0, which helps reduce the learning rate and enhances learning speed. The output from the hidden layer is processed by the following activation function:
The model uses Mean Squared Error (MSE) as the loss function. For the inference model of a single class, since the dataset is relatively small, the trainlm function in MATLAB 2024a is employed. This function uses the Levenberg-Marquardt algorithm, which is known for its fast convergence. The training parameters include a maximum iteration count (epochs) of 1000, a learning rate ( ) of 0.005, and an error threshold (goal) of .
As shown in Figure 4, Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9, for the BP neural network inference models constructed for categories 24, 41, 52, 67, 79, and 188, the Root Mean Square Error (RMSE) of the predicted outputs compared to the actual values is controlled between 0.00035 and 0.00073, while the coefficient of determination ( ) remains within the high range of 0.9294 to 0.9745. The experimental results indicate that, thanks to the hierarchical architecture design of the Hybrid framework of SVM and BPNN, this machine learning-based inference model is capable of capturing the complex coupling relationships between environmental features and passability even when training data is scarce. It exhibits stronger adaptability when dealing with high-dimensional coupled features and dynamic environments.
This high level of accuracy is primarily attributed to the characteristics of the traversability mapping task, which resides in a relatively low-dimensional feature space with high data fidelity and low redundancy. Since the input environmental variables and the resulting traversability coefficient K follow consistent physical and computational patterns established in our framework, the neural network is capable of converging to a near-optimal approximation with minimal residual variance. Specifically, the relationship between the inputs X and the output K is largely deterministic, allowing the model to capture the underlying mapping with high fidelity, as reflected in the extremely low values of the residual sum of squares:
where and denote the ground-truth and predicted traversability coefficients, respectively. These results confirm that the proposed learning module provides a reliable and precise mechanism for fusing multi-layer environmental information into a unified traversability index.
For complex wilderness environments where the road network is incomplete and the road network planning problem cannot be solved based on the complete road network, we propose a method for subdividing and constructing road network models. By using a direct graph and applying network road length differences as key elements, it enhances the communication of dynamic route planning and uses frequency adjustment for valid routes. The method combines the optimization sequence of the Dijkstra algorithm to effectively search the longest and optimal path.
The road network map is constructed by extracting the road network from the map, which needs to contain road nodes and edges. The node represents the start and end points of a road, and the edge represents the road itself.
A node is represented as a 3-dimensional array . Here, lon and lat represent the longitude and latitude coordinates of the node, and ID is the unique identifier for the node. The ID is used to locate the node in the entire road network for correct identification. The edge between nodes is represented as a 2-dimensional array , where u and v represent two nodes that are adjacent to each other. The edge connects the two adjacent nodes and represents the road between them. In this study, we use the Haversine formula to calculate the distance between nodes based on the spherical geometry model:
where R is the Earth’s radius, , , represent the latitude coordinates of the two nodes, and represent the longitude coordinates of the two nodes. In continuous routes, the road network can be evaluated by various other factors, such as traffic conditions. These factors can be used to derive weights in the network’s edge, providing additional information for the planning process. The road network graph is represented by a set of nodes and edges, which allows for the application of algorithms like the Dijkstra algorithm to find the optimal path between nodes in the network.
For the path from a single node to a target node in the road network, when the distance between the node and the target is greater than a predefined threshold (e.g., as set in this study), the path analysis process is carried out. The value of dis helps determine the road network and path efficiency, and further analysis can optimize the selection of roads based on the calculated values. Consider the set of candidate nodes , where is a node in the road network, and each node is associated with its distance. To analyze the next node selection, we calculate the new node’s longitude and latitude using the following formula:
where d represents the distance from the current node to the next node, and is the distance between the current and next node. The network structure is based on node sets , where V is the set of nodes and E is the set of edges. The road network is represented as a graph structure, which provides a framework for the next step of network modeling.
In the road network constructed for the modeling base, starting from the node set in the road network, we assign weights based on the Euclidean distances between the nodes and their geographical locations. Consider the node set of the road network. For each node , we calculate the corresponding Euclidean distance, , between nodes, which provides the edge distance in the network. Using the set , we can find the shortest path from the current node to the target node. This is achieved by using the Dijkstra algorithm, which calculates the shortest path between nodes in a network. The shortest path distance is obtained using the formula:
where k is a constant factor. In this case, the path length is determined by the weighted sum of distances along the edges. We continue this process until all paths between the nodes have been evaluated and the optimal path is selected. The basic road network used in this experiment is shown in Figure 10:
Based on the above foundation, the road network expansion was carried out using the method described in this paper, and the result is shown in Figure 11, where the green line represents the extended road line.
4. Convergence Analysis
Initially, a fundamental lemma is introduced, which is subsequently utilized to verify the convergence properties of the neural network with Gaussian function. Consider the objective function formulated as follows:
where denotes a function depending on , with and . For the sake of brevity, the scalar product symbol will be suppressed in the subsequent derivations. We designate the element-wise product operator as:
where and .
The partial derivative with respect to the output weight vector is derived as:
Similarly, the gradient regarding the width parameter is given by:
For iteration steps , sample indices , and dimensions , we define the following auxiliary variables:
Lemma 1. Assuming that the objective function is strongly convex and Lipschitz smooth, for any iteration step , sample index , and neuron index , the following inequalities hold:
where α represents the learning rate, denote constants independent of t and k, and is a scalar value lying between and .
Proof. Based on the premise of Assumption (A1), the bounds are given by: , for all and
- Let us introduce the following definitions:
Utilizing these notations alongside Equation (8), the validity of the inequalities in (9) is readily apparent. □
Referring to Equation (6), the derivation of Equation (10) is straightforward:
Subsequently, we proceed to verify inequality (11). From (5), (8) and (9), we deduce that:
Applying the Lagrange Mean Value Theorem yields:
where lies in the interval between and .
Consequently, we have:
Thus, we can conclude:
where the constant is defined as:
This concludes the derivation of inequality (11). We now move to prove inequality (12).
Employing Taylor expansion results in:
with the terms defined as:
where is positioned between and .
It is observed that:
Using Equations (7), (8) and (25), we obtain:
Then, referencing (9) and (17), it holds that:
Combining the inequalities derived above allows us to formulate inequality (12) as follows:
where .
Note that . Following a similar logic and utilizing Equation (19), the proof for inequality (13) proceeds as:
where . The convergence is guaranteed if the step-size satisfies the criteria in Equations (10)–(13). In practical scenarios, a learning rate of approximately 0.01 is utilized, which has been empirically verified to yield stable convergence. It should be noted that while the theory focuses on the global optimum of the regularized objective, the actual training process navigates the non-convex landscape to find a stable local minimum that represents a consistent traversability assessment. Failure to maintain these stability conditions could result in inaccurate K values, thereby compromising the safety of the generated path.
5. Numerical Experiments
In order to verify the effectiveness of the road network expansion algorithm, this study extracted the road network data of a certain urban-rural combined area and constructed the road network model in the experimental region. The road network has multiple dead ends, and the adjacent road network is sparse. The starting point is located in the lower left corner of the map, where the road planning algorithm is applied. The experimental setup is as follows: the road network distance , the line segment length , the road length factor , and the sampling number . The road network after expansion was used in Dijkstra’s algorithm to find the optimal path. The result of the road network optimization is shown in Figure 12, where the red dots in the figure represent the key points of the planned path.
5.1. Global Path Planning Algorithm with or Without Road Networks
In the previous works, the path planning framework based on expanded road networks significantly improved network integrity through direct road connections and key node filtering. However, in complex wilderness environments characterized by typical scenarios such as “roads are present but impassable” and “no roads available”, relying solely on road network models still has limitations. By establishing virtual connections between road network nodes and tile center points, a hybrid model of ’hard road network + soft passability’ is formed. This model provides redundant options for specialized vehicles to avoid threats and traverse complex terrain.
In complex off-road environments where no road network is available, path planning relies on the analysis of terrain passability. This paper uses a hexagonal tile map to represent off-road environments without a road network. Compared to traditional square grid maps, hexagonal tile maps offer advantages such as higher coverage area, consistent adjacency relationships, compact structure, and better angular resolution, making them more suitable for research on vehicle passability and path planning under off-road conditions.
To express the passability of off-road areas, virtual connections are established between the center points of hexagonal tiles. These connections represent passable paths after evaluation. The generation of these paths is based on the construction rules of the hexagonal tile map, by connecting the center points of adjacent hexagons. In the simulation study, a circular area with a radius of 1050 m, centered at geographic coordinates 116.161394° E, 39.864316° N, was designated as the research area. In practical applications, the passability of each region on the hexagonal tile map should be evaluated based on actual terrain exploration results. To validate the algorithm logic, random numbers were introduced in this paper to randomly generate passable roads, as shown by the green lines in Figure 13.
5.2. Path Planning Algorithm for Road Network Integration with Off-Road Environments
In complex off-road environments, path planning for various terrain types often requires the integration of road network data with the terrain’s variability. To fully explore the off-road traversal capabilities of specialized vehicles, a method based on hybrid road network integration is proposed, where both conventional road network data and off-road environment features are integrated. This paper presents a method that combines hexagonal tile maps with traditional road network models to create a hybrid model for path planning in environments where there are no existing roads. In this method, virtual connections are created between the centers of hexagonal tiles, forming a “hard road network + soft passability” hybrid model. This model provides redundant options for specialized vehicles to bypass threats and traverse complex terrain.
In off-road environments without a road network, path planning depends on analyzing the terrain’s passability. This paper uses a hexagonal tile map to represent environments without a road network. Compared to traditional square grid maps, hexagonal tile maps offer several advantages, such as better coverage, consistent adjacency relationships, compact structure, and improved angular resolution, making them more suitable for off-road vehicle path planning.
To represent the passability of the off-road area, virtual connections are established between the center points of the hexagonal tiles. These connections represent passable paths after evaluation. The paths are generated based on the rules for constructing the hexagonal tile map, connecting the centers of adjacent hexagons. In the simulation study, a circular area with a radius of 1050 m, centered at geographic coordinates 116.161394° E and 39.864316° N, was designated as the research area. In practical applications, the passability of each region in the hexagonal tile map should be evaluated based on actual terrain exploration results. To verify the algorithm’s logic, a random number generator was introduced to randomly generate passable paths, shown as red lines in Figure 14.
Simulation with Road Network Integration
By introducing a random number generator, random paths can be generated, as shown in the road network integration map in Figure 15 with blue lines:
The core idea of this algorithm is based on the connection of conditions, where the center of the hexagonal tile map is connected to the road network nodes. A “virtual road” is constructed, which forms a hybrid between the road network and the tile map. Using the Dijkstra algorithm for path planning, various types of off-road paths are identified and used in the expanded road network, providing options for vehicle movement. When constructing the expanded road network, the Dijkstra algorithm was used to identify the optimal path between nodes in the network, as shown in Figure 16, where the blue line represents the optimization process, and the red line represents the final optimal path.
In this case, the total road length of the path is 2895 m, with a deviation of 3070 m for the road network’s expansion. The final length of the road after expansion was 2530 m, which shows that the path expansion technique leads to a reduction in the total length of the road. After applying the Dijkstra algorithm to the path, the planning result optimized the path by selecting the shortest path based on the criteria. The optimization result is clearly better than the previous, as the road network used for calculation has more valid paths. At the same time, the method ensures that the path is navigable and adjusts for obstacles. This results in a more efficient route planning process, allowing vehicles to bypass complex terrain areas, significantly reducing the total travel time for the vehicle.
Through the simulation verification above, it is clear that the path planning algorithm based on road network integration provides advantages over single-road network planning. Road network integration offers flexibility in providing optimal off-road routes, but in practical applications, a fully connected road network may still present possible risks for vehicles. Therefore, even though the model using road network integration ensures passability, it is still influenced by environmental conditions, such as damaged roads or blocked paths. This results in an integrated model that is more adaptable to complex wilderness environment conditions. The results presented in Table 18 highlight the performance of different road network models based on their optimal path length. By comparing the proposed hybrid model against single-domain baselines (road-only and terrain-only), we demonstrate the significant gains achieved through multi-source information fusion. The algorithm achieves a practical runtime within seconds across all tested scenarios. While the current evaluation focuses on path length and information synergy, expanding the framework to include additional search-based baselines and optimizing for metrics such as feasibility and risk-averse costs remain key objectives for our future research.
In practical applications, the system can continuously collect environmental data, using real-time dynamic road network updates to adjust the vehicle’s path accordingly. This allows for optimal path planning under complex wilderness environment conditions by dynamically adapting to the changes in road network availability and terrain obstacles. The dynamic responsiveness of the proposed system is currently achieved through full recomputation of the path whenever the road network or environmental constraints are updated.
6. Conclusions
This paper has presented a hybrid global path planning framework tailored for specialized autonomous platforms operating in unstructured and post-disaster environments where infrastructure is often compromised. By establishing a fine-grained traversability evaluation model based on vehicle–terrain matching, the proposed method effectively quantifies the interaction between the platform’s kinematic constraints and complex topography, such as steep slopes and ravines. Furthermore, the novel integration of a road network expansion strategy with off-road search algorithms addresses the limitations of traditional planners, enabling a seamless transition between efficient on-road transit and flexible cross-country maneuvering to maximize the utility of high-mobility vehicles. In future work, we aim to enhance the system’s adaptability by incorporating real-time perception data to address dynamic environmental hazards. Additionally, we plan to validate the algorithm’s robustness through field experiments on physical platforms under authentic complex terrain conditions. For broader applications involving large-scale maps, the system’s scalability can be further enhanced by incorporating incremental update mechanisms and distributed parallel computing strategies, which are identified as key directions for our future work to optimize the computational budget and response frequency.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Mohanty P.K. Chaudhary V. Prajapati R. Review on path planning methods for autonomous underwater vehicle Proc. Inst. Mech. Eng. Part M J. Eng. Marit. Environ.202523933710.1177/14750902241263250 · doi ↗
- 2Tang Y. Zakaria M.A. Younas M. Path planning trends for autonomous mobile robot navigation: A review Sensors 202525120610.3390/s 2504120640006435 PMC 11861809 · doi ↗ · pubmed ↗
- 3BreitfußM. Schöberl M. Fottner J. Safety through Perception: Multi-modal Traversability Analysis in Rough Outdoor Environments IFAC-Papers On Line 20215422322810.1016/j.ifacol.2021.08.026 · doi ↗
- 4Basil N. Mohammed A.F. Sabbar B.M. Marhoon H.M. Dessalegn A.A. Alsharef M. Ali E. Ghoneim S.S. Performance analysis of hybrid optimization approach for UAV path planning control using FOPID-TID controller and HAOAROA algorithm Sci. Rep.202515484010.1038/s 41598-025-86803-439924550 PMC 11808095 · doi ↗ · pubmed ↗
- 5Shu Y. Dong L. Liu J. Liu C. Wei W. Overview of terrain traversability evaluation for autonomous robots J. Field Robot.2025421724176510.1002/rob.22461 · doi ↗
- 6Wang Z. Wang L. Huang G. Han Q. Xu F. Yue C. Research on Multi-source Heterogeneous Data Fusion Algorithm for Landslide Monitoring Based on BP Neural Network J. Geomech.20202657558210.1002/nag.3012 · doi ↗
- 7Chen C. Coarse Error Elimination Algorithm and Implementation Mode for Terrain Survey Data Using Ground 3D Laser Scanning Resour. Inf. Eng.201732130131
- 8Zhao P. Huo L. Zhu J. Research on Fast Calculation Method of Terrain Analysis Based on Terrain Tiles Mine Surv.202048105108