Dual-Stream Difference Modeling with Deep-Guided Multiscale Fusion for Mangrove Change Detection
Xin Wang, Shuai Tang, Qin Qin, Shunqi Yuan, Xiansheng Liang

TL;DR
This paper introduces a new deep learning method for detecting changes in mangrove ecosystems, which improves accuracy in challenging coastal environments affected by tides.
Contribution
The novel DSDGMNet method combines dual-stream difference modeling and deep-guided multiscale fusion to better detect true mangrove changes despite tidal interference.
Findings
DSDGMNet achieved an F1-score of 71.36% on the GBCNR dataset, outperforming existing methods like SNUNet and ChangeFormer.
On the WHU-CD dataset, DSDGMNet scored 91.38%, surpassing DDLNet and ChangeFormer in detecting mangrove changes.
Abstract
Accurate mangrove change detection is important for coastal ecosystem monitoring but remains challenging due to tidal disturbances, unstable land–water boundaries, and multi-scale distribution variability. Tidal fluctuations introduce spectral variations that obscure real changes. As a result, existing deep learning methods face difficulties in distinguishing tide-induced pseudo-changes while balancing semantic consistency and boundary accuracy. To address these issues, we propose DSDGMNet, which incorporates Dual-Stream Difference Modeling and Deep-Guided Multiscale Fusion. The dual-stream difference-driven strategy is designed to reduce tidal interference and improve sensitivity to true structural changes, and the deep-guided multiscale fusion module integrates global context with fine boundary details. Experiments on the GBCNR dataset show that DSDGMNet achieves an F1-score of 71.36%…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1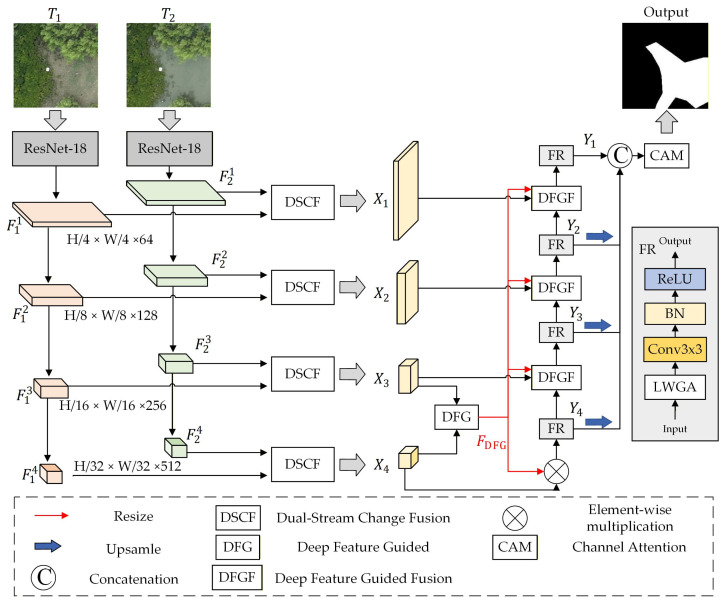 Figure 2
Figure 2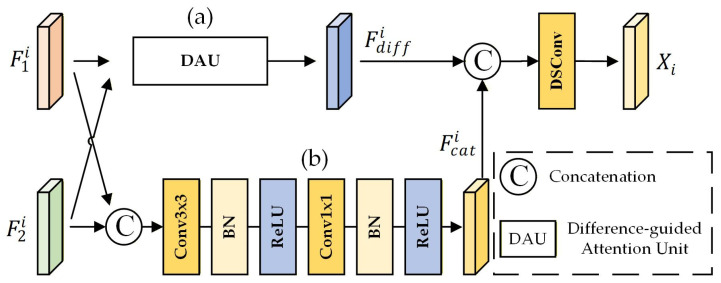 Figure 3
Figure 3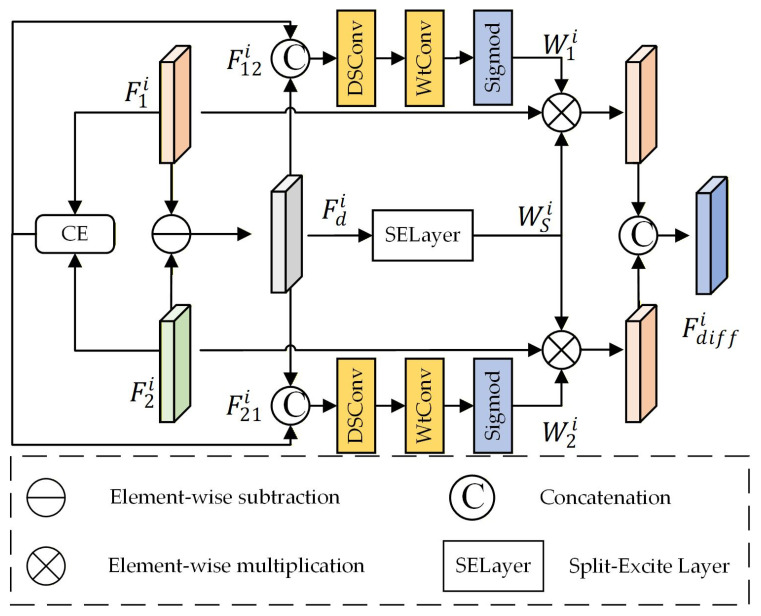 Figure 4
Figure 4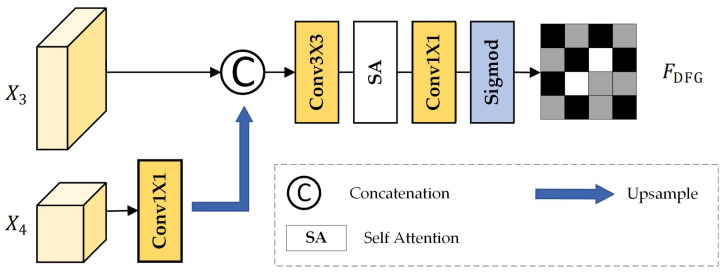 Figure 5
Figure 5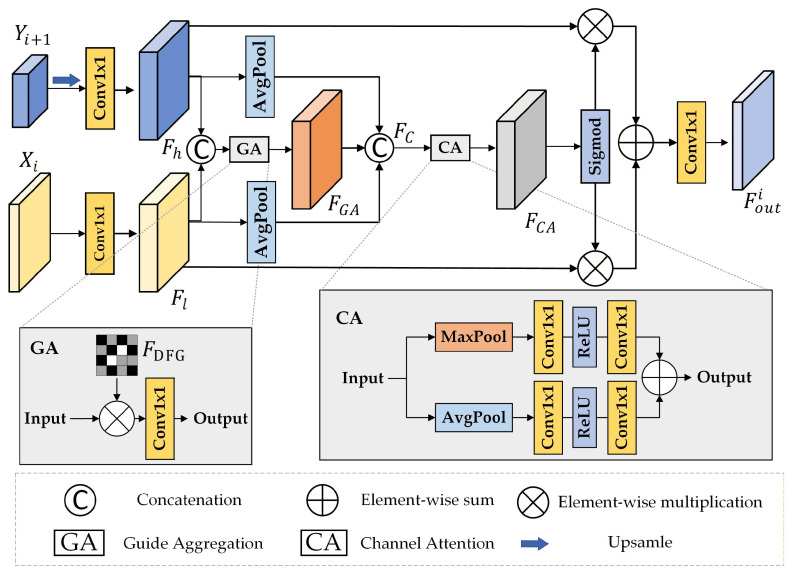 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8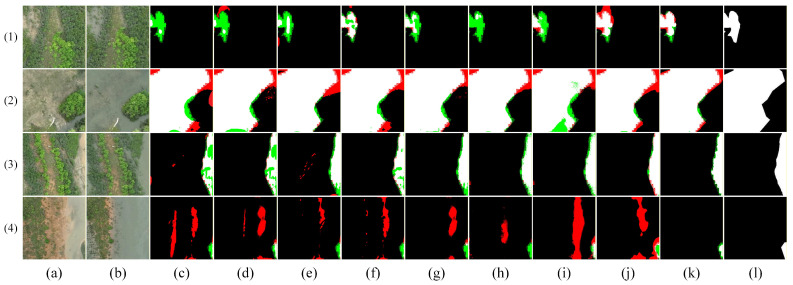 Figure 9
Figure 9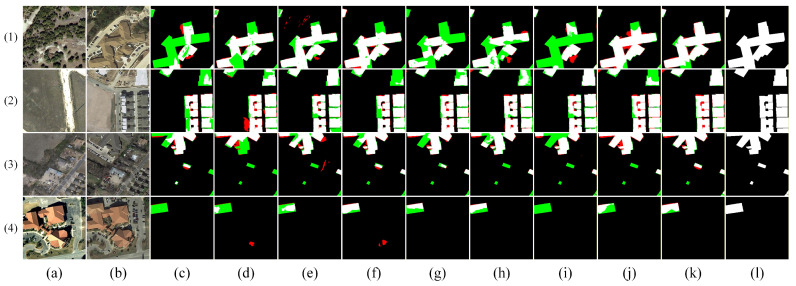 Figure 10
Figure 10 Figure 11
Figure 11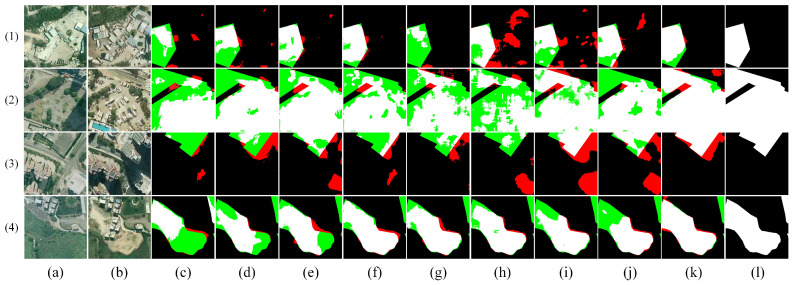 Figure 12
Figure 12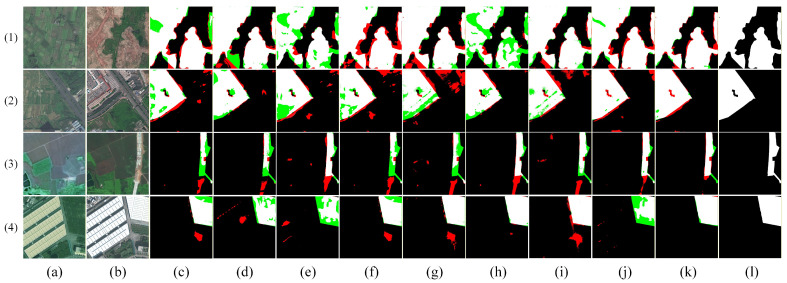 Figure 13
Figure 13 Figure 14
Figure 14- —Guangxi Science and Technology, Major Project
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCoastal wetland ecosystem dynamics · Remote-Sensing Image Classification · Flood Risk Assessment and Management
1. Introduction
Mangrove ecosystems serve as critical transitional zones linking land and sea, playing vital roles in maintaining coastal stability, conserving biodiversity, sequestering carbon, and mitigating climate change [1]. However, driven by multiple factors such as urban expansion, coastal development, aquaculture, and extreme weather events, mangroves worldwide face ongoing degradation with increasing ecological pressures. Therefore, timely and accurate monitoring of mangrove distribution and dynamic changes holds significant practical value for ecological conservation, environmental assessment, and resource management. Remote sensing technology, with its advantages of large-scale coverage, periodicity, and objectivity, is widely applied in mangrove monitoring, providing a reliable data foundation for revealing their spatiotemporal evolution [2].
With the advent of deep learning [3,4,5], deep neural networks have become the mainstream approach for remote sensing change detection, enabling more powerful feature learning in complex scenarios. Recent studies have advanced change detection in complex wetland environments, providing important insights for this work. Pan et al. proposed a spatio-temporal attention network (STANet) and a semantic change detection (SCD) framework to capture fine-grained “from-to” change information in wetlands [6,7]. Qian et al. addressed spectral similarity and pseudo-change in tidal wetlands with the Time-Spectral-Semantic Aware Convolutional Transformer (TSSA-CTNet) [8], integrating spectral and semantic priors to improve robustness across diverse wetland habitats. These studies highlight the importance of integrating spatio-temporal, spectral, and semantic information while suppressing environmental noise in wetland change detection. In addition, Luo et al. proposed the Bayesian Tile Attention Network (BTCDNet) [9] to alleviate data scarcity in mangrove mapping, introducing Bayesian prior guidance and efficient tile-based attention for robust and lightweight detection under limited sample.
Despite significant progress, most existing studies either focus on long-term sequence analysis or treat mangroves as a generic class within tidal wetlands, without explicitly addressing their unique identification challenges. Meanwhile, substantial advances have been made in the fundamental techniques underpinning our approach, particularly in bi-temporal feature fusion and multiscale representation learning, which provide a solid methodological foundation for this work.
For bi-temporal feature fusion, early Siamese-based approaches, such as FC-Siam (Fully Convolutional Siamese Networks) [10], employ symmetric encoders and simple fusion operations (e.g., differencing or concatenation), forming a classical paradigm for change detection. However, such linear and static fusion mechanisms are limited in modeling complex spatio-temporal interactions. Subsequent studies have enhanced feature interactions through dense connections [11,12], attention mechanisms [13], and adaptive gating [14], while recent works explored fine-grained pattern-aware fusion strategies, such as patch-based multi-head fusion in SRC-Net [15].
For multi-scale feature fusion, typical fusion strategies include upsampling, concatenation, and summing by elements [16,17,18]. However, early decoders mainly relied on linear fusion schemes and did not explicitly model cross-scale feature relationships, which limited their ability to achieve semantic consistency and boundary accuracy in ecohydrological coupling scenarios such as mangrove intertidal zones. Recent studies have proposed improved multiscale decoders. ChangFormer [19] and MFIN [20] adopt MLP-based fusion to enhance cross-scale integration, while MSFF-CDNet [21] introduces mask-guided fusion to capture gradual changes. ACMFNet [22] densely aggregates multi-level features to preserve spatial details.
Despite significant progress in related research, these methods still have shortcomings when directly applied to mangrove change detection. The challenges stem from two intertwined phenomena: the conflict between tidal-induced visual changes and structural stability, and the inherent scale inconsistency of mangrove boundaries.
First, under tidal disturbance, the visual appearance of mangroves changes dramatically even when the ecosystem itself remains intact. As illustrated in Figure 1a, at different tidal heights, the extent of water bodies and boundary morphology undergo substantial shifts—yet the main mangrove structure shows no ecological change. This “apparent dramatic change vs. structural stability” conflict causes conventional methods to respond to tidal-induced pseudo-variations rather than genuine ecological changes.
Second, mangrove changes exhibit inherent scale inconsistency. At coarse scales, the overall distribution of mangroves may shift; at fine scales, boundaries between mangroves, water bodies, and mudflats fluctuate significantly with the tides (Figure 1b). This multi-scale boundary drift leads to blurred boundaries and easily submerged details, making it difficult to stabilize change detection across scales.
To address the aforementioned challenges, this paper employs a dual-level design approach encompassing Bi-Temporal Feature Fusion and cross-scale fusion. The primary contributions are as follows:
- (1)To mitigate the issue where pronounced surface variations caused by differing tidal heights obscure the stable structure of mangroves, we propose the Dual-Stream Change Fusion (DSCF) module. This module achieves fine-grained alignment and fusion of dual-phase mangrove features through a difference-guided feature interaction mechanism.
- (2)To address inconsistent mangrove change patterns across scales and unstable boundaries under tidal influence, we introduce the Deep-Guided Multiscale Decoder (DGMD). This module generates high-level semantic guidance information to adaptively weight and fuse multiscale features, thereby enhancing change boundary localization accuracy while preserving semantic consistency.
Compared to existing Siamese-based, attention-guided, and Transformer-based change detection methods, DSDGMNet exhibits two key distinctions. First, we explicitly model cross-temporal discrepancies through a dual-stream difference-driven interaction mechanism, which helps suppress tide-induced pseudo-changes. Second, we introduce a deep-guided multiscale fusion strategy that leverages high-level semantic representations to guide feature integration, aiming to improve semantic consistency and boundary precision. These design choices provide an alternative to conventional static or multiscale fusion strategies and, as demonstrated in our experiments, contribute to improved performance in mangrove change detection tasks.
2. Methods
2.1. Architecture Overview
The overall architecture of the proposed network is illustrated in Figure 2, comprising two main components: the Bi-Temporal Feature Fusion encoder and the Multiscale Feature Fusion decoder. The core of the former is the proposed Dual-Stream Change Fusion (DSCF) module, which conducts difference-guided fine-grained alignment and fusion of bi-temporal features extracted by ResNet at various scales, thereby mitigating the dominance of non-structural differences over change information. The latter component is the Deep-Guided Multiscale Decoder (DGMD). It utilizes deep semantic features to generate guidance information, selectively adjusting multiscale features affected by tidal disturbances to facilitate a stable representation of mangrove change. This design addresses the challenges of coordinating multi-scale features and managing unstable change boundaries in mangrove imagery.
Specifically, the workflow of our proposed DSDGMNet is as follows. Given bi-temporal images , a shared-weight ResNet-18 backbone extracts four levels of feature maps: for , with spatial resolutions of , , , and , and channel dimensions of 64, 128, 256, and 512, respectively. For each level , the bi-temporal feature pair is fused by the Dual-Stream Change Fusion (DSCF) module, producing . The deepest features and then pass through a Difference Feature Guidance (DFG) module to generate a guidance map , which is multiplied with to enhance change-salient regions. A Feature Refinement (FR) module with Light Weight Grouped Attention (LWGA) module [23] further refines the result to produce . Subsequently, a cascade of DFGF modules performs cross-scale guided fusion from deep to shallow layers. Each DFGF module takes , , and as inputs, producing refined features sequentially. All refined features are summed and passed to a lightweight decoder [24] to generate the final change map. Detailed module descriptions are provide in the subsequent subsections.
Table 1 provides a detailed summary of the proposed architecture, specifying the input/output feature maps, channel dimensions, and spatial resolutions of each module, which is intended to improve the reproducibility and implementation clarity of our method.
2.2. Dual-Stream Change Fusion
Patch-Mode joint fusion in SRC-Net [15] is a representative approach for bi-temporal feature fusion, and the comparison results are shown in Table 2. where bi-temporal features are treated as time-varying signals and change modes are inferred probabilistically. In contrast, the proposed DSCF module adopts a difference-guided explicit modeling strategy. Specifically, we compute the difference map between bi-temporal features and use it as an attention prior to guide feature enhancement, aiming to mitigate tidal-induced pseudo-changes. This explicit modeling of change information, combined with the dual-branch design, contributes to more effective suppression of false changes in mangrove environments.
This module employs a difference-guided approach to achieve more robust interaction between bi-temporal features. It primarily consists of two branches: the difference branch (as shown in Figure 3a) and the connection branch (as shown in Figure 3b). Input features are .
The connection branch maintains the overall structure and contextual information of mangroves by concatenating and convolving the bi-temporal features, thereby mitigating potential detail loss and noise amplification associated with pure difference calculations. It consists of a 3 × 3 convolutional block followed by a 1 × 1 convolutional block. The 3 × 3 block captures local spatial context, while the 1 × 1 block reduces the channel dimension to match the output of the subtraction branch. Each convolutional block comprises a convolution layer, batch normalization (BN), and a ReLU activation function. The input bi-temporal features are first concatenated along the channel dimension and then processed by this branch to yield the connection branch output, denoted as . The difference branch employs a Difference-Aided Attention Unit (DAU), which explicitly models difference information derived from the bi-temporal features. It generates difference weights to modulate the original features, establishing a “difference-guided attention” mechanism for feature enhancement. This design enables the module to adaptively highlight regions of genuine change at both the channel and spatial levels while mitigating false change responses induced by factors such as tidal fluctuations and water coverage variations.
The bi-temporal features and are processed by the connection branch to generate , while is derived via the difference branch. Subsequently, these features are concatenated and processed through a single dilated convolution to yield the preliminary fusion result . This integration of the original difference features ensures that the dilated convolution incorporates both the refined context from the connection branch and the direct change signals from the difference branch, facilitating the adaptive integration of complementary information beyond mere feature stacking. By leveraging these complementary features, the two branches contribute to the alignment of bi-temporal mangrove features under complex tidal interference, thereby supporting the model’s capacity to discern genuine ecological changes.
Difference-Guided Attention Unit (DAU)
The DAU serves as the core of the difference branch, with its architecture illustrated in Figure 4. The module first computes the difference map between the two input feature maps and generates global attention weights via a Split-Excite Layer [25,26]. Concurrently, it performs a partial channel exchange between the inputs and integrates the exchanged features with the difference map to derive spatial attention weights. These weights are then applied to the original input feature maps for refinement. Finally, the two enhanced feature maps are concatenated and processed through a depthwise separable convolution to yield the final fusion result.
Given the bi-temporal features of the -th layer, denoted as and , an element-wise subtraction is first performed to generate a coarse change representation, . Subsequently, these features undergo channel-wise concatenation via the Channel Exchange (CE) module [13] to yield and , respectively. This operation facilitates cross-channel interaction between the two temporal phases prior to explicit subtraction, thereby accentuating variations while attenuating invariant regions. Next, the features obtained by integrating with and are independently processed through depthwise separable convolutions (DSConv) and wavelet convolutions (WtConv) [27]. The output of the WtConv layer is subjected to a sigmoid activation function to generate weight matrices and , which are then combined. This design aims to reduce the parameter count while improving the feature extraction efficacy of the network. The process can be formulated as follows:
where ⊕ denotes concatenation. Subsequently, σ denotes the sigmoid activation function.
To further enhance the expressive power of multi-scale features, we introduce a SELayer to process the initial difference , aiming to capture richer inter-channel dependencies. Its formula is expressed as
where denotes a Dense Multi-Layer Perceptron (DMLP), which consists of a linear mapping and a ReLU activation function, while represents connections along the channel, in our model, k is set to 4. This module leverages global knowledge to enhance more discriminative features in regions that vary over the temporal dimension.
Finally, we apply the spatially augmented weight matrices and the attention weights derived from the SELayer to the source feature map , yielding the fusion result :
where denotes element-wise multiplication. Finally, the feature maps obtained from the concatenation branch and the subtraction branch are fused:
Obtain the final fusion result from DSCF for subsequent module processing.
2.3. Deep-Guided Multiscale Decoder (DGMD)
In change detection tasks, shallow features retain rich spatial details and boundary information, while deep features exhibit stronger semantic representation capabilities, facilitating the characterization of the overall distribution and change trends of mangrove forests. However, in mangrove scenarios subject to significant tidal interference, features at different scales demonstrate inherent inconsistencies in their response to change: shallow features are vulnerable to noise induced by water inundation and boundary displacement, whereas deep features may fail to capture local change details due to their reduced resolution. Consequently, direct cross-scale fusion may introduce redundant information and potentially compromise the model’s efficacy in identifying genuine change areas.
To address these challenges, we propose the Deep-Guided Multiscale Decoder (DGMD), illustrated in Figure 2, which comprises a Deep Feature Guidance (DFG) module, a Deep Feature Guided Fusion (DFGF) module, and a Feature Refinement (FR) module. The DFG module leverages high-level semantic information from two distinct scales integrated with a self-attention mechanism to generate a guidance map, denoted as , characterizing stable and discriminative change regions. Subsequently, the DFGF module utilizes to facilitate cross-scale feature fusion, aligning shallow and deep features within change regions to promote complementary learning. This strategy mitigates tidal-induced boundary perturbations while preserving critical spatial details. Following processing by the FR module, the fused features from each layer demonstrate enhanced saliency in high-change areas, retaining rich spatial information while suppressing irrelevant variations. Consequently, this framework enables a refined characterization of mangrove distribution changes.
In contrast to MSFCTNet [28], which employs a representative multi-scale decoder architecture by concatenating features from four encoding stages, processing them via a Hybrid Convolutional Neural Network–Transformer Module (HCTM), and filtering cross-scale information through a Gated Attention Module (GAM), our approach presents several distinct architectural advantages.
First, while MSFCTNet executes full-scale feature aggregation followed by global processing, our DGMD implements a progressive decoding strategy that iteratively refines features in a layer-by-layer fashion. Second, the GAM in MSFCTNet leverages SE-based attention to perform implicit channel reweighting across scales; conversely, our DFG module constructs explicit semantic guidance maps derived from the two deepest features ( and ) to direct feature enhancement, thereby avoiding the uniform treatment of all scales. This design promotes more targeted refinement of change regions and aids in the preservation of mangrove boundaries amidst tidal disturbances. The quantitative comparison between MSFCTNet and our DGMD is presented in Table 3.
2.3.1. Deep Feature Guided (DFG)
The architecture of the proposed DFG module is shown in Figure 5. The input features are and . The output is .
Considering the differing spatial and channel dimensions of and , upsampling and 1 × 1 convolution are employed to align their spatial scales. The channel dimension of the high-level features is compressed, after which the two feature maps at the same spatial scale are concatenated. These concatenated features are then further processed using 3 × 3 convolution operations to enhance feature representation. The formalized process of this operation is as follows:
where up denotes the upsampling operation, represents a i × i convolution.
Due to the limited receptive field of the 3 × 3 convolution kernel, the output correlates only with a local portion of the input, resulting in sufficient global contextual information. To address this, a self-attention mechanism is employed in the subsequent processing. Next, a 1 × 1 convolution reduces the number of channels to one, aiming to fuse multi-dimensional feature information into a compact representation for further processing. Finally, the sigmoid activation function generates the DFG map:
where SA denotes the self-attention mechanism, and represents the output DFG mapping.
This process ensures the DFG mapping effectively integrates local and global feature information, enhancing the representational capacity of the DFG mapping.
2.3.2. Deep Feature Guided Fusion (DFGF)
The architecture of the proposed DFGF module is shown in Figure 6. This module is designed to perform multiscale feature fusion using the generated . It first upsamples the fusion result from the previous layer and adjusts its channels to align with the shallow features in spatial resolution. Next, it expands the channels of both features and performs gated weighted fusion guided by . Global context information is then introduced and concatenated with the fused features, followed by channel attention and spatial selection mechanisms to generate adaptive weights. Finally, these weights are used to perform weighted fusion of the original features, and the result is passed through a projection layer to produce the final output.
Subsequently, the processed features are concatenated along the channel dimension. Concurrently, the guidance map is processed by a Guide Aggregation (GA) layer, in which each element is subjected to a sigmoid activation followed by the addition of a unit value (i.e., +1). This strategy enhances the preservation of original features, mitigating information loss attributed to potential instability within the guidance map. The GA layer then applies element-wise multiplication to the two processed features, as formulated below. The resulting feature map possesses dimensions of :
where the denotes element-wise multiplication.
In parallel with this step, the processed deep features are combined with shallow features via global features, which are then concatenated with :
where Avg denotes the operation of computing the average value of the feature map and extending it across the entire pixel space. This operation aims to obtain a global feature capturing the overall properties of the input features.
The concatenated feature map is subsequently input into the Channel Attention (CA) layer, which executes global channel-level filtering and recalibration on the fused features, yielding . This mechanism ensures that the features propagated to the decoder exhibit enhanced compactness and discriminability, thereby improving change detection accuracy. The process is formulated as follows:
where FC denotes the fully connected layer, and Max represents max pooling.
Finally, we apply a Sigmoid activation to , then multiply it with the shallow features and the deep fusion features respectively, and sum the results to obtain the fusion output:
The dimension of is .
The Deep Feature Guided Fusion (DFGF) module takes as input the current layer’s features , the fused features derived from the preceding layer, and the guidance map . Initially, is upsampled to match the spatial resolution of . Subsequently, a convolution is applied to expand the channel dimension of both feature maps by a factor of two, yielding .
2.4. Loss Function
In remote sensing change detection, changed pixels typically comprise only a negligible fraction of the image, leading to a severe class imbalance between changed and unchanged regions. This disparity causes standard cross-entropy loss to be dominated by the prevalent unchanged pixels, thereby obscuring the learning signals critical for change regions. To mitigate this issue, we propose a hybrid loss function that integrates Focal Loss and Dice Loss. Focal Loss dynamically reweights samples to prioritize hard-to-classify pixels, whereas Dice Loss maximizes the spatial overlap between predicted segments and ground truth labels. This synergistic combination effectively alleviates the class imbalance problem, steering the model toward more precise identification of change areas. The formulation is presented as follows:
Among these, denotes the focal loss, formulated as
Among these, hyperparameters α (set to 0.2) and γ (set to 2) are used to balance the weights of positive and negative samples and focus on difficult-to-detect samples, respectively; p represents the prediction probability, and y denotes the binary label (0 or 1) indicating whether a pixel has changed or remained unchanged.
represents the loss from dice rolls, calculated using the following formula:
where E denotes the ground truth, represents the change map, and indicates a point within .
3. Experiments and Analysis
3.1. Datasets
We systematically evaluated the performance of the proposed DSDGMNet for mangrove change detection. The core experiment was conducted on the mangrove change detection dataset GBCNR, independently compiled in our laboratory. Additionally, we performed supplementary validation on several public datasets: LEVIR-CD [29], WHU [30], CLCD [31], and SYSU-CD [32].
GBCNR: The Guangxi Coastal National Wetland Reserve Mangrove Tidal Change Detection Dataset (GBCNR) was collected using DJI Mavic series UAVs (Shenzhen DJI Innovation Technology Co., Ltd., Shenzhen, China) along the Fengjia River in Beihai, Guangxi, China. Representative mangrove areas were selected, and multiple surveys were conducted under different tidal conditions. The UAVs operated at altitudes up to 500 m, and each image has a resolution of 5280 × 3956 pixels. Under the guidance of environmental ecology experts, wetland areas were annotated using LabelMe. The images were cropped into tiles and resized to 256 × 256 pixels to meet deep learning input requirements. Data augmentation, including horizontal and vertical flipping, was applied. The dataset was divided into 1748 training pairs, 499 validation pairs, and 249 test pairs. Examples of the GBCNR dataset under different tidal conditions are shown in Figure 7, where (a) and (b) represent the same location at Time T1 and Time T2, respectively.
LEVIR-CD: A building change detection dataset containing 637 image pairs (0.5 m resolution, 1024 × 1024 pixels) from 20 regions in Texas, USA. We cropped them into 256 × 256 non-overlapping patches, resulting in 7120/1024/2048 patches for training/validation/test.
WHU: Consists of a single pair of aerial images (0.2 m resolution, 32,507 × 15,354 pixels) capturing earthquake-induced building changes. We cropped it into 256 × 256 non-overlapping patches, yielding 6095/737/787 patches for training/validation/test.
CLCD: A land cover change detection dataset based on Landsat imagery (30 m resolution) covering China from 1985 onward. Images are provided as 512 × 512 tiles (each covering ~15.36 km^2^). We used the official split of 360/120/120 for training/validation/test.
SYSU-CD: Contains high-resolution optical images (0.5 m resolution, 256 × 256 patches) from Shenzhen, China, covering various urban change types. The dataset is split into 12,000/4000/4000 patches for training/validation/test.
Figure 8 shows representative image pairs from these datasets, with (a) and (b) corresponding to Time T1 and Time T2 for each example.
3.2. Quality Control
The GBCNR dataset was constructed for mangrove change detection using high-resolution satellite and UAV imagery. This section details the annotation protocol and quality control measures.
3.2.1. Annotation Protocol
All annotations were conducted by three remote sensing experts, each possessing more than five years of experience in wetland interpretation. Utilizing ArcGIS (version 10.8.2) and LabelMe (version 5.8.2) software, the annotators adhered to a rigorous temporal contrast annotation protocol comprising the following steps: (1) Image Registration: Bi-temporal UAV images were precisely aligned using the Scale-Invariant Feature Transform (SIFT) algorithm [33] to rectify positional discrepancies; (2) Change Delineation: Experts manually mapped mangrove changes—including expansion, degradation, and anthropogenic disturbances—by conducting a comparative analysis of the registered image pairs, augmented by NDVI and NDWI indices for spectral verification.
3.2.2. Quality Control and Inter-Annotator Consistency
To guarantee annotation reliability, we implemented a rigorous two-stage cross-validation strategy:
- (1)Independent Annotation: Each image pair was independently labeled by two experts. Both annotators adhered to the identical protocol and were blinded to each other’s results during this phase.
- (2)Disagreement Adjudication: All annotations from Stage 1 were subjected to pixel-wise comparison. For discrepant pixels, a third senior expert conducted a review and rendered the final verdict. This adjudication process ensured the consistent resolution of all ambiguous cases.
Inter-annotator agreement was quantitatively evaluated using Cohen’s Kappa coefficient. The average Kappa score across all samples achieved 0.87, indicating substantial agreement. Consequently, only samples exhibiting a Kappa score exceeding 0.85 were included in the final dataset. The quality control metrics and standards used in this annotation process are summarized in Table 4. SSIM means Structural Similarity Index Measure.
3.2.3. Dataset Variability
The dataset comprises imagery acquired between 2023 and 2024, facilitating the observation of subtle dynamic changes within mangrove ecosystems. To explicitly address tidal variability, flight missions were strategically scheduled in accordance with tidal predictions at two distinct tidal regimes: 5.11 m (high tide) and 0.23 m (low tide). This approach ensures comprehensive representation of ecological characteristics across diverse tidal conditions.
3.3. Implementation Details and Metrics
3.3.1. Implementation Details
We implemented our method using the PyTorch (version 2.0.0) framework on an NVIDIA GeForce RTX 3090 GPU with 24 GB of memory. The model was trained for 200 epochs using the SGD optimizer with an initial learning rate of 0.05, momentum of 0.9, and weight decay of 5 × 10^−5^. A step learning rate decay strategy was adopted, reducing the learning rate by a factor of 0.1 every 50 epochs.
For the loss function, we employed a combination of Focal Loss and Dice Loss with equal weights (0.5 each). The Focal Loss was configured with γ = 0 and without class weighting (α = None), while Dice Loss included an epsilon value of 1 × 10^−7^ for numerical stability.
Input images were resized to 256 × 256 pixels for the GBCNR, LEVIR-CD, WHU-CD, and SYSU-CD datasets, and to 512 × 512 pixels for CLCD. The batch size was set to 8 for all datasets except CLCD, where a batch size of 4 was used due to the larger input resolution and GPU memory constraints.
Data augmentation was applied to the bi-temporal images. On the GBCNR dataset, random rotation (probability = 0.15), vertical flip (probability = 0.3), and horizontal flip (probability = 0.5) were performed.
To ensure reproducibility, all experiments except the statistical evaluation in Section 3.6 were conducted with a fixed random seed of 1234. For statistical evaluation, five different random seeds (1234, 2345, 3456, 4567, and 5678) were used to report the mean and standard deviation.
3.3.2. Metrics
To quantitatively assess the effectiveness of the CD method, we employed five widely used metrics to compare the predicted change map with the actual situation. These include Precision (Pre), Recall (Rec), F1 Score (F1), and Intersection over Union (IoU). Their definitions are as follows:
TP, TN, FP, and FN represent the number of true positives, true negatives, false positives, and false negatives, respectively. Their values range from 0 to 1, with higher values indicating better performance.
3.3.3. Computational Efficiency
We evaluated the training time and inference speed of our method. All models were trained for 200 epochs. Table 5 summarizes the training time across datasets.
For inference, we measured the processing speed on the WHU-CD test set (787 images, 256 × 256). Our model processes a single image in 11.8 ms, equivalent to 84.8 FPS. Since all 256 × 256 datasets share the same input resolution, the inference speed is consistent across them. For the CLCD dataset with 512 × 512 resolution, inference time scales approximately at 45.7 ms per image, equivalent to 21.9 FPS.
3.4. Ablation Experiments
3.4.1. Effect of Core Modules
To validate the effectiveness of the core modules proposed in this paper, we conducted systematic ablation experiments across five datasets. The experiments included a baseline model STNet [24] with no modified modules, a model incorporating the DSCF module, a variant without the DFG module (denoted as DSDGMNet w/o DFG) and the full DSDGMNet. Results are shown in Table 6.
Ablation experiments across five datasets demonstrate that both DSCF and DGMD contribute positively to model performance. The baseline model achieves F1 scores ranging from 51.54% to 90.42% across datasets. Adding DSCF alone yields consistent improvements (0.09–1.53%), while DGMD alone produces larger gains, particularly on GBCNR (+19.82%), highlighting its critical role in multiscale feature fusion for mangrove change detection. Removing the DFG module leads to performance degradation across all datasets (e.g., 1.01% on GBCNR and 0.61% on WHU), confirming its effectiveness in feature guidance. The full model combining both modules achieves the highest F1 scores on all datasets, with the most notable improvements on WHU-CD (+1.66%) and CLCD (+1.77%). These results validate that DSCF and DGMD complement each other, and their integration is essential for optimal performance across diverse change detection scenarios.
3.4.2. Effect of Loss Functions
We conducted a comparative study to evaluate the effect of different loss function configurations on model performance. Specifically, three variants were examined: (1) using Focal loss alone, (2) using Dice loss alone, and (3) employing a combined loss function (Focal + Dice), as implemented in our full model. All experiments were carried out on the GBCNR dataset, and the results are summarized in Table 7.
The combined loss achieves the best performance (F1: 71.36%, IoU: 55.47%), outperforming focal-only (F1: 69.35%, IoU: 53.08%) and Dice-only (F1: 69.89%, IoU: 53.71%). The combined loss yields significantly higher recall (84.57% vs. 76.06%/77.35%), indicating its effectiveness in identifying change regions. These results confirm that both loss components contribute positively to mangrove change detection.
3.4.3. Effect of Backbone Networks
We assessed the performance of three backbone architectures under consistent experimental settings on the GBCNR dataset: ResNet-18 (adopted as our default), ResNet-34, and ResNet-50. All experiments were executed in a single run. Furthermore, we quantified computational complexity via floating-point operations (FLOPs, in G) and parameter count (Params, in M) to evaluate efficiency.
The results, presented in Table 8, reveal that ResNet-18 yields the optimal overall performance, achieving an F1-score of 71.36% and an IoU of 55.47%, thereby surpassing both deeper variants by a significant margin. Specifically, relative to ResNet-34 (F1: 68.83%, IoU: 52.48%), ResNet-18 delivers gains of 2.53% in F1 and 2.99% in IoU; similarly, against ResNet-50 (F1: 68.69%, IoU: 52.31%), it registers improvements of 2.67% in F1 and 3.16% in IoU. Notably, ResNet-18 incurs only 12.84 G FLOPs and 38.09 M parameters—figures substantially lower than those of ResNet-34 (17.68 G, 48.21 M) and ResNet-50 (19.40 G, 51.82 M)—underscoring its superior trade-off between accuracy and computational efficiency.
These results indicate that deeper backbone architectures do not necessarily enhance mangrove change detection performance on our dataset. This phenomenon can be attributed to the fact that increased model capacity may induce overfitting given the relatively limited scale of the GBCNR dataset. Moreover, mangrove change detection hinges critically on precise boundary localization rather than solely on deep semantic abstraction. Shallower architectures, such as ResNet-18, are more effective at preserving fine spatial details in early feature layers, which are paramount for accurately delineating tidally influenced boundaries. Consequently, ResNet-18 is selected as the default backbone, providing an optimal balance between accuracy and computational efficiency.
3.5. Comparative Experiments
To comprehensively evaluate the performance and generalization capabilities of our proposed DSDGMNet model, we conducted extensive experiments on four publicly available remote sensing change detection datasets and the GBCNR dataset. We selected multiple state-of-the-art methods for comparison, including: FC-EF (Fully Convolutional Early Fusion), FC-Siam-diff (Fully Convolutional Siamese Networks with Difference), FC-Siam-conc (Fully Convolutional Siamese Networks with Concatenation) [10], LGPNet [34], SNUNet [35], ChangeFormer [19], USSFCNet [36], and DDL-Net [37]. All experiments were performed under identical data partitioning and hardware/software environments to ensure fairness.
As shown in Table 9, our method achieves the highest recall (84.57%), F1 (71.36%), and IoU (55.47%) on the GBCNR dataset. Compared to multi-scale methods like SNUNet (F1: 68.87%) and LGPNet (F1: 69.13%), and Transformer-based approaches like ChangeFormer (F1: 66.39%), our model improves F1 by 2.2–4.9%. The precision (61.71%) remains comparable to other methods, indicating that the gain in recall does not come at the cost of excessive false alarms. This demonstrates the effectiveness of our tide-aware design in complex mangrove environments.
On the LEVIR-CD dataset, our method achieved the best overall performance (Table 10), with an F1 score of 90.68% and an IoU of 82.95%. The model achieves a balance trade-off between Pr (91.36%) and Re (90.01%), avoiding the imbalance issues seen in methods like FC-Siam-diff (high precision, low recall) or FC-Siam-conc (high recall, low precision). This is primarily attributed to the core dual-stream change fusion module, which enhances regions of genuine change through difference-aware attention while supplementing details via the connection branch. Consequently, it outperforms competitors like ChangeFormer and DDLNet in building change detection.
On the WHU dataset, our model demonstrates even more pronounced advantages (Table 11), achieving an F1 score of 91.38%—outperforming other methods and surpassing the second-place DDLNet by 1.53 percentage points. The model simultaneously achieves the highest Re (91.85%) and a very high Pr (90.92%), indicating its ability to detect nearly all changed buildings while effectively controlling false positives. Its IoU (84.13%) also ranks first, suggesting that the deep feature-guided fusion module effectively utilizes deep semantic guidance for multiscale Feature Fusion, enhancing change regions while suppressing background redundancy.
The SYSU-CD dataset encompasses diverse changes across buildings, roads, water bodies, and other elements, presenting complex scenes. As shown in Table 12, all models exhibit performance degradation, reflecting the dataset’s challenging nature. Despite this, our approach ranked first with an F1 score of 82.43% and an IoU of 70.11%, outperforming the second-place DDLNet by 1.01% and 1.45%, respectively. The model also achieved the highest Pr (85.89%), highlighting its ability to suppress false changes in complex terrain. This is attributed to the multi-scale guided fusion architecture, which integrates deep semantic information with shallow details within a global context, thereby improving decision reliability.
The CLCD dataset features diverse targets, complex backgrounds, and significant noise, and the resolution (512 × 512) set for this experiment further increases detection difficulty. As shown in Table 13, all models perform noticeably worse than on other datasets. In this highly challenging environment, our model once again demonstrates robustness, achieving an F1 score of 75.31%—0.82% higher than the second-place DDLNet and 1.04% higher in IoU. The model achieved the highest Re (74.65%) while maintaining high Pr (75.98%), indicating its ability to capture subtle, irregular changes in targets such as farmland. The dual-stream change fusion module sensitively responds to weak difference signals and effectively locates genuine changes within complex backgrounds.
3.6. Statistical Evaluation
To evaluate the stability and robustness of the proposed method, we conducted five independent runs on our self-constructed GBCNR dataset and the publicly available WHU dataset using different random seeds (1234, 2345, 3456, 4567, 5678) [31]. All results of our method are reported as mean ± standard deviation, providing a more reliable assessment of the model’s performance under different initialization conditions. The results are shown in Table 14. Due to computational constraints, all competing methods were evaluated with a single run.
3.7. Visualization of Comparison Experiments
3.7.1. Qualitative Comparison on Representative Scenes
To more intuitively demonstrate the effectiveness of the proposed method, this section will analyze and discuss the visualization results and model efficiency of the comparative experiments.
Figure 9, Figure 10, Figure 11, Figure 12 and Figure 13 show the visual results of randomly selecting four pairs of remote sensing images from each of the five databases.
In the figure, white represents true positives, black represents true negatives, red represents false positives, and green represents false negatives. The labels in the figure denote: (a) T_1_ image, (b) T_2_ image, (c) FC-EF [10], (d) FC-Siam-diff [10], (e) FC-Siam-conc [10], (f) LGPNet [34], (g) SNUNet [35], (h) ChangeFormer [19], (i) USSFC-Net [36], (j) DDL-Net [37], (k) Ours, and (l) Ground Truth.
As shown in Figure 9, visualization results on the GBCNR dataset provide intuitive validation of the proposed network’s effectiveness in addressing the two core challenges of mangrove change detection. Regarding the issue of apparent changes under tidal disturbances while mangrove structures remain stable, examples (1) and (3) reveal that most comparison methods (e.g., d–k) tend to misinterpret changes in water body extent and tidal channel morphology as mangrove changes, generating extensive false positives. In contrast, our method (l) accurately focuses on genuine mangrove distribution changes while significantly suppressing false responses caused by tides, water surface reflections, and other factors. Addressing the challenge of inconsistent change scales and highly unstable boundaries, in the more complex examples (2) and (4), the proposed method maintains overall semantic consistency of change areas while clearly delineating fine-grained boundary structures at mangrove–water interfaces. This effectively reduces fragmented noise and boundary blurring. Collectively, these results demonstrate that our method achieves robust and adaptable performance in coastal wetland scenarios with significant tidal interference, simultaneously ensuring accurate modeling of real-world changes and stable representation of multi-scale boundary details.
As shown in Figure 10, the visualization comparison on the LEVIR-CD test set demonstrates that DSDGMNet exhibits outstanding performance across multiple typical scenarios. For instance, in scenario (1), compared to the fragmented results produced by FC-EF, FC-Siam-diff, and FC-Siam-conc, DSDGMNet achieves complete coverage of the building area while maintaining shape consistency. For complex-contoured buildings (3), its boundaries are the clearest, outperforming SNUNet and ChangeFormer; in road and shadow interference scenarios (2), DSDGMNet effectively suppresses false detections seen in BIT and DDLNet; and for sparse, small-scale building detection (4), it successfully captures changes missed by other methods. Overall, DSDGMNet achieves higher integrity, accuracy, and robustness in building change detection.
The visualization results on the WHU-CD dataset (Figure 11) clearly demonstrate that our proposed DSDGMNet achieves outstanding performance in building change detection. As shown in examples (1) and (3), our method (k) can completely reconstruct the building contours, significantly reducing the internal voids (false negatives) and boundary defects observed in other methods (e.g., c–j). Simultaneously, in the complex backgrounds of examples (2) and (4), our model nearly completely suppresses false detections in non-building areas (e.g., open spaces, vegetation), generating the cleanest and most accurate change maps. This fully demonstrates DSDGMNet’s dual advantages in achieving high-integrity detection and high-precision localization.
In the visual comparison of the SYSU-CD dataset (Figure 12), DSDGMNet demonstrates outstanding performance in complex multi-class change detection tasks. For instance, in mixed change scenarios involving roads, vegetation, and buildings (Examples 1 and 2), methods like BIT and SNUNet exhibit significant false detections, whereas DSDGMNet accurately distinguishes genuine changes from background interference, generating the cleanest change maps. Regarding change region integrity (Examples 3 and 4), DSDGMNet effectively preserves change region continuity through Multiscale Feature Fusion, overcoming the false negative issues observed in FC-Siam-diff and USSFC-Net. Simultaneously, it achieves the highest precision in boundary localization, producing clear and natural contours. Overall, DSDGMNet demonstrates superior detection reliability and robustness in multi-category complex scenarios.
The visualization results on the CLCD dataset (Figure 13) fully demonstrate the exceptional robustness of our proposed DSDGMNet in challenging scenarios. As shown in examples (1) and (2), our method effectively suppresses false detections when confronted with complex farmland variations and substantial noise interference, significantly outperforming other comparative approaches. Similarly, in examples (3) and (4), our model achieves more complete identification of genuine change areas, effectively reducing missed detections. These results demonstrate its robust capability to accurately distinguish real changes from background noise in challenging scenarios.
3.7.2. Challenging and Failure Case Analysis
To further assess the robustness of the proposed method, several challenging and failure cases on the GBCNR dataset are presented in Figure 14. These examples illustrate the limitations of the compared methods under extreme tidal variations and boundary drift conditions.
In Cases (a) and (c), significant tidal inundation causes large spectral variations while the mangrove structure remains unchanged, leading to false positives in appearance-driven models. In Cases (b) and (d), boundary drift and narrow mangrove strips result in missed detections, highlighting the difficulty of capturing fine-scale changes under strong class imbalance. Although the proposed method suppresses a large portion of tidal-induced pseudo-changes, residual errors persist under extremely complex hydrological conditions, suggesting directions for future research.
3.8. Model Efficiency
To comprehensively evaluate the practicality of the proposed method, we conducted a comparative analysis of the number of parameters (Params) and computational complexity (FLOPs) of various models on the GBCNR dataset, with input image size standardized to 256 × 256 × 3 and batch size set to 1, as shown in Table 15. DSDGMNet has 38.09 M parameters and 12.84 G floating-point operations. Compared with current mainstream models, our method achieves a good balance between computational efficiency and detection accuracy. Specifically, compared with the similarly performing ChangeFormer (202.78 G FLOPs, 41.03 M Params), our method reduces computation by approximately 93.7% and parameters by 7.2%, while achieving better detection performance. Compared with DDLNet, although the number of parameters increases slightly, our FLOPs are only 1.75 times those of DDLNet, and the F1 score improves significantly (71.36% vs. 66.27%). Notably, compared with LGPNet, which has a similar number of parameters (70.99 M), our parameters are reduced by 46.4%, FLOPs decrease by 89.8%, yet the F1 score is higher by 2.23%. This indicates that DSDGMNet, through a carefully designed dual-stream difference modeling and semantic guidance mechanism, achieves optimal detection accuracy at a relatively economical computational cost. However, we also note that there is still room to optimize the model’s parameter count. Future work will focus on lightweight design to further reduce model complexity while maintaining detection accuracy, thereby better meeting practical deployment needs.
4. Conclusions
This paper proposes the DSDGMNet network for detecting mangrove forest changes in tidal disturbance scenarios, focusing on addressing two critical challenges in detecting mangrove distribution changes under varying tidal heights: First, tidal-induced water coverage variations cause significant visual differences between Bi-Temporal images, complicating the identification of genuine changes; second, mangrove distribution changes exhibit high inconsistency at both spatial scales and boundary levels, hindering precise localization. To address these challenges, the network employs a dual-stream difference-driven Bi-Temporal Feature Fusion mechanism to effectively model the differential relationships between Bi-Temporal features. This approach preserves the stable structure of mangroves while enhancing responsiveness to genuine distribution changes. Concurrently, a semantically guided multiscale feature fusion strategy is introduced, enabling adaptive alignment of features across different scales within change areas. This ensures both overall distribution identification and detailed boundary delineation.
Extensive experiments on the self-built GBCNR mangrove change detection dataset demonstrate that the proposed method effectively distinguishes tidal disturbances from mangrove distribution changes in complex intertidal environments, achieving 71.36% F1 and 84.57% recall. We acknowledge that the GBCNR dataset is relatively small due to the high cost of pixel-level annotation in complex mangrove ecosystems, which may limit the statistical power of the evaluation. Nevertheless, validation on public datasets such as WHU-CD (91.38% F1) and LEVIR-CD (90.68% F1) demonstrates the method’s generalization capabilities across diverse change detection scenarios. The model still has room for improvement in parameter scale and computational efficiency. Future research will focus on structural simplification and efficient inference to explore lightweight change detection solutions better suited for large-scale, long-term mangrove monitoring, as well as expanding the dataset to cover more diverse tidal conditions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Friess D.A. Mangrove Forests Curr. Biol.201626 R 746R 74810.1016/j.cub.2016.04.00427554647 · doi ↗ · pubmed ↗
- 2Wang L. Jia M. Yin D. Tian J. A Review of Remote Sensing for Mangrove Forests: 1956–2018 Remote Sens. Environ.201923111122310.1016/j.rse.2019.111223 · doi ↗
- 3Yan J. Cheng Y. Wang Q. Liu L. Zhang W. Jin B. Transformer and Graph Convolution-Based Unsupervised Detection of Machine Anomalous Sound Under Domain Shifts IEEE Trans. Emerg. Top. Comput. Intell.202482827284210.1109/TETCI.2024.3377728 · doi ↗
- 4Yan J. Cheng Y. Zhang F. Li M. Zhou N. Jin B. Wang H. Yang H. Zhang W. Research on Multimodal Techniques for Arc Detection in Railway Systems with Limited Data Struct. Health Monit.20251475921725133679710.1177/14759217251336797 · doi ↗
- 5Yan J. Cheng Y. Zhang F. Zhou N. Wang H. Jin B. Wang M. Zhang W. Multimodal Imitation Learning for Arc Detection in Complex Railway Environments IEEE Trans. Instrum. Meas.202574352941310.1109/TIM.2025.3556896 · doi ↗
- 6Pan Y. Xu X. Long J. Lin H. Change Detection of Wetland Restoration in China’s Sanjiang National Nature Reserve Using STA Net Method Based on GF-1 and GF-6 Images Ecol. Indic.202214510961210.1016/j.ecolind.2022.109612 · doi ↗
- 7Pan Y. Lin H. Zang Z. Long J. Zhang M. Xu X. Jiang W. A New Change Detection Method for Wetlands Based on Bi-Temporal Semantic Reasoning U Net++ in Dongting Lake, China Ecol. Indic.202315511099710.1016/j.ecolind.2023.110997 · doi ↗
- 8Qian S. Xue Z. Jia M. Chen Y. Su H. Temporal-Spectral-Semantic-Aware Convolutional Transformer Network for Multi-Class Tidal Wetland Change Detection in Greater Bay Area ISPRS J. Photogramm. Remote Sens.202421612614110.1016/j.isprsjprs.2024.07.024 · doi ↗