Targetless LiDAR–Camera Extrinsic Calibration via Class-Agnostic Boundary Mask Alignment and SPSA-Based Optimization
Han-You Jeong, Woo-Hyuk Son, Dong-Wook Shin, Kyuna Cho, Minwoo Chee, Tae (Tom) Oh

TL;DR
This paper introduces a new method for calibrating LiDAR and camera systems without using targets, by aligning boundary masks and optimizing parameters efficiently.
Contribution
The novel approach uses class-agnostic boundary mask alignment and SPSA-based optimization for robust targetless calibration.
Findings
The method achieves superior accuracy-runtime trade-off on the KITTI benchmark.
Real-world tests confirm stable cross-modal alignment despite vibration and timing jitter.
Abstract
Targetless LiDAR–camera extrinsic calibration remains challenging due to unreliable cross-modal correspondences and sensitivity to initialization. We present a targetless extrinsic calibration framework based on class-agnostic boundary mask alignment in a shared image-plane representation. This scheme first constructs consistent LiDAR–camera mask pairs from image-plane depth and intensity projections of LiDAR data and camera images. It then obtains robust initial pose candidates through bounded rotation-only global initialization and refines them using a computationally efficient stochastic gradient approximation to estimate the optimal extrinsic parameters. Experiments on the KITTI benchmark demonstrate a superior accuracy–runtime trade-off compared with a segmentation-based global optimization baseline, while real-world driving tests confirm stable cross-modal alignment under…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
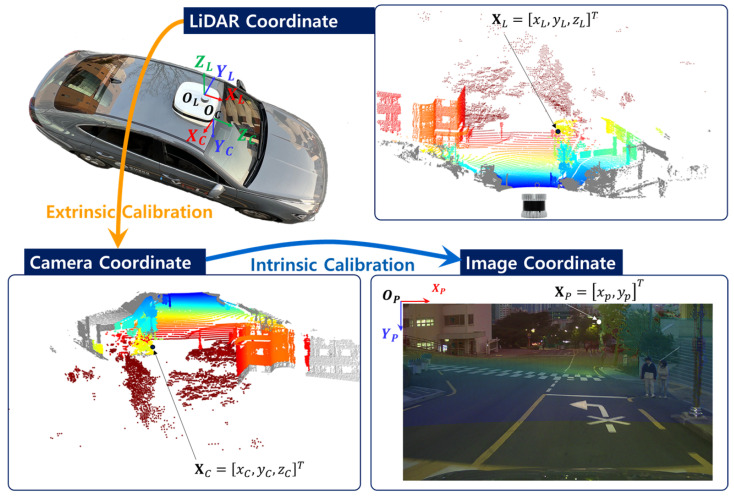 Figure 1
Figure 1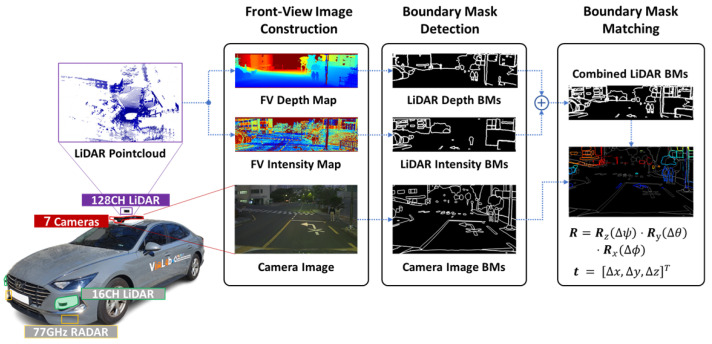 Figure 2
Figure 2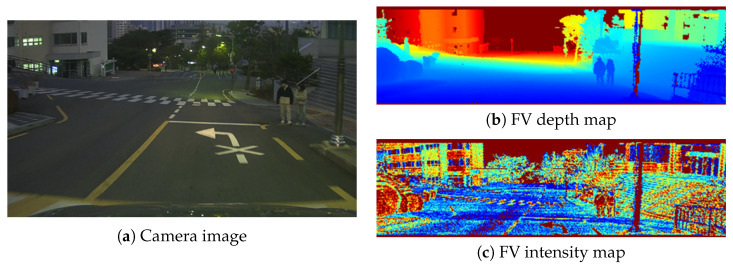 Figure 3
Figure 3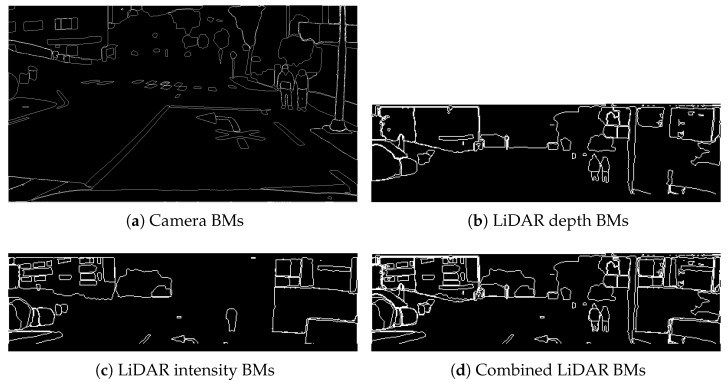 Figure 4
Figure 4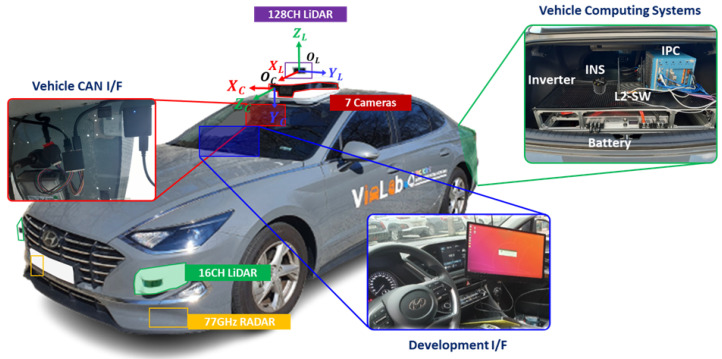 Figure 5
Figure 5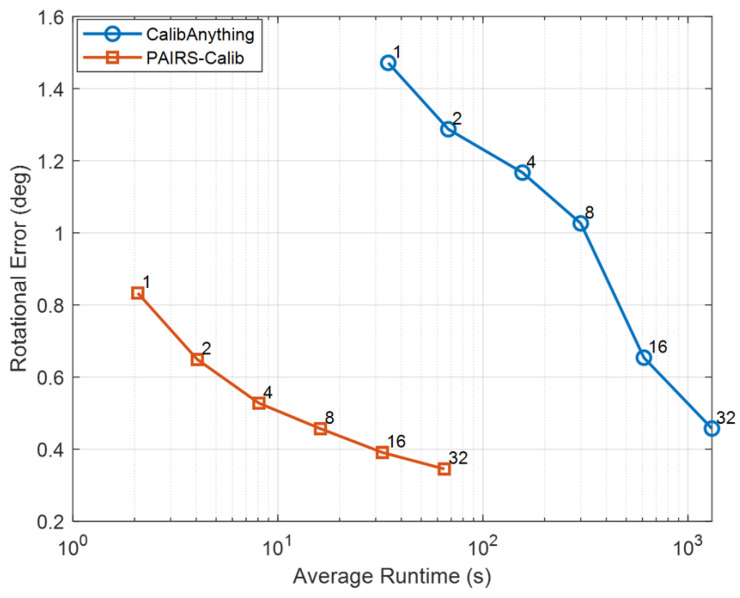 Figure 6
Figure 6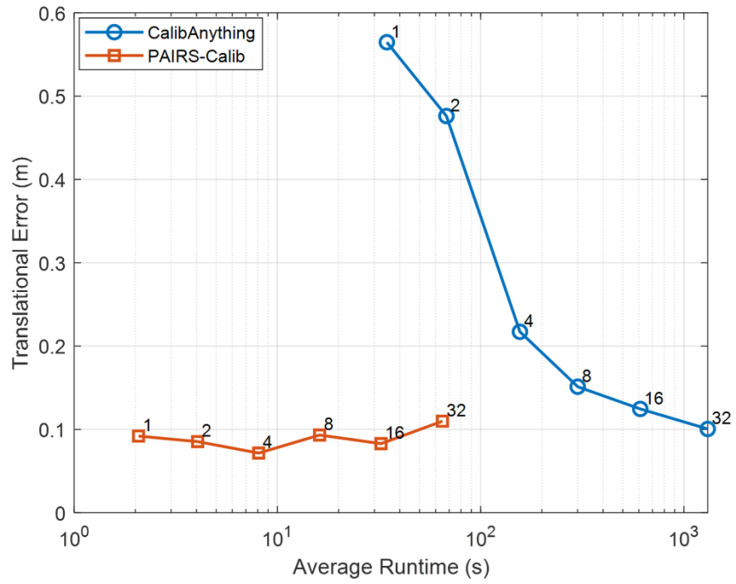 Figure 7
Figure 7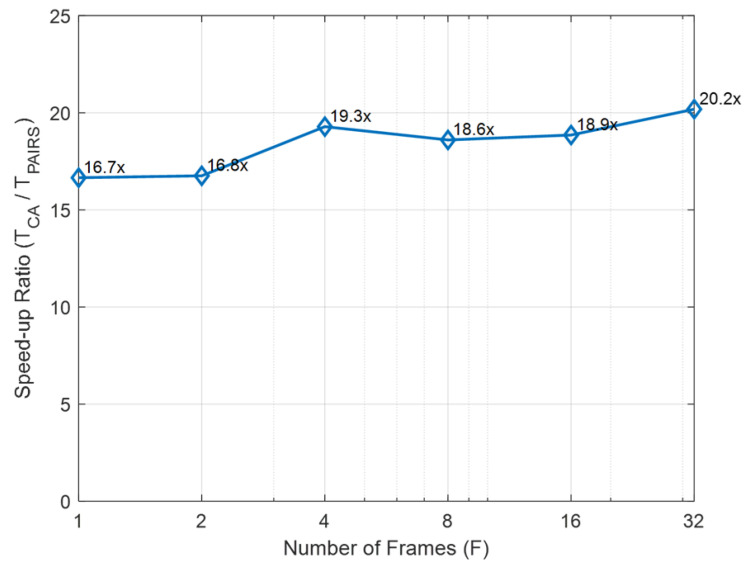 Figure 8
Figure 8 Figure 9
Figure 9- —Pusan National University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Optical measurement and interference techniques · Advanced Vision and Imaging
1. Introduction
The advancement of autonomous driving technologies critically depends on multi-sensor perception systems, among which the fusion of LiDAR and cameras has become a cornerstone for achieving high-precision object recognition and spatial understanding. A prerequisite for effective fusion is the accurate alignment of their coordinate systems, commonly referred to as extrinsic calibration. Calibration errors can directly propagate into perception pipelines, leading to mislocalized objects and inaccurate distance estimation and ultimately degrading perception accuracy and driving safety [1,2].
Conventional LiDAR–camera calibration approaches predominantly rely on physical targets such as checkerboards or custom calibration boards, where corresponding points are extracted and projection errors are minimized [3,4,5]. These approaches can achieve high accuracy in controlled laboratory conditions but require precise installation and constrained capture setups, which make them impractical for large-scale or outdoor driving environments. To overcome these limitations, targetless calibration approaches have been actively explored. These approaches leverage sensor data directly, aligning structural features such as edges, contours, or projection regions across modalities, and in some cases integrating them into deep-learning pipelines [6,7]. Although more flexible, targetless approaches often depend on specific environmental structures or task-driven learning, and their performance is typically sensitive to initialization. In practice, this sensitivity is further amplified by imperfect cross-modal associations and real-world disturbances (e.g., sensor vibration and inter-modal timing jitter). Moreover, exhaustive exploration of the six degree of freedom (DoF) space can be computationally demanding. This motivates a targetless calibration framework that builds reliable cross-modal associations and refines extrinsics efficiently from a coarse but informative initialization, enabling accurate and practical deployment across diverse driving scenarios.
Building on these observations, we propose PAIRS-Calib (Pairwise Assignment and Iterative Refinement via SPSA), a targetless LiDAR–camera extrinsic calibration framework that estimates 6-DoF extrinsics from class-agnostic boundary mask (BM) alignment in a common image-plane representation. Using class-agnostic segmentation, BMs are extracted from both the projected LiDAR maps and the RGB image. PAIRS-Calib leverages image-plane depth and intensity projections of LiDAR data to enable direct cross-modal comparison via overlap- and boundary-level consistency, without requiring explicit 2D–3D point correspondences. Our approach first forms consistent projected LiDAR–camera mask pairs by jointly considering image-plane overlap/coverage and a lightweight shape-consistency cue. It then computes coarse pose initialization candidates cost-efficiently through bounded rotation-only global exploration, and refines them using a computationally efficient Simultaneous Perturbation Stochastic Approximation (SPSA). Both coarse initialization and refinement exploit effective geometric objectives based on boundary-to-boundary distances (via a distance transform) and intersection-over-union (IoU) consistency between projected and image-derived masks. Unlike motion-cue-based schemes that rely on sensor odometry for miscalibration detection and correction [8], PAIRS-Calib performs calibration from boundary alignments, enabling adaptive recalibration without motion estimation.
The main contributions of this paper are three-fold: (1) PAIRS-Calib, a targetless image-plane calibration framework with overlap- and shape-aware mask pairing; (2) a cost-efficient coarse initialization and SPSA-based refinement pipeline using boundary-distance and IoU objectives for 6-DoF recovery; and (3) extensive validation on a public benchmark and a real driving platform, demonstrating a favorable accuracy–runtime trade-off and stable performance under practical disturbances.
The remainder of this paper is organized as follows: Section 2 reviews related work and positions PAIRS-Calib within targetless LiDAR–camera calibration. Section 3 defines the problem formulation, and then Section 4 presents the proposed PAIRS-Calib framework. Section 5 evaluates its accuracy, efficiency, and practical applicability, and finally, Section 6 concludes this paper.
2. Related Work
Targetless LiDAR–camera calibration has been explored under diverse representations and inference strategies [1,2]. To clarify the design space concisely, Table 1 summarizes representative approaches along four axes: LiDAR representation, camera representation, matching space (3D–2D vs. 2D–2D), and inference paradigm. This section follows the same taxonomy to systematically compare representation and inference strategies and to position class-agnostic approaches within this design space.
Beyond the division between target-based and targetless strategies, LiDAR–camera calibration approaches can be classified by LiDAR data representation. Early studies relied on raw point clouds aligned with 2D image features [3,4,11], but establishing reliable 2D–3D correspondences has remained challenging [1,2]. To address this gap, Bird’s-Eye View (BEV) projections have been widely adopted, offering global geometric layouts and improved robustness in large-scale scenes [9,12], though often at the expense of fine detail due to sparse sampling. As an alternative, Front-View (FV) projections preserve the native perspective of sensors, enable direct point-to-pixel correspondence, and facilitate boundary-level alignment [13,14,15]. Although FV alignment reduces calibration to a 2D–2D problem with limited depth cues, it provides a natural basis for extracting geometry-consistent features. In this work, we adopt FV as a practical image-plane projection domain and focus on boundary-level alignment that is applicable to general image-plane representations.
From the perspective of camera representation, targetless approaches differ in what image-domain cues are extracted for cross-modal consistency. Classical pipelines often rely on handcrafted edges or gradients [11,16], while instance/semantic segmentation introduces mask-level structures but may be constrained by category priors and domain specificity [17]. Recent progress in class-agnostic segmentation enables extracting object boundaries without semantic labels [18], offering a more general way to obtain mask/boundary cues that can be compared against projected LiDAR structures. This trend is reflected in Table 1, where camera-side cues range from edge detection [6] to class-agnostic masks [10] and learned convolutional neural network (CNN) features [7].
With a chosen representation, targetless calibration can be organized by matching space: 3D–2D alignment that couples 3D LiDAR structures with 2D image cues, and 2D–2D alignment that compares projected LiDAR representations with image-domain features on a common plane [2]. 3D–2D formulations can leverage explicit geometry but often require careful correspondence design and can be sensitive to sparsity and occlusion [3,11]. In contrast, 2D–2D formulations reduce correspondence burden by operating in a common projection space, but their success hinges on the stability of the projection and the reliability of extracted cues. Table 1 illustrates this split: MFCalib and CalibAnything operate in 3D–2D matching [6,10], whereas BEVCalib and CalibRefine adopt 2D–2D matching in BEV or FV space [7,9].
Given the representation and matching space, approaches differ most clearly in their inference paradigm. Geometric optimization aligns explicit edge/mask structures through handcrafted objectives (e.g., MFCalib) [6]. Global optimization seeks extrinsics that maximize projection consistency, often at higher computational cost (e.g., CalibAnything) [10]. Learning-based pipelines align latent representations and perform refinement through trained networks (e.g., BEVCalib and CalibRefine) [7,9]. Overall, these paradigms highlight a recurring tension between robustness to imperfect observations and practical computational cost, which is a central concern in real-world targetless calibration [1,2].
In this context, CalibAnything demonstrates the attractiveness of class-agnostic cues for targetless calibration by leveraging Segment Anything Model (SAM)-derived masks [10,18]. By casting calibration as a projection-consistency optimization over segmentation masks, it removes reliance on predefined object categories and handcrafted correspondences, thereby broadening applicability across diverse environments. However, its global optimization formulation introduces two practical challenges. First, segmentation uncertainty may yield unreliable or partially inconsistent mask instances under occlusion or sparse observations, affecting the stability of a single global objective. Second, the computational burden of global search can increase when robustness over wide pose perturbations is required. These observations suggest that while class-agnostic masks provide a powerful representation, their effectiveness depends critically on how uncertainty and optimization are structured.
Motivated by these observations, PAIRS-Calib is positioned as a class-agnostic, image-plane BM calibration framework that retains the generality of class-agnostic cues while explicitly addressing segmentation uncertainty and optimization sensitivity. Rather than relying on a single global optimization trajectory, PAIRS-Calib organizes estimation around multiple pairwise pose hypotheses derived from projected LiDAR–camera mask pairs. Concretely, it first constructs consistent matching pairs in the image plane, then computes cost-efficient coarse initialization candidates through bounded rotation-only exploration and finally performs iterative refinement using SPSA [19]. By separating pair construction, coarse exploration, and lightweight stochastic refinement, this framework reduces dependence on any single mask instance and mitigates the risk of local-minimum entrapment. By narrowing the search space through bounded coarse initialization and refining candidates via SPSA, the proposed framework achieves a practical accuracy–runtime balance under real-world disturbances, offering improved robustness without relying on large-scale global exploration.
3. Formulation of the LiDAR–Camera Extrinsic Calibration Problem
LiDAR–camera calibration broadly refers to estimating the geometric relationship between LiDAR and camera sensors so that their measurements can be expressed in a common coordinate framework [1,2]. In the case of extrinsic calibration, this typically involves recovering the 6-DoF rigid transformation between the LiDAR and camera coordinate systems. We focus on a targetless extrinsic calibration scenario that operates directly on sensor data collected during driving, without the need for artificial calibration targets or controlled setup procedures. In this work, this targetless formulation is addressed by estimating the extrinsic parameters through structural consistency between projected LiDAR measurements and image-domain features in a shared image-plane representation. As shown in Figure 1, three coordinate systems are considered: the LiDAR coordinate system with origin and points expressed in axes , the camera coordinate system with origin and points expressed in axes , and the image coordinate system with origin and points defined in axes . The transformation from the LiDAR frame to the camera frame is determined by the extrinsic parameters, while the projection onto the image plane is governed by the intrinsic parameters of the camera.
The extrinsic parameters, denoted by the vector , describe the relative pose between the LiDAR and the camera coordinate systems:
where the first three elements represent roll, pitch, and yaw rotations, respectively, and the last three denote the translation vector , with its components corresponding to the x, y, and z axes, respectively. The rotation matrix is constructed as a composition of elemental rotations in the Z–Y–X order:
The rigid-body transformation from LiDAR to camera coordinates is written in homogeneous form as
Given a LiDAR point , its homogeneous representation is mapped to the corresponding point in the camera frame:
The projection of onto the image coordinates is then obtained using the intrinsic matrix :
Finally, the calibration task can be formulated as the following optimization problem:
where denotes a geometric misalignment loss that measures the discrepancy between projected LiDAR structures and image-derived structural cues in the image plane.
In summary, the problem of LiDAR–camera extrinsic calibration is to estimate such that the projected LiDAR points achieve maximum consistency with image features. The specific choice of distance metric and the optimization strategy are detailed in the next section presenting the PAIRS-Calib framework.
4. The Proposed PAIRS-Calib Framework
This section presents a detailed description of the proposed PAIRS-Calib framework. This framework is designed to address targetless LiDAR–camera calibration under real-world conditions, where irregular sampling density, viewpoint differences, and segmentation noise make direct 2D–3D correspondence unreliable. The overall system configuration is illustrated in Figure 2.
To ensure clarity and modularity, this framework is structured hierarchically into input construction, procedural overview, and stage-wise optimization components. Section 4.1 describes input data generation via image-plane projection and BM construction; Section 4.2 provides an overview of the overall PAIRS-Calib procedure; and Section 4.3, Section 4.4 and Section 4.5 detail each stage of PAIRS-Calib procedure. The central idea of PAIRS-Calib is to derive boundary representations consistently from both LiDAR and camera modalities and to use these representations as reliable structural features for estimating the extrinsic parameters.
4.1. Image-Plane Representation and Boundary Mask Extraction
This subsection describes the input construction pipeline used by the subsequent PAIRS-Calib procedure. As illustrated in Figure 3, LiDAR pointclouds are projected into the camera viewing domain to form FV representations that share the same image-plane coordinates as the RGB image. The camera resolution defines the pixel grid, while the LiDAR configuration determines the effective sampling density within this grid. By restricting the LiDAR’s full field of view to the camera’s effective viewing angle, both modalities are aligned within a common spatial domain, enabling direct comparison in the image plane. The resulting FV depth map encodes range information per pixel, and the FV intensity map encodes reflectance per pixel, as shown in Figure 3b and Figure 3c, respectively.
To improve the stability of intensity-based boundary extraction, LiDAR intensity is normalized to reduce depth-dependent attenuation. Specifically, depth values are discretized into bins with interval , and each measurement is normalized using the average intensity of its depth bin. This produces a depth-invariant intensity representation that remains comparable across different ranges, which is beneficial for boundary detection.
Building upon these image-plane depth and intensity representations, BM detection are extracted as compact structural inputs for PAIRS-Calib. For each input image (camera RGB, FV depth, and FV intensity), S seed points are sampled uniformly over the image grid and fed into a class-agnostic segmentation model to generate local region masks. These masks are produced as SAM-style class-agnostic segmentation outputs. From the resulting segmentation masks, boundary pixels are mapped to 1 while both interior and exterior regions are set to 0, yielding a binary BM as illustrated in Figure 4. The resulting camera BM and the LiDAR depth/intensity BMs are finally used as the modality-aligned structural inputs to PAIRS-Calib, as introduced in Section 4.2 and used throughout Section 4.3, Section 4.4 and Section 4.5.
4.2. Overview of the PAIRS-Calib Procedure
The proposed PAIRS-Calib framework integrates the three processing stages—mask matching, global initialization, and SPSA refinement—into a unified calibration pipeline. Given a set of F frames, the optimal extrinsic parameters in (6) are estimated by jointly evaluating candidate poses constructed from BM correspondences across all frames. The candidates are assessed according to the consistency between LiDAR- and camera-derived BMs, and SPSA refinement is applied to obtain a stable estimate.
To formalize the overall procedure, Algorithm 1 presents a high-level overview of PAIRS-Calib, which integrates mask-level association, global initialization, and SPSA-based refinement into a unified calibration pipeline. The inputs consist of LiDAR pointclouds and camera images over F frames, together with camera intrinsics , an initial extrinsic estimate , and a bounded 6-DoF search domain centered around this initial pose. In addition, the algorithm takes hyperparameters controlling global sampling and refinement, including the number of global samples , the number of retained candidates , and the maximum number of SPSA iterations . For clarity, we denote by the rotational subspace of used for rotation-only sampling in global initialization, while the translation components are fixed to those of . The overall procedure is organized into three conceptual stages. Algorithm 1 PAIRS-Calib: mask matching, global initialization, and SPSA refinement
-
Input: LiDAR pointclouds , Camera images , Intrinsic matrix , Initial pose , Search bounds , Number of global samples , Number of top candidates , Maximum SPSA iterations
-
Output: Sequence-level extrinsic estimate
-
▹ Stage 1: Mask Matching (ROI clipping and shape-aware pairing)
-
1:for do
-
2: Project LiDAR points to image plane under
-
3: Extract projected LiDAR masks and image masks from
-
4: for each do
-
5: Compute pairwise score matrix ▹ As defined in (12)
-
6: end for
-
7: HungarianAssignment
-
8:end for ▹ Stage 2: Global Initialization (rotation-only sampling)
-
9:Generate rotational samples
-
10:for do
-
11: Form 6-DoF pose by combining sampled rotation with translation of
-
12: ▹ As defined in (18)
-
13:end for
-
14:Select top candidates with the smallest ▹ *Stage 3: SPSA Refinement and Joint Integration over *
-
15:Construct the joint index set
-
16:for each do
-
17: Initialize
-
18: Refine by SPSA for steps within :
-
19: Draw ; Evaluate ;
-
20: Estimate from the two losses; Update
-
21: Store and
-
22:end for ▹ Joint gating and aggregation
-
23:
-
24: ▹ As defined in (24)
-
25: ▹ As defined in (25)
-
26:return
The first stage performs mask matching at the frame level. For each frame f, LiDAR points are projected onto the image plane under the initial pose . Since the LiDAR horizontal FoV is defined with sufficient margin, only the projected points that fall within the image frame are retained for subsequent processing, while the image domain itself remains fixed. Two-dimensional masks are then extractedfrom the camera image, and candidate 2D–2D matching scores are computed between projected LiDAR masks and camera masks based on overlap (IoU), coverage, and shape consistency. The optimal one-to-one correspondences are then obtained by maximizing the total matching score via Hungarian assignment, yielding a frame-wise mapping set . These correspondences form the observation model used in the global initialization and refinement stages.
The second stage carries out global initialization. Instead of directly optimizing all six DoF, PAIRS-Calib first samples candidate poses from the rotational subspace , while keeping the translational components fixed to those of the initial pose . Each sampled pose is evaluated using a pose-dependent misalignment loss in (18), which aggregates the frame-wise boundary alignment cost across all frames based on the matched pairs . The candidates with the smallest loss values are retained as promising initializations for subsequent SPSA refinement.
The third stage performs SPSA-based refinement on the retained candidates [19]. For each candidate index m, the SPSA updates are applied to the 6-DoF parameter vector within the bounded domain for iterations. At iteration k, a Rademacher perturbation vector is sampled to form two perturbed poses, which are evaluated using the same pose-dependent misalignment loss in (18). A stochastic gradient estimate is computed from the difference of the two loss values, and the parameters are updated with step size while enforcing the bounds via . Here, and the SPSA perturbation gain are refinement hyperparameters. A small positive constant is introduced as a loss floor to ensure numerical stability in the confidence weighting and normalization steps, and denotes the cardinality (i.e., the number of 3D LiDAR points) of the matched subset associated with mask at frame f, which serves as a pair-wise confidence factor in the aggregation weight definition. All these settings, including the loss-based gating threshold , will be clarified in Section 4.5. Repeating this procedure over the joint index yields refined solutions and their losses . The final extrinsic estimate is then obtained by pooling all refined solutions, applying a loss-based gating threshold, and computing a confidence-weighted average of the retained poses.
Together, these three stages define the core design of PAIRS-Calib: frame-wise mask association establishes reliable cross-modal correspondences; global rotational sampling improves robustness against poor local minima through exploration of the bounded search space; and SPSA refinement enables efficient gradient-free optimization of the extrinsic parameters. The following subsections detail the matching metrics, loss formulation, and optimization strategy.
4.3. Mask Matching via IoU–Coverage–Shape Screening
This subsection constructs reliable 2D–2D mask correspondences that remain fixed throughout the global initialization and SPSA refinement stages. The goal is to obtain a strict one-to-one mapping set for each frame f, where each pair links a LiDAR mask label to a camera mask label . Since is used in the computation of in Algorithm 1, this stage suppresses ambiguous or spurious associations that could otherwise destabilize the downstream optimization, by enforcing geometric consistency at the bounding-box level and structural consistency at the pixel level.
Given a camera segmentation map , a binary mask is formed for each . On the LiDAR side, we reuse the 3D points associated with the LiDAR masks constructed in Section 4.1. Specifically, for each , the corresponding point subset is denoted by . Using the initial pose , is projected into the image plane to form a binary projection mask . For geometric consistency evaluation, bounding boxes and are computed from and , respectively, and their areas are used in the subsequent overlap and coverage definitions.
Candidate associations are evaluated by measuring overlap consistency at the bounding-box level. Let and denote the intersection and union of the two masks, respectively. The intersection-over-union is defined as
In addition, two directional coverage measures are computed based on the bounding-box areas as
and combined into a symmetric fused coverage term
To improve the stability of the fixed correspondence set under noisy or fragmented class-agnostic masks, a shape-consistency term is introduced. Unlike the overlap and coverage terms, which are computed at the bounding-box level, the shape-consistency term operates directly on pixel and projected point coordinates to preserve fine-grained structural alignment. Principal component analysis is applied to the pixel coordinates of and to the image-plane coordinates of the projected 3D points . Let and denote the eigenvalues of the respective covariance matrices. The corresponding aspect ratios are defined as
The shape-consistency score is then computed as
which approaches 1 when the projected 3D structure and the 2D mask exhibit similar elongation and decreases as their aspect ratios diverge.
The final candidate score used for association is defined as
subject to hard gates on , , and . The score is used for ranking and assignment, while the hard gates remove pairs that lack sufficient geometric overlap support.
Finally, strict one-to-one matching is enforced by formulating the candidate association problem as a bipartite assignment and solving it using the Hungarian algorithm [20]. All candidate pairs that satisfy the gating conditions are collected, and a cost matrix is constructed from the negative matching scores , such that maximizing the total matching score is equivalent to minimizing the assignment cost. The Hungarian algorithm yields a globally optimal one-to-one correspondence, producing the mapping set
which is free from one-to-many or many-to-one ambiguities by construction. Each matching stores the corresponding projected LiDAR mask and the 2D image mask , along with their overlap statistics. These fixed correspondences provide the observation model consumed by in Algorithm 1.
4.4. Global Initialization and Pose-Dependent Misalignment Loss
This subsection describes the global initialization stage in Algorithm 1 (Stage 2), which identifies promising extrinsic candidates prior to SPSA refinement. Rather than directly optimizing all six DoF, PAIRS-Calib samples candidate poses within the bounded search space . More specifically, sampling focuses on the rotational components , while the translational components are fixed to those of the initial pose , yielding the DoF candidates .
Following Algorithm 1, each candidate is evaluated by a misalignment loss and the top- candidates are selected via and forwarded to the SPSA stage (Stage 3). Importantly, is a pose-dependent geometric misalignment loss that is distinct from the association score used to construct in Section 4.3.
To compute , PAIRS-Calib reuses the fixed correspondences and evaluates a per-pair loss for each matched pair under a candidate pose . For a given frame f and pair index j, projection consistency is evaluated using a distance transform map computed from the camera-derived BM: letting denote the pixel-wise distance between the projected location of the i-th valid 3D point and the nearest boundary pixel of the corresponding 2D mask, the point-wise proximity loss is computed as
where is the number of valid projected points for the pair, and controls the spatial sensitivity.
Complementing the distance term, a bounding-box alignment loss is computed between the stored 2D mask box and the projected point box :
To handle invalid or out-of-image projections, we define the out-of-image ratio for the pair as
where counts points violating the depth gate ( ) and counts points projected outside the image bounds.
The final per-pair loss is then defined by linearly combining these three losses
Since is defined at the matching-pair level, the pose-dependent misalignment loss is obtained by aggregating scores over all matched pairs and frames. Let denote the number of matched pairs at frame f. The pose-dependent misalignment loss used in Stage 2 and Stage 3 is defined as
Consequently, lower values of indicate better geometric alignment and are favored in both the global candidate selection and the subsequent SPSA refinement.
4.5. SPSA-Based Refinement of Top-K Candidates
The third stage performs SPSA-based refinement on the candidate poses retained from the global initialization stage. While Stage 2 provides coarse exploration of the bounded search space, this stage focuses on local optimization of the full 6-DoF parameter vector with respect to the misalignment loss in (18).
Importantly, Stage 3 can be executed independently over the joint index , where denotes the candidate index, the frame index, and the matched pair index. SPSA refinement yields optimized 6-DoF solutions together with their corresponding loss values . The final extrinsic estimate is obtained by pooling all refined solutions across and applying a single loss-based gating and confidence-weighted aggregation scheme.
For completeness, the SPSA update rule is summarized below: the parameter vector is iteratively updated for steps, and at iteration k a Rademacher perturbation vector is sampled to construct two perturbed candidates.
where denotes the current iterate associated with the joint index , controls the perturbation magnitude, and enforces the bounded search domain. The stochastic gradient estimate for the -th refinement mask is obtained directly from the pose-dependent misalignment loss as
and the parameter vector is updated according to
where denotes the step size. After iterations, SPSA refinement under the m-th initialization yields pair-wise optimized poses and their corresponding loss values
To obtain the final extrinsic estimate, we collect all refined solutions across candidates and pairs, apply a single loss-based gating rule,
and assign confidence weights to the retained 3-tuples as
where loss floor prevents numerical instability. The final 6-DoF extrinsic estimate is then obtained by a single confidence-weighted aggregation over ,
By pooling refined solutions across the joint index , this formulation retains the robustness benefits of multiple initializations while avoiding redundant two-stage aggregation, thereby yielding a concise and consistent integration rule.
5. Experimental Results
This section presents the experimental assessment of the proposed PAIRS-Calib framework. Section 5.1 describes the experimental setup and evaluation protocols for both the KITTI dataset [21] and our in-house vehicle platform. Section 5.2 reports KITTI benchmark results, directly comparing rotational and translational errors, as well as runtime, against CalibAnything [10]. Finally, Section 5.3 presents real driving results on the in-house platform to demonstrate robustness to synchronization disturbances and pose variations.
5.1. Experimental Setup
This section evaluates the proposed PAIRS-Calib on both a public benchmark dataset and a real-world vehicle platform to ensure reproducibility and practical validation. For benchmark evaluation, we use the KITTI dataset [21], which provides synchronized LiDAR–camera pairs with ground-truth poses. The KITTI setup includes a 64-channel Velodyne LiDAR (Velodyne Lidar Inc., San Jose, CA, USA) and a forward-facing monocular camera, enabling direct computation of rotational and translational errors with respect to the ground-truth extrinsic parameters. Section 5.2 reports the KITTI benchmark comparison against CalibAnything [10] using rotational error, translational error, and runtime.
Figure 5 shows the experimental vehicle platform, based on a Hyundai SONATA Dn8, which integrates multiple subsystems to support autonomous driving research. A roof-mounted Ouster OS-1-128 LiDAR (Ouster Inc., San Francisco, CA, USA) serves as the primary ranging sensor. Directly beneath the LiDAR, six short-range rolling-shutter Leopard LI-USB30-M021XB cameras (Leopard Imaging Inc., Fremont, CA, USA) are installed at 60° intervals to provide panoramic coverage, and a single long-range camera is co-located for forward perception. In this study, extrinsic calibration was performed between the 128-channel LiDAR and the forward-facing short-range camera, as indicated in Figure 5. A 16-channel LiDAR and a 77 GHz radar are also integrated on the platform but are not used in this work. The sensors were synchronized using recorded timestamps; in our system, the forward-facing camera is triggered via a ROS topic when the LiDAR scan reaches the camera-facing direction. As a result, residual triggering latency and timestamp uncertainty may occur, leading to slight temporal misalignment between the LiDAR and camera measurements.
The experimental parameters are summarized in Table 2. These include general settings such as the number of frames, segmentation seeds, and the rotational/translational search ranges used for global initialization and SPSA-based refinement. Sensor-specific parameters for both KITTI and the in-house platform are also provided (e.g., camera resolution/FoV and LiDAR channel count/frame rate), together with mask-matching gates and score weights, pose-dependent misalignment loss parameters (spatial sensitivity, loss weights, and depth gate), and optimization hyperparameters to ensure reproducibility across both datasets.
Outdoor experiments were conducted on the Pusan National University campus along a 50 s driving route, which included lane markings, sidewalks, vegetation, and pedestrian crossings. Because the objective is to examine robustness under practical driving conditions, the calibration is performed in a frame-wise manner by setting the number of frames to in PAIRS-Calib. This configuration avoids implicit temporal smoothing and allows each frame to be evaluated independently. Due to inter-sensor time offsets and rolling-shutter effects, small pose disturbances may arise between LiDAR and camera measurements during motion. Since such dynamic disturbances prevent the definition of reliable per-frame ground truth, the outdoor evaluation is designed to assess qualitative alignment behavior rather than absolute error metrics.
5.2. Quantitative Evaluation on the KITTI Dataset
This section quantitatively evaluates the proposed PAIRS-Calib framework on the KITTI dataset [21], assessing estimation accuracy and computational efficiency using rotational error (deg), translational error (m), and average runtime (s). To examine how performance varies with the amount of geometric information, the number of frames was varied over . For each setting, 100 initial extrinsic poses were sampled from a uniform distribution within the bounded search space defined in Table 2, centered at the KITTI ground-truth extrinsic parameters. Each algorithm was then executed independently from these randomized initializations, and the reported results correspond to averages over the 100 trials, thereby reducing bias from favorable starting conditions.
Figure 6 shows the Pareto relationship between runtime and rotational error, highlighting the fundamental scaling difference between PAIRS-Calib and CalibAnything. As the number of frames increases, CalibAnything gradually reduces rotational error from 1.287 at to 0.457 at ; however, this improvement is accompanied by a substantial increase in runtime from 34.54 s to 1308.94 s. In contrast, PAIRS-Calib consistently achieves lower rotational error across all frame counts while maintaining substantially reduced runtime. For instance, at , PAIRS-Calib attains 0.345 within only 64.86 s, and even at it already yields significantly smaller rotational error (0.833 vs. 1.287 ) with more than an order-of-magnitude reduction in runtime. Considering that rotational error is the dominant factor influencing projection consistency and overall extrinsic calibration quality, this consistent advantage directly translates into more stable cross-modal alignment. These results therefore demonstrate that PAIRS-Calib forms a consistently superior Pareto frontier in the rotation–runtime space, simultaneously improving geometric accuracy and computational efficiency.
A similar trend is observed in Figure 7, which illustrates translational error versus runtime. While CalibAnything achieves slightly lower translational error at the largest frame count ( ), reaching 0.101 m compared to 0.110 m for PAIRS-Calib, the proposed scheme outperforms CalibAnything across most practical operating regimes with small-to-moderate frame counts. In particular, for , PAIRS-Calib consistently attains lower translational error while maintaining significantly lower runtime. Notably, even in the single-frame configuration ( ), PAIRS-Calib achieves 0.092 m translational error with 2.07 s runtime, whereas CalibAnything reports 0.565 m with 34.54 s. These results indicate that the proposed global initialization and SPSA refinement scheme effectively recovers extrinsic parameters without relying on extensive temporal aggregation, while preserving competitive accuracy at larger frame counts.
The computational advantage is further quantified in Figure 8, which reports the runtime speed-up ratio across frame counts. The speed-up remains consistently between approximately 16 and 20 times, indicating stable efficiency gains as F increases. This improvement results from the balanced combination of three efficiency-oriented components in Section 4.3, Section 4.4 and Section 4.5. First, the mask matching in Section 4.3 suppresses unreliable class-agnostic segmentation outputs through IoU–coverage–shape screening and one-to-one assignment, ensuring that subsequent optimization focuses on a compact set of reliable correspondences. Second, the global initialization strategy in Section 4.4 efficiently identifies promising starting poses via bounded rotation-only sampling, which reduces unnecessary exploration of the full 6-DoF space while remaining highly sensitive to boundary misalignment. Third, the SPSA refinement in Section 4.5 further lowers computational burden while preserving convergence properties reported in prior work [19], since it avoids full-gradient computation and instead updates parameters using a stochastic estimate constructed from only two loss evaluations per iteration. Importantly, these runtime savings are not achieved by sacrificing accuracy; rather, PAIRS-Calib maintains competitive (often better) calibration performance while forming a consistently superior accuracy–efficiency trade-off across operating points.
Overall, the KITTI benchmark demonstrates that PAIRS-Calib delivers a substantially improved accuracy–efficiency trade-off, supporting both frame-wise calibration and scalable multi-frame refinement with significantly reduced computational burden.
5.3. Qualitative Results on the In-House Driving Platform (F = 1)
This section presents qualitative results of PAIRS-Calib obtained from real driving experiments on the in-house vehicle platform under the frame-wise setting ( ). During on-road driving, inter-sensor time offsets and rolling-shutter effects can induce small but non-negligible pose disturbances between the LiDAR scan and the camera image, which may appear as frame-to-frame fluctuations in the effective extrinsic parameters. Because such dynamic disturbances prevent the definition of a reliable per-frame ground truth extrinsic, the performance is assessed visually by examining cross-modal boundary alignment in representative scenes, rather than by absolute error metrics or target-based references.
To qualitatively assess calibration performance, Figure 9 shows representative samples where the projected LiDAR structures are overlaid on the camera image after frame-wise extrinsic recovery. Each sample is organized into two panels: Figure 9a,c,e show depth overlays on the camera images to visualize range-consistent projection behavior, whereas Figure 9b,d,f show projected LiDAR boundary overlays to highlight boundary-level alignment with salient scene structures (e.g., lane markings, sidewalks, vegetation, and pedestrians). Across the three examples, the overlays remain geometrically consistent despite potential synchronization-induced pose variations, indicating that PAIRS-Calib can restore stable extrinsic alignment under practical driving disturbances.
6. Conclusions
This paper presented PAIRS-Calib, a targetless LiDAR–camera extrinsic calibration framework that estimates 6-DoF extrinsics using class-agnostic boundary masks in a common image-plane representation. PAIRS-Calib constructs reliable cross-modal mask pairs using overlap/coverage and lightweight shape-consistency cues, computes cost-efficient coarse initialization candidates through bounded rotation-only exploration, and refines candidates via SPSA using a pose-dependent geometric misalignment loss defined on image-plane boundary and region consistency. By integrating multiple pairwise pose hypotheses rather than relying on a single optimization trajectory, the proposed pipeline improves robustness to practical disturbances such as segmentation noise, vehicle vibration, and inter-modal timing jitter, while maintaining a favorable accuracy–runtime balance on both a public benchmark and a real driving platform. Future work will focus on improving real-time capability by accelerating class-agnostic mask extraction and pair construction, reducing candidate evaluations through adaptive sampling and warm-start strategies, and exploiting temporal continuity for incremental updates. For practical applicability, further validation under challenging conditions, such as severe occlusions, adverse weather, and highly dynamic scenes, will be pursued to strengthen robustness.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Loquercio A. Niklaus S. Liao Y. Koltun V. Deep Learning for Camera Calibration and Beyond: A Surveyar Xiv 20232306.04671
- 2Zhai C. Liu B. Huang Y. Automatic Targetless Li DAR–Camera Calibration: A Survey Artif. Intell. Rev.20225526952731
- 3Levinson J. Thrun S. Automatic Online Calibration of Cameras and Lasers Proceedings of the Robotics: Science and Systems (RSS)Berlin, Germany 24–28 June 201318
- 4Geiger A. Moosmann F. CarÖ. Schuster B. Automatic camera and range sensor calibration using a single shot Proceedings of the IEEE International Conference on Robotics and Automation (ICRA)IEEE Piscataway, NJ, USA 20123936394310.1109/ICRA.2012.6224570 · doi ↗
- 5Tsai D. Worrall S. Shan M. Lohr A. Nebot E. Optimising the Selection of Samples for Robust Li DAR Camera Calibration Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021 IEEE Piscataway, NJ, USA 20212631263810.1109/ITSC 48978.2021.9564700 · doi ↗
- 6Ye T. Xu W. Zheng C. Cui Y. MF Calib: Single-shot and Automatic Extrinsic Calibration for Li DAR and Camera in Targetless Environments Based on Multi-Feature Edgear Xiv 20242409.00992
- 7Cheng L. Guo L. Zhang T. Bang T. Harris A. Hajij M. Sartipi M. Cao S. Calib Refine: Deep Learning-Based Online Automatic Targetless Li DAR–Camera Calibration with Iterative and Attention-Driven Post-Refinementar Xiv 20252502.1764810.1109/TIM.2025.3647989 · doi ↗
- 8Peng P. Pi D. Yin G. Wang Y. Xu L. Feng J. Automatic Miscalibration Detection and Correction of Li DAR and Camera Using Motion Cues Chin. J. Mech. Eng.2024375010.1186/s 10033-024-01035-3 · doi ↗