APVCPC: An Adaptive Predicted Value Computation and Pixel Classification Framework for Reversible Data Hiding in Encrypted Images
Yaomin Wang, Wenguang He, Gangqiang Xiong, Yuyun Chen

TL;DR
This paper introduces a new framework for hiding data in encrypted images that improves data capacity and image quality.
Contribution
The novel contribution is a context-aware prediction engine that adapts to image texture complexity for better performance.
Findings
APVCPC achieves an average embedding rate exceeding 2.0 bpp.
The framework ensures perfect reversibility of the original image after data extraction.
APVCPC outperforms existing methods in both embedding capacity and security.
Abstract
With the proliferation of Internet of Things (IoT) deployments and mobile sensing systems, reversible data hiding in encrypted images (RDHEI) has emerged as a cornerstone technology for secure cloud-based sensor data management. RDHEI ensures data confidentiality while enabling bit-to-bit restoration of original visual assets. However, conventional RDHEI methods often struggle to optimize the trade-off between high embedding capacity (EC) and the fidelity requirements of sensor-acquired content. This paper proposes an advanced RDHEI framework based on Adaptive Predicted Value Computation and Pixel Classification (APVCPC). The core contribution is a context-aware prediction engine that adaptively selects optimal estimation functions based on local texture complexity, significantly enhancing prediction accuracy in heterogeneous image regions. Subsequently, a content-driven pixel…
Click any figure to enlarge with its caption.
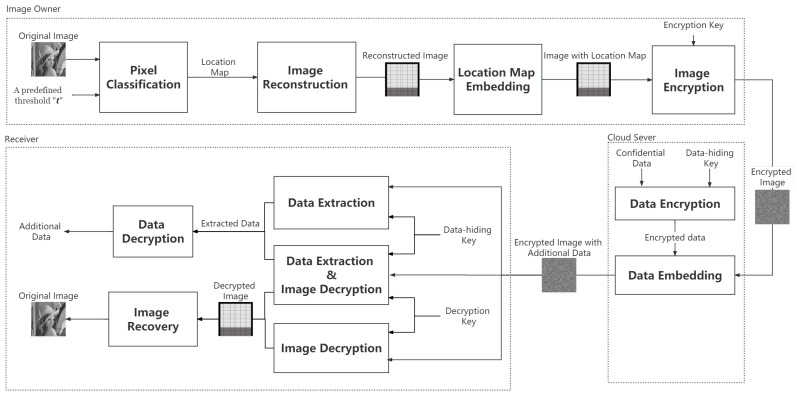 Figure 1
Figure 1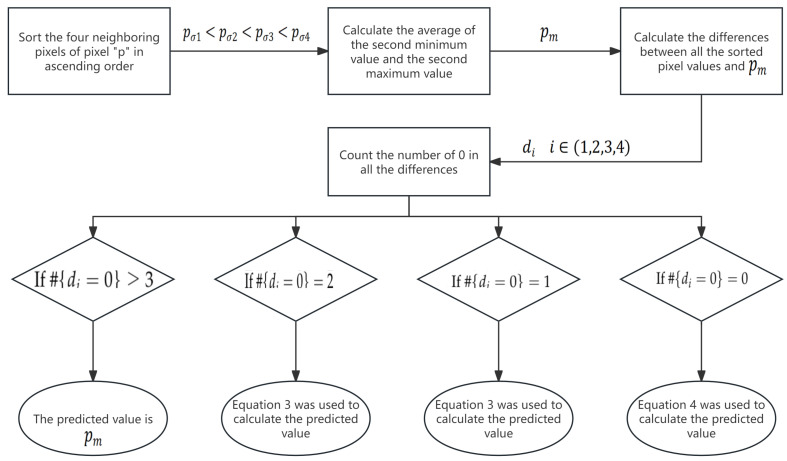 Figure 2
Figure 2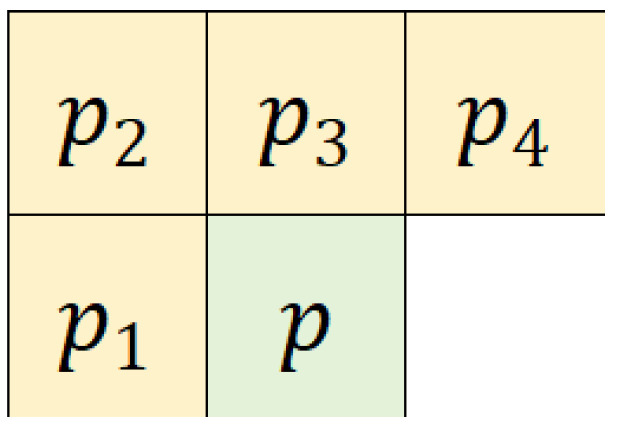 Figure 3
Figure 3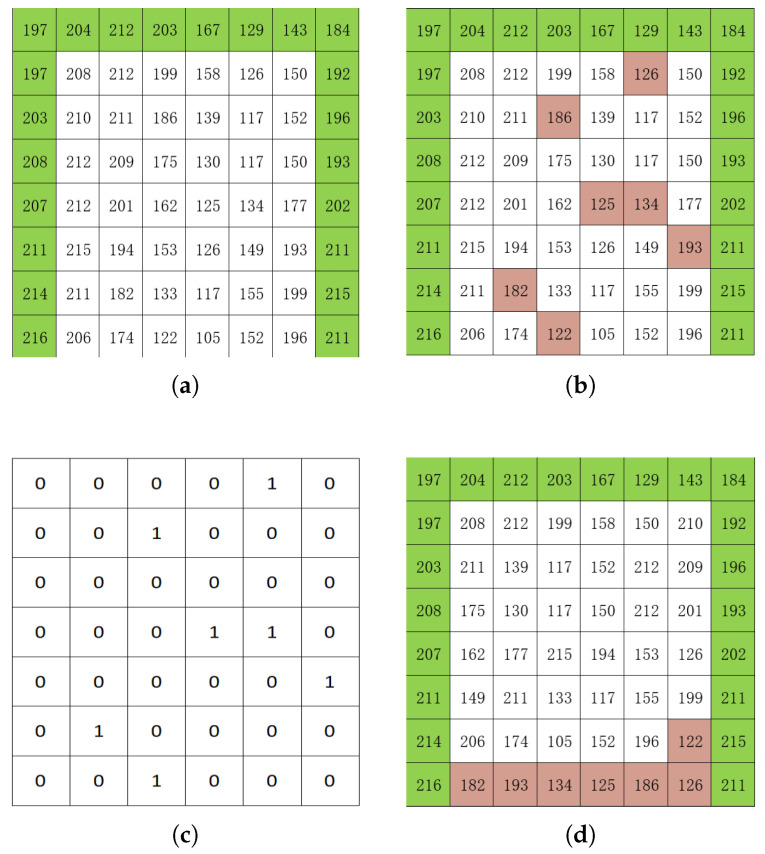 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9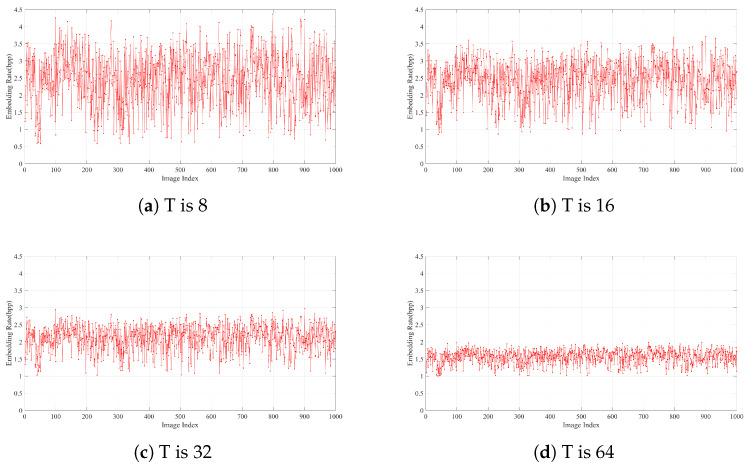 Figure 10
Figure 10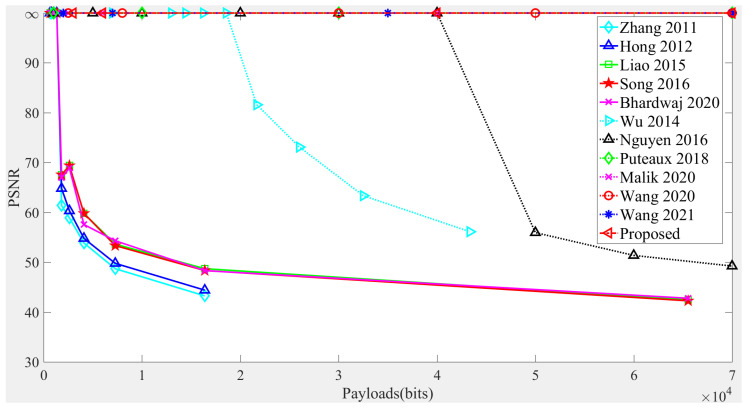 Figure 11
Figure 11- —National Natural Science Foundation of China
- —Guangdong Basic and Applied Basic Research Foundation
- —Guangdong Medical Research Foundation
- —Guangdong Medical University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Steganography and Watermarking Techniques · Chaos-based Image/Signal Encryption · Cryptography and Data Security
1. Introduction
Unprecedented volumes of visual sensing data have been generated by the extensive deployment of Internet of Things (IoT) sensors and Wireless Multimedia Sensor Networks (WMSNs), where effective data collection is vital for environment perception [1,2]. These data streams are increasingly offloaded to cloud infrastructures for storage and analytical processing [3]. In such sensor-rich ecosystems, maintaining data privacy and content authenticity is paramount when handling sensitive telemetry or proprietary visual assets. Consequently, reversible data hiding (RDH) has emerged as a key technology for integrating supplementary information—such as sensor metadata or authentication signatures—into digital imagery while ensuring bit-to-bit restoration of the original sensing content [4].
While the RDH field has evolved through difference expansion and histogram modification [5], the escalating risk of cyber-threats necessitates robust encryption prior to cloud transmission. Specialized encryption techniques for sensor nodes now provide multilevel privacy protection but transform images into high-entropy, noise-like representations [6]. This effectively neutralizes the spatial redundancy that conventional RDH schemes rely upon. To address this, reversible data hiding in encrypted images (RDHEI) has become a specialized paradigm designed to reconcile the competing demands of cryptographic security and embedding capacity in secure cloud-based sensor management systems.
Substantial progress has been achieved in RDHEI research. The existing methods can be broadly classified into two paradigms according to the operational sequence of encryption and embedding: Vacating Room After Encryption (VRAE) and Reserving Room Before Encryption (RRBE) [7,8]. VRAE embeds data after image encryption, whereas RRBE pre-allocates embedding regions prior to encryption. A seminal VRAE framework proposed in [7] operates through block-based processing. The host image is partitioned into non-overlapping blocks, where each block embeds one data bit via selective inversion of three least significant bits (LSBs) in half of its pixels. Data extraction relies on a complexity-aware fluctuation function, necessitating sufficiently large block sizes to ensure error-free reversibility. Inadequate block dimensions risk extraction errors and irreversible image degradation. Hong [8] improved this approach using a “side match” technique to reduce extraction errors for fixed block sizes. Subsequent refinements [9,10,11] optimized the fluctuation function, yet these enhancements retained limited embedding capacity despite achieving reversibility. To address capacity constraints, Wu et al. [12] introduced a chessboard-like pixel classification into “qualified” and “forbidden” sets. Qualified pixels carry payloads via multi-bit LSB flipping (≥4 bits), while forbidden pixels facilitate lossless prediction. This innovation significantly boosts embedding capacity while maintaining reversibility through structured pixel utilization.
All the aforementioned methods are categorized as joint RDHEI since data extraction has to be carried out subsequent to image decryption. Zhang pioneered the first separable RDHEI approach by introducing the idea of compressing least significant bits (LSBs) [13]. Following this, lossless compression techniques have also been incorporated into other related methods [14]. Some RDHEI schemes [15,16] achieve the liberation of embedding capacity by utilizing low density parity check code (LDPC) as the compression mechanism. The work in [17] generates space for data hiding by leveraging Hamming distance. In [18], researchers designed a universal RDHEI by exploiting Golomb–Rice codewords. Several studies [19,20,21] have also developed separable RDHEI methods specifically for JPEG images. Additionally, regarding certain VRAE-based methodologies referenced in [22,23,24], the extraction of confidential data can be performed either before or after image decryption.
The limitation of VRAE methods stems from their limited embedding capacity, which arises due to the disrupted correlation between adjacent pixels. In contrast, RRBE methods offer greater capacity, thus drawing significant research attention. The inaugural RRBE method, presented in [25], divides the cover image into two separate segments: the complex segment and the smooth segment. After that, several least significant bits (LSBs) from pixels in the complex segment were embedded into pixels in the smooth segment to create space for data hiding. Subsequently, to protect the image owner’s privacy, the reconstructed image was encrypted. The encrypted result was then transmitted to a remote server via an insecure channel. At the remote server, confidential data were embedded into the reserved space. In [26], Nguyen et al. further developed the idea of partitioning the original image in a chessboard-like pattern. Prior to image encryption, all pixels in the white set were divided into two parts: the smooth part and the complex part. Pixels in the smooth part were then used for space reservation, while the values of white set pixels were predicted using pixels from the black set. In [27], Zhang et al. proposed an estimation error technique, where most pixels are used to estimate the remaining small number of pixels. In [28], confidential data are embedded into the original image by replacing its lower bit-planes, with the replaced bit-planes transmitted through the higher bit-planes. In [29], researchers utilized the homomorphic and probabilistic properties of the Paillier cryptosystem, randomly selecting pixels for space reservation. The work proposed in [30] adopts patch-level sparse representation, achieving an embedding rate (ER) exceeding 0.5 bpp (bits per pixel). In [31], Malik et al. suggested preprocessing the cover image through prediction-error estimation, resulting in an ER of up to 0.75 bpp. Using reversible contrast mapping, the method propoed in [32] achieved an ER approaching 1 bpp. Given that the most significant bit (MSB) plane has the strongest correlation, Puteaux et al. proposed two MSB prediction-based methods in [33]. While these methods can also reach an ER of 1 bpp, they do not always guarantee reversibility. In [34], the MSB is more effectively utilized to develop an efficient RDHEI method with an ER exceeding 1 bpp. In [35], Wang et al. proposed a block-based adaptive MSB encoding scheme, which can achieve an ER of more than 1 bpp. By leveraging the Laplacian-like distribution characteristic of prediction errors and adaptively selecting between “L”-shaped block embedding and improved binary-block embedding, the method proposed in [36] is capable of achieving an ER higher than 1.5 bpp. Another RDHEI approach, which employs hybrid coding (combining entropy coding and hierarchical coding) to construct the embedding space, is proposed in [37]; this approach can achieve a high ER exceeding 1.5 bpp. Furthermore, a subset of researchers has attempted to introduce machine learning techniques into the field of RDHEI. For instance, Panchikki et al. established an ensemble model in [38], which fuses three distinct machine learning models: Support Vector Machine (SVM), Convolutional Neural Network (CNN), and k-Nearest Neighbor (KNN). Incorporating a voting mechanism, this model enables the extraction of embedded data and the restoration of the original image. As a preliminary exploration of machine learning applications in RDHEI, their proposed algorithm can only achieve an embedding capacity of 0.0625 bpp. Nevertheless, this approach holds considerable promise for addressing the robustness challenges confronting the RDHEI field and represents an extremely valuable research exploration. In summary, existing methods indicate that there is still room for improvement in high-capacity RDHEI, and MSB prediction deserves in-depth exploration.
A novel RDHEI method founded on predicted value adaptive computation (APVCPC) is introduced in this paper. Initially, the pixels in the original image is divided into two categories: candidate pixels and prediction pixels. Next, all candidate pixels are further classified into two types: loadable pixels (Lpxls), which are used to carry confidential data, and non-loadable pixels (NLpxls), which need to be excluded from the data-carrying process. To increase the proportion of loadable pixels—and thereby enhance the overall embedding capacity—a new pixel classification approach based on APVCPC is proposed in this work. The proposed method fabricates the embedding capacity by evacuating several MSBs of the Lpxls to further increase the embedding capacity. Here, the number of substituted MSBs is determined by a pre-defined threshold. Moreover, within the proposed method, the independent accomplishment of image recovery and data extraction is achieved. Upon the acquisition of decryption and data-hiding keys, receivers are thereby empowered to access heterogeneous information. Precisely, those receivers furnished with the data-hiding key possess the capacity to extract the confidential data, while those equipped with the decryption key are in a position to retrieve the original image. In the scenario where both keys are available, the receiver is capable of attaining both the image and the confidential data, thus ensuring a stratified access paradigm and upholding security integrity.
The principal contributions of this paper, which collectively address the longstanding trade-off between embedding capacity and reversibility in RDHEI, are articulated as follows:
- A Context-Adaptive Prediction Engine for Enhanced Spatial Redundancy Exploitation. This mechanism breaks through the limitations of static prediction and lay a highly reliable theoretical foundation for subsequent pixel classification. Specifically, we propose a novel prediction paradigm that abandons the one-size-fits-all fixed prediction function and designs a suite of prediction rules tailored to different local complexity contexts. Through an intelligent decision mechanism, it analyzes the statistical distribution (concentration) of each pixel’s neighborhood and dynamically selects the optimal prediction rule for it. This context-sensitive approach can significantly improve prediction accuracy, especially in heterogeneous image regions. It not only achieves a theoretical breakthrough over fixed prediction schemes but, more importantly, builds a more reliable foundation for the subsequent core step of pixel classification, fully exploiting the value of image spatial redundancy.
- A Prediction-Driven Pixel Classification Paradigm Shifting from Geometry to Content. This contribution realizes the transformation of pixel classification from geometry-oriented to content-oriented, which is the core driver for improving the algorithm’s embedding capacity. We completely depart from the traditional fixed-pattern (e.g., chessboard) pixel classification approach and propose a dynamic classification method based on the coherence between a pixel’s original value and its adaptively calculated predicted value at the most significant bit (MSB) level, categorizing pixels into loadable pixels (Lpxls) and non-loadable pixels (NLpxls). This content-aware classification can accurately identify pixels whose MSBs are reliably predictable and thus safely vacatable, maximizing the proportion of Lpxls. This strategic shift from geometric to semantic classification is the primary reason for the significant improvement in the embedding capacity of our method.
- A Holistic Framework Integrating Adaptive MSB Substitution with Guaranteed Separable Reversibility. This framework integrates the advantages of the preceding modules to achieve efficient embedding, lossless recovery, and flexible access control, enhancing the security and practicality of the algorithm. We design a high-efficiency integrated embedding framework that synergistically combines the advantages of the above two modules: it locks in the optimal carrier pixels (Lpxls) through adaptive classification and strategically vacates their multiple MSB bits to build a stable embedding space. Meanwhile, it ensures the perfect recovery of the original image through a losslessly compressed location map, achieving reversibility. More importantly, the framework is designed from the ground up to support genuine separable operations, adapting to flexible access control in cloud scenarios: data extraction and image recovery are independent processes, enabling users with different keys to access only the information they are authorized for, thereby improving both the security and practical application value of the algorithm.
The rest parts of the paper is constructed as follows: Section 2 provides a detailed description of the proposed method. In Section 3, the experimental results and analysis are presented, while Section 4 concludes with a summary of this paper.
2. Proposed Method
This section elaborates on the details of the proposed method, focusing on four key aspects: (1) details of APVCPC, (2) image encryption, (3) data hiding, and (4) data extraction and image recovery. Figure 1 depicts a schematic diagram of the proposed method. It can be seen that three key entities, namely, the image owner, the cloud server, and the receiver, participate in the execution of the proposed method. Initially, all pixels of original image are classified into two categories: Lpxls and NLpxls. Subsequently, a location map is acquired to guide image reconstruction. After undergoing lossless compression, the location map is smoothly merged into the reconstructed image. Subsequently, the encryption key is applied to conduct the encryption operation on the reconstructed image in tandem with the location map. Upon completion of this encryption process, the encrypted image is then dispatched and transmitted to the cloud server as the final step on the image owner side. Within the cloud server environment, the encryption of the specific confidential data is effected by means of a data-hiding key. Thereafter, the substitution of several MSBs of the Lpxls is enacted so as to embed the encrypted confidential data within the encrypted image. At the receiver end, different receivers with varying access rights to the secret keys may obtain different outcomes.
2.1. Details of APVCPC
This section provides a comprehensive overview of the APVCPC system, detailing its components, functionality, and operational principles. Table 1 summarizes the symbols employed throughout this paper along with their respective definitions, while Table 2 outlines the specific functions utilized in this paper and their corresponding roles. To simplify the analytical process, the cover image is assumed to have a size of . In APVCPC, the adaptive computation of predicted value is first performed. Initially, pixels in the original image are divided into two sets: the prediction set and the candidate set. The prediction set is composed of the pixels located in the first row, the first column, and the last column, whereas the remaining pixels are allocated to the candidate set. For each pixel within the candidate set, its predicted value is initially computed. Figure 2 illustrates the specific procedural steps involved in the calculation of predicted value. The detailed process for calculating is described in the following. As manifested in Figure 3, the prediction pixels are chosen from the four neighboring pixels of the candidate pixel P, labeled as , , , and . They undergo a sorting process, yielding the result that .
Then, their concentration is described as
where . As shown in Table 1, the symbol # denotes the cardinality of a set, and the predicted value is determined by the number of elements for which .
Case 1: If , the predicted value directly adopts the median reference
Case 2: If , neither nor is equal to . is computed as
Case 3: If , there is . is similarly calculated according to (2).
Case 4: If , all neighboring pixels are different. is calculated as
After is obtained, it is combined with the predefined threshold t to activate pixel classification. Before pixel classification is performed, a binary matrix having a size of is taken as the location map. For each accessible pixel p, if is fulfilled, it is categorized as Lpxl. Here, . Subsequently, the element that locates the corresponding position in the location map is assigned a value of 0. Alternatively, it is classified as NLpxl, and the value of 1 is assigned to its corresponding element of the location map.
Figure 4 demonstrates the pixel classification workflow with the threshold parameter . Figure 4a displays the original image, where green markers identify candidate pixels for prediction. Figure 4b highlights seven NLpxls detected through our classification protocol, shown in pink. The corresponding location map is presented in Figure 4c, facilitating the achievement of reversible image reconstruction via pixel rearrangement. Figure 4d displays the reconstructed image and reveals the rearrangement rule: Lpxls are ordered first, followed by NLpxls in reverse sequence.
It is notable that, with the assistance of the location map, Figure 4d can be precisely reverted to Figure 4b. Consequently, following the creation of the reconstructed image and location map, the latter is subjected to lossless compression and subsequently embedded into the initial few pixels of the former by substituting MSBs. In this paper, the arithmetic compression algorithm is employed to compress the position map. Once the position map has been compressed, its length is recorded and embedded into the initial pixels of the reconstructed image. In the proposed method, the maximum size of the compressed location map can be obtained as
That implies that the first bits of the vacated room should be filled with . Accordingly, the first pixels of the candidate set within the reconstructed image are occupied by the length of the location map (Lm). Ultimately, the Lm and the compressed location map are organized in the format illustrated in Figure 5 and embedded into the top of the reconstructed image.
The APVCPC exhibits a linear time complexity of O(N), where N is the number of pixels in the candidate set. This complexity arises from processing each pixel a constant number of times: computing its predicted value (involving fixed-size neighbor operations and sorting) and then classifying it based on the threshold T. The space complexity is also linear, O(N), mainly due to the storage of the binary location map. Only a small, constant amount of additional working memory is needed for intermediate calculations for each pixel.
2.2. Image Encryption
Following the embedding of the location map, image encryption is carried out to avoid the receiver accessing the image content without authentication. For pixel falling into [0, 255], it is expressed in 8 bits by using Equation (6), where represents a rounding down function.
Subsequently, leveraging the encryption key in tandem with a stream cipher algorithm, exemplified by RC4 or SEAL, gives rise to the generation of an encryption matrix. This matrix, sized precisely , adheres to the characteristics of a pseudo-random matrix. For each element of the generated matrix (designated as ), it is comparably decomposed into 8 bits. Subsequently, encryption is attained by employing Equation (7), where ⊕ represents the XOR operation and the stands for the k-th encrypted bit.
Finally, the encrypted pixel is calculated by
Note that, after the encrypted image is obtained, the Lm should be re-embedded into the initial pixels within the candidate set.
2.3. Data Hiding
In this step, some confidential data, including access control information, user details, or copyright information, are embedded by the data hider. To ensure the confidentiality and security of this sensitive information, the data are encrypted using the data-hiding key prior to the initiation of the data hiding process. Subsequently, the Lm is extracted from the first pixels within the candidate set of the received image, thereby determining the starting position of the available embedding space (i.e., the “vacated room” referenced in the original text). Then, by replacing MSBs, the encrypted confidential data are concealed in Lpxls except for the initial few ones. It should be noted that once all confidential bits have been embedded, an end mark, such as 16 consecutive “0”s, should be embedded.
2.4. Data Extraction and Image Recovery
The proposed method enables the accomplishment of separable execution regarding image recovery and data extraction. Based on their access to the data-hiding key and decryption key, three categories of receivers are identified in the proposed method.
Case 1: Receivers having the data-hiding key but lacking the decryption key.
For the recipients of this category, the image content is inaccessible. However, the embedded data can be retrieved without any degradation in fidelity. In specific terms, the MSBs of the initial pixels are first extracted; this step serves to acquire the starting position of the confidential data, which is prerequired for secret data extraction. Subsequently, the same number of MSBs are sequentially extracted from the remaining Lpxls, commencing from the identified start point and continuing until a predefined end marker (e.g., 16 consecutive zeros) is detected. Finally, the complete set of extracted bits is decrypted using the data-hiding key, thereby perfectly reconstructing the original confidential data. Moreover, the data recovery exhibits O(n) time complexity, where N is the number of embedded secret bits, dominated by the sequential MSB extraction from Lpxls and the subsequent decryption, both linear operations. The initial position retrieval requires only constant time. Space complexity is also O(n), primarily for storing the extracted bitstream before decryption, with O(1) additional working memory.
Case 2: Receivers possessing decryption key but lacking the data-hiding key.
In this scenario, although these receivers cannot access the confidential data, they are still able to obtain the content of the original image. The recovery process, which shares its initial step with Case 1, begins by extracting the auxiliary data (Lm) from the first MSBs of the initial pixels within the candidate set. Subsequently, the received image is decrypted by employing the decryption key; following this decryption process, the compressed location map is further extracted on the basis of the retrieved Lm. Thereafter, the original location map can be effectively retrieved through decompression. On this basis, all Lpxls and NLpxls are distinguished and repositioned to their original positions in line with the retrieved location map. Subsequently, all pixels within the candidate set are restored in a raster scanning sequence, as illustrated in Figure 6. Here, the pixels within the prediction set are marked in green, while those in the candidate set are marked in white. As it is shown in Step 1, the candidate pixel is retrieved initially. Specifically, its predicted value is calculated with the assistance of its neighboring pixels , , and , adopting the same methodology as that employed in pixel classification. Upon obtaining the predicted value , the original pixel is restored through the application of Equation (9), where denotes the restored value of the pixel . Following this restoration, the recovered value becomes one of the neighboring pixels of . With the support of the pixels , , , and , is then restored to its original state, denoted as . Thereafter, as illustrated in Figure 6, the candidate pixels and are restored in the same manner as and . Upon completion of all these restoration steps, the original image is successfully retrieved.
Notably, the restoration involves linear traversal of candidate pixels and temporary storage of their restored values without redundant operations, resulting in a time complexity and a space complexity of O(N), respectively (N is the total number of candidate pixels)
Case 3: Receivers are entitled to access all keys.
In this case, the encrypted confidential data are first extracted from the received image. Subsequently, with the assistance of data-hiding key, receivers in this category can access the confidential data. After that, the original image is perfectly retrieved by utilizing the decryption key. Moreover, the time complexity and the space complexity of this scenario are the sum of that in Case 1 and Case 2.
3. Experimental Results and Analyses
In this section, a series of experiments, including image recovery, data extraction, performance analysis, and comparison with existing methodologies, are conducted to evaluate the performance of the proposed method. To rigorously evaluate the performance of the proposed reversible data hiding in encrypted images (RDHEI) scheme, this study employs a diverse set of eight standard grayscale test images. These include the widely adopted “Lenna” image—selected for its balanced composition of smooth regions (e.g., facial skin and background) and highly textured areas (e.g., hair and hat)—which makes it particularly suitable for comprehensive assessment of image processing algorithms. Complementing “Lenna”, the testing set comprises the relatively smooth “Peppers” image, moderately textured images (“Barbara”, “F16”, and “Boat”), and highly textured images (“Lake” and “Tank”). This deliberate selection ensures systematic evaluation across varying structural complexities and texture densities. The aforementioned eight images have dimensions of . All programs were coded in MATLAB R2016a. The experimental configuration utilized a PC furnished with a 64-bit Windows 11, 16 GB of RAM, and an Intel Core CPU operating at a speed of 1.8 GHz.
3.1. Image Recovery and Data Extraction
In this experiment, as presented in Figure 7, the confidential data are in the form of a binary image having a size of . The standard test image “Lenna” is selected as the cover image. It is of utmost importance to note that, for the “Lenna” image to be able to carry the confidential data, the embedding rate must reach 1 bpp. Figure 8 presents the results of several key stages of the proposed method, with the encryption key set as “123456” and T = 8. Figure 8b shows the reconstructed image, where Lpxls are highlighted in red. The observation demonstrates that more than half of the cover image consists of Lpxls when T = 8, suggesting that a high capacity can be attained. Figure 8c displays the encrypted image, and it is impossible to capture any contents of the original image. Therefore, the image contents have been effectively safeguarded through the application of image encryption. The encrypted result of the confidential data and its embedded output are presented in Figure 8d,e. The directly extracted data, as illustrated in Figure 8f, indicate that the confidential content remains undetectable to receivers without data-hiding key. The extracted result is shown in Figure 8f, and its decrypted result is presented in Figure 8g. As can be seen, the decrypted result perfectly aligns with Figure 7. This indicates that the extraction of hidden data is flawless, thereby guaranteeing its reversibility. Similarly, the recovered result of the received image is presented in Figure 8h. As can be seen, the recovered result is precisely identical to Figure 8a, which depicts the original image. This indicates that the reversibility of the cover image is achieved in the proposed method.
According to the discussion mentioned above, the reversibility of the RDHEI is accomplished by the proposed method. Simultaneously, the contents of confidential data and the original image are effectively protected.
3.2. Performance Analysis
It is obvious that the quantity of Lpxls varies in accordance with the parameter T and the cover image. To verify the influence of these two factors on the performance of the proposed method. All the aforementioned test images were utilized to assess the performance of the proposed method. Figure 9 presents the reconstructed results of “Lenna” for , with Lpxls highlighted in red. It can be observed that the red area expands as T increases. This indicates that a larger T results in a greater quantity of Lpxls. The embedding capacity, in the proposed method, is obtained by Equation (10), where N and represent the quantity of Lpxls and the length of the compressed location map, respectively.
For the purpose of more effectively evaluating the performance of the proposed method, an additional set of 1000 images from the BOW-2 database (https://data.mendeley.com/datasets/kb3ngxfmjw/1, accessed on 2 June 2023) is utilized as test images. Figure 10a presents the test results when “8” is set as T. As depicted, the embedding rates of the majority of test images exceed 4 bpp. In contrast, only a small number of images have embedding rates below 1 bpp. The occurrence of embedding rates lower than 1 bpp becomes increasingly rare with , as illustrated in Figure 10b. However, for or , the embedding rate consistently exceeds 1 bpp, as demonstrated in Figure 10c,d. These experimental results indicate that although a larger T can increase the embedding rate for some test images, Figure 10 reveals that it actually leads to a decrease in the embedding rate for the majority of test images. A detailed quantitative summary of the results on the 1000 BOW-2 images is provided in Table 3. The data show that the highest embedding capacity (EC) is attained at , where the average embedding rate (ER) reaches 2.48 bpp—both measures surpassing those achieved with other T values. This observation initially indicates that T = 8 may be the optimal threshold parameter for the majority of cover images. However, Table 3 also highlights that the lowest recorded ER at is 0.58 bpp, which represents the poorest minimum performance among all tested thresholds. In contrast, the best minimum EC is observed at (1.02 bpp), closely followed by (1.01 bpp). This implies that, for certain specific images—presumably those with less favorable local pixel distributions—adopting a higher T value (32 or 64) can yield a more reliable minimum embedding capacity. Furthermore, the proposed method maintains an average embedding rate above 2 bpp for , confirming its ability to deliver high embedding capacity across multiple parameter settings. Collectively, these comprehensive experiments—spanning multiple threshold configurations and a large, diverse test dataset—robustly validate the conclusion that the proposed method achieves a substantially high embedding capacity, with its performance characteristics adaptable to different image types through appropriate adjustment of the threshold T.
For a better comprehension of the relationship between the performance and the parameter T, Table 4 enumerates the performance of all test images for different T. It is observable that the quantity of Lpxls typically ascends as T increases. Nevertheless, the MSBs of Lpxls are employed for data hiding. Hence, it cannot be inferred that the parameter T and the embedding capacity are in a positive correlation.
Therefore, the proposed method is extremely appropriate for the practical applications of RDHEI.
3.3. Comparison with Several Existing Methods
Fist of all, the standard image “Lenna” is selected to test the Peak Signal-to-Noise Ratio (PSNR) of the proposed method and several state-of-the-art RDHEI methods. Here, PSNR is employed as a quantitative measure to evaluate the disparity between the recovered cover images and the original ones. Subsequently, the embedding capacity is utilized to compare their respective performances. Figure 11 illustrates the PSNR comparison at different payload levels, with Lenna being used as the cover image. It is observed that the PSNRs of methods [7,8,9,10,11,12,26] cannot remain at for all payloads, suggesting a loss of reversibility. In contrast, for the given payloads, the methods in [31,33,34,35] and the proposed method consistently yield a PSNR of . This suggests that the reversibility is achieved by methods [31,33,34,35] and the proposed method.
Table 5 presents a detailed delineation of the embedding capacities obtained by the proposed method and several prior ones on the eight aforementioned test images. As Table 5 illustrates, the proposed method exhibits a markedly superior embedding capacity over previous methods, with a prominent margin in performance. The maximum capacity of the image “Lenna” achieved by the previous methods reaches 477,282 bits. However, with a capacity of 564,116 bits, the proposed method achieves a remarkable increase over previous approaches. For these eight test images, the proposed method achieves an average capacity of 500,710 bits, compared with an average capacity ranging from 922 to 430,797 bits for previous methods. Evidently, the proposed method has achieved a significant superiority in capacity. Based on the foregoing discussion, it can be rationally postulated that the proposed method distinctly exhibits an augmented and preponderant suitability for practical RDHEI applications.
3.4. Security Analysis
Attackers can be categorized into three groups based on the keys they possess. The first group encompasses those solely in possession of the data-hiding key, with the objective of attaining access to the image content. The secondary group comprises those who only possess the decryption key and harbor the intention of extracting the confidential data. The tertiary group consists of those lacking both keys but endeavoring to access both the image content and the confidential data.
The security scrutiny pertinent to each attacker category is elucidated hereinafter, commensurate with the attributes of their motives and competencies.
Case 1: Attackers possessing only the data-hiding key.
With the application of the data-hiding key, the extraction and decryption of the confidential data can be achieved without any detriment in this given situation. He can obtain the secret data as shown in Figure 8g. As we can see, the content of secret data is readable for this kind of attackers. However, as visualized in Figure 8c, the encrypted image can be obtained in this scenario. However, due to the non-availability of the decryption key, the image decryption becomes impracticable. Thus, the safety and wholeness of the original cover image stay unaltered and intact.
Case 2: Attackers possessing only decryption key.
In this scenario, an attacker can successfully extract the auxiliary location map (Lm) from the leading pixels of the candidate set. Consequently, the starting position of the secret data payload can be determined. Following this, the encrypted secret data themselves can be retrieved, as visually outlined in Figure 8d. However, the absence of the data-hiding key prevents the attacker from performing the final decryption operation on the extracted ciphertext. As a result, both the integrity and confidentiality of the embedded information remain fully preserved against this type of adversarial access.
Case 3: Attackers without any key.
In this scenario, attackers have access to both the encrypted secret data (Figure 8d) and the encrypted image (Figure 10c), facilitated by the . Critically, however, the absence of both the decryption key and the data-hiding key renders them incapable of executing either decryption operation. Consequently, the privacy of the original image content and the security (i.e., integrity and confidentiality) of the embedded confidential data remain entirely preserved against such attackers.
As outlined above, the proposed method effectively guarantees the security of confidential data and protects the privacy of image owners.
4. Conclusions
This paper presents an advanced RDHEI framework, termed APVCPC, designed to enhance embedding capacity while concurrently ensuring robust security and bit-to-bit reversibility for visual sensing assets. The core innovation lies in an adaptive prediction engine that dynamically computes pixel estimates based on local contextual complexity, significantly improving the precision of spatial redundancy utilization. By leveraging the alignment between most significant bits (MSBs) and these adaptive predictions, the proposed pixel classification paradigm effectively identifies optimal regions for data embedding. Experimental evaluations across diverse image datasets demonstrate that our method consistently outperforms state-of-the-art approaches in terms of embedding rate and reconstruction fidelity. Furthermore, the architecture supports fully separable operations for data extraction and image recovery, providing flexible access control for cloud-based storage. Nevertheless, the present work primarily focuses on maximizing embedding capacity, with less emphasis on a detailed analysis of the algorithm’s space and time complexity—specifically, its execution speed and memory consumption during operation. Additionally, the robustness of the scheme against potential corruption of the embedded auxiliary data (e.g., the location map) has not been addressed. These identified aspects constitute promising directions for future research. Subsequent work will therefore concentrate on developing algorithms that holistically balance embedding capacity, computational efficiency, and storage overhead. Concurrently, investigations will be undertaken to enhance the algorithm’s robustness, ensuring reliable data recovery even under conditions of partial auxiliary information loss. Given its high embedding capacity, the proposed scheme offers a promising solution for safeguarding information security in remote monitoring systems.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Yao Y.D. Wen Q. Cui Y.P. Zhao F. Zhao B.Z. Zeng Y.P. Coverage Enhancement Strategy in WMS Ns Based on a Novel Swarm Intelligence Algorithm: Army Ant Search Optimizer IEEE Sens. J.202222212992131110.1109/JSEN.2022.3203147 · doi ↗
- 2Cui J. Shi L. Alkhayyat A. Enhanced security for Io T cloud environments using Efficient Net and enhanced football team training algorithm Sci. Rep.2025152076410.1038/s 41598-025-08343-140595318 PMC 12217636 · doi ↗ · pubmed ↗
- 3Khan A.A. Laghari A.A. Elmannai H. Shaikh A.A. Bourouis S. Hadjouni M. Alroobaea R. GAN-Io TVS: A Novel Internet of Multimedia Things-Enabled Video Streaming Compression Model Using GAN and Fuzzy Logic IEEE Sens. J.202323294342944110.1109/JSEN.2023.3316088 · doi ↗
- 4Barton J.M. Method and Apparatus for Embedding Authentication Information Within Digital Data US 5646997 A 8June 1997
- 5Gandhi S. Kumar R. Survey of reversible data hiding: Statistics, current trends, and future outlook Comput. Stand. Interfaces 20259410400310.1016/j.csi.2025.104003 · doi ↗
- 6He X. Li L. Peng H. Tong F. 2-D Compressive Sensing-Based Visually Secure Multilevel Image Encryption Scheme IEEE Sens. J.2024243286330010.1109/JSEN.2023.3341428 · doi ↗
- 7Zhang X. Reversible data hiding in encrypted image IEEE Signal Process. Lett.20111825525810.1109/LSP.2011.2114651 · doi ↗
- 8Hong W. Chen T.S. Wu H.Y. An improved reversible data hiding in encrypted images using side match IEEE Signal Process. Lett.20121919920210.1109/LSP.2012.2187334 · doi ↗