SGE-Flow: 4D mmWave Radar 3D Object Detection via Spatiotemporal Geometric Enhancement and Inter-Frame Flow
Huajun Meng, Zijie Yu, Cheng Li, Chao Li, Xiaojun Liu

TL;DR
This paper introduces SGE-Flow, a new 4D radar object detection system that improves accuracy and speed using spatiotemporal enhancements and motion inference.
Contribution
The novel contribution is the integration of lightweight spatiotemporal geometric enhancements and a Transformer-based motion inference module for 4D radar perception.
Findings
SGE-Flow achieves 53.23% 3D mean Average Precision on the VoD dataset.
The system runs at 72 FPS on an NVIDIA RTX 3090 while maintaining accuracy.
The proposed modules are effective in improving other strong baselines like MAFF-Net.
Abstract
4D millimeter-wave radar provides a promising solution for robust perception in adverse weather. Existing detectors still struggle with sparse and noisy point clouds, and maintaining real-time inference while achieving competitive accuracy remains challenging. We propose SGE-Flow, a streamlined PointPillars-based 4D radar 3D detector that embeds lightweight spatiotemporal geometric enhancements into the voxelization front-end. Velocity Displacement Compensation (VDC) leverages compensated radial velocity to align accumulated points in physical space and improve geometric consistency. Distribution-Aware Density (DAD) enables fast density feature extraction by estimating per-pillar density from simple statistical moments, which also restores vertical distribution cues lost during pillarization. To compensate for the absence of tangential velocity measurements, a Transformer-based…
Click any figure to enlarge with its caption.
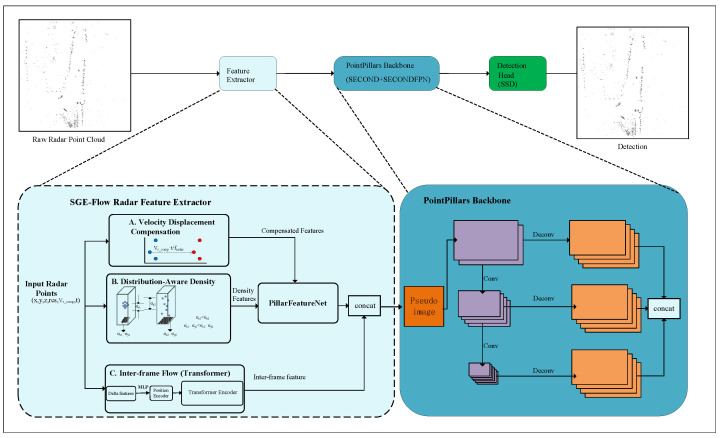 Figure 1
Figure 1 Figure 2
Figure 2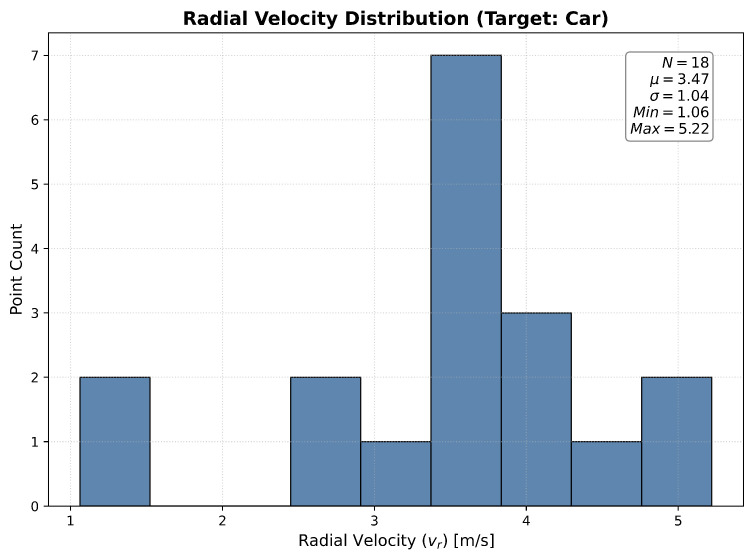 Figure 3
Figure 3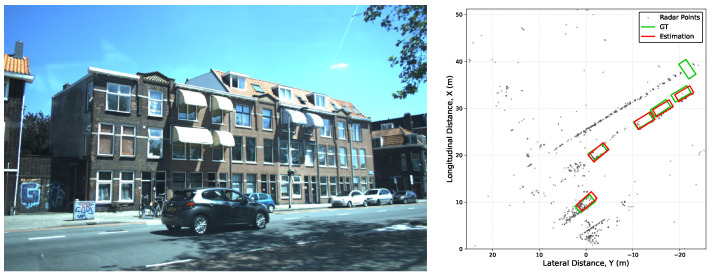 Figure 4
Figure 4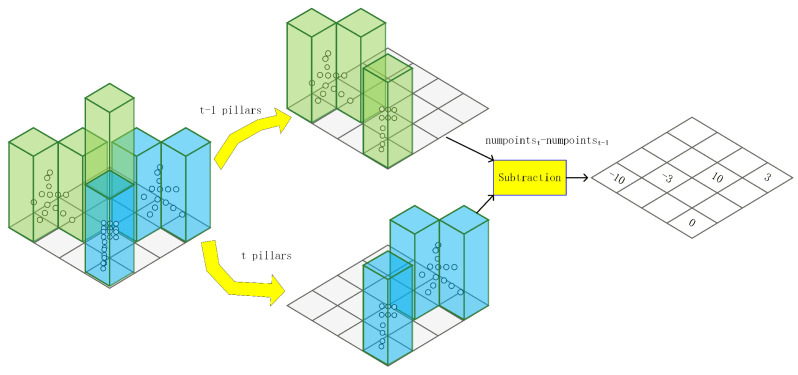 Figure 5
Figure 5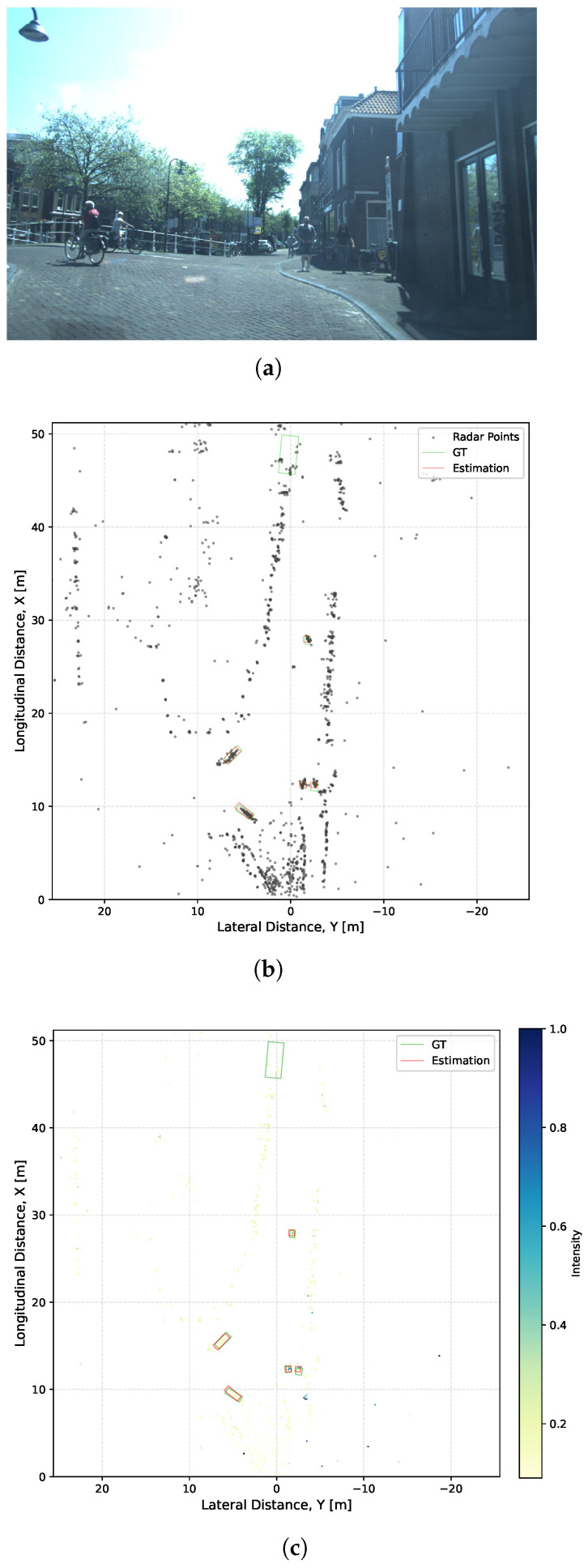 Figure 6
Figure 6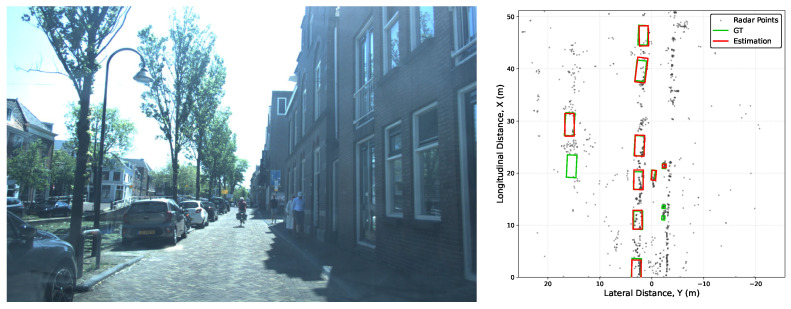 Figure 7
Figure 7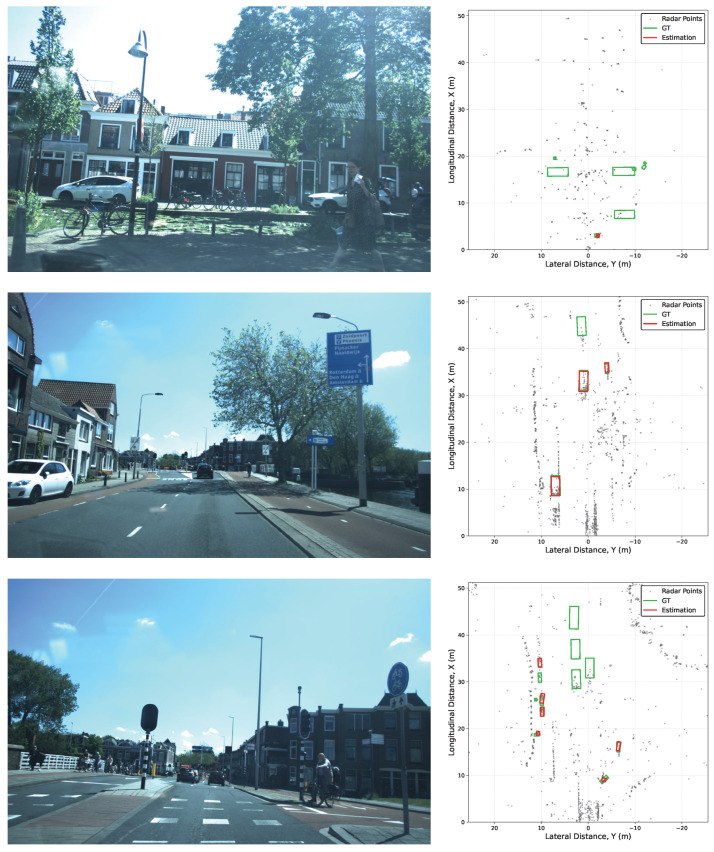 Figure 8
Figure 8- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced SAR Imaging Techniques · Microwave Imaging and Scattering Analysis · Advanced Optical Sensing Technologies
1. Introduction
Environmental perception is the foundation of the autonomous driving system, and 3D object detection is a key sub-task of environmental perception [1,2]. While current systems rely heavily on Light Detection and Ranging (LiDAR) [3,4] and cameras, these sensors have a major limitation: their performance degrades significantly in adverse weather like heavy rain, fog, or snow [5]. This limitation has driven increasing interest among researchers in 4D millimeter-wave radar. In addition to its robustness in all weather, 4D radar provides a unique advantage by directly extracting object radial velocity from the Doppler effect. Furthermore, recent hardware improvements have increased its resolution, providing point densities closer to low-beam LiDAR [6].
However, directly applying LiDAR-based algorithms to radar data is difficult. 4D radar point clouds are extremely sparse—often less than 1% of LiDAR’s density—and contain significant noise. Current research generally falls into two categories: accuracy-focused methods like SMURF [7] and MAFF-Net [8], which are slow due to heavy feature extraction; and efficiency-focused designs like RadarPillars [9], which often perform poorly because they ignore geometric distortions caused by ego-motion. A key challenge remains: reconciling a competitive detection accuracy with inference efficiency.
To address these challenges, we propose a lightweight enhancement framework designed specifically for 4D radar. Instead of introducing architectural complexity, our approach—based on a PointPillars [4] baseline—focuses on using physical and geometric insights directly in the feature extraction process. We handle multi-frame “ghosting” artifacts with a Velocity Displacement Compensation (VDC) strategy that aligns points in physical space. To recover vertical information lost during 2D pillarization, we introduce a Distribution-Aware Density (DAD) metric based on statistical dispersion. Most importantly, we address the radar’s inability to measure tangential velocity with a Transformer-based Inter-frame Flow (IFF) module, which identifies motion by analyzing the pillar’s occupancy changes over time.
Our main contributions are summarized as follows:
- To address the tangential velocity indeterminacy, we introduce a Transformer-based Inter-frame Flow (IFF) module. This module identifies latent motion cues by modeling the “Inflow and outflow” of pillar occupancy across frames without requiring explicit velocity measurements.
- We mitigate the vertical resolution deficiency with a Distribution-Aware Density (DAD) metric. By computing statistical moments within each pillar, the metric reconstructs the vertical details often lost during voxelization.
- We resolve “ghosting” artifacts in multi-frame data by a Velocity Displacement Compensation (VDC) strategy. This ensures geometric consistency by aligning features in physical space, rectifying the motion-induced smearing effect for moving targets.
- The proposed framework strikes a superior balance between latency and accuracy, maintaining 72 FPS on an NVIDIA GeForce RTX 3090 GPU. The modular design allows for easy integration into state-of-the-art networks like MAFF-Net [8], demonstrating robust generalization.
2. Related Work
2.1. 3D Object Detection with 4D Radar Point Clouds
Recent comprehensive surveys [6,10] have systematically summarized the advancements in 4D millimeter-wave radar, emphasizing its robust perception capabilities and all-weather operational characteristics as a solution to the limitations of camera and LiDAR-based systems. Since 4D radar data is structurally similar to LiDAR point cloud data, early algorithms are mainly adapted from established LiDAR frameworks. Point cloud datasets such as VoD [11] and TJ4DRadSet [12] have been important, driving the development of radar-based detection by establishing baselines with LiDAR-based models.
In the LiDAR domain, VoxelNet [3] introduced voxel-based feature extraction but suffered from high computational costs, and PointPillars [4] improved the cost by projecting 3D space into 2D pillars, significantly increasing efficiency. Subsequent works such as PV-RCNN [13] and CenterPoint [14] further optimized detection performance by combining point-voxel features or adopting center-based anchor-free designs. Recognizing this advantage, the 4D radar community has largely adopted voxelization architectures. For instance, RadarPillars [9] introduces self-attention among non-empty pillars to aggregate features belonging to the same object; and RPFA-Net [15] uses self-attention mechanisms to extract global information from radar pillars for better orientation estimation. Departing from these single-view voxelization methods, MVFAN [16] addresses vertical feature deficiency by projecting point clouds into multiple views, including Bird’s Eye View (BEV) and cylindrical coordinates; RadarNeXt [17] proposes a robust detector tailored for 4D radar characteristics, while RCBEVDet [18] explores effective radar-camera fusion strategies in the BEV space.
However, directly applying LiDAR algorithms to 4D radar often produces suboptimal results due to the inherent sparsity and significant noise of radar data [10]. To solve these problems, recent studies have focused on advanced feature enhancement. SMURF [7] addresses density issues by adding a Kernel Density Estimation (KDE) branch to improve sparsity awareness. MAFF-Net [8] proposes a cylindrical denoising assist module to identify keypoints around objects, thereby reducing noise interference. Additionally, SCKD [19] uses cross-modality distillation to transfer knowledge from LiDAR to 4D radar, filtering out noise without reducing inference speed.
2.2. Radar Feature Extractor
In pillar-based detection frameworks, the effectiveness of the feature extractor is critical. Addressing the specific characteristics of 4D radar, existing designs primarily focus on distribution feature modeling and velocity information utilization.
The extreme sparsity of single-frame radar data poses a fundamental challenge. Approaches such as RadarMFNet [20] use a modified PointPillars on aggregated multi-frame 4D radar point clouds to alleviate this issue. The 4D radar dataset VoD provides preprocessed single-frame, three-frame, and five-frame data. Furthermore, many methods design specific feature extractors. For instance, DADAN [21] effectively addresses the foreground–background confusion in sparse point clouds by using the unique dynamic information (velocity and intensity) of 4D radar. Similarly, drawing inspiration from the Dual Attention Network [22] in scene segmentation, PillarDAN [23] incorporates a pillar-based dual attention mechanism to capture long-range dependencies in sparse radar data. SMURF [7] designs a density feature by KDE. However, these methods often rely on computationally intensive operations. A key limitation of the PointPillars architecture is the lack of vertical geometric information during the flattening process. To resolve this efficiently, we introduce a lightweight Distribution-Aware Density (DAD) feature that recovers lost structural details with negligible computational cost.
Considering the raw data feature, Doppler velocity gives radar a distinct advantage over LiDAR. RadarPillars [9] demonstrated that decomposing radial velocity boosts performance by aligning features with convolution kernels. Nevertheless, radar’s instantaneous velocity alone is insufficient for complex dynamic scenes. Resolving the limitation that radar cannot measure tangential velocity, we design an Inter-frame Flow (IFF) module inspired by the temporal consistency observed in recent works [5].
While previous methods have improved accuracy, complex additions like those in SMURF and MAFF-Net often compromise latency. We aim to resolve this trade-off by proposing an efficient scheme that simultaneously addresses sparsity and velocity information utilization while ensuring real-time performance.
3. Materials and Methods
We present a streamlined 3D object detection framework, SGE-Flow, architected to maximize the trade-off between algorithmic depth and computational efficiency. As illustrated in Figure 1, our approach confronts the sensor’s physical limitations, specifically sparsity, tangential motion ambiguity, and multi-frame geometric distortions. The framework consists of three parallel Modules: Velocity Displacement Compensation (VDC), Distribution-Aware Density (DAD), and Inter-frame Flow (IFF). Rather than stacking heavy, serial branches, we embed these modules directly into the PointPillars voxelization front-end. This design exploits the natural sparsity of 4D radar, channeling computational power specifically to non-empty pillars.
3.1. Challenges of Radar Doppler Features
Unlike LiDAR, which relies on Time of Flight (ToF) for ranging, millimeter-wave radar [11] leverages the Doppler effect to directly measure target velocity. This capability offers an advantage in dynamic scene perception and mitigates the limitations of sparse radar data. While advanced 4D radar hardware may implement internal tracking and filtering to estimate full velocity vectors, the input to point-cloud-based 3D object detectors is typically the direct radial velocity measurements derived from the Doppler effect. However, it also introduces a fundamental physical paradox: radar can effectively measure radial velocity ( ), but is blind to tangential motion. Consequently, for targets with significant lateral motion, the radial velocity component fails to describe the true motion state, often leading neural networks to treat the valid data as noise.
To visualize this, consider the typical lateral motion scenario analyzed in Figure 2, where a vehicle crosses the field of view. Figure 3 shows the velocity distribution of the 4D radar points in the vehicle’s bounding boxes.
The true displacement velocity is defined physically as:
where represents the vehicle’s displacement over time .
Using annotations from the VoD dataset [11] (vehicle length ≈ 4 m, sampling rate 13 Hz), the ground truth velocity is approximately 17.3 m/s. However, statistical analysis of the compensated radial velocity within the vehicle’s bounding box reveals a measured speed of only around 4 m/s—far lower than the actual displacement velocity. This discrepancy highlights how the lack of tangential velocity information causes Doppler data to exhibit noise-like characteristics in lateral motion scenarios.
3.2. Velocity Displacement Compensation (VDC)
While multi-frame accumulation effectively increases the density of sparse radar point clouds, it inevitably introduces motion-induced smearing. Simply superimposing historical frames onto the current coordinate system—compensating only for ego-motion—leaves a trailing “ghosting” artifact along the trajectory of moving targets as shown in Figure 4. Furthermore, the raw velocity data lack directional vector information, creating a geometric mismatch with the Cartesian-based convolution operators of Convolutional Neural Networks (CNNs).
Thus, we propose the Velocity Displacement Compensation (VDC) feature and its intuition is straightforward: by recovering the radial location of a point at a past timestamp relative to the current frame, we can align the “ghosts” with the target’s current position. Let the raw radar point cloud be denoted as , where each point carries a feature vector , with representing the Doppler radial velocity, representing the radial velocity after compensating for the ego-motion of the sensor platform, and the timestamp index.
To correct geometric distortion, we first calculate the unit direction vector and time lag :
where is the raw data of the point cloud, and is the radar sampling frequency.
From this, we derive the spatial displacement vector driven by the target’s motion:
This spatial displacement is calculated by projecting the compensated radial velocity into 3D Cartesian coordinates along the direction vector over the duration .
The final enhanced feature is defined as . This explicit displacement modeling effectively projects the radial scalar into Cartesian space, reconciling the misalignment between polar velocity and Euclidean convolution kernels.
3.3. Distribution-Aware Density (DAD)
Density features carry a significant impact on 3D object detection and extensive research has been conducted to exploit this information [24]. Standard PointPillars voxelization [4] relies on lossy compressional max-pooling for feature aggregation. This operation strips away many geometric details, particularly along the vertical (Z-axis). Furthermore, conventional voxelization partitions point clouds into fixed-size grids. This rigid quantization implies that any points within a single pillar—regardless of whether they are dispersed or tightly clustered—will yield an identical density feature as long as their cardinality remains constant, exacerbating foreground–background confusion [25].
We propose the Distribution-Aware Density (DAD) feature. Our core intuition is to treat the various statistical moments of the point cloud within each pillar as a representative descriptor of its spatial geometric distribution.
For any non-empty Pillar , let be the set of point indices, and the point count. We describe the local micro-structure by calculating the geometric center and standard deviation in spatial dimensions :
Recognizing that the BEV plane (XY) and height direction (Z) carry distinct semantic weights, we decouple the density features into planar distribution and height dispersion , weighted by the point count :
where denotes the standard Z-score normalization (i.e., ) applied to features within each pillar to stabilize numerical ranges. captures the horizontal occupancy density, while compensates for the vertical information compressed by pillarization, enabling the network to distinguish between volumetric targets (like pedestrians) and planar clutter.
3.4. Inter-Frame Flow (IFF)
Although VDC exploits velocity information, a critical gap remains: the radar’s inability to measure tangential velocity. To recover these latent motion cues, we introduce the Inter-frame Flow (IFF) module, a Transformer-based architecture [26]. The utilization of sequence learning to capture complex spatiotemporal dependencies has also demonstrated effectiveness in other dynamic perception tasks, such as pose forecasting [27].
Our core insight is that for a moving target, the point cloud traverses different pillars across consecutive time frames, resulting in positive, negative, or zero values when computing the difference between adjacent frames. For instance, an object moving from Pillar A to Pillar B induces a decrease in point count in Pillar A (outflow) and a corresponding increase in Pillar B (inflow). This inter-pillar state difference implicitly encodes the target’s motion flow. In contrast, pillars occupied by stationary objects remain consistent across frames, leading to a zero-value difference. This process is visualized in Figure 5, where the pillars of the previous and current frames are color-coded in green and blue, respectively. Based on the inter-frame difference, pillars representing the outflow of moving targets yield negative values, those representing inflow result in positive values, and stationary pillars result in zero. By capturing these temporal transitions, the network can effectively infer the underlying kinematic characteristics from the discretized spatial grid.
A qualitative visualization of the IFF module’s impact is presented in Figure 6. While Figure 6a displays the raw scene, Figure 6b provides the BEV visualization of estimated and ground-truth bounding boxes. Figure 6c illustrates the L2-norm of the feature residuals induced by the IFF module, where deeper blue intensities signify a more pronounced feature enhancement. As highlighted by the red circles, the regions corresponding to cyclists and pedestrians exhibit significantly higher activation compared to the ambient environment. Although some isolated dark blue pixels appear elsewhere—likely stemming from inherent sensor noise—these discrete activations do not correspond to coherent target structures and thus exert no adverse influence on the final detection performance. This observation confirms the module’s robustness in selectively isolating kinematic signatures from potential clutter.
3.4.1. Temporal Difference Feature Construction
We treat each Pillar as a temporal vessel. For timestamps , we first aggregate the point-wise features. Let denote the point count at time t. We derive the mean compensated radial velocity and mean radar reflectivity :
where and are the compensated radial velocity and Radar Cross Section (RCS) of point p.
To capture the local flow, we construct the first-order Feature Gradient between adjacent steps:
where signals an object entering the pillar, while indicates departure.
These difference quantities form the raw sequence describing the local flow dynamics.
3.4.2. Transformer Temporal Aggregation
To model global temporal correlations, we map these difference features to a high-dimensional embedding vector by a Multi-Layer Perceptron (MLP), injecting Positional Encoding (PE) to preserve spatial context:
where the denotes the specific index of each pillar in the flattened sequence, while represents the dimension index. These equations represent standard sine and cosine positional encodings, consistent with the Transformer architecture [26].
Introducing such sinusoidal modulation is essential to break the permutation invariance inherent in the Transformer encoder, thereby allowing the network to perceive the spatial relative positions of pillars in the pseudo-image.
The input feature is then constructed by adding the position encodings to the high-dimensional embedding vector :
This sequence is then fed into the Transformer Encoder to distill global temporal context, followed by a global residual connection and layer normalization:
Finally, the temporal flow feature and the static geometric feature from the Pillar Encoder are concatenated. This results in a pseudo-image feature map rich in both spatiotemporal and geometric information, serving as the input for the backbone network.
3.5. Other Parts of the Network
We adopt the SECOND network [28] as the 2D backbone, utilizing a simplified PointNet [29] as the initial pillar encoder to efficiently extract scene-level features. As shown in the standard configuration, the backbone contains three convolutional blocks with layer depths of {3, 5, 5}, downsampling strides of {2, 2, 2}, and output channel counts of {64, 128, 256}. To fuse multi-scale features, we adopt SECOND-FPN (Feature Pyramid Network) as the Neck. It upsamples features from different levels (strides {1, 2, 4}) and concatenates them into a unified representation. Finally, we use the standard Anchor3DHead for detection. The detection head estimates the class score, 3D box regression residuals, and direction estimation of targets based on predefined Anchors.
Loss Function: The training of the network uses a multi-task loss function for end-to-end optimization. Specifically, we use Focal Loss [30] with parameters and to calculate the classification loss ( ), Smooth L1 Loss to calculate the bounding box regression loss ( ), and Cross-Entropy Loss to calculate the direction classification loss ( ). The total loss is defined as a weighted linear combination of these components:
where , , and are balancing coefficients, set to 1.0, 2.0, and 0.2, respectively, to harmonize the different loss magnitudes.
4. Results and Discussion
4.1. Datasets and Evaluation Metrics
To verify the effectiveness of the proposed method, we conducted extensive evaluations on the View-of-Delft (VoD) dataset [11]. The dataset contains 8693 synchronized frames collected in complex urban driving scenarios. It provides 64-line LiDAR, stereo camera, and 3+1D millimeter-wave radar data. In this work, we present a pure 4D-radar-based detection framework; the LiDAR data are utilized solely for generating ground-truth labels and providing accuracy benchmarks during evaluation, while the inference process relies exclusively on 4D radar point clouds. Given the sparsity of radar point clouds, we follow the standard settings of existing research. We use five-frame accumulated (five scans) radar point clouds as network input and conduct performance tests on the officially divided validation set. Experiments use Average Precision (AP) and Mean Average Precision (mAP) as the main evaluation metric, evaluating the detection performance of three categories: Car, Pedestrian, and Cyclist in the Entire Annotated Area and Driving Corridor, respectively. In addition, random flip, global scaling, and global rotation were used as data augmentation strategies during training. The robustness of the model was further improved through input data normalization.
The model proposed in this paper is built based on the MMDetection3D framework. We chose PyTorch 1.13.0 as the primary development library due to its dynamic computational graph and flexible debugging capabilities, which are essential for prototyping complex spatiotemporal feature extraction modules. For hardware acceleration, the CUDA 11.7 environment is utilized to leverage the massively parallel processing power of NVIDIA GPUs. This setup is critical for efficiently handling computationally intensive operations, such as large-scale point cloud voxelization and Transformer-based temporal attention, thereby ensuring the real-time inference performance (72 FPS) required for autonomous driving. All experiments were completed on the Ubuntu 20.04 operating system (Canonical Ltd., London, UK) with eight NVIDIA RTX3090 (24 GB) GPUs (NVIDIA Corporation, Santa Clara, CA, USA). The inference speed in Table 1 was measured by a single NVIDIA RTX3090 (24 GB) with a batch size of 1.
In terms of network parameter settings, we set the detection range of the point cloud to m, m, m. To balance detection accuracy and inference speed, the voxel size is set to m, and the final generated pseudo-image resolution is . The training process uses the AdamW optimizer with a weight decay of 0.05. The learning rate adjustment adopts a strategy combining Warmup and Cosine Annealing. The model is trained for a total of 120 epochs, with a warm-up period spanning the first 5 epochs, the peak learning rate set to 0.006, and the Batch Size set to 16. In addition, we conducted dedicated ablation studies on the use of the radial velocity ( ) and timestamps (t) to determine the optimal feature input combination.
4.2. Comparison of with State-of-the-Art (SOTA)
Table 1 details the quantitative landscape, positioning our method against existing state-of-the-art (SOTA) radar detection networks. Our model establishes a strong baseline, outperforming the majority of competing methods in overall 3D detection. MAFF-Net relies on a computationally heavy clustering generation mechanism to refine fine-grained features, whereas our approach prioritizes architectural efficiency.
Despite this, our model remains highly competitive in detecting rigid targets like cars and cyclists. Crucially, within the Driving Corridor area (RoI)—the region most vital for immediate autonomous driving safety—our model exhibits robust performance, underscoring its reliability in perceiving core close-range threats.
Efficiency is not merely a metric but a core design principle of our framework. As shown in Table 1, our SGE-Flow achieves a real-time inference speed of 72 FPS on an RTX 3090, which is significantly faster than high-performance yet computationally expensive models like MAFF-Net [8] (28.7 FPS). While MAFF-Net reaches higher accuracy, its heavy feature extraction pipelines may hinder deployment in high-speed autonomous driving scenarios where latency is critical. By embedding DAD and IFF features directly into the voxelization front-end, SGE-Flow ensures that computational resources are focused on non-empty pillars, maintaining a superior balance between latency and precision.
To further demonstrate the versatility of the proposed modules, we conducted a plug-and-play (PnP) validation study by integrating the IFF module into the state-of-the-art MAFF-Net architecture (denoted as “MAFF-Net + Ours (IFF)”). We specifically selected IFF for this cross-model validation because it addresses the most fundamental physical constraint—the lack of tangential velocity—that persists across different radar detection backbones. The results indicate that adding IFF boosts the overall mAP of MAFF-Net to 55.00%, achieving a significant +7.70% AP gain for cars in the Driving Corridor. This consistent improvement proves that IFF can serve as a universal enhancement for radar temporal modeling, irrespective of the underlying feature extraction complexity.
4.3. Ablation Studies
We conducted a detailed series of ablation experiments on the VoD validation set in Table 2. Our results demonstrate a synergistic effect: when Velocity Displacement Compensation (VDC), Distribution-Aware Density (DAD), and Inter-frame Flow (IFF) are introduced at once, the model achieves its greatest performance, increasing Entire-Area mAP by 5.38% over the baseline.
We initiated our work by actively utilizing the foundational architecture of PointPillars to establish the initial baseline configuration for comparison. The empirical results from Experiment 2 clearly show that the deliberate integration of the VDC module provided a measurable boost of 2.99% in mAP across the entire evaluation area. Within this recorded overall gain, it was the categories of Pedestrians and Cyclists that manifested the most substantial degree of performance enhancement, achieving resultant increases of 4.42% and 4.20%, respectively. When concentrating the analysis specifically on the defined driving area, the performance improvement for pedestrians was registered as the most significant, reaching approximately 8.38%. The performance can be attributed to the fact that both pedestrians and cyclists are consistently engaged in continuous motion, a state that allows them to derive substantially greater benefit from the mechanisms responsible for displacement compensation, but the Vehicle category includes both moving cars and those are parked along the roadside.
Experiment 3 indicates that subsequent to the formal incorporation of the DAD module, only the Cyclist category demonstrated a statistically meaningful performance increase, which was approximately 1.76% across the entire spatial area. We attribute this performance gain not only to the derived point cloud density descriptors but also to the vertical distribution cues recovered by the DAD module. In contrast to vehicles and pedestrians, cyclists exhibit a unique vertical profile—characterized by a higher central elevation and a narrower horizontal span—a geometric detail that DAD effectively reconstructs by modeling height dispersion despite 2D pillarization.
Experiment 4 indicates that the IFF module ultimately yielded a perceptible rise of 3.59% for pedestrians and a subsequent increase of 2.76% for cyclists in the full area, thereby making a formal contribution to an overall mAP growth measured at 2.09%. In the driving area, the performance enhancements for pedestrians and cyclists were at 2.97% and 2.52%, respectively, accompanied by an mAP gain of 2.11%. According to this measure, this module exerts the most pronounced impact among all proposed modules. As targets frequently in a state of motion within road scenes, pedestrians and cyclists derive greater gains from IFF due to IFF module’s inherent capability to effectively extract underlying motion-related features.
Secondly, we explored the impact of data augmentation strategies on the physical consistency of radar velocity features (as shown in Table 3). Radar radial velocity is a physical quantity highly coupled with the observation angle; previous studies have cautioned that the migration of LiDAR-based data augmentation techniques to 4D radar point clouds must be approached with prudence [11]. Experimental results show that when using and , although Object Translation and Object Rotation increase the spatial diversity of data, they only bring a slight mAP improvement of 0.24% and 0.13%. This finding highlights a critical nuance in radar perception: while translation generally improves generalization in LiDAR or image domains, in radar, it risks destroying the physical constraints of radial velocity. Specifically, simply translating an object without re-computing its radial velocity components leads to a physical mismatch between the target’s new position and its Doppler signature, introducing noise that offsets the benefits of data diversity. In contrast, Global Rotation preserves the relative geometric relationships and physical consistency of velocity components, significantly increasing mAP to 51.04% (an increase of 1.80%). Furthermore, we observe that when we choose to rely solely upon the compensated radial velocity ( ) as input, consciously setting aside the raw —a feature which is highly susceptible to contamination from the ego-motion of the sensor platform—the overall model performance peaks notably at 53.23%. This suggests that possesses superior rotational invariance and serves as a more robust motion feature. Therefore, our final strategy relies exclusively on as velocity input, utilizing Global Rotation as the primary geometric augmentation technique.
Since the VoD dataset [11] uses five-frame accumulated point clouds to alleviate sparsity, introducing effective temporal identifiers is crucial for distinguishing historical frame information and understanding target motion states. We compared two temporal information encoding methods in Table 4: directly concatenating raw timestamps (t) vs. only using the Inter-frame Flow (IFF) proposed in this paper. Experimental results show that IFF provides superior feature representational capacity compared to discrete time markers. Specifically, under the configuration based on velocity compensation features (VDC), after replacing the input from raw timestamp t to the IFF module, the Entire-Area mAP and Driving Corridor mAP increased by +0.62% and +1.05%; under the configuration based on DAD, the IFF module also brought performance gains, increasing Entire-Area mAP by +0.83%. This consistent improvement strongly proves that the IFF module extracted richer motion semantics than simple timestamps by explicitly modeling the temporal correlation between pillars.
We further investigated the potential of combining both features. However, experimental results indicate that re-introducing the raw timestamp t alongside the IFF module does not yield cumulative performance gains; instead, it leads to a slight degradation. Consequently, our final configuration retains only the IFF feature and discards the raw timestamp t.
In terms of inference efficiency, although the introduction of the Transformer structure increases the computational overhead, resulting in a decrease in inference speed (for example, dropping from 96.1 FPS to 74.7 FPS in the VDC group), the model still maintains a high real-time performance of over 70 FPS. This indicates that the IFF module exchanges acceptable computational cost for better detection accuracy and is a more efficient and robust temporal representation method than the raw timestamp.
The IFF module uses a transformer to model the correlation between pillars. The hyperparameter layer num also has a significant impact on performance. The results obtained using different numbers are shown in Table 5. Based on the results, we comprehensively consider selecting layer num as 2.
The architectural depth of the Transformer encoder that is situated within the IFF module demonstrably exerts a substantial and critical impact upon the overall system performance. We systematically undertook an evaluation of the hyperparameter L, which corresponds to the total number of layers, testing it across the specific range of . The results derived from these controlled experiments unequivocally indicate that the setting of is the specific configuration that successfully achieves the maximally optimal performance level. Although the action of incrementally increasing the layer count from a value of 1 to 2 effectively enhances the representational capacity of the extracted features, the subsequent act of further extending this count to was observed to bring about a slight, measurable degradation in overall performance. This phenomenon is largely and logically attributable to the onset of over-parameterization, a condition that becomes readily apparent when operating with the inherently sparse data structure characteristic of 4D radar point clouds.
4.4. Qualitative Analysis
To evaluate the practical performance of the SGE-Flow framework, we present qualitative detection results across various urban scenarios in Figure 7. Each row in the figure displays a camera-view image (left) and the corresponding BEV radar point cloud (right). Our model successfully estimates the 3D bounding boxes of cars, pedestrians, and cyclists in complex and dynamic environments.
However, certain failure modes remain under specific conditions, primarily driven by the inherent sparsity of 4D radar point clouds. For instance, the second scenario exhibits noticeably lower point density compared to others, resulting in degraded estimation performance where only close-range moving pedestrians are successfully detected. Similarly, missed detections at longer ranges across various scenarios are largely attributable to this severe sparsity. Furthermore, the random distribution characteristic of mmWave radar points means that, unlike LiDAR, it struggles to capture the complete geometric contour of a target. Consequently, in complex environments where targets are in close proximity to buildings or other background objects, even short-range targets can be missed. A clear example of this is observed in the first scenario, where two pedestrians on the right side failed to be detected. These observations highlight the ongoing challenges in 4D radar perception and provide a clear direction for future research.
5. Discussion
The results indicate that the proposed modules contribute complementary benefits rather than redundant gains. VDC most strongly benefits pedestrians and cyclists, which is consistent with their higher motion variability and the sensitivity of Doppler features to displacement. DAD provides a more modest but stable improvement by alleviating vertical sparsity artifacts introduced by pillarization, while IFF delivers the largest overall gains by explicitly modeling temporal correlations that are otherwise lost in accumulated point clouds. Regarding random motion noise such as wind-shaken trees, since their movement across different pillars lacks target-level coherence and their Doppler signals typically manifest as local small-range fluctuations rather than continuous pillar-wise occupancy transitions, the Transformer encoder employed in this study can effectively distinguish structured target motion flows from random environmental fluctuations by capturing global context information. The ablation and augmentation studies also highlight an important practical constraint: radar velocity features are physically coupled to viewing geometry, so naive translations and rotations can degrade motion consistency even when they increase spatial diversity. This suggests that future work should prioritize physics-aware augmentation and domain-specific regularization. Finally, the mild performance drop observed with deeper IFF Transformer layer nums underscores a trade-off between model capacity and data sparsity, indicating that lightweight temporal modeling is preferable for 4D radar. These findings collectively support the use of compact, physically grounded feature engineering as a reliable path to real-time radar perception.
In addition, our current results are based on multi-frame point clouds, and ego-motion compensation has a substantial impact on performance; while the VoD dataset provides this step, extending the method to other millimeter-wave radar datasets may require extra effort to implement reliable compensation.
6. Conclusions
We have presented a streamlined feature extraction framework that redefines efficient 4D radar perception. We have demonstrated the potential of Doppler velocity and multi-frame temporal cues. This was achieved by directly addressing the intrinsic limitations of radar data: sparsity, the absence of tangential velocity, and motion-induced geometric distortion. Our experiments show that the Transformer-based Inter-frame Flow (IFF) module is key, significantly enhancing the representation of moving targets by capturing the temporal changes of pillar occupancy.
Architecturally, we have embedded these feature extraction modules seamlessly into the PointPillars voxelization process, avoiding complex, independent branches in favor of a streamlined design. This embedded strategy delivers a superior balance between precision and speed on the View-of-Delft (VoD) dataset: achieving a high 3D mAP of 53.23% while sustaining an inference speed of 72 FPS on an RTX 3090. Additionally, we integrate our IFF module into the MAFF-Net to achieve superior performance without significantly compromising the frame rate. This performance perfectly aligns with the stringent real-time demands of autonomous driving. Ultimately, our work serves as a proof of concept: 4D radar can indeed serve as a robust, primary sensor for autonomous perception without compromising real-time responsiveness.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zou Z. Chen K. Shi Z. Guo Y. Ye J. Object detection in 20 years: A survey Proc. IEEE 202311125727610.1109/JPROC.2023.3238524 · doi ↗
- 2Mao J. Shi S. Wang X. Li H. 3D object detection for autonomous driving: A comprehensive survey Int. J. Comput. Vis.20231311909196310.1007/s 11263-023-01790-1 · doi ↗
- 3Zhou Y. Tuzel O. Voxel Net: End-to-end learning for point cloud based 3D object detection Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)Salt Lake City, UT, USA 18–23 June 201844904499
- 4Lang A.H. Vora S. Caesar H. Zhou L. Yang J. Beijbom O. Point Pillars: Fast encoders for object detection from point clouds Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)Long Beach, CA, USA 15–20 June 20191269712705
- 5Zang S. Ding M. Smith D. Tyler P. Rakotoarivelo T. Kaafar M.A. The impact of adverse weather conditions on autonomous vehicles: How rain, snow, fog, and hail affect the performance of a self-driving car IEEE Veh. Technol. Mag.20191410311110.1109/MVT.2019.2892497 · doi ↗
- 6Bialer O. Jonas A. Jankirana M. Katz D. Moosazadeh S. Amram N. The rise of 4D imaging radar: A survey IEEE Signal Process. Mag.2023407889
- 7Liu J. Zhao Q. Xiong W. Huang T. Han Q.-L. Zhu B. SMURF: Spatial multi-representation fusion for 3D object detection with 4D imaging radar IEEE Trans. Intell. Veh.20249245257
- 8Bi X. Weng C. Tong P. Fan B. Eichberger A. MAFF-Net: Enhancing 3D Object Detection with 4D Radar via Multi-assist Feature Fusion IEEE Robot. Autom. Lett.2025104284429110.1109/LRA.2025.3550707 · doi ↗