Efficient UAV High-Resolution Image Stitching via Dense Deep Kernelized Feature
Jianglei Zhou, Zhaoyu Wei, Yisen Zhong, Xianqiang He

TL;DR
This paper introduces a fast and accurate method for stitching high-resolution UAV images into panoramic views using deep learning techniques.
Contribution
The novel method uses dense deep kernelized features and geometric constraints to improve speed and accuracy in UAV image stitching.
Findings
The proposed method reduces stitching time to 17.5% of the baseline while maintaining visual quality.
It achieves subpixel-level dense matching, overcoming limitations of traditional methods like SIFT.
The two-layer filtering strategy improves alignment accuracy in low-texture and large-parallax scenarios.
Abstract
Unmanned aerial vehicle (UAV) image stitching aims to generate panoramic remote sensing images beyond the field of view of a single camera. However, there are still significant challenges in constructing panoramic images of a target area quickly and accurately, especially in terms of computationally intensive feature matching extraction and feature alignment accuracy, which are particularly sensitive to high-resolution and low-texture scenes. To address this problem, this study proposes an efficient image stitching method that incorporates dense depth kernelized feature extraction and geometric constraint optimization. The learning-based kernelized feature matching framework is adopted to achieve subpixel-level dense matching, which effectively overcomes the time-consuming and sparse matching deficiencies of traditional manual features (e.g., SIFT) in high-resolution images. Second, a…
Click any figure to enlarge with its caption.
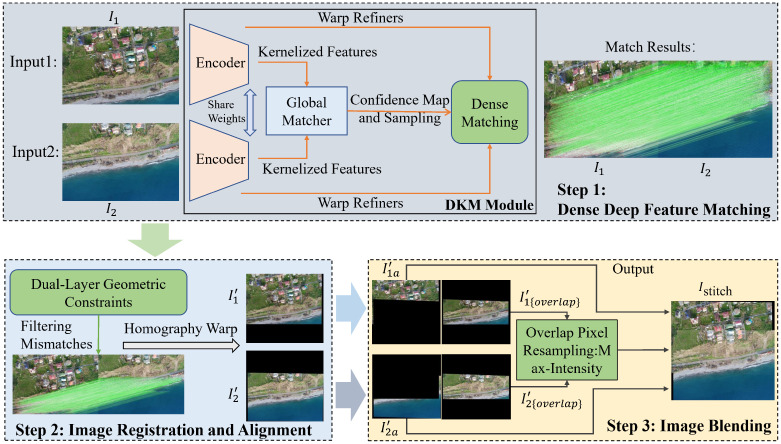 Figure 1
Figure 1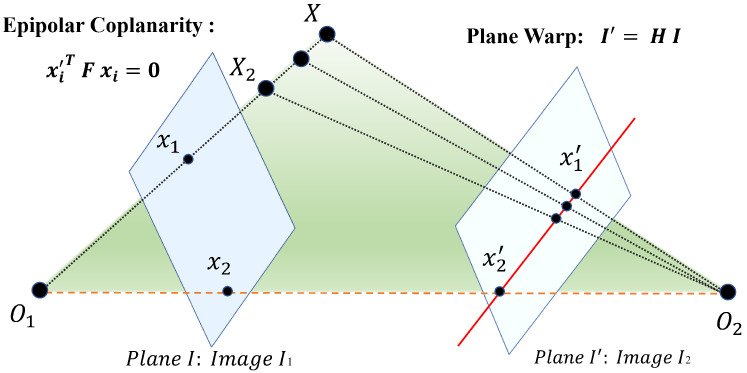 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Image and Video Retrieval Techniques · Robotics and Sensor-Based Localization · Advanced Vision and Imaging
1. Introduction
With the rapid development of unmanned aerial vehicle (UAV) remote sensing technology, UAVs have demonstrated irreplaceable advantages in disaster emergency response, precision agriculture monitoring, and urban planning [1,2,3,4,5]. Compared to traditional satellite and aerial photography, UAVs can capture images with a decimeter-level resolution, enabling the precise acquisition of surface details [6]. However, due to the physical limitations of a single camera’s field of view, an individual image cannot cover large-scale target areas. As a result, image stitching techniques have emerged as a critical solution for extending the observation coverage [7,8].
However, unlike satellite imaging, which benefits from stable orbital paths and near-nadir perspectives, UAV acquisition is characterized by unstable flight attitudes, significant erratic motion, and large perspective variations [9]. These factors introduce non-linear geometric distortions and unpredictable overlap fluctuations, making standard stitching pipelines insufficient [10]. Furthermore, UAVs are often deployed for rapid responses to target areas rather than for long-term monitoring like satellites, making them significantly more sensitive to the stitching efficiency [11]. Despite recent advancements, high-resolution UAV image stitching still faces two major challenges: (1) the trade-off between computational efficiency and feature matching accuracy [12] and (2) the suppression of mismatches in low-texture and repetitive-structure scenes [13].
Image stitching fundamentally aims to detect overlapping regions among images and to merge multi-view image sequences into a unified panoramic representation via geometric transformation or mesh warping. A typical image stitching pipeline [14,15,16] consists of three key stages: feature extraction, geometric registration, and pixel blending. The accuracy of geometric registration directly determines the spatial consistency of the final stitch, while feature matching plays a crucial role in ensuring precise alignment [17]. Traditional approaches [12,18,19] often employ handcrafted local features such as SIFT [20] for sparse matching. However, these methods exhibit significant limitations when processing high-resolution images. First, the computational complexity of feature extraction and descriptor computation grows quadratically with the image resolution, leading to excessive processing delays [13]. Second, in low-texture areas such as farmland and water bodies, the sparse distribution of key points can cause cumulative registration errors or even the complete failure of the stitching process [21]. Although binary descriptors such as ORB [22] are introduced in some methods [23] to reduce the feature detection overhead and improve the computational efficiency, their sensitivity to scale changes and large parallax may limit their matching performance when applied to high-resolution imagery.
Pixel blending aims to alleviate or eliminate brightness and chromatic discrepancies caused by illumination variations, texture differences, and exposure inconsistencies, with the objective of smoothing transitions between images to achieve visual coherence and content consistency. Representative blending techniques include average blending (AB) [24], linear weighted blending (LWB) [25], Poisson blending (PB) [26], and Laplacian pyramid blending [27], as well as seam-driven methods [13,28,29,30,31]. Among these approaches, seam-driven methods generally yield the most favorable perceptual results and, in some cases, can partially compensate for minor alignment errors, which has motivated extensive subsequent research [32]. However, seam searching is a computationally expensive process [33], severely limiting its applicability to high-resolution image stitching. When adjacent images exhibit negligible color differences and misalignments, the blending step can be omitted without significantly affecting the visual quality of the stitched result. This motivates stitching pipelines to place greater emphasis on high-precision matching, since accurate correspondences directly translate into improved alignment and lessen the dependence on blending quality for achieving seamless results.
Recently, deep learning-based feature extraction methods, such as SuperPoint [34], D2-Net [35], and CSPM [8], have significantly increased the matching accuracy by leveraging convolutional neural networks (CNNs) to generate dense feature descriptors. However, these approaches suffer from two critical drawbacks. On the one hand, the local receptive fields of CNNs limit feature discriminability, making it difficult to distinguish similar structures in high-parallax scenes [36]. On the other hand, end-to-end feature matching models often overlook explicit geometric constraints, and directly regressing the homography matrix can lead to global distortions [37]. For example, Mo et al. [38] proposed a deep feature-based stitching method, which performs well on hyperspectral images but exhibits a high failure rate in low-overlap scenarios due to insufficient feature associations.
Furthermore, feature matching inevitably introduces outlier correspondences, necessitating robust mismatch filtering to ensure accurate geometric transformations. Existing methods, such as RANSAC [39] and LLT [40], typically rely on statistical hypothesis testing. However, their performance is highly dependent on the initial inlier ratio. In low-texture or repetitive-pattern regions, the reduced inlier ratio of sparse feature matching can lead to unstable geometric model estimation or complete failure [41,42]. Therefore, adopting an efficient dense feature matching strategy within the stitching pipeline is crucial, as it directly affects the efficiency of feature detection and the geometric alignment accuracy for high-resolution images and ultimately determines the overall quality and computational efficiency of image stitching.
The stitching of high-resolution images requires a careful balance between accuracy and computational efficiency. To address these challenges, this paper proposes an efficient image stitching method that integrates dense deep kernelized feature extraction with geometric constraint optimization. The key contributions of this work can be summarized as follows:
- It proposes an efficient stitching framework tailored to high-resolution aerial images, which achieves a significant reduction in computational time while preserving high-quality stitching results.
- It introduces a deep kernelized feature matching method, which ensures a sufficient number of interior points, as traditional handcrafted features suffer from sparse matching and high computational costs in high-resolution images.
- We design a dual-layer geometric constraint-based mismatch filtering strategy, which not only leverages statistical methods to remove outliers but also incorporates spatial geometric relationships to improve the alignment accuracy, particularly in low-texture and repetitive-structure scenes.
2. Materials and Methods
In this section, Figure 1 illustrates the overall framework of the proposed high-resolution UAV image stitching method, which consists of three main stages: dense feature matching, image registration and alignment, and pixel blending. The framework is designed to efficiently handle large-size UAV imagery while maintaining high accuracy in challenging scenarios such as low-texture regions and repetitive structures.
Specifically, the primary objective of Step 1 is to identify and match key feature points between the images to be stitched, and , where H, W, and C denote the image height, width, and number of color channels, respectively. In contrast to traditional handcrafted feature matching methods such as SIFT [20], SURF, and ORB [22], we adopt deep kernelized matching (DKM) [43] to generate a larger quantity of higher-quality candidate matches. These pixel-level correspondence pairs are visualized in the output of Step 1 in Figure 1, represented by green connecting lines. The technical specifications of Step 1 are detailed in Section 2.1. In Step 2, a dual-layer geometric constraint strategy is designed to filter out initial outliers. Subsequently, the geometric transformation between the two image views is estimated based on the image coordinates of the refined matches, achieving planar alignment for both images. The details of Step 2 are provided in Section 2.2 and Section 2.3. Finally, the aligned images are integrated through image blending in the overlapping regions to complete the stitching process. This blending procedure can be effectively regarded as the pixel-level resampling of the overlapping areas. In the proposed method, we implement a maximum-intensity preservation strategy to reduce the computational complexity. The specific implementation of this step is elaborated upon in Section 2.4.
2.1. Dense Feature Extraction and Matching
Feature matching plays a crucial role in establishing a transformation relationship between images. Given two overlapping images, we employ the dense kernelized matching (DKM) algorithm [43] to extract deep kernel regression features, which serve as the basis for accurate and robust matching. The DKM matcher converts the deep confidence map into a dense set of feature correspondences, ensuring high-precision alignment across image pairs.
The DKM method employs ResNet-50 [44] pre-trained on ImageNet-1K [45] as the backbone encoder. The encoder extracts features from the input images, and , at multiple strides of . This hierarchical feature pyramid enables the acquisition of multi-scale features, ranging from coarse global structures to fine-grained geometric details. To ensure feature consistency between the image pairs, the two ResNet encoders utilize shared weights. Subsequently, a global matcher estimates the global warp and the matching confidence for each set of features from these deep representations. Specifically, a kernel function considering cosine similarity is applied to enhance the sensitivity to feature discrepancies, which is a key factor in achieving reliable matching. Finally, a CNN-based refinement module progressively upsamples the global matching results to pixel-level correspondences. The final matching output is represented as a four-dimensional vector , where and denote the corresponding coordinates in the two images. The loss function of the DKM method is formulated as follows. The training of the dense feature matching network is supervised by a composite loss function that jointly optimizes the coordinate regression accuracy and match reliability. The total loss function is defined as the weighted sum of the warp loss and the confidence loss:
where and are the balance hyperparameters. Specifically, the warp loss measures the Euclidean distance between the predicted dense correspondence field and the ground truth warp field :
where p denotes the pixel coordinates in image , and represents the set of pixels within the valid overlapping region. To handle occlusions and non-overlapping areas, the confidence loss is formulated using binary cross-entropy (BCE):
where is the predicted probability of a pixel p having a valid match, and is the ground truth binary label. This joint optimization ensures that the encoder extracts geometrically discriminative features while the matching module remains robust to outliers.
The loss architecture transitions the matching task into a dense regression problem, which is specifically optimized for the high-resolution textures of UAV imagery. This ensures that the network ignores non-matchable areas (via ) while maintaining pixel-level alignment precision (via ).
Beyond the advantage of a significantly higher number of feature correspondences, DKM achieves subpixel-level accuracy, establishing robust global feature correspondences with greater precision compared to traditional handcrafted descriptors [14,22]. Unlike conventional methods such as SIFT or ORB, which often struggle with sparse or unreliable key points in high-resolution and low-texture environments, DKM effectively captures both local fine-grained structures and global contextual relationships.
As a result, even in challenging scenarios where the region has minimal overlap and the scene contains repetitive or low-texture surfaces, DKM remains highly robust and reliable. This ensures that the overlapping areas are accurately identified, laying a solid foundation for precise image registration and seamless stitching.
2.2. Dual-Layer Geometric Constraints
Incorrect matching points can lead to error accumulation and trigger image misalignment. We propose a dual-layer geometric constraint strategy to filter anomalous matching features, which ensures that the matching points are spatially consistent in the overlapping region.
The strategy utilizes a Graph-Cut RANSAC (GC-RANSAC) sampler [46] to estimate the fundamental matrix between views, performs camera position estimation for densely matched point pairs, and rejects unsatisfactory matching features by using epipolar constraints and graph-cut constraints to eliminate them.
According to the pinhole camera model, as illustrated in Figure 2, the epipolar plane intersects with the image planes of both cameras, forming epipolar lines. Regardless of the position of the target point in 3D space, all epipolar planes and their corresponding epipolar lines converge at the epipoles. Epipolar geometry describes the fundamental geometric relationship between two views. Given a pair of matched points and , their correspondences must satisfy the epipolar constraint
where F is the fundamental matrix that encapsulates the epipolar geometry between the two images.
To measure the deviation of a match from the epipolar constraint, we employ the Sampson distance:
where denotes the j-th element of the transformed point. Matches with a Sampson distance above a predefined threshold are classified as outliers and removed:
Since the estimation of the fundamental matrix requires only eight pairs of corresponding feature points, traditional RANSAC treats each match independently and ignores the spatial relationships between correspondences. The Graph-Cut RANSAC algorithm is introduced to further refine the estimation and obtain the optimal fundamental matrix.
The correspondence model contains a Markov random field, where each match is a node and neighboring matches are connected by edges. The inlier selection process is then formulated as an energy minimization problem:
where represents the label for match i (inlier or outlier); is the unary potential term measuring the transformation residual; is the pairwise potential term enforcing spatial smoothness; denotes the set of neighboring matches; and controls the influence of spatial regularization.
The pairwise potential function penalizes label inconsistencies in neighboring correspondences:
where is a parameter that determines the influence of spatial proximity.
The final model F chosen by GC-RANSAC is the one that minimizes the objective function :
To solve Equation (9), we apply GC-RANSAC, which efficiently finds the optimal labeling that minimizes the energy function. This ensures that inliers form spatially coherent clusters, while isolated mismatches are removed.
Figure 3 illustrates the matching performance achieved using the proposed strategy. Compared to the traditional SIFT method, the DKM approach provides a significantly larger number of correspondence features. This enables the acquisition of abundant matching results even in aerial scenes with low or repetitive textures, ensuring sufficient raw input for the subsequent stitching process. The red boxes in Figure 2 highlight the outliers (mismatches) eliminated by the proposed strategy; these filtered regions primarily originate from complex areas such as featureless water surfaces, which validates the effectiveness of our multi-layer geometric constraints.
2.3. Homography Warp and Image Alignment
After filtering outliers using epipolar constraints and GC-RANSAC, the refined inliers are used to estimate the final homography matrix H. Then, the source image is warped to the target image:
where and represent corresponding feature inlier points in homogeneous coordinates, and H is a matrix:
GC-RANSAC iteratively selects a minimal set of correspondences, estimates a transformation model H, and classifies inliers as
where represents the transformation residual. Matches with residuals below a threshold are considered inliers:
The homography warp matrix H is also minimized regarding the objective function via Equation (9).
Once the homography matrix H is estimated, it is used to warp the input image onto the reference view plane. Overlapping images aligned by homography transformation:
It should be noted that, since the view transformation process employs a global homography, the scene is assumed to lie on a single plane. Local transformations or mesh-based deformations are not considered, which may pose challenges when processing scenes with multiple depth planes.
For multiple images , the homography matrix that warps image to align with image can be expressed as
where represents the homography transformation between consecutive images and . This formulation enables global alignment by propagating local transformations through the image sequence.
2.4. Max-Intensity Pixel Blending Strategy
Despite the target images being aligned as accurately as possible, misalignments remain inevitable as the images do not perfectly satisfy the planar assumption. Consequently, image blending techniques are required to smooth the overlapping regions, mitigating misalignments and eliminating artifacts. This blending operation is essentially the pixel-level resampling of the overlapping areas, using the intensity levels of the original images as a reference.
Traditional approaches, such as intensity averaging and multi-band blending, are commonly used to handle overlapping regions. However, considering that an RGB image sequence is essentially a large three-dimensional matrix, computational efficiency remains a crucial factor.
To further enhance the efficiency, we adopt a max-intensity pixel blending strategy, which retains the pixel with the highest intensity value at each location within the overlapping region. Formally, the blended intensity at each pixel is computed as
where the brightest pixel from all contributing images is selected. This method ensures that bright pixels are retained, preserving detail and reducing artifacts from unaligned overlapping areas.
3. Results
3.1. Dataset and Implementation Details
In this study, to comprehensively evaluate the performance of the proposed stitching framework across diverse and challenging environments, we selected 70 representative image pairs from three high-resolution public UAV datasets: Cynthia H20T [47], Switzerland Agriculture, and Dominica Hurricane Damage [48]. Detailed information about the test images is shown in Table 1.
The selection criteria prioritized scene diversity and high-resolution complexity over simple frame counts. Specifically, the selected sequences represent three major challenges in UAV stitching: (1) repetitive textures in the Cynthia H20T shrublands; (2) low-texture regions in Switzerland’s agricultural areas; (3) low-overlap scenarios in the Dominica hurricane dataset.
To ensure that the evaluation focused on steady-state flight performance, we primarily selected continuous sequences from the stable mid-phases of each flight mission, avoiding the erratic motion typical of take-off and landing. The sample size of 70 high-resolution pairs is consistent with recent research focusing on fine-grained alignment accuracy in large-scale imagery [11]. To further demonstrate the generalizability of our method, additional results obtained on 70 supplementary sequences are provided in Appendix A.
In panoramic stitching, we focus on the visual details of multiple images and the stitching duration and qualitatively compare them with those of several other methods. In image pair stitching, we use three commonly used evaluation metrics, namely the image peak signal-to-noise ratio (PSNR) [49], structural similarity index (SSIM) [50], and learned perceptual image patch similarity (LPIPS) [51], to quantitatively assess the image stitching quality and compare it with that of seven advanced stitching methods. These metrics provide comprehensive evaluations considering pixel differences, signal-to-noise ratios, structural consistency, and perceptual quality.
The PSNR evaluates the visual quality of the reconstructed image, with higher values indicating better quality. The formula is
where L is the maximum pixel intensity (typically 255), and MSE is the mean squared error.
The SSIM measures the similarity in structure, luminance, and contrast between two images. It ranges within , with higher values indicating greater structural consistency. It is defined as
where and are local means, and are local variances, is the covariance, and and are stabilization constants.
LPIPS is a perceptual metric based on deep learning, measuring perceptual differences between images. Lower LPIPS values indicate better quality. It is expressed as
where represents the feature map from a deep neural network, and denotes the layer’s weight.
All experiments were performed on a computer with an Intel i7-14700kf CPU, an Nvidia 3090Ti GPU, and a deep environment set to cuda12.4 + pyrorch2.3.1.
3.2. Multi-Image Sequence Panorama Stitching
Table 2 and Figure 4 illustrate the stitching results and execution times across the three high-resolution datasets, comparing the proposed framework with representative classic methods and the recent method by Peng et al. [13]. In our experiments, Peng’s method required nearly 20 min to process a single pair of images at the original resolution. To ensure that the comparative experiments could be completed, Peng’s method was executed with downsampling. The failure of Peng’s method to process full sequences and its prohibitive computation time further demonstrate that achieving seamless registration in high-resolution, low-overlap scenarios often entails a heavy computational burden. In contrast, our method preserves global geometric consistency and efficiently completes the entire stitching task across all datasets in approximately one minute. The proposed stitching method offers significant computational efficiency advantages over existing approaches.
Regarding panoramic detail, Hossein’s method [18] produces the sharpest visual results but exhibits noticeable seams and edge distortions. Additionally, the Autostitch method [14] struggles with low-texture recognition in Dataset_fields, leading to visible line misalignment. Meanwhile, Agissoft MetaShape [52] shows significant content loss in panorama stitching. While Peng’s method produces superior visual quality, it lacks the scalability required for processing extended image sequences. Specifically, it failed to complete the full sequences for Dataset_fields and Dataset_buildings, successfully stitching only the first 11 and 18 frames, respectively, before encountering alignment failures.
It is observed that the proposed method yields superior visual quality on Dataset_fields, which features flat terrain and low-texture backgrounds. In contrast, for the other two datasets, while the images are effectively aligned, the vertical parallax induced by 3D structures such as trees and buildings leads to localized misalignment. Since our pixel blending strategy prioritizes computational efficiency, it does not sufficiently mitigate these misalignments and seams, thereby impacting the overall visual experience. Furthermore, these misalignments tend to accumulate as the image sequence grows. On the other hand, for Dataset_buildings, characterized by low overlap, most existing methods require significantly more processing time, whereas our method remains unaffected. This indicates the superiority of our method in challenging scenarios, as dense feature matching is well suited for complex registration tasks.
Overall, compared to other methods, the proposed approach demonstrates superior robustness across all three datasets, achieving comparable or even leading visual quality while requiring the least computational time. This trade-off is particularly critical for time-sensitive missions, such as rapid rescue and emergency monitoring, where the timeliness of mapping takes precedence over the complete elimination of minor residual artifacts. A more comprehensive analysis of this efficiency–quality balance is given in Section 4.
3.3. Image Pair Quantitative Evaluation Results
To further evaluate the effectiveness of the proposed method, we performed image pair stitching for adjacent views. However, since acquiring ground truth real images is challenging, we utilized Peng’s method [13] to generate reference images. The stitching results of other methods were then compared against these reference images for image quality assessment. The reference images were generated using optimal seamline retrieval, a highly precise yet computationally intensive process, ensuring their reliability as approximations of real images.
Table 3 presents the performance of various advanced methods based on commonly used image quality metrics, including the PSNR, SSIM, and LPIPS. In the quantitative analysis of the three datasets, the proposed method achieved two best results and seven second-best results, outperforming most other stitching methods. Due to the low texture in Dataset_fields and Dataset_shrubs, all methods generally exhibited lower quantitative scores compared to Dataset_buildings, highlighting the greater challenge of stitching low-texture images. The failure of the UDIS++ method further supports this observation. Additionally, Dataset_buildings contains fewer directly overlapping regions between image pairs, contributing to stitching failures. With successful stitching results across all three datasets and consistently ranking in at least second place, the proposed method demonstrates its superiority in both accuracy and robustness.
3.4. Ablation Experiments
We investigated the effectiveness of the proposed stitching pipeline through ablation studies, with all experiments conducted on Dataset_shrubs. The baseline method used for comparison was Hossein’s approach (SIFT + RANSAC + AB) [18]. Table 4 presents the ablation results, including the remapping error for image transformations and the average runtime for panoramic stitching. The remapping error is defined as the root mean square error (RMSE):
where N is the total number of matching points, are the original pixel coordinates in , and are the corresponding reprojected coordinates in .
The results indicate that the DKM component in our method significantly improves the feature matching efficiency for high-resolution images, drastically reducing the processing time to just 17.5% of that required by the baseline method. Additionally, it lowers the RMSE from 65.4 to 26.82, achieving an improvement of approximately 58.99%. Furthermore, the DGC component effectively enhances the image RMSE, demonstrating its ability to filter out incorrect matches and improve the registration accuracy. Notably, when applied to the baseline method, DGC yielded an impressive RMSE of 4.09, suggesting that, while the original SIFT-based matches contain precise key points, they also include a substantial number of mismatched features. In contrast, the proposed method produces a more evenly distributed set of matches with fewer outliers, leading to a 2.05% improvement in remapping accuracy compared to the variant without DGC. Additionally, the MPB strategy contributes to improving the stitching efficiency, reducing the baseline method’s runtime.
3.5. Robustness Evaluation
3.5.1. Natural Image Stitching
Natural scenes often contain significant depth-of-field variations and multiple background planes, making them a recognized challenge for image stitching [55]. Following the approach in [56], we selected 10 sets of natural images from the dataset [57], covering various scenes such as parks, buildings, bridges, and skies.
These varying depths of field pose a severe challenge to global transformations. We compared our proposed method with three classic methods designed for multi-plane transformation or mesh warping: [58], [19], and [57]. The results, illustrated in Figure 5 and Figure 6, show that, although our method employs a global projective transformation without local warping, it adapts remarkably well to these datasets. In some cases, our method even delivers more visually natural results (see, e.g., the first column of Figure 5 and the fifth column of Figure 6) and achieves seamless, artifact-free stitching in others (see, e.g., the fourth column of Figure 5 and the second column of Figure 6).
We attribute this performance to the existence of a dominant coplanar region within the overlapping 3D space. Benefiting from dense matching and robust estimation, our method aligns the transformation specifically to this plane, ensuring registration even amid depth variations. While this may induce perspective distortion in non-overlapping regions, the results remain visually acceptable—akin to observing the target from an oblique perspective. These examples successfully demonstrate the robust stitching capabilities of the proposed framework.
3.5.2. Infrared Image Stitching
To further verify the generalization capabilities, we tested our method on an infrared (IR) dataset [47], comparing it against a -based pipeline. Figure 7 presents the matching and stitching results of both methods. Unlike visible-light ( ) images, IR images are characterized by low contrast, significant sensor noise, and a lack of fine textural detail due to the nature of thermal radiation imaging.
The results indicate that our method generates dense correspondences and achieves successful stitching, whereas the -based method fails to align due to inadequate matching quality. This highlights the critical importance of matching robustness; while suboptimal blending may introduce ghosting, a failure in robust matching leads directly to registration failure. This underscores the advantages of our method in terms of robust feature representation and dense matching. Although primarily designed for visible-light UAV imagery, the framework’s success on IR data demonstrates its potential for all-weather UAV missions, such as nighttime search and rescue, forest fire monitoring, and power line inspection.
4. Discussion
Although the proposed method demonstrates robust performance in large-scale aerial image stitching across complex natural scenes, it remains challenged by extreme cases involving highly variable scene geometries or very long image sequences. These limitations primarily arise from the use of a global homography to model inter-image geometric relationships, which improves the efficiency but limits the representation of local non-rigid deformations.
When significant height variations and multiple non-coplanar structures are present, discrepancies between local and global homographic relationships may result in ghosting or local misalignment. To mitigate this issue, the proposed method preserves the original content within overlapping regions and performs fusion only along seam areas, partially reducing geometric inconsistencies. However, since geometric transformation estimation is inherently approximate, long image sequences with hundreds of frames may still suffer from error propagation and accumulation. The preliminary image filtering strategy is therefore designed to reduce redundant stitching operations and limit error accumulation.
These limitations reflect a necessary and strategic trade-off between stitching quality and computational efficiency to ensure robust performance in common scenarios. For efficiency-sensitive missions, including disaster response, wildfire monitoring, and large-scale emergency mapping, we argue that a marginal sacrifice in visual metrics is entirely acceptable in exchange for a substantial gain in processing speed. In these time-critical situations, the resulting timeliness of information delivery can yield significant decision-making benefits by providing immediate situational awareness. This capability is often far more vital for operational success than the complete elimination of minor residual artifacts.
Future work will explore the incorporation of overlapping regions as priors for global geometric optimization and feature reconstruction, with the aim of directly generating a single panoramic image from multiple views. Such generative strategies may provide a more efficient alternative to iterative image warping in suppressing error accumulation and local misalignment.
5. Conclusions
This study proposes an efficient UAV image stitching method. The pipeline adopts a framework consisting of dense depth kernelized feature matching, two-layer geometric constraints, and a max-intensity pixel blending strategy to complete the necessary steps of image matching, alignment, and blending. Experimental results obtained across multiple datasets show that the proposed method effectively overcomes the bottlenecks of traditional matching in high-resolution and low-texture imagery. Crucially, the framework achieves a significant efficiency leap, reducing the stitching time to 17.5% of that of the baseline and completing the stitching of over 20 images in approximately one minute. While prioritizing speed, our method yields competitive visual results in both large-parallax natural scenes and low-texture infrared (IR) imagery, validating its robustness and scene generalization capabilities. Despite the advantages of global warping, its application remains limited in ultra-low-altitude urban environments with extreme 3D parallax. Future work will explore generative content reconstruction to further mitigate localized artifacts and enhance the visual coherence in complex urban terrain.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Tao H. Zhao W. Zhao L. Wang J. Research on Disaster Environment Map Fusion Construction and Reinforcement Learning Navigation Technology Based on Air–Ground Collaborative Multi-Heterogeneous Robot Systems Sensors 202525498810.3390/s 2516498840871852 PMC 12390346 · doi ↗ · pubmed ↗
- 2Singh R. Singh S. A Review of Indian-Based Drones in the Agriculture Sector: Issues, Challenges, and Solutions Sensors 202525487610.3390/s 2515487640808040 PMC 12349003 · doi ↗ · pubmed ↗
- 3Zhao Y. Chen L. Zhang X. Xu S. Bu S. Jiang H. Han P. Li K. Wan G. RT Sf M: Real-Time Structure from Motion for Mosaicing and DSM Mapping of Sequential Aerial Images with Low Overlap IEEE Trans. Geosci. Remote Sens.202160560741510.1109/TGRS.2021.3090203 · doi ↗
- 4Liu C. Zhang S. Akbar A. Ground Feature Oriented Path Planning for Unmanned Aerial Vehicle Mapping IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens.2019121175118710.1109/JSTARS.2019.2899369 · doi ↗
- 5Liu H. Hu B. Hou X. Yu T. Zhang Z. Liu X. Wang X. Tan Z. Large-Scale Stitching of Hyperspectral Remote Sensing Images Obtained from Spectral Scanning Spectrometers Mounted on Unmanned Aerial Vehicles Electronics 20251445410.3390/electronics 14030454 · doi ↗
- 6Yang T. Ren Q. Zhang F. Xie B. Ren H. Li J. Zhang Y. Hybrid Camera Array-Based UAV Auto-Landing on Moving UGV in GPS-Denied Environment Remote Sens.201810182910.3390/rs 10111829 · doi ↗
- 7Avola D. Cinque L. Foresti G.L. Martinel N. Pannone D. Piciarelli C. A UAV Video Dataset for Mosaicking and Change Detection from Low-Altitude Flights IEEE Trans. Syst. Man Cybern. Syst.2018502139214910.1109/TSMC.2018.2804766 · doi ↗
- 8Fan X. Sun L. Zhang Z. Liu S. Durrani T.S. Content-Seam-Preserving Multi-Alignment Network for Visual-Sensor-Based Image Stitching Sensors 202323748810.3390/s 2317748837687944 PMC 10490656 · doi ↗ · pubmed ↗