Adaptive Remote Sensing Image Enhancement for KOMPSAT Imagery
Giwoong Lee, Jingi Ju, Minwoo Kim, Jeongyeol Choe, Jaeyoung Chang, Kwang-Jae Lee

TL;DR
This paper introduces ARSIE, an automated system using reinforcement learning to enhance KOMPSAT satellite images, improving segmentation accuracy.
Contribution
The novelty is an adaptive reinforcement learning framework that automatically selects image-specific enhancement operations to improve segmentation performance.
Findings
ARSIE automatically discovers effective enhancement combinations for degraded KOMPSAT imagery.
The method consistently improves segmentation accuracy compared to manual techniques.
ARSIE's approach is shown to be extendable to other satellite imagery.
Abstract
Remote sensing images are often degraded by atmospheric effects, low illumination, and off-nadir viewing, which reduces the segmentation performance of deep models. KOMPSAT (Korea Multi-Purpose Satellite) imagery suffers from quality degradation because the Korean Peninsula is surrounded by sea on three sides and is subject to frequent weather and atmospheric variations. In practice, operators apply heuristic image enhancement techniques by hand, but these approaches are labor-intensive and inconsistent. To address this issue, we have proposed Adaptive Remote Sensing Image Enhancement (ARSIE), an automated reinforcement learning–based framework that improves segmentation performance on degraded KOMPSAT imagery. ARSIE takes only an existing segmentation network and training data as input, and learns, for each image, a sequence of enhancement operations selected from a filter pool. The…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
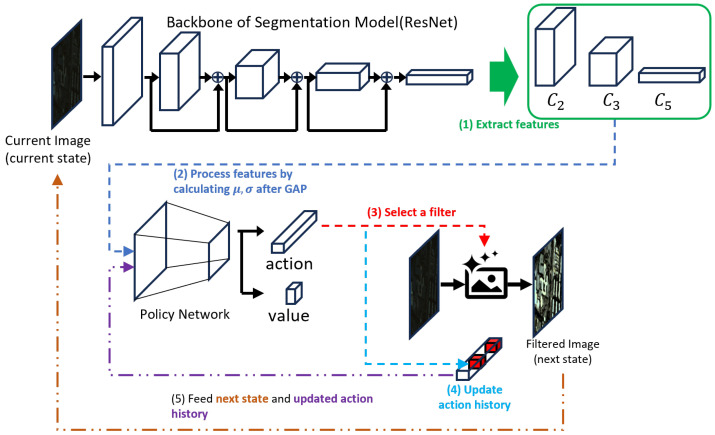 Figure 1
Figure 1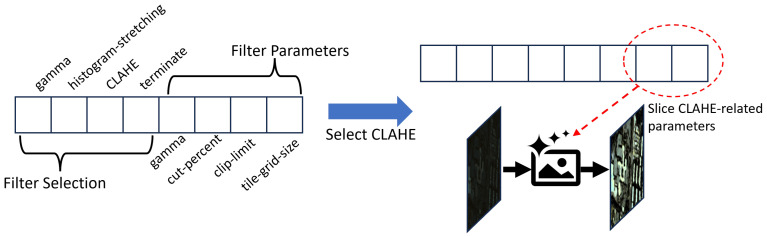 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6- —Korea Aerospace Administration
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsImage Enhancement Techniques · Advanced Image Processing Techniques · Satellite Image Processing and Photogrammetry
1. Introduction
In computer vision, especially in remote sensing image analysis, adverse and degraded conditions such as low-light, fog and rain are major factors that severely degrade the performance of high-level vision recognition tasks like segmentation and detection. Since remote sensing imagery (satellite imagery) can cover vast earth areas, spatial correlations play a crucial role [1]. However, images acquired at night or under poor weather suffer from severe noise, low contrast and color distortion, which fundamentally hinder the segmentation model from identifying objects and areas. In particular, the data acquisition process in Korea is vulnerable to this problem. Because the Korean Peninsula is surrounded by seas on three sides, weather and atmospheric conditions often introduce noise in optical sensors. As a result, the quality of remote sensing imagery is frequently degraded. We show that our proposed method is practical to Korean remote sensing imagery by evaluating the quality improvement from KOMPSAT imagery.
Traditionally, a common way to mitigate this issue is to apply histogram equalization (HE) during the data pre-processing stage. HE redistributes the pixel intensities to enhance image contrast. Prior studies [2,3,4,5] report that various HE-based methods, such as CLAHE (Contrast Limited Adaptive Histogram Equalization) [6] and BBHE (Brightness Preserving Bi-Histogram Equalization) [2], can effectively improve the visual quality of remote-sensing imagery. These methods often make degraded images more interpretable to humans and can benefit downstream computer vision tasks.
More recently, remote-sensing research has also explored learning-based strategies to cope with the lack of clean references and strong appearance variations, including self-supervised blind-spot learning [7] and interactive temporal correlation modeling to suppress pseudo-variations [8]. Motivated by these trends, we focus on task-driven enhancement that directly improves semantic segmentation performance without requiring original images during training.
To achieve greater performance improvements, prior studies [4,9] employ hybrid filtering, in which two or more filters are used in combination. These studies show that such combinations enhance image quality and, in turn, benefit image segmentation. However, applying multiple filters may lead to issues such as the image becoming excessively brighter or darker. Ref. [10] shows that applying multiple filters does not always improve performance, and that a specific combination of filters was found to be suitable for the dataset.
Despite the effectiveness of hybrid filtering, existing approaches still face practical limitations when deployed on diverse remote-sensing imagery. First, the optimal filter combination is often dataset-dependent, and exhaustive search over combinations quickly becomes infeasible as the number of candidate filters increases. Second, applying multiple filters without adaptation can easily introduce over-enhancement artifacts (e.g., overly bright or dark results), which may degrade downstream segmentation performance. Moreover, many enhancement pipelines implicitly assume access to reference (original) images or rely on fixed, hand-tuned filter parameters, making them less suitable for real-world scenarios where degradation patterns vary and clean references are unavailable.
These observations motivate an adaptive enhancement framework that (i) dynamically selects an appropriate sequence of filter operations for each input image, (ii) controls filter strengths to avoid over-enhancement, and (iii) directly optimizes enhancement for semantic segmentation performance rather than generic image-quality metrics. To this end, we introduce an RL-based model that learns image-specific enhancement policies, bridging the gap between heuristic hybrid filtering and task-driven enhancement.
Our contributions in this paper are below:
- We have proposed a Reinforcement Learning (RL)-based adaptive image enhancement model which finds a “sequence” of filter operations to improve the performance of segmentation models.
- We also find parameters of a filter (continuous values) at the same time. We do not need an additional phase to find parameters of a filter.
- Although our experiments were conducted solely on KOMPSAT imagery (Satellite Imagery), the results indicate that the proposed model can be extended and applied to other image domains in the future.
The following Section 2, Section 3, Section 4 and Section 5 are Related Works, Methods, Experimental Results and Conclusions.
2. Related Works
2.1. Image Segmentation in Satellite Imagery
Remote sensing imagery poses unique challenges for semantic segmentation tasks due to its large spatial extent, multi-/hyper-spectral characteristics, and strong spatial autocorrelation. Deep convolutional encoder–decoder architectures and their variants have become the primary choice for high-resolution aerial and satellite scenes, demonstrating substantial gains over traditional pipelines on public benchmarks [11,12,13]. Despite these improvements, segmentation accuracy remains highly sensitive to data acquisition conditions (e.g., low-light, fog, rain), which depress signal-to-noise ratio and contrast and thereby disturb to detect fine object boundaries and small structures essential for mapping tasks [13].
Classical contrast enhancement methods—e.g., histogram equalization and its local variant CLAHE—are often used as generic pre-processing to mitigate low contrast before segmentation. CLAHE limits local contrast amplification to suppress noise over-enhancement and has been widely adopted across imaging domains [6,14]. However, fixed pre-processing is agnostic to scene-specific degradations and task objectives; it may make the image overly brighter or darker in certain regions and can even be harmful for semantic segmentation if not tuned to the dataset and weather/illumination regime. This motivates adaptive, task-aware enhancement strategies that respond to individual images with unique degradations and the needs of the downstream model.
Beyond network architectures, segmentation performance can be improved through training strategies such as Masked Supervised Learning (MaskSup), which introduces random masking during supervised training to promote contextual reasoning and robustness [15]. Our method is orthogonal to this line of work, as it improves segmentation via adaptive input enhancement without relying on clean reference images.
2.2. Deep Reinforcement Learning for Image Enhancement
Recent work formulates low-light enhancement as a Markov Decision Process (MDP), learning sequential policies to adjust image-specific curves or to select restoration operators. ReLLIE learns a lightweight policy that iteratively estimates pixel-wise curves under non-reference rewards, yielding customizable enhancement under diverse low-light conditions [16]. RL-Restore constructs a toolbox of restoration tools and trains an agent to select a sequence of actions (including early stopping), becoming robust to unknown or mixed degradations [17]. PixelRL further demonstrates pixel-wise agents with local interactions for denoising, local color enhancement, and restoration, highlighting interpretability of the learned operations [18]. AdaptiveISP demonstrates that the filter-selection agent helps object detection model to improve its performance, while adverse images are processed through selected filters with appropriate sequences [19]. RL-SeqISP is a similar work to the proposed method. It is a task-specific image enhancement model based on RL but it fixes the sequence of ISP operations and finds parameters of ISP [20].
While these DRL paradigms are promising, they are largely developed for natural photography and optimize perceptual/quality metrics rather than downstream recognition. For remote sensing image segmentation under adverse and degraded conditions, a task-aware agent that (i) selects both the type and parameters of enhancement operators (e.g., CLAHE, BBHE and denoising filters) and (ii) is trained with segmentation-aware rewards (e.g., the change in mIoU) offers a principled path to bridge low-level enhancement and high-level segmentation performance. Our work follows this direction by learning an adaptive filter-selection policy tailored to the dataset’s degradation patterns and the segmentation model’s requirements.
3. Methods
ARSIE, the proposed method consists of policy network to select a sequence of actions (filters) and the segmentation network. To fully utilize the segmentation network, we extract features from the backbone network of the segmentation model. And our policy trains suitable sequences of actions by adapting the changes in features from filtered images. First of all, we formally introduce the notations. There are RL related notations: we write state, action, reward, action-history, transition as , , , , at processing timestamp t respectively. We have N filters and the set of filters which contains terminate, a stopping operation. means the maximum number of available actions. We intend our RL agent to use not all filters but some appropriate filters. is an input image and is a final processed image. Following two subsections explain the network architecture of the ARSIE policy and RL environment setup including how to design reward of the environment.
3.1. Policy Network Architecture
As above mentioned, we utilize the backbone network of the segmentation model to extract features maps. From now on, we write the segmentation model and the backbone of it as and . Normally speaking, the feature maps of are treated as semantic essences of an image. However, recent backbone networks yield multiple stages of feature maps; early stage features have contexture information such as edges and last stage features have semantical meaning with low-resolution. Therefore, we carefully choose the feature maps which are helpful to detect the changes in images before and after filtering and also capture semantical meaning simultaneously. For this reason, we use feature maps from the first two stages and the final stage of —ResNet’s , , and [21]. We extract them in the fixed order → → . Hereafter, we follow the standard ResNet notation and refer to the early-stage feature maps as and , and the final-stage feature map as .
The policy network uses these feature maps as inputs of the network. Firstly, we get Global Average Pooling (GAP) [22] of and ; and ; and standard deviation of , . Global average pooling (GAP) yields compact descriptors from multi-level features: / primarily encode local edges and mid-level context, whereas captures global semantics. As and are sensitive to both degradations and noise, we overcome this limitation by utilizing GAP and standard deviation of [23,24,25]. is relatively insensitive to additive noise, while is informative about degradations, as degraded images often exhibit background equalization and contrast reduction that suppress feature variance. After extracting these features from the backbone network, we concatenate and and . After concatenation, we apply Layer Normalization (LN) [26], and feed the normalized feature as the first input to the policy network. The second input is an action-history vector ( ) encoding the applied filters (actions) and their parameter values; this vector is processed by the LN layer. For the detailed architecture of the policy network, see Figure 1.
3.2. RL Environment Setup
The environment setup for RL is crucial for training the ARSIE agent to select better filters. In this sub-section, we describe the details of the RL environment.
state, : Simply saying an image such as a degraded image or filtered image. Every first state in an episode is a degraded image and filtered images are followed after that. It is an input of the backbone network in policy.action, : It consists of two parts: the discrete action vector and its parameter vector (continuous). All filter parameters are represented in the action vector at once. In the action phase, we select an action in discrete action vector and slice its parameter from parameter vector : (please see Figure 2). Detailed filter information is shown in the Section 4.action-history, : The action-history mechanism prevents re-selecting the same action multiple times. represents all actions (filter information) to construct , current state (image): . You can check that stores not only which actions are used but also the parameters of used filters. It serves as input to the policy network and plays a role as an action mask to suppress the repeated selection of filters. Please see Figure 2 to check the detailed structure.reward, : The reward signal comes from the change in mIoU ( ) between consecutive states: we compute between the segmentation outputs of the current image ( ) and the ground truth and between the filtered image ( ) and ground truth.
The detailed description of reward follows after the list; we have proposed two types of reward design.state transition, : The transition function updates the filtered image as the new current state.termination, : The agents do only terminate and the environment returns “done-signal” if all filters are used or agent reaches the state when ; t is the processing timestamp and is the maximum number of filters (actions) to process the image, ; last action must be termination.
We design the reward function based on the difference mIoU. Basically, we find sequences of filters to improve the performance of the segmentation model. Therefore, the gains of mIoU are thought as the metric to measure the performance improvement of the segmentation model intuitively. We have two designs of reward. The first reward design is:
where means reward type 1, and are constant values to amplify the reward signal and is a threshold value. The second reward design is:
where means reward type 2, and are constant values to amplify the reward signal (e.g., use in experiments respectively) and is the average of batch states at step . To generate batch states, we process the batch of degraded images at the episode start time.
The designs of and are intended to amplify the reward signal, because the actual mIoU lies in , whereas step-to-step changes in mIoU are typically much smaller, often within .
In , we require the agent to achieve at least a minimal improvement by setting an -threshold. The intended effect of is used to compensate for variance due to image difficulty, so the agent can get meaningful rewards from the images which is hard to enhance.
To prevent reward over-expose, we clip the reward to . The experiment results from these two reward types are shown in the Section 4.
We train the ARSIE agent with Proximal Policy Optimization (PPO) [27]. PPO is a stable RL algorithm which incrementally trains the actor and critic of the agent; therefore, it has still been widely used until recently. The overall training procedure is described in Algorithm 1. Algorithm 1 Training loop for ARSIE
- Input: , (segmentation ground truth), , , F (Available Filters), (maximum iterations for training),
- Output: (policy)
- 1:
- 2:
- 3:
- 4:Freeze weights of
- 5:for to do
- 6: Get Data
- 7: CalculateMIoU
- 8: for to do
- 9: GetFeatureMaps
- 10: ComputeStats
- 11: ConcatStats
- 12:
- 13: SelectFilter
- 14: ProcessImage
- 15: GetReward
- 16: ▹ Fix the reward type
- 17: UpdateActionHistory
- 18: CheckTermination
- 19: Store data( ) to buffer
- 20: if then
- 21: Break the loop
- 22: Update policy using collected trajectories
- 23: ▹ Update policy using PPO
- 24:return
4. Experimental Results
4.1. Datasets
4.1.1. K3A-CITY
K3A is the name of the Korean satellite—KOMPSAT-3A: Korea Multi-Purpose Satellite-3A. K3A-CITY consists of the satellite images for various locations in Korea (Sejong City and its surrounding areas) with labels: background, building, road, plastic house, farmland, forest, waterside. The satellite images have a 16-bit format, so we process the images using Histogram Stretching which clips of top and bottom pixel values. The ground sampling distance (GSD) of K3A-CITY is 0.55 m. It consists of 8309 pieces of training data and 1269 pieces of testing data. This dataset is only used to train segmentation models.
4.1.2. K3A-CITY-8bit
K3A-CITY-8 bit is constructed by converting 16 bit K3A-CITY images to 8 bit by dividing pixel values by 256. This dataset seems to be like low-light filtered images. This is used only for conceptual proof of the proposed method (See Figure 3a). It consists of 3431 training data and 524 testing data.
4.1.3. K3A-CITY-D
“D” in K3A-CITY-D stands for “Degradation”. For each image, we randomly apply a composition of one to three degradation types selected from gain gamma, vignetting, haze, Poisson–Gaussian noise, motion blur, and Gaussian blur. After applying degradations, we convert the images from 16-bit to 8-bit. Therefore, K3A-CITY-D has variously degraded images (See Figure 3b). This dataset contains the same number of data as K3A-CITY.
4.2. Segmentation Models
We train two segmentation models; DeepLabV3+ [28] with ResNet-101 [21] backbone and PSP-Net [29] with U-Net [30] backbone. As mentioned before, we utilize K3A-CITY-8bit dataset to train these models. In ARSIE agent training phase, the segmentation models are not updated; their model parameters are fixed.
4.3. Reinforcement Learning Settings
As mentioned before, we introduce two reward types. In Equation (3), we set and as and respectively. In Equation (2), we set and as and respectively. And in Equation (2) is set as . We find these constant values experimentally while we train the ARSIE model on K3A-CITY-D. We encourage the agent to find the sequence of filters to improve the segmentation performance, even if the performance gains are small. To do this, and become relatively higher values compared to and . In view of traditional RL setting, multiple state processing is not allowed unless asynchronous RL setting [31,32]. However, we compute mIoU of image batch in parallel manner to reduce computation time cost. Except computing mIoU, we apply different filters to each image in the batch and transit each state in the batch one by one. We process multiple states (images) at once, but we need to notice that each of the states follows individual episodic trajectory; it is crucial to compute advantages and returns for Generalized Advantage Estimation (GAE). These trajectories are managed individually and inserted to the replay buffer. We use the number of images to be processed as 4, training batch size as 32 and size of episode replay buffer as 128.
4.4. Filters
We use a total of nine filters including terminate. Below is the description of the filter details with their parameter ranges:
- gamma [33]: Nonlinear brightness adjustment; brightens shadows, compresses highlights.
- hist_stretch [34]: Global contrast expansion (percentile-based min–max); simple and fast. cut_percent
- unsharp_mask [35]: Edge sharpening via subtracting a blurred copy. kernel_size
- clahe [6]: Local contrast enhancement with a clip limit; robust to non-uniform illumination. clip_limit tile_grid_size
- bbhe [36]: Bi-histogram equalization preserving mean brightness; less color shift than standard HE.
- dsihe [37]: Median-based bi-histogram equalization; balances dark and bright regions.
- rmshe [38]: Recursive mean-separate equalization; improves fine tones but can over-amplify noise. recursion_depth
- wthe [39]: Weighted/thresholded histogram equalization; boosts contrast while limiting over-enhancement.
- terminate: No operation; stop further processing to avoid over-adjustment.
4.5. Analysis
We demonstrate the image enhancement performance of ARSIE in this section. However, we cannot compare the previous methods [18,19,20] with some reasons. Previous methods are mainly applicable to settings where the original images are available (e.g., computing PSNR during training or comparing against filtered outputs), or where evaluation is limited to object detection. In contrast, our method aims to produce enhanced images tailored to semantic segmentation, and it does so without access to original images during training. So we demonstrate our method compared to conventional image enhancement methods.
4.5.1. Results on K3A-CITY-8bit and K3A-CITY-D
We report the experimental results of ARSIE on two datasets: K3A-CITY-8bit and K3A-CITY-D. Table 1 summarizes the performance of DeepLabV3+. On K3A-CITY-8bit, ARSIE consistently improves mIoU over the baseline.
4.5.2. Action Sequence Characteristics
We further analyze the action sequences selected by the trained agents. For K3A-CITY-8bit, the learned policies tend to converge to a small set of sequences. In particular, agents trained with and frequently choose and , respectively. This behavior is expected because K3A-CITY-8bit is generated only by bit-depth conversion, which resembles a single-type degradation; therefore, a nearly fixed enhancement recipe becomes effective. To mitigate the above limitation, we train ARSIE agents on K3A-CITY-D, which contains images with diverse degradation types and levels. On K3A-CITY-D, the agents exhibit substantially more diverse enhancement behaviors. For example, the agents with ( , ) and ( , ) select 77 and 24 unique action sequences, respectively, across 524 test images.
4.5.3. Effect of Navail
To study the impact of the action budget, we additionally train agents with ( , ) and ( , ) on K3A-CITY-D. We observe that these agents apply between at least 3 actions and at most actions per image, indicating that the policies learn to avoid unnecessary operations by terminating early. However, both ( , ) and ( , ) yield lower mIoU than ( , ). This suggests that training with a stricter constraint (i.e., a smaller, carefully chosen ) can be more beneficial for constructing effective ARSIE agents on degraded datasets.
4.5.4. Comparison with Heuristic Pipelines
We construct two heuristic pipelines, , . The results for heuristic pipelines are shown in Table 1. We compare ARSIE and heuristic pipelines in only K3A-CITY-D because ARSIE constructs fixed sequences of filters on K3A-CITY-8bit. These pipelines make enhanced results but these results cannot exceed the performance of ARSIE variants. This demonstrates that ARSIE finds appropriate filter sequences suitable for degraded images.
4.5.5. Results with U-Net-Based PSPNet
Table 2 reports the results of ARSIE agents with the U-Net-based PSPNet backbone. The overall trends are consistent with those of DeepLabV3+ in Table 1: mIoU improves by approximately 20.0, and remains on a similar scale. For fair comparison, we use the same feature-map selection order as in the DeepLabV3+ experiments during training.
4.5.6. Segmentation Results for Filtered Images
Figure 4 shows enhanced images processed by the filters selected from ARSIE agents with ( , ) and ( , ) and their segmentation results. In row 3 in Figure 4a, the agent with ( , ) selects almost 5 filters (including terminate); the images have low contrast. However, the agent with ( , ) has a case of using 4 filters in row 4; also the images are clearer and more colorful than the images in row 3. Since directly gives the negative rewards, we can conclude that the agent avoids selecting negative-effected filters during processing and unnecessary filters. The segmentation results (Figure 4b) for the processed images show the performance gains; the segmentation model can find a more desired segmentation area from the filtered images than the predictions from the only brightness-enhanced images. When comparing the 3rd prediction results in row 3 and 4, the result from row 4 has fewer false-positive pixels than the one from row 3. The numerical denoising results of image enhancement are described in Appendix B.
4.5.7. Computational Costs
We measured the runtime of a single classical filter and ARSIE on the same device (Intel(R) Core(TM) i9-10900X CPU @ 3.70 GHz, NVIDIA RTX 4090, and 256 GB RAM). On average, ARSIE required – s per image when executing four filters followed by terminate (i.e., five actions in total). Executing a single classical filter required – s, resulting in approximately s for four filters. Therefore, the additional overhead introduced by ARSIE (policy inference and control logic) was about s per image, with a average GPU memory usage of approximately GB. To reduce inference time for the segmentation model, we use AMP (Automatic Mixed Precision package) with BFfloat16.
5. Conclusions
We have studied the automatic and adaptive enhancement of remote-sensing images acquired under adverse conditions with the goal of improving semantic segmentation performance. To this end, we have proposed ARSIE (Adaptive Remote Sensing Image Enhancement), which automatically selects a sequence of classical filter operations for degraded images. We have demonstrated that ARSIE agents choose image-specific filter sequences, producing enhanced images that improve segmentation predictions and remain visually interpretable (see Figure 4).
Despite these encouraging results, several limitations remain and motivate future work. First, the current filter pool primarily consists of brightness- and contrast-related operators. A more comprehensive pool grounded in the physical characteristics of remote-sensing imagery (e.g., atmospheric effects and sensor-specific artifacts) should be constructed, and the agent should be trained to select only necessary operations from this pool. Second, we have found that constraining the action budget via is important: without this constraint, performance gains have been modest and the agent has tended to apply redundant filters. Although the constraint mitigates over-processing and helps prevent overfitting, a more principled mechanism for adaptive early termination and sequence-length control is required. Third, the proposed framework requires a segmentation model during both training and inference, which increases computational cost and runtime. Reducing this overhead is essential for practical deployment, including potential on-board computing scenarios. Finally, does not reach , indicating that enhancement is not consistently beneficial across all inputs. We hypothesize that some samples exhibit severe or atypical degradations that are not sufficiently addressed by the current degradation modeling and filter pool. Future work will investigate improved degradation strategies and will evaluate the method on real-world noisy imagery to better understand failure cases and improve robustness.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Liang D. Xu Z. Li L. Wei M. Chen S. Pie: Physics-inspired low-light enhancement Int. J. Comput. Vis.20241323911393210.1007/s 11263-024-01995-y · doi ↗
- 2Patel O. Maravi Y.P. Sharma S. A comparative study of histogram equalization based image enhancement techniques for brightness preservation and contrast enhancementar Xiv 20131311.403310.5121/sipij.2013.4502 · doi ↗
- 3Modak S. Heil J. Stein A. Pansharpening low-altitude multispectral images of potato plants using a generative adversarial network Remote Sens.20241687410.3390/rs 16050874 · doi ↗
- 4Braik M. Al-Betar M.A. Mahdi M.A. Al-Shalabi M. Ahamad S. Saad S.A. Enhancement of satellite images based on CLAHE and augmented elk herd optimizer Artif. Intell. Rev.2024583810.1007/s 10462-024-11022-8 · doi ↗
- 5Vidhya G.R. Ramesh H. Effectiveness of contrast limited adaptive histogram equalization technique on multispectral satellite imagery Proceedings of the International Conference on Video and Image Processing Shanghai, China 11–13 December 2017234239
- 6Zuiderveld K.J. Contrast Limited Adaptive Histogram Equalization Graphics Gems Heckbert P.S. Elsevier Amsterdam, The Netherlands 199447448510.1016/b 978-0-12-336156-1.50061-6 · doi ↗
- 7Wang D. Zhuang L. Gao L. Sun X. Zhao X. Global feature-injected blind-spot network for hyperspectral anomaly detection IEEE Geosci. Remote Sens. Lett.2024211510.1109/LGRS.2024.3449635 · doi ↗
- 8He S. Shen J. Yang H. Xu G. Yang L.T. A Temporal Correlation Networks Based on Interactive Modelling for Remote Sensing Images Change Detection CAAI Trans. Intell. Technol.2025101904191810.1049/cit 2.70080 · doi ↗