Semi-Supervised Traffic Sign Detection with Dual Confidence Fusion Module and Structured Block-Regularized Neck
Chenhui Xia, Yeqin Shao, Meiqin Che, Guoqing Yang

TL;DR
This paper introduces a new semi-supervised learning framework for traffic sign detection that improves accuracy with limited labeled data.
Contribution
A novel framework combining Dual Confidence Fusion and Structured Block-Regularized Neck for better pseudo-label filtering and detection accuracy.
Findings
The proposed method achieves higher mAP50 scores than the baseline using 1% to 10% labeled data.
The framework improves pseudo-label reliability and feature representation through dual confidence fusion and structured regularization.
Results show consistent performance gains in complex traffic sign detection scenarios.
Abstract
Reliable traffic sign detection is essential for the safety of autonomous driving systems. However, manually annotating large-scale datasets for this task is resource-intensive, making semi-supervised learning (SSL) a vital alternative. Despite their potential, current SSL methods often struggle with unreliable pseudo-label filtering and limited detection accuracy. To address these limitations, we propose a novel framework integrating a Dual Confidence Fusion (DC-Fusion) module and a Structured Block-Regularized Neck (SBR-Neck). The former improves pseudo-label reliability by combining classification and localization confidence scores, while the latter optimizes feature representation through multi-scale fusion and block-wise regularization. To preserve high-frequency spatial details, SBR-Neck incorporates Spatial-Context-Aware Upsampling (SCA-Upsampling), which utilizes…
Click any figure to enlarge with its caption.
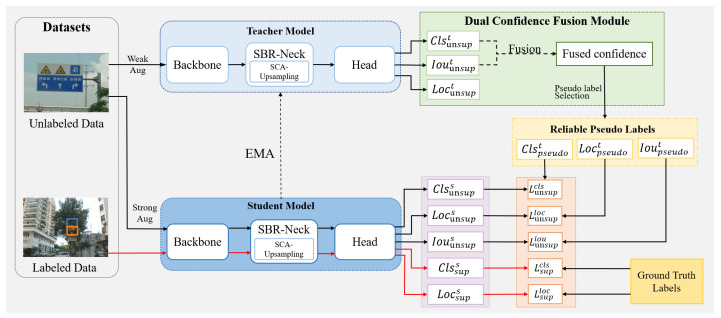 Figure 1
Figure 1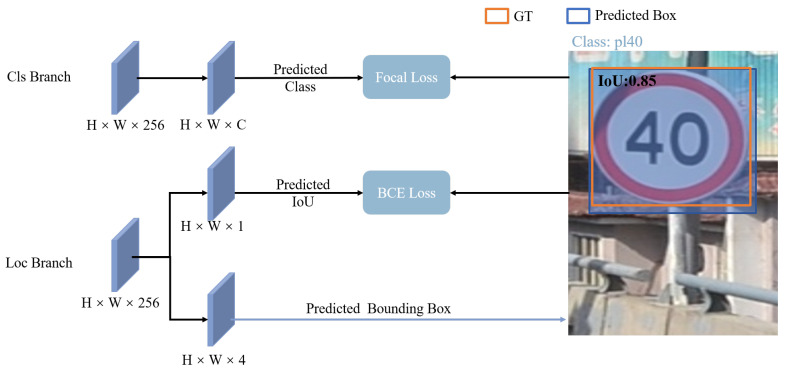 Figure 2
Figure 2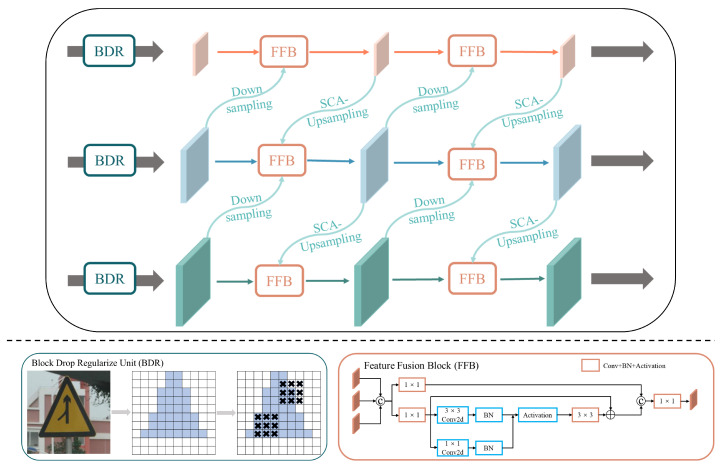 Figure 3
Figure 3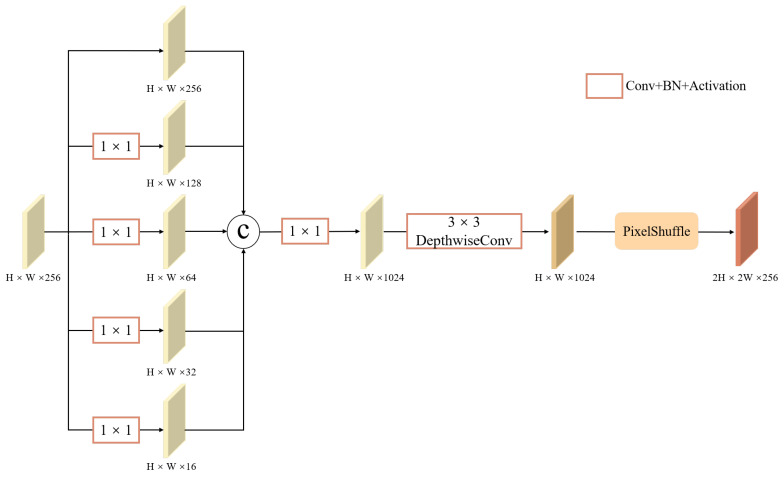 Figure 4
Figure 4 Figure 5
Figure 5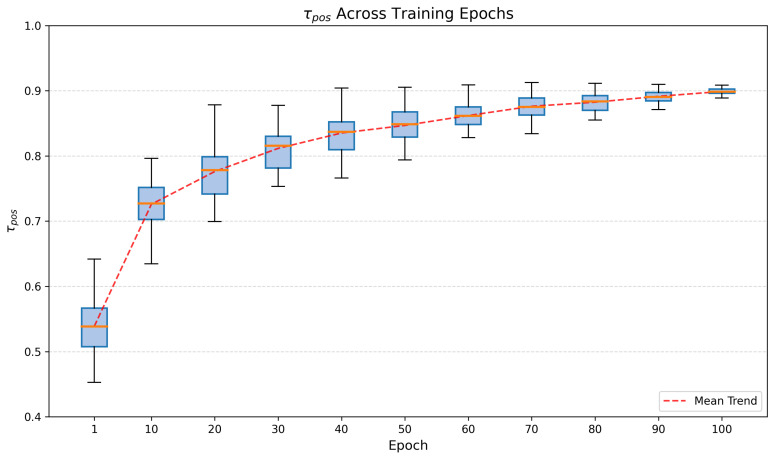 Figure 6
Figure 6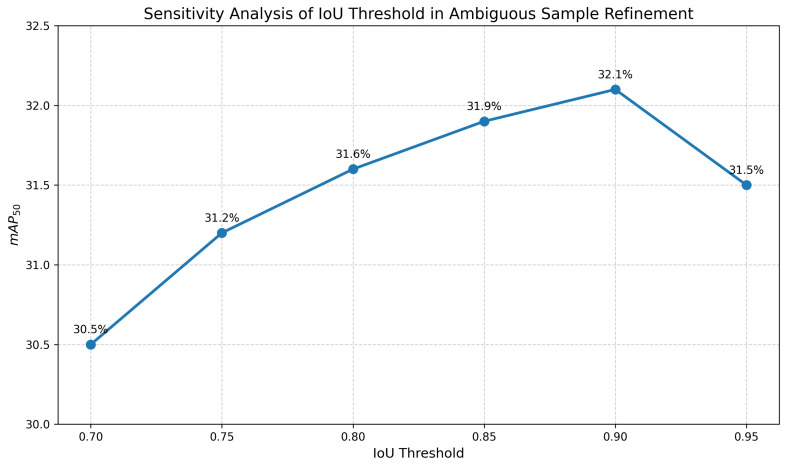 Figure 7
Figure 7 Figure 8
Figure 8- —National Natural Science Foundation of China
- —Nantong Social Livelihood Science and Technology Plan
- —Jiangsu Province’s “Qinglan Project”
- —Postgraduate Research & Practice Innovation Program of Jiangsu Province
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Autonomous Vehicle Technology and Safety · Adversarial Robustness in Machine Learning
1. Introduction
Traffic signs provide key visual information to drivers, while misinterpretation or missed detection of traffic signs can lead to serious traffic accidents. Recently, the rapid development of Intelligent Transportation Systems (ITSs) has significantly enhanced urban traffic management and efficiency [1]. In particular, advanced cooperative control architectures for connected and automated vehicles, such as the MAS-based hierarchical cooperation framework proposed in [2], demonstrate the increasing intelligence and system-level integration in modern transportation systems. In this context, with the advancement of autonomous driving and advanced driver-assistance systems (ADASs), accurate detection of traffic signs has become increasingly critical to guarantee driving safety [3].
Deep learning-based object detection methods have achieved great breakthroughs in recent years, mainly thanks to the availability of large-scale labeled datasets [4,5,6,7,8,9]. These fully supervised approaches have shown excellent performance in various domains. However, their dependence on extensive human annotation leads to significant limitations, as the process of labeling is time-consuming and expensive in terms of finance and human effort, especially for traffic sign detection with high-accuracy requirements.
To reduce dependence on labeled data, researchers have turned to semi-supervised learning methods [10,11,12,13,14], which depend on a small set of labeled data and a large pool of unlabeled data. By exploiting the information of unlabeled data, semi-supervised learning can achieve accurate and robust detection results with much less dependence on costly annotations, especially when labeled data is difficult to obtain.
Recently, semi-supervised deep learning methods have shown promising experimental results in traffic sign detection, making better use of large amounts of unlabeled data [15,16,17,18,19,20,21,22,23,24,25]. Among these methods, pseudo-labeling has attracted significant attention, where a teacher model generates pseudo-labels for unlabeled data, which are then used to train a student model.
While traditional methods rely on classification confidence for pseudo-label filtering, recent confidence-aware SSOD approaches, such as Soft Teacher [26] and Unbiased Teacher [27], have attempted to assess localization reliability using box jittering or uncertainty estimation. However, these methods generally estimate localization quality through statistical variance, which serves as an indirect and computationally intensive proxy rather than a reflection of instance-level geometric accuracy. They lack a unified and explicit metric to jointly evaluate the reliability of semantic classification and geometric localization, leading to localization errors that propagate into the pseudo-label assignment process. Furthermore, the feature fusion strategies in current frameworks often fail to fully exploit multi-scale image features, limiting generalization ability, especially for long-distance traffic signs. By comparison, our DC-Fusion establishes a dual-branch structure that outputs classification confidence and IoU prediction. By utilizing the product of these two metrics as the final confidence score, our method introduces a missing, unified, and explicit metric by directly binding semantic probability with geometric precision. This avoids reliance on indirect statistical proxies to directly evaluate instance-level accuracy, thereby addressing the problem that high classification scores are often accompanied by inaccurate localization.
To address these limitations, we propose a novel semi-supervised traffic sign detection framework with Dual Confidence Fusion and Structured Block-Regularized Neck. Based on the lightweight and efficient end-to-end architecture of YOLOv11, our approach leverages its fully convolutional one-stage design to directly predict object classes and bounding boxes without region proposals, enabling real-time inference. The proposed framework further incorporates a dual-branch confidence fusion strategy and structured feature enhancement modules to improve pseudo-label quality and enhance the detection robustness of long-distance traffic signs under limited supervision. Our main contributions can be summarized as follows:
- 1.To improve the reliability of pseudo-labels, we design a Dual Confidence Fusion Module (DC-Fusion) that jointly integrates classification and localization confidences of each object into a unified scoring mechanism for more accurate filtering of high-quality pseudo-labels. We introduce a refined positive–negative–ambiguous sample assignment strategy, mitigating the negative effects of noisy pseudo-boxes and enhancing the robustness of the student model during training.
- 2.To enhance detection performance for long-distance traffic signs, we propose a Structured Block-Regularized Neck network (SBR-Neck) to replace the conventional neck network. SBR-Neck incorporates multi-level feature fusion and block-wise spatial perturbation, which regularizes local activations and strengthens the generalization of learned representations.
- 3.To preserve spatial details of traffic signs during feature upsampling, we introduce a Spatial-Context-Aware Upsampling (SCA-Upsampling) operation. This operation explicitly models spatial context by multi-granularity feature decomposition and depthwise separable convolution, thus improving localization accuracy for long-distance or low-contrast traffic signs.
Experimental results on our self-built traffic sign detection dataset demonstrate that the proposed method consistently outperforms state-of-the-art semi-supervised detection models. In particular, under the 10% labeled data setting, our method achieves a mAP_50_ improvement of 7.5% over the baseline model (Efficient Teacher), proving the effectiveness of our proposed method.
2. Related Work
2.1. Traffic Sign Detection
Traditional methods for traffic sign detection typically follow a two-stage pipeline [28]. In the first stage, candidate regions that potentially contain traffic signs are generated based on hand-crafted features such as color, shape, or edge information. This stage aims to significantly reduce the search space by filtering out irrelevant background regions. In the second stage, these candidate regions are further analyzed using machine learning classifiers such as Support Vector Machines (SVMs) or AdaBoost, which are often trained on discriminative features like the Histogram of Oriented Gradients (HOG) [29,30]. This two-step process enables traditional methods to achieve basic detection capabilities, but their heavy reliance on manually designed features often limits robustness under complex road environments.
With the advent of deep learning, Convolutional Neural Networks (CNNs) have outperformed traditional methods by learning features directly from raw data [31,32]. Wang et al. [33] proposed an improved feature pyramid network, which incorporates an adaptive attention module and a feature enhancement module. Omid et al. [34] introduced a pyramid transformer that combines local attention with a hierarchical structure to capture both local and global features. Their method uses multi-head self-attention with residual connections to enhance global feature extraction. Wang et al. [35] designed a context-aware and attention-driven weighted fusion network. It leverages multi-head self-attention and convolutional layers to extract contextual features and applies relative positional encoding for improved spatial representation. A spatial attention mechanism is used to enhance important regions during feature fusion. Zhang et al. [36] proposed a cascaded R-CNN framework using a multi-scale attention mechanism within a feature pyramid. This design focuses on highlighting traffic sign features across different resolutions and refines detection results through a multi-stage cascade process. These methods reflect recent studies in combining multi-scale representation, attention mechanisms, and context modeling to improve the accuracy and robustness of traffic sign detection models.
2.2. Semi-Supervised Object Detection
In semi-supervised object detection (SSOD), the ideas of self-training and consistency-based methods derive from semi-supervised image classification. A representative example is the Noisy Student framework, which inspired the design of STAC [37]. STAC uses a multi-stage process where a fixed teacher model first generates pseudo-labels for unlabeled data, and a student model is then trained using these labels. To address the limitations of this disjointed training process and improve pseudo-label quality, other SSOD frameworks [19,26,27,38,39] have been proposed. These methods typically adopt an Exponential Moving Average (EMA) to dynamically update the teacher model based on the student model’s parameters, which enables high-quality pseudo-labels to be generated during training. Within this framework, research has expanded from single-stage to more complex two-stage detectors. For instance, Unbiased Teacher [27] applies focal loss calibration to reduce bias in pseudo-labels, while Instant-Teaching [19] encourages the student and teacher to correct each other’s errors, reducing confirmation bias. Humble Teacher [38] introduces soft pseudo-labels for smoother knowledge transfer, and Soft Teacher [26] improves pseudo-label reliability by score-weighted classification loss and box jitter techniques. More recently, SSOD has extended to transformer-based object detectors. Semi-DETR [39] adapts DETR to the semi-supervised setting by introducing stage-wise hybrid matching to combine one-to-many and one-to-one assignment strategies, cross-view query consistency to maintain semantic consistency across data augmentations, and cost-based pseudo-label mining to filter out unreliable pseudo-boxes. Based on these methods, our work focuses on addressing selection and assignment ambiguities within the single-stage detector-based semi-supervised learning framework.
3. Materials and Methods
3.1. Overview of Our Method
The framework of our semi-supervised method for traffic sign detection, based on the Dual Confidence Fusion Module and the Structured Block-Regularized Neck, is illustrated in Figure 1. First, the original dataset is divided into labeled data and unlabeled data , where and denote the numbers of labeled and unlabeled samples, respectively, and typically. The labels for the labeled samples are denoted as , each containing the center coordinates, width, height, and class information of the target bounding box.
To further enhance the effectiveness of our semi-supervised framework, we replace the original YOLOv5 detector with the advanced YOLOv11 architecture in both the teacher and student models, due to the specific challenges of semi-supervised traffic sign detection addressed in this work. Semi-supervised learning is highly sensitive to pseudo-label noise; hence, a backbone network that can obtain more accurate classification and localization predictions is essential. The attention-enhanced C3k2 module in the YOLOv11 backbone enhances feature discrimination and spatial modeling, improving the reliability of fused confidence estimation in our DC-Fusion module and reducing error propagation during teacher–student model training. Moreover, its strengthened multi-scale feature representation further helps in detecting long-distance traffic signs, complementing the proposed SBR-Neck and SCA-Upsampling.
To address ambiguity in pseudo-label selection and assignment, the Dual Confidence Fusion Module adopts a dual-branch structure that combines the classification response and the localization quality score , obtaining a fused confidence vector defined as . A dynamic threshold is then applied to divide the sample set into positive, ambiguous, and negative samples. The positive samples are directly used for classification and localization tasks. The ambiguous samples are employed as follows: for classification, all ambiguous samples are trained via consistency learning to mimic teacher responses; for localization, only spatially aligned ambiguous samples are selected, and their target bounding boxes are generated by weighted averaging of high-confidence samples. The negative samples are ignored.
To enhance multi-scale feature fusion efficiency and prevent overfitting in YOLOv11, we design the Structured Block-Regularized Neck network (SBR-Neck) to replace the standard neck network. SBR-Neck builds upon cross-level feature interactions inspired by the Generalized Feature Pyramid Network [40] and introduces block-wise spatial perturbations to regularize feature activations and enhance global representation robustness.
In addition, to enhance the ability of upsampling to model spatial contextual information in the feature map and to address the problem of degrading object detail, we utilize the Spatial-Context-Aware Upsampling operation, which explicitly separates feature representations at different semantic levels via multi-granularity feature decomposition to perform high-resolution reconstruction.
During training, the teacher model is first pre-trained using labeled data, and its weights are copied to initialize the student model. The teacher model processes weakly augmented images to generate pseudo-labels, while the student model learns from strongly augmented inputs to improve robustness.
3.2. Dual Confidence Fusion Module
Most semi-supervised methods employ a classification score threshold to filter reliable pseudo-labels, but these methods only consider classification confidence while ignoring localization quality, which leads to unreliable pseudo-labels. To address this, we design the Dual Confidence Fusion Module, which integrates classification and localization confidences, and further introduces a neighborhood-based consistency check on ambiguous samples to improve pseudo-label selection and optimize positive–negative sample assignment.
The primary objective of this module is to compute a fused confidence score to guide pseudo-label selection. As illustrated in Figure 2, DC-Fusion adopts a dual-branch structure: (1) a primary classification branch for object class prediction, and (2) an auxiliary branch for localization quality estimation. The black arrows represent the computation flow of joint confidence, which merges the outputs from the two branches. The resulting joint confidence score is used as supervision for both classification and IoU prediction with focal loss and binary cross-entropy loss, respectively. Meanwhile, the blue arrows indicate the prediction of the bounding box and its corresponding IoU score, which are also utilized to generate soft labels for training.
The fused confidence vector is obtained by combining class confidence and localization quality predicted by the teacher model:
where denotes the class probability distribution produced by the classification branch of the teacher model and normalized via a Softmax function. is the self-assessment score of the teacher model for its own positioning accuracy, which serves as pseudo-positioning confidence in unlabeled data. The fused confidence thus encodes both semantic confidence and localization reliability for each class, and is used to guide the selection of pseudo-labels in the unsupervised branch.
We subsequently assign labels based on the fused confidence score produced by the teacher model, rather than depending on unreliable pseudo-boxes, as the fused confidence score more accurately reflects sample quality. The samples with very high or low confidence can be readily classified as positive or negative, respectively, while those samples with intermediate confidence remain ambiguous. Therefore, these ambiguous samples are selected for classification and localization tasks, respectively, as the sensitivities of different tasks to label uncertainty are different.
Specifically, we categorize each unlabeled sample into negative, ambiguous, or positive pseudo-labeled categories based on a fixed negative threshold and a dynamically computed positive threshold :
where denotes the fused confidence vector produced by the teacher model for the i-th unlabeled sample. The operator returns the maximum fused confidence score among the C dimensions; this score serves as a unified indicator for evaluating the reliability of the pseudo-label.
In this setting, the negative samples mainly refer to false positives with very low fused confidence and are therefore treated as background objects during the training procedure. The negative threshold is fixed to 0.1, and the positive threshold is dynamically computed in each batch based on the statistical distribution of the maximum fused confidence score over ambiguous samples and positive samples:
where and denote the mean and standard deviation of the maximum fused confidence scores from the ambiguous and positive samples in the current batch, respectively.
After dividing the unlabeled samples into positive, ambiguous, and negative sets based on the fused confidence, the teacher model provides pseudo-labels that serve as targets for subsequent tasks. The pseudo-labels are defined as
where and are 70-dimensional vectors, denoting the class probability distributions for positive and ambiguous samples. is a four-dimensional vector representing the bounding box coordinates for positive samples, and is also a four-dimensional vector, obtained by confidence-weighted averaging of matched positive boxes for ambiguous samples. is a scalar representing the IoU confidence for positive samples, and is a scalar computed as the IoU between the refined pseudo-box and the original teacher-predicted box.
For the classification task, we define loss functions for labeled and unlabeled data to guide the student model.
For labeled data, we use the ground truth labels to supervise the classification branch of the student model. The classification loss for supervised data is defined as
where denotes the class probability from the student’s classification output , regarding the class index extracted from the ground-truth one-hot vector . obtains the index of the maximum value in a vector.
For unlabeled data, we adopt pseudo-labels generated by the teacher model, and retain both positive and ambiguous samples after confidence-based filtering. These selected samples are used in consistency learning, as ambiguous samples may still contain meaningful semantic clues. The classification loss for unsupervised data is defined as
where denotes the class probability from the student’s classification output , regarding the class index extracted from the pseudo-label one-hot vector , which is provided by the teacher model after filtering.
For the localization task, we separately define the loss for labeled and unlabeled data to ensure stable optimization of the regression branch.
For labeled data, we use the ground-truth bounding boxes as supervision. The regression loss is calculated using the GIoU loss between the student model’s predicted boxes and the ground-truth boxes:
where is the ground-truth bounding box, and is the predicted box from the student model for the labeled sample.
For unlabeled data, to enhance the reliability of ambiguous samples, we first examine whether any high-confidence positive samples exist within the local neighborhood of each ambiguous box. If no positive samples are found, the ambiguous box itself is re-validated by expanding its grid cell to the same region for local re-prediction. If the re-predicted box achieves an IoU with the initial box higher than 0.9 and its fused confidence exceeds the dynamic threshold , it is promoted to a validated box; otherwise, the ambiguous box follows a refinement process.
In the refinement process, ambiguous samples are matched with existing high-confidence positive samples and validated boxes based on three criteria: (1) class consistency—the predicted class of the ambiguous sample must match that of the positive sample; (2) IoU overlap—the IoU between the ambiguous and positive boxes must exceed a predefined threshold; and (3) spatial inclusion—the ambiguous box must be located within the positive box. If all conditions are satisfied, the ambiguous sample is treated as a potential positive and assigned a refined pseudo-box as the regression target.
The refined pseudo-box is computed by weighted averaging over the matched positive boxes:
where denotes the maximum fused confidence score of the j-th matched positive sample, and is the bounding box predicted by the teacher model. represents the number of matched positive samples satisfying the selection criteria.
The regression loss for unlabeled data is then computed as
where is the student model’s predicted box for the corresponding unlabeled sample.
To guide the auxiliary IoU prediction branch of the teacher model, we introduce an additional binary cross-entropy loss:
where denotes the IoU confidence scores for the selected pseudo-boxes, and is the student model’s predicted IoU for the corresponding samples.
To optimize the student model, we define a total loss that combines both supervised and unsupervised objectives:
where controls the relative importance of the IoU prediction loss.
Unlike the student model, the teacher model does not participate in backpropagation. Instead, its parameters are updated via the Exponential Moving Average (EMA) using the student’s weights.
3.3. Structured Block-Regularized Neck
To address the common challenge of low detection accuracy for long-distance traffic signs, we propose the Structured Block-Regularized Neck (SBR-Neck) network, which represents an improvement over conventional efficient feature pyramid architectures. The core innovation is twofold, combining multi-scale efficient feature aggregation with a layer-wise block regularization strategy, which introduces spatial-structural perturbations into feature flows. This design effectively suppresses redundancy and improves generalization.
Specifically, we enhance the original pyramid feature fusion pathway by embedding Block Drop Regularize (BDR) units before the input of each layer’s feature channel. This architectural modification systematically prevents the network from becoming overly dependent on local features during training.
As shown in Figure 3, the architectural design of SBR-Neck consists of two core components. First, it inherits the multi-level feature-aggregation strategy from classical efficient feature-fusion architectures. Through both horizontal and vertical information flows, the network efficiently integrates features across different semantic hierarchies. Each Feature Fusion Block (FFB) consists of multi-scale convolutional layers and nonlinear transformations. Specifically, each block begins with a convolutional layer for channel adjustment, followed by a convolution for local spatial feature extraction. Batch normalization and activation functions are then applied to enhance nonlinear representation capabilities. After an additional convolution, the sequence ends with a convolution to further refine feature representations. This hierarchical design effectively fuses semantic information across scales while balancing computational efficiency and representational capacity by progressive channel compression and expansion.
Second, we introduce the BDR unit preceding the input feature pathway at each layer. For an input feature map , the BDR unit probabilistically masks contiguous feature blocks with probability p and block size . The output features are computed as follows:
where is the set of all currently masked spatial block positions, and p denotes the block drop probability, namely the probability that a spatial block is randomly set to zero during training. By incorporating BDR prior to each feature fusion stage, the network is compelled to learn independence from specific spatial regions. This mechanism significantly enhances the model’s generalization capability in semi-supervised scenarios by maintaining discriminative power when processing sparse or incomplete information, while effectively suppressing overfitting to local noise patterns.
3.4. Spatial-Context-Aware Upsampling
The upsampling process in the object detection task plays a critical role in the accurate localization of multi-scale targets. However, conventional upsampling methods such as bilinear interpolation and transposed convolution often fail to recover high-frequency details, which are essential for precise object boundary representation. To overcome this limitation, we propose a Spatial-Context-Aware Upsampling operation, as illustrated in Figure 4.
First, the input feature map is passed through a set of parallel convolutional branches, each followed by batch normalization and the SiLU activation function where applicable. These branches generate multi-granularity feature representations with exponentially decreasing channel dimensions:
The resulting feature maps are concatenated along the channel dimension to form a unified multi-scale representation. This is followed by a convolutional transformation to expand the feature space, facilitating richer feature interactions.
To enhance spatial continuity during upsampling, we introduce a depthwise separable convolutional layer before applying the PixelShuffle operation. This layer independently performs spatial filtering on each channel and then fuses channel-wise information, thereby preserving localized spatial structures such as edges and textures.
Finally, the refined feature map undergoes a convolution to align the channel dimensions, followed by PixelShuffle-based upsampling. This parameter-free sub-pixel rearrangement effectively increases the spatial resolution, generating an upsampled feature map with improved detail fidelity.
4. Experiments
4.1. Datasets
The experiments were conducted on the TT100K dataset, which was jointly created and released by Tsinghua University and the Tencent Joint Laboratory. The original dataset includes 128 categories of traffic signs captured across diverse environments. However, a detailed statistical analysis of the dataset reveals a significant class imbalance; specifically, a large number of categories contain very few instances, with some rare classes appearing fewer than 10 times throughout the dataset. These rare categories often lack sufficient samples for effective feature learning, which leads to convergence difficulties during network training and degrades overall detection performance. Consequently, to ensure the reliability of the model, we excluded these rare and extremely low-proportion categories, retaining 84 prevalent traffic sign categories that are critical for urban and expressway driving scenarios.
We constructed a supplementary self-built dataset to address data insufficiency for specific classes and enhance the robustness of the model. The data collection process strictly adhered to the acquisition specifications and environmental diversity standards of the original TT100K benchmark. Specifically, the images were captured using high-definition dashboard cameras and mobile phones, simulating the viewpoints of actual driving scenarios. The collection was conducted primarily during daytime hours, covering a wide range of complex traffic scenes, including urban arterial roads and expressways. This approach ensures that the self-built data maintains consistency with the original dataset in terms of resolution, viewing angles, and background complexity.
To further mitigate overfitting and improve generalization, we employed data augmentation strategies to obtain a final augmented dataset comprising 32,894 images. The dataset is partitioned into training, validation, and test sets with a ratio of 8:1:1.
We also validated the model’s cross-dataset generalization and conducted comparative experiments on the Chinese Traffic Sign Detection Benchmark (CTSDB). Featuring diverse weather and lighting conditions, CTSDB groups traffic signs into three macro-categories: mandatory, prohibitory, and warning. Utilizing this dataset effectively demonstrates the robustness and adaptability of the proposed model to complex background interference in real-world environments.
4.2. Implementation Details
In this paper, we present a semi-supervised traffic sign detection method implemented in Python with the PyTorch deep learning framework. The specific software and hardware configurations employed in our experiments are detailed in Table 1.
The proposed method employs YOLOv11s as the detector, with pre-training involving over 300 epochs and semi-supervised training involving 100 epochs. During the training process, the batch size for both unlabeled and labeled data is 16. The Adam optimizer is utilized with a constant learning rate of 0.001 throughout the training procedure. The Exponential Moving Average (EMA) parameter is set to 0.999, and the loss function weight coefficient is maintained at 1.
4.3. Ablation Study
We conducted both quantitative and qualitative ablation studies to validate the proposed modules of our semi-supervised traffic sign detection method.
We conducted a comparative study of three representative YOLO backbones (v5, v8, and v11) under the same semi-supervised setting (Efficient Teacher with 10% labeled data) to validate the choice of YOLOv11. As shown in Table 2, while YOLOv5s achieves the highest inference speed, its detection accuracy is limited to 21.1% due to its relatively simple feature extraction capabilities. Although YOLOv8s improves accuracy to 22.4%, it introduces a significant computational burden, with Parameters increasing by 54% and GFLOPs increasing by 73% compared to v5, leading to a notable drop in FPS. By contrast, YOLOv11s achieves the highest accuracy while maintaining a much lower computational cost than v8s. Thanks to the efficient C3k2 module and attention-driven C2PSA design, YOLOv11s effectively balances model complexity and performance, making it the optimal backbone for our semi-supervised framework where both accuracy and efficiency are paramount.
Table 3 presents the ablation study result for each component of our proposed method with 10% labeled data. We report the mean and standard deviation derived from five folds to demonstrate the stability of the proposed modules. The DC-Fusion module boosts mAP_50_ to 27.9% ± 0.37% and achieves a 4.7% improvement over the baseline. Furthermore, DC-Fusion introduces negligible computational overhead and maintains the inference speed and parameter count at the same level as the baseline.
The integration of SBR-Neck increases mAP_50_ to 27.5% ± 0.26% with a 4.3% gain, and introduces a moderate increase of 1.8 M in Parameters and 5.3 G in FLOPs compared to the baseline. Consequently, this addition causes a decrease in FPS from 62.3 to 55.4, but the significant improvement in detection accuracy justifies this computational cost.
SCA-Upsampling independently yields a mAP_50_ of 25.7% ± 0.38% and adds 0.65 M Parameters to the model. Nevertheless, it incurs a higher computational demand, increasing FLOPs by 6.6 G, due to multi-granularity feature decomposition and depthwise separable convolutions applied to high-resolution feature maps. When all three modules are combined, mAP_50_ reaches 32.1% ± 0.21% and indicates a total improvement of 8.9% over the baseline. The final model operates at 11.85 M Parameters and 33.4 G FLOPs with a speed of 45.8 FPS. These results demonstrate a favorable trade-off between accuracy and efficiency.
Figure 5 illustrates the effectiveness of the proposed DC-Fusion, SBR-Neck, and SCA-Upsampling. The baseline model tends to detect false positives—such as misclassified road obstacles and wrong detections—because it relies solely on classification confidence while ignoring localization quality. This limitation also leads to under-confident predictions even when objects are correctly detected, and makes it difficult to capture long-distance targets or avoid errors in large-object detection (see yellow arrows). By contrast, DC-Fusion effectively integrates classification and localization confidences to filter low-quality predictions and enforce spatial consistency checks, thereby reducing positional errors and ensuring geometrically plausible pseudo-boxes. As a result, pseudo-labels are more reliable, and confidence calibration is improved. Furthermore, while DC-Fusion alleviates false positives on large objects, the addition of SBR-Neck further boosts the identification of long-distance targets, and SCA-Upsampling enhances fine-grained spatial representation, ultimately enabling accurate detection across diverse object scales.
To further evaluate the computational overhead introduced by the additional architectural components, we analyze the training cost under the 10% labeled data setting. As shown in Table 4, incorporating DC-Fusion, SBR-Neck, and SCA-Upsampling results in increased resource consumption; specifically, GPU memory consumption increases from 11.4 to 12.8 GB, and the total training time rises from 31.0 to 36.8 h. Although the proposed modules introduce an additional training time and increase the memory footprint, this specific overhead is easily manageable on Tesla T4. More importantly, this small computational investment yields a highly favorable performance efficiency: it achieves a substantial 8.9% improvement in mAP_50_. Therefore, despite the minor increase in training time, the framework remains efficient and practical for robust traffic sign detection.
Table 5 presents the ablation study results of the components in the proposed SCA-Upsampling module. The baseline model achieves only 23.2% mAP_50_, whereas after multi-scale feature concatenation is introduced, the model’s parameter count increases to 638 K, and its mAP_50_ increases to 24.5%. This is because multi-scale feature concatenation separates features across different semantic hierarchies by fusing multi-granularity representations, thereby enhancing cross-scale feature interactions and capturing fine-grained details of traffic signs. Subsequent incorporation of the depthwise separable convolution further increases mAP_50_ to 25.7%, with an increment in parameter number to 647 K. Since the depthwise separable convolution strengthens spatial continuity modeling with its decoupled spatial filtering and channel fusion mechanisms, the model effectively mitigates the degradation in high-frequency detail caused by conventional PixelShuffle methods.
To analyze the stability of the dynamic threshold design, we present a box-plot visualization (Figure 6) to show the distribution of the dynamic threshold across different batches at each epoch. is usually different across different batches at each training epoch. Unlike traditional methods, where thresholds are fixed or updated in an epoch-wise manner, our proposed strategy computes a unique based on the real-time confidence distribution of the current samples. The box plots explicitly illustrate this diversity: at each epoch, the values span a range, reflecting the model’s adaptive response to the varying difficulty of different data batches. The relatively large inter-quartile range in the early stages shows that the threshold actively fluctuates to accommodate the model’s unstable predictions. As training converges, the boxes flatten to a single line, demonstrating that while the model becomes stable, the mechanism retains the flexibility to fine-tune the threshold for individual batches, thereby maintaining robustness against hard samples.
To justify the design of SBR-Neck, we analyze the effects of BDR units under different insertion positions and parameter settings. With 10% labeled data, ablation studies are conducted on three configurations: (1) insertion between the backbone and neck, (2) insertion between the neck and prediction heads, and (3) insertion at both junctions. The results are summarized in Table 6 and show that applying BDR only between the backbone and neck yields the best performance.
This placement leverages the backbone’s multi-scale, high-resolution features before fusion, where structured dropout suppresses redundancy while preserving spatial correlations crucial for localization. Perturbation after the neck may corrupt refined semantic features, and dual-position insertion overly disrupts feature continuity.
Under the 10% labeled data setting, in this study, we conduct ablation experiments on two critical parameters in BDR, the drop probability p and block size , as presented in Table 7. Experimental results demonstrate that the model achieves optimal performance when the block size is configured as and the drop probability is set to . The masking region effectively compels the model to focus on inter-region feature correlations by structured dropping, while avoiding semantic discontinuity caused by excessive masking. Concurrently, the drop probability establishes a dynamic balance between regularization intensity and feature preservation, ensuring sufficient regularization strength without compromising critical feature representations.
To investigate the impact of IoU threshold choices on the ambiguous sample refinement process (Equation (12)), we conducted a sensitivity analysis under the 10% labeled-data setting. The IoU threshold determines the strictness of matching ambiguous samples with high-confidence positive samples. As shown in Figure 7, we evaluated the model performance by varying the threshold from 0.70 to 0.95.
The experimental results demonstrate an inverted U-shaped trend. When the threshold is set to a lower value, the model achieves a lower mAP_50_ of 30.5% and 31.2%, respectively. This performance degradation is attributed to the inclusion of low-quality matches, which introduces noise into the pseudo-labels and misguides the student model. Conversely, an overly strict threshold leads to a slight performance drop to 31.5%, as it filters out potentially useful ambiguous samples that could contribute to training. The optimal performance of 32.1% is achieved when the threshold is set to 0.90, which strikes a balance between filtering noisy samples and mining informative pseudo-labels. Based on this observation, we set the IoU threshold to 0.90 for all subsequent experiments.
Overall, these experimental results comprehensively demonstrate the effectiveness of each module in our proposed method.
4.4. Comparison with Other Upsampling Methods
Table 8 demonstrates the performance comparison between the proposed SCA-Upsampling and other upsampling methods under the 10% labeled data setting. The experimental results reveal that traditional upsampling methods achieve mAP_50_ scores below 24%, with negligible parameter counts or minimal adjustments via simple convolutional layers. This indicates that relying solely on interpolation or shallow convolutions fails to effectively restore high-frequency detail features, resulting in blurred edges for long-distance targets and insufficient localization accuracy. By contrast, the Meta-Upscale method [41], which optimizes the upsampling process by meta-learning, improves mAP_50_ to 24.8%. However, its parameter count and moderate FPS exhibit limited cost–performance efficiency relative to the performance gain, and it does not explicitly model multi-scale contextual information. The proposed SCA-Upsampling addresses these limitations by incorporating multi-granularity feature decomposition and enhancing spatial continuity with depthwise separable convolutions. Notably, SCA-Upsampling achieves the highest detection accuracy while maintaining real-time inference speed, achieving a favorable balance between performance and efficiency.
4.5. Comparison with the State-of-the-Art Methods
To comprehensively validate the effectiveness of our proposed method, we conducted a comparative evaluation against recent state-of-the-art semi-supervised object detection methods. The comparison includes end-to-end frameworks such as Omni-DETR [43] and Semi-DETR [39], two-stage approaches like STAC [37] and PseCo [44], and one-stage detectors including Efficient Teacher [45] and Dense Teacher [46]. Table 9 presents the performance using mAP_50_ across varying labeled data ratios, while Table 10 details the mAP_50:95_ metric under the same experimental settings to provide a deeper analysis of localization accuracy. All reported results represent the mean and standard deviation over five folds to ensure a rigorous comparison.
The quantitative results demonstrate that our proposed method consistently outperforms all compared approaches across the 1%, 2%, 5%, and 10% labeled data settings. As shown in Table 9, our framework achieves higher mAP_50_ scores than the leading end-to-end method Semi-DETR, with improvements of 0.68%, 1.6%, 2.2%, and 2.7% across the four settings, respectively. Furthermore, our model shows significant gains over PseCo, which represents the top performance among two-stage methods. When compared to the one-stage baseline Efficient Teacher and the closest competitor Dense Teacher, our method exhibits consistent superiority and achieves a mAP_50_ of 32.1% under the 10% setting.
Table 10 further highlights the robustness of our approach in terms of high-precision localization. Although transformer-based methods like Semi-DETR typically excel in boundary regression due to their global attention mechanisms, our method achieves a mAP_50:95_ of 19.8% and surpasses Semi-DETR by 1.7% under the 10% labeled data setting. This result indicates that the integration of the Dual Confidence Fusion Module and Spatial-Context-Aware Upsampling effectively enhances the geometric quality of the predicted bounding boxes. Moreover, our method maintains a real-time inference speed of 45.8 FPS, which is significantly faster than the 9.1 FPS of Semi-DETR and comparable to other one-stage detectors. These findings confirm that our approach achieves an optimal balance between detection accuracy and computational efficiency.
Although our method’s FPS is slightly lower than some one-stage detectors, it significantly exceeds all end-to-end methods in inference speed and remains faster than most two-stage counterparts. This demonstrates a strong trade-off between detection accuracy and computational efficiency, which is crucial for real-world deployment.
Figure 8 shows visual comparisons among representative SSOD methods, where yellow arrows indicate missed or incorrect detections. In this figure, column (a) shows cases where different scales of traffic signs coexist, column (b) illustrates cases involving long-distance targets, and column (c) shows detection results under low-light conditions. As illustrated, methods such as Efficient Teacher and Unbiased Teacher often fail to detect long-distance traffic signs, especially under low-light conditions. In these challenging cases, traffic signs are completely missed.
By contrast, our method shows improved robustness. It reliably detects traffic signs under low-light conditions, while substantially reducing false positives. For long-distance signs, the predicted boxes are more accurate and stable. These improvements are primarily due to the proposed DC-Fusion strategy, which filters unreliable pseudo-labels, and the Structured Block-Regularized Neck, which guides the model to focus on discriminative spatial features.
To address the concern regarding dataset diversity, we further evaluate the proposed method on the CTSDB dataset under the 10% labeled setting. The same training protocol and hyperparameter configuration are adopted to ensure fair comparison.
As shown in Table 11, our method achieves 35.3% mAP_50_, outperforming all competing methods. Compared with the strongest baseline, Semi-DETR, our approach yields a performance gain of 3.7%.
5. Conclusions
Current semi-supervised traffic sign detection methods often suffer from low-quality pseudo-labels due to the limited performance of teacher models trained on small labeled datasets, which results in false positives. To address these challenges, we propose a semi-supervised traffic sign detection framework that integrates the Dual Confidence Fusion Module (DC-Fusion) and the Structured Block-Regularized Neck. DC-Fusion improves pseudo-label quality by jointly evaluating classification and localization confidences. The proposed Structured Block-Regularized Neck network (SBR-Neck) reduces local overfitting with structured feature perturbation and improves feature generalization across scales. Additionally, Spatial-Context-Aware Upsampling (SCA-Upsampling) enhances spatial detail recovery and localization accuracy with multi-granularity feature decomposition and depthwise separable convolutions. These improvements significantly reduce missed detections, especially for long-distance traffic signs, and demonstrate strong performance under limited supervision.
Limitations and Future Work: While our method achieves substantial performance gains, several limitations remain:
- 1.Training Efficiency: The integration of DC-Fusion, SBR-Neck, and SCA-Upsampling increases model complexity and computational overhead. Future work will explore lightweight architectural designs and dynamic computation strategies to enhance training efficiency.
- 2.Domain Adaptation: Distributional discrepancies between labeled and unlabeled data in the early training stages can lead to model instability. Incorporating domain adaptation techniques could mitigate this challenge and enhance model robustness.
Future research will focus on addressing these limitations and further exploring the generalization capabilities of the proposed framework in real-world applications such as autonomous driving and industrial inspection. Our ultimate objective is to develop a more efficient and robust semi-supervised object detection system adaptable to diverse application scenarios.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Li Y. Zhan Y. Liang M. Zhang Y. Liang J. UPTM-LLM: Large language models-powered urban pedestrian travel modes recognition for intelligent transportation system Appl. Soft Comput.202618611399910.1016/j.asoc.2025.113999 · doi ↗
- 2Liang J. Li Y. Yin G. Xu L. Lu Y. Feng J. Shen T. Cai G. A MAS-Based Hierarchical Architecture for the Cooperation Control of Connected and Automated Vehicles IEEE Trans. Veh. Technol.2023721559157310.1109/TVT.2022.3211733 · doi ↗
- 3Mogelmose A. Trivedi M.M. Moeslund T.B. Vision-Based Traffic Sign Detection and Analysis for Intelligent Driver Assistance Systems: Perspectives and Survey IEEE Trans. Intell. Transp. Syst.2012131484149710.1109/TITS.2012.2209421 · doi ↗
- 4Bochkovskiy A. Wang C.Y. Liao H.Y.M. YOL Ov 4: Optimal Speed and Accuracy of Object Detectionar Xiv 202010.48550/ar Xiv.2004.109342004.10934 · doi ↗
- 5Ge Z. Liu S. Wang F. Li Z. Sun J. YOLOX: Exceeding YOLO Series in 2021 ar Xiv 202110.48550/ar Xiv.2107.084302107.08430 · doi ↗
- 6Wang C.Y. Bochkovskiy A. Liao H.Y.M. YOL Ov 7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectorsar Xiv 20222207.02696
- 7Tian Z. Shen C. Chen H. He T. FCOS: Fully Convolutional One-Stage Object Detection Proceedings of the IEEE/CVF International Conference on Computer Vision Seoul, Republic of Korea 27 October–2 November 201996279636
- 8Tan M. Pang R. Le Q.V. Efficient Det: Scalable and Efficient Object Detection Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Seattle, WA, USA 13–19 June 20201078110790